实验一 阻抗匹配 实验报告
实验一 :阻抗匹配 实验报告
一、实验目的
1. 了解基本的阻抗匹配理论及阻抗变换器的设计方法。
2. 利用实验模组实际测量以了解匹配电路的特性。
二、实验内容
1、型阻抗转换器的S11及S21测量以了解Π型阻抗匹配电路的特性;测量MOD-2B: T 型阻抗转换器的S11及S21测量以了解T 型阻抗匹配电路的特性。 二、试验仪器
项次 设 备 名 称 数 量 备 注
1 MOTECH RF2000 测量仪 1套 亦可用网络分析仪
2 阻抗交换器模组 1组 RF2KM2-1A
(T 型,π型 3 50ΩBNC 连接线 2条 CA-1、CA-2 4
1M Ω BNC 连接线
2条
CA-3、CA-4
三、实验原理
(一) 基本阻抗匹配理论:
如图2-1(a )所示:输入信号经过传输以后,其输出功率与输入功率之间存在以下关系,信号的输出功率直接决定于输入阻抗与输出阻抗之比。
in out S
S
in S L L
L S S
L P k k
P R V P R k R R R R V R I Pout ?+=
?=?=?+=?=2
2
2
2
2)
1()(
当R L =R S 时可获得最大输出功率,此时为阻抗匹配状态。 阻抗匹配电路也可以称为阻抗变换器。
(二)阻抗匹配电路 T 型阻抗匹配电路:
Rs
RL
Vs
V out
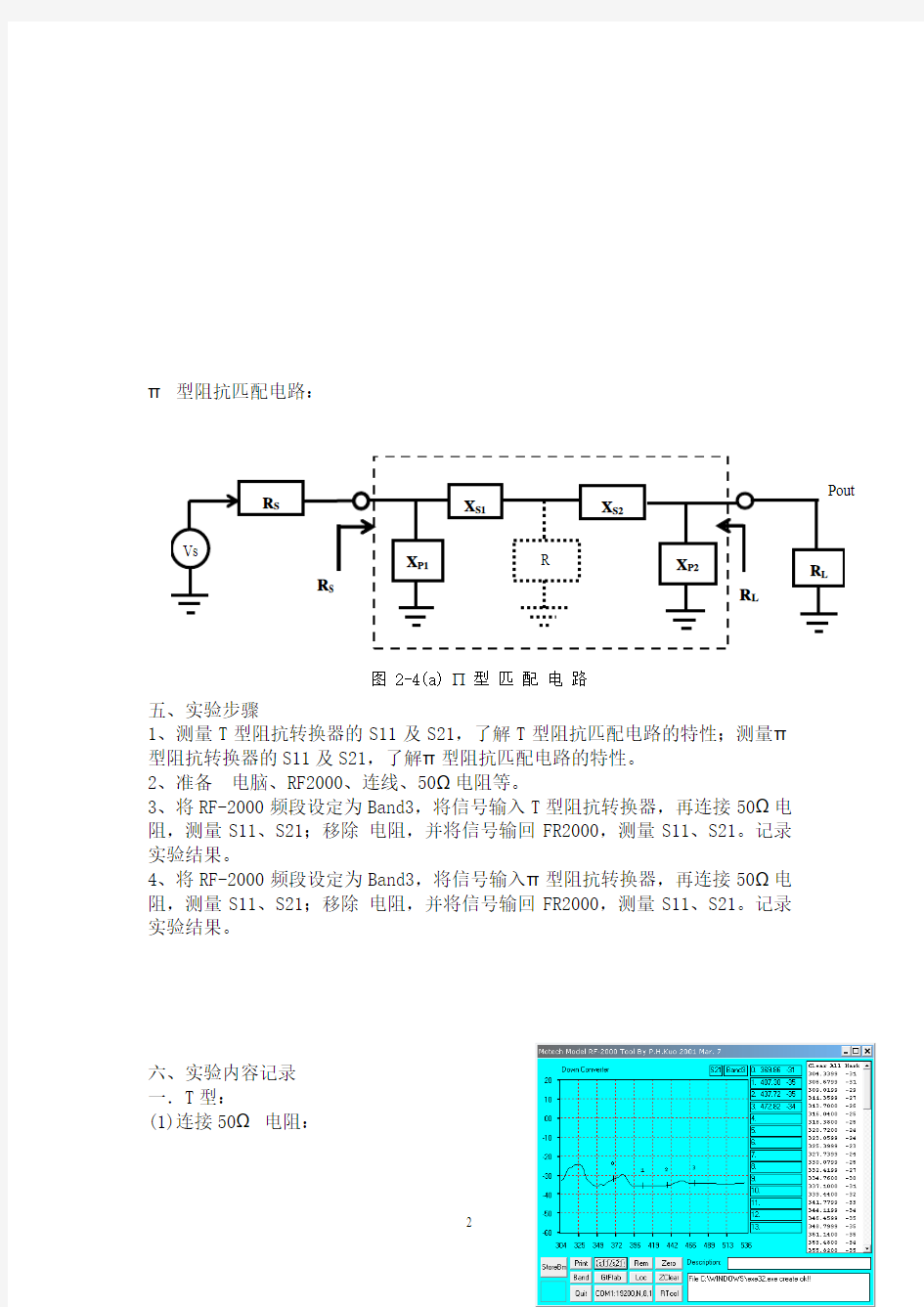
π 型阻抗匹配电路:
五、实验步骤
1、测量T 型阻抗转换器的S11及S21,了解T 型阻抗匹配电路的特性;测量π型阻抗转换器的S11及S21,了解π型阻抗匹配电路的特性。
2、准备 电脑、RF2000、连线、50Ω电阻等。
3、将RF-2000频段设定为Band3,将信号输入T 型阻抗转换器,再连接50Ω电阻,测量S11、S21;移除 电阻,并将信号输回FR2000,测量S11、S21。记录实验结果。
4、将RF-2000频段设定为Band3,将信号输入π型阻抗转换器,再连接50Ω电阻,测量S11、S21;移除 电阻,并将信号输回FR2000,测量S11、S21。记录实验结果。
六、实验内容记录 一.T 型:
(1)连接50Ω 电阻:
R S
Vs
R S
R L
Pout
R L
X S1
X P1
图 2-4(a) 型 匹 配 电 路 X P2
X S2
R
(2)不接50Ω电阻:
二.π型:
(1)连接50Ω电阻:
(2)不接50Ω电阻:
七、实验结果分析
