分治与递归 循环赛编程

实验一:分治与递归
【实验目的】
深入理解分治法算法思想,并采用分治法进行程序设计。
【实验性质】
验证性实验。
【实验内容与要求】
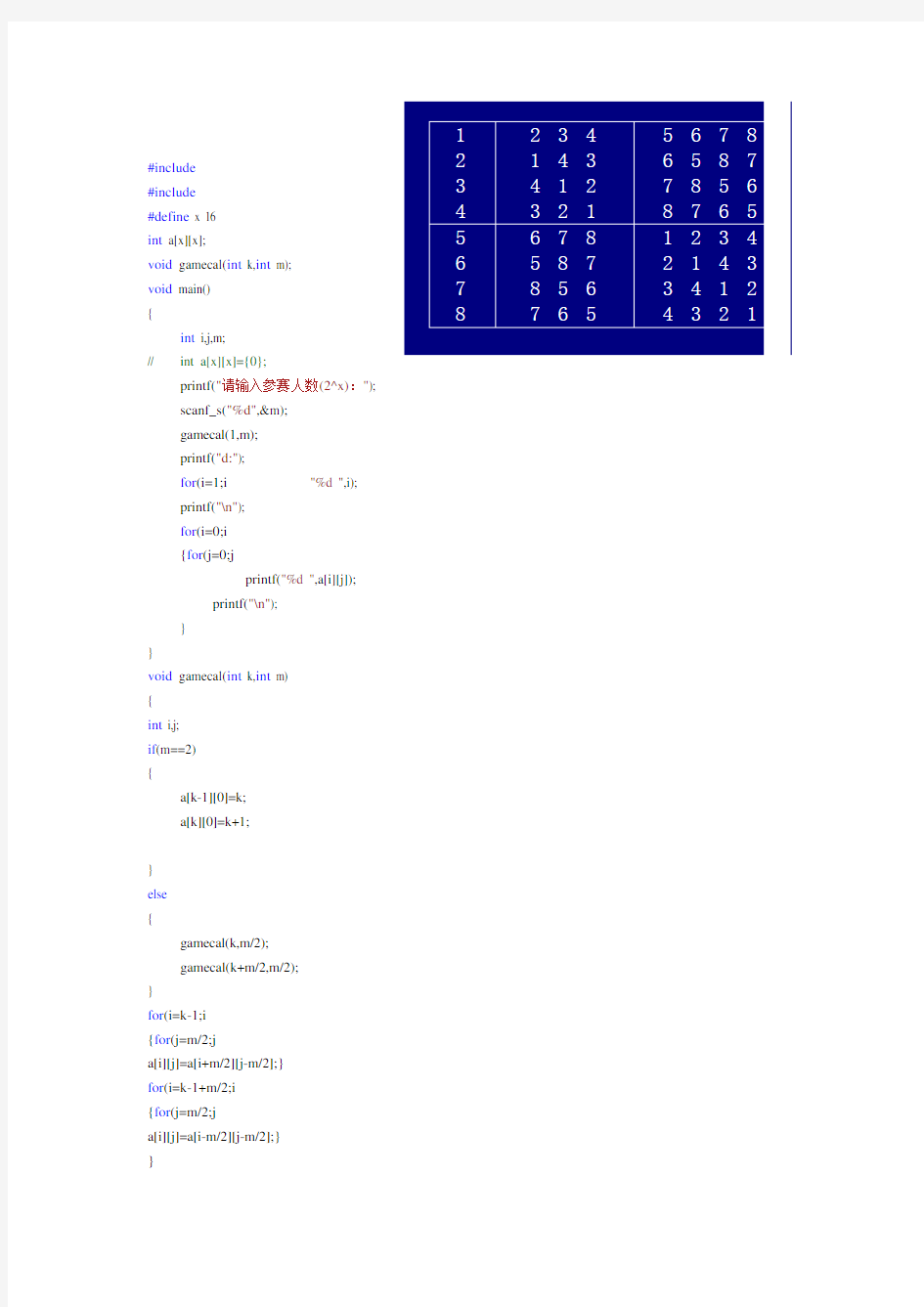
设有n=2k个运动员要进行网球循环赛。现要设计一个满足以下要求的比赛日程表:⑴每个选手必须与其他n-1个选手各赛一次;⑵每个选手一天只能赛一次;⑶循环赛一共进行n-1天。按此要求可将比赛日程表设计-成有n行和n-l列的一个表。在表中第i行和第j列处填入第i个选手在第j天所遇到的选手。用分治法编写为该循环赛设计一张比赛日程表的算法并运行实现、对复杂度进行分析。
算法思想:按分治策略,我们可以将所有选手对分为两组,n个选手的比赛日程表就可以通过为n/2个选手设计的比赛日程表来决定。递归地用这种一分为二的策略对选手进行分割,直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让这2个选手进行比赛就可以了。
下图所列出的正方形表是4个选手的比赛日程表。其中左上角与左下角的两小块分别为选手1至选手2和选手3至选手4第1天的比赛日程。据此,将左上角小块中的所有数字按其相对位置抄到右下角,将左下角小块中的所有数字按其相对位置抄到右上角,这样我们就分别安排好了选手1至选手2和选手3至选手4在后2天的比赛日程。这种安排是符合要求的。
程安排表。
#include
#include
#define x 16
int a[x][x];
void gamecal(int k,int m);
void main()
{
int i,j,m;
// int a[x][x]={0};
printf("请输入参赛人数(2^x):");
scanf_s("%d",&m);
gamecal(1,m);
printf("d:");
for(i=1;i printf("\n"); for(i=0;i {for(j=0;j printf("%d ",a[i][j]); printf("\n"); } } void gamecal(int k,int m) { int i,j; if(m==2) { a[k-1][0]=k; a[k][0]=k+1; } else { gamecal(k,m/2); gamecal(k+m/2,m/2); } for(i=k-1;i {for(j=m/2;j a[i][j]=a[i+m/2][j-m/2];} for(i=k-1+m/2;i {for(j=m/2;j a[i][j]=a[i-m/2][j-m/2];} } 实验报告分治与递归 中国矿业大学计算机科学与技术学院孟靖宇 一、实验目的与要求 1、熟悉C/C++语言的集成开发环境; 2、通过本实验加深对递归过程的理解 二、实验内容: 掌握递归算法的概念和基本思想,分析并掌握“整数划分”问题的递归算法。 三、实验题 任意输入一个整数,输出结果能够用递归方法实现整数的划分。 四、算法思想 对于数据n,递归计算最大加数等于x 的划分个数+最大加数不大于x-1的划分个数。最大加数x 从n 开始,逐步变小为n-1, (1) 考虑增加一个自变量:对于数据n,最大加数n1不大于m 的划分个数记作),(m n q 。则有: ???????>>=<==-+--+=1 1,1),()1,()1,(1),(1),(m n m n m n m n m m n q m n q n n q n n q m n q 五、代码实现 #include "stdafx.h" #include return 0; } int q(intn,int m){ if((n<1)||(m<1)) return 0; if((n==1)||(m==1)) return 1; if(n 算法分析(第二章):递归与分治法 一、递归的概念 知识再现:等比数列求和公式: 1、定义:直接或间接地调用自身的算法称为递归算法。 用函数自身给出定义的函数称为递归函数。 