solr集群搭建

solrcloud集群搭建
1什么是SolrCloud
1.1什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
1.2SolrCloud结构
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud 需要由多台服务器组成,由zookeeper来进行协调管理。
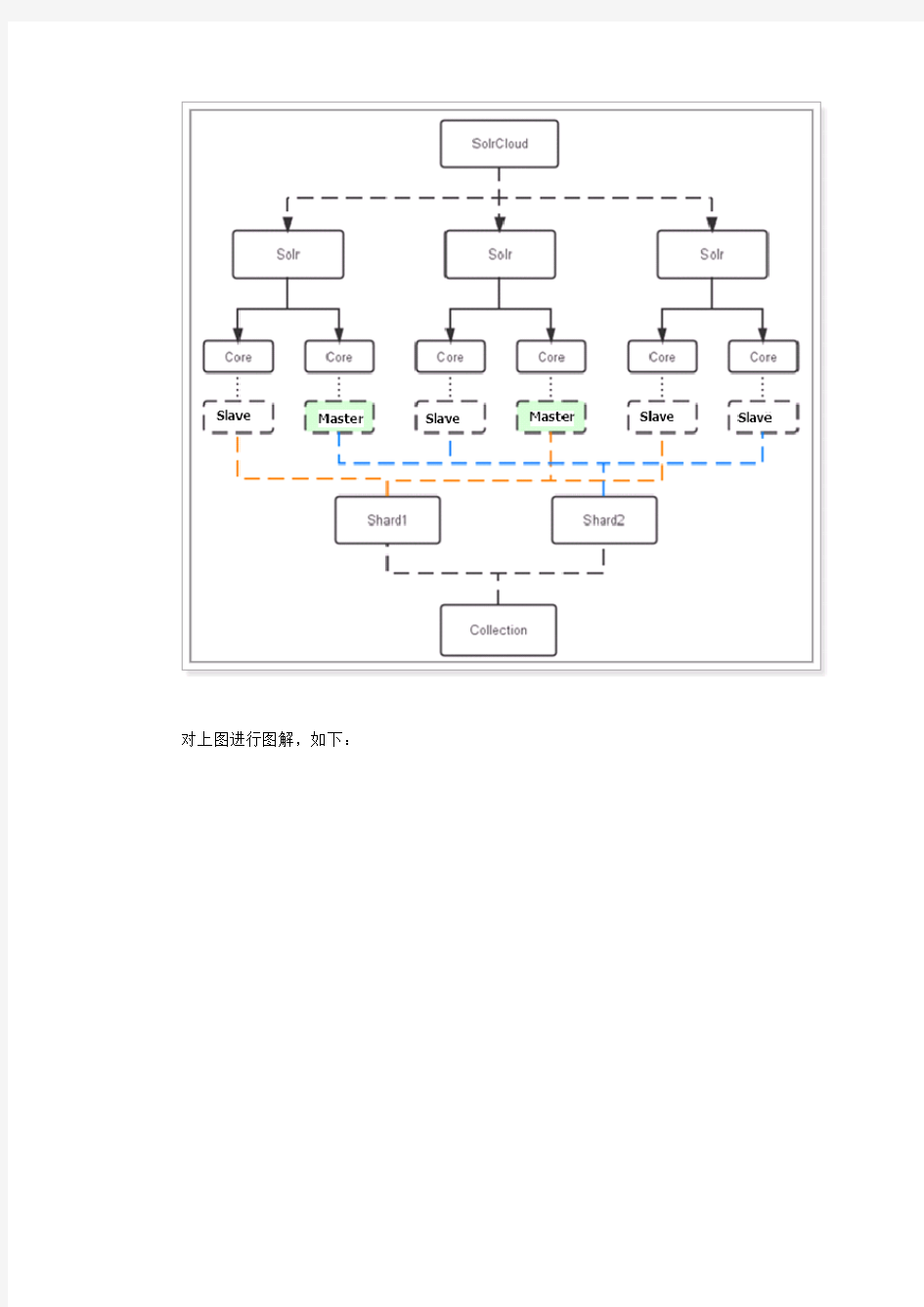
下图是一个SolrCloud应用的例子:
对上图进行图解,如下:
1.2.1物理结构
三个Solr实例(每个实例包括两个Core),组成一个SolrCloud。
1.2.2逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard 上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
1.2.2.1c ollection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
1.2.2.2C ore
每个Core是Solr中一个独立运行单位,提供索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
1.2.2.3M aster或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
1.2.2.4S hard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
2SolrCloud搭建
SolrCloud结构图如下:
参考:“solrcloud搭建.docx”文档
2.1环境准备
CentOS-6.5-i386-bin-DVD1.iso
jdk-7u72-linux-i586.tar.gz
apache-tomcat-7.0.57.tar.gz
zookeeper-3.4.6.tar.gz
solr-4.10.3.tgz
服务器7台:
zookeeper三台:192.168.0.5,192.168.0.6,192.168.0.7
Solr三台:192.168.0.1,192.168.0.2,192.168.0.3,192.168.0.4
2.2环境安装
2.3CentOs 6.5安装
略
2.4jdk7安装
略
2.5zookeeper集群安装
2.5.1解压zookeeper 安装包
tar -zxvf zookeeper-3.4.6.tar.gz
将zookeeper-3.4.6拷贝到/usr/local下并将目录名改为zookeeper
至此zookeeper的安装目录为/usr/local/zookeeper
2.5.2进入zookeeper文件夹,创建data 和logs
创建目录并赋于写权限
指定zookeeper的数据存放目录和日志目录
2.5.3拷贝zookeeper配制文件zoo_sample.cfg
拷贝zookeeper配制文件zoo_sample.cfg并重命名zoo.cfg
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper /conf/zoo.cfg 2.5.4修改zoo.cfg
加入dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
server.1=192.168.0.5:2888:3888
server.2=192.168.0.6:2888:3888
server.3=192.168.0.7:2888:3888
zoo.cfg配制完后如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://www.360docs.net/doc/9e13168004.html,/doc/current/zookeeperAdmin.html#sc_maintenance #
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#dataLogDir=/usr/local/zookeeper/logs
server.1=192.168.0.5:2888:3888
server.2=192.168.0.6:2888:3888
server.3=192.168.0.7:2888:3888
2.5.5进入data文件夹建立对应的myid文件
例如server.1为192.168.0.5则data文件夹下的myid文件内容为1
server.2为192.168.0.6则data文件夹下的myid文件内容为2
依此类推
2.5.6拷贝zookeeper文件夹到其他机器(192.168.0.6和
192.168.0.7)
2.5.7开启zookeeper的端口
/sbin/iptables -I INPUT -p tcp --dport 2181 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 2888 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 3888 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 8080 -j ACCEPT--这里开启tomcat 8080端口
/etc/rc.d/init.d/iptables save #将更改进行保存
/etc/init.d/iptables restart #重启防火墙以便改动生效
2.5.8启动三台服务器的zookeeper
进入/usr/local/zookeeper/bin
./zkServer.sh start
查看集群状态
./zkServer.sh status
刚启动可能会有错误,集群中其他节点一并起来后就正常了
2.6tomcat安装
将apache-tomcat-7.0.57.tar.gz拷贝到/usr/local下并解压
cd /usr/local
tar -zxvf apache-tomcat-7.0.57.tar.gz
2.7solr单机部署
2.7.1解压solr.4.10.
3.tgz
在其中一台服务器上解压solr.4.10.3.tgz,将solr.4.10.3.tgz拷贝到/usr/local下,解压缩:tar -zxvf solr-4.10.3.tgz
压缩后在/usr/local下有solr-4.10.3目录。
2.7.2solrhome
在/home下创建solr作为solrhome 并赋于读写权限
2.7.3部署solr.war
