数据库备份策略步骤
手工发起数据库归档日志备份策略执行步骤
因xxxx出帐期会产生较多归档日志,需要
手工发起归档日志备份策略。执行因手工发起的出帐程序时间而异,通常选择在每月1号早晨06:00~08:00和下午16:00~17:00两次执行。
需要先安装一个Xwindow管理软件,在10.32.200.138 10.32.200.139指纹客户端上有Xmanger软件。步骤如下:
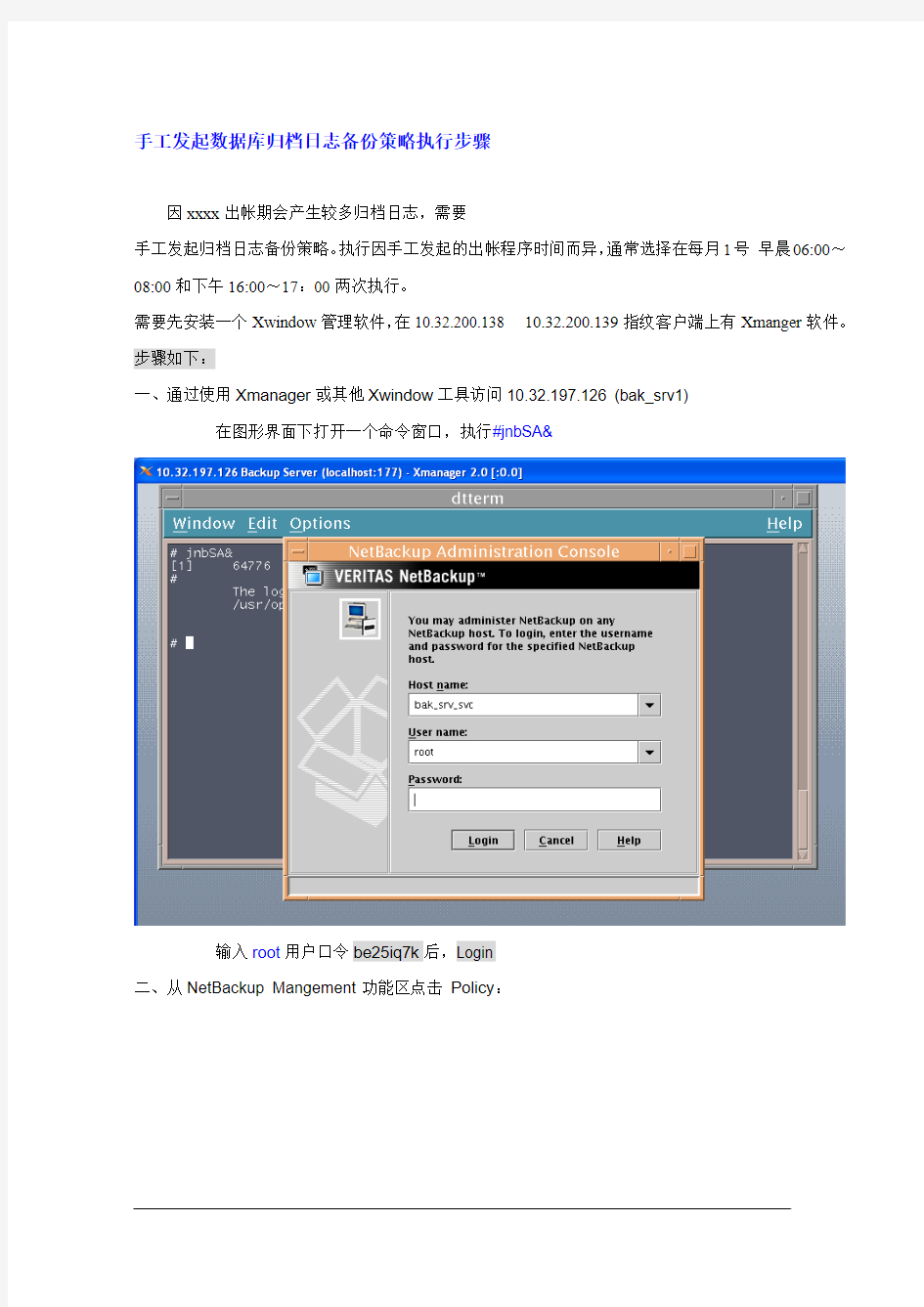
一、通过使用Xmanager或其他Xwindow工具访问10.32.197.126 (bak_srv1)
在图形界面下打开一个命令窗口,执行#jnbSA&
输入root用户口令be25iq7k后,Login
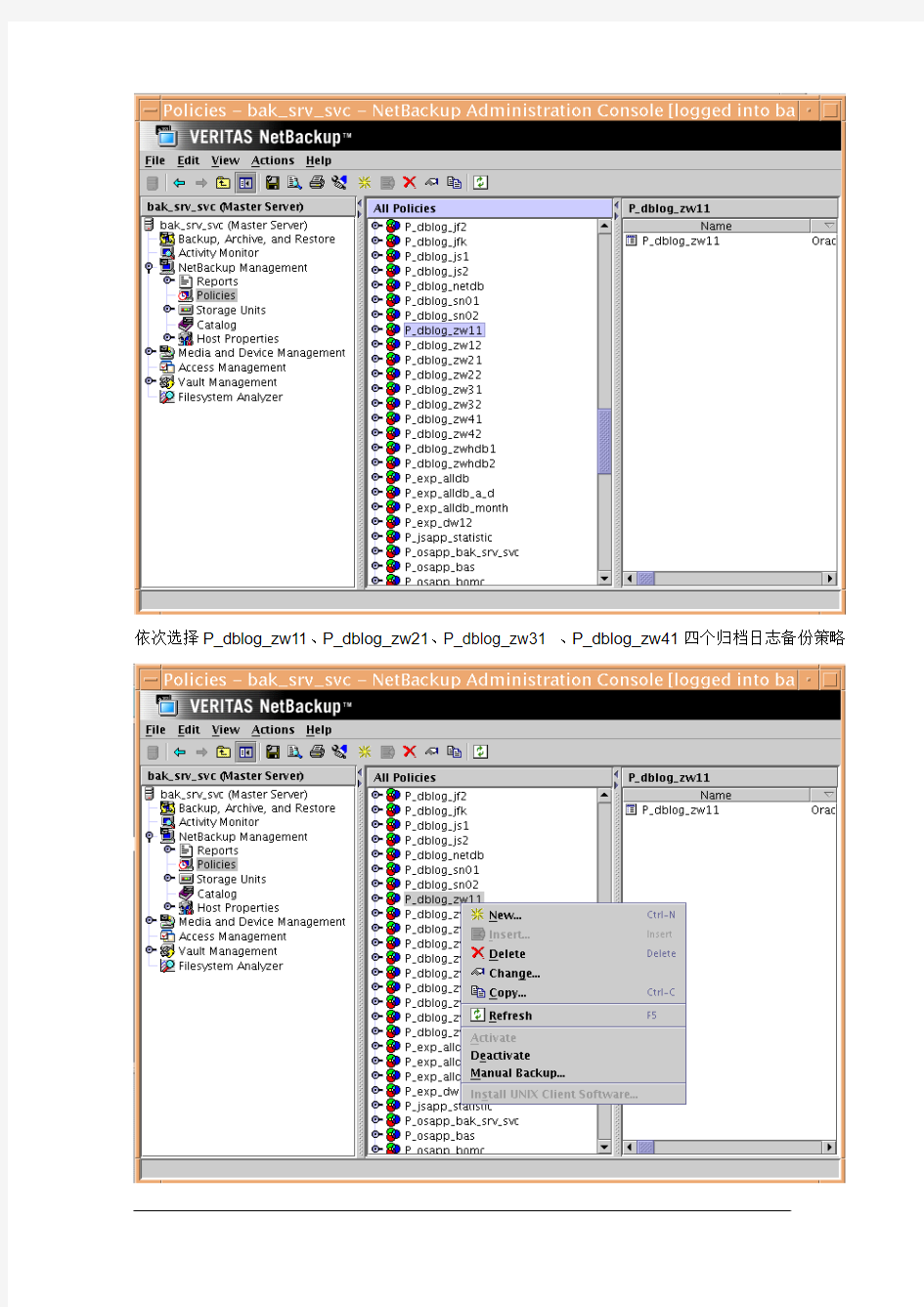
二、从NetBackup Mangement功能区点击Policy:
依次选择P_dblog_zw11、P_dblog_zw21、P_dblog_zw31 、P_dblog_zw41四个归档日志备份策略
分别右击策略名称P_dblog_zw11 选择
Manual Backup
选择对应时间点的schedule后,点击OK执行备份
备份任务通常会在1~10分钟之内调度。
可以从Activity Monitor功能区观察备份任务执行情况,在右边区域内以Job ID自大到小排序。
我们也只要在zw_db11、zw_db21、zw_db31、zw_db41即每个实例的单号节点上发起归档日志的备份。因为在RMAN脚本中同时连接两个节点进行备份:
$ORACLE_HOME/rman/hot_archivelog_backup.sh
configure channel 1 device type sbt connect 'sys/password@zwdb11' parms='ENV=(NB_ORA_POLICY=P_dblog_zw11,NB_ORA_CLIENT=zw_db11)' ; configure channel 2 device type sbt connect 'sys/password@z wdb11' parms='ENV=(NB_ORA_POLICY=P_dblog_zw11,NB_ORA_CLIENT=zw_db11)' ; configure channel 3 device type sbt connect 'sys/password@zwdb11' parms='ENV=(NB_ORA_POLICY=P_dblog_zw11,NB_ORA_CLIENT=zw_db11)' ; configure channel 4 device type sbt connect 'sys/password@zwdb12' parms='ENV=(NB_ORA_POLICY=P_dblog_zw12,NB_ORA_CLIENT=zw_db12)' ; configure channel 5 device type sbt connect 'sys/password@zwdb12' parms='ENV=(NB_ORA_POLICY=P_dblog_zw12,NB_ORA_CLIENT=zw_db12)' ; configure channel 6 device type sbt connect 'sys/password@zwdb12' parms='ENV=(NB_ORA_POLICY=P_dblog_zw12,NB_ORA_CLIENT=zw_db12)' ; backup filesperset 10 archivelog all delete all input;
三、如果长时间备份任务没有发起,可以从两方面进行监控:
1、使用tail –f 检查归档日志输出文件,文件位于zw_db11、zw_db21、zw_db31、zw_db41 的
$ORACLE_HOME/rman目录下,对应的输出文件为hot_archivelog_backup.sh.out
$tail –f $ORACLE_HOME/rman/hot_archivelog_backup.sh.out
查看备份任务执行过程。
2、监控RMAN Catalog库rman用户是否已经连接到catalog库;
[oracle/bak_srv1]$sqlplus “/as sysdba”
SQL>alter session set NLS_DATE_FORMAT=?YYYY-MM-DD HH24:MI:SS?;
SQL>select username,logon_time,program,machine from v$session where username like
…%RMAN%?;
附:数据库备份失败判断、处理方法:
●检查T arget 库v$backup_redolog动态性能视图,检查SEQUENCE# 是否连续
SQL>alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS';
SQL>select a.recid,a.sequence#,a.first_time from v$backup_redolog a where thread#=1 order by a.SEQUENCE#;
●或通过RMAN 验证
1.验证zw_db21的备份是否完整
1.1 检查归档目录中当天最早产生的日志
oracle@zw_db21:/archlog1$ zw_db21: zwdb21_s0000205366.arc
1.2 验证当天已备份的最后一个归档日志
rman catalog /@ target /@
RMAN>list backup of archivelog from time …SYSDATE-1?;
List of Archived Logs in backup set 2676783
