第五章 主成分分析(1)(主成分模型)

第五章主成分分析与经验正交分解
5.1主分量分析的数学模型
当存在若干个随机变量时,寻求它们的少量线性组合(即主成分),用以解释这些随机变量,是很必要的。首先我们看一个例子。
几个数据集
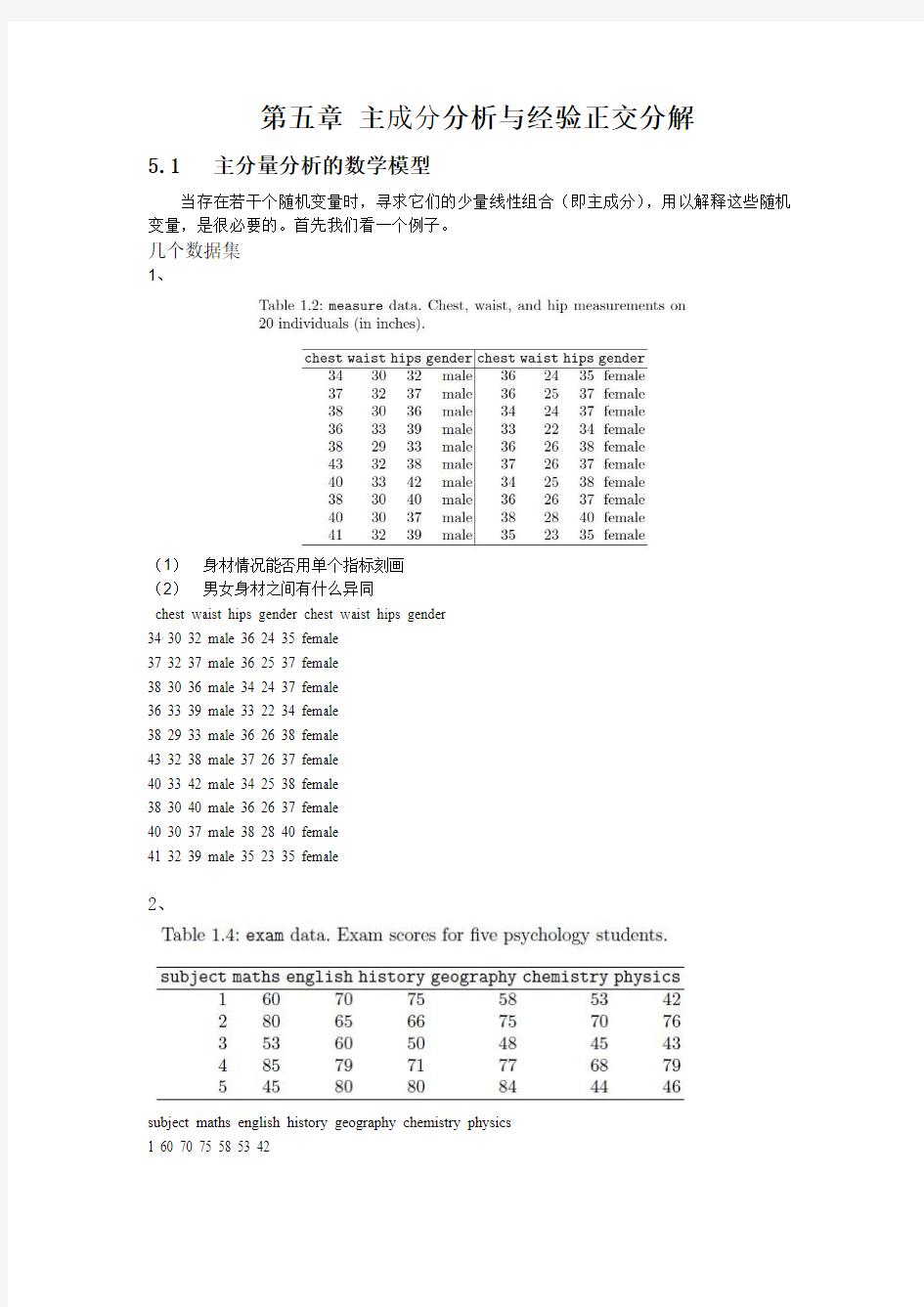
1、
(1)身材情况能否用单个指标刻画
(2)男女身材之间有什么异同
chest waist hips gender chest waist hips gender
34 30 32 male 36 24 35 female
37 32 37 male 36 25 37 female
38 30 36 male 34 24 37 female
36 33 39 male 33 22 34 female
38 29 33 male 36 26 38 female
43 32 38 male 37 26 37 female
40 33 42 male 34 25 38 female
38 30 40 male 36 26 37 female
40 30 37 male 38 28 40 female
41 32 39 male 35 23 35 female
2、
subject maths english history geography chemistry physics
1 60 70 75 58 53 42
2 80 65 66 75 70 76
3 53 60 50 48 45 43
4 8
5 79 71 77 68 79 5 45 80 80 84 44 4
6 3、
air pollution in cities in the USA. The following variables were obtained for 1 US cities: SO2: SO 2 content of air in micrograms per cubic metre; temp: average annual temperature in degrees Fahrenheit;
manu: number of manufacturing enterprises employing 20 or more workers; popul: population size (1970 census) in thousands; wind: average annual wind speed in miles per hour; precip: average annual precipitation in inches;
predays: average number of days with precipitation per year.
例5.1 为了调查学生的身材状况,可以测量他们的身高(1x )、体重(2x )、胸围(3x )和坐高(4x )。可是用这4个指标表达学生身材状况不方便。但若用
1y =3.63561x +3.32422x +2.47703x +2.16504x
表示学生身体魁梧程度;用
2y =-3.97392x +1.35821x +3.73233x -1.57294x
表示学生胖瘦程度。则这两个指标(1y ,2y )很好概括了4个指标(1x -4x )。
例中,学生不同,身高(1x )、体重(2x )、胸围(3x )和坐高(4x )不同;(1x , 2x , 3x , 4x )
是4维随机向量;1y ,2y 是他们的2个线性组合,1y ,2y 能很好表示1x , 2x , 3x ,
4x 的特性。类似的问题在许多地方出现:可观测的随机变量很多,需要选出所有所有随机变
量的少数线性组合,使之尽可能刻划全部随机变量的特性,选出的线性组合就是诸多随机变量的主成分,又称为主分量。寻求随机向量主成分,并加以解释,称为主成分分析,又称为主分量分析。主成分分析在许多学科中都有应用,细节可参看张尧廷(1991)、Richard(2003),主成分分析在气象等科学中称为PCA 方法,见吴洪宝(2005)。
主成分分析的数学模型是:对于随机向量X ,想选一些常数向量i c ,用X c i '尽可能多反映随机向量X 的主要信息,也即)'(X c D i 尽量大。但是i c 的模可以无限增大,从而使
)'(X c D i 无限变大,这是我们不希望的;于是限定i c 模的大小,而改变i c 各分量的比例,
使)'(X c D i 最大;通常取i c 的模为1最方便。
定义5.1 设随机向量)',...(1p x x X =二阶矩存在,若常数向量1c ,在条件c =1下 使)'(X c D 最大,则称X c Y '11=是X 的第一主成分或第一主分量。
由定义可见,1Y 尽可能多地反映原来p 个随机变量变化的信息。但是一个主成分往往不能完全反映随机向量特色,必须建立其它主成分,它们也应当最能反映随机向量变化,而且他们应当与第一主成分不相关(不包含1Y 的信息)。
定义5.2 若常数向量c=2c 在条件c =l ,0)',cov(1=X c Y 下,使)'(X c D 最大, 则称X c Y '22=是 X 的第二主成分;若常数向量c=3c 在条件c =l ,0)',cov(1=X c Y ,
0)',cov(2=X c Y 下,使)'(X c D 最大,则称X c Y '33=是 X 的第三主成分;…。
当随机向量方差已知时,定理5.1给出主成分的计算公式。
定理5.1 设随机向量)',...(1p X X X =方差存在为∑。∑特征值从大到小为
p λλλ≥≥≥...21,j λ对应的彼此正交单位特征向量为j c 。则X 的第j 个主成分
为 j c 与X 的内积,即
X c Y j j '= (5.1)
且i i Y Var λ=)(
证明:任取
p
维单位向量
c,必有∑∑==
1,2
j
j
j t
c t c 。于是
∑=∑=j j t c c X c D λ2')'(,
而在条件∑=12
j t 下,当11=t ,0...2===p t t 即1c c =时,
∑=j j t X c D λ2)'(最大,所以X 的第一主成分是1c 与X 的内积X
c Y '11=。由条件0)',cov(1=X c Y ,可得0''11111===∑t c c c c λλ,于是X c t X c j p
j j ''2
∑==,从而
∑==∑=p
j j j t c c X c D 2
2')'(λ;
所以在条件c =1、0)',cov(1=X c Y 下,当2c c =时,c c X c D ∑=')'(最大,所以X 的第2个主成分为2c 与X 的内积X c Y '22=。对第三,第四……主成分同样可证。
例5.2 设)',,(321X X X X =,且
????
