面板数据协整分析

面板数据的协整检验
一、引言
改革开放以来,随着中国经济的快速增长,城镇居民的人均收入和人均消费均有较大幅度的增长。随着国民经济的迅猛发展,我国城镇居民生活水平不断提高,基本实现了从贫困到小康的历史性跨越。在1991年—2009年中,随着经济的高速增长,中国人均消费水平翻了三番,人均实际收入也翻了4番。但是同西方发达国家相比,中国以及其他一些东亚地区的储蓄率明显偏高而边际消费倾向较低。特别是从20世纪90年代开始,我国出现了持续的消费倾向偏低的现象。而人均收入,却在不断的增长,且区域差异性较大,东西部地区差距也在变大。在这种情形下,有必要研究中国城镇人均消费和人均收入之间的关系。
现代消费理论强调个体家庭的效用最大化,因此在研究城镇人均消费和人均收入之间的关系时,可以从个体角度出发,直接采用微观的家庭数据。但中国还很难得到连贯的家庭消费和收入的数据,常见的处理方法是将全国总量数据视为一个典型的家庭所产生的数据来进行研究。本文选取华北地区为研究对象,运用面板数据的协整分析进行实证研究。
二、国内外研究
西方发达国家在消费和收入方面进行了大量研究,近年来,国内在这方面的研究也开始增多。大概分为三个阶段:第一阶段为线性回归模型阶段。国内一些学者如李子奈(1992)、臧旭恒(1994)等尝试用普通最小二乘回归、序列相关分析、自回归移动平均误差处理和多项式分布滞后模型等方法来研究消费与收入之间的关系,时间大约为20世纪90年代。第二阶段为单纯时间序列建模。如杭斌(2004)、孙慧钧(2004)等开始采用协整模型和误差修正模型来处理非平稳时序数据,从而有效地解决了伪回归问题。第三个阶段为面板数据分析建模。面板数据单位根和协整理论是时间序列的单位根和协整理论研究的继续与发展,它将来自时间序列的信息和来自横截面的信息结合起来,使对单位根和协整关系的推断检验更为直接和精确,从而为人们处理非平稳面板数据提供了良好的计量工具,如苏良军(2006)等研究了中国城乡居民消费和收入之间的关系。
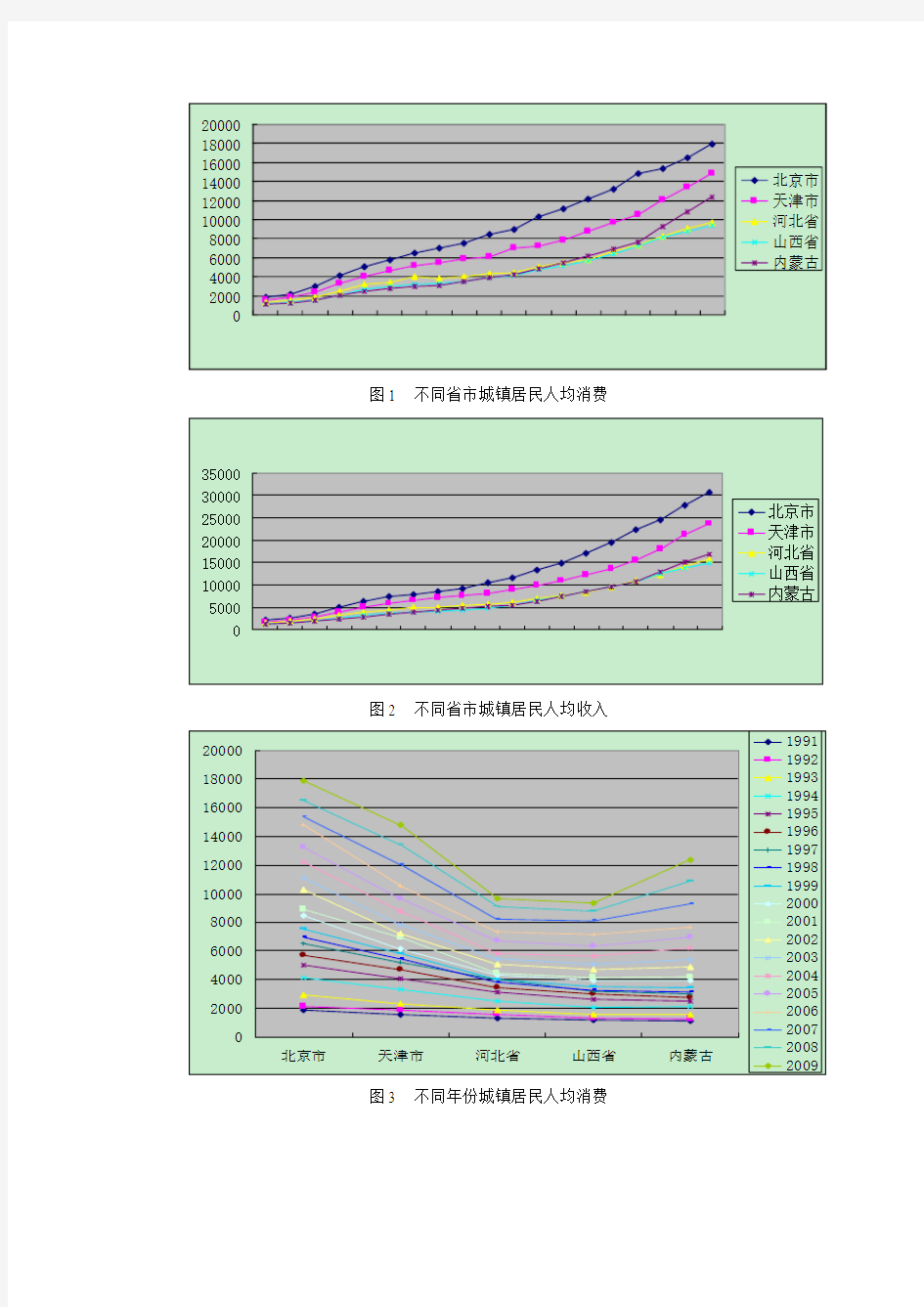
三、居民收入与消费的描述性统计分析
本文选取华北地区五省市(北京、天津、河北、山西、内蒙古)进行统计分析,数据来源于1991年—2009年的中国统计年鉴,人均收入和人均消费的面板数据纵剖面观察分别如图1和图2所示,从横截面观察分别为图3和图4
图1 不同省市城镇居民人均消费
图2 不同省市城镇居民人均收入
图3 不同年份城镇居民人均消费
图4 不同年份城镇居民人均收入
从图1和图2可知,在华北地区人均消费和人均收入的逐年趋势排名依次为北京市、天津市、内蒙古、河北省、山西省。显而易见,北京市的人均消费和人均收入一直居于首位,北京市居民的平均生活水平位居华北地区之首,并且有逐年提高的趋势。相对于其他4省市来说,北京市的增长速度要快得多,其次是天津市,而河北省和山西省的增长速度最慢。从图3和图4可知,对于华北地区不同省市来说,人均消费和人均收入都是逐年上涨的,说明了华北地区城镇居民的平均生活水平是逐年提高的,其中北京市的增幅较大,河北省和山西省最小。综合图1至图4,可以知道,北京市无论人均消费还是人均收入,都居华北地区首位,河北省和山西省排最后。换句话说,北京市对华北地区经济的发展和拉动起到很大的作用。
四、 居民收入与消费的协整分析
(一) 面板数据单位根检验
1. 面板数据的单位根
对面板数据考虑如下AR(1)过程:
(i=1,2,…N;t=1,2,…,T )
不同截面之间的随机误差项u it 为相互独立的随机扰动。若自回归系数︱ρi ︱<1,则说明序列y i 是稳定的,若︱ρi ︱=1则说明yi 包含单位根。
2. 面板数据的单位根检验方法
(1)Common unit root process(同质单位根检验法)
指各截面单元序列具有相同的单位根过程。具体检验方法有三种:LLC 检验(Levin-Lin-Chu Test)、Breitung 检验、Hadri 检验。 (2)Individual unit root process(异质单位根检验法)
指各截面单元序列具有不同的单位根过程。这种情况下,需要分别对每个
it
i it t i i it u x y y ++=-βρ1,
截面序列进行单位根检验,再综合各个截面检验的结果,构造检验统计量进行判断。具体检验方法有三种:IPS 检验(Im-Pesaran-Skin Test )、Fisher-ADF 检验与Fisher-PP 检验。
3. 面板数据单位根检验结果
