实验一盲目搜索算法

百度文库-让每个人平等地提升自我
实验一:盲目搜索算法
一、实验目的
掌握盲目搜索算法之一的宽度优先搜索求解算法的基本思想。对于宽度优先搜索算法基本过程,算法分析有一个清晰的思路,了解宽度优先搜索算法在实际生活中的应用。
二、实验环境
PC 机一台,VC++
三、实验原理
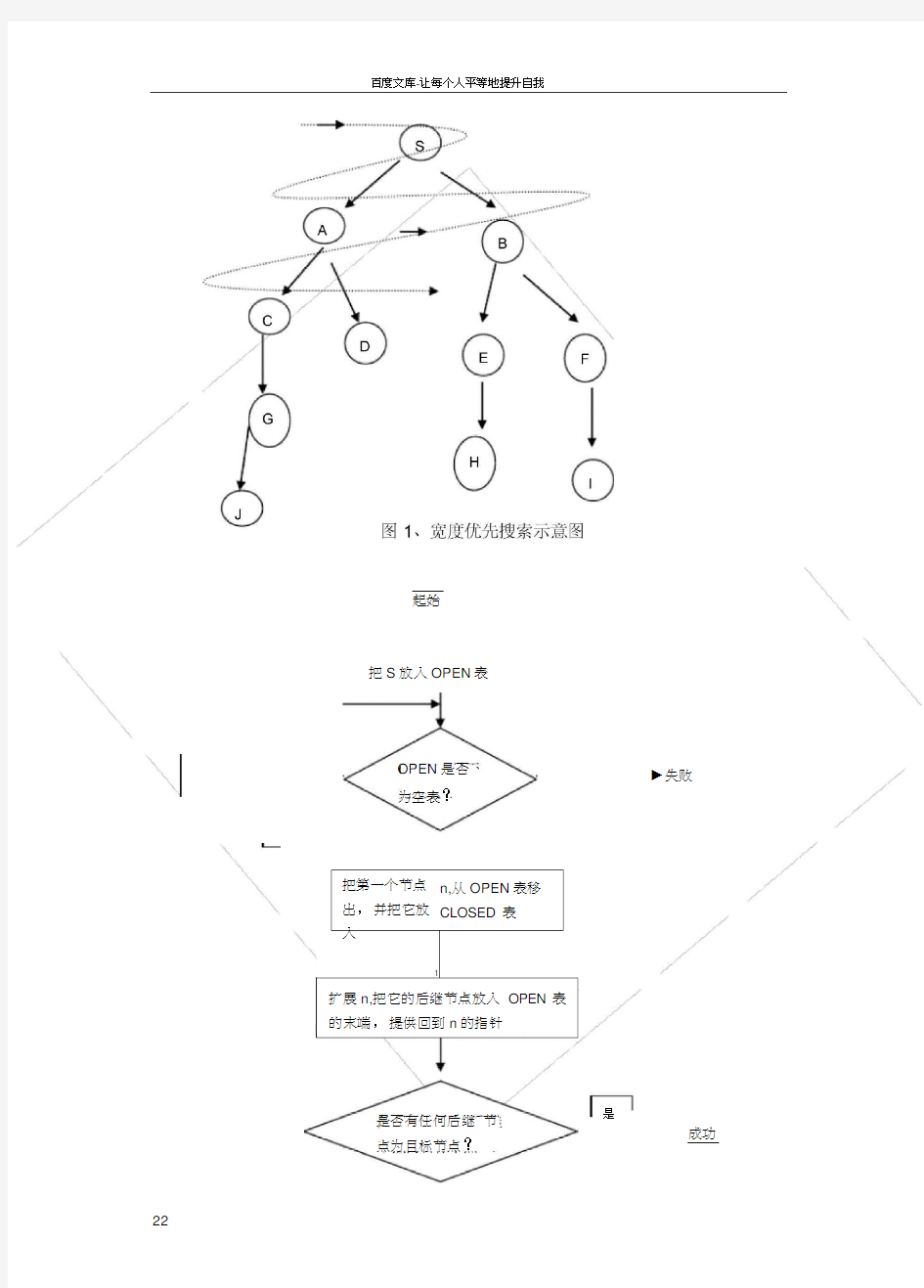
宽度优先(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra 算法和Prim算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。同时,宽度优先搜索算法是的一种策略。因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较广的区域,故得名。
其基本思想是:
(1)把起始节点放到OPEN表中(如果该起始节点为一目标节点,则求得一个解答)。
\ (2)如果OPEN是个空表,则没有解,失败退出;否则继续。
、、(3)把第一个节点(节点n)从OPEN表移出,并把它放入CLOSE扩展节点表中。
(4) 扩展节点n。如果没有后继节点,则转向上述第(2)步。
(5) 把n的所有后继节点放到OPEN表的末端,并提供从这些后继节点回到n的指针。
(6) 如果n的任一个后继节点是个目标节点,则找到一个解答,成功退出;否则转向第(2)步。
宽度优先搜索示意图和宽度优先算法流程图如下图1和图2所示:
百度文库
-让每个人平等地提升自我
起始
把S放入OPEN表
OPEN是否
为空表?
?失败
把第一个节点
出,并把它放
入
n,从OPEN表移
CLOSED 表
1
扩展n,把它的后继节点放入OPEN 表
的末端,提供回到n的指针
是
是否有任何后继节
点为目标节点?
