SPSS数据录入及处理

安徽新华学院实验报告姓名朱俊杰学号1141153149 专业班级财管1班
课程名称统计学A 指导教师田老师实验日期2013.9.6 实验名称SPSS数据录入及处理
得分
一、实验目的
1、熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;
2、掌握SPSS的数据录入功能。
二、实验内容
根据数据特点建立SPSS数据文件
三、实验步骤(实验结果、实验分析等)
1:打开SPSS
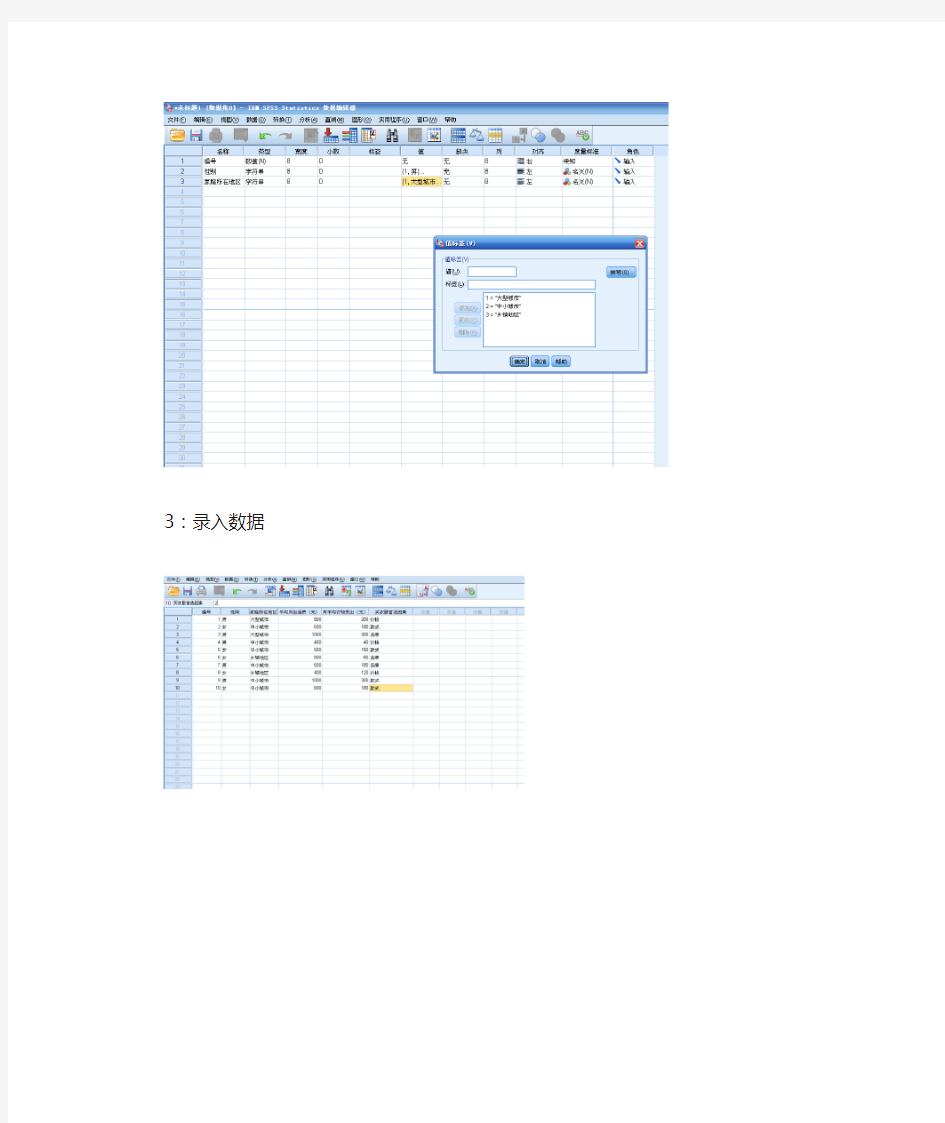
2:定义变量
3:录入数据
spss复习整理讲课教案
一、单项选择题:(本大题小题,1 分/每小题,共分) 1.SPSS 的数据文件后缀名是: (A) .sav 2. 对数据的各种统计处理,SPSS是在下面哪一个选项中进行: (A) 数据编辑窗口; 3. 在SPSS中,下面哪一个不是SPSS的运行方式 (A) 输入运行方式; 4. 下面哪一个选项不属于SPSS的数据分析步骤: (D)数据扩展; 5. 在SPSS中,下面哪一个选项不属于对变量(列)的描述: (B) 变量名称大小; 6. 在SPSS的定义中,下面哪一个变量名的定义是错误的: (D)A_BFG_ ;首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或数字。下划线、圆点不能为变量名的最后一个字符。SPSS允许用汉字作为变量名。 7. 在SPSS的定义中,下面哪一个变量名的定义是错误的: (A)AND ;SPSS有默认的变量名,以字母"VAR开头,后面补足5位数字,如VAR00001 VAR00012等。变量名不能与SPSS内部特有的具有特定含义的保留字同名,如ALL、BY、AND、NOT、OR等。 8. 在SPSS数据文件中,下面那一项不属于数据的结构: (D)数据值; 9. 在SPSS数据文件中,下面那一项属于数据的内容: (D)数据值; 10. 通常来说,发放了900份问卷,可直接得到的有效问卷有800份,贝U SPSS所建立的相关数据文件中的行数为 (D)800; 11. 下面那一项不属于SPSS的基本变量类型: (D)整数型; 12. 当在SPSS数据文件中输入变量为“职工姓名”,则应选择的变量类型是: (B) 字符串型; 13. 当在SPSS数据文件中输入变量为“职工工资数”,则应选择的变量类型是: (A) 数值型; 13. 当在SPSS数据文件中输入变量为“公司成立日期”,则应选择的变量类型是: (C) 日期型; 14. 在SPSS的数据结构中,下面那一项不是“缺失数据”的定义: (D) 数据不是科学计数法; 15. 统计学依据变量的计量尺度将变量分为三类,以下哪一类不属于这三类: (D)科学计数类型; 16. 在统计学中,变量“身高”属于计量尺度中的: (A) 数值型变量;身高(定距)、优良中差(定序)、性别(定类) 17. 在统计学中,将变量“年龄”分为“老年”、“中年”、“青年”三个取值,分别用1、2、3 表示,则变量“年龄”属于计量尺度中的: (B) 定序型变量; 18. 在统计学中,将变量“性别”分为“男”、“女”、两个取值,分别用1、2表示,则变量 “性别”属于计量尺度中的: (C) 定类型变量; 19. 下面哪一个选项不能被SPSS系统正常打开: (C) 文本文件格式; 20. 下面哪一个选项不能被SPSS系统正常打开: (D) .exe ; 21. 在SPSS数据编辑窗口中,需要定义变量的数据结构,以下哪一项不属于变量的数据结构: (D) 变量值;
spss数据处理结构分析
公司的行政人员认为自己与市场部的人员和研发部的人员差异太大;公司总经理则认 为行政人员的综合技能、教育背景与市场部人员和研发部人员也存在明显差异,行政 人员如何通过统计方法证实自己的结论?请构造相关数据,选择合适的统计方法进行 统计验证,并对统计结果进行分析和说明 (1)本例中职工按行政人员、市场人员、研发人员依次设为 合技能、教育背景和工资四个变量,采用单因素方差分析。 (2)SPSS 分析过程: 1、进入SPSS10.0,打开相关数据文件,选择“分析 均值检验 单因素方差分析”, 弹出单因素方差分析对话框,选择变量“职位”使其进入因子( F )框中,选择变量 “综合技能、教育背景、工资”使其进入因变量列表( D )框中。 I I L 対比紗… 两心做 凹?, Boatctrap(fl). ?定]岸陽曰]单? [取消J 、帮切J 2、单击两两比较按钮,选中假定方差齐性框中的 LSD (最小显著差法),同时选中 Equal 未假定方差齐性框中的 Tamhane 'T2。 趟羊吕秦AHOVA;两比较 | S | 佃疋性 1( L5D L) □ S-N-KO) Wall IF -Dune an
spss复习资料整理
