图像放大算法
一、图像放大算法
图像放大有许多算法,其关键在于对未知像素使用何种插值方式。以下我们将具体分析几种常见的算法,然后从放大后的图像是否存在色彩失真,图像的细节是否得到较好的保存,放大过程所需时间是否分配合理等多方面来比较它们的优劣。
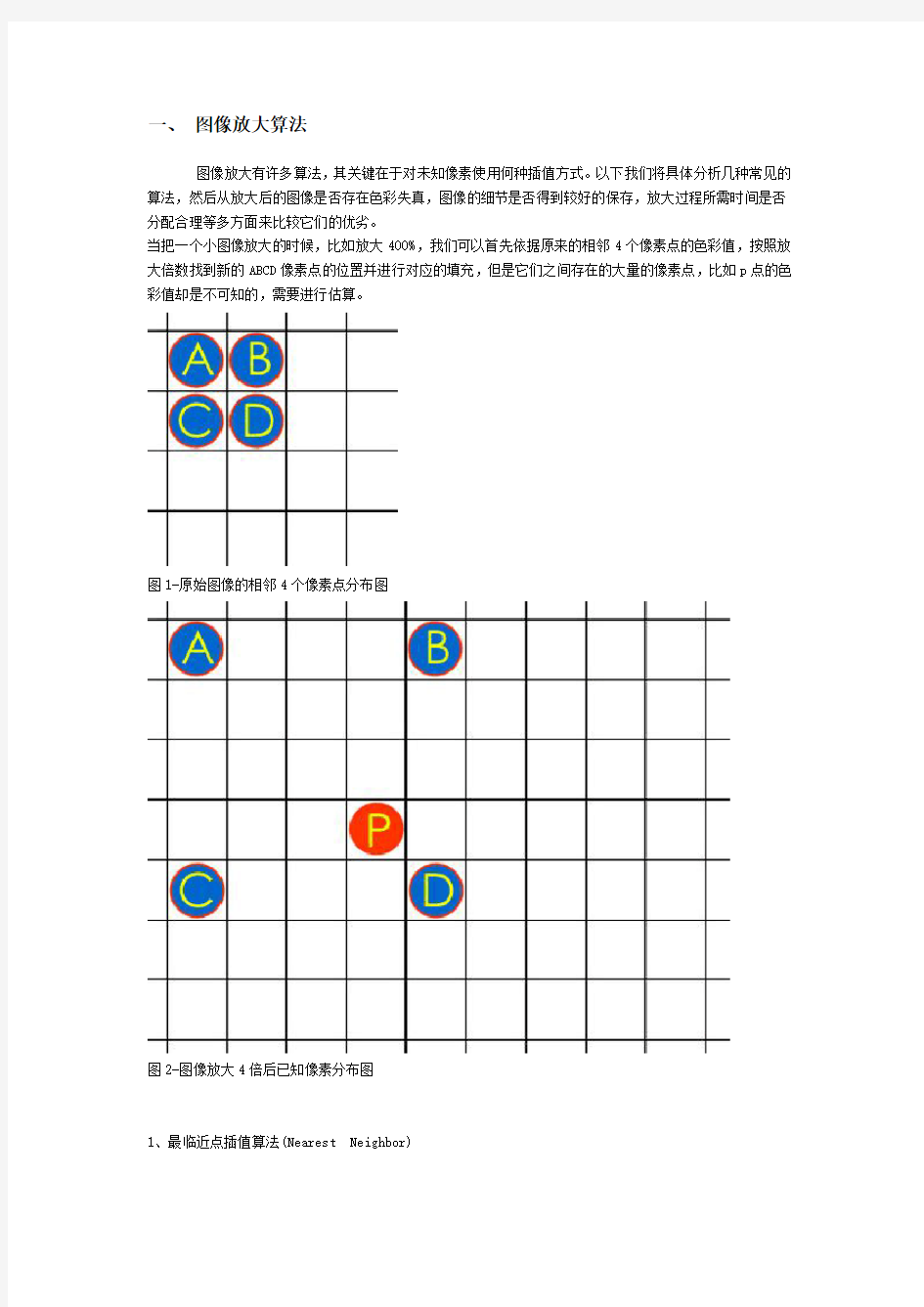
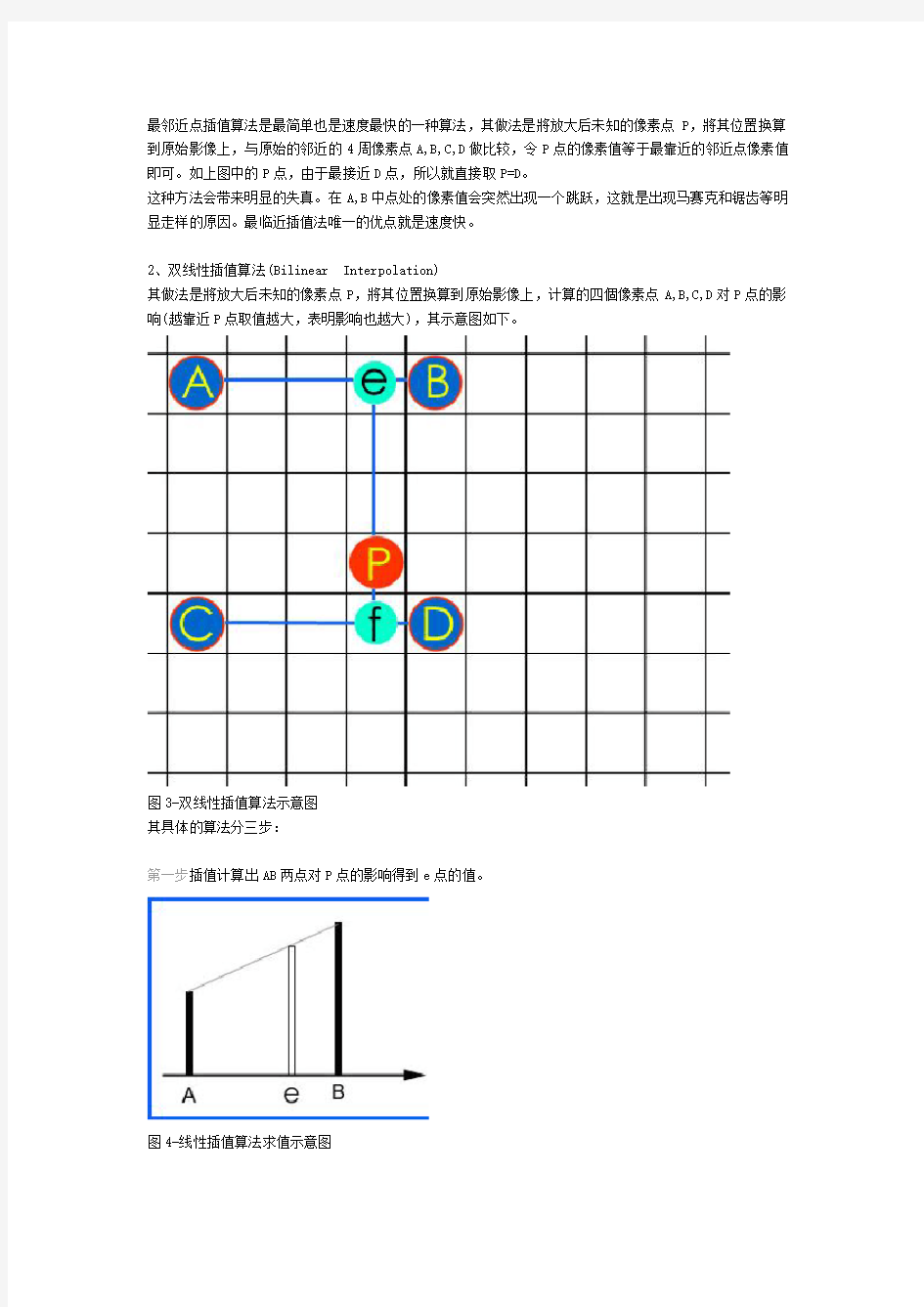
当把一个小图像放大的时候,比如放大400%,我们可以首先依据原来的相邻4个像素点的色彩值,按照放大倍数找到新的ABCD像素点的位置并进行对应的填充,但是它们之间存在的大量的像素点,比如p点的色彩值却是不可知的,需要进行估算。
图1-原始图像的相邻4个像素点分布图
图2-图像放大4倍后已知像素分布图
1、最临近点插值算法(Nearest Neighbor)
最邻近点插值算法是最简单也是速度最快的一种算法,其做法是將放大后未知的像素点P,將其位置换算到原始影像上,与原始的邻近的4周像素点A,B,C,D做比较,令P点的像素值等于最靠近的邻近点像素值即可。如上图中的P点,由于最接近D点,所以就直接取P=D。
这种方法会带来明显的失真。在A,B中点处的像素值会突然出现一个跳跃,这就是出现马赛克和锯齿等明显走样的原因。最临近插值法唯一的优点就是速度快。
2、双线性插值算法(Bilinear Interpolation)
其做法是將放大后未知的像素点P,將其位置换算到原始影像上,计算的四個像素点A,B,C,D对P点的影响(越靠近P点取值越大,表明影响也越大),其示意图如下。
图3-双线性插值算法示意图
其具体的算法分三步:
第一步插值计算出AB两点对P点的影响得到e点的值。
图4-线性插值算法求值示意图
对线性插值的理解是这样的,对于AB两像素点之间的其它像素点的色彩值,认定为直线变化的,要求e点处的值,只需要找到对应位置直线上的点即可。换句话说,A,B间任意一点的值只跟A,B有关。
第二步,插值计算出CD两点对P点的影响得到f点的值。
第三步,插值计算出ef两点对P点的影响值。
双线性插值算法由于插值的结果是连续的,所以视觉上会比最邻近点插值算法要好一些,不过运算速度稍微要慢一点,如果讲究速度,是一个不错的折衷。
3、双立方插值算法(Bicubic Interpolation)
双立方插值算法与双线性插值算法类似,对于放大后未知的像素点P,将对其影响的范围扩大到邻近的16个像素点,依据对P点的远近影响进行插值计算,因P点的像素值信息来自16个邻近点,所以可得到较细致的影像,不过速度比较慢。
图5-双线性插值算法4个邻近点影响未知点信息示意图
图6-双立方插值算法16个邻近点影响未知点信息示意图
不过双立方插值算法与双线性插值算法的本质区别不仅在于扩大了影响点的范围,还采用高级的插值算法,如图所示。
图7-非线性插值算法求值示意图
要求A,B两点之间e点的值,需要利用A,B周围A-1,A,B,B+1四个点的像素值,通过某种非线性的计算,得到光滑的曲线,从而算出e点的值来。
所谓“双”或者叫“二次”的意思就是在计算了横向插值影响的基础上,把上述运算拓展到二维空间,再计算纵向插值影响的意思。
双立方插值算法能够得到相对清晰的画面质量,不过计算量也变大。该算法在现在的众多图像处理软件中最为常用,比如Photoshop,After Effects,Avid,Final Cut Pro等。
为了得到更好的图像质量,在以上的基础上,许多新的算法不断涌现,它们使用了更加复杂的改进的插值方式。譬如B样条(B-SPline), 米切尔(Mitchell)等插值算法,它们的目的是使插值的曲线显得更平
滑,图像边缘的表现更加完美。
4、自适应样条插值极其增强技术( S-Spline & S-Spline XL)
与上述经典的插值方法最大的区别在于, S-Spline 采用了一种自适应技术,那些传统的方法总是依据周围的像素点来求未知点的色彩值,也就是说需要求解的色彩值仅仅依靠该像素点在图像中的位置,而非实际的图像的像素信息,而自适应样条算法还会考虑实际图像的像素信息。实验表明,经过 S-Spline 算法得到的图像效果要优于双立方插值算法。
现在 S-Spline 算法又出现了增强版 S-Spline XL,新版本的 S-Spline XL 算法较 S-Spline 而言画面的锐度得到进一步增强,物体的轮廓更加清晰,边缘的锯齿现象大大减弱,图像感受更加自然。
二、图像放大算法实际测试
现在我们来对以上几种插值算法进行实际测试,看看它们的效果。首先打开原始的图像bird.jpg.这是一个分辨率为360×270的图像。
图8-原始图像
我们采用 BenVista 公司著名的 PhotoZoom Pro 2 软件,在pc电脑上进行测试,电脑的CPU配置为Inte r Core 2 T5500 1.66GHz,分别采用以上5种插值方法把原始图像放大8倍得到5个2880×2160的图像。
图9-最临近点插值N earrst_ N eighbour
图10-双线性插值B ilinear
图11-双立方插值B icubic
图12-自适应样条插值S-S pline
对比以上各图并结合实验数据,我把效果参数列举如下表。
_ XL)技术来放大图像。
全景拼接算法简介
全景拼接算法简介 罗海风 2014.12.11 目录 1.概述 (1) 2.主要步骤 (2) 2.1. 图像获取 (2) 2.2鱼眼图像矫正 (2) 2.3图片匹配 (2) 2.4 图片拼接 (2) 2.5 图像融合 (2) 2.6全景图像投射 (2) 3.算法技术点介绍 (3) 3.1图像获取 (3) 3.2鱼眼图像矫正 (4) 3.3图片匹配 (4) 3.3.1与特征无关的匹配方式 (4) 3.3.2根据特征进行匹配的方式 (5) 3.4图片拼接 (5) 3.5图像融合 (6) 3.5.1 平均叠加法 (6) 3.5.2 线性法 (7) 3.5.3 加权函数法 (7) 3.5.4 多段融合法(多分辨率样条) (7) 3.6全景图像投射 (7) 3.6.1 柱面全景图 (7) 3.6.2 球面全景图 (7) 3.6.3 多面体全景图 (8) 4.开源图像算法库OPENCV拼接模块 (8) 4.1 STITCHING_DETAIL程序运行流程 (8) 4.2 STITCHING_DETAIL程序接口介绍 (9) 4.3测试效果 (10) 5.小结 (10) 参考资料 (10) 1.概述 全景视图是指在一个固定的观察点,能够提供水平方向上方位角360度,垂直方向上180度的自由浏览(简化的全景只能提供水平方向360度的浏览)。 目前市场中的全景摄像机主要分为两种:鱼眼全景摄像机和多镜头全景摄像机。鱼眼全景摄像机是由单传感器配套特殊的超广角鱼眼镜头,并依赖图像校正技术还原图像的鱼眼全景摄像机。鱼眼全景摄像机
