树形结构数据表的设计

树形结构的数据库表Schema设计
程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门、栏目结构、商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化。然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,因此是不能直接将Tree 存入DBMS,设计合适的Schema及其对应的CRUD算法是实现关系型数据库中存储树形结构的关键。
理想中树形结构应该具备如下特征:数据存储冗余度小、直观性强;检索遍历过程简单高效;节点增删改查CRUD操作高效。无意中在网上搜索到一种很巧妙的设计,原文是英文,看过后感觉有点意思,于是便整理了一下。本文将介绍两种树形结构的Schema设计方案:一种是直观而简单的设计思路,另一种是基于左右值编码的改进方案。
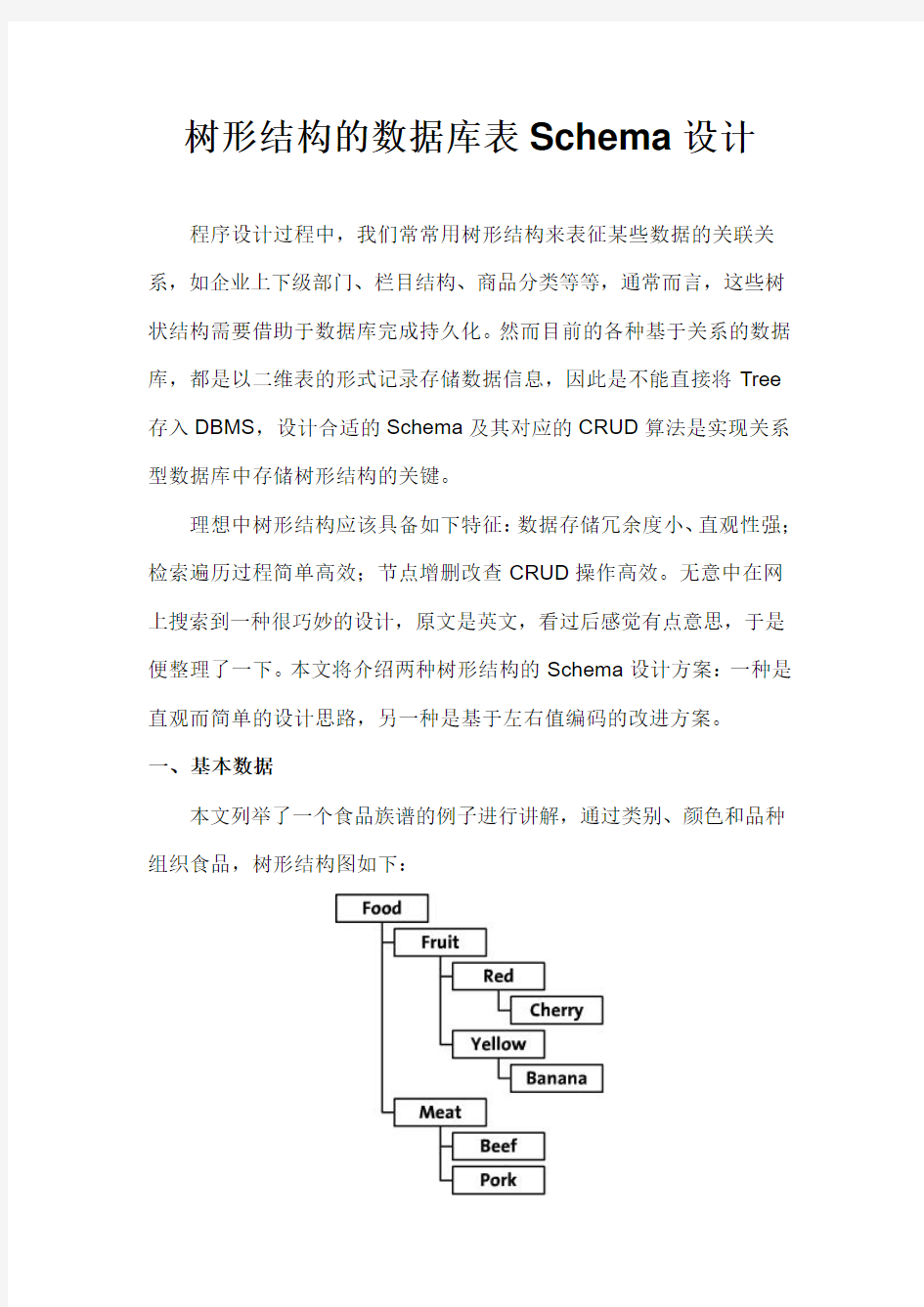
一、基本数据
本文列举了一个食品族谱的例子进行讲解,通过类别、颜色和品种组织食品,树形结构图如下:
二、继承关系驱动的Schema设计
对树形结构最直观的分析莫过于节点之间的继承关系上,通过显示地描述某一节点的父节点,从而能够建立二维的关系表,则这种方案的Tree表结构通常设计为:{Node_id,Parent_id},上述数据可以描述为如下图所示:
这种方案的优点很明显:设计和实现自然而然,非常直观和方便。缺点当然也是非常的突出:由于直接地记录了节点之间的继承关系,因此对Tree的任何CRUD操作都将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。当然,这种方案并非没有用武之地,在Tree规模相对较小的情况下,我们可以借助于缓存机制来做优化,将Tree的信息载入内存进行处理,避免直接对数据库IO操作的性能开销。
三、基于左右值编码的Schema设计
在基于数据库的一般应用中,查询的需求总要大于删除和修改。为了避免对于树形结构查询时的“递归”过程,基于Tree的前序遍历设计一种全新的无递归查询、无限分组的左右值编码方案,来保存该树的数
据。
第一次看见这种表结构,相信大部分人都不清楚左值(Lft)和右值(Rgt)是如何计算出来的,而且这种表设计似乎并没有保存父子节点的继承关系。但当你用手指指着表中的数字从1数到18,你应该会发现点什么吧。对,你手指移动的顺序就是对这棵树进行前序遍历的顺序,如下图所示。当我们从根节点Food左侧开始,标记为1,并沿前序遍历的方向,依次在遍历的路径上标注数字,最后我们回到了根节点Food,并在右边写上了18。
第一次看见这种表结构,相信大部分人都不清楚左值(Lft)和右值(Rgt)是如何计算出来的,而且这种表设计似乎并没有保存父子节点的继承关系。但当你用手指指着表中的数字从1数到18,你应该会发现点什么吧。对,你手指移动的顺序就是对这棵树进行前序遍历的顺序,如下图所示。当我们从根节点Food左侧开始,标记为1,并沿前序遍历的方向,依次在遍历的路径上标注数字,最后我们回到了根节点Food,并在右边写上了18。
依据此设计,我们可以推断出所有左值大于2,并且右值小于11的节点都是Fruit的后续节点,整棵树的结构通过左值和右值存储了下来。然而,这还不够,我们的目的是能够对树进行CRUD操作,即需要构造出与之配套的相关算法。
四、树形结构CRUD算法
(1)获取某节点的子孙节点
只需要一条SQL语句,即可返回该节点子孙节点的前序遍历列表,以Fruit为例:SELECT* FROM Tree WHERE Lft BETWEEN 2 AND 11 ORDER BY Lft ASC。查询结果如下所示:
那么某个节点到底有多少的子孙节点呢?通过该节点的左、右值我们可以将其子孙节点圈进来,则子孙总数= (右值–左值– 1) / 2,以Fruit为例,其子孙总数为:(11 –2 – 1) / 2 = 4。同时,为了更为直观地展现树形结构,我们需要知道节点在树中所处的层次,通过左、右值的SQL查询即可实现,以Fruit为例:SELECTCOUNT(*) FROM Tree WHERE Lft <= 2 AND Rgt >=11。为了方便描述,我们可以为Tree建
立一个视图,添加一个层次数列,该列数值可以写一个自定义函数来计算,函数定义如下:
[sql]view plaincopy
1CREATE FUNCTION dbo.CountLayer
2(
3 @node_id int
4)
5RETURNS int
6AS
7begin
8declare @result int
9set @result = 0
10declare @lft int
11declare @rgt int
12 if exists(select Node_id from Tree where Node_id = @node_id)
13begin
14select @lft = Lft, @rgt = Rgt from Tree where node_id = @node_id
15select @result = count(*) from Tree where Lft <= @lft and Rgt >= @rgt 16end
17return @result
18end
19GO
基于层次计算函数,我们创建一个视图,添加了新的记录节点层次的数列:
[sql]view plaincopy
20CREATE VIEW dbo.TreeView
21AS
22SELECT Node_id, Name, Lft, Rgt, dbo.CountLayer(Node_id) AS Layer FROM dbo.Tree ORDER BY Lft
23GO
创建存储过程,用于计算给定节点的所有子孙节点及相应的层次:[sql]view plaincopy
24CREATE PROCEDURE [dbo].[GetChildrenNodeList]
25(
26 @node_id int
27)
28AS
29declare @lft int
30declare @rgt int
31if exists(select Node_id from Tree where node_id = @node_id)
32begin
33select @lft = Lft, @rgt = Rgt from Tree where Node_id = @node_id 34select * from TreeView where Lft between @lft and @rgt order by Lft ASC 35end
36GO
现在,我们使用上面的存储过程来计算节点Fruit所有子孙节点及对应层次,查询结果如下:
从上面的实现中,我们可以看出采用左右值编码的设计方案,在进行树的查询遍历时,只需要进行2次数据库查询,消除了递归,再加上查询条件都是数字的比较,查询的效率是极高的,随着树规模的不断扩大,基于左右值编码的设计方案将比传统的递归方案查询效率提高更
