一种多源异构数据融合技术在PGIS系统中的研究与应用

一种多源异构数据融合技术在PGIS系统中
的研究与应用
周凯1,2
(1.四川省公安科研中心,四川成都610015;2.四川大学,四川成都610064)
[摘要]警用地理信息系统是公安机关维稳处突、打击违法犯罪行为的重要技术支撑平台。多源异构数据是维护该平台安全稳定、高效运行的底层核心数据。文章以某PGIS平台为例,针对多源异构数据使用中遇到的数据不兼容、格式不统一、属性数据非空间化、空间数据格式转化等问题,提出了一种多源异构数据的融合模型。通过属性清洗、属性追加、空间匹配、格式转化等流程化操作,实现了空间与非空间、结构与非结构等数据的融合使用。并可以基于PGIS平台,统一加载、统一展示、统一应用。通过利用该技术,挖掘了数据的利用价值,为类似平台数据处理提供了技术参考与经验。
[关键词]多源异构;PGIS;数据融合
[中图分类号]P208[文献标识码]A[文章编号]1674-5019(2019)02-0051-05
A Multi-Source Heterogeneous Data Fusion Technology in PGIS
System Research and Application
ZHOU Kai
1引言
数据融合的本质是多方数据协同处理,以达到减少冗余、综合互补和捕捉协同信息的目的。该技术已成为数据处理、目标识别、态势评估以及智能决策等领域的研究热点[1]。通过数据融合,能够将研究对象获取的所有信息全部统一在一个时空体系内,得到比单独输入数据更多的信息。警用地理信息系统(Police Geographic Information System,简称“PGIS”)是多源异构数据技术、地理信息技术和公安系统业务工作高度结合的产物[2]。利用多源异构数据融合技术的PGIS平台,可以实现跨省、市、县等行政区域的一张图展示,可达到资源的高度统一利用。但在实际工作过程中,支撑PGIS平台的基础地理信息数据种类繁多,从平面线划图到精细化三维成果,从空间数据到非空间数据,从海量兴趣点数据(poi)到各种图像数据应有尽有。面对大数据时代海量的数据资源,如何保障PGIS平台业务数据、测绘地理信息数据、“一标三实”等数据高效利用,互补短板,统一承载于警用地理信息平台,协同发挥数据最大价值,提高数据在分析决策中的应用价值,是当下PGIS平台发展研究的热点问题[2-3]。
2研究方法2.1多源异构数据融合技术
数据集成是数据融合的基础,融合是集成基础上的深化应用,通过数据集成与融合,可派生出更高更有价值的新数据,从而得到数据的更多利用价值[4]。马茜等人[5]基于物联网背景下多源数据获取、存储等存在的不足,提出了一种约束数据质量的异构多源多模态感知数据获取方法,提高了数据精度,降低了网络资源消耗。韩双旺[6]基于XML语言实现异构多源空间数据的映射和模式转换,利用WebGIS技术实现了空间数据的集成和互操作。惠国保[7]结合深度学习技术,构思了一种泛化性强的多源异构影像数据融合深度学习模型,实现了深度学习技术在多源异构数据方面的信息提取与挖掘。李文闯等人[8]提出了一种基于可交换图像文件(EXIF)原理以数字图像为载体融合空间位置信息和一般形式属性的数据模型,实现了空间位置和一般属性嵌入到数字图像物理结构,达到了数据融合的效果。
本文不仅需要解决各种数据的属性嵌套、数据集成,而且要解决空间数据和非空间数据、空间数据与空间数据、结构数据与非结构数据之间的转化问题。因此鉴于实际需求,本文提出了基于FME平台下自主构建多源异构数据引擎,开展数据融合,实现多源异构数据的集成统一、高效利用。
智慧城市多源异构大数据处理框架
