模式识别实验报告_3

第一次实验
实验目的:
1.学习使用ENVI
2.会用MATLAB读入遥感数据并进行处理
实验内容:
一学习使用ENVI
1.使用ENVI打开遥感图像(任选3个波段合成假彩色图像,保存写入报告)
2.会查看图像的头文件(保存或者copy至报告)
3.会看地物的光谱曲线(保存或者copy至报告)
4.进行数据信息统计(保存或者copy至报告)
5.设置ROI,对每类地物自己添加标记数据,并保存为ROI文件和图像文件(CMap贴到报告中)。
6.使用自己设置的ROI进行图像分类(ENVI中的两种有监督分类算法)(分类算法名称和分类结果写入报告)
二MATLAB处理遥感数据(提交代码和结果)
7.用MATLAB读入遥感数据(zy3和DC两个数据)
8.用MATLAB读入遥感图像中ROI中的数据(包括数据和标签)
9.把图像数据m*n*L(其中m表示行数,n表示列数,L表示波段数),重新排列为N*L的二维矩阵(其中N=m*n),其中N表示所有的数据点数量m*n。(提示,用reshape函数,可以help查看这个函数的用法)
10.计算每一类数据的均值(平均光谱),并把所有类别的平均光谱画出来(plot)(类似下面的效果)。
11.画出zy3数据中“农作物类别”的数据点(自己ROI标记的这个类别的点)在每个波段的直方图(matlab函数:nbins=50;hist(Xi,nbins),其中Xi表示这类数据在第i波段的数值)。计算出这个类别数据的协方差矩阵,并画出(figure,imagesc(C),colorbar)。
1.打开遥感图像如下:
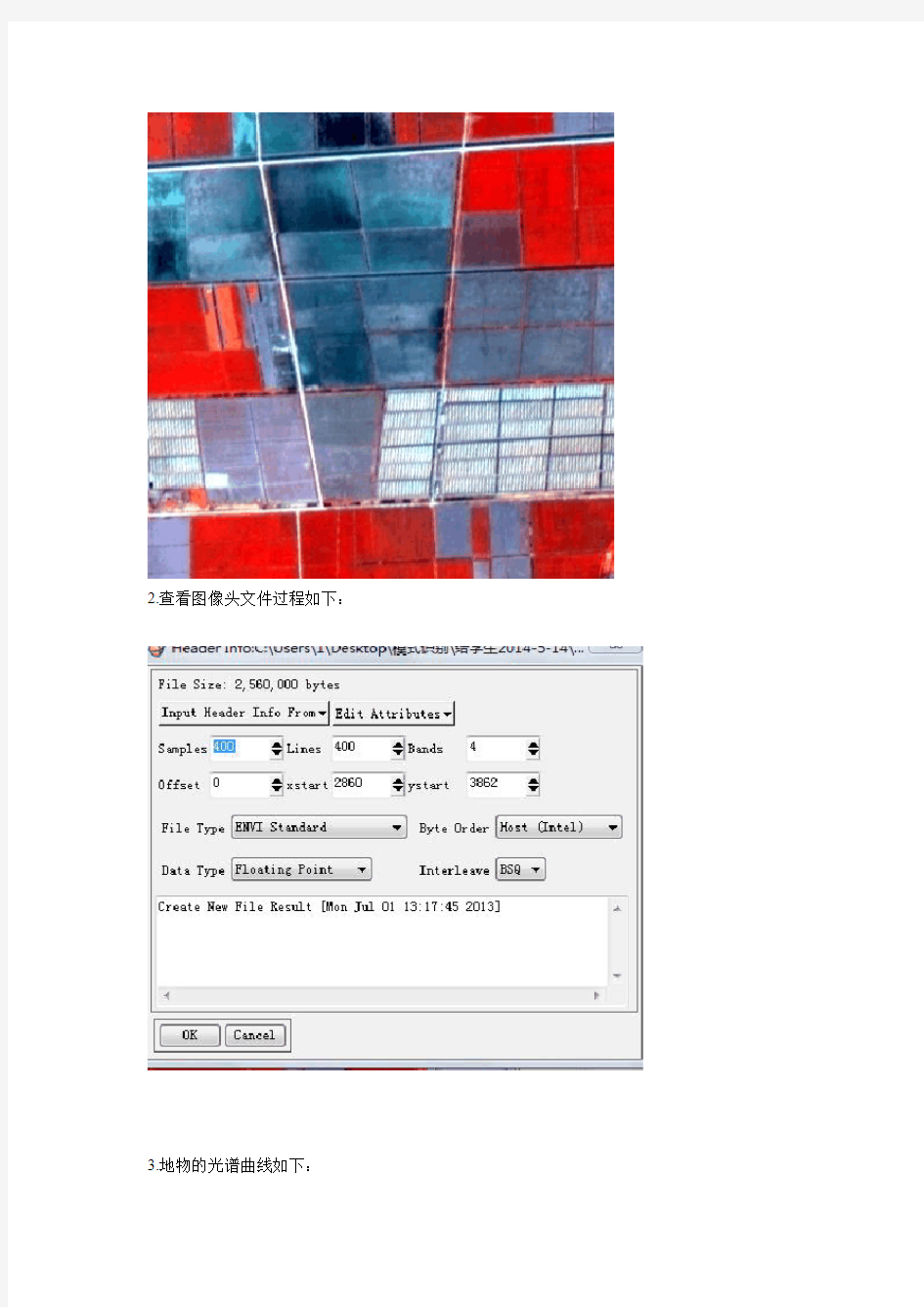
2.查看图像头文件过程如下:
3.地物的光谱曲线如下:
4.数据信息统计如下:
(注:由于保存的txt文件中的数据信息过长,所以采用截图的方式只显示了出一部分数据信息)
5.设置ROI,对每类地物自己添加标记数据,CMap如下:
6.使用自己设置的ROI进行图像分类(使用支持向量机算法和最小距离算法),支持向量机算法分类结果如下:
最小距离算法分类结果如下:
对比两种算法的分类结果可以看出支持分量机算法分类结果比最小距离算法分类结果好一些。
Matlab处理遥感数据
用MATLAB读入遥感数据及遥感图像中ROI中的数据(包括数据和标签)如下:
Img=multibandread('zy3sample1',[400,400,4],'float',0,'bsq','n',{' Band','Direct',[1:4]});%将高光谱数据读入
GT=multibandread('ddzm',[400,400,1],'uint8',0,'bsq','n',{'Band',' Direct',[1:1]});%将ground truth读入(也就是带标签的CMap或说ROI信息读入)test_class=1:4;
C=length(test_class);
NbRow=400;
NbCol=400;
NbDim=4;
dataname='zy3';
第一种方式读入带标签数据
[X,Y]=ExtractDataFromROI(Img,GT);
img1=reshape(Img,NbRow*NbCol,NbDim);把图像数据m*n*L(其中m表示行数,n表示列数,L表示波段数),重新排列为N*L的二维矩阵(其中N=m*n)。
计算每一类数据的均值(平均光谱)
T=1:5
T(2)=length(find(Y==1));
for i=3:5
T(i)=T(i-1)+length(find(Y==(i-1)));
end
for j=1:4
for n=1:4
s(n,j)=sum(X(T(n):T(n+1),j))/(T(n+1)-T(n));
end
end
figure(5);
plot(s);
输出结果:
%画直方图和求协方差矩阵
nbins=50;
figure(1);
hist(X(T(2):T(3),1),nbins); figure(2);
hist(X(T(2):T(3),2),nbins); figure(3);
hist(X(T(2):T(3),3),nbins); figure(4);
hist(X(T(2):T(3),4),nbins); C=cov(X(T(2):T(3),:)); figure(6);
imagesc(C);
colorbar;
输出结果:
实验心得:本次实验分为两个部分,第一部分比较简单,就是学会ENVI软件的基本操作,第二部分则相对困难,特别是求平均光谱遇到很大困难,通过借鉴并询问同学才得以解决,总之,第一次实验学到了很多。
第二次实验:
实验目标:
1.掌握K-means算法原理
2.用MATLAB实现k-means算法,并进行结果分析
实验原理:
本次实验是用MATLAB实现k-means算法,首先简述一下k-means算法的算法思想。
该方法事先取定K个类别和选取K个初始聚类中心,按最小距离原则将各数据点分配到K类中的某一类,之后不断地计算类心和调整各模式的类别,最终使各数据点到其判属类别中心的距离平方之和最小。
而本次实验程序的思路也是严格按照k-means算法的算法思想进行的,我先用rand函数随机产生四个初始聚类类心,然后用欧式距离计算类心与分类点间的距离,随后按最小距离原则将各数据点分配到4类中的某一类,之后进行四次迭代重复计算类心和调整各模式的类别,最终使各数据点到其判属类别中心的距离
平方之和最小,此时标签数据分类完毕,最后再对分类结果进行颜色填充。
实验代码如下:
%%读遥感数据,以及读入带标签的数据
clear all