Thrd Seq Low SCN Low Time Next SCN Next Time
---- ------- ---------- --------- ---------- ---------
1 205364 9000092022764 09-FEB-07 9000093116634 09-FEB-07
1 2053659000093116634 09-FEB-07 9000094039951 09-FEB-07
2 239070 9000091590120 09-FEB-07 9000092022804 09-FEB-07
2 2390719000092022804 09-FEB-07 9000094042104 09-FEB-07
2. 验证zw_db22的备份是否完整
2.1 检查归档目录中当天最早产生的日志
oracle@zw_db22:/archlog2$ zw_db22:zwdb22_s0000239072.arc
2.2 验证当天已备份的最后一个归档日志
rman catalog /@ target /@
RMAN>list backup of archivelog from time …SYSDATE-1?;
List of Archived Logs in backup set 2676783
Thrd Seq Low SCN Low Time Next SCN Next Time
---- ------- ---------- --------- ---------- ---------
2 239070 9000091590120 09-FEB-07 9000092022804 09-FEB-07
2 239071 9000092022804 09-FEB-07 9000094042104 09-FEB-07
数据库备份方案
《客户名称》备份管理系统设计方案 上海鸿翼数字计算机网络有限公司
目录 1.项目概述 (3) 2.系统需求分析 (4) 1. (4) 2. (4) 1 (4) 2 (4) 1.1系统现状分析 (4) 1.2备份系统风险评估 (4) 1.3备份系统需求分析 (5) 3.系统备份理念 (5) 1 (5) 2 (5) 3 (5) 3.1系统设计指引 (5) 3.2数据保护技术选择 (6) 3.3连续数据保护 (7) 3.4备份管理系统组成 (7) 4.系统备份结构设计 (9) 1 (9) 2 (9) 3 (9) 4 (9)
4.1整体系统架构设计 (9) 5.系统备份方案介绍 (11) 1 (11) 2 (11) 3 (11) 4 (11) 5 (11) 5.1W INDOWS服务器自身备份 (11) 5.2双机热备 (13) 5.3爱数备份 (14) 6.总结 (17) 1.项目概述
上海鸿翼数字计算机网络有限公司将根据《》的网络实际需求,制定一套完整的集数据备份、灾难恢复、服务器整合及虚拟化一身的方案。一个完整的企业数据备份与恢复解决方案就意味着数据安全与性能(机器和网络)的完美结合,一条龙式的服务标准(产品的服务与支持)。所以在选择备份系统时,既要做到满足系统容量不断增加的需求,又要所用的备份方式能够支持多系统平台操作。要达到这些,就要充分使用网络数据存储系统,在分布式网络环境下,通过专业的数据存储软件,配合系统备份及双机备份,结合相应的硬件和存储设备,对网络的数据备份进行集中管理,从而实现自动化备份、文件归档、数据分级存储和灾难恢复。 2.系统需求分析 1.1系统现状分析 《》网络基础结构是基于Windows平台,现在拥有X台服务器。《》的文档管理系统包含了文件服务器、转档服务器、数据库服务器等企业信息管理系统,为企业的发展提供了强有力的信息化支持。主要数据库包含了Microsoft SQL Server、Oracle、DB2等。 1.2备份系统风险评估 《》的信息系统管理人员十分重视数据的保护,在没有备份软件的情况下,已经采用了重要数据镜像备份、服务器系统镜像备份等常规保护方法,为企业的数据财产提供了安全的保障。但是以上方法很难实现快速备份和灾难后的迅速恢复,很难保证业务的连续性。 根据上面的备份管理系统的风险评估,建议《》使用ESioo安全备份专家软件,配合Windows自带备份和双机虚拟备份,并重新设计相关备份的恢复策略,达到可以快速恢复数据备份和快速恢复文档管理系统备份的水平,从而提高整个企业的数据安全级别。
ORACLE数据备份与数据恢复方案
O R A C L E数据备份与数据恢 复方案 Prepared on 24 November 2020
摘要 结合金华电信IT系统目前正在实施的备份与恢复策略,重点介绍电信业务计算机管理系统(简称97系统)和营销支撑系统的ORALCE数据库备份和恢复方案。 Oracle数据库有三种标准的备份方法,它们分别是导出/导入 (EXP/IMP)、热备份和冷备份。要实现简单导出数据(Export)和导入数据(Import),增量导出/导入的按设定日期自动备份,可考虑,将该部分功能开发成可执行程序,然后结合操作系统整合的任务计划,实现特定时间符合备份规划的备份应用程序的运行,实现数据库的本级备份,结合ftp简单开发,实现多服务器的数据更新同步,实现数据备份的异地自动备份。 关键字:数据库远程异地集中备份 目录