多。当然,前面我们只给出了一个简单的获取节点子孙的算法,真正地使用这棵树我们需要实现插入、删除同层平移节点等功能。
(2)获取某节点的族谱路径
假定我们要获得某节点的族谱路径,则根据左、右值分析只需要一条SQL语句即可完成,以Fruit为例:SELECT* FROM Tree WHERE Lft < 2 AND Rgt > 11 ORDER BY Lft ASC ,相对完整的存储过程:[sql]view plaincopy
37CREATE PROCEDURE [dbo].[GetParentNodePath]
38(
39 @node_id int
40)
41AS
42declare @lft int
43declare @rgt int
44if exists(select Node_id from Tree where Node_id = @node_id)
45begin
46select @lft = Lft, @rgt = Rgt from Tree where Node_id = @node_id 47select * from TreeView where Lft < @lft and Rgt > @rgt order by Lft ASC 48end
49GO
(3)为某节点添加子孙节点
假定我们要在节点“Red”下添加一个新的子节点“Apple”,该树将变成如下图所示,其中红色节点为新增节点。
仔细观察图中节点左右值变化,相信大家都应该能够推断出如何写SQL脚本了吧。我们可以给出相对完整的插入子节点的存储过程:[sql]view plaincopy
50CREATE PROCEDURE [dbo].[AddSubNode]
51(
52 @node_id int,
53 @node_name varchar(50)
54)
55AS
56declare @rgt int
57if exists(select Node_id from Tree where Node_id = @node_id)
58begin
59SET XACT_ABORT ON
60BEGIN TRANSCTION
61select @rgt = Rgt from Tree where Node_id = @node_id
62update Tree set Rgt = Rgt + 2 where Rgt >= @rgt
63update Tree set Lft = Lft + 2 where Lft >= @rgt
64insert into Tree(Name, Lft, Rgt) values(@node_name, @rgt, @rgt + 1) 65COMMIT TRANSACTION
66SET XACT_ABORT OFF
67end
68GO
(4)删除某节点
如果我们想要删除某个节点,会同时删除该节点的所有子孙节点,而这些被删除的节点的个数为:(被删除节点的右值–被删除节点的左值+ 1) / 2,而剩下的节点左、右值在大于被删除节点左、右值的情况下会进行调整。来看看树会发生什么变化,以Beef为例,删除效果如下图所示。
则我们可以构造出相应的存储过程:
[sql]view plaincopy
69CREATE PROCEDURE [dbo].[DelNode]
70(
71 @node_id int
72)
73AS
74declare @lft int
75declare @rgt int
76if exists(select Node_id from Tree where Node_id = @node_id)
77begin
78SET XACT_ABORT ON
79BEGIN TRANSCTION
80select @lft = Lft, @rgt = Rgt from Tree where Node_id = @node_id 81delete from Tree where Lft >= @lft and Rgt <= @rgt
82update Tree set Lft = Lft – (@rgt - @lft + 1) where Lft > @lft 83update Tree set Rgt = Rgt – (@rgt - @lft + 1) where Rgt > @rgt 84COMMIT TRANSACTION
85SET XACT_ABORT OFF
86end
87GO
五、总结
我们可以对这种通过左右值编码实现无限分组的树形结构Schema设计方案做一个总结:
(1)优点:在消除了递归操作的前提下实现了无限分组,而且查询条件是基于整形数字的比较,效率很高。
(2)缺点:节点的添加、删除及修改代价较大,将会涉及到表中多方面数据的改动。
当然,本文只给出了几种比较常见的CRUD算法的实现,我们同样可以自己添加诸如同层节点平移、节点下移、节点上移等操作。有兴趣的朋友可以自己动手编码实现一下,这里不在列举了。值得注意的是,实现这些算法可能会比较麻烦,会涉及到很多条update语句的顺序执行,如果顺序调度考虑不周详,出现Bug的话将会对整个树形结构表产生惊人的破坏。因此,在对树形结构进行大规模修改的时候,可以采用临时表做中介,以降低代码的复杂度,同时,强烈推荐在做修改之前对表进行完整备份,以备不时之需。在以查询为主的绝大多数基于数据库的应用系统中,该方案相比传统的由父子继承关系构建的数据库Schema更为适用。
数据结构课程设计图的遍历和生成树求解
数学与计算机学院 课程设计说明书 课程名称: 数据结构与算法课程设计 课程代码: 6014389 题目: 图的遍历和生成树求解实现 年级/专业/班: 学生姓名: 学号: 开始时间: 2012 年 12 月 09 日 完成时间: 2012 年 12 月 26 日 课程设计成绩: 指导教师签名:年月日
目录 摘要 (3) 引言 (4) 1 需求分析 (5) 1.1任务与分析 (5) 1.2测试数据 (5) 2 概要设计 (5) 2.1 ADT描述 (5) 2.2程序模块结构 (7) 软件结构设计: (7) 2.3各功能模块 (7) 3 详细设计 (8) 3.1结构体定义 (19) 3.2 初始化 (22) 3.3 插入操作(四号黑体) (22) 4 调试分析 (22) 5 用户使用说明 (23) 6 测试结果 (24) 结论 (26)
摘要 《数据结构》课程主要介绍最常用的数据结构,阐明各种数据结构内在的逻辑关系,讨论其在计算机中的存储表示,以及在其上进行各种运算时的实现算法,并对算法的效率进行简单的分析和讨论。进行数据结构课程设计要达到以下目的: ?了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力; ?初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能; ?提高综合运用所学的理论知识和方法独立分析和解决问题的能力; 训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。 这次课程设计我们主要是应用以前学习的数据结构与面向对象程序设计知识,结合起来才完成了这个程序。 因为图是一种较线形表和树更为复杂的数据结构。在线形表中,数据元素之间仅有线性关系,每个元素只有一个直接前驱和一个直接后继,并且在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。因此,本程序是采用邻接矩阵、邻接表、十字链表等多种结构存储来实现对图的存储。采用邻接矩阵即为数组表示法,邻接表和十字链表都是图的一种链式存储结构。对图的遍历分别采用了广度优先遍历和深度优先遍历。 关键词:计算机;图;算法。