智慧城市多源异构大数据处理框架 摘要:智慧城市建设的重心已由传统IT系统和信息资源共享建设,转变为数据的深度挖掘利用和数据资产的运营流通。大数据中心是数据资产管理和利用的实体基础,其核心驱动引擎是大数据平台及各类数据挖掘与分析系统。讨论了智慧城市大数据中心建设的功能架构,围绕城市多源异构数据处理的实际需要,对数据中心大数据平台的架构进行了拆分讲解,并以视频大数据处理为例,阐述了数据中心数据平台的运转流程。 关键词:智慧城市;大数据;多源异构;视频分析 1 引言 随着智慧城市建设逐步由信息基础设施和应用系统建设迈入数据资产集约利用与运营管理阶段,城市大数据中心已成为智慧城市打造核心竞争力、提升政府管理效能的重要工具。一方面政府借助大数据中心建设可以将有限的信息基础设施资源集中高效管理和利用,大幅降低各自为政、运维机关庞杂、财政压力过大的问题;另一方面,可以在国务院、发展和改革委员会大力支持的政策东风下,打破部门间数据壁垒,推动政府各部门职能由管理转为服务,提高数据共享利用率和透明度。以大数据中心为核心构建城市驾驶舱,实现城市运转过程的实时全面监控,提高政府决策的科学性和及时性。智慧城市大数据中心建设功能框架如图1所示,其中针对不同部门的数据源,由数据收集系统完成数据的汇聚,并根据数据业务类型和容的差异进行粗分类。为避免过多“脏数据”对大数据平台的污染,对于批量数据,不推荐直接将数据汇入大数据平台,而是单设一个前端原始数据资源池,在这里暂时存储前端流入的多源异构数据,供大数据平台处理调用。 图1 智慧城市大数据中心功能框架
大数据平台是城市大数据中心运转的核心驱动引擎,主要完成多源数据导入、冗余存储、冷热迁移、批量计算、实时计算、图计算、安全管理、资源管理、运维监控等功能[1],大数据平台的主体数据是通过专线连接或硬件复制各政府部门数据库的方式获得,例如地理信息系统(geographic information system,GIS)数据、登记信息等。部分数据通过直连业务部门传感监测设备的方式获得,例如监控视频、河道流量等。大数据平台的输出主要是结构化关联数据以及统计分析结果数据,以方便各类业务系统的直接使用。 不同部门间共享与交换的数据不推荐直接使用原始数据,一方面是因为原始数据容密级存在差异,另一方面是因为原始数据容可能存在错误或纰漏。推荐使用经过大数据平台分类、过滤和统计分析后的数据。不同使用部门经过政务信息门户统一需求申请和查看所需数据,所有数据的交换和审批以及数据的监控运维统一由数据信息中心负责,避免了跨部门协调以及数据管理不规等人为时间的损耗,极提高了数据的流通和使用效率。另外,针对特定的业务需求,可以基于大数据平台拥有的数据进行定制开发,各业务系统属于应用层,建设时不宜与大数据平台部署在同一服务器集群,并且要保证数据由大数据平台至业务系统的单向性,尽量设置业务数据过渡区,避免应用系统直接对大数据平台核心区数据的访问。 目前主流大数据平台都采用以Hadoop为核心的数据处理框架,例如Cloudera公司的 (Transwarp)的TDH(Transwarp CDH(Cloud er a Distribution for Hadoop)和星环信息科技() Data Hub)、Apache Hadoop等。以Hadoop为核心的大数据解决方案占大数据市场95%以上的份额,目前国80%的市场被 Cloudera占有,剩余20%的市场由星环信息科技()、红象云腾系统技术、华为技术等大数据公司分享。随着数据安全意识的增强、价格竞争优势的扩大,国企业在国大数据市场的份额和影响力正在快速提升。大数据的应用历程可归纳为3个阶段:第一个阶段是面向互联网数据收集、处理的搜索推荐时代;第二个阶段是面向金融、安全、广播电视数据的用户画像和关系发现时代;第三个阶段是面向多数据源与多业务领域数据的融合分析与数据运营时代,并且对数据处理规模和实时性的要求大幅提高。 本文在智慧城市大数据中心建设方案的基础上,阐述了多源异构大数据处理的框架和流程,并以最典型的非结构化视频大数据处理为例,介绍了多源异构大数据处理框架运转的流程。 2 多源异构大数据处理框架 2.1 系统整体架构 多源异构是大数据的基本特征[2],为适应此类数据导入、存储、处理和交互分析的需求,本文设计了如图2所示的系统框架,主要包括3个层面的容:基础平台层、数据处理层、应用展示层。