Dijkstra算法原理详细讲解

Dijkstra算法原理详细讲解
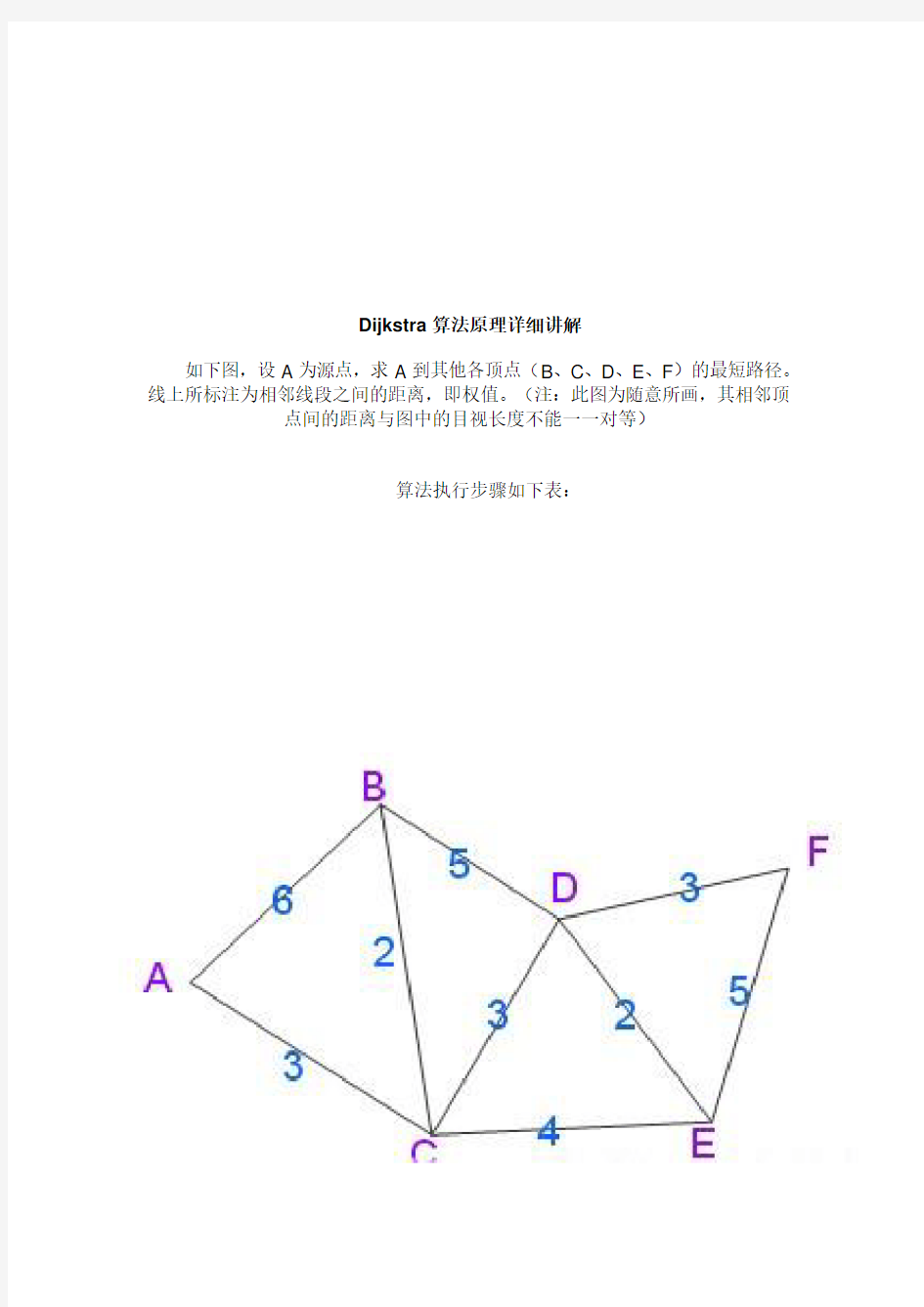
如下图,设A为源点,求A到其他各顶点(B、C、D、E、F)的最短路径。线上所标注为相邻线段之间的距离,即权值。(注:此图为随意所画,其相邻顶点间的距离与图中的目视长度不能一一对等)
算法执行步骤如下表:
Dijkstra算法的完整实现版本之算法的源代码
样例图:
输入格式:
输出格式:
输入时,将s,t,x,y,z五个点按照1,2,3,4,5起别名,输入格式按照下图例所示当提示Please enter the vertex where Dijkstra algorithm starts:时输入算法的起
始点
比如计算结果v1v4v2表示从点1到点2经过1,4,2为最短路径
Dijkstra算法的完整实现版本,算法的源代码
/* Dijkstra.c
Copyright (c) 2002, 2006 by ctu_85
All Rights Reserved.