参考solr单机部署方法。
启动tomcat访问http://192.168.0.1:8080/solr如图,至此单机版solr配制完成
2.8solrCloud部署
2.8.1启动zookeeper
solrCloud部署依赖zookeeper,需要启动每一台zookeeper服务器。
2.8.2zookeeper管理配置文件
由于zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml),solrCloud 各各节点使用zookeeper管理的配置文件。
将上边部署的solr单机的conf拷贝到/home/solr下。
执行下边的命令将/home/solr/conf下的配置文件上传到zookeeper:
sh /solr/solr-4.10.3/example/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.200.149:2181,192.168.200.150:2181,192.168.200.151:2181
-cmd upconfig -confdir
/solr/solr-4.10.3/example/solr/collection1/conf -confname myconf -solrhome /solr/solr-4.10.3/example/solr
登陆zookeeper服务器查询配置文件:
cd /solr/zookeeper/bin/
./zkCli.sh
2.8.3修改SolrCloud监控端口为8080:
修改每个solr的/solr/solr-4.10.3/example/solr/solr.xml文件。
2.8.4每一台solr和zookeeper关联
修改每一台solr的tomcat 的bin目录下catalina.sh文件中加入DzkHost指定zookeeper服
务器地址:
JAVA_OPTS="-DzkHost=192.168.0.5:2181,192.168.0.6:2181,192.168.0.7:2181" 2.8.5启动所有的solr服务
启动每一台solr的tomcat服务。
2.8.6访问solrcloud
访问任意一台solr,左侧菜单出现Cloud:
2.8.7SolrCloud集群配置
上图中的collection1集群只有一片,可以通过下边的方法配置新的集群。
创建新集群collection2,将集群分为两片,每片两个副本。
http://192.168.200.149:8080/solr/admin/collections?action=CREATE&name=collection2&numSh ards=2&replicationFactor=2
删除集群命令;
http://192.168.200.149:8080/solr/admin/collections?action=DELETE&name=collection1 执行后原来的collection1删除,如下:
更多的命令请参数官方文档:apache-solr-ref-guide-4.10.pdf
另一种配置方法:如下
${solr_home}/collenction1/core.properties
numShards=2
name=collection1
shard=shard1
coreNodeName=core_node1
以上参数说明
numShards=2 //分片数量
name=collection1 //core名称
shard=shard1 //所属分片
coreNodeName=core_node1 //结点名称
2.9SolrCloud测试
创建索引:
测试1:在一台solr上创建索引,从其它solr服务上可以查询到。
测试2:一次创建100个文档甚至更多,通过观察每个solr的core下边都有索引文档,说明索引文档是分片存储。
查询索引:
从任意一台Solr上查询索引,返回一个完整的结果,说明查询请求从不同的分片上获取数据,最终返回集群上所有匹配的结果。
2.10solrJ访问solrCloud
publicclass SolrCloudTest {
// zookeeper地址
privatestatic String zkHostString =
"192.168.101.7:2181,192.168.101.8:2181,192.168.101.9:2181";
// collection默认名称,比如我的solr服务器上的collection是
collection2_shard1_replica1,就是去掉“_shard1_replica1”的名称privatestatic String defaultCollection = "collection2";
// 客户端连接超时时间
privatestaticint zkClientTimeout = 3000;
// zookeeper连接超时时间
privatestaticint zkConnectTimeout = 3000;
// cloudSolrServer实际
private CloudSolrServer cloudSolrServer;
// 测试方法之前构造 CloudSolrServer
@Before
publicvoid init() {
cloudSolrServer = new CloudSolrServer(zkHostString);
cloudSolrServer.setDefaultCollection(defaultCollection);
cloudSolrServer.setZkClientTimeout(zkClientTimeout);
cloudSolrServer.setZkConnectTimeout(zkConnectTimeout);
cloudSolrServer.connect();
}
// 向solrCloud上创建索引
@Test
publicvoid testCreateIndexToSolrCloud() throws SolrServerException, IOException {
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "100001");
document.addField("title", "李四");
cloudSolrServer.add(document);
https://www.360docs.net/doc/9e13168004.html,mit();
}
// 搜索索引
@Test
publicvoid testSearchIndexFromSolrCloud() throws Exception {