2、与分治法的关系: 由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。这自然导致递归过程的产生。分治与递归经常同时应用在算法设计之中,并由此产生许多高效算法。 3、递推方程: (1)定义:设序列01,....n a a a简记为{ n a},把n a与某些个() i a i n <联系起来的等式叫做关于该序列的递推方程。 (2)求解:给定关于序列{n a}的递推方程和若干初值,计算n a。 4、应用:阶乘函数、Fibonacci数列、Hanoi塔问题、插入排序 5、优缺点: 优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。 缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。 二、递归算法改进: 1、迭代法: (1)不断用递推方程的右部替代左部 (2)每一次替换,随着n的降低在和式中多出一项 (3)直到出现初值以后停止迭代 (4)将初值代入并对和式求和 (5)可用数学归纳法验证解的正确性 2、举例: -----------Hanoi塔算法----------- ---------------插入排序算法----------- ()2(1)1 (1)1 T n T n T =?+ = ()(1)1 W n W n n W =?+? (1)=0 分治算法 一、分治算法 分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。 分治法解题的一般步骤: (1)分解,将要解决的问题划分成若干规模较小的同类问题; (2)求解,当子问题划分得足够小时,用较简单的方法解决; (3)合并,按原问题的要求,将子问题的解逐层合并构成原问题的解。 当我们求解某些问题时,由于这些问题要处理的数据相当多,或求解过程相当复杂,使得直接求解法在时间上相当长,或者根本无法直接求出。对于这类问题,我们往往先把它分解成几个子问题,找到求出这几个子问题的解法后,再找到合适的方法,把它们组合成求整个问题的解法。如果这些子问题还较大,难以解决,可以再把它们分成几个更小的子问题,以此类推,直至可以直接求出解为止。这就是分治策略的基本思想。下面通过实例加以说明。 【例1】[找出伪币] 给你一个装有1 6个硬币的袋子。1 6个硬币中有一个是伪造的,并且那个伪造的硬币比真的硬币要轻一些。你的任务是找出这个伪造的硬币。为了帮助你完成这一任务,将提供一台可用来比较两组硬币重量的仪器,利用这台仪器,可以知道两组硬币的重量是否相同。比较硬币1与硬币2的重量。假如硬币1比硬币2轻,则硬币1是伪造的;假如硬币2比硬币1轻,则硬币2是伪造的。这样就完成了任务。假如两硬币重量相等,则比较硬币3和硬币4。同样,假如有一个硬币轻一些,则寻找伪币的任务完成。假如两硬币重量相等,则继续比较硬币5和硬币6。按照这种方式,可以最多通过8次比较来判断伪币的存在并找出这一伪币。 另外一种方法就是利用分而治之方法。假如把1 6硬币的例子看成一个大的问题。第一步,把这一问题分成两个小问题。随机选择8个硬币作为第一组称为A组,剩下的8个硬币作为第二组称为B组。这样,就把1 6个硬币的问题分成两个8硬币的问题来解决。第二步,判断A和B组中是否有伪币。可以利用仪器来比较A组硬币和B组硬币的重量。假如两组硬币重量相等,则可以判断伪币不存在。假如两组硬币重量不相等,则存在伪币,并且可以判断它位于较轻的那一组硬币中。最后,在第三步中,用第二步的结果得出原先1 6个硬币问题的答案。若仅仅判断硬币是否存在,则第三步非常简单。无论A组还是B组中有伪币,都可以推断这1 6个硬币中存在伪币。因此,仅仅通过一次重量的比较,就可以判断伪币是否存在。 递归与循环的优缺点(转载) 2011-08-24 17:49:40| 分类:算法数据结构| 标签:|字号大中小订阅 递归的话函数调用是有开销的,而且递归的次数受堆栈大小的限制。 