负载与传输系统的匹配,就是要消除负载的反射,由实验可知,信号通过T型、π型阻抗转换器时,衰减几乎为零,而通过50Ω电阻时信号衰减约为1000倍。所以在传输系统与负载连接时,在其间连接一个阻抗转换器,消除负载的反射。
实验三____串的模式匹配
实验三串的模式匹配 一、实验目的 1.利用顺序结构存储串,并实现串的匹配算法。 2.掌握简单模式匹配思想,熟悉KMP算法。 二、实验要求 1.认真理解简单模式匹配思想,高效实现简单模式匹配; 2.结合参考程序调试KMP算法,努力算法思想; 3.保存程序的运行结果,并结合程序进行分析。 三、实验内容 1、通过键盘初始化目标串和模式串,通过简单模式匹配算法实现串的模式匹配,匹配成功后要求输出模式串在目标串中的位置; 2、参考程序给出了两种不同形式的next数组的计算方法,请完善程序从键盘初始化一目标串并设计匹配算法完整调试KMP算法,并与简单模式匹配算法进行比较。 参考程序: #include "stdio.h" void GetNext1(char *t,int next[])/*求模式t的next值并寸入next数组中*/ { int i=1,j=0; next[1]=0; while(i<=9)//t[0] { if(j==0||t[i]==t[j]) {++i; ++j; next[i]=j; } else j=next[j]; } } void GetNext2(char *t , int next[])/* 求模式t 的next值并放入数组next中 */ { int i=1, j = 0; next[1]= 0; /* 初始化 */ while (i<=9) /* 计算next[i+1] t[0]*/ { while (j>=1 && t[i] != t[j] ) j = next[j]; i++; j++;
if(t[i]==t[j]) next[i] = next[j]; else next[i] = j; } } void main() { char *p="abcaababc"; int i,str[10]; GetNext1(p,str); printf("\n"); for(i=1;i<10;i++) printf("%d",str[i]); GetNext2(p,str); printf("\n"); for(i=1;i<10;i++) printf("%d",str[i]); printf("\n\n"); }
信息论与编码实验报告.