为了消除异方差可能产生的影响和避免伪回归问题的发生,需要先对面板数据进行对数处理,分别记为LC 和LI ,然后进行单位根检验,以确定其平稳性。本文主要采用LLC 检验和IPS 检验,并且分别考虑了变量包含截距项、截距和时间,分别存在两种情况下的检验结果。检验统计量和相伴概率值见表1。结果表明,在只含有截距的检验情况下,两种方法的检验结果表明LC 不存在单位根,而LI 存在单位根,在含有截距项和趋势项的情况下,两种方法的结果为相伴概率同时拒绝原假设,表明变量不存在单位根。
表1 面板数据单位根检验结果
检验形式
含截距
含截距和趋势
检验方法 变量 LLC IPS LLC IPS 统计量(p 值) 统计量(p 值) 统计量(p 值) 统计量(p 值) LC -4.995(0.00) -1.896(0.029) -3.8(0.00) -5.85(0.00) LI 0.476(0.6831) 1.90(0.97) -10.27(0.00) -10.41(0.00)
(二) 面板数据协整关系检验
在得出面板数据存在单位根后,再检验面板数据是否存在协整关系。协整关
系的检验主要有两类:
一类是建立在Johansen 协整检验基础上的Fisher (combinedJohansen)检验(Maddala and Wu ,1999),Fisher(1932)成功利用多个个体独立检验的结果来进行整体的联合检验。Maddala and Wu(1999)基于Fisher 的结论,通过联合单个截面个体JJ 检验的结果获得对应于面板数据的检验统计量。主要步骤如下:第一,分别对截面个体i 进行单独的JJ 检验,设p i 为截面个体i 的特征根统计量或最大特征根统计量所对应的p 值。第二,利用Fisher 的结论建立如下统计量
2(ln 221n p p Asy n
i i χ?→?-=∑=,Maddala and Wu 证明在“H 0:存在相应个数协整向
量”时,上述统计量p 服从卡方分布。
一类是建立在Engle and Granger 二步法检验基础上Pedroni 检验( Pedroni ,1999)和Kao 检验(Kao ,1999),其中Pedroni 构造的7个检验面板数据协整关系的统计量,前4个是用联合组内维度(within-dimension)来描述,即Panelv 、Panel rho 、Panel PP 和Panel ADF 统计量,另外3个用组间维度(between-dimension)描述,即Grouprho 、Group PP 和Group ADF 统计量,Pedroni 指出,每一个标准化的统计量都趋于正态分布,但在小样本情况下,Panel ADF 和Group ADF 统计量的检验效果更好,在检验结果不一致时,要以这两个统计量为标准。
本文主要采用Kao (1999)提出的统计量来判断人均消费的对数(LC )与人均收入的对数(LI )之间是否存在协整关系。由表2可知,所得到的统计量和相伴概率表明,LC 和LI 之间存在长期均衡稳定关系。
表2 KAO协整检验结果
接下来利用面板数据的Fisher(combinedJohansen)检验拒绝了变量LC与LI之间不存在协整关系的零假设,但不能拒绝这两个变量最多存在1个协整关系的零假设,所以变量LC和LI是协整的。检验结果如表3所示:
表3 Johansen Fisher Panel Cointegration Test
五、面板数据模型建立
格兰杰指出“如果时间变量之间是协整的,那么至少存在一个方向上的格兰杰因果关系”,对于面板数据同样适用。根据格兰杰因果关系理论模型构造中的协整检验方程式(1)和式(2),通过面板OLS回归,得到2个协整方程的估计值。
-
=(1)
.0+
LC
LI108
.1
274
T (-8.16) (121.87)
R2=0.9938 AIC=-4.428
.0+
269
=(2)
LI
.0
LC896
T (9.564) (121.87)
R2=0.9938 AIC=-4.64
(1)式的估计值说明,LC每增长1个百分点,LI就增长1.108个百分点;反之,(2)式说明LI每增长1个百分点,LC就增长0.896个百分点,由此说明LC与LI之间存在长期双向的作用关系,但是LC对LI的影响程度要大于反向的影响程度,这就暗示了从总体水平上,华北地区城镇居民随着人均消费水平的不断提高,人均收入也在不断提高,而且其增长速度要略快于人均消费的增长速度。也就是说,总体上华北地区的城镇居民人均收入水平较高,生活水平得到较大的改善,较为富裕。但是中国人长期以来有着“保守”的消费思想观念,“超前消费”意识不强,喜欢储蓄,所以人均消费的增长就略低于人均收入的增长。