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
try {
QueryResponse response = cloudSolrServer.query(query);
SolrDocumentList docs = response.getResults();
System.out.println("文档个数:" + docs.getNumFound());
System.out.println("查询时间:" + response.getQTime());
for (SolrDocument doc : docs) {
ArrayList title = (ArrayList) doc.getFieldValue("title");
String id = (String) doc.getFieldValue("id");
System.out.println("id: " + id);
System.out.println("title: " + title);
System.out.println();
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch (Exception e) {
System.out.println("Unknowned Exception!!!!");
e.printStackTrace();
}
}
// 删除索引
@Test
publicvoid testDeleteIndexFromSolrCloud() throws SolrServerException, IOException {
// 根据id删除
UpdateResponse response = cloudSolrServer.deleteById("zhangsan");
// 根据多个id删除
// cloudSolrServer.deleteById(ids);
// 自动查询条件删除
// cloudSolrServer.deleteByQuery("product_keywords:教程");
// 提交
https://www.360docs.net/doc/9e13168004.html,mit();
}
}
solr教程
Apache Solr 初级教程 (介绍、安装部署、Java接口、中文分词)Apache Solr 介绍 Solr 是什么? Solr 是一个开源的企业级搜索服务器,底层使用易于扩展和修改的Java 来实现。服务器通信使用标准的HTTP 和XML,所以如果使用Solr 了解Java 技术会有用却不是必须的要求。 Solr 主要特性有:强大的全文检索功能,高亮显示检索结果,动态集群,数据库接口和电子文档(Word ,PDF 等)的处理。而且Solr 具有高度的可扩展,支持分布搜索和索引的复制。 Lucene 是什么? Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。也是目前最为流行的基于 Java 开源全文检索工具包。 目前已经有很多应用程序的搜索功能是基于 Lucene ,比如 Eclipse 帮助系统的搜索功能。Lucene 能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。 Solr VS Lucene Solr 与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene ,因为Solr 底层的核心技术是使用Apache Lucene 来实现的,简单的说Solr 是Lucene 的服务器化。需要注意的是Solr 并不是简单的对Lucene 进行封装,它所提供的大部分功能都区别于Lucene 。 安装搭建Solr
安装Java 虚拟机 Solr 必须运行在Java1.5 或更高版本的Java 虚拟机中,运行标准Solr 服务只需要安装JRE 即可,但如果需要扩展功能或编译源码则需要下载JDK 来完成。可以通过下面的地址下载所需JDK 或JRE : ?OpenJDK (https://www.360docs.net/doc/9e13168004.html,/j2se/downloads.html) ?Sun (https://www.360docs.net/doc/9e13168004.html,/j2se/downloads.html) ?IBM (https://www.360docs.net/doc/9e13168004.html,/developerworks/java/jdk/) ?Oracle (https://www.360docs.net/doc/9e13168004.html,/technology/products/jrockit/index.html)安装步骤请参考相应的帮助文档。 安装中间件 Solr 可以运行在任何Java 中间件中,下面将以开源Apache Tomcat 为例讲解Solr 的安装、配置与基本使用。本文使用Tomcat5.5 解压版进行演示,可在下面地址下载最新版本https://www.360docs.net/doc/9e13168004.html,/download-55.cgi 安装Apache Solr 下载最新的Solr 本文发布时Solr1.4 为最新的版本,下文介绍内容均针对该版本,如与Solr 最新版本有出入请以官方网站内容为准。Solr官方网站下载地址: https://www.360docs.net/doc/9e13168004.html,/dyn/closer.cgi/lucene/solr/ Solr 程序包的目录结构 ?build :在solr 构建过程中放置已编译文件的目录。 ?client :包含了一些特定语言调用Solr 的API 客户端程序,目前只有Ruby 可供选择,Java 客户端叫SolrJ 在src/solrj 中可以找到。 ?dist :存放Solr 构建完成的JAR 文件、WAR 文件和Solr 依赖的JAR 文件。 ?example :是一个安装好的Jetty 中间件,其中包括一些样本数据和Solr 的配置信息。 o example/etc :Jetty 的配置文件。 o example/multicore :当安装Slor multicore 时,用来放置多个Solr 主目录。 o example/solr :默认安装时一个Solr 的主目录。 o example/webapps :Solr 的WAR 文件部署在这里。
solr技术方案
