华南理工大学《人工智能》复习资料汇总

华南理工大学《人工智能》复习资料
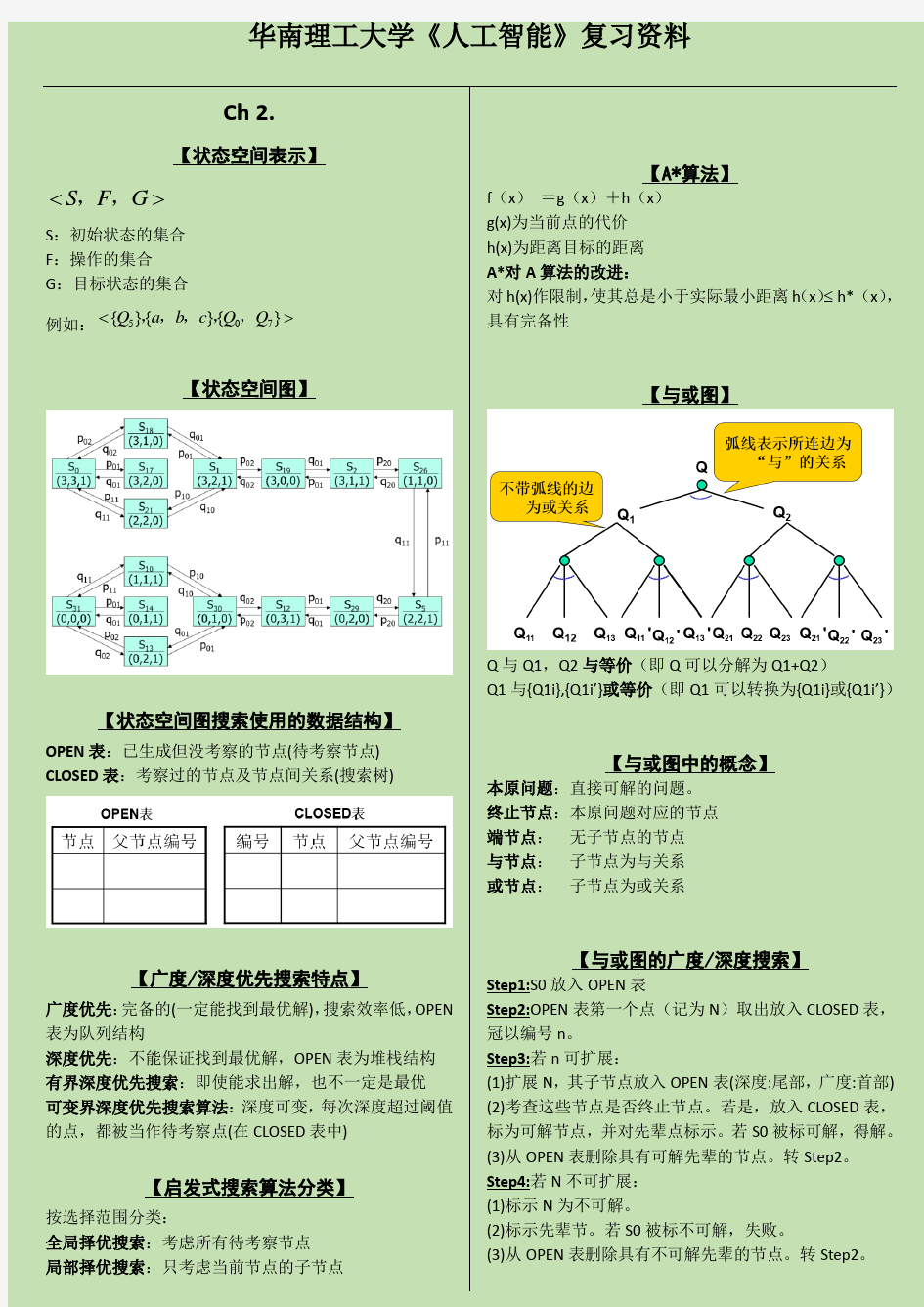
Ch 2.
【状态空间表示】 S F G <>,, S :初始状态的集合 F :操作的集合 G :目标状态的集合 例如:507{}{}{}Q a b c Q Q <>,,,,,
【状态空间图】
【状态空间图搜索使用的数据结构】 OPEN 表:已生成但没考察的节点(待考察节点)
CLOSED 表:考察过的节点及节点间关系(搜索树)
【广度/深度优先搜索特点】
广度优先:完备的(一定能找到最优解),搜索效率低,OPEN
表为队列结构
深度优先:不能保证找到最优解,OPEN 表为堆栈结构
有界深度优先搜索:即使能求出解,也不一定是最优
可变界深度优先搜索算法:深度可变,每次深度超过阈值
的点,都被当作待考察点(在CLOSED 表中)
【启发式搜索算法分类】 按选择范围分类: 全局择优搜索:考虑所有待考察节点 局部择优搜索:只考虑当前节点的子节点
【A*算法】
f (x ) =
g (x )+
h (x )
g(x)为当前点的代价
h(x)为距离目标的距离
A*对A 算法的改进:
对h(x)作限制,使其总是小于实际最小距离h (x )≤ h* (x ),
具有完备性
【与或图】
Q 与Q1,Q2与等价(即Q 可以分解为Q1+Q2) Q1与{Q1i},{Q1i’}或等价(即Q1可以转换为{Q1i}或{Q1i’})
【与或图中的概念】
本原问题:直接可解的问题。
终止节点:本原问题对应的节点
端节点: 无子节点的节点
与节点: 子节点为与关系
或节点: 子节点为或关系
【与或图的广度/深度搜索】 Step1:S0放入OPEN 表 Step2:OPEN 表第一个点(记为N )取出放入CLOSED 表,冠以编号n 。 Step3:若n 可扩展: (1)扩展N ,其子节点放入OPEN 表(深度:尾部,广度:首部) (2)考查这些节点是否终止节点。若是,放入CLOSED 表,标为可解节点,并对先辈点标示。若S0被标可解,得解。 (3)从OPEN 表删除具有可解先辈的节点。转Step2。
Step4:若N 不可扩展:
(1)标示N 为不可解。
(2)标示先辈节。若S0被标不可解,失败。
(3)从OPEN 表删除具有不可解先辈的节点。转Step2。
【与或图启发式搜索】
由下往上更新函数值,函数值=子节点价值+子节点与父节点距离。例子见PP3 Ch3.P117-120
【博弈树】
与结点:对手(MIN)力图干扰MAX的选择。因此站在我方(MAX)的立场,由MIN出棋的结点具有与结点的性质。或结点:我方(MAX)力图通往取胜。MAX出棋的结点具有或结点的性质。
【α剪枝,β剪枝】
α剪枝:对MIN节点,若其倒推上确界β不大于MIN的父节点倒推下确界α,即α≥β,则不必扩展该MIN节点其余子节点
β剪枝:对MAX节点,若其倒推下确界α不小于MAX的父节点倒推上确界β,即α≥β,则不必扩展该MAX节点其余子节点
Ch 3.
【离散数学相关定义】
命题(proposition):具有真假意义的语句
谓词(predicate):刻画个体的性质、状态或个体间的关系,例如P(x,y): x是y的父亲
个体域:个体变元的变化范围。(如P(x,y)中,x,y是变元) 全总个体域:包揽一切事物的集合
函数:个体之间的对应关系,例如father(x): 值为x的父亲项:个体常元和变元都是项。若t1,t2,…,tn是项,则f(t1,t2,…,tn )是项
原子公式:若t1,t2,…,tn为项,P(t1,t2,…,tn)称为原子谓词公式,简称原子或原子公式
谓词公式:原子公式是谓词公式。若A、B是谓词公式,则? A,A∪B等都是谓词公式
辖域:紧接于量词之后被量词作用的谓词公式
指导变量:量词后的变量
约束变量:量词辖域中,与该量词的指导变元相同的变量自由变量:除了约束变量之外的变量
一阶谓词:仅个体变元被量化的谓词
二阶谓词:个体变元、函数符号、谓词符号被量化
从谓词公式得到命题:
(1)把谓词中的个体变元代入个体常元
(2)把谓词中的个体变元全部量化
如P(x)表示"x是素数", 则?x P(x),P(a)都是命题
合取范式:B1 ∧ B2 ∧…∧B n,如
(()())(()())(()())
P x Q x Q y R y P z S z
∨∧?∨∧?∨8
析取范式:B1 ∨B2 ∨…∨B n,如
(()())(
D y L a y P x C z P u L u v
?∧∨?∧∨?∧?