第一章 1.SPSS是软件英文名称的首字母缩写,其最初为Statistical Package for the Social Sciences的缩写,即“社会科学统计软件包”。 2.SPSS系统运行管理方式(SPSS的几种基本运行方式)有: (1)完全窗口菜单运行方式 (2)程序运行管理方式 (3)混合运行管理方式 3.SPSS的界面提供的五个窗口:数据编辑窗口、结果管理窗口、结果编辑窗口、语法编辑窗口、脚本窗口。 第二章 1.SPSS的文件类型:语法文件(*.sps)、数据文件(*.sav)、结果输出文件(*.spv)。 2.SPSS数据编辑器的每一行数据称为一个个案(Case),每一个数据代表个体的属性,即变量(V ariable)。 3.SPSS变量名的命名规则: 1)必须以英文字母开头,其他部分可以含有字母、数字、下划线(即“-”); 2)变量名尽量避免和SPSS已有的关键字重复,例如sum、compute、anova等; 3)SPSS13及以后版本支持变量名最长为64Byte,即变量名最长为64个英文字符,或者32个中文字符; 4)SPSS变量名不区分大小写,即SPSS认为Name、name、nAme这三个变量名没有区别。 4.变量度量类型:定量(个数、高度、温度等)、定序(“十分重要”、“重要”、“一般”、“不重要”)、定类(名字、地址、电话等)。 5.列和宽度的区别: 变量宽度:对字符型变量,该数值决定了你能输入的字符串的长度; 列:设定该变量数据视图中列的宽度。 7.默认的缺失值类型:数值型类型(.)、字符串类型(空格)。 8.数据文件的合并包括:纵向合并和横向合并(合并个案和合并变量),合并变量包括一对一合并和一对多合并。 9.SPSS用“(*)”表示变量来自于当前活动数据文件中的变量,而用“(+)”表示将要和当前数据文件进行合并的数据文件中的变量。 10.在合并数据文件之前,所有需要合并的数据文件必须预先按照关键变量进行升序排列。否则,合并文件程序将失败。 11.(选择题)一对一合并变量时,两个文件都要提供个案;一对多合并时,活动的和非活动的文件都可以作为关键字。 课后练习题: 6.下列可以作为SPSS变量名的是 A).PRENTS12 B).1Name C).NOT TRUE D).@result 7.SPSS中可以设置工作目录,具体设置可以按照以下菜单: A).【选项】→【设置】 B).【编辑】→【选项】→【设置】 C).【编辑】→【选项】→【文件位置】
实验二--SPSS数据录入与编辑
实验二--SPSS数据录入与编辑
实验二 SPSS数据录入与编辑 一、实验目的 通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.录入数据 2.保存数据文件 3.编辑数据文件 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗 4.按要求录入数据 5.联系基本的数据修改编辑方法 6.保存数据文件 7.关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 一、定义变量 1.试录入以下数据文件,并按要求进行变量定义。 学号姓名性 别生日身高 (cm) 体重 (kg) 英语(总 分100 分) 数学(总 分100 分) 生活费 ($代表 人民币) 200201 刘一迪男1982.01.12 156.42 47.54 75 79 345.00 200202 许兆辉男1982.06.05 155.73 37.83 78 76 435.00 200203 王鸿屿男1982.05.17 144.6 38.66 65 88 643.50 200204 江飞男1982.08.31 161.5 41.68 79 82 235.50 200205 袁翼鹏男1982.09.17 161.3 43.36 82 77 867.00 200206 段燕女1982.12.21 158 47.35 81 74 200207 安剑萍女1982.10.18 161.5 47.44 77 69 1233.00 200208 赵冬莉女1982.07.06 162.76 47.87 67 73 767.80 200209 叶敏女1982.06.01 164.3 33.85 64 77 553.90 200210 毛云华女1982.09.12 144 33.84 70 80 343.00 200211 孙世伟男1981.10.13 157.9 49.23 84 85 453.80 200212 杨维清男1981.12.6 176.1 54.54 85 80 843.00 200213 欧阳已 祥 男1981.11.21 168.55 50.67 79 79 657.40 200214 贺以礼男1981.09.28 164.5 44.56 75 80 1863.90 200215 张放男1981.12.08 153 58.87 76 69 462.20 200216 陆晓蓝女1981.10.07 164.7 44.14 80 83 476.80 200217 吴挽君女1981.09.09 160.5 53.34 79 82 200218 李利女1981.09.14 147 36.46 75 97 452.80 200219 韩琴女1981.10.15 153.2 30.17 90 75 244.70 200220 黄捷蕾女1981.12.02 157.9 40.45 71 80 253.00 1)对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。 3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