Solr技术方案 一用户需求 以前的互动平台只能对固定表的固定字段做like这样的数据库层面的索引,性能低下,用户体验很差,很难满足业务提出的简化搜索的需求。 需求原型: 业界通用的做全站搜索的基本上两种: 1 选择googleAPI,百度API做。同第三方搜索引擎绑定太死,无法满足后期业务扩展需要,而且全站的SEO做的也不是很好,对于动态的很多ajax请求需要做快照,所以暂时不采用。 2 选择现有成熟的框架。
这里我们选择使用solr。 Solr是一个基于Lucene的Java搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON 格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与Lucene 搜索引擎库完全兼容。通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他Lucene 应用程序中的索引。此外,很多Lucene 工具(如Nutch、Luke)也可以使用Solr 创建的索引。 这里我们主要需要以下几种功能: 1 可用性及成熟性。 2 中文分词。 3 词库与同义词的管理(比如我们使用最高的:股票代码)。 4 高亮显示。 5 方便的导入数据。 6 Facet的轻松配置 7 扩展性。 二Solr的体系结构 体系结构 Solr体系,功能模块介绍及配置。
以上是solr的架构图。具体应用时需要理解一下模块的作用及配置。 RequestHandler:接受请求,分发请求。另外也包含导入数据,如importhandler。UpdateHandlers –处理索引请求。 Search Components:作为handlder的成员变量。处理请求。 Facet:分类搜索 Tika:apache下处理文件的一个项目。 Filter,spelling :处理字符串 Http query/update Database/html importhandler 默认基本可以满足要求。如果不够则扩展相应的handler和component。
zheng-环境搭建及系统部署文档20170213(三版)
1Een 项目描述 基于Spring+SpringMVC+Mybatis分布式敏捷开发系统架构:内容管理系统(门户、博客、论坛、问答等)、统一支付中心(微信、支付宝、在线网银等)、用户权限管理系统(RBAC细粒度用户权限、统一后台、单点登录、会话管理)、微信管理系统、第三方登录系统、会员系统、存储系统 https://www.360docs.net/doc/9e13168004.html,/zhengAdmin/src/ 2项目组织结构
3项目模块图 4项目使用到的技术4.1后端技术 Spring Framework SpringMVC: MVC框架
Spring secutity|Shiro: 安全框架 Spring session: 分布式Session管理MyBatis: ORM框架 MyBatis Generator: 代码生成 Druid: 数据库连接池 Jsp|Velocity|Thymeleaf: 模板引擎ZooKeeper: 协调服务 Dubbo: 分布式服务框架 TBSchedule|elastic-job: 分布式调度框架Redis: 分布式缓存数据库 Quartz: 作业调度框架 Ehcache: 缓存框架 ActiveMQ: 消息队列 Solr|Elasticsearch: 分布式全文搜索引擎FastDFS: 分布式文件系统 Log4J: 日志管理 Swagger2: 接口文档 sequence: 分布式高效ID生产 https://www.360docs.net/doc/9e13168004.html,/yu120/sequence AliOSS|Qiniu: 云存储 Protobuf|json: 数据传输 Jenkins: 持续集成工具 Maven|Gradle: 项目构建管理
SolrCloud使用教程、原理介绍 我心动了
SolrCloud使用教程、原理介绍 发布于2013 年 8 月 24 日,属于搜索分类,7,446 浏览数 SolrCloud 是基于 Solr 和 Zookeeper 的分布式搜索方案,是正在开发中的 Solr4.0 的核心组件之一,它的主要思想是使用 Zookeeper 作为集群的配置信息中心。 它有几个特色功能:①集中式的配置信息②自动容错③近实时搜索④查询时自动负载均衡。
下面看看 wiki 的文档: 1、SolrCloud SolrCloud 是指 Solr 中一套新的潜在的分发能力。这种能力能够通过参数让你建立起一个高可用、 容错的 Solr 服务集群。当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud(solr 云)。 看看下面“启动”部分内容,快速的学会怎样启动一个集群。后面有 3 个快速简单的例子, 它们展现怎样启动一个逐步越来越复杂的集群。检出例子之后,需要翻阅后面的部分了解 更加细节的信息。 2、关于 SolrCores 和 Collections 的一点儿东西 对于单独运行的 Solr 实例,它有个东西叫 SolrCore(Solr.xml 中配置的),它是本质上独立的 索引块。如果你打算多个索引块,你就创建多个 SolrCores。当同时部署SolrCloud 的时, 独立的索引块可以跨越多个 Solr 实例。这意味着一个单独的索引块能由不同服务器设备上多个 SolrCore 的索引块组成。我们把组成一个逻辑索引块的所有 SolrCores 叫做一个独立 索引块儿(collection)。一个独立索引块是本质上一个独立的跨越多个 SolrCore 索引块的索 引块,同时索引块尽可能随着多余的设备进行缩放。如果你想把你的两个 SolrCore Solr 建 立成 SolrCloud,你将有 2 个独立索引块,每个有多个独立里的 SolrCores 组成。 3、启动 下载 Solr4-Beta 或更高版本。 如果你还没了解,通过简单的Solr 指南让自己熟悉Solr。注意:在通过指南了解云特点前,重设所有的配置和移除指南的文档.复制带有预先存在的 Solr 索引的例子目录将导致文档计数关闭Solr 内嵌使用了Zookeeper 作为集群配置和协调运作的仓储。协调考虑作为一个包 含所有 Solr 服务信息的分布式文件系统。 如果你想用一个其他的而不是 8983 作为 Solr 端口,去看下面’ Parameter Reference’部分下 的关于solr.xml 注解 例 A:简单的 2 个 shard 集群 这个例子简单的创建了一个代表一个独立索引块的两个不同的 shards 的两个 solr 服务组成
基于solr的异构数据融合检索技术_梁艳