,(()())())(,))
谓词公式永真性:P对个体域D全部成立,则P在D上永真。P在全总个体集成立,则P永真
谓词公式可满足性:P对个体域D至少有一个个体成立,则P在D上可满足。
【常用逻辑等价式】
【常用推理定律】
【子句集】
文字:原子谓词公式及其否定
子句:任何文字的析取
【子句集特点】
1.没有蕴含词、等值词
2.“?”作用原子谓词
3.没有量词( ?、? )
4.合取范式
5.元素之间变元不同
6.集合形式
【由谓词公式得到子句集】
(对应子句集特点的序号)
1.根据蕴含等价式消去蕴含关系
2.根据量词转换律、双重否定律、摩根定律转换
3.存在量词:受?x约束,则定义f(x)替换y (Skolem函数)
不受?x约束,常量代替y (Skolem常量) 全称量词:直接消去
4.根据分配率合取
5.各个合取子句变量改名
6.把合取符号替换为逗号,组成集合
【Skolem标准型】
消去存在量词,把全称量词移到最左,右式为合取,如
?x [P(x,f(x)) ∧? R(x,g(x)) ]
Skolem标准型与原公式一般并不等价
【命题逻辑中的归结原理定义】
逻辑结论与前提:G是F1、F2 、…、F n的逻辑结论,当且仅当对每个解释I,如果F1、F2 、…、F n都为真,则
G也为真。F1、F2 、…、F n为G的前提。
互补文字:L与?L
归结式:C1包含L1,C2包含L2,L1与L2互补。把L1和L2删除,并把剩余部分析取,得到C12
亲本子句:上例中C1与C2
消解基:上例中L1与L2
例如:
【归结原理定理】
1.谓词公式A不可满足当且仅当其子句集S不可满足。
2.G是公式F1、F2、…、F n的逻辑结论,当且仅当
F1 ∧F2 ∧…∧F n => G
3.G是公式F1、F2、…、F n的逻辑结论,当且仅当
F1 ∧F2 ∧…∧F n ∧ ? G不可满足
4.归结式是其亲本子句的逻辑结果
5.子句集S的C1,C2替换为C12得到S1,则
S1不满足=>S不满足
6.子句集S添加C12得到S2,则
S2不满足=>S不满足
【归结反演法】
否定目标公式G,? G加入到F1 ∧F2 ∧…∧F n中,得到子句集S。对S进行归结,并把归结结果并入S,直到得到空子句,原问题得证。
【替换定义】
替换:{t1/x1, t2/x2, …, tn/xn}
替换的分子:t1, t2, …, tn是项
替换的分母:x1, x2, …, xn是互不相同的个体变元(ti,,xi不同,xi不循环出现在tj中,如{f(x)/y,g(y)/x}不是替换) 基替换:t1, t2, …, tn是不含变元的项(称为基项)
空替换:没有元素的替换,记作ε
表达式:项、原子公式、文字、子句的统称
基表达式:没有变元的表达式
例/特例:对公式E实施替换θ,记为Eθ,所得结果称为E在θ下的例
复合/乘积:
θ={t1/x1, t2/x2, …, tm/xm},
λ={u1/y1, u2/y2, …, un/yn},
删除{t1λ/x1,t2λ/x2,…,tmλ/xm ,u1/y1,u2/y2,…,un/yn}中:
(1)tiλ/xi 当tiλ=xi
(2)ui/yi 当yi∈{x1,…, xn}
得到θ与λ的复合或乘积,记为θ?λ
例如:
θ= {a/x, f(u)/y ,y/z},λ={b/u,z/y,g(x)/z}
从{a/x,f(b)/y ,z/z,b/u,z/y,g(x)/z},删去:
z/z,z/y,g(x)/z
得到:θ·λ= {a/x,f(b)/y ,b/u}
【合一定义】合一:F1λ=F2λ=…=Fnλ则λ为F的合一,F为可合一的(一个公式的合一一般不唯一)
最一般合一:σ为F的一个合一,如果对F任何合一θ都存在λ使得θ=σ?λ,则σ为F的最一般合一,极为MGU(一个公式集的MGU不唯一)
差异集:S是具有相同谓词名的原子公式集,从各公式左边开始,同时向右比较,直到发现第一个不都相同的项为止,用这些项的差异部分组成的集合
【合一算法】
Step1:置k=0,Fk=F,σk =ε;
Step2:若Fk只含有一个谓词公式,则算法停止,σk就是最一般合一;
Step3:求Fk的差异集Dk;
Step4:若Dk中存在元素xk和tk ,其中xk是变元,tk 是项且xk不在tk中出现,则置Sk +1=Fk{tk/ xk} ,σk+1= σk ?{tk/ xk} ,k=k+1然后转Step2;
Step5:算法停止,F的最一般合一不存在。
对任一非空有限可合一的公式集,一定存在最一般合一,而且用合一算法一定能找到最一般合一
【合一算法例子】
求公式集F={Q(a,x,f(g(y))),Q(z,h(z,u),f(u))}的最一般合一解:
解
k=0;
F0=F,σ0=ε,D0={a,z}
σ1=σ0·{a/z}= {a/z}
F1= F0{a/z}= {Q(a,x,f(g(y))),Q(a,h(a,u),f(u))}
k=1;
D1={x, h(a,u)}
σ2= σ1·{h(a,u) /x}={a/z,h(a,u) /x}
F2= F1{a/z, h(a,u) /x}= {P(a, h(a,u) ,f(g(y))),P(a,h(a,u),f(u))}
k=2;
D2={g(y),u}
σ3={a/z ,h(a, g(y)) /x ,g(y)/u}
F3= F2{g(y)/u}= {P(a,h(a,g(y)),f(g(y)))}
S3单元素集,σ3为MGU。
【谓词逻辑中的归结原理定义】
二元归结式(二元消解式):
(C1σ-{L1σ})∪(C2σ-{L2σ}),其中:
亲本子句:C1,C2为无相同变元的子句
消解文字:L1,L2
σ为L1和?L2的最一般合一
因子:C σ。其中σ为C的子句文字的最一般合一
单因子:C σ为单元句子
R
S
P
C∨
∨
?
=
12
【归结式】
子句的C1,C2归结式,是下列二元归结式之一:
(1)C1和C2的二元归结式;
(2)C1和C2的因子的二元归结式;
(3)C1因子和C2的二元归结式;
(4)C1的因子和C2的因子的二元归结式。
归结注意事项:
(1) 两个子句不能含有相同的变元
(2) 归结的子句内部含有可合一的文字,则需进行简化
【谓词逻辑的消解原理/归结原理】
谓词逻辑中的消解(归结)式是它的亲本子句的逻辑结果:C1∧ C2=>(C1σ -{L1σ})∪(C2σ-{L2σ})
【谓词逻辑的定理】
如果子句集S是不可满足的,那么必存在一个由S推出空子句的消解序列。
【应用归结原理求取问题答案】
Step1:前提化为子句集S
Step2:确定目标谓词,化为子句,并析取助谓词新子句,并入到S形成S’。
Step3:对S’应用归结原理。
Step4:当只剩辅助谓词时,归结结束。
(例子见CH3 P105 )
【归结策略】
Step1:子句集S置入CLAUSES表
Step2:若Nil在CLAUSES,归结成功
Step3:若CLAUSES存在可归结子句对,则归结,并将归结式并入CLAUSES表,step2
Step4:归结失败
【广度优先搜索归结策略】
用于确定归结策略step3的搜索次序
第一轮:0层(原子句集S)两两进行归结,产生1层
下一轮:1层与0、1层两两进行归结,得到2层
再一轮:2层与0、1、2层两两进行归结,得到3层
如此类推,直至出现Nil
【归结策略完备性】
一个归结策略是完备的,如果对于不可满足的子句集,使用该策略进行归结,最终必导出空子句Nil。
(广度优先是完备的,亦称水平浸透法)
【归结策略出发点】
(1)简化性策略。
(2)限制性策略。(3)有序性策略(包含排序策略)
【归结策略类型】
删除策略
支持集策略
线性归结策略
单元归结策略
语义归结策略
祖先过滤型策略
【正向演绎推理--初始事实F0】
●任意谓词公式
●前束范式表示;消去量词,改名
●与或图表示:析取部分用与节点表示
合取部分用或节点表示
【正向演绎推理--F-规则】
●形如L=>W,L为单一文字
●W为任意与或型谓词公式;(消去量词,改名)
【正向演绎推理—目标谓词】
●文字的析取式(消去量词,改名)
【正向演绎推理图解】
1
2
':()(()())
':()()
':()()
':()()
F P x Q x R x
F P y S y
F Q z N z
G S a N a
?∨∧
???
?