其中,基础平台层由Hadoop生态系统组件以及其他数据处理工具构成,除了提供基本的存储、计算和网络资源外,还提供分布式流计算、离线批处理以及图计算等计算引擎;数据处理层由多个数据处理单元组成,除了提供基础的数据抽取与统计分析算法外,还提供半结构化和非结构化数据转结构化数据处理算法、数据容深度理解算法等,涉及自然语言处理、视频图像容理解、文本挖掘与分析等,是与人工智能联系最紧密的层,该层数据处理效果的好坏直接决定了业务应用层数据统计分析的准确性和客户体验;应用展示层由SSH(Struts+Spring+Hibernate)框架及多类前端可视化工具组成,对应用层的约束是比较宽松的,主要是对数据处理层结果的进一步归纳和总结,以满足具体业务的需要。系统框架的使用优先推荐开源生态系统及其组件,系统存储主要依托Hadoop分布式文件系统(Hadoop distributed file system,HDFS)、HBase,同时支持Oracle、MySQL等结构化数据存储系统,计算框架涵盖MapReduce、Storm、Spark以及定制分布式视频流处理引擎,可视化系统基于SSH框架设计,可根据实际需求,灵活配置。
多源信息融合软件的设计与实现精编WORD版
多源信息融合软件的设计与实现精编W O R D 版 IBM system office room 【A0816H-A0912AAAHH-GX8Q8-GNTHHJ8】
多源信息融合软件的设计与实现 摘要:针对多源信息类型不一致影响信息利用效率的问题,文章在分析传统多源数据融合模型的基础上,研究了多源信息融合软件的架构及相关技术,设计并开发的软件具有较高的实用价值。 关键词:多源信息;信息融合;软件开发 多源信息融合是通过将多种信源在空间上和时间上的互补与冗余信息依据某种优化准则组合起来,产生对特点对象的一致性解释与描述。数据融合技术是指利用计算机对获得的信息,在一定准则下加以自动分析、综合,以完成所需决策和评估任务而进行的信息处理技术。主要包括对各类信息源给出有用信息的采集、传输、综合、过滤、相关及合成,以便辅助人们进行态势/环境判定、规划、探测、验证。 数据格式统一是进行数据处理的前提。由于信息的来源多,数据格式类别差异较大,对于数据处理带来不便。多源信息融合软件能够实现多源异构数据信息整合,对于充分利用信息资源、提高数据处理系统性能具有实用价值。 1 多源数据融合模型 根据对输入信息的抽象或融合输出结果的不同,可以将信息融合分为不同的3级,包括数据级融合、特征级融合及决策级融合。 作为数据级的多源数据融合模型的结构如图1所示。多源数据经过数据清理、数据集成、数据变换,形成有效数据,通过数据处理形成数据挖掘分析等处理工作的有效数据。
数据清理是指去除源数据集中的噪声数据和无关数据,处理遗留数据和清洗脏数据,去除数据域的知识背景上的白噪声,考虑时间顺序和数据变化等。主要包括处理噪声数据,处理空值,纠正不一致数据等。 数据集成就是将多文件或多数据库运行环境中的异构数据进行合并处理,将多个数据源中的数据结合起来存放在一个一致的数据存储中。 数据变换就是将数据变换成统一的适合处理的形式。数据变换主要包括平滑、聚集、属性构造、数据泛化和规范化等内容。 2 多源信息融合软件设计 2.1 软件架构 多源信息融合软件的技术要求是实现多源异构数据向指定关系数据库进行可靠转换。就是按照指定关系数据库的表结构要求,实现多源异构数据的数据导入及格式转换问题。软件的组成框图如图2所示。软件主要包括2个主要模块,多源数据预处理模块和数据导入模块。数据预处理模块主要进行数据清理及格式转换,实现常用的数据(txt、xls、关系数据库等数据)转换为目标数据库支持的数据格式。数据导入实现指定类型数据转换为指定结构数据。 2.2 关键技术 为了保证多源信息软件的可靠运行,需解决数据类型的适应性和扩展性问题,以及数据转换的可靠性、可预制性、数据转换过程的可监督性问题。 2.2.1 基于模块化设计的类型转换
电力大数据应用现状及多源异构数据分析技术研究
