【原创】R语言版数据挖掘常用模型构建示例附代码数据
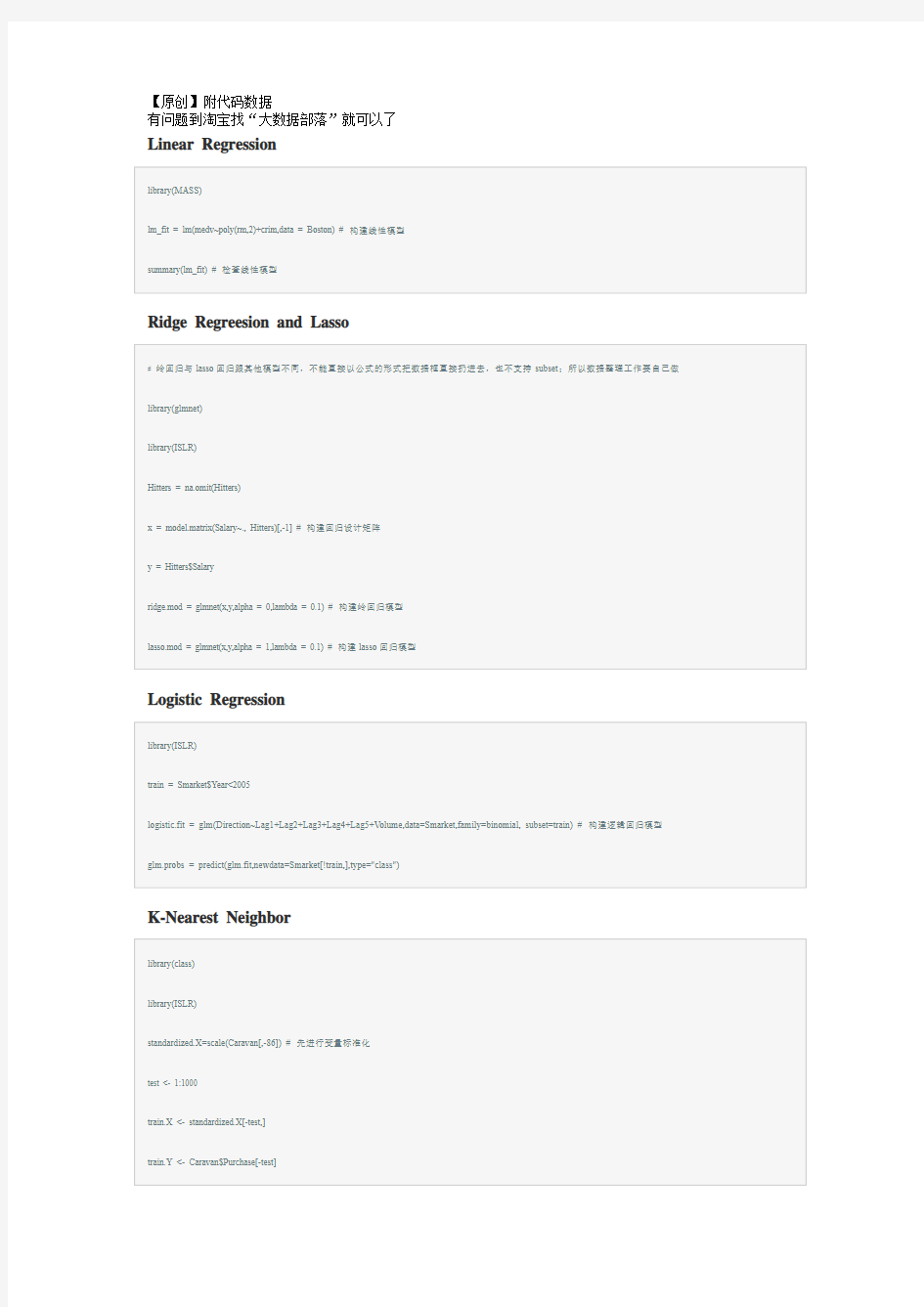
Linear Regression
Ridge Regreesion and Lasso
Logistic Regression
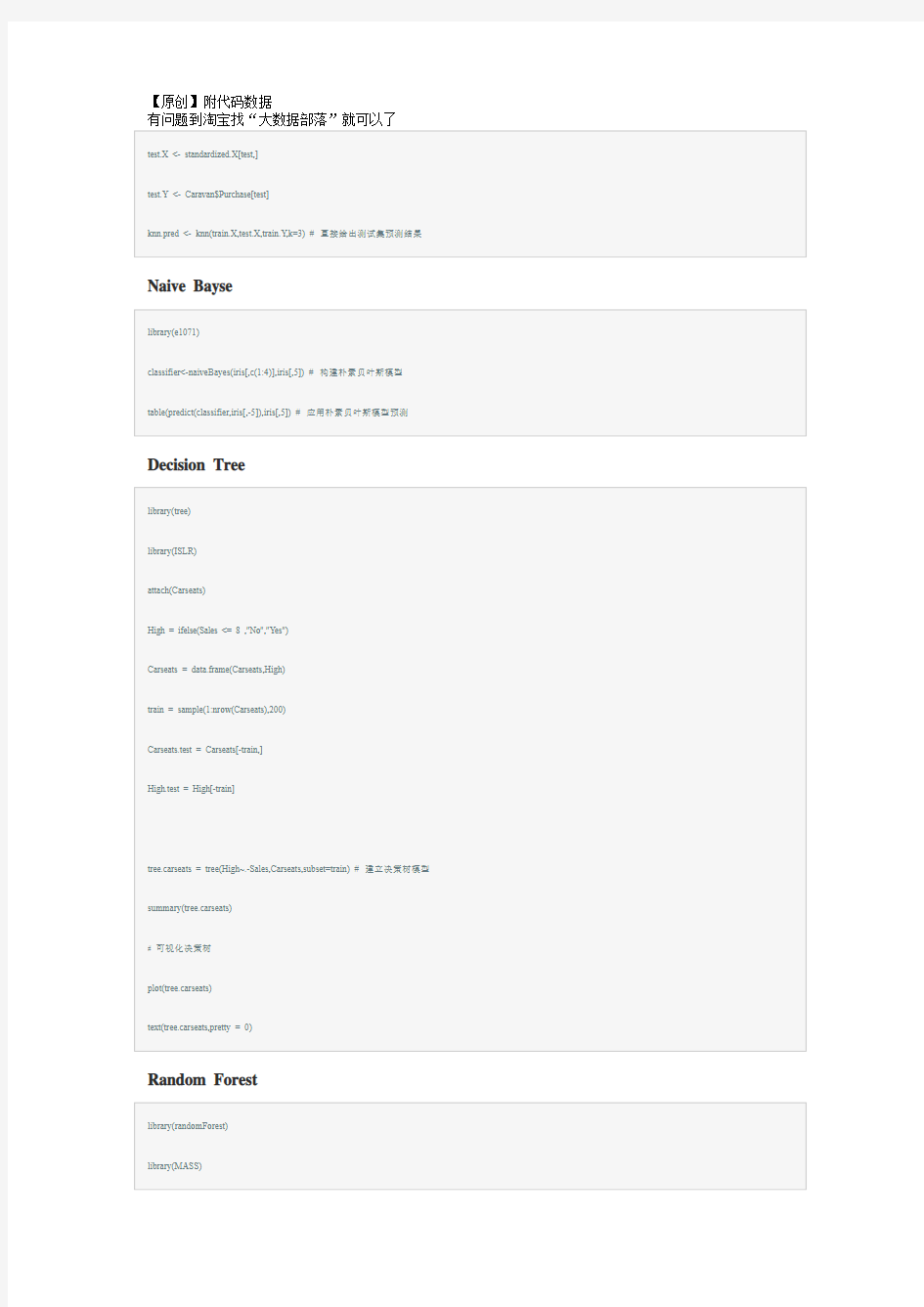
K-Nearest Neighbor
Naive Bayse
Decision Tree
Random Forest
Boosting
Princpal Content Analysis
Apriori
数据挖掘试卷一
数据挖掘整理(熊熊整理-----献给梦中的天涯) 单选题 1.下面哪种分类方法是属于神经网络学习算法?() A. 判定树归纳 B. 贝叶斯分类 C. 后向传播分类 D. 基于案例的推理 2.置信度(confidence)是衡量兴趣度度量( A )的指标。 A、简洁性 B、确定性 C.、实用性 D、新颖性 3.用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?(A) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 4.数据归约的目的是() A、填补数据种的空缺值 B、集成多个数据源的数据 C、得到数据集的压缩表示 D、规范化数据 5.下面哪种数据预处理技术可以用来平滑数据,消除数据噪声? A.数据清理 B.数据集成 C.数据变换 D.数据归约 6.假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内?(B) A 第一个 B 第二个 C 第三个 D 第四个 7.下面的数据操作中,()操作不是多维数据模型上的OLAP操作。 A、上卷(roll-up) B、选择(select) C、切片(slice) D、转轴(pivot) 8.关于OLAP和OLTP的区别描述,不正确的是: (C) A. OLAP主要是关于如何理解聚集的大量不同的数据.它与OTAP应用程序不同. B. 与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务. C. OLAP的特点在于事务量大,但事务内容比较简单且重复率高. D. OLAP是以数据仓库为基础的,但其最终数据来源与OLTP一样均来自底层的数据库系统,两者面对的用户是相同的 9.下列哪个描述是正确的?() A、分类和聚类都是有指导的学习 B、分类和聚类都是无指导的学习
数据挖掘复习章节知识点整理
数据挖掘:是从大量数据中发现有趣(非平凡的、隐含的、先前未知、潜在有用)模式,这些数据可以存放在数据库,数据仓库或其他信息存储中。 挖掘流程: 1.学习应用域 2.目标数据创建集 3.数据清洗和预处理 4.数据规约和转换 5.选择数据挖掘函数(总结、分类、回归、关联、分类) 6.选择挖掘算法 7.找寻兴趣度模式 8.模式评估和知识展示 9.使用挖掘的知识 概念/类描述:一种数据泛化形式,用汇总的、简洁的和精确的方法描述各个类和概念,通过(1)数据特征化:目标类数据的一般特性或特征的汇总; (2)数据区分:将目标类数据的一般特性与一个或多个可比较类进行比较; (3)数据特征化和比较来得到。 关联分析:发现关联规则,这些规则展示属性-值频繁地在给定数据集中一起出现的条件,通常要满足最小支持度阈值和最小置信度阈值。 分类:找出能够描述和区分数据类或概念的模型,以便能够使用模型预测类标号未知的对象类,导出的模型是基于训练集的分析。导出模型的算法:决策树、神经网络、贝叶斯、(遗传、粗糙集、模糊集)。 预测:建立连续值函数模型,预测空缺的或不知道的数值数据集。 孤立点:与数据的一般行为或模型不一致的数据对象。 聚类:分析数据对象,而不考虑已知的类标记。训练数据中不提供类标记,对象根据最大化类内的相似性和最小化类间的原则进行聚类或分组,从而产生类标号。 第二章数据仓库 数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理部门的决策过程。从一个或多个数据源收集信息,存放在一个一致的模式下,并且通常驻留在单个站点。数据仓库通过数据清理、变换、继承、装入和定期刷新过程来构造。面向主题:排除无用数据,提供特定主题的简明视图。集成的:多个异构数据源。时变的:从历史角度提供信息,隐含时间信息。非易失的:和操作数据的分离,只提供初始装入和访问。 联机事务处理OLTP:主要任务是执行联机事务和查询处理。 联系分析处理OLAP:数据仓库系统在数据分析和决策方面为用户或‘知识工人’提供服务。这种系统可以用不同的格式和组织提供数据。OLAP是一种分析技术,具有汇总、合并和聚集功能,以及从不同的角度观察信息的能力。
数据库及基本表的建立