?∨
? P(x)∨(Q(x)∧R(x))
Q(x)∧R(x)
? P(x)
Q(x)R(x)
Q(z)
? P(y)
N(x)
? S(x)
F0
F1 {x/z}
F2 {x/y}
{a/x}
{a/x}
N(a)
? S(a)
【代换集一致性】
设有代换集{u1,u2,…,u n},其中每个u i都是代换{t i1/ v i1, t i2/ v i2,…,t im(i)/ v im(i)}
U1={v11, …, v im(1),…,v n1, …, v nm(n)}(所有下边的变量)
U2={t 11, …, t im(1),…, t n1, …, t nm(n)} (所有上边的项)
{u 1,u 2,…,u n }是一致的,当且仅当U1和U2是可合一
合一复合:U1和U2的最一般合一
解树上所有代换是一致的,则该问题有解,最后的代换是
合一复合U
【反向演绎推理--目标公式】
任意谓词公式(消去量词,改名)
与或图表示:与节点对应合取;
或节点对应析取
【反向演绎推理--B -规则】
● W=>L ;
● L 为单一文字;
● W 为任意与或型谓词公式(消去量词,改名)
【反向演绎推理—图解】 ()MEOWS MYERTLE {x /x
5}{MYRTLE /x }
{FIDO /y }{y /x 1}{FIDO /y }R 1{FIDO /y }{x /y 2,y /x 2}
()()(,)
CAT x DOG y AFRAID x y ∧∧?()CAT x ()DOG y (,)AFRAID x y ?22(,)AFRAID y x ?5()CAT x ()MEOWS x ()BARKS y ?()
FRIENDLY y 1()
FRIENDLY x ()WAGS TAIL y -()DOG y R 2R 5
()BARKS FIDO ?()WAGS TAIL FEDO -()DOG FIDO ()DOG FIDO {FIDO /y }
【正向/反向演绎对比】 【双向演绎推理】 ● 分别从基于事实的F-规则正向推理出发,也从基于目标的B-规则逆向推理出发,同时进行双向演绎推理。 ● 终止的条件:正向推理和逆向推理互相完全匹配。即
所有得到的正向推理与或树的叶节点,正好与逆向推
理得到的与或图的叶节点一一对应匹配
【不确定性知识分类】
随机不确定性(概率) 模糊不确定性(软概念) 不完全性(事物了解不充分) 不一致性(时间推移) 【逆概率方法公式】
1(|)()(|)(|)()i i i n j j j P E H P H P H E P E H
P H ==
∑ 【逆概率—多个证据】
1212121(/)(/)(/)()
(/)(/)(/)(/)()
i i m i i i m n j
j m j j j P E H P E H P E H P H P H E E E P E H P E H P E H P H =∑
其实就是bayes 公式。严格要求各证据独立。
【修正因子】
方括号内为修正因子:
)(])()|([)|(H P E P H E P E H P =
【可信度法—不确定性度量】
If E then H (CF(H, E))
其中CF(H, E)为可信度因子/规则强度
CF(H,E)=MB(H,E) - MD(H,E)
【MB 和MD 】
MB (Measure Belief ):
信任增长度,因证据E 的出现使结论H 为真的信任增长度:
?????--=否则)(1)()}(),|(max{1=)(当1),(H P H P H P E H P H P E H MB MD (Measure Disbelief ): 不信任增长度,因E 的出现使H 为真的不信任增长度: ?????--=否则)()()}(),|(min{0=)(当1),(H P H P H P E H P H P E H MD 因此,CF(H,E)为:
?????????<-->--=)()|(当)()|()()(=)|(当0
)()|(当)(1)()|(),(H P E H P H P E H P H P H P E H P H P E H P H P H P E H P E H CF
【可信度法--不确定性传播】 组合证据:
E=E 1∧ E 2 ∧… ∧ E n :
CF(E)=min{CF(E 1) ,CF(E 2) , … CF(E n )}
E=E 1 ∨ E 2 ∨ … ∨ E n :
CF(E)=max{CF(E 1) ,CF(E 2) , … CF(E n )}
E=? E 1 :
CF(E)=-CF(E 1)
推理结论的CF 值:
CF(H) = CF(H,E) ? max { 0, CF(E) }
重复结论的CF 值:
【主观贝叶斯法】 表示形式:
if E then (LS, LN ) H ( P(H) )
))((),(H P H E LN LS ????→? 【LS 和LN 】
LS :充分性量度,E 对H 支持程度,范围为[ 0, ∞ ):
LN :必要性量度,? E 对H 支持程度,范围为[ 0, ∞ ):
LS 、LN>0,不独立,有如下约束关系:
当LS>1时,LN<1;
当LS<1时,LN>1;
当LS=1时,LN=1; 通过LN,LS 把先验概率转化为后验概率: ● LS= O(H|E)/ O(H) P(H|E) 越大,O(H|E)越大,则LS 越大,表明E 对H 为真的支持越强,当 LS → ∞ ,P(H|E) → 1,E 的存在对 H 为真是充分的
● LN=O(H| ? E) /O(H)
P(H| ?E )越大,O(H|? E)越大,则LN 越大,表明? E 对 H
为真的支持越强。当 LN = 0 ,P(H| ? E) = 0,E 的不存在
导致 H 为假,说明E 对H 是必要的
【几率函数】
【P(E|S)与P(H|S)】
其中C(E|S)由题目给出,用于刻画不确定性,值越大,证明在观察S 下,E 存在的可能性越大。
将两式结合,和得到CP 公式:
【贝叶斯网络图示】 ● 以随机变量为节点,以条件概率为节点间关系强度的有向无环图(Directed Acyclic Graph ,DAG ) ● 每个节点旁的条件概率表(简称CPT)中的值对应一个条件事件的概率
【条件独立关系】
贝叶斯网络中节点相互独立:
(1)给定父节点,一个节点与它的非后代节点是条件独立的
(2)给定一个节点的父节点、子节点以及子节点的父节点
(Markov blanket),这个节点对于其它节点都是条件独立的
【条件独立关系的判定】
d-分离(d-separation):
给定y ,x 和z 条件独立:
(|,)(|)P z x y P z y =
给定y ,x 和z 条件独立:(|,)(|)P z x y P z y =
给定y ,x 和z 不条件独立:(,)()()P x z P x P z =
【贝叶斯网络推理】
概率推理可分为:
因果推理、诊断推理、辩解推理、混合推理
【因果推理】
由原因到结果的推理,自上而下的推理,例如已知L 成立
时,求
P(M|L) (|)(,|)(,|)P M L P M B L P M B L =+?
【诊断推理】
由结果到原因的推理,自下而上的推理。例如已知?M 成
立,求P(?L |?M
)
(|)()
(|)()P M L P L P L M P M ?????=? 【辩解推理】
仅仅给定?B ,求P(?L)。这种情况下,可以说?B 解释?M ,
使?L 不确定。
(,|)()
(|,)(,)P M B L P L P L B M P M B ???????=?? Ch 5.
“?”:可接受任何值
“φ”:不接受任何值 算法流程:
1.将h 初始化为H 中最特殊假设
2.对每个正例x (循环)
对h 的每个属性约束a i 如果x 满足a i 那么不做任何处理 否则 将h 中a i 替换为x 满足的更一般的约束 3.输出假设h 【候选消除算法】
【BP 算法误差项】
更新规则
:
【BP 算法权值更新】
The learning rule for the hidden-to-output units :
The learning rule for the input-to-hidden units:
Summary:
Ch 6.
【遗传算法的基本操作】
(1)复制
从旧种群选择生命力强的个体进行复制。
实现方法:根据个体适应度/总适应度,为每个个体分配概率范围(0~1),产生随机数,选择匹配的个体:
(2)交叉
在匹配池中任选两个染色体,随机选择一点或多点交换点位置;交换双亲染色体交换点右边的部分,即可得到两个新的染色体数字串
(3)变异
在染色体以二进制编码的系统中,它随机地将染色体的某一个基因由1变为0,或由0变为1。
【遗传算法的特点】
(1)对参数的编码进行操作,而非参数本身
(因此可模仿自然界进化机制)
(2)同时使用多个搜索点的搜索信息
(搜索效率高、并行、不陷入局部最优)
(3)直接以目标函数作为搜索信息
(不需导数和其他辅助信息)
(4)使用概率搜索技术
(复制交叉变异基于概率,有很好灵活性)
(5)在解空间进行高效启发式搜索
(而非盲目搜索、完全随机搜索)
(6)对待寻优的函数基本无限制
(不要求连续、可微)
(7)具有并行计算的特点
(适合大规模复杂问题的优化)
【遗传算法的构成要素】
(1)染色体编码方法
使用固定长度的二进制符号来表示群体中的个体(2)个体适应度评价
目标函数值J到个体适应度f之间的转换规则
(3)遗传算子
①选择运算:使用比例选择算子;
②交叉运算:使用单点交叉算子;
③变异运算:使用基本位变异算子或均匀变异算子
(4)基本遗传算法的运行参数
下述4个运行参数需要提前设定:
①M:群体大小,即群体中所含个体的数量,一般取
为20~100;
②G:遗传算法的终止进化代数,一般取为100~500;
③Pc:交叉概率,一般取为0.4~0.99;
④ Pm:变异概率,一般取为0.0001~0.1。
十大算法
1.【C4.5】
【信息增益的计算】
期望信息:
设样本集合s含有si 个类为Ci 的元组, i = {1, …, m},则对一个给定的样本分类所需的期望信息是:
熵:
具有值{a1,a2,…,a v}的属性A的熵E(A)为属性A导致的s 的划分的期望信息的加权平均和:
信息增益:
例子
:
【信息增益比】
【C4.5算法】
1.创建根节点
2.若所有样本为类x,标记为类x
3.若Attribute为空,标记为最普遍的类
4.选择信息增益比最大的属性,每个可能值建立子节点,递归解决
2.【k-means】
【聚类目标】
聚类内部距离平方之和的最小化:
【k-means算法】
定义:
k-means算法以k为输入参数,把n个对象的集合分为k个集,使得结果簇内的相似度高,而簇间的相似度低。
簇的相似度是关于簇中对象的均值度量,可以看做簇的质心或重心。
算法:
1. 把对象划分成k 个非空子集;
2. 计算当前的每个聚类的质心作为每个聚类的种子点;
3. 把每一个对象分配到与它最近的种子点所在的聚类
4. 返回到第2步, 当满足某种停止条件时停止。
停止条件: 1. 当分配不再发生变化时停止; 2. 当前后两次迭代的目标函数值小于某一给定的阈值;
3. 当达到给定的迭代次数时。
时间复杂性:
计算复杂度为
O(nkt),其中n 是对象的总数,k 是簇的个数,t 是迭代的次数
3.【SVM 】 【Margin 】 * Margin is defined as the width that the boundary could be increased by before hitting a data point
* The linear discriminant function (classifier) with
the
maximum margin is the best.