龙源期刊网 https://www.360docs.net/doc/5817702056.html, 电力大数据应用现状及多源异构数据分析技术研究 作者:马平徐伟东沈浩钦吴杭 来源:《中国科技纵横》2014年第23期 【摘要】智能电网运行、检修和管理过程中会产生海量异构、多态数据,如何将它们进行高效可靠存储,并实现快速分析访问已是当前电力系统中重要的研宄课题。本文在分析电力生产各个环节大数据的产生来源和特点基础上,阐述市场已有大数据技术在电力系统应用的优势和不足。最后,从电网异构多源信息融合及可视化方向提出了一种应用方法。 【关键词】智能电网 ;大数据 ;异构分析 ;可视化 1 引言 近年来,随着全球能源问题日益严峻[1],世界各国都开展了智能电网的研究工作。智能 电网的最终目标是建设成为覆盖电力系统整个生产过程,包括发电、输电、变电、配电、用电及调度等多个环节的全景实时系统。而支撑智能电网的基础是电网大数据全景实时数据采集、传输、存储以及快速分析。目前智能电网中的大数据主要来自以下几个方面: (1)海量电网状态信息采集设备。常规的调度自动化系统含数十万个采集点,配用电、数据中心将达到百万甚至千万级。需要监测的设备数量巨大,每个设备都装有若干传感器,构成了一个庞大的数据网。 (2)高频电网状态信息捕获技术。为满足上层应用需求,设备的采样频率逐渐提高。在输变电设备状态监测系统中,为了能对绝缘放电等状态进行诊断,信号的采样频率必须在 200kHz以上,特高频检测需要GHz的采样率。 (3)视频及模式识别系统推广。智能电网视频监控系统不仅要求能够真实地反映电力系统的情况,并且还需自动判断情况的好与坏,同时自动采取相关措施,是一个“会思考”、“能做事”的智能化系统。为此,需要电网具备强大存储及处理能力。 2 现有大数据处理技术局限性 谷歌公司提出的分布式文件系统(distributed file system,DFS)和MapReduce技术,已成为现阶段Facebook、雅虎等网络公司大数据应用的解决方案[2]。 DFS技术,具备高容错性特点,可部署在海量且价格低廉的硬件设备上,而且它为应用程序提供了高吞吐量的数据访问,适合那些有着超大数据集程序。MapReduce为2004年由谷歌公司提出的一个用来进行并行处理和生成大数据集的并行编程模型。应用“解析器”,将复杂数
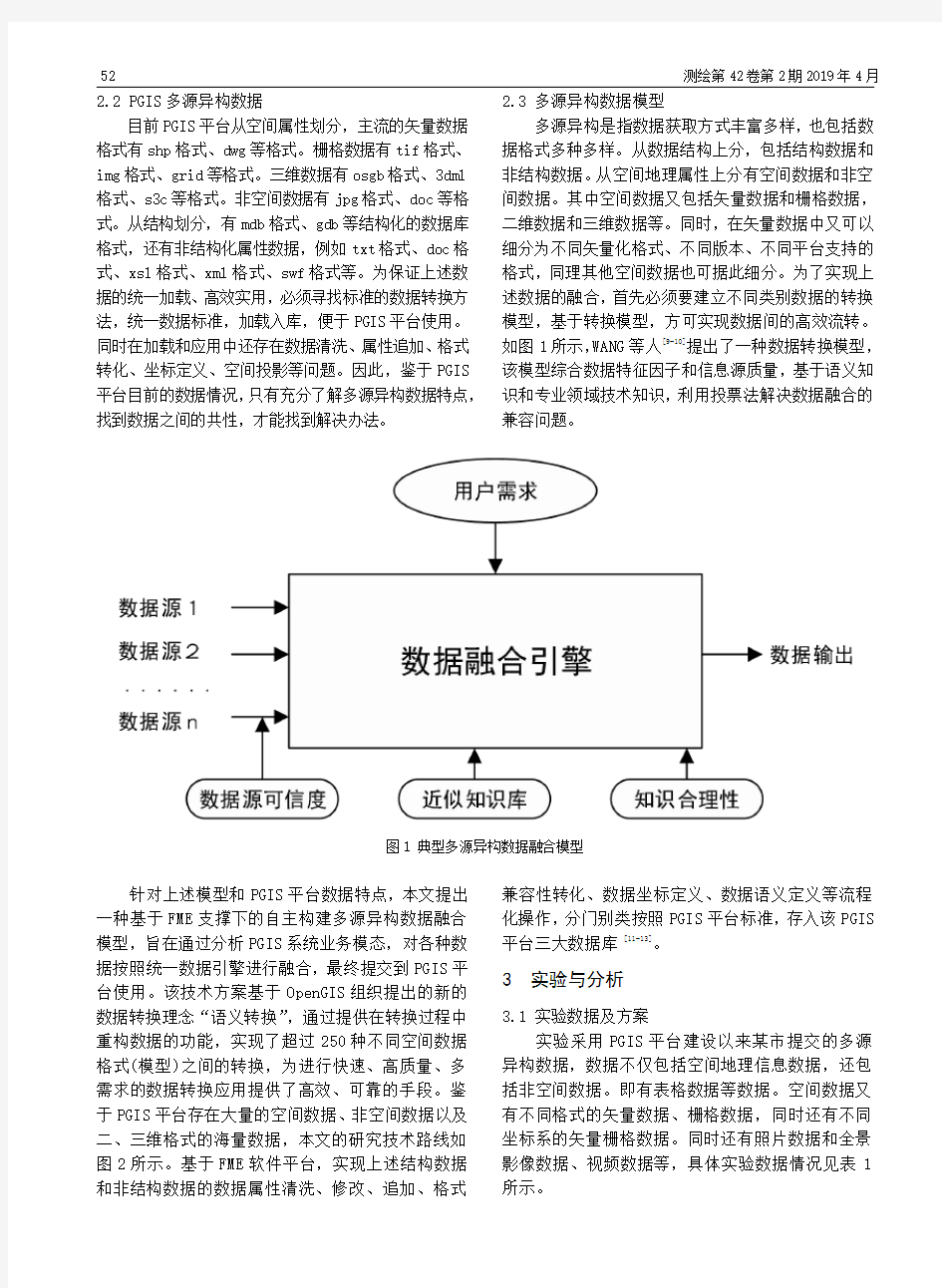
一种多源异构数据融合技术在PGIS系统中的研究与应用
一种多源异构数据融合技术在PGIS系统中 的研究与应用 周凯1,2 (1.四川省公安科研中心,四川成都610015;2.四川大学,四川成都610064) [摘要]警用地理信息系统是公安机关维稳处突、打击违法犯罪行为的重要技术支撑平台。多源异构数据是维护该平台安全稳定、高效运行的底层核心数据。文章以某PGIS平台为例,针对多源异构数据使用中遇到的数据不兼容、格式不统一、属性数据非空间化、空间数据格式转化等问题,提出了一种多源异构数据的融合模型。通过属性清洗、属性追加、空间匹配、格式转化等流程化操作,实现了空间与非空间、结构与非结构等数据的融合使用。并可以基于PGIS平台,统一加载、统一展示、统一应用。通过利用该技术,挖掘了数据的利用价值,为类似平台数据处理提供了技术参考与经验。 [关键词]多源异构;PGIS;数据融合 [中图分类号]P208[文献标识码]A[文章编号]1674-5019(2019)02-0051-05 A Multi-Source Heterogeneous Data Fusion Technology in PGIS System Research and Application ZHOU Kai 1引言 数据融合的本质是多方数据协同处理,以达到减少冗余、综合互补和捕捉协同信息的目的。该技术已成为数据处理、目标识别、态势评估以及智能决策等领域的研究热点[1]。通过数据融合,能够将研究对象获取的所有信息全部统一在一个时空体系内,得到比单独输入数据更多的信息。