手机输入法中的语音识别

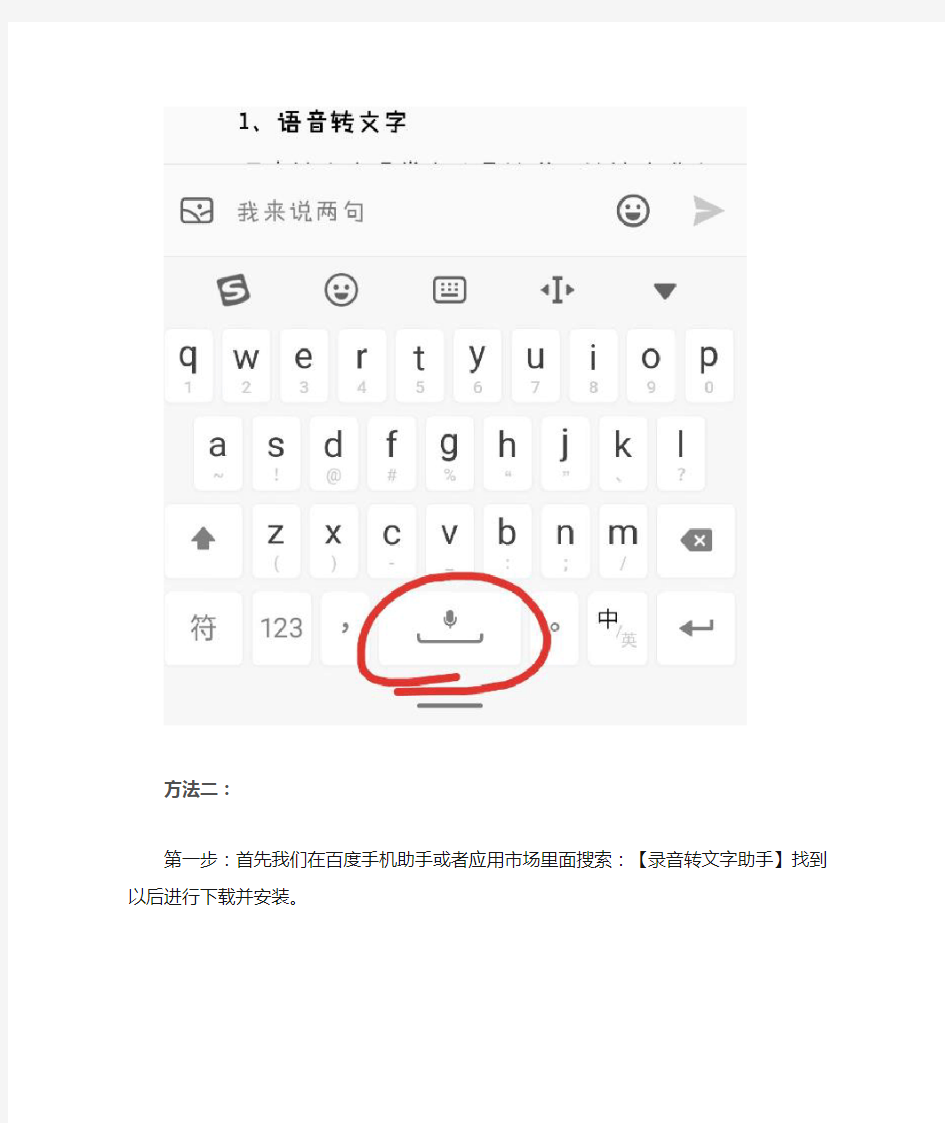
大家知道手机输入法里边也有语音识别的功能吗,可以直接把语音转成文字了,减少打字的数量,提升效率。
方法一:
咱们按住内置输入法的那个话筒,对着魅族手机说普通话,就可以识别成文字了,错别字真的很少。
方法二:
第一步:首先我们在百度手机助手或者应用市场里面搜索:【录音转文字助手】找到以后进行下载并安装。
第二步:接着打开软件就可以看到【录音识别】、【文件识别】和【录音机】的功能,【录音识别】是直接录音进行文字的识别,而【文件识别】则是上传音频文件进行文字识别,【录音机】仅仅支持录音。这里我们就举例说明下【文件识别】。
第三步:选择【文件识别】之后,进入的是文件库的界面,文件库内是手机已经保存好的音频文件,在这里选择我们需要转换的文件。
第四步:选择好文件之后,然后软件就会对音频进行识别,等待时间视个人大小文件而定,识别完成之后音频中的文字就会显示出来。
第五步:也可以直接点击页面中的【翻译】按钮,等待自动中英文互译,识别好的文字内容就会直接翻译为英文啦。
第六步:还可以点击【复制】在弹出的对话框中选择好需要复制的选项,将识别的内容粘贴到你需要的地方。
第七步:如果你还想把识别的内容分享给你的好友,可以点击【导出】,选择好你需要需要导出的选项,然后发送给你的好友就可以了,识别完成的文件信息在本地也会自动保存一份,点击底部文件库就可以看得到。
以上就是语音识别的操作步骤了,以前是全部靠打字,但是现在用语音识别就能轻松帮你做到。
语音识别输入系统
IBM语音识别输入系统(ViaVioce) V9.1 简体中文光盘版| 用嘴巴控制电脑... sjyhsyj 2009-8-28 12:13:271# 软件大小:276.08MB 软件语言:多国语言 软件类别:国外软件 / 汉字输入 运行环境:Win9x/NT/2000/XP/ 软件介绍: 该系统可用于声控打字和语音导航。只要对着微机讲话,不用敲键盘即可打汉字,每分钟可输入150个汉字,是键盘输入的两倍,是普通手写输入的六倍。该系统识别率可达95%以上。并配备了高性能的麦克风,使用便利,特别适合于起草文稿、撰写文章、和准备教案,是文职人员、作家和教育工作者的良好助手。 IBM潜心研究26年,他领导了世界的语音识别技术,其语音识别产品在全球销售已达一百万套以上。使用语音输入方式,您的工作空间更加自由舒畅: *即使您不会打字,也可迅速准备好文稿; *只要集中精力思考问题,无须琢磨怎样拼音,怎样拆字; *当您疲劳时,闭上眼、伸伸腰,双手方在脑后,然后轻松地说:开始听写吧... ... 注:价值超数千元的IBM的中文语音录入工具,有耳麦的朋友可以试一试,也可以当作学习普通话的工具,没有理由不下载使用它。 IBM ViaVoice语音输入系统详解 作者: 艾寒出处: 天极网 目前汉字输入的方式主要有四种:键盘输入,手写输入,扫描输入和我们现在要谈到的语音输入。让我们先来了解一下这四种输入方式。 键盘输入:键盘输入基本上是基于各种输入法,主要又分为字形输入法和拼音输入法。实际上字形输入法是不符合人的写作思维习惯,因为人们在措辞时,头脑中首先反映出的是即将这个词语的语音,所以字形输入法更适合专业录入人员使用。拼音输入法也分两种,一种以词语为输入单位,另一种以语句为输入单位,而后者不符合写作的思维习惯,因为人们在写作时是以词为思考单位。键盘输入法在输入速度有要求的情况下对于键盘操作、指法要求比较高; 手写输入:手写输入是最容易上手的输入方法,但是同样由于手写输入的先天不足,很难达到较高的输入速度; 扫描输入:扫描输入对于硬件要求比较高,主要是适用于资料的整理; 语音输入:语音输入对输入人员的键盘操作能力、指法要求很低,几乎可以说你只要会说汉语,就可以进行语音输入。 语音输入尤其是汉字语音输入经历了很长时间的研究和应用,到目前已经达到了一个相
手机基本功能测试方式
手机基本功能测试 手机基本测试软件测试 关于手机软件测试的工具应用 手机软件测试是否也和以下联系起来: 漫谈人机界面测试 【正文】本文列数了软件黑盒测试过程中,在被测试软件中可能存在的常见软件问题。本文不会详细讨论基本的软件测试思想与常用技术,仅针对在软件黑盒测试过程中若干的问题做描述,并提供个人的参考测试意见与防范意见,希望可以为初学者提供些许帮助。 俗话说“人靠衣裳马靠鞍”,良好的外观往往能够吸引眼球,激发顾客(用户)的购买欲望,最终达成商业利益的实现。软件的设计亦如此,Window XP 在商业上的巨大成功很大一方面来自于它一改往日呆板,以突出“应用”的灰色界面,从“用户体验”角度来设计界面,使界面具有较大的亲和力。就目前的软件设计的发展趋势来说,良好的人机界面设计越来越受到系统分析、设计人员的重视。但是如何对设计的人机界面(包括帮助等)进行测试,给出客观、公正的评价,却鲜见于报端。本文试从共性分析和个性分析的角度,给出一些测试意见和原则,简单且易于上手。起到一个抛砖引玉的目的、以飨读者。 我们知道:“不立规矩无以成方圆”。在软件界面设计强调张扬个性的同时,我们不能忘记软件界面的设计先要讲求规矩-简洁、一致、易用,这是一切软件界面设计和测试的必循之道,是软件人机界面在突出自我时的群体定位。美观、规整的软件人机界面破除新用户