最终生成的全景图像即使经过校正也依然存在一定程度的失真和不自然。多镜头全景摄像机可以避免鱼眼镜头图像失真的缺点,但是或多或少也会存在融合边缘效果不真实、角度有偏差或分割融合后有"附加"感的缺撼。 本文档中根据目前所查找到的资料,对多镜头全景视图拼接算法原理进行简要的介绍。 2.主要步骤 2.1. 图像获取 通过相机取得图像。通常需要根据失真较大的鱼眼镜头和失真较小的窄视角镜头决定算法处理方式。单镜头和多镜头相机在算法处理上也会有一定差别。 2.2鱼眼图像矫正 若相机镜头为鱼眼镜头,则图像需要进行特定的畸变展开处理。 2.3图片匹配 根据素材图片中相互重叠的部分估算图片间匹配关系。主要匹配方式分两种: A.与特征无关的匹配方式。最常见的即为相关性匹配。 B.根据特征进行匹配的方式。最常见的即为根据SIFT,SURF等素材图片中局部特征点,匹配相邻图片中的特征点,估算图像间投影变换矩阵。 2.4 图片拼接 根据步骤2.3所得图片相互关系,将相邻图片拼接至一起。 2.5 图像融合 对拼接得到的全景图进行融合处理。 2.6 全景图像投射 将合成后的全景图投射至球面、柱面或立方体上并建立合适的视点,实现全方位的视图浏览。
BMP位图图片的一种平滑放大技术
黑龙江大学自然科学学报 第15卷第1期1998年3月JO U RNAL OF NAT U RAL SCI EN CE OF HEIL ON GJIAN G U NI VERSIT Y Vol.15No.1 M arch,1998 BMP位图图片的一种平滑放大技术 李宏李春岩1伍一o高耀辉?张承江? (哈尔滨工业大学数学系,哈尔滨150006) 摘要介绍一种将BMP位图图片进行平滑放大的技术,该技术利用埃特金插值算法,使BMP位图图片缩放后的颜色或灰度变化过程较为平缓,同时有效地清除了边界锯齿及交接处模糊不清的现象。 关键词BMP位图图片平滑放大埃特金插值 位图是一种功能很强的图形对象,运用它可以建立和操作图象(指缩放、滚动、旋转和配色),而且可以把图象作为文件存储在磁盘上。我们在软件系统开发过程中。对位图图片的放大技术进行了一些探讨。 在利用Visual Basic进行软件开发时,要想实现图片的放大或缩小,只需将图片放置在图象(Image)控件中,并把图象控件的Stretch属性设置为T rue即可。使用时,只需改变图象的Heig ht和Width值,图片的大小就可得到变化。但是,采用上述方法实现图片放大时,若放大倍数较大,则被放大图象的边缘会出现明显的锯齿现象,原本光滑的边界显得凹凸不平,同时画面显得十分模糊。造成上述现象的原因是用Image的Stretch方法实现图象放大的算法,只是将图片中的各象素点通过简单的重复来实现数目的增加,也就是通过使图象的象素点变粗来实现图象的放大,这势必造成放大后的图象的产生锯齿状和图象模糊不清的现象。为了解决这个问题,我们对BM P位图文件进行了分析,并利用埃特金插值算法。实现了BMP位图图片的平滑放大。 1BMP位图文件结构 在用户眼里,位图是形成视觉图象的象素矩形。然而,对于开发者来说,位图则是指定或包含下列元素的一组结构。一个头结构,它描述了建立该象矩形的设备的分辨率,矩形的尺寸,位阵列的大小等等。一个逻辑色版。一个位索引阵列,它定义位图图象素与逻辑色版人口之间的关系。 位图文件应有BM P三字母的扩充名。下图显示的是它的Windows文件的格式及数据字节。 BITMAPFILEHEADER结构的成员指定了该文件的字节规模;并指定了从页眉第一字节 收稿日期1996-10-15 1黑龙江伊思特信息技术有限公司o黑龙江大学数学系?黑龙江经济管理干部学院?黑龙江大学计算机科学系
线性插值算法实现图像缩放详解
线性插值算法实现图像缩放详解 在Windows中做过图像方面程序的人应该都知道Windows的GDI有?个API函数:StretchBlt,对应在VCL中是 TCanvas类的StretchDraw方法。它可以很简单地实现图像的缩放操作。但问题是它是用了速度最快,最简单但效果也是最差的“最近邻域法”,虽然在大多数情况下,它也够用了,但对于要求较高的情况就不行了。 不久前做了?个小玩意儿,用于管理我用DC拍的?堆照片,其中有?个插件提供了缩放功能,目前的版本就是用了StretchDraw,有时效果不能令人满意,我?直想加入两个更好的:线性插值法和三次样条法。经过研究发现三次样条法的计算量实在太大,不太实用,所以决定就只做线性插值法的版本了。 从数字图像处理的基本理论,我们可以知道:图像的变形变换就是源图像到目标图像的坐标变换。简单的想法就是把源图像的每个点坐标通过变形运算转为目标图像的相应点的新坐标,但是这样会导致?个问题就是目标点的坐标通常不会是整数,而且像放大操作会导致目标图像中没有被源图像的点映射到,这是所谓 “向前映射”方法的缺点。所以?般都是采用“逆向映射”法。 但是逆向映射法同样会出现映射到源图像坐标时不是整数的问题。这里就需要“重采样滤波器”。这个术语看起来很专业,其实不过是因为它借用了电子信号处理中的惯用说法(在大多数情 况下,它的功能类似于电子信号处理中的带通滤波器),理解起来也不复杂,就是如何确定这个非整数坐标处的点应该是什么颜色的问题。前面说到的三种方法:最近邻域法,线性插值法和三次样条法都是所谓的“重采样滤波器”。 所谓“最近邻域法”就是把这个非整数坐标作?个四舍五入,取最近的整数点坐标处的点的颜色。而“线性插值法”就是根据周围最接近的几个点(对于平面图像来说,共有四点)的颜色作线性插值计算(对于平面图像来说就是二维线性插值)来估计这点的颜色,在大多数情况下,它的准确度要高于最近邻域法,当然效果也要好得多,最明显的就是在放大时,图像边缘的锯齿比最近邻域法小非常多。当然它同时还带业个问题:就是图像会显得比较柔和。这个滤波器用专业术语来说(呵呵,卖弄?下偶的专业^_^)叫做:带阻性能好,但有带通损失,通带曲线的矩形系数不高。至于三次样条法我就不说了,复杂了?点,可自行参考数字图像处理方面的专业书籍,如本文的参考文献。 再来讨论?下坐标变换的算法。简单的空间变换可以用?个变换矩阵来表示: [x’,y’,w’]=[u,v,w]*T 其中:x’,y’为目标图像坐标,u,v为源图像坐标,w,w’称为齐次坐标,通常设为1,T为?个3X3的变换矩阵。 这种表示方法虽然很数学化,但是用这种形式可以很方便地表示多种不同的变换,如平移,旋转,缩放等。对于缩放来说,相当于: [Su 0 0 ] [x, y, 1] = [u, v, 1] * | 0 Sv 0 | [0 0 1 ] 其中Su,Sv分别是X轴方向和Y轴方向上的缩放率,大于1时放大,大于0小于1时缩小,小于0时 反转。 矩阵是不是看上去比较晕?其实把上式按矩阵乘法展开就是: { x = u * Su
360°全景拼接技术简介