一、实验目的 1、掌握SQL SERVER的查询分析器和企业管理器的使用; 2、掌握创建数据库和表的操作; 二、实验内容和要求 1、练习使用SQL语句、企业管理器(Enterprise Manager)创建数据库; 2、练习使用SQL语句、企业管理器(Enterprise Manager)创建数据库表; 三、实验主要仪器设备和材料 1.计算机及操作系统:PC机,Windows 2000/xp; 2.数据库管理系统:SQL sever 2005; 四、实验方法、步骤及结果测试 题目1、创建数据库“学生情况”: 实现代码及截图: SQL语句 create database学生情况 题目2、将数据库“学生情况”改名为“student” SQL语句 alter database学生情况modify name=student 题目3、创建基本表 SQL语句 S表: use Student create table S (Sno char(10) primary key, Sname char(10) not null, Ssex char(2) check(Ssex='男'or Ssex='女'), Ssp char(20), Sdept char(20), Sbirth datetime, Sfrom varchar(30), Schg char(10), Spa char(8) default('团员'), Snation char(8) default('汉族'), ); C表: use Student
create table C (Cno char(10) primary key, Cname char(10) unique, Tname char(8), Cdept char(20), CCredit real check(CCredit>=0and CCredit<=20), ); SC表: use Student create table Sc (Sno char(10), Cno char(10), Grade real check(Grade>=0and Grade<=100), Remark varchar(50), primary key(Sno,Cno), foreign key(Sno) references S(Sno), foreign key(Cno) references C(Cno), ); 题目4、用sql语句将C表中的ccredit改为整型 use Student /*首先手动删除约束才可以修改*/ alter table C alter column CCredit int; /*重新建立约束*/ alter table C add check(CCredit>=0and CCredit<=20); 题目5、用sql语句在“学生”表中添加一格“备注”字段remark,变长字符型,并保存结果 alter table S add remark varchar(50); 题目6. 用sql语句将“学生”表中“专业”字段数据类型改为varchar,长度为30并保存结果 alter table S alter column Ssp varchar(30); 题目7. 用sql语句删除“学生成绩”表中的“备注”字段并保存结果 alter table Sc drop column Remark; 题目8. 通过sql语句向s表中添加信息。 INSERT INTO S(Sno,Sname,Ssex,Ssp,Sdept,Sbirth,Sfrom,Schg,Spa,Snation,remark) VALUES ('001','李春刚','男','计算机应用','CS','1985-5-10','河源','','团员','汉',''); INSERT INTO S(Sno,Sname,Ssex,Ssp,Sdept,Sbirth,Sfrom,Schg,Spa,Snation,remark) VALUES ('002','东学婷','女','计算机应用','CS','1986-10-24','包头','转系','团员','蒙 ','');
数据挖掘的方法
数据挖掘的方法有哪些? 时间:2012-11-1111:24来源:百度空间作者:温馨小筑围观:1436次 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。 1、分类 分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。 2、回归分析 回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。它可以应用到市场营销的各个方面,如客户寻求、保持和预防客户流失活动、产品生命周期分析、销售趋势预测及有针对性的促销活动等。 3、聚类 聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。它可以应用到客户群体的分类、客户背景分析、客户购买趋势预测、市场的细分等。 4、关联规则 关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客户群,客户寻求、细分与保持,市场营销与推销,营销风险评估和诈骗预测等决策支持提供参考依据。 5、特征 特征分析是从数据库中的一组数据中提取出关于这些数据的特征式,这些特征式表达了该数据集的总体特征。如营销人员通过对客户流失因素的特征提取,可以得到导致客户流失的一系列原因和主要特征,利用这些特征可以有效地预防客户的流失。
《数据挖掘》试题与答案
