已基因组测序物种
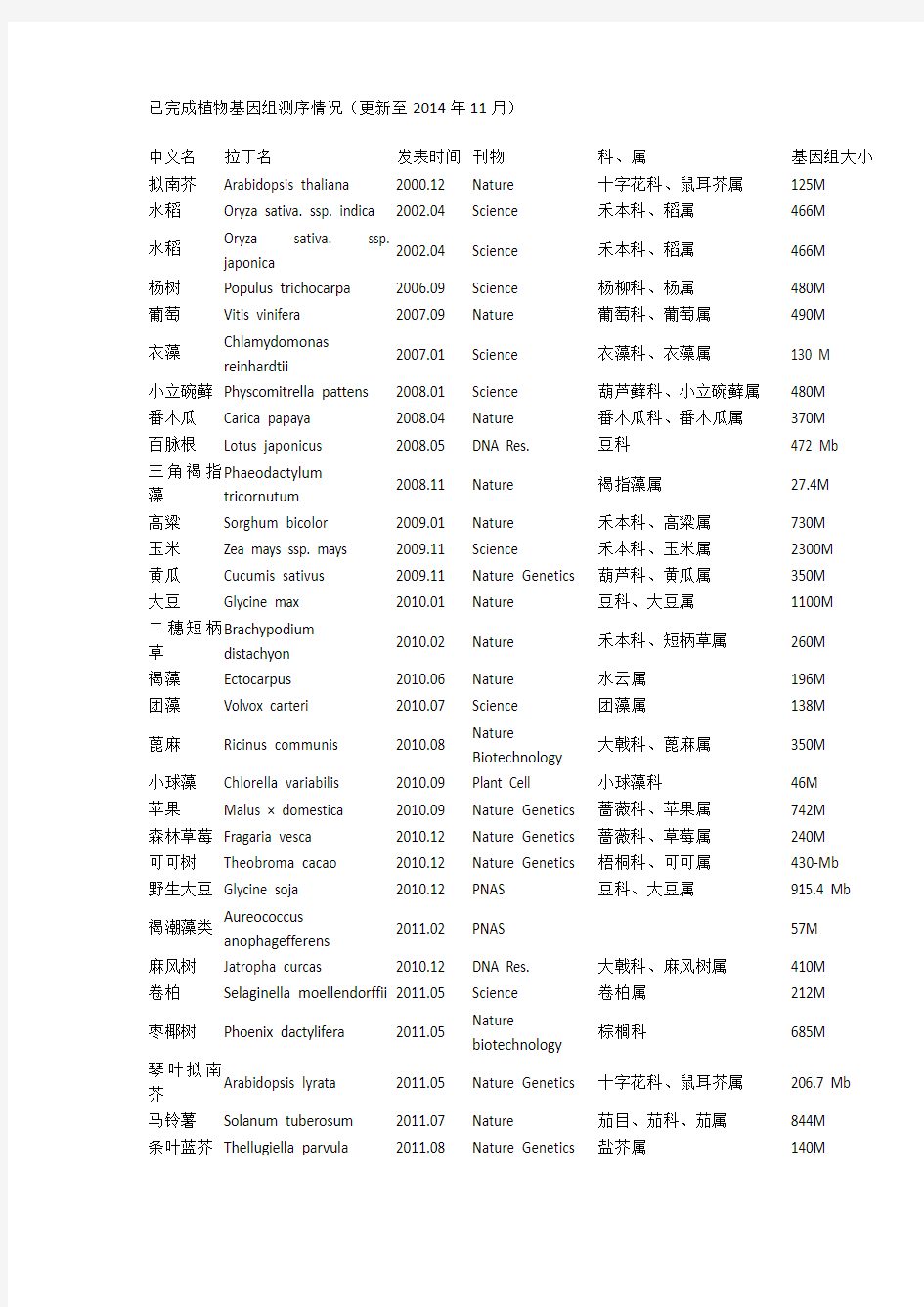

已完成植物基因组测序情况(更新至2014年11月)
中文名拉丁名发表时间刊物科、属基因组大小拟南芥Arabidopsis thaliana 2000.12 Nature 十字花科、鼠耳芥属125M
水稻Oryza sativa. ssp. indica 2002.04 Science 禾本科、稻属466M
水稻Oryza sativa. ssp.
japonica
2002.04 Science 禾本科、稻属466M
杨树Populus trichocarpa 2006.09 Science 杨柳科、杨属480M 葡萄Vitis vinifera 2007.09 Nature 葡萄科、葡萄属490M
衣藻Chlamydomonas
reinhardtii
2007.01 Science 衣藻科、衣藻属130 M
小立碗藓Physcomitrella pattens 2008.01 Science 葫芦藓科、小立碗藓属480M 番木瓜Carica papaya 2008.04 Nature 番木瓜科、番木瓜属370M 百脉根Lotus japonicus 2008.05 DNA Res. 豆科472 Mb
三角褐指藻Phaeodactylum
tricornutum
2008.11 Nature 褐指藻属27.4M
高粱Sorghum bicolor 2009.01 Nature 禾本科、高粱属730M 玉米Zea mays ssp. mays 2009.11 Science 禾本科、玉米属2300M 黄瓜Cucumis sativus 2009.11 Nature Genetics 葫芦科、黄瓜属350M 大豆Glycine max 2010.01 Nature 豆科、大豆属1100M
二穗短柄草Brachypodium
distachyon
2010.02 Nature 禾本科、短柄草属260M
褐藻Ectocarpus 2010.06 Nature 水云属196M 团藻Volvox carteri 2010.07 Science 团藻属138M
蓖麻Ricinus communis 2010.08 Nature
Biotechnology
大戟科、蓖麻属350M
小球藻Chlorella variabilis 2010.09 Plant Cell 小球藻科46M
苹果Malus × domestica 2010.09 Nature Genetics 蔷薇科、苹果属742M
森林草莓Fragaria vesca 2010.12 Nature Genetics 蔷薇科、草莓属240M
可可树Theobroma cacao 2010.12 Nature Genetics 梧桐科、可可属430-Mb 野生大豆Glycine soja 2010.12 PNAS 豆科、大豆属915.4 Mb
褐潮藻类Aureococcus
anophagefferens
2011.02 PNAS 57M
麻风树Jatropha curcas 2010.12 DNA Res. 大戟科、麻风树属410M 卷柏Selaginella moellendorffii 2011.05 Science 卷柏属212M
枣椰树Phoenix dactylifera 2011.05 Nature
biotechnology
棕榈科685M
琴叶拟南
芥
Arabidopsis lyrata 2011.05 Nature Genetics 十字花科、鼠耳芥属206.7 Mb 马铃薯Solanum tuberosum 2011.07 Nature 茄目、茄科、茄属844M
条叶蓝芥Thellugiella parvula 2011.08 Nature Genetics 盐芥属140M
白菜Brassica rapa 2011.08 Nature Genetics 十字花科、芸薹属485M 印度大麻Cannabis sativa 2011.1 Genome biology 大麻属534M
木豆Cajanus cajan 2011.11 Nature
biotechnology
豆科、木豆属833M
蒺藜苜蓿Medicago truncatula 2011.11 Nature 豆科苜蓿属500M 蓝载藻Cyanophora paradoxa 2012.02 Science 灰胞藻门70M
谷子Setaria italica 2012.05 Nature
biotechnology
禾本科、狗尾草属490M
谷子Setaria italica 2012.05 Nature
biotechnology
禾本科、狗尾草属
预估510M,组
装出400M
番茄Solanum lycopersicum 2012.05 Nature 茄科、茄属900Mb 甜瓜Cucumis melo 2012.07 PNAS 葫芦科、甜瓜属450Mb 亚麻Linum usitatissimum 2012.07 Plant Journal 亚麻科、亚麻属373Mb 盐芥Thellungiella salsuginea 2012.07 PNAS 十字花科、盐芥属260Mb 香蕉Musa acuminata 2012.07 Nature 芭蕉科、芭蕉属523Mb 雷蒙德氏