本文为技术简介,详细算法可以参考后面的参考资料。 1.概述 全景图像(Panorama)通常是指大于双眼正常有效视角(大约水平90度,垂直70度)或双眼余光视角(大约水平180度,垂直90度),在一个固定的观察点,能够提供水平方向上方位角360度,垂直方向上180度的自由浏览(简化的全景只能提供水平方向360度的浏览),乃至360度完整场景范围拍摄的照片。 生成全景图的方法,通常有三种:一是利用专用照相设备,例如全景相机,带鱼眼透镜的广角相机等。其优点是容易得到全景图像且不需要复杂的建模过程,但是由于这些专用设备价格昂贵,不宜普遍适用。二是计算机绘制方法,该方法利用计算机图形学技术建立场景模型,然后绘制虚拟环境的全景图。其优点是绘制全景图的过程不需要实时控制,而且可以绘制出复杂的场景和真实感较强的光照模型,但缺点是建模过程相当繁琐和费时。三是利用普通数码相机和固定三脚架拍摄一系列的相互重叠的照片,并利用一定的算法将这些照片拼接起来,从而生成全景图。 近年来随着图像处理技术的研究和发展,图像拼接技术已经成为计算机视觉和计算机图形学的研究焦点。目前出现的关于图像拼接的商业软件主要有Ptgui、Ulead Cool 360及ArcSoft Panorama Maker等,这些商业软件多是半自动过程,需要排列好图像顺序,或手动点取特征点。 2.全景图类型: 1)柱面全景图 柱面全景图技术较为简单,发展也较为成熟,成为大多数构建全景图虚拟场景的基础。这种方式是将全景图像投影到一个以相机视点为中心的圆柱体内表面,
视线的旋转运动即转化为柱面上的坐标平移运动。这种全景图可以实现水平方向360度连续旋转,而垂直方向的俯仰角度则由于圆柱体的限制要小于180度。柱面全景图有两个显著优点:一是圆柱面可以展开成一个矩形平面,所以可以把柱面全景图展开成一个矩形图像,而且直接利用其在计算机内的图像格式进行存取;二是数据的采集要比立方体和球体都简单。在大多数实际应用中,360度的环视环境即可较好地表达出空间信息,所以柱面全景图模型是较为理想的一种选择。 2)立方体全景图 立方体全景图由六个平面投影图像组成,即将全景图投影到一个立方体的内表面上。这种方式下图像的采集和相机的标定难度较大,需要使用特殊的拍摄装置,依次在水平、垂直方向每隔90度拍摄一张照片,获得六张可以无缝拼接于一个立方体的六个面上的照片。这种方法可以实现水平方向360度旋转、垂直方向180度俯仰的视线观察。 3)球面全景图 球面全景图是指将源图像拼接成一个球体的形状,以相机视点为球心,将图像投影到球体的内表面。与立方体全景图类似,球面全景图也可以实现水平方向360度旋转、垂直方向180度俯仰的视线观察。球面全景图的拼接过程及存储方式较柱面全景图大为复杂,这是因为生成球面全景图的过程中需要将平面图像投影成球面图像,而球面为不可展曲面。因此这是一个平面图像水平和垂直方向的非线性投影过程,同时也很难找到与球面对应且易于存取的数据结构来存放球面图像。目前国内外在这方面提出的研究算法较其他类型全景图少,而且在可靠性和效率方面也存在一些问题。 3.主要内容
位图的处理算法
承诺书 我们仔细阅读了四川理工学院大学生数学建模竞赛的竞赛规则。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果实违反竞赛规则的,如果引用别人的成果后其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公平、公正性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): 我们的参赛队(组)号为: 所属学校(请填写完整的全名): 参赛队员(打印并签名) :1. 2. 3. 日期:年月日评阅编号(由评委团评阅前进行编号,学生不填):
编号专用页评阅编号(由评委团评阅前进行编号):评阅记录表
C题位图的处理算法 摘要 本文主要对位图的一系列的处理问题进行了分析,建立了多种模型,较好的解决了题目所提出的问题。 针对问题一,我们首先对位图矢量化课题进行了深入研究,然后针对位图矢量化过程中的几个关键点问题与技术, 特别针对图像轮廓的提取, 跟踪及关键特征点提取和曲线拟合, 提出行之有效的解决算法,比如为准确地提取出图案的边界线条,并将其用方程表示出来的曲线拟合算法;接着在matlab环境下对算法进行处理,得出了边界线条的拟合曲线函数;最后我们运用罗曼诺夫斯基R一检验方法对本问算法进行了模型的检验,得出了这种思路与方法,其处理速度快、曲线拟合光滑、失真小, 验证了算法的可行性, 为其在位图与矢量图转化邻域的初步应用奠定了基础。 针对问题二,首先,我们对位图的具体背景进行了详细的分析,总的来说,即:“在用户眼里,位图是形成视觉图象的象素矩形;然而,对于开发者来说,位图则是指定或包含下列元素的一组结构”这种理论;然后,我们通过采用一种将BMP位图图片进行平滑放大的技术,该技术即利用埃特金插值算法,用此法建立模型;最后,我们将埃特金插值算法得出的数据在matlab中处理,并在最后用改进埃特金插值法进行模型的检验,得出了该方法能够使BMP位图图片缩放后的颜色或灰度变化过程较为平缓,同时有效地清除了边界锯齿及交接处模糊不清的结论。 本文在最后对结果进行分析,结果较好的符合题中所给数据,并对模型进行推广。关键字:图像轮廓;曲线拟合;矢量化;埃特金插值算法
【CN109978766A】图像放大方法及图像放大装置【专利】
(19)中华人民共和国国家知识产权局 (12)发明专利申请 (10)申请公布号 (43)申请公布日 (21)申请号 201910185936.9 (22)申请日 2019.03.12 (71)申请人 深圳市华星光电技术有限公司 地址 518132 广东省深圳市光明新区塘明 大道9-2号 (72)发明人 朱江 赵斌 周明忠 吴宇 (74)专利代理机构 深圳市德力知识产权代理事 务所 44265 代理人 林才桂 王中华 (51)Int.Cl. G06T 3/40(2006.01) (54)发明名称 图像放大方法及图像放大装置 (57)摘要 本发明提供一种图像放大方法及图像放大 装置。该图像放大方法包括如下步骤:获取具有 第一分辨率的原图像;通过预设的第一插值算法 对原图像进行插值放大,得到具有第二分辨率的 第一过渡图像,第二分辨率大于第一分辨率;通 过预设的第二插值算法对原图像进行插值放大, 并对插值放大后的图像进行平滑处理,得到具有 第二分辨率的第二过渡图像;对原图像进行边缘 检测,得到原图像的边缘信息;建立权值输出模 型,并将原图像的边缘信息输入权值输出模型, 产生目标图像的融合权值;根据融合权值和预设 的融合公式融合第一过渡图像和第二过渡图像, 得到具有第二分辨率的目标图像,能够实现图像 边缘平滑过渡,提升图像放大效果,降低图像放 大成本。权利要求书4页 说明书9页 附图2页CN 109978766 A 2019.07.05 C N 109978766 A