*/
#include "stdio.h"
#include "malloc.h"
#define maxium 32767
#define maxver 9 /*defines the max number of vertexs which the programm
can handle*/
#define OK 1
struct Point
{
char vertex[3];
struct Link *work;
struct Point *next;
};
struct Link
{
char vertex[3];
int value;
struct Link *next;
};
struct Table /*the workbannch of the algorithm*/
{
int cost;
int Known;
char vertex[3];
char path[3];
struct Table *next;
};
int Dijkstra(struct Point *,struct Table *);
int PrintTable(int,struct Table *);
int PrintPath(int,struct Table *,struct Table *);
struct Table * CreateTable(int,int);
struct Point * FindSmallest(struct Table *,struct Point *);/*Find the vertex which has the smallest value reside in the table*/
int main()
{
int i,j,num,temp,val;
char c;
struct Point *poinpre,*poinhead,*poin;
struct Link *linpre,*linhead,*lin;
struct Table *tabhead;
poinpre=poinhead=poin=(struct Point *)malloc(sizeof(struct Point));
poin->next=NULL;
poin->work=NULL;
restart:
printf("Notice:if you wanna to input a vertex,you must use the format of
number!\n");
printf("Please input the number of points:\n");
scanf("%d",&num);
if(num>maxver||num<1||num%1!=0)
{
printf("\nNumber of points exception!");
goto restart;
}
for(i=0;i { printf("Please input the points next to point %d,end with 0:\n",i+1); poin=(struct Point *)malloc(sizeof(struct Point)); poinpre->next=poin; poin->vertex[0]='v'; poin->vertex[1]='0'+i+1; poin->vertex[2]='\0'; linpre=lin=poin->work; linpre->next=NULL; for(j=0;j { printf("The number of the %d th vertex linked to vertex %d:",j+1,i+1); scanf("%d",&temp); if(temp==0) { lin->next=NULL; break; } else { lin=(struct Link *)malloc(sizeof(struct Link)); linpre->next=lin; lin->vertex[0]='v'; lin->vertex[1]='0'+temp; lin->vertex[2]='\0'; printf("Please input the value betwixt %d th point towards %d th point:",i+1,temp); scanf("%d",&val); lin->value=val; linpre=linpre->next; lin->next=NULL; } } poinpre=poinpre->next; poin->next=NULL; } printf("Please enter the vertex where Dijkstra algorithm starts:\n"); scanf("%d",&temp); tabhead=CreateTable(temp,num); Dijkstra(poinhead,tabhead); PrintTable(temp,tabhead); return OK; } struct Table * CreateTable(int vertex,int total) { struct Table *head,*pre,*p; int i; head=pre=p=(struct Table *)malloc(sizeof(struct Table)); p->next=NULL; for(i=0;i { p=(struct Table *)malloc(sizeof(struct Table)); pre->next=p; if(i+1==vertex) { p->vertex[0]='v'; p->vertex[1]='0'+i+1; p->vertex[2]='\0'; p->cost=0; p->Known=0; } else { p->vertex[0]='v'; p->vertex[1]='0'+i+1; p->vertex[2]='\0'; p->cost=maxium; p->Known=0; } p->next=NULL; pre=pre->next; } return head; } int Dijkstra(struct Point *p1,struct Table *p2) /* Core of the programm*/ { int costs; char temp; struct Point *poinhead=p1,*now; struct Link *linna; struct Table *tabhead=p2,*searc,*result; while(1) { now=FindSmallest(tabhead,poinhead); if(now==NULL) break; result=p2; result=result->next; while(result!=NULL) { if(result->vertex[1]==now->vertex[1]) break; else result=result->next; } linna=now->work->next; while(linna!=NULL) /* update all the vertexs linked to the signed vertex*/ { temp=linna->vertex[1]; searc=tabhead->next; while(searc!