第八章 时间序列计量经济学模型(DOC)
1.1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。
表8 中国人口时间序列数据(单位:亿人)
年份人口y t年份人口y t年份人口y t年份人口y t年份人口y t
1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517
1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985
1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121
1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389
1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626
1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761
1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786
1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743
1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627
1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823
1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171
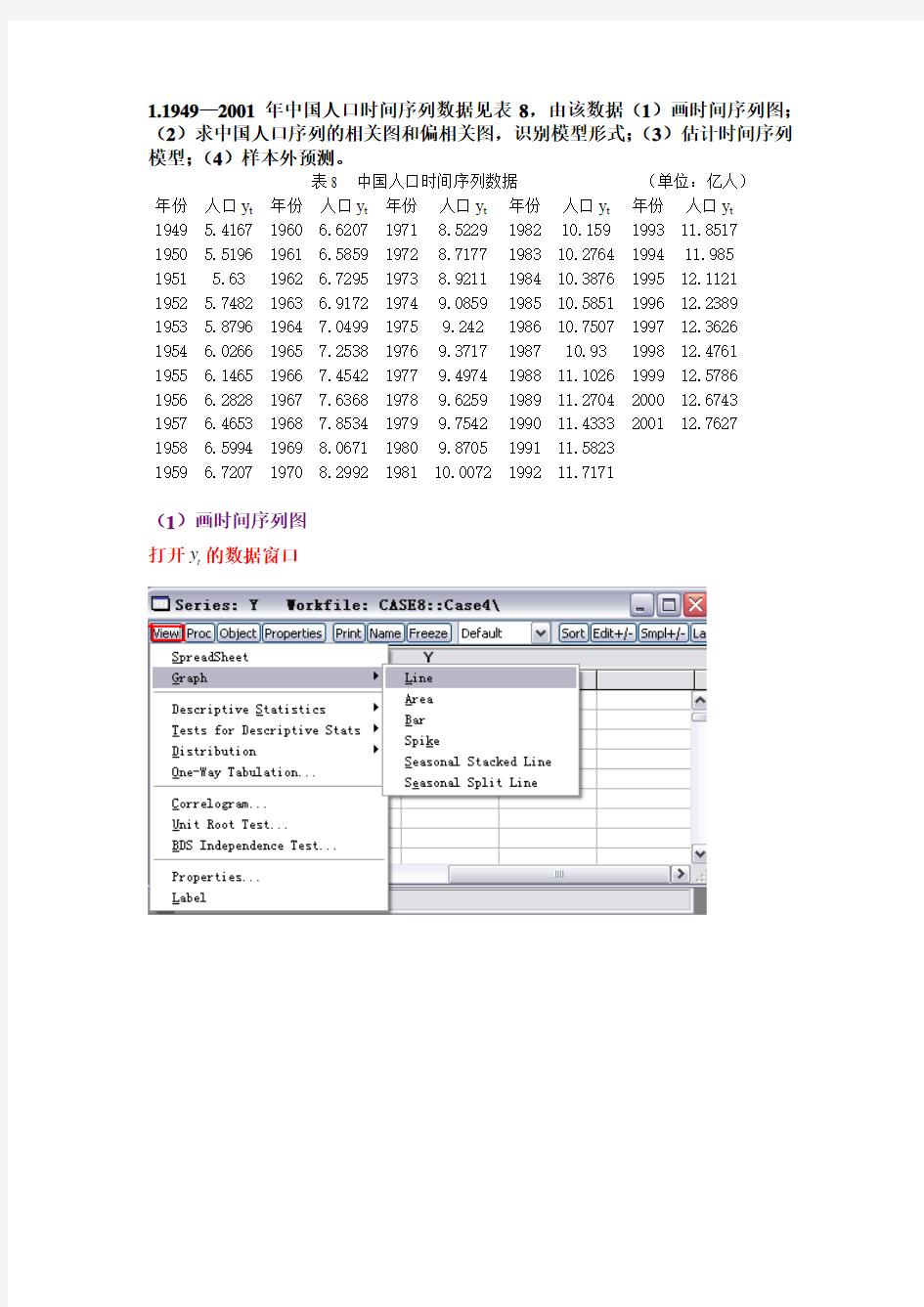
(1)画时间序列图
打开
y的数据窗口
t
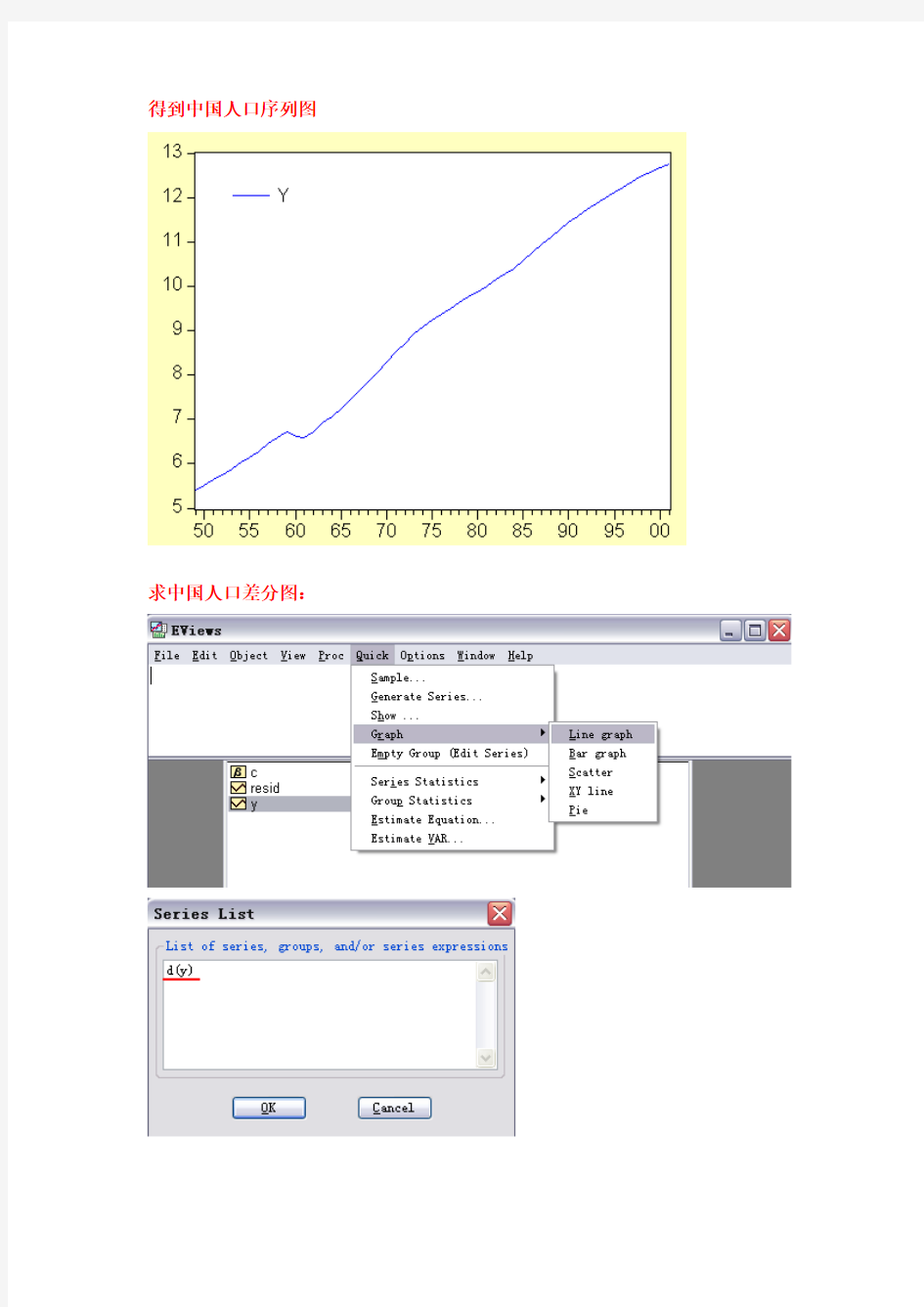
求中国人口差分图:
从人口序列图和人口差分序列图可以看出我国人口总水平除在1960年和1961年两年出现回落外,其余年份基本上保持线性增长趋势。52年间平均每年增加人口1412.6923万人,年平均增长率为1.66%。由于总人口数逐年增加,实际上的年人口增长率是逐渐下降的。把52年分为两个时期,即改革开放以前时期(1949—1978年)和改革开放以后时期(1979—2001年),则前一个时期的人
口年平均增长率为2%,后一个时期的年平均增长率为1.23%。从人口序列
y的
t
变化特征看,这是一个非平稳序列。
(2)求中国人口序列的相关图和偏相关图,识别模型形式
打开
y数据窗口,过程如下:
t
Level表示选择对
y画相关图、偏相关图。滞后期为10。
t
结果如下:
y是非平稳序列。由相关图衰减缓慢可以知道,中国人口序列
t
做
dy的相关图和偏相关图如下:
t
由上图可以看出,自相关函数呈指数衰减,偏自相关函数1阶或2阶截尾。所以是一个1阶或2阶自回归过程。
(3)时间序列模型估计
模型估计命令如下,同时将样本改为1949—2000年,留下2001年的值用于计算预测精度。
输出结果如下:
从上面的输出结果可以看出,AR(2)的系数没有显著性,因此需要从模型中将其剔除继续估计。
得到重新的估计结果如下:
对应的模型表达式为:
0.1429t t Dy u =+
(8.7)
10.6171t t t u u v -=+
(5.4)
直接写为: 10.14290.6171(0.1429)t t t Dy Dy v -=+-+
输出结果中的0.1429是t Dy 的均值,表示年平均人口增量是0.1429亿人。 整理上述输出结果,得:
110.1429(10.6171)0.61710.05470.6171t t t t t Dy Dy v Dy v --=-++=++ 0.0547表示线性趋势的增长速度。
从输出结果的最后一行可以知道,特征根是1/0.62=1.61,满足平稳性要求。
检验模型的误差项:
选滞后期为10
得到如下输出结果:
从对应的概率值可以看出,所有的Q值都小于检验水平为0.05的2 分布,所以模型的随机误差项是一个白噪声序列。
(4)样本外预测
过程如下:
预测方法选择静态预测。
结果如下:
已知2001年中国人口实际数是12.7627亿人,预测值为12.788亿人,误差为0.2%。
2.1967—1998年天津市保费收入(t y ,万元)和人口(t x ,万人)数据见表9。
表9 天津市保费收入(t y )和人口(t x )数据
年份
Y t (万元)
X t (万人) 年份 Y t (万元)
X t (万人) 1967 259 649.72 1983 5357 785.28 1968 304 655.04 1984 6743 795.52 1969 313 650.75 1985 8919 804.8 1970 315 652.7 1986 14223 814.97 1971 322 663.41 1987 19007 828.73 1972
438
674.65 1988
23540
839.21
1973 706 683.31 1989 29264 852.35 1974 624 692.47 1990 34327 866.25 1975 632 702.86 1991 39474 872.63 1976 591 706.5 1992 49624 878.97 1977 622 712.87 1993 67412 885.89 1978 806 724.27 1994 100561 890.55 1979 1172 739.42 1995 123655 894.67 1980 2865 748.91 1996 171768 898.45 1981 4223 760.32 1997 243377 899.8 1982 5112 774.92 1998 271654 905.09
对数的天津保费收入ln t y 和人口t x 的散点图如下图:
所以可以建立半对数模型。输出结果如下:
相应表达式为:
ln 11.180.0254t t y x =-+
(-20.9) (37.2) 20.9788,0.36R DW ==
因为DW=0.36,说明模型误差项存在严重自相关。观察残差序列的自相关结构。 过程如下:
得到如下结果:
由上图可以看出自相关函数拖尾,偏自相关函数2阶截尾,残差序列是一个明显的AR(2)过程。重新进行回归分析,得如下结果:
相应表达式是:
?ln 11.580.0259 1.17(1)0.45(2)t t y
x AR AR =-++- (-8.6) (15.3) (6.5) (-2.2) 2
0.993, 1.97R DW ==
这种模型称作回归于时间序列组合模型。通过对回归模型残差序列建立时间序
列模型提高回归参数估计量的有效性,所以组合模型估计的回归参数0.0259要比OLS 估计结果0.0254的品质要好。拟合度也有所提高,并且消除了残差的自相关性。
3.做663天的深证成指(SZ)序列:
从SZ的序列走势可以看出,SZ序列既不是确定性趋势非平稳序列,也不是随机趋势序列。所以先按随机趋势序列设定检验式。
过程如下:
打开SZ的数据文件
对SZ原序列进行ADF检验,检验式不包括趋势项,包括截距项。
得到ADF的检验结果如下:
带有截距项的DF 检验式的估计结果如下:
12.85410.0050t t DSZ SZ -=-
(1.9) (-1.8) 2.0,660DW T ==
从1t SZ -的系数的t 检验可以看出,SZ 序列存在单位根。但是常数项也没有通过t 检验,所以从检验式中去掉截距项,继续进行单位根检验。 结果如下:
则DF 检验式的估计结果如下:
10.0002t t DSZ SZ -=
(0.4) 2.0,660DW T ==
DF=0.4,大于临界值。SZ 序列是一个随机游走过程,并不含有随机趋势。
对t SZ 的差分序列t DSZ 继续做单位根检验。过程如下:
得到的结果如下:
所以: 211.0017t t D SZ DSZ -=-
(-25.7) 2.0,659DW T ==
ADF=-25.7,所以(0)t DSZ I 是平稳序列,(1)t
SZ I 。
4.利用表9.1的数据(1)做出时间序列ln GDP 与ln CONS 的样本相关图,并通过图形判断该两时间序列的平稳性。(2)对ln GDP 与ln CONS 序列进行单位检验,以进一步明确它们的平稳性。(3)如果不进行进一步的检验,直接估计以下简单的回归模型,是否认为此回归是虚假回归:01ln ln t t t CONS GDP u ββ=++。
表9.1 中国GDP 与消费支出 单位:亿元
年份 CONS GDP 年份 CONS GDP 1978 1759.100 3605.600 1990 9113.200 18319.50 1979 2005.400 4074.000 1991 10315.90 21280.40 1980 2317.100 4551.300 1992 12459.80 25863.70 1981 2604.100 4901.400 1993 15682.40 34500.70 1982 2867.900 5489.200 1994 20809.80 46690.70 1983 3182.500 6076.300 1995 26944.50 58510.50 1984 3674.500 7164.400 1996 32152.30 68330.40 1985 4589.000 8792.100 1997 34854.60 74894.20 1986 5175.000 10132.80 1998 36921.10 79003.30 1987 5961.200 11784.70 1999 39334.40 82673.10 1988 7633.100 14704.00 2000
42911.90
89112.50
1989
8523.500
16466.00
(1)首先做ln GDP与ln CONS的样本相关图,过程如下:
做ln GDP的样本相关图。
由于是做ln GDP的水平序列,所以选择level,并包括12期滞后。
得到ln GDP的样本相关图如下:
从样本的自相关函数图可以看出,函数并没有迅速趋向于零,并在零附近波动,说明ln GDP序列是非平稳的。
用同样的方法,做ln CONS序列的自相关函数图如下:
从上面的样本自相关函数图可以看出,ln CONS的自相关函数并没有迅速趋于零,并在零附近波动,说明ln CONS序列也是非平稳的。
(2)首先对ln GDP进行单位根检验,过程如下:
先从模型3进行检验,包括截距项,时间趋势及一阶滞后项的模型。
我国通货膨胀的混合回归和时间序列模型
2000年9月系统工程理论与实践第9期 文章编号:100026788(2000)0920138203 我国通货膨胀的混合回归和时间序列模型 叶阿忠,李子奈 (清华大学经济管理学院,北京100084) 摘要: 回归模型的残差项反映了对被解释变量有影响但未列入解释变量的因素所产生的噪音,这 部分噪音可由时间序列模型进行拟合Λ本文对通货膨胀建立了一个混合回归和时间序列模型,并将该 模型的预测结果与单纯用回归模型的预测结果进行了比较Λ 关键词: 通货膨胀;回归模型;时间序列模型;自相关函数;预测误差 中图分类号: O212 α T he Com b ined R egressi on2ti m e2series M odel of Ch inese Inflati on YE A2zhong,L I Zi2nai (Schoo l of Econom ics&M anagem en t,T singhua U n iversity,Beijing100084) Abstract: T he residual term in the regressi on model is the no ise generated by the om itted variab les that influen t dependen t variab le in the model.T he ti m e series model can fit th is no ise.W e estab lish the com b ined regressi on-ti m e-series model fo r Ch inese inflati on and compare its fo recast resu lts to that of regressi on model. Keywords: inflati on;regressi on model;ti m