四川大学《结构设计原理1643》在线作业答案
川大15秋《结构设计原理1643》在线作业答案 一、单选题: 1.题面如下: (满分:2) A. a B. b C. c D. d 2.预应力混凝土构件,当采用钢绞线、钢丝、热处理钢筋做预应力钢筋时,混凝土强度等级不宜低于( )。 (满分:2) A. C25 B. C30 C. C40 D. C45 3.适筋梁在逐渐加载过程中,当受拉钢筋刚刚屈服后,则( )。 (满分:2) A. 该梁达到最大承载力而立即破坏 B. 该梁达到最大承载力,一直维持到受压区边缘混凝土达到极限压应变而破坏 C. 该梁达到最大承载力,随后承载力缓慢下降,直至破坏 D. 该梁承载力略有增加,待受压区边缘混凝土达到极限压应变而破坏 4.题面如下: (满分:2) A. a B. b C. c D. d 5.提高截面刚度的最有效措施是( )。 (满分:2) A. 提高混凝土强度等级 B. 增大构件截面高度 C. 增加钢筋配筋量 D. 改变截面形状 6.钢筋混凝土大偏压构件的破坏特征是( )。 (满分:2) A. 远离纵向力作用一侧的钢筋拉屈,随后另一侧钢筋压屈,混凝土亦压碎 B. 靠近纵向力作用一侧的钢筋拉屈,随后另一侧钢筋压屈,混凝土亦压碎 C. 靠近纵向力作用一侧的钢筋和混凝土应力不定,而另一侧受拉钢筋拉屈 D. 远离纵向力作用一侧的钢筋和混凝土应力不定,而另一侧受拉钢筋拉屈 7.热轧钢筋冷拉后,( )。 (满分:2) A. 可提高抗拉强度和抗压强度 B. 只能提高抗拉强度 C. 可提高塑性,强度提高不多 D. 只能提高抗压强度 8.题面如下: (满分:2) A. a B. b C. c D. d
新编机械结构设计大作业
《结构设计》课程大作业 、课程大作业的目的: 1、课程大作业属于机械专业设计类课程的延续,是机械系统设计的一次全面训练,可以为毕业设计打下良好基础。通过课程大作业,进一步学习掌握机械系统设计的一般方法,培养学生综合运用机械制图、机械设计、机械原理、公差与配合、金属工艺学、材料热处理及结构工艺等相关知识,联系实际并运用所学过的知识,提高进行工程设计的能力。 2、加强学生运用有关设计资料、设计手册、标准、规范及经验数据的能力,提高技术总结及编制技术文件的能力,培养和提高学生独立的分析问题、解决问题的能力,也是毕业设计教学环节实施的前期技术准备。 二、课程大作业的基本要求: 1 、分组与选题: ①自由组合,每组原则上三人(最少2人);每组的同学统一提交、共同答辩。 ②具体课题题目(由指导教师给出),同组同学集体研讨后完成。 2、大作业的基本要求: ①大作业的论述必须合理; ②大作业中的内容要注明出处,注明资料来源(参考文献及资料); ③总的文字(含图、表)不少于2万字,使用标准A4纸打印成稿(文字选用宋体小四号,页边距均为2cm,单倍行距),封面需要注明课题详细名称、参加学生姓名、班级学号、指导教师等。 三、课程大作业题目及其要点 举例说明在下列的机械结构设计中,如何提高机械结构性能的途径或措施有那些?(围绕题目和要点) 机自082-28吴铁健、-29张明、-14张钦亮:
(1)便于退刀准则 (2)最小加工量准则 (3)可靠夹紧准则 (4)一次夹紧成形准则 (5)便利切削准则 (6)减少缺口效应准则 (7)避免斜面开孔准则 (8)贯通空优先准则 (9)孔周边条件相近准则 机自083 -06焦文、-36张浩然、-14 丁世洋: (一)提高强度和刚度的结构设计 1、载荷分担 2、载荷均布 3、减少机器零件的应力集中 4、利用设置肋板的措施提高刚度 (二)提高耐磨性的结构设计
c#窗体设计之树形文件结构
using System; using System.Collections.Generic; using https://www.360docs.net/doc/6c8965031.html,ponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using System.IO; namespace 树形窗体 { public partial class Form1 : Form { public Form1() { InitializeComponent(); } private void Form1_Load(object sender, EventArgs e) { } private void button1_Click(object sender, EventArgs e) { folderBrowserDialog1.RootFolder= Environment.SpecialFolder.MyComputer; folderBrowserDialog1.ShowNewFolderButton = false; if(folderBrowserDialog1.ShowDialog()!=DialogResult.OK) return; TreeNode Node ; treeView1.Nodes.Clear(); Node = treeView1.Nodes.Add(folderBrowserDialog1.SelectedPath); createchildNode(Node); Node.Expand(); } private void createchildNode(TreeNode fu) { TreeNode child; string path=fu.Text;
四川大学网络教育学院《结构设计原理》第二次作业答案
四川大学网络教育学院《结构设计原理》第二次作业答案 你的得分: 90.0 完成日期:2014年09月09日 16点03分 说明:每道小题括号里的答案是您最高分那次所选的答案,标准答案将在本次作业结束(即2014年09月11日)后显示在题目旁边。 一、单项选择题。本大题共25个小题,每小题 2.0 分,共50.0分。在每小题给出的选项中,只有一项是符合题目要求的。 1. ( D ) A. a B. b C. c D. d 2.下列说法正确的是()。 ( D ) A.加载速度越快,则得的混凝土立方体抗压强度越低 B.棱柱体试件的高宽比越大,测得的抗压强度越高 C.混凝土立方体试件比棱柱体试件能更好地反映混凝土的实际受压 情况 D.混凝土试件与压力机垫板间的摩擦力使得混凝土的抗压强度提高 3. ( B ) A. a B. b C. c D. d 4.在保持不变的长期荷载作用下,钢筋混凝土轴心受压构件中,()。 ( C )
