Solr课件
solr入门
课程计划:
1、solr服务介绍
2、solr服务的安装
3、solrhome的目录结构
4、自定义索引库
5、将数据库数据导入索引库
6、solrj对索引库的维护
7、solr案例
1solr服务介绍
1.1什么是solr
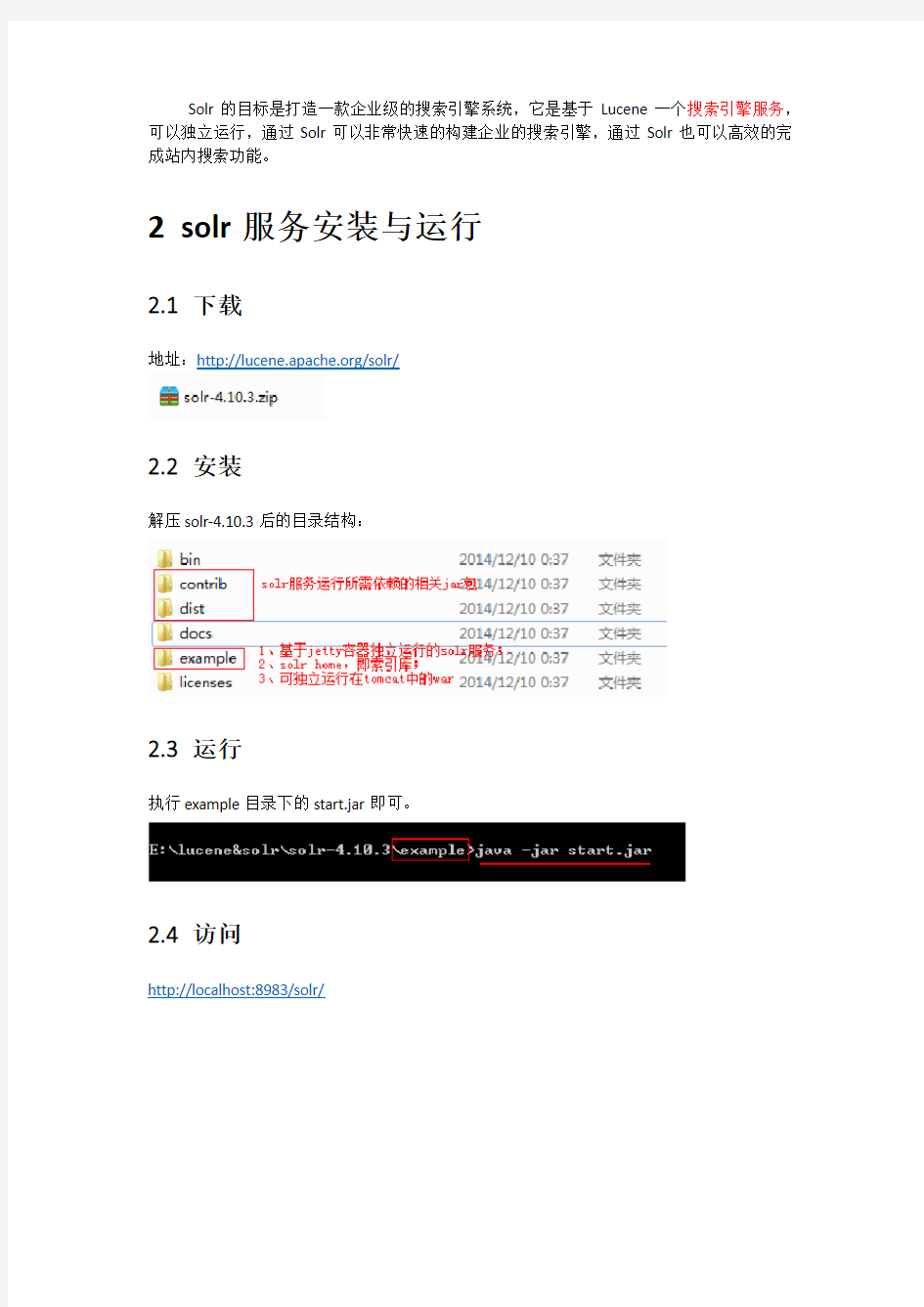
Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene?.
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene 的全文搜索服务。
Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr提供了比Lucene更为丰富的查询语言,
同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
1.2solr与Lucene区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
2solr服务安装与运行
2.1下载
地址:https://www.360docs.net/doc/3f13210076.html,/solr/
2.2安装
解压solr-4.10.3后的目录结构:
2.3运行
执行example目录下的start.jar即可。
2.4访问
http://localhost:8983/solr/
2.5solr运行在tomcat中
2.5.1copy solr.war
将solr解压后的/example/webapps目录下的solr.war copy到tomcat 的webapps目录下中。
2.5.2启动tomcat
2.5.2.1错误一
通过查看日志,需要导入jar包。该包在example/lib/ext目录下。
2.5.2.2错误二
原因:需要指定索引库的位置(类似于访问项目需要指定数据库一样)。
2.5.3指定索引库的位置
为了不混淆,我们将example目录下的solr(solr home)copy到d盘下。
2.5.
