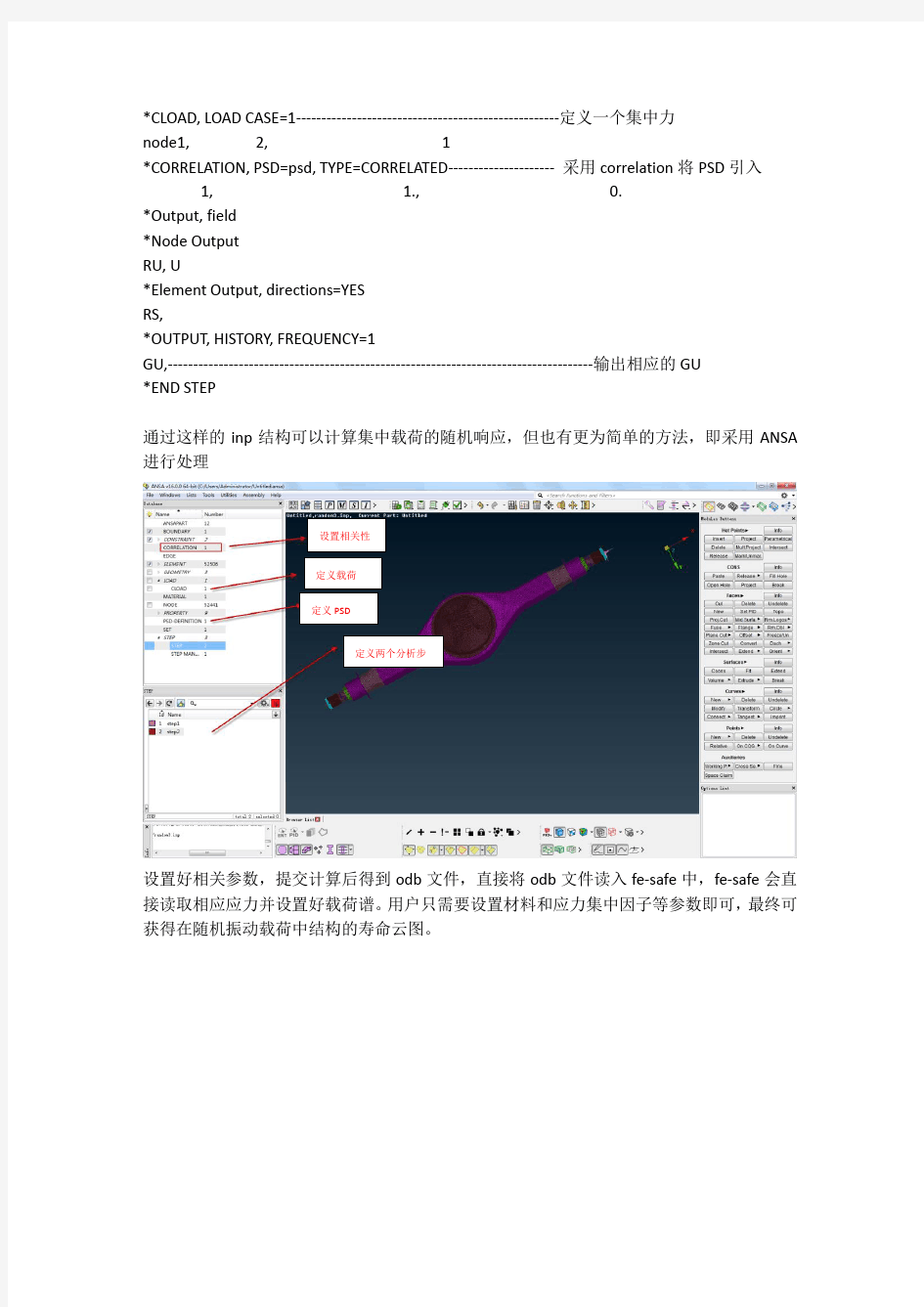
Fe-safe随机疲劳分析方法

水文随机分析
基于小波分析方法的水文随机模拟 摘要:本文对小波分析进行了简要介绍,包括小波分析的发展历史、分析方法、应用领域以及发展现状,在此基础之上介绍了小波分析在水文随机模拟中的应用,最后,对小波分析方法在今后水文水资源领域中的应用进行了展望。总而言之,小波分析在水文预报、水文随机模拟、水文多时间尺度分析、水文时间序列变化特性分析等很多方面具有很大的研究价值和发展前景。 关键词:小波分析;不确定性;水文随机模拟 1引言 由于水文系统较为复杂,受制于气候和人为活动等多因素的影响,所以目前没有一个准确的数学物理方程能够描述并求解这一过程,而传统的随机模型结构简单、参数少,能描述水文序列的主要统计特性。但通过数理统计方法得到的参数描述水文过程过于粗糙,信息量少。小波分析是一种多分辨率分析方法,能充分展示水文序列的精细结构,挖掘更多的信息,可揭示水文系统的多时间尺度特性,较方便识别出水文时间序列中隐含的主要周期。通过小波消噪技术可把高频成分有效分离,从两方面分别研究其水文序列特性。鉴此,本文提出了基于小波分析的随机水文模型。 1.1小波分析的分析方法及发展历史 小波分析或小波转换是指用有限长或快速衰减的、称为母小波的振荡波形来表示信号。该波形被缩放和平移以匹配输入的信号。 小波变换的概念是由法国从事石油信号处理的工程师J.Morlet在1974年首先提出的,通过物理的直观和信号处理的实际需要经验的建立了反演公式,当时未能得到数学家的认可。随后,1986年著名数学家Y.Meyer偶然构造出一个真正的小波基,小波分析自此才开始蓬勃发展起来。小波变换与Fourier变换、窗口Fourier变换相比,这是一个时间和频率的局域变换,因而能有效的从信号中提取信息,通过伸缩和平移等运算功能对函数或信号进行多尺度细化分析,解决了Fourier变换不能解决的许多困难问题,因此,小波变化被誉为“数学显微镜”,它是调和分析发展史上里程碑式的进展。 1.2小波分析的应用领域及发展现状 事实上小波分析的应用领域十分广泛,包括数学领域的许多学科、信号分析、图像处理、理论物理、医学成像与诊断、地震勘探数据处理、大型机械的故障诊断等方面;例如,在数学方面,它已用于数值分析、构造快速数值方法、曲线曲面构造、微分方程求解、控制论等;
常用决策分析方法(基本方法)
常用决策分析方法(基本方法) 上一节我们说了决策分析的基本概念,这一节我们谈谈决策分析常用的三种方法:决策树法、Bayes方法、Markov 方法。 决策树法决策树法(decision tree-based method):是通过确定一系列的条件(if-then)逻辑关系,形成一套分层规则,将所有可能发生的结局的概率分布用树形图来表达,生成决策树(decision tree),从而达到对研究对象进行精确预测或正确分类的目的。树的扩展是基于多维的指标函数,在医学领域主要用于辅助临床诊断及卫生资源配置等方面。 决策树分类:按功能分:分类树和和回归树按决策变量个数:单变量树和多变量树按划分后得到分类项树:二项分类树和多项分类树 决策树的3类基本节点:决策节点(用□表示)机会节点(用○表示)结局节点(用?表示) 从决策节点引出一些射线,表示不同的备选方案,射线上方标出决策方案名称。射线引导到下一步的决策节点、机会节点或结局节点。从机会节点引出的线表示该节点可能出现的随机事件,事件名称标在射线上方,先验概率在下方。每个结局节点代表一种可能的结局状态。在结局节点的右侧标出各种状态的效用(utility),即决策者对于可能发生的各种结
局的(利益或损失)感觉和反应,用量化值表示。绘制决策树基本规则:各支路不能有交点每一种方案各种状态发生概率之和为1 决策树分析法步骤:1 提出决策问题,明确决策目标2 建立决策树模型--决策树生长2.1决策指标的选择的两个步骤:2.1.1 提出所有分值规则2.1.2 选择最佳规则 2.2 估计每个指标的先验概率3 确定各终点及计算综合指标 3.1 各终点分配类别3.2 各终点期望效用值得确定3.3 综合指标的计算3.4 计算值排序选优树生长停止情况:子节点内只有一个个体子节点内所有观察对象决策变量的分布完全一致,不能再分达到规定标准一棵树按可能长到最大,通常是过度拟合(overfit)的。训练集:用于决策树模型建立的数据集测试集:决策树进行测评的数据集。过度拟合的树需要剪枝,即去掉噪声(拟合中的误差)。剪枝需要兼顾复杂度(节点数目)和预测精度(决策损失)。决策损失(decision lose):指随机抽取的某一个个体,在树的某决策节点被错误分类所引起的效用损失。建立决策树的目的在于获得最高精度的分类或预测值,以期为决策提供依据。可按照这几个特性对其评估:准确、简洁、易行、易理解和能发掘复杂数据内在关系。Bayes方法在实际决策过程中,决策者通常是将状态变量当作随机变量,状态变量发生的可能性用先验概率(prior probability)表示,以期望值准则(expectation rule)作为选择最优方案的标准。但是先验概率
疲劳分析方法