A.徐变使混凝土压应力减小 B.混凝土及钢筋的压应力均不变 C.徐变使混凝土压应力减小,钢筋压应力增大 D.徐变使混凝土压应力增大,钢筋压应力减小 5.适筋梁在逐渐加载过程中,当受拉钢筋刚刚屈服后,则()。 ( D ) A.该梁达到最大承载力而立即破坏 B.该梁达到最大承载力,一直维持到受压区边缘混凝土达到极限压应 变而破坏 C.该梁达到最大承载力,随后承载力缓慢下降,直至破坏 D.该梁承载力略有增加,待受压区边缘混凝土达到极限压应变而破坏 6. ( B ) A. a B. b C. c D. d 7.提高受弯构件正截面受弯能力最有效的方法是()。 ( C ) A.提高混凝土强度等级 B.增加保护层厚度 C.增加截面高度 D.增加截面宽度 8.在T形截面梁的正截面承载力计算中,假定在受压区翼缘计算宽度b′ f 内,()。 ( A ) A.压应力均匀分布 B.压应力按抛物线型分布
数据库的设计与实现
《数据库原理》课程设计论文 院(系、部)名称: 专业名称: 学生姓名: 学生学号: 指导教师:
系统简介 开发目的和任务 客户信息是个人,机关,企事业等进行业务联系所必需而频繁使用的信息资料,在许多大型应用系统中都有客户信息管理工具,它是企业单位现代化管理的一个重要的组成部分。本系统的任务是制作一个简单,实用的通讯薄,既可以单独使用,也可以作为其他大型应用系统的一个组成部分来使用。 1.系统功能 (1) 总体功能要求 本系统将介绍如何让在Visual FoxPro 6.0开发环境下快速开发数据库和数据表的方法,并在此基础上建立一个表单,通过表单的运行,可以初步体会到什么是程序,什么是数据库应用程序,数据库应用程序是如何进行编辑,修改,增加,删除,查询和退出的. (2) 客户信息管理系统的基本功能 1)登录:本功能主要是为了防止非操作人员对系统随意更改. 2)主界面:为用户提供了一个友好的界面,是维护,查询模块间相互切换的桥梁. 3)维护:本功能模块主要实现数据的浏览,添加,删除,退出等功能. 4)查询:本功能模块主要实现按姓名,职务,出生日期等查询功能. 2. 系统的特点 (1) 数据库设计的考虑 本系统的信息两不太大,因此只涉及一个库,一个表.库名为通讯
录.DBC表名为通讯录.DBF. (2) 提高系统集成化的考虑 为了是系统短小精悍,并最大限度的提高系统设计的效率,在设计中较多的应用了Visual FoxPro 提供的“选项卡”控件和容器控件.除此之外,还采用了页框控件,其目的是在一个窗口上尽可能多的扩展应用空间,容纳最多的信息量. (3)提高可操作性的考虑 由于使用本系统的人员不一定熟悉计算机基本操作,因此要求系统的操作应尽量简单,本系统在设计时已考虑到这一点,尽可能少的使用键盘的地方,要保证用起来“顺手”. 3. 开发工具与运行环境 (1) 开发工具. VFP6.0 为集成开发环境提供了项目管理器,设计器,生成器和向导机制等,使其成为强有力的数据库开发工具. 1)项目管理器. 2)设计器. 3)生成器. 4)向导. (2)运行环境 硬件环境: PⅡ350MHz以上处理器,16MB以上内存,一般需240MB 硬盘空间. 软件环境:Windows 95及以上的操作系统支持.
数据库课后题答案 第7章 数据库设计
第7章数据库设计 1.试述数据库设计过程。 答:这里只概要列出数据库设计过程的六个阶段:( l )需求分析;( 2 )概念结构设计;( 3 )逻辑结构设计;( 4 )数据库物理设计;( 5 )数据库实施;( 6 )数据库运行和维护。这是一个完整的实际数据库及其应用系统的设计过程。不仅包括设计数据库本身,还包括数据库的实施、运行和维护。设计一个完善的数据库应用系统往往是上述六个阶段的不断反复。 2 .试述数据库设计过程各个阶段上的设计描述。 答:各阶段的设计要点如下:( l )需求分析:准确了解与分析用户需求(包括数据与处理)。( 2 )概念结构设计:通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS 的概念模型。( 3 )逻辑结构设计:将概念结构转换为某个DBMS 所支持的数据模型,并对其进行优化。( 4 )数据库物理设计:为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。( 5 )数据库实施:设计人员运用DBMS 提供的数据语言、工具及宿主语言,根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。( 6 )数据库运行和维护:在数据库系统运行过程中对其进行评价、调整与修改。 3 .试述数据库设计过程中结构设计部分形成的数据库模式。 答:数据库结构设计的不同阶段形成数据库的各级模式,即:( l )在概念设计阶段形成独立于机器特点,独立于各个DBMS 产品的概念模式,在本篇中就是 E 一R 图;( 2 )在逻辑设计阶段将 E 一R 图转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式,然后在基本表的基础上再建立必要的视图( Vi 娜),形成数据的外模式;( 3 )在物理设计阶段,根据DBMS 特点和处理的需要,进行物理存储安排,建立索引,形成数据库内模式。 4 .试述数据库设计的特点。 答:数据库设计既是一项涉及多学科的综合性技术又是一项庞大的工程项目。其主要特点有:( l )数据库建设是硬件、软件和干件(技术与管理的界面)的结合。( 2 )从软件设计的技术角度看,数据库设计应该和应用系统设计相结合,也就是说,整个设计过程中要把结构(数据)设计和行为(处理)设计密切结合起来。 5 .需求分析阶段的设计目标是什么?调查的内容是什么? 答:需求分析阶段的设计目标是通过详细调查现实世界要处理的对象(组织、部门、企业等),充分了解原系统(手工系统或计算机系统)工作概况,明确用户的各种需求,然后在此基础上确定新系统的功能。调查的内容是“数据’夕和“处理”,即获得用户对数据库的如下要求:( l )信息要求,指用户需要从数据库中获得信息的内容与性质,由信息要求可以导出数据要求,即在数据库中需要存储哪些数据;( 2 )处理要求,指用户要完成什么处理功能,对处理的响应时间有什么要求,处理方式是批处理还是联机处理;( 3 )安全性与完整性要求。 6 .数据字典的内容和作用是什么? 答:数据字典是系统中各类数据描述的集合。数据字典的内容通常包括:( l )数据项;( 2 )数据结构;( 3 )数据流;( 4 )数据存储;( 5 )处理过程五个部分。其中数据项是数
二叉树的应用数据结构课程设计样本
信息科学与技术学院 数据结构课程设计报告 题目名称: 二叉树的应用专业班级: 计算机科学与技术学生姓名: 陈杰 学生学号: 指导教师: 高攀 完成日期: -04 目录