对软件的生疏感,使老用户更易于上手、充分重用已有使用经验,并尽量少犯错误。由此我们在对软件人机界面进行测试时(设计评审阶段和系统测试阶段结合进行),不妨从下列一些角度测试软件的人机界面。 一致性测试 一致性使软件人机界面的一个基本要求。目的是使用户在使用时,很快熟悉软件的操作环境,同时避免对相关软件操作发生理解歧义。这要求我们在进行测试时,需要判断软件的人机界面是否可以作为一个整体而存在。下面是进行一致性测试的一些参考意见:――提示的格式是否一致 ――菜单的格式是否一致 ――帮助的格式是否一致 ――提示、菜单、帮助中的术语是否一致 ――各个控件之间的对齐方式是否一致 ――输入界面和输出界面在外观、布局、交互方式上是否一致 ――命令语言的语法是否一致 ――功能类似的相关界面是否在在外观、布局、交互方式上是否一致(比如商品代码检索和商品名称检索) ――存在同一产品族的时候,是否与其他产品在外观、布局、交互方式上是否一致(例:Office产品族)
语音识别系统实验报告材料
语音识别系统实验报告 专业班级:信息安全 学号: 姓名:
目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6)
3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12) 一、设计任务及要求 实现语音识别功能。 二、语音识别的简单介绍
基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,
语音识别发展现状与展望
中国中文信息学会第七次全国会员代表大会 暨学会成立30周年学术会议 语音识别发展现状与展望中科院自动化研究所徐波 2011年12月4日
报告提纲 ?语音识别技术现状及态势?语音识别技术的行业应用?语音识别技术研究方向?结论与展望
2010年始语音识别重新成为产业热点?移动互联网的兴起成为ASR最重要的应用环境。在Google引领下,互联网、通信公司纷纷把语音识别作为重要研究方向 –Android系统内嵌语音识别技术,Google语音 翻译等; –iPhone4S 上的Siri软件; –百度、腾讯、盛大、华为等都进军语音识别领 域; –我国语音技术领军企业讯飞2010年推出语音云识别、讯飞口讯 –已有的QQ2011版语音输入等等
成熟度分析-技术成熟度曲线 ?美国市场调查咨询公司Gartner于2011年7月发布《2011新兴技术成熟度曲线》报告:
成熟度分析-新兴技术优先矩阵?Gartner评出了2011年具有变革作用的技术,包括语音识别、语音翻译、自然语言问答等。其中语音翻译和自然语言问答有望在5-10年内获得大幅利用,而语音识别有望在2-5年内获得大幅利用;
三十年语音识别技术发展 ---特征提取与知识方面?MFCC,PLP,CMS,RASTA,VTLN;?HLDA, fMPE,neural net-based features ?前端优化 –融入更多特征信息(MLP、TrapNN、Bottle Neck Features等) ?特征很大特点有些是跟模型的训练算法相匹配?大规模FSN图表示,把各种知识源集中在一起–bigram vs. 4-gram, within word dependencies vs. cross-word
史上最全的手机硬件测试用例
XXX手机硬件测试列表 1.1.1 LCD测试 1.数量:2pcs以上; 2.测试方法及内容:手机正常开机后,距离30cm,与水平成45o角并在各个方向15o范围内观察LCD工作是否正常。 a. LCD显示是否正常,是否存在斑点、阴影等; b.彩屏LCD各种颜色能否正常显示,分辨率、色素、响应时间等性能指标是否符合要求; c.分别在暗室、荧光(约750Lux)和阳光(大于3500Lux)下测试LCD显示是否正常,各性能指标是否符合要求; d.将电源设置成高(4.2v)、中(3.8v)、低(3.5v)不同电压,LCD显示是否有差异或异常。 3.预期结果: a. LCD显示正常,不存在斑点、阴影等; b.彩屏LCD各种颜色正常显示,分辨率、色素、响应时间等性能指标符合要求(结合项目的具体指标规定); c.在暗室、荧光(约750Lux)和阳光(大于3500Lux)下测试LCD显示均应正常,各项性能符合项目的具体指标要求; d.在高、中、低不同电压下,LCD显示应正常且基本一致。 1.1.2 LCD背光及键盘背光测试 1.数量:2pcs以上; 2.测试方法及内容:手机正常开机后,选择进入手机功能菜单中的相应设置进行测试。 a.测试手机背光及LED能够正常工作; b.分别在暗室、荧光(约750Lux)和阳光(约2000Lux)下测试LED亮度是否正常; c.背光亮度是否符合要求,测试在不同电池电压情况下,背灯的亮度是否具有一致性; d. LED是否能够按照要求打开和关闭。 