* Data closest to the hyper plane are support vectors.
【Maximum Margin Classification 】
* Maximizing the margin is good according to intuition
and theory.
* Implies that only support vectors are important; other
training examples are ignorable. 【Kernels 】 * We may use Kernel functions to implicitly map to a
new feature space
* Kernel must be equivalent to an inner product in
some feature space 【Solving of SVM 】
* Solving SVM is a quadratic programming problem
Target: maximum margin -> ==> Such that
【Nonlinear SVM 】
The original feature space can always be mapped to
some higher-dimensional feature space where the
training set is separable
【Optimization Problem 】
Dual Problem for (a i is Lagrange multiplier): Solution (Each non-zero a i indicates that corresponding x i is a support vector.): Classifying function (relies on an inner product between the test point x and the support vectors xi.
involved computing the inner products x i ‘ * x j between
all training points):
【Slack variables 】 Target :
Dual Problem of the soft margin is the same for hard .
Solution: Classifying function of the soft margin is the same.
【Kernel Trick 】 * Map data points to higher dimensional space in order
to make them linearly separable.
* Since only dot product is used, we do not need to
represent the mapping explicitly.
Discriminant function: (No need to know this mapping
explicitly, because we only use the dot product of
feature vectors in both the training and test.)
Kernel function : dot product of two feature vectors in
some expanded feature spce :
【Nonlinear SVM optimization】
4.【Apriori】
【支持度与置信度】
规则A→C:
【用Apriori算法挖掘强关联规则】
连接操作: {A B C …X} 和{A B C …Y}可连接,生成
{A B C … X Y}
(个数相同,只有最后一个元素不同) 生成频繁k-项集L k的算法:
·根据k-1项集L k-1,连接生成候选集C k
·筛选出C k中支持度大于min_sup的元素,构成L k 例子:
从频繁项集产生关联规则
根据频繁项集I,生成全部非空子集。
对于每个子集m, 若sup(m→( I-m )) ≥ min_sup,输出此规其中sup(m→( I-m )
) =
=
5.【EM】
在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量。
最大期望算法经过两个步骤交替进行计算:
●第一步是计算期望(E),利用对隐藏变量的现有估
计值,计算其最大似然估计值;
●第二步是最大化(M),最大化在E 步上求得的最
大似然值来计算参数的值。
M 步上找到的参数估计值被用于下一个E 步计算中,这个过程不断交替进行。
总体来说,EM的算法流程如下:
1.初始化分布参数
2.重复直到收敛:
E步骤:估计未知参数的期望值,给出当前的参数估计。M步骤:重新估计分布参数,以使得数据的似然性最大,给出未知变量的期望估计。
6.【PageRank】
【基本思想】
* PageRank将网页x指向网页y的链接视为x给y的
一张投票。
* 然而PageRank 不仅仅考虑网页得票的绝对数目,它
还分析投票者本身的权威性.
- 来自权威网页的投票能够提升被投票网页的权威
性
【更具基本思想】
* 链接是源网页对目标网页权威性的隐含表达.
- 网页i 入边(in-links )越多,表示i 的权威性值越高。
* 指向网页i 的网页本身也有自己的权威性值
- 对于网页i 的权威性得分而言,一个具有高分值的源
网页比一个低分值的源网页更加重要。
- 换言之,若其它权威性网页指向网页i ,则i 也可能是
权威性网页。
【PageRank 优点与缺点】
优点:
(1) 防欺骗
网页所有者难以设置其它重要网页指向自己的网
页.
(2) ageRank 值独立于查询,是一种全局度量.
PageRank 值是通过所有网页计算得到并加以存
储,而不是提交查询时才计算.
缺点:
不能区分全局重要性网页和查询主题重要性网页
【Web 图】
把Web 视为有向图 G = (V, E),V 表示顶点(网页),一
条边(i, j) ∈ E 当且仅当网页i 指向网页j ,n 为总的网页
数。 网页P(i)定义为
: Oj 是网页j 的出边数 A 是Web 图的邻接矩阵表示:
通过使用幂法可以求解P A P T =,但是Web 图不符合求解条件。
【转移概率矩阵】
Aij 表示用户在状态i (网页i )转移到状态j (网页j )的概率。(公式和web 图一致) k 步转移后的概率分布: 【稳态概率分布】 对于任意初始概率向量P 0, P k 将收敛于一个稳定的概率向量π, 即
, π 可作为PageRank 值向量,其合理性: - 它反映了随机冲浪的长期概率. - 一个网页被访问的概率越高,其权威性越高. 【收敛性】 一个有限马尔可夫链收敛于一个唯一的稳态概率分布:如果矩阵A 是不可约(irreducible )和非周期的(aperiodic )。 条件1:随机矩阵 A 不是一个随机矩阵,因为很多网页没有出边,导致A 中某些行全为0. 解决方案1:删除没有出边的网页. 解决方案2:将没有出边的网页指向网络中所有其它网页 条件2:不可约
不可约意味着强连通(所有点对都有双向路径),A 不符
合。
条件3:非周期
从i 到i 的所有路径都是K 的倍数(k>1),则成为周期的。
一个马尔科夫链所有状态都是非周期的,则为非周期。
解决方案:指定一个参数d ,将每一个网页(状态)都
以概率d 指向其它所有网页。此方法顺便解决了不可约
问题,处理后(原始文献阻尼因子d=0.85):
其中E = ee T (E=ones(n)),令 e T P = n
:
因此,每个网页
7.【
Adaboost】
【Strength and weakness of AdaBoost】
【AdaBoost Algorithm】
【Reweighting】
8.【KNN】
9.【naive Bayes】
【Bayes formula】
【Bayes Decision Rule】
【Maximum Likelihood (ML) Rule
】
When p(w1)=p(w2),the decision is based entirely on the
likelihood p(x|w j) --> p(x|w)∝p(x|w)
【
Error analysis】
Probability of error for multi-class problems:
Error = Bayes Error + Added Error:
【Lost function】
Conditional risk(expected loss of taking action ai):
Overall risk (expected loss):
zero-one loss function is used to minimize the error rate
【Minimum Risk Decision Rule】
【Normal Distribution】
Multivariate Normal Density in d dimensions:
【ML Parameter Estimation】
【Discriminant function】
10.【CART】
【概念】
分类回归树是二叉树,且每个非叶子节点都有两个孩子,
所以对于第一棵子树其叶子节点数比非叶子节点数多1
【与ID3区别】
●CART中用于选择变量的不纯性度量是Gini指数;
●如果目标变量是标称的,并且是具有两个以上的类
别,则CART可能考虑将目标类别合并成两个超类别
(双化);
●如果目标变量是连续的,则CART算法找出一组基于
树的回归方程来预测目标变量。
【CART分析步骤】
1、从根节点t=1开始,从所有可能候选S集合中搜索使
不纯性降低最大的划分S*,然后,使用划分S*将节点1