疲劳寿命分析方法 摘要:本文简单介绍了在结构件疲劳寿命分析方法方面国内外的发展状况,重点讲解了结构件寿命疲劳分析方法中的名义应力法、局部应力应变法、应力应变场强度法四大方法的估算原理。 疲劳是一个既古老又年轻的研究分支,自Wohler将疲劳纳入科学研究的范畴至今,疲劳研究仍有方兴未艾之势,材料疲劳的真正机理与对其的科学描述尚未得到很好的解决。疲劳寿命分析方法是疲分研究的主要内容之一,从疲劳研究史可以看到疲劳寿命分析方法的研究伴随着整个历史。 金属疲劳的最初研究是一位德国矿业工程帅风W.A.J.A1bert在1829年前后完成的。他对用铁制作的矿山升降机链条进行了反复加载试验,以校验其可靠性。1843年,英国铁路工程师W.J.M.Rankine对疲劳断裂的不同特征有了认识,并注意到机器部件存在应力集中的危险性。1852年-1869年期间,Wohler对疲劳破坏进行了系统的研究。他发现由钢制作的车轴在循环载荷作用下,其强度人大低于它们的静载强度,提出利用S-N 曲线来描述疲劳行为的方法,并是提出了疲劳“耐久极限”这个概念。1874年,德国工程师H.Gerber开始研究疲劳设计方法,提出了考虑平均应力影响的疲劳寿命计算方法。Goodman讨论了类似的问题。1910年,O.H.Basquin提出了描述金属S-N曲线的经验规律,指出:应力对疲劳循环数的双对数图在很大的应力范围内表现为线性关系。Bairstow通过多级循环试验和测量滞后回线,给出了有关形变滞后的研究结果,并指出形变滞后与疲劳破坏的关系。1929年B.P.Haigh研究缺口敏感性。1937年H.Neuber指出缺口根部区域内的平均应力比峰值应力更能代表受载的严重程度。1945年M.A.Miner 在J.V.Palmgren工作的基础上提出疲劳线性累积损伤理论。L.F.Coffin和S.S.Manson各自独立提出了塑性应变幅和疲劳寿命之间的经验关系,即Coffin—Manson公式,随后形成了局部应力应变法。 中国在疲劳寿命的分析方面起步比较晚,但也取得了一些成果。浙江大学的彭禹,郝志勇针对运动机构部件多轴疲劳载荷历程提取以及在真实工作环境下的疲劳寿命等问题,以发动机曲轴部件为例,提出了一种以有限元方法,动力学仿真分析以及疲劳分
随机信号分析习题
随机信号分析习题一 1. 设函数???≤>-=-0 , 0 ,1)(x x e x F x ,试证明)(x F 是某个随机变量ξ的分布函数。并求下列 概率:)1(<ξP ,)21(≤≤ξP 。 2. 设),(Y X 的联合密度函数为 (), 0, 0 (,)0 , other x y XY e x y f x y -+?≥≥=? ?, 求{}10,10<<< 8. 两个随机变量1X ,2X ,已知其联合概率密度为12(,)f x x ,求12X X +的概率密度? 9. 设X 是零均值,单位方差的高斯随机变量,()y g x =如图,求()y g x =的概率密度 ()Y f y \ 10. 设随机变量W 和Z 是另两个随机变量X 和Y 的函数 22 2 W X Y Z X ?=+?=? 设X ,Y 是相互独立的高斯变量。求随机变量W 和Z 的联合概率密度函数。 11. 设随机变量W 和Z 是另两个随机变量X 和Y 的函数 2() W X Y Z X Y =+?? =+? 已知(,)XY f x y ,求联合概率密度函数(,)WZ f z ω。 12. 设随机变量X 为均匀分布,其概率密度1 ,()0X a x b f x b a ?≤≤? =-???, 其它 (1)求X 的特征函数,()X ?ω。 (2)由()X ?ω,求[]E X 。 13. 用特征函数方法求两个数学期望为0,方差为1,互相独立的高斯随机变量1X 和2X 之和的概率密度。 14. 证明若n X 依均方收敛,即 l.i.m n n X X →∞ =,则n X 必依概率收敛于X 。 15. 设{}n X 和{}n Y (1,2,)n = 为两个二阶矩实随机变量序列,X 和Y 为两个二阶矩实随机变量。若l.i.m n n X X →∞ =,l.i.m n n Y Y →∞ =,求证lim {}{}m n m n E X X E XY →∞→∞ =。 实验一 随机序列的产生及数字特征估计 一、实验目的 1、学习和掌握随机数的产生方法; 2、实现随机序列的数字特征估计。 二、实验原理 1. 随机数的产生 随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。进行随机信号仿真分析时,需要模拟产生各种分布的随机数。 在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。 (0,1)均匀分布随机数是最最基本、最简单的随机数。(0,1)均匀分布指的是在[0,1]区间上的均匀分布,即U(0,1)。实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下: N y x N ky Mod y y n n n n /))((110===-, (1.1) 序列{}n x 为产生的(0,1)均匀分布随机数。 下面给出了上式的3组常用参数: (1) 7101057k 10?≈==,周期,N ; (2) (IBM 随机数发生器)8163110532k 2?≈+==,周期,N ; (3) (ran0)95311027k 12?≈=-=,周期,N ; 由均匀分布随机数,可以利用反函数构造出任意分布的随机数。 