棉
Gossypium raimondii 2012.08 Nature Genetics 锦葵科、棉属775.2Mb 大麦Hordeum vulgare 2012.1 Nature 禾本科、大麦属 5.1Gb
梨Pyrus bretschneideri 2012.11 Genome Research 蔷薇科、梨属527Mb 西瓜Citrullus lanatus 2012.11 Nature Genetics 葫芦科、西瓜属425 Mb 甜橙Citrus sinensis 2012.11 Nature Genetics 芸香科、柑橘属367 Mb 小麦Triticum aestivum 2012.11 Nature 禾本科、小麦属17Gb
两种小型藻Bigelowiella natans,
Guillardia theta
2012.11 Nature 95Mb 87Mb
棉花(雷蒙
德氏棉)
Gossypium raimondii 2012.12 Nature 锦葵科、棉属761.4Mb
梅花Prunus mume 2012.12 Nature
Communications
蔷薇科、梨属280M
鹰嘴豆Cicer arietinum 2013.01 Nature
biotechnology
豆科、鹰嘴豆属738Mb
橡胶树Hevea brasiliensis 2013.02 BMC Genomics 大戟科、橡胶树属 2.15Gb 毛竹Phyllostachys heterocycla 2013.02 Nature Genetics 竹科、钢竹属 2.075 Gb
短花药野生稻Oryza brachyantha 2013.03
Nature
Communications
禾本科稻属342Mb-362Mb
小麦A Triticum urartu 2013.03 Nature 禾本科、小麦属 4.94 Gb 小麦D grassAegilops tauschii 2013.03 Nature 禾本科、小麦属 4.36Gb 桃树Prunus persica 2013.03 Nature Genetics 蔷薇科、梨属265 Mb 丝叶狸藻Utricularia gibba 2013.05 Nature 狸藻科、狸藻属82Mb
中国莲Nelumbo nucifera Gaertn 2013.05 Genome biology 睡莲科、莲属929 Mb 挪威云杉Picea abies 2013.05 Nature 松科、云杉属19.6G
海洋球石Emiliania huxleyi 2013.06 Nature 定鞭藻纲141.7Mb
藻
虫黄藻Symbiodinium minutum 2013.07 Current Biology 甲藻门 1.5G 油棕榈Elaeis guineensis 2013.07 Nature 棕榈科、油棕榈属 1.8G
枣椰树Phoenix dactylifera 2013.08 Nature
Communications
棕榈科、刺葵属671 Mb
醉蝶花Tarenaya hassleriana 2013.08 Plant Cell 醉蝶花科、醉蝶花属290 Mb 莲Nelumbo nucifera 2013.08 Plant Journal 睡莲科、莲属879 Mb
桑树Morus notabilis 2013.09 Nature
Communications
桑科、桑属357 Mb
猕猴桃Actinidia chinensis 2013.10 Nature
Communications
猕猴桃属616.1 Mb
胡杨Populus euphratica 2013.11 Nature
Communications
杨属496.5 Mb
八倍体草
莓
F. x ananassa 2013.12 DNA Research 草莓属698 Mb 康乃馨Dianthus caryophyllus L. 2013.12 DNA Research 石竹属622 Mb 甜菜Beta vulgaris ssp. vulgaris 2013.12 Nature 藜科甜菜属566.6?Mb 无油樟(互
叶梅)
Amborella trichopoda 2013.12 Science 无油樟属748 Mb
辣椒Capsicum annuum
(Criolo de Morelos
334)
2014.1 Nature Genetics 辣椒属 3.48G
芝麻Sesamum indicum 2014.2 Genome Biology 胡麻科胡麻属274 Mb
辣椒Capsicum annuum
(Zunla-1)
2014.3 PNAS 辣椒属 3.48G
火炬松Pinus taeda(Loblolly
pine)
2014.3 Genome Biology 松属23.2G
棉花(亚洲
棉)
Gossypium arboreum 2014.5 Nature Genetics 锦葵科、棉属1694Mb 萝卜Raphanus sativus L. 2014.5 DNA Research 十字花科、萝卜属402Mb
甘蓝Brassica oleracea 2014.5 Nature
communications
十字花科、芸薹属630Mb
菜豆Phaseolus vulgaris L.