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2. 时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
物流管理系统的SQL数据库设计(含代码)
物流管理信息系统的数据库设计 班级 xxx 系统名称:物流管理信息系统 一、需求分析 物流管理系统是为制造商和零售商设计的管理系统数据库系统,目的是: 1、实现上游制造商的信息管理。 2、实现下游零售商的信息管理。 3、实现进库与配送的信息管理。从而提高物流效率,降低物流成 本并提高企业管理化水平。经过调研分析,得到系统的如下功能需求。 (1)数据检索 1、制造商、零售商查询某一产品名称,规格和单位 输入:产品编号
输出:产品名称,产品规格,产品单位,制造商编号 2、物流中心、制造商查询某一零售商名称,联系人,地址,电话号码,网址 输入:零售商编号 输出:零售商名称,联系人,地址,电话号码,网址 3、零售商、物流中心查询某一制造商信息表 输入:制造商编号 输出:制造商名称,联系人,地址,电话号码,网址 4、物流中心、制造商、零售商查询某一产品的出库信息表 输入:仓库编号 输出:仓库编号,库名,地址,电话 5、物流中心、零售商查询某一产品的制造商和产品信息表 输入:产品编号编号 输出:制造商名称,联系人,地址,电话号码,网站,产品名称,产品名称,产品规格,产品单位 6、查询某一产品对应的物流中心编号及产品信息
输入:产品编号 输出:物流中心编号,货物价格,提取.产品编号,产品.产品名称,产品名称,产品规格,产品单位 7、制造商,零售商查询某一物流中心信息 输入:物流中心编号 输出:物理中心名称,联系人,地址,电话号码,网址 (2)数据插入 ①产品数据插入 ②制造商数据插入 ③零售商数据插入 ④物流中心数据插入 (3)数据修改 ①产品数据修改:某产品数据变化时,输入该产品编号以及需修 改的属性,完成对产品表的修改 ②制造商数据修改:某制造商数据变化时,输入该制造商编号以 及需修改的属性,完成对制造商表的修改
大数据时代的数据挖掘
大数据时代的数据挖掘 大数据是2012的时髦词汇,正受到越来越多人的关注和谈论。大数据之所以受到人们的关注和谈论,是因为隐藏在大数据后面超千亿美元的市场机会。 大数据时代,数据挖掘是最关键的工作。以下内容供个人学习用,感兴趣的朋友可以看一下。 智库百科是这样描述数据挖掘的“数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。 数据挖掘的定义 技术上的定义及含义 数据挖掘(Data Mining )就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。这个定义包括好几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海皆准的知识,仅支持特定的发现问题。 与数据挖掘相近的同义词有数据融合、人工智能、商务智能、模式识别、机器学习、知识发现、数据分析和决策支持等。 ----何为知识从广义上理解,数据、信息也是知识的表现形式,但是人们更把概念、规则、模式、规律和约束等看作知识。人们把数据看作是形成知识的源泉,好像从矿石中采矿或淘金一样。原始数据可以是结构化的,如关系数据库中的数据;也可以是半结构化的,如文本、图形和图像数据;甚至是分布在网络上的异构型数据。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。发现的知识可以被用于信息管理,查询优化,决策支持和过程控制等,还可以用于数据自身的维护。因此,数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。在这种需求牵引下,汇聚了不同领域的研究者,尤其是数据库技术、人工智能技术、数理统计、可视化技术、并行计算等方面的学者和工程技术人员,投身到数据挖掘这一新兴的研究领域,形成新的技术热点。 这里所说的知识发现,不是要求发现放之四海而皆准的真理,也不是要去发现崭新的自然科学定理和纯数学公式,更不是什么机器定理证明。实际上,所有发现的知识都是相对的,是有特定前提和约束条件,面向特定领域的,同时还要能够易于被用户理解。最好能用自然语言表达所发现的结果。n x _s u x i a n g n i n g
实验一创建数据库和表
实验一创建数据库和表 1、目的和要求 (1)了解SQL Server数据库的逻辑结构和物理结构。 (2)了解表的结构特点 (3)了解SQL Server的基本数据类型。 2、实验内容 (1)实验题目 ①创建一个新的数据库。创建用于企业管理的员工数据库,数据库名称为YGGL。 ②在创建好的数据库YGGL中创建数据表。考虑到数据库YGGL中包含员工的信息、部分信息以及员工的薪水信息,所以数据库YGGL应该包含三个表:Employees(员工自然信息)表、Departments(部门信息)表和Salary(员工薪水情况)表。 3、实验步骤 (1)在对象资源管理器中创建数据库YGGL。 (2)删除数据库YGGL。 ①界面操作删除数据库 删除数据库YGGL时,右键单击数据库,弹出菜单点击“删除”,弹出“删除对象”窗口,确认删除。 ② T-SQL语句删除数据库 在代码空白处右击鼠标,弹出菜单选择“执行(X)”或者键盘“F5”运行代码,在下方会显示运行成功。 此时在左侧“对象资管理器”中右键点击“数据库”选择刷新数据库,会发现数据库“PX”已经删除。 注意:当执行过一遍代码时,也就是执行了T-SQL语句删除数据库后再次执行代码会出现这样的警告。原因是由于执行过一遍T-SQL语句,进行操作的数据库已经被删除,不存在。 (3)使用T-SQL语句创建数据库YGGL。 新建查询后,在窗口中输入上面代码,右键代码空白处执行。然后在“对象资源管理器”中查看。如果“数据库”列表中并未列出YGGL数据库,则单击右键“数据库”,选择“刷新”选项,“数据库”列表中就会出现创建的YGGL数据库。 (4)在对象资源管理器中创建表。 ①创建表。Employees(员工自然信息)表、Departments(部门信息)表和Salary(员工薪水情况)表。 在对象资源管理器中选择创建的数据库“YGGL”,展开数据库YGGL,选择“表”,右键
数据挖掘常用的方法
数据挖掘常用的方法 在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪 声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知 识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统 计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正 确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可 以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖 掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。 (1)分类。分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。 可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情 况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。 (2)回归分析。回归分析反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的 研究中去。在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的 回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。 (3)聚类。聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的 相似性很小,跨类的数据关联性很低。 (4)关联规则。关联规则是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。关联规则的挖掘过程主要包括两个阶段:第一阶 段为从海量原始数据中找出所有的高频项目组;第二极端为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各 银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。 (5)神经网络方法。神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知 识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神 经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络 模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组
SQL数据库操作步骤及代码
第2章数据库高级编程 ADO、NET就是为、NET框架而创建的,就是对ADO(ActiveX Data Objects)对象模型的扩充。ADO、NET提供了一组数据访问服务的类,可用于对Microsoft SQL Server、Oracle等数据源的一致访问。ADO、NET模型分为、NET Data Provider(数据提供程序)与DataSet数据集(数据处理的核心)两大主要部分。 、NET数据提供程序提供了四个核心对象,分别就是Connection、Command、DataReader 与DataAdapter对象。功能如表2-1所示。 表2-1 ADO、NET核心对象 2、1 SQL Server相关配置 在使用C#访问数据库之前,首先创建一个名为“chap2”的数据库,此数据库作为2、1节及2、2节中例题操作的默认数据库。然后创建数据表Products,表结构如表2-2所示。创建完毕后可录入初始化数据若干条。 表2-2 Products表表结构 上机课的操作中出现问题较多的地方。 1.身份验证方式 SQL Server 2012在安装时默认就是使用Windows验证方式的,但就是安装过后用户可随时修改身份验证方式。 启动SQL Server 2012 Management Studio,在“连接到服务器”对话框中选择“Windows