一、前言 目前,数据已成为信息系统的基础核心和重要资源,同时也是各单位的宝贵财富,数据的丢失将导致直接经济损失和用户数据的丢失,严重影响对社会提供正常的服务。另一方面,随着信息技术的迅猛发展和广泛应用,业务数据还将会随业务的开展而快速增加。但由于系统故障,数据库有时可能遭到破坏,这时如何尽快恢复数据就成为当务之急。如做了备份,恢复数据就显得很容易。由此可见,做好数据库的备份至关重要。因此,建立一个满足当前和将来的数据备份需求的备份系统是必不可少的。传统的数据备份方式主要采用主机内置或外置的磁带机对数据进行冷备份,这种方式在数据量不大、操作系统种类单一、服务器数量有限的情况下,不失为一种既经济又简明的备份手段。但随着计算机规模的扩大,数据量几何级的增长以及分布式网络环境的兴起,将越来越多的业务分布在不同的机器、不同的操作平台上,这种单机的人工冷备份方式越来越不适应当今分布式网络环境。 因此迫切需要建立一个集中的、自动在线的企业级备份系统。备份的内容应当包括基于业务的业务数据,又包括IT系统中重要的日志文件、参数文件、配置文件、控制文件等。本文以ORACLE数据库为例,结合金华电信的几个相关业务系统目前正在实施的备份方案,介绍ORACLE数据库的备份与恢复。 二、金华电信ORACLE数据库的备份与恢复方案 由于金华电信IT系统以前只采用逻辑备份方式进行数据库备份,速度较慢并且数据存储管理都很分散,甚至出现备份数据不完整的现象。为了提高备份数据的效率,提供可靠的数据备份,完善备份系统,保证备份数据的完整性,降低数据备份对网络和服务器的影响,对每个IT系统的备份数据进行集中管理,我们对备份工作进行了改进,将逻辑备份与物理备份相结合,在远程建立了一个异地集中、自动在线的备份系统即网络存储管理系统。(这里用到的物理备份指热备份)其具备的主要功能如下:(1)集中式管理 :网络存储备份管理系统对整个网络的数据进行管理。利用集中式管理工具的帮助,系统管理员可对全网的备份策略进行统一管理,备份服务器可以监控所有机器的备份作业,也可以修改备份策略,并可即时浏览所有目录。所有数据可以备份到同备份服
数据库备份策略说明
数据库备份策略说明 1、备份目的 保障项目数据安全,防止服务器故障导致数据无法恢复的情况。 2、备份策略 综述:所有mysql实例已经实现了master、slave结构,我们备份一般在slave服务器进行。部分备份完成之后,会上传一份数据到存储机或者其他服务器进行异机及异地备份,另外备份保存一份。 一、备份方式 1、本机备份 该备份模式,适合于快速恢复数据。比如:误操作删除数据等 2、异机容灾备份 该备份模式,能比较好的规避单机故障问题。 3、异地容灾备份 该备份模式,规避大规模IDC故障(比如:火灾、地震、空调故障等)、数据安全问题 二、备份频率 1、主站www、bbs、blog等核心项目,进行每天完整备份。结合各项目数据库实例master 与slave结构,以及当前slave服务器负载和带宽情况,采用crontab定时备份。 2、对于跟商业有关的项目,备份策略同核心项目。 3、非核心项目90%备份策略采用核心项目备份机制,其他采用每周备份策略。 4、对于近期大规模更新数据或者数据库结构变更的数据库实例,采用人员干预备份模式,即走备份申请流程。 三、备份准备 1、创建备份目录 /opt/phpdba/backup/database 2、脚本编写 详见第四项,备份脚本 3、加入计划任务crontab 4、检查备份情况 5、添加每天检查列表 四、备份脚本
#!/bin/sh LogFile=db$(date +%y%m%d).log week=`date +%w` cd /opt/phpdba/backup/database for DBName in database do NewFile=db$DBName$(date +%y%m%d).tar.gz OldLogFile=db$(date -d '7 days ago' +%y%m%d).log if [ -f $OldLogFile ] then rm -f $OldLogFile >> $LogFile 2>&1 echo "[$OldLogFile]Delete Old log File Success!" >> $LogFile else echo "[$OldLogFile]No Old log File!" >> $LogFile fi case $week in 1) date=`date -d '56 days ago' +%y%m%d` OldFile=db$DBName$date.tar.gz if [ -f $OldFile ] then rm -f $OldFile >> $LogFile 2>&1 echo "[$OldFile]Delete Old File Success!" >> $LogFile else echo "[$OldFile]No Old Backup File!" >> $LogFile fi ;; 2|3|4|5|6|0) date=`date -d '7 days ago' +%y%m%d` OldFile=db$DBName$date.tar.gz if [ -f $OldFile ] then rm -f $OldFile >> $LogFile 2>&1 echo "[$OldFile]Delete Old File Success!" >> $LogFile else echo "[$OldFile]No Old Backup File!" >> $LogFile fi ;; esac if [ -f $NewFile ] then echo "[$NewFile]The Backup File is exists,Can't Backup!" >> $LogFile else
数据库备份与恢复
Oracle数据库备份与恢复的三种方法 2009-11-04 16:00 Oracle数据库有三种标准的备份方法,它们分别是导出/导入(EXP/IMP)、热备份和冷备份。导出备件是一种逻辑备份,冷备份和热备份是物理备份。 一、导出/导入(Export/Import) 利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中去。 1、简单导出数据(Export)和导入数据(Import) Oracle支持三种方式类型的输出: (1)、表方式(T方式),将指定表的数据导出。 (2)、用户方式(U方式),将指定用户的所有对象及数据导出。 (3)、全库方式(Full方式),瘵数据库中的所有对象导出。 数据导入(Import)的过程是数据导出(Export)的逆过程,分别将数据文件导入数据库和将数据库数据导出到数据文件。 2、增量导出/导入 增量导出是一种常用的数据备份方法,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。在进行此种导出时,系统不要求回答任何问题。导出文件名缺省为export.dmp,如果不希望自己的输出文件定名为export.dmp,必须在命令行中指出要用的文件名。 增量导出包括三种类型: (1)、“完全”增量导出(Complete) 即备份三个数据库,比如: (2)、“增量型”增量导出 备份上一次备份后改变的数据,比如:
(3)、“累积型”增量导出 累计型导出方式是导出自上次“完全”导出之后数据库中变化了的信息。比如: 数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效的完成。 比如数据库的被封任务可以做如下安排: 星期一:完全备份(A) 星期二:增量导出(B) 星期三:增量导出(C) 星期四:增量导出(D) 星期五:累计导出(E) 星期六:增量导出(F) 星期日:增量导出(G) 如果在星期日,数据库遭到意外破坏,数据库管理员可按一下步骤来回复数据库: 第一步:用命令CREATE DATABASE重新生成数据库结构; 第二步:创建一个足够大的附加回滚。 第三步:完全增量导入A: 第四步:累计增量导入E: 第五步:最近增量导入F:
算法分析实验报告--分治策略
《算法设计与分析》实验报告 分治策略 姓名:XXX 专业班级:XXX 学号:XXX 指导教师:XXX 完成日期:XXX
一、试验名称:分治策略 (1)写出源程序,并编译运行 (2)详细记录程序调试及运行结果 二、实验目的 (1)了解分治策略算法思想 (2)掌握快速排序、归并排序算法 (3)了解其他分治问题典型算法 三、实验内容 (1)编写一个简单的程序,实现归并排序。 (2)编写一段程序,实现快速排序。 (3)编写程序实现循环赛日程表。设有n=2k个运动员要进行网球循环赛。现 要设计一个满足以下要求的比赛日程表:(1)每个选手必须与其它n-1个选手各赛一次(2)每个选手一天只能赛一场(3)循环赛进行n-1天 四、算法思想分析 (1)编写一个简单的程序,实现归并排序。 将待排序元素分成大小大致相同的2个子集合,分别对2个子集合进行 排序,最终将排好序的子集合合并成为所要求的排好序的集合。 (2)编写一段程序,实现快速排序。 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有 数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数
据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
(3)编写程序实现循环日赛表。 按分治策略,将所有的选手分为两组,n个选手的比赛日程表就可以通 过为n/2个选手设计的比赛日程表来决定。递归地用对选手进行分割, 直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让 这2个选手进行比赛就可以了。 五、算法源代码及用户程序 (1)编写一个简单的程序,实现归并排序。 #include
回归分析及独立性检验的基本知识点及习题集锦
回归分析的基本知识点及习题 本周题目:回归分析的基本思想及其初步应用 本周重点: (1)通过对实际问题的分析,了解回归分析的必要性与回归分析的一般步骤;了解线性回归模型与函数模型的区别; (2)尝试做散点图,求回归直线方程; (3)能用所学的知识对实际问题进行回归分析,体会回归分析的实际价值与基本思想;了解判断刻画回归模型拟合好坏的方法――相关指数和残差分析。 本周难点: (1)求回归直线方程,会用所学的知识对实际问题进行回归分析. (2)掌握回归分析的实际价值与基本思想. (3)能运用自己所学的知识对具体案例进行检验与说明. (4)残差变量的解释; (5)偏差平方和分解的思想; 本周内容: 一、基础知识梳理 1.回归直线: 如果散点图中点的分布从整体上看大致在一条直线附近,我们就称这两个变量之间具有线性相关关系,这条直线叫作回归直线。 求回归直线方程的一般步骤: ①作出散点图(由样本点是否呈条状分布来判断两个量是否具有线性相关关系),若存在线性相关关系→②求回归系数→ ③写出回归直线方程,并利用回归直线方程进行预测说明. 2.回归分析: 对具有相关关系的两个变量进行统计分析的一种常用方法。 建立回归模型的基本步骤是: ①确定研究对象,明确哪个变量是解释变量,哪个变量是预报变量; ②画好确定好的解释变量和预报变量的散点图,观察它们之间的关系(线性关系). ③由经验确定回归方程的类型. ④按一定规则估计回归方程中的参数(最小二乘法); ⑤得出结论后在分析残差图是否异常,若存在异常,则检验数据是否有误,后模型是否合适等. 3.利用统计方法解决实际问题的基本步骤: (1)提出问题; (2)收集数据; (3)分析整理数据; (4)进行预测或决策。 4.残差变量的主要来源: (1)用线性回归模型近似真实模型(真实模型是客观存在的,通常我们并不知道真实模型到底是什么)所引起的误差。 可能存在非线性的函数能够更好地描述与之间的关系,但是现在却用线性函数来表述这种关系,结果就会产生误差。这 种由于模型近似所引起的误差包含在中。 (2)忽略了某些因素的影响。影响变量的因素不只变量一个,可能还包含其他许多因素(例如在描述身高和体重 关系的模型中,体重不仅受身高的影响,还会受遗传基因、饮食习惯、生长环境等其他因素的影响),但通常它们每一个因素的影响可能都是比较小的,它们的影响都体现在中。 (3)观测误差。由于测量工具等原因,得到的的观测值一般是有误差的(比如一个人的体重是确定的数,不同的秤可 能会得到不同的观测值,它们与真实值之间存在误差),这样的误差也包含在中。 上面三项误差越小,说明我们的回归模型的拟合效果越好。