?
?????--=∑=210131011)(X Var
则
1λ=3.87939,'1c =[0.293128,-0.84403,-0.449099] 2λ=1.6527,'2c =[0.449099,-0.293128,0.84403] 3λ=0.467911,'3c =[0.84403,0.449099,-0.293128]
所以第一主成分就是X c Y '11==0.2931281X -0.84403 2X -0.4490993X ;
第二主成分就是X c Y '22==0.4490991X -0.2931282X +0.844033X ; 第三主成分就是X c Y '33
==0.844031X +0.4490992X -0.2931283X 。
它们的方差贡献分别是87939.3)(11==λY Var ;6527.1)(22==λY Var ; 467911
.0)(33==λY Var 。
5.2 相关系数阵和协方差阵的主分量分析
在实际问题中,X 的每一分量可取不同单位,单位取小时(例如长度单位取毫米,甚至
微米)该分量的方差会变大,从而在主成分中变得突出;而单位选取不应影响主成分。为了
避免量纲对主成分的影响。常常将随机变量都标化,即令)(/)(*i i i i X Var EX X X -=,它就是无量纲量,令*)'*,...(*1p X X X =再求X*的主成分,即标准化后的主成分。将
)(/)(*i i i i X Var EX X X -=代入,可求随机向量X 的主成分。容易证明
定理5.2 设随机向量X 的相关阵为ρ,ρ特征值为*...*1p λλ≥≥,j λ对应的彼此正交单位特征向量为*j c ,则标准化后X 的第j 个主成分是***T X c Y j
j =。
因此,标准化后的主成分称为由相关阵决定的主成分。直接由随机向量的协方差阵算出的主成分称为由协差阵决定的主成分。
同样一组随机变量,用它们的协差阵和相关阵求出的主成分是不一样的。这是因为优化的准则(目标函数)不同:前者要求)'(X c D =c c ∑'最大,而后者要求
*)'(X c D ==c F F c 2/12/1'--∑最大,其中
??????
????????=)(0...)(0)
(21p X D X D X D F 。
例 5.3 (协差阵和相关阵决定的主成分不同)设随机变量)',(21X X X =;其协方差阵是
??
?
???=∑100221,特征值和特征向量是)'9998.0,0202.0(,04.10011==c λ,
)'0202.0,9998.0(,9596.022-==c λ。因而由协方差阵决定的主成分是:
2119998.00202.0X X Y +=,
2120202.09998.0Y Y Y -=。
但随机变量X 标准化后得到)'1.01.0,(*)'*,(*221121μμ--==X X X X X ;其中
2211,μμ==EX EX 。
X*的协差阵即X 的相关阵是?
?
????=12.02.01ρ,其特征值和特征向量是 )'7071.0,7071.0(*,
2000.1*11==c λ,)'7071.0,7071.0(*,
8000.0*22-==c λ
从而由相关阵决定的主成分是:
)(07071.0)(7071.0*7071.0*7071.0*2211211μμ-+-=+=X X X X Y )(07071.0)(7071.0*7071.0*7071.0*2211212μμ---=-=X X X X Y 。
由于主成分由方差决定,可以略去常数,因而由相关阵得到的主成分可写为:
21107071.07071.0*X X Y += 21207071.07071.0*X X Y -=,
可见由协方差阵与相关阵决定的主成分不同。
分别从相关系数阵和协方差阵计算主成分的例子。该例取自Jolliffe (2002). 该数据包含72位病人的八项血液化验指标。
data blood_corr(type=cov);
input rblood plate wblood neut lymph bilir sodium potass; cards ;
1.000 0.290 0.202 -0.055 -0.105 -0.252 -0.229 0.058 0.290 1.000 0.415 0.285 -0.376 -0.349 -0.164 -0.129 0.202 0.415 1.000 0.419 -0.521 -0.441 -0.145 -0.076 -0.055 0.285 0.419 1.000 -0.877 -0.076 0.023 -0.131 -0.105 -0.376 -0.521 -0.877 1.000 0.206 0.034 0.151 -0.252 -0.349 -0.441 -0.076 0.206 1.000 0.192 0.077 -0.229 -0.164 -0.145 0.023 0.034 0.192 1.000 0.423 0.058 -0.129 -0.076 -0.131 0.151 0.077 0.423 1.000 ;
proc princomp ; /*用相关系数计算主成分*/
var rblood plate wblood neut lymph bilir sodium potass; run ;
data blood_cov(type=cov);
input rblood plate wblood neut lymph bilir sodium potass; cards ;
0.137641000 4.4384103 0.14501277 -0.001571185 -0.002765805 -0.37742720 -0.232107988 0.006390846 4.438410270 1701.8100090 33.12719033 0.905297085 -1.101290088 -58.12188799 -18.483324144 -1.580526189 0.145012770 33.1271903 3.74422500 0.062428905 -0.071577585 -3.44491339 -0.766530900 -0.043676820 -0.001571185 0.9052971 0.06242890 0.005929000 -0.004794559 -0.02362452 0.004838372 -0.002995839 -0.002765805 -1.1012901 -0.07157758 -0.004794559 0.005041000 0.05904516 0.006595048 0.003184137 -0.377427204 -58.1218880 -3.44491339 -0.023624524 0.059045162 16.29736900 2.117584128 0.092322153 -0.232107988 -18.4833241 -0.76653090 0.004838372 0.006595048 2.11758413 7.463824000 0.343223892 0.006390846 -1.5805262 -0.04367682 -0.002995839 0.003184137 0.09232215 0.343223892 0.088209000
;
proc princomp cov ; /*用协方差计算主成分*/
var rblood plate wblood neut lymph bilir sodium potass; run ;
5.3 主成分个数的确定
下面讨论对变量很多时,选择多少个主成分
i i Y Var λ=)(。它称为第i 个主成分的方差贡献,表示第i 个主成分变化大小,从而反映
第i 个主成分提供的信息的大小。 定义5.3 ∑j
i λ
λ/
称为主成分i y 的方差贡献率;
∑∑
=j i k
i λλ/1
称为前k 个主成分的累计
方差贡献率;i y 与X 第k 个分量的相关系数),(k i x y ρ称为因子负荷量。
当某个主成分的方差贡献率很小时,认为它提供的信息很少,可以略去此主成分。通常取q,使前q个主成分的累计方差贡献率达到70%-80%,然后只考虑前q个主分量,用它们解释随机向量X的特性,其余主成分认为是观测误差等随机因素造成的。
Jolliffe (2002),Rencher (2002).给出了许多实例,一些常用的选择主成分个数的法则如下:
1.Retain just enough components to explain some speci_ed large percentage of the total variation of
the original variables. Values between 70% and 90% are usually suggested, although smaller
values might be appropriate as q or n, the sample size, increases.
2 . Exclude those principal components whose eigenvalues are less than the average,
the average eigenvalue is also the average variance of the original variables. This method then retains·those components that account for more variance than the average for the observed
variables.
3.When the components are extracted from the correlation matrix, trace(R) = q, and the average
variance is therefore one, so applying the rule in the previous bullet point, components with
eigenvalues less than one are excluded. This rule was originally suggested by Kaiser (1958), but Jolliffe (1972), on the basis of a number of simulation studies, proposed that a more appropriate procedure would be to exclude components extracted from a correlation matrix whose associated eigenvalues are less than 0.7.
4. Cattell (1966) suggests examination of the plot of the against i, the socalled scree diagram.
The number of components selected is the value of I corresponding to an\elbow"in the curve,
i.e., a change of slope from\steep" to \shallow". In fact, Cattell was more speci_c than this,
recommending to look for a point on the plot beyond which the scree diagram de_nes a more or less straight line, not necessarily horizontal. The _rst point on the straight line is then taken to be the last component to be retained. And it should also be remembered that Cattell
suggested the scree diagram in the context of factor analysis rather than applied to principal components analysis.
5. A modification of the scree digram described by Farmer (1971) is the log-eigenvalue diagram
consisting of a plot of against i.