以二叉树搜索为例: bool search(btree* p, int v) { if (null == p) return false; if (v == p->v) return true else { if (v < p->v) return search(p->left, v); else return search(p->right, v); } } 如果这个二叉树很庞大,反复递归函数调用开销就很大,万一堆栈溢出怎么办?现在我们用循环改写: bool search(btree* p, int v) { while (p) { if (v == p->v) return true; else { if (v < p->v) p = p->left; else p = p->right; } } return false; } --------------------------------------------------------------------------------------------------------- 递归好处:代码更简洁清晰,可读性更好 递归可读性好这一点,对于初学者可能会反对。实际上递归的代码更清晰,但是从学习的角度要理解递归真正发生的什么,是如何调用的,调用层次和路线,调用堆栈中保存了什么,可能是不容易。但是不可否认递归的代码更简洁。一般来说,一个人可能很容易的写出前中后序的二叉树遍历的递归算法,要写出相应的非递归算法就比较考验水平了,恐怕至少一半的人搞不定。所以说递归代码更简洁明了。 递归坏处:由于递归需要系统堆栈,所以空间消耗要比非递归代码要大很多。而且,如果递归深度太大,可能系统撑不住。 楼上的有人说: 小的简单的用循环, 太复杂了就递归吧,,免得循环看不懂 话虽然简单,其实非常有道理:对于小东西,能用循环干嘛要折腾?如果比较复杂,在系统撑的住的情况下,写递归有利于代码的维护(可读性好) 另:一般尾递归(即最后一句话进行递归)和单向递归(函数中只有一个递归调用地方)都可以用循环来避免递归,更复杂的情况则要引入栈来进行压栈出栈来改造成非递归,这个栈不一定要严格引入栈数据结构,只需要有这样的思路,用数组什么的就可以。 至于教科书上喜欢n!的示例,我想只是便于递归思路的引进和建立。真正做代码不可能的。 -------------------------------------------------------------------------------------------------------------------- 循环方法比递归方法快, 因为循环避免了一系列函数调用和返回中所涉及到的参数传递和返回值的额外开销。 递归和循环之间的选择。一般情况下, 当循环方法比较容易找到时, 你应该避免使用递归。这在问题可以按照一个递推关系式来描述时, 是时常遇到的, 比如阶乘问题就是这种情况。反过来, 当很难建立一个循环方法时, 递归就是很好的方法。实际上, 在某些情形下, 递归方法总是显而易见的, 而循环方法却相当难找到。当某些问题的底层数据结构本身就是递归时, 则递归也就是最好的方法了。 《算法设计与分析》实验报告 分治策略 姓名:XXX 专业班级:XXX 学号:XXX 指导教师:XXX 完成日期:XXX 一、试验名称:分治策略 (1)写出源程序,并编译运行 (2)详细记录程序调试及运行结果 二、实验目的 (1)了解分治策略算法思想 (2)掌握快速排序、归并排序算法 (3)了解其他分治问题典型算法 三、实验内容 (1)编写一个简单的程序,实现归并排序。 (2)编写一段程序,实现快速排序。 (3)编写程序实现循环赛日程表。设有n=2k个运动员要进行网球循环赛。现 要设计一个满足以下要求的比赛日程表:(1)每个选手必须与其它n-1个选手各赛一次(2)每个选手一天只能赛一场(3)循环赛进行n-1天 四、算法思想分析 (1)编写一个简单的程序,实现归并排序。 将待排序元素分成大小大致相同的2个子集合,分别对2个子集合进行 排序,最终将排好序的子集合合并成为所要求的排好序的集合。 (2)编写一段程序,实现快速排序。 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有 数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数 据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据 变成有序序列。 (3)编写程序实现循环日赛表。 按分治策略,将所有的选手分为两组,n个选手的比赛日程表就可以通 过为n/2个选手设计的比赛日程表来决定。递归地用对选手进行分割, 直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让 这2个选手进行比赛就可以了。 五、算法源代码及用户程序 (1)编写一个简单的程序,实现归并排序。 #include 应用数学学院信息安全专业班学号姓名 实验题目递归与分治法 综合实验评分表 实验报告 一、实验目的与要求 1.掌握递归算法的设计思想 2.掌握分治法设计算法的一般过程 3.理解并掌握算法渐近时间复杂度的分析方法 二、实验内容 1、折半查找的递归算法 (1)源程序代码 #include if(-1 != addr) cout << endl << n << "是上述整数中的第" << addr << "个数" << endl; else cout << endl << n << "不在上述的整数中" << endl << endl; getchar(); return 0; } (2)运行界面 ①查找成功 ②查找失败 递归与分治实验报告 班级:计科1102 姓名:赵春晓学号:2011310200631 实验目的:进一步掌握递归与分治算法的设计思想,通过实际问题来应用递归与分治设计算法。 实际问题:1集合划分问题,2输油管道问题,3邮局选址问题,4整数因子分解问题,5众数问题。 问题1:集合划分 算法思想:对于n个元素的集合,可以划分为由m个子集构成的集合,例如{{1,2}{3,4}}就是由2个子集构成的非空子集。假设f(n,m)表示将n个元素划分成由m个子集构成的集合的个数。那么1)若m == 1 ,则f(n,m)= 1 ;2)若n == m ,则f(n,m)= 1 ;3)若不是上面两种情况则有下面两种情况构成:3.1)向n-1个元素划分成的m个集合里面添加一个新的元素,则有m*f(n-1,m)种方法;3.2)向n-1个元素划分成的m-1个集合里添加一个由一个元素形成的独立的集合,则有f(n-1,m-1)种方法。 实验代码: #include 归并排序算法实现(迭代和递归)\递归实现归并排序的原理如下: 递归分割: 递归到达底部后排序返回: 最终实现排序: #include } while(i 实验一递归与分治策略 实验目的 1.了解并掌握递归的概念,递归算法的基本思想; 2.掌握分治法的基本思想方法; 3.了解适用于用分治法求解的问题类型,并能用递归或非递归的方式设计相应的分治法算法; 4.掌握分治法复杂性分析方法,比较同一个问题的递归算法与循环迭代算法的效率。预习与实验要求 1.预习实验指导书及教材的有关内容,掌握分治法的基本思想; 2.严格按照实验内容进行实验,培养良好的算法设计和编程的习惯; 3.认真听讲,服从安排,独立思考并完成实验。 实验原理 简单说来,当一个函数用它自己来定义时就称为递归。一般来说,递归需要有边界条件、递归前进段和递归返回段。当边界条件不满足时,递归前进;当边界条件满足时,递归返回。因此,在考虑使用递归算法编写程序时,应满足两点:1)该问题能够被递归形式描述;2)存在递归结束的边界条件。递归的能力在于用有限的语句来定义对象的无限集合。用递归思想写出的程序往往十分简洁易懂。一般说来,一个递归算法可以转换称为一个与之等效的非递归算法,但转换后的非递归算法代码将成倍地增加。 