数据库备份和还原操作方法
数据库备份和还原 在收费系统运行一段时间后,如发生系统不正常要重装WINDOWS操作系统或更换电脑时,须按照下面“数据库备份”方法将原系统的数据文件备份,并将备份文件妥善保存(避免随系统重装而丢失数据),在重装系统或更换电脑后,按照软件的安装方法顺序安装SQL2000数据库和消费/水控管理软件,然后按照下面“数据还原”方法进行数据库还原,完成后系统中的数据即与原数据完全[相同。 数据库备份: 以ICSF为例,打开ICSF软件,选择菜单栏下的系统维护,然后选择数据备份。(系统维护——数据备份)如图(1-1): 1-1 数据备份完成后,可以在基本资料——系统参数里(1-2),在弹出的对话框上的备份路径二(手动备份)里可以找到数据备份的路径(1-3)。如图:
1-2 1-3 提示: 1、上述方法为手动备份,本系统在使用后正常腿出系统时也会自动进行 数据备份,如已经无法正常开启原电脑(无法进行手动备份)则可将 原电脑硬盘连接到其他电脑中,找到“备份路径一”所指向的路径, 找到备份文件夹,将其中修改日期最近的备份文件拷贝出来用于数据 还原。 2、在安装收费/水控系统时建议不要将安装目录选在C盘,避免因格式 化的操作是备份数据丢失,如果已经将软件安装在C盘,则建议将备 份文件路径指定为其他盘。 数据还原 数据还原,首先要找到备份的数据文件。如上所述,备份文件存放在E:\软件\ICSF5.74\Mdbbak上,根据路径找到Mdbbak文件夹并打开。 打开Mdbbak文件夹后,里面有类似这样的(1-4)BAK文件。 找寻最新的BAK文件,并把它与软件安装包(光盘)中IC挂接数据库.exe软件拷贝到电脑任意一个目录(文件夹)中,然后将备份文件重命名(光标放在备份文件 上点鼠标右键,选择重命名),改为ICSF.db。如图:(1-5)
分治算法实验(用分治法实现快速排序算法)
算法分析与设计实验报告第四次附加实验
while (a[--j]>x); if (i>=j) { break; } Swap(a[i],a[j]); } a[p] = a[j]; //将基准元素放在合适的位置 a[j] = x; return j; } //通过RandomizedPartition函数来产生随机的划分 template vclass Type> int RandomizedPartition(Type a[], int p, int r) { int i = Random(p,r); Swap(a[i],a[p]); return Partition(a,p,r); } 较小个数排序序列的结果: 测试结果 较大个数排序序列的结果:
实验心得 快速排序在之前的数据结构中也是学过的,在几大排序算法中,快速排序和归并排序尤其是 重中之重,之前的快速排序都是给定确定的轴值,所以存在一些极端的情况使得时间复杂度 很高,排序的效果并不是很好,现在学习的一种利用随机化的快速排序算法,通过随机的确 定轴值,从而可以期望划分是较对称 的,减少了出现极端情况的次数,使得排序的效率挺高了很多, 化算法想呼应,而且关键的是对于随机生成函数,通过这一次的 学习终于弄明白是怎么回事了,不错。 与后面的随机实 验和自己的 实验得分助教签名 附录: 完整代码(分治法) //随机后标记元素后的快速排序 #i nclude
分治法
分治法 【摘要】:分治法可以通俗的解释为:把一片领土分解,分解为若干块小部分,然后一块块地占领征服,被分解的可以是不同的政治派别或是其他什么,然后让他们彼此异化。本文主要叙述了分治法的设计思想及与之有关的递归思想,了解使用分治法解决问题的过程。 【关键词】:分治法分解算法递归二分搜索 Partition Method (Junna Wei) 【abstract 】: the partition method can explain to popular: decomposition, put a slice of territory is decomposed into several pieces of small, then pieces of land occupation of conquest, the decomposition can be different political factions or something, then let them each other alienation. This paper mainly describes the design idea of the partition method and recursive thinking, related to understand the process of solving the problem using the partition method. 【key words 】: partition method decomposition algorithm recursive Binary search 1.引论
总结:线性回归分析的基本步骤
总结:线性回归分析的基本 步骤 -标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
线性回归分析的基本步骤 步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下: 作出其散点图如下:
②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。
数据库备份策略说明讲课稿
数据库备份策略说明