Returning to the results of the principal components analysis of the blood chemistry data given in Section 3.3, we find that the first four components account for nearly 80% of the total variance, but it takes a further two components to push this figure up to 90%. A cutoffb of one for the eigenvalues leads to retaining three components, and with a cuto_ of 0.7 four components are kept. Figure 3.1 shows the scree diagram and log-eigenvalue diagram for the data
5.4 样本主成分
实际问题中随机向量的协差阵、相关阵都是未知的,只能得到样品)()2()1(,...,n X X X 。这时总用样本协差阵与样本相关阵代替协差阵、相关阵求主成分。
定义5.4 样本协差阵与样本相关阵的特征向量,计算主成分。所得的主成分称为样本主成分。
这样求主成分是有道理的:若总体),(~∑μN X ,∑的特征值和正交单位特征向量是
j λ和j c ;∧∑是∑的极大似然估计,即)')((1)
(1
)(-=-∧
--=∑∑X X X X n i n i i 。∧∑的特征值为
p τττ≥≥...21,j τ相应正交单位特征向量为j d ,则可证
定理5.3 若X 服从正态分布,则j τ是j λ的极大似然估计;j d 是j c 的极大似然估计。
因此,若X 服从正态分布,应当用第j 个样本主成分X d j '作为总体主成分j Y 的估计值。从样本协差阵或样本相关阵出发,做主成分分析,所得样本主成分通常简称为主成分。
通常取)')((11R )
(1
)(-=----=∑X X X X n i n i i 为样本协差阵(∑的无偏估计),由∧∑或R 算出的样本相关阵是相同的,所产生(相关差阵决定)的主成分当然相同。而R 与∧
∑有相同的特征向量,R 的特征值是∧
∑特征值的n/(n-1)倍。因而由R 与∧
∑所产生的(协方差阵决定的)主成分相同。
若X 不一定服从正态分布,这时仍可由样本协差阵R 或相关阵ρ出发,计算主成分。 同上节指出的一样:样本相关阵和样本协差阵决定的主成分是不同的。
5.5 SAS 软件计算样本主成分
样本主成分的计算量很大,通常用软件计算,以下介绍用SAS 软件计算的基本方法。 SAS 调用PRINCOMP 过程(即主成分过程)作主成分分析。PROC PRINCOMP 过程对输入资料文件执行主成分分析。其输入资料文件可以是原始数据,也可以是一个相关系数矩阵,或是协方差阵。输出资料则包括特征根、特征向量及标准化的主成分值。 主成分分析是一个多变量统计程序,可用来鉴定多个数值变量之间的关系。主成分分析除了用来概述变量之间的关系外,还可用来削减回归或集群分析中变量的数目。它的主要目的是求出一组变量的线性组合(即主成分),这些线性组合就是原变量矩阵的特征向量。每个向量的内积就是该向量对原变量群能解释的方差百分比。这些特征向量之间应该是彼此线性独立的。
PROC PRINCOMP 语法
PROC PRINCOMP DATA= SAS-data-set /*输入资料文件名称*/
OUT= SAS-data-set /*输出资料文件名称*/
OUTSTAT= SAS-data-set /*输出资料文件名称*/
NOINT
COVARIANCE(COV)
N= n
STANDARD(STD)
PREFIX= name
NOPRINT
SINGULAR= value
VARDEF= DF|N|WEIGHT|WDF; 或N,或WGT,或WDF)
VAR variable-list; /*指明那些数值变量作主成分分析*/ PARTIAL variable-list;
FREQ variable;
WEIGHT variable;
BY variable-list;
调用PRLNCOMP过程时常用两个语句:即PROC PRINCOMP ,VAR。
(1)PROC PRINCOMP语句。
一般形式是 PROC PRINCOMP;其功能是调用PRINCOMP过程。加选项cov指示电脑用协差阵计算样本主成分,不加选项cov则电脑用相关阵计算主成分;加选项out=文件名,指示电脑将每个观测的主成分得分存入一个数据集,即“文件名”所表示的数据集,加选项n=k 指示电脑只计算k个主成分,不加选项n=k则电脑计算全部p个主成分。例如proc princomp data=wang1 out=wang2 n=3;指示电脑对数据集wang1中数据做主成分分析,求3个主成分,并将各次观测的主成分得分存入数据集wang2。
(2)VAR语句
其功能是规定要分析的变量。例如var x1-x3 u1 v2;表示将变量x1,x2,x3,u1,v作为随机向量进行主成分分析。
计算主成分固然重要,解释主成分的意义更重要。下面我们介绍用SAS作主成分分析的实例,并对于算出的主成分加以解释,希望学者对练习题中的主成分也试作解释。
例5.4 北京1951~1976年冬季的气温资料如表5-1,第一列为年度,第二列为该年12月的月平均温度。第三、四列为次年1、2月的月平均温度。试做主成分分析。
表 5-1 北京1951~1976年冬季月平均气温
解:因为所有变量单位相同,可用协方差阵求主成分。以变量year Dec Jan Feb分别表示年度、12月、1月、2月的温度。采用下列程序
data temperat; /*建立数据集temperat*/
input year Dec Jan Feb; /*建立变量year、Dec、Jan和Feb*/
cards; /*以下为数据体*/
1951 1.0 -2.7 -4.3
1952 -5.3 -5.9 -3.5
1953 -2.0 -3.4 -0.8
1954 -5.7 -4.7 -1.1
1955 -0.9 -3.8 -3.1
1956 -5.7 -5.3 -5.9
1957 -2.1 -5.0 -1.6
1958 0.6 -4.3 -0.2
1959 -1.7 -5.7 2.0
1960 -3.6 -3.6 1.3
1961 -3.0 -3.1 -0.8
1962 0.1 -3.9 -1.1
1963 -2.6 -3.0 -5.2
1964 -1.4 -4.9 -1.7
1965 -3.9 -5.7 -2.5
1966 -4.7 -4.8 -3.3
1967 -6.0 -5.6 -4.9
1968 -1.7 -6.4 -5.1
1969 -3.4 -5.6 -2.0
1970 -3.1 -4.2 -2.9
1971 -3.8 -4.9 -3.9
1972 -2.0 -4.1 -2.4
1973 -1.7 -4.2 -2.0
1974 -3.6 -3.3 -2.0
1975 -2.7 -3.7 0.1
1976 -2.4 -7.6 -2.2
; /*空语句,结束数据体*/
proc princomp cov; /* 用协差阵做主成分分析*/
var Dec Jan Feb; /* 对变量Dec Jan Feb 作主成分分析*/ run;
执行上述程序,得到得许多表,主要的是:基本统计量(Simple Statistic);协方差矩阵(Covariance Matrix);样本协差阵的特阵值表(Eigenvalues of the Covariance Matrix)、方差贡献、方差贡献率及累计方差贡献率;样本协差阵的特征向量表(即主成分的系数表,Eigenvectors)。这些表及分析如下
Eigenvalues
Eigenvalue Difference Proportion Cumulative
PRIN1 4.79742 2.06927 0.552919 0.55292
PRIN2 2.72815 1.57720 0.314429 0.86735
PRIN3 1.15095 . 0.132652 1.00000 上表是样本协差阵的特征值表(表头为Eigenvalues),其中PRIN1、PRIN2、PRIN3表示3个主成分,上表第2列给出样本协差阵的特征值,第4列给出方差贡献,第5列给出方差贡献累计百分比。由于前两个特阵值方差贡献累计百分比等于0.867354,它大于0.7,所以只需取两个主成分。
Eigenvectors
PRIN1 PRIN2 PRIN3
DEC 0.643587 0.709882 -.286116
JAN 0.213039 0.192899 0.957812
FEB 0.735126 -.677390 -.027085
上表是特征向量表(表头为Eigenvectors)上表给出所考察变量样本协差阵的特征向量(0.643587,0.213039,0.735126)’、(0.709882,0.192899,-0.677390)’和(-0.286116,0.957812,-0.027085)’。因此第一、二、三主成分分别是
y=0.643587Dec+0.213039Jan+0.735126Feb,
1
y=0.709882Dec+0.192899Jan-0.677390Feb,
2
y=-0.286116Dec+0.957812Jan-0.027085Feb
3
由于第一主成分中Dec,Feb系数是较大正数,Jan系数是较小正数,说明第一主成分主要表示冬季气温偏高的程度,由于1月分的系数变化较小,冬季气温偏高主要由12月,2月温度的偏高形成。第二主成分Dec系数与Feb系数反号较大,反映第二主成分主要表示12月与2月温度距平的反差,即12月温度距平减去2月温度距平所得值的反差。
例5.5 美国各州犯罪率情况如表5-2。试以murder(谋杀),rape(强奸),robbery(抢
劫),assult(斗殴),burglary(夜盗),larceny(偷窃),auto(汽车犯罪)为7元随机向量,做主成分分析。
解:评估美国各州犯罪率时,用7种犯罪率为7维随机向量,以50个州的统计数据为50次观测。考虑不同犯罪的犯罪率差异很大,用相关阵计算主成分。采用程序
data crime; /*建立数据集crime*/
input state $ 1-15 murder rape robbery assult burglary larceny auto;