3.预期结果: a.手机背光及LED工作正常; b.在暗室、荧光(约750Lux)和阳光(约2000Lux)下,LED亮度均应正常; c.背光亮度应符合要求且在不同电池电压情况下,背灯亮度基本一致; d. LED能够按照要求打开和关闭,且亮度正常。 1.1.3 TP触摸屏承重能力测试 4.数量:5pcs以上; 5.测试方法及内容:重压头25kg,静压30秒之后,等待30秒,再重新放置重压头。 6.预期结果: a. 200次重压后样品不出现牛顿环,则为良品; 1.1.4 Camera测试 1.数量:4pcs以上; 2.测试方法及内容:手机正常开机后,选择手机功能菜单进入拍照状态,对标准测试板进行拍照。 a. Camera是否能够正常工作; b. 拍摄的照片效果是否符合规范要求; c. 用标准色板照片色块的对比测试; d. 测试Digital Camera的反应时间; e. 开启闪光灯功能,看闪光灯是否正常工作。 3.预期结果: a. Camera工作正常,能正常开启与关闭; b.照片效果符合规范要求,参考Camera Spec; c.反应时间达到规范要求;
语音识别技术
目前主流的语音识别技术是基于统计模式识别的基本理论。一个完整的语音识别系统可大致分为三部分: (1)语音特征提取: (2)声学模型与模式匹配(识别算法) (3)语义理解:计算机对识别结果进行语法、语义分析。 语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR), 语音识别的发展简史 1952年AT& T Bell实验室实现了一个单一发音人孤立发音的十个英文数字的语音识别系统,到现在的人机语音交互。语音识别研究从二十世纪50年代开始到现在历半个多世纪的蓬勃发展,在这期间获得了巨大的进展。 现代语音识别技术研究重点包括即兴口语的识别和理解,自然口语对话,以及多语种的语音同声翻译。 语音识别应用的特点 1.语音识别系统必须覆盖的功能包括: (1)语音识别系统要对用户有益(希望它是能检测到的)。例如提高生产率,容易使用,更好的人机界面,或更自然的信息交流模式。 (2)语音识别系统要对用户“友好”。这种“友好”的含义是:用户在和系统进行语音对话时感到舒适;系统的语音提示既有帮助,又很亲近。 (3)语音识别系统必须有足够的精度 (4)语音识别系统要有实时处理能力;例如系统对用户询问的响应时间要很短。 2. 语音识别错误的处理 有以下四种方式可以处理这个问题。 (1)错误弱化法。这种处理仅仅花费用户很少一点时间,对用户几乎没什么其它不利影响。 (2)错误自检纠正法 系统利用已知任务的限制自动地检测并纠正错误。 (3)确认或多层次判定
(4)拒绝/转向人工座席。系统对其中通常较易导致系统识别错误的极少部分语音指令拒绝做出识别决定,而是将其转给人工座席。 在很多情况下,语音识别技术可以充分发挥出RFID的潜能: 1.积压产品、脱销产品 2.被废弃、被召回或已过期产品 3.回收的商品 4.促销产品 RFID系统在利用原有语音导向投资的情况下可以大大增加收益 语音识别技术在邮件分拣中的应用 现代化分拣设备在邮政上的应用大大提高了邮件处理的效率。但是,并不是所有的邮件都能上分拣机处理,那些需要人工处理的邮件成了邮政企业实现自动化的瓶颈。邮政使用人工标码技术以及先进的计算机软件 系统来处理不能上机的邮件,仍需要大量的劳动力。 由MailCode公司开发并准备申请专利的Spell-ItTM软件技术通过提高系统数据库能力的方式对语音识别自动化设备进行了革命性的变革。这种技术提供了无限的数据库能力,并且保证分拣速度不会因数据库的增大而减小。由各大语音引擎公司开发的系统还支持世界上的各种主要语言,这样,语音技术就成为世界性的产品。 以英语语音识别系统为例,系统建立了36个可识别字符26个字母加上0~9的10个数字,同时还建立了一套关键词。Spell-It软件使用这些字符来识别成千上万的口语词汇和无数的词语组合。 对于大公司的邮件收发中心来说,使用MailCode公司的Spell-It软件技术,分拣员实际上只需发出几个字符的音来找到和数据库中相对应的词。例如:碰到了寄给Joseph Schneider的邮件,操作员只需发出“J”、“S”、“C”和“H”几个音就可以得到准确的分拣信息。 姓名和邮箱编码:Jennifer Schroeder, 软件工程部;Joseph Schneider, 技术操作部;Josh Schriver, 技术操作部,因为这三个姓名全都符合(J,S,C,H)的发音标准。邮件中心的操作员知道邮件实际上是寄给Joseph Schneider的,就可以把邮件投入Joseph Schneide的信箱了。 邮局要把邮件按投递路线分发,分拣员必须熟悉长长的投递段列表以及各种各样的国际邮件投递信息。Spell-It技术把地址、投递路线等信息都存入了系统,这样就大大方便了分拣工作。 例如,有一件寄往Stonehollow 路2036号的邮件。使用语音识别技术,分拣员仅仅需要发出“2”、“0”、“S”、“T”和“O”几个音,如表2所示,数据库就会给出所有可能和这几
