SIFT算法C语言逐步实现详解

SIFT算法C语言逐步实现详解(上)
引言:
在我写的关于sift算法的前倆篇文章里头,已经对sift算法有了初步的介绍:九、图像特征提取与匹配之SIFT算法,而后在:九(续)、sift算法的编译与实现里,我也简单记录下了如何利用opencv,gsl等库编译运行sift程序。
但据一朋友表示,是否能用c语言实现sift算法,同时,尽量不用到opencv,gsl等第三方库之类的东西。而且,Rob Hess维护的sift 库,也不好懂,有的人根本搞不懂是怎么一回事。
那么本文,就教你如何利用c语言一步一步实现sift算法,同时,你也就能真正明白sift算法到底是怎么一回事了。
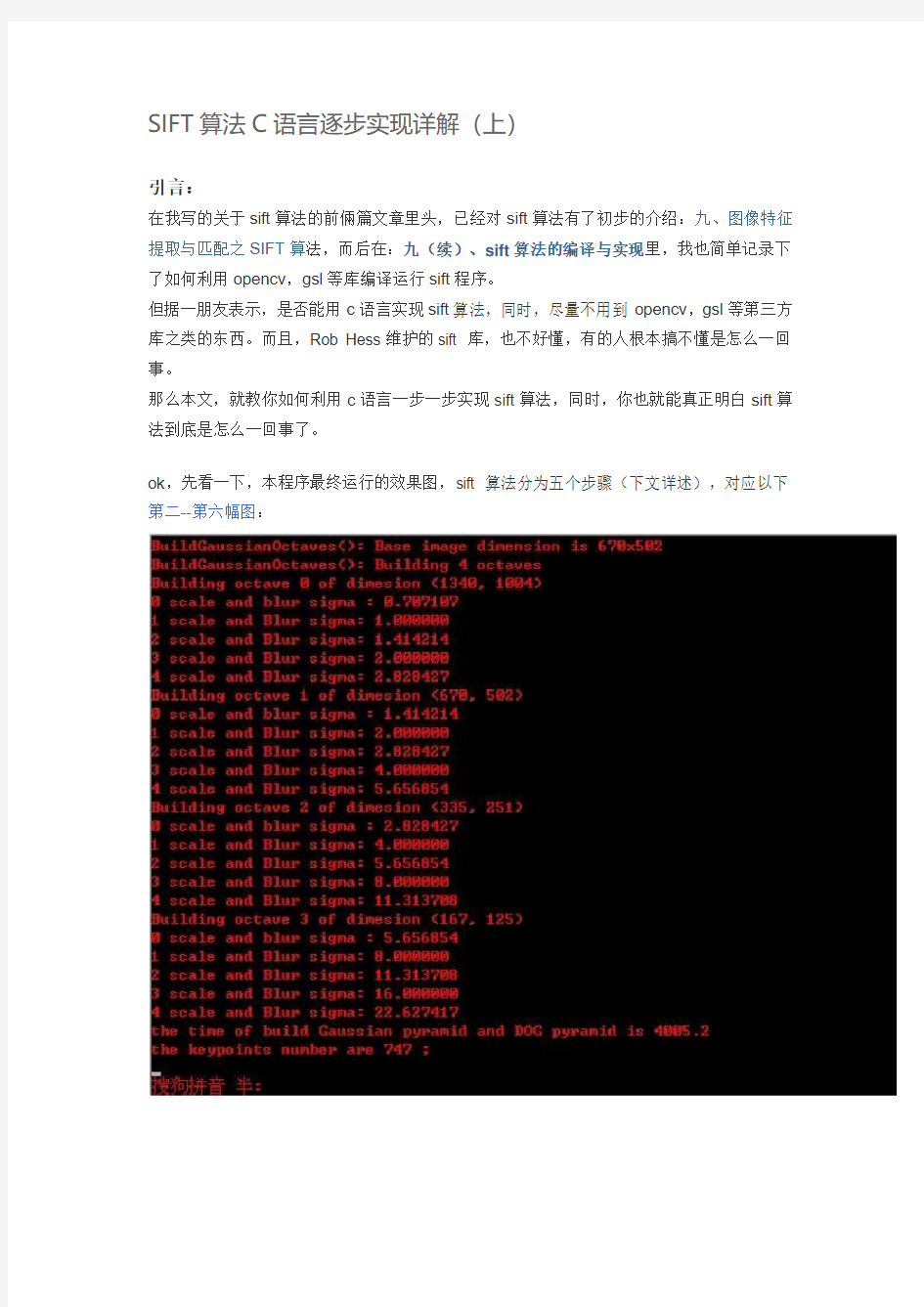
ok,先看一下,本程序最终运行的效果图,sift 算法分为五个步骤(下文详述),对应以下第二--第六幅图:
sift算法的步骤
要实现一个算法,首先要完全理解这个算法的原理或思想。咱们先来简单了解下,什么叫sift算法:
sift,尺度不变特征转换,是一种电脑视觉的算法用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量,此算法由David Lowe 在1999年所发表,2004年完善总结。
所谓,Sift算法就是用不同尺度(标准差)的高斯函数对图像进行平滑,然后比较平滑后图像的差别,
差别大的像素就是特征明显的点。
以下是sift算法的五个步骤:
一、建立图像尺度空间(或高斯金字塔),并检测极值点
首先建立尺度空间,要使得图像具有尺度空间不变形,就要建立尺度空间,sift算法采用了高斯函数来建立尺度空间,高斯函数公式为:
上述公式G(x,y,e),即为尺度可变高斯函数。
而,一个图像的尺度空间L(x,y,e) ,定义为原始图像I(x,y)与上述的一个可变尺度的2维高斯函数G(x,y,e) 卷积运算。
即,原始影像I(x,y)在不同的尺度e下,与高斯函数G(x,y,e)进行卷积,得到L(x,y,e),如下:
以上的(x,y)是空间坐标,e,是尺度坐标,或尺度空间因子,e的大小决定平滑程度,大尺度对应图像的概貌特征,小尺度对应图像的细节特征。大的e值对应粗糙尺度(低分辨率),反之,对应精细尺度(高分辨率)。
尺度,受e这个参数控制的表示。而不同的L(x,y,e)就构成了尺度空间,具体计算的时候,即使连续的高斯函数,都被离散为(一般为奇数大小)(2*k+1) *(2*k+1)矩阵,来和数字图像进行卷积运算。
随着e的变化,建立起不同的尺度空间,或称之为建立起图像的高斯金字塔。
但,像上述L(x,y,e) = G(x,y,e)*I(x,y)的操作,在进行高斯卷积时,整个图像就要遍历所有的像素进行卷积(边界点除外),于此,就造成了时间和空间上的很大浪费。
为了更有效的在尺度空间检测到稳定的关键点,也为了缩小时间和空间复杂度,对上述的操作作了一个改建:即,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分与原始图像I(x,y)相乘,卷积生成。
DOG算子计算简单,是尺度归一化的LOG算子的近似。
ok,耐心点,咱们再来总结一下上述内容:
1、高斯卷积
在组建一组尺度空间后,再组建下一组尺度空间,对上一组尺度空间的最后一幅图像进行二分之一采样,得到下一组尺度空间的第一幅图像,然后进行像建立第一组尺度空间那样的操作,得到第二组尺度空间,公式定义为
L(x,y,e) = G(x,y,e)*I(x,y)
图像金字塔的构建:图像金字塔共O组,每组有S层,下一组的图像由上一组图像降采样得到,效果图,图A如下(左为上一组,右为下一组):
2、高斯差分
在尺度空间建立完毕后,为了能够找到稳定的关键点,采用高斯差分的方法来检测那些在局部位置的极值点,即采用俩个相邻的尺度中的图像相减,即公式定义为:
D(x,y,e) = ((G(x,y,ke) - G(x,y,e)) * I(x,y)
= L(x,y,ke) - L(x,y,e)
效果图,图B:
SIFT的精妙之处在于采用图像金字塔的方法解决这一问题,我们可以把两幅图像想象成是连续的,分别以它们作为底面作四棱锥,就像金字塔,那么每一个截面与原图像相似,那
么两个金字塔中必然会有包含大小一致的物体的无穷个截面,但应用只能是离散的,所以我们只能构造有限层,层数越多当然越好,但处理时间会相应增加,层数太少不行,因为向下采样的截面中可能找不到尺寸大小一致的两个物体的图像。
咱们再来具体阐述下构造D(x,y,e)的详细步骤:
1、首先采用不同尺度因子的高斯核对图像进行卷积以得到图像的不同尺度空间,将这一组图像作为金子塔图像的第一层。
2、接着对第一层图像中的2倍尺度图像(相对于该层第一幅图像的2倍尺度)以2倍像素距离进行下采样来得到金子塔图像的第二层中的第一幅图像,对该图像采用不同尺度因子的高斯核进行卷积,以获得金字塔图像中第二层的一组图像。
3、再以金字塔图像中第二层中的2倍尺度图像(相对于该层第一幅图像的2倍尺度)以2倍像素距离进行下采样来得到金字塔图像的第三层中的第一幅图像,对该图像采用不同尺度因子的高斯核进行卷积,以获得金字塔图像中第三层的一组图像。这样依次类推,从而获得了金字塔图像的每一层中的一组图像,如下图所示:
4、对上图得到的每一层相邻的高斯图像相减,就得到了高斯差分图像,如下述第一幅图所示。下述第二幅图中的右列显示了将每组中相邻图像相减所生成的高斯差分图像的结果,限于篇幅,图中只给出了第一层和第二层高斯差分图像的计算(下述俩幅图统称为图2):
图像金字塔的建立:对于一幅图像I,建立其在不同尺度(scale)的图像,也成为子八度(octave),这是为了scale-invariant,也就是在任何尺度都能够有对应的特征点,第一个子八度的scale为原图大小,后面每个octave为上一个octave降采样的结果,即原图的1/4(长宽分别减半),构成下一个子八度(高
一层金字塔)。
5、因为高斯差分函数是归一化的高斯拉普拉斯函数的近似,所以可以从高斯差分金字塔分层结构提取出图像中的极值点作为候选的特征点。对DOG 尺度空间每个点与相邻尺度和相邻位置的点逐个进行比较,得到的局部极值位置即为特征点所处的位置和对应的尺度。
二、检测关键点