/*建立变量state murder rape robbery assult burglary larceny auto。state $ 1-15表示前15列存州名。murder rape robbery assult burglary larceny auto 表7种罪的犯罪率*/
cards; /*以下为数据体*/
Albama 14.2 25.2 96.8 278.3 1135.5 1881.9 280.7 Alaska 10.8 51.6 96.8 284.0 1331.7 3369.8 753.3
Arirona 9.5 34.2 138.2 312.3 2346.1 4467.4 439.5
Arkansas 8.8 34.2 138.2 312.3 2346.1 4467.4 439.5
Califonia 11.5 49.4 287.0 358.0 2139.4 3499.8 663.5
Colorado 6.3 42.0 170.7 292.9 1935.2 3903.2 477.1 Conecticat 4.2 16.8 129.5 131.8 1346.0 2620.7 593.2
Delaware 6.0 24.9 157.0 194.2 1682.6 3678.4 467.0
Florida 10.2 39.6 187.9 449.1 1859.9 3840.5 351.4
Geogia 11.7 31.1 140.5 256.5 1351.1 2170.2 297.9
Hawaii 7.2 25.5 128.0 64.1 1911.5 3920.4 489.4
Idaho 5.5 19.4 39.6 172.5 1050.8 2599.6 237.6
Illinois 9.9 21.8 211.3 209.0 1085.0 2828.5 528.6
Indiana 7.4 26.5 123.2 153.5 1086.2 2498.7 377.4
Iowa 2.3 10.6 41.2 89.8 812.5 2685.1 219.9
Kansas 6.6 22.0 100.7 180.5 1270.4 2739.3 244.3
Kentaky 10.1 19.1 81.1 123.3 872.2 1662.1 245.4
Loisana 15.5 30.9 142.9 335.5 1165.5 2469.9 337.7 Maine 2.4 13.5 38.7 170.0 1253.1 2350.7 246.9
Maryland 8.0 34.8 292.1 358.9 1400.0 3177.7 428.5 Masschusetts 3.1 20.8 169.1 231.6 1532.2 2311.3 1140.1
Michigan 9.3 38.9 261.9 274.6 1522.7 3159.0 545.5
Minnesota 2.7 19.5 85.9 85.8 1134.7 2559.3 343.1
Mississippi 14.3 19.6 65.7 189.1 915.6 1239.9 144.4
Missouri 9.6 28.3 189.0 233.5 1318.3 2424.2 378.4
Montana 5.4 16.7 39.2 156.8 804.9 2773.2 309.3
Nebraska 3.9 18.1 64.7 112.7 760.0 2316.1 249.1
Nevada 15.8 49.1 323.1 355.0 2453.1 4212.6 559.2 Mew Hampashare 3.2 10.7 23.2 76.0 1041.7 2343.9 293.4
New Jersey 5.6 21.0 180.4 185.1 1435.8 2774.5 511.5
New Maxico 8.8 39.1 109.6 343.4 1418.7 3008.6 259.5
New York 10.7 29.4 472.6 319.1 1728.0 2782.0 745.8
North Carolina 10.6 17.0 61.3 318.3 1154.1 2037.8 192.1
North Dakoda 100.9 9.0 13.3 43.8 446.1 1843.0 144.7
Ohio 7.8 27.3 190.5 181.1 1216.0 2696.8 400.4
Oklahoma 8.6 29.2 73.8 205.0 1288.2 2228.1 326.8
Oregan 4.9 39.9 124.1 286.9 1636.4 3506.1 388.9 Pennsyvania 5.6 19.0 130.3 128.0 877.5 1624.1 333.2
Rhode Island 3.6 10.5 86.5 201.0 1849.5 2844.1 791.4
South Carolina 11.9 33.0 105.9 485.3 1613.6 2342.4 245.1
South Dakoda 2.0 13.5 17.9 155.7 570.5 1704.4 147.5
Tennessee 10.1 29.7 145.8 203.9 1259.7 1776.5 314.0
Texas 13.3 33.8 152.4 208.2 1603.1 2988.7 397.6
Utah 3.5 20.3 68.8 147.3 1171.6 3004.6 334.5
Vermont 1.4 15.9 30.8 101.2 1348.2 2201.0 265.2
Virginia 9.0 23.3 92.1 165.7 986.2 2521.2 226.7
Wasinton 4.3 39.6 106.2 224.8 1605.6 3386.9 360.3 West Viginia 6.0 13.2 42.2 90.9 597.4 1341.7 163.3
Wiskonsin 2.8 12.9 52.2 63.7 846.9 2614.2 220.7
Wyoming 5.4 21.9 39.7 173.9 811.6 2772.2 282.0
;
proc princomp out=crimprin; /*调用PRINCOMP过程,用相关阵做主成分分析*/ var murder rape robbery assult burglary larceny auto; /*对这7个变量做分析*/ run;
执行以上程序,电脑按相关阵做主成分分析;输出主要数表有:样本相关阵的特征值(表头为Eigenvalues of the Correlation Matrix)表,方差贡献、方差贡献率及累计方差贡献率;样本相关阵的特征向量(表头为Eigenvectors)。表及解释如下
Eigenvalues of the Correlation Matrix
Eigenvalue Difference Proportion Cumulative
1 3.81730007 2.78454963 0.5453 0.5453
2 1.03275044 0.22145080 0.1475 0.6929
3 0.81129963 0.14770303 0.1159 0.8088
4 0.66359660 0.35782066 0.0948 0.9036
5 0.30577594 0.06348335 0.0437 0.9472
6 0.24229259 0.11530785 0.0346 0.9819
7 0.12698474 0.0181 1.0000
Eigenvectors
Prin1 Prin2 Prin3 Prin4 Prin5 Prin6 Prin7 murder -.094836 0.893895 0.335604 0.264209 0.087862 0.037372 -.020129 rape 0.433768 0.218170 -.298382 -.102754 -.033667 -.772201 -.259286 robbery 0.398823 0.091935 0.367321 -.422729 -.696268 0.173693 0.062497 assult 0.39223 0.2585 -.37199 -.431946 0.445511 0.353752 0.361585 burglary 0.463531 -.067937 -.044742 0.305199 0.096792 0.445645 -.690946 larceny 0.402967 -.071041 -.14078 0.678773 -.216768 -.005623 0.55226 auto 0.335705 -.261558 0.709373 -.021882 0.501519 -.219929 0.123736
由特征值表(表头为 Eigenvalues of the Correlation Matrix ),第5列可见,前3个特征值所占比例之和为0.80,只要取3个主成分就够了。由特征向量表(表头为
Eigenvectors ),从第2列起,每列是1个特征向量。第1个特征向量各个分量值大体相同,近似于7/1=0.38;所以第1主成分表示各州犯罪程度的严重性。第2个特征向量各分量对应murder,rape , assult ,分量值为负的,对应burglary,larceny,auto 分量是正的,murder,rape, assult 暴力程度重, burglary,larceny,auto 暴力程度轻,因此第二主成分反映暴力程度的轻重,第二主成分的值越大,暴力成分越轻。第三主成分的特性不明显,不考虑。第一、第二主成分分别为:
y 1=0.303311murder+0.432675rape+0.391443robbery+0.401331assult +0.4434023burglary+0.361074larceny+0.29296226auto;
y 2=-0.6634076murder-0.167388rape+0.019456robbery-0.335621assult +0.237752burglary+0.391665 arceny+0.496972 auto
许多统计资料简化成样本协差阵,或样本相关阵;这时仍可用SAS 的princomp 过程计算,只是在data 步输入数据时要用“_type_=COV ”语句说明。
例5.6 测量雄龟甲的长、宽、厚,并求其自然对数,得到变量321,,X X X ;所得24只龟数据的协方差阵如下表,试作主成分分析。
表5.3 龟甲数据的协方差阵
??
??
?
