用身高和体重数据进行性别分类的实验报告

用身高和体重数据进行性别分类的实验报告 一、 基本要求
用FAMALE.TXT 和MALE.TXT 的数据作为训练样本集,建立Bayes 分类器,用测试样本数据对该分类器进行测试。调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
二、 具体做法
(1)应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关,在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。比较相关假设和不相关假设下结果的差异。在分类器设计时可以考察采用不同先验概率(如0.5 vs. 0.5, 0.75 vs. 0.25, 0.9 vs. 0.1等)进行实验,考察对决策和错误率的影响。 (2)自行给出一个决策表,采用最小风险的Bayes 决策重复上面的实验。
三、 原理简述及程序框图
A. 正态分布的监督参数估计
监督参数估计:样品所属的类别及类条件总体概率密度函数的形式
为已知,而表征概率密度函数的某些参数是未知的。
本实验符合上述条件且在正态分布假设下估计分布密度参数故使用正态分布的监督参数估计
对于多元正态分别,其最大似然估计的结果为:
1
1?N
K K X n μ
==∑ ()()1
1???N T K K K X X N μμ=∑=--∑ B. 最小错误率Bayes 分类器
在多元正态模型下的最小错误率角度来分析Bayes 分类器
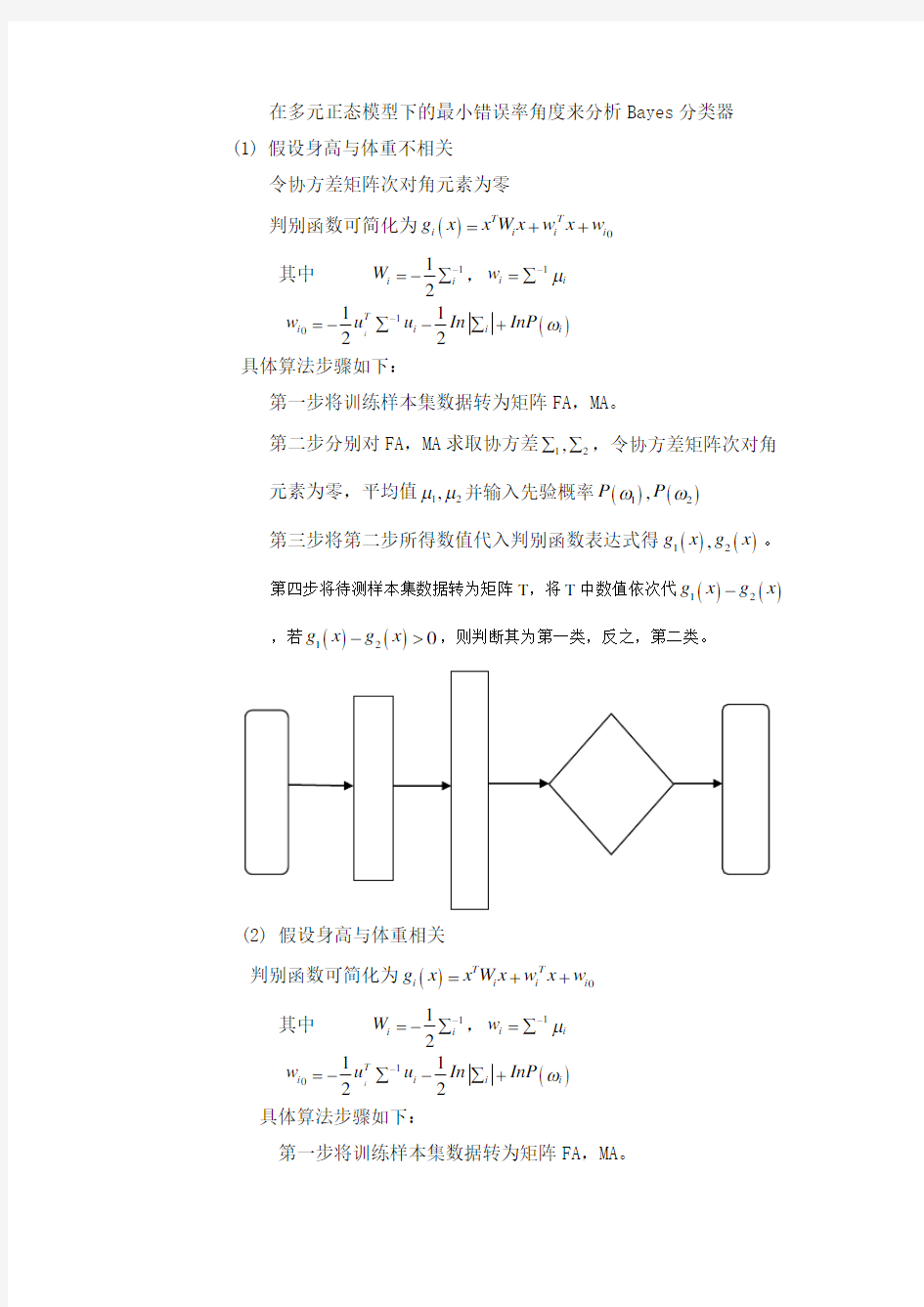
(1) 假设身高与体重不相关 令协方差矩阵次对角元素为零
判别函数可简化为()0T T i i i i g x x W x w x w =++
其中 11
2
i i W -=-∑,1i i w μ-=∑
()1
01122
i
T i i i i w u u In InP ω-=-∑-∑+ 具体算法步骤如下:
第一步将训练样本集数据转为矩阵FA ,MA 。
第二步分别对FA ,MA 求取协方差12,∑∑,令协方差矩阵次对角
元素为零,平均值12,μμ并输入先验概率()()12,P P ωω
第三步将第二步所得数值代入判别函数表达式得()()12,g x g x 。
第四步将待测样本集数据转为矩阵T ,将T 中数值依次代()()12g x g x -
,若()()120g x g x ->,则判断其为第一类,反之,第二类。
(2) 假设身高与体重相关
判别函数可简化为()0T T i i i i g x x W x w x w =++
其中 11
2
i i W -=-∑,1i i w μ-=∑