数据库备份策略说明 1、备份目的 保障项目数据安全,防止服务器故障导致数据无法恢复的情况。 2、备份策略 综述:所有mysql实例已经实现了master、slave结构,我们备份一般在slave服务器进行。部分备份完成之后,会上传一份数据到存储机或者其他服务器进行异机及异地备份,另外备份保存一份。 一、备份方式 1、本机备份 该备份模式,适合于快速恢复数据。比如:误操作删除数据等 2、异机容灾备份 该备份模式,能比较好的规避单机故障问题。 3、异地容灾备份 该备份模式,规避大规模IDC故障(比如:火灾、地震、空调故障等)、数据安全问题 二、备份频率
1、主站www、bbs、blog等核心项目,进行每天完整备份。结合各项目数据库实例master与slave结构,以及当前slave服务器负载和带宽情况,采用crontab 定时备份。 2、对于跟商业有关的项目,备份策略同核心项目。 3、非核心项目90%备份策略采用核心项目备份机制,其他采用每周备份策略。 4、对于近期大规模更新数据或者数据库结构变更的数据库实例,采用人员干预备份模式,即走备份申请流程。 三、备份准备 1、创建备份目录 /opt/phpdba/backup/database 2、脚本编写 详见第四项,备份脚本 3、加入计划任务 crontab 4、检查备份情况 5、添加每天检查列表 四、备份脚本 #!/bin/sh LogFile=db$(date +%y%m%d).log week=`date +%w` cd /opt/phpdba/backup/database for DBName in database do NewFile=db$DBName$(date +%y%m%d).tar.gz OldLogFile=db$(date -d '7 days ago' +%y%m%d).log if [ -f $OldLogFile ] then rm -f $OldLogFile >> $LogFile 2>&1 echo "[$OldLogFile]Delete Old log File Success!" >> $LogFile
Oracle数据库备份方式
Oracle数据库备份方式 Oracle的内核提供数据库的备份和恢复机制,SQL*DBA按表空间进行数据的备份和恢复。Oracle提供两种方式:备份恢复和向前滚动,保证意外故障恢复数据库的一致性和完整性。 ____1. 备份恢复方式 ____对数据库的某个一致状态建立副本,并储存在介质上脱机保存,以此作为数据库恢复的基础。现以Oracle实用程序Export/Import来介绍备份恢复方式。 ____Export/Import是Oracle提供的两个互补性程序,即卸载和装载。它们既完成数据库与操作系统文件的互为转载,同时可以有效地回收数据库的碎片,提供不同版本间Oracle 数据传送的手段,进行不同用户间的数据传送。 ____Export数据卸载,将数据从Oracle写到指定的操作系统文件进行备份。卸载的对象、内容与数量有三种模式:TABLE MODE(表模式)、USER MODE(用户模式)、FULL DATABASEM ODE(所有数据库模式)。使用方式既可用交互方式,也可采用命令行方式,以"关键字=值" 将所需信息在命令行中逐一描述来进行卸载。Export要求用户具有CONNECT或DBA特权。 ____Import与Export互逆,将操作系统文件重新装载至Oracle数据库中,使用方式如Expo rt。使用者要求具有CONNECT和RESOURCE特权,且可选择部分或全部装入。 ____Export/Import非常方便,系统开销小,它的限制是输出的操作系统文件采用专门的压缩方式存放,仅提供给Import使用。 ____也可采用SQL*PLUS和SQL*LOADER实用工具进行备份。使用SQL*PLUS的SPOOL 命令通过脱机定向输出,使用PLUS格式化结果,形成指定格式的ASCII文件,需要时可用SQL*LOADER 进行加载。它的方便之处是ASCII文件可以编辑,可方便地加载至其他数据库(如FoxPro、Sybase中)。 ____2. 向前滚动方式 ____Oracle提供向前滚动方式,使建立备份后成功的事务不会丢失。恢复的基础是数据库的某个一致性状态(即方式1完成的备份恢复),恢复的依据是存档的重作记录文件。启动重作记录文件方法如下: ____(1) 启动Oracle; ____(2) 连接Oracle:CONNECT SYSTEM/PASSWORD; ____(3) 启动ARCHIVE LOG。 ____出现介质故障时,可用SQL*DBA的RECOVER命令,利用存档的重作记录文件恢复一个或多个表空间。RECOVER命令对DATABASE或TABLASPACE进行恢复。前者要求SQL*DBA START UP已被排斥方式装载且未被打开;后者对无活跃回退段的表空间执行脱机,要求数据库已装载且被打
算法分析实验报告--分治策略
分治策略 姓名:XXX 专业班级:XXX 学号:XXX 指导教师:XXX 完成日期:XXX
一、试验名称:分治策略 (1)写出源程序,并编译运行 (2)详细记录程序调试及运行结果 二、实验目的 (1)了解分治策略算法思想 (2)掌握快速排序、归并排序算法 (3)了解其他分治问题典型算法 三、实验内容 (1)编写一个简单的程序,实现归并排序。 (2)编写一段程序,实现快速排序。 (3)编写程序实现循环赛日程表。设有n=2k个运动员要进行网球循环赛。现 要设计一个满足以下要求的比赛日程表:(1)每个选手必须与其它n-1个选手各赛一次(2)每个选手一天只能赛一场(3)循环赛进行n-1天 四、算法思想分析 (1)编写一个简单的程序,实现归并排序。 将待排序元素分成大小大致相同的2个子集合,分别对2个子集合进行 排序,最终将排好序的子集合合并成为所要求的排好序的集合。 (2)编写一段程序,实现快速排序。 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有 数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数 据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据 变成有序序列。 (3)编写程序实现循环日赛表。 按分治策略,将所有的选手分为两组,n个选手的比赛日程表就可以通 过为n/2个选手设计的比赛日程表来决定。递归地用对选手进行分割, 直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让