3.1通过catalina.bat指定
通过tomcat的bin目录下的Catalina.bat来指定solr运行所需要指定的solr的仓库。
2.5.
3.2通过web.xml指定
在tomcat的solr目录下,通过web.xml来指定solr home的位置。
3solr home的目录结构
3.1什么叫solr home
solr home顾名思义,就是solr的家,即solr的存放数据的仓库(索引库)。每个solr home下可以有多个solr core,这个就是用来存放索引的地方。
solr home -------->对应数据库
solr core -------->对应数据库下的表。
3.2solr home目录结构
3.3solr core目录结构
3.3.1core.properties
作用:用来指定solr core(索引库)的名称
3.3.2data
作用:用来存放创建的索引文件。
3.3.3conf
3.3.3.1schema.xml配置文件
作用:用来配置索引数据的字段名称、字段类型等。
1、field节点
作用:配置索引的字段,该节点具有以下常用属性:
●name:代表数据字段名称
●type:代表数据类型
●indexed:true or false,代表是否被创建索引
●stored:true or false,代表是否被存储
●multivalued:是否是多值,存储多个值时设置为true,比如
存储一个用户的好友id(多个),商品的图片(多个,大图
和小图)。
2、dynamicField
作用:动态的检索字段。
例如:检索时,根据[product_i:手机]条件检索,这个时候我们无需重新定义一个product_i字段,可以通过*_i匹配来检索。
3、uniqueKey
作用:相当于数据库主键
4、copyField
作用:将多个字段的值复制到同一个目标字段中。检索时可以根据指定的dest的字段检索。
●source:源字段
●dest:目标字段
5、fieldType
作用:指定索引字段的类型。具有如下常见属性:
●name:索引字段的类型名,并filed节点中的name引用
●class:代表solr的类型
●analyzer:指定分词器,type=index/query,index:创建索引;
query:查询索引
●tokenizer:指定分词器
●filter:指定过滤器
3.3.3.2solrconfig.xml
作用:定义了solr服务的一些处理规则,包括索引数据的存放位置;更新、删除、查询的一些规则配置。常用的节点有:
●luceneMatchVersion:指定底层使用的Lucene版本号
●lib:指定solr服务运行需要的jar
●dataDir:指定索引的存放位置
●requestHandler:配置solr CRUD的规则
4自定义索引库
4.1copy solr的模板collection1
copy collection1并改名为products(任意)
4.2修改索引库名称
4.3修改schema.xml文件
配置索引字段。这里使用了IK分词器,需要将IK的jar包导入到solr 中。
4.4修改solrconfig.xml文件
指定默认检索的字段信息。
5将数据库数据导入索引库
5.1添加dataimporthandler jar包
5.2引入jar包
5.3配置requestHandler
5.4conf目录下添加db-data-config.xml
5.5添加mysql驱动包到solr中
5.6执行导入请求
6solrj对索引库的维护
6.1什么是solrj
Solrj is a java client to access solr. It offers a java interface to add, update, and query the solr index(solrj是通过Java客户端去操作solr,它提供了一个Java接口用于添加、更新和查询solr的索引)
6.2添加索引
6.3更新索引
如果id相同,则执行更新操作。
6.4根据索引查询6.4.1简单查询
6.5删除索引6.5.1根据id删除
7JD案例7.1需求
需求:
1、根据关键字检索;
2、根据商品分类
3、根据价格过滤;
4、根据价格排序;
5、对检索内容高亮;
6、分页
7.2环境搭建
7.2.1导入jar包
略
7.2.2添加配置文件
略
7.2.3添加jsp等静态资源
7.3商品列表显示
7.4创建pojo
7.4.1创建Product
根据jsp页面分析,Product应该有如下属性:
7.4.2创建Result
同理:根据jsp页面创建Result对象。
7.5编写service接口、实现类
接口:通过搜索的页面分析,我们controller层方法中需要接收5个形参。分别是:queryString、catalog_name、price、page、sort
7.5.1service接口定义
7.5.2service实现类
7.6完善controller
solr教程
Apache Solr 初级教程 (介绍、安装部署、Java接口、中文分词)Apache Solr 介绍 Solr 是什么? Solr 是一个开源的企业级搜索服务器,底层使用易于扩展和修改的Java 来实现。服务器通信使用标准的HTTP 和XML,所以如果使用Solr 了解Java 技术会有用却不是必须的要求。 Solr 主要特性有:强大的全文检索功能,高亮显示检索结果,动态集群,数据库接口和电子文档(Word ,PDF 等)的处理。而且Solr 具有高度的可扩展,支持分布搜索和索引的复制。 Lucene 是什么? Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。也是目前最为流行的基于 Java 开源全文检索工具包。 目前已经有很多应用程序的搜索功能是基于 Lucene ,比如 Eclipse 帮助系统的搜索功能。Lucene 能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。 Solr VS Lucene Solr 与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene ,因为Solr 底层的核心技术是使用Apache Lucene 来实现的,简单的说Solr 是Lucene 的服务器化。需要注意的是Solr 并不是简单的对Lucene 进行封装,它所提供的大部分功能都区别于Lucene 。 安装搭建Solr