六、结论
通过面板数据的协整分析表明,华北地区城镇居民人均消费的对数和人均收入的对数之间存在长期均衡稳定关系,格兰杰因果关系检验进一步肯定这种长期均衡稳定关系,同时也表明在短期内,人均收入的对数与人均消费的对数之间有偏离均衡关系的可能性,但其均衡状态可以较快恢复。总的说,通过上述定量分析方法,可以得出如下结论:
一方面,可以知道华北地区城镇居民的人均消费和人均收入之间存在着长期均衡稳定的关系,同时平均收入水平的增长速度略高于平均消费水平的增长速度,但是受到中国人的传统思想观念的影响,这个地区的城镇居民总体上“超前消费”意识不强,略偏向于储蓄。
另一方面,华北地区城镇居民的人均收入和人均消费两者之间的作用强度存在一定差异,但是研究结论再次证明两者之间存在较强的相关关系,在一定意义上面表明,高收入的地区消费水平也比较高,即收入与消费的互动机制基本形成,从而推动该地区经济的发展。
七、政策建议
根据文章的研究结论,针对华北地区城镇居民的消费现状,我认为需要从以下几方面努力,以改善华北地区居民的消费状况。
首先,引导消费者转变传统观念,建立积极的消费理念。要通过理论讨论和宣传,使人们改变依靠积蓄消费的保守的消费观念,排除由于认识偏误给人们消费观念更新带来的束缚。合理调整消费结构,采取有效措施引导和激发居民消费。培育新的持续性消费热点,拓宽消费领域。针对当前住房、汽车、旅游等消费热点,要加强行业的规范管理和创新力度。
其次,加快收入分配体制改革,促进居民消费的升级。制度环境影响居民消费,我国居民消费状况将随着改革的深化而发生巨大的改变。收入分配制度改革应有利于调动劳动者创造财富的积极性,兼顾社会各个方面的利益关系和社会承受力。政府经济管理部门要从研究生产和供给,逐步向研究消费和需求方面转变;应从各地区的实际情况出发,着力从体制和政策上调整消费结构,启动不同层次的消费需求;制定居民的收入和消费政策,千方百计拓宽就业渠道,提高就业率,着力提高居民收入,大力增强中低收入居民的消费能力,形成合理的收入差距,提高居民消费倾向;建立居民合理的消费模式和居民适度的消费规模,以利于我国经济更快更好的发展。
再次,消除阻碍经济发展的各种因素,积极促进经济稳定健康发展。提高消费的一个重要方面就是提高居民的收入总量,要提高收入总量,关键在于提高就业水平,而要提高就业水平,根本在于保持经济高速增长。2008年出现的金融危机导致的经济衰退引发了严重的失业问题,从而对居民的收入水平产生了重大影响。这说明我们必须有力地采取各种手段,努力降低失业,促进经济增长,这样才能确保居民的收入增长。而且,保持国民经济和居民收入增长的稳定性,也能为人们消费观念的转变和更新奠定坚实的物质基础。
此外,破解瓶颈制约因素,充分挖掘消费潜力。要把经济结构战略性调整与居民消费结构升级结合起来,适应居民消费需求的变化,实现区域营销活动的差异化;要建立适合我国国情的社会保障体系,化解人们的后顾之忧,增强消费的安全感和便利感;发展文化教育,增强我国居民尤其是落后地区居民的消费意识,提高其消费层次,从而提升消费水平。
面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)
面板数据分析简要步骤与注意事项(面板单位根检验—面板协整—回归分析) 面板数据分析方法: 面板单位根检验—若为同阶—面板协整—回归分析 —若为不同阶—序列变化—同阶建模随机效应模型与固定效应模型的区别不体现为R2的大小,固定效应模型为误差项和解释变量是相关,而随机效应模型表现为误差项和解释变量不相关。先用hausman检验是fixed 还是random,面板数据R-squared值对于一般标准而言,超过0.3为非常优秀的模型。不是时间序列那种接近0.8为优秀。另外,建议回归前先做stationary。很想知道随机效应应该看哪个R方?很多资料说固定看within,随机看overall,我得出的overall非常小0.03,然后within是53%。fe和re输出差不多,不过hausman检验不能拒绝,所以只能是re。该如何选择呢? 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993)很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al.(2002)的改进,提出了检验面板单位根的LLC法。Levin et al.(2002)指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250之间,截面数介于10~250之间)的面板单位根检验。Im et al.(1997)还提出了检验面板单位根的IPS法,但Breitung(2000)发现IPS法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T、BR-T、IPS-W、ADF-FCS、PP-FCS、H-Z分别指Levin,Lin&Chu t*