基于solr的异构数据融合检索技术 梁 艳1 刘双广1 劳定雄2 (1.重庆邮电大学通信与信息工程学院,重庆 400065;2.高新兴科技集团股份有限公司研发中心,广东 广州 510530) 摘 要:针对企业异构数据融合检索的需求,介绍了异构数据整合的常用方法和企业级搜索服务器solr的基本功能,结合xml异构数据整合、中文分词技术和友好的用户界面搭建了基于solr的异构数据融合检索系统,实现了对xml文件的索引和检索,为异构数据融合检索提供了解决方案。 关键词:solr;异构数据;XML;融合;检索 The Retrieval Technology of Heterogeneous Data Integration Based on Solr Abstract:For the need of enterprise heterogeneous data integration retrieval, this thesis introduces the common method of heterogeneous data integration and the basic function of Solr which is enterprise search server. Combined the XML heterogeneous data integration with the Chinese word segmentation technology and the friendly user interface,this paper built the heterogeneous data integration retrieval system based on Solr, realized the indexing and retrieval of XML document and provided solutions for heterogeneous data integration retrieval. Key words:solr; Heterogeneous data;xml;integration;retrieval 作者简介: 梁艳(1988-),女,汉族,重庆市潼南县人,重庆邮电大学硕士在读,研究方向:信息检索;刘双广(1965-),男,汉族,广东省广州人,重庆邮电大学硕士生导师,EMBA,研究方向:物联网;劳定熊(1976-),汉族,男,广东省广州人,高新兴科技集团股份有限公司架构师,硕士,研究方向:云计算。 1 背景 互联网技术的发展,使得信息数据爆炸式增长。特别是在企业信息中,其非结构数据占到了增长数据的80%,包括PDF、word文档,图像、音频和视频等。企业在不同的应用平台拥有不同的检索系统,这给用户检索信息带来了诸多不便。如何构建一个统一的检索平台,使得用户在海量的异构数据中实现统一检索,一直是研究人员研究的热点。 2 异构数据融合技术 异构数据是指数据格式不同,内容不一,描述不同内容的数据,包括结构化数据(如数据库)、半结构化数据(如HTML、 XML)和非结构化数据(如文本、图片)[1] 。数据的统一访问的基 础在于数据融合集成,目前对于解决异构数据融合的研究有数据仓库、数据抽取和数据转换。 数据仓库是指不同来源的数据在进入数据仓库之前,转换为统一的格式为复杂的查询提供统一的视图,实现数据的统一访问[2]。其代表性的成果是ETL集成工具,ETL [3]允许提取、转换和加载异构数据到数据仓库中和实现数据迁移任务。但数据仓库主要是针对不同数据库中的结构化数据的整合,很难应用于非结构化数据的集成、实现非结构化数据的统一访问[4]。 数据抽取是指将无结构的的文本结构化处理,即输入原始文本输出固定格式[5]。部分数据库管理系统自带有数据抽取工具,能够低成本的解决异构数据整合问题,但在实际应用中有一定的局限性。 XML整合是数据转换技术的代表,即将各种异构数据转换为统一的xml文本格式,实现异构数据整合。XML(eXtensible Markup Language,扩展标记语言)是互联网下的一个关键技术,它能很好地实现来源极端异构的数据描述和传输。XML能独立于应用系统,不受任何特殊的软件或者硬件平台限制,并且这些数据能重复使用,简单易懂,成为交换各种结构化、半结构化、非结构化信息的良好方式[6]。因此,采用XML文档作为底层数据的融合与集成技术,实现了异构数据源间数据共享并且更有效地利用信息资源。XML整合数据的一般模型为下图一所示: 3 solr搜索引擎 3.1 solr简介 Solr (Searching on Lucene Replication)[7] 是Apache 软件基金会下的一个开源子项目,它是一个高性能的、采用java5开发的、基于lucene全文搜索库的企业搜索服务器。提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。 3.2 solr体系架构 Solr的系统结构图[8]如图2所示,solr主要分为3层,solr 在lucene的基础上进行了大量的改进,其中solr的底层为对lucene一些功能的改进封装。中间层为solr的核心层,搜索引 擎的主要功能都是在这一层实现的,包括对文档进行分析、建立索引、配置solr运行文件和保存索引文件等。最顶层包括HTTP接口,负责通过HTTP传入和返回XML文档;管理界面和索引更新模块。另外,索引复制功能是一个独立的模块,它是由一个主索引和多个从索引构成,从索引从主索引复制索引,主索引负 图一 xml数据整合模型
Solr总结-吐血总结
Solr调研总结 1. Solr 是什么? Solr它是一种开放源码的、基于Lucene Java 的搜索服务器,易于加入到Web 应用程序中。Solr 提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。可以使用Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。Solr的特性包括: ?高级的全文搜索功能 ?专为高通量的网络流量进行的优化 ?基于开放接口(XML和HTTP)的标准 ?综合的HTML管理界面 ?可伸缩性-能够有效地复制到另外一个Solr搜索服务器 ?使用XML配置达到灵活性和适配性 ?可扩展的插件体系 2. Lucene 是什么? Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是Apache Jakarta(雅加达)家族中的一个开源项目。也是目前最为流行的基于Java开源全文检索工具包。目前已经有很多应用程序的搜索功能是基于Lucene ,比如Eclipse 帮助系统的搜索功能。Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。