=NULL) { if(searc->vertex[1]==temp)/*find the vertex linked to the signed vertex in the table and update*/ { if((result->cost+linna->value) { searc->cost=result->cost+linna->value;/*set the new value*/ searc->path[0]='v'; searc->path[1]=now->vertex[1]; searc->path[2]='\0'; } break; } else searc=searc->next; } linna=linna->next; } } return 1; } struct Point * FindSmallest(struct Table *head,struct Point *poinhead) { struct Point *result; struct Table *temp; int min=maxium,status=0; head=head->next; poinhead=poinhead->next; while(head!=NULL) { if(!head->Known&&head->cost { min=head->cost; result=poinhead; temp=head; status=1; } head=head->next; poinhead=poinhead->next; } if(status) { temp->Known=1; return result; } else return NULL; } int PrintTable(int start,struct Table *head) { struct Table *begin=head; head=head->next; while(head!=NULL) { if((head->vertex[1]-'0')!=start) PrintPath(start,head,begin); head=head->next; } return OK; } int PrintPath(int start,struct Table *head,struct Table *begin) { struct Table *temp=begin->next,*p,*t; p=head; t=begin; if((p->vertex[1]-'0')!=start&&p!=NULL) { while(temp->vertex[1]!=p->path[1]&&temp!=NULL) temp=temp->next; PrintPath(start,temp,t); printf("%s",p->vertex); } else if(p!=NULL) printf("\n%s",p->vertex); return OK; } AAC解码算法原理详解 原作者:龙帅 (loppp138@https://www.360docs.net/doc/3d16402110.html,) 此文章为便携式多媒体技术中心提供,未经站长授权,严禁转载,但欢迎链接到此地址。 本文详细介绍了符合ISO/IEC 13818-7(MPEG2 AAC audio codec) , ISO/IEC 14496-3(MPEG4 Audio Codec AAC Low Complexity)进行压缩的的AAC音频的解码算法。 1、程序系统结构 下面是AAC解码流程图: AAC解码流程图 在主控模块开始运行后,主控模块将AAC比特流的一部分放入输入缓冲区,通过查找同步字得到一帧的起始,找到后,根据ISO/IEC 13818-7所述的语法开始进行Noisless Decoding(无噪解码),无噪解码实际上就是哈夫曼解码,通过反量化(Dequantize)、联合立体声(Joint Stereo),知觉噪声替换(PNS),瞬时噪声整形(TNS),反离散余弦变换(IMDCT),频段复制(SBR)这几个模块之后,得出左右声道的PCM码流,再由主控模块将其放入输出缓冲区输出到声音播放设备。 2. 主控模块 主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。其中,输入输出缓冲区均由DSP控制模块提供接口。输出缓冲区中将存放的数据为解码出来的PCM数据,代表了声音的振幅。它由一块固定长度的缓冲区构成,通过调用DSP控制模块的接口函数,得到头指针,在完成输出缓冲区的填充后,调用中断处理输出至I2S接口所连接的音频ADC芯片(立体声音频DAC和DirectDrive 耳机放大器)输出模拟声音。 3. 同步及元素解码 同步及元素解码模块主要用于找出格式信息,并进行头信息解码,以及对元素信息进行解码。这些解码的结果用于后续的无噪解码和尺度因子解码模块。 AAC的音频文件格式有以下两种: ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。 ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。 AAC的ADIF格式见下图: 3.1 ADIF的组织结构 AAC的ADTS的一般格式见下图: 3.2 ADTS的组织结构 图中表示出了ADTS一帧的简明结构,其两边的空白矩形表示一帧前后的数据。ADIF和ADTS的header是不同的。它们分别如下所示: 蚁群算法浅析 摘要:介绍了什么是蚁群算法,蚁群算法的种类,对四种不同的蚁群算法进行了分析对比。详细阐述了蚁群算法的基本原理,将其应用于旅行商问题,有效地解决了问题。通过对旅行商问题C++模拟仿真程序的详细分析,更加深刻地理解与掌握了蚁群算法。 关键词:蚁群算法;旅行商问题;信息素;轮盘选择 一、引言 蚁群算法(Ant Colony Optimization, ACO),是一种用来在图中寻找优化路径的算法。它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质。 蚁群算法成功解决了旅行商问题(Traveling Salesman Problem, TSP):一个商人要到若干城市推销物品,从一个城市出发要到达其他各城市一次而且最多一次最后又回到第一个城市。寻找一条最短路径,使他从起点的城市到达所有城市一遍,最后回到起点的总路程最短。若把每个城市看成是图上的节点,那么旅行商问题就是在N个节点的完全图上寻找一条花费最少的回路。 最基本的蚁群算法见第二节。目前典型的蚁群算法有随机蚁群算法、排序蚁群算法和最大最小蚁群算法,其中后两种蚁群算法是对前一种的优化。本文将终点介绍随机蚁群算法。 二、基本蚁群算法 (一)算法思想 各个蚂蚁在没有事先告诉他们食物在什么地方的前提下开始寻找食物。当一只找到食物以后,它会向环境释放一种信息素,信息素多的地方显然经过这里的蚂蚁会多,因而会有更多的蚂蚁聚集过来。假设有两条路从窝通向食物,开始的时候,走这两条路的蚂蚁数量同样多(或者较长的路上蚂蚁多,这也无关紧要)。当蚂蚁沿着一条路到达终点以后会马上返回来,这样,短的路蚂蚁来回一次的时间就短,这也意味着重复的频率就快,因而在单位时间里走过的蚂蚁数目就多,洒下的信息素自然也会多,自然会有更多的蚂蚁被吸引过来,从而洒下更多的信息素。