Img= multibandread('zy3sample1',[400,400,4],'float',0,'bsq','n',{'Band ','Direct',[1:4]});%将高光谱数据读入
GT= multibandread('ddzm',[400,400,1],'uint8',0,'bsq','n',{'Band','Dir ect',[1:1]});%将ground truth读入(也就是带标签的CMap或说ROI信息读入)test_class=1:4;
C=length(test_class);
NbRow=400;
NbCol=400;
NbDim=4;
dataname='zy3';
%%第一种方式读入带标签数据
[X,Y]=ExtractDataFromROI(Img,GT);
img1=reshape(Img,NbRow*NbCol,NbDim);
%%K-MEAN算法
%%随机产生四个初始聚类类心
c=zeros(4,4);
for i=1:4
c(i,:)=img1(fix(rand(1)*length(img1)),:);
end
%%初始化类心与分类点的距离,分类结果以及标签数据
Dis=[];
R=zeros(length(img1),4);%初始化分类结果
Q=zeros(1,length(img1));%初始化距离
%%按最小距离原则将各数据点分配到4类中的某一类,之后进行四次迭代重复计算类心和调整各模式的类别,最终使各数据点到其判属类别中心的距离平方之和最小。
for y=1:4
for i=1:length(img1(:,1))
for j=1:4
Dis(j)=sqrt(sum((img1(i,:)-c(j,:)).*(img1(i,:)-c(j,:))));%用欧式距离计算类心与分类点间的距离
end
[B,IX]=sort(Dis);%B是原来的矩阵x按照行,每行从小到大重新排列得到的新矩阵。IX告诉你重排的详细信息,也就是做了什么样的变动。将算出的距离从小到大进行排序,找出最小距离。将排列的索引信息返回IX。
R(i,IX(1))=img1(i,1);
if(IX(1)==1)
Q((i))=1;
end
if(IX(1)==2)
Q((i))=2;
end
if(IX(1)==3)
Q((i))=3;
end
if(IX(1)==4)
Q((i))=4;
end
end
for j=1:4
c(j)=sum(R(:,j))/length(find(R(:,j)~=0));%重新计算新的聚类类心end
end
M=reshape(Q,400,400);%将分类后标签数据转化为二维矩阵
S=zeros(400,400,3);%初始化输出结果
%%对分类输出结果进行颜色填充
for i=1:400
for j=1:400
if(M(i,j)==1)
S(i,j,:)=[255,0,0];%红色
end
if(M(i,j)==2)
S(i,j,:)=[0,255,0];%绿色
end
if(M(i,j)==3)
S(i,j,:)=[0,0,255];%蓝色
end
if(M(i,j)==4)
S(i,j,:)=[255,0,255];%紫色
end
end
end
imshow(S);
输出结果:
结果分析:由于初始类心是随机产生的,所以输出结果各不相同,效果也有差别,我选取了效果较好的一张图
心得体会:
本次实验我了解了k-means算法的基本算法思想,但在用matlab编程时还是遇到了很大困难,幸好通过同学的帮助才得以解决,本次代码也有很多是借鉴同学的,自己在基础上也做了一些修改和完善。这次实验过后对使用matlab编程更加透彻了。
操作系统上机实验报告(西电)
操作系统上机题目 一、题目 实验1:LINUX/UNIX Shell部分 (一)系统基本命令 1.登陆系统,输入whoami 和pwd ,确定自己的登录名和当前目录; 登录名yuanye ,当前目录/home/yuanye 2.显示自己的注册目录?命令在哪里? a.键入echo $HOME,确认自己的主目录;主目录为/home/yuanye b.键入echo $PA TH,记下自己看到的目录表;/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games c.键入which abcd,看看得到的错误信息; 再键入which ls 和which vi,对比刚刚得到的结果的目录是否在a.、b. 两题看到的目录表中; /bin/ls /usr/bin/vi 3.ls 和cd 的使用: a.键入ls,ls -l ,ls -a ,ls -al 四条命令,观察输出,说明四种不同使用方式的区别。 1. examples.desktop 公共的模板视频图片文档音乐桌面; 总计32 2.-rw-r--r-- 1 yuanye yuanye 357 2011-03-22 22:15 examples.desktop drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 公共的 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 模板 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 视频 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 图片 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 文档 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 音乐 