警用地理信息系统(Police Geographic Information System,简称“PGIS”)是多源异构数据技术、地理信息技术和公安系统业务工作高度结合的产物[2]。利用多源异构数据融合技术的PGIS平台,可以实现跨省、市、县等行政区域的一张图展示,可达到资源的高度统一利用。但在实际工作过程中,支撑PGIS平台的基础地理信息数据种类繁多,从平面线划图到精细化三维成果,从空间数据到非空间数据,从海量兴趣点数据(poi)到各种图像数据应有尽有。面对大数据时代海量的数据资源,如何保障PGIS平台业务数据、测绘地理信息数据、“一标三实”等数据高效利用,互补短板,统一承载于警用地理信息平台,协同发挥数据最大价值,提高数据在分析决策中的应用价值,是当下PGIS平台发展研究的热点问题[2-3]。 2研究方法2.1多源异构数据融合技术 数据集成是数据融合的基础,融合是集成基础上的深化应用,通过数据集成与融合,可派生出更高更有价值的新数据,从而得到数据的更多利用价值[4]。马茜等人[5]基于物联网背景下多源数据获取、存储等存在的不足,提出了一种约束数据质量的异构多源多模态感知数据获取方法,提高了数据精度,降低了网络资源消耗。韩双旺[6]基于XML语言实现异构多源空间数据的映射和模式转换,利用WebGIS技术实现了空间数据的集成和互操作。惠国保[7]结合深度学习技术,构思了一种泛化性强的多源异构影像数据融合深度学习模型,实现了深度学习技术在多源异构数据方面的信息提取与挖掘。李文闯等人[8]提出了一种基于可交换图像文件(EXIF)原理以数字图像为载体融合空间位置信息和一般形式属性的数据模型,实现了空间位置和一般属性嵌入到数字图像物理结构,达到了数据融合的效果。 本文不仅需要解决各种数据的属性嵌套、数据集成,而且要解决空间数据和非空间数据、空间数据与空间数据、结构数据与非结构数据之间的转化问题。因此鉴于实际需求,本文提出了基于FME平台下自主构建多源异构数据引擎,开展数据融合,实现多源异构数据的集成统一、高效利用。
【大数据】多源异构通用大数据处理服务平台
一、项目背景及必要性 (一)国内外现状和技术发展趋势 大数据是指海量的数据加上复杂的数据类型。从产业的发展角度看,我们对数据的利用经历了传输、传播、处理三个阶段,而今眼目下,对数据的利用正处在处理这个阶段,即如何处理、如何管理、如何应用,如何优化是现阶段的主要工作。 大数据的具体特点主要表现为四个“V”:一是体量浩大(Volume),数据集合的规模已从GB到TB再到PB级,甚至已经开始以EB和ZB来计算。著名咨询公司IDC的研究报告称,未来10年全球大数据将增加50倍,管理数据仓库的服务器的数量将增加10倍。二是类型复杂(Variety),大数据类型包括结构化数据、半结构化数据和非结构化数据。现代互联网应用呈现出非结构化数据大幅增长的特点,到20152年末非结构化数据将达到整个数据量的75%以上。三是生成迅速(Velocity),大数据通常以数据流的形式动态、快速地产生,具有很强的时效性。数据自身的状态与价值也随时空变化而发生演变,数据的涌现特征明显。四是价值巨大但利用密度低(Value),基于传统思维与技术让人们在实际环境中面临信息泛滥而知识匮乏的窘态。 当今社会,新摩尔定律得到验证,大数据以成为各行各业的焦点。数据的来源多样化:以多源异构数据为代表的非结构化数据占世界上信息总量的95%以上,剩下的5%为结构化数据,包括网页、文本、交易数据、邮件、高清视频、3D视频、语音、图片、地质勘测