2014.6 Nature Genetics 豆科,菜豆属587Mb
野生大豆Glycine soja
2014.7
Nature
communications
豆科、大豆属868 Mb
普通小麦Triticum aestivum 2014.7 Science 禾本科17Gb
野生西红柿Solanum pennellii 2014.7 Nature Genetics
茄科
942 Mb
非洲野生稻Oryza glaberrima
2014.8 Nature Genetics
禾本科
316 Mb
油菜Brassica napus
2014.8 Science
十字花科
630 Mb
中果咖啡Coffea canephora 2014.9 Science 茜草科,咖啡属
710 Mb
茄子Solanum melongena 2014.9 DNA Research 茄科、茄属1093 Mb
多个野生大豆Glycine soja 2014.9
Nature
biotechnology
豆科、大豆属
889.33~1,118.34
Mb
绿豆Vigna radiata 2014.10 Nature
communications
豆科、豇豆属
543 Mb
啤酒花Humulus lupulus 2014.11 Plant and Cell
Physiology
大麻科、葎草属 2.57 Gb
蝴蝶兰Phalaenopsis equestris
2014.11 Nature Genetics 兰科、蝴蝶兰属 1.16 Gb
植物数量性状全基因组选择研究进展
4期吴永升等:植物数量性状全基因组选择研究进展1511 全基因组选择的概念和原理 全基因组选择(Genome-wideselection,GWS),又称基因组选择(Genomicselection,GS),由Meu—wissen于2001年首先提出∞J。主要是通过全基因组中大量的分子标记和参照群体(trainingpopula—tion)的表型数据建立BLUP模型估计出每一标记的育种值,然后仅利用同样的分子标记估计出后代个体育种值并进行选择[7】。 全基因组选择理论主要利用连锁不平衡信息,即假设标记与其相邻的QTL处于连锁不平衡状态,因而由相同标记估计的不同群体的染色体片段效应是相同的,这就要求标记密度足够高以使所有的QTL与标记处于连锁不平衡(LD)状态哺J。而目前随着拟南芥、水稻、玉米等植物基因组序列图谱及SNP图谱的完成或即将完成,提供了大量的SNP标记用于基因组研究。而随着SNP芯片等大规模高通量SNP检测技术的发展和成本的降低,使得全基因组选择应用成为可能。 2全基因组选择的基本方法及案例说明 2.1全基因组选择的基本方法 全基因组选择在实施过程中应该包括以下几个基本步骤:在需要实行选择的参照群体中获取参照群体的基因型数据和表现型数据;然后,通过BLUP程序估计出每个标记位点的标记效应值,从而获得育种值;最后,在接下来每一轮的选择中,不再需要表型数据,根据每一轮次群体基因型信息估计育种值,直接选择群体的优良单株【9j。 全基因组选择的核心过程就是用从参照群体中每一个体的表现型数据和基因型数据建立的数学模型来估算接下来的育种群体中仅有基因型数据的个体的GEBV值。由既有表现型数据又有基因型数据的每一个体组成的群体被成为参照群体。参照群体用来估计数学模型的参数,这个参数接着用来计算仅有基因型数据的育种个体GEBV值,然后根据计算的GEBV值对育种群体进行选择并提升到下一轮次的选择中。因此,通过模型来预测个体的育种值,可以不进行表型鉴定就直接对育种群体的个体进行选择(Meuvissen,2001)。为了使估算的GEBV值尽可能地准确,参照群体必须具有代表性,尽可能地代表接下来在育种过程中用全基因组选择方法来进行选择的分离群体。 2.2全基因组选择方法案例 如图l所示,在这个例子中,笔者的目标是把外来种质中的优良性状基因(包括产量、矮杆、抗逆等)导入本地优良的自交系,从而实现种质的改良 图1在玉米中利用全基因组选择方法导入外源种质 Fig.1Genomewideselectionto introgr%exotictraitsintoadaptedmaize
诺禾致源高分文章集锦-植物基因组
陆地棉基因组测序揭示四倍体棉进化与纤维发育机制Sequencing of allotetraploid cotton (Gossypium hirsutum L. acc. TM-1) provides a resource for fiber improvement 研究对象:陆地棉遗传标准系TM-1 期刊:Nature Biotechnology 影响因子:41.514 合作单位:南京农业大学 发表时间:2015年4月 摘 要 Upland cotton is a model for polyploid crop domestication and transgenic improvement. Here we sequenced the allotetraploid Gossypium hirsutum L. acc. TM-1 genome by integrating whole-genome shotgun reads, bacterial artificial chromosome (BAC)-end sequences and genotype-by-sequencing genetic maps. We assembled and annotated 32,032 A-subgenome genes and 34,402 D-subgenome genes. Structural rearrangements, gene loss, disrupted genes and sequence divergence were more common in the A subgenome than in the D subgenome, suggesting asymmetric evolution. However, no genome-wide expression dominance was found between the subgenomes. Genomic signatures of selection and domestication are associated with positively selected genes (PSGs) for fiber improvement in the A subgenome and for stress tolerance in the D subgenome. This draft genome sequence provides a resource for engineering superior cotton lines.关键词 陆地棉;de novo;四倍体 研究背景 陆地棉(Gossypium hirsutum L.)隶属锦葵目(Malvales),锦葵科(Malvaceae),棉属(Gossypium),因最早在美洲大陆种植而得名,是世界上最重要的棉花栽培品种,占全球棉花种植面积的90%以上。尽管陆地棉在棉花产业中占据核心地位,但由于其为异源四倍体,相关的全基因组测序工作一直难以开展。来自南京农业大学、北京诺禾致源、美国德克斯大学的国际团队,利用最新测序技术,成功构建了高质量的陆地棉全基因组图谱,为进一步改良棉花的农艺性状提供了基础,同时也为多倍体植物的形成和演化机制提供了新的启示。
全基因组关联分析的原理和方法