分治是一种被广泛应用的有效方法,它的基本思想是把最初的问题分解成若干子问题,然后在逐个解决各个子问题的基础上得到原始问题的解。所谓分治就是“分而治之”的意思。由于分解出的每个子问题总是要比最初的问题容易些,因而分治策略往往能够降低原始问题的难度,或者提高解决原始问题的效率。 根据如何由分解出的子问题求出原始问题的解,分治策略又可分为两种情形:第一,原始问题的解只存在于分解出的某一个子问题中,则只需要在原始问题的一个划分中求解即可;第二,原始问题的解需要由各个子问题的解再经过综合处理得到。无论是哪一种情况,分治策略可以较快地缩小问题的求解范围,从而加快问题求解的速度。 分治策略运用于计算机算法是,往往会出现分解出来的子问题与原始问题类型相同的现象,而与原问题相比,各个子问题的规模变小了,这刚好符合递归的特征。因此分治策略往往是和递归联系在一起的。 迭代算法是用计算机解决问题的一种基本方法。它利用计算机运算速度快、适合做重复性操作的特点,让计算机对一组指令(或一定步骤)进行重复执行,在每次执行这组指令(或这些步骤)时,都从变量的原值推出它的一个新值。 利用迭代算法解决问题,需要做好以下三个方面的工作: 一、确定迭代变量。在可以用迭代算法解决的问题中,至少存在一个直接或间接地不断由旧值递推出新值的变量,这个变量就是迭代变量。 二、建立迭代关系式。所谓迭代关系式,指如何从变量的前一个值推出其下一个值的公式(或关系)。迭代关系式的建立是解决迭代问题的关键,通常可以使用递推或倒推的方法来完成。 三、对迭代过程进行控制。在什么时候结束迭代过程?这是编写迭代程序必须考虑的问题。不能让迭代过程无休止地重复执行下去。迭代过程的控制通常可分为两种情况:一种是所需的迭代次数是个确定的值,可以计算出来;另一种是所需的迭代次数无法确定。对于前一种情况,可以构建一个固定次数的循环来实现对迭代过程的控制;对于后一种情况,需要进一步分析出用来结束迭代过程的条件。 例 1 :一个饲养场引进一只刚出生的新品种兔子,这种兔子从出生的下一个月开始,每月新生一只兔子,新生的兔子也如此繁殖。如果所有的兔子都不死去,问到第 12 个月时,该饲养场共有兔子多少只? 分析:这是一个典型的递推问题。我们不妨假设第 1 个月时兔子的只数为 u 1 ,第 2 个月时兔子的只数为 u 2 ,第 3 个月时兔子的只数为 u 3 ,……根据题意,“这种兔子从出生的下一个月开始,每月新生一只兔子”,则有 u 1 = 1 , u 2 = u 1 +u 1 × 1 = 2 , u 3 = u 2 +u 2 × 1 = 4 ,…… 根据这个规律,可以归纳出下面的递推公式: u n = u n - 1 × 2 (n ≥ 2) 对应 u n 和 u n - 1 ,定义两个迭代变量 y 和 x ,可将上面的递推公式转换成如下迭代关系: y=x*2 x=y 让计算机对这个迭代关系重复执行 11 次,就可以算出第 12 个月时的兔子数。参考程序如下: cls 淮海工学院计算机工程学院实验报告书 课程名:《算法分析与设计》 题目:实验1 递归与分治算法 班级: 学号: 姓名: 实验1 递归与分治算法 实验目的和要求 (1)进一步掌握递归算法的设计思想以及递归程序的调试技术; (2)理解这样一个观点:分治与递归经常同时应用在算法设计之中。 (3)分别用蛮力法和分治法求解最近对问题; (4)分析算法的时间性能,设计实验程序验证分析结论。 实验内容 设p1=(x1, y1), p2=(x2, y2), …, pn=(xn, yn)是平面上n个点构成的集合S,设计算法找出集合S中距离最近的点对。 