成功
图2、宽度优先算法流程图
四、实验数据及步骤
这部分内容是通过一个实例来对宽度优先算法进行一个演示,分析其思想。问题描述了《迷宫问题》的出路求解办法。
定义一个二维数组:
int maze[5][5] = {
0,1,0,0,0,
0,1,0,1,0,
0,0,0,0,0,
0,1,1,1,0,
0,0,0,1,0,
};
它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的最短路线。题目保证了输入是一定有解的。下面我们队问题进行求解:
对应于题目的输入数组:
0,1,0,0,0,
0,1,0,1,0,
0,0,0,0, 0,
0,1,1,1,0,
0,0,0,1,0,
我们把节点定义为(y,x),(y,x)表示数组maze的项maze[x][y]。于是起点就是(0,0),终点是(4,4)。我们大概梳理一遍:
初始条件:起点Vs为(0,0),终点Vd为(4, 4),灰色节点集合Q={},初始化所有节点为白色节点,说明:初始全部都是白色(未访问),即将搜索起点(灰色),已经被搜索过了(黑色)。开始我们的宽度搜索。执行步骤:1?起始节点Vs变成灰色,加入队列Q,Q={(0,0)}
2. 取出队列Q的头一个节点Vn, Vn={0,0},Q={}
3. 把Vn={0,0}染成黑色,取出Vn所有相邻的白色节点{(1,0)}
4. 不包含终点(4, 4),染成灰色,加入队列Q, Q={(1 , 0)}
5. 取出队列Q的头一个节点Vn, Vn={1,0},Q={}
6. 把Vn={1,0}染成黑色,取出Vn所有相邻的白色节点{(2,0)}
7. 不包含终点(4,4),染成灰色,加入队列Q,Q={(2,0)}
8. 取出队列Q的头一个节点Vn, Vn={2,0},Q={}
9. 把Vn={2,0}染成黑色,取出Vn所有相邻的白色节点{(2,1),(3, 0)}
10. 不包含终点(4, 4),染成灰色,加入队列Q, Q={(2 , 1), (3, 0)}
11取出队列Q的头一个节点Vn, Vn={2 , 1}, Q={(3 , 0)}
12. 把Vn={2 , 1}染成黑色,取出Vn所有相邻的白色节点{(2 , 2)}
13. 不包含终点(4, 4),染成灰色,加入队列Q, Q={(3 , 0), (2, 2)}
14. 持续下去,知道Vn的所有相邻的白色节点中包含了(4, 4)……
15. 此时获得最终答案
我们来看看广度搜索的过程中节点的顺序情况:
1. NodefO^O)
*
2. Node(l.t))
3 Node(2.0>
图3迷宫问题的搜索树
图中标号即为我们搜索过程中的顺序,我们观察到,这个搜索顺序是按照上图的层次关系来的,例如节点(0, 0)在第1层,节点(1, 0)在第2层,节点(2, 0)在第3层,节点(2,1)和节点(3, 0)在第3层。
我们的搜索顺序就是第一层->第二层->第三层->第N层这样子。
我们假设终点在第N层,因此我们搜索到的路径长度肯定是N,而且这个N 定是所求最短的。
4 Node(2;l>
5 Node(3,0)
r1
6 Node(2.2)
7 Nod?(4 0)
t9 Node(2.3)
1
r
1 I
HNod^(0 2)12 Nod?(2^)
...J F j r
14 Nod?(03)15 Nod&(2r4)
1r
16 Node(0 4)17 Node(4.4)
IS Node(14)
13.riode(4.2)
10 Nod f (4.1)
我们用简单的反证法来证明:假设终点在第N层上边出现过,例如第M M 所以根据广度优先搜索的话,搜索到终点时,该路径一定是最短的。 五、实验核心代码 /** *广度优先搜索 */ void course(char **maze,i nt han g,i nt lie) { int i=1,j=1,n=-1; step *Step; ;=i; =j; while(maze[ha ng][lie]!='.') { 表示已经走过并通了的路径 \ if(maze[i][j+1]!='1'&&maze[i][j+1]!='.'&&maze[i][j+1]!='+'); '、j=j+1; \ n++; Step[ n].x=i; Step[ n].y=j; coutvv"第"vv*v"步:"vv"向右走到:"vv"("vvivv","vvjvv")"vve ndl; } else if(maze[i+1][j]!='1'&&maze[i+1][j]!='.'&&maze[i+1][j]!='+')层, M 禁忌搜索算法浅析 摘要:本文介绍了禁忌搜索算法的基本思想、算法流程及其实现的伪代码。禁忌搜索算法(Tabu Search或Taboo Search,简称TS算法)是一种全局性邻域搜索算法,可以有效地解决组合优化问题,引导算法跳出局部最优解,转向全局最优解的功能。 关键词:禁忌搜索算法;组合优化;近似算法;邻域搜索 1禁忌搜索算法概述 禁忌搜索算法(Tabu Search)是由美国科罗拉多州大学的Fred Glover教授在1986年左右提出来的,是一个用来跳出局部最优的搜寻方法。在解决最优问题上,一般区分为两种方式:一种是传统的方法,另一种方法则是一些启发式搜索算法。使用传统的方法,我们必须对每一个问题都去设计一套算法,相当不方便,缺乏广泛性,优点在于我们可以证明算法的正确性,我们可以保证找到的答案是最优的;而对于启发式算法,针对不同的问题,我们可以套用同一个架构来寻找答案,在这个过程中,我们只需要设计评价函数以及如何找到下一个可能解的函数等,所以启发式算法的广泛性比较高,但相对在准确度上就不一定能够达到最优,但是在实际问题中启发式算法那有着更广泛的应用。 禁忌搜索是一种亚启发式随机搜索算法,它从一个初始可行解出发,选择一系列的特定搜索方向(移动)作为试探,选择实现让特定的目标函数值变化最多的移动。为了避免陷入局部最优解,TS搜索中采用了一种灵活的“记忆”技术,对已经进行的优化过程进行记录和选择,指导下一步的搜索方向。 TS是人工智能的一种体现,是局部领域搜索的一种扩展。禁忌搜索是在领域搜索的基础上,通过设置禁忌表来禁忌一些已经历的操作,并利用藐视准则来奖励一些优良状态,其中涉及邻域(neighborhood)、禁忌表(tabu list)、禁忌长度(tabu 1ength)、候选解(candidate)、藐视准则(candidate)等影响禁忌搜索算法性能的关键因素。迄今为止,TS算法在组合优化、生产调度、机器学习、电路设计和神经网络等领域取得了很大的成功,近年来又在函数全局优化方面得到较多的研究,并大有发展的趋势。 