e2series model;au toco rrelati on functi on; fo recast erro r 1 引言 一般我们对通货膨胀建立模型或是采用回归模型或是采用时间序列模型,但回归模型中解释变量解释被解释变量的能力总是有限的,且由于存在对被解释变量有影响但未列入解释变量的因素而产生了回归模型无法预测的噪音,因而预测的效果不佳;而时间序列模型只反映时间序列过去行为的规律,没有利用经济现象的因果关系,再加上A R I M A(p,d,q)模型识别的困难,造成预测精度的下降Λ本文将两种方法结合起来,对我国通货膨胀建立一个混合回归和时间序列模型,并进行预测Λ 2 混合回归和时间序列模型 假定我们喜欢利用一个回归模型预测变量y tΖ一般地,这样的模型包括可解释的一些解释变量,它们之间不存在共线性Ζ假定我们的回归模型有k个解释变量x1,…,x k,回归模型如下: y t=Β0+Β1x1t+…+Βk x k t+Εt(1)其中误差项Εt反映除了解释变量外其它变量对y t的影响Ζ方程被估计后,R2将小于1,除非y t与解释变量完全相关,R2才等于1Ζ然后,方程可被用于预测y tΖ预测误差的一个来源是附加的噪声项,它的未来不可预测Ζ 时间序列分析的一个有效应用是对该回归的残差Εt序列建立A R I M A模型Ζ我们将原回归方程的误α收稿日期:1999203202 资助项目:国家教委“九五”重点教材基金
试验一异方差的检验与修正-时间序列分析
案例三 ARIMA 模型的建立 一、实验目的 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2007年中国进出口贸易总额数据运用经典B-J 方法论建立合适的ARIMA (,,p d q )模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated –regular frequency ”,在“Date specification ”栏中分别选择“Annual ”(年数据) ,分别在起始年输入1950,终止年输入2007,点击ok ,见图3-1,这样就建立了一个工作文件。点击File/Import ,找到相应的Excel 数据集,导入即可。
计量经济学——时间序列
课程论文 题目:第三产业产值的影响因素分析 学院财会学院_ 专业会计专硕 班级会计专硕1501 课程名称计量经济学(课程设计) 学号 学生姓名 60 指导教师赵卫亚 成绩 二○一五年十二月
第三产业产值的影响因素分析 摘要:本文利用计量经济分析方法和1990—2010年的时间序列统计资料,建立了我国第三产业产值影响因素模型。建模过程中,处理了模型中的协整检验、自相关性等问题。本文认为我国第三产业产值主要受GDP和我国城乡居民存款储蓄的影响,因此需要引起足够的重视,正确开展工作,促进第三产业的发展。 关键词:第三产业产值;时间序列分析;GDP;城乡居民存款储蓄 一、引言 第三产业是指除第一二产业以外的其他行业。自从我国进入改革开放以来,我国不仅在积极发展第一产业和第二产业的同时,也在积极扶植第三产业的发展。我国属于发展中国家,仅靠出口农产品或初级工业品很难在国际社会中立有一足之地。进入21世纪,第三产业的发展迫切需要成为促进经济发展的主要动力。这主要是因为第三产业基本以服务业为主,这就使其具有了行业多,范围广等特点,从而能够提供更多的就业机会,相对于其他产业服务业的就业门滥相对来说也较低,能吸纳农村等剩余劳动力,并且第三产业的发展,也能有效地促进第一产业和第二产业的发展,加速推进我国的工业化和现代化进程,提高我国的综合国力。我国的第三产业较其他发达国家仍有很大的差距,所以加快本国第三产业发展迫在眉睫。 第三产业不仅在占国民生产总值比重方面不断提高,其内部的产业结构也在不断地发生着变化。最初我国第三产业的发展主要集中以餐饮等为主的传统服务业上,而随着新型服务业的产生,我国开始侧重向金融保险业、房地产业等方面的发展,其数量和质量的提高使得第三产业在我国经济发展的过程中产生的作用也越来越显著。 因此,研究第三产业产值的影响因素分析具有实际意义。 二、文献综述 江小涓、李辉(2004)建立了一个多元回归模型来分析收入水平、消费结构、城市化以及其他因素对第三产业未来发展的影响,提出第三产业比例随着人均GDP水平增长而增加[1]。郭彩霞(2009)对1978到2008年相关数据进行实证分析,得到要想加快农村现代化就必须要促进第三产业的发展结论[2]。王小宁(2009)认为第三产业固定资产的投资对第三产业产值具有重大的影响[3]。徐群、于德淼、赵春阁在对第三产业发展研究时主要是利用线性回归模型来对我国第三产业的影响因素进行分析,对我国第三产业发展现状的研究和趋势预测就是利用的主成分分析和逐步回归分析方法[4]。
第十三章 时间序列回归
第十三章 时间序列回归 本章讨论含有ARMA 项的单方程回归方法,这种方法对于分析时间序列数据(检验序列相关性,估计ARMA 模型,使用分布多重滞后,非平稳时间序列的单位根检验)是很重要的。 §13.1序列相关理论 时间序列回归中的一个普遍现象是:残差和它自己的滞后值有关。这种相关性违背了回归理论的标准假设:干扰项互不相关。与序列相关相联系的主要问题有: 一、一阶自回归模型 最简单且最常用的序列相关模型是一阶自回归AR(1)模型 定义如下:t t t u x y +'=β t t t u u ερ+=-1 参数ρ是一阶序列相关系数,实际上,AR(1)模型是将以前观测值的残差包含到现观测值的回归模型中。 二、高阶自回归模型: 更为一般,带有p 阶自回归的回归,AR(p)误差由下式给出: t t t u x y +'=β t p t p t t t u u u u ερρρ++++=--- 2211 AR(p)的自回归将渐渐衰减至零,同时高于p 阶的偏自相关也是零。 §13.2 检验序列相关 在使用估计方程进行统计推断(如假设检验和预测)之前,一般应检验残差(序列相关的证据),Eviews 提供了几种方法来检验当前序列相关。 1.Dubin-Waston 统计量 D-W 统计量用于检验一阶序列相关。 2.相关图和Q-统计量 计算相关图和Q-统计量的细节见第七章 3.序列相关LM 检验 检验的原假设是:至给定阶数,残差不具有序列相关。 §13.3 估计含AR 项的模型 随机误差项存在序列相关说明模型定义存在严重问题。