1、课程设计的目的、课程设计题目、题目要求错误!未定义书签。 1.1课程设计的目的 ............................................... 错误!未定义书签。 1.2课程设计的题目 ............................................... 错误!未定义书签。 1.3题目要求............................................................ 错误!未定义书签。2课程设计的实验报告内容:................................. 错误!未定义书签。3课程设计的原程序代码: ..................................... 错误!未定义书签。4运行结果 .............................................................. 错误!未定义书签。 5. 课程设计总结..................................................... 错误!未定义书签。6参考书目 .............................................................. 错误!未定义书签。
1课程设计的目的 1.1课程设计的目的: 经过以前的学习以及查看相关资料,按着题目要求编写程序,进一步加强对编程的训练,使得自己掌握一些将书本知识转化为实际应用当中.在整个程序中,主要应用的是链表,可是也运用了类.经过两种方法解决现有问题. 1.2课程设计的题目: 二叉树的应用 1.3题目要求: 1.建立二叉树的二叉链表存储算法 2.二叉树的先序遍历, 中序遍历和后序遍历输出 3.非递归的先序遍历, 中序遍历 4.二叉树的层次遍历 5.判断此二叉树是否是完全二叉树 6.二叉树的左右孩子的交换 2课程设计的实验报告内容: 7.经过递归对二叉树进行遍历。二叉树的非递归遍历主要采用利 用队进行遍历。此后的判断此二叉树是否是完全二叉树也才采
机械原理大作业3 凸轮结构设计
机械原理大作业(二) 作业名称:机械原理 设计题目:凸轮机构设计 院系:机电工程学院 班级: 设计者: 学号: 指导教师:丁刚陈明 设计时间: 哈尔滨工业大学机械设计
1.设计题目 如图所示直动从动件盘形凸轮机构,根据其原始参数设计该凸轮。 表一:凸轮机构原始参数 序号升程 (mm) 升程运动 角(o) 升程运动 规律 升程许用 压力角 (o) 回程运动 角(o) 回程运动 规律 回程许用 压力角 (o) 远休止角 (o) 近休止角 (o) 12 80 150 正弦加速 度30 100 正弦加速 度 60 60 50 2.凸轮推杆运动规律 (1)推杆升程运动方程 S=h[φ/Φ0-sin(2πφ/Φ0)]
V=hω1/Φ0[1-cos(2πφ/Φ0)] a=2πhω12sin(2πφ/Φ0)/Φ02 式中: h=150,Φ0=5π/6,0<=φ<=Φ0,ω1=1(为方便计算) (2)推杆回程运动方程 S=h[1-T/Φ1+sin(2πT/Φ1)/2π] V= -hω1/Φ1[1-cos(2πT/Φ1)] a= -2πhω12sin(2πT/Φ1)/Φ12 式中: h=150,Φ1=5π/9,7π/6<=φ<=31π/18,T=φ-7π/6 3.运动线图及凸轮线图 运动线图: 用Matlab编程所得源程序如下: t=0:pi/500:2*pi; w1=1;h=150; leng=length(t); for m=1:leng; if t(m)<=5*pi/6 S(m) = h*(t(m)/(5*pi/6)-sin(2*pi*t(m)/(5*pi/6))/(2*pi)); v(m)=h*w1*(1-cos(2*pi*t(m)/(5*pi/6)))/(5*pi/6); a(m)=2*h*w1*w1*sin(2*pi*t(m)/(5*pi/6))/((5*pi/6)*(5*pi/6)); % 求退程位移,速度,加速度 elseif t(m)<=7*pi/6 S(m)=h; v(m)=0; a(m)=0; % 求远休止位移,速度,加速度 elseif t(m)<=31*pi/18 T(m)=t(m)-21*pi/18; S(m)=h*(1-T(m)/(5*pi/9)+sin(2*pi*T(m)/(5*pi/9))/(2*pi)); v(m)=-h/(5*pi/9)*(1-cos(2*pi*T(m)/(5*pi/9))); a(m)=-2*pi*h/(5*pi/9)^2*sin(2*pi*T(m)/(5*pi/9)); % 求回程位移,速度,加速度
大数据表的分表处理设计思想和实现(MySQL)
分表处理设计思想和实现 一、概述 分表是个目前算是比较炒的比较流行的概念,特别是在大负载的情况下,分表是一个良好分散数据库压力的好方法。 首先要了解为什么要分表,分表的好处是什么。我们先来大概了解以下一个数据库执行SQL的过程:接收到SQL --> 放入SQL执行队列--> 使用分析器分解SQL --> 按照分析结果进行数据的提取或者修改--> 返回处理结果 当然,这个流程图不一定正确,这只是我自己主观意识上这么我认为。那么这个处理过程当中,最容易出现问题的是什么?就是说,如果前一个SQL没有执行完毕的话,后面的SQL是不会执行的,因为为了保证数据的完整性,必须对数据表文件进行锁定,包括共享锁和独享锁两种锁定。共享锁是在锁定的期间,其它线程也可以访问这个数据文件,但是不允许修改操作,相应的,独享锁就是整个文件就是归一个线程所有,其它线程无法访问这个数据文件。一般MySQL中最快的存储引擎MyISAM,它是基于表锁定的,就是说如果一锁定的话,那么整个数据文件外部都无法访问,必须等前一个操作完成后,才能接收下一个操作,那么在这个前一个操作没有执行完成,后一个操作等待在队列里无法执行的情况叫做阻塞,一般我们通俗意义上叫做“锁表”。 锁表直接导致的后果是什么?就是大量的SQL无法立即执行,必须等队列前面的SQL全部执行完毕才能继续执行。这个无法执行的SQL就会导致没有结果,或者延迟严重,影响用户体验。 特别是对于一些使用比较频繁的表,比如SNS系统中的用户信息表、论坛系统中的帖子表等等,都是访问量大很大的表,为了保证数据的快速提取返回给用户,必须使用一些处理方式来解决这个问题,这个就是我今天要聊到的分表技术。 分表技术顾名思义,就是把若干个存储相同类型数据的表分成几个表分表存储,在提取数据的时候,不同的用户访问不同的表,互不冲突,减少锁表的几率。比如,目前保存用户分表有两个表,一个是user_1表,还有一个是user_2 表,两个表保存了不同的用户信息,user_1 保存了前10万的用户信息,user_2保存了后10万名用户的信息,现在如果同时查询用户heiyeluren1 和heiyeluren2 这个两个用户,那么就是分表从不同的表提取出来,减少锁表的可能。 我下面要讲述的两种分表方法我自己都没有实验过,不保证准确能用,只是提供一个设计思路。下面关于分表的例子我假设是在一个贴吧系统的基础上来进行处理和构建的。(如果没有用过贴吧的用户赶紧Google一下) 二、基于基础表的分表处理 这个基于基础表的分表处理方式大致的思想就是:一个主要表,保存了所有的基本信息,如果某个项目需要找到它所存储的表,那么必须从这个基础表中查找出对应的表名等项目,好直接访问这个表。如果觉得这个基础表速度不够快,可以完全把整个基础表保存在缓存或者内存中,方便有效的查询。 我们基于贴吧的情况,构建假设如下的3张表: 1. 贴吧版块表: 保存贴吧中版块的信息 2. 贴吧主题表:保存贴吧中版块中的主题信息,用于浏览 3. 贴吧回复表:保存主题的原始内容和回复内容 “贴吧版块表”包含如下字段: 版块ID board_id int(10) 版块名称board_name char(50) 子表ID table_id smallint(5) 产生时间created datetime “贴吧主题表”包含如下字段: 主题ID topic_id int(10) 主题名称topic_name char(255) 版块ID board_id int(10)