2禁忌搜索算法的基本思想 禁忌搜索最重要的思想是标记对应已搜索的局部最优解的一些对象,并在进一步的迭代搜索中尽量避开这些对象(而不是绝对禁止循环),从而保证对不同的有效搜索途径的探索,TS的禁忌策略尽量避免迂回搜索,它是一种确定性的局部极小突跳策略。 禁忌搜索是对局部邻域搜索的一种扩展,是一种全局逐步寻求最优算法。局部邻域搜索是基于贪婪思想持续地在当前解的邻域中进行搜索,虽然算法通用易实现,且容易理解,但搜索性能完全依赖于邻域结构和初解,尤其会陷入局部极小而无法保证全局优化型。 禁忌搜索算法中充分体现了集中和扩散两个策略,它的集中策略体现在局部搜索,即从一点出发,在这点的邻域内寻求更好的解,以达到局部最优解而结束,为了跳出局部最优解,扩散策略通过禁忌表的功能来实现。禁忌表中记下已经到达的某些信息,算法通过对禁 教学案例基本信息 2.2 获取信息策略与技巧(XX教育)——教学设计 XX潍坊滨海中学王伟亮教学分析: 一、教学目标: 1、学会使用目录搜索引擎和全文搜索引擎检索网络信息,能根据不同需求选择检索方法,培 养学生运用因特网浏览、搜集信息的能力。 2、学会灵活运用贴切的搜索关键词进行信息的搜索,提高迅速准确地筛选信息的能力。 3、能对常用搜索引擎的比较与评价,培养学生主动探究知识、获取信息的兴趣和协作与交流 的意识与能力;让学生进一步认识到掌握检索技巧的重要性,为学生终身受用奠定基础。 二、教学重点: 掌握搜索引擎的分类查找、关键词查找方法。 说明:运用不同的搜索策略可以获得高效的检索结果,帮助帮助学生为今后奠定基础。 三、教学难点 掌握关键词搜索的技巧。 说明:搜索技巧需要在实践中不断地积累经验,难以依靠老师的“教”来得到更多的技巧。 教学设计 一、教学方法 采用“任务驱动”和“分组合作”的学习方式,即在任务驱动下,自学教材上相关内容和学习上的资源,上网操作实践,小组交流讨论,合作完成任务,掌握网络信息搜索的几种主要策略和技巧。 二、教学课时:1课时 三、教学环境:网络教室 四、教学过程: 2.2学生学案——获取信息的策略与技巧小组号: 成员:—————————————————————————————————————————————一、网络信息检索的方法: 任务一 借助网络,开展下列题目的查找活动。 1)利用搜索引擎(百度)查找我校,并阅读我校最新动态。 2)目前世界上濒危动物华南虎的数量。 3)查找潍坊市最近三天的天气预报 4)哈雷慧星的最早记录是哪国人留下的? 5)查找关于一种鸟名为黄胸鹀(wu)的生物特性(提示:.zoology.csdb./index.asp) 6)查找出中央电视台今晚各套的电视节目单 7)查找到XX列车的车次、时间与票价。 任务二 二、用好关键词 任务三: 学习并利用教材第27页的表2-10“搜索引擎的使用技巧”,找出下面题目的相关资料。交流讨论,共同完成下表相关栏目的填写。 搜索引擎的使用技巧: ①理解搜索内容,使用最具代表性的关键词。 ②增加关键词细化搜索条件。 ③用好逻辑符号。 ④使用英文双引号进行强制搜索。 网上搜索的方法和技巧 我们已经知道网上有多种多样的教育资源,从技术上讲,它们是在Internet的多种服务功能的支持下实现的,包含WWW、e-mail、Usenet、FTP、BBS等,其中发展最快,也是最为流行的是WWW。因此我们着重介绍WWW信息的检索方法。 据1999年底的统计,网上大约有15亿个网页,并且以每天增加190万个网页的速度在增长,到2002年已达到80亿个网页。要想在这么大的一个资源库中查找一条具体的信息,犹如大海捞针一般。因此,有人发出这样的感叹:"我们淹没在数据资料的的海洋中,却又在忍受着知识的饥渴"。 现在出现了许多种在网上查找信息的方法。这些方法可以分为两类:一类是有既定目标的查找,一类是没有目标的查找,而后者往往是指一种网上"冲浪"游戏。在具有既定目标的情况下,如果已有信息线索,可以用浏览器航行的办法寻找信息对象;如果信息线索未定,则需要利用搜索工具首先获得信息线索。 搜索工具又有传统工具和现代工具之分。传统工具是在索引数据库中进行主题树/目录检索或KWDSEs(关键词搜索引擎)进行建设而索引库的建设是一个极其繁重的任务,现在已经可以利用"机器人"程序来帮忙,它们通过跟踪最新建立的HTML网页的URL对整个网络进行浏览,可以在网上从这一个网站爬到另一个网站,并记录下它们访问过的网页的各自特征(这种只有十来年历史的搜索技术就被称为传统工具了,你觉得奇怪吗?)。而现代搜索工具是利用智能代理来工作,它们不是对整个网络进行索引,而是在接到一个新任务时就出发,去搜索网上资源并提取有价值的信息。因此,智能代理是利用神经网络技术进行搜索,它试图去发现自然语言与样本网页的模式及它们之间的相互关系,这些将与新近发现的网上资源相匹配,最后以一串网址的形式供用户访问。图2_3_10显示了网上信息检索工具的选择方法。 (一)搜索工具 在Internet上现有的检索工具成百上千,比较普及且功能较强的就有几十种。这些检索按照其工作原理的不同,大概可以分为3种类型: 盲目搜索 搜索的含义 依问题的实际情况寻找可利用的知识,构造代价较少的推理路径从而解决问题的过程 离散的问题通常没有统一的求解方法 搜索策略的优劣涉及能否找到最好的解、计算时间、存储空间等 搜索分为盲目搜索和启发式搜索 盲目搜索:按预定的策略进行搜索,未用问题相关的或中间信息改进搜索。效率不高,难求解复杂问题,但不失可用性 启发式搜索:搜索中加入问题相关的信息加速问题求解,效率较高,但启发式函数不易构造 盲目搜索也叫无信息搜索,只适合用于求解比较简单的问题。 我们没有指定问题的任何推理信息,例如要搜索这一部分而不是另一部分,就像到目前为止的只要发现一条到目标的路径即可。这种过程被称为是盲目的。 盲目搜索过程只把算子应用到节点,它没有使用问题领域的任何特殊知识(除了关于什么动作是合法的知识外)。最简单的盲目搜索过程就是广度优先搜索。该过程把所有的算子应用到开始节点以产生一个显式的状态空间图,再把所有可能的算子应用到开始节点的所有直接后继,再到后继的后继,等等。搜索过程一律从开始节点向外扩展。由于每一步将所有可能的算子应用到一个节点,因此可把它们组成一个叫后继函数的函数。当把后继函数应用到一个节点时,产生一个节点集,该节点集就是把所有能应用到那个节点的算子应用到该节点而产生的。一个节点的后继函数的每一次应用称为节点的扩展相同代价搜索是广度优先搜索的一种变体,在该方法中,节点从开始节点顺着代价等高点向外扩展,而不是顺着相同深度等高线。如果图中所有弧的代价相同,那么相同代价搜索就和广度优先搜索一致。反过来,相同代价搜索可以看作是下一章要讲的启发式搜索的一个特殊情况。