(t=1)划分成两个节点t=2和t=3;
2、在t=2和t=3上分别重复划分搜索过程。
【基尼系数】
例子:
Calculate impurity:
Build tree:
11.【Deep learning】
【核心思想】
把学习结构看作一个网络,则深度学习的核心思路如下:
①无监督学习用于每一层网络的pre-train;
②每次用无监督学习只训练一层,将其训练结果作为其高
一层的输入;
③用自顶而下的监督算法去调整所有层
【需要使用深度学习解决的问题的特征】
深度不足会出现问题。
人脑具有一个深度结构。
认知过程逐层进行,逐步抽象。
【
BP
例子】
2020年公需科目《人工智能》答案
1.目前,人工智能发展存在的问题不包括()。( 2.0分) A.泡沫化 B.重复化 C.与应用结合不够紧密 D.缺乏热情 我的答案:D √答对 2.智能制造的核心是改变传统产品的本质,最终实现产品的“三化”,其中不包括()。(2.0分) A.数字化 B.网络化 C.智能化 D.规模化 我的答案:D √答对 3.微博上面人们最关心的与人工智能相关的关键词是()。(2.0分) A.善恶、安全、就业、进化、终结 B.善恶、安全、就业、进化、法律 C.善恶、安全、就业、风险、终结 D.善恶、安全、进化、风险、法律 我的答案:B ×答错 4.2016年8月,日本电视台报道称,东京大学医学研究所通过运用IBM的人工智能平台Watson仅用10分钟就诊断出了资深医师难以判别出来的()。(2.0分) A.甲状腺癌 B.胰腺癌 C.淋巴癌 D.白血病 我的答案:D √答对 5.成年男性的正常脉搏为每分钟()次。(2.0分) A.60~80 B.70~90 C.80~100 D.90~120 我的答案:A √答对 6.成年女性的正常脉搏为每分钟()次。(2.0分) A.60~80 B.70~90 C.80~100 D.90~120 我的答案:B √答对 7.世界上第一个将芯片植入体内的人是()。(2.0分) A.凯文·沃里克 B.布鲁克斯 C.罗斯·昆兰 D.杰弗里·辛顿 我的答案:A √答对
8.约瑟夫·维森鲍姆教授开发的()被设计成一个可以通过谈话帮助病人完成心理恢复的心理治疗师。(2.0分) A.微软小冰 B.苹果Siri C.谷歌Allo D.ELIZA 我的答案:D √答对 9.()是没有人驾驶、靠遥控或自动控制在水下航行的器具。(2.0分) A.无人机 B.战场机器人 C.无人潜航器 D.无人作战飞船 我的答案:C √答对 10.智能制造的本质是通过新一代信息技术和先进制造技术的深度融合,实现跨企业价值网络的横向集成,来贯穿企业设备层、控制层、管理层的纵向集成,以及产品全生命周期的端到端集成,而()是实现全方位集成的关键途径。(2.0分) A.标准化 B.数据化 C.流程化 D.网络化 我的答案:A √答对 11.()是普遍推广机器学习的第一人。(2.0分) A.约翰·冯·诺依曼 B.约翰·麦卡锡 C.唐纳德·赫布 D.亚瑟·塞缪尔 我的答案:C √答对 12.在农业领域的()环节,智能的农业机器人可以利用图像识别技术获取农作物的生长状况,判断哪些杂草需要清除,判断哪里需要灌溉、施肥、打药,并立即执行。(2.0分) A.产前 B.产中 C.产后 D.全程 我的答案:B √答对 13.当我们需要寻求健康咨询服务时,应该拨打的热线电话是()。(2.0分) A.12315 B.12301 C.12345 D.12320 我的答案:D √答对 14.下列关于人工智能对实体经济的影响说法不正确的是()。(2.0分) A.人工智能能够提升实体经济能级 B.人工智能能够加快经济转型 C.人工智能能够加快创新驱动发展
西电人工智能大作业
人工智能大作业 学生:021151** 021151** 时间:2013年12月4号
一.启发式搜索解决八数码问题 1.实验目的 问题描述:现有一个3*3的棋盘,其中有0-8一共9个数字,0表示空格,其他的数字可以和0交换位置(只能上下左右移动)。给定一个初始状态和一个目标状态,找出从初始状态到目标状态的最短路径的问题就称为八数码问题。 例如:实验问题为
到目标状态: 从初始状态: 要求编程解决这个问题,给出解决这个问题的搜索树以及从初始节点到目标节点的最短路径。 2.实验设备及软件环境 利用计算机编程软件Visual C++ 6.0,用C语言编程解决该问题。 3.实验方法 (1).算法描述: ①.把初始节点S放到OPEN表中,计算() f S,并把其值与节点S联系 起来。 ②.如果OPEN表是个空表,则失败退出,无解。 ③.从OPEN表中选择一个f值最小的节点。结果有几个节点合格,当其 中有一个为目标节点时,则选择此目标节点,否则就选择其中任一节点作为节点i。 ④.把节点i从OPEN表中移出,并把它放入CLOSED的扩展节点表中。 ⑤.如果i是目标节点,则成功退出,求得一个解。 ⑥.扩展节点i,生成其全部后继节点。对于i的每一个后继节点j: a.计算() f j。 b.如果j既不在OPEN表中,也不在CLOSED表中,则用估价函数f
把它添加入OPEN表。从j加一指向其父辈节点i的指针,以便一旦 找到目标节点时记住一个解答路径。 c.如果j已在OPEN表或CLOSED表上,则比较刚刚对j计算过的f 值和前面计算过的该节点在表中的f值。如果新的f值较小,则 I.以此新值取代旧值。 II.从j指向i,而不是指向它的父辈节点。 III.如果节点j在CLOSED表中,则把它移回OPEN表。 ⑦转向②,即GO TO ②。 (2).流程图描述: (3).程序源代码: #include
机器人大作业
IRB1600型机器人的运动学分析及仿真
目录 1.引言................................................................................................................ - 2 - 1.1 ABB公司简介.................................................................................... - 3 - 1.2ABB发展历史 .................................................................................... - 4 - 2. IRB1600 ........................................................................................................ - 5 - 2.1 IRB1600的资料................................................................................. - 6 - 2.2建立基于D-H方法的连杆坐标系 ................................................... - 8 - 2.3建立六自由度点焊机器人的运动学方程....................................... - 10 - 3. 虚拟样机的建立........................................................................................ - 12 - 3.1 导入.................................................................................................. - 12 - 3.2 添加约束副...................................................................................... - 13 - 3.3 基于ADAMS的机器人运动学仿真 ............................................. - 14 - 4. 结语............................................................................................................ - 18 - 5. 参考资料.................................................................................................... - 19 -
人工智能和发展