语音识别技术概述
语音识别技术概述 摘要:本文简要介绍了语音识别技术理论基础及分类方式,所采用的关键技术以及所面临的困难与挑战,最后讨论了语音识别技术的发展前景和应用。 关键词:语音识别;特征提取;模式匹配;模型训练 Abstract:This text briefly introduces the theoretical basis of the speech-identification technology,its mode of classification,the adopted key technique and the difficulties and challenges it have to face.Then,the developing prospect ion and application of the speech-identification technology are discussed in the last part. Keywords:Speech identification;Character Pick-up;Mode matching;Model training 一、语音识别技术的理论基础 语音识别技术:是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高级技术。语音识别以语音为研究对象,它是语音信号处理的一个重要研究方向,是模式识别的一个分支,涉及到生理学、心理学、语言学、计算机科学以及信号处理等诸多领域,甚至还涉及到人的体态语言(如人在说话时的表情、手势等行为动作可帮助对方理解),其最终目标是实现人与机器进行自然语言通信。 不同的语音识别系统,虽然具体实现细节有所不同,但所采用的基本技术相似,一个典型语音识别系统主要包括特征提取技术、模式
手机app测试方法
1 APP测试基本流程 1.1流程图 仍然为测试环境
1.2测试周期 测试周期可按项目的开发周期来确定测试时间,一般测试时间为两三周(即15个工作日),根据项目情况以及版本质量可适当缩短或延长测试时间。正式测试前先向主管确认项目排期。 1.3测试资源 测试任务开始前,检查各项测试资源。 --产品功能需求文档; --产品原型图; --产品效果图; --行为统计分析定义文档; --测试设备(ios3.1.3-ios5.0.1;Android1.6-Android4.0;Winphone7.1及以上;Symbian v3/v5/Nokia Belle等); --其他。 1.4日报及产品上线报告 1)测试人员每天需对所测项目发送测试日报。 2)测试日报所包含的内容为: --对当前测试版本质量进行分级; --对较严重的问题进行例举,提示开发人员优先修改; --对版本的整体情况进行评估。 3)产品上线前,测试人员发送产品上线报告。 4)上线报告所包含的内容为: ---对当前版本质量进行分级; ---附上测试报告(功能测试报告、兼容性测试报告、性能测试报告以及app可用性能标准结果); --总结上线版本的基本情况。若有遗留问题必须列出并记录解决方案。 2 App测试点 2.1安全测试 2.1.1软件权限 1)扣费风险:包括发送短信、拨打电话、连接网络等
2)隐私泄露风险:包括访问手机信息、访问联系人信息等 3)对App的输入有效性校验、认证、授权、敏感数据存储、数据加密等方面进行检测 4)限制/允许使用手机功能接人互联网 5)限制/允许使用手机发送接受信息功能 6)限制/允许应用程序来注册自动启动应用程序 7)限制或使用本地连接 8)限制/允许使用手机拍照或录音 9)限制/允许使用手机读取用户数据 10) 限制/允许使用手机写人用户数据 11) 检测App的用户授权级别、数据泄漏、非法授权访问等 2.1.2安装与卸载安全性 1)应用程序应能正确安装到设备驱动程序上 2)能够在安装设备驱动程序上找到应用程序的相应图标 3)是否包含数字签名信息 4)JAD文件和JAR包中包含的所有托管属性及其值必需是正确的 5)JAD文件显示的资料内容与应用程序显示的资料内容应一致 6)安装路径应能指定 7)没有用户的允许,应用程序不能预先设定自动启动 8)卸载是否安全,其安装进去的文件是否全部卸载 9)卸载用户使用过程中产生的文件是否有提示 10)其修改的配置信息是否复原 11)卸载是否影响其他软件的功能 12)卸载应该移除所有的文件 2.1.3数据安全性 1)当将密码或其他的敏感数据输人到应用程序时,其不会被储存在设备中,同时密码也不会被解码 2)输人的密码将不以明文形式进行显示 3)密码,信用卡明细,或其他的敏感数据将不被储存在它们预输人的位置上 4)不同的应用程序的个人身份证或密码长度必需至少在4一8个数字长度之间 5)当应用程序处理信用卡明细,或其他的敏感数据时,不以明文形式将数据写到其它单独的文件或者临时文件中。以防止应用程序异常终止而又没有侧除它的临时文件,文件可能遭受人侵者的袭击,然后读取这些数据信息。 6)当将敏感数据输人到应用程序时,其不会被储存在设备中 7)备份应该加密,恢复数据应考虑恢复过程的异常通讯中断等,数据恢复后再使用前应该经过校验 8)应用程序应考虑系统或者虚拟机器产生的用户提示信息或安全替告 9)应用程序不能忽略系统或者虚拟机器产生的用户提示信息或安全警告,更不能在安全警