广度优先和相同代价搜索方法的简要描述只给出了它们的主要思想,但是要解决其他复杂的情况则需要技术改进 学生实验报告 实验课名称:人工智能 实验项目名称:八数码实验 专业名称:计算机科学与技术 班级: 2012240201 学号: 201224020102 学生姓名:张璐 教师姓名:陈亮亮 2014年12 月13 日 实验日期:2014 年12 月9 日实验室名称:明远2202 最后,为提高程序的运行效率,减少程序扩展节点时搜索量,将当前0所处位置(i_0:0在s[3][3]中所处行号,j_0:0在s[3][3]中所处列号)也存储在DATA中。 五.源程序: struct array { int id; int depth; int Wx; //错位个数 int moveNum;//计算移动距离 int a[MAX_X][MAX_Y]; int x; //0的横坐标(在数组里的) int y; //0的纵坐标 }; class EightDigital { public: EightDigital(int a[MAX_X][MAX_Y],int b[MAX_X][MAX_Y]); ~EightDigital(); bool safe(int x,int y); //判断与0相邻的位置能否交换,防止数组越界bool compare(); //判断是否到达目标 void search(int x,int y); //搜索目标 void addOpenTable(int x0,int y0,int x1,int y1);//x0,y0是交换前0的坐标,x1,y1是交换后0的坐标,加入open表 void addCloseTable(); //create close table void deleteOpenTable(); void insertSort(); void exchange(int x0,int y0,int x1,int y1); //交换数组值,移动0 int Wx(); //计算错位个数 void print(); //打印数组 bool haveSolution(); int moveNum(); 百度搜索引擎的使用方法和技巧 学生姓名: 学院:信息技术学院 专业:信管(电) 班级: 学号: 指导教师: 完成日期: 2015年3月28日 辽东学院 Eastern Liaoning University 一、简单搜索 1. 关键词搜索 只要在搜索框中输入关键词,并按一下“搜索”,百度就会自动找出相关的网站和资料。百度会寻找所有符合您全部查询条件的资料,并把最相关的网站或资料排在前列。 小技巧:输入关键词后,直接按键盘上的回车键(即Enter健),百度也会自动找出相关的网站或资料。 关键词,就是您输入搜索框中的文字,也就是您命令百度寻找的东西。可以是任何中文、英文、数字,或中文英文数字的混合体。可以命令百度寻找任何内容,所以关键词的内容可以是:人名、网站、新闻、小说、软件、游戏、星座、工作、购物、论文、、、 例如:可以搜索[windows]、[918]、[F-1赛车]。 可以输入一个关键词,也可以输入两个、三个、四个,您甚至可以输入一句话。 例如:可以搜索[博客]、[原创爱情文学]、[知音,不需多言,要用心去交流;友谊,不能言表,要用心去品尝。悠悠将用真诚,尊敬和大家来建立真正的友谊]。 注意:多个关键词之间必须留一个空格。 2. 准确的关键词 百度搜索引擎严谨认真,要求一字不差。 例如:分别输入 [舒淇] 和 [舒琪] ,搜索结果是不同的。 分别输入 [电脑] 和 [计算机] ,搜索结果也是不同的。 因此,如果您对搜索结果不满意,建议检查输入文字有无错误,并换用不同的关键词搜索。 3. 输入两个关键词搜索 输入多个关键词搜索,可以获得更精确更丰富的搜索结果。 例如,搜索[悠悠情未老],可以找到几千篇资料。而搜索[悠悠情未老],则只有严格含有“悠悠情未老”连续5个字的网页才能被找出来,不但找到的资料只有几十篇,资料的准确性也比前者差得多。 因此,当你要查的关键词较为长时,建议将它拆成几个关键词来搜索,词与词之间用空格隔开。 多数情况下,输入两个关键词搜索,就已经有很好的搜索结果。 4. 减除无关资料 有时候,排除含有某些词语的资料有利于缩小查询范围。 百度支持“-“功能,用于有目的地删除某些无关网页,但减号之前必须留一空格,语法是“A -B”。 汽车尾气的排放控制新技术 第二部分:检索策略部分 1.课题分析 交通系统消耗了全球约1/3 的能源,以石油产品为燃料的汽车是最主要的现代交通运输工具,它给人们带来方便和快捷的同时,也带来了无法回避的问题。根据上个世纪七八十年代美国、日本对城市空气污染源的调查,城市空气中90%以上的一氧化碳、60%以上的碳氢化合物和30%以上的氮氧化物都来自汽车尾气的排放,这些污浊的气体使人类的生存环境受到极大威胁。汽车污染已成为世界性公害,其对于温室气体浓度增加的“贡献”不容忽视。随着世界各国汽车保有量的增加,汽车已成为城市大气质量恶化的主要污染源,其排放的CO、NOx、HC、SO2、Pb 等污染物不仅危害人体健康,还是造成酸雨和光化学烟雾的主要成分,汽车尾气污染已受到全球广泛的注视。截止2006年底,我国民用汽车保有量已接近3700万辆,并仍保持着快速增长的趋势。虽与发达国家相比,其总量不多,但由于主要集中在大城市,而且车况差,燃油质量低,单车的排污量往往高出国外同类车的几倍,汽车尾气对我国城市空气质量造成巨大的威胁。因此,研究汽车尾气的排放控制的新技术,减少有害气体的排放量,对提高城市空气的质量,保障人类生存环境,具有重大意义。本作业利用自己这学期所学的文献检索课的知识,检索了国内有关汽车尾气的排放、控制、净化方面的文献,经初步整理给出一篇肤浅的文献综述,有望老师给予指正。 2. 制定检索策略 2.1 选择检索工具 2.2 选择检索词 2.3 拟定检索式 由于不同检索工具的字段不同,因此将检索式(亦称提问式)在“检索步骤及检索结果”的各个具体检索工具中给出。 3. 检索步骤及检索结果 3.1 谷歌搜索引擎 3.1.1 检索式 A.篇名=汽车 and 尾气 and 排放and 控制 3.1.2 检索步骤与结果 打开谷歌高级搜索:在第一行检索框内输入检索式A,“and”用空格形式表示。限定在“简体中文”和“网页标题”内检索。得到212条检索结果。经过筛选,选择其中2条: [1] 【篇名】申城推广燃油清净剂控制汽车尾气排放 【摘要】有关研究及开发证明,在燃油中添加合格的清净剂,能明显降低一氧化碳、碳氢化合物、氮氧化物和颗粒物等污染的排放量,而且能使节油率达到15%左右,燃油清净剂技术已成为我国在治理汽车尾气污染的一项高新技术。据了解,目前日本有80%的车用汽油使用汽油清净剂,欧美19个国家普遍使用汽油清净剂。上海目前机动车尾气污染仍十分严重,改善废气排放迫在眉睫。