数据、多源异构数据探测数据等等,这些数亿TB的数据正以超乎人们想象的速度增长,这对数据的存储系统的容量和实时计算速度提出了空前的要求。同时,大到智慧地球,小到智慧城市的数字化建设,使其越来越多的人、设备和传感器通过数字网络连接起来,产生、传送、分享和访问数据的能力也得到彻底变革。这些行业包括:互联网、制造业、医疗行业、媒体行业、零售销售行业、金融业、能源业、航空航天等等。预计2015年,超过40亿人(世界人口的60%)在使用各种智能终端,以全方位的方式与各行各业发生交互融合。其中大约12%拥有智能终端——其渗透率以每年20%以上的速度增长。如今,3000多万联网传感器节点分布在互联网、交通、汽车、工业、公用事业和零售部门,其数量正以每年30%以上的速度增长。预计到2020年,全球数据使用量预计暴增44倍,达到35.2ZB。35.2ZB也就是说全球大概需要376亿个1TB硬盘来存储数据。 人们对数据日益广泛的需求导致存储系统的规模变得越来越庞大,管理越来越复杂,数据的爆炸性增长和管理能力的相对不足之间的矛盾日益尖锐。同时,数据的高速增长也对存储系统的可靠性和扩展性提出了挑战,海量数据的共享、分析、搜索也显得越来越重要,充分挖掘海量数据中的有效价值。这就要求我们得实现一种有别于传统系统而全新的存储管理平台,该平台必须具备高扩展性、高可靠性、高时效性,同时也需要具备高经济性,只有这样才能更好的为国民经济和生活服务。 国外的大数据发展现状,以GOOGLE/FACEBOOK为代表的
【CN110110082A】多源异构数据融合优化方法【专利】
(19)中华人民共和国国家知识产权局 (12)发明专利申请 (10)申请公布号 (43)申请公布日 (21)申请号 201910294678.8 (22)申请日 2019.04.12 (71)申请人 黄红梅 地址 510610 广东省广州市天河区沾益直 街1号 申请人 何卓华 谢新屋 (72)发明人 黄红梅 何卓华 谢新屋 (74)专利代理机构 北京联瑞联丰知识产权代理 事务所(普通合伙) 11411 代理人 张学府 (51)Int.Cl. G06F 16/35(2019.01) G06F 16/903(2019.01) (54)发明名称 多源异构数据融合优化方法 (57)摘要 本发明公开了一种多源异构数据融合优化 方法,包括如下步骤:A)对数据实例、类别和属性 进行提取和分析,建立词库和短文本库;B)从互 联网获取多源异构数据;C)对多源异构数据进行 规范化处理,生成短文本;短文本有多个词构成, 规范化处理包括分词和去除停用词;D)将短文本 作为待匹配短文本,将待匹配短文本与短文本库 中存储的短文本进行匹配,得到短文本匹配结 果;E )根据短文本匹配结果对数据进行融合,建 立大数据内容模型,得到数据融合结果;F )对数 据融合结果进行评价,得到评价结果;评价结果 包括优、良、中和差。本发明能建立完整性、准确 性和一致性较强的高质量的大数据知识库。权利要求书2页 说明书5页 附图1页CN 110110082 A 2019.08.09 C N 110110082 A
1.一种多源异构数据融合优化方法,其特征在于,包括如下步骤: A)对数据实例、类别和属性进行提取和分析,建立词库和短文本库; B)从互联网获取多源异构数据; C)对所述多源异构数据进行规范化处理,生成短文本;所述短文本由多个词构成,所述规范化处理包括分词和去除停用词; D)将所述短文本作为待匹配短文本,将所述待匹配短文本与短文本库中存储的短文本进行匹配,得到短文本匹配结果; E)根据所述短文本匹配结果对数据进行融合,建立大数据内容模型,得到数据融合结果; F)对所述数据融合结果进行评价,得到评价结果;所述评价结果包括优、良、中和差。 2.根据权利要求1所述的多源异构数据融合优化方法,其特征在于,所述步骤D)进一步包括: D1)计算所述待匹配短文本与短文本库中的短文本之间的字符匹配因子; D2)计算所述待匹配短文本与短文本库中的短文本之间的词匹配因子; D3)根据所述字符匹配因子和词匹配因子,对所述待匹配短文本与短文本库中的短文本进行匹配,计算短文本匹配因子。 3.根据权利要求2所述的多源异构数据融合优化方法,其特征在于,所述字符匹配因子 采用如下公式进行计算: 其中,F 1表示所述字符匹配因子,c 1表示所述待匹配短文本包含的字符数,c 2表示所述短文本库中的短文本包含的字符数,p表示匹配的字符数,h表示换位的数目。 4.