?????=773.6005.6160.8005.6417.6019.8160.8019.8072.11*001.0S
由于观测资料已被处理为协方差阵,而协方差阵是对称的,只需要输入下三角阵即可,
协差阵乘以常数不改变特征向量和累积方差贡献率,所以0.001不用输入。我们采用如下程序
data turtle(type=cov); /*建立数据集turtle*/ _type_='cov'; /*数据集为协方差阵类型*/ input name $ x1-x3; /*建立变量name x1 x2 x3 */ cards; /*以下是数据体*/
x1 11.072 . . x2 8.019 6.417 . x3 8.160 6.005 6.773
; /*空语句,结束数据体*/
proc princomp COV; /*用协方差阵计算3个主成分*/
var x1-x3; /*对变量x1 x2 x3求主成分*/
run;
执行后电脑按相关阵做主成分分析;输出主要数表有:协方差阵的特征值(表头为Eigenvalues),特征向量表(表头为Eigenvectors)。解释如下
Eigenvalues
Eigenvalue Difference Proportion Cumulative PRIN1 23.3035 22.7048 0.960493 0.96049
PRIN2 0.5987 0.2389 0.024676 0.98517
PRIN3 0.3598 . 0.014831 1.00000 上表是特征值表,由表第2列可见,特征值分别是23.303496、0.5986906、0.3598188;由上表第5列可见,第1特征值占总变差的96%,所以只需1个主成分,就能解释全部变化。
Eigenvectors
PRIN1 PRIN2 PRIN3
X1 0.683103 -.158344 -.712950
X2 0.510212 -.595012 0.621002
X3 0.522546 0.787964 0.325666 上是特征向量表,由表可见,第1主成分的系数0.683103、0.510212、0.522546相差不多,所以第1主成分表示龟甲的尺寸的自然对数和,即龟甲体积的自然对数。
5.6 主成分得分
实际问题中常需要知道主成分的值,例如例3中需要知道哪个州犯罪程度严重,哪个州犯罪程度较轻,这就需要计算每个州第一主成分的值;需要知道哪个州暴力犯罪严重,哪个州暴力犯罪较轻,这就需要计算每个州第二主成分的值。同时由于经验正交分解的需要和计算等原因,我们也往往要计算主成分得分。
将各变量值代入主成分的表达式,就能计算主成分的值。例如例2中北京气温的第一主成分是
prin1=0.643587Dec +0.213039Jan+0.735126Feb,
而1951年Dec、Jan、Feb的值分别是1.0、-2.7、-4.3;所以1951年第一主分量的值就是prin1=0.643587*1.0+0.213039*(-2.7)+0.735126*(-4.3)。
定义5.5当用样本协方差阵求主成分时,求各观测值距平(观测值减去其平均值),再代入主成分的公式,所得称为(协方差阵生成的)主成分得分。
例如例2中第一主成分是0.643587*Dec+0.213039*Jan+0.735126*Feb; Dec,Jan,Feb的样本均值分别是-2.74,-4.59,-2.27;1951年Dec,Jan,Feb的值分别是1.0,-2.7,-4.3;所以1951年(协方差阵生成的)的第一主成分得分就是
0.643587*(1.0+2.74)+0.213039*(-2.7+4.59)+0.735126*(-4.3+2.27)=1.32。
定义5.6当用样本相关阵阵求主成分时,将各观测标准化(观测值减去其平均值,除以样本标准差)再代入主成分的公式,所得称为(相关阵生成的)主成分得分。
例如例2用相关阵计算时,第一主成分是0.6388*Dec+0.5734*Jan+0.5129*Feb。而1951
年标准化的Dec,Jan,Feb的值分别是2.013,1.613,-1.034;于是1951年的(相关阵生成的)第一主成分得分就是
6388*2.013+0.5734*1.613 +0.5129*(-1.034)=1.681
由主成分得分的值很容易算出主成分的值,但由于主成分得分与主成分的值差一常数,因而在比较各次观测主成分的值时,只需比较主成分得分的值即可。
SAS-PRINCOMP过程作主成分分析时,能计算主成分得分,在PROC PRINCOMP语句中加选项OUT=文件名,主成分得分的值即存在该文件中。
例5.4(续)北京1951~1976年冬季的气温资料,求(协方差阵生成的)各年主成分得分。解:采用下列程序
data temperat;
input year Dec Jan Feb;
cards;
1951 1.0 -2.7 -4.3
1952 -5.3 -5.9 -3.5
1953 -2.0 -3.4 -0.8
1954 -5.7 -4.7 -1.1
1955 -0.9 -3.8 -3.1
1956 -5.7 -5.3 -5.9
1957 -2.1 -5.0 -1.6
1958 0.6 -4.3 -0.2
1959 -1.7 -5.7 2.0
1960 -3.6 -3.6 1.3
1961 -3.0 -3.1 -0.8
1962 0.1 -3.9 -1.1
1963 -2.6 -3.0 -5.2
1964 -1.4 -4.9 -1.7
1965 -3.9 -5.7 -2.5
1966 -4.7 -4.8 -3.3
1967 -6.0 -5.6 -4.9
1968 -1.7 -6.4 -5.1
1969 -3.4 -5.6 -2.0
1970 -3.1 -4.2 -2.9
1971 -3.8 -4.9 -3.9
1972 -2.0 -4.1 -2.4
1973 -1.7 -4.2 -2.0
1974 -3.6 -3.3 -2.0
1975 -2.7 -3.7 0.1
1976 -2.4 -7.6 -2.2
;
proc princomp cov out=prin; /*各次观测的主成分值存入数据集prin。*/
var Dec Jan Feb; /* 对变量Dec Jan Feb 作主成分分析*/
proc print data=prin; /* 打印数据集prin所存各次观测的的主成分得分*/ run;
proc sort data=prin; /*将主成分得分按第一主成分得分排序*/
by prin1;
proc print; /* 打印数据集排序后的各次观测的主成分得分*/ run;
proc sort data=prin; /*将主成分得分按第二主成分得分排序*/
by prin2;
proc print; /* 打印数据集排序后的各次观测的主成分得分*/ run;
执行上述程序,与例5.4相比,增加的SAS输出是下表,其中PRIN1、PRIN2、PRIN3分别表示第1、2、3主成分得分。
表5-4 北京冬季气温主成分得分
OBS YEAR DEC JAN FEB PRIN1 PRIN2 PRIN3
1 1951 1.0 -2.7 -4.3 1.32159 4.39464 0.79664
2 1952 -5.
3 -5.9 -3.5 -2.82663 -1.23681 -0.48750
3 1953 -2.0 -3.
4 -0.8 1.81464 -0.24090 0.88972
4 1954 -5.7 -4.7 -1.1 -1.06412 -2.91502 0.71132
5 1955 -0.9 -3.8 -3.1 0.74659 2.02081 0.25417
6 1956 -5.
7 -5.3 -5.9 -4.72054 0.22071 0.26664
7 1957 -2.1 -5.0 -1.6 0.82132 -0.07862 -0.59250
8 1958 0.6 -4.3 -0.2 3.73731 1.02475 -0.73246
9 1959 -1.7 -5.7 2.0 3.57608 -2.36830 -1.47492
10 1960 -3.6 -3.6 1.3 2.28606 -2.83781 1.09907
11 1961 -3.0 -3.1 -0.8 1.23497 -0.89291 1.46318
12 1962 0.1 -3.9 -1.1 2.83912 1.35662 -0.18190
13 1963 -2.6 -3.0 -5.2 -1.72085 2.39084 1.56369
14 1964 -1.4 -4.9 -1.7 1.21963 0.50533 -0.69429
15 1965 -3.9 -5.7 -2.5 -1.14787 -0.88178 -0.72358
16 1966 -4.7 -4.8 -3.3 -2.05911 -0.73417 0.38901
17 1967 -6.0 -5.6 -4.9 -4.24241 -0.72751 0.03805
18 1968 -1.7 -6.4 -5.1 -1.79244 2.30614 -1.95308
19 1969 -3.4 -5.6 -2.0 -0.43721 -0.84625 -0.78440
20 1970 -3.1 -4.2 -2.9 -0.60750 0.24643 0.49508
21 1971 -3.8 -4.9 -3.9 -1.94226 0.29187 0.05198
22 1972 -2.0 -4.1 -2.4 0.48932 0.70789 0.26259
23 1973 -1.7 -4.2 -2.0 0.95514 0.63061 0.07014
24 1974 -3.6 -3.3 -2.0 -0.07594 -0.54455 1.47579
25 1975 -2.7 -3.7 0.1 1.96183 -1.40534 0.77828
26 1976 -2.4 -7.6 -2.2 -0.36673 -0.38669 -2.98072
Obs year Dec Jan Feb Prin1 Prin2 Prin3
1 1956 -5.7 -5.3 -5.9 -4.72054 0.22071 0.26664
2 1967 -6.0 -5.6 -4.9 -4.24241 -0.72751 0.03805
主成分分析案例
姓名:XXX 学号:XXXXXXX 专业:XXXX 用SPSS19软件对下列数据进行主成分分析: ……
一、相关性 通过对数据进行双变量相关分析,得到相关系数矩阵,见表1。 表1 淡化浓海水自然蒸发影响因素的相关性 由表1可知: 辐照、风速、湿度、水温、气温、浓度六个因素都与蒸发速率在0.01水平上显著相关。 分析:各变量之间存在着明显的相关关系,若直接将其纳入分析可能会得到因多元共线性影响的错误结论,因此需要通过主成份分析将数据所携带的信息进行浓缩处理。 二、KMO和球形Bartlett检验 KMO和球形Bartlett检验是对主成分分析的适用性进行检验。 KMO检验可以检查各变量之间的偏相关性,取值范围是0~1。KMO的结果越接近1,表示变量之间的偏相关性越好,那么进行主成分分析的效果就会越好。实际分析时,KMO统计量大于0.7时,效果就比较理想;若当KMO统计量小于0.5时,就不适于选用主成分分析法。 Bartlett球形检验是用来判断相关矩阵是否为单位矩阵,在主成分分析中,若拒绝各变量独立的原假设,则说明可以做主成分分析,若不拒绝原假设,则说明这些变量可能独立提供一些信息,不适合做主成分分析。