身份验证”连接服务器,连接成功后,在窗体左侧的“对象资源管理器”中右键单击服务器实例节点,并在弹出的快捷菜单中选择“属性”菜单项,系统将弹出“服务器属性”窗体,切换至“安全性”选项卡,如图2-1所示。 图2-1 “服务器属性”对话框-“安全性”选项卡 在“服务器身份验证”部分选择“SQL Server与Windows身份验证模式”选项,并单击【确定】按钮。系统将提示需要重新启动SQL Server以使配置生效,如图2-2所示。 图2-2 系统提示框 右键单击“对象资源管理器”的服务器实例节点,在弹出的快捷菜单中选择“重新启动”菜单项,SQL Server将重新启动服务,重启成功后即可使用混合验证方式登录SQL Server服务器。 2.添加登录账户 大部分初学者都习惯于使用SQL Server的系统管理员账号“sa”来登录数据库服务器,而在实际工作环境中使用sa账号登录服务器就是不合理的。因为很多情况下系统的数据库就是部署在租用的数据库服务器上的,此时数据库设计人员或编程人员都不可能具有sa账号的使用权限,因此在将身份验证方式修改为SQL Server与Windows混合验证后,需要为某应用程序创建一个专用的登录账户。其操作步骤描述如下。 (1)使用Windows身份验证登录SQL Server,在对象资源管理器中点击“安全性”节点前面的加号“+”,在展开后的“登录名”子节点上单击右键,如图2-3所示,并在弹出的快捷菜单中选择“新建登录名”选项。
实验一-创建数据库和表
实验一-创建数据库和表
实验一创建数据库和表 1、目的和要求 (1)了解SQL Server数据库的逻辑结构和物理结构。 (2)了解表的结构特点 (3)了解SQL Server的基本数据类型。 2、实验内容 (1)实验题目 ①创建一个新的数据库。创建用于企业管理的员工数据库,数据库名称为YGGL。 ②在创建好的数据库YGGL中创建数据表。考虑到数据库YGGL中包含员工的信息、部分信息以及员工的薪水信息,所以数据库YGGL应该包含三个表:Employees(员工自然信息)表、Departments(部门信息)表和Salary(员工薪水情况)表。 3、实验步骤 (1)在对象资源管理器中创建数据库YGGL。
(2)删除数据库YGGL。 ①界面操作删除数据库 删除数据库YGGL时,右键单击数据库,弹出菜单点击“删除”,弹出“删除对象”窗口,确认删除。 ②T-SQL语句删除数据库
在代码空白处右击鼠标,弹出菜单选择“执行(X)”或者键盘“F5”运行代码,在下方会显示运行成功。 此时在左侧“对象资管理器”中右键点击“数据库”选择刷新数据库,会发现数据库“PX”已经删除。 注意:当执行过一遍代码时,也就是执行了T-SQL语句删除数据库后再次执行代码会出现这样的警告。原因是由于执行过一遍T-SQL语句,进行操作的数据库已经被删除,不存在。 (3)使用T-SQL语句创建数据库YGGL。
新建查询后,在窗口中输入上面代码,右键代码空白处执行。然后在“对象资源管理器”中查看。如果“数据库”列表中并未列出YGGL数据库,则单击右键“数据库”,选择“刷新”选项,“数据库”列表中就会出现创建的YGGL数据库。 (4)在对象资源管理器中创建表。 ①创建表。Employees(员工自然信息)表、Departments(部门信息)表和Salary(员工薪水情况)表。 在对象资源管理器中选择创建的数据库“YGGL”,展开数据库YGGL,选择“表”,右键单击“表”在弹出的菜单中选择“新建表”。将表保存并命名为“Employees”。下面是相同方法创建的Employees(员工自然信息)表、
数据挖掘流程模型CRISP-DM
CRISP-DM 1.0 数据挖掘方法论指南 Pete Chapman (NCR), Julian Clinton (SPSS), Randy Kerber (NCR), Thomas Khabaza (SPSS), Thomas Reinartz (DaimlerChrysler), Colin Shearer (SPSS) and Rüdiger Wirth (DaimlerChrysler)
该手册描述了CRISP-DM(跨行业数据挖掘标准流程)过程模型,包括CRISP-DM的方法论、相关模型、用户指南、报告介绍,以及一个含有其他相关信息的附录。 本手册和此处的信息均为CRISP-DM协会以下成员的专利:NCR Systems Engineering Copenhagen (USA and Denmark), DaimlerChrysler AG (Germany), SPSS Inc. (USA) and OHRA Verzekeringen en Bank Groep B.V (The Netherlands)。 著作权? 1999, 2000 本手册中所有商标和服务标记均为它们各自所有者的标记,并且为CRISP-DM协会的成员所公认。