特别的,应注意使用OLS 得出的过分限制的定义。有时,在回归方程中添加不应被排除的变量会消除序列相关。 1.一阶序列相关 在EViews 中估计一AR(1)模型,选择Quick/Estimate Equation 打开一个方程,用列表法输入方程后,最后将AR(1)项加到列表中。例如:估计一个带有AR(1)误差的简单消费函数 t t t u GDP c c CS ++=21 t t t u u ερ+=-1 应定义方程为: cs c gdp ar(1) 2.高阶序列相关 估计高阶AR 模型稍稍复杂些,为估计AR(k ),应输入模型的定义和所包括的各阶AR 值。如果想估计一个有1-5阶自回归的模型 t t t u GDP c c CS ++=21 t t t t u u u ερρ+++=--5511 应输入: cs c gdp ar(1) ar(2) ar(3) ar(4) ar(5) 3.存在序列相关的非线性模型 EViews 可以估计带有AR 误差项的非线性回归模型。例如: 估计如下的带有附加AR(2)误差的非线性方程 t c t t u GDP c CS ++=21
第九章时间序列计量经济学模型案例
第九章时间序列计量经济学模型案例 1、1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图和差分图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。 表9.1 中国人口时间序列数据(单位:亿人) 年份人口y t 年份人口y t年份人口y t年份人口y t年份人口y t 1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517 1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985 1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121 1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389 1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626 1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761 1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786 1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743 1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627 1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823 1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171 (1)画时间序列图 y的数据窗口 打开 t 得到中国人口序列图
第六章时间序列分析
第六章时间序列分析 重点: 1、增长量分析、发展水平及增长量 2、增长率分析、发展速度及增长速度 3、时间数列影响因素、长期趋势分析方法 难点: 1、增长量与增长速度 2、长期趋势与季节变动分析 第一节时间序列的分析指标 知识点一:时间序列的含义 时间序列是指经济现象按时间顺序排列形成的序列。这种数据称为时间序列数据。 时间序列分析就是根据这样的数列分析经济现象的发展规律,进而预测其未来水平。 时间数列是一种统计数列,它是将反映某一现象的统计指标在不同时间上的数值按时间先后顺序排列所形成的数列。表现了现象在时间上的动态变化,故又称为动态数列。 一个完整的时间数列包含两个基本要素: 一是被研究现象或指标所属的时间; 另一个是该现象或指标在此时间坐标下的指标值。 同一时间数列中,通常要求各指标值的时间单位和时间间隔相等,如无法保证相等,在计算某些指标时就涉及到“权”的概念。 研究时间数列的意义:了解与预测。 [例题·单选题]下列数列中哪一个属于时间数列(). a.学生按学习成绩分组形成的数列 b.一个月内每天某一固定时点记录的气温按度数高低排列形成的序列 c.工业企业按产值高低形成的数列 d.降水量按时间先后顺序排列形成的数列 答案:d 解析:时间序列是一种统计数列,它是将反映某一现象的统计指标在不同时间上的数值按时间先后顺序排列所形成的数列,表现了现象在时间上的动态变化。 知识点二:增长量分析(水平分析)
一.发展水平 发展水平是指客观现象在一定时期内(或时点上)发展所达到的规模、水平,一般用y t (t=1,2,3,…,n) 。 在绝对数时间数列中,发展水平就是绝对数; 在相对数时间数列中,发展水平就是相对数或平均数。 几个概念:期初水平y 0,期末水平y t ,期间水平(y 1 ,y 2 ,….y n-1 ); 报告期水平(研究时期水平),基期水平(作为对比基础的水平)。 二.增长量 增长量是报告期发展水平与基期发展水平之差,增长量的指标数值可正可负,它反映的是报告期相对基期增加或减少的绝对数量,用公式表示为: 增长量=报告期水平-基期水平 根据基期的不同确定方法,增长量可分为逐期增长量和累计增长量。 1.逐期增长量:是报告期水平与前一期水平之差,用公式表示为: △ = y n - y n-1 (i=1,2,…,n) 2.累计增长量:是报告期水平与某一固定时期水平(通常是时间序列最初水平)之差,用公式表示为: △ = y n - y (i=1,2,…,n)(i=1,2,…,n) 二者关系:逐期增长量之和=累计增长量 3.平均增长量 平均增长量是时间序列中的逐期增长量的序时平均数,它表明现象在一定时段内平均每期增加(减少)的数量。 一般用累计增长量除以增长的时期数目计算。 (y n - y )/n [例题·单选题]某社会经济现象在一定时期内平均每期增长的绝对数量是()。 a.逐期增长量 b.累计增长量 c.平均增长量 d.增长速度 答案:c 解析:平均每期增长的绝对数量是平均增长量。 知识点三:增长率分析(速度分析) 一.发展速度
时间序列及分析