SPSS简明教程(X2检验和T检验)
SPSS最适用的统计学方法(X2检验和T检验) 1.SPSS的启动 (1)在windows[开始]→[程序]→[spss20],进入SPSS for Windows对话框, 2.创建一个数据文件 三个步骤: (1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。 (2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。 (3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。3.读取外部数据 当前版本的SPSS可以很容易地读取Excel数据,步骤如下: (1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对
话框,在文件类型下拉列表中选择数据文件,如图2.2所示。 图2.2 Open File对话框 (2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。对话框中各选项的意义如下: 工作表下拉列表:选择被读取数据所在的Excel工作表。 范围输入框:用于限制被读取数据在Excel工作表中的位置。 图2.3 Open Excel Data Source对话框 4.数据编辑
在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。5.SPSS数据的保存 SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS数据保存。 图2.5 SPSS数据的保存 5. 数据分析 在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下 6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文 第六章:描述性统计分析(X2检验) 完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
Spss数据处理方法
Spss数据处理方法 1.打开软件,新建文件,双击变量一栏,出现一个表格,在名称一栏中依次填写指标名称 (只能是字母),输入后其他栏自动显示,小数点可调整到3,其他可不变;同时要输入组别名称 2.输完后在视图中点数据,就会出现数据栏,在相应的指标名称下输入数据,在组别名称 下输入样本标记,每组样本用同一个数字表示。 3.输完后点窗口上面的分析下拉菜单中的比较均衡,其中有单因素方差分析,出现对话框, 因变量中输入指标名称,因子中输入组的名称。 4.对话框中有选项,对比,两两比较,选项中描述性和两两比较中的LSD必选,其他的 项目也可以选,选完后确定就可以了。 LSD最小显著性差别S-N-K waller-duncan dunnett Tukey检验scheffe多重比较 Bonferroni邦弗伦尼统计量 Using repeated-measures single factor analysis of variance and Bonferroni statistical tests (P < 0. 05), intervertebral motion redistribution of each construct was compared with the intact. 使用重复测量变异的单因子分析和Bonferroni统计学测试,我们将每个结构的椎间盘运动再分布与完整运动进行了比较。 levene Tukey HSD Dunnett T3 bonferroni Using repeated-measures single factor analysis of variance and Bonferroni statistical tests (P < 0. 05), intervertebral motion redistribution of each construct was compared with the intact. 使用重复测量变异的单因子分析和Bonferroni统计学测试,我们将每个结构的椎间盘运动再分布与完整运动进行了比较。 LSD:最小显著性差异 ?Scheffe: (四)雪費法(Scheffe)事後檢定:經單因子變異數分析之後,如果F值達到顯著水準,再以雪費法(Scheffe)進行事後比較以瞭解真正存有差異組別之基于20个网页 - 搜索相关网页 ?雪费 本研究结果显示研究对象在籍贯的不同其牙医医疗服务利用有显著差异(P=0.046),且经雪费(Scheffe)的事后检定显示外省人在牙医医疗服务利用高于本省闽南,在其他的研究中未有此发现,研究者于是进一步的去了解,发现本研究对象中... 基于13个网页 - 搜索相关网页 ?以雪費 分析檢定;若P值小於0.05達到顯著水準,再以雪費(Scheffe)進行事後檢定,比較其差異,以下將一一進行分析。 基于12个网页 - 搜索相关网页 ?雪費法 (四)雪費法(Scheffe)事後檢定:經單因子變異數分析之後,如果F值達到顯著水準,再以雪費法(Scheffe)進行事後比較以瞭解真正存有差異組別之基于12个网页 - 搜索相关网页 -Scheffe Method:事后比较 ?事后比较