前言 1996年下半年,数据挖掘市场尚处于萌芽状态,CRISP-DM率先由三家资深公司共同提出。DaimlerChrysler (即后来的Daimler-Benz) 在其商业运营中运用数据挖掘的经验颇为丰富,远远领先于其他大多数商业组织。SPSS(即后来的ISL)自1990年以来一直致力于提供基于数据挖掘的服务,并于1994年推出了第一个商业数据挖掘平台——Clementine。至于NCR,作为对其Teradata数据仓库客户增值目标的一部分,它已经建立了数据挖掘顾问和技术专家队伍以满足其客户的需要。 当时,数据挖掘所引起的市场关注开始表明其进入爆炸式增长和广泛应用的迹象。这既令人兴奋又使人害怕。随着我们在这条路上不断走下去,所有人都不断研究和发展数据挖掘方法。可是我们做的是否正确?是否每一个数据挖掘的新使用者都必须像我们当初一样经历反复试验和学习?此外,从供应商的角度来看,我们怎样向潜在客户证明数据挖掘技术已足够成熟到可以作为它们商业流程的一个关键部分? 在这种情况下,我们认为急需一个标准的流程模型——非私人所有并可以免费获取——向我们和所有的从业者很好的回答这些问题。 一年后我们组建了联盟,名字CRISP-DM取自CRoss-Industry Standard Process for Data Mining的缩写,由欧洲委员会提供资助,开始实施我们最初的想法。因为CRISP-DM的定位是面向行业、工具导向和面向应用的,所以我们明白必须“海纳百川,博采众家之长”,必须在一个尽可能宽的范围内吸引人们的兴趣(比如数据仓库制造商和管理咨询顾问)。于是我们决定成立CRISP-DM 专门兴趣小组(即大家所知道的“The SIG”)。我们邀请所有感兴趣的团体和个人到阿姆斯特丹参加为期一天的工作会议,讨论并正式成立SIG组织:我们观念共享,鼓励与会者畅所欲言,为发展CRISP-DM共商大计。 当天每个协会成员都心怀惴惴,会不会没有人对CRISP-DM有足够的兴趣?即使有,那他们是否认为实际上并未看到一种对标准化流程的迫切需求?或者我们的想法迄今为止与别人的步调不一致,任何标准化的念头只是不切实际的白日梦? 事实上,讨论的结果大大超出了我们的期望。下面三点最为突出: 当天的与会人数是我们原先期望的两倍 行业需要而且现在就需要一个标准化流程——大家压倒性的一致同意 每个出席者从他们的项目经验出发陈述了自己关于数据挖掘的看法,这使我们越来越清晰地看到:尽管表述上有些区别——主要是在阶段的划分和术语方面,但在如何看待数据挖掘流程上大家具有极大的相似之处。 在工作组结束的时候,我们充满了自信,受SIG的启发和批评,我们能够建成一个标准化流程模型,为数据挖掘事业作出贡献。 接下来的两年半里,我们努力工作来完善和提炼CRISP-DM。我们不断地在Mercedes-Benz、保险部门的伙伴及OHRA的实际大型数据挖掘项目中进行尝试。同时也运用商业数据挖掘工具来整合CRISP-DM。SIG证明了是无价的,其成员增长到200多,并且在伦敦、纽约和布鲁塞尔都拥有工作组。 到该项目的欧洲委员会支持基金部分结束时——1999年年中,我们提出了自己觉得质量优良的流程模型草案。熟悉这一草案的人将会发现,一年以来,尽管现在的CRISP-DM1.0更完整更好,但从根本上讲并没有什么本质不同。我们强烈地意识到:在整个项目中,流程模型仍然是一个持续进行的工作;CRISP-DM还只是在一系列有限的项目中得到证实。过去的一年里,DaimlerChrysler有机会把CRISP-DM运用于更为广阔的范围。SPSS和NCR的专业服务团体采纳了CRISP-DM,而且用之成功地完成了无数客户委托,包括许多工业和商业的问题。这段时间以来,我们看到协会外部的服务供应商也采用了CRISP-DM;分析家不断重复地提及CRISP-DM
土地规划数据库类型代码
创作编号: GB8878185555334563BT9125XW 创作者:凤呜大王* 一、主要图层命名对照表: CZJSKZQ 村镇建设控制区 JSYDGZQ 建设用地管制区 TDYTQ 土地用途区 JQDLTB 基期地类图斑 MZJCSS 面状基础设施 MZZDJSXM 面状重点建设项目 XZQ 行政区 JBNTGHTB 基本农田规划图斑JQXZDW 基期现状地物 DLMCZJ 地类名称注记 XZQJX 行政区界线 二、主要图层类型代码表 1.①建设用地管制区 属性代码表达图式 代 码 管制区类型SM 图式符号RGB 线宽 010 允许建设区011 现状建设用 地 RGB(170,0,130) RGB(245,140,140) 1.5
012 新增建设用 地 RGB(170,0,130) RGB(220,100,120) 1.5 020 有条件建设区/ / RGB(170,0,130) RGB(255,210,125) 1.5 030 限制建设区/ / RGB(165,255,115) / 040 禁止建设区/ / RGB(40,115,0) RGB(60,180,70) 1.5 ②建设用地管制区(土地利用总体规划图) 建设用地管制分区 表达图式 图示符号RGB 允许建设区RGB(170,0,130) 有条件建设区 RGB(170,0,130) RGB(220,100,120) 2.土地用途区 属性代码表达图式代码土地用途区类型图式符号RGB 010 基本农田保护区RGB(250,255,50) 020 一般农地区RGB(245,255,125) 030 城镇建设用地区 RGB(170,0,130) RGB(220,100,120) 040 村镇建设用地区 RGB(170,0,130) RGB(245,140,140) 050 独立工矿用地区RGB(210,160,120) 060 风景旅游用地区RGB(0,135,255) 070 生态环境安全控制区RGB(40,110,25) 080 自然与文化遗产保护区RGB(20,230,0) 090 林业用地区RGB(120,220,120) 100 牧业用地区RGB(210,255,115)