为此许多专家认为,上海应当大力推广燃油清净剂。 【出处】解放日报2002年3月27日 [2] 【篇名】控制尾气排放新方法-汽车试“喝”纳米燃油 【摘要】普通汽车上通过加装一套EPS纳米燃油装置,就可以节省燃油10%-30%,降低尾气排放约50%-90%,同时还能使动力增加10%-30%。日前,一种可将普通燃油变成纳米燃油 . 用盲目搜索技术解决八数码问题 题目 在3×3的棋盘,有八个棋子,每个棋子上标有1至8的某一数字,不同棋子上 标的数字不相同。棋盘上还有一个空格,与空格相邻的棋子可以移到空格中。要解决的问题是:任意给出一个初始状态和一个目标状态,找出一种从初始转变成目标状态的移动棋子步数最少的移动步骤。 算法流程 使用宽度优先搜索 从初始节点开始,向下逐层对节点进形依次扩展,并考察它是否为目标节点,再对下层节点进行扩展(或搜索)之前,必须完成对当层的所有节点的扩展。再搜 索过程中,未扩展节点表OPEN中的节点排序准则是:先进入的节点排在前面, 后进入的节点排在后面。 宽度优先算法如下: 把初始结点S0放入OPEN表中 若OPEN表为空,则搜索失败,问题无解 取OPEN表中最前面的结点N放在CLOSE表中,并冠以顺序编号n 若目标结点,则搜索成功,问题有解N?Sg若N无子结点,则转2 扩展结点N,将其所有子结点配上指向N的放回指针,依次放入OPEN表的尾部,转2 源程序 #include using namespace std; const int ROW = 3;//行数 const int COL = 3;//列数 const int MAXDISTANCE = 10000;//最多可以有的表的数目const int MAXNUM = 10000; typedef struct _Node{ int digit[ROW][COL]; int dist;//distance between one state and the destination 一个表和目的表的距离 int dep; // the depth of node深度 // So the comment function = dist + dep.估价函数值 int index; // point to the location of parent父节点的位置} Node; Node src, dest;// 父节表目的表 vector 竭诚为您提供优质文档/双击可除 二分搜索实验报告 篇一:算法设计与分析二分查找实验报告 课程设计说明书 设计题目:二分查找程序的实现 专业:班级: 设计人: 山东科技大学年月日 课程设计任务书 学院:信息科学与工程学院专业:班级:姓名: 一、课程设计题目:二分查找程序的实现二、课程设计主要参考资料 (1)计算机算法设计与分析(第三版)王晓东著(2)三、课程设计应解决的主要问题 (1)二分查找程序的实现(2)(3)四、课程设计相关附件(如:图纸、软件等): (1)(2) 五、任务发出日期:20XX-11-21课程设计完成日期: 20XX-11-24 指导教师签字:系主任签字: 指导教师对课程设计的评语 成绩: 指导教师签字: 年月日 二分查找程序的实现 一、设计目的 算法设计与分析是计算机科学与技术专业的软件方向的必修课。同时,算法设计与分析既有较强的理论性,也有较强的实践性。算法设计与分析的实验过程需要完成课程学习过程各种算法的设计和实现,以达到提高教学效果,增强学生实践动手能力的目标。 用分治法,设计解决二分查找程序的实现问题的一个简捷的算法。通过解决二分查找程序的实现问题,初步学习分治策略。 二、设计要求 给定已按升序排好序的n个元素a[0:n-1],现要在这n 个元素中找出一特定元素x。实现二分搜索的递归程序并进行跟踪分析其执行过程。 用顺序搜索方法时,逐个比较a[0:n-1]中的元素,直至找出元素x,或搜索遍整个数组后确定x不在其中。这个方 法没有很好的利用n个元素已排好序这个条件,因此在最坏情况下,顺序搜索方法需要o(n)次比较。要求二分法的时间复杂度小于o(n)。 三、设计说明(一)、需求分析 二分搜索方法充分利用了元素间的次序关系,采用分治策略,可在最坏情况下用o(logn)时间完成搜索任务。 该算法的流程图如下: (二)、概要设计 二分查(:二分搜索实验报告)找的基本思路是将n个元素分成大致相等的两部分,取a[n/2]与x做比较,如果 x=a[n/2],则找到x,算法终止;如果xa[n/2],则只要在数组a的右半部分继续搜索x。 由于二分查找的数组不一定是一个整数数组,所以我采用了c++中的模板函数,将排序函数sort和二分查找函数binarysort写为了模板函数,这样不尽可以查找整数数组,也可以查找小数数组。 由于查找的数组的长度不固定,所以我用了c语言中的malloc和realloc函数,首先定义一个数组指针,用malloc 函数该它分配空间,然后向数组中存数,当数组空间满时,在用realloc函数为数组再次分配空间。由于在随机输入一组数时不知在什么位置停止,所以 篇二:二分搜索实验报告 禁忌搜索算法评述(一) 摘要:工程应用中存在大量的优化问题,对优化算法的研究是目前研究的热点之一。禁忌搜索算法作为一种新兴的智能搜索算法具有模拟人类智能的记忆机制,已被广泛应用于各类优化领域并取得了理想的效果。本文介绍了禁忌搜索算法的特点、应用领域、研究进展,概述了它的算法基本流程,评述了算法设计过程中的关键要点,最后探讨了禁忌搜索算法的研究方向和发展趋势。 关键词:禁忌搜索算法;优化;禁忌表;启发式;智能算法 1引言 工程领域内存在大量的优化问题,对于优化算法的研究一直是计算机领域内的一个热点问题。优化算法主要分为启发式算法和智能随机算法。启发式算法依赖对问题性质的认识,属于局部优化算法。智能随机算法不依赖问题的性质,按一定规则搜索解空间,直到搜索到近似优解或最优解,属于全局优化算法,其代表有遗传算法、模拟退火算法、粒子群算法、禁忌搜索算法等。禁忌搜索算法(TabuSearch,TS)最早是由Glover在1986年提出,它的实质是对局部邻域搜索的一种拓展。TS算法通过模拟人类智能的记忆机制,采用禁忌策略限制搜索过程陷入局部最优来避免迂回搜索。同时引入特赦(破禁)准则来释放一些被禁忌的优良状态,以保证搜索过程的有效性和多样性。TS算法是一种具有不同于遗传和模拟退火等算法特点的智能随机算法,可以克服搜索过程易于早熟收敛的缺陷而达到全局优化1]。 迄今为止,TS算法已经广泛应用于组合优化、机器学习、生产调度、函数优化、电路设计、路由优化、投资分析和神经网络等领域,并显示出极好的研究前景2~9,11~15]。目前关于TS 的研究主要分为对TS算法过程和关键步骤的改进,用TS改进已有优化算法和应用TS相关算法求解工程优化问题三个方面。 