定理1.1 若随机变量X 具有连续分布函数F X (x),而R 为(0,1)均匀分布随机变量,则有 )(1R F X x -= (1.2) 由这一定理可知,分布函数为F X (x)的随机数可以由(0,1)均匀分布随机数按上式进行变换得到。 2. MATLAB 中产生随机序列的函数 (1) (0,1)均匀分布的随机序列 函数:rand 用法:x = rand(m,n) 功能:产生m ×n 的均匀分布随机数矩阵。 (2) 正态分布的随机序列 函数:randn 用法:x = randn(m,n) 功能:产生m ×n 的标准正态分布随机数矩阵。 如果要产生服从2N(,)μσ分布的随机序列,则可以由标准正态随机序列产生。 (3) 其他分布的随机序列 MATLAB 上还提供了其他多种分布的随机数的产生函数,下表列出了部分函数。 MATLAB 中产生随机数的一些函数 表1.1 MATLAB 中产生随机数的一些函数 3、随机序列的数字特征估计 对于遍历过程,可以通过随机序列的一条样本函数来获得该过程的统计特性。这里我们假定随机序列X (n)为遍历过程,样本函数为x(n),其中n=0,1,2,…,N-1。那么,X (n)的均值、方差和自相关函数的估计为 随机信号分析常用函数及示例 1、熟悉练习使用下列MATLAB函数,给出各个函数的功能说明和内部参数的意 义,并给出至少一个使用例子和运行结果。 rand(): 函数功能:生成均匀分布的伪随机数 使用方法: r = rand(n) 生成n*n的包含标准均匀分布的随机矩阵,其元素在(0,1)内。 rand(m,n)或rand([m,n]) 生成的m*n随机矩阵。 rand(m,n,p,...)或rand([m,n,p,...]) 生成的m*n*p随机矩数组。 rand () 产生一个随机数。 rand(size(A)) 生成与数组A大小相同的随机数组。 r = rand(..., 'double')或r = rand(..., 'single') 返回指定类型的标准随机数,其中double指随机数为双精度浮点数,single 指随机数为单精度浮点数。 例:r=rand(3,4); 运行结果: r= 0.4235 0.4329 0.7604 0.2091 0.5155 0.2259 0.5298 0.3798 0.3340 0.5798 0.6405 0.7833 randn(): 函数功能:生成正态分布伪随机数 使用方法: r = randn(n) 生成n*n的包含标准正态分布的随机矩阵。 randn(m,n)或randn([m,n]) 生成的m*n随机矩阵。 randn(m,n,p,...)或randn([m,n,p,...]) 生成的m*n*p随机矩数组。 randn () 产生一个随机数。 randn(size(A)) 生成与数组A大小相同的随机数组。 r = randn(..., 'double')或r = randn(..., 'single') 返回指定类型的标准随机数,其中double指随机数为双精度浮点数,single 指随机数为单精度浮点数。 例: 第7章随机有限元法 §7.1 绪论 结构工程中存在诸多的不确定性因素,从结构材料性能参数到所承受的主要荷载,如车流、阵风或地震波,无不存在随机性。在有限单元法已成为分析复杂结构的强有力的工具和广泛使用的数值方法的今天,人们已不满足精度越来越高的确定性有限元计算,而设法用这一强有力的工具去研究工程实践中存在的大量不确定问题。随机有限元法(Stochastic FEM),也称概率有限元法(Probabilistic FEM)正是随机分析理论与有限元方法相结合的产物,是在传统的有限元方法的基础上发展起来的随机的数值分析方法。 最初是Monte-Carlo法与有限元法直接结合,形成独特的统计有限元方法。Astill和Shinozuka(1972)首先将Monte-Carlo法引入结构的随机有限元法分析。该法通过在计算机上产生的样本函数来模拟系统的随机输入量的概率特征,并对于每个给定的样本点,对系统进行确定性的有限元分析,从而得到系统的随机响应的概率特征。由于是直接建立在大量确定性有限元计算的基础上,计算量极大,不适用于大型结构,而且最初的直接Monte-Carlo 法还不是真正意义上的随机有限元法。但与随后的摄动随机有限元法(PSFEM)相比,当样本容量足够大时,Monte-Carlo有限元法的结果更可靠也更精确。 结构系统的随机分析一般可分为两大类:一类是统计方法,另一类是非统计方法。因此,随机有限元法同样也有统计逼近和非统计逼近两种类型。前者通过样本试验收集原始的数据资料,运用概率和统计理论进行分析和整理,然后作出科学推断。这里,样本试验和数据处理的工作量很大,随着计算机的普及和发展,数值模拟法,如蒙特卡罗(Monte Carlo)模拟,已成为最常用的统计逼近法。后者从本质上来说是利用分析工具找出结构系统的(确定的或随机的)输出随机信号与输入随机信号之间的关系,采用随机分析与求解系统控制方程相结合的方法得到输出信号的各阶随机统计量的数字特征(如各阶原点矩或中心矩)。 在20世纪70年代初,Cambou首先采用一次二阶矩方法研究线弹性问题。由于这种方法将随机变量的影响量进行Taylor级数展开,就称之为Taylor展开法随机有限元(TSFEM)。Shinozuka和Astill(1972)分别独立运用摄动技术研究了随机系统的特征值问题。