为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如下图,图3所示,中间的检测点和它同尺度的8个相邻
点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。
因为需要同相邻尺度进行比较,所以在一组高斯差分图像中只能检测到两个尺度的极值点(如上述第二幅图中右图的五角星标识),而其它尺度的极值点检测则需要在图像金字塔的上一层高斯差分图像中进行。依次类推,最终在图像金字塔中不同层的高斯差分图像中完成不同尺度极值的检测。
当然这样产生的极值点并不都是稳定的特征点,因为某些极值点响应较弱,而且DOG算子会产生较强的边缘响应。
三、关键点方向的分配
为了使描述符具有旋转不变性,需要利用图像的局部特征为给每一个关键点分配一个方向。利用关键点邻域像素的梯度及方向分布的特性,可以得到梯度模值和方向如下:
其中,尺度为每个关键点各自所在的尺度。
在以关键点为中心的邻域窗口内采样,并用直方图统计邻域像素的梯度方向。梯度直方图的范围是0~360度,其中每10度一个方向,总共36个方向。
直方图的峰值则代表了该关键点处邻域梯度的主方向,即作为该关键点的方向。
在计算方向直方图时,需要用一个参数等于关键点所在尺度1.5倍的高斯权重窗对方向直方图进行加权,上图中用蓝色的圆形表示,中心处的蓝色较重,表示权值最大,边缘处颜色潜,
表示权值小。如下图所示,该示例中为了简化给出了8方向的方向直方图计算结果,实际sift创始人David Lowe的原论文中采用36方向的直方图。
方向直方图的峰值则代表了该特征点处邻域梯度的方向,以直方图中最大值作为该关键点的主方向。为了增强匹配的鲁棒性,只保留峰值大于主方向峰值80%的方向作为该关键点的辅方向。因此,对于同一梯度值的多个峰值的关键点位置,在相同位置和尺度将会有多个关键点被创建但方向不同。仅有15%的关键点被赋予多个方向,但可以明显的提高关键点匹配的稳定性。
至此,图像的关键点已检测完毕,每个关键点有三个信息:位置、所处尺度、方向。由此可以确定一个SIFT特征区域。
四、特征点描述符
通过以上步骤,对于每一个关键点,拥有三个信息:位置、尺度以及方向。接下来就是为每个关键点建立一个描述符,使其不随各种变化而改变,比如光照变化、视角变化等等。并且描述符应该有较高的独特性,以便于提高特征点正确匹配的概率。
首先将坐标轴旋转为关键点的方向,以确保旋转不变性。
接下来以关键点为中心取8×8的窗口。
上图,图5中左部分的中央黑点为当前关键点的位置,每个小格代表关键点邻域所在尺度空间的一个像素,箭头方向代表该像素的梯度方向,箭头长度代表梯度模值,图中蓝色的圈代表高斯加权的范围(越靠近关键点的像素梯度方向信息贡献越大)。
然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点,如图5右部分所示。此图中一个关键点由2×2共4个种子点组成,每个种子点有8个方向向量信息。这种邻域方向性信息联合的思想增强了算法抗噪声的能力,同时对于含有定位误差的特征匹配也提供了较好的容错性。
实际计算过程中,为了增强匹配的稳健性,Lowe建议对每个关键点使用4×4共16个种子点来描述,这样对于一个关键点就可以产生128个数据,即最终形成128维的SIFT特征向量。此时SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则可以进一步去除光照变化的影响。
五、最后一步:当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取上图中,图像A中的某个关键点,并找出其与图像B中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。关于sift 算法的更多理论介绍请参看此文:
https://www.360docs.net/doc/269646699.html,/abcjennifer/article/details/7639681。
sift算法的逐步c实现
ok,上文搅了那么多的理论,如果你没有看懂它,咋办列?没关系,下面,咱们来一步一步实现此sift算法,即使你没有看到上述的理论,慢慢的,你也会明白sift算法到底是怎么一回事,sift算法到底是怎么实现的...。
yeah,请看:
前期工作:
在具体编写核心函数之前,得先做几个前期的准备工作:
0、头文件:
1.#ifdef _CH_
2.#pragma package
3.#endif
4.
5.#ifndef _EiC
6.#include
7.
8.#include "stdlib.h"
9.#include "string.h"
10.#include "malloc.h"
11.#include "math.h"
12.#include
13.#include
14.#include
15.#include
16.#include
17.#include
18.#include
19.#endif
20.
21.#ifdef _EiC
22.#define WIN32
23.#endif
[cpp]view plaincopy
1.#ifdef _CH_
2.#pragma package
3.#endif
4.
5.#ifndef _EiC
6.#include
7.
8.#include "stdlib.h"
9.#include "string.h"
10.#include "malloc.h"
11.#include "math.h"
12.#include
13.#include
14.#include
15.#include
16.#include
17.#include
18.#include
19.#endif
20.
21.#ifdef _EiC
22.#define WIN32
23.#endif
1、定义几个宏,及变量,以免下文函数中,突然冒出一个变量,而您却不知道怎么一回事:[cpp]view plaincopy
1.#define NUMSIZE 2
2.#define GAUSSKERN
3.5
3.#define PI 3.14159265358979323846
4.