实验环境 Turbo C 或VC++ 实验学时 2学时,必做实验 数据结构与算法 核心源代码 蛮力法: #include { scanf("%d",&y[i]); } ClosestPoints(x,y,4); return 0; } int ClosestPoints(int x[ ], int y[ ], int n) { int index1, index2; //记载最近点对的下标 int d, minDist = 1000; //假设最大距离不超过1000 for (int i = 0; i < n - 1; i++) for (int j = i + 1; j < n; j++) //只考虑i<j的点对 { d =sqrt ((x[i]-x[j])* (x[i]-x[j]) + (y[i]-y[j])* (y[i]-y[j])); if (d < minDist) { minDist = d; index1 = i; index2 = j; } } cout<<"最近的点对是:"< 一、用迭代法求斐波那契数列。 #include printf("输入sin(x)中的x:\n"); scanf("%lf",&x); do { sum=sum+sign*pow(x,n)/factorial(n); n=n+2; sign=-sign; }while(pow(x,n)/factorial(n)>=1e-6); printf("sin(%.2lf)=%.2lf\n",x,sum); return 0; } 实验一:分治与递归 【实验目的】 深入理解分治法算法思想,并采用分治法进行程序设计。 【实验性质】 验证性实验。 【实验内容与要求】 设有n=2k个运动员要进行网球循环赛。现要设计一个满足以下要求的比赛日程表:⑴每个选手必须与其他n-1个选手各赛一次;⑵每个选手一天只能赛一次;⑶循环赛一共进行n-1天。按此要求可将比赛日程表设计-成有n行和n-l列的一个表。在表中第i行和第j列处填入第i个选手在第j天所遇到的选手。用分治法编写为该循环赛设计一张比赛日程表的算法并运行实现、对复杂度进行分析。 算法思想:按分治策略,我们可以将所有选手对分为两组,n个选手的比赛日程表就可以通过为n/2个选手设计的比赛日程表来决定。递归地用这种一分为二的策略对选手进行分割,直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让这2个选手进行比赛就可以了。 下图所列出的正方形表是4个选手的比赛日程表。其中左上角与左下角的两小块分别为选手1至选手2和选手3至选手4第1天的比赛日程。据此,将左上角小块中的所有数字按其相对位置抄到右下角,将左下角小块中的所有数字按其相对位置抄到右上角,这样我们就分别安排好了选手1至选手2和选手3至选手4在后2天的比赛日程。这种安排是符合要求的。 程安排表。 #include 《算法设计与分析》 课程设计报告 题目:循环赛日程表 院(系):信息科学与工程学院 专业班级:软工 学生姓名: 学号: 指导教师: 2018 年 1 月 8 日至 2018 年 1 月 19 日 算法设计与分析课程设计任务书 目录 1 常用算法 (1) 1.1分治算法 (1) 基本概念: (1) 1.2递推算法 (2) 2 问题分析及算法设计 (5) 2.1分治策略递归算法的设计 (5) 2.2 分治策略非递归算法的设计 (7) 2.3 递推策略算法的设计 (8) 3 算法实现 (9) 3.1分治策略递归算法的实现 (9) 3.2 分治策略非递归算法的实现 (10) 3.3 递推策略算法的实现 (12) 4 测试和分析 (15) 4.1分治策略递归算法测试 (15) 4.2分治策略递归算法时间复杂度的分析 (16) 4.3 分治策略非递归算法测试 (16) 4.4分治策略非递归算法时间复杂度的分析 (17) 时间复杂度为:O(5^(n-1)) (17) 4.5 递推策略算法测试 (17) 4.6 递推策略算法时间复杂度的分析 (18) 时间复杂度为:O(5^(n-1)) (18) 4.7 三种算法的比较 (18) 5 总结 (19) 参考文献 (20) 1 常用算法 1.1分治算法 基本概念: 在计算机科学中,分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换)…… 任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。