matlab语音识别系统(源代码)最新版
matlab语音识别系统(源代码)最新版
目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6) 3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12)
一、设计任务及要求 用MATLAB实现简单的语音识别功能; 具体设计要求如下: 用MATLAB实现简单的数字1~9的语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。
语音识别基本知识及单元模块方案设计
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产业。 1语音识别的基本原理 语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示: 未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。2语音识别的方法 目前具有代表性的语音识别方法主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等方法。 动态时间规整算法(Dynamic Time Warping,DTW)是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出现较早、较常用的一种算法。在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按照某种距离测度得出两模板间的相似程度并选择最佳路径。 隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov链演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。 矢量量化(Vector Quantization)是一种重要的信号压缩方法。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个语音信号波形或特征参数的标量数据组成一个矢量在多维空间进行整体量化。把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表矢量代替。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量实现最大可能的平均信噪比。在实际的应用过程中,人们还研究了多种降低复杂度的方法,包括无记忆的矢量量化、有记忆的矢量量化和模糊矢量量化方法。 人工神经网络(ANN)是20世纪80年代末期提出的一种新的语音识别方法。其本质上是一
语音识别-科普性介绍
随机过程理论在语音识别中的应用 第一章语音识别总述 1.1语音识别技术简介 语音识别技术就是让机器通过识别和理解过程,把语音信号转变为相应的文本或命令的技术。在当下流行的即时通讯软件(如:微信、QQ等)里,语音识别技术得到了非常广泛的应用。当对方发来一段语音信息而自己不方便收听时便可以使用语音转化功能将语音信息转化成文字信息。此外,在许多输入法(如:讯飞输入法)中也可以使用语音输入功能。用户只需要对着麦克风说话,输入法便可以将语音转换为文字填入输入框,在方便用户的同时也提高了文字输入效率。 语音识别涉及的领域包括:数字信号处理、声学、语音学、计算机科学、心理学、人工智能等,是一门涵盖多个学科领域的交叉科学技术。 语音识别的技术原理是模式识别,其一般过程可以总结为:预处理、特征提取、基于语音模型库下的模式匹配、基于语言模型库下的语言处理、完成识别。 图1.0.1 语音识别过程 第二章预处理 声音的实质是波。在现如中得到广泛应用的音频文件格式(如:mp3等)都经过了压缩无法直接识别。语音识别所使用的音频文件格式必须是未经压缩处理的wav格式文件。下图是一个波形示例。