由表2可知: 1、KMO=0.631<0.7,表明变量之间没有特别完美的信息的重叠度,主成分分析得到的模型又可能不是非常完善,但仍然值得实验。 2、显著性小于0.05,则应拒绝假设,即变量间具有较强的相关性。 三、公因子方差 公因子方差表示变量共同度。表示各变量中所携带的原始信息能被提取出的主成分所体现的程度。 由表3可知: 几乎所有变量共同度都达到了75%,可认为这几个提取出的主成分对各个变量的阐释能力比较强。 四、解释的总方差 解释的总方差给出了各因素的方差贡献率和累计贡献率。
第5章 主成分分析
第五章主成分分析 一、填空题 1.主成分分析就是设法将原来众多的指标,重新组合成一组新的的综合指标来代替原来指标。 2.主成分分析的数学模型可简写为,该模型的系数要求。 3.主成分分析中,利用的大小来寻找主成分。 4.第k个主成分 y的贡献率为,前k个主成分的累积贡献率 k 为。 5.确定主成分个数时,累积贡献率一般应达到,在spss中,系统默认为。 6.主成分的协方差矩阵为_________矩阵。 7.原始变量协方差矩阵的特征根的统计含义是________________。 8.原始数据经过标准化处理,转化为均值为__ __,方差为__ __的标准值,且其________矩阵与相关系数矩阵相等。 9.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为________。10.SPSS中主成分分析采用______________命令过程。
二、判断题 1.主成分分析就是设法将原来众多具有一定相关性的指标,重新组合成一组新的相互无关的综合指标来代替原来指标。 ( ) 2.主成分y 的协差阵为对角矩阵。 ( ) 3.p x x x ,,,21 的主成分就是以∑的特征向量为系数的一个组合,它们互不相关,其方差为∑的特征根。 ( ) 4.原始变量i x 的信息提取率()m i V 表示这m 个主成分所能够解释第i 个原始变量变动的程度。 ( ) 5.在spss 中,可以直接进行主成分分析。 ( ) 6.主成分分析可用于筛选回归变量。 ( ) 7.SPSS 中选取主成分的方法有两个:一种是根据特征根≥1来选取; 另一种是按照累积贡献率≥85%来选取。 ( ) 8.主成分方差的大小说明了该综合指标反映p 个原始观测变量综合变动程度的能力的大小。 ( ) 9.主成分表达式的系数向量是协方差矩阵∑的特征向量。 ( ) 10.主成分k y 与原始变量i x 的相关系数()i k x y ,ρ反映了第k 个公共因子对第i 个原始变量的解释程度。 ( )
主成分分析PCA(含有详细推导过程以及案例分析matlab版)
主成分分析法(PCA) 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 I. 主成分分析法(PCA)模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。 主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求 0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ??????? ??=np n n p p x x x x x x x x x X 21 222 21112 11()p x x x ,,21=
主成分分析计算方法和步骤
主成分分析计算方法和步骤: 在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。而主成分分析法可以很好地解决这一问题。 主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。 主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。 结合数据进行分析 本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。 表5-6 相关系数矩阵 本科院校 数招生人数教育经费投入 相关性师生比0.279 0.329 0.252 重点高校数0.345 0.204 0.310 教工人数0.963 0.954 0.896 本科院校数 1.000 0.938 0.881 招生人数0.938 1.000 0.893
数学建模主成分分析方法
主 成分分析方法 地理环境是多要素的复杂系统,在我们进行地理系统分析时,多变量问题是经常会遇到的。变量太多,无疑会增加分析问题的难度与复杂性,而且在许多实际问题中,多个变量之间是具有一定的相关关系的。因此,我们就会很自然地想到,能否在各个变量之间相关关系研究的基础上,用较少的新变量代替原来较多的变量,而且使这些较少的新变量尽可能多地保留原来较多的变量所反映的信息事实上,这种想法是可以实现的,这里介绍的主成分分析方法就是综合处理这种问题的一种强有力的方法。 一、主成分分析的基本原理 主成分分析是把原来多个变量化为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。假定有n个地理样本,每个样本共有p个变量描述,这样就构成了一个n×p阶的地理数据矩阵:
111212122212p p n n np x x x x x x X x x x ???=????L L L L L L L (1) 如何从这么多变量的数据中抓住地理事物的内在规律性呢要解决这一问题,自然要在p 维空间中加以考察,这是比较麻烦的。为了克服这一困难,就需要进行降维处理,即用较少的几个综合指标来代替原来较多的变量指标,而且使这些较少的综合指标既能尽量多地反映原来较多指标所反映的信息,同时它们之间又是彼此独立的。那么,这些综合指标(即新变量)应如何选取呢显然,其最简单的形式就是取原来变量指标的线性组合,适当调整组合系数,使新的变量指标之间相互独立且代表性最好。 如果记原来的变量指标为x 1,x 2,…,x p ,它们的综合指标——新变量指标为z 1,z 2,…,zm (m≤p)。则 11111221221122221122,,......................................... ,p p p p m m m mp p z l x l x l x z l x l x l x z l x l x l x =+++??=+++????=+++?L L L (2)
R语言主成分分析的案例
R 语言主成分分析的案例
R 语言也介绍到案例篇了,也有不少同学反馈说还是不是特别明白一些基础的东西,希望能 够有一些比较浅显的可以操作的入门。其实这些之前 SPSS 实战案例都不少,老实说一旦用 上了开源工具就好像上瘾了,对于以前的 SAS、clementine 之类的可视化工具没有一点 感觉了。本质上还是觉得要装这个、装那个的比较麻烦,现在用 R 或者 python 直接简单 安装下,导入自己需要用到的包,活学活用一些命令函数就可以了。以后平台上集成 R、 python 的开发是趋势,包括现在 BAT 公司内部已经实现了。 今天就贴个盐泉水化学分析资料的主成分分析和因子分析通过 R 语言数据挖掘的小李 子: 有条件的同学最好自己安装下 R,操作一遍。 今有 20 个盐泉,盐泉的水化学特征系数值见下表.试对盐泉的水化学分析资料作主成分分 析和因子分析.(数据可以自己模拟一份)
其中 x1:矿化度(g/L);
x2:Br?103/Cl; x3:K?103/Σ 盐; x4:K?103/Cl; x5:Na/K; x6:Mg?102/Cl; x7:εNa/εCl.
1.数据准备
导入数据保存在对象 saltwell 中 >saltwell<-read.table("c:/saltwell.txt",header=T) >saltwell
2.数据分析
1 标准误、方差贡献率和累积贡献率
>arrests.pr<- prcomp(saltwell, scale = TRUE) >summary(arrests.pr,loadings=TRUE)
2 每个变量的标准误和变换矩阵
>prcomp(saltwell, scale = TRUE)
3 查看对象 arests.pr 中的内容
>> str(arrests.pr)
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 公司销售净利率(X1)资产净利率(X2)净资产收益率(X3)销售毛利率(X4) 歌华有线五粮液用友软件太太药业浙江阳光烟台万华方正科技红河光明贵州茅台中铁二局红星发展伊利股份青岛海尔湖北宜化雅戈尔福建南纸43.31 17.11 21.11 29.55 11.00 17.63 2.73 29.11 20.29 3.99 22.65 4.43 5.40 7.06 19.82 7.26 7.39 12.13 6.03 8.62 8.41 13.86 4.22 5.44 9.48 4.64 11.13 7.30 8.90 2.79 10.53 2.99 8.73 17.29 7.00 10.13 11.83 15.41 17.16 6.09 12.97 9.35 14.3 14.36 12.53 5.24 18.55 6.99 54.89 44.25 89.37 73 25.22 36.44 9.96 56.26 82.23 13.04 50.51 29.04 65.5 19.79 42.04 22.72 第一,将EXCEL中的原始数据导入到SPSS软件中; 注意: 导入Spss的数据不能出现空缺的现象,如出现可用0补齐。 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。 所做工作: a. 原始数据的标准化处理
数学建模-主成分分析法模板
根据主成分分析的方法,分析……的数据。步骤如下: Step 1:为了消除不同变量的量纲的影响,首先需要对变量进行标准化,设检测数据样本共有n 个,指标共有p 个,分别设1X ,2X ,p X ,令ij X (i=1,2,…,n;j=1,2,…,p)为第i 个样本第j 个指标的值。作变换 ) Var(X )E(X X Y j j j j -= (j=1,2,…,p) 得到标准化数据矩阵j j ij ij s x x y -= ,其中∑==i 1i ij j x n 1x ,∑=-=n 1 i 2j ij 2 j )x x (n 1s Step 2:在标准化数据矩阵p n ij )y (Y ?=的基础上计算p 个原始指标相关系数矩阵 ??? ??? ????? ???==?pp 2 p 1p p 22221p 112 11p p ij r r r r r r r r r )r (R ΛM M M M Λ Λ 其中,∑∑∑===----= n 1 k n 1 k 2 j k j 2i k i n 1 k j k j i k i ij )x x ()x x () x x )(x x (r (i,j=1,2,…,p) Step 3:求相关系数矩阵R 的特征值并排序0p 21≥λ≥≥λ≥λΛ,再求出R 的特征值相应的正则化特征向量)e ,,e ,e (e ip i21i i K =,则第i 个主成分表示为各指标k X 的组合∑=?=p 1i k ik i X e Z 。 Step 4:计算累积贡献率确定主成分的数目。主成分i Z 的贡献率为 )p ,,2,1i (w p 1 k k i i Λ=λ λ= ∑= 累计贡献率为 ) p ,,2,1i (p i 1 k k Λ=λ∑=