根据权利要求3所述的多源异构数据融合优化方法,其特征在于,所述词匹配因子采 用如下公式进行计算: 其中,F 2表示所述词匹配因子,n表示维数较高短文本向量的维数,σ表示修正因子,σ∈ [0.9,1.3],用于修正增加词带来的误差,A i 为所述待匹配短文本中的第i个词,B i 为短文本库中的短文本中的第i个词。 5.根据权利要求4所述的多源异构数据融合优化方法,其特征在于,所述短文本匹配因 子采用如下公式进行计算: 其中,Y表示短文本的匹配因子;设定匹配阈值Y 0,若Y≥Y 0,则说明所述待匹配短文本与短文本库中的短文本相匹配,若Y<Y 0,则说明所述待匹配短文本与短文本库中的短文本不匹配。 6.根据权利要求5所述的多源异构数据融合优化方法,其特征在于,所述步骤E)具体 权 利 要 求 书1/2页2CN 110110082 A
论中医药多源异构大数据融合方法研究的意义
Traditional Chinese Medicine 中医学, 2018, 7(5), 282-285 Published Online September 2018 in Hans. https://www.360docs.net/doc/5817702056.html,/journal/tcm https://https://www.360docs.net/doc/5817702056.html,/10.12677/tcm.2018.75047 On the Significance of the Method of Multi-Source Heterogeneous Data Fusion in TCM Hanqing Zhao, Zhiguo Wang* Institute of Basic Research in Clinical Medicine, China Academy of Chinese Medical Sciences, Beijing Received: Aug. 18th, 2018; accepted: Aug. 26th, 2018; published: Sep. 3rd, 2018 Abstract Multi-source isomerism is one of the basic features of large data. It is a hot issue in recent years to study traditional Chinese medicine diagnosis and treatment methods based on data. Building a generalization model is one of the methods to solve multisource heterogeneous data fusion and shares and extends the scope of traditional Chinese medicine data. However, the complexity of the large data of traditional Chinese medicine is high. Many problems, such as rich semantics, uneven distribution and poor objectivity, have greatly restricted the research and application of big data in Chinese medicine. In this paper, the importance of multi-source heterogeneous data fusion me-thod under the background of Internet+ large data is discussed, and the importance of mul-ti-source