1.一种图像放大方法,其特征在于,包括如下步骤: 步骤S1、获取具有第一分辨率的原图像; 步骤S2、通过预设的第一插值算法对所述原图像进行插值放大,得到具有第二分辨率的第一过渡图像,所述第二分辨率大于第一分辨率; 步骤S3、通过预设的第二插值算法对所述原图像进行插值放大,并对插值放大后的图像进行平滑处理,得到具有第二分辨率的第二过渡图像; 步骤S4、对所述原图像进行边缘检测,得到所述原图像的边缘信息; 步骤S5、建立权值输出模型,并将原图像的边缘信息输入权值输出模型,产生目标图像的融合权值; 步骤S6、根据融合权值和预设的融合公式融合所述第一过渡图像和第二过渡图像,得到具有第二分辨率的目标图像。 2.如权利要求1所述的图像放大方法,其特征在于,所述第一插值算法为最邻近插值、双线性插值、双三次插值或多项式插值算法,所述第二插值算法为最邻近插值算法; 所述步骤S3中平滑处理的方式为利用预设的平滑算子对步骤S3中插值放大后的图像进行卷积; 其中, 所述平滑算子为矩阵1至矩阵5中的任一个: 3.如权利要求1所述的图像放大方法,其特征在于,所述原图像包括阵列排布的多个原像素,所述第一过渡图像包括阵列排布的多个第一像素,所述第二过渡图像包括阵列排布的多个第二像素,所述目标图像包括阵列排布的多个目标像素; 所述步骤S4中,所述原图像的边缘信息包括所述原图像中各个原像素的边缘信息;所述步骤S5中,将各个原像素对应的边缘信息输入权值输出模型,产生与该原像素的位置相对应目标像素的融合权值; 所述步骤S6中,所述预设的融合公式为: Vp=(1-λ)×Vcb+λ×Vs; 其中,所述Vp为目标像素的灰度值,Vcb为与该目标像素的位置相对应的第一像素的灰度值,Vs为与该目标像素的位置相对应的第二像素的灰度值,λ为该目标像素的融合权值,0≤λ≤1。 4.如权利要求3所述的图像放大方法,其特征在于,所述步骤S5中建立权值输出模型的步骤具体包括:获取多条训练数据,并根据所述多条训练数据通过机器学习训练产生所述权值输出模型; 其中,所述获取所述多条训练数据的方法为: 提供具有第一分辨率的训练图像,所述训练图像包括阵列排布的多个训练像素;对所述训练图像进行边缘检测,获取各个训练像素的边缘信息; 通过预设的第一插值算法对所述训练图像进行插值放大,得到具有第二分辨率的第一 权 利 要 求 书1/4页2CN 109978766 A
(完整版)基于matlab的图像缩小算法
一、基于matlab图像缩小算法 缩小算法与放大算法不同,图像缩小是通过减少像素个数来实现的。因此,需要根据缩小的尺寸来选择合适的像素点,使得图像缩小后尽可能保持源图像特征。基于等间隔采样的缩小算法。 这种算法是通过对图像像素的均匀采样来保持所选择的像素仍旧保持像素的概貌特征。 算法1通过matlab实现可得: function small=big2small(A,h,l) [m,n]=size(A); k1=m/h;k2=n/l; small=zeros(h,l); for i=1:h for j=1:l i0=i*k1;j0=j*k2; i1=floor(i0+0.5); j1=floor(j0+0.5); small(i,j)=A(i1,j1); end end end 1、基于局部均值的缩小算法。 这种算法通过采样间隔dx,dy将原图像矩阵分割为一系列小的矩阵,并计算这些小矩阵的元素的和,再求其均值赋给目标矩阵相应的像素。这样就避免了算法1中某些未取到的元素不能将其信息反映到目标矩阵的缺点。 算法2通过matlab实现可得: function small=big2small2(A,h,l) [m,n]=size(A); %获得矩阵A大小 A=im2double(A); small=zeros(h,l); for i=1:h for j=1:l sum=0; i1=round((m/h).*(i-1)+1); %将矩阵分块 j1=round((n/l).*(j-1)+1); %i1,j1为矩阵小块左上角元素下标 i2=round((m/h).*i); j2=round((n/l).*j); %i2,j2为矩阵小块右下角元素下标 for ii=i1:i2 for jj=j1:j2 sum=sum+A(ii,jj); %计算矩阵内元素值的和 end end small(i,j)=sum/((i2-i1+1).*(j2-j1+1)); %将均值赋给目标矩阵 end end end
任意比例视频图像放大算法的研究与实现
任意比例视频图像放大算法的研究与实现 摘要:随着多媒体信息技术的发展,针对视频信号的处理技术应运而生。其中实时缩放正是视频信号处理技术的关键。对于图像缩放,所用数学模型的优劣会直接影响用户观看图像的质量。在视频处理中,图像的缩放算法不仅影响视频质量,而且算法的处理速度也会影响视频流的显示,从而影响用户观看的连续性。本文针对视频信号对处理速度和精度的要求,采用只对亮度信号进行复杂处理的方法。分析图像边缘区域的特性,并通过数学推导,在边缘区域的插值中设计四个模板,从而设计改进的视频缩放算法。实验结果表明,本设计的视频信号缩放算法在主观视觉上保持了图像纹理细节和边缘信息。客观评价中,本算法处理得到的图像高频分量丢失少,且保证较好的低频分量处理效果;平均峰值信噪比较双线性插值提高0.24dB。 关键词:视频信号;图像处理;缩放;边缘 ABRSTRACT:With the rapid development of multimedia information technology,video signal's processing technology emerges at that time. Video’s real-time scaling is the key issue in video signal's processing technology. For image scaling,the mathematical model affects the picture’s visual quality. In video processing,not only the scaling algorithm influences the video’s quality,but also the alg orithm’s performance affects the display of the video so that influences the video playing smoothly.Due to the speed and precision demanded in video signal’s processing,only employ the proposed algorithm in Y channel signal. Under the analysis on the characteristic of the edge in image,four scaling masks are deduced mathematically. This paper issues a lot of experiments on the infrastructure of the theoretical study,which show that the video signal's scaling