本科生实验报告 实验课程信息论与编码 学院名称信息科学与技术学院 专业名称通信工程 学生姓名 学生学号 指导教师谢振东 实验地点6C601 实验成绩 二〇一五年十一月二〇一五年十一月
实验一:香农(Shannon )编码 一、实验目的 掌握通过计算机实现香农编码的方法。 二、实验要求 对于给定的信源的概率分布,按照香农编码的方法进行计算机实现。 三、实验基本原理 给定某个信源符号的概率分布,通过以下的步骤进行香农编码 1、将信源消息符号按其出现的概率大小排列 )()()(21n x p x p x p ≥≥≥ 2、确定满足下列不等式的整数码长K i ; 1)(l o g )(l o g 22+-<≤-i i i x p K x p 3、为了编成唯一可译码,计算第i 个消息的累加概率 ∑ -== 1 1 )(i k k i x p p 4、将累加概率P i 变换成二进制数。 5、取P i 二进制数的小数点后K i 位即为该消息符号的二进制码。 四、源程序: #include int i,j; for(i=0;i 《Linux操作系统》实验日志 班级: 姓名: 学号: 指导老师: 实验一:Linux常用命令实验日志 指导教师刘锐实验时间:2009 年10 月13 日学院计算机科学与技术学院专业信息安全 班级学号姓名实验室S308 实验题目: Linux常用命令 实验目的: ●练习并掌握Linux的常用命令 ●使用命令方式对用户,用户组及文件使用进行管理 ●使用图形界面方式对用户,用户组及文件使用进行管理 ●编写一个简单的C语言程序,并在linux环境下调试并运行 实验内容: 1.在命令交互方式下完成添加一个用户AA和一个用户组AAteam,并在AA用 户下建立一个名为test的文件,同时改变对该文件的访问权限。 2.在图形交互方式下添加一个用户BB和一个用户组BBteam,并建立一个名为 test文件,同时设置它的访问权限。 3.用C语言编写一个最简单的hello world程序 实验主要步骤: 1.练习Linux初学者需要掌握的常用50条命令 2.helloworld程序用vi或vim编辑器先编写源代码取名为hello.c 1)退出源文件编辑状态到命令行模式, 2)在命令行模式下输入gcc –o hello hello.c,其中hello是经编译过后生成的可执 行文件 3)用chmod命令修改hello文件的权限 4)在命令行模式下输入./hello 实验结果: 心得体会: 第一次实验课,我们开始接触Linux操作系统,很生疏和平时用的基本不一样。更别说命令方式了。这次实验用户组及文件使用进行管理,使用图形界面方式对用户,用户组及文件使用进行管理编写一个简单的C语言程序,并在linux环境下调试并运行。通过这次试验,我们学习和实践了一些基本命令.这些命令对于linux来说是必须的。-o选项表示我们要求输出的可执行文件名. -c表示只要求编译器输出目标代码,而不必要输出可执行文件. -g 表示要求编译器在编译的时候提供以后对程序进行调试的信息。对于编辑和修改程序我们需要应该运用VI编辑器来修改,而VI编辑器给我们提供了关键字的颜色等等,这使我们能更便捷的找到错误。我想这次实验告诉我如果对于一个陌生的操作系统,不仅要了解其基本理论,对于常用的基本操作也要了解。 实验四串 【实验目的】 1、掌握串的存储表示及基本操作; 2、掌握串的两种模式匹配算法:BF和KMP。 3、了解串的应用。 【实验学时】 2学时 【实验预习】 回答以下问题: 1、串和子串的定义 串的定义:串是由零个或多个任意字符组成的有限序列。 子串的定义:串中任意连续字符组成的子序列称为该串的子串。 2、串的模式匹配 串的模式匹配即子串定位是一种重要的串运算。设s和t是给定的两个串,从主串s的第start个字符开始查找等于子串t的过程称为模式匹配,如果在S中找到等于t的子串,则称匹配成功,函数返回t在s中首次出现的存储位置(或序号);否则,匹配失败,返回0。 【实验内容和要求】 1、按照要求完成程序exp4_1.c,实现串的相关操作。调试并运行如下测试数据给出运行结果: ?求“This is a boy”的串长; ?比较”abc 3”和“abcde“; 表示空格 ?比较”english”和“student“; ?比较”abc”和“abc“; ?截取串”white”,起始2,长度2; ?截取串”white”,起始1,长度7; ?截取串”white”,起始6,长度2; ?连接串”asddffgh”和”12344”; #include typedef struct { char data[MAXSIZE]; int length; } SqString; int strInit(SqString *s); /*初始化串*/ int strCreate(SqString *s); /*生成一个串*/ int strLength(SqString *s); /*求串的长度*/ int strCompare(SqString *s1,SqString *s2); /*两个串的比较*/ int subString(SqString *sub,SqString *s,int pos,int len); /*求子串*/ int strConcat(SqString *t,SqString *s1,SqString *s2); /*两个串的连接*/ /*初始化串*/ int strInit(SqString *s) { s->length=0; s->data[0]='\0'; return OK; }/*strInit*/ /*生成一个串*/ int strCreate(SqString *s) { printf("input string :"); gets(s->data); s->length=strlen(s->data); return OK; }/*strCreate*/ /*(1)---求串的长度*/ int strLength(SqString *s) { return s->length; }/*strLength*/ /*(2)---两个串的比较,S1>S2返回>0,s1 实验报告 课程名称:信息论与编码姓名: 系:专 业:年 级:学 号:指导教 师:职 称: 年月日 目录 实验一信源熵值的计算 (1) 实验二Huffman 信源编码. (5) 实验三Shannon 编码 (9) 实验四信道容量的迭代算法 (12) 实验五率失真函数 (15) 实验六差错控制方法 (20) 实验七汉明编码 (22) 实验一信源熵值的计算 、实验目的 1 进一步熟悉信源熵值的计算 2 熟悉Matlab 编程 、实验原理 熵(平均自信息)的计算公式 q q 1 H(x) p i log2 p i log2 p i i 1 p i i 1 MATLAB实现:HX sum( x.* log2( x));或者h h x(i)* log 2 (x(i )) 流程:第一步:打开一个名为“ nan311”的TXT文档,读入一篇英文文章存入一个数组temp,为了程序准确性将所读内容转存到另一个数组S,计算该数组中每个字母与空格的出现次数( 遇到小写字母都将其转化为大写字母进行计数) ,每出现一次该字符的计数器+1;第二步:计算信源总大小计算出每个字母和空格出现的概率;最后,通过统计数据和信息熵公式计算出所求信源熵值(本程序中单位为奈特nat )。 程序流程图: 三、实验内容 1、写出计算自信息量的Matlab 程序 2、已知:信源符号为英文字母(不区分大小写)和空格输入:一篇英文的信源文档。输出:给出该信源文档的中各个字母与空格的概率分布,以及该信源的熵。 四、实验环境 Microsoft Windows 7 五、编码程序 #include"stdio.h" #include 《信息论与信源编码》实验报告 1、实验目的 (1) 理解信源编码的基本原理; (2) 熟练掌握Huffman编码的方法; (3) 理解无失真信源编码和限失真编码方法在实际图像信源编码应用中的差异。 2、实验设备与软件 (1) PC计算机系统 (2) VC++6.0语言编程环境 (3) 基于VC++6.0的图像处理实验基本程序框架imageprocessing_S (4) 常用图像浏览编辑软件Acdsee和数据压缩软件winrar。 (5) 实验所需要的bmp格式图像(灰度图象若干幅) 3、实验内容与步骤 (1) 针对“图像1.bmp”、“图像2.bmp”和“图像3.bmp”进行灰度频率统计(即计算图像灰度直方图),在此基础上添加函数代码构造Huffman码表,针对图像数据进行Huffman编码,观察和分析不同图像信源的编码效率和压缩比。 (2) 利用图像处理软件Acdsee将“图像1.bmp”、“图像2.bmp”和“图像 3.bmp”转换为质量因子为10、50、90的JPG格式图像(共生成9幅JPG图像),比较图像格式转换前后数据量的差异,比较不同品质因素对图像质量的影响; (3) 数据压缩软件winrar将“图像1.bmp”、“图像2.bmp”和“图像3.bmp”分别生成压缩包文件,观察和分析压缩前后数据量的差异; (4) 针对任意一幅图像,比较原始BMP图像数据量、Huffman编码后的数据量(不含码表)、品质因素分别为10、50、90时的JPG文件数据量和rar压缩包的数据量,分析不同编码方案下图像数据量变化的原因。 4、实验结果及分析 (1)在VC环境下,添加代码构造Huffman编码表,对比试验结果如下: a.图像1.bmp: 利用事件管理器产生四个匹配事件控制四盏灯实验 一、实验目的 1、通过对做实验进一步了解DSP的工作原理。 2、检测一学期上课效果。 二、实验要求 1、利用事件管理器模块的定时器的四匹配事件中的中断来控制D6、D7、D8、D9显示。 三、实验器材 合众达DSP开发板以及装有ccs3.3的笔记本电脑 四、实验内容以及方法 本次实验操作主要是涉及到事件管理器中断,基本设想是事件管理器包含EV A和EVB 两个,一共四个通用定时器,正好可以产生上溢、下溢、比较、周期中断,每次中断产生时候,所对应的LED灯置位,当所对应的LED灯显示亮的时候就证明这种中断已经产生,所对应的程序流程图已经程序和说明如下: Main函数基本流程如下 头文件、延时 函数、定时器 中断声明 进入主函数,初始化系 统、PIE控制寄存器、 禁止和清除CPU中断 EALLOW 四个定时器映 射到相应的中 断位 EDIS 事件管理器初始 化,使能四个PIE级 中断,使能全局中 断,使能实时中断 进入FOR循环 中断函数程序流程图如下: 进入比较中断*LED置1,进入延时,中断标志寄存器和中断屏蔽寄存器 置位 响应中断 进入周期中断 *LED置2,进入 延时,中断标 志寄存器和中 断屏蔽寄存器 置位 响应中断 进入上溢中断 *LED置4,进入 延时,中断标 志寄存器和中 断屏蔽寄存器 置位 响应中断 进入下溢中断 *LED置8,进入 延时,中断标 志寄存器和中 断屏蔽寄存器 置位 