禁忌搜索提出了一种基于智能记忆的框架,在实际实现过程中可以根据问题的性质做有针对性的设计,本文在给出禁忌搜索基本流程的基础上,对如何设计算法中的关键步骤进行了有益的总结和分析。 2禁忌搜索算法的基本流程 TS算法一般流程描述1]: (1)设定算法参数,产生初始解x,置空禁忌表。 (2)判断是否满足终止条件?若是,则结束,并输出结果;否则,继续以下步骤。 (3)利用当前解x的邻域结构产生邻域解,并从中确定若干候选解。 (4)对候选解判断是否满足藐视准则?若成立,则用满足藐视准则的最佳状态y替代x成为新的当前解,并用y对应的禁忌对象替换最早进入禁忌表的禁忌对象,同时用y替换“bestsofar”状态,然后转步骤(6);否则,继续以下步骤。 (5)判断候选解对应的各对象的禁忌情况,选择候选解集中非禁忌对象对应的最佳状态为新的当前解,同时用与之对应的禁忌对象替换最早进入禁忌表的禁忌对象。 (6)转步骤(2)。 算法可用图1所示的流程图更为直观的描述。 3禁忌搜索算法中的关键设计 3.1编码及初始解的构造 禁忌搜索算法首先要对待求解的问题进行抽象,分析问题解的形式以形成编码。禁忌搜索的过程就是在解的编码空间里找出代表最优解或近似优解的编码串。编码串的设计方式有多种策略,主要根据待解问题的特征而定。二进制编码将问题的解用一个二进制串来表示2],十进制编码将问题的解用一个十进制串来表示3],实数编码将问题的解用一个实数来表示4],在某些组合优化问题中,还经常使用混合编码5]、0-1矩阵编码等。 禁忌搜索对初始解的依赖较大,好的初始解往往会提高最终的优化效果。初始解的构造可以 比较各种搜索方法与技巧 因特网上的信息爆炸式的增长,而且毫无秩序。为了方便我们在网上快速准确地找到需要的信息,一些网站提供了搜索引擎服务。搜索引擎的使用看似简单,其实不然。如何快速、正确的寻找到我们所需的资源也需要一定的方法和技巧,关于搜索引擎的使用方法有多种多样,搜索引擎检索信息主要有目录检索和关键词查询两种方法。 目录检索:也称为分类检索,是因特网上最早提供WWW资源查询的服务,主要通过搜集和整理因特网的资源,根据搜集到的网页的内容,将其网址分配到相关分类主题目录的不同层次的类目之下,形成像图书馆目录一样的分类树形结构索引。目录检索无需输入任何文字,只要根据网站提供的主要分类目录,层层点击进入,便可查找到所需要的网络信息资源。当前国内具有代表性的提供目录检索服务的网站有雅虎中国()和搜狗)等。 使用技巧 1、简单查询 在搜索引擎中输入关键词,然后点击“搜索”就行了,系统很快会返回查询结果,这是最简单的查询方法,使用方便,但是查询的结果却不准确,可能包含着许多无用的信息。所以选择正确的关键词才是一切的开始。学会从复杂搜索意图中提练出最具代表性和指示性的关键词对提高信息查询效率至关重要,这方面的技巧是所有搜索技巧之母。在输入关键词过程中,要避免错别字的使用、选取的关键词太 常见和多义词,这些都容易造成检索的信息量过大或与自己想选取内容相悖。 2、使用双引号用 给要查询的关键词加上双引号(半角,以下要加的其它符号同此),可以实现精确的查询,这种方法要求查询结果要精确匹配,不包括演变形式。例如在搜索引擎的文字框中输入“电传”,它就会返回网页中有“电传”这个关键字的网址,而不会返回诸如“电话传真”之类网页。 3、使用加号(+)或减号(-) 在关键词的前面使用加号,也就等于告诉搜索引擎该单词必须出现在搜索结果中的网页上。在关键词的前面使用减号,也就意味着在查询结果中不能出现该关键词。 4、使用括号 当两个关键词用另外一种操作符连在一起,而你又想把它们列为一组时,就可以对这两个词加上圆括号。 5、使用空格 在搜索关键词中加入“空格”进行信息搜索是最为常见的搜索技巧应用,空格起到的作用是“与”的意思。比方说我们在搜索中国的长城方面的信息时,只需输入“中国长城”就可以了。这个空格加上后,它的搜索范围既可能是“中国的长城”,也可能是“中国和长城”,还可能是“中国长城”或是“中国北京的长城”等信息,这样一来信息的范围无疑将会大大增加了。在使用空格组成关键词时,要 1.怎样成为搜索高手——选择适当的查询词 搜索技巧,最基本同时也是最有效的,就是选择合适的查询词。选择查询词是一种经验积累,在一定程度上也有章可循: A.表述准确百度会严格按照您提交的查询词去搜索,因此,查询词表 述准确是获得良好搜索结果的必要前提。 一类常见的表述不准确情况是,脑袋里想着一回事,搜索框里输入 的是另一回事。 例如,要查找2004年国内十大新闻,查询词可以是“2004年国内十 大新闻”;但如果把查询词换成“2004年国内十大事件”,搜索结果就 没有能满足需求的了。 另一类典型的表述不准确,是查询词中包含错别字。 例如,要查找林心如的写真图片,用“林心如写真”,当然是没什么 问题;但如果写错了字,变成“林心茹写真”,搜索结果质量就差得 远了。 不过好在,百度对于用户常见的错别字输入,有纠错提示。您若输 入“林心茹写真”,在搜索结果上方,会提示“您要找的是不是: 林心 如写真”。 B.查询词的主题关联与简练目前的搜索引擎并不能很好的处理自然 语言。因此,在提交搜索请求时,您最好把自己的想法,提炼成简单的,而且与希望找到的信息内容主题关联的查询词。 还是用实际例子说明。某三年级小学生,想查一些关于时间的名人名言,他的查询词是“小学三年级关于时间的名人名言”。 这个查询词很完整的体现了搜索者的搜索意图,但效果并不好。 绝大多数名人名言,并不规定是针对几年级的,因此,“小学三年级” 事实上和主题无关,会使得搜索引擎丢掉大量不含“小学三年级”,但非常有价值的信息;“关于”也是一个与名人名言本身没有关系的词,多一个这样的词,又会减少很多有价值信息;“时间的名人名言”,其中的“的”也不是一个必要的词,会对搜索结果产生干扰;“名人名言”,名言通常就是名人留下来的,在名言前加上名人,是一种不必要的重复。 因此,最好的查询词,应该是“时间名言”。 试着找出下述查询词的问题,并想出更好的能满足搜索需求的查询词: 所得税会计处理问题探讨 周星驰个人档案和所拍的电影 实验一启发式搜索算法 学号:2220103430 班级:计科二班 姓名:刘俊峰 一、实验内容: 使用启发式搜索算法求解8数码问题。 1、编制程序实现求解8数码问题A *算法,采用估价函数 ()()()()w n f n d n p n ??=+??? , 其中:()d n 是搜索树中结点n 的深度;()w n 为结点n 的数据库中错放的棋子个数;()p n 为结点n 的数据库中每个棋子与其目标位置之间的距离总和。 2、 分析上述⑴中两种估价函数求解8数码问题的效率差别,给出一个是()p n 的上界 的()h n 的定义,并测试使用该估价函数是否使算法失去可采纳性。 