algorithm designed in this paper has obtained the better effectiveness than traditional algorithms. Our design keeps texture details in subjective vision,raises the PSNR 0.24dB on average,and it has well performance in both high and low frequency component in spectrum at the same. This is satisfied with the designated target of the project. Key words: video signals; image processing; scaling; edge 1 绪论 1.1 研究背景及意义 信息技术和互联网发展到今天,多媒体信息技术的应用范围日趋广泛,多媒体信息包括音频数据、图像和视频数据及文字数据。而人类获取的各种信息中,图像信息占有绝大部分,图像带给人们直观并具体的事物形象,这是声音、语言和文字不能比拟的。 人眼看到的是连续变化的景物,是模拟图像,而在数字设备中存储和显示的图像是经过采样和量化的数字图像。为满足人类视觉和实现信息传输的需求,针对图像和视频信息的实时缩放技术在生活中起着不可忽略的作用[1]。 视频图像的后期缩放处理势必将会作为显示呈现在终端之前的一个重要环节。无论其输入视频信源的分辨率大小尺寸多少,最终都应该以用户的实际物理显示设备的最佳观看分辨率作为显示输出结果,通常由于带宽有限的关系,该显示过程通常以放大为主,即输入视频图像分辨率小于输出分辨率。为了满足不同终端用户对图像尺寸的需求,改变图像尺寸的缩放技术应运而生。 图像缩放是数字图像处理中非常重要的技术之一。对于网络传输的图像,由于客观条件的种种限制,想要快速地传输高分辨率的图像一般难以达到,同时由于硬件性能的限制,图片往往也无法满足所需要的分辨率,而硬件的改进却需要复杂的技术并付出昂贵的代价,所以如果能够从软件技术方面进行改进,采用图像插值技术提高图像质量来达到所期望的分辨率和清晰度,其具有的实用意义将是十分重大的。因此,利用插值的方法将低分辨率图像插值放大成高分辨率图像就成为人们追求的目标。 用图像缩放算法进行处理时,存在一对相悖的要素:图像处理速度和图像精度。一般情况下,要想获得比较高的速度甚至达到实时的图像输出速率,只能采用相对来说运算量比较简单的缩放算法;而如果要想获得处理效果比较好的图像,就只能考虑牺牲处理速度,采用计算量大、比较复杂的缩放算法。图像缩
图像拼接算法及实现(一).
图像拼接算法及实现(一) 论文关键词:图像拼接图像配准图像融合全景图 论文摘要:图像拼接(image mosaic)技术是将一组相互间重叠部分的图像序列进行空间匹配对准,经重采样合成后形成一幅包含各图像序列信息的宽视角场景的、完整的、高清晰的新图像的技术。图像拼接在摄影测量学、计算机视觉、遥感图像处理、医学图像分析、计算机图形学等领域有着广泛的应用价值。一般来说,图像拼接的过程由图像获取,图像配准,图像合成三步骤组成,其中图像配准是整个图像拼接的基础。本文研究了两种图像配准算法:基于特征和基于变换域的图像配准算法。在基于特征的配准算法的基础上,提出一种稳健的基于特征点的配准算法。首先改进Harris角点检测算法,有效提高所提取特征点的速度和精度。然后利用相似测度NCC(normalized cross correlation——归一化互相关),通过用双向最大相关系数匹配的方法提取出初始特征点对,用随机采样法RANSAC(Random Sample Consensus)剔除伪特征点对,实现特征点对的精确匹配。最后用正确的特征点匹配对实现图像的配准。本文提出的算法适应性较强,在重复性纹理、旋转角度比较大等较难自动匹配场合下仍可以准确实现图像配准。 Abstract:Image mosaic is a technology that carries on the spatial matching to a series of image which are overlapped with each other, and finally builds a seamless and high quality image which has high resolution and big eyeshot. Image mosaic has widely applications in the fields of photogrammetry, computer vision, remote sensing image processing, medical image analysis, computer graphic and so on. 。In general, the process of image mosaic by the image acquisition, image registration, image synthesis of three steps, one of image registration are the basis of the entire image mosaic. In this paper, two image registration algorithm: Based on the characteristics and transform domain-based image registration algorithm. In feature-based registration algorithm based on a robust feature-based registration algorithm points. First of all, to improve the Harris corner detection algorithm, effectively improve the extraction of feature points of the speed and accuracy. And the use of a similar measure of NCC (normalized cross correlation - Normalized cross-correlation), through the largest correlation coefficient with two-way matching to extract the feature points out the initial right, using random sampling method RANSAC (Random Sample Consensus) excluding pseudo-feature points right, feature points on the implementation of the exact match. Finally with the correct feature point matching for image registration implementation. In this