因此,越来越多地蚂蚁聚集到较短的路径上来,最短的路径就找到了。 蚁群算法的基本思想如下图表示: 蚁群算法,PSO算法以及两种算法可以融合的几种方法 蚁群算法(ACO)是受自然界中蚂蚁搜索食物行为的启发,是一种群智能优化算法。它基于对自然界真实蚁群的集体觅食行为的研究,模拟真实的蚁群协作过程。算法由若干个蚂蚁共同构造解路径,通过在解路径上遗留并交换信息素提高解的质量,进而达到优化的目的。蚁群算法作为通用随机优化方法,已经成功的应用于TSP等一系列组合优化问题中,并取得了较好的结果。但由于该算法是典型的概率算法,算法中的参数设定通常由实验方法确定,导致方法的优化性能与人的经验密切相关,很难使算法性能最优化。 蚁群算法中每只蚂蚁要选择下一步所要走的地方,在选路过程中,蚂蚁依据概率函数 选择将要去的地方,这个概率取决于地点间距离和信息素的强度。(t+n) = (t)+ Δ (t+n) 上述方程表示信息素的保留率,1-表示信息素的挥发率,为了防止信息的无限积累,取值范围限定在0~1。Δ ij 表示蚂蚁k在时间段t到(t +n)的过程中,在i到j的路径上留下的残留信息浓度。 在上述概率方程中,参数α和β:是通过实验确定的。它们对算法性能同样有很大的影响。α值的大小表明留在每个节点上信息量受重视的程度,其值越大,蚂蚁选择被选过的地点的可能性越大。β值的大小表明启发式信息受重视的程度。 这两个参数对蚁群算法性能的影响和作用是相互配合,密切相关的。但是这两个参数只能依靠经验或重复调试来选择。 在采用蚁群-粒子群混合算法时,我们可以利用PSO对蚁群系统参数α和β的进行训练。 具体训练过程:假设有n个粒子组成一个群落,其中第i个粒子表示为一个二维的向量xi = ( xi1 , xi2 ) , i = 1, 2, ?,n,即第i个粒子在搜索空间的中的位置是xi。换言之,每个粒子的位置就是一个潜在的解。将xi带入反馈到蚁群系统并按目标函数就可以计算出其适应值,根据适应值的大小衡量解的优劣。 蚁群算法的优点: 蚁群算法与其他启发式算法相比,在求解性能上,具有很强的鲁棒性(对基本蚁群算法模型稍加修改,便可以应用于其他问题)和搜索较好解的能力。 蚁群算法是一种基于种群的进化算法,具有本质并行性,易于并行实现。 蚁群算法很容易与多种启发式算法结合,以改善算法性能。 智能车P I D算法实现 原理讲解 为了实现PID控制所需要的等间隔采样,我们使用了一个定时中断,每2ms进行一次数据采样和PID计算。与此并行,系统中还设计了一个转速脉冲检测中断,从而实现了转速检测。为了调试的需要,程序中还在main{}函数中加入了相关的调试代码,这部分代码有最低的优先级,可以在保证不影响控制策略的情况下实现发送调试数据等功能。检测环节对整个控制系统的质量起到至关重要的作用 4.3.2 PID控制调整速度 本系统采用的是增量式数字PID控制,通过每一控制周期(10ms)读入脉冲数间接测得小车当前转速vi_FeedBack,将vi_FeedBack与模糊推理得到的小车期望速度vi_Ref比较,由以下公式求得速度偏差error1与速度偏差率d_error。 error1 = vi_Ref– vi_FeedBack; (公式3) d_error = error1 –vi_PreError; (公式4)公式4中, vi_PreError为上次的速度偏差。考虑到控制周期较长,假设按2.5m/s的平均速度计算,则一个控制周期小车大概可以跑过2.5cm,如果按这种周期用上述PID调节速度,则会导致加速减速均过长的后果,严重的影响小车的快速性和稳定性。为了解决这个问题,可以在PID调速控制中加入BANG-BANG控制思想:根据error1的大小,如果正大,则正转给全额占空比;如果负大,则自由停车或给一个反转占空比;否则就采用PID计算的占空比。 PID控制算法 为了使赛车平滑得保持在黑线中央,即使赛车的偏移量平滑地保持在0,实用了PID控制算法。 P为比例参数,D为微分参数。基准值为0,PID输入为水平偏移量X0,PID输出为转角,转角方向:向左转为正,向右转为负。 P参数在智能车控制器中表示水平偏差量的权,D参数在智能车控制器中表示水平偏差速度的权。 水平偏差量直接反映了赛车偏离黑线的程度,例如赛车偏向黑线的左边越厉害,则赛车的右转角度将越大。水平偏差量,是PID控制器的P部分。 水平偏差速度则直接反映了赛车的运动倾向,因为有了赛车的水平偏差速度,对赛车的掌握,将更加精确。例如赛车偏向黑线左边,然而它的运动方向是向右的,那么,他的转角将比向左运动时的转角要小,因为,我知道赛车已经开始朝正确的方向调整了。水平偏差速度,是PID控制器的D部分。 通过两个相隔一定采样时间的水平偏差量的差,来得到赛车的水平偏差速度。然而,这个时间间隔多少比较合适呢? 《算法与程序设计》导学 一、编程的步骤: 启动VB——标准EXE——对象——属性——代码——调试——保存——生成EXE 1、VB窗口组成:控件工具箱、对象窗口、工程窗口、属性窗口、代码窗口 2、对象:标签(Label)、文本框(text)、命令按钮(command) 计时器(timer)、简单图形(shape) 3、属性:caption(标题) 4、保存:窗体文件(.frm)、工程文件(.vbp) 二、算法的特征: 1、有穷性 2、确定性 3、能行性 4、有0个或多个输入 5、有1个或多个输出 三、算法的表示: 1、自然语言 2、流程图 (1)标准:GB1526—89、ISO5807-1985 (2)常用符号: 3、计算机语言(伪代码) 四、算法的三种基本结构: 1、顺序模式: 2、选择模式: 3、循环模式: 五、四种基本算法: 1、枚举算法:(循环模式的应用) (1)、把问题所有可能的解全部列举出来,在列举的过程式中根据条件进行判断,满足条件的则是问题真正的解,不满足的去掉。 (2)、包装问题的分析及流程图: 2、解析算法:(公式求解的过程) 3、排序: (1)、冒泡排序:它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。 这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端,故名。 (2)、选择排序:每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。选择排序是不稳定的排序方法。 冒泡排序、选择排序都是比较排序。 4、查找: (1)、顺序查找:序列的最头走到最尾,挨个和目标进行比较,如果找到了,就停止遍历,如果走完了,还没找到,那么表示失败了 (2)、对分查找:对分查找是效率很高的查找方法,但被查找的数据必须是有序的。A,首先将查找的数与有序数组内处于中间位置的数据比较,如果中间位置上的数与查找的数不同,根据有序性,就可确定应该在数组的前半部分还是后半部分继续查找。B,在新确定的范围内,继续按上述方法进行查找,直到获得最终结果 六、VB基本数据类型: Dijkstra算法原理详细讲解 如下图,设A为源点,求A到其他各顶点(B、C、D、E、F)的最短路径。线上所标注为相邻线段之间的距离,即权值。