5.//Sigma of base image -- See D.L.'s paper.
6.#define INITSIGMA 0.5
7.//Sigma of each octave -- See D.L.'s paper.
8.#define SIGMA sqrt(3)//1.6//
9.
10.//Number of scales per octave. See D.L.'s paper.
11.#define SCALESPEROCTAVE 2
12.#define MAXOCTAVES 4
13.int numoctaves;
14.
15.#define CONTRAST_THRESHOLD 0.02
16.#define CURVATURE_THRESHOLD 10.0
17.#define DOUBLE_BASE_IMAGE_SIZE 1
18.#define peakRelThresh 0.8
19.#define LEN 128
20.
21.// temporary storage
22.CvMemStorage* storage = 0;
[cpp]view plaincopy
1.#define NUMSIZE 2
2.#define GAUSSKERN
3.5
3.#define PI 3.14159265358979323846
4.
5.//Sigma of base image -- See D.L.'s paper.
6.#define INITSIGMA 0.5
7.//Sigma of each octave -- See D.L.'s paper.
8.#define SIGMA sqrt(3)//1.6//
9.
10.//Number of scales per octave. See D.L.'s paper.
11.#define SCALESPEROCTAVE 2
12.#define MAXOCTAVES 4
13.int numoctaves;
14.
15.#define CONTRAST_THRESHOLD 0.02
16.#define CURVATURE_THRESHOLD 10.0
17.#define DOUBLE_BASE_IMAGE_SIZE 1
18.#define peakRelThresh 0.8
19.#define LEN 128
20.
21.// temporary storage
22.CvMemStorage* storage = 0;
2、然后,咱们还得,声明几个变量,以及建几个数据结构(数据结构是一切程序事物的基础麻。):
1.//Data structure for a float image.
2.typedef struct ImageSt { /*金字塔每一层*/
3.
4.float levelsigma;
5.int levelsigmalength;
6.float absolute_sigma;
7.CvMat *Level; //CvMat是OPENCV的矩阵类,其元素可以是图像的象素值
8.} ImageLevels;
9.
10.typedef struct ImageSt1 { /*金字塔每一阶梯*/
11.int row, col; //Dimensions of image.
12.float subsample;
13.ImageLevels *Octave;
14.} ImageOctaves;
15.
16.ImageOctaves *DOGoctaves;
17.//DOG pyr,DOG算子计算简单,是尺度归一化的LoG算子的近似。
18.
19.ImageOctaves *mag_thresh ;
20.ImageOctaves *mag_pyr ;
21.ImageOctaves *grad_pyr ;
22.
23.//keypoint数据结构,Lists of keypoints are linked by the "next" field.
24.typedef struct KeypointSt
25.{
26.float row, col; /* 反馈回原图像大小,特征点的位置 */
27.float sx,sy; /* 金字塔中特征点的位置*/
28.int octave,level;/*金字塔中,特征点所在的阶梯、层次*/
29.
30.float scale, ori,mag; /*所在层的尺度sigma,主方向orientation (range [-PI,PI]),
以及幅值*/
31.float *descrip; /*特征描述字指针:128维或32维等*/
32.struct KeypointSt *next;/* Pointer to next keypoint in list. */
33.} *Keypoint;
34.
35.//定义特征点具体变量
36.Keypoint keypoints=NULL; //用于临时存储特征点的位置等
37.Keypoint keyDescriptors=NULL; //用于最后的确定特征点以及特征描述字
[cpp]view plaincopy
1.//Data structure for a float image.
2.typedef struct ImageSt { /*金字塔每一层*/
3.
4.float levelsigma;
5.int levelsigmalength;
6.float absolute_sigma;
7. CvMat *Level; //CvMat是OPENCV的矩阵类,其元素可以是图像的象素值
8.} ImageLevels;
9.
10.typedef struct ImageSt1 { /*金字塔每一阶梯*/
11.int row, col; //Dimensions of image.
12.float subsample;
13. ImageLevels *Octave;
14.} ImageOctaves;
15.
16.ImageOctaves *DOGoctaves;
17.//DOG pyr,DOG算子计算简单,是尺度归一化的LoG算子的近似。
18.
19.ImageOctaves *mag_thresh ;
20.ImageOctaves *mag_pyr ;
21.ImageOctaves *grad_pyr ;
22.
23.//keypoint数据结构,Lists of keypoints are linked by the "next" field.
24.typedef struct KeypointSt
25.{
26.float row, col; /* 反馈回原图像大小,特征点的位置 */
27.float sx,sy; /* 金字塔中特征点的位置*/
28.int octave,level;/*金字塔中,特征点所在的阶梯、层次*/
29.
30.float scale, ori,mag; /*所在层的尺度sigma,主方向orientation (range [-PI,PI]),
以及幅值*/
31.float *descrip; /*特征描述字指针:128维或32维等*/
32.struct KeypointSt *next;/* Pointer to next keypoint in list. */
33.} *Keypoint;
34.
35.//定义特征点具体变量
36.Keypoint keypoints=NULL; //用于临时存储特征点的位置等
37.Keypoint keyDescriptors=NULL; //用于最后的确定特征点以及特征描述字
3、声明几个图像的基本处理函数:
1.CvMat * halfSizeImage(CvMat * im); //缩小图像:下采样
2.CvMat * doubleSizeImage(CvMat * im); //扩大图像:最近临方法
3.CvMat * doubleSizeImage2(CvMat * im); //扩大图像:线性插值
4.float getPixelBI(CvMat * im, float col, float row);//双线性插值函数
5.void normalizeVec(float* vec, int dim);//向量归一化
6.CvMat* GaussianKernel2D(float sigma); //得到2维高斯核
7.void normalizeMat(CvMat* mat) ; //矩阵归一化
8.float* GaussianKernel1D(float sigma, int dim) ; //得到1维高斯核
9.
10.//在具体像素处宽度方向进行高斯卷积
11.float ConvolveLocWidth(float* kernel, int dim, CvMat * src, int x, int y) ;
12.//在整个图像宽度方向进行1D高斯卷积
13.void Convolve1DWidth(float* kern, int dim, CvMat * src, CvMat * dst) ;
14.//在具体像素处高度方向进行高斯卷积
15.float ConvolveLocHeight(float* kernel, int dim, CvMat * src, int x, int y) ;
16.//在整个图像高度方向进行1D高斯卷积
17.void Convolve1DHeight(float* kern, int dim, CvMat * src, CvMat * dst);
18.//用高斯函数模糊图像
19.int BlurImage(CvMat * src, CvMat * dst, float sigma) ;
[cpp]view plaincopy
1.CvMat * halfSizeImage(CvMat * im); //缩小图像:下采样
2.CvMat * doubleSizeImage(CvMat * im); //扩大图像:最近临方法
3.CvMat * doubleSizeImage2(CvMat * im); //扩大图像:线性插值
4.float getPixelBI(CvMat * im, float col, float row);//双线性插值函数
5.void normalizeVec(float* vec, int dim);//向量归一化
6.CvMat* GaussianKernel2D(float sigma); //得到2维高斯核
7.void normalizeMat(CvMat* mat) ; //矩阵归一化
8.float* GaussianKernel1D(float sigma, int dim) ; //得到1维高斯核
9.