SPSS数据录入与编辑
实验二 SPSS数据录入与编辑 一、实验目的 通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.录入数据 2.保存数据文件 3.编辑数据文件 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗 4.按要求录入数据 5.联系基本的数据修改编辑方法 6.保存数据文件 7.关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 一、定义变量 1. 试录入以下数据文件,并按要求进行变量定义。 1)对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。 3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
2.试录入以下数据文件,保存为“数据1.sav”。
实验三统计图的制作与编辑 一、实验目的 通过本次实验,了解如何制作与编辑各种图形。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.条形图的绘制与编辑 2.直方图的绘制与编辑 3.饼图的绘制与编辑 五、实验学时 2学时 六、实验方法与步骤 1.开机; 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS; 3.按要求完成上机作业; 4. 关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。 3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
spss简明教程检验和t检验
S P S S最适用的统计学方法(X2检验和T检验) 1.SPSS的启动 (1)在windows[开始]→[程序]→[spss20],进入SPSSforWindows对话框, 2.创建一个数据文件 三个步骤: (1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。 (2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。 (3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。 3.读取外部数据 当前版本的SPSS可以很容易地读取Excel数据,步骤如下: (1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。 图2.2OpenFile对话框 (2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。对话框中各选项的意义如下: 工作表下拉列表:选择被读取数据所在的Excel工作表。 范围输入框:用于限制被读取数据在Excel工作表中的位置。 图2.3OpenExcelDataSource对话框 4.数据编辑 在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。 5.SPSS数据的保存 SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS数据保存。 图2.5SPSS数据的保存 5.数据分析 在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下 6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文 第六章:描述性统计分析(X2检验) 完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
SPSS多选题的数据录入方法
SPSS问卷分析之编码录入及描述统计详解 问卷调查的方法用得很广泛,第一步面临的就是问卷编码问题,有很多外专业的同学都在问这个问题,现在通过举例的方法详细讲解如下,以方便第一次接触SPSS的同学也能做简单的分析。后面还有分析时的操作步骤,以及比较适用的深入统计分析方法的简单介绍。自己写的,错误之处请指正. 调查分析问卷回收,在经过核实和清理后就要用SPSS做数据分析,首先的第一步就是把问题编码录入。 SPSS的问卷分析中一份问卷是一个案,首先要根据问卷问题的不同定义变量。定义变量值得注意的两点:一区分变量的度量,Measure的值,其中Scale是定量、Ordinal是定序、Nominal是指定类;二注意定义不同的数据类型Type 各色各样的问卷题目的类型大致可以分为单选、多选、排序、开放题目四种类型,他们的变量的定义和处理的方法各有不同,我们详细举例介绍如下: 1 单选题:答案只能有一个选项 例一当前贵组织机构是否设有面向组织的职业生涯规划系统? A有 B 正在开创 C 没有D曾经有过但已中断 编码:只定义一个变量,Value值1、2、3、4分别代表A、B、C、D 四个选项。 录入:录入选项对应值,如选C则录入3 2 多选题:答案可以有多个选项,其中又有项数不定多选和项数定多选。 (1)方法一(二分法): 例二贵处的职业生涯规划系统工作涵盖哪些组群?画钩时请把所有提示考虑在内。 A月薪员工B日薪员工C钟点工 编码:把每一个相应选项定义为一个变量,每一个变量Value值均如下定义:“0” 未选,“1” 选。