(注:此图为随意所画,其相邻顶点间的距离与图中的目视长度不能一一对等) 算法执行步骤如下表: Dijkstra算法的完整实现版本之算法的源代码 样例图: 输入格式: 输出格式: 输入时,将s,t,x,y,z五个点按照1,2,3,4,5起别名,输入格式按照下图例所示当提示Please enter the vertex where Dijkstra algorithm starts:时输入算法的起 始点 比如计算结果v1v4v2表示从点1到点2经过1,4,2为最短路径 Dijkstra算法的完整实现版本,算法的源代码 /* Dijkstra.c Copyright (c) 2002, 2006 by ctu_85 All Rights Reserved. */ #include "stdio.h" #include "malloc.h" #define maxium 32767 #define maxver 9 /*defines the max number of vertexs which the programm can handle*/ #define OK 1 struct Point { char vertex[3]; struct Link *work; struct Point *next; }; struct Link { char vertex[3]; int value; struct Link *next; }; struct Table /*the workbannch of the algorithm*/ { int cost; int Known; char vertex[3]; 数学与统计学院 智能计算及应用课程设计 设计题目:智能计算解决旅行商问题 摘要 本文以遗传算法、模拟退火、蚁群算法三个算法解决旅行商问题,将三个算法进行比较分析。目前这三个算法广泛应用于各个领域中,本文以31个城市为例,运用遗传算法、模拟退火、蚁群算法分别进行了计算,将他们的计算结果进行了比较分析。 关键词:遗传算法模拟退火蚁群算法旅行商问题 背景: 遗传算法: 20世纪60年代初,美国Michigan大学的John Holland教授开始研究自然和人工系统的自适应行为,在从事如何建立能学习的机器的研究过程中,受达尔文进化论的启发,逐渐意识到为获得一个好的算法仅靠单个策略建立和改进是不够的,还要依赖于一个包含许多候选策略的群体的繁殖,从而提出了遗传算法的基本思想。 20世纪60年代中期,基于语言智能和逻辑数学智能的传统人工智能十分兴盛,而基于自然进化思想的模拟进化算法则遭到怀疑与反对,但Holland及其指导的博士仍坚持这一领域的研究。Bagley发表了第一篇有关遗传算法应用的论文,并首先提出“遗传算法”这一术语,在其博士论文中采用双倍体编码,发展了复制、交叉、变异、显性、倒位等基因操作算子,并敏锐地察觉到防止早熟的机理,发展了自组织遗传算法的概念。与此同时,Rosenberg在其博士论文中进行了单细胞生物群体的计算机仿真研究,对以后函数优化颇有启发,并发展了自适应交换策略,在遗传操作方面提出了许多独特的设想。Hollistien在其1971年发表的《计算机控制系统的人工遗传自适应方法》论文中首次将遗传算法应用于函数优化,并对优势基因控制、交叉、变异以及编码技术进行了深入的研究。 人们经过长期的研究,在20世纪}o年代初形成了遗传算法的基本框架。1975年Holland 出版了经典著作“Adaptation in Nature and Artificial System",该书详细阐述了遗传算 算法案例 【学习目标】 1.理解辗转相除法与更相减损术中蕴含的数学原理,并能根据这些原理进行算法分析; 2.基本能根据算法语句与程序框图的知识设计完整的程序框图并写出算法程序; 3.了解秦九韶算法的计算过程,并理解利用秦九韶算法可以减少计算次数提高计算效率的实质; 4.了解各种进位制与十进制之间转换的规律,会利用各种进位制与十进制之间的联系进行各种进位制之间的转换. 【要点梳理】 要点一、辗转相除法 也叫欧几里德算法,它是由欧几里德在公元前300年左右首先提出的.利用辗转相除法求最大公约数的步骤如下: 第一步:用较大的数m除以较小的数n得到一个商q0和一个余数r0; 第二步:若r0=0,则n为m,n的最大公约数;若r0≠0,则用除数n除以余数r0得到一个商q1和一个余数r1; 第三步:若r1=0,则r0为m,n的最大公约数;若r1≠0,则用除数r0除以余数r1得到一个商q2和一个余数r2; …… 依次计算直至r n=0,此时所得到的r n-1即为所求的最大公约数. 用辗转相除法求最大公约数的程序框图为: 程序: INPUT “m=”;m INPUT “n=”;n IF m 1 空间电压矢量调制 SVPWM 技术 SVPWM 是近年发展的一种比较新颖的控制方法,是由三相功率逆变器的六个功率开关元件组成的特定开关模式产生的脉宽调制波,能够使输出电流波形尽 可能接近于理想的正弦波形。空间电压矢量PWM 与传统的正弦PWM 不同,它是从三相输出电压的整体效果出发,着眼于如何使电机获得理想圆形磁链轨迹。 SVPWM 技术与SPWM 相比较,绕组电流波形的谐波成分小,使得电机转矩脉动降低,旋转磁场更逼近圆形,而且使直流母线电压的利用率有了很大提高,且更易于实现数字化。下面将对该算法进行详细分析阐述。 SPWM 通过控制开关器件的关断得到正弦的输入电压;SVPWM 的控制目标在于如何获得一个圆形的旋转磁场。之所以成为矢量控制,是因为通过SVPWM 对晶闸管导通的控制可以得到一系列大小和方向可变的空间电压矢量,通过对空间电压矢量进行控制,从而得到圆形旋转磁场。 1.1 SVPWM 基本原理 SVPWM 的理论基础是平均值等效原理,即在一个开关周期内通过对基本电压矢量加以组 合,使其平均值与给定电压矢量相等。在某个时刻,电压矢量旋转到某个区域中,可由组成这个区域的两个相邻的非零矢量和零矢量在时间上的不同组合来得到。两个矢量的作用时间在一个采样周期内分多次施加,从而控制各个电压矢量的作用时间,使电压空间矢量接近按圆轨迹旋转,通过逆变器的不同开关状态所产生的实际磁通去逼近理想磁通圆,并由两者的比较结果来决定逆变器的开关状态,从而形成PWM 波形。逆变电路如图 2-8 示。 设直流母线侧电压为Udc ,逆变器输出的三相相电压为UA 、UB 、UC ,其分别加在空间上互差120°的三相平面静止坐标系上,可以定义三个电压空间矢量 UA(t)、UB(t)、UC(t),它们的方向始终在各相的轴线上,而大小则随时间按正弦规律做变化,时间相位互差120°。假设Um 为相电压有效值,f 为电源频率,则有: ?????+=-==) 3/2cos()()3/2cos()()cos()(πθπθθm C m B m A U t U U t U U t U (2-27) 其中,ft πθ2=,则三相电压空间矢量相加的合成空间矢量 U(t)就可以表示为: 空间电压矢量调制SVPWM 技术 SVPWM 是近年发展的一种比较新颖的控制方法,是由三相功率逆变器的六个功率开关元件组成的特定开关模式产生的脉宽调制波,能够使输出电流波形尽可能接近于理想的正弦波形。空间电压矢量PWM 与传统的正弦PWM 不同,它是从三相输出电压的整体效果出发,着眼于如何使电机获得理想圆形磁链轨迹。SVPWM 技术与SPWM 相比较,绕组电流波形的谐波成分小,使得电机转矩脉动降低,旋转磁场更逼近圆形,而且使直流母线电压的利用率有了很大提高,且更易于实现数字化。