响应中断 由程序流程图写得程序如下: 主函数: /******************************************************************/ /*Copyright (C), ; 华东交通大学*/ /* Module Name : */ /* File Name : main.c */ /* Author : */ /* Create Date : 2013/12/27 */ /* Version : */ /* Function : 四个匹配事件控制四盏灯*/ /* Description : */ /* Support : */ /******************************************************************/ /*****************头文件********************/ #include "DSP28_Device.h" #include "ext_inf.h" /****************端口宏定义*****************/ /****************常量宏定义*****************/ void delay_loop(void); /***************全局变量定义****************/ /****************函数声明*******************/ interrupt void EV A_Timer1_isr(void); interrupt void EV A_Timer2_isr(void); 实验四:KMP算法实验报告 一、问题描述 模式匹配两个串。 二、设计思想 这种由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现的改进的模式匹配算法简称为KM P算法。 注意到这是一个改进的算法,所以有必要把原来的模式匹配算法拿出来,其实理解的关键就在这里,一般的匹配算法: int Index(String S,String T,int pos)//参考《数据结构》中的程序 { i=pos;j=1;//这里的串的第1个元素下标是1 while(i<=S.Length && j<=T.Length) { if(S[i]==T[j]){++i;++j;} else{i=i-j+2;j=1;}//**************(1) } if(j>T.Length) return i-T.Length;//匹配成功 else return 0; } 匹配的过程非常清晰,关键是当‘失配’的时候程序是如何处理的?为什么要回溯,看下面的例子: S:aaaaabababcaaa T:ababc aaaaabababcaaa ababc.(.表示前一个已经失配) 回溯的结果就是 aaaaabababcaaa a.(babc) 如果不回溯就是 aaaaabababcaaa aba.bc 这样就漏了一个可能匹配成功的情况 aaaaabababcaaa ababc 这是由T串本身的性质决定的,是因为T串本身有前后'部分匹配'的性质。如果T为a bcdef这样的,大没有回溯的必要。 改进的地方也就是这里,我们从T串本身出发,事先就找准了T自身前后部分匹配的位置,那就可以改进算法。 如果不用回溯,那T串下一个位置从哪里开始呢? 还是上面那个例子,T为ababc,如果c失配,那就可以往前移到aba最后一个a的位置,像这样: 实验一 绘制二进熵函数曲线(2个学时) 一、实验目的: 1. 掌握Excel 的数据填充、公式运算和图表制作 2. 掌握Matlab 绘图函数 3. 掌握、理解熵函数表达式及其性质 二、实验要求: 1. 提前预习实验,认真阅读实验原理以及相应的参考书。 2. 在实验报告中给出二进制熵函数曲线图 三、实验原理: 1. Excel 的图表功能 2. 信源熵的概念及性质 ()()[] ()[]())(1)(1 .log )( .) ( 1log 1log ) (log )()(10 , 110)(21Q H P H Q P H b n X H a p H p p p p x p x p X H p p p x x X P X i i i λλλλ-+≥-+≤=--+-=-=≤≤? ?????-===??????∑ 单位为 比特/符号 或 比特/符号序列。 当某一符号xi 的概率p(xi)为零时,p(xi)log p(xi) 在熵公式中无意义,为此规定这时的 p(xi)log p(xi) 也为零。当信源X 中只含有一个符号x 时,必有p(x)=1,此时信源熵H (X )为零。 四、实验内容: 用Excel 和Matlab 软件制作二进熵函数曲线。根据曲线说明信源熵的物理意义。 (一) Excel 具体步骤如下: 1、启动Excel 应用程序。 2、准备一组数据p 。在Excel 的一个工作表的A 列(或其它列)输入一组p ,取步长为0.01,从0至100产生101个p (利用Excel 填充功能)。 3、取定对数底c,在B列计算H(x) ,注意对p=0与p=1两处,在B列对应位置直接输入0。Excel中提供了三种对数函数LN(x),LOG10(x)和LOG(x,c),其中LN(x)是求自然对数,LOG10(x)是求以10为底的对数,LOG(x,c)表示求对数。选用c=2,则应用函数LOG(x,2)。 