安装Java 虚拟机 Solr 必须运行在Java1.5 或更高版本的Java 虚拟机中,运行标准Solr 服务只需要安装JRE 即可,但如果需要扩展功能或编译源码则需要下载JDK 来完成。可以通过下面的地址下载所需JDK 或JRE : ?OpenJDK (https://www.360docs.net/doc/3f13210076.html,/j2se/downloads.html) ?Sun (https://www.360docs.net/doc/3f13210076.html,/j2se/downloads.html) ?IBM (https://www.360docs.net/doc/3f13210076.html,/developerworks/java/jdk/) ?Oracle (https://www.360docs.net/doc/3f13210076.html,/technology/products/jrockit/index.html)安装步骤请参考相应的帮助文档。 安装中间件 Solr 可以运行在任何Java 中间件中,下面将以开源Apache Tomcat 为例讲解Solr 的安装、配置与基本使用。本文使用Tomcat5.5 解压版进行演示,可在下面地址下载最新版本https://www.360docs.net/doc/3f13210076.html,/download-55.cgi 安装Apache Solr 下载最新的Solr 本文发布时Solr1.4 为最新的版本,下文介绍内容均针对该版本,如与Solr 最新版本有出入请以官方网站内容为准。Solr官方网站下载地址: https://www.360docs.net/doc/3f13210076.html,/dyn/closer.cgi/lucene/solr/ Solr 程序包的目录结构 ?build :在solr 构建过程中放置已编译文件的目录。 ?client :包含了一些特定语言调用Solr 的API 客户端程序,目前只有Ruby 可供选择,Java 客户端叫SolrJ 在src/solrj 中可以找到。 ?dist :存放Solr 构建完成的JAR 文件、WAR 文件和Solr 依赖的JAR 文件。 ?example :是一个安装好的Jetty 中间件,其中包括一些样本数据和Solr 的配置信息。 o example/etc :Jetty 的配置文件。 o example/multicore :当安装Slor multicore 时,用来放置多个Solr 主目录。 o example/solr :默认安装时一个Solr 的主目录。 o example/webapps :Solr 的WAR 文件部署在这里。
拓薪教育-solr教程
全文检索技术Solr 讲师:任亮
1课程计划 1、站内搜索技术的选型 2、什么是Solr 3、Solr的安装及配置,solr整合tomcat。 4、Solr对索引库的维护,基于solr的后台管理界面 a)增加文档 b)删除文档 c)修改文档 5、Solr查询索引,基于solr的后台管理界面 6、Solr的客户端SolrJ a)索引的维护 b)索引的查询 7、综合案例,电商网站的搜索功能 2站内搜索技术的选型 1、Lucene实现站内搜索。开发工作量大,还要对索引库的维护投入大量的工作,索引的优化查询的优化,大并发量的考虑。不推荐使用。 2、可以使用搜索搜索引擎提供站内搜索功能。索引库放在搜索引擎上,不能维护。优点就非常简单。 3、solr技术,solr是基于lucene开发的一个全文检索服务器,提供了全套的全文检索解决方案。推荐使用的技术。 3什么solr 3.1 Solr的概念 Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。 Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用POST 方法向Solr 服务器发送一个描述Field 及其内容的XML 文档,Solr 根据xml文档添加、删除、更新索引。Solr 搜索只需要发送HTTP GET 请求,然后对Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
轻松使用SaltStack管理成千上万台服务器(入门教程)
目录树引言:一个”非专职运维人员“的烦恼 Salt快速入门 1. 安装配置 2. 安装管理端(master) 3. 安装被管理端(minion) 4. 接受minion的托管请求 5. 测试 Salt的强大功能 1. 批量操作(targeting) 2. 节点分组(nodegroups) 3. 命令执行(execution) 4. 节点信息(grains) 5. 配置管理(state) 6. 小结 Salt state实例解析 1. 目录结构 2. apache/init.sls 3. ssh/init.sls 4. ssh/server.sls 5. ssh/custom-server.sls 引言:一个”非专职运维人员“的烦恼加入到某证券公司的IT部门,尽管所在的部门挂了一个“研发部”的名字,但是我发现有大概40%的时间是在做运维工作。