二、实验目的: 熟练掌握启发式搜索A * 算法及其可采纳性。 三、实验原理: (一)问题描述 在一个3*3的方棋盘上放置着1,2,3,4,5,6,7,8八个数码,每个数码占一格,且有一个空格。这些数码可以在棋盘上移动,其移动规则是:与空格相邻的数码方格可以移入空格。现在的问题是:对于指定的初始棋局和目标棋局,给出数码的移动序列。该问题称八数码难题或者重排九宫问题。 (二)问题分析 八数码问题是个典型的状态图搜索问题。搜索方式有两种基本的方式,即树式搜索和线式搜索。搜索策略大体有盲目搜索和启发式搜索两大类。盲目搜索就是无“向导”的搜索,启发式搜索就是有“向导”的搜索。 启发式搜索:由于时间和空间资源的限制,穷举法只能解决一些状态空间很小的简单问题,而对于那些大状态空间的问题,穷举法就不能胜任,往往会导致“组合爆炸”。所以引入启发式搜索策略。启发式搜索就是利用启发性信息进行制导的搜索。它有利于快速找到问题的解。 由八数码问题的部分状态图可以看出,从初始节点开始,在通向目标节点的路径上,各节点的数码格局同目标节点相比较,其数码不同的位置个数在逐渐减少,最后为零。所以,这个 互联网信息搜索的方法与技巧】互联网信息搜索服务 互联网信息搜索的方法与技巧 搜索引擎在我们日常生活中的地位已是举足轻重。无论怎样,要想在浩如烟海的互联网信息中找到自己所需的信息,都需要一点点技巧。有人说,会搜索才叫会上网。 网络信息搜索是一项实践性很强的工作,学习一些网络搜索的原理和表达方式对提高网络搜索效率大有益处。但同时还要通过实践不断摸索,在实践中掌握不同数据库的特点,以便提高搜索效率。 网络信息搜索的一般原理 网络信息的搜索主要是通过搜索引擎对网上信息进行查找,它的基本原理是使用搜索程序来遍历因特网,将Web上分布的信息下载到本地文档库,然后对文档内容进行分析并建立索引,对于用户提出的查询提问,搜索引擎通过查找索引找出匹配的文档或链接,再返回给用户。目前搜索引擎主要通过两种技术实现信息搜索:一是使用网站分类技术,把网站进行树状的归类,对每个网站都有简略的描述;二是使用全文搜索技术;全文处理的对象是文本,通过网页抓取程序对大量网页数据建立由字(词)组成的倒排索引,以便使用户用关键词对文档进行查询,系统则返回含该关键词的网页。 网络信息的搜索技巧 1. 分析搜索主题,决定从何处开始进行搜索。在搜索中,有两个最为关键的步骤:一是概括搜索提问,选择精确的搜索词语;这是最基本同时也是最有效的技巧。目前的搜索引擎还并不能很好地处理自然语言。因此,在提交搜索请求时最好把自己想法提炼成简练而与希望找到的信息内容主题关联的查询词。一般说来查询词选应用名词和动词的组合。二是正确运用搜索提问的方式。 2. 考虑搜索提问中的关键词是否有同义词、近义词以及词形的各种变化,灵活运用各种运算符号,扩大词语的搜索范围,降低检索结果出现遗漏的可能性。例如:要查询酸奶方面的,与酸奶有关的词还包括牛奶、酸牛乳、乳酸饮料、乳酸菌饮料。因此,为了查到更全的,合并同类项后的搜索词为:酸奶、酸牛、乳酸。 3. 当有多个搜索词语之间逻辑关系复杂时,就分期分步制定搜索词语:(1) 分析搜索词语之间的逻辑关系,分门别类地建立“子逻辑 式”;(2) 根据搜索提问中涉及的主要主题概念,构造搜索提问式;(3) 尽量选专指词、特定概念或专业术语作关键词,避免普通词和太泛指的词语;(4) 短语搜索时应加双引号,提高查找的准确度;(5) 使用邻接算符可以提高搜索的准确性和灵活性;(6) 在关键词前可用不同符号表示词的重 目录 一、摘要 (2) 二、禁忌搜索简介 (2) 三、禁忌搜索的应用 (2) 1、现实情况 (2) 2、车辆路径问题的描述 (3) 3、算法思路 (3) 4、具体步骤 (3) 5、程序设计简介 (3) 6、算例分析 (4) 四、禁忌搜索算法的评述和展望 (4) 五、参考文献 (5) 禁忌搜索及应用 一、摘要 工程应用中存在大量的优化问题,对优化算法的研究是目前研究的热点之一。禁忌搜索算法作为一种新兴的智能搜索算法具有模拟人类智能的记忆机制,已被广泛应用于各类优化领域并取得了理想的效果。本文介绍了禁忌搜索算法的特点、应用领域、研究进展,概述了它的算法基本流程,评述了算法设计过程中的关键要点,最后探讨了禁忌搜索算法的研究方向和发展趋势。 二、禁忌搜索简介 禁忌搜索(Tabu Search或Taboo Search,简称TS)的思想最早由Glover(1986)提出,它是对局部领域搜索的一种扩展,是一种全局逐步寻优算法,是对人类智力过程的一种模拟。TS算法通过引入一个灵活的存储结构和相应的禁忌准则来避免迂回搜索,并通过藐视准则来赦免一些被禁忌的优良状态,进而保证多样化的有效探索以最终实现全局优化。相对于模拟退火和遗传算法,TS是又一种搜索特点不同的meta-heuristic算法。 迄今为止,TS算法在组合优化、生产调度、机器学习、电路设计和神经网络等领域取得了很大的成功,近年来又在函数全局优化方面得到较多的研究,并大有发展的趋势。 禁忌搜索是人工智能的一种体现,是局部领域搜索的一种扩展。禁忌搜索最重要的思想是标记对应已搜索的局部最优解的一些对象,并在进一步的迭代搜索中尽量避开这些对象(而不是绝对禁止循环),从而保证对不同的有效搜索途径的探索。禁忌搜索涉及到邻域(neighborhood)、禁忌表(tabu list)、禁忌长度(tabu length)、候选解(candidate)、藐视准则(aspiration criterion)等概念。 三、禁忌搜索的应用 禁忌搜索应用的领域多种多样,下面我们简单的介绍下基于禁忌搜索算法的车辆路径选择。 1、现实情况 物流配送过程的成本构成中,运输成本占到52%之多,如何安排运输车辆的行驶路径,使得配送车辆依照最短行驶路径或最短时间费用,在满足服务时间限制、车辆容量限制、行驶里程限制等约束条件下,依次服务于每个客户后返回起点,实现总运输成本的最小化,车辆路径问题正是基于这一需求而产生的。求解车辆路径问题(vehicle routing problem简记vrp)的方法分为精确算法与启发式算法,精确算法随问题规模的增大,时间复杂度与空间复杂度呈指数增长,且vrp问题属于np-hard问题,求解比较困难,因此启发式算法成为求解vrp问题的主要方法。禁忌搜索算法是启发式算法的一种,为求解vrp提供了新的工具。本文通过一种客户直接排列的解的表示方法,设计了一种求解车辆路径问题的新的禁忌搜索算法。 因此研究车辆路径问题,就是要研究如何安排运输车辆的行驶路线,使运输车辆依照最 互联网信息搜索的方法与技巧 搜索引擎在我们日常生活中的地位已是举足轻重。无论怎样,要想在浩如烟海的互联网信息中找到自己所需的信息,都需要一点点技巧。