这2个选手进行比赛就可以了。 五、算法源代码及用户程序 (1)编写一个简单的程序,实现归并排序。 #include
数据库备份方案
《客户名称》备份管理系统设计方案上海鸿翼数字计算机网络有限公司
目录 1.项目概述 (3) 2.系统需求分析 (3) 1.1系统现状分析 (3) 1.2备份系统风险评估 (3) 1.3备份系统需求分析 (4) 3.系统备份理念 (5) 3.1系统设计指引 (5) 3.2数据保护技术选择 (5) 3.3连续数据保护 (6) 3.4备份管理系统组成 (6) 4.系统备份结构设计 (8) 4.1整体系统架构设计 (9) 5.系统备份方案介绍 (10) 5.1W INDOWS服务器自身备份 (10) 5.2方案2:双机热备 (12) 5.3方案3:爱数备份 (13)
1.项目概述 上海鸿翼数字计算机网络有限公司将根据《》的网络实际需求,制定一套完整的集数据备份、灾难恢复、服务器整合及虚拟化一身的方案。一个完整的企业数据备份与恢复解决方案就意味着数据安全与性能(机器和网络)的完美结合,一条龙式的服务标准(产品的服务与支持)。所以在选择备份系统时,既要做到满足系统容量不断增加的需求,又要所用的备份方式能够支持多系统平台操作。要达到这些,就要充分使用网络数据存储系统,在分布式网络环境下,通过专业的数据存储软件,配合系统备份及双机备份,结合相应的硬件和存储设备,对网络的数据备份进行集中管理,从而实现自动化备份、文件归档、数据分级存储和灾难恢复。 2.系统需求分析 1.1系统现状分析 《》网络基础结构是基于Windows平台,现在拥有X台服务器。《》的文档管理系统包含了文件服务器、转档服务器、数据库服务器等企业信息管理系统,为企业的发展提供了强有力的信息化支持。主要数据库包含了Microsoft SQL Server、Oracle、DB2等。 1.2备份系统风险评估 《》的信息系统管理人员十分重视数据的保护,在没有备份软件的情况下,已经采用了重要数据镜像备份、服务器系统镜像备份等常规保护方法,为企业的数据财产提供了安全的保障。但是以上方法很难实现快速备份和灾难后的迅速恢复,很难保证业务的连续性。
线性回归分析报告地基本步骤
步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周 作出其散点图如下:
②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例
实用标准文案 由于()01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。 如将()()222777100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据:
那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。 ④样本回归方程(线):通过样本数据估计出?β ,得到样本观测值的拟合值与解释变量之间的关系方程??Y X β=称为样本回归方程。如下图所示: ⑤四者之间的关系: ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖关系。这种近似表现在两个方面:一是结构参数?β 是其真实值β的一种近似估计;二是残差e 是随机误差项U 的一个近似估计; ⅱ:总体回归方程是根据总体数据得到的,它描述的是因变量的条件均值
oracle数据库备份与恢复实施方案
oracle数据库备份与恢复方案
————————————————————————————————作者:————————————————————————————————日期:
oracle数据库 备份与恢复方案 文件控制?受控?不受控 文档编号日期项目名称版本号 分册名称第册/共册总页数正文附录 编制审批生效日期
目录 一、编写目的 (1) 二、备份工具及备份方式 (1) 三、软件备份 (1) 四、软件恢复 (1) 五、数据备份 (2) 六、备份的存储 (2) 七、备份数据的保存规定 (2) 八、备份介质的格式 (3) 九、数据恢复 (4)
一、编写目的 本文档主要说明公司项目在实施现场的软件及数据的备份和恢复方案。 二、备份工具及备份方式 1.备份工具 Oracle RMAN(Recovery Manager):是一种用于备份(backup)、还原(restore)和恢复(recover)数据库的Oracle 工具。RMAN只能用于ORACLE8或更高的版本中。它能够备份整个数据库或数据库部件,如表空间、数据文件、控制文件、归档文件以及Spfile参数文件。RMAN也允许您进行增量数据块级别的备份,增量RMAN备份是时间和空间有效的,因为他们只备份自上次备份以来有变化的那些数据块。 2.备份方式 (1)自动备份:由Windows 计划任务调度完成; (2)手工备份:完成特殊情况下的备份,分热备份和冷备份,热备份是指在不关闭数据库情况下进行备份,冷备份则需要停止Oracle实例服务。 三、软件备份 1.以七天为一个周期每天23:00将所有软件拷贝到其他存储介质上 2.超出七天的备份依次删除 3.每月一号将上月最后7天的备份文件刻录到光盘上 四、软件恢复 1.找出最近的备份程序覆盖到正式运行环境的相应目录中
系统历史数据迁移方案