面板数据分析简要步骤与注意事项 面板单位根—面板协整—回归分析
面板数据分析简要步骤与注意事项 (面板单位根—面板协整—回归分析)步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程,Hadri Z 统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验LLC(Levin-Lin-Chu)检验和不同根单位根检验Fisher-ADF检验(注:对普通序列(非面板序列)的单位根检验方法则常用ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我们说此序列是平稳的,反之则不平稳。如果我们以T(trend)代表序列含趋势项,以I(intercept)代表序列含截距项,T&I代表两项都含,N(none)代表两项都不含,那么我们可以基于前面时序图得出的结论,在单位根检验中选择相应检验模式。 但基于时序图得出的结论毕竟是粗略的,严格来说,那些检验结构均
面板数据分析简要步骤与注意事项面板单位根面板协整回归分析
面板数据分析简要步骤与注意事项 面板单位根—面板协整—回归分析) 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实 际意义的。这种情况称为称为虚假回归或伪回归( spurious regression )。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中 ,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布 , 这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002) 的改进, 提出了检验面板单位根的LLC法。Levin et al. (2002)指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25?250之间,截面数介于10?250之间)的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的 IPS 法, 但 Breitung(2000) 发现 IPS 法对限定性趋势的设定极为敏感 , 并提出了面板单位根检验的 Breitung 法。Maddala and Wu(1999)又提出了 ADF-Fisher 和 PP-Fisher 面板单位根检验方法。 由上述综述可知,可以使用 LLC、IPS、Breintung 、ADF-Fisher 和 PP-Fisher5 种方法进行面板单位根检验。其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS、H-Z 分 别指 Levin, Lin & Chu t* 统计量、 Breitung t 统计量、 lm Pesaran & Shin W 统 量、计 ADF- Fisher Chi-square 统计量、PP-Fisher Chi-square 统计量、Hadri Z 统计 量,并且 Levin, Lin & Chu t* 统计量、 Breitung t 统计量的原假设为存在普通的单位根过程, lm Pesaran & Shin W 统计量、 ADF- Fisher Chi-square 统计量、 PP-Fisher Chi-square 统计量的原假设为存在有效的单位根过程, Hadri Z 统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验 LLC(Levin-Lin-Chu )检验和不同根单位根检验 Fisher-ADF 检验(注:对普通序列(非面板序列)的单位根检验方法则常用 ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我 们说此序列是平稳的,反之则不平稳。 如果我们以 T(trend )代表序列含趋势项,以 I (intercept )代表序列含截距项, T&I 代表两项都含,N (none)代表两项都不含,那么我们可以基于前面时序图得出的结论,在单位根检验中选择相应检验模式。 但基于时序图得出的结论毕竟是粗略的,严格来说,那些检验结构均需一一检验。具体操作可以参照李子奈的说法:ADF检验是通过三个模型来完成,首先从含有截距和趋势项的模型开始,再检验只含截距项的模型,最后检验二者都不含的模型。并且认