下 面将对该算法进行详细分析阐述。 SPWM 通过控制开关器件的关断得到正弦的输入电压;SVPWM 的控制目标在于如何获得一个圆形的旋转磁场。之所以成为矢量控制,是因为通过SVPWM 对晶闸管导通的控制可以得到一系列大小和 方向可变的空间电压矢量,通过对空间电压矢量进行控制,从而得到圆形旋转磁场。 1.1 S VPWM 基本原理 SVPWM 的理论基础是平均值等效原理,即在一个开关周期内通过对基本电压矢量加以组合,使其平均值与给定电压矢量相等。在某个时刻,电压矢量旋转到某个区域中,可由组成这个区域的两个相邻的非零矢量和零矢量在时间上的不同组合来得到。两个矢量的作用时间在一个采样周期内分多次施加,从而控制各个电压矢量的作用时间,使电压空间矢量接近按圆轨迹旋转,通过逆变器的不同开关状态所产生的实际磁通去逼近理想磁通圆,并由两者的比较结果来决定逆变器的开关状 态,从而形成PWM 波形。逆变电路如图2-8示。 设直流母线侧电压为Udc ,逆变器输出的三相相电压为UA 、UB 、UC ,其分别加在空间上互差120°的三相平面静止坐标系上,可以定义三个电压空间矢量UA(t)、UB(t)、UC(t),它们的方向始终在各相的轴线上,而大小则随时间按正弦规律做变化,时间相位互差120°。假设Um 为相电压有效 值,f 为电源频率,则有: ?????+=-==)3/2cos()()3/2cos( )()cos()(πθπθθm C m B m A U t U U t U U t U (2-27) 其中,ft πθ2=,则三相电压空间矢量相加的合成空间矢量U(t)就可以表示为: θππj m j C j B A e U e t U e t U t U t U 2 3)()()()(3/43/2=++=(2-28) 可见U(t)是一个旋转的空间矢量,它的幅值为相电压峰值的1.5倍,Um 为相电压峰值,且以角频率ω=2πf 按逆时针方向匀速旋转的空间矢量,合成空间电压矢量U (t )为一个幅值恒定、逆时针旋转速度恒定的一个空间电压矢量。而空间矢量U(t)在三相坐标轴(a ,b ,c )上的投影就是对称的三相正弦量。其中3/2πj e 、3/4πj e 表示时间向量的空间位置。为了实现对PMSM 的控制就需要通过对晶闸管导通关断的控制来使得得到的空间电压矢量逼近这一旋转电压矢量。(将逆变电路和 PMSM 看作一个电机控制整体,通过控制PWM 的占空比来实现控制磁场的目的)。 定子三相绕组通入相电流后,会产生与实际相绕组等同的磁动势矢量,3个轴线圈磁动势矢量合成后即为磁动势矢量fs 。设想,在fs 轴线上设置一个单轴线圈(可设想为定子铁心中旋转线圈S ),与fs 一道旋转。为满足功率不变约束条件(输入单轴线圈的功率应等于输入原定子三相绕组的功率)。根据合成规则,设定单轴线圈有效匝数为定子每相绕组有效匝数的3/2倍,假设通入单轴电 流is 后,这个单轴线圈产生的磁动势矢量为fs ,则可由它代替空间固定的3个轴线圈。则 Fs=4/pi*1/2*3/2*Ns*Kws1*Is=4/pi*1/2*Ns*Kws1*(Ia+aIb+a2Ic) 由上式可推得 Is=2/3*(Ia+aIb+a2Ic) 猴群算法 1. 选题背景 自然界的智慧无穷无尽. 受自然规律的启迪, 人类进行了各种发明创造, 智能算法就是其一. 经典的智能算法主要包括人工神经网络、遗传算法、粒子群算法、蚁群算法等等. 2008年Zhao和Tang根据自然界中猴群爬山过程中爬、望、跳几个动作, 设计开发了另外一种群体智能搜索算法—猴群算法. 该算法除具有经典智能搜索算法的消耗低、效率高的特性外, 其优势表现在求解高维数、多峰值的大规模优化问题时能够逃脱“维数灾难”, 快速搜索到最优或近似最优解. (1)人工神经网络. “人工神经网络”是在对人脑组织结构和运行机制的认识理解基础之上模拟其结构和智能行为的一种工程系统. 这种网络依靠系统的复杂程度, 通过调整内部大量节点之间相互连接的关系, 从而达到处理信息的目的. 心理学家McCulloch、数学家Pitts提出了第一个人工神经网络的数学模型.其后, Rosenblatt、Widrow和Hopfield等学者又先后提出了感知模型, 使得人工神经网络技术得以蓬勃发展. 到目前为止, 已有近40种神经网络模型, 其中有反传网络、感知器、自组织映射、Hopfield网络、波耳兹曼机、适应谐振理论等[1, 2].人工神经网络具有四个基本特征:非线性、非局限性、非常定性和非凸性.这四个特征决定了其具备很强的自学习和自适应能力, 可以通过预先提供的一批相互对应的输入-输出数据, 分析掌握两者之间潜在的规律, 最终根据这些规律, 用新的输入数据来推算输出结果.人工神经网络特有的非线性适应性信息处理能力, 克服了传统人工智能方法对于直觉, 如模式、语音识别、非结构化信息处理方面的不足, 使之在神经专家系统、模式识别、智能控制、组合优化、预测等领域得到成功应用. (2)遗传算法. 遗传算法是基于对达尔文生物进化论的“优胜劣汰”的模拟而发展起来的一种广为应用的、高效的随机搜索与优化的方法. 遗传算法最早是由Holland教授[3]于1975年提出的, 随后被众多学者推广[4–6]. 其主要特点是群体搜索策略和群体中个体之间的信息交换, 搜索不依赖于梯度信息. 进入90年代, 遗传算法迎来了兴盛发展时期, 无论是理论研究还是应用研究都成了十分热门的课题. 尤其是遗传算法的应用研究显得格外活跃, 不但它的应用领域扩大,而且利用遗传算法进行优化和规则学习的能力也显著提高. 迄今为止,遗传算法是进化算法中最广为人知的算法. 近些年关于遗传算法的研究主要集中在以下几个方面:i), 遗传算法在机器学习方面的应用. 这一方向把把遗传算法扩展到具有独特的规则生成功能的崭新的机器学习算法中. ii), 遗传算法和神经网络、模糊推理以及混沌理论等计算方法的结合. iii), 遗传算法的并行处理研究. iv),遗传算法和进化计算理论的结合. 同时, 遗传算法本质上是一种随机搜索优化算法, 当问题规模较大或问题较复杂时, 由于被搜索的空间非常之大, 从而导致遗传算法的收敛速度很慢. 加之遗传算法本身存在着群体分散性和GA的早熟之间的矛盾, 这给遗传算法的实时应用带来了很大的不便. 另外, 收敛过早也是遗传算法的一个较难克服的不足.由于遗传算法中选择及杂交变异等算子的作用, 使得一些优秀的基因片段过早丢失, 从而限制了搜索范围, 使得搜索只能在局部范围内找到最优值, 而不能得到满意的全局最优值. 1 空间电压矢量调制 S V P W M 技术 SVPWM 是近年发展的一种比较新颖的控制方法,是由三相功率逆变器的六个功率开关元件组成的特定开关模式产生的脉宽调制波,能够使输出电流波形尽 可能接近于理想的正弦波形。空间电压矢量PWM 与传统的正弦PWM 不同,它是从三相输出电压的整体效果出发,着眼于如何使电机获得理想圆形磁链轨迹。 SVPWM 技术与SPWM 相比较,绕组电流波形的谐波成分小,使得电机转矩脉动降低,旋转磁场更逼近圆形,而且使直流母线电压的利用率有了很大提高,且更易于实现数字化。下面将对该算法进行详细分析阐述。 SPWM 通过控制开关器件的关断得到正弦的输入电压;SVPWM 的控制目标在于如何获得一个圆形的旋转磁场。