K分布海杂波参数估计方法

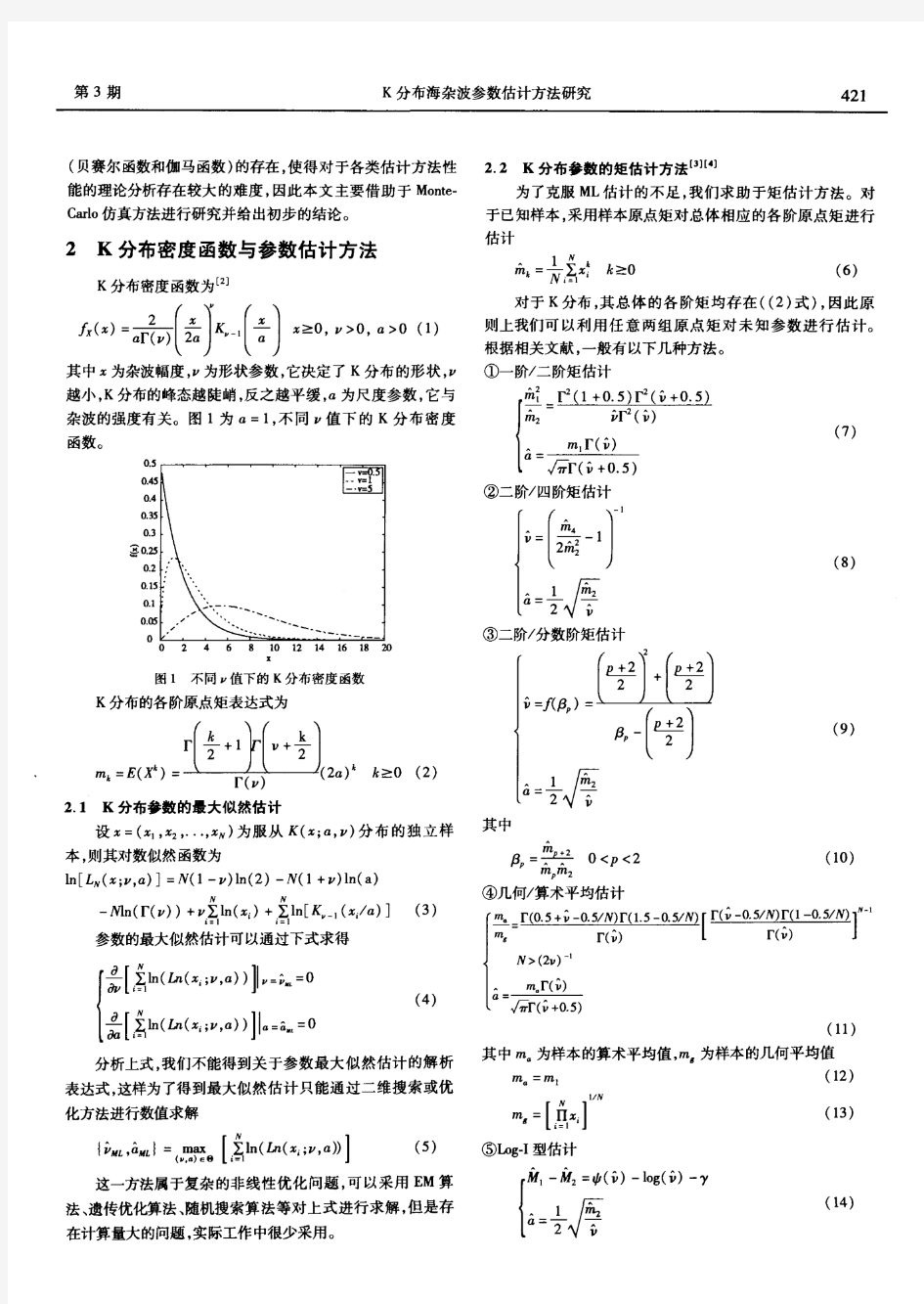
参数估计在实际问题中当所研究的总体分布类型已知但分布
第六章 参数估计 在实际问题中, 当所研究的总体分布类型已知, 但分布中含有一个或多个未知参数时, 如何根据样本来估计未知参数,这就是参数估计问题. 参数估计问题分为点估计问题与区间估计问题两类. 所谓点估计就是用某一个函数值作为总体未知参数的估计值;区间估计就是对于未知参数给出一个范围,并且在一定的可靠度下使这个范围包含未知参数. 例如, 灯泡的寿命X 是一个总体, 根据实际经验知道, X 服从),(2σμN , 但对每一批灯泡而言, 参数2,σμ是未知的,要写出具体的分布函数, 就必须确定出参数. 此类问题就属于参数估计问题. 参数估计问题的一般提法: 设有一个统计总体, 总体的分布函数为),(θx F , 其中θ为未知参数(θ可以是向量). 现从该总体中随机地抽样, 得一样本 n X X X ,,,21 , 再依据该样本对参数θ作出估计, 或估计参数θ的某已知函数).(θg 第一节 点估计问题概述 内容分布图示 ★ 引言 ★ 点估计的概念 ★ 例1 ★ 评价估计量的标准 ★ 无偏性 ★ 例2 ★ 例3 ★ 有效性 ★ 例4 ★ 例5 ★ 例6 ★ 相合性 ★ 例7 ★ 例8 ★ 内容小结 ★ 课堂练习 ★ 习题6-1 内容要点: 一、点估计的概念 设n X X X ,,,21 是取自总体X 的一个样本, n x x x ,,,21 是相应的一个样本值. θ是总体分布中的未知参数, 为估计未知参数θ, 需构造一个适当的统计量 ),,,,(?2 1 n X X X θ 然后用其观察值 ),,,(?21n x x x θ 来估计θ的值. 称),,,(?21n X X X θ为θ的估计量. 称),,,(?21n x x x θ为θ的估计值. 在不致混淆的情况下, 估计量与估计值统称为点估计,简称为估计, 并简记为θ?. 注: 估计量),,,(?21n X X X θ是一个随机变量, 是样本的函数,即是一个统计量, 对不同的样本值, θ的估计值θ?一般是不同的. 二、评价估计量的标准 从例1可见,参数点估计的概念相当宽松, 对同一参数,可用不同的方法来估计, 因而得到不同的估计量, 故有必要建立一些评价估计量好坏的标准. 估计量的评价一般有三条标准:
双参数威布尔分布函数的确定及曲线拟合(精)