在单元格B2中输入公式:=-A2*LOG(A2,2)-(1-A2)*LOG(1-A2,2) 双击B2的填充柄,即可完成H(p)的计算。 4、使用Excel的图表向导,图表类型选“XY散点图”,子图表类型选“无数据点平滑散点图”,数据区域用计算出的H(p)数据所在列范围,即$B$1:$B$101。在“系列”中输入X值(即p值)范围,即$A$1:$A$101。在X轴输入标题概率,在Y轴输入标题信源熵。 (二)用matlab软件绘制二源信源熵函数曲线 p = 0.0001:0.0001:0.9999; h = -p.*log2(p)-(1-p).*log2(1-p); plot(p,h) 五、实验结果 《数据结构实验》的实验题目及实验报告模板 实验一客房管理(链表实验) ●实现功能:采用结构化程序设计思想,编程实现客房管理程序的各个功能函数,从而熟练 掌握单链表的创建、输出、查找、修改、插入、删除、排序和复杂综合应用等操作的算法 实现。以带表头结点的单链表为存储结构,实现如下客房管理的设计要求。 ●实验机时:8 ●设计要求: #include 竭诚为您提供优质文档/双击可除串的模式匹配算法实验报告 篇一:串的模式匹配算法 串的匹配算法——bruteForce(bF)算法 匹配模式的定义 设有主串s和子串T,子串T的定位就是要在主串s中找到一个与子串T相等的子串。通常把主串s称为目标串,把子串T称为模式串,因此定位也称作模式匹配。模式匹配成功是指在目标串s中找到一个模式串T;不成功则指目标串s中不存在模式串T。bF算法 brute-Force算法简称为bF算法,其基本思路是:从目标串s的第一个字符开始和模式串T中的第一个字符比较,若相等,则继续逐个比较后续的字符;否则从目标串s的第二个字符开始重新与模式串T的第一个字符进行比较。以此类推,若从模式串T的第i个字符开始,每个字符依次和目标串s中的对应字符相等,则匹配成功,该算法返回i;否则,匹配失败,算法返回0。 实现代码如下: /*返回子串T在主串s中第pos个字符之后的位置。若不存在,则函数返回值为0./*T非空。 intindex(strings,stringT,intpos) { inti=pos;//用于主串s中当前位置下标,若pos不为1则从pos位置开始匹配intj=1;//j用于子串T中当前位置下标值while(i j=1; } if(j>T[0]) returni-T[0]; else return0; } } bF算法的时间复杂度 若n为主串长度,m为子串长度则 最好的情况是:一配就中,只比较了m次。 最坏的情况是:主串前面n-m个位置都部分匹配到子串的最后一位,即这n-m位比较了m次,最后m位也各比较了一次,还要加上m,所以总次数为:(n-m)*m+m=(n-m+1)*m从最好到最坏情况统计总的比较次数,然后取平均,得到一般情况是o(n+m). 设计模式实验二 实验报告书 专业班级软件0703 学号24 姓名吉亚云 指导老师刘伟 时间2010年4月24日 中南大学软件学院 实验二设计模式上机实验二 一、实验目的 使用PowerDesigner和任意一种面向对象编程语言实现几种常用的设计模式,加深对这些模式的理解,包括装饰模式、外观模式、代理模式、职责链模式、命令模式、迭代器模式、观察者模式、状态模式、策略模式和模板方法模式。 二、实验内容 使用PowerDesigner和任意一种面向对象编程语言实现装饰模式、外观模式、代理模式、职责链模式、命令模式、迭代器模式、观察者模式、状态模式、策略模式和模板方法模式,包括根据实例绘制相应的模式结构图、编写模式实现代码,运行并测试模式实例代码。 三、实验要求 1. 正确无误绘制装饰模式、外观模式、代理模式、职责链模式、命令模式、迭代器模式、观察者模式、状态模式、策略模式和模板方法模式的模式结构图; 2. 使用任意一种面向对象编程语言实现装饰模式、外观模式、代理模式、职责链模式、命令模式、迭代器模式、观察者模式、状态模式、策略模式和模板方法模式,代码运行正确无误。 四、实验步骤 1. 使用PowerDesigner绘制装饰模式结构图并用面向对象编程语言实现该模式; 2. 使用PowerDesigner绘制外观模式结构图并用面向对象编程语言实现该模式; 3. 使用PowerDesigner绘制代理模式结构图并用面向对象编程语言实现该模式; 4. 使用PowerDesigner绘制职责链模式结构图并用面向对象编程语言实现该模式; 5. 使用PowerDesigner绘制命令模式结构图并用面向对象编程语言实现该模式; 6. 使用PowerDesigner绘制迭代器模式结构图并用面向对象编程语言实现该模式; 7. 使用PowerDesigner绘制观察者模式结构图并用面向对象编程语言实现该模式; 8. 使用PowerDesigner绘制状态模式结构图并用面向对象编程语言实现该模式; 9. 使用PowerDesigner绘制策略模式结构图并用面向对象编程语言实现该模式; 10. 使用PowerDesigner绘制模板方法模式结构图并用面向对象编程语言实现该模式。 五、实验报告要求 1. 提供装饰模式结构图及实现代码; 2. 提供外观模式结构图及实现代码; 3. 提供代理模式结构图及实现代码; 4. 提供职责链模式结构图及实现代码; 信息论与编码实验报告-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII 实验一关于硬币称重问题的探讨 一、问题描述: 假设有N 个硬币,这N 个硬币中或许存在一个特殊的硬币,这个硬币或轻 或重,而且在外观上和其他的硬币没什么区别。