全基因组关联分析(Genome-wide association study;GWAS)是应用基因组中 数以百万计的单核苷酸多态性(single nucleotide ploymorphism ,SNP)为分子 遗传标记,进行全基因组水平上的对照分析或相关性分析,通过比较发现影响复杂性状的基因变异的一种新策略。 随着基因组学研究以及基因芯片技术的发展,人们已通过GWAS方法发现并鉴定了大量与复杂性状相关联的遗传变异。近年来,这种方法在农业动物重要经济性状主效基因的筛查和鉴定中得到了应用。 全基因组关联方法首先在人类医学领域的研究中得到了极大的重视和应用,尤其是其在复杂疾病研究领域中的应用,使许多重要的复杂疾病的研究取得了突破性进展,因而,全基因组关联分析研究方法的设计原理得到重视。 人类的疾病分为单基因疾病和复杂性疾病。单基因疾病是指由于单个基因的突变导致的疾病,通过家系连锁分析的定位克隆方法,人们已发现了囊性纤维化、亨廷顿病等大量单基因疾病的致病基因,这些单基因的突变改变了相应的编码蛋白氨基酸序列或者产量,从而产生了符合孟德尔遗传方式的疾病表型。复杂性疾病是指由于遗传和环境因素的共同作用引起的疾病。目前已经鉴定出的与人类复杂性疾病相关联的SNP位点有439 个。全基因组关联分析技术的重大革新及其应用,极大地推动了基因组医学的发展。(2005年, Science 杂志首次报道了年龄相关性视网膜黄斑变性GWAS结果,在医学界和遗传学界引起了极大的轰动, 此后一系列GWAS陆续展开。2006 年, 波士顿大学医学院联合哈佛大学等多个研究机构报道了基于佛明翰心脏研究样本关于肥胖的GWAS结果(Herbert 等. 2006);2007 年, Saxena 等多个研究组联合报道了与2 型糖尿病( T2D ) 关联的多个位点, Samani 等则发表了冠心病GWAS结果( Samani 等. 2007); 2008 年, Barrett 等通过GWAS发现了30 个与克罗恩病( Crohns ' disrease) 相关的易感位点; 2009 年, W e is s 等通过GWAS发现了与具有高度遗传性的神经发育疾病——自闭症关联的染色体区域。我国学者则通过对12 000 多名汉族系统性红斑狼疮患者以及健康对照者的GWAS发现了5 个红斑狼疮易感基因, 并确定了4 个新的易感位点( Han 等. 2009) 。截至2009 年10 月, 已经陆续报道了关于人类身高、体重、 血压等主要性状, 以及视网膜黄斑、乳腺癌、前列腺癌、白血病、冠心病、肥胖症、糖尿病、精神分 裂症、风湿性关节炎等几十种威胁人类健康的常见疾病的GWAS结果, 累计发表了近万篇 论文, 确定了一系列疾病发病的致病基因、相关基因、易感区域和SNP变异。) 标记基因的选择: 1)Hap Map是展示人类常见遗传变异的一个图谱, 第1 阶段完成后提供了 4 个人类种族[ Yoruban ,Northern and Western European , and Asian ( Chinese and Japanese) ] 共269 个个体基因组, 超过100 万个SNP( 约1
基因组重测序
基因组重测序 背景介绍 全基因组重测序,是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。与已知序列比对,寻找单核苷酸多态性位点(SNP )、插入缺失位点(InDel ,Insertion/Deletion )、结构变异位点(SV ,Structure Variation )位点及拷贝数变化(CNV) 。 可以寻找到大量基因差异,实现遗传进化分析及重要性状候选基因的预测。涉 及临床医药研究、群体遗传学研究、关联分析、进化分析等众多应用领域。 随着测序成本的大幅度降低以及测序效率的数量级提升, 全基因组重测序已经成为研究人类疾病及动植物分子育种最为快速有效的方法之一。利用illumina Hiseq 2000 平台,将不同插入片段文库和双末端测序相结合,可以高效地挖掘基因序列差异和结构变异等信息, 为客户进行疾病研究、分子育种等提供准确依据。 重测序的两个条件:(1)该物种基因组序列已知;(2)所测序群体之间遗传性差异不大( >99% 相似度 ) 在已经完成的全基因组测序及其基因功能注释的基础上,采用全基因组鸟枪法(WGS )对DNA 插入片段进行双末端测序。 技术路线 生物信息学分析
送样要求 1.样品总量:每次样品制备需要大于5ug 的样品。为保证实验质量及延续性,请一次性提供至少20ug的样品。如需多次制备样品,按照制备次数计算样品总量。 2.样品纯度:OD值260/280应在1.8~2.0 之间;无蛋白质、RNA或肉眼可见杂质污染。 3.样品浓度:不低于50 ng/μL。 4.样品质量:基因组完整、无降解,电泳结果基因组DNA主带应在λ‐Hind III digest 最大条带23 Kb以上且主带清晰,无弥散。 5.样品保存:限选择干粉、酒精、TE buffer或超纯水一种,请在样品信息单中注明。 6.样品运输:样品请置于1.5 ml管中,做好标记,使用封口膜封好;基因组DNA如果用乙醇沉淀,可以常温运输;否则建议使用干冰或冰袋运输,并选择较快的运输方式。 提供结果 根据客户需求,提供不同深度的信息分析结果。
植物功能基因组学及其研究技术_崔兴国
第9卷 第1期2007年3月 衡水学院学报 J o u r n a l o f H e n g s h u i U n i v e r s i t y V o l.9,N o.1 Ma r.2007植物功能基因组学及其研究技术 崔兴国 (衡水学院 生命科学系,河北 衡水053000) 摘 要:植物基因组的研究已经由以全基因组测序为目标的结构基因组学转向以基因功能鉴定为目标的功能基因组学研究.植物功能基因组学研究是利用结构基因组学积累的数据,从中得到有价值的信息,阐述D N A序列的功能,从而对所有基因如何行使其职能并控制各种生命现象的问题作出回答.近年来植物功能基因组学的研究技术主要包括表达序列标签、基因表达的系列分析、D N A微阵列和反向遗传学等.对植物功能基因组学的研究将有利于我们对基因功能的理解和对植物形状的定性改造和利用. 关键词:植物;功能基因组学;研究技术 中图分类号:Q3-3 文献标识码:A 文章编号:1673-2065(2007)01-0023-04 基因是细胞的遗传物质,决定细胞的生物学形状,细胞的生物学功能最终是由大量的基因表达完成的.随着人类基因组“工作框架图”的完成,生命科学研究的重点已经从结构基因组学转移到了功能基因组学的研究,特别是模式植物拟南芥(A r a b i d o p-s i s t h a l i a n a)和水稻(O r y z a s a t i v a)基因组测序的完成,公共数据库中已经积累了大量基因序列信息,获得了许多与植物发育相关的功能基因,在此基础上应用实验分析方法并结合统计和计算机分析来研究基因的表达、调控与功能,并相应诞生和发展了一批新的研究技术,为功能基因组学的研究提供了必要而有效的技术支撑.功能基因组学研究的最终目标是解析所有基因的功能,即从基因水平上大规模批量鉴定基因的功能,进而全面研究控制植物生长发育及响应环境变化的遗传机制,在基因组序列与细胞学行为之间起到桥梁作用,共同承担起从整体水平上解析生命现象的重任. 1 植物功能基因组学研究 植物的生长和发育是一个有机体或有机体的一部分形态建成和功能按一定次序而进行的一系列生化代谢反应的总合,反应在分子水平上,它要求相应的遗传代谢途径必须按照特定的时空次序严格进行以保证正常发育.植物功能基因组研究就是要利用植物全基因组序列的信息,通过发展和应用系统基因组水平的实验方法来研究和鉴别基因组序列的作用;研究基因组的结构、组织与植物功能在细胞、有机体和进化上的关系以及基因与基因间的调控关系;从表达时间、表达部位和表达水平3个方面对目的基因在植物中的精细调控进行系统研究.当前植物功能基因组学研究主要集中于一年生的拟南芥与水稻两个物种上,这主要是由于它们的遗传背景清楚,基因组较小,基因结构简单而且易于进行分子生物学操作.拟南芥研究组“2010计划”的宏伟目标是充分利用拟南芥基因组计划获得的序列信息并结合功能基因组研究技术来获知其25000个基因的全部功能,例如开花的诱导过程是植物生活周期中最奇妙的过程,目前从拟南芥中鉴定了提早开花和延迟开花的多种突变体,显示植物开花受多个遗传基因的控制,如延迟开花的两个突变体是由等位基因 C O(C O N S T A N S)和L D(C O L D L U M I N I D E P E N- D E N S)突变引起,这两个基因均已被克隆,并使其在转基因植物的叶片中进行表达,将C O基因转移到拟南芥中,高效表达C O蛋白的转基因植株即使处于短日照条件下也会开花,这说明C O基因具有激活开花基因的作用.对模式植物功能基因组的研究将有助于整个植物基因组学的研究. 目前的功能基因组研究主要包括以下几个方面:(1)c D N A全长克隆与测序;(2)获得D N A芯片 ①收稿日期:2006-10-12 作者简介:崔兴国(1963-),女,河北冀州市人,衡水学院生命科学系副教授.