2007.NO.4. CN35-1272/TK 图 1威布尔函数拟合曲线的仿真系统模块 作者简介 :包小庆 (1959~ , 男 , 高级工程师 , 从事可再生能源的研究。 大型风电场的建设不但可以减缓用电短缺情况 , 而且并网后还能为电网提供很大一部分电能。而大型风电场的选址 , 与该地的风速分布情况有关。用于描述风速分布的模型很多 , 如瑞利分布、对数正态分布、 r 分布、双参数威布尔分布、 3参数威布尔分布 , 皮尔逊曲线拟合等。经过大量的研究表明 , 双参数威布尔分布函数更接近风速的实际分布。本文采用 4种方法计算威布尔分布函数的参数 , 并利用计算出的参数确定威布尔分布函数的实际数学模型进行曲线拟合。最后以白云鄂博矿区风电场拟选址为例 , 使用计算机软件 (MATLAB 对该地区风速威布尔分布函数进行曲线拟合 , 得到该地区不同高度的风速分布函数曲线。 1双参数威布尔分布函数的确定 双参数威布尔分布是一种单峰的正偏态分布函数 , 其概 率密度函数表达式为 : p(x=k x " exp-x " (1 式中 :k ———形状参数 , 无因次量 ; c ———
尺度参数 , 其量纲与速度相同。为了确定威布尔分布函数的实际模型 , 需计算出实际情况下对应函数的 2个参数。估算风速威布尔参数的方法很多 , 本文给出4种有效的方法以确定 k 和 c 值。 1.1HOMER 软件法 HOMER 是一个对发电系统优化配置与经济性分析的软件。通过输入 1a 逐时风速数据或者月平均风速数据 , 根据实际情况设置相应参数 , 即可计算得到 k 和c 值 , 此时计算出的 k 和 c 值是计算机系统认为的最佳值。 1.2Wasp 软件法 Wasp 是一个风气候评估、 计算风力发电机组年发电量、风电场年总发电量的软件。通过输入风速统计资料 , 计算机可以直接计算出 k 和 c 值。 1.3最小二乘法 通过风速统计资料计算出最小二乘法拟合直线 y=ax+b 的斜率 a 和截距 b 。由下式确定 k 和 c 的值 : k=b (2 c=esp a (3 1.4平均风速和最大风速估计法 从常规气象数据获得平均风速和时间 T 观测到的 10min 平均最大风速 V m ax , 设全年的平均风速为通过下式计算 k 和 c 值 : k=ln (lnT (4 c=(5
参数估计练习题
第七章参数估计练习题 一.选择题 1. 估计量的含义是指() A. 用来估计总体参数的统计量的名称 B. 用来估计总体参数的统计量的具体数值 C.总体参数的名称 D.总体参数的具体取值 2.一个95%的置信区间是指() A. 总体参数有95%的概率落在这一区间内 B. 总体参数有5%的概率未落在这一区间内 C. 在用同样方法构造的总体参数的多个区间中,有95%的区间包含该总体参数。 D. 在用同样方法构造的总体参数的多个区间中,有95%的区间不包含该总体参数。 %的置信水平是指() A. 总体参数落在一个特定的样本所构造的区间内的概率是95% B.在用同样方法构造的总体参数的多个区间中,包含总体参数的区间比例为95% C.总体参数落在一个特定的样本所构造的区间内的概率是5% D.在用同样方法构造的总体参数的多个区间中,包含总体参数的区间比例为5% 4. 根据一个具体的样本求出的总体均值的95%的置信区间() A.以95%的概率包含总体均值 B.有5%的可能性包含总体均值 C. 一定包含总体均值 D.要么包含总体均值,要么不包含总体均值 5. 当样本量一定时,置信区间的宽度() A.随着置信水平的增大而减小 B. .随着置信水平的增大而增大 C.与置信水平的大小无关D。与置信水平的平方成反比 6. 当置信水平一定时,置信区间的宽度() A.随着样本量的增大而减小 B. .随着样本量的增大而增大 C.与样本量的大小无关D。与样本量的平方根成正比 7. 在参数估计中,要求通过样本的统计量来估计总体参数,评价统计量的标准之一是使它与 总体参数的离差越小越好。这种评价标准称为() A.无偏性 B. 有效性 C. 一致性 D. 充分性 8. 置信水平(1-α)表达了置信区间的() A.准确性 B. 精确性 C. 显着性 D. 可靠性 9. 在总体均值和总体比例的区间估计中,边际误差由()A.置信水平决定 B. 统计量的抽样标准差确定 C. 置信水平和统计量的抽样标准差 D. 统计量的抽样方差确定 10. 当正态总体的方差未知,且为小样本条件下,估计总体均值使用的分布是() A.正态分布 B. t 分布 C.χ2分布 D. F分布
第4章总体参数估计讲解
◎第4章参数估计 ※一、单一总体的参数估计※ ●(一)估计的含义 ●估计:人人都做过。如: ?上课时,你会估计一下老师提问你的概率有多大? ?当你去公司应聘时,会估计你被录用的可能性是多少??推销员年初时要估计今年超额完成任务的概率有多大?◎估计量:用来估计总体参数的样本统计量。如:算术平均数、中位数、标准差、方差等。 ●估计的可能性与科学性:数理统计证明,一个“优良”的样本统计量应具备以下特征: (1)、无偏性。样本估计量的期望值应等于总体参数。无系统偏差。 (2)、有效性。与离散度相联系。在多个无偏估计量中,方差最小的估计量最有效。 (3)、一致性。随着样本容量的增加,可以使估计量越来越靠近总体参数。 (4)、充分性。估计量能够充分利用有关信息,中位数和众数不具备这一点。 ※估计的类型包括:
1、 点估计:只有一个取值。 就 是总体平均数μ的点估计值。 2、区间估计:给出取值范围(值域)。见PPT ▲两种估计类型哪一种更科学? ※ 区间估计的优点在于:它在给出估计区间时, 还可以给予一个“可信程度”。例如:销售经理想 估计一下明年的出口总值,甲估计是53万美元,乙估计 是50—56万美元之间,并可以确切地说“有95%的把握”。 显然后者的可信程度大于前者。那么,50—56万美元之 间的范围是如何计算的?“有95%的把握”是什么意思? 【引例】:某食品进出口公司向东南亚出口一批花生制品,管 理人员从中抽取50包作为样本,计算其平均数为250克。另 外,合同规定总体标准差为6克。 如果问这批花生制品的平均重量,可用样本平均数作为总 体平均数的最佳估计量:250克。但这是远远不够的,在许多 时候,管理人员还想了解“这个估计值的平均误差是多少?” “总体平均数可能落入样本平均数上、下多大范围内?”“ 这 个估计值的可靠程度是多少?” 〖1〗由于n=50,根据中心极限定理可作图: n=50,σ=6 〖2〗抽样平均误差:8485.0506 ===n x σσ
Poisson分布的参数估计
Poisson 分布的参数估计 作者:高晨 指导老师:戴林送 摘要 泊松分布是概率统计学科中一种重要的离散分布,在参数估计这块,对点估计,矩估计,最大似然 估计以及近似的区间估计等,该文中对泊松分布的相关知识,包括其性质,参数的相关估计,研究了泊松分布的一些性质,参数的估计,以及一些在生活中的简单应用。 关键词 P o i s s o 分布 参数估计 性质 简单应用 1 引言 Poisson 分布是离散型随机变量X 作为大量试验中稀有事件出现的频数的概率分布的数学模型,其中X 可能取值为0,1,2,……而取各个值的概率为: {},0,1,2! k e P x k k k λ λ-== = 其中0λ>是常数,称X 服从参数为λ的泊松~(;)X P k x . 1.1相关定义 1. 离散型随机变量X 的函数分布律{},0,1,2k k P X x P k === ,若级数1k k k x p ∞ =∑绝 对收敛,称级数 1 k k k x p ∞ =∑为随机变量X 的数学期望[]E x , []E x =1k k k x p ∞ =∑. 2. 定理:Y 是随机变量X 的函数,(),(Y g x g =是连续函数),X 是离散型随机变量, 若 1 ()k k k g x p ∞ =∑绝对收敛,则 [][()]E Y E g x ==1 ()k k k g x p ∞ =∑. 3. 随机变量X ,若2{[()]}E X E X -存在,则称2{[()]}E X E X -为X 的方差,记 为()D x 或()Var x ,即 ()D x =()Var x =2{[()]}E X E X -.