主成分分析法matlab实现,实例演示
利用Matlab 编程实现主成分分析 1.概述 Matlab 语言是当今国际上科学界 (尤其是自动控制领域) 最具影响力、也是 最有活力的软件。它起源于矩阵运算,并已经发展成一种高度集成的计算机语言。它提供了强大的科学运算、灵活的程序设计流程、高质量的图形可视化与界面设计、与其他程序和语言的便捷接口的功能。Matlab 语言在各国高校与研究单位起着重大的作用。主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。 1.1主成分分析计算步骤 ① 计算相关系数矩阵 ?? ? ???? ???? ?? ?=pp p p p p r r r r r r r r r R 2 122221 11211 (1) 在(3.5.3)式中,r ij (i ,j=1,2,…,p )为原变量的xi 与xj 之间的相关系数,其计算公式为 ∑∑∑===----= n k n k j kj i ki n k j kj i ki ij x x x x x x x x r 1 1 2 2 1 )() () )(( (2) 因为R 是实对称矩阵(即r ij =r ji ),所以只需计算上三角元素或下三角元素即可。
② 计算特征值与特征向量 首先解特征方程0=-R I λ,通常用雅可比法(Jacobi )求出特征值 ),,2,1(p i i =λ,并使其按大小顺序排列,即0,21≥≥≥≥p λλλ ;然后分别求 出对应于特征值i λ的特征向量),,2,1(p i e i =。这里要求i e =1,即112 =∑=p j ij e ,其 中ij e 表示向量i e 的第j 个分量。 ③ 计算主成分贡献率及累计贡献率 主成分i z 的贡献率为 ),,2,1(1 p i p k k i =∑=λ λ 累计贡献率为 ) ,,2,1(11 p i p k k i k k =∑∑==λ λ 一般取累计贡献率达85—95%的特征值m λλλ,,,21 所对应的第一、第二,…,第m (m ≤p )个主成分。 ④ 计算主成分载荷 其计算公式为 ) ,,2,1,(),(p j i e x z p l ij i j i ij ===λ (3)
主成分分析 实例
§8 实例 实例1 计算得 1x =71.25,2x =67.5 分析1:基于协差阵∑ 求主成分。 369.6117.9117.9214.3S ?? = ??? 特征根与特征向量(S无偏,用SPSS ) Factor 1 Factor 2 11x x - 0.880 -0.474 22x x - 0.474 0.880 特征值 433.12 150.81 贡献率 0.7417 0.2583 注:样本协差阵为无偏估计11(11)1n n n S X I X n n ''= --, 所以,第一、二主成分的表达式为 112212 0.88(71.25)0.47(67.5) 0.47(71.25)0.88(67.5)y x x y x x =-+-?? =--+-? 第一主成分是英语与数学的加权和(反映了综合成绩),且英语的权数要大于数学的权数。1y 越大,综合成绩越好。(综合成分) 第二主成分的两个系数异号(反映了两科成绩的均衡性)。不妨将英语称为文科,数学称为理科。2y 越大,说明偏科(文、理成绩不均衡),2y 越小,越接近于零,说明不偏科(文、理成绩均衡)。(结构成分)
问题:英语的权数为何大?如何解释? 分析2: 基于相关阵R 求主成分。因为 1x =71.25,2x =67.5 所以相关阵 11R ? =? ? ? 解得R 的特征根为:1λ=1.419,2λ=0.581,对应的单位特征向量分别为: Factor 1 Factor 2 11 1x x s - 0.707 0.707 22 2 x x s - 0.707 -0.707 特征根 1.419 0.581 贡献率 0.709 0.291 所以,第一、二主成分的表达式为 12112271.2567.50.7070.70717.9813.6971.2567.50.7070.70717.9813.69x x y x x y --? =+=+?? ? --?=-=-?? 1122120.039(71.25)0.052(67.5) 0.039(71.25)0.052(67.5)y x x y x x =-+-?? =---? 112212 0.0390.052 6.273 0.0390.0520.671y x x y x x =+-?? =-+? * 2*11707.0707.0x x y += *2*12707.0707.0x x y -= 基于相关阵的更说明了: 第一主成分是英语与数学的加权总分。 第二主成分是对两科成绩均衡性的度量。 此例说明:基于协差阵与基于相关阵的主成分分析的结果不一致。结合此例的实际背景,经对比分析可知,基于协差阵的主成分分析更符合实际。
PCA降维方法(主成分分析降维)
一、简介 PCA(Principal Components Analysis)即主成分分析,是图像处理中经常用到的降维方法,大家知道,我们在处理有关数字图像处理方面的问题时,比如经常用的图像的查询问题,在一个几万或者几百万甚至更大的数据库中查询一幅相近的图像。这时,我们通常的方法是对图像库中的图片提取响应的特征,如颜色,纹理,sift,surf,vlad等等特征,然后将其保存,建立响应的数据索引,然后对要查询的图像提取相应的特征,与数据库中的图像特征对比,找出与之最近的图片。这里,如果我们为了提高查询的准确率,通常会提取一些较为复杂的特征,如sift,surf等,一幅图像有很多个这种特征点,每个特征点又有一个相应的描述该特征点的128维的向量,设想如果一幅图像有300个这种特征点,那么该幅图像就有300*vector(128维)个,如果我们数据库中有一百万张图片,这个存储量是相当大的,建立索引也很耗时,如果我们对每个向量进行PCA处理,将其降维为64维,是不是很节约存储空间啊?对于学习图像处理的人来说,都知道PCA是降维的,但是,很多人不知道具体的原理,为此,我写这篇文章,来详细阐述一下PCA及其具体计算过程: 二、PCA原理 1、原始数据: 为了方便,我们假定数据是二维的,借助网络上的一组数据,如下: x=[2.5, 0.5, 2.2, 1.9, 3.1, 2.3, 2, 1,1.5, 1.1]T y=[2.4, 0.7, 2.9, 2.2, 3.0, 2.7, 1.6, 1.1, 1.6, 0.9]T 2、计算协方差矩阵 什么是协方差矩阵?相信看这篇文章的人都学过数理统计,一些基本的常识都知道,但是,也许你很长时间不看了,都忘差不多了,为了方便大家更好的理解,这里先简单的回顾一下数理统计的相关知识,当然如果你知道协方差矩阵的求法你可以跳过这里。
主成分分析法概念及例题
主成分分析法 主成分分析(principal components analysis,PCA)又称:主分量分析,主成分回归分析法 [编辑] 什么是主成分分析法 主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析(principal components analysis,PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。 [编辑] 主成分分析的基本思想
在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [编辑] 主成分分析的主要作用
数学建模各种分析报告方法
现代统计学 1.因子分析(Factor Analysis) 因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量),以较少的几个因子反映原资料的大部分信息。 运用这种研究技术,我们可以方便地找出影响消费者购买、消费以及满意度的主要因素是哪些,以及它们的影响力(权重)运用这种研究技术,我们还可以为市场细分做前期分析。 2.主成分分析 主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。主成分分析一般很少单独使用:a,了解数据。(screening the data),b,和cluster analysis一起使用,c,和判别分析一起使用,比如当变量很多,个案数不多,直接使用判别分析可能无解,这时候可以使用主成份发对变量简化。(reduce dimensionality)d,在多元回归中,主成分分析可以帮助判断是否存在共线性(条件指数),还可以用来处理共线性。 主成分分析和因子分析的区别 1、因子分析中是把变量表示成各因子的线性组合,而主成分分析中则是把主成分表示成个变量的线性组合。 2、主成分分析的重点在于解释个变量的总方差,而因子分析则把重点放在解释各变量之间的协方差。 3、主成分分析中不需要有假设(assumptions),因子分析则需要一些假设。因子分析的假设包括:各个共同因子之间不相关,特殊因子(specific factor)之间也不相关,共同因子和特殊因子之间也不相关。 4、主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的时候,的主成分一般是独特的;而因子分析中因子不是独特的,可以旋转得到不同的因子。 5、在因子分析中,因子个数需要分析者指定(spss根据一定的条件自动设定,只要是特征值大于1的因子进入分析),而指定的因子数量不同而结果不同。在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分。 和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势。大致说来,当需要寻找潜在的因子,并对这些因子进行解释的时候,更加倾向于使用因子分析,并且借助旋转技术帮助更好解释。而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这中情况也可以使用因子得分做到。所以这中区分不是绝对的。 总得来说,主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。主成分分析一般很少单独使用:a,了解数据。(screening the data),b,
主成分分析原理