heterogeneous data fusion method based on the combination of disease and syndrome is discussed. It is the original cause of the important component of the large data of traditional Chi-nese medicine in the future, and the further study of the multi-source isomerism of traditional Chinese medicine. The method of large data fusion provides a theoretical reference. Keywords TCM Informatization, Diagnosis and Treatment Mode, Combination of Disease and Syndrome, Big Data, Multi-Source Heterogeneous Fusion 论中医药多源异构大数据融合方法研究的意义 赵汉青,王志国* 中国中医科学院中医临床基础医学研究所,北京 收稿日期:2018年8月18日;录用日期:2018年8月26日;发布日期:2018年9月3日 *通讯作者。
多源异构数据采集和可视化解决方案
工业互联网先进应用案例集 案例 可快速部署的低成本多源异构数据采集 和可视化解决方案 ——基于宜科边缘控制器和IoTHub平台的设 备智能管理应用 宜科(天津)电子有限公司成立于2003年,位于天津市西青经济开发区,在中国天津和德国德累斯顿设有研发中心。公司将“自动化技术+数字化工厂+工业互联网”定义为重要的发展战略,围绕工业互联网和智能制造业务持续发力,在工业互联网、智能制造、工业软件等方面积累了大量项目案例和实施经验,在工业互联网领域拥有核心产品和方案,在系统集成解决方案领域处于国内领先地位。 一、项目概况 宜科边缘控制器利用宜科IoTHub TM工业互联网赋能平台和Workbench工业APP快速开发工具,提供“设备连接+数据可视化”应用模式,将成为中小企业管理者直观了解工厂运行状态的最有效方式。
1. 项目背景 工业互联网平台是工业互联网建设的核心。工业设备上云正成为牵引工业互联网平台发展的先导性应用,也是当前工业互联网平台建设的切入点。 工业设备上云就是通过建立实时、系统、全面的工业设备数据采集体系。构建基于云计算的数据汇聚、分析和服务平台,实现工业设备状态监测、预测预警、性能优化,引导带来工业互联网平台的功能演进和规模商用。工业设备种类繁杂、数量多、通信协议与数据格式各异,当前尚缺乏有效的技术手段能够低成本、便捷地实现工业设备快速接入平台,导致绝大部分平台的设备接入数量有限。2. 项目简介 基于宜科边缘控制器,提供“数据+应用”的服务,充分利用IoTHub TM工业互联网赋能平台IaaS和PaaS资源,以及边缘计算设备的性能,提供数据采集能力和数据可视化应用。 数据:系统提供多种协议接口,支持典型的工业控制器、传感器、物联网采集监控终端,并提供协议连接及数据交互操作。 应用:工业APP开发工具,方便提供生产过程监控、调试维护配置、报警相应及处理、报表实时更新及显示生成等功能,方便平台应用。 数据+应用=服务 3. 项目目标 面向工业互联网应用,支持市场二十种以上主流工业协议解析,支持二十万台设备并发连接,提供面向工业现场的图形化、拖拽式和低代码快速开发APP 工具,支持本地、私有云、共有云混合或单一部署,提供多个重点垂直领域的基础应用APP。 在汽车整车及零部件、装备制造、冶金、电子信息领域发展客户上千家,设备连接数超百万。在设备监控、设备预测性维护、生产现场数据可视化、数据分析、实时报警等方面,帮助广大中小制造业企业解决“数据之痛”,提升生产效率,降低运营成本,提高管理水平,助力企业做大做强。