现在有一个标准天平,但是无刻度。现在要找出这个硬币,并且知道它到底是比真的硬币重还是轻,或者所有硬币都是真的。请问: 1)至少要称多少次才能达到目的; 2)如果N=12,是否能在3 次之内将特殊的硬币找到;如果可以,要怎么称? 二、问题分析: 对于这个命题,有几处需要注意的地方: 1)特殊的硬币可能存在,但也可能不存在,即使存在,其或轻或重未知; 2)在目的上,不光要找到这只硬币,还要确定它是重还是轻; 3)天平没有刻度,不能记录每次的读数,只能判断是左边重还是右边重,亦或者是两边平衡; 4)最多只能称3 次。 三、解决方案: 1.关于可行性的分析 在这里,我们把称量的过程看成一种信息的获取过程。对于N 个硬币,他们 可能的情况为2N+1 种,即重(N 种),轻(N 种)或者无假币(1 种)。由于 这2N+1 种情况是等概率的,这个事件的不确定度为: Y=Log(2N+1) 对于称量的过程,其实也是信息的获取过程,一是不确定度逐步消除的过程。 每一次称量只有3 种情况:左边重,右边重,平衡。这3 种情况也是等概率 的,所以他所提供的信息量为: y=Log3 在K 次测量中,要将事件的不确定度完全消除,所以 K= Log(2N+1)/ Log3 根据上式,当N=12 时,K= 2.92< 3 所以13 只硬币是可以在3 次称量中达到 实验 1 PacketTrace基本使用 一、实验目的 掌握 Cisco Packet Tracer软件的使用方法。 二、实验任务 在 Cisco Packet Tracer中用HUB组建局域网,利用PING命令检测机器的互通性。 三、实验设备 集线器( HUB)一台,工作站PC三台,直连电缆三条。 四、实验环境 实验环境如图1-1 所示。 图 1-1交换机基本配置实验环境 五、实验步骤 (一)安装模拟器 1、运行“ PacketTracer53_setup”文件,并按如下图所示完成安装; 点“ Next ” 选择“ I accept the agreement”后,点“ next”不用更改安装目录,直接点“ next ” 点“ next ” 点“ next ” 点“ install” 正在安装 点“ Finish ”,安装完成。 2、进入页面。 (二)使用模拟器 1、运行Cisco Packet Tracer 软件,在逻辑工作区放入一台集线器和三台终端设备PC,用 直连线按下图将HUB 和PC工作站连接起 来, HUB端 接 Port 口, PC端分别接以太网口。 2、分别点击各工作站PC,进入其配置窗口,选择桌面项,选择运行IP 地址配置(IP Configuration ),设置IP 地址和子网掩码分别为PC0:1.1.1.1 ,255.255.255.0 ;PC1:1.1.1.2 ,255.255.255.0 ; PC2: 1.1.1.3 , 255.255.255.0 。 3、点击 Cisco Packet Tracer软件右下方的仿真模式按钮,如图1-2所示。将Cisco Packet Tracer的工作状态由实时模式转换为仿真模式。 图1-2 按Simulation Mode 按钮 4、点击PC0进入配置窗口,选择桌面Desktop 项,选择运行命令提示符Command Prompt,如图1-3 所示。 图5、在上述DOS命令行窗口中,输入(Simulation Panel)中点击自动捕获1-3进入PC配置窗口 Ping 1.1.1.3命令,回车运行。然后在仿真面板 / 播放( Auto Capture/Play)按钮,如图1-4 所示。 图 1-4 点击自动抓取 /运行按钮 6、观察数据包发送的演示过程,对应地在仿真面板的事件列表( 的类型。如图1-5 和图 1-6 所示。 Event List )中观察数据包 数据结构 实 验 报 告 学院软件学院 年级2009级 班级班 学号 姓名 2010 年 3 月24 日 目录 一、实验内容 (1) 二、实验过程……………………………………….X 三、实验结果……………………………………….X 一、实验内容: 1、实验题目:KMP算法 2、实验要求:实现教材中字串比较kmp算法,比较模式串abaabcac与主串acabaabaabcacaabc。 3、实验目标:了解并掌握串的类型定义和基本操作,并在此基础上实现kmp算法。了解kmp算法的基本原理和next函数的使用。 二、实验过程: 1、任务分配 2、设计思想 (1)KMP算法:在模式匹配中,每当一趟匹配过程出现字符比较不等时,不需要回溯i指针,而是利用已经得到的“部分匹配”的结果将模式向右滑动尽可能远的一段距离之后,继续进行比较。 (2)next函数:看成一个模式匹配问题,整个模式串既是主串又是模式串,可仿照KMP算法。 3、需求分析 (1) 输入的形式和输入值的范围:输入主串S,模式串T,位置pos (2) 输出的形式:模式串在主串中开始匹配的位置i (3) 程序所能达到的功能:利用kmp算法完成模式串和主串的模式匹 配,并输出模式串在主串中开始匹配的位置 (4) 测试数据: S=acabaabaabcacaabc T=abaabcac Pos=6 4、概要设计 1).抽象数据类型 Class String()定义字符串 Int StrLength()返回串的长度 V oid get_next()求模式串T的next函数值并存入next int kmp()利用模式串T的next函数求出T在主串S中第pos个字符之后的位置的KMP算法 2).