图像放大算法总结及MATLAB源程序
1,插值算法(3种): (1)最邻近插值(近邻取样法): 最邻近插值的的思想很简单,就是把这个非整数坐标作一个四舍五入,取最近的整数点坐标处的点的颜色。可见,最邻近插值简单且直观,速度也最快,但得到的图像质量不高。 最邻近插值法的MATLAB源代码为: A=imread('F:\lena.jpg');%读取图像信息 imshow(A);%显示原图 title('原图128*128'); Row=size(A,1);Col=size(A,2);%图像行数和列数 nn=8;%放大倍数 m=round(nn*Row);%求出变换后的坐标的最大值 n=round(nn*Col); B=zeros(m,n,3);%定义变换后的图像 for i=1:m for j=1:n x=round(i/nn);y=round(j/nn);%最小临近法对图像进行插值 if x==0x=1;end if y==0y=1;end if x>Row x=Row;end if y>Col y=Col;end B(i,j,:)=A(x,y,:); end end B=uint8(B);%将矩阵转换成8位无符号整数 figure; imshow(B); title('最邻近插值法放大8倍1024*1024'); 运行程序后,原图如图1所示:
图1 用最邻近插值法放大4倍后的图如图2所示: 图2 (2)双线性内插值法: 在双线性内插值法中,对于一个目的像素,设置坐标通过反向变换得到的浮点坐标为(i+u,j+v),其中i、j均为非负整数,u、v为[0,1)区间的浮点数,则这个像素得值f(i+u,j+v)可由原图像中坐标为(i,j)、(i+1,j)、(i,j+1)、(i+1,j+1)所对应的周围四个像素的值决定,即:f(i+u,j+v)=(1-u)(1-v)f(i,j)+(1-u)vf(i,j+1)+u(1-v)f(i+1,j)+uvf(i+1,j+1) 其中f(i,j)表示源图像(i,j)处的的像素值,以此类推。 这就是双线性内插值法。双线性内插值法计算量大,但缩放后图像质量高,不会出现像素值不连续的的情况。由于双线性插值具有低通滤波器的性质,使高频分量受损,所以可能会使图像轮廓在一定程度上变得模糊。 在MATLAB中,可用其自带的函数imresize()来实现双线性内插值算法。
遥感图像处理实例分析01(算法、图像增强)
图像处理(Image processing) 基本概念 数字图像处理(digital image processing)指的是使用计算机巧妙处理以数字格式存储图像数据的过程。其目的是提高地理数据质量,使其对使用者更有意义,并能提取定量信息,解决问题。 数字图像(digital image)的存储是以二维数组或网格的形式保存像素值,每个像素在空间上对应着地表一块小面积。数组或网格又称光栅,所以图像数据经常叫着光栅数据。光栅数据的排列是这样:水平行叫着线(lines),垂直列叫着样品(samples)(如图1-1)。图像光栅数据的每个像素代表着是数字(digital number),简称DN。 图1-1 光栅数据 图像数字DNs在不同的数据源中,代表着不同的数据类型。如对Landsat、SPOT卫星数据,DNs代表的是地物在可见光、红外或其它波段的反射强度。对雷达图像,DNs代表的是雷达脉冲返回到天线的强度。对数字地形模型(DTMs),DNs代表的是地形高程。 通过应用数学变换,图像转化为数字图像。ER Mapper可以增强数字图像,突出和提取传统手工方法难以得到的细小信息。这就是为什么图像处理能成为所有地球科学应用的强大工具的原因 多光谱数据(multispectral data)指的是多波段数据,图像数据中含有多个波段的反射强度。图像处理技术随着合并不同波段的信息而发展,突出了一些特别类型的信息,如植被指数、水质量参数、地表矿物出现类型等。 图像处理广泛应用在地球科学的制图、分析和模型应用上。主要有:土地利用/土地覆盖制图和变迁勘察(land use/land cover mapping and change detection)、农业评价和监测(agricultural assessment and monitoring)、海岸线和海洋资源管理(coastal and marine resource management)、矿产勘查(mineral exploration)、石油和天然气勘查(o il & gas exploration)、森林资源管理(forest resource management)、城市规划和变迁勘察( urban planning and change detection)、无线通讯定点和规划(telecommunications siting and planning)、海洋物理学(physical oceanography)、地质和地形制图(geology and topographic mapping)、冰川探测和制图(sea ice detection and mapping)等。 ER Mapper图像处理特点:发展了一个全新的方法,叫算法,将许多处理过程合并成简单的
图像放大算法
一、图像放大算法 图像放大有许多算法,其关键在于对未知像素使用何种插值方式。以下我们将具体分析几种常见的算法,然后从放大后的图像是否存在色彩失真,图像的细节是否得到较好的保存,放大过程所需时间是否分配合理等多方面来比较它们的优劣。 当把一个小图像放大的时候,比如放大400%,我们可以首先依据原来的相邻4个像素点的色彩值,按照放大倍数找到新的ABCD像素点的位置并进行对应的填充,但是它们之间存在的大量的像素点,比如p点的色彩值却是不可知的,需要进行估算。 图1-原始图像的相邻4个像素点分布图 图2-图像放大4倍后已知像素分布图 1、最临近点插值算法(Nearest Neighbor)
最邻近点插值算法是最简单也是速度最快的一种算法,其做法是將放大后未知的像素点P,將其位置换算到原始影像上,与原始的邻近的4周像素点A,B,C,D做比较,令P点的像素值等于最靠近的邻近点像素值即可。如上图中的P点,由于最接近D点,所以就直接取P=D。 这种方法会带来明显的失真。在A,B中点处的像素值会突然出现一个跳跃,这就是出现马赛克和锯齿等明显走样的原因。最临近插值法唯一的优点就是速度快。 2、双线性插值算法(Bilinear Interpolation) 其做法是將放大后未知的像素点P,將其位置换算到原始影像上,计算的四個像素点A,B,C,D对P点的影响(越靠近P点取值越大,表明影响也越大),其示意图如下。 图3-双线性插值算法示意图 其具体的算法分三步: 第一步插值计算出AB两点对P点的影响得到e点的值。 图4-线性插值算法求值示意图