这来自两种情况: 1. 自主开发的应用,需要持续的改进,不断的更新、发布、部署、调整配置,这不是运维部门喜欢的状态。 2. 软件商提供的“产品”无法满足运维部门的要求:无法通过简单的 Q&A 文档保证系统的正常运行,经常需要有一定技术能力的人员解决系统运行过程中各种稀奇古怪的问题。 这种情况下只能自己做一个“非专职运维人员”,需要频繁的登录各种服务器,执行一些命令来查看状态或者更改配置(包括配置文件的变更和软件包的安装部署)。很多操作都是不断的重复,日复一日,让人厌烦。 ”重复的工作应该交给程序去做“,所以我自己写过一些脚本。为了避免将脚本上传到几十台服务器并且不时进行更改,我使用Fabric来进行服务器的批量操作。 尽管避免了”批量的人工操作“,但我还是在进行”人工的批量操作“。远远没有实现自动管理。将有限的生命解放出来,投入到更有意义的编码工作是一个奔四程序员应有的追求,所以我又睁大红肿的眼睛,迷茫的搜索这个世界。 我发现了Puppet,Chef和CFEngine,但是并不满意。直到我发现了Salt,我的眼前一亮:这正是我所需要的东西。 如果说Salt有什么独特之处打动了我,那就是: 简单:可能是源于python的简约精神,Salt的安装配置和使用简单到了令人发 指的地步。任何稍有经验的linux使用者可以在10分钟之内搭建一个测试环境并跑通一个例子(相比之下,puppet可能需要30--60分钟)。 高性能:Salt使用大名鼎鼎的ZeroMQ作为通讯协议,性能极高。可以在数秒钟之内完成数据的传递 可伸缩:基于ZeroMQ通信,具备很强的扩展性;可以进行分级管理,能够管理分布在广域网的上万台服务器。 尽管twitter、豆瓣、oracle、等著名网站的运维团队都在使用puppet,但是我相信,他们切换到salt只是一个时间问题。毕竟不是所有的人都喜欢操纵傀儡(puppet),但是谁又能离开盐(salt)呢? 关于Salt和Puppet的对比,可以参考这里,或者看看中文版。
非常经典的solr教程
非常经典的solr教程,照着上面做完全能成功! duogemajia Solr 3.5 入门配置应用 机器上已安装: Tomcat 6.0 jdk1.7 mysql 5.0 1 访问https://www.360docs.net/doc/3f13210076.html,/dyn/closer.cgi/lucene/solr , 在这个网址里选择一个路径, 下载solr 3.5 的版本 2 solr3.5 在本机解压缩以后, 把apache-solr-3.5.0\example\webapps 目录下 的solr.war 文件拷贝到Tomcat 6.0 的webapps 目录下 3 在Tomcat 6.0\webapps\solr 目录里新建一个文件夹conf 4 把solr3. 5 本机解压缩文件夹apache-solr-3.5.0\example 下的multicore 文件夹 考本到Tomcat 6.0\webapps\solr\conf 目录下 5 在Tomcat 6.0\conf\Catalina\localhost 目录下新建一个solr.xml 文件, 里面的内容如下
SolrCloud使用教程、原理介绍 我心动了
SolrCloud使用教程、原理介绍 发布于2013 年 8 月 24 日,属于搜索分类,7,446 浏览数 SolrCloud 是基于 Solr 和 Zookeeper 的分布式搜索方案,是正在开发中的 Solr4.0 的核心组件之一,它的主要思想是使用 Zookeeper 作为集群的配置信息中心。 它有几个特色功能:①集中式的配置信息②自动容错③近实时搜索④查询时自动负载均衡。
下面看看 wiki 的文档: 1、SolrCloud SolrCloud 是指 Solr 中一套新的潜在的分发能力。这种能力能够通过参数让你建立起一个高可用、 容错的 Solr 服务集群。当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud(solr 云)。 看看下面“启动”部分内容,快速的学会怎样启动一个集群。后面有 3 个快速简单的例子, 它们展现怎样启动一个逐步越来越复杂的集群。检出例子之后,需要翻阅后面的部分了解 更加细节的信息。 2、关于 SolrCores 和 Collections 的一点儿东西 对于单独运行的 Solr 实例,它有个东西叫 SolrCore(Solr.xml 中配置的),它是本质上独立的 索引块。如果你打算多个索引块,你就创建多个 SolrCores。当同时部署SolrCloud 的时, 独立的索引块可以跨越多个 Solr 实例。这意味着一个单独的索引块能由不同服务器设备上多个 SolrCore 的索引块组成。我们把组成一个逻辑索引块的所有 SolrCores 叫做一个独立 索引块儿(collection)。一个独立索引块是本质上一个独立的跨越多个 SolrCore 索引块的索 引块,同时索引块尽可能随着多余的设备进行缩放。如果你想把你的两个 SolrCore Solr 建 立成 SolrCloud,你将有 2 个独立索引块,每个有多个独立里的 SolrCores 组成。 3、启动 下载 Solr4-Beta 或更高版本。 如果你还没了解,通过简单的Solr 指南让自己熟悉Solr。注意:在通过指南了解云特点前,重设所有的配置和移除指南的文档.复制带有预先存在的 Solr 索引的例子目录将导致文档计数关闭Solr 内嵌使用了Zookeeper 作为集群配置和协调运作的仓储。协调考虑作为一个包 含所有 Solr 服务信息的分布式文件系统。 如果你想用一个其他的而不是 8983 作为 Solr 端口,去看下面’ Parameter Reference’部分下 的关于solr.xml 注解 例 A:简单的 2 个 shard 集群 这个例子简单的创建了一个代表一个独立索引块的两个不同的 shards 的两个 solr 服务组成
美团O2O的CRM系统架构设计教程文件
美团O2O的CRM系统架构设计 众所周知,O2O(Online To Offline),是指将线下的商务机会与互联网结合,让互联网成为线下交易的前台。但是O2O平台自身并不提供用户最终享受的商品、服务,这些服务都来自线下商户提供的服务,换句话说平台只是服务的搬运工。 线上风景固然靓丽,但是并不像看到的那样风光,就拿“团购”来讲,美团、点评、百度糯米的APP在功能布局、操作体验等方面差异化越来越小,这样极大的降低了用户使用门槛,作为理性逐利的C端用户来讲,最长见的结果谁便宜就会用谁。那么问题来了,如何在这场纷争中抓住用户,最终胜出呢? 对,线下能力! 线下的能力包括线下资源的控制能力和线下服务品质的控 制能力。线下能力最终决定了平台能够提供给线上用户的服务和服务品质,只有能够提供丰富、实惠、高品质的服务,来能够帮助平台在线上赢得用户,取得成功。美团之所以成功,就在于强大的地面、运营团队所建立起的线下能力。而这些团队背后所依赖的,就是我们称之为秘密武器的B端产品。CRM,就是其中之一。CRMCRM系统,立足于帮助美团解决线下资源控制的能力。CRM通过商家关系的建立和维系客户