算法 a.kmp算法模块:实现主串和模式串的模式匹配 b.next函数模块:实现模式串自身的模式匹配,并存入nxet函数中 c.接收处理命令(初始化数据) 5、详细设计 程序代码(含注释) 串行通信实验报告 班级学号日期 一、实验目的: 1、掌握单片机串行口工作方式的程序设计,及简易三线式通讯的方法。 2、了解实现串行通讯的硬环境、数据格式的协议、数据交换的协议。 3、学习串口通讯的程序编写方法。 二、实验要求 1.单机自发自收实验:实现自发自收。编写相应程序,通过发光二极管观察收发状态。 2.利用单片机串行口,实现两个实验台之间的串行通讯。其中一个实验台作为发送方,另一侧为接收方。 三、实验说明 通讯双方的RXD、TXD信号本应经过电平转换后再行交叉连接,本实验中为减少连线可将电平转换电路略去,而将双方的RXD、TXD直接交叉连接。也可以将本机的TXD接到RXD上。 连线方法:在第一个实验中将一台实验箱的RXD和TXD相连,用P1.0连接发光二极管。波特率定为600,SMOD=0。 在第二个实验中,将两台实验箱的RXD和TXD交叉相连。编写收发程序,一台实验箱作为发送方,另一台作为接收方,编写程序,从内部数据存储器20H~3FH单元中共32个数据,采用方式1串行发送出去,波特率设为600。通过运行程序观察存储单元内数值的变化。 四、程序 甲方发送程序如下: ORG 0000H LJMP MAIN ORG 0023H LJMP COM_INT ORG 1000H MAIN: MOV SP,#53H MOV 78H,#20H MOV 77H,00H MOV 76H,20H MOV 75H,40H ACALL TRANS HERE: SJMP HERE TRANS: MOV TMOD,#20H MOV TH1,#0F3H MOV TL1,#0F3H MOV PCON,#80H SETB TR1 MOV SCON,#40H MOV IE,#00H CLR F0 MOV SBUF,78H WAIT1: JNB TI,WAIT1 CLR TI MOV SBUF,77H WAIT2: JNB TI,WAIT2 CLR TI MOV SBUF,76H WAIT3: JNB TI,WAIT3 CLR TI 实验成绩 华中师范大学计算机科学系 实验报告书 实验项目:串匹配问题 课程名称:算法分析与设计 班级: 1 实验时间:周六早上8:30-11:30 实验目的:一、深刻理解并掌握蛮力法的设计思想。 二、提高应用蛮力法设计算法的技能。 三、理解这样一个观点:用蛮力法设计的算法,一般来说,经过适 当的努力之后,都可以对算法的第一个版本进行一定程度的改 良,改进其时间性能。 实验报告要求:1、实现BF算法。 2、实现BF的改进算法:KMP算法。 3、对上述算法进行时间复杂性分析,并设计实验程序,分析结果。 BF算法内容: #include if(count==strlen(T)) { cout<<"子串从长串的第"< 信息论与编码实验报告 课程名称:信息论与编码 实验名称:霍夫曼编码 班级: 学号: 姓名: 实验目的 1、熟练掌握Huffman编码的原理及过程,并熟练运用; 2、熟练运用MATLAB应用软件,并实现Huffman编码过程。 一、实验设备 装有MATLAB应用软件的PC计算机。 二、实验原理及过程 原理: 1、将信源符号按概率从大到小的排列,令P (X1)>=P(X2)>=P(X3)......P(Xn) 2、给两个概率最小的信源符号P(Xn-1)和P(Xn)各分配一个码位“0”和“1”,将这两个信源符号合并成一个新符号,并用这两个最小的概率之和作为新符号的概率,结果得到一个只包含(n-1)个信源符号的新信源。称为信源的第一次缩减信源,用S1表示。 3、将缩减信源S1的符号仍按概率从大到小顺序排列,重复步骤2,得到只含(n-2)个符号的缩减信源S2. 4、重复上述步骤,直至缩减信源只剩两个符号为止,此时所剩两个符号的概率之和必为1。然后从最后一级缩减信源开始,依编码路径向前返回,就得到各信源符号所对应的码字。 过程: 用MATLAB编写代码实现Huffman编码其程序为: %哈夫曼编码的MA TLAB实现(基于0、1编码): clc; clear; A=[0.3,0.2,0.1,0.2,0.2];信源消息的概率序列 A=fliplr(sort(A));%按降序排列 T=A; [m,n]=size(A); B=zeros(n,n-1);%空的编码表(矩阵) for i=1:n B(i,1)=T(i);%生成编码表的第一列 end r=B(i,1)+B(i-1,1);%最后两个元素相加 T(n-1)=r; T(n)=0; T=fliplr(sort(T)); t=n-1; for j=2:n-1%生成编码表的其他各列 for i=1:t B(i,j)=T(i); end K=find(T==r); B(n,j)=K(end);%从第二列开始,每列的最后一个元素记录特征元素在操作实验报告
数据结构实验报告-串
信息论与编码实验报告材料
《信息论与信源编码》实验报告
实验报告
模式匹配KMP算法实验报告
信息论与编码实验报告
《数据结构实验》实验题目及实验报告模板
串的模式匹配算法实验报告
设计模式上机实验二实验报告
信息论与编码实验报告
网络实验报告总结.doc
kmp算法实验报告
串行通信实验报告
串匹配实验报告
信息论霍夫曼编码