随后,Handa(1975)等人在考虑随机变量波动性时采用一阶和二阶摄动技术,并将这种摄动法随机有限元成功地应用于框架结构分析。Vanmarcke等人(1983)提出随机场的局部平均理论,并将它引入随机有限元。局部平均理论是用随机场函数在每一个离散单元上的局部平均的随机变量来代表该单元的统计量的近似理论。Liu W. K.等人(1986、1988)的系列工作,提供了一种“主模态”技术,运用随机变量的特征正交化方法,将满秩的协方差矩阵变换为对角矩阵,减少计算工作量,对摄动随机有限元法的发展做出贡献,此外,提出了一个随机变分原理。 Yamazaki和Shinozuka(1987)创造性地将算子的Neumann级数展开式引入随机有限元的列式工作。从本质上讲,Neumann级数展开方法也是一类正则的小参数摄动方法,正定的随机刚度矩阵和微小的随机扰动量是两个基本要求,这两个基本要求保证了摄动解的正则性和收敛性,其优点在于摄动形式较简单并可以得到近似解的高阶统计量。Shinozuka等人(1987)将随机场函数的Monte-Carlo模拟与随机刚度矩阵的Neumann级数展开式结合,得到具有较好计算精度和效率的一类Neumann随机有限元列式(称NSFEM)。Benaroya等(1988)指出,将出现以随机变分原理为基础的随机有限元法来逐渐取代以摄动法为基础的随机有限元法。Spanos和Ghanem等人(1989,1991)结合随机场函数的Karhuen-Loeve展式和Galerkin (迦辽金)射影方法建立了相应的随机有限元列式,并撰写了随机有限元法领域的第一本专著《随机有限元谱方法》。 国内对随机有限元的研究起步较晚。吴世伟等人(1988)提出随机有限元的直接偏微 耐久疲劳分析S N方法概 述 Revised by BLUE on the afternoon of December 12,2020. 耐久疲劳分析-SN方法概述 SN(名义应力)法是疲劳计算的最古老方法,由德国铁路工程师August Whler 于1852 年到1870 年之间建立。他用如下左图所示的实验台同时对两根铁路车轴进行旋转弯曲疲劳试验来研究车轴的累积失效问题,然后将名义应力值和发生失效的循环周数的对应关系绘制在一个图表上,这就是众所周知的SN 曲线图,SN 曲线也叫Whler 曲线。SN 方法是目前应用最为广泛的疲劳分析方法,一条典型的SN 曲线如下右图所示。SN 曲线的几个特征需要说明:在约1000 次循环的转折点以下的SN 曲线是无效的,因为此时的名义应力是弹塑性的,其发生失效的循环次数较少,也成为低周疲劳。由于疲劳是由塑性剪切应变能的释放来驱动的,因此材料发生屈服之后,应力与应变不再是线性关系,应力就不能再作为疲劳计算的参数,这将由后续介绍到的EN(应变寿命)法来处理。 在转折点和疲劳极限(约10E6-10E8 次循环)之间的应力范围,SN 分析是有效的。低于疲劳极限的部分,SN 曲线的斜率急剧下降趋于水平,即无限寿命区。然后实际应用中,无限寿命是很难达到的。比如,铝合金的SN 曲线没有水平部分,不表现出无限寿命特征。疲劳分析器中应用“三段线性”曲线来表征SN 曲线,即由三段对数坐标的直线分别对应低周(塑性)、高周(弹性)和无限寿命区间。两条典型SN 曲线如右图所示,分别代表低合金钢MANTEN和高强度钢RQC100,低于1000 次循环的虚线代表低周区间,10E8次循环处代表疲劳极限点。为计算构件的疲劳寿命,疲劳分析器需要材料的SN曲线和失效点处的交变应力时域历程两个信息。首先,疲劳分析器会对时域信号进行雨流分析以提取疲劳循环,然后通过SN 曲线来计算每个循环产生的损伤并对所有损伤值进行线性累积,系统将自动执行这一过程。 摘要:疲劳破坏是结构的主要失效形式,疲劳失效研究在结构安全分析中扮演着举足轻重的角色。因此结构的疲劳强度和疲劳寿命是其强度和可靠性研究的主要内容之一。机车车辆结构的疲劳设计必须服从一定的疲劳机理,并在系统结构的可靠性安全设计中考虑复合的疲劳设计技术的应用。国内的机车车辆主要结构部件的疲劳寿命评估和分析采用复合的疲劳设计技术,国外从疲劳寿命的理论计算和疲劳试验两个方面在疲劳研究和应用领域有很多新发展的理论方法和技术手段。不论国内国外,一批人几十年如一日致力于疲劳的研究,对疲劳问题研究贡献颇多。 关键词:疲劳 UIC标准疲劳载荷 IIW标准 S-N曲线机车车辆 一、国内外轨道车辆的疲劳研究现状 6月30日15时,备受关注的京沪高铁正式开通运营。作为新中国成立以来一次建设里程最长、投资最大、标准最高的高速铁路,京沪高铁贯通“三市四省”,串起京沪“经济走廊”。京沪高铁的开通,不仅乘客可以享受到便捷与实惠,沿线城市也需面对高铁带来的机遇和挑战。在享受这些待遇的同时,专家指出,各省市要想从中分得一杯羹,配套设施建设以及机车车辆的安全性绝对不容忽略。根据机车车辆的现代设计方法,对结构在要求做到尽可能轻量化的同时,也要求具备高度可靠性和足够的安全性。这两者之间常常出现矛盾,因此,如何准确研究其关键结构部件在运行中的使用寿命以及如何进行结构的抗疲劳设计是结构强度寿命预测领域研究中的前沿课题。 在随机动载作用下的结构疲劳设计更是成为当前机车车辆结构疲劳设计的研究重点,而如何预测关键结构和部件的疲劳寿命又是未来机车车辆结构疲劳设计的重要发展方向之一。机车车辆承受的外部载荷大部分是随时间而变化的循环随机载荷。