对线性插值的理解是这样的,对于AB两像素点之间的其它像素点的色彩值,认定为直线变化的,要求e点处的值,只需要找到对应位置直线上的点即可。换句话说,A,B间任意一点的值只跟A,B有关。 第二步,插值计算出CD两点对P点的影响得到f点的值。 第三步,插值计算出ef两点对P点的影响值。 双线性插值算法由于插值的结果是连续的,所以视觉上会比最邻近点插值算法要好一些,不过运算速度稍微要慢一点,如果讲究速度,是一个不错的折衷。 3、双立方插值算法(Bicubic Interpolation) 双立方插值算法与双线性插值算法类似,对于放大后未知的像素点P,将对其影响的范围扩大到邻近的16个像素点,依据对P点的远近影响进行插值计算,因P点的像素值信息来自16个邻近点,所以可得到较细致的影像,不过速度比较慢。
实验5:数字图像处理(图像放大与缩小)
X x大学数字图像处理与通信课程实验报告 班级: 学号: 姓名: 实验项目名称:图像的放大或缩小 实验项目性质:设计性实验 实验所属课程:数字图像处理与图像通信实验室(中心):网络实验中心 指导教师: 实验完成时间: 2012 年 10 月 30 日
教师评阅意见: 签名:年月日实验成绩: 一、实验目的: 1. 首先,通过实验进一步熟悉matlab、matlab 编程环境以及其基本操作,和对图像的读取、显示、保存等一些基本操作,同时增加自己的实际动手能力。加强了解MATLAB 的操作环境。 2. 完成对图像放大(或缩小)n倍的操作。 二、实验主要内容及要求: 内容:完成对图像放大(或缩小)n倍的操作。 要求:自写函数。 三、实验设备及软件: PC机一台,MATBLAB。 四、设计方案 1、首先通过读入一张图片,然后将图像进行二值操作; 2、从而调用函数,判断参数w是大于1还是小于1,如果大于1,就执行放大 处理,反之则反; 3、最后将处理后的图像输出,与原图像进行比较分析。 五、主要代码及必要说明: function y=fs(w) f=imread('lu.jpg');
f1=im2double(f); figure,imshow(f1); [m,n,k]=size(f1); %对图像进行放大处理 if w>1 g=zeros(m*w,n*w,k); for x=1:m for y=1:n g(ceil(x*w)+1,ceil(y*w),1)=f1(x,y,1); g(ceil(x*w)+1,ceil(y*w),2)=f1(x,y,2); g(ceil(x*w)+1,ceil(y*w),3)=f1(x,y,3); End figure,imshow(g); title(‘放大后的图像’); end %对图像进行缩小处理 else g=zeros(ceil(m*w),ceil(n*w),k); for x=1:ceil(m*w) for y=1:ceil(n*w) g(x,y,1)=f1(ceil(x/w),ceil(y/w),1); g(x,y,2)=f1(ceil(x/w),ceil(y/w),2); g(x,y,3)=f1(ceil(x/w),ceil(y/w),3); end e nd figure,imshow(g); title(‘缩小后的图像’); end; 六、测试结果及说明: 1、经过处理,缩小后的图像如下图所示: 2、经过处理,放大后的图像如下图所示:
图像缩放算法比较分析(IJIGSP-V5-N5-7)
I.J. Image, Graphics and Signal Processing, 2013, 5, 55-62 Published Online April 2013 in MECS (https://www.360docs.net/doc/7e4453293.html,/) DOI: 10.5815/ijigsp.2013.05.07 A Comparative Analysis of Image Scaling Algorithms Chetan Suresh Department of Electrical and Electronics Engineering, BITS Pilani Pilani - 333031, Rajasthan, India E-mail: shivchetan@https://www.360docs.net/doc/7e4453293.html, Sanjay Singh, Ravi Saini, Anil K Saini Scientist, IC Design Group, CSIR – Central Electronics Engineering Research Institute (CSIR-CEERI) Pilani – 333031, Rajasthan, India Abstract—Image scaling, fundamental task of numerous image processing and computer vision applications, is the process of resizing an image by pixel interpolation. Image scaling leads to a number of undesirable image artifacts such as aliasing, blurring and moiré. However, with an increase in the number of pixels considered for interpolation, the image quality improves. This poses a quality-time trade off in which high quality output must often be compromised in the interest of computation complexity. This paper presents a comprehensive study and comparison of different image scaling algorithms. The performance of the scaling algorithms has been reviewed on the basis of number of computations involved and image quality. The search table modification to the bicubic image scaling algorithm greatly reduces the computational load by avoiding massive