3. Solr vs Lucene Solr与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene,因为Solr底层的核心技术是使用Lucene 来实现的,Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene 不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括Solr: Solr 是Lucene面向企业搜索应用的扩展。 Solr与Lucene架构图: Solr使用Lucene并且扩展了它! ?一个真正的拥有动态字段(Dynamic Field)和唯一键(Unique Key)的数据模式(Data Schema) ?对Lucene查询语言的强大扩展! ?支持对结果进行动态的分组和过滤 ?高级的,可配置的文本分析 ?高度可配置和可扩展的缓存机制 ?性能优化
虚拟机学习云环境第二篇Hadoop和Hbase 部署
目标: 在本人的T450笔记本win7操作系统环境下熟悉云计算环境基于开源项目nutch实现大量文本内容的快速分词及检索. Hadoop、HBase、ZooKeep、Solr、Nutch 上一篇完成了Linux基础环境的搭建和集群内SSH无密码登录的设置 这一篇完成Hadoop软件安装 一、创建集群目录 mkdir -p /data/cluster cd /data/cluster mkdirtmp mkdir-p hdfs/data mkdir-p hdfs/name mkdir-p hdfs/journal 二、zookeep安装 在MNODE节点上执行: 把zookeeper-3.4.9.tar.gz拷贝到/data/cluster目录下 cd /data/cluster tarvzxf zookeeper-3.4.9.tar.gz cd /data/cluster/zookeeper-3.4.9/conf cpzoo_sample.cfgzoo.cfg 修改zoo.cfg,修改后内容如下: # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/data/cluster/zookeeper-3.4.9/data # the port at which the clients will connect clientPort=2181 server.1=MNODE :2888:3888 server.2=SNODE :2888:3888 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60
Solr课件
solr入门 课程计划: 1、solr服务介绍 2、solr服务的安装 3、solrhome的目录结构 4、自定义索引库 5、将数据库数据导入索引库 6、solrj对索引库的维护 7、solr案例 1solr服务介绍 1.1什么是solr Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene?. Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene 的全文搜索服务。 Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。 Solr提供了比Lucene更为丰富的查询语言, 同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。 1.2solr与Lucene区别 Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。 2solr服务安装与运行 2.1下载 地址:https://www.360docs.net/doc/9e13168004.html,/solr/ 2.2安装 解压solr-4.10.3后的目录结构: 2.3运行 执行example目录下的start.jar即可。 2.4访问 http://localhost:8983/solr/
我终于深入参与了一个分布式系统了,好多想法不一样了!
我终于深入参与了一个分布式系统了,好多想法不一样了! 原文出处:Turbo Zhang 的博客前言 过去两个月深入的参与了一个分布式系统的开发,记得之前有人说过“想成为架构师之前,都是从微观架构开始的”。尽 管我从没想过将来的某一天要成为一个架构师,或者领域专家,我只是想萌萌哒的编码,写着自己喜欢的Code,和一 群志同道合的朋友做出大家喜欢的商品和产品。但是工作久了慢慢的搭架子的事情还是会来到你的面前,因为时间总会把一部分人慢慢推向海边,使得他们成为最早见到阳光的人。不扯淡了,为什么要说阳光呢,还是因为过去的两(三)个月可能过的太充实也太痛苦了,完成之后,曙光来临的时候整个人是会发光的哦。“深度”参与是因为我终于有机会在搭 架子的过程中有了话语权和选择权,同时也会承担70%以上的编码工作。 之前我的自我认知是我可能在软件方面的积累还可以,比如设计模式,架构分层,程序解耦,API入手等方面,但是总觉得我在硬件网络方面积累的太少,太薄了。 比如: 不同操纵系统之间的特点;
网络端口管理与分发; 哪些网络协议可以帮助我们更好的完成工作,监控虚拟机的时候是在虚机上加代理好还是用协议去控制; 硬件是否支持分布式,在扩展过程中对于.net C#的兼容怎么样; 什么时候使用多线程,在把线程交给程序调度的时候我们怎么控制和捕捉线程的异常; 日志系统对于整个分散的系统是多么的重要; 何时使用关系数据库,什么时候使用Nosql; 消息队列用擅长的MSMQ还是RabbitMQ. 怎样有效的和其他部门的同事沟通; 用什么样的方式去有效调度不同语言开发的系统; 测试用例对于大系统从零散到完整是多么的重要; 系统标准,代码原则对于后期的维护余扩展是多么的重要;等; 项目简介 首先项目详细内容不便多说,简答的说,就是为国内某大型厂商建立一套协调其自身搭建的私有云以及其购买的公有 云的一套系统。说牛X一点就是:一套混合云系统。 使用Restful
solr完整快速搭建版(学习笔记)