3-第7章统计学参数估计练习题(20200627170347)
第7章参数估计 练习题 一、填空题(共10题,每题2分,共计20分) 1 ?参数估计就是用_________ 去估计____________ 。 2?点估计就是用_____________ 的某个取值直接作为总体参数的 _____________ 。 3. ______________________ 区间估计是在的基础上,给出总体参数估计的一个区间范围,该区间 通常由样本统计量加减___________ 得到。 4. 如果将构造置信区间的步骤重复多次,置信区间中包含总体参数真值的次数所占的 比例称为___________ ,也成为_____________ 。 5. __________________________________________________________ 当样本量给定时,置信区间的宽度随着置信系数的增大而__________________________ ;当置信水 平固定时,置信区间的宽度随着样本量的增大而_____________ 。 6. 评价估计量的标准包含无偏性、 ___________ 和____________ 。 7. 在参数估计中,总是希望提高估计的可靠程度,但在一定的样本量下,要提高估计 的可靠程度,就会___________ 置信区间的宽度;如要缩小置信区间的宽度,又不降 低置信程度,就要____________ 样本量。 8. 估计总体均值置信区间时的估计误差受总体标准差、 ___________ 和___________ 的影响。 9?估计方差未知的正态总体均值置信区间用公式_____________ ;当样本容量大于等于30时,可以用近似公式__________ 。 10?估计正态总体方差的置信区间时,用___________ 分布,公式为___________ 。 二、选择题(共10题,每题1分,共计10分) 1 ?根据一个具体的样本求出的总体均值的95%勺置信区间()。 A. 以95%勺概率包含总体均值 B. 有5%勺可能性包含总体均值 C?一定包含总体均值
正态总体参数的区间估计
第19讲 正态总体参数的区间估计 教学目的:理解区间估计的概念,掌握各种条件下对一个正态总体的均值和方差进行 区间估计的方法。 教学重点:置信区间的确定。 教学难点:对置信区间的理解。 教学时数: 2学时。 教学过程: 第六章 参数估计 §6.3正态总体参数的区间估计 1. 区间估计的概念 我们已经讨论了参数的点估计,但是对于一个估计量,人们在测量或计算时,常不以得到近似值为满足,还需估计误差,即要求知道近似值的精确程度。因此,对于未知参数θ,除了求出它的点估计?θ外,我们还希望估计出一个范围,并希望知道这个范围包含参数θ真值的可信程度。 设?θ为未知参数θ的估计量,其误差小于某个正数ε的概率为1(01)αα-<<,即 ?{||}1P θθεα -<=- 或 αεθθεθ-=+<<-1)??(P 这表明,随机区间)?,?(εθεθ+-包含参数θ真值的概率(可信程度)为1α-,则这个区间)?,?(εθεθ+-就称为置信区间,1α-称为置信水平。 定义 设总体X 的分布中含有一个未知参数θ。若对于给定的概率1(01)αα-<<,存在两个统计量1112(,,,)n X X X θθ= 与2212(,,,)n X X X θθ= ,使得 12{}1P θθθα <<=-
则随机区间12(,)θθ称为参数θ的置信水平为1α-的置信区间,1θ称为置信下限,2θ称为置信上限,1α-称为置信水平。 注(1)置信区间的含义:若反复抽样多次(各次的样本容量相等,均为n ),每一组样本值确定一个区间12(,)θθ,每个这样的区间要么包含θ的真值,要么不包含θ的真值。按伯努利大数定理,在这么多的区间中,包含θ真值的约占100(1)%α-,不包含θ真值的约仅占100%α。例如:若0.01α=,反复抽样1000次,则得到的1000个区间中,不包含θ真值的约为10个。 (2)置信区间的长度表示估计结果的精确性,而置信水平表示估计结果的可靠性。对于置信水平为1α-的置信区间12(,)θθ,一方面置信水平1α-越大,估计的可靠性越高;另一方面区间12(,)θθ的长度(2)ε越小,估计的精确性越好。但这两方面通常是矛盾的,提高可靠性通常会使精确性下降(区间长度变大),而提高精确性通常会使可靠性下降(1α-变小),所以要找两方面的平衡点。 在学习区间估计方法之前,我们先介绍标准正态分布的α分位点概念。 设 () ~0,1X N ,若 z α 满足条件 { },01 P X z α αα>=<<,则称点z α为标准正态分布的α分位点。例如求0.01z 。按照α分位点定义,我们有 {}0.010.01P X z >=,则{}0.010.99P X z ≤=,即0.01()0.99z φ=。查表可得0.01 2.327z =. 又 由()x ?图形的对称性知1z z αα-=-。下面列出了几个常用的z α值: 2. 正态总体均值μ的区间估计 设已给定置信水平为1α-,总体()2~,X N μσ,12,,,n X X X 为一个样本,2 ,X S 分别是样本均值和样本方差。