人工智能和发展 摘要:人工智能是20世纪计算机科学发展的重大成就,在许多领域有着广泛的应用。论述了人工智能的定义,分析了目前在管理、教育、工程、技术、等领域的应用,总结了人工智能研究现状,分析了其发展方向。关键词:人工智能;计算机科学;发展方向 1 人工智能的定义 人工智能(Artificial Intelligence,AI),是一门综合了计算机科学、生理学、哲学的交叉学科。“人工智能”一词最初是在1956年美国计算机协会组织的达特莫斯(Dartmouth)学会上提出的。自那以后,研究者们发展了众多理论和原理,人工智能的概念也随之扩展。由于智能概念的不确定,人工智能的概念一直没有一个统一的标准。著名的美国斯坦福大学人工智能研究中心尼尔逊教授对人工智能下了这样一个定义“人工智能是关于知识的学科——怎样表示知识以及怎样获得知识并使用知识的科学。”而美国麻省理工学院的温斯顿教授认为“人工智能就是研究如何使计算机去做过去只有人才能做的智能工作。”童天湘在《从“人机大战”到人机共生》中这样定义人工智能:“虽然现在的机器不能思维也没有“直觉的方程式”,但可以把人处理问题的方式编入智能程序,是不能思维的机器也有智能,使机器能做那些需要人的智能才能做的事,也就是人工智能。”诸如此类的定义基本都反映了人工智能学科的基本思想和基本内容。即人工智能是研究人类智能活动的规律,构造具有一定智能的人工系统,研究如何让计算机去完成以往需要人的智力才能胜任的工作,也就是研究如何应用计算机的软硬件来模拟人类某些智能行为的基本理论、方法和技术。 2 人工智能的应用领域 2.1 人工智能在管理及教学系统中的应用人工智能在企业管理中的应用。刘玉然在《谈谈人工智能在企业管理中的应用》一文中提到把人工智能应用于企业管理中,认为要做的工作就是搞清楚人的智能和人工智能的关系,了解人工智能的外延和内涵,搭建人工智能的应用平台,搞好企业智能化软件的开发工作,这样,人工智能就能在企业决策中起到关键的作用。人工智能在智能教学系统中的应用。焦加麟,徐良贤,戴克昌(2003)在总结国际上相关研究成果的基础上,结合其在开发智能多媒体汉德语言教学系统《二十一世纪汉语》的过程中累积的实践经验,介绍了智能教学系统的历史、结构和主要技术,着重讨论了人工智能技术与方法在其中的应用,并指出了当今这个领域上存在的一些问题。 2.2 人工智能专家系统在工程领域的应用人工智能专家系统在医学中的应用。国外最早将人工智能应用于医疗诊断的是MYCIN专家系统。1982年,美国Pittsburgh大学Miller发表了著名的作为内科医生咨询的Internist 2I内科计算机辅助诊断系统的研究成果,1977年改进为Internist 2Ⅱ,经过改进后成为现在的CAU-CEUS,1991年美国哈佛医学院Barnett等开发的DEX-PLAIN,包含有2200种疾病和8000种症状。我国研制基于人工智能的专家系统始于上世纪70年代末,但是发展很快。早期的有北京中医学院研制成“关幼波肝炎医疗专家系统”,它是模拟著名老中医关幼波大夫对肝病诊治的程序。上世纪80年代初,福建中医学院与福建计算机中心研制的林如高骨伤计算机诊疗系统。其他如厦门大学、重庆大学、河南医科大学、长春大学等高等院校和其他研究机构开发了基于人工智能的医学计算机专家系统,并成功应用于临床。人工智能在矿业中的应用。与矿业有关的第一个人工智能专家系统是1978年美国斯坦福国际研究所的矿藏勘探和评价专家系统PROSPECTOR,用于勘探评价、
人工智能大作业
第一章 1、3 什么就是人工智能?它的研究目标就是什么? 人工智能(Artificial Intelligence),英文缩写为AI。它就是研究、开发用于模拟、延伸与扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 研究目标:人工智能就是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理与专家系统等。 1、7 人工智能有哪几个主要学派?各自的特点就是什么? 主要学派:符号主义,联结主义与行为主义。 1.符号主义:认为人类智能的基本单元就是符号,认识过程就就是符号表示下的符号计算, 从而思维就就是符号计算; 2.联结主义:认为人类智能的基本单元就是神经元,认识过程就是由神经元构成的网络的信 息传递,这种传递就是并行分布进行的。 3.行为主义:认为,人工智能起源于控制论,提出智能取决于感知与行动,取决于对外界复 杂环境的适应,它不需要只就是,不需要表示,不需要推理。 1、8 人工智能有哪些主要研究与应用领域?其中有哪些就是新的研究热点? 1、研究领域:问题求解,逻辑推理与定理证明,自然语言理解,自动程序设计,专家系统,机器 学习,神经网络,机器人学,数据挖掘与知识发现,人工生命,系统与语言工具。 2、研究热点:专家系统,机器学习,神经网络,分布式人工智能与Agent,数据挖掘与知识发 现。 第二章 2、8 用谓词逻辑知识表示方法表示如下知识: (1)有人喜欢梅花,有人喜欢菊花,有人既喜欢梅花又喜欢菊花。 三步走:定义谓词,定义个体域,谓词表示 定义谓词 P(x):x就是人
重庆大学网教作业答案-互联网及其应用 ( 第1次 )
第1次作业 一、单项选择题(本大题共30分,共 10 小题,每小题 3 分) 1. 中国制定的3G技术标准是()。 A. WCDMA B. CDMA2000 C. TD-SCDMA D. WiMAX 2. 某个程序员设计了一个网络游戏,他选择的端口号应该是() A. 77 B. 199 C. 567 D. 2048 3. TCP拥塞窗口控制没有采用以下哪种技术() A. 慢启动 B. 拥塞避免 C. 加速递减 D. 滑动窗口 4. 以太网采用共享总线方式工作的接入机制为()。 A. CSMA B. 时隙CSMA C. CSMA/CA D. CSMA/CD 5. IGMP协议通过__________来传输() A. IP B. UDP C. TCP D. 以太网数据帧 6. IGMP报文的长度为()。 A. 4个八位组 B. 8个八位组 C. 12个八位组 D. 可变长度 7. FTP协议下层采用的协议是:() A. UDP B. TCP C. IP D. TELNET 8. 在电子邮件中,我们往往会添加附件信息,例如图片。请问它与哪个协议最相关()。 A. SMTP B. POP3 C. IMAP D. MIME 9. 以下哪个协议采用了OSPF的数据库信息()。 A. DVMRP B. PIM C. MOSPF D. CBT 10. 请问以下哪个IP地址与224.129.2.3映射为相同的以太网组播地址 ()。 A. 224.1.2.3 B. 224.130.2.3 C. 224.135.2.3 D. 224.11.2.3 二、多项选择题(本大题共40分,共 10 小题,每小题 4 分) 1. 移动视频主要在以下()平台上。 A. 智能手机 B. 平板电脑 C. 笔记本 电脑 D. 台式电脑 E. 网络服务器 2. 物联网的感应器可以安装在以下()物体中。 A. 电网 B. 铁路 C. 桥梁 D. 隧道 E. 公路 3. MIME对以下哪些内容的发送是必须的()。 A. 汉字内容 B. 图片附件 C. WORD文档附件 D. 动画附件 E. 视频附件 4. IP路由表设计中采用了哪些技术来缩小路由表的规模() A. IP网络号代替主机号
西安电子科技大学人工智能试题
1.(该题目硕士统招生做)请用框架法和语义网络法表示下列事件。(10分) 2015年2月20日上午11点40分,广东省深圳市光明新区柳溪工业园附近发生山体滑坡,经初步核查,此次滑坡事故共造成22栋厂房被掩埋,涉及公司15家,截至目前已安全撤离900人,仍有22人失联。 答:框架表示法(5分):(给分要点:确定框架名和框架槽,根据报道给出的相关数据填充,主要内容正确即可给分,不必与参考答案完全一致) <山体滑坡> 时间:2015年2月20日上午11点40分 地点:广东省深圳市光明新区柳溪工业园附近 掩埋厂房:22栋 涉及公司数目:15家 安全撤离人数:900人 失联人数:22人 语义网络表示法(5分):(给分要点:确定语义网络的节点及其连接关系,根据报道内容进行填充,主要内容正确即可给分,不必与参考答案完全一致) 1. (该题目全日制专业学位硕士做)请用一种合适的知识表示方法来表示下面知识。(10分) How Old Are YOU是微软推出的一款测年龄应用,该应用架设在微软服务平台Azure上,该平台具有机器学习的开发接口,第三方开发者可以利用相关的接口和技术,分析人脸照片。
(给分要点:采用合适的知识表示方法,正确即可给分,不必与参考答案完全一致) 答:
高级人工智能训练师
高级人工智能训练师 Company number:【WTUT-WT88Y-W8BBGB-BWYTT-19998】
1. 当产品参数中没有对应的参数信息,想要回复给买家比较精确的答案,我们可以通过 以下哪个方法来配置商品属性问题 话术中设置固定属性,配置不同答案关联对应商品 2. 我们可以实时根据“未解决榜”的问题聚类来进行配置优化。以上这种说法是否正确 否 3. 欢迎语卡片的问题点击情况,我们最快可以在隔天看到效果。以上这种说法是否正确 否 4. 关于转人工率的计算方法,以下哪个说法是正确的 转人工率=店小蜜请求转人工数/店小蜜接待买家数 5. 询单转化率中的店小蜜接待UV,包含以下哪些人群的UV 都包 含 6.关于尺码表和官方知识库选码场景关系,以下哪个说法是正确的 7. 优先匹配尺码表,官方选码场景兜底 8. 在“旺旺分流”-“离线消息”板块中,不能查看聊天记录。以上这种说法是否正确 否 9. 我们可以根据当天的“转人工知识高频列表”的问题来进行配置优化。以上这种说法是否 正确 否 10. 关于变量标签规范的使用方式,以下哪个选项是正确的答 案编辑框点击插入 11. 自定义知识库配置时应当尽可能简化用户的问题,精简到短语。以上这种说法是否正 确否 12. 柳柳想要在知识库中快速找到关联某一时效的答案,那么她应该按照以下哪个方法进 行操作 点击知识库左上角的“搜时效”,输入时效名称搜索 13. 冷门自定义问法的定义是指:连续两周该自定义知识的所有问法,热度均几乎为0。以 上这种说法是否正确 是 14. 某条知识配置了一条任意类型的答案,那么这条知识就不会出现在“没有配置答案转人 工”的列表里。以上这种说法是否正确 否
重庆市普通高中2018级学业水平考试信息技术复习题(一)高清版
重庆市普通高中2018级学生学业水平考试 信息技术测试题(一) 注意事项: 1.满分100分,考试时间为90分钟。 2.答题前,考生务必将考场地点、毕业学校、姓名、准考证号、考试科目等填写在答题卡上的规定 位置,并用2B铅笔填涂相关信息。 3.所有试题的答案请用2B铅笔填涂在答题卡上。 一、判断题(共25题,每题1分,共计25分) 1.农民丰收后农产品没有销路,有农民在互联网上发布了农产品的信息,一下子打开了销路。这充分说明了信息的价值性。() A.正确 B.错误 2.利用网际快车下载文件,如果没有下载完成就关闭计算机,下次开机下载的时候,不可以接着在上次下载的断点处继续下载。() A.正确 B.错误 3.如果字母C的ASCII码为67,那么字母A的ASCII码为65。() A.正确 B.错误 4.在如下图所示的Word文档中,人物图片“加里·基尔代尔”的环绕方式为上下型() A.正确 B.错误 5.在Excel中,当使用菜单“格式”→“列”→“列宽”设列宽为9个字符(如右图所示)时,表示其储存格所能显示的字符个数不论字形大小都只能显示9个字符() A.正确 B.错误 6.在Word中输入一组学生姓名,每输完一个学生姓名后按一下“Enter”键, 全部输入完毕后,选择所有学生姓名后单击复制按钮。再启动Excel后能进行粘 贴,粘贴后所有学生的姓名在同一列() A.正确 B.错误