在这种随机动载荷的作用下,机车车辆的许多构件都产生动态应力,引起疲劳损伤,而损伤累积后的结构破坏的形式经常是疲劳裂纹的萌生和最终结构的断裂破坏。随着国内铁路运行速度的不断提高,一些关键结构部件,如转向架的构架、牵引拉杆等都出现了一些断裂事故。因此,机车车辆的结构疲劳设计已经逐渐成为机车车辆新产品开发前期的必要过程之一,而通过有效的计算方法预测结构的疲劳寿命是结构设计的重要目标。 1.1国外 早在十九世纪后期德国工程师Wohler系统论述了疲劳寿命和循环应力的关系并提出了S-N 曲线和疲劳极限的概念以来,国内外疲劳领域的研究已经产生了大量新的研究方法和研究成果。 结构疲劳设计中主要有两方面的问题:一是用一定材料制成的构件的疲劳寿命曲线;二是结构件的工作应力谱,也就是载荷谱。载荷谱包括外部的载荷及动态特性对结构的影响。根据疲劳寿命曲线和工作应力谱的关系,有3种设计概念:静态设计(仅考虑静强度);工作应力须低于疲劳寿命曲线的疲劳耐久限设计;根据工作强度设计,即运用实际使用条件下的载荷谱。实际载荷因为受到车辆等诸多因素的影响而有相当大的离散性,它严重地影响了载荷谱的最大应力幅值、分布函数及全部循环数。为了对疲劳寿命进行准确的评价,必须知道设计谱的存在概率,并且考虑实际载荷离散性,才可以确定结构可靠的疲劳寿命。 20世纪60年代,世界上第一条高速铁路建成,自那时起,一些国外高速铁路发达国家已经深入研究机车车辆结构轻量化带来的关键结构部件的疲劳强度和疲劳寿命预测问题。其中,包括日本对车轴和焊接构架疲劳问题的研究;法国和德国采用试验台仿真和实际线路相结合的技术开发出试验用的机车车辆疲劳分析方法;英国和美国对转向架累计损伤疲劳方面的研究等等。在这些研究中提出了大量有效的疲劳寿命的预测研究方法。 1.2、国内 1.2.1国内疲劳研究现状与方法 国内铁路相关的科研院所对结构的疲劳寿命也展开了大量的研究和分析,并且得到了很多研 随机信号分析 朱华,等北京理工大学出版社2011-07-01 《随机信号分析》是高等学校工科电子类专业基础教材。内容为概率论基础、平稳随机过程、窄带随机过程、随机信号通过线性与非线性系统的理论与分析方法等。在相应的部分增加了离散随机信号的分析。《随即信号分析》的特点侧重在物理概念和分析方法上,对复杂的理论和数学问题着重用与实际的电子工程技术问题相联系的途径及方法去处理。《随即信号分析》配套的习题和解题指南将与《随即信号分析》同期出版。《随即信号分析》适用于电子工程系硕士研究生及高年级本科生,也适用于科技工作者参考。 第一章概率论 1.1 概率空间的概念 1.1.1 古典概率 1.1.2 几何概率 1.1.3 统计概率 1.2 条件概率空间 1.2.1 条件概率的定义 1.2.2 全概率公式 1.2.3 贝叶斯公式 1.2.4 独立事件、统计独立 1.3 随机变量及其概率分布函数 1.3.1 随机变量的概念 1.3.2 离散型随机变量及其分布列 1.3.3 连续型随机变量及其密度函数 1.3.4 分布函数及其基本性质 1.4 多维随机变量及其分布函数 1.4.1 二维分布函数及其基本性质 1.4.2 边沿分布 1.4.3 相互独立的随机变量与条件分布 1.5 随机变量函数的分布 1.5.1 一维随机变量函数的分布 1.5.2 二维随机变量函数的分布 1.5.3 二维正态随机变量函数的变换 1.5.4 多维情况 1.5.5 多维正态概率密度的矩阵表示法 1.6 随机变量的数字特征 1.6.1 统计平均值与随机变量的数学期望值 1.6.2 随机变量函数的期望值 1.6.3 条件数学期望 1.6.4 随机变量的各阶矩 1.7 随机变量的特征函数 1.7.1 特征函数的定义 1.7.2 特征函数的性质 疲劳是指结构在低于静态极限强度载荷的重复载荷作用下,出现断裂破坏的现象。例如一根能够承受 300 KN 拉力作用的钢杆,在 200 KN 循环载荷作用下,经历1,000,000 次循环后亦会破坏。导致疲劳破坏的主要因素如下: 载荷的循环次数; 每一个循环的应力幅; 每一个循环的平均应力; 存在局部应力集中现象。 真正的疲劳计算要考虑所有这些因素,因为在预测其生命周期时, 它计算“消耗”的某个部件是如何形成的。 3.1.1 ANSYS程序处理疲劳问题的过程 ANSYS 疲劳计算以ASME锅炉和压力容器规范(ASME Boiler and Pressure Vessel Code)第三节(和第八节第二部分)作为计算的依据,采用简化了的 弹塑性假设和Mimer累积疲劳准则。 除了根据 ASME 规范所建立的规则进行疲劳计算外,用户也可编写 自己的宏指令,或选用合适的第三方程序,利用 ANSYS 计算的结果进行疲劳计算。《ANSYS APDL Programmer‘s Guide》讨论了上述二种功能。 ANSYS程序的疲劳计算能力如下: 对现有的应力结果进行后处理,以确定体单元或壳单元模型的疲劳 寿命耗用系数(fatigue usage factors)(用于疲劳计算的线单元模型的应力必须人工 输入); 可以在一系列预先选定的位置上,确定一定数目的事件及组成这些 事件的载荷,然后把这些位置上的应力储存起来; 可以在每一个位置上定义应力集中系数和给每一个事件定义比例系数。 3.1.2 基本术语 位置(Location):在模型上储存疲劳应力的节点。这些节点是结构上 某些容易产生疲劳破坏的位置。 