10.//在具体像素处宽度方向进行高斯卷积
11.float ConvolveLocWidth(float* kernel, int dim, CvMat * src, int x, int y) ;
12.//在整个图像宽度方向进行1D高斯卷积
13.void Convolve1DWidth(float* kern, int dim, CvMat * src, CvMat * dst) ;
14.//在具体像素处高度方向进行高斯卷积
15.float ConvolveLocHeight(float* kernel, int dim, CvMat * src, int x, int y) ;
16.//在整个图像高度方向进行1D高斯卷积
17.void Convolve1DHeight(float* kern, int dim, CvMat * src, CvMat * dst);
18.//用高斯函数模糊图像
19.int BlurImage(CvMat * src, CvMat * dst, float sigma) ;
算法核心
本程序中,sift算法被分为以下五个步骤及其相对应的函数(可能表述与上,或与前俩篇文章有所偏差,但都一个意思):
[cpp]view plaincopy
1.//SIFT算法第一步:图像预处理
2.CvMat *ScaleInitImage(CvMat * im) ; //金字塔初始化
3.
4.//SIFT算法第二步:建立高斯金字塔函数
5.ImageOctaves* BuildGaussianOctaves(CvMat * image) ; //建立高斯金字塔
6.
7.//SIFT算法第三步:特征点位置检测,最后确定特征点的位置
8.int DetectKeypoint(int numoctaves, ImageOctaves *GaussianPyr);
9.void DisplayKeypointLocation(IplImage* image, ImageOctaves *GaussianPyr);
10.
11.//SIFT算法第四步:计算高斯图像的梯度方向和幅值,计算各个特征点的主方向
12.void ComputeGrad_DirecandMag(int numoctaves, ImageOctaves *GaussianPyr);
13.
14.int FindClosestRotationBin (int binCount, float angle); //进行方向直方图统计
15.void AverageWeakBins (double* bins, int binCount); //对方向直方图滤波
16.//确定真正的主方向
17.bool InterpolateOrientation
(double left, double middle,double right, double*degreeCorrection, double *p eakValue);
18.//确定各个特征点处的主方向函数
19.void AssignTheMainOrientation(int numoctaves, ImageOctaves
*GaussianPyr,ImageOctaves *mag_pyr,ImageOctaves *grad_pyr);
20.//显示主方向
21.void DisplayOrientation (IplImage* image, ImageOctaves *GaussianPyr);
22.
23.//SIFT算法第五步:抽取各个特征点处的特征描述字
24.void ExtractFeatureDescriptors(int numoctaves, ImageOctaves *GaussianPyr);
25.
26.//为了显示图象金字塔,而作的图像水平、垂直拼接
27.CvMat* MosaicHorizen( CvMat* im1, CvMat* im2 );
28.CvMat* MosaicVertical( CvMat* im1, CvMat* im2 );
29.
30.//特征描述点,网格
31.#define GridSpacing 4
[cpp]view plaincopy
1.//SIFT算法第一步:图像预处理
2.CvMat *ScaleInitImage(CvMat * im) ; //金字塔初始化
3.
4.//SIFT算法第二步:建立高斯金字塔函数
5.ImageOctaves* BuildGaussianOctaves(CvMat * image) ; //建立高斯金字塔
6.
7.//SIFT算法第三步:特征点位置检测,最后确定特征点的位置
8.int DetectKeypoint(int numoctaves, ImageOctaves *GaussianPyr);
9.void DisplayKeypointLocation(IplImage* image, ImageOctaves *GaussianPyr);
10.
11.//SIFT算法第四步:计算高斯图像的梯度方向和幅值,计算各个特征点的主方向
12.void ComputeGrad_DirecandMag(int numoctaves, ImageOctaves *GaussianPyr);
13.
14.int FindClosestRotationBin (int binCount, float angle); //进行方向直方图统
计
15.void AverageWeakBins (double* bins, int binCount); //对方向直方图滤波
16.//确定真正的主方向
17.bool InterpolateOrientation (double left, double middle,double right, double
*degreeCorrection, double *peakValue);
18.//确定各个特征点处的主方向函数
19.void AssignTheMainOrientation(int numoctaves, ImageOctaves *GaussianPyr,Imag
eOctaves *mag_pyr,ImageOctaves *grad_pyr);
20.//显示主方向
21.void DisplayOrientation (IplImage* image, ImageOctaves *GaussianPyr);
22.
23.//SIFT算法第五步:抽取各个特征点处的特征描述字
24.void ExtractFeatureDescriptors(int numoctaves, ImageOctaves *GaussianPyr);
25.
26.//为了显示图象金字塔,而作的图像水平、垂直拼接
27.CvMat* MosaicHorizen( CvMat* im1, CvMat* im2 );
28.CvMat* MosaicVertical( CvMat* im1, CvMat* im2 );
29.
30.//特征描述点,网格
31.#define GridSpacing 4
主体实现
ok,以上所有的工作都就绪以后,那么接下来,咱们就先来编写main函数,因为你一看主函数之后,你就立马能发现sift算法的工作流程及其原理了。
(主函数中涉及到的函数,下一篇文章:一、教你一步一步用c语言实现sift算法、下,咱们自会一个一个编写):
1.int main( void )
2.{
3.//声明当前帧IplImage指针
4.IplImage* src = NULL;
5.IplImage* image1 = NULL;
6.IplImage* grey_im1 = NULL;
7.IplImage* DoubleSizeImage = NULL;
8.
9.IplImage* mosaic1 = NULL;
10.IplImage* mosaic2 = NULL;
11.
12.CvMat* mosaicHorizen1 = NULL;
13.CvMat* mosaicHorizen2 = NULL;
14.CvMat* mosaicVertical1 = NULL;
15.
16.CvMat* image1Mat = NULL;
17.CvMat* tempMat=NULL;
18.
19.ImageOctaves *Gaussianpyr;
20.int rows,cols;
21.
22.#define Im1Mat(ROW,COL) ((float *)(image1Mat->data.fl +
image1Mat->step/sizeof(float) *(ROW)))[(COL)]
23.
24.//灰度图象像素的数据结构
25.#define Im1B(ROW,COL) ((uchar*)(image1->imageData +
image1->widthStep*(ROW)))[(COL)*3]
26.#define Im1G(ROW,COL) ((uchar*)(image1->imageData +
image1->widthStep*(ROW)))[(COL)*3+1]
27.#define Im1R(ROW,COL) ((uchar*)(image1->imageData +
image1->widthStep*(ROW)))[(COL)*3+2]
28.
29.storage = cvCreateMemStorage(0);
30.
31.//读取图片
32.if( (src = cvLoadImage( "street1.jpg", 1)) == 0 ) // test1.jpg einstein.pgm
back1.bmp
33.return -1;
34.
35.//为图像分配内存
36.image1 = cvCreateImage(cvSize(src->width, src->height), IPL_DEPTH_8U,3);
37.grey_im1 = cvCreateImage(cvSize(src->width, src->height), IPL_DEPTH_8U,1);
38.DoubleSizeImage = cvCreateImage(cvSize(2*(src->width), 2*(src->height)),
IPL_DEPTH_8U,3);
39.
40.//为图像阵列分配内存,假设两幅图像的大小相同,tempMat跟随image1的大小
41.image1Mat = cvCreateMat(src->height, src->width, CV_32FC1);
42.//转化成单通道图像再处理
43.cvCvtColor(src, grey_im1, CV_BGR2GRAY);
44.//转换进入Mat数据结构,图像操作使用的是浮点型操作
45.cvConvert(grey_im1, image1Mat);
46.
47.double t = (double)cvGetTickCount();
48.//图像归一化
49.cvConvertScale( image1Mat, image1Mat, 1.0/255, 0 );
50.
51.int dim = min(image1Mat->rows, image1Mat->cols);
52.numoctaves = (int) (log((double) dim) / log(2.0)) - 2; //金字塔阶数
53.numoctaves = min(numoctaves, MAXOCTAVES);
54.
55.//SIFT算法第一步,预滤波除噪声,建立金字塔底层
56.tempMat = ScaleInitImage(image1Mat) ;
57.//SIFT算法第二步,建立Guassian金字塔和DOG金字塔
58.Gaussianpyr = BuildGaussianOctaves(tempMat) ;
59.