7.在Flash动画制作中,制作“遮罩动画”时,遮罩图层必须在被遮罩图层的上方() A.正确 B.错误 8.张老师收上来的学生作业,在电脑上显示如下图所示,文件”015.PPT”很有可能打不开() A.正确 B.错误 9.视频和动画都是利用人眼的视觉暂留效应来产生画面连续的运动效果() A.正确 B.错误 10.观察下面声音控制面板,如想利用话筒进行扩音,应对声音控制面板进行取消③项的操作() A.正确 B.错误 11.在VB中,表达式Int(-5.8)的结果是-6 ( ) A.正确 B.错误 12.在程序运行过程中其值可以被改变的量称为常量。() A.正确 B.错误 13.人们经常要将纸质材料扫描成电子材料再进行编辑,现有一些OCR软件能够将扫描图片中的文字转换为普通字符。OCR软件利用的技术是模式识别。() A.正确 B.错误 14.张琳对着自己的手机说“请关机”,手机马上就执行了关机命令,这其中主要应用了人工字符识别技术。() A.正确 B.错误 15.用QQ或MSN等工具软件,可以实现一对一在线视频或语音交流() A.正确 B.错误 16.在一个数据表中修改了某条记录后,与其相关的查询结果不会随之改变() A.正确 B.错误 17.我们通常所说的IP电话就是利用互联网进行语音传输的电话() A.正确 B.错误 18.我们通常说的“黑客”(Hacker)是指对网络危害极大的一些不健康的网站( ) A.正确 B.错误
西电电院人工智能课程大作业
西电人工智能大作业
八数码难题 一.实验目的 八数码难题:在3×3的方格棋盘上,摆放着1到8这八个数码,有1个方格是空的,其初始状态如图1所示,要求对空格执行空格左移、空格右移、空格上移和空格下移这四个操作使得棋盘从初始状态到目标状态。例如: (a) 初始状态 (b) 目标状态 图1 八数码问题示意图 请任选一种盲目搜索算法(深度优先搜索或宽度优先搜索)或任选一种启发式搜索方法(A 算法或 A* 算法)编程求解八数码问题(初始状态任选),并对实验结果进行分析,得出合理的结论。 本实验选择宽度优先搜索:选择一个起点,以接近起始点的程度依次扩展节点,逐层搜索,再对下一层节点搜索之前,必先搜索完本层节点。 二.实验设备及软件环境 Microsoft Visual C++,(简称Visual C++、MSVC、VC++或VC)微软公司的C++开发工具,具有集成开发环境,可提供编辑C语言,C++以及C++/CLI 等编程语言。 三.实验方法 算法描述: (1)将起始点放到OPEN表; (2)若OPEN空,无解,失败;否则继续; (3)把第一个点从OPEN移出,放到CLOSE表; (4)拓展节点,若无后继结点,转(2); (5)把n的所有后继结点放到OPEN末端,提供从后继结点回到n的指针; (6)若n任意后继结点是目标节点,成功,输出;否则转(2)。
流程图:
代码: #include
重庆大学机械设计试题及答案
重庆大学机械设计试题及答案(一) 单项选择题(每题2分,共40分) 1、采用螺纹联接时,若被联接件之一厚度较大且材料较软,强度较低,需要经常装拆,则一般宜采 用()。 A、螺栓联接 B、双头螺柱联接 C、螺钉联接 D、紧定螺钉联接 2、齿轮齿根弯曲强度计算中的齿形系数与()无关。 A、模数m B、变位系数x C、齿数z D、螺旋角b 3、带传动产生弹性滑动的原因是由于()。 A、带不是绝对挠性体 B、带与带轮间的摩擦因数偏低 C、带绕过带轮时产生离心力 D、带的紧边与松边拉力不等 4、带传动张紧的目的是()。 A、减轻带的弹性滑动 B、提高带的寿命 C、改变带的运动方向 D、使带具有足够的初拉力 5、对于受循环变应力作用的零件,影响疲劳破坏的主要因数是()。 A、最大应力 B、平均应力 C、应力幅 D、最大应力和平均应力 6、对轴进行弯扭合成强度校核计算时,将T乘以折算系数a是考虑到()。 A、扭应力可能不是对称循环变应力
B、弯曲应力可能不是对称循环变应力 C、轴上有应力集中 D、提高安全性 7、非液体摩擦滑动轴承正常工作时,其工作面的摩擦状态是()。 A、完全液体摩擦状态 B、干摩擦状态 C、边界摩擦或混合摩擦状态 D、不确定 8、高速重载齿轮传动,当润滑不良时,最可能出现的失效形式是()。 A、齿面胶合 B、齿面疲劳点蚀 C、齿面磨损 D、轮齿疲劳折断 9、滚动轴承基本额定动载荷对应的基本额定寿命是()转。 A、107 B、25×107 C、106 D、5×106 10、滚子链传动中,滚子的作用是()。 A、缓和冲击 B、减小链条与链轮轮齿间的磨损 C、提高链的破坏载荷 D、保证链条与轮齿间的良好啮合 11、键的剖面尺寸通常根据()按标准选取。 A、传递扭矩大小 B、功率大小 C、轴的直径 D、轴毂的宽度 12、链传动中,限制链轮最少齿数的目的之一是为了()。 A、减少链传动的不均匀性和动荷载
人工智能大作业翻译
Adaptive Evolutionary Artificial Neural Networks for Pattern Classification 自适应进化人工神经网络模式分类 Abstract—This paper presents a new evolutionary approach called the hybrid evolutionary artificial neural network (HEANN) for simultaneously evolving an artificial neural networks (ANNs) topology and weights. Evolutionary algorithms (EAs) with strong global search capabilities are likely to provide the most promising region. However, they are less efficient in fine-tuning the search space locally. HEANN emphasizes the balancing of the global search and local search for the evolutionary process by adapting the mutation probability and the step size of the weight perturbation. This is distinguishable from most previous studies that incorporate EA to search for network topology and gradient learning for weight updating. Four benchmark functions were used to test the evolutionary framework of HEANN. In addition, HEANN was tested on seven classification benchmark problems from the UCI machine learning repository. Experimental results show the superior performance of HEANN in fine-tuning the network complexity within a small number of generations while preserving the generalization capability compared with other algorithms. 摘要——这片文章提出了一种新的进化方法称为混合进化人工神经网络(HEANN),同时提出进化人工神经网络(ANNs)拓扑结构和权重。进化算法(EAs)具有较强的全局搜索能力且很可能指向最有前途的领域。然而,在搜索空间局部微调时,他们效率较低。HEANN强调全局搜索的平衡和局部搜索的进化过程,通过调整变异概率和步长扰动的权值。这是区别于大多数以前的研究,那些研究整合EA来搜索网络拓扑和梯度学习来进行权值更新。四个基准函数被用来测试的HEANN进化框架。此外,HEANN测试了七个分类基准问题的UCI机器学习库。实验结果表明在少数几代算法中,HEANN在微调网络复杂性的性能是优越的。同时,他还保留了相对于其他算法的泛化性能。 I. INTRODUCTION Artificial neural networks (ANNs) have emerged as a powerful tool for pattern classification [1], [2]. The optimization of ANN topology and connection weights training are often treated separately. Such a divide-and-conquer approach gives rise to an imprecise evaluation of the selected topology of ANNs. In fact, these two tasks are interdependent and should be addressed simultaneously to achieve optimum results. 人工神经网络(ANNs)已经成为一种强大的工具被用于模式分类[1],[2]。ANN 拓扑优化和连接权重训练经常被单独处理。这样一个分治算法产生一个不精确的评价选择的神经网络拓扑结构。事实上,这两个任务都是相互依存的且应当同时解决以达到最佳结果。