数据挖掘过程说明文档
生产再生钢的过程如下:组合后的废钢通过炉门送入炉子,电流通过悬浮在炉内的电极输送到熔化的废钢中。提供给这些电极的高电流通过电弧传输到内部的金属废料,对其加热并产生超过3000°C的温度。 通过添加各种活性气体和惰性气体以及固体物质来维持和优化炉内条件。然后,钢水从熔炉中流出,进入移动坩埚,并浇铸到钢坯中。 你将得到一个数据集,代表从各种金属废料lypes生产回收钢坯的过程。Hie数据集包含大 ?这是一个基于团队的项目。你需要组成一个小组,由三名(或两名)组员来完成这项练习。?您可以使用Weka或任何其他可用的数据挖掘资源和软件包来帮助您制定问题、计算、评
估等。 ?您的团队绩效将完全根据团队的结果和您的报告进行评估。 ?作为一个团队,您需要决定给定问题的性质;什么类型的数据挖掘问题公式适合解决此类问题;您的团队可以遵循什么样的基本数据挖掘过程;您的团队希望尝试什么类型的算法;以何种方式,您可以进一步利用或最大化您的性能,等等。 ?您的团队应致力于涵盖讲座、教程中包含的领域,考虑预处理、特征选择、各种算法、验证、测试和性能评估方法。 ?对于性能基准,建议您使用准确度和/或错误率作为评估指标。 ?表现最好的球队将被宣布为本次迷你KDD杯冠军,并将获得10%的加分,最高100%满分。 数据挖掘流程: 一、数据建模 1. 数据获取 2. 数据分析 3. 数据预处理 二、算法建模 1. 模型构建 2. 模型检验 三、评估 一、数据建模 1.数据获取及分析 数据集:EAF_process_dataqqq.csv 根据《assignment 2》中,数据集的说明,可知:
大数据挖掘技术之DM经典模型(上)
大数据挖掘技术之DM经典模型(上) 数据分析微信公众号datadw——关注你想了解的,分享你需要的。 实际上,所有的数据挖掘技术都是以概率论和统计学为基础的。 下面我们将探讨如何用模型来表示简单的、描述性的统计数据。如果我们可以描述所要找的事物,那么想要找到它就会变得很容易。这就是相似度模型的来历——某事物与所要寻找的事物越相似,其得分就越高。 下面就是查询模型,该模型正在直销行业很受欢迎,并广泛用于其它领域。朴素贝叶斯模型是表查找模型中一种非常有用的泛化模型,通常表查询模型适用于较低的维度,而朴素贝叶斯模型准许更多的维度加入。还有线性回归和逻辑回归模型,都是最常见的预测建模技术。回归模型,用于表示散点图中两个变量之间的关系。多元回归模型,这个准许多个单值输入。随后介绍逻辑回归分析,该技术扩展了多元回归以限制其目标范围,例如:限定概率估计。还有固定效应和分层回归模型,该模型可将回归应用于个人客户,在许多以客户为中心的数据挖掘技术之间搭建了一座桥梁。 1、相似度模型 相似度模型中需要将观察值和原型进行比较,以得到相应的相似度得分。观察值与原型相似度越高,其得分也就越高。一种度量相似度的方法是测量距离。观察值与原型值之间的距离越近,观察值的得分就越高。当每个客户细分都有一个原型时,该模型可以根据得分把客户分配到与其最相似的原型所在的客户细分中。 相似度模型有原型和一个相似度函数构成。新数据通过计算其相似度函数,就可以计算出相似度得分。 1.1、相似度距离 通过出版社的读者比一般大众要富有,而且接受教育的程度要高为例。通常前者要比后者在富有程度、教育程度的比例大三倍。这样我们
数据库建表操作SQL代码大全
?首页 ?发现小组 ?发现小站 ?线上活动 joshua的日记 ?joshua的主页 ?广播 ?相册 ?喜欢 ?二手 ?活动 ?发豆邮 数据库建表操作SQL代码大全 2009-04-23 17:39:37 决定在这里建立自己的学习数据库的日记,以便随时学习,随时回顾。 从今天开始。 新建表: create table [表名] ( [自动编号字段] int IDENTITY (1,1) PRIMARY KEY , [字段1] nVarChar(50) default '默认值' null , [字段2] ntext null , [字段3] datetime, [字段4] money null , [字段5] int default 0, [字段6] Decimal (12,4) default 0, [字段7] image null , ) 删除表: Drop table [表名]