关系,同时借助于新技术、和方法改进来提升工作效率,从而达成链接美团和商户的使命! 接下来我会从两大维度四个方面来介绍一下美团CRM的特点:合作篇 销售(建立合作)、运营(持续合作) 效能篇 信息之战(数据)、移动办公(场景支持)销售(建立合作)众所周知,在CRM系统中线索是非常重要的资源,提供丰富、有价值的线索是CRM系统的首要职责。在美团,线索对象通常指商家门店(POI),通过对门店关键人物(KP)的拜访和机会转化,最终为美团提供合作商家(可上单的商家)。 线索通过多种渠道获得: 网上数据爬取(初期) BD(业务拓展人员)采集 商家创建 众包采集 美团数据中心(MDC)将信息收集完成后,POI将会进入审核环节,未经校准的POI会经由人工(运营审核、众包采集)、机器审核进行校准、去重工作,通过反向拉取、消息队列通知等方式,线索数据最终会同步到CRM。 基于美团的大数据服务,在CRM中的POI数据将会被标记分类(300大商家、头部商家、竞对在线、券、多、免)和信息
solr使用手册
Solr全文检索服务 一、企业站内搜索技术选型 ?在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查 询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按 相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。 1.使用Lucene实现?什么是Lucene ? ?Lucene是一个基于Java的全文信息检索工具包,它不是一个完整 的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是Apache Jakarta(雅加达) 家族中的一个开源项目。也是目前 最为流行的基于Java开源全文检索工具包。目前已经有很多应用程 序的搜索功能是基于Lucene ,比如Eclipse 帮助系统的搜索功能。 Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的 数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索 ●单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索 引维护、索引性能优化、搜索性能优化等,因此不建议采用。 2.使用Google或Baidu接口? ●通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依 赖紧密,不方便扩展,不建议采用。 3.使用Solr实现? Solr是什么? ?Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于 Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语 言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。 ?Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中, Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一 个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删 除、更新索引。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr
人世间Solr为何物
人世间Solr为何物 下面的几张图熟悉吗? 图(1) 图(2) 图(3)
?高扩展的Java搜索服务器 ?基于Lucene搜索库 ?通过HTTP接收XML/JSON格式的文档(轻量级的"REST"形式) ?没有内建的索引蜘蛛,可以与Nutch等爬虫集成 ?使用Lucene文档解析器解析HTML, OpenOffice, Microsoft Word, Excel, PowerPoint, IMAP, RTF, PDF等格式的文件 ?不仅支持字段数据模式定义, 也支持Lucene 动态字段 ?自定义分词器(Tokenizer)、过滤器(Filter)、分析器(Analyzer)以便控制索引和查询进程
?除了支持富文本字段(rich text)和元数据(metadata)外,对数字和日期等进行了很好的区分 ?能合并多个文本字段为一个全文类型(full text)的字段,方便搜索(copy field) ?可以基于性能的考虑调节各种参数(option tuning) ?支持所有的Lucene查询语法,包括Internet查询操作符(+, -, "") ?各种自定义查询处理选项 ?能够跨越多个字段搜索 ?可配置同义词(synonym words)和过滤词(stop words)文本文件 ?支持拼写检查(spell check)器 ?支持高亮(high light)显示搜索结果中的匹配关键字 ?复杂、强大的结果排序选项 ?Faceted metadata搜索结果 ?能够动态分组搜索结果 ?可配置的缓存选项,加速查询响应速度 ?可为扩展性和容灾配置索引复制(replication),like mysql replication? ?基于web浏览器的管理接口,提供统计、报告、调试等 ?丰富的操作客户端:Client for Ruby, PHP,Java, Python等 How To Get Solr UP And Running? 实际上,得到Solr并且使其运行起来是件很容易的事。首先,从apache的官方网站上下载Solr 的Package。下载后解压zip(for windows)或者tar.gz(for linux),当前最新稳定版本为1.3.0。 Solr包结构图 打开example文件夹,如图:
Solr开发指南
Solr 全文检索技术
1.Solr介绍 15 2.Solr安装配置-SolrCore配置 15 3.Solr安装配置-Solr工程部署 10 4.Solr安装配置-Solr工程测试 15 5.Solr安装配置-多SorlCore配置 10 6.Solr入门--schema 20 7.Solr入门-安装中文分词器 15 8.Solr入门-自定义业务系统Field 20 9.Solr入门-SolrJ介绍10 10.Solr入门-SolrJ索引维护 20 11.Solr入门-数据导入处理器20 12.Solr入门-搜索语法 10 13.Solr入门-SolrJ-搜索 20 14.Solr案例-需求分析 10 15.Solr案例-架构设计 15 16.Solr案例-Service 20 17.Solr案例-Controller 20 18.Solr案例-主体调试 20 19.Solr案例-功能完善
1【Solr介绍】 1.1S olr是什么 Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。 Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。 1.2S olr与Lucene的区别 Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。 Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。 1.3Solr下载 从Solr官方网站(https://www.360docs.net/doc/3f13210076.html,/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。 Solr使用指南可参考:https://https://www.360docs.net/doc/3f13210076.html,/solr/FrontPage。
Nutch相关框架视频教程(Hadoop、Hbase、Lucene、Solr、Tika、Gora)(13-20讲)
第十三讲 1、改变负载 三台机器,改变负载 host2(NameNode、DataNode、TaskTracker) host6(SecondaryNameNode、DataNode、TaskTracker) host8(JobTracker 、DataNode、TaskTracker) 指定SecondaryNameNode为host6: vi conf/masters指定host6 scp conf/masters host6:/home/hadoop/hadoop-1.1.2/conf/masters scp conf/masters host8:/home/hadoop/hadoop-1.1.2/conf/masters vi conf/hdfs-site.xml
Solr文档
Solr 全文检索服务 1企业站内搜索技术选型 在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
1.1单独使用Lucene实现 单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。 1.2使用Google或Baidu接口 通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。 1.3使用Solr实现 基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为S olr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。 2什么是Solr 什么是Solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。 Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI 的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
UG_OpenGrip语言经典教程
UG Open/Grip语言总结简明教程,Grip语言具备完整的语法规则、程序结构、内部函数、Grip程序必须经过编译、连接、生成可执行文件之后才能运行。利用Grip程序能够实现与UG的各种交互操作,例如几何体的创建、文件的管理、系统参数的控制、UG数据库的存取等。本文就为大家总结了Grip语言的语法,并附注释讲解。 $$ 注释 $$ Grip启动和编译:先找到UG的安装路径,如C:\Program Files\EDS\Unigraphics NX。 $$ 进入该路径下的UGOPEN目录,找到grade.bat文件,打开它,将环境变量base_dir $$ 设置成set base_dir=C:\Program Files\EDS\Unigraphics NX,保存并运行。 $$ Grip程序的编写和编译:在Grip的运行程序中,键入4,将你编写的Grip程序所在的目 $$ 录写入并回车。在Grip的运行程序中,键入1,写入新建Grip程序的文件名并回车,此时 $$ Grip会打开写字板,你可以在其中写入你的程序。在Grip的运行程序中,键入2,写入 $$ 所编译的文件名,编译无错后,键入3,写入所链接的文件名,链接无错后完成。 $$ 你所编写的Grip程序保存成*.grs文件,编译后Grip会生成*.gri文件,链接后Grip会 $$ 生成*.grx文件,此文件为Grip的运行文件。 $$ Grip程序的运行:打开UG,点击File->Execute->Grip,选择*.grx文件,就可运行它。 $$ 编译时应先编译子函数文件,生成*.gri,子函数文件不需要链接,此时再编译主函数 $$ 文件,生成*.gri,最后链接成*.grx。 $$ Grip主函数文件必须以HALT结束,Grip子函数文件必须以RETURN结束。 $$ 定义的变量不能超过6个字符,Grip会认为Point_1和Point_2是同一个变量。 $$ 一行不能超过80个字符,若超过,可用$符号来换行。 $$ Grip不区分大小写,也就是Grip会认为POINT和point都是画点函数,但是我建议Grip $$ 的函数名和关键字用大写,用户定义的变量用小写。但是用户定义的变量不能和Grip的 $$ 函数名和关键字重名。 $$ Grip的帮助文件在C:\EDS\Unigraphics NX\UGDOC\html_files\mainlibrary.chm\ $$ Open\GRIP Reference Guide下。一个简便的Grip函数查找方法:打开...\Word & $$ Symbol Lists\Major Word List,根据首字母来查函数。 HALT $$ 结束语 $$ 注释 ENTITY/p,l,c $$ 实体变量定义 NUMBER/i,f(5) $$ 数值变量定义 STRING/str(10) $$ 字符串变量定义 p=POINT/0,0,0 $$ 画点
solr集群搭建
solrcloud集群搭建 1什么是SolrCloud 1.1什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。 1.2SolrCloud结构 SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。 SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud 需要由多台服务器组成,由zookeeper来进行协调管理。 下图是一个SolrCloud应用的例子:
对上图进行图解,如下:
1.2.1物理结构 三个Solr实例(每个实例包括两个Core),组成一个SolrCloud。 1.2.2逻辑结构 索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard 上三个Core的索引数据一致,解决高可用问题。 用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。 1.2.2.1c ollection Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。 比如:针对商品信息搜索可以创建一个collection。 collection=shard1+shard2+....+shardX
SOLR中文教程
SOLR中文帮助文档 2010-10
目录 1概述 (4) 1.1企业搜索引擎方案选型 (4) 1.2Solr的特性 (4) 1.2.1Solr使用Lucene并且进行了扩展 (4) 1.2.2Schema(模式) (5) 1.2.3查询 (5) 1.2.4核心 (5) 1.2.5缓存 (5) 1.2.6复制 (6) 1.2.7管理接口 (6) 1.3Solr服务原理 (6) 1.3.1索引 (6) 1.3.2搜索 (7) 1.4源码结构 (8) 1.4.1目录结构说明 (8) 1.4.2Solr home说明 (9) 1.4.3solr的各包的说明 (10) 1.5版本说明 (11) 1.5.1 1.3版本 (11) 1.5.2 1.4版本 (12) 1.6分布式和复制Solr 架构 (12) 2Solr的安装与配置 (13) 2.1在Tomcat下Solr安装 (13) 2.1.1安装准备 (13) 2.1.2安装过程 (13) 2.1.3验证安装 (14) 2.2中文分词配置 (15) 2.2.1mmseg4j (15) 2.2.2paoding (19) 2.3多核(MultiCore)配置 (22) 2.3.1MultiCore的配置方法 (22) 2.3.2为何使用多core ? (23) 2.4配置文件说明 (23) 2.4.1schema.xml (24) 2.4.2solrconfig.xml (25) 3Solr的应用 (29) 3.1SOLR应用概述 (29) 3.1.1Solr的应用模式 (29) 3.1.2SOLR的使用过程说明 (30) 3.2一个简单的例子 (30) 3.2.1Solr Schema 设计 (30) 3.2.2构建索引 (30) 3.2.3搜索测试 (31) 3.3搜索引擎的规划设计 (32) 3.3.1定义业务模型 (32) 3.3.2定制索引服务 (34) 3.3.3定制搜索服务 (34) 3.4搜索引擎配置 (34) 3.4.1Solr Schema 设计(如何定制索引的结构?) (34)
GRIP简明教程
UG Open/Grip简明教程 $$ 注释 $$ Grip启动和编译:先找到UG的安装路径,如C:\Program Files\EDS\Unigraphics NX。 $$ 进入该路径下的UGOPEN目录,找到grade.bat文件,打开它,将环境变量base_dir $$ 设置成set base_dir=C:\Program Files\EDS\Unigraphics NX,保存并运行。$$ Grip程序的编写和编译:在Grip的运行程序中,键入4,将你编写的Grip程序所在的目 $$ 录写入并回车。在Grip的运行程序中,键入1,写入新建Grip程序的文件名并回车,此时 $$ Grip会打开写字板,你可以在其中写入你的程序。在Grip的运行程序中,键入2,写入 $$ 所编译的文件名,编译无错后,键入3,写入所链接的文件名,链接无错后完成。$$ 你所编写的Grip程序保存成*.grs文件,编译后Grip会生成*.gri文件,链接后Grip 会 $$ 生成*.grx文件,此文件为Grip的运行文件。 $$ Grip程序的运行:打开UG,点击File->Execute->Grip,选择*.grx文件,就可运行它。 $$ 编译时应先编译子函数文件,生成*.gri,子函数文件不需要链接,此时再编译主函数 $$ 文件,生成*.gri,最后链接成*.grx。 $$ Grip主函数文件必须以HALT结束,Grip子函数文件必须以RETURN结束。$$ 定义的变量不能超过6个字符,Grip会认为Point_1和Point_2是同一个变量。$$ 一行不能超过80个字符,若超过,可用$符号来换行。 $$ Grip不区分大小写,也就是Grip会认为POINT和point都是画点函数,但是我建议Grip