有人说,会搜索才叫会上网。 网络信息搜索是一项实践性很强的工作,学习一些网络搜索的原理和表达方式对提高网络搜索效率大有益处。但同时还要通过实践不断摸索,在实践中掌握不同数据库的特点,以便提高搜索效率。 网络信息搜索的一般原理 网络信息的搜索主要是通过搜索引擎对网上信息进行查找,它的基本原理是使用搜索程序来遍历因特网,将Web上分布的信息下载到本地文档库,然后对文档内容进行分析并建立索引,对于用户提出的查询提问,搜索引擎通过查找索引找出匹配的文档或链接,再返回给用户。目前搜索引擎主要通过两种技术实现信息搜索:一是使用网站分类技术,把网站进行树状的归类,对每个网站都有简略的描述;二是使用全文搜索技术;全文处理的对象是文本,通过网页抓取程序对大量网页数据建立由字(词)组成的倒排索引,以便使用户用关键词对文档进行查询,系统则返回含该关键词的网页。 网络信息的搜索技巧 1.分析搜索主题,决定从何处开始进行搜索。在搜索中,有两个最为关键的步骤:一是概括搜索提问,选择精确的搜索词语;这是最基本同时也是最有效的技巧。目前的搜索引擎还并不能很好地处理自然语言。因此,在提交搜索请求时最好把自己想法提炼成简练而与希望找到的信息内容主题关联的查询词。一般说来查询词选应用名词和动词的组合。二是正确运用搜索提问的方式。 2.考虑搜索提问中的关键词是否有同义词、近义词以及词形的各种变化,灵活运用各种运算符号,扩大词语的搜索范围,降低检索结果出现遗漏的可能性。例如:要查询酸奶方面的资料,与酸奶有关的词还包括牛奶、酸牛乳、乳酸饮料、乳酸菌饮料。因此,为了查到更全的信息,合并同类项后的搜索词为:酸奶、酸牛、乳酸。 3.当有多个搜索词语之间逻辑关系复杂时,就分期分步制定搜索词语:(1)分析搜索词语之间的逻辑关系,分门别类地建立 百度搜索技巧的四个方法 大家都知道搜索方法正确后可以大大提高搜索效率,会使大家的工作既省心又省力!网上针对百度搜索技巧的方法也很多,但是我在这里做一个总结,总结出十大百度搜索技巧!这十大百度搜索技巧可以帮助大家更迅速准确的找到相应信息,详情如下: 1、十大百度搜索技巧之(一)—-“-” 百度支持减除不相关的资料的“-”功能,可以用于删除某些无关页面,注意建号前面必须要有空格 例如:“A-B”意思就是说想在搜索A的同时屏蔽关于B的信息 2、十大百度搜索技巧之(二)—-“|“ 百度支持并行搜索功能来搜索例如:“A|B”意思是想要搜索包含A的信息或者包含B的信息比方说你要查询seo和侯瑞男时,可以用”seo|侯瑞男“来搜索,无需分两次查询,百度就会提供跟“|”前后任何相关关键词相关的网站和资料 3、十大百度搜索技巧(三)—-intitle intitle的作用是把搜索范围限定在网页标题中,网页标题往往就是本篇内容的简要概括,将查询内容界定在网页标题中会起到很好的效果。 使用方法:把查询内容中,特别关键的部分用”intitle:“做前缀 例如:想要查找标题中带有Yadid’s World的如何优化长尾关键词的内容,您就可以如下: 可以用[如何优化长尾关键词intitle:Yadid's World]输入搜索框就可以查 到想要得到的结果注意:“intitle:”后面不能有空格 4、十大百度搜索技巧(四)—-site site的作用就是将搜索范围界定在指定网站中,有时我们如果知道某一个站内就有自己想要的东西,那么我们就可以把这个界定界定到这个站内,来提高查询效率 本文由销售技巧培训整理编辑https://www.360docs.net/doc/5f16530379.html,/ 法律检索——方法和技巧 一、学习法律检索的重要性 第一,无论你在律师行业中是什么身份处于何等地位,是初出茅庐还是经验老道,法律检索都贯穿你的执业生涯全程。这里的法律检索,是一个相对广义的概念,不仅仅包括在数据库里找具体法条。在座的每一位,可能都曾经有过这样的时候:资深律师或者合伙人交给你一沓材料,或者你刚刚听客户滔滔不绝讲了三个小时还拿到一大堆文件,你看来看去就是发现不了其中需要研究的地方,哪些是会引起争议的点。而当你们成长为资深律师或者合伙人,本身仍然要参与案件或者项目,也需要自己去进行法律研究。在合伙人与助理磨合还没有非常默契的时候,在合伙人对助理的工作能力、检索能力、认真程度尚不能完全确信的时候,他势必要亲自验证或者说核查你搜索到的是否就已经穷尽了所有正确的答案。所以,我说法律检索是做律师一辈子的工作内容之一。 第二,无论你擅长的是什么业务类型,是做诉讼还是非诉讼业务,法律检索都是必备技能之一。以诉讼业务为例,无非就是“接案子”和“做案子”。大家都有个最基本的常识,那就是法院判案要“以事实为基础,以法律为准绳”。这里的事实和法律,都需要我们通过法律检索或者说法律研究来协助法官完成,以使得判决更加有利于你这一方。在这我来说说法律检索在接案过程中的重要作用。在梳理事实现状与了解客户要求的基础上,只有做好法律检索才能制定出更加完备的策略报告,才能提供更加充实、可行、准确的诉讼方案,甚至于通过完整的法律检索得到的答案决定你主观是否要接这个案子。我曾经听过大成所张健律师“诉讼策略报告如何写作”的讲座,他谈到“在你不具备经验的时候,你只能靠逻辑”。我想这里还可以补充一点,即便是“经验”也是可以通过法律检索去获得的,比如说某种案情的案件原告如何起诉被告如何答辩,你完全可以通过在数据库中搜索同类型案件裁判文书来学习、观摩与模仿。前阵子听说律师代理案件的政府指导价要取消了,律师的价值将会由市场决定,那么你如何才能脱颖而出或者说不被远远甩在后面,让客户认可你的价值,就需要你能拿出比别人更多更好的方案,取决于你发现了哪些问题以及就这些问题你找到了什么样的答案。 第三,无论社会发展到什么程度,变幻莫测的交易模式、产品以及专业术语怎样层出不穷,法律检索仍然是每位律师必须掌握的基本功之一。我每天都会关注行业新闻,几乎几天就会出现一个新的产品或者交易架构,但是我认为从根本上讲,暂时还没有脱离民商法的基本法律概念或者说基本的法律关系。在座的助理们来自不同的合伙人团队,大家平时接触的业务也都不尽相同。我就举两个金融方面的例子来印证我刚才的观点。第一个某银行计划操作一个“信贷资产证券化项目”,考虑选用“债权转让+权利完善措施”的模式,需要律师帮他们做一个完整的法律论证。第二个互联网金融方面的争议解决,李某通过禁忌搜索算法浅析
获取信息的策略与技巧
网上搜索的方法和技巧
盲目搜索
搜索策略实验报告
搜索引擎的使用方法和技巧
检索策略
用盲目搜索技术解决八数码问题
二分搜索实验报告
禁忌搜索算法评述(一)
比较各种搜索方法与技巧
搜索方法
实验一 启发式搜索算法
互联网信息搜索的方法与技巧互联网信息搜索服务
禁忌搜索和应用
互联网信息搜索的方法与技巧
百度搜索技巧的四个方法
法律检索方法和技巧