Solr学习笔记 由于公司一个网站需要实现搜索功能的更新换代,在和编辑和领导沟通了一段时间之后,我们决定不再使用之前的通过JDBC发送sql语句进行搜索的方法。一番比较,我们决定选用Lucene来搭建我们全文搜索的框架。后来由于开发时间有限,Solr对lucene的集成非常好,我们决定使用Struts+Spring+Solr+IKAnalyzer的一个开发模式来快速搭建一个企业级搜索平台。自己之前没有接触过这方面的东西,从不断看网上的帮助文档,逛论坛,逛wiki,终于一点一点的开发出一个有自己风格并又适合公司搜索要求的这么一个全文搜索功能。网上对于lucene,solr的资料并不是那么多,而且大多是拷贝再拷贝,开发起来难度是有的,项目缺陷也是有的,但是毕竟自己积累了这么一个搭建小型搜索引擎的经验,很有收获,所以准备写个笔记记录下来,方便自己以后回忆,而且可以帮助一下其他学者快速搭建一个企业级搜索。 主要思想: 此企业级搜索分2块,一块是Solr项目:仅关于Solr一系列配置,索引,建立/更新索引配置。另一块是网站项目:Action中通过httpclient通信,类似webService一个交互实现,访问配置完善并运行中的Solr,发送查询请求,得到返回的结果hits(solrJ查询,下面详解),传递给jsp页面。 1.下载包 Lucene3.5 Solr3.5 IKAnalyzer3.2.8中文分词器(本文也仅在此分词器配置的基础上) 开发时段:2011.12中旬至1月中旬 (请自己下载…) 都是最新版,个人偏好新东西,稳定不稳定暂不做评论。 2.搭建Solr项目: 1.apache-solr-3.5.0\dist下得apache-solr-3.5.0.war复制到tomcat下webapps目录, 并更改名字为solr.war,运行生成目录. 2.将IKAnalyzer的jar包导入刚生成的项目中lib目录下。 3.Solr项目配置中文分词: 在solr/conf/schema.xml中 【黑马程序员】面试题-利用solr实现商品的搜索功 能 问题提出:当我们访问购物网站的时候,我们可以根据我们随意所想的内容输入关键字就可以查询出相关的内容,这是怎么做到呢?这些随意的数据不可能是根据数据库的字段查询的,那是怎么查询出来的呢,为什么千奇百怪的关键字都可以查询出来呢? 答案就是全文检索工具的实现,luncence采用了词元匹配和切分词。举个例子:北京天安门------luncence切分词:北京京天天安安门等等这些分词。所以我们搜索的时候都可以检索到。 有一种分词器就是ik中文分词器,它有细粒度切分和智能切分,即根据某种智能算法。 这就使用solr的最大的好处:检索功能的实现。 使用步骤; (1)solr服务器搭建,因为solr是用java5开发的,所以需要jdk和tomcat。搭建部署 (2)搭建完成后,我们需要将要展示的字段引入solr的库中。配置sring与solr结合,工程启动的时候启动solr (3)将数据库中的查询内容导入到solr索引库,这里使用的是solrj的客户端实现的。具体使用可以参考api (4)建立搜索服务,供客户端调用。调用solr,查询内容,这中间有分页功能的实现。solr高亮显示的实现。 (5)客户端接收页面的请求参数,调用搜索服务,进行搜索。 业务字段判断标准: 1、在搜索时是否需要在此字段上进行搜索。例如:商品名称、商品的卖点、商品的描述 (这些相当于将标签给了solr,导入商品数据后,solr对这些字段的对应的商品的具体内容进行分词切分,然后,我们就可以搜索到相关内容了) 2、后续的业务是否需要用到此字段。例如:商品id。 需要用到的字段: 1、商品id 2、商品title 3、卖点 4、价格 5、商品图片 6、商品分类名称 7、商品描述 Solr中的业务字段: 1、id——》商品id 其他的对应字段创建solr的字段。 [AppleScript] 纯文本查看复制代码 ? 01 02 03 04 05 06 07 SOLR技术文档 1.了解lucene 原理,全文搜索概念,参考(https://www.360docs.net/doc/9e13168004.html,/category/30179) .建立 自己的索引库. 2.了解solr参考(https://www.360docs.net/doc/9e13168004.html,/developerworks/cn/java/j-solr1/, https://www.360docs.net/doc/9e13168004.html,/developerworks/cn/java/j-solr2/).并下载实例程序. 3.搭建SOLR服务器 3.1官方下载 apache-solr-1.3.0.zip 和tomcat5.5 3.2将apache-solr-1.3.0\example\webapps\solr.war部署有 tomcat 下 3.3设置 solr 环境变量 apache-tomcat-5.5.26\conf\Catalina\localhost\下新建solr.xml文 件内容如下: solrcloud 高可用集群搭建 一、环境准备 (3) 二、环境安装 (4) 1、CentOs 6.4安装 (4) 1)配制用户 (4) 2)修改当前机器名称 (4) 3)修改当前机器ip (4) 4)上传安装包(工具上传WinSCP) (5) 2、jdk安装 (5) 3、zookeeper集群安装 (6) 1)解压zookeeper 安装包 (6) 2)进入zookeeper-3.4.5文件夹,创建data 和log (6) 3)拷贝zookeeper配制文件zoo_sample.cfg (6) 4)修改zoo.cfg (7) 5)进入data文件夹建立对应的myid文件 (8) 6)制zookeeper-3.4.5文件夹到其他机器 (8) 7)开启zookeeper的端口 (8) 8)启动zookeeper (8) 4、solr集群安装 (9) 1)在solrcloud下新建solrhome,并赋于读写权限 (9) 2)将上传的solr.4.6.0压缩包解压缩, (9) 3)将solr.4.6.0/dist/solr-4.6.0.war 复制到/solrcloud/solrhome 并重命为 solr.war (9) 4)将上传的tomcat解压缩 (9) 5)进入tomcat bin目录,启动tomcat (9) 6)停tomcat 再次启动tomcat, webapps 下边多了解压出来的solr文件夹 (10) 7)将/solrcloud/solr-4.6.0/example/solr 文件夹下所有东西复制到 /solrcloud/solrhome (10) 8)复制solr-4.6.0/example/lib/ext下所有jar包到tomcat 的lib下 (11) 9)启动tomcat 访问http://localhost:8080/solr 如图,至此单机版solr配制完 成 (11) 一、环境准备 CentOS-6.4-x86_64-minimal.iso jdk-6u45-linux-i586-rpm.bin zookeeper-3.4.5.tar solr-4.6.0.zip 服务器6台: 192.168.56.11- SolrCloud.Shard1.Leader 1、官网下载solr-5.4.1.tgz并上传到linux服务上 2、新建一个solr5目录解压 解压之后的solr5.4.1文件夹包含了几乎所有你需要的东西。