结构设计常用数据表格
建筑结构安全等级 2 纵向受力钢筋混凝土保护层最小厚度(mm) 不同根数钢筋计算截面面积(mm2)
板宽1000mm内各种钢筋间距时钢筋截面面积表(mm2) 每米箍筋实配面积 钢筋混凝土结构构件中纵向受力钢筋的最小配筋百分率(%) 框架柱全部纵向受力钢筋最小配筋百分率(%)
框架梁纵向受拉钢筋的最小配筋白分率(%) 柱箍筋加密区的箍筋最小配箍特征值λν(ρν=λνf/f)
受弯构件挠度限值 注:1 表中lo为构件的计算跨度; 2 表中括号内的数值适用于使用上对挠度有较高要求的构件; 3 如果构件制作时预先起拱,且使用上也允许,则在验算挠度时,可将计算所得的挠度值减去起拱值;对预应力混凝土构件,尚可减去预加力所产生的反拱值; 4 计算悬臂构件的挠度限值时,其计算跨度lo按实际悬臂长度的2倍取用。
注: 1 表中的规定适用于采用热轧钢筋的钢筋混凝土构件和采用预应力钢丝、钢绞线及热处理钢筋的预应力混凝土构件;当采用其他类别的钢丝或钢筋时,其裂缝控制要求可按专门标准确定; 2 对处于年平均相对湿度小于60%地区一类环境下的受弯构件,其最大裂缝宽度限值可采用括号内的数值; 3 在一类环境下,对钢筋混凝土屋架、托架及需作疲劳验算的吊车梁,其最大裂缝宽度限值应取为0.2mm;对钢筋混凝土屋面梁和托梁,其最大裂缝宽度限值应取为0.3mm; 4 在一类环境下,对预应力混凝土屋面梁、托梁、屋架、托架、屋面板和楼板,应按二级裂缝控制等级进行验算;在一类和二类环境下,对需作疲劳验算的须应力混凝土吊车梁,应按一级裂缝控制等级进行验算; 5 表中规定的预应力混凝土构件的裂缝控制等级和最大裂缝宽度限值仅适用于正截面的验算;预应力混凝土构件的斜截面裂缝控制验算应符合本规范第8章的要求; 6 对于烟囱、筒仓和处于液体压力下的结构构件,其裂缝控制要求应符合专门标准的有关规定; 7 对于处于四、五类环境下的结构构件,其裂缝控制要求应符合专门标准的有关规定; 8 表中的最大裂缝宽度限值用于验算荷载作用引起的最大裂缝宽度。 梁内钢筋排成一排时的钢筋最多根数
二叉树数据结构课程设计
目录 第一章需求分析 (1) 1.1课程设计题目 (1) 1.2 课程设计任务及要求 (1) 1.21 课程设计目的 (1) 1.22设计要求 (1) 1.3课程设计思想 (2) 1.4软件运行环境及开发工具 (2) 第二章概要设计 (3) 2.1 数据结构 (3) 2.2 所用方法及其原理说明 (3) 第三章详细设计 (4) 3.1详细设计方案 (4) 3.2 模块设计 (4) 3.21二叉树定义 (4) 3.22 树状显示二叉树设计 (7) 3.22 主函数设计 (10) 第四章调试和操作说明 (11) 4.1 调试 (11) 4.2 操作说明 (12) 第五章总结与体会 (12) 5.1本文的主要工作 (12) 5.2 存在问题 (12) 5.3心得体会 (12) 致谢 (13) 参考文献 (14)
第一章需求分析 1.1课程设计题目 树状显示二叉树: 编写函数displaytree(二叉树的根指针,数据值宽度,屏幕的宽度)输出树的直观示意图。输出的二叉树是垂直打印的,同层的节点在同一行上。 [问题描述] 假设数据宽度datawidth=2,而屏幕宽度screenwidth为64=26,假设节点的输出位置用 (层号,须打印的空格数)来界定。 第0层:根在(0,32)处输出; 第1层:因为根节点缩进了32个空格,所以下一层的偏移量(offset)为32/2=16=screenwidth/22。即第一层的两个节点的位置为(1,32-offset),(1,32+offset)即(1,16),(1,48)。 第二层:第二层的偏移量offset为screenwidth/23。第二层的四个节点的位置分别是(2,16-offset),(2,16+offset),(2,48-offset),(2,48+offset)即(2,8),(2,24),(2,40),(2,56)。 …… 第i层:第i层的偏移量offset为screenwidth/2i+1。第i层的每个节点的位置是访问第i-1层其双亲节点时确定的。假设其双亲的位置为(i-1,parentpos)。若其第i层的节点是其左孩子,那末左孩子的位置是(i,parentpos-offset),右孩子的位置是(i,parentpos+offset)。 [实现提示] 利用二叉树的层次遍历算法实现。利用两个队列Q,QI。队列Q中存放节点信息,队列QI中存相应于队列Q中的节点的位置信息,包括层号和需要打印节点值时需要打印的空格数。当节点被加入到Q时,相应的打印信息被存到QI中。二叉树本身采用二叉链表存储。 1.2 课程设计任务及要求 1.21 课程设计目的 据结构是计算机专业的核心课程,是一门实践性很强的课程。课程设计是加强学生实践能力的一个强有力手段,要求学生掌握数据结构的应用、算法的编写、类C语言的算法转换成C(C++)程序并上机调试的基本方法,还要求学生在完成程序设计的同时能够写出比较规范的设计报告。严格实施课程设计这一环节,对于学生基本程序设计素养的培养和软件工作者工作作风的训练,将起到显著的促进作用。 1.22设计要求 1、课程设计题目每组一题,每个学生必须独立完成; 2、课程设计时间为2周; 3、设计语言C(C++)不限; 1
结构设计原理第一次作业答案
首页-我的作业列表-《结构设计原理》第一次作业答案 欢迎你,刘晓星(DI4131R6009 '你的得分:100.0 完成日期:2014年07月02日10点04分 一、单项选择题。本大题共25个小题,每小题2.0 分,共50.0分。在每小题给出的选项中,只有一 项是符合题目要求的。 若用S表示结构或构件截面上的荷载效应,用R表示结构或构件截面的抗力,结构或构件截面处于极限状态时,对应于()式。 (B ) R> S R= S R v S R WS 对所有钢筋混凝土结构构件都应进行()。 (D ) 抗裂度验算 裂缝宽度验算 变形验算 承载能力计算混凝土各项强度指标的基本代表值是()。 (B ) 轴心抗压强度标准值立方体抗压强度标准值 轴心抗压强度平均值立方体抗压强度平均值 工程结构的可靠指标3与失效概率P f之间存在下列()关系。 (D ) 3愈大,P f愈大 3与P f呈反比关系 3与P f呈正比关系 3与P f存在一一对应关系,3 愈大,P f愈小
(B ) a b c d 热轧钢筋冷拉后,()。 (A ) 可提高抗拉强度和抗压强度只能提高抗拉强度 可提高塑性,强度提高不多 只能提高抗压强度 无明显流幅钢筋的强度设计值是按()确定的。 (C ) 材料强度标准值x材料分布系数 材料强度标准值/材料分项系数 0.85 x材料强度标准值/材料分项系数 材料强度标准值/ (0.85 x材料分项系数) 钢筋混凝土梁的受拉区边缘混凝土达到下述哪一种情况时,开始出现裂缝?( ) (A ) 达到混凝土实际的轴心抗拉强度 达到混凝土轴心抗拉强度标准值 达到混凝土轴心抗拉强度设计值 达到混凝土弯曲受拉时的极限拉应变值 (D ) a b c d