INSERT INTO [表名] (字段1,字段2) VALUES (100,'https://www.360docs.net/doc/3015293576.html,') 删除数据: DELETE FROM [表名] WHERE [字段名]>100 更新数据: UPDATE [表名] SET [字段1] = 200,[字段2] = 'https://www.360docs.net/doc/3015293576.html,' WHERE [字段三] = 'HAIWA' 新增字段: ALTER TABLE [表名] ADD [字段名] NVARCHAR (50) NULL 删除字段: ALTER TABLE [表名] DROP COLUMN [字段名] 修改字段: ALTER TABLE [表名] ALTER COLUMN [字段名] NVARCHAR (50) NULL 重命名表:(Access 重命名表,请参考文章:在Access数据库中重命名表) sp_rename '表名', '新表名', 'OBJECT' 新建约束: ALTER TABLE [表名] ADD CONSTRAINT 约束名CHECK ([约束字段] <= '2000-1-1') 删除约束: ALTER TABLE [表名] DROP CONSTRAINT 约束名 新建默认值 ALTER TABLE [表名] ADD CONSTRAINT 默认值名DEFAULT 'https://www.360docs.net/doc/3015293576.html,' FOR [字段名] 删除默认值 ALTER TABLE [表名] DROP CONSTRAINT 默认值名 删除Sql Server 中的日志,减小数据库文件大小 dump transaction 数据库名with no_log backup log 数据库名with no_log dbcc shrinkdatabase(数据库名) exec sp_dboption '数据库名', 'autoshrink', 'true' \'添加字段通用函数 Sub AddColumn(TableName,ColumnName,ColumnType) Conn.Execute("Alter Table "&TableName&" Add "&ColumnName&" "&ColumnType&"") End Sub
【精品】(最新)案例四数据挖掘之七种常用的方法
数据挖掘之七种常用的方法 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据 进行挖掘。 1.分类 分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为 不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。 它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。 2.回归分析 回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。 它可以应用到市场营销的各个方面,如客户寻求、保持和预防客户流失活动、产品生命周期分析、销售趋势预测及有针对性的促销活动等。 3.聚类 聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。 它可以应用到客户群体的分类、客户背景分析、客户购买趋势预测、市场的细分等。 4.关联规则 关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。 在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客户群,客户寻求、细分与保持,市场营销与推销,营销风险评估和诈骗预测等决策支持提供参考依据。 5.特征 特征分析是从数据库中的一组数据中提取出关于这些数据的特征式,这些特征式表达了该数据集的总体特征。如营销人员通过对客户流失因素的特征提取,可以得到导致客户流失的一系列原因和主要特征,利用这些特征可以有效地预防客户的流失。
数据挖掘之七种常用的方法
数据挖掘之七种常用的方法 2014-06-04 大数据 数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。 ①分类 分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。 它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。 ②回归分析 回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。 它可以应用到市场营销的各个方面,如客户寻求、保持和预防客户流失活动、产品生命周期分析、销售趋势预测及有针对性的促销活动等。 ③聚类 聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。 它可以应用到客户群体的分类、客户背景分析、客户购买趋势预测、市场的细分等。 ④关联规则 关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。 在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客