已完成基因组测序的生物(植物部分)分析解析
水稻、玉米、大豆、甘蓝、白菜、高粱、黄瓜、西瓜、马铃薯、番茄、拟南芥、杨树、麻风树、苹果、桃、葡萄、花生 拟南芥籼稻粳稻葡萄番木瓜高粱黄瓜玉米栽培大豆苹果蓖麻野草莓马铃薯白菜野生番茄番茄梨甜瓜香蕉亚麻大麦普通小麦西瓜甜橙陆地棉梅毛竹桃芝麻杨树麻风树卷柏狗尾草属花生甘蓝 物种基因组大小和开放阅读框文献 Sesamum indicum L. Sesame 芝麻(2n = 26)293.7 Mb, 10,656 orfs 1 Oryza brachyantha短药野生稻261 Mb, 32,038 orfs 2 Chondrus crispus Red seaweed爱尔兰海藻105 Mb, 9,606 orfs 3 Pyropia yezoensis susabi-nori海苔43 Mb, 10,327 orfs 4 Prunus persica Peach 桃226.6 of 265 Mb 27,852 orfs 5 Aegilops tauschii 山羊草(DD)4.23 Gb (97% of the 4.36), 43,150 orfs 6 Triticum urartu 乌拉尔图小麦(AA)4.66 Gb (94.3 % of 4.94 Gb, 34,879 orfs 7 moso bamboo (Phyllostachys heterocycla) 毛竹2.05 Gb (95%) 31,987 orfs 8 Cicer arietinum Chickpea鹰嘴豆~738-Mb,28,269 orfs 9 520 Mb (70% of 740 Mb), 27,571 orfs 10 Prunus mume 梅280 Mb, 31,390 orfs 11 Gossypium hirsutum L.陆地棉2.425 Gb 12 Gossypium hirsutum L. 雷蒙德氏棉761.8?Mb 13 Citrus sinensis甜橙87.3% of ~367 Mb, 29,445 orfs 14 甜橙367 Mb 15 Citrullus lanatus watermelon 西瓜353.5 of ~425 Mb (83.2%) 23,440 orfs 16 Betula nana dwarf birch,矮桦450 Mb 17
全基因组重测序数据分析
全基因组重测序数据分析 1. 简介(Introduction) 通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排 突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使 得在disease(cancer)genome中的mutation产生对应的易感机制和功能。我们将在基因组 学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。 实验设计与样本 (1)Case-Control 对照组设计; (2)家庭成员组设计:父母-子女组(4人、3人组或多人); 初级数据分析 1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。 2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。并根据参考基 因组信息对检测到的变异进行注释。 4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。在检测过程中,gap的长度为1~5个碱基。对于每个InDel的检测,至少需 要3个Paired-End序列的支持。 5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。根据测序个体序列与参考基因组序列比对分析结果,检测全基因组水平的结构变异并对检测到的变异进行注释。
植物基因组测序
千年基因将应邀参加第十六届全国植物基因组学大会 第十六届全国植物基因组学大会将于2015年8月19日-22日在陕西杨凌召开,千年基因应邀参加此次会议,并将在会场学术交流区设立展台。届时千年基因的技术团队会向大家展示我们最全面的测序平台、一站式的基因组学解决方案以及近年来在植物基因组学领域取得的科研成果,欢迎广大科研人员莅临指导交流! 在测序平台方面,千年基因目前拥有国内最全面的测序平台,能够为科研人员提供一站式解决方案。以PacBio RS II三代平台为例,千年基因自去年提供PacBio RS II测序以来,通过项目经验的积累及严格的质量控制,目前各项数据指标已达国内最高水平。数据产出已稳步升级至1.4Gb/ SMRT cell,读长最长可达42 Kb,reads N50高达18Kb,远超PacBio官方提供的数据标准!在植物基因组de novo测序的研究中,千年基因提供的超长读长测序可更好地跨越基因组高重复序列、转座子区域以及大的拷贝数变异区域和结构变异区,从而实现对高杂合及高重复基因组的完美组装。在植物转录组测序的研究中,千年基因提供的超长读长测序无需拼接即可获得全长转录组序列信息,同时可获得全面的可变剪切、融合基因以及Isoform信息。另外,千年基因提供的HiSeq 4000及HiSeq 2000/2500测序可解决研究人员在植物基因组重测序、转录组测序、小RNA测序等方面的科研需求。 在项目经验方面,千年基因与来自全球的科研人员合作开展了大量植物基因组项目,相关成果已发表于Nature、Nature Genetics、Science等杂志。例如,油棕榈基因组项目在Nature 杂志同时发表两篇文章,辣椒基因组项目的成果发表于Nature Genetics,玉米基因组项目的成果发表于Science。在国外合作方面,千年基因与美国爱荷华州立大学Patrick Schnable教授领导的国际玉米基因组团队合作开展的上万份玉米样本重测序项目也正在进行中;千年基因与国际半干旱热带作物研究所建立长期战略合作关系,正在开展上千份木豆、鹰嘴豆及高粱样本的群体遗传学研究;同时千年基因与华盛顿大学的Evan Eugene Eichler院士及佐治亚大学的Jeffrey Lynn Bennetzen院士也有大量基因组项目合作。在国内合作方面,千年基因与广东省农科院、山东省农科院共同启动的花生基因组项目已全部完成de novo测序及数据挖掘,同时与中国科学院、北京大学、中国农业大学、中国科学技术大学、上海交通大学、
美科学家完成大豆基因组测序