高层建筑结构大作业.doc
作业 说明:《高层建筑结构》是应用性较强的课程,为了培养学生的设计能力,掌 握核心知识点,同时也为了较大程度地减轻学生的课业负担,这次作业没有考 虑大型设计作业,而是采用了分散的题型,请大家在规定的时间内完成作业。 一、基础题 1,一幢 10 层的框架结构,柱网尺寸为8m× 8m,混凝土强度等级C30,试完成下列各题: (1)按高规条估算底层中框架柱的截面尺寸。 (2)假设天然地基承载力设计值 fa=120kPa,确定底层中框架柱的基础尺寸 (独 立基础 )。 答:(1)《高层建筑混凝土结构技术规程》 P66,抗震设计时,钢筋混凝土柱轴 压比不宜超过表的规定:对于 VI 类场地上较高的高层建筑,其轴压比限值应适当 减小 框架结构三类抗震等级,柱子轴压比限值为 .根据《混凝土结构设计规范》可知,当选用 HrB400 钢筋时,竹子的配筋率最小为 %,最大为 5%。珠子配筋率选为 4% 。则混凝土柱承受的最大轴向应力值σ=*360+*30=。 《高层建筑结构设计》 P13,楼层竖向荷载值取 13KN/m2.仅考虑柱子受竖向荷载作用,则每根珠子承受的竖向荷载值 N=10*64*13=8320KN。柱子的截面积 S=(* )=,设柱子截面为方形,边长 a=。 (2) 8320./120=,设独立基础为方形,边长 b=。 2,确定上海市奉贤区海湾镇、南桥镇和徐汇区的徐家汇等区域的地面粗糙度。 答:《高层建筑结构设计》 P13 提到,地面粗糙度应分为四类: A 类指近海海面和 海盗、海岸、湖岸及沙漠地区; B 类指田野、乡村、丛林、丘陵以及房屋比较稀疏 的乡镇和城市郊区; C 类指有墨迹建筑群的城市市区; D 类指有密集建筑群且房屋较高的城市市区。
数据结构课程设计报告,含菜单
算法与数据结构课程设计 报告 系(院):计算机科学学院 专业班级:计科11005 姓名:张林峰 学号: 201003784 指导教师:詹泽梅 设计时间:2012.6.11 - 2012.6.18 设计地点:12教机房
目录 一、课程设计目的 (2) 二、设计任务及要求 (2) 三、需求分析 (2) 四、总体设计 .............. 错误!未定义书签。 五、详细设计与实现[含代码和实现界面].. 8 六、课程设计小结 (15)
一.设计目的 1.能根据实际问题的具体情况,结合数据结构课程中的基本理论和基本算法,分析并正确确定数据的逻辑结构,合理地选择相应的存储结构,并能设计出解决问题的有效算法。 2.提高程序设计和调试能力。学生通过上机实习,验证自己设计的算法的正确性。学会有效利用基本调试方法,迅速找出程序代码中的错误并且修改。 3.初步掌握软件开发过程中问题分析、系统设计、程序编码、测试等基本方法和技能。 4.训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。 5.培养根据选题需要选择学习书籍,查阅文献资料的自学能力。二.设计任务及要求 根据《算法与数据结构》课程的结构体系,设计一个基于DOS菜单的应用程序。要利用多级菜单实现各种功能。比如,主界面是大项,主要是学过的各章的名字诸如线性表、栈与队列、串与数组及广义表等,子菜单这些章中的节或者子节。要求所有子菜单退出到他的父菜单。编程实现时,要用到C++的面向对象的功能。 三.需求分析 菜单运用极其广泛,应用于各行各业。菜单运用起来极其方便。随着社会的发展,社会的行业出现多样化,也就需要各式
结构优化设计大作业(北航)
《结构优化设计》 大作业报告 实验名称: 拓扑优化计算与分析 1、引言 大型的复杂结构诸如飞机、汽车中的复杂部件及桥梁等大型工程的设计问题,依靠传统的经验和模拟实验的优化设计方法已难以胜任,拓扑优化方法成为解决该问题的关键手段。近年来拓扑优化的研究的热点集中在其工程应用上,如: 用拓扑优化方法进行微型柔性机构的设计,车门设计,飞机加强框设计,机翼前缘肋设计,卫星结构设计等。在其具体的操作实现上有两种方法,一是采用计算机语言编程计算,该方法的优点是能最大限度的控制优化过程,改善优化过程中出现的诸如棋盘格现象等数值不稳定现象,得到较理想的优化结果,其缺点是计算规模过于庞大,计算效率太低;二是借助于商用有限元软件平台。本文基于matlab软件编程研究了不同边界条件平面薄板结构的在各种受力情况下拓扑优化,给出了几种典型结构的算例,并探讨了在实际优化中优化效果随各参数的变化,有助于初学者初涉拓扑优化的读者对拓扑优化有个基础的认识。
2、拓扑优化研究现状 结构拓扑优化是近20年来从结构优化研究中派生出来的新分支,它在计算结构力学中已经被认为是最富挑战性的一类研究工作。目前有关结构拓扑优化的工程应用研究还很不成熟,在国外处在发展的初期,尤其在国内尚属于起步阶段。1904 年Michell在桁架理论中首次提出了拓扑优化的概念。自1964 年Dorn等人提出基结构法,将数值方法引入拓扑优化领域,拓扑优化研究开始活跃。20 世纪80 年代初,程耿东和N. Olhoff在弹性板的最优厚度分布研究中首次将最优拓扑问题转化为尺寸优化问题,他们开创性的工作引起了众多学者的研究兴趣。1988年Bendsoe和Kikuchi发表的基于均匀化理论的结构拓扑优化设计,开创了连续体结构拓扑优化设计研究的新局面。1993年Xie.Y.M和Steven.G.P 提出了渐进结构优化法。1999年Bendsoe和Sigmund证实了变密度法物理意义的存在性。2002 年罗鹰等提出三角网格进化法,该方法在优化过程中实现了退化和进化的统一,提高了优化效率。目前常使用的拓扑优化设计方法可以分为两大类:退化法和进化法。结构拓扑优化设计研究,已被广泛应用于建筑、航天航空、机械、海洋工程、生物医学及船舶制造等领域。 3、拓扑优化建模(SIMP) 结构拓扑优化目前的主要研究对象是连续体结构。优化的基本方法是将设计区域划分为有限单元,依据一定的算法删除部分区域,形成带孔的连续体,实现连续体的拓扑优化。连续体结构拓扑优化方法目前比较成熟的是均匀化方法、变密度方法和渐进结构优化方法。 变密度法以连续变量的密度函数形式显式地表达单元相对密度与材料弹性模量之间的对应关系,这种方法基于各向同性材料,不需要引入微结构和附加的均匀化过程,它以每个单元的相对密度作为设计变量,人为假定相对密度和材料弹性模量之间的某种对应关系,程序实现简单,计算效率高。变密度法中常用的插值模型主要有:固体各向同性惩罚微结构模型(solidisotropic microstructures with penalization,简称SIMP)和材料属性的合理近似模型(rational approximation ofmaterial properties,简称RAMP)。而本文所用即为SIMP插值模型。
软件设计大作业