时间序列 (一)时间序列及其分类 同一现象在不同时间上的相继观察值排列而成的序列称为时间序列。例如,下表就是我国国内生产总值、人口等在不同时间上得到的观察值排列而成的序列。 由表可以看出,时间序列形式上由现象所属的时间和现象在不同时间上的观察值两部分组成。根据所处的观察时间不同,现象所属的时间可以是年份、季度、月份或其他任何时间形式。现象的观察值根据表现形式不同有绝对数、相对数和平均数等。因此,从观察值的表现形式上看,时间序列可分为绝对数时间序列、相对数时间序列和平均数时间序列等。 由一系列绝对数按时间顺序排列而成的序列称为绝对数时间序列。它是时间序列中最基本的表现形式,用于反映现象在不同时间上所达到的绝对水平。绝对数时间序列根据观察值所属的时间状况不同,可以分为时期序列和时点序列。例如,表中的国内生产总值序列就是时期序列。时期序列中的观察值反映现象在一段时期内的活动总量,并且各观察值通常可以直接相加,用于反映现象在更长一段时期内的活动总量。表中的年末总人口序列属于时点序列,时点序列中的观察值反映现象在某一瞬间时点上的总量,它是在某一时点上统计得到的,序列中的各观察值通常不能相加。由绝对数时间序列可以派生出相对数和平均数时间序列,它们分别是由一系列相对数和平均数按时间顺序排列而成的。例如,表中的人口自然增长率序列就是相对数时间序列,居民消费水平序列则是平均数时间序列。 时间序列的描述性分析包括水平分析和速度分析两方面的内容。 (二)时间序列的水平分析 1.序时平均数 在时间序列中,我们用i t表示现象所属的时间,i Y表示现象在不同时间上观察值。i Y也称为现象在时间i t上的发展水平,它表示现象在某一时间上所达到的一种数量状态。若观察的时间范围为1t,2t,…,n t,相应的观察值表示为1Y,2Y,…,3Y,其中1Y称为最初发展水平,n Y称为最末发展水平;若对两个观察值进行比较时,把现在的这个时期称为报 告期,用于比较的过去的那个时期称为基期。 序时平均数是现象在不同时间上的观察值的平均数。它可以概括性地描述出现象在一段时期内所达到的一般水平。在证券市场上,对股票价格或股票价格指数的分析中常用到序时
第八章 时间序列计量经济学模型(DOC)
1.1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。 表8 中国人口时间序列数据(单位:亿人) 年份人口y t年份人口y t年份人口y t年份人口y t年份人口y t 1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517 1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985 1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121 1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389 1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626 1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761 1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786 1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743 1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627 1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823 1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171 (1)画时间序列图 打开 y的数据窗口 t
计量经济学时间序列计量经济模型
计量经济学引子:是真回归还是伪回归?问题:●如果直接将非平稳时间序列当作平稳时间序列来进行分析,会造成什么不良后果; ●如何判断一个时间序列是否为平稳序列;●当我们在计量经济分析中涉及到非平稳时间序列时,应作如何处理?第一节时间序列基本概念本节基本内容: ●伪回归问题●随机过程的概念●时间序列的平稳性一、伪回归问题传统计量经济学模型的假定条件:序列的平稳性、正态性。所谓“伪回归”,是指变量间本来不存在相依关系,但回归结果却得出存在相依关系的错误结论。 20世纪70年代,Grange、Newbold 研究发现,造成“伪回归”的根本原因在于时序序列变量的非平稳性三、时间序列的平稳性所谓时间序列的平稳性,是指时间序列的统计规律不会随着时间的推移而发生变化。直观上,一个平稳的时间序列可以看作一条围绕其均值上下波动的曲线。从理论上,有两种意义的平稳性,一是严格平稳,另一种是弱平稳。时间序列的非平稳性是指时间序列的统计规律随着时间的位移而发生变化,即生成变量时间序列数据的随机过程的特征随时间而变化。在实际中遇到的时间序列数据很可能是非平稳序列,而平稳性在计量经济建模中又具有重要地位,因此有必要对观测值的时间序列数据进行平稳性检验。第二节 时间序列平稳性的单位根检验本节基本内容: ●单位根检验● Dickey-Fuller检验● Augmented Dickey-Fuller检验一、单位根过程单位根过程结论: 随机游动过程是非平稳的。
因此,检验序列的非平稳性就变为检验特征方程是否有单位根,这就是单位根检验方法的由来。二、Dickey-Fuller检验(DF检验)大多数经济变量呈现出强烈的趋势特征。这些具有趋势特征的经济变量,当发生经济振荡或冲击后,一般会出现两种情形: ●受到振荡或冲击后,经济变量逐渐又回它们的长期趋势轨迹;●这些经济变量没有回到原有轨迹,而呈现出随机游走的状态。若我们研究的经济变量遵从一个非平稳过程,一个变量对其他变量的回归可能会导致伪回归结果。这是研究单位根检验的重要意义所在。 2 提出假设检验用统计量为常规t统计量, 3 计算在原假设成立的条件下t统计量值,查DF检验临界值表得临界值,然后将t统计量值与DF检验临界值比较:若t统计量值小于DF检验临界值,则拒绝原假设,说明序列不存在单位根;若t统计量值大于或等于DF检验临界值,则接受原假设,说明序列存在单位根。Dickey、Fuller研究发现,DF检验的临界值同序列的数据生成过程以及回归模型的类型有关,因此他们针对如下三种方程编制了临界值表,后来Mackinnon把临界值表加以扩充,形成了目前使用广泛的临界值表,在EViews软件中使用的是Mackinnon临界值表。 DF检验存在的问题是,在检验所设定的模型时,假设随机扰动项不存在自相关。但大多数的经济数据序列是不能满足此项假设的,当随机扰动项存在自相关时,直接使用DF检验法会出现偏误,为了保证单位根检验的有效性,人们对DF检验进行拓展,从而形成了扩展的DF检验Augmented Dickey-Fuller Test ,简称为ADF检验。根据《中国