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 桌面 3. . .fontconfig .local .Xauthority .. .gconf .mozilla .xsession-errors .bash_logout .gconfd .nautilus 公共的 .bashrc .gksu.lock .profile 模板 .cache .gnome2 .pulse 视频 .chewing .gnome2_private .pulse-cookie 图片 .config .gnupg .recently-used.xbel 文档 .dbus .gstreamer-0.10 .scim 音乐 .dmrc .gtk-bookmarks .sudo_as_admin_successful 桌面 .esd_auth .gvfs .update-manager-core
数值分析实验报告1
实验一误差分析 实验1.1(病态问题) 实验目的:算法有“优”与“劣”之分,问题也有“好”与“坏”之别。对数值方法的研究而言,所谓坏问题就是问题本身对扰动敏感者,反之属于好问题。通过本实验可获得一个初步体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 问题提出:考虑一个高次的代数多项式 显然该多项式的全部根为1,2,…,20共计20个,且每个根都是单重的。现考虑该多项式的一个扰动 其中ε(1.1)和(1.221,,,a a 的输出b ”和“poly ε。 (1(2 (3)写成展 关于α solve 来提高解的精确度,这需要用到将多项式转换为符号多项式的函数poly2sym,函数的具体使用方法可参考Matlab 的帮助。 实验过程: 程序: a=poly(1:20); rr=roots(a); forn=2:21 n form=1:9 ess=10^(-6-m);
ve=zeros(1,21); ve(n)=ess; r=roots(a+ve); -6-m s=max(abs(r-rr)) end end 利用符号函数:(思考题一)a=poly(1:20); y=poly2sym(a); rr=solve(y) n
很容易的得出对一个多次的代数多项式的其中某一项进行很小的扰动,对其多项式的根会有一定的扰动的,所以对于这类病态问题可以借助于MATLAB来进行问题的分析。 学号:06450210 姓名:万轩 实验二插值法
模式识别第二次上机实验报告
北京科技大学计算机与通信工程学院 模式分类第二次上机实验报告 姓名:XXXXXX 学号:00000000 班级:电信11 时间:2014-04-16
一、实验目的 1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等; 二、实验内容 2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: label index1:value1 index2:value2 ... 其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。(我主要要用到回归) Index是从1开始的自然数,value是每一维的特征值。 该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。FormatDataLibsvm.xls使用说明: 先将数据按照下列格式存放(注意label放最后面): value1 value2 label value1 value2 label 然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。就可以得到libsvm要求的数据格式。将该数据存放到文本文件中进行下一步的处理。 3.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。缩放规则文件可以用文本浏览器打开,看到其格式为: y lower upper min max x lower upper index1 min1 max1 index2 min2 max2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为: (Value-lower)*(max-min)/(upper - lower)+lower 其中value为归一化后的值,其他参数与前面介绍的相同。 建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。 4.训练数据,生成模型。 用法:svmtrain [options] training_set_file [model_file] 其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默
《 Windows7 操作系统》实验报告
实验(一) Windows 7基本操作 一、实验目的 1.掌握文件和文件夹基本操作。 2.掌握“资源管理器”和“计算机”基本操作。 二、实验要求 1.请将操作结果用Alt+Print Screen组合键截图粘贴在题目之后。 2.实验完成后,请将实验报告保存并提交。 三、实验内容 1.文件或文件夹的管理(提示:此题自行操作一遍即可,无需抓图)★期末机试必考题★ (1) 在D:盘根目录上创建一个名为“上机实验”的文件夹,在“上机实验”文件夹中创建1个名为“操作系统上机实验”的空白文件夹和2个分别名为“2.xlsx”和“3.pptx”的空白文件,在“操作系统上机实验”文件夹中创建一个名为“1.docx”的空白文件。 (2) 将“1.docx”改名为“介绍信.docx”;将“上机实验”改名为“作业”。 (3) 在“作业”文件夹中分别尝试选择一个文件、同时选择两个文件、一次同时选择所有文件和文件夹。 (4) 将“介绍信.docx”复制到C:盘根目录。 (5) 将D:盘根目录中的“作业”文件夹移动到C:盘根目录。 (6) 将“作业”文件夹中的“2.xlsx”文件删除放入“回收站”。 (7) 还原被删除的“2.xlsx”文件到原位置。 2.搜索文件或文件夹,要求如下: 查找C盘上所有以大写字母“A”开头,文件大小在10KB以上的文本文件。(提示:搜索时,可以使用“?”和“*”。“?”表示任意一个字符,“*”表示任意多个字符。)