最新 面板数据的自适应Lasso分位回归方法的统计分析-精品
面板数据的自适应Lasso分位回归方法 的统计分析 一、引言 面板数据模型是当前学术界讨论最多的模型之一。传统的面板数据模型实际上是一种条件均值模型,即讨论在给定解释变量的条件下响应变量均值变化规律。这种模型的一个固有缺陷是只描述了响应变量的均值信息,其他信息则都忽略了。然而,数据的信息应该是全方位的,这种只对均值建模的方法有待改进。Koenker等提出的分位回归模型是对均值回归模型的一种有效改进,该模型可以在给定解释变量后对响应变量的任意分位点处进行建模,从而可以从多个层次刻画数据的分布信息[1]。同时,分位回归的参数估计是通过极小化加权残差绝对值之和得到,比传统均值回归模型下二次损失函数获得的最小二乘估计更为稳健[2]。 对于简单的线性模型,与分位回归方法相对应的参数点估计、区间估计、模型检验及预测已经有很多成熟的研究结果,但有关面板数据模型的分位回归方法研究文献还不多见。Koenker对固定效应的面板数据模型采用带Lasso惩罚的分位回归方法,通过对个体固定效应实施L1范数惩罚,该方法能够在各种偏态及厚尾分布下得到明显优于均值回归的估计,然而惩罚参数如何确定是该方法的一个难点[3];罗幼喜等也提出了3种新的固定效应面板数据分位回归方法,模拟显示,这些新方法在误差非正态分布情况下所得估计优于传统的最小二乘估计和极大似然估计,但新方法对解释变量在时间上进行了差分运算,当解释变量中包含有不随时间变化的协变量时,这些方法则无法使用[4];Tian等对含随机效应的面板数据模型提出了一种分层分位回归法,并利用EQ算法给出模型未知参数的估计,但该算法只针对误差呈正态分布而设计,限制了其应用范围[5]。以上文献均是直接从损失函数的角度考虑分位回归模型的建立及求解;Liu等利用非对称拉普拉斯分布与分位回归检验损失函数之间的关系,从分布的角度建立了含随机效应面板数据的条件分位回归模型,通过蒙特卡罗EM算法解决似然函数高维积分问题[6];Luo等则在似然函数的基础上考虑加入参数先验信息,从贝叶斯的角度解决面板数据的分位回归问题,模拟显示,贝叶斯分位回归法能有效地处理模型中随机效应参数[7];朱慧明等也考虑过将贝叶斯分位回归法应用于自回归模型,模拟和实证显示该方法能有效地揭示滞后变量对响应变量的位置、尺度和形状的影响[8]。 然而,上述方法均不能对模型中自变量进行选择,但在实际的经济问题中,人们在建立模型之前经常会面临较多解释变量,且对哪个解释变量最终应该留在模型中没有太多信息。如果将一些不重要的噪声变量包含在模型之中,不仅会影响其他重要解释变量估计的准确性,也会使模型可解释性和预测准确性降低。Park等在研究完全贝叶斯分层模型时提出了一种新的贝叶斯Lasso方法,通过假定回归系数有条件Laplace先验信息给出了参数估计的Gibbs抽样算法,这一工作使得一些正则化的惩罚方法都能够纳入到贝叶斯的框架中来,通过特殊的先验信息对回归系数进行压缩,该方法能够在估计参数的同时对模型中自变量进行选择[9-10]。Alhamzawi等将贝叶斯Lasso方法引入到面板数据分位回归模型中来,使得在估计分位回归系数的同时能够对模型中重要解释变
面板数据的分析步骤
面板数据的分析步骤 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square 统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程,Hadri Z统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验LLC (Levin-Lin-Chu)检验和不同根单位根检验Fisher-ADF检验(注:对普通序列(非面板序列)的单位根检验方法则常用ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我们
面板数据协整分析