第八章 时间序列分析
第八章时间序列分析与预测 【课时】6学时 【本章内容】 § 时间序列的描述性分析 时间序列的含义、时间序列的图形描述、时间序列的速度分析 § 时间序列及其构成分析 时间序列的构成因素、时间序列构成因素的组合模型 § 时间序列趋势变动分析 移动平均法、指数平滑法、模型法 § 时间序列季节变动分析 [ 原始资料平均法、趋势-循环剔除法、季节变动的调整 § 时间序列循环变动分析 循环变动及其测定目的、测定方法 本章小结 【教学目标与要求】 1.掌握时间序列的四种速度分析 2.掌握时间序列的四种构成因素 3.掌握时间序列构成因素的两种常用模型 4.掌握测定长期趋势的移动平均法 5.了解测定长期趋势的指数平滑法 6.; 7.掌握测定长期趋势的线性趋势模型法 8.了解测定长期趋势的非线性趋势模型法 9.掌握分析季节变动的原始资料平均法 10.掌握分析季节变动的循环剔出法 11.掌握测定循环变动的直接法和剩余法 【教学重点与难点】 1.对统计数据进行趋势变动分析,利用移动平均法、指数平滑法、线性模型法求得数 据的长期趋势; 2.对统计数据进行季节变动分析,利用原始资料平均法、趋势-循环剔除法求得数据 的季节变动; 3.对统计数据进行循环变动分析,利用直接法、剩余法求得循环变动。 【导入】 ; 很多社会经济现象总是随着时间的推移不断发展变化,为了探索现象随时间而发展变化的规律,不仅要从静态上分析现象的特征、内部结构以及相互关联的数量关系,而且应着眼于现象随时间演变的过程,从动态上去研究其发展变动的过程和规律。这时需要一些专门研究按照时间顺序观测的序列数据的统计分析方法,这就是统计学中的时间序列分析。 通过介绍一些时间序列分析的例子,让同学们了解时间序列的应用,并激发学生学习本章知识的兴趣。 1.为了表现中国经济的发展状况,把中国经济发展的数据按年度顺序排列起来,
8时间序列回归模型——R实现
时间序列回归模型 1干预分析 1.1概念及模型 Box和Tiao引入的干预分析提供了对于干预影响时间序列的效果进行评估的一个框架,假设干预是可以通过时间序列的均值函数或者趋势而对过程施加影响,干预可以自然产生也可 以人为施加的,如国家的宏观调控等。 其模型可以如下表示: 其中mt代表均值的变化,Nt是ARIMA过程。 1.2干预的分类 阶梯响应干预 區案1“ 書聲新镖第应干严的苕爭第见複也[榔帝右一牛时闽单恆的延遇) 01 "4》 * a_e—4 f-辜—右4—*— T 1)诅畠严 to it r ■P■1 F V*1 脉冲响应干预 图聲1J4荷关脉冲愉血于预的一牲常见棋型(都带衬一个时伺单也的延迟)
1.3干预的实例分析 1.3.1 模型初探 对数化航空客运里程的干预模型的估计 现任回到每月航空客运蚩程的数据.如前所述’ 2(X)1年9刀的悉怖裳击事杵便航空客运徘徊于萧条之中,该T?预效应可用在200]年9月有脉亦输入的AR (1)过程柬表示*这一意外爭件对航克容运虽即时造底了一种强烈的激冷效应*因此*对此干预效应<9-11 ?应)建模如下’ 叭=咖戶汙十1 3'严 1 —M M 展中,T代表2001年9小在这一衷示中*纽+助代表即时的9/11效应?且当^>1时* 纳(毗尸代表9门1效应对苴后A个月粉所造成的影响.这里还需要确定華础无扰过思的季节ARTMA 构*基于预干预数据,輛用一个AR1MA (0, 1, l)X<0?1, 0儿模型表示未愛扰的过程I券见图表11-5< > data(airmiles) > acf(as.vector(diff(diff(wi ndow(log(airmiles),e nd=c(2001,8)),12))) ,lag.max=48)# 用window 得到在911事件以前的未爱干预的时间序列子集 Seri?es碍皿伽〔aimaiffi(響¥蹄[嚅律「皿"河,enc, =口起 M 刖人 对暂用的模型进行诊断 >fitmode<-arima(airmiles,order=c(0,1,1),seas on al=list(order=c(0,1 ,0))) > tsdiag(fitmode)
计量经济学:时间序列模型习题与解析(1)复习课程
第九章 时间序列计量经济学模型的理论与方法 练习题 1、 请描述平稳时间序列的条件。 2、 单整变量的单位根检验为什么从DF 检验发展到ADF 检验? 3、设,10,sin cos ≤≤+=t t t x t θηθξ其中ηξ,是相互独立的正态分布N(0, 2 σ)随机变 量,θ是实数。试证:{10,≤≤t x t }为平稳过程。 4、 用图形及LB Q 法检验1978-2002年居民消费总额时间序列的平稳性,数据如下: 5、 利用4中数据,用ADF 法对居民消费总额时间序列进行平稳性检验。 6、 利用4中数据,对居民消费总额时间序列进行单整性分析。 7、 根据6中的结论,对居民消费总额的差分平稳时间序列进行模型识别。 8、 用Yule Walker 法和最小二乘法对7中的居民消费总额的差分平稳时间序列进行时间序 列模型估计,并比较估计结果。 9、 有如下AR(2)随机过程: t t t t X X X ε++=--2106.01.0 该过程是否是平稳过程? 10、求MA(3)模型3213.05.08.01---+-++=t t t t t u u u u y 的自协方差和自相关函数。 11、设动态数据,92.0,82.0,74.0,9.0,7.0,8.0654321======x x x x x x ,78.07=x ,84.0,72.0,86.01098===x x x 求样本均值x ,样本方差0?γ,样本自协方差1?γ、2?γ和样 本自相关函数1?ρ 、2?ρ。 12、判断如下ARMA 过程是否是平稳过程: 12114.01.07.0----+-=t t t t t x x x εε