图2.0.2 语音波形示例 有了声波源文件输入便可以按照图2.1.1所示的各个步骤进行识别。 2.1静音切除 如图2.1.2所示,在得到的声波信号输入中需要实际处理的信号并不一定占满整个时域,会有静音和噪声的存在。因此,必须先对得到的输入信号进行一定的预处理,消去静音的部分并且滤除噪声的干扰才能对实际需要处理的有效语音进行识别。 噪声处理部分本文已在上文进行过讨论,这里不再赘述。去除静音需要用到V AD算法,本文对其做简单介绍。 2.1.1 V AD算法 V AD算法全称为V oice Activity Detection,又称语音边界检测。其可实现的功能有对语音信号进行打断、去除语音信号中的静音部分从而获取有效语音,还可以去除一部分噪声对后续语音识别过程造成的干扰。V AD主要是对输入语音信号的一些时域或频域特征判断其是否属于静音部分。本文只对这些参数做简要介绍,具体算法不属于本文重点因而不在此做细致讨论。 2.1.2时域参数 时域参数是通过对输入信号在时域上的特征参量进行区分。在信噪比较高的环境下使用时域参数进行区分效果显著。 1.相关性分析 通过对足够短的时间范围内的语音信号进行相关性检测可以初步判定该时间范围内的信号是否属于静音部分。在实际应用中,静音的部分实际上会混有各种各样的噪声,因此并非绝对意义上静音。噪声在各个时间范围内的相关性比较低,而人说话的语音相关性则比较强。因此,在高信噪比的条件下区分成功率很
语音识别输入软件
《语音识别输入软件》(Dragon NaturallySpeaking 10 SP1、10.1)[光盘镜像] Dragon NaturallySpeaking 10 Dragon Naturally Speaking 10 Preferred gives small business and advanced PC users the power to create documents, reports and emails three times faster than most people type —with up to 99% accuracy. Surf the Web by voice or dictate and edit in Microsoft Word and Excel, Corel WordPerfect, and most other Windows-based applications. Create voice commands to quickly insert blocks of texts or images —such as your name, title, and signature. Dictate into a handheld device when you're away from your PC, or use a Bluetooth microphone for the same great dictation results without the wires. A high-quality headset is included. 请大家看清自己的操作系统选择合适自己的对应版本!该版本软件不支持中文语音输入《语音识别输入软件》软件售价:249.99美元 专业工作人员每天都在为完成创建文档、编写邮件、完成表格以及流线型工作任务而忙碌着,现在,拥有了Dragon NaturallySpeaking Professional 9,您只需开口说话就可以完成以上任务!Dragon Naturally Speaking 速度为动手输入字符速度的三倍,而且准确率高达99%。对着您的电脑讲话,您说的话会立即在office文件、IE浏览器、Corel WordPerfect软件、Lotus Notes 系统或其他基于Windows操作系统的应用程序上显示。您还可以创建语音命令,同时进行多种计算机任务,由此而知,您将节约多少时间!Dragon Naturally Speaking Professional 9经Section 508检验完全合格,并为身有残疾的使用者创造了完全脱离手工操作使用个人计算机的机会。Dragon Naturally Speaking Professional 9 同时也含有多种可供选择的网络部署的工具,如支持Citrix瘦客户机必需设施的配置。 您想象不到的准确率 Dragon Naturally Speaking Professional 9实现了前所未有的准确率,甚至比打字都要准确。Dragon Naturally Speaking 从来没有出现过拼写错误,而且,事实上,使用次数越多,Dragon NaturallySpeaking 就越灵活,其准确率越高。 快于打字的速度! 大多数人说话的速度为每分钟120个字,而打字的速度每分钟少于40个字,Dragon Naturally Speaking 的速度将近手工输入字符速度的三倍! 使用简易 您马上就可以通过声音来进行信笺、邮件的完成以及进行网上冲浪,不再需要从输入可读字符来开始这一切了。随软件我们附赠事业能够指南和Nuance认可的完全隔离噪音的麦克风。
语音识别技术概述(一)