Animal Reproduction,Prague(C),Blackwell Publishing Inc, November23-25 Ptak G.,Tischer M.,Bernabo N.,and Loi P.,2003,Donor-depen-dent developmental competence of oocytes from lambs sub-jected to repeated hormonal stimulation,Biology of Repro-duction,69:278-285 Revel F.,Mermillod P.,Peynot N.,Renard J.P.,and Heyman Y., 1995,Low developmental capacity of in vitro matured and fertilize oocytes from calves compared with that of cows, Journal of Reproduction and Fertility,103:115-120Salkamone D.F.,Damiani P.,Fissore R.A.,Robl J.M.,and Duby R.T.,2001,Biochemical and developmental evidence that ooplasmic maturation of prepubertal bovine oocytes is com-promised,Biology of Reproduction,64:1761-1768 Taneja M.,Bols P.E.J.,van de Velde A.,Ju J.C.,Schreiber D., Tripp M.W.,Levine H.,Echelard Y.,Riesen J.,and Yang X. Z.,2000,Developmental competence of juvenile calf oocytes in vitro and in vivo:Influence of donor animal varia-tion and repeated gonadotropin stimulation1,Biology of Re-production,62:206-213 幼畜繁殖(JIVET)技术在性成熟前奶牛上的应用 Application of Juvenile in intro Embryo Transfer(JIVET)Technology on Prepubertal Dairy Cattle !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 美科学家完成大豆基因组测序 US Scientists Sequenced the Genome of Soybean 期待已久的大豆基因组序列终于测通。在2010年1月14日的《Nature》杂志上,公布了由美国农业部、美国能源部联合基因组研究所和普渡大学等多家科研机构联合完成的豆科植物最重要的物种大豆的完整基因组序列草图。 科学家门利用全基因组鸟枪测序法对大豆基因组的1.1GB的序列进行了测序,结合物理图谱和高密度遗传图谱,获得了大豆基因组的序列拼接草图。研究结果表明大豆中有46320个编码蛋白的臆测基因,约78%的臆测基因位于染色体末端,这些基因在数量上不到染色体基因组的一半,但几乎全部发生了遗传重组。大豆基因组的编码蛋白比双子叶模式植物拟南芥多70%,与同为“古老的多倍体”的杨树的基因组大小相似。研究人员推测大豆基因组的复制至少发生了两次,一次大约是在5900万年前,另一次则可能发生在1300万年前,由此引起了整个基因组的高度重复,约75%的基因以多拷贝形式出现。两次复制发生后紧接着出现了基因多样化和基因丢失,大量的染色体发生重排。 毫无疑问,精确的大豆基因组序列图谱将为更多的大豆性状遗传基础的鉴定提供便利,并加快大豆品种改良的步伐。大豆是人类最重要的食用油来源作物,研究人员通过对大豆基因组基因序列的分析,发现了约1110个基因与脂代谢有关,这些基因及其相关通路对大豆油含量有重要的影响,通过对某些基因的修饰和调控,或许可增加大豆的油脂产量。 作者:Courtney H.Wilcox,本刊通讯员 本文引用格式:Courtney Wilcox,2010,美科学家完成大豆基因组测序,农业生物技术学报,18(1):191 信息来源:https://www.360docs.net/doc/4917516233.html,/nature/journal/v463/n7278/full/nature08670.html 191
全基因组从头测序(de novo测序)
全基因组从头测序(de novo测序) https://www.360docs.net/doc/4917516233.html,/view/351686f19e3143323968936a.html 从头测序即de novo 测序,不需要任何参考序列资料即可对某个物种进行测序,用生物信息学分析方法进行拼接、组装,从而获得该物种的基因组序列图谱。利用全基因组从头测序技术,可以获得动物、植物、细菌、真菌的全基因组序列,从而推进该物种的研究。一个物种基因组序列图谱的完成,意味着这个物种学科和产业的新开端!这也将带动这个物种下游一系列研究的开展。全基因组序列图谱完成后,可以构建该物种的基因组数据库,为该物种的后基因组学研究搭建一个高效的平台;为后续的基因挖掘、功能验证提供DNA序列信息。华大科技利用新一代高通量测序技术,可以高效、低成本地完成所有物种的基因组序列图谱。包括研究内容、案例、技术流程、技术参数等,摘自深圳华大科技网站 https://www.360docs.net/doc/4917516233.html,/service-solutions/ngs/genomics/de-novo-sequencing/ 技术优势: 高通量测序:效率高,成本低;高深度测序:准确率高;全球领先的基因组组装软件:采用华大基因研究院自主研发的SOAPdenovo软件;经验丰富:华大科技已经成功完成上百个物种的全基因组从头测序。 研究内容: 基因组组装■K-mer分析以及基因组大小估计;■基因组杂合模拟(出现杂合时使用); ■初步组装;■GC-Depth分布分析;■测序深 度分析。基因组注释■Repeat注释; ■基因预测;■基因功能注释;■ ncRNA 注释。动植物进化分析■基因家族鉴定(动物TreeFam;植物OrthoMCL);■物种系统发育树构建; ■物种分歧时间估算(需要标定时间信息);■基因组共线性分析; ■全基因组复制分析(动物WGAC;植物WGD)。微生物高级分析 ■基因组圈图;■共线性分析;■基因家族分析; ■CRISPR预测;■基因岛预测(毒力岛); ■前噬菌体预测;■分泌蛋白预测。 熊猫基因组图谱Nature. 2010.463:311-317. 案例描述 大熊猫有21对染色体,基因组大小2.4 Gb,重复序列含量36%,基因2万多个。熊猫基因组图谱是世界上第一个完全采用新一代测序技术完成的基因组图谱,样品取自北京奥运会吉祥物大熊猫“晶晶”。部分研究成果测序分析结果表明,大熊猫不喜欢吃肉主要是因为T1R1基因失活,无法感觉到肉的鲜味。大熊猫基因组仍然具备很高的杂合率,从而推断具有较高的遗传多态性,不会濒于灭绝。研究人员全面掌握了大熊猫的基因资源,对其在分子水平上的保护具有重要意义。 黄瓜基因组图谱黄三文, 李瑞强, 王俊等. Nature Genetics. 2009. 案例描述国际黄瓜基因组计划是由中国农业科学院蔬菜花卉研究所于2007年初发起并组织,并由深圳华大基因研究院承担基因组测序和组装等技术工作。部分研究成果黄瓜基因组是世界上第一个蔬菜作物的基因组图谱。该项目首次将传