之所以成为矢量控制,是因为通过SVPWM 对晶闸管导通的控制可以得到一系列大小和方向可变的空间电压矢量,通过对空间电压矢量进行控制,从而得到圆形旋转磁场。 1.1 SVPWM 基本原理 SVPWM 的理论基础是平均值等效原理,即在一个开关周期内通过对基本电压矢量加以组合,使其平均值与给定电压矢量相等。在某个时刻,电压矢量旋转到某个区域中,可由组成这个区域的两个相邻的非零矢量和零矢量在时间上的不同组合来得到。两个矢量的作用时间在一个采样周期内分多次施加,从而控制各个电压矢量的作用时间,使电压空间矢量接近按圆轨迹旋转,通过逆变器的不同开关状态所产生的实际磁通去逼近理想磁通圆,并由两者的比较结果来决定逆变器的开关状态,从而形成PWM 波形。逆变电路如图 2-8 示。 设直流母线侧电压为Udc ,逆变器输出的三相相电压为UA 、UB 、UC ,其分别加在空间上互差120°的三相平面静止坐标系上,可以定义三个电压空间矢量 UA(t)、UB(t)、UC(t),它们的方向始终在各相的轴线上,而大小则随时间按正弦规律做变化,时间相位互差120°。假设Um 为相电压有效值,f 为电源频率,则有: ??? ??+=-==)3/2cos()()3/2cos( )()cos()(πθπθθm C m B m A U t U U t U U t U (2-27) 其中,ft πθ2=,则三相电压空间矢量相加的合成空间矢量 U(t)就可以表示为: θππj m j C j B A e U e t U e t U t U t U 2 3 )()()()(3/43/2=++= (2-28) 可见 U(t)是一个旋转的空间矢量,它的幅值为相电压峰值的1.5倍,Um 为相电压峰值,且以角频率ω=2πf 按逆时针方向匀速旋转的空间矢量,合成空间电压矢量U (t )为一个幅值恒定、逆时针旋转速度恒定的一个空间电压矢量。而空间矢量 U(t)在三相坐标轴(a ,b ,c )上的投影就是对称的三相正弦量。 蚁群算法在物流系统优化中的应用 ——配送中心选址问题 LOGO https://www.360docs.net/doc/3d16402110.html, 框架 蚁群算法概述 蚁群算法模型 物流系统中配送中心选择问题 蚁群算法应用与物流配送中心选址 算法举例 蚁群算法简介 ?蚁群算法(Ant Algorithm简称AA)是近年来刚刚诞生的随机优化方法,它是一种源于大自然的新的仿生类算法。由意大利学者Dorigo最早提出,蚂蚁算法主要是通过蚂蚁群体之间的信息传递而达到寻优的目的,最初又称蚁群优化方法(Ant Colony Optimization简称ACO)。由于模拟仿真中使用了人工蚂蚁的概念,因此亦称蚂蚁系统(Ant System,简称AS)。 蚁群觅食图1 ?How do I incorporate my LOGO and URL to a slide that will apply to all the other slides? –On the [View]menu, point to [Master],and then click [Slide Master]or [Notes Master].Change images to the one you like, then it will apply to all the other slides. [ Image information in product ] ?Image : www.wizdata.co.kr ?Note to customers : This image has been licensed to be used within this PowerPoint template only. You may not extract the image for any other use. 先新建一个主程序M文件ACATSP.m 代码如下: function [R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta,Rho,Q) %%================================================================ ========= %% 主要符号说明 %% C n个城市的坐标,n×2的矩阵 %% NC_max 蚁群算法MATLAB程序最大迭代次数 %% m 蚂蚁个数 %% Alpha 表征信息素重要程度的参数 %% Beta 表征启发式因子重要程度的参数 %% Rho 信息素蒸发系数 %% Q 表示蚁群算法MATLAB程序信息素增加强度系数 %% R_best 各代最佳路线 %% L_best 各代最佳路线的长度 %%================================================================ ========= %% 蚁群算法MATLAB程序第一步:变量初始化 n=size(C,1);%n表示问题的规模(城市个数) D=zeros(n,n);%D表示完全图的赋权邻接矩阵 for i=1:n for j=1:n if i~=j D(i,j)=((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5; else D(i,j)=eps; % i = j 时不计算,应该为0,但后面的启发因子要取倒数,用eps(浮点相对精度)表示 一直以来对SVPWM 原理和实现方法困惑颇多,无奈现有资料或是模糊不清,或是错误百 出。 经查阅众多书籍论文,长期积累总结,去伪存真,总算对其略窥门径。未敢私藏,故公之于众。其中难免有误,请大家指正,谢谢! 1 空间电压矢量调制 SVPWM 技术 SVPWM 是近年发展的一种比较新颖的控制方法,是由三相功率逆变器的六个功率开关元件组成的特定开关模式产生的脉宽调制波,能够使输出电流波形尽 可能接近于理想的正弦波形。空间电压矢量PWM 与传统的正弦PWM 不同,它是从三相输出电压的整体效果出发,着眼于如何使电机获得理想圆形磁链轨迹。 SVPWM 技术与SPWM 相比较,绕组电流波形的谐波成分小,使得电机转矩脉动降低,旋转磁场更逼近圆形,而且使直流母线电压的利用率有了很大提高,且更易于实现数字化。下面将对该算法进行详细分析阐述。 1.1 SVPWM 基本原理 SVPWM 的理论基础是平均值等效原理,即在一个开关周期内通过对基本电压矢量加以组 合,使其平均值与给定电压矢量相等。在某个时刻,电压矢量旋转到某个区域中,可由组成这个区域的两个相邻的非零矢量和零矢量在时间上的不同组合来得到。两个矢量的作用时间在一个采样周期内分多次施加,从而控制各个电压矢量的作用时间,使电压空间矢量接近按圆轨迹旋转,通过逆变器的不同开关状态所产生的实际磁通去逼近理想磁通圆,并由两者的比较结果来决定逆变器的开关状态,从而形成PWM 波形。逆变电路如图 2-8 示。 设直流母线侧电压为Udc ,逆变器输出的三相相电压为UA 、UB 、UC ,其分别加在空间上互差120°的三相平面静止坐标系上,可以定义三个电压空间矢量 UA(t)、UB(t)、UC(t),它们的方向始终在各相的轴线上,而大小则随时间按正弦规律做变化,时间相位互差120°。假设Um 为相电压有效值,f 为电源频率,则有: ?????