事件(Event):是在特定的应力循环过程中,在不同时刻的一系列应 随机分析在金融套利中的应用 习宇 (华中师范大学物理科学与技术学院 2010210421(10班)) 摘要:依据证券市场的资产定价模型、指数模型、因素模型、套利模型,引进随机信号分析,提出随机分析在套利模型中的初步尝试性应用。 关键词:CAPM;APT;SIM;套利模式;随机分析;单边上扬套利;震荡套利。 0引言: 当今世界金融数学(Financial Mathematics),又称数理金融学、数学金融学、分析金融学,是利用数学工具研究金融,用随机分析,随机最优控制,倒向随机微分方程,非线性分析,分形几何等现代数学,进行数学建模、理论分析、数值计算等定量分析,,以求找到金融动内在规律并用以指导实践,是基于应用数学在金融中的运用。其所涉及的数学知识主要有率论、随机分析、控制论金融数学里面用的主要是随机控制、粘性解、数值算法、时间序列。继而推广到了经济学中发展产生的现如今计量经济学的基础。而今我们基于以上来探讨股票的价格的各种波动受到随机市场信息及各种相关的因素随时间的变化,来建立股票的套利模式。 首先探讨何谓套利?套利定价理论(APT)是一种资产定价模式,其重点是每项资产的回报率均可从该资产与众多的共同风险因素的关系推测得到由斯蒂芬·罗斯创于1976年提出这一理论,这一理论从众多独立的宏观经济因素变量的线性组合预测投资组合的回报。当资产被错误定价时,套利定价理论(APT)会指出正确的价格何在。它通常被视为资本资产定价模型(CAPM)的替代品,因为APT具有更灵活的假设要求。鉴于CAPM的公式需要市场的预期回报,APT则套用风险资产的预期收益率和各宏观经济因素的风险溢价。套利者使用APT模型,利用证券的错误定价从中取利。当证券出现错误定价,其价格将异于从理论模式预测出来的价格。 数学概率上的套利定义是:初始投入为X的资产组合,在将来的某个有限时刻T,该组合的价值为v(t),如果v(t)的概率p满足p(v(t)>=X)=1且p(v (t)>X)>0,则称这样的情况为套利。如果一个初始投资为X的资产组合,在将来能获得概率1的带来严格正的收益,那么这个市场就存在套利机会。在证券市场中,该定义就可以理解为,在买入证券时的价格为P,在将来某个时间卖出的时 结构疲劳分析的方法以及应用 目前,对结构进行疲劳分析主要有两种途径:1)利用有限元分析软件直接对结构进行疲劳分析,最终求得结构的疲劳寿命;2)根据不同的疲劳工况,利用有限元软件分析计算出结构应力的变化,然后将其与利用规范计算出的许用疲劳应力相比较,看是否满足要求。对于前者,最为关键的是定义输入载荷谱或应力谱,而当结构的工况相对较为复杂时,载荷谱或应力谱的定义过程就相当于后者的前期处理过程;同时,客户一般会在协议中指定结构设计计算时必须参考的标准规范,所以为了更好地满足客户的需求,建议结构疲劳计算时采用后者的方法。根据标准规范对结构进行疲劳分析时一般包括以下五个方面: 1.疲劳载荷的确定 结构所承受的载荷可以分为三种:1)基本载荷,主要指设备在正常工作情况下通常出现的载荷(如结构自重、物料载荷、永久性动载等);2)附加载荷,主要指设备运行或停止时可能断续出现的载荷(如设备工作风载、摩擦阻力、运行阻力、非永久性动载等);3)特殊载荷,是指在设备工作和非工作状态时不应产生,但又无法避免的载荷(如非工作风载、结构碰撞、地震载荷等)。疲劳计算时只需考虑基本载荷,而且对于物料载荷或其它的基本载荷,有的标准规范中还规定了疲劳计算时载荷的缩小系数。 2.循环次数的确定 同一结构,所考虑的疲劳载荷不同时,其循环次数也不尽相同,这主要是因为不同的疲劳载荷产生的原因是不同的。例如,对于堆取料机来说,考虑物料载荷的扰动影响时是指传送皮带上物料的有无,而考虑永久性动载的扰动影响时则是指设备在工作过程中的正常启、制动,即便是同一结构的同一载荷,针对不同的工作工艺流程,其循环次数也是不同的。所以,设备的工作工艺流程是不同载荷循环次数计算的决定性因素。当载荷的循环次数确定后,首先应该判断其对结构的循环扰动作用是否足够多,当循环次数N≤103(104)(低周疲劳)时,无需对结构进行疲劳校核。 3.构件焊接形式的选择 工程中的钢结构多为焊接结构,构件的疲劳强度除取决于结构使用的材料外,还与接头的形状和制造方法密切相关。被连接件的形状和连接方法会影响到应力集中的形成,从而使构件的疲劳强度大为降低。不同的标准规范在经过大量试验的前提下,给出了针对不同的焊接接头形式的构件疲劳强度(图1,为 AS4100-1998标准中所列举的针对载荷循环次数为2×106构件的焊接形式及其许用应力幅值,左边的数字便为其疲劳强度值,单位为MPa)。因此,如何根据结构的实际焊接形式恰当地对照标准中的焊接类型来确定结构具体部分的疲劳强度值,也需要一定经验的积累。 概率论基础 1.概率空间、概率(条件概率、全概率公式、贝叶斯公式) 2.随机变量的定义(一维、二维实随机变量) 3.随机变量的描述: ⑴统计特性 一维、二维概率密度函数、一维二维概率分布函数、边缘分布 概率分布函数、概率密度函数的关系 ⑵数字特征 一维数字特征:期望、方差、均方值(定义、物理含义、期望和方差的性质、三者之间的关系) 二维数字特征:相关值、协方差、相关系数(定义、相互关系) ⑶互不相关、统计独立、正交的定义及其相互关系 4.