问题的规模越小,越容易直接求解,解题所需的计算时间也越少。例如,对于n个元素的排序问题,当n=1时,不需任何计算。n=2时,只要作一次比较即可排好序。n=3时只要作3次比较即可,…。而当n较大时,问题就不那么容易处理了。要想直接解决一个规模较大的问题,有时是相当困难的。 基本思想及策略: 分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。 分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。 如果原问题可分割成k个子问题,1 迭代方法(也称为“折返”方法)是一个过程,在该过程中,不断使用变量的旧值来递归推导新值。与迭代方法相对应的是直接方法(或称为第一求解方法),即问题已解决一次。迭代算法是使用计算机来解决问题的一种基本方式,它利用计算机的运行速度,适合于重复操作的特性,让计算机对一组指令(或步骤)必须每次都重复执行在执行的这组指令(或这些步骤)中,由于变量的原始值是新值,因此迭代方法分为精确迭代和近似迭代。典型的迭代方法(例如“二分法”和“牛顿迭代”)属于近似迭代方法。 迭代方法的主要研究主题是构造收敛的迭代方案,并分析问题的收敛速度和收敛范围。迭代方法的收敛定理可以分为以下三类:(1)局部收敛定理:假设问题的解存在,则得出结论:当初始逼近足够接近解时,迭代法收敛。 (2)半局部收敛定理:结论是,迭代方法根据迭代方法在初始逼近时所满足的条件收敛到问题的解,而不假定解的存在。 (3)大范围收敛定理:得出的结论是,迭代方法收敛到问题的解,而无需假设初始近似值足够接近解。 迭代法广泛用于求解线性和非线性方程,优化计算和特征值计算。 迭代法是一种迭代法,用于数值分析中,它从初始估计值开始寻找一系列解决问题的迭代解法(通常为迭代法),以解决问题(迭代法)。 通常,可以做出以下定义:对于给定的线性方程组(x,B和F 都是矩阵,任何线性方程组都可以转换为这种形式),公式(表示通过迭代获得的x k次,并且初始时间k = 0)逐渐替换为该方法以找到近似解,这称为迭代方法(或一阶时间不变迭代方法)。如果存在,则将其表示为x *,并称迭代方法收敛。显然,x *是该系统的解,否则称为迭代散度。 迭代方法的对应方法是直接方法(或第一种解决方法),它是对问题的快速一次性解决方案,例如通过求平方根来求解方程x + 3 = 4。通常,如果可能,直接解决方案始终是首选。但是,当我们遇到复杂的问题时,尤其是当未知数很多并且方程是非线性的时,我们无法找到直接解(例如,第五和更高阶代数方程没有解析解,请参见Abelian 定理)。时候,我们可以通过迭代的方法寻求方程(组)的近似解。 最常见的迭代方法是牛顿法。其他方法包括最速下降法,共轭迭代法,可变尺度迭代法,最小二乘法,线性规划,非线性规划,单纯形法,罚函数法,斜率投影法,遗传算法,模拟退火等。 实验一分治与递归 一、实验目的与要求 1、熟悉C/C++语言的集成开发环境; 2、通过本实验加深对递归过程的理解 二、实验内容: 掌握递归算法的概念和基本思想,分析并掌握“整数划分”问题的递归算法。 三、实验题 任意输入一个整数,输出结果能够用递归方法实现整数的划分。 四、实验步骤 1.理解算法思想和问题要求; 2.编程实现题目要求; 3.上机输入和调试自己所编的程序; 4.验证分析实验结果; 5.整理出实验报告。 五.实验源代码: (1)//基本递归算法整数划分 #include return integer_split(n-m,m)+integer_split(n,m-1); } int main() { int n; scanf("%d",&n); int count=0; //for(int m=n;m>=1;m--) //{ count=integer_split(n,n); //} printf("%d",count); return 0; } (2)运行结果: Input:请输入一个待划分的整数 Output:输出有多少种划分 样例: Input:6 Output:11; (3)算法思路: 首先要找出递归的公式来,首先分析几种简单的情况,n==1||m==1可以直接得出结果为1;而当n 华北水利水电学院算法分析与设计实验报告 20010~2011学年第二学期2008级计算机科学与技术专业 班级:2008109 学号:200810906 姓名:刘景超 实验一递归与分治算法的设计与实现 一、实验目的: 1、了解递归、分治算法的设计思路与设计技巧,理解递归的概念,掌握设计有效算法的 分治策略。 