语音识别技术概述(一) 作者:刘钰马艳丽董蓓蓓 摘要:本文简要介绍了语音识别技术理论基础及分类方式,所采用的关键技术以及所面临的困难与挑战,最后讨论了语音识别技术的发展前景和应用。 关键词:语音识别;特征提取;模式匹配;模型训练 Abstract:Thistextbrieflyintroducesthetheoreticalbasisofthespeech-identificationtechnology,itsmo deofclassification,theadoptedkeytechniqueandthedifficultiesandchallengesithavetoface.Then,the developingprospectionandapplicationofthespeech-identificationtechnologyarediscussedinthelast part. Keywords:Speechidentification;CharacterPick-up;Modematching;Modeltraining 一、语音识别技术的理论基础 语音识别技术:是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高级技术。语音识别以语音为研究对象,它是语音信号处理的一个重要研究方向,是模式识别的一个分支,涉及到生理学、心理学、语言学、计算机科学以及信号处理等诸多领域,甚至还涉及到人的体态语言(如人在说话时的表情、手势等行为动作可帮助对方理解),其最终目标是实现人与机器进行自然语言通信。 不同的语音识别系统,虽然具体实现细节有所不同,但所采用的基本技术相似,一个典型语音识别系统主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。此外,还涉及到语音识别单元的选取。 (一)语音识别单元的选取 选择识别单元是语音识别研究的第一步。语音识别单元有单词(句)、音节和音素三种,具体选择哪一种,由具体的研究任务决定。 单词(句)单元广泛应用于中小词汇语音识别系统,但不适合大词汇系统,原因在于模型库太庞大,训练模型任务繁重,模型匹配算法复杂,难以满足实时性要求。 音节单元多见于汉语语音识别,主要因为汉语是单音节结构的语言,而英语是多音节,并且汉语虽然有大约1300个音节,但若不考虑声调,约有408个无调音节,数量相对较少。因此,对于中、大词汇量汉语语音识别系统来说,以音节为识别单元基本是可行的。 音素单元以前多见于英语语音识别的研究中,但目前中、大词汇量汉语语音识别系统也在越来越多地采用。原因在于汉语音节仅由声母(包括零声母有22个)和韵母(共有28个)构成,且声韵母声学特性相差很大。实际应用中常把声母依后续韵母的不同而构成细化声母,这样虽然增加了模型数目,但提高了易混淆音节的区分能力。由于协同发音的影响,音素单元不稳定,所以如何获得稳定的音素单元,还有待研究。 (二)特征参数提取技术 语音信号中含有丰富的信息,但如何从中提取出对语音识别有用的信息呢?特征提取就是完成这项工作,它对语音信号进行分析处理,去除对语音识别无关紧要的冗余信息,获得影响语音识别的重要信息。对于非特定人语音识别来讲,希望特征参数尽可能多的反映语义信息,尽量减少说话人的个人信息(对特定人语音识别来讲,则相反)。从信息论角度讲,这是信息压缩的过程。 线性预测(LP)分析技术是目前应用广泛的特征参数提取技术,许多成功的应用系统都采用基于LP技术提取的倒谱参数。但线性预测模型是纯数学模型,没有考虑人类听觉系统对语音的处理特点。 Mel参数和基于感知线性预测(PLP)分析提取的感知线性预测倒谱,在一定程度上模拟了人耳对语音的处理特点,应用了人耳听觉感知方面的一些研究成果。实验证明,采用这种技术,语音识别系统的性能有一定提高。
语音识别技术原理及应用
语音AgentNet 的整体实现张宇伟
摘要: 本文论述了一个人机对话应用的实现(我命名它为AgentNet)。其应用实例为一种新的整合了语音技术的智能代理网络服务。 服务器端开发使用了微软SQL SERVER 7.0技术,客户端使用了微软Agent ,微软Specch SDK5语音合成,和语音识别技术。网络连接使用了SOCKET 技术,并论述了高层网络协议的实现。 [关键词] 人机对话,MS-AGENT,语音合成,语音识别,网络编程 [Abstract] This paper discuss a new actualization of man-machine conversation application, which is based on a modal of network service. And I name this service with the name of AgentNet. The development of this service used Microsoft SQL SERVER 7.0. And the client used the technology of Microsoft Agent, TTS (Text To Speech),SR(Speech Recognition).Also the client and the server connect with SOCKET. On the SOCKET, the paper discuss the development of High-Level net protocol. [Key Words] Man-Machine Conversation, MS-AGENT, TTS , SR ,Net Work Programming