录入:被调查者选了的选项录入1、没选录入0,如选择被调查者选AC,则三个变量分别录入为1、0、1。 (2)方法二: 例三你认为开展保持党员先进性教育活动的最重要的目标是那三项: 1()2 ()3() A、提高党员素质 B、加强基层组织 C、坚持发扬** D、激发创业热情 E、服务人民群众 F、促进各项工作 编码:定义三个变量分别代表题目中的1、2、3三个括号,三个变量Value值均同样的以对应的选项定义,即:“1” A,“2” B,“3” C,“4” D,“5” E,“6” F 录入:录入的数值1、2、3、4、5、6分别代表选项ABCDEF,相应录入到每个括号对应的变量下。如被调查者三个括号分别选ACF,则在三个变量下分别录入1、3、6。 注:能用方法二编码的多选题也能用方法编码,但是项数不定的多选只能用二分法,即方法一是多选题一般处理方法。 3 排序题:对选项重要性进行排序 例四您购买商品时在①品牌②流行③质量④实用⑤价格中对它们的关注程度先后顺序是(请填代号重新排列)第一位第二位第三位第四位第五位 编码:定义五个变量,分别可以代表第一位第五位,每个变量的Value都做如下定义:“1” 品牌,“2” 流行,“3” 质量,“4” 实用,“5” 价格 录入:录入的数字1、2、3、4、5分别代表五个选项,如被调查者把质量排在第一位则在代表第一位的变量下输入“3“。 4 选择排序题: 例五把例三中的问题改为“你认为开展保持党员先进性教育活动的最重的目标是那三项,并按重要性从高到低排序”,选项不变。 编码:以ABCDEF6个选项分别对应定义6个变量,每个变量的Value都做同样的如下定义:“1” 未选,“2” 排第一,“3” 排第二,“4” 排第三。
T检验相关spss数据
第一问:两组评酒员的评价结果有显著性差异,第二组更可靠一些T检验 单个样本统计量 N 均值标准差均值的标准误 第一组红27 73.056 7.3426 1.4131 第二组红27 70.515 3.9780 .7656 频率
频率表 第一组红 频率百分比有效百分比累积百分比有效53.9 1 3.7 3.7 3.7 58.7 1 3.7 3.7 7.4 59.9 1 3.7 3.7 11.1 62.7 1 3.7 3.7 14.8 68.6 1 3.7 3.7 18.5 69.2 1 3.7 3.7 22.2 70.1 1 3.7 3.7 25.9 71.5 1 3.7 3.7 29.6 72.2 1 3.7 3.7 33.3 72.3 1 3.7 3.7 37.0 73.0 2 7.4 7.4 44.4 73.3 1 3.7 3.7 48.1 73.8 1 3.7 3.7 51.9 74.2 1 3.7 3.7 55.6 74.6 1 3.7 3.7 59.3 74.9 1 3.7 3.7 63.0 77.1 1 3.7 3.7 66.7 77.2 1 3.7 3.7 70.4 78.0 1 3.7 3.7 74.1 78.6 2 7.4 7.4 81.5 79.3 1 3.7 3.7 85.2 80.3 1 3.7 3.7 88.9 80.4 1 3.7 3.7 92.6 81.5 1 3.7 3.7 96.3 85.6 1 3.7 3.7 100.0 合计27 100.0 100.0 第二组红 频率百分比有效百分比累积百分比有效61.6 1 3.7 3.7 3.7 65.3 1 3.7 3.7 7.4 65.4 1 3.7 3.7 11.1
SPSS数据初步整理须知
SPSS数据初步整理须知 对于问卷收集到的调查数据或通过其它方法,如眼动仪、脑电仪以及生理记录仪等获得的数据,在进入SPSS分析前最好对数据进行预处理,其作用:防止错误数据导致不恰当的推论。本次主要谈谈问卷数据在分析前的一些预处理工作。 数据预处理的步骤: 1. 对所有数据源的质量进行初步审核。 1.1 剔除无效答卷。如是问卷数据,可以查看被调查者的回答是否呈现某种规律,或者回答者不符合我们调查的人群,或者存在大量题目漏答现象。 1.2 检查是否有明显错误回答。如是否按指导语进行回答,基本信息是否有误。是否有明显的回答矛盾等等。 2. 对数据进行编码。 编码主要有事前编码和事后编码,事前编码主要针对封闭式问卷,而事后编码则主要是针对开放式问题。 编码有三个工作:第一是定义数据的变量名,第二定义变量名标签,即这个变量代表什么意思。第三定义变量值及值标签。即变量的取值,以及这个取值的含义。如变量名为sex,其变量标签为“性别”,其变量的取值为“1”或“2”,分别表示“男”和“女”(变量值标签)。 2 2.1 单选题的编码。第一定义变量名,一般用题目序号,如第6题,则变量名为Q6,其变量名标签一般用问题。而变量的取值则为单选题的选项。有几个选项就有几个变量值,而值的标签则是选项的内容。 2.2 多选题的编码。每一个选项就得作为一个新变量。如第7题是多选题,有五个选项,可多选三项。则五道选项分别定义变量名为Q71,……Q75,每个变量名的标签即这五道选项的内容。而变量值及标签为“0”或“1”,0表示未选,1表示选中。 2.3 排序题的编码。有两种方法:其一跟多选题类似。如第7题要求对所选的三个选项进行排序。变量名及标签同上。而变量值除了“0”(表示未选)外,还有“1”“2”“3”分别表示排序第一,排序第二,排序第三。其二根据要求选择三项进行排序,则只需要定义三个变量,Q71,Q72,Q73,变量名标签则表示排序第一,排序第二,排序第三。变量值为五道选项的序号,而变量值标签则分别是五道选项的内容。 2.4 开放题的编码。首先应将开放题中受试所填写的选项进行分类汇总。初次归类尽量归细一点。再做统计分析时如果觉得分类太细可以再次进行归大类。