SOLR的应用教程
开源企业搜索引擎SOLR的 应用教程 2010-10
目录 1概述 (4) 1.1企业搜索引擎方案选型 (4) 1.2Solr的特性 (4) 1.2.1Solr使用Lucene并且进行了扩展 (4) 1.2.2Schema(模式) (5) 1.2.3查询 (5) 1.2.4核心 (5) 1.2.5缓存 (5) 1.2.6复制 (6) 1.2.7管理接口 (6) 1.3Solr服务原理 (6) 1.3.1索引 (6) 1.3.2搜索 (7) 1.4源码结构 (8) 1.4.1目录结构说明 (8) 1.4.2Solr home说明 (9) 1.4.3solr的各包的说明 (10) 1.5版本说明 (11) 1.5.1 1.3版本 (11) 1.5.2 1.4版本 (12) 1.6分布式和复制Solr 架构 (12) 2Solr的安装与配置 (13) 2.1在Tomcat下Solr安装 (13) 2.1.1安装准备 (13) 2.1.2安装过程 (13) 2.1.3验证安装 (14) 2.2中文分词配置 (15) 2.2.1mmseg4j (15) 2.2.2paoding (19) 2.3多核(MultiCore)配置 (22) 2.3.1MultiCore的配置方法 (22) 2.3.2为何使用多core ? (23) 2.4配置文件说明 (23) 2.4.1schema.xml (24) 2.4.2solrconfig.xml (25) 3Solr的应用 (29) 3.1SOLR应用概述 (29) 3.1.1Solr的应用模式 (29) 3.1.2SOLR的使用过程说明 (30) 3.2一个简单的例子 (30) 3.2.1Solr Schema 设计 (30) 3.2.2构建索引 (30) 3.2.3搜索测试 (31) 3.3搜索引擎的规划设计 (32) 3.3.1定义业务模型 (32) 3.3.2定制索引服务 (34) 3.3.3定制搜索服务 (34) 3.4搜索引擎配置 (34) 3.4.1Solr Schema 设计(如何定制索引的结构?) (34)
svn搭建
登录 | 注册 【拥抱变化 -- 知识改变命运】=== 知识,在实践行动中产生,在沟通交流中升华,在真诚分享中传播!=== 目录视图摘要视图订阅 7月推荐文章 【限时活动】建专辑得大奖 专访张路斌:从HTML5到Unity的游戏开发之路 当青春遇上互联网,能否点燃你的创业梦 推荐有礼--找出您心中的技术大牛 软件版本控制SVN服务器搭建 分类: 精品网络文章转载 2009-12-18 11:37 1974人阅读 评论(0) 收藏 举报 svn服务器subversion版本控制系统tortoisesvneclipse插件 什么是Subversion? Subversion 是一个自由/开源的版本控制系统。也就是说,在Subversion管理下,文件和目录可以超越时空。Subversion将文件存放在中心版本库里。这个版本库很像一个普通的文件服务器,不同的是,它可以记录每一次文件和目录的修改情况。于是我们就可以籍此将数据回复到以前的版本,并可以查看数据的更改细节。正因为如此,许多人将版本控制系统当作一种神奇的“时间机器”。 Subversion 的版本库可以通过网络访问,从而使用户可以在不同的电脑上进行操作。从某种程度上来说,允许用户在各自的空间里修改和管理同一组数据可以促进团队协作。因为修改不再是单线进行(单线进行也就是必须一个一个进行),开发进度会进展迅速。此外,由于所有的工作都已版本化,也就不必担心由于错误的更改而影响软件质量—如果出现不正确的更改,只要撤销那一次更改操作即可。 某些版本控制系统本身也是软件配置管理(SCM)系统,这种系统经过精巧的设计,专门用来管理源代码树,并且具备许多与软件开发有关的特性—比如,对编程语言的支持,或者提供程序构建工具。不过Subversion并不是这样的系统。它是一个通用系统,可以管理任何类型的文件集。对你来说,这些文件这可能是源程序—而对别人,则可能是一个货物清单或者是数字电影。 一、获取资源 (1)CollabNetSubversion-server-1.6.6-4.win32.exe SVN 服务器端 https://www.360docs.net/doc/3f13210076.html,/ (2)TortoiseSVN-1.6.6.17493-win32-svn-1.6.6.msi SVN 的客户端 https://www.360docs.net/doc/3f13210076.html,/ (3)LanguagePack_1.6.6.17493-win32-zh_CN.msi 中文简体的语言包 (能看英文的话就不用下) 服务器和程序下载 : https://www.360docs.net/doc/3f13210076.html,/getting.html#binary-packages Windows常用客户端TortoiseSVN:https://www.360docs.net/doc/3f13210076.html,/downloads AnkhSVN(Visual Studio插件):https://www.360docs.net/doc/3f13210076.html,/ Subclipse(Eclipse插件):https://www.360docs.net/doc/3f13210076.html,/ SCPlugin(Mac OS x客户端):https://www.360docs.net/doc/3f13210076.html,/ 二、安装 上面的 1 、2 、3 均为直接安装即可,注意在安装完1再安装3的时候要重启一下,然后将4 解压到1 中安装目录下的 bin 目录中。至此安装完毕