60.t = (double)cvGetTickCount() - t;
61.printf( "the time of build Gaussian pyramid and DOG pyramid is %.1f/n",
t/(cvGetTickFrequency()*1000.) );
62.
63.#define ImLevels(OCTAVE,LEVEL,ROW,COL) ((float
*)(Gaussianpyr[(OCTAVE)].Octave[(LEVEL)].Level->data.fl +
Gaussianpyr[(OCTAVE)].Octave[(LEVEL)].Level->step/sizeof(float)
*(ROW)))[(COL)]
64.//显示高斯金字塔
65.for (int i=0; i 66.{ 67.if (i==0) 68.{ C语言的学习要从基础,100个经典的算法 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少? ________________________________________________________________ 程序分析:兔子的规律为数列1,1,2,3,5,8,13,21.... __________________________________________________________________ 程序源代码: main() { long f1,f2; int i; f1=f2=1; for(i=1;i<=20;i++) { printf("%12ld %12ld",f1,f2); if(i%2==0) printf("\n");/*控制输出,每行四个*/ f1=f1+f2;/*前两个月加起来赋值给第三个月*/ f2=f1+f2;/*前两个月加起来赋值给第三个月*/ } } 上题还可用一维数组处理,you try! 题目:判断101-200之间有多少个素数,并输出所有素数。 _________________________________________________________________ 程序分析:判断素数的方法:用一个数分别去除2到sqrt(这个数),如果能被整除,则表明此数不是素数,反之是素数。 ___________________________________________________________________ 程序源代码: #include "math.h" main() { int m,i,k,h=0,leap=1; printf("\n"); for(m=101;m<=200;m++) { k=sqrt(m+1); for(i=2;i<=k;i++) if(m%i==0) {leap=0;break;} if(leap) {printf("%-4d",m);h++; if(h%10==0) printf("\n"); } leap=1; } printf("\nThe total is %d",h); } 题目:打印出所有的“水仙花数”,所谓“水仙花数”是指一个三位数,其各位数字立方和等于该数本身。例如:153是一个“水仙花数”,因为153=1的三次方+5的三次方+3的三次方。 __________________________________________________________________ 程序分析:利用for循环控制100-999个数,每个数分解出个位,十位,百位。 ___________________________________________________________________ 程序源代码: 《数据结构与算法》期末复习题 一、选择题。 1.在数据结构中,从逻辑上可以把数据结构分为 C 。 A.动态结构和静态结构B.紧凑结构和非紧凑结构 C.线性结构和非线性结构D.内部结构和外部结构 2.数据结构在计算机内存中的表示是指 A 。 A.数据的存储结构B.数据结构C.数据的逻辑结构D.数据元素之间的关系 3.在数据结构中,与所使用的计算机无关的是数据的 A 结构。 A.逻辑B.存储C.逻辑和存储D.物理 4.在存储数据时,通常不仅要存储各数据元素的值,而且还要存储 C 。 A.数据的处理方法B.数据元素的类型 C.数据元素之间的关系D.数据的存储方法 5.在决定选取何种存储结构时,一般不考虑 A 。 A.各结点的值如何B.结点个数的多少 C.对数据有哪些运算D.所用的编程语言实现这种结构是否方便。 6.以下说法正确的是 D 。 A.数据项是数据的基本单位 B.数据元素是数据的最小单位 C.数据结构是带结构的数据项的集合 D.一些表面上很不相同的数据可以有相同的逻辑结构 7.算法分析的目的是 C ,算法分析的两个主要方面是 A 。 (1)A.找出数据结构的合理性B.研究算法中的输入和输出的关系C.分析算法的效率以求改进C.分析算法的易读性和文档性 (2)A.空间复杂度和时间复杂度B.正确性和简明性 C.可读性和文档性D.数据复杂性和程序复杂性 8.下面程序段的时间复杂度是O(n2) 。 s =0; for( I =0; i 3.1.1尺度空间极值检测 尺度空间理论最早出现于计算机视觉领域,当时其目的是模拟图像数据的多尺度特征。随后Koendetink 利用扩散方程来描述尺度空间滤波过程,并由此证明高斯核是实现尺度变换的唯一变换核。Lindeberg ,Babaud 等人通过不同的推导进一步证明高斯核是唯一的线性核。因此,尺度空间理论的主要思想是利用高斯核对原始图像进行尺度变换,获得图像多尺度下的尺度空间表示序列,对这些序列进行尺度空间特征提取。二维高斯函数定义如下: 222()/221 (,,)2x y G x y e σσπσ-+= (5) 一幅二维图像,在不同尺度下的尺度空间表示可由图像与高斯核卷积得到: (,,(,,)*(,)L x y G x y I x y σσ)= (6) 其中(x,y )为图像点的像素坐标,I(x,y )为图像数据, L 代表了图像的尺度空间。σ称为尺度空间因子,它也是高斯正态分布的方差,其反映了图像被平滑的程度,其值越小表征图像被平滑程度越小,相应尺度越小。大尺度对应于图像的概貌特征,小尺度对应于图像的细节特征。因此,选择合适的尺度因子平滑是建立尺度空间的关键。 在这一步里面,主要是建立高斯金字塔和DOG(Difference of Gaussian)金字塔,然后在DOG 金字塔里面进行极值检测,以初步确定特征点的位置和所在尺度。 (1)建立高斯金字塔 为了得到在不同尺度空间下的稳定特征点,将图像(,)I x y 与不同尺度因子下的高斯核(,,)G x y σ进行卷积操作,构成高斯金字塔。 高斯金字塔有o 阶,一般选择4阶,每一阶有s 层尺度图像,s 一般选择5层。在高斯金字塔的构成中要注意,第1阶的第l 层是放大2倍的原始图像,其目的是为了得到更多的特征点;在同一阶中相邻两层的尺度因子比例系数是k ,则第1阶第2层的尺度因子是k σ,然后其它层以此类推则可;第2阶的第l 层由第一阶的中间层尺度图像进行子抽样获得,其尺度因子是2k σ,然后第2阶的第2层的尺度因子是第1层的k 倍即3 k σ。第3阶的第1层由第2阶的中间层尺度图像进行子抽样获得。其它阶的构成以此类推。 (2)建立DOG 金字塔 DOG 即相邻两尺度空间函数之差,用(,,)D x y σ来表示,如公式(3)所示: (,,)((,,)(,,))*(,)(,,)(,,)D x y G x y k G x y I x y L x y k L x y σσσσσ=-=- (7) DOG 金字塔通过高斯金字塔中相邻尺度空间函数相减即可,如图1所示。在图中,DOG 金字塔的第l 层的尺度因子与高斯金字塔的第l 层是一致的,其它阶也一样。 看懂一个程序,分三步:1、流程;2、每个语句的功能;3、试数; 小程序:1、尝试编程去解决他;2、看答案;3、修改程序,不同的输出结果; 4、照答案去敲; 5、调试错误; 6、不看答案,自己把答案敲出来; 7、实在不会就背会。。。。。周而复始,反复的敲。。。。。 【程序1】 题目:有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少? ============================================================== 【程序2】 题目:企业发放的奖金根据利润提成。利润(I)低于或等于10万元时,奖金可提10%;利润高 于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提 成7.5%;20万到40万之间时,高于20万元的部分,可提成5%;40万到60万之间时高于 40万元的部分,可提成3%;60万到100万之间时,高于60万元的部分,可提成1.5%,高于 100万元时,超过100万元的部分按1%提成,从键盘输入当月利润I,求应发放奖金总数? ============================================================== 【程序3】 题目:一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?============================================================== 【程序4】 题目:输入某年某月某日,判断这一天是这一年的第几天? ============================================================== 【程序5】 题目:输入三个整数x,y,z,请把这三个数由小到大输出。 ============================================================== 【程序6】 题目:用*号输出字母C的图案。 ============================================================== 【程序7】 题目:输出特殊图案,请在c环境中运行,看一看,Very Beautiful! ============================================================== 【程序8】 题目:输出9*9口诀。 ============================================================== 【程序9】 题目:要求输出国际象棋棋盘。 ============================================================== 【程序10】 题目:打印楼梯,同时在楼梯上方打印两个笑脸。 -------------------------------------------------------------------------------- 【程序11】 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月 后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少? ============================================================== 一、基本算法 1.交换(两量交换借助第三者) 例1、任意读入两个整数,将二者的值交换后输出。 main() {int a,b,t; scanf("%d%d",&a,&b); printf("%d,%d\n",a,b); t=a; a=b; b=t; printf("%d,%d\n",a,b);} 【解析】程序中加粗部分为算法的核心,如同交换两个杯子里的饮料,必须借助第三个空杯子。 假设输入的值分别为3、7,则第一行输出为3,7;第二行输出为7,3。 其中t为中间变量,起到“空杯子”的作用。 注意:三句赋值语句赋值号左右的各量之间的关系! 【应用】 例2、任意读入三个整数,然后按从小到大的顺序输出。 main() {int a,b,c,t; scanf("%d%d%d",&a,&b,&c); /*以下两个if语句使得a中存放的数最小*/ if(a>b){ t=a; a=b; b=t; } if(a>c){ t=a; a=c; c=t; } /*以下if语句使得b中存放的数次小*/ if(b>c) { t=b; b=c; c=t; } printf("%d,%d,%d\n",a,b,c);} 2.累加 累加算法的要领是形如“s=s+A”的累加式,此式必须出现在循环中才能被反复执行,从而实现累加功能。“A”通常是有规律变化的表达式,s在进入循环前必须获得合适的初值,通常为0。例1、求1+2+3+……+100的和。 main() {int i,s; s=0; i=1; while(i<=100) {s=s+i; /*累加式*/ i=i+1; /*特殊的累加式*/ } printf("1+2+3+...+100=%d\n",s);} 【解析】程序中加粗部分为累加式的典型形式,赋值号左右都出现的变量称为累加器,其中“i = i + 1”为特殊的累加式,每次累加的值为1,这样的累加器又称为计数器。 经典算法SIFT实现即代码解释: 以下便是sift源码库编译后的效果图: 为了给有兴趣实现sift算法的朋友提供个参考,特整理此文如下。要了解什么是sift算法,请参考:九、图像特征提取与匹配之SIFT算法。ok,咱们下面,就来利用Rob Hess维护的sift 库来实现sift算法: 首先,请下载Rob Hess维护的sift 库: https://www.360docs.net/doc/269646699.html,/hess/code/sift/ 下载Rob Hess的这个压缩包后,如果直接解压缩,直接编译,那么会出现下面的错误提示: 编译提示:error C1083: Cannot open include file: 'cxcore.h': No such file or directory,找不到这个头文件。 这个错误,是因为你还没有安装opencv,因为:cxcore.h和cv.h是开源的OPEN CV头文件,不是VC++的默认安装文件,所以你还得下载OpenCV并进行安装。然后,可以在OpenCV文件夹下找到你所需要的头文件了。 据网友称,截止2010年4月4日,还没有在VC6.0下成功使用opencv2.0的案例。所以,如果你是VC6.0的用户请下载opencv1.0版本。vs的话,opencv2.0,1.0任意下载。 以下,咱们就以vc6.0为平台举例,下载并安装opencv1.0版本、gsl等。当然,你也可以用vs编译,同样下载opencv(具体版本不受限制)、gsl等。 请按以下步骤操作: 一、下载opencv1.0 https://www.360docs.net/doc/269646699.html,/projects/opencvlibrary/files/opencv-win/1.0/OpenCV_1.0.exe 2008-02-18 18:48 【程序1】 题目:有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少? 1.程序分析:可填在百位、十位、个位的数字都是1、2、3、4。组成所有的排列后再去 掉不满足条件的排列。 2.程序源代码: main() { int i,j,k; printf("\n"); for(i=1;i<5;i++) /*以下为三重循环*/ for(j=1;j<5;j++) for (k=1;k<5;k++) { if (i!=k&&i!=j&&j!=k) /*确保i、j、k三位互不相同*/ printf("%d,%d,%d\n",i,j,k); } } ============================================================== 【程序2】 题目:企业发放的奖金根据利润提成。利润(I)低于或等于10万元时,奖金可提10%;利润高 于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提 成7.5%;20万到40万之间时,高于20万元的部分,可提成5%;40万到60万之间时高于 40万元的部分,可提成3%;60万到100万之间时,高于60万元的部分,可提成1.5%,高于 100万元时,超过100万元的部分按1%提成,从键盘输入当月利润I,求应发放奖金总数? 1.程序分析:请利用数轴来分界,定位。注意定义时需把奖金定义成长整型。 2.程序源代码: main() { long int i; int bonus1,bonus2,bonus4,bonus6,bonus10,bonus; scanf("%ld",&i); bonus1=100000*0.1;bonus2=bonus1+100000*0.75; bonus4=bonus2+200000*0.5; bonus6=bonus4+200000*0.3; bonus10=bonus6+400000*0.15; if(i<=100000) SIFT: Scale Invariant Feature Transform The algorithm SIFT is quite an involved algorithm. It has a lot going on and can be come confusing, So I’ve split up the entire algorithm into multiple parts. Here’s an outline of what happens in SIFT. Constructing a scale space This is the initial preparation. You create internal representations of the original image to ensure scale invariance. This is done by generating a “scale space”. LoG Approximation The Laplacian of Gaussian is great for finding interesting points (or key points) in an image. But it’s computationally expensive. So we cheat and approximate it using the representation created earlier. Finding keypoints With the super fast approximation, we now try to find key points. These are maxima and minima in the Difference of Gaussian image we calculate in step 2 Get rid of bad key points Edges and low contrast regions are bad keypoints. Eliminating these makes the algorithm efficient and robust. A technique similar to the Harris Corner Detector is used here. Assigning an orientation to the keypoints An orientation is calculated for each key point. Any further calculations are done relative to this orientation. This effectively