spss缺失值处理
spss数据录入时缺失值怎么处理 录入的时候可以直接省略不录入 分析的时候也一般剔除这样的样本。但也有替换的方法,一般有: 均值替换法(mean imputation),即用其他个案中该变量观测值的平均数对缺失的数据进行替换,但这种方法会产生有偏估计,所以并不被推崇。 个别替换法(single imputation)通常也被叫做回归替换法(regression imputation),在该个案的其他变量值都是通过回归估计得到的情况下,这种 方法用缺失数据的条件期望值对它进行替换。这虽然是一个无偏估计,但是却倾向于低估标准差和其他未知性质的测量值,而且这一问题会随着缺失信息的增多而变得更加严重。 多重替代法(multiple imputation)(Rubin, 1977) 。 ?它从相似情况中或根据后来在可观测的数据上得到的缺省数据的分布情况给每个缺省数据赋予一个模拟值。结合这种方法,研究者可以比较容易地,在不舍弃任何数据的情况下对缺失数据的未知性质进行推断(Little and Rubin,1987; ubin,1987, 1996)。 (一)个案剔除法(Listwise Deletion) 最常见、最简单的处理缺失数据的方法是用个案剔除法(listwise deletion),也是很多统计软件(如SPSS和SAS)默认的缺失值处理方法。在这种方法中如果任何一个变量含有缺失数据的话,就把相对应的个案从分析中剔除。如果缺失值所占比例比较小的话,这一方法十分有效。至于具体多大的缺失比例算是“小”比例,专家们意见也存在较大的差距。有学者认为应在5%以下,也有学者认为20%以下即可。然而,这种方法却有很大的局限性。它是以减少样本量来换取信息的完备,会造成资源的大量浪费,丢弃了大量隐藏在这些对象中的信息。在样本量较小的情况下,删除少量对象就足以严重影响到数据的客观性和结果的正确性。因此,当缺失数据所占比例较大,特别是当缺数据非随机分布时,这种方法可能导致数据发生偏离,从而得出错误的结论。 (二)均值替换法(Mean Imputation) 在变量十分重要而所缺失的数据量又较为庞大的时候,个案剔除法就遇到了困难,因为许多有用的数据也同时被剔除。围绕着这一问题,研究者尝试了各种各样的办法。其中的一个方法是均值替换法(mean imputation)。我们将变量的属性分为数值型和非数值型来分别进行处理。如果缺失值是数值型的,就根据该变量在其他所有对象的取值的平均值来填充该缺失的变量值;如果缺失值是非数值型的,就根据统计学中的众数原理,用该变量在其他所有对象的取值次数最多的值来补齐该缺失的变量值。但这种方法会产生有偏估计,所以并不被推崇。均值替换法也是一种简便、快速的缺失数据处理方法。使用均值替换法插补缺失数据,对该变量的均值估计不会产生影响。但这种方法是建立在完全随机缺失(MCAR)的假设之上的,而且会造成变量的方差和标准差变小。 (三)热卡填充法(Hotdecking)
用SPSS进行单样本T检验(OneSampleTTest)
用SPSS进行单样本T检验(One -Sample T Test) 在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。看例子: 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 分析:此检验的假设是: H0:该市五年级学生的400米平均成绩是仍为100秒。 H1:该市五年级学生的400米平均成绩是不为100秒。 打开SPSS,读入数据
从结果中可以判断: 1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。 2、95%的置信区间端点一正一负,必然覆盖总体均值。应该接受零假设(假设H0)。 这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。 再看一个更有趣的例子。 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 同上,打开SPSS,读入数据,结果: 从结果中判断: t统计值的显著性概率为0.005小于1%,在1%犯错误的水平上拒绝零假设。可以认为,今年该市五年级学生的400米平均成绩明显下降了。
SPSS所处理的数据文件有两种来源
SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件。 1 在SPSS数据编辑窗口建立数据文件 当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。 图进入SPSS数据编辑器 (1) 数据编辑(SPSS Data Editor)界面介绍 窗口名显示栏:在窗口的顶部,显示窗口名称和编辑的数据文件名,没有文件名时显示为“Untitled-SPPS Data Editor”。 窗口控制按钮:在窗口的顶部的右上角,第一个按钮是窗口最小化,第二个按钮是窗口最大化,第三个按钮是关闭窗口。SPSS主菜单:在窗口显示的第二行上,有:File文档,Edit编辑,View显视,Data数据,Transform转换,Analyze分析,Graphs 图形,Utilities公用项,Windows视窗。
图 SPSS窗口界面 常用工具按钮:在窗口显示的第三行上,有:打开文档,保存文档,打印,对话检索,取消当前操作,重做操作,转到图形窗口,指向记录,指定变量操作,查找,在当前记录的上方插入新的空白记录,在当前变量的左边插入新的空白变量,切分文件,设置权重单元,标记单元,显示价值标签。 数据单元格信息显示栏:在编辑显示区的上方,左边显示单元格和变量名(单元格:变量名),右边显示单元里的内容。 编辑显示区:在窗口的中部,最左边列显示单元序列号,最上边一行显示变量名称,缺省为“Var”。 编辑区选择栏:在编辑显示区下方,Data View 在编辑显示区中显示编辑数据,Variable View在编辑显示区中显示编辑数据变量信息。 状态显示栏:在窗口的底部,左边显示执行的系统命令,右边显示窗口状态。 (2) 数据文件格式 数据文件格式以每一行为一个记录,或称观察单位(Cases),每一列为一个变量(Variable)。由于SPSS不同的统计分
调查问卷的SPSS的基本处理方法
调查问卷的SPSS的基本处理方法(Z)SPSS是常用的数理统计软件之一,也可以用于调查问卷的统计分析,一下就调查问卷的一些基本分析处理方法做一些简单的描写。另外,虽然SPSS也有图表功能,但个人认为不是很好用,建议还是将统计分析的数据导到EXCEL中再作图表。 频度分析 频度就是某个选项出现的次数,一般用来描述单选项。 问卷设计实例: 企业经营规模为(年销售额:人民币): □>30亿□5~30亿□0.5~5亿□<0.5亿 数据记录要点: 单列记录,第几项选中记录数值几,例如选中“0.5~5亿”则记录3。 SPSS基本操作方法: 导入数据; Analyze……Descriptive statistics……Freq uencies 选入该列数据,“OK”。 多项频次分析 用来描述多选项目的频次。 问卷设计实例: 贵公司产品的主要竞争力表现在(多选): □外观□功能□质量□个性化□价格(成本)□交货期□其它 数据记录要点: 多列记录,有几个选项记几列,选中记为1,未选中记为0。例如如果选中了外观和质量,则多列的记录为1,0,1,0,0,0,0。 SPSS基本操作方法: 导入数据; Analyze……Multiple Response……Define Sets 选入该问题的多列数据,给新的集合变量取名(在Name那里填一个名字,例如“竞争力”),在Dichotomies Counted value中输入1,“Add”。 Analyze……Multiple Response……Frequencies 选人自定义的集合变量,“OK”。 交叉频次分析
用来描述变量之间的关联性,比如分析不同销售额企业的产品竞争力的关联关系(这两项之间不一定有关系,可以用logistic分析验证一下)。 问卷设计实例: 参见上面的两项。 数据记录要点: 参见上面两项。 SPSS基本操作方法(单选对单选,单选对多选,单选对多选在操作上略有不同): 导入数据;如果有多选项需要按2的方法定义集合变量。 如果是单选对单选 Analyze……Descriptive statistics……Crosstabs 否则: Analyze……Multiple Response……Crosstabs 将两变量分别选入行和列中(多选项是选人集合变量,如果是单选对多选还要设置单选项的最大最小值),“OK” 描述分析 一般用来描述单变量的描述统计量,这些述统计量有平均值、算术和、标准差,最大值、最小值、方差、范围和平均数标准误等。问卷中用得不是特别多。 问卷设计实例(一般是开放性问题): 贵企业三维CAD已经应用了年。 数据记录要点: 单列记录,直接记录所填数据。 SPSS基本操作方法: 导入数据; Analyze……Descriptive statistics……Descriptives 选入该列数据,“Options…”,在其中选择需要的统计项目,问卷常用的项目有Mean(平均值)、Minimum( 最小值)、Maximum(最大值)等,“Continue”, “OK”。
调查问卷数据SPSS分析中—多项选择问题处理方法