面板数据的协整检验 一、引言 改革开放以来,随着中国经济的快速增长,城镇居民的人均收入和人均消费均有较大幅度的增长。随着国民经济的迅猛发展,我国城镇居民生活水平不断提高,基本实现了从贫困到小康的历史性跨越。在1991年—2009年中,随着经济的高速增长,中国人均消费水平翻了三番,人均实际收入也翻了4番。但是同西方发达国家相比,中国以及其他一些东亚地区的储蓄率明显偏高而边际消费倾向较低。特别是从20世纪90年代开始,我国出现了持续的消费倾向偏低的现象。而人均收入,却在不断的增长,且区域差异性较大,东西部地区差距也在变大。在这种情形下,有必要研究中国城镇人均消费和人均收入之间的关系。 现代消费理论强调个体家庭的效用最大化,因此在研究城镇人均消费和人均收入之间的关系时,可以从个体角度出发,直接采用微观的家庭数据。但中国还很难得到连贯的家庭消费和收入的数据,常见的处理方法是将全国总量数据视为一个典型的家庭所产生的数据来进行研究。本文选取华北地区为研究对象,运用面板数据的协整分析进行实证研究。 二、国内外研究 西方发达国家在消费和收入方面进行了大量研究,近年来,国内在这方面的研究也开始增多。大概分为三个阶段:第一阶段为线性回归模型阶段。国内一些学者如李子奈(1992)、臧旭恒(1994)等尝试用普通最小二乘回归、序列相关分析、自回归移动平均误差处理和多项式分布滞后模型等方法来研究消费与收入之间的关系,时间大约为20世纪90年代。第二阶段为单纯时间序列建模。如杭斌(2004)、孙慧钧(2004)等开始采用协整模型和误差修正模型来处理非平稳时序数据,从而有效地解决了伪回归问题。第三个阶段为面板数据分析建模。面板数据单位根和协整理论是时间序列的单位根和协整理论研究的继续与发展,它将来自时间序列的信息和来自横截面的信息结合起来,使对单位根和协整关系的推断检验更为直接和精确,从而为人们处理非平稳面板数据提供了良好的计量工具,如苏良军(2006)等研究了中国城乡居民消费和收入之间的关系。 三、居民收入与消费的描述性统计分析 本文选取华北地区五省市(北京、天津、河北、山西、内蒙古)进行统计分析,数据来源于1991年—2009年的中国统计年鉴,人均收入和人均消费的面板数据纵剖面观察分别如图1和图2所示,从横截面观察分别为图3和图4
EViews6.0在面板数据模型估计中的操作
EViews 6.0在面板数据模型估计中的实验操作 1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯 2、建立面板数据工作文件workfile (1)最好不要选择EViews默认的blanaced panel 类型 Moren_panel (2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件
3、建立pool对象 (1)新建对象 (2)选择新建对象类型并命名 (3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图
关闭建立的pool对象,它就出现在当前工作文件中。 4、在pool对象中建立面板数据序列 双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表) 在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。展开表(类似excel)中等待你输入、贴入数据。 (1)打开编辑(edit)窗口
(2)贴入数据 (3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验 选择单位根检验 设置单位根检验
第七讲_面板数据的协整检验
第七讲面板数据的协整检验 众所周知,时间序列观测数据的长度直接关系到协整关系检验的效果,经济变量的观测数据序列越长,协整检验的功效也就越高,即,协整检验过程中犯第Ⅱ类型错误的概率越小(Pedroni (1995))。然而,由于实际研究环境限制,在许多经济问题研究中,经济变量的时间序列很短。尤其是,转型经济国家宏观经济变量的观测值更是如此。同样,微观经济数据也普遍存在类似问题。所以,它们制约了协整理论的广泛应用。为此,计量经济学者试图综合经济变量源于不同经济个体(国家、区域、产业、企业或个体)的时间序列信息发展协整理论。于是,面板数据的协整检验应运而生。然而,在面板数据模型中,由于个体的异质性、非平衡面板、纵剖面时间序列的相关性(或称为空间相关性)、纵剖面时间序列的协整性(或称为空间协整性)和二维渐近性等问题的存在,使得面板数据协整检验远远复杂于时间序列的协整理论。 