cancels out the effect of orientation, making it rotation invariant. Generate SIFT features Finally, with scale and rotation invariance in place, one more representation is generated. This helps uniquely identify features. Lets say you have 50,000 features. With this representation, you can easily identify the feature you’re looking for (sa y, a particular eye, or a sign board). That was an overview of the entire algorithm. Over the next few days, I’ll go through each step in detail. Finally, I’ll show you how to implement SIFT in OpenCV! What do I do with SIFT features? After you run through the algorithm, you’ll have SIFT features for your image. Once you have these, you can do whatever you want. Track images, detect and identify objects (which can be partly hidden as well), or whatever you can think of. We’ll get into this later as well. But the catch is, this algorithm is patented. >.< So, it’s good enough for academic purposes. But if you’re looking to make something commercial, look for something else! [Thanks to aLu for pointing out SURF is patented too] 1. Constructing a scale space Real world objects are meaningful only at a certain scale. You might see a sugar cube perfectly on a table. But if looking at the entire milky way, then it simply does not exist. This multi-scale nature of objects is quite common in nature. And a scale space attempts to replicate this concept 1.定积分近似计算: /*梯形法*/ double integral(double a,double b,long n) { long i;double s,h,x; h=(b-a)/n; s=h*(f(a)+f(b))/2; x=a; for(i=1;i } 3.素数的判断: /*方法一*/ for (t=1,i=2;i SIFT 特征提取算法总结 主要步骤 1)、尺度空间的生成; 2)、检测尺度空间极值点; 3)、精确定位极值点; 4)、为每个关键点指定方向参数; 5)、关键点描述子的生成。 L(x,y,σ), σ= 1.6 a good tradeoff D(x,y,σ), σ= 1.6 a good tradeoff 关于尺度空间的理解说明:图中的2是必须的,尺度空间是连续的。在 Lowe 的论文中, 将第0层的初始尺度定为1.6,图片的初始尺度定为0.5. 在检测极值点前对原始图像的高斯平滑以致图像丢失高频信息,所以Lowe 建议在建立尺度空间前首先对原始图像长宽扩展一倍,以保留原始图像信息,增加特征点数量。尺度越大图像越模糊。 next octave 是由first octave 降采样得到(如2) , 尺度空间的所有取值,s为每组层数,一般为3~5 在DOG尺度空间下的极值点 同一组中的相邻尺度(由于k的取值关系,肯定是上下层)之间进行寻找 在极值比较的过程中,每一组图像的首末两层是无法进行极值比较的,为了满足尺度 变化的连续性,我们在每一组图像的顶层继续用高斯模糊生成了 3 幅图像, 高斯金字塔有每组S+3层图像。DOG金字塔每组有S+2层图像. If ratio > (r+1)2/(r), throw it out (SIFT uses r=10) 表示DOG金字塔中某一尺度的图像x方向求导两次 通过拟和三维二次函数以精确确定关键点的位置和尺度(达到亚像素精度)? 直方图中的峰值就是主方向,其他的达到最大值80%的方向可作为辅助方向 Identify peak and assign orientation and sum of magnitude to key point The user may choose a threshold to exclude key points based on their assigned sum of magnitudes. 利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备 旋转不变性。以关键点为中心的邻域窗口内采样,并用直方图统计邻域像素的梯度 方向。梯度直方图的范围是0~360度,其中每10度一个柱,总共36个柱。随着距中心点越远的领域其对直方图的贡献也响应减小.Lowe论文中还提到要使用高斯函 数对直方图进行平滑,减少突变的影响。 线性方程组AX=B 的数值计算方法实验 一、 实验描述: 随着科学技术的发展,线性代数作为高等数学的一个重要组成部分, 在科学实践中得到广泛的应用。本实验的通过C 语言的算法设计以及编程,来实现高斯消元法、三角分解法和解线性方程组的迭代法(雅可比迭代法和高斯-赛德尔迭代法),对指定方程组进行求解。 二、 实验原理: 1、高斯消去法: 运用高斯消去法解方程组,通常会用到初等变换,以此来得到与原系数矩阵等价的系数矩阵,达到消元的目的。初等变换有三种:(a)、(交换变换)对调方程组两行;(b)、用非零常数乘以方程组的某一行;(c)、将方程组的某一行乘以一个非零常数,再加到另一行。 通常利用(c),即用一个方程乘以一个常数,再减去另一个方程来置换另一个方程。在方程组的增广矩阵中用类似的变换,可以化简系数矩阵,求出其中一个解,然后利用回代法,就可以解出所有的解。 2、选主元: 若在解方程组过程中,系数矩阵上的对角元素为零的话,会导致解出的结果不正确。所以在解方程组过程中要避免此种情况的出现,这就需要选择行的判定条件。经过行变换,使矩阵对角元素均不为零。这个过程称为选主元。选主元分平凡选主元和偏序选主元两种。平凡选主元: 如果()0p pp a ≠,不交换行;如果()0p pp a =,寻找第p 行下满足() 0p pp a ≠的第一 行,设行数为k ,然后交换第k 行和第p 行。这样新主元就是非零主元。偏序选主元:为了减小误差的传播,偏序选主元策略首先检查位于主对角线或主对角线下方第p 列的所有元素,确定行k ,它的元素绝对值最大。然后如果k p >,则交换第k 行和第p 行。通常用偏序选主元,可以减小计算误差。 3、三角分解法: 由于求解上三角或下三角线性方程组很容易所以在解线性方程组时,可将系数矩阵分解为下三角矩阵和上三角矩阵。其中下三角矩阵的主对角线为1,上三角矩阵的对角线元素非零。有如下定理: 如果非奇异矩阵A 可表示为下三角矩阵L 和上三角矩阵U 的乘积: A LU = (1) 则A 存在一个三角分解。而且,L 的对角线元素为1,U 的对角线元素非零。得到L 和U 后,可通过以下步骤得到X : (1)、利用前向替换法对方程组LY B =求解Y 。 (2)、利用回代法对方程组UX Y =求解X 。 4、雅可比迭代: C语言常用算法集合 1.定积分近似计算: /*梯形法*/ double integral(double a,double b,long n) { long i;double s,h,x; h=(b-a)/n; s=h*(f(a)+f(b))/2; x=a; for(i=1;i if(n==1||n==2) *s=1; else{ fib(n-1,&f1); fib(n-2,&f2); *s=f1+f2; } } 3.素数的判断: /*方法一*/ for (t=1,i=2;i SIFT算法分析 1 SIFT 主要思想 SIFT算法是一种提取局部特征的算法,在尺度空间寻找极值点,提取位置,尺度,旋转不变量。 2 SIFT 算法的主要特点: a)SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。 b)独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进 行快速、准确的匹配。 c)多量性,即使少数的几个物体也可以产生大量SIFT特征向量。 d)高速性,经优化的SIFT匹配算法甚至可以达到实时的要求。 e)可扩展性,可以很方便的与其他形式的特征向量进行联合。 3 SIFT 算法流程图: 4 SIFT 算法详细 1)尺度空间的生成 尺度空间理论目的是模拟图像数据的多尺度特征。 高斯卷积核是实现尺度变换的唯一线性核,于是一副二维图像的尺度空间定义为: L( x, y, ) G( x, y, ) I (x, y) 其中G(x, y, ) 是尺度可变高斯函数,G( x, y, ) 2 1 2 y2 (x ) 2 e / 2 2 (x,y)是空间坐标,是尺度坐标。