3. 在桌面上为C:盘根目录下的“作业”文件夹创建一个桌面快捷方式。★期末机试必考题★ 3.“计算机”或“资源管理器”的使用 (1) 在“资源管理器”窗口,设置以详细信息方式显示C:\WINDOWS中所有文件和文件夹,使所有图标按类型排列显示,并不显示文件扩展名。(提示:三步操作全部做完后,将窗口中显示的最终设置结果抓一张图片即可) (2) 将C:盘根目录中“介绍信.docx”的文件属性设置为“只读”和“隐藏”,并设置在窗口中显示“隐藏属性”的文件或文件夹。(提示:请将“文件夹”对话框中选项设置效果与C:盘根目录中该文件图标呈现的半透明显示效果截取在一整张桌面图片中即可) 4.回收站的设置 设置删除文件后,不将其移入回收站中,而是直接彻底删除功能。
模式识别实验报告
模式识别实验报告
————————————————————————————————作者:————————————————————————————————日期:
实验报告 实验课程名称:模式识别 姓名:王宇班级: 20110813 学号: 2011081325 实验名称规范程度原理叙述实验过程实验结果实验成绩 图像的贝叶斯分类 K均值聚类算法 神经网络模式识别 平均成绩 折合成绩 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年 6月
实验一、 图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为
操作系统上机实验报告
大连理工大学实验报告 学院(系):专业:班级: 姓名:学号:组:___ 实验时间:实验室:实验台: 指导教师签字:成绩: 实验名称:进程控制 一、实验目的和要求 (1)进一步加强对进程概念的理解,明确进程和程序的区别 (2)进一步认识并发执行的实质 二、实验环境 在windows平台上,cygwin模拟UNIX运行环境 三、实验内容 (1) getpid()---获取进程的pid 每个进程都执行自己独立的程序,打印自己的pid; (2) getpid()---获取进程的pid 每个进程都执行自己独立的程序,打印自己的pid; 父进程打印两个子进程的pid;
(3)写一个命令处理程序,能处理max(m,n), min(m,n),average(m,n,l)这几个命令(使用exec函数族)。 Max函数 Min函数 Average函数 Exec函数族调用 四、程序代码 五、运行结果 六、实验结果与分析 七、体会 通过这次上机,我了解了fork函数的运行方法,同时更深刻的了解了进程的并行执行的本质,印证了在课堂上学习的理论知识。同时通过编写实验内容(3)的命令处理程序,学会了exec函数族工作原理和使用方法。通过这次上机实验让我加深了对课堂上学习的理论知识的理解,收获很多。
大连理工大学实验报告 学院(系):专业:班级: 姓名:学号:组:___ 实验时间:实验室:实验台: 指导教师签字:成绩: 实验名称:进程通讯 一、实验目的和要求 了解和熟悉UNIX支持的共享存储区机制 二、实验环境 在windows平台上,cygwin模拟UNIX运行环境 三.实验内容 编写一段程序, 使其用共享存储区来实现两个进程之间的进程通讯。进程A创建一个长度为512字节的共享内存,并显示写入该共享内存的数据;进程B将共享内存附加到自己的地址空间,并向共享内存中写入数据。 四、程序代码 五、运行结果 六、实验结果与分析 七、体会
数值分析上机实验报告
数值分析上机实验报告
《数值分析》上机实验报告 1.用Newton 法求方程 X 7-X 4+14=0 在(0.1,1.9)中的近似根(初始近似值取为区间端点,迭代6次或误差小于0.00001)。 1.1 理论依据: 设函数在有限区间[a ,b]上二阶导数存在,且满足条件 {}α?上的惟一解在区间平方收敛于方程所生的迭代序列 迭代过程由则对任意初始近似值达到的一个中使是其中上不变号 在区间],[0)(3,2,1,0,) (') ()(],,[x |))(),((|,|,)(||)(|.4;0)(.3],[)(.20 )()(.110......b a x f x k x f x f x x x Newton b a b f a f mir b a c x f a b c f x f b a x f b f x f k k k k k k ==- ==∈≤-≠>+ 令 )9.1()9.1(0)8(4233642)(0)16(71127)(0)9.1(,0)1.0(,1428)(3 2 2 5 333647>?''<-=-=''<-=-='<>+-=f f x x x x x f x x x x x f f f x x x f 故以1.9为起点 ?? ?? ? ='- =+9.1)()(01x x f x f x x k k k k 如此一次一次的迭代,逼近x 的真实根。当前后两个的差<=ε时,就认为求出了近似的根。本程序用Newton 法求代数方程(最高次数不大于10)在(a,b )区间的根。