智能机器人语音识别技术
智能机器人语音识别技术 姓名:李占博 学号:201215715
关键词:智能机器人;语音识别;隐马尔可夫模型 DSP 摘要:给出了一种由说话者说出控制命令,机器人进行识别理解,并执行相应动作的实现技术。在此,提出了一种高准确率端点检测算法、高精度定点DSP动态指数定标算法,以解决定点DSP实现连续隐马尔科夫模型CHMM识别算法时所涉及的大量浮点小数运算问题,提高了定点DSP实现的实时性、精度,及其识别率。 关键词:智能机器人;语音识别;隐马尔可夫模型;DSP 1 语音识别概述 语音识别技术最早可以追溯到20世纪50年代,是试图使机器能“听懂”人类语音的技术。按照目前主流的研究方法,连续语音识别和孤立词语音识别采用的声学模型一般不同。孤立词语音识别一般采用DTW动态时间规整算法。连续语音识别一般采用HMM模型或者HMM与人工神经网络ANN相结合。 语音的能量来源于正常呼气时肺部呼出的稳定气流,喉部的声带既是阀门,又是振动部件。语音信号可以看作是一个时间序列,可以由隐马尔可夫模型(HMM)进行表征。语音信号经过数字化及滤噪处理之后,进行端点检测得到语音段。对语音段数据进行特征提取,语音信号就被转换成为了一个向量序列,作为观察值。在训练过程中,观察值用于估计HMM 的参数。这些参数包括观察值的概率密度函数,及其对应的状态,状态转移概率等。当参数估计完成后,估计出的参数即用于识别。此时经过特征提取后的观察值作为测试数据进行识别,由此进行识别准确率的结果统计。训练及识别的结构框图如图1所示。
1. 1 端点检测 找到语音信号的起止点,从而减小语音信号处理过程中的计算量,是语音识别过程中一个基本而且重要的问题。端点作为语音分割的重要特征,其准确性在很大程度上影响系统识别的性能。 能零积定义:一帧时间范围内的信号能量与该段时间内信号过零率的乘积。 能零积门限检测算法可以在不丢失语音信息的情况下,对语音进行准确的端点检测,经过450个孤立词(数字“0~9”)测试准确率为98%以上,经该方法进行语音分割后的语音,在进入识别模块时识别正确率达95%。 当话者带有呼吸噪声,或周围环境出现持续时间较短能量较高的噪声,或者持续时间长而能量较弱的噪声时,能零积门限检测算法就不能对这些噪声进行滤除,进而被判作语音进入识别模块,导致误识。图2(a)所示为室内环境,正常情况下采集到的带有呼气噪声的数字“0~9”的语音信号,利用能零积门限检测算法得到的效果示意图。最前面一段信号为呼气噪声,之后为数字“0~9”的语音。
语音识别技术的发展与未来
语音识别技术的发展与未来-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
语音识别技术的发展与未来 与机器进行语音交流,让它听明白你在说什么。语音识别技术将人类这一曾经的梦想变成了现实。语音识别就好比“机器的听觉系统”,该技术让机器通过识别和理解,把语音信号转变为相应的文本或命令。 在1952年的贝尔研究所,Davis等人研制了世界上第一个能识别10个英文数字发音的实验系统。1960年英国的Denes等人研制了第一个计算机语音识别系统。 大规模的语音识别研究始于上世纪70年代以后,并在小词汇量、孤立词的识别方面取得了实质性的进展。上世纪80年代以后,语音识别研究的重点逐渐转向大词汇量、非特定人连续语音识别。 同时,语音识别在研究思路上也发生了重大变化,由传统的基于标准模板匹配的技术思路开始转向基于统计模型的技术思路。此外,业内有专家再次提出了将神经网络技术引入语音识别问题的技术思路。 上世纪90年代以后,在语音识别的系统框架方面并没有什么重大突破。但是,在语音识别技术的应用及产品化方面出现了很大的进展。比如,DARPA是在上世界70年代由美国国防部远景研究计划局资助的一项计划,旨在支持语言理解系统的研究开发工作。进入上世纪90年代,DARPA计划仍在持续进行中,其研究重点已转向识别装置中的自然语言处理部分,识别任务设定为“航空旅行信息检索”。 我国的语音识别研究起始于1958年,由中国科学院声学所利用电子管电路识别10个元音。由于当时条件的限制,中国的语音识别研究工作一直处于缓慢发展的阶段。直至1973年,中国科学院声学所开始了计算机语音识别。 进入上世纪80年代以来,随着计算机应用技术在我国逐渐普及和应用以及数字信号技术的进一步发展,国内许多单位具备了研究语音技术的基本条件。与此同时,国际上语音识别技术在经过了多年的沉寂之后重又成为研究的热点。在这种形式下,国内许多单位纷纷投入到这项研究工作中去。 1986年,语音识别作为智能计算机系统研究的一个重要组成部分而被专门列为研究课题。在“863”计划的支持下,中国开始组织语音识别技术的研究,并决定了每隔两年召开一次语音识别的专题会议。自此,我国语音识别技术进入了一个新的发展阶段。 自2009年以来,借助机器学习领域深度学习研究的发展以及大数据语料的积累,语音识别技术得到突飞猛进的发展。