SPSS多项选择问题处理方法 多项选择题是定量问卷调查中常见的封闭式选择题,这种选择题的出现可以在确定的范围内更多的考察被调研对象的看法。在针对消费者的调研中,这种选择题多是出现在针对品牌知名度,包括提示前知名度、第一提及率,提示后知名度的分析中。 ?常见的分析方法 一般的研究分析手段主要应用包括EXCEL与SPSS在内的频次分析,然后再将在不同数据字段同一类选项数据进行加总,然后再以被调研对象的总体数量为基数,二者相除来得到多项选择题中各选项在总体中的占有率,这种各选项占有率的加总大于1。 例如某类产品品牌知名度调查中,关于该类产品您能想起哪些品牌? 01 品牌A 02品牌B 03品牌C 04品牌D 05品牌E 06品牌F 07其它品牌_____ 该问题在数据字段设计时最少要设计10个字段以供数据录入与分析。按上面的数据分析方法,先在这10个字段中进行分别的频次计算,然后进行加总再除以总基数,得到该选项的总体占有比率。以A选项为例: (01字段中A的占有率+02字段中A的占有率+ …… +06字段中A的占有率)/被调对象总数=A的占有率以此类推分别计算出其它品牌的占有率,频次计算次数与分类加和计算次数比较繁杂,其工作量在被选项较少时还算省事,但当被选项数量在十几个、二十几个甚至三十几个时,该分析方法则极大降低了分析人员的工作效率。 ?高效率数据分析方法 运用SPSS重组再分析的数据方法将极大提高数据分析效率并降低人为计算失误。 在SPSS数据库中运用 “Multiple Response”对多组数据进行组合再定义,这样会针对每个单一选择题定义出一个新的字段组,在新字段组中对变量区间进行定义,再针对新字段组进行频次分析。当完成单一字段设置后,可运用程序段对其它多项选择题进行再利用分析,这样可以大大提高多项选择题数据分析效率。 分析程序例举: ************** MULT RESPONSE GROUPS=$tsh '新字段组名称' (var00018 var00019 var00020 var00021 var00022 var00013 var00014 var00015 var00016 var00017 (1,111))
SPSS对数据进行T检验统计分析
SPSS对数据进行T检验统计分析 下面将做此项目的最后一个环节,即使用SPSS进行统计分析。先用SPSS来做组设计两样本均数比较的T检验,其步骤如下。 (1)执行Analyze/Compare Means/Independent-Samples T test命令,打开如图1-43所示的对话框。 (2)在该对话框中选择X放入TEST列表框中,选择Group放入Grouping Variable文本框中,如图1-44所示。 图1-43 打开T检验对话框 图1-44 选择入列表
(3)单击Define Groups按钮,系统弹出比较组定义对话框,如图1-45所示。 (4)在该对话框中的两个值框中分别输入1和2,然后单击Continue按钮,如图1-46所示。 图1-45 比较组定义对话框 图1-46 输入值 (5)单击T检验对话框中的OK按钮,如图1-47所示。
图1-47 进行T检验 (6)系统经过计算后,会弹出结果浏览窗口。首先给出的是两组的基本情况描述,如样本量、均数等,然后是T检验的结果,如图1-48所示。 图1-48 T检验结果 从上图中可见,结果分为两大部分:第一部分为Levene's方差检验,用于判断两体方差是否齐,这里的检验结果为F=0.032,p=0.860,可见在本例中方差齐;第二部分则分别给出两组所在部体方差齐和方差不齐时的T检验结果,即上面一行列出的T=2.542,V=22,p=0.019。从而最终的统计结论为按=0.05水准,拒绝H0,认为克山病患者与健康人的血磷值是不同的。从样本均数来看,可以确定克山病患者的血磷值较高。
spss简明教程(x检验和t检验)
SPSS 最适用的统计学方法(X 2 检验和T 检验) 1. SPSS 的启动 (1) 在windows[开始]→[程序]→[spss20],进入SPSS for Windows 对话框, 2.创建一个数据文件 三个步骤: (1)选择菜单 【文件】→【新建】→【数据】新建一个数据文件。 (2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。 (3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。 3.读取外部数据 当前版本的SPSS 可以很容易地读取Excel 数据,步骤如下: (1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。 图2.2 Open File 对话框 (2)选择要打开的Excel 文件,单击“打开”按钮,调出打开Excel 数据源对话框,如图2.3所示。对话框中各选项的意义如下: 工作表 下拉列表:选择被读取数据所在的Excel 工作表。 范围 输入框:用于限制被读取数据在Excel 工作表中的位置。 图2.3 Open Excel Data Source 对话框 4.数据编辑 在SPSS 中,对数据进行基本编辑操作的功能集中在Edit 和Data 菜单中。 5.SPSS 数据的保存 SPSS 数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS 数据保存。 图2.5 SPSS 数据的保存 5. 数据分析 在SPSS 中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下 6.语言切换:编辑(E )—选项(N )--用户界面-语言--简体中文 第六章:描述性统计分析(X 2检验) 完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X 2检验也 在其中完成。