1.2 C语言程序原代码: #include
操作系统实验报告生产者与消费者问题模拟
操作系统上机实验报告 实验名称: 生产者与消费者问题模拟 实验目的: 通过模拟生产者消费者问题理解进程或线程之间的同步与互斥。 实验内容: 1、设计一个环形缓冲区,大小为10,生产者依次向其中写入1到20,每个缓冲区中存放一个数字,消费者从中依次读取数字。 2、相应的信号量; 3、生产者和消费者可按如下两种方式之一设计; (1)设计成两个进程; (2)设计成一个进程内的两个线程。 4、根据实验结果理解信号量的工作原理,进程或线程的同步\互斥关系。 实验步骤及分析: 一.管道 (一)管道定义 所谓管道,是指能够连接一个写进程和一个读进程的、并允许它们以生产者—消费者方式进行通信的一个共享文件,又称为pipe文件。由写进程从管道的写入端(句柄1)将数据写入管道,而读进程则从管道的读出端(句柄0)读出数据。(二)所涉及的系统调用 1、pipe( ) 建立一无名管道。 系统调用格式 pipe(filedes) 参数定义 int pipe(filedes); int filedes[2]; 其中,filedes[1]是写入端,filedes[0]是读出端。 该函数使用头文件如下: #include
int read(fd,buf,nbyte); int fd; char *buf; unsigned nbyte; 3、write( ) 系统调用格式 read(fd,buf,nbyte) 功能:把nbyte 个字节的数据,从buf所指向的缓冲区写到由fd所指向的文件中。如文件加锁,暂停写入,直至开锁。 参数定义同read( )。 (三)参考程序 #include
数值分析拉格朗日插值法上机实验报告
课题一:拉格朗日插值法 1.实验目的 1.学习和掌握拉格朗日插值多项式。 2.运用拉格朗日插值多项式进行计算。 2.实验过程 作出插值点(1.00,0.00),(-1.00,-3.00),(2.00,4.00)二、算法步骤 已知:某些点的坐标以及点数。 输入:条件点数以及这些点的坐标。 输出:根据给定的点求出其对应的拉格朗日插值多项式的值。 3.程序流程: (1)输入已知点的个数; (2)分别输入已知点的X坐标; (3)分别输入已知点的Y坐标; 程序如下: #include
插值算法*/ { int i,j; float *a,yy=0.0; /*a作为临时变量,记录拉格朗日插值多项*/ a=(float*)malloc(n*sizeof(float)); for(i=0;i<=n-1;i++) { a[i]=y[i]; for(j=0;j<=n-1;j++) if(j!=i) a[i]*=(xx-x[j])/(x[i]-x[j]); yy+=a[i]; } free(a); return yy; } int main() { int i; int n; float x[20],y[20],xx,yy; printf("Input n:");
scanf("%d",&n); if(n<=0) { printf("Error! The value of n must in (0,20)."); getch();return 1; } for(i=0;i<=n-1;i++) { printf("x[%d]:",i); scanf("%f",&x[i]); } printf("\n"); for(i=0;i<=n-1;i++) { printf("y[%d]:",i);scanf("%f",&y[i]); } printf("\n"); printf("Input xx:"); scanf("%f",&xx); yy=lagrange(x,y,xx,n); printf("x=%f,y=%f\n",xx,yy); getch(); } 举例如下:已知当x=1,-1,2时f(x)=0,-3,4,求f(1.5)的值。
数值分析实验报告1
实验一 误差分析 实验(病态问题) 实验目的:算法有“优”与“劣”之分,问题也有“好”与“坏”之别。对数值方法的研究而言,所谓坏问题就是问题本身对扰动敏感者,反之属于好问题。通过本实验可获得一个初步体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 问题提出:考虑一个高次的代数多项式 )1.1() ()20()2)(1()(20 1∏=-=---=k k x x x x x p 显然该多项式的全部根为1,2,…,20共计20个,且每个根都是单重的。现考虑该多项式的一个扰动 )2.1(0 )(19=+x x p ε 其中ε是一个非常小的数。这相当于是对()中19x 的系数作一个小的扰动。我们希望比较()和()根的差别,从而分析方程()的解对扰动的敏感性。 实验内容:为了实现方便,我们先介绍两个Matlab 函数:“roots ”和“poly ”。 roots(a)u = 其中若变量a 存储n+1维的向量,则该函数的输出u 为一个n 维的向量。设a 的元素依次为121,,,+n a a a ,则输出u 的各分量是多项式方程 01121=+++++-n n n n a x a x a x a 的全部根;而函数 poly(v)b =