面板数据的协整理论研究始于1995年,Pedroni (1995)、Kao与Chen (1995) 、Kao与Chiang (1997)、McCoskey与Kao (1998)、Kao(1999)以及Westerlund (2005a)和Breitung (2005)等等分别研究了面板数据的虚假回归(spurious regressions)和协整检验。Kao (1999)发现面板数据的LSDV估计是超一致估计,但是,回归系数的t 统计量却是发散的,所以,有关回归系数的统计推断是错误的。随着面板单位根检验理论的发展,近十年来面板协整检验理论得到了不断丰富。关于面板协整检验的理论研究文献已有数十篇之多,面板协整检验的应用研究主要集中在购买力平价理论的验证、经济增长收敛性实证分析和国际研发溢出效应的检验等研究,应用研究的文献相当丰富。 综合分析面板协整检验的应用研究文献,近年来,Pedroni (1995)、McCoskey等(1998)、Kao(1999)、 Larsson等(2001)和Groen等(2002)提出的面板协整检验在经济学领域获得了广泛应用。因此,本章将重点介绍这些面板协整检验的理论和应用。 纵观面板协整检验的理论研究文献,首先,按检验方法的基本思路划分,面板协整检验分为两类。 一类是基于面板数据协整回归检验式残差(面板)数据单位根检验的面板协整检验,即,Engle–Granger二步法的推广,这类检验通常称为第一代面板协整检验。第一代面板协整检验的显著特点表现为:(1)忽视了可能存在的不可观测共同因素,或者试图通过退势方法,或者借助于可观测的共同效应克服不可观测的共同效应;(2)通常只适用于在个体时间序
面板数据分析简要步骤与注意事项面板单位根—面板协整—回归分析
面板数据分析简要步骤与注意事项面板单位根—面板协整—回归分析 SANY标准化小组 #QS8QHH-HHGX8Q8-GNHHJ8-HHMHGN#
面板数据分析简要步骤与注意事项 (面板单位根—面板协整—回归分析) 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统 计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程, Hadri Z统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验LLC(Levin-Lin-Chu)检验和不同根单位根检验Fisher-ADF检验(注:对普通序列(非面板序列)的单位根检验方法则常用ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我们说此序列是平稳的,反之则不平稳。
面板数据模型资料讲解
面板数据模型
精品资料 仅供学习与交流,如有侵权请联系网站删除 谢谢2 一、我对几种面板数据模型的理解 1 混合效应模型 pooled model 就是所有的省份,都是相同,即同一个方程 ,截距项和斜率项都相同 y it =c+bx it +?it c 与b 都是常数 2 固定效应模型fixed-effect model 和随机效应模型random-effects model 就是所有省份,既有相同的部分,即斜率项都相同;也有不同的部分,即截距项不同。 2.1 固定效应模型 fixed-effect model y it =a i +bx it +?it cov(c i ,x it )≠0 固定效应方程隐含着跨组差异可以用常数项的不同刻画。每个a i 都被视 为未知的待估参数。x it 中任何不随时间推移而变化的变量都会模拟因个体而已 的常数项 2.2 随机效应模型 random-effects model y it =a+u i +bx it +?it cov(a+u i ,x it )=0 A 是一个常数项,是不可观察差异性的均值,u i 为第i 个观察的随机差 异性,不随时间变化。 3 变系数模型Variable Coefficient Models(变系数也分固定效应和随机效应) 每一个组,都采用一个方程进行估计。就是所有省份的线性回归方程的截距项和斜率项都不相同。 y it =u i +b i x it +?it 1.混合估计模型就是各个截面估计方程的截距和斜率项都一样,也就是说回归方程估计结果在截距项和斜率项上是一样的。如果是考察各个省份,历年的收入对消费影响。则各个省份的回归方程就完全相同,无论是截距,还是斜率。 2.随机效应模型和固定效应模型在斜率项都是相同的,都是截距项不同。区别在于截距项和自变量是否相关,不相关选择随机效应模型,相关选择固定效应模型。则说明各个省份的回归方程,斜率相同,差别的是截距项,即平移项。 3 .变系数模型,就是无论是截距项,还是系数项,对于不同省份,每个省份都有一个回归方程,都一个最适合自己的回归方程,完全不管整体。每个省份的回归方程与其他省份的,无论在斜率上,还是截距上都不相同。 总之,从混合估计模型,到变截距模型,再到变系数模型,考察省份是从完全服从整体和没有个性(回归方程是从整体角度而定的和估计的,是一