时间序列的速度分析
时间序列的速度分析 一、学习目标: 1.掌握发展速度、增长速度、平均发展速度、平均增长速度指标 2.掌握定基发展速度和环比发展速度之间的关系 二、知识梳理: 1.发展速度的概念 2.发展速度的分类及联系: 3.增长速度的概念 4.增长速度的分类及联系: 5.平均发展速度的概念及计算: 6.平均增长速度的概念及计算: 三、典例解析: 1.时间序列中的速度指标包括()、()、() ()四类。 2.定基发展速度与环比发展速度的关系是:某期的定基发展速度等于相应的各环比发展速度的(),某期的环比发展速度等于该期的定基发展速度()上期的定基发展速度。 3.平均发展速度也属于(),它是对各期()求得的(),这种方法称作()或()。 4.某企业产品产量年年增加20万吨,则产量环比发展速度() A.年年下降 B.年年增长 C.年年不变 D.不确定 5.若各环比增长速度为4%,5%,8%,9%,则定基增长速度为() A. 4%*5%*8%*9% B 4%*5%*8%*9%—1 C.104%*105%*108%*109% D. 104%*105%*108%*109%—1
6.用几何平均法计算平均发展速度时,被开方的数是( ) A.环比发展速度之和 B.环比发展速度的连乘积 C.报告期发展水平与基期发展水平之比 D.发展总速度 E. 报告期发展水平与基期发展水平之差 试计算1995—2000年 (1) 该企业产量的平均发展水平; (2) 该企业的年平均增长量和平均增长速度。 四、限时训练: 1.增长速度的计算方法有两种,即( )和( )。 2.绝对增长量除以相应的用%表达的增长速度,叫( )。 3.说明现象在较长时期内发展的总速度是( ) A.环比发展速度 B.平均发展速度 C.定基增长速度 D.各年逐期增长量 4.已知各时期环比发展速度和时期数,便能计算出( ) A.平均发展速度 B.平均发展水平 C.各期定基发展速度 D.各年逐期增长量 E.累计增长量 要求:(1)计算并填列表中所缺数字。 (2)计算该地区1997—2001年间的平均国民生产总值。 (3)计算1998—2001年间国民生产总值的平均发展速度和平均增长速度。
时间序列分析法原理及步骤
时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征, 以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动, 即方差和数学期望稳定为常数 识别序列特征可利用函数 ACF :其中是的 k 阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于 0, 前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上, 预测模型大都难以满足这些条件, 现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归 AR(p模型
模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用 PACF 函数判别 (从 p 阶开始的所有偏自相关系数均为 0 2》移动平均 MA(q模型 识别条件
平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到 0, 则该时间序列可能是 ARMA(p,q模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解 p,q 和φ、θ的值,检验和的值。 模型阶数 实际应用中 p,q 一般不超过 2. 3》自回归综合移动平均 ARIMA(p,d,q模型 模型含义 模型形式类似 ARMA(p,q模型, 但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用 ARMA(p,q模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中 d (差分次数一般不超过 2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是 ARIMA(p,d,q模型。若时间序列存在周期性波动, 则可按时间周期进
基于时间序列模型与线性回归模型的历史数据预测
基于时间序列模型与线性回归模型的历史数据预测 摘要:本文通过具体案例,简要说明根据时间序列数据建立和相应经济理论建立线性回归模型的简要步骤及基本原则,并着重介绍了在模型建立和模型有效性检验过程中需要注意的三个主要问题,最后简单介绍了进行模型修正的相应方法。 一、引言 多元线性回归模型的一般形式为: Y=β0+β1X1+β2X2+…+βkXk+μi(k,i=1,2,…,n) 其中k为解释变量的数目,βk(k=1,2,…,n)称为回归系数,上式也被称为总体回归函数的随机表达式。 从统计意义上说,所谓时间序列模型就是将某一个指标在不同时间上的不同数值,按照时间的先后顺序排列而成的数列。这种数列由于受到各种偶然因素的影响,往往表现出某种随机性,彼此之间存在着统计上的依赖关系。从数学意义上说,如果我们对某一过程中的某一个变量或一组变量X(t)进行观察测量,在一系列时刻t1,t2,…,tn(t为自变量,且t1 时间序列数据的计量分析方法 1.时间序列平稳性问题及处理方案 1.1序列平稳性的定义 从平稳时间序列中任取一个随机变量集,并把这个序列向前移动h 个时期,那么其联合概率分布仍然保持不变。 平稳时间序列要求所有序列间任何相邻两项之间的相关关系有相同的性质。 1.2不平稳序列的后果 可能两个变量本身不存在关系而仅仅因为有相似的时间趋势而得出它有关系,也就是出现伪回归;破坏回归分析的假设条件,使得回归结果和各种检验结果不可信。 1.3平稳性检验方法:ADF 检验 1.3.1ADF 检验的假设: 辅助回归方程:11t t i t i t i Y Y t Y ραργβμ--==+++?+∑(是否有截距和时间趋势项 在做检验时要做选择) 原假设:H 0:p=0,存在单位根 备择假设:H 1:P<0,不存在单位根 结果识别方法:ADF Test Statistic 值小于显著性水平的临界值,或者P 值小于显著性水平则拒绝原假设并得出结论:所检测序列不存在单位根,即序列是平稳序列。 