机器人10-11期末试卷
重庆大学《机器人技术基础》课程试卷 2010 ~2011学年第1学期 开课学院:机械工程考试日期:2010.12.16 考试方式: 考试时间:120 分钟 一、单项选择题(2分/每小题,共30分) ⒈“Robot”一词最早是由()提出的。 ①加藤一郎②卡雷尔·查培克 ③恩格尔伯格④阿西莫夫 ⒉机器人三定律是由()提出的。 ①加藤一郎②卡雷尔·查培克 ③恩格尔伯格④阿西莫夫 ⒊被称作工业机器人之父是()。 ①加藤一郎②卡雷尔·查培克 ③恩格尔伯格④阿西莫夫 ⒋被称作仿人形机器人之父是()。 ①加藤一郎②卡雷尔·查培克 ③恩格尔伯格④阿西莫夫 ⒌被称作中国水下机器人之父是()。 ①张启先②蒋新松 ③蔡鹤皋④宋健 ⒍世界第一台工业机器人大约是在()年发明的。 ①1950; ②1960; ③1970; ④1980; ⒎世界第一台工业机器人是根据()的专利发明的。 ①加藤一郎②戴沃尔 ③恩格尔伯格④阿西莫夫 ⒏目前大多数工业机器人属于()机器人。 ①第一代②第二代 ③第三代④第四代 ⒐世界第一台工业机器人是属于()。 ①直角坐标型②圆柱坐标型 ③球坐标型④关节坐标型 ⒑平行关节型机器人是由()科学家发明的。 ①中国②美国 ③日本④德国11. “先行者”仿人形机器人是()研制的。 ①国防科技大学 ②北京航空航天大学 ③沈阳自动化研究所④哈尔滨工业大学 12. D-H参数是由Denauit和Hartenbery提出的。这两个人名的拼写出现了()个错误。 ①1 ②2 ③3 ④4 13.目前90%的工业机器人的驱动系统采用()。 ①液压驱动②交流伺服电机驱动 ③步进电机驱动④直流伺服电机驱动 14.首末两点有位置、速度、加速度限制时,关节插补必须用()。 ①简谐运动规律②3-4-5多项式 ③3次多项式④5次多项式 15.普通商用工业机器人有()自由度。 ①根据工况需要而设定的数个②5个 ③6个④7个 二、分析题(6分/每小题,共30分) ⒈传感器的性能可用基本参数、环境参数和使用条件3个指标描述,简述这3个指标所包含的内容。 ⒉简述图示增量式光电编码器如何测转速、如何测转向以及C相的作用。 题二(2)图3.简述交流伺服电动机的特点。
2020年徐州市公共科目一《人工智能与健康》考试试卷1
2020年徐州市公共科目一《人工智能与健康》考试试卷1 一、判断题(每题2分) 1.虚拟现实是一种将真实世界信息和虚拟世界信息“无缝”集成的新技术 正确 错误 2.在国外,还没有银行尝试利用人工智能技术通过客户表情分析提供投资决策 正确 错误 3.人工智能将融合大数据、云计算技术,对数据信息的收集、识别、判断实现实时处理 正确 错误 4.深度学习技术可利用海量金融交易数据,自动识别欺诈交易行为,进而实时拦截,以降低风险。典型应用场景有基于知识图谱技术的征信与风险控制、反欺诈等 正确 错误 5.智能保顾即智能化的保险顾问,它是基于客户自身的保险需要,通过算法和产品来完成保险顾问的服务,作为对比,这个服务以往通常是由人来实现的 正确
6.通过互联网及移动装置,智能保顾在线实时且随时随地为用户提供服务,满足互联网时代下用户的习性及需求,提升用户投保时的体验 正确 错误 7.通过AI分析技术与机器学习相互结合,极大地提高了医疗服务质量和预后 正确 错误 8.临床上,常规病理诊断方法需要大量人力成本,结果仍然缺乏质量保证。在AI基础上开发的病理诊断方法更加精确和具有可预测性。许多医疗机构正在尝试利用图像识别技术辅助癌症诊断 正确 错误 9.AI技术不可以用于辅助临床决策 正确 错误 10.Ginger.IO能够通过收集手机数据,推测用户生活习惯是否发生了变化,根据用户习惯来主动对用户提问 正确 错误 11.对电子健康档案数据的分析将在精确医学和癌症研究中发挥重要作用 正确
12.人类思维模式趋向于快思维(fast thinking)捷径,能够从少数样本、数据和碎片化信息中迅速得出普遍性结论的本能。但这种天赋并不适用于癌症和阿尔兹海默症等复杂疾病现象。深度学习则擅长识别潜在的模式和细节之间的联系正确 错误 13.人工智能技术是专家系统的一个分支。主要由包含大量规则的知识库和模拟人类推理方式的推理机组成。 正确 错误 14.最贴近市民的健康保障是智慧家庭医疗系统 正确 错误 15.人工智能是人类一直以来的梦想 正确 错误 二、单项选择(每题2分) 16.智能医疗可以实现实现患者与医生、医院以及什么之间的联系与互动 护士 药房 医疗设备 手术室
人工智能大作业
人工智能基础 大作业 —---八数码难题 学院:数学与计算机科学学院 班级:计科14—1 姓名:王佳乐 学号:12 2016、12、20 一、实验名称 八数码难题得启发式搜索 二、实验目得 八数码问题:在3×3得方格棋盘上,摆放着1到8这八个数码,有1个方格就是空得,其初始状态如图1所示,要求对空格执行空格左移、空格右移、空格上移与空格下移这四个操作使得棋盘从初始状态到目标状态. 要求:1、熟悉人工智能系统中得问题求解过程; 2、熟悉状态空间得启发式搜索算法得应用; 3、熟悉对八数码问题得建模、求解及编程语言得应用。 三、实验设备及软件环境 1.实验编程工具:VC++ 6、0 2.实验环境:Windows7 64位 四、实验方法:启发式搜索 1、算法描述 1.将S放入open表,计算估价函数f(s)
2.判断open表就是否为空,若为空则搜索失败,否则,将open表中得第 一个元素加入close表并对其进行扩展(每次扩展后加入open表中 得元素按照代价得大小从小到大排序,找到代价最小得节点进行扩展) 注:代价得计算公式f(n)=d(n)+w(n)、其中f(n)为总代价,d(n)为节点得度,w(n)用来计算节点中错放棋子得个数. 判断i就是否为目标节点,就是则成功,否则拓展i,计算后续节点f(j),利用f(j)对open表重新排序 2、算法流程图: 3、程序源代码: #include<stdio、h> # include<string、h> # include
机械设计 重庆大学 练习题库及答案
1、一般参数的闭式软齿面齿轮传动的主要失效形式是()。 ?A、齿面点蚀 ?B、轮齿折断 ?C、齿面塑性变形 ? ?A、直齿圆柱齿轮传动 ?B、斜齿圆柱齿轮传动 ?C、直齿锥齿轮传动 ? ?A、小带轮上的包角 ?B、大带轮上的包角 ?C、带轮的宽度 ? 4、在进行疲劳强度计算时,其极限应力应为材料的()。 ?A、屈服点 ?B、疲劳极限 ?C、强度极限 ? 5、对蜗杆传动进行热平衡计算,其主要目的是为了防止温升过高导致()。?A、材料的机械性能下降 ?B、润滑油变质 ?C、蜗杆热变形过大 ?D、润滑条件恶化而产生胶合失效
6、滑动螺旋传动,其失效形式多为()。 ?A、螺纹牙弯断 ?B、螺纹磨损 ?C、螺纹牙剪切 ? 7、两轴的角位移达30°,这时宜采用()联轴器。 ?A、万向 ?B、齿式 ?C、弹性套柱销 ? 8、 V带传动设计中,限制小带轮的最小直径主要是为了()。 ?A、使结构紧凑 ?B、限制弯曲应力 ?C、保证带和带轮接触面间有足够摩擦力 ? 9、链传动中,F为工作拉力,作用在轴上的力F Q可近似地取为()。?A、 F ?B、 1.2F ?C、 1.5F ? 10、一般参数的闭式硬齿面齿轮传动的主要失效形式是()。 ?A、齿面点蚀 ?B、轮齿折断 ?C、齿面塑性变形 ?D、齿面胶合
11、一般参数的开式齿轮传动,其主要失效形式是()。 ?A、齿面点蚀 ?B、齿面磨损 ?C、齿面胶合 ? 12、带传动中,带每转一周,带中应力是()。 ?A、有规律变化的 ?B、不变的 ?C、无规律变化的 ? 13、一对标准渐开线圆柱齿轮要正确啮合时,它们的()必须相等。 ?A、直径 ?B、模数 ?C、齿宽 ? 14、 V带中的离心拉应力与带的线速度()。 ?A、的平方成正比 ?B、的平方成反比 ?C、成正比 ? 15、确定紧连接螺栓中拉伸和扭转复合载荷作用下的当量应力时,通常是按()来进行计算的。?A、第一强度理论 ?B、第二强度理论 ?C、第三强度理论 ?D、第四强度理论
高级人工智能训练师认证答案
1单项选择题 在“旺旺分流”-“离线消息”板块中,不能查看聊天记录。以上这种说法是否正确? 是 否 2单项选择题 某商家在官方知识库中只配置了一个关联部分商品的答案,导致买家咨询该问题后转人工,且该问题出现在了“无答案问题”列表中,以下哪一个是可以进行优化的方法? 添加一条针对所有商品都生效的通用答案 删除关联部分商品的答案 添加答案的时效性,保持长期有效 答案中增加关联买家问的商品 3单项选择题 转人工率越低,解决能力越高。以上这个说法是否正确? 是 否 4单项选择题 冷门自定义问法的定义是指:连续两周该自定义知识的所有问法,热度均几乎为0。以上这种说法是否正确? 是 否
5单项选择题 我们可以根据当天的“转人工知识高频列表”的问题来进行配置优化。以上这种说法是否正确? 是 否 6单项选择题 某条知识配置了一条任意类型的答案,那么这条知识就不会出现在“没有配置答案转人工”的列表里。以上这种说法是否正确? 是 否 7单项选择题 自定义知识库每个问法都必须要进行划词。以上这种说法是否正确? 是 否 8单项选择题 训练师柳柳想要将店小蜜离线消息分流给人工客服,她可以按照以下哪个维度进行筛选? 是否请求转人工 是否下单 是否接待
都不对 9单项选择题 关于一个店铺可以订阅行业包的个数,以下哪个选项是正确的? 最多1个 最多5个 最多3个 不限制 10单项选择题 关于答案回复优先级排序,以下哪个选项是正确的? 人工直连-关键词-官方知识库 关键词-人工直连-官方知识库 人工直连-官方知识库-关键词 关键词-官方知识库-人工直连 11单项选择题 在知识库配置答案时,我们只需要引导买家去宝贝详情页面进行查看就可以了。以上这种说法是否正确? 是 否 12单项选择题