的输出b 是一个n+1维变量,它是以n 维变量v 的各分量为根的多项式的系数。可见“roots ”和“poly ”是两个互逆的运算函数。 ;000000001.0=ess );21,1(zeros ve = ;)2(ess ve = ))20:1((ve poly roots + 上述简单的Matlab 程序便得到()的全部根,程序中的“ess ”即是()中的ε。 实验要求: (1)选择充分小的ess ,反复进行上述实验,记录结果的变化并分析它们。 如果扰动项的系数ε很小,我们自然感觉()和()的解应当相差很小。计算中你有什么出乎意料的发现表明有些解关于如此的扰动敏感性如何 (2)将方程()中的扰动项改成18x ε或其它形式,实验中又有怎样的现象 出现 (3)(选作部分)请从理论上分析产生这一问题的根源。注意我们可以将 方程()写成展开的形式, ) 3.1(0 ),(1920=+-= x x x p αα 同时将方程的解x 看成是系数α的函数,考察方程的某个解关于α的扰动是否敏感,与研究它关于α的导数的大小有何关系为什么你发现了什么现象,哪些根关于α的变化更敏感 思考题一:(上述实验的改进) 在上述实验中我们会发现用roots 函数求解多项式方程的精度不高,为此你可以考虑用符号函数solve 来提高解的精确度,这需要用到将多项式转换为符号多项式的函数poly2sym,函数的具体使用方法可参考Matlab 的帮助。
《模式识别》实验报告
《模式识别》实验报告 一、数据生成与绘图实验 1.高斯发生器。用均值为m,协方差矩阵为S 的高斯分布生成N个l 维向量。 设置均值 T m=-1,0 ?? ??,协方差为[1,1/2;1/2,1]; 代码: m=[-1;0]; S=[1,1/2;1/2,1]; mvnrnd(m,S,8) 结果显示: ans = -0.4623 3.3678 0.8339 3.3153 -3.2588 -2.2985 -0.1378 3.0594 -0.6812 0.7876 -2.3077 -0.7085 -1.4336 0.4022 -0.6574 -0.0062 2.高斯函数计算。编写一个计算已知向量x的高斯分布(m, s)值的Matlab函数。 均值与协方差与第一题相同,因此代码如下: x=[1;1]; z=1/((2*pi)^0.5*det(S)^0.5)*exp(-0.5*(x-m)'*inv(S)*(x-m)) 显示结果: z = 0.0623 3.由高斯分布类生成数据集。编写一个Matlab 函数,生成N 个l维向量数据集,它们是基于c个本体的高斯分布(mi , si ),对应先验概率Pi ,i= 1,……,c。 M文件如下: function [X,Y] = generate_gauss_classes(m,S,P,N) [r,c]=size(m); X=[]; Y=[]; for j=1:c t=mvnrnd(m(:,j),S(:,:,j),fix(P(j)*N)); X=[X t]; Y=[Y ones(1,fix(P(j)*N))*j]; end end
调用指令如下: m1=[1;1]; m2=[12;8]; m3=[16;1]; S1=[4,0;0,4]; S2=[4,0;0,4]; S3=[4,0;0,4]; m=[m1,m2,m3]; S(:,:,1)=S1; S(:,:,2)=S2; S(:,:,3)=S3; P=[1/3,1/3,1/3]; N=10; [X,Y] = generate_gauss_classes(m,S,P,N) 二、贝叶斯决策上机实验 1.(a)由均值向量m1=[1;1],m2=[7;7],m3=[15;1],方差矩阵S 的正态分布形成三个等(先验)概率的类,再基于这三个类,生成并绘制一个N=1000 的二维向量的数据集。 (b)当类的先验概率定义为向量P =[0.6,0.3,0.1],重复(a)。 (c)仔细分析每个类向量形成的聚类的形状、向量数量的特点及分布参数的影响。 M文件代码如下: function plotData(P) m1=[1;1]; S1=[12,0;0,1]; m2=[7;7]; S2=[8,3;3,2]; m3=[15;1]; S3=[2,0;0,2]; N=1000; r1=mvnrnd(m1,S1,fix(P(1)*N)); r2=mvnrnd(m2,S2,fix(P(2)*N)); r3=mvnrnd(m3,S3,fix(P(3)*N)); figure(1); plot(r1(:,1),r1(:,2),'r.'); hold on; plot(r2(:,1),r2(:,2),'g.'); hold on; plot(r3(:,1),r3(:,2),'b.'); end (a)调用指令: P=[1/3,1/3,1/3];
数值分析实验报告模板
数值分析实验报告模板 篇一:数值分析实验报告(一)(完整) 数值分析实验报告 1 2 3 4 5 篇二:数值分析实验报告 实验报告一 题目:非线性方程求解 摘要:非线性方程的解析解通常很难给出,因此线性方程的数值解法就尤为重要。本实验采用两种常见的求解方法二分法和Newton法及改进的Newton法。利用二分法求解给定非线性方程的根,在给定的范围内,假设f(x,y)在[a,b]上连续,f(a)xf(b) 直接影响迭代的次数甚至迭代的收敛与发散。即若x0 偏离所求根较远,Newton法可能发散的结论。并且本实验中还利用利用改进的Newton法求解同样的方程,且将结果与Newton法的结果比较分析。 前言:(目的和意义) 掌握二分法与Newton法的基本原理和应用。掌握二分法的原理,验证二分法,在选对有根区间的前提下,必是收