第七章主成分分析 (一)教学目的 通过本章的学习,对主成分分析从总体上有一个清晰地认识,理解主成分分析的基本思想和数学模型,掌握用主成分分析方法解决实际问题的能力。 (二)基本要求 了解主成分分析的基本思想,几何解释,理解主成分分析的数学模型,掌握主成分分析方法的主要步骤。 (三)教学要点 1、主成分分析基本思想,数学模型,几何解释 2、主成分分析的计算步骤及应用 (四)教学时数 3课时 (五)教学内容 1、主成分分析的原理及模型 2、主成分的导出及主成分分析步骤 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 第一节主成分分析的原理及模型 一、主成分分析的基本思想与数学模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。
主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ??????? ??=np n n p p x x x x x x x x x X 21 222 21112 11()p x x x ,,21= 其中:p j x x x x nj j j j ,2,1,21=?????? ? ??= 主成分分析就是将p 个观测变量综合成为p 个新的变量(综合变量),即 ???????+++=+++=+++=p pp p p p p p p p x a x a x a F x a x a x a F x a x a x a F 22112222121212121111 简写为: p jp j j j x x x F ααα+++= 2211 p j ,,2,1 = 要求模型满足以下条件:
《多元统计分析》第五章 主成分分析
《多元统计分析》MOOC 5.1 引言 王学民
例1(书中习题7.6)下表给出的是美国50个州每100 000个人中七种犯罪的比率数据。这七种犯罪是: 杀人罪(x 1)夜盗罪(x 5 ) 强奸罪(x 2)盗窃罪(x 6 ) 抢劫罪(x 3)汽车犯罪(x 7 ) 伤害罪(x 4 ) 希望对50个州的这些犯罪情况进行(整体的)比较分析。
州杀人罪强奸罪抢劫罪伤害罪夜盗罪盗窃罪汽车犯罪Alabama14.225.296.8278.31135.51881.9280.7 Alaska10.851.696.82841331.73369.8753.3 Arizona9.534.2138.2312.32346.14467.4439.5 Arkansas8.827.683.2203.4972.61862.1183.4 California11.549.42873582139.43499.8663.5 Colorado 6.342170.7292.91935.23903.2477.1 Connecticut 4.216.8129.5131.813462620.7593.2 Delaware624.9157194.21682.63678.4467 Florida10.239.6187.9449.11859.93840.5351.4 Georgia11.731.1140.5256.51351.12170.2297.9 Hawaii7.225.512864.11911.53920.4489.4 Idaho 5.519.439.6172.51050.82599.6237.6 Illinois9.921.8211.320910852828.5528.6 Indiana7.426.5123.2153.51086.22498.7377.4 Iowa 2.310.641.289.8812.52685.1219.9 Kansas 6.622100.7180.51270.42739.3244.3┆┆┆┆┆┆┆┆
主成分分析也称主分量分析
主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析(principal components analysis,PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。 [编辑] 主成分分析的基本思想 在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的
数学建模-主成分分析法模板
根据主成分分析的方法,分析 ……的数据。步骤如下: Step 1为了消除不同变量的量纲的影响,首先需要对变量进行标准化,设检测 数据样本 共有n 个,指标共有p 个,分别设X i ,X 2,X p ,令 X j (i=1,2,…,n;j=1,2,…,p)为第i 个样本第j 个指标的值。作变换 X 乂」已心“,…,p ) Var(X j ) Step 2:在标准化数据矩阵Y (y j )np 的基础上计算p 个原始指标相关系数矩阵 R (r j )pp r 11 *2 r 21 r 22 r 1p r 2p r p1 r p2 r pp n (X ki X i )(x kj X j ) 其中,r j k 1 (i j=1 2 -?? p) n n ( I,J=I ,2, ,p) (X ki X i ) (X X j )2 .k 1 k 1 Step 3:求相关系数矩阵 R 的特征值并排序1 2 p 0,再求出R 的特征 值相应的正则化特征向量 e i (e i1 , e i2 , ,e ip ) , 则第i 个主成分表示为各指标X k p 的组合Z i e ik X k i 1 Step 4:计算累积贡献率确定主成分的数目。主成分 累计贡献率为 (i 1,2, ,p) 得到标准化数据矩阵y j X ij S j 仝,其中X j 2 X j ,S j n i i (X j X j )2 n i i w i i p k k 1 (i 1,2, ,p) 乙的贡献率为
般取累计贡献率达85%~95%的特征值 1, 2 , m 所对应的第1、第2,…, 2 / 5 第m (m W p )个主成分 Step 5:计算主成分载荷,确定综合得分。当主成分之间不相关时,主成分载荷 是主成分 和各指标的相关系数,相关系数越大,说明主成分对该指标变量的代 表性就越好,计算公式为 l j P ( Z i ,xj ... i e j (i,j 1,2, ,p) Step 6:各主成分的得分,确定综合评分函数。得到各主成分的载荷以后,可以 计算各主 成分的得分 m 则第i 个样本的综合得分f i W k Z ik (i=1,2,…,n); k 1 附件中共有28个月的数据,这里仅随机选择 2005年4月的数据来说明利 分析进行水质综合评价的过程(同理可进行其他月份的数据分析)。 调用MATLAB 统计工具箱princomp 函数,格式为: [pc,score,late nt,tsquare]=pri ncomp(i ngredie nts) 其中in gredie nts 指标准化后的样本指标矩阵,pc 是指各主成分关于指标的线性 组合的系数矩阵,score 为各主成分得分,late nt 是方差矩阵的特征值,tsquare 为 Hotelling T 2 统计量。 各种指标的相关系数矩阵: Z i 111 X i l 12 X 2 l 1p X Z 2 1 21 X 1 1 2 2 X 2 2p X p m1X 1 1 m 2X 2 m p X p Z (Z j )n Z 11 Z 12 Z 21 Z 22 Z 1 m Z 2m ,其中z ij 表示第i 个样本第j 个主成分得分, Z n1 Z n2 z nm
主成分分析方法及matlab运用解释
主成分分析方法 在许多实际问题中,多个变量之间是具有一定的相关关系的。因此,我们就会很自然地想到,能否在各个变量之间相关关系研究的基础上,用较少的新变量代替原来较多的变量,而且使这些较少的新变量尽可能多地保留原来较多的变量所反映的信息事实上,这种想法是可以实现的,这里介绍的主成分分析方法就是综合处理这种问题的一种强有力的方法。 一、主成分分析的基本原理 主成分分析是把原来多个变量化为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。假定有n 个地理样本,每个样本共有p 个变量描述,这样就构成了一个n×p 阶的地理数据矩阵: 11 12121 2221 2 p p n n np x x x x x x X x x x ???=? ???(1) 如何从这么多变量的数据中抓住地理事物的内在规律性呢要解决这一问题,自然要在p 维空间中加以考察,这是比较麻烦的。为了克服这一困难,就需要进行降维处理,即用较少的几个综合指标来代替原来较多的变量指标,而且使这些较少的综合指标既能尽量多地反映原来较多指标所反映的信息,同时它们之间又是彼此独立的。那么,这些综合指标(即新变量)应如何选取呢显然,其最简单的形式就是取原来变量指标的线性组合,适当调整组合系数,使新的变量指标之间相互独立且代表性最好。 如果记原来的变量指标为x 1,x 2,…,x p ,它们的综合指标——新变量指标为z 1,z 2,…,zm (m≤p)。则 11111221221122221122 ,,.........................................,p p p p m m m mp p z l x l x l x z l x l x l x z l x l x l x =+++?? =+++?? ??=+++?(2) 在(2)式中,系数l ij 由下列原则来决定:
主成分分析在数学建模中的应用
第一讲 主成分分析在数学建模中的应用 1.学习目的 1.理解主成分分析的基本思想; 2.会用SAS 软件编写相关程序,对相关数据进行主成分分析; 3.会用SAS 软件编程结合主成分分析方法解决实际问题。 2.学习要求 1.理解主成分分析的基本原理,掌握主成分分析的基本步骤; 2.会用SAS 软件编写相关程序,对相关数据进行分析处理和假设检验; 3.撰写不少于3000字的小论文; 4. 精读一篇优秀论文。 理论基础 1基本思想 在实际问题的研究中,往往会涉及众多的变量。但是,变量太多不但会增加计算的复杂性,而且也给合理地分析问题和解释问题带来困难。一般来说,虽然每个变量提供了一定的信息,但其重要性有所不同,而在很多情况下,变量间有一定的相关性,从而使得这些变量所提供的信息在一定程度上有所重叠。因而人们希望对这些变量加以“改造”,用为数较少的互不相关的新变量来反映原来变量所提供的绝大部分信息,通过对新变量的分析达到解决问题的目的。主成分分析就是在这种降维的思想下产生的处理高维数据的方法。 基本原理 (1).总体的主成分 定义1.设' 12(,,)X X X =p …,X 为P 维随机向量,称' i i Z a X =为X 的第i 主成分(i=1,2,…P ),如果: (1) ' 1(1,2,);i i a a i ==…,p (2) 当i>1时,' 0(1,2,);i j a a j ==∑…i-1 (3) ''' 1,0(1,) ()max ()j i a a a a j Var Z Var a X ====∑…i-1 定理 1.设' 12(,,)X X X =p …,X 是P 维随机向量,且()D X =∑, ∑的特征值为 120p λλλ≥≥≥≥…,12,,p a a a …,为相应的单位正交特征向量,则X 的第i 主成分为 'i i Z a X = (1,2,).i =…,p