随机变量函数的分布 △雅柯比变换(随机变量函数的变换一维随机变量函数的单值和双值变换、二维随机变量函数的单值变换) 5、高斯随机变量 一维和二维概率密度函数表达式 高斯随机变量的性质 △随机变量的特征函数及基本性质 、 随机信号的时域分析 1、随机信号的定义 从三个方面来理解①随机过程(),X t ζ是,t ζ两个变量的函数②(),X t ζ是随时间t 变化的随机变量③(),X t ζ可看成无穷多维随机矢量在0,t n ?→→∞的推广 2、什么是随机过程的样本函数?什么是过程的状态?随机过程与随机变量、样本函数之间的关系? 3、随机信号的统计特性分析:概率密度函数和概率分布函数(一维、二维要求掌握) 4、随机信号的数字特征分析(定义、物理含义、相互关系) 一维:期望函数、方差函数、均方值函数。(相互关系) 二维:自相关函数、自协方差函数、互相关函数、互协方差函数(相互关系) 5、严平稳、宽平稳 定义、二者关系、判断宽平稳的条件、平稳的意义、联合平稳定义及判定 6、平稳随机信号自相关函数的性质: 0点值,偶函数,均值,相关值,方差 7、两个随机信号之间的“正交”、“不相关”、“独立”。 (定义、相互关系) 8、高斯随机信号 定义(掌握一维和二维)、高斯随机信号的性质 9、各态历经性 定义、意义、判定条件(时间平均算子、统计平均算子)、平稳性与各态历经性的关系直流分量、直流平均功率、总平均功率、交流平均功率 随机信号的频域分析 1、随机信号是功率信号,不存在傅里叶变换,在频域只研究其功率谱。 功率谱密度的含义,与总平均功率的关系 2、一般随机信号功率谱计算公式与方法 3、平稳随机信号的功率谱密度计算方法 职业决策方法——SWOT 决策分析法和平衡单分析法分类:职业生涯规划2008-04-23 10:24 一、SWOT 决策分析法 SWOT 分析是市场营销管理中经常使用的功能强大的分析工具:S 代表strength(优势),W 代表weakness(弱势),O 代表opportunity(机会),T 代表threat(威胁)。其中,S、W 是内部因素,O、_______T 是外部因素。 SWOT 分析是一个职业决策的非常有用工具。如你对自己做个细致的SWOT 分析,那么,你会很明了地知道自己的个人优点和弱点在哪里,并且你会仔细地评估出自己所感兴趣的不同职业道路的机会和威胁所在。 一般来说,在进行SWOT 分析时,应遵循以下四个步骤: (1)评估自己的长处和短处我们每个人都有自己独特的价值观、性格、兴趣和能力。在当今分工非常细的市场经济里,每个人擅长于某一领域,而不是样样精通。有些人不喜欢整天坐在办公桌旁,而有些人则一想到不得不与陌生人打交道时,心里就发麻,惴惴不安。请填下面的表,列出你自己喜欢做的事情和你的长处所在。 同样,通过列表,你可以找出自己不是很喜欢做的事情和你的弱势。找出你的短处与发现你的长处同等重要,因为你可以基于自己的长处和短处做两种选择:一是努力去改正你常犯的错误,提高你的技能,二是放弃那些对你不擅长的技能要求很高的职业。列出你认为自己所具备的很重要的强项和对你的职业选择产生影响的弱势,然后再标出那些你认为对你很重要的强、弱势。 (2)找出你的职业机会和威胁 我们知道,不同的行业(包括这些行业里不同的公司)都面临不同的外部机会和威胁,所以,找出这些外界因素将助你成功地找到一份适合自己的工作是非常重要的,因为这些机会和威胁会影响你的第一份工作和今后的职业发展。如果公司处于一个常受到外界不利因素影响的行业里,很自然,这个公司能提供的职业机会将是很少的,而且没有职业升迁的机会。相反,充满了许多积极的外界因素的行业将为求职者提供广阔的职业前景。请列出你感兴趣的一两个行业,然后认真地评估这些行业所面临的机会和威胁。 (3)提纲式地列出今后五年内你的职业目标 仔细地对自己做一个SWOT 分析评估,列出你从学校毕业后5 年内最想实现的三个职业目标。这些目标可以包括:你想从事哪一种职业,或者你希望自己拿到的薪水属哪一级别。请时刻记住:你必须竭尽所能地发挥出自己的优势,使之与行业提供的工作机会完满匹配。 (4)提纲式地列出一份今后5 年的职业行动计划 这一步主要涉及到一些具体的东西。请你拟出一份实现上述第三步列出的每一目标的行动计划,并且详细地说明为了实现每一目标,你要做的每一件事,何时完成这些事。如果你觉得你需要一些外界帮助,请说明你需要何种帮助和你如何获取这种帮助。举个例子,你的个人 第十六章 随机性决策分析方法 人们在日常生活和工作中经常会遇到一些与随机因素有关、后果不确定,而又必须做出判断和决定的问题.这类问题称为随机性决策问题.任何一个随机性决策问题都包含两个方面的内容,即决策人所采取的行动方案(简称决策)和问题的自然状态(简称状态),而且具有两个基本特点:后果的不确定性和后果的效用. 所谓后果的不确定性,主要是由于问题的随机性,使得问会出现什么状态是不确定的,所以对策人做出的某种决策以后会出现什么后果也是不确定的.而效用是后果价值的量化,由于不确定性,无论决策人采用什么策略,都可能会遇到事先不能完全预料的后果,这要承担一定的风险,不同的决策人对待风险的态度会不同.因而,同样的后果对不同的策略人产生的效用也会不同.即使在没有风险的情况下,不同的决策人对待各种后果也有不同的偏好,为此,在进行定量分析之前,就应该确定出所有后果的效用.只有这样,人们才能比较各种策略的优劣,根据自己的喜好来选择最佳的决策方案. 在决策分析中,后果的不确定性和对于后果赋予的效用是两个关键性的问题.