一需求分析 此系统是一个类似于淘宝网的在线衣服销售系统,相当于淘宝网上的一个专门买衣服的网店,它具有用户注册,用户登录,修改密码,显示系统功能,查看订购历史以及订货。 1.1需求列表: (1)用户管理:用户管理的需求包括用户注册,用户登录以及修改密码。 用户注册是添加一个我们网上衣店的新用户;用户登录是用户想要进 入系统时必须采取验证身份的步骤;修改密码是为了用户的安全性考 虑,当密码存在不安全的因素时,适时修改密码。 (2)商品衣服的管理:商品管理包括订购衣服和查看订购衣服的历史。订购衣服是当我们衣店的库存数量不足时必须采取的;查看订购衣服的 历史有助于我们更好地了解衣服的订购情况。 (3)显示系统功能:此功能是用来让用户能很清楚地了解此系统所实现的各种功能。 1.2系统用例图:
1.3用例分析及场景描述: 用户注册用例: 这部分主要是新用户进行注册的过程,首先用户进入到注册页面,填写注册信息并提交,如果无误的话系统会给予注册成功的提示,如果注册失败会提示注册失败信息。 用户登录用例: 此功能模块针对的对象是本网站的会员既已经注册的会员,会员首先填写用户名和密码,然后点击登录按钮,如果网站数据库中存在此会员并且密码正确则提示登录成功提示,如果网站不存在此用户或密码不正确,系统会提示用户登录失败。 修改密码用例: 此用例针对注册会员进行操作。用户登录成功会可以进入网站主页面,如果用户想修改密码的话可以单击修改密码按钮,进行密码修改,用户输入新密码单击修改按钮即可完成密码修改。
显示系统功能用例: 此功能针对注册会员,会员首先登录到网站,进入主页,主页会有相关操作的按钮,显示系统所提供给会员操作的功能,用户可以针对自己的需要选择系统提供的功能。 订货衣服用例: 此功能针对注册登录会员,网站提供两种订购方案:单件订购和定制套装。用户可以根据自己的需求来选择。 单件订购方案:用户选择是上衣还是裤子,并填写订购的数量,确认无误后单击订购按钮即可,如果订购成功,系统会提示订购成功,失败则会提示订购失败。 定制套装方案:用户选择定制套装的档次(高、中、低),并填写订购的数量,确认无误后单击订购按钮即可,如果订购成功,系统会提示订购成功,失败则会提示订购失败。 显示订购历史用例: 此功能针对注册会员,用户登录到系统后,主页显示系统功能中包括历史查看选项,用户可以单击进入历史交易记录页面,页面将显示用户所有的交易记录。 二设计模式 2.1单件模式 2.1.1单件模式的定义
数据库设计与实践试题
数据库设计与实践试 题 https://www.360docs.net/doc/6c8965031.html,work Information Technology Company.2020YEAR
内蒙古广播电视大学2015-2016学年度第一学期《数据库设计与实践》期末试题 题号一二三四五六总分 得分 题号一 得分 一、单项选择 1.若实体A和B是多对多的联系,实体B和C是1对1的联系,则实体A和C是() A.一对一 B。一对多 C.多对一 D。多对多 2.若一个关系的任何属性都不部分依赖和传递依赖于任何候选码,则该关系最高过到了()范式。 A、第一 B、第二 C、第三 D、BC 3.在SQL中,create table为数据库中()基本表结构的命令。 A、建立 B、修改 C 、删除 D、查询 4.若规定基本表中某一列或若干列为非空和唯一值双重约束,则这些列就是该基本表的地()码,若只规定为唯一值约束,则不允许空值重复出现。 A、主码 B、外码 C、备用码 D、内码 5.设一个集合A={3 , 4 , 5 , 6 , 7} ,集合B={1 , 3 , 5 , 7 ,9} ,则A 减B 的差集中包含有()个元素。 A. 10 B. 5 C. 3 D. 2 6. 下列哪一个不是设置表间"关系"时的选项( )。 A. 实施参照完整性 B. 级联追加相关记录 c.级联更新相关字段 D. 级联删除相关记录 7. 在Access 2000 数据库系统中,不能建立索引的数据类型是( )。 A. 文本型 B. 备注型 c.数值型 D. 日期/时间型 8. Access 2000 用户操作界面由( )个部分组成。 A.4 B. 5 C. 3 D. 6 9. 下列( )图标是Access 2000 中新建查询的标志。 A. 新建 B.新建 C.新建 D.新建 学号 姓名 分校(工作 站) 2
进销存数据库表结构设计
1.帐类表(KIND) 无索引 序号中文名称英文名称类型备注 1 帐类编号K_SERIAL byte 2 帐类名称K_NAME text*10 本表系统自动建立,共划分为15种帐类,不可增删 帐类编号帐类名称备注 0 上期结存进货,不参加进货统计 1 购入进货,购入时必需输入供货单位名称 2 自制进货 3 投资转入进货 4 盘盈进货 5 领料出库,领料必需输入领料部门名称 6 调拨出库 7 报损出库 8 盘亏出库 9 退库对低值易耗品,在用品退为在用库存 10 直接报废对于低值易耗品,在用品转报废 11 领用对于低值易耗品,在用库存转在用 12 调拨对于低值易耗品,在用库存减少 13 报废对于低值易耗品,在用库存报废 14 直进直出进出库,购入与领料对库存无影响 2.物品表(GOODS) 序号索引名称索引域唯一? 主索引? 1 G_CODING +G_CODING Y N 2 G_SERIAL +G_SERIAL Y Y 序号中文名称英文名称类型备注 1 物品内部编号G_SERIAL INT->long 系统内部唯一标识该物品 2 物品编号G_CODING TEXT * 10 用户使用此编号访问物品 &3 物品名称G_NAME TEXT*40 非空 &4 物品单位G_UNIT TEXT*8 非空 &5 物品规格G_STATE TEXT*20
6 物品类别G_CLASS INT 取自表CLASS 7 备注G_REMARKS MEMO 8 最小库存量G_MIN CURRENCY 为零,即无最小库存 9 最大库存量G_MAX CURRENCY 为零,即无最大库存 10 库存数量G_QUANT CURRENCY 控制出库数量 11 虚拟库存数量G_VQUANT CURRENCY 出库时用 12 库存金额G_AMOUNT CURRENCY 3.类别表(CLASS) 序号索引名称索引域唯一? 主索引? 1 C_CODING +C_CODING Y N 2 C_SERIAL +C_SERIAL Y Y 序号中文名称英文名称类型备注 1 类别内部序号C_SERIAL INT 系统内部唯一标识该物品 2 类别编号C_CODING TEXT *10 用户使用该编号访问类别信息 3 类别名称C_NAME TEXT*20 非空 4 出库类型C_KIND BYTE 1.移动平均 2..先进先出 3.后进先出 4.实际计价 *5.月末平均 5 备注C_REMARKS MEMO *6 底标志C_BOTTOM BOOLEAN *7 类别级别C_LEVEL BYTE 4.供货单位、使用部门(DEPART) 序号索引名称索引域唯一? 主索引? 1 D_CODING +D_CODING Y N 2 D_SERIAL +D_SERIAL Y Y 序号中文名称英文名称类型备注 1 内部序号D_SERIAL INT 系统内部唯一标识该部门 >0 供货单位 =0 库房 <0 使用部门 2 单位编号D_CODING TEXT*10