大小决定图像的平滑程度,大尺度对应图像的概貌特征,小尺度对应图像的细节特征。大的值对应粗糙尺度(低分辨率),反之,对应精细尺度(高分辨率)。 为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。 D( x, y, ) (G( x, y,k ) G( x, y, )) I ( x, y) L( x, y,k ) L( x, y, ) DOG算子计算简单,是尺度归一化的LoG算子的近似。图像金字塔的构建:图像金字塔共O组,每组有S层,下一组的图像由上一 组图像降采样得到。 图1由两组高斯尺度空间图像示例金字塔的构建,第二组的第一副图像由第一组的第一副到最后一副图像由一个因子2降采样得到。图2 DoG算子的构建: 图1 Two octaves of a Gaussian scale-space image pyramid with s =2 intervals. The first image in the second octave is created by down sampling to last image in the previous C语言经典算法大全 老掉牙 河内塔 费式数列 巴斯卡三角形 三色棋 老鼠走迷官(一) 老鼠走迷官(二) 骑士走棋盘 八个皇后 八枚银币 生命游戏 字串核对 双色、三色河内塔 背包问题(Knapsack Problem) 数、运算 蒙地卡罗法求PI Eratosthenes筛选求质数 超长整数运算(大数运算) 长PI 最大公因数、最小公倍数、因式分解 完美数 阿姆斯壮数 最大访客数 中序式转后序式(前序式) 后序式的运算 关于赌博 洗扑克牌(乱数排列) Craps赌博游戏 约瑟夫问题(Josephus Problem) 集合问题 排列组合 格雷码(Gray Code) 产生可能的集合 m元素集合的n个元素子集 数字拆解 排序 得分排行 选择、插入、气泡排序 Shell 排序法- 改良的插入排序Shaker 排序法- 改良的气泡排序Heap 排序法- 改良的选择排序快速排序法(一) 快速排序法(二) 快速排序法(三) 合并排序法 基数排序法 搜寻 循序搜寻法(使用卫兵) 二分搜寻法(搜寻原则的代表)插补搜寻法 费氏搜寻法 矩阵 稀疏矩阵 多维矩阵转一维矩阵 上三角、下三角、对称矩阵 奇数魔方阵 4N 魔方阵 2(2N+1) 魔方阵 1.河内之塔 说明河内之塔(Towers of Hanoi)是法国人M.Claus(Lucas)于1883年从泰国带至法国的,河内为越 战时北越的首都,即现在的胡志明市;1883年法国数学家Edouard Lucas曾提及这个故事,据说创世纪时Benares有一座波罗教塔,是由三支钻石棒(Pag)所支撑,开始时神在第一根棒上放置64个由上至下依由小至大排列的金盘(Disc),并命令僧侣将所有的金盘从第一根石棒移至第三根石棒,且搬运过程中遵守大盘子在小盘子之下的原则,若每日仅搬一个盘子,则当盘子全数搬运完毕之时,此塔将毁损,而也就是世界末日来临之时。 解法如果柱子标为ABC,要由A搬至C,在只有一个盘子时,就将它直接搬至C,当有两个盘 子,就将B当作辅助柱。如果盘数超过2个,将第三个以下的盘子遮起来,就很简单了,每次处理两个盘子,也就是:A->B、A ->C、B->C这三个步骤,而被遮住的部份,其实就是进入程式的递回处理。事实上,若有n个盘子,则移动完毕所需之次数为2^n - 1,所以当盘数为64时,则所需次数为:264- 1 = 18446744073709551615为5.05390248594782e+16年,也就是约5000世纪,如果对这数字没什幺概念,就假设每秒钟搬一个盘子好了,也要约5850亿年左右。 #include SIFT算法C语言逐步实现详解(上) 引言: 在我写的关于sift算法的前倆篇文章里头,已经对sift算法有了初步的介绍:九、图像特征提取与匹配之SIFT算法,而后在:九(续)、sift算法的编译与实现里,我也简单记录下了如何利用opencv,gsl等库编译运行sift程序。 但据一朋友表示,是否能用c语言实现sift算法,同时,尽量不用到opencv,gsl等第三方库之类的东西。而且,Rob Hess维护的sift 库,也不好懂,有的人根本搞不懂是怎么一回事。 那么本文,就教你如何利用c语言一步一步实现sift算法,同时,你也就能真正明白sift算法到底是怎么一回事了。 ok,先看一下,本程序最终运行的效果图,sift 算法分为五个步骤(下文详述),对应以下第二--第六幅图: sift算法的步骤 要实现一个算法,首先要完全理解这个算法的原理或思想。咱们先来简单了解下,什么叫sift算法: sift,尺度不变特征转换,是一种电脑视觉的算法用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量,此算法由David Lowe 在1999年所发表,2004年完善总结。 所谓,Sift算法就是用不同尺度(标准差)的高斯函数对图像进行平滑,然后比较平滑后图像的差别, 差别大的像素就是特征明显的点。 以下是sift算法的五个步骤: 一、建立图像尺度空间(或高斯金字塔),并检测极值点 首先建立尺度空间,要使得图像具有尺度空间不变形,就要建立尺度空间,sift算法采用了高斯函数来建立尺度空间,高斯函数公式为: 上述公式G(x,y,e),即为尺度可变高斯函数。 而,一个图像的尺度空间L(x,y,e) ,定义为原始图像I(x,y)与上述的一个可变尺度的2维高斯函数G(x,y,e) 卷积运算。 即,原始影像I(x,y)在不同的尺度e下,与高斯函数G(x,y,e)进行卷积,得到L(x,y,e),如下: 以上的(x,y)是空间坐标,e,是尺度坐标,或尺度空间因子,e的大小决定平滑程度,大尺度对应图像的概貌特征,小尺度对应图像的细节特征。大的e值对应粗糙尺度(低分辨率),反之,对应精细尺度(高分辨率)。 尺度,受e这个参数控制的表示。而不同的L(x,y,e)就构成了尺度空间,具体计算的时候,即使连续的高斯函数,都被离散为(一般为奇数大小)(2*k+1) *(2*k+1)矩阵,来和数字图像进行卷积运算。 随着e的变化,建立起不同的尺度空间,或称之为建立起图像的高斯金字塔。 但,像上述L(x,y,e) = G(x,y,e)*I(x,y)的操作,在进行高斯卷积时,整个图像就要遍历所有的像素进行卷积(边界点除外),于此,就造成了时间和空间上的很大浪费。 为了更有效的在尺度空间检测到稳定的关键点,也为了缩小时间和空间复杂度,对上述的操作作了一个改建:即,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分与原始图像I(x,y)相乘,卷积生成。 DOG算子计算简单,是尺度归一化的LOG算子的近似。 ok,耐心点,咱们再来总结一下上述内容: 1、高斯卷积 在组建一组尺度空间后,再组建下一组尺度空间,对上一组尺度空间的最后一幅图像进行二分之一采样,得到下一组尺度空间的第一幅图像,然后进行像建立第一组尺度空间那样的操作,得到第二组尺度空间,公式定义为 L(x,y,e) = G(x,y,e)*I(x,y) 概率论问题征解报告: (算法分析类) SIFT算法与RANSAC算法分析 班级:自23 姓名:黄青虬 学号:2012011438 作业号:146 SIFT 算法是用于图像匹配的一个经典算法,RANSAC 算法是用于消除噪声的算法,这两者经常被放在一起使用,从而达到较好的图像匹配效果。 以下对这两个算法进行分析,由于sift 算法较为复杂,只重点介绍其中用到的概率统计概念与方法——高斯卷积及梯度直方图,其余部分只做简单介绍。 一. SIFT 1. 出处:David G. Lowe, The Proceedings of the Seventh IEEE International Conference on (Volume:2, Pages 1150 – 1157), 1999 2. 算法目的:提出图像特征,并且能够保持旋转、缩放、亮度变化保持不变性,从而 实现图像的匹配 3. 算法流程图: 原图像 4. 算法思想简介: (1) 特征点检测相关概念: ◆ 特征点:Sift 中的特征点指十分突出、不会因亮度而改变的点,比如角点、边 缘点、亮区域中的暗点等。特征点有三个特征:尺度、空间和大小 ◆ 尺度空间:我们要精确表示的物体都是通过一定的尺度来反映的。现实世界的 物体也总是通过不同尺度的观察而得到不同的变化。尺度空间理论最早在1962年提出,其主要思想是通过对原始图像进行尺度变换,获得图像多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取等。尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。尺度越大图像越模糊。 ◆ 高斯模糊:高斯核是唯一可以产生多尺度空间的核,一个图像的尺度空间,L (x,y,σ) ,定义为原始图像I(x,y)与一个可变尺度的2维高斯函数G(x,y,σ) 卷积运算 高斯函数: 高斯卷积的尺度空间: 不难看到,高斯函数与正态分布函数有点类似,所以在计算时,我们也是 ()()() ,,,,*,L x y G x y I x y σσ=()22221 ()(),,exp 22i i i i x x y y G x y σπσσ??-+-=- ? ??c语言经典算法
数据结构与算法C语言版期末复习题
SIFT算法原理
C语言经典算法100例题目
非常全的C语言常用算法
SIFT算法实现及代码详解
C语言经典算法100例(1---30)
SIFT算法英文详解
C语言常用算法集合
SIFT 特征提取算法详解
线性方程组的数值算法C语言实现(附代码)
最新C语言常用算法集合汇总
SIFT算法分析
C语言经典算法大全
SIFT算法C语言逐步实现详解
SIFT算法与RANSAC算法分析