为此,对于状态的不确定性主要用主观概率来表示,而后果的效用则用效用理论来研究. 随机性决策问题的基本概念 主观概率 随机性决策问题的后果的不确定性,主要是由状态的不确定性所引起的.状态的不确定性,往往不能通过在相同条件下的大量重复试验来确定其概率分布(此称客观概率)是有区别的. 主观概率是决策人进行决策分析的依据,虽然他与客观概率有本质的区别,但在定义概率方面有不 同之处,同样遵循客观概率应该遵循的若干假设、公理和性质等,因此,适用于客观概率的所有的逻辑推理方法均适用于主观概率.这里仅给出主观概率所服从的基本假设(或称公理系统): (1)设Ω为一非空集合,其元素可以是某种试验或观察的结果,也可以是自然的状态.将这些元素记作抽象的点ω,因而有{}.ωΩ= (2)设F 是Ω中的一些子集A 所构成的集合,F 满足下列条件: 1)F Ω∈ 2)如果A F ∈,则\A A F =Ω∈; 3)如果可列多个n A F ∈,1,2,,n =L 则它们的并集 1 n n A F ∞ =∈U . (3)设()()P A A F ∈是定义在F 上的实值集函数,如果它满足下列条件,就称为F 上的(主观或客观) 概率测度,或简称概率,这些条件是 1)对于每个A F ∈,有0()1;P A ≤≤ 2)()1;P Ω= 3)如果可列多个n A F ∈(1,2,)n =L ,i j A A ?=?()i j ≠,则 疲劳就是指结构在低于静态极限强度载荷的重复载荷作用下,出现断裂破坏的现象。例如一根能够承受 300 KN 拉力作用的钢杆,在 200 KN 循环载荷作用下,经历 1,000,000 次循环后亦会破坏。导致疲劳破坏的主要因素如下: 载荷的循环次数; 每一个循环的应力幅; 每一个循环的平均应力; 存在局部应力集中现象。 真正的疲劳计算要考虑所有这些因素,因为在预测其生命周期时,它计算“消耗”的某个部件就是如何形成的。 3、1、1 ANSYS程序处理疲劳问题的过程 ANSYS 疲劳计算以ASME锅炉与压力容器规范(ASME Boiler and Pressure Vessel Code)第三节(与第八节第二部分)作为计算的依据,采用简化了的弹塑性假设与Mimer累积疲劳准则。 除了根据 ASME 规范所建立的规则进行疲劳计算外,用户也可编写自己的宏指令,或选用合适的第三方程序,利用 ANSYS 计算的结果进行疲劳计算。《ANSYS APDL Programmer‘s Guide》讨论了上述二种功能。 ANSYS程序的疲劳计算能力如下: 对现有的应力结果进行后处理,以确定体单元或壳单元模型的疲劳寿命耗用系数(fatigue usage factors)(用于疲劳计算的线单元模型的应力必须人工输入); 可以在一系列预先选定的位置上,确定一定数目的事件及组成这些事件的载荷,然后把这些位置上的应力储存起来; 可以在每一个位置上定义应力集中系数与给每一个事件定义比例系数。 3、1、2 基本术语 位置(Location):在模型上储存疲劳应力的节点。这些节点就是结构上某些容易产生疲劳破坏的位置。 事件(Event):就是在特定的应力循环过程中,在不同时刻的一系列 信号分析与处理 第一章绪论:测试信号分析与处理的主要内容、应用;信号的分类,信号分析与信号处理、测试信号的描述,信号与系统。 测试技术的目的是信息获取、处理和利用。 测试过程是针对被测对象的特点,利用相应传感器,将被测物理量转变为电信号,然后,按一定的目的对信号进行分析和处理,从而探明被测对象内在规律的过程。 信号分析与处理是测试技术的重要研究内容。 信号分析与处理技术可以分成模拟信号分析与处理和数字信号分析与处理技术。 一切物体运动和状态的变化,都是一种信号,传递不同的信息。 信号常常表示为时间的函数,函数表示和图形表示信号。 信号是信息的载体,但信号不是信息,只有对信号进行分析和处理后,才能从信号中提取信息。 信号可以分为确定信号与随机信号;周期信号与非周期信号;连续时间信号与离散时间信号;能量信号与功率信号;奇异信号; 周期信号无穷的含义,连续信号、模拟信号、量化信号,抽样信号、数字信号 在频域里进行信号的频谱分析是信号分析中一种最基本的方法:将频率作为信号的自变量,在频域里进行信号的频谱分析; 信号分析是研究信号本身的特征,信号处理是对信号进行某种运算。 信号处理包括时域处理和频域处理。时域处理中最典型的是波形分析,滤波是信号分析中的重要研究内容; 测试信号是指被测对象的运动或状态信息,表示测试信号可以用数学表达式、图形、图表等进行描述。 常用基本信号(函数)复指数信号、抽样函数、单位阶跃函数单位、冲激函数(抽样特性和偶函数)离散序列用图形、数列表示,常见序列单位抽样序列、单位阶跃序列、斜变序列、正弦序列、复指数序列。 系统是指由一些相互联系、相互制约的事物组成的具有某种功能的整体。被测系统和测试系统统称为系统。输入信号和输出信号统称为测试信号。系统分为连续时间系统和离散时间系统。随机信号分析实验
matlab随机信号分析常用函数
随机有限元法
耐久疲劳分析SN方法概述
疲劳分析流程 fatigue
随机信号分析
ansys疲劳分析报告基本方法
随机分析在套利分析中的应用
结构疲劳分析的方法以及应用.
《随机信号分析基础》总复习提
职业决策方法——SWOT 决策分析法和平衡单分析法
随机决策分析方法
ansys疲劳分析基本方法
信号分析与处理