解压命令如下: tar-xvfz solr-5.4.1.tgz 3、复制solr-5.4.1/server/solr-webapp/webapp到tomcat下的webapps目录下,改名为solr。 cp -r /home/developer/solr5/solr-5.4.1/server/solr-webapp/webapp /home/d eveloper/tomcat7/webapps/ mvwebappsolr 4、将solr-5.4.1/server/lib/ext/目录下的所有jar包复制到tomcat/webapps/solr/WEB-INF/lib/下 cp -r /home/developer/solr5/solr-5.4.1/server/lib/ext/* /home/developer/ tomcat7/webapps/solr/WEB-INF/lib/ 5、将solr-5.4.1/server/solr目录复制到tomcat目录下并重命名为solr_home(存放检索数据) cp -r /home/developer/solr5/solr-5.4.1/server/solr/ /home/developer/tomc at7/ mvsolrsolrhome 6、将solr-5.4.1/server/resouce下的log4j.properties文件复制到tomcat/weapps/solr/WEB-INF/classes目录下,如果没有则新建 cp /home/developer/solr5/solr-5.4.1/server/resources/log4j.properties /h ome/developer/tomcat7/webapps/solr/WEB-INF/classes/ 7、将solr-5.4.1/dist目录下的solr-dataimporthandler-5.4.0.jar和solr-dataimporthandler-extras-5.4.0.jar复制到 tomcat/webapps/solr/WEB-INF/lib/下,这个是为了以后导入数据库表数据 cp /home/developer/solr5/solr-5.4.1/dist/solr-dataimporthandler-5.4.0.ja r /home/developer/tomcat7/webapps/solr/WEB-INF/lib/ cp /home/developer/solr5/solr-5.4.1/dist/solr-dataimporthandler-extras-5. 4.0.jar /home/developer/tomcat7/webapps/solr/WEB-INF/lib/ 8、修改tomcat底下的solr对应的web.xml配置文件,找到以下片段 1 2 1. 环境 apache-tomcat-7.0.50-windows-x64.zip solr-4.7.0.zip zookeeper-3.4.6.tar.gz 2. 搭建一个带有两个shard,每个shard对应一个replica的SolrCloud环境 绿色箭头表示原件,搭建好之后可以删除; 蓝色框里面的是Cloud所需的目录; 红色的分别是配置和库; 2.1 在D盘下创建主目录:D:\__SOLR__CLOUD__HOME__,下面省略该路径为{home}! 2.2 (1)复制两份tomcat,分别改名为:solr_tomcat_1, solr_tomcat_2; (2)修改{home}\zookeeper\conf\zoo_sample.conf重命名为zoo.conf,修改内容:tickTime=2000 initLimit=10 syncLimit=5 # zookeeper数据存放目录(感觉跟缓存差不多,数据可以删除) dataDir=D:/__SOLR__CLOUD__HOME__/zookeeper/data clientPort=9081 2.3 把{home}\solr-4.7.0\example\webapps下的solr.war 分别拷贝到{home}\solr_tomcat_1\webapps,{home}\solr_tomcat_2\webapps下; 2.4 在启动solr_tomcat_*之前,还需要分别修改tomcat端口,和启动命令: 2.4.1 端口修改:略; 2.4.2 修改tomcat\bin 下的catalina.bat,在第一行添加:set CA TALINA_HOME={home}\solr_tomcat_*(将*替换为对应路径); 2.5 分别启动两个solr_tomcat_*,solr.war将会自动解压,下面对解压后的solr进行设置: 2.5.1 库 目录结构 一、主流架构选用技术 二、Hadoop版本选型方案 三、选用的技术与其他工具的对比 四、大数据相关的技术选型版本确定 五、市场上的hadoop发行版厂商资料 六、具体操作 一、主流架构选用技术: 采集层:flume;sqoop 存储层:包括文件存储层和数据存储层 文件:采用hdfs存储 数据:采用hbase,redis等 模型层:离线处理:mr/yarn;实时流式处理spark streaming(比storm的优势) 分析层:hive 管理层:zookeeper(调度;ha) 二、Hadoop版本选型方案: Hadoop提供的经典方案:HDP(Hadoop Data Platform) 管理一体化数据接入 Flume Script SQL Nosql Stream Search In-Memory Others Sqoop Pig Hive Hbase Storm Solr Spark YARN-Ready Apps NFS -------------------------------------------------------------------------------------------------------- WebHDFS YARN Falcon -------------------------------------------------------------------------------------------------------- HDFS --------------------------------------------------------------------------------------------------------- 数据管理【黑马程序员】面试题-利用solr实现商品的搜索功能
solr中文文档
SolrCloud高可用集群搭建
linux-centos7 solr-5.4.1环境布署
单机搭建伪分布SolrCloud
大数据项目技术选型初稿