新老系统迁移及整合方案 本次总局综合业务系统是在原有系统的基础上开发完成,因此,新旧系统间就存在着切换的问题。另外,新开发的系统还存在与其他一些应用系统,例如,企业信用联网应用系统、企业登记子网站、外资登记子网站等系统进行整合使之成为一个相互连通的系统。本章将针对新老系统迁移和整合提出解决方案。 新老系统迁移及整合需求分析 系统迁移又称为系统切换,即新系统开发完成后将老系统切换到新系统上来。 系统切换得主要任务包括:数据资源整合、新旧系统迁移、新系统运行监控过程。数据资源整合包含两个步骤:数据整理与数据转换。数据整理就是将原系统数据整理为系统转换程序能够识别的数据;数据转换就是将整理完成后的数据按照一定的转换规则转换成新系统要求的数据格式,数据的整合是整合系统切换的关键;新旧系统迁移就是在数据正确转换的基础上,制定一个切实可行的计划,保证业务办理顺利、平稳过渡到新系统中进行;新系统运行监控就是在新系统正常运转后,还需要监控整个新系统运行的有效性和正确性,以便及时对数据转换过程中出现的问题进行纠正。 系统整合是针对新开发的系统与保留的老系统之间的整合,以保证新开发的系统能与保留的老系统互动,保证业务的顺利开展。主要的任务是接口的开发。 需要进行迁移的系统 需要进行整合的系统 需要与保留系统整合的系统包括: 1、企业登记管理(含信用分类),全国企业信用联网统计分析,不冠行政区划企业名称核准,大屏幕触摸屏系统与企业信用联网应用,企业登记子网站,属
地监管传输,网上业务受理之间的整合; 2、外资企业登记管理(含信用分类),全国外资企业监测分析与属地监管传输,外资登记子网站,网上业务受理,大屏幕触摸屏系统之间的整合; 3、广告监管系统与广告监管子网站之间的整合; 4、12315数据统计分析与12315子网站之间的整合; 5、通用信息查询、统计系统与数据采集转换之间的整合; 数据迁移和转换分析 根据招标文件工商总局新建系统的数据库基于IBM DB2,而原有系统的数据库包括ORACLE,SQL Server,DB2。这种异构数据在总局主要存在于两个方面,即部门内部的异构数据和上下级部门之间的异构数据。同时,系统的技术构件有.NET和J2EE两大类。 对于部门内部的异构数据的集成采用数据移植的方法,如:如果数据有基于DB2管理的,有ORACLE管理的,有SQL Server管理的,就根据新系统DB2的要求,把ORACLE的数据迁移到DB2数据库中,把SQL Server的数据迁移到DB2数据库中。 上下级国工商局之间的异构数据的集成利用数据交换系统来完成,重点在于数据库存储标准、交换标准的制定和遵守,保证数据的共享,这部分工作由数据中心完成。 系统迁移和整合目标 一、系统切换的主要目标: ●保证系统正常运行 在数据转换过程中,由于原有的系统数据的复杂性,给数据转换工作带来了很大的难度,为了在新系统启动后不影响原系统正常的业务,因此数据转换完成后,必须保证新系统的正常运行。 ●保证原有系统在新系统中的独立性 原有系统是独立运行的系统,数据在新系统中虽然是集中存放的,但是各个系统由于存在业务上的差别,数据在逻辑上应当保持一定的独立性。
oracle数据库备份与恢复的三种方法(1)
Oracle数据库有三种标准的备份方法,它们分别是导出/导入(EXP/IMP)、热备份和冷备份。导出备件是一种逻辑备份,冷备份和热备份是物理备份。 一、导出/导入(Export/Import) 利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中去。 1、简单导出数据(Export)和导入数据(Import) Oracle支持三种方式类型的输出: (1)、表方式(T方式),将指定表的数据导出。 (2)、用户方式(U方式),将指定用户的所有对象及数据导出。 (3)、全库方式(Full方式),瘵数据库中的所有对象导出。 数据导入(Import)的过程是数据导出(Export)的逆过程,分别将数据文件导入数据库和将数据库数据导出到数据文件。 2、增量导出/导入 增量导出是一种常用的数据备份方法,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。在进行此种导出时,系统不要求回答任何问题。导出文件名缺省为export.dmp,如果不希望自己的输出文件定名为export.dmp,必须在命令行中指出要用的文件名。 增量导出包括三种类型: (1)、“完全”增量导出(Complete) 即备份三个数据库,比如: (2)、“增量型”增量导出 备份上一次备份后改变的数据,比如: (3)、“累积型”增量导出 累计型导出方式是导出自上次“完全”导出之后数据库中变化了的信息。比如: 数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效的完成。 比如数据库的被封任务可以做如下安排: 星期一:完全备份(A)
星期二:增量导出(B) 星期三:增量导出(C) 星期四:增量导出(D) 星期五:累计导出(E) 星期六:增量导出(F) 星期日:增量导出(G) 如果在星期日,数据库遭到意外破坏,数据库管理员可按一下步骤来回复数据库: 第一步:用命令CREATE DATABASE重新生成数据库结构; 第二步:创建一个足够大的附加回滚。 第三步:完全增量导入A: 第四步:累计增量导入E: 第五步:最近增量导入F: 二、冷备份 冷备份发生在数据库已经正常关闭的情况下,当正常关闭时会提供给我们一个完整的数据库。冷备份时将关键性文件拷贝到另外的位置的一种说法。对于备份Oracle信息而言,冷备份时最快和最安全的方法。冷备份的优点是: 1、是非常快速的备份方法(只需拷文件) 2、容易归档(简单拷贝即可) 3、容易恢复到某个时间点上(只需将文件再拷贝回去) 4、能与归档方法相结合,做数据库“最佳状态”的恢复。 5、低度维护,高度安全。 但冷备份也有如下不足: 1、单独使用时,只能提供到“某一时间点上”的恢复。 2、再实施备份的全过程中,数据库必须要作备份而不能作其他工作。也就是说,在冷备份过程中,数据库必须是关闭状态。