敛,但精度不够。熟悉Matlab语言编程,学习编程要点。体会Newton使用时的优点,和局部收敛性,而在初值选取不当时,会发散。 数学原理: 对于一个非线性方程的数值解法很多。在此介绍两种最常见的方法:二分法和Newton法。 对于二分法,其数学实质就是说对于给定的待求解的方程f(x),其在[a,b]上连续,f(a)f(b) Newton法通常预先要给出一个猜测初值x0,然后根据其迭代公式xk?1?xk?f(xk) f'(xk) 产生逼近解x*的迭代数列{xk},这就是Newton法的思想。当x0接近x*时收敛很快,但是当x0选择不好时,可能会发散,因此初值的选取很重要。另外,若将该迭代公式改进为 xk?1?xk?rf(xk) 'f(xk) 其中r为要求的方程的根的重数,这就是改进的Newton 法,当求解已知重数的方程的根时,在同种条件下其收敛速度要比Newton法快的多。 程序设计: 本实验采用Matlab的M文件编写。其中待求解的方程写成function的方式,如下 function y=f(x);
模式识别实验报告(一二)
信息与通信工程学院 模式识别实验报告 班级: 姓名: 学号: 日期:2011年12月
实验一、Bayes 分类器设计 一、实验目的: 1.对模式识别有一个初步的理解 2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识 3.理解二类分类器的设计原理 二、实验条件: matlab 软件 三、实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1)在已知 ) (i P ω, ) (i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计 算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x 2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a 3)对(2)中得到的a 个条件风险值) (X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的 决策k a ,即()() 1,min k i i a R a x R a x == 则 k a 就是最小风险贝叶斯决策。 四、实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。 现有一系列待观察的细胞,其观察值为x : 已知先验概率是的曲线如下图:
)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果 进行分类。 五、实验步骤: 1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。 2.根据例子画出后验概率的分布曲线以及分类的结果示意图。 3.最小风险贝叶斯决策,决策表如下: 结果,并比较两个结果。 六、实验代码 1.最小错误率贝叶斯决策 x=[ ] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2; m=numel(x); %得到待测细胞个数 pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵
操作系统实验报告18038
福州大学数学与计算机科学(软件)学院 实验报告 课程名称:计算机操作系统 学号:221100218 姓名: 专业:软件工程 年级:2011级 学期:2012学年第2学期 2013年10 月24 日
实验一 Linux操作系统的使用和分析 一、实验目的 本实验主要学习和掌握Linux操作系统的基本应用。通过本实验,学生能够熟练掌握Linux环境下各种基本操作命令接口的应用。从系统安全角度出发,学习掌握系统的基本安全优化和配置,在操作系统层次进行有效安全加固,提高Linux系统的安全性能。通过本次实验,有助于学生进一步理解操作系统原理中的相关内容,加深认识。 二、实验要求 1、熟练掌握Linux系统的基本操作命令。 2、熟悉Linux 系统的基本配置。 3、实现Linux系统的安全加固。 4、掌握一种以上的网络应用软件的安装、配置与应用。 三、实验内容 系统的启动,如图: 关闭使用shutdowm 还有列出文件夹内的信息ls,cp复制拷贝,touch创建文件命令等等 ①下载文件压缩包pro.gz,解压如图:
②然后修改安装路径: ③之后用make编译文件 ④在安装路径/home/liaoenrui/11里的etc中修改文件的组名和用户名: 将groud 命名也命名为ftp,然后用groudadd和useradd命令将这两个添加在该目录的sbin目录下:
⑤最后运行文件,./profile即可 四、实验总结 通过本次的操作系统的上机实验,我熟练了Linux系统的基本操作命令,并且对安装文件有更深入的了解,比如在上述安装过程中对于通过froftpd来架构linux的ftp,由于之前都是用window系统,所以对于这些非常的生疏,因此在请教了多人和上网查询之后,终于有所了解,并且成功的将此实验顺利完成。在本次实验中,我发现自己的动手能力又有很大的提高,相信以后继续努力的话会有更大的进步,当然这也要归功于老师的教导。 参考文献 [1] Neil Maththew Richard Stones Linux 程序设计第四版人民邮电出版社 [2] 周茜,赵明生.中文文本分类中的特征选择研究[J].中文信息学报,2003,Vol.18 No.3
(完整版)哈工大-数值分析上机实验报告
实验报告一 题目:非线性方程求解 摘要:非线性方程的解析解通常很难给出,因此线性方程的数值解法就尤为重要。本实验采用两种常见的求解方法二分法和Newton法及改进的Newton法。 前言:(目的和意义) 掌握二分法与Newton法的基本原理和应用。 数学原理: 对于一个非线性方程的数值解法很多。在此介绍两种最常见的方法:二分法和Newton法。 对于二分法,其数学实质就是说对于给定的待求解的方程f(x),其在[a,b]上连续,f(a)f(b)<0,且f(x)在[a,b]内仅有一个实根x*,取区间中点c,若,则c恰为其根,否则根据f(a)f(c)<0是否成立判断根在区间[a,c]和[c,b]中的哪一个,从而得出新区间,仍称为[a,b]。重复运行计算,直至满足精度为止。这就是二分法的计算思想。