已基因组测序物种
已完成植物基因组测序情况(更新至2014年11月) 中文名拉丁名发表时间刊物科、属基因组大小拟南芥Arabidopsis thaliana 2000.12 Nature 十字花科、鼠耳芥属125M 水稻Oryza sativa. ssp. indica 2002.04 Science 禾本科、稻属466M 水稻Oryza sativa. ssp. japonica 2002.04 Science 禾本科、稻属466M 杨树Populus trichocarpa 2006.09 Science 杨柳科、杨属480M 葡萄Vitis vinifera 2007.09 Nature 葡萄科、葡萄属490M 衣藻Chlamydomonas reinhardtii 2007.01 Science 衣藻科、衣藻属130 M 小立碗藓Physcomitrella pattens 2008.01 Science 葫芦藓科、小立碗藓属480M 番木瓜Carica papaya 2008.04 Nature 番木瓜科、番木瓜属370M 百脉根Lotus japonicus 2008.05 DNA Res. 豆科472 Mb 三角褐指藻Phaeodactylum tricornutum 2008.11 Nature 褐指藻属27.4M 高粱Sorghum bicolor 2009.01 Nature 禾本科、高粱属730M 玉米Zea mays ssp. mays 2009.11 Science 禾本科、玉米属2300M 黄瓜Cucumis sativus 2009.11 Nature Genetics 葫芦科、黄瓜属350M 大豆Glycine max 2010.01 Nature 豆科、大豆属1100M 二穗短柄草Brachypodium distachyon 2010.02 Nature 禾本科、短柄草属260M 褐藻Ectocarpus 2010.06 Nature 水云属196M 团藻Volvox carteri 2010.07 Science 团藻属138M 蓖麻Ricinus communis 2010.08 Nature Biotechnology 大戟科、蓖麻属350M 小球藻Chlorella variabilis 2010.09 Plant Cell 小球藻科46M 苹果Malus × domestica 2010.09 Nature Genetics 蔷薇科、苹果属742M 森林草莓Fragaria vesca 2010.12 Nature Genetics 蔷薇科、草莓属240M 可可树Theobroma cacao 2010.12 Nature Genetics 梧桐科、可可属430-Mb 野生大豆Glycine soja 2010.12 PNAS 豆科、大豆属915.4 Mb 褐潮藻类Aureococcus anophagefferens 2011.02 PNAS 57M 麻风树Jatropha curcas 2010.12 DNA Res. 大戟科、麻风树属410M 卷柏Selaginella moellendorffii 2011.05 Science 卷柏属212M 枣椰树Phoenix dactylifera 2011.05 Nature biotechnology 棕榈科685M 琴叶拟南 芥 Arabidopsis lyrata 2011.05 Nature Genetics 十字花科、鼠耳芥属206.7 Mb 马铃薯Solanum tuberosum 2011.07 Nature 茄目、茄科、茄属844M 条叶蓝芥Thellugiella parvula 2011.08 Nature Genetics 盐芥属140M
植物功能基因组学概述
植物功能基因组学概述 XXX* (XXXXX) 摘要:植物功能基因组学是从整体水平研究基因的功能及表达规律的科学。对植物功能基因组学的研究将助于我们对基因功能的理解和对植物性状的定性改造和利用。本文简要介绍了植物功能基因组学的概念、研究内容和研究方法。 关键词:植物;功能基因组学;ESTs;SAGE Summarize of Plant Functional Genomics XXX (XXXXX) Abstract:Plant functional genomics studies provide a novel approach to the identification of genome-wide gene expression. It is currently being widely focused on the gene expression by transcript profiling and takes us rapidly forward in our understanding of plant biological traits. In this review, comprehensive of concepts, research contents and methodologies regarding plant functional genomics and transcript profiling are described. Key words: Plant; functional genomics; ESTs; SAGE 1 植物功能基因组学 基因组学(Genomics)是20世纪最后10年研究最活跃的领域之一。基因组学是指对所有基因的结构和功能进行分析的一门学科, 1986年由美国科学家Thomas Roderick提出, 兴起于20世纪90年代[1]。基因组学研究分为结构基因组学( structural genomics) 和功能基因组学( functional genomics)。结构基因组学代表基因组分析的早期阶段, 以建立生物体高分辨率遗传、物理和转录图谱为主, 以研究基因序列为目标。功能基因组学(Functional genomics)的研究又被称为后基因组学(Post genomics)研究,它是利用结构基因组学提供的信息和产物,通过在基因组或系统水平上全面分析基因的功能,使得生物学研究从对单一基因或蛋白质的研究转向对多个基因或蛋白质同时进行系统研究。 植物功能基因组学是植物后基因时代研究的核心内容,它强调发展和应用整体的(基因 组水平或系统水平)实验方法分析基因组序列信息、阐明基因功能,其特点是采用高通量的实验方法结合大规模的数据统计计算方法进行研究。基本策略是从研究单一基因或蛋白质上升到从系统角度研究所有基因或蛋白质。在植物功能基因组学的研究中,拟南芥和水稻是两种最常用的模式植物。目前, 功能基因组学在水稻、拟南芥等模式植物中取得了较快进展, 主要原因在于这两种植物已完成全基因组测序工作[2], 获得了结构基因组数据, 且遗传背景清楚, 易于开展分子生物学研究, 已率先步入后基因组时代。 2 植物功能基因组学研究内容 2、1基因组多样性研究[1] *联系人Tel:XXXXX;E-mail:XXXXX