cubic and floating point operations without significantly losing image quality. Index Terms—Image Scaling, Nearest-neighbour, Bilinear, Bicubic, Lanczos, Modified Bicubic I.I NTRODUCTION Image scaling is a geometric transformation used to resize digital images and finds widespread use in computer graphics, medical image processing, military surveillance, and quality control [1]. It plays a key role in many applications [2] including pyramid construction [3]-[4], super-sampling, multi-grid solutions [5], and geometric normalization [6]. In surveillance-based applications, images have to be monitored at a high frame rate. Since, the images need not be of the same size, image scaling is necessary for comparison and manipulation of images. However, image scaling is a computationally intensive process due to the convolution operation, which is necessary to band-limit the discrete input and thereby diminishes undesirable aliasing artifacts [2]. Various image scaling algorithms are available in literature and employ different interpolation techniques to the same input image. Some of the common interpolation algorithms are the nearest neighbour, bilinear [7], and bicubic [8]-[9]. Lanczos algorithm utilizes the 3-lobed Lanczos window function to implement interpolation [10]. There are many other higher order interpolators which take more surrounding pixels into consideration, and thus also require more computations. These algorithms include spline [11] and sinc interpolation [12], and retain the most of image details after an interpolation. They are extremely useful when the image requires multiple rotations/distortions in separate steps. However, for single-step enlargements or rotations, these higher-order algorithms provide diminishing visual improvement and processing time increases significantly. Novel interpolation algorithms have also been proposed such as auto-regression based method [13], fuzzy area-based scaling [14], interpolation using classification and stitching [15], isophote-based interpolation [16], and even interpolation scheme combined with Artificial Neural Networks [17]. Although these algorithms perform well, they require a lengthy processing time due to their complexity. This is intolerable for real-time image scaling in video surveillance system. Hence, these algorithms have not been considered for the comparative analysis in this paper. In this paper, firstly, image interpolation algorithms are classified and reviewed; then evaluation and comparison of five image interpolation algorithms are discussed in depth based on the reason that evaluation of image interpolation is essential in the aspect of designing a real-time video surveillance system. Analysis results of the five interpolation algorithms are summarized and presented. II.I MAGE S CALING Image scaling is obtained by performing interpolation over one or two directions to approximate a pixel’s colour and intensity based on the values at neighbouring