+=-==) 3/2cos()()3/2cos()()cos()(πθπθθm C m B m A U t U U t U U t U (2-27) 其中,ft πθ2=,则三相电压空间矢量相加的合成空间矢量 U(t)就可以表示为: θππj m j C j B A e U e t U e t U t U t U 2 3 )()()()(3/43/2=++= (2-28) 可见 U(t)是一个旋转的空间矢量,它的幅值为相电压峰值的1.5倍,Um 为相电压峰值,且以角频率ω=2πf 按逆时针方向匀速旋转的空间矢量,而空间矢量 U(t)在三相坐标轴(a , 为了实现PID控制所需要的等间隔采样,我们使用了一个定时中断,每2ms进行一次数据采样和PID计算。与此并行,系统中还设计了一个转速脉冲检测中断,从而实现了转速检测。为了调试的需要,程序中还在main{}函数中加入了相关的调试代码,这部分代码有最低的优先级,可以在保证不影响控制策略的情况下实现发送调试数据等功能。检测环节对整个控制系统的质量起到至关重要的作用 4.3.2 PID控制调整速度 本系统采用的是增量式数字PID控制,通过每一控制周期(10ms)读入脉冲数间接测得小车当前转速vi_FeedBack,将vi_FeedBack与模糊推理得到的小车期望速度vi_Ref比较,由以下公式求得速度偏差error1与速度偏差率d_error。 error1 = vi_Ref– vi_FeedBack; (公式3) d_error = error1 –vi_PreError; (公式4) 公式4中, vi_PreError为上次的速度偏差。考虑到控制周期较长,假设按2.5m/s的平均速度计算,则一个控制周期小车大概可以跑过2.5cm,如果按这种周期用上述PID调节速度,则会导致加速减速均过长的后果,严重的影响小车的快速性和稳定性。为了解决这个问题,可以在PID调速控制中加入BANG-BANG控制思想:根据error1的大小,如果正大,则正转给全额占空比;如果负大,则自由停车或给一个反转占空比;否则就采用PID计算的占空比。 PID控制算法 为了使赛车平滑得保持在黑线中央,即使赛车的偏移量平滑地保持在0,实用了PID控制算法。 P为比例参数,D为微分参数。基准值为0,PID输入为水平偏移量X0,PID输出为转角,转角方向:向左转为正,向右转为负。 P参数在智能车控制器中表示水平偏差量的权,D参数在智能车控制器中表示水平偏差速度的权。 水平偏差量直接反映了赛车偏离黑线的程度,例如赛车偏向黑线的左边越厉害,则赛车的右转角度将越大。水平偏差量,是PID控制器的P部分。 水平偏差速度则直接反映了赛车的运动倾向,因为有了赛车的水平偏差速度,对赛车的掌握,将更加精确。例如赛车偏向黑线左边,然而它的运动方向是向右的,那么,他的转角将比向左运动时的转角要小,因为,我知道赛车已经开始朝正确的方向调整了。水平偏差速度,是PID控制器的D部分。 通过两个相隔一定采样时间的水平偏差量的差,来得到赛车的水平偏差速度。然而,这个时间间隔多少比较合适呢? function [y,val]=QACS tic load att48 att48; MAXIT=300; % 最大循环次数 NC=48; % 城市个数 tao=ones(48,48);% 初始时刻各边上的信息最为1 rho=0.2; % 挥发系数 alpha=1; beta=2; Q=100; mant=20; % 蚂蚁数量 iter=0; % 记录迭代次数 for i=1:NC % 计算各城市间的距离 for j=1:NC distance(i,j)=sqrt((att48(i,2)-att48(j,2))^2+(att48(i,3)-att48(j,3))^2); end end bestroute=zeros(1,48); % 用来记录最优路径 routelength=inf; % 用来记录当前找到的最优路径长度 % for i=1:mant % 确定各蚂蚁初始的位置 % end for ite=1:MAXIT for ka=1:mant %考查第K只蚂蚁 deltatao=zeros(48,48); % 第K只蚂蚁移动前各边上的信息增量为零 [routek,lengthk]=travel(distance,tao,alpha,beta); if lengthk 一直以来对SVPWM原理和实现方法困惑颇多,无奈现有资料或是模糊不清,或是错误百出。经查阅众多书籍论文,长期积累总结,去伪存真,总算对其略窥门径。未敢私藏,故公之于众。其中难免有误,请大家指正,谢谢! 1空间电压矢量调制 SVPWM 技术 SVPWM是近年发展的一种比较新颖的控制方法,是由三相功率逆变器的六个功率开关元件组成的特定开关模式产生的脉宽调制波,能够使输出电流波形尽可能接近于理想的正弦波形。空间电压矢量PWM与传统的正弦PWM不同,它是从三相输出电压的整体效果出发,着眼于如何使电机获得理想圆形磁链轨迹。 SVPWM 技术与SPWM相比较,绕组电流波形的谐波成分小,使得电机转矩脉动降低,旋转磁场更逼近圆形,而且使直流母线电压的利用率有了很大提高,且更易于实现数字化。下面将对该算法进行详细分析阐述。 1.1 SVPWM基本原理 SVPWM 的理论基础是平均值等效原理,即在一个开关周期内通过对基本电压矢量加以组合,使其平均值与给定电压矢量相等。在某个时刻,电压矢量旋转到某个区域中,可由组成这个区域的两个相邻的非零矢 量和零矢量在时间上的不同组合来得到。两个矢量的作用时间在一个采样周期内分多次施加,从而控制各个电压矢量的作用时间,使电压空间矢量接近按圆轨迹旋转,通过逆变器的不同开关状态所产生的实际磁通去逼近理想磁通圆,并由两者的比较结果来决定逆变器的开关状态,从而形成PWM 波形。逆变电路如图 2-8 示。 设直流母线侧电压为Udc ,逆变器输出的三相相电压为UA 、UB 、UC ,其分别加在空间上互差120°的三相平面静止坐标系上,可以定义三个电压空间矢量 UA(t)、UB(t)、UC(t),它们的方向始终在各相的轴线上,而大小则随时间按正弦规律做变化,时间相位互差120°。假设Um 为相电压有效值,f 为电源频率,则有: ??? ??+=-==)3/2cos()()3/2cos( )()cos( )(πθπθθm C m B m A U t U U t U U t U (2-27) 其中,ft πθ2=,则三相电压空间矢量相加的合成空间矢量 U(t)就可以表示为: θ ππj m j C j B A e U e t U e t U t U t U 2 3 )()()()(3/43/2=++= (2-28) 可见 U(t)是一个旋转的空间矢量,它的幅值为相电压峰值的1.5倍,Um 为相电压峰值,且以角频率ω=2πf 按逆时针方向匀速旋转的空间矢量,而空间矢量AAC解码算法原理详解
基本蚁群算法
蚁群算法相关概念
智能车PID 算法实现原理讲解
算法理论详细讲解
Dijkstra算法原理详细讲解
遗传-模拟退火-蚁群三个算法求解TSP的对比讲解
知识讲解_算法案例_基础
SVPWM的原理及法则推导和控制算法详解
SVPWM的原理及法则推导和控制算法详解
猴群算法讲解学习
SVPWM的原理及法则推导和控制算法详解
蚁群算法原理与应用讲解
蚁群算法matlab程序代码
SVPWM的原理及法则推导和控制算法详解
智能车PID_算法实现原理讲解
蚁群算法matlab程序实例整理
SVPWM的原理及法则推导和控制算法详解