科学家完成马铃薯基因组测序
中国科技通讯 中华人民共和国科学技术部 第625期 2011年7月20日 《国家“十二五”科学和技术发展规划》正式发布 科技部会同发改委、财政部、教育部、中科院、工程院、国家自然科学基金会、中国科协、国防科工局等有关部门和单位编制完成的《国家“十二五”科学和技术发展规划》近日正式发布实施。 《规划》提出“十二五”科技发展的总体目标是:自主创新能力大幅提升,科技竞争力和国际影响力显著增强,重点领域核心关键技术取得重大突破,为加快经济发展方式转变提供有力支撑,基本建成功能明确、结构合理、良性互动、运行高效的国家创新体系,国家综合创新能力世界排名由目前第21位上升至前18位,科技进步贡献率力争达到55%,创新型国家建设取得实质性进展。同时,从研发投入强度、原始创新能力、科技与经济结合、科技惠及民生、创新基地建设布局、科技人才队伍建设、体制机制创新等方面提出了具体目标和指标。 《规划》对未来五年我国科技发展和自主创新的战略任务进行了部署,突出以下重点:一是加快实施国家科技重大专项,二是大力培育和发展战略性新兴产业,三是推进重点领域核心关键技术突破,四是前瞻部署基础研究和前沿技术研究,五是加强科技创新基地和平台建设,六是大力培养造就创新型科技人才,七是提升科技开放与合作水平。 科技部发布《关于加快发展民生科技的意见》 7月18日,第四次全国社会发展科技工作会议在京召开,科技部发布了《关于加快发展民生科技的意见》。科技部表示,将根据《关于加快发展民生科技的意见》,组织实施国家民生科技行动,重点围绕人口健康、生态环境、公共安全、防灾减灾四个领域大力推进相关科技工作。 全国政协副主席、科技部长万钢提出了具体要求:全面加强民生科技的领导;切实加大民生科技的投入;加快民生科技创新和能力建设;加强民生科技的国际合作;加强民生相关的科学知识宣传和技术成果的应用普及。 会上,科技部副部长王伟中对“十一五”我国社会发展科技工作的成就进行了全面回顾,对“十二五”社会发展科技工作的重点任务进行了部署。王伟中说,在“十二五”期间,我国社会发展科技工作将把保障和改善民生放在突出位置,重点围绕六个方面开展工作:一是加强科技管理体制机制创新;二是加快组织实施国家科技重大专项;三是加快实施社会发展科技专项规划和计划;四是组织实施国家民生科技行动;五是加强可持续发展实验区建设;六是积极开展社会发展科技领域的国际合作。 “十二五”粮食丰产工程启动 科技部、农业部、财政部和国家粮食局近日在北京分别与湖南等13个粮食主产省(区)签订协议,实施新一轮“国家粮食丰产科技工程”,“十二五”国家粮食丰产科技工程正式启动实施。 科技部在“十一五”期间牵头组织实施了粮食丰产工程。五年来,在国家粮食丰产工程带动下,各相关省市自治区发挥以科技创新为核心,政府引导和市场为主体有机结合,使国家粮食丰产科技工程取得显著成效。工程实施过程中,突出了水稻、小麦和玉米“三大作物”增产,立足东北、华北、长江中下游“三大平原”,强化攻关田、核心区、示范区、辐射区“一田三区”建设。工程的实施为全国粮食大面积高产树立了典范,也为实现粮食增产、保障国家粮食安全提供了强有力的技术支撑。 全国政协副主席、科技部长万钢指出,要促进粮食丰产技术集成和大面积均衡增产;要强化粮食科技服务,鼓励和支持科技人员深入农村基层一线,组织实施好“百千万科技特派员”专项行动,在粮食主产省建立新型科技服务体系;要积极创造条件,强化粮食丰产科技基地、平台、人才队伍建设,稳步推进粮食丰产科技工作;要增加粮食科技投入,逐步完善粮食科技稳定支持的长效机制。
动植物基因组denovo常见问题
动植物基因组de novo常见问题 基础知识 1、什么是基因组de novo测序 答:对某一物种进行高通量测序,利用高性能计算平台和生物信息学方法,在不依赖于参考基因组的情况下进行组装,从而绘制该物种的全基因组序列图谱。 2、普通基因组的定义 答:单倍体,纯合二倍体或者杂合度<%,且重复序列含量<50%,GC 含量为35%到65%之间的二倍体。 3、复杂基因组的定义 答:杂合率>%,重复序列含量>50%,GC含量处于异常的范围(GC 含量<35%或者GC含量>65%=的二倍体,多倍体。 诺禾致源对二倍体复杂基因组进一步细分为微杂合基因组(%<杂合率<%=、高杂合基因组(杂合率>%)以及高重复基因组(重复序列比例>50%)。 4、怎么查询基因组的大小 答:查询植物基因组大小的网站:; 查询动物基因组大小的网站:。
5、基因组的项目周期 6、基因组承诺的组装指标 答:简单基因组:contig N50>20K,scaffold N50>500K; 复杂基因组:contig N50>20K,scaffold N50>300K。 样品要求 1、动植物基因组测序对取样有什么要求 答:植物:需要黑暗无菌条件下培养的黄化苗、组培苗,基因组样本量500μg~1mg,越多越好。选择纯合或杂合度尽可能小的样品(杂合度<%)。 动物:应选取肌肉、血液等含脂肪较少的部位取样,尽量选择同一个体取样,以减少个体差异性对后续拼接的影响。基因组样本量
500μg~1mg,越多越好。样本的性别决定模式是XY型,则尽量选择雌性个体(XX型),如果是ZW型,则尽量选择雄性个体(ZZ型)。 2、全基因组测序对DNA样本有什么要求 答:(1)样品需求量(单次):小片段文库,≥3μg;2Kb~5Kb大片段文库,≥20μg;10Kb~20Kb大片段文库,≥60μg;完成全基因组测序样品DNA量需求约为500μg~1mg; (2)样品浓度:对于小片段文库,≥50ng/μl,对于2Kb~5Kb 大片段文库,≥150ng/μl;对于10Kb~20Kb大片段文库,≥150ng/μl; (3)样品纯度:OD260/280=~;无蛋白质、RNA污染或肉眼可见杂质污染; (4)样品质量:基因组完整。如需建立≥5Kb的插入片段文库,则电泳结果,基因组DNA主带≥23Kb;脉冲场电泳结果,基因组DNA 主带≥40Kb。 文库构建 1、基因组测序的文库构建及测序策略 答:简单基因组:180bp、500bp、2K、5K、10K;PE100测序;测序深度一般为100-150X;