面板数据的计量方法
面板数据的计量方法 1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输
面板数据分析方法步骤全解
面板数据分析方法步骤全解 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序
列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、
面板数据分析简要步骤与注意事项面板单位根面板协整回归分析
面板数据分析简要步骤与注意事项面板单位根面板 协整回归分析 This manuscript was revised on November 28, 2020
面板数据分析简要步骤与注意事项 (面板单位根—面板协整—回归分析)步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的
面板数据的协整检验与协整回归
面板数据的协整检验与协整回归1、前提: 待检验的两个或多个变量之间(自变量与因变量),(单整:单个变量的差分平稳,一阶平稳:差分一次;二阶级平稳:差分两次;,,,,)必须是同阶单整。 原因:只有同阶单整,变量之间才有共同的增长趋势,才能同涨同落。时间序列的协整检验: 先做回归,后做协整检验。 2、面板数据的协整检验: 先做协整检验,后做回归。 协整:变量之间的长期的稳定的协调关系。
3、面板数据的协整回归: (1)不变系数模型(各单位之间的回归系数大体相同) (2)变系数模型(各单位之间的回归系数大体不同) F检验:略。 (1)固定影响模型(总体数据)(2)随机影响模型(样本数据) 三大回归: 1、截面数据的回归 (1)异方差(穷人的额外消费与富人的额外消费差距甚大:收入作为自变量;消费作为因变量) 影响:自变量“纳伪” 消除:WLS
(2)自相关(时间序列的残差之间相互关联) 如果模型成功,残差之间应该无自相关。白噪声WN。 影响:自变量“纳伪” 消除:广义差分法:既对因变量进行差分,也对自变量进行差分。 (狭义差分:只对因变量进行差分)。(3)共线性 信息重叠。 VIF:大于10 剔除法(剔点)。 2、时间序列 ARMA模型(自回归移动平均模型)
平稳性检验:单位根检验ADF (1)等均值(实际:等观测值,08年GDP与09年GDP相等)(2)同方差(实际:同残差,08年残差与09年的残差相同)(3)协方差(相关系数):只与时间跨度的长短有关。时间间隔越 长,相互影响越弱。 随机漫步:(random walk)
u t t Y Y Y E u Y E Y E u Y Y u u u Y u Y Y u u Y u Y Y u Y Y t t t t t ====+=+=+++=+=++=+=+=∑∑2 000032103232 102121 01)var()()()(...... σ 随机漫步:方差变得无穷大,均值变得无意义。 “单位”根:回归系数为1. 。 ,则此过程为平稳过程小于反之,若位根检验。 对此过程的检验称为单根过程。非平稳过程又称为单位,称为单位根。所以,此时,特征方程的根为1111 110 1)1(111γγγγγ====-=-=-=-+=---L L L u Y L u Y Y u Y Y u Y Y t t t t t t t t t t t
面板数据分析方法步骤
1.面板数据分析方法步骤 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我 们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简 要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介 于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、 ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程,Hadri Z统计量的检验原假设为不存在普通的单位根过程。