2、通过实际案例,领会算法的执行效率 二、试验内容: 棋盘覆盖、最接近点对、排序算法、矩阵乘法等,(也可选作其它问题); 三、核心程序源代码: #include 五、小结 本想用MFC采用图形的方式展示移动的过程,可惜水平有限,实在是写不出来,只好采用控制台程序了。采用控制台程序表述还是很简单的,算法也不复杂。这次实验让我认识到我在MFC方面基础还很薄弱,还需要多多练习,慢慢提升自己。 例详解dns递归和迭代查询原理及过程 在互联网中,一个域名的顺利解析离不开两类域名服务器,只有由这两类域名服务器可以提供“权威性”的域名解析。 第一类就是国际域名管理机构,也就InterNIC,主要负责国际域名的注册和解析,第二类就是国内域名注册管理机构,在中国就是 CNNIC了,主要负责国内域名注册和解析,当然,尽管分为国际和国内,但两者一主一辅,相互同步信息,毕竟最终的目的是在全球任何一个有网络的地方都可以顺利访问任何一个有效合法的域名,其间的联系就可见一斑了。 有的朋友可能会有这个疑问,域名服务器不是有很多吗?为什么说只有2类呢?是的,ISP何其多?当我们输入某一网址(或域名),系统将这个域名发送至需要将其当前已配置的DNS服务器,以便转换为IP地址进行访问,通常会是当地的公共DNS服务器(内网环境可能直接提交到防火墙或路由器上做进一步转发处理)。公网DNS服务器收到此请求后,并非立刻处理,比如转发至上一级的DNS服务器(在第一节讲过DNS有着很严格的逻辑层次关系),而是首先会查看自己的DNS缓存,如果有这个域名对应的IP,则直接返回给用户,系统收到这个IP后交给浏览器做进一步处理。在这个轮回的过程中,客户端所得到的DNS的回复就是“非权威的性”的,也就是说这个结果并不是来自这个域名所直接授权的DNS服务器,而是该记录的副本。简单的说,“非权威性”的应答是从别的 DNS服务器上复制过来的,与之对应的,就是“权威性”应答则是由域名所在的服务器作出的应答,听起来似乎不易理解,我们来看一个例子。 我所在地是深圳,这里的公共DNS服务器是202.96.134.133,我们来检测一下。 如下图: 这里用到了nslookup命令,用来查询当前本机解析域名所依赖的DNS服务器,从上图中文名可以得知当前默认的DNS解析服务器是 https://www.360docs.net/doc/3310894078.html,,对应的IP地址为202.96.134.133,也就是说在这台机子上运行的网络程序,如果需要用到DNS域名解析的,都会将请求到这个服务器上,寻求解析。 当然,如果你是在内网,或是其他类型的局域网,在解析时候可能无法顺利得到上图的结果,多半是代理或防火墙的缘故。建议ADSL用户可以自测一下,加深印象。现在,我们来解析一个网站的别名记录,以此来了解一下何为“非授权记录” 以网易为例吧。如下图:实验报告 分治与递归
算法之2章递归与分治
递归与分治
递归与循环的优缺点
算法分析实验报告--分治策略
算法设计与分析:递归与分治法-实验报告
递归与分治实验报告
归并排序算法实现 (迭代和递归)
算法分析与设计实验一递归与分治策略
迭代与递归的区别
实验1++递归与分治算法
C语言(迭代法与递归法)
分治与递归 循环赛编程
使用分治策略递归和非递归和递推算法解决循环赛日程表课程设计报告
迭代法
实验一 分治与递归
实验一 递归与分治策略算法设计与实现实验报告
例详解dns递归和迭代查询原理及过程