Newton法通常预先要给出一个猜测初值x0,然后根据其迭代公式 产生逼近解x*的迭代数列{x k},这就是Newton法的思想。当x0接近x*时收敛很快,但是当x0选择不好时,可能会发散,因此初值的选取很重要。另外,若将该迭代公式改进为 其中r为要求的方程的根的重数,这就是改进的Newton法,当求解已知重数的方程的根时,在同种条件下其收敛速度要比Newton法快的多。 程序设计: 本实验采用Matlab的M文件编写。其中待求解的方程写成function的方式,如下 function y=f(x); y=-x*x-sin(x); 写成如上形式即可,下面给出主程序。 二分法源程序: clear %%%给定求解区间 b=1.5; a=0;
%%%误差 R=1; k=0;%迭代次数初值 while (R>5e-6) ; c=(a+b)/2; if f12(a)*f12(c)>0; a=c; else b=c; end R=b-a;%求出误差 k=k+1; end x=c%给出解 Newton法及改进的Newton法源程序:clear %%%% 输入函数 f=input('请输入需要求解函数>>','s') %%%求解f(x)的导数 df=diff(f);
《大学计算机基础》上机实验报告
《大学计算机基础》 上机实验报告 班级: 姓名: 学号: 授课教师: 日期:年月日
目录 一、Windows操作系统基本操作 ............................. - 1 - 二、Word文字处理基本操作 ................................ - 4 - 三、Excel电子表格基本操作 ............................... - 6 - 四、PowerPoint幻灯片基本操作 ............................ - 8 - 五、网页设计基本操作..................................... - 9 - 六、Access数据库基本操作 ............................... - 10 - 上机实验作业要求: ○1在实验报告纸上手写并粘贴实验结果; ○2每人将所有作业装订在一起(要包封面); ○3全部上机实验结束后全班统一上交; ○4作业内容不得重复、输入的数据需要有差别。
实验名称一、Windows操作系统基本操作 实验目的1、掌握Windows的基本操作方法。 2、学会使用“画图”和PrntScr快捷键。 3、学会使用“计算器”和Word基本操作。 实验内容 1、日历标注 利用“画图”和Word软件,截取计算机上日历的图片并用文字、颜色、图框等标注出近期的节假日及其名称,并将结果显示保存在下面(参考下面样图)。 运行结果是: 主要操作步骤是: 2、科学计算 利用“计算器”和Word软件,计算下列题目,并将结果截图保存在下面(参考样图)。 ○1使用科学型计算器,求8!、sin(8)、90、74、20、67、39、400、50.23、ln(785)的平均值、和值,并用科学计数法显示。 运行结果是: ②将以下十、八、十六进制数转换为二进制数:(894.8125)10、(37.5)8、(2C.4B)16 运行结果是:(需要下载使用“唯美计算器”) ○3计算下列二进制数的加法与乘法:101.1+11.11;1101*1011 运行结果是:(参考样图) 写出主要操作步骤: 3、实验心得体会
数值分析实验报告总结
数值分析实验报告总结 随着电子计算机的普及与发展,科学计算已成为现代科 学的重要组成部分,因而数值计算方法的内容也愈来愈广泛和丰富。通过本学期的学习,主要掌握了一些数值方法的基本原理、具体算法,并通过编程在计算机上来实现这些算法。 算法算法是指由基本算术运算及运算顺序的规定构成的完 整的解题步骤。算法可以使用框图、算法语言、数学语言、自然语言来进行描述。具有的特征:正确性、有穷性、适用范围广、运算工作量少、使用资源少、逻辑结构简单、便于实现、计算结果可靠。 误差 计算机的计算结果通常是近似的,因此算法必有误差, 并且应能估计误差。误差是指近似值与真正值之差。绝对误差是指近似值与真正值之差或差的绝对值;相对误差:是指近似值与真正值之比或比的绝对值。误差来源见表 第三章泛函分析泛函分析概要 泛函分析是研究“函数的函数”、函数空间和它们之间 变换的一门较新的数学分支,隶属分析数学。它以各种学科
如果 a 是相容范数,且任何满足 为具体背景,在集合的基础上,把客观世界中的研究对象抽 范数 范数,是具有“长度”概念的函数。在线性代数、泛函 分析及相关的数学领域,泛函是一个函数,其为矢量空间内 的所有矢量赋予非零的正长度或大小。这里以 Cn 空间为例, Rn 空间类似。最常用的范数就是 P-范数。那么 当P 取1, 2 ,s 的时候分别是以下几种最简单的情形: 其中2-范数就是通常意义下的距离。 对于这些范数有以下不等式: 1 < n1/2 另外,若p 和q 是赫德尔共轭指标,即 1/p+1/q=1 么有赫德尔不等式: II = ||xH*y| 当p=q=2时就是柯西-许瓦兹不等式 般来讲矩阵范数除了正定性,齐次性和三角不等式之 矩阵范数通常也称为相容范数。 象为元素和空间。女口:距离空间,赋范线性空间, 内积空间。 1-范数: 1= x1 + x2 +?+ xn 2-范数: x 2=1/2 8 -范数: 8 =max oo ,那 外,还规定其必须满足相容性: 所以