1.3.2实例 对1978年2008年的中国GDP 数据进行ADF 检验,结果如表一。 表一 ADF 检验结果 Augmented Dickey-Fuller test statistic t-Statistic Prob.* 3.063621 1 Test critical values: 1% level -3.699871 5% level -2.976263 10% level -2.62742 从结果可以看出,ADF 的t 统计量值大于10%显著性水平上的临界值,P 值为1,接受原假设,说明所检测的GDP 数据是不平稳序列。 1.4不平稳序列的处理方法 1.4.1方法 如果所要分析的数据是不平稳序列,可以对序列进行差分使其变成平稳序列,但是这样做的后果是使新得出的数据丧失了许多原序列的特征,我们能从数据中得到的信息会变少,通常差分的次数不能超过两次。 经验表明,存量数据是二阶单整,做二次差分可以使其平稳,流量数据是一阶单整,做一次差分可以使其平稳,增量数据通常就是平稳序列。 1.4.2实例 第三节 时间序列的速度分析 【本节考点】 1、发展速度与增长速度的概念 2、发展速度和增长速度的计算方法 3、定基发展速度与环比发展速度之间的关系,并能利用这种关系进行速度之间的相互推算。 4、平均发展速度和平均增长速度的含义及计算方法 5、 速度分析中应注意的问题,增长1%绝对值的含义及其用途, 增长1%绝对值的计算方法。 【本节内容】 【知识点一】发展速度与增长速度 (一)发展速度 1、发展速度:是以相对数形式表示的两个不同时期发展水平的比值,表明报告期水平已发展到基期水平的几分之几或若干倍。 发展速度= 基期水平报告期水平 由于基期选择的不同,发展速度有定基发展速度与环比发展速度之分。 (1)定基发展速度:报告期水平与某一固定时期水平(通常是最初水平)的比值,用i a 表示, i y y 最初水平报告期水平定基发展速度= i a (2)环比发展速度是报告期水平与其前一期水平的比值,用i b 表示, 1 i i y y -= 报告期前一期水平报告期水平环比发展速度i b 【应用举例】某地区2000~2002年钢材使用量(单位:万吨)如下: (3)定基发展速度与环比发展速度之间的关系 第一,定基发展速度等于相应时期内各环比发展速度的连乘积 推导: 定基发展速度 1 2312010-??????=n n n y y y y y y y y y y =各环比发展速度的连乘积 第二,两个相邻时期定基发展速度的比率等于相应时期的环比发展速度 推导: 相邻时期定基发展速度的比率 0y y n /01y y n -=1 -n n y y =相应时期的环比发展速度 【例题14:2005年、2006年、2007年单选题】以2000年为基期,我国2002、2003年广义货币供应量的定基发展速度分别是137.4%和164.3%,则2003年与2002年相比的环比发展速度是( )。 A.16.4% B.19.6% C.26.9% D.119.6% 【答案】D 【解析】相邻时期定基发展速度的比率 0y y n /01y y n -=1 -n n y y =相应时期的环比发展速度 所以,2003年与2002年环比发展速度 =2003年定基发展速度÷2002年定基发展速度 =164.3%÷137.4%=119.6% 【例题15:单选题】已知某地区以1990年为基期,1991-1996年财政收入的环比发展速度为115.71%、118.23%、108.01%、131.9%、122.95%、101.54%,以1990年为基期的1996年财政收入的定基发展速度为() A.40.55% 回归分析时间序列分析答案 一、单项选择题 1、下面的关系中不是相关关系的是(D ) A、身高与体重之间的关系 B、工资水平与工龄之间的关系 C、农作物的单位面积产量与降雨量之间的关系 D、圆的面积与半径之间的关系 2、具有相关关系的两个变量的特点是(A ) A、一个变量的取值不能由另一个变量唯一确定 B、一个变量的取值由另一个变量唯一确定 C、一个变量的取值增大时另一个变量的取值也一定增大 D、一个变量的取值增大时另一个变量的取值肯定变小 3、下面的假定中,哪个属于相关分析中的假定(B) A、两个变量之间是非线性关系 B、两个变量都是随机变量 C、自变量是随机变量,因变量不是随机变量 D、一个变量的数值增大,另一个变量的数值也应增大 4、如果一个变量的取值完全依赖于另一个变量,各观测点落在一条直线上,则称这两个变量之间为(A ) A、完全相关关系 B、正线性相关关系 C、非线性相关关系 D、负线性相关关系 5、根据你的判断,下面的相关系数取值哪一个是错误的( C ) A、–0.86 B、0.78 C、1.25 D、0 x6、某校经济管理类的学生学习统计学的时间()与考试成绩(y)之间建立线性回归方程y x=a+b。经计算,方程为y =200—0.8x,该方程参数的计算(C) cc A a值是明显不对的 B b值是明显不对的 C a值和b值都是不对的 D a值和b值都是正确的 7、在回归分析中,描述因变量y如何依赖于自变量x和误差项ε的方程称为(B) A、回归方程 B、回归模型 C、估计回归方程 D、经验回归方程 ,,,x,,8、在回归模型y=中,ε反映的是(C ) 01 A、由于x的变化引起的y的线性变化部分 B、由于y的变化引起的x的线性变化部分 C、除x和y的线性关系之外的随机因素对y的影响 D、由于x和y的线性关系对y的影响 9、如果两个变量之间存在负相关关系,下列回归方程中哪个肯定有误(B) ,, A、=25–0.75x B、= –120+ 0.86x yy ,, C、=200–2.5x D、= –34–0.74x yy 10、说明回归方程拟合优度的统计量是(C ) A、相关系数 B、回归系数 C、判定系数 D、估计标准误差 211、判定系数R是说明回归方程拟合度的一个统计量,它的计算公式为(A ) SSRSSRSSESSTA、 B、 C、 D、 SSTSSESSTSSR 12、为了研究居民消费(C)与可支配收入(Y)之间的关系,有人运用回归分析的方法,得到以下方程:在该方程中0.76的含义是(B ) LnC,2.36,0.76LnY, A、可支配收入每增加1元,消费支出增加0.76元计量经济学--时间序列数据分析
第三节时间序列的速度分析
回归分析时间序列分析答案.doc