()1
01122
i T i i
i i w u u In InP ω-=-∑-∑+ 具体算法步骤如下:
第一步将训练样本集数据转为矩阵FA ,MA 。
第二步分别对FA ,MA 求取协方差12,∑∑平均值12,μμ并输入先验
概率()()12,P P ωω
第三步将第二步所得数值代入判别函数表达式得()()12,g x g x 。
第四步将待测样本集数据转为矩阵T ,将T 中数值依次代()()12g x g x -,
若()()120g x g x ->,则判断其为第一类,反之,第二类。
C. 最小风险Bayes 分类器
(1)在已知先验概率()j P ω和类条件概率密度()j P x ω,j=1, …c 及给出带识别的x 的情况下,根据Bayes 公式计算后验概率:
()()()
()()
1
,1,,c j j j c
i
i
i P x P P x j P x P ωωωωω==
=∑
(2)利用后验概率及决策表,计算条件风险()i R a x
()()()1,1,,c
i i j j i R x P x i a αλαωω===∑
(3)()()1,,min k i i a
R a x R a x == ,k a 就是最小风险Bayes 决策。
其中(1)中先验概率()j P ω根据自行输入,类条件概率密度
()j P x ω=()()
()11
2
2
1
1exp ()22T d
P x x u x u π-??
=
--∑-????
∑
,本实验
为二维二类,故d=2,(2)中决策表自行输入。
四、 实验结果及分析总结
(1)用最小错误率Bayes 决策
假设身高与体重相关(以训练样本建立判别函数)
由表可知:
对于训练样本,当女生先验概率为0.5时,判别错误率最小
对于测试样本,当女生先验概率为1/6时,判别错误率最小
故可推测用最小错误率Bayes 决策假设身高与体重相关当女 生先验概率等于待测样本中女生样本占待测样本的概率时, 错误率最小,且越远离此概率,错误率越大。
最佳决策对于训练样本,当女生先验概率为0.5
对于测试样本,当女生先验概率为1/6
假设身高与体重不相关(以训练样本建立判别函数)
对于训练样本当女生先验概率接近0.5时错误率最小最佳决策对于训练样本,当女生先验概率为0.5
(2)用最小风险的Bayes决策
当决策表为
身高体重相关
对于训练样本,当女生先验概率为0.5时,判别错误率最小
对于测试样本,当女生先验概率为1/6时,判别错误率最小故可推测用最小风险Bayes决策假设身高与体重相关当女
生先验概率等于待测样本中女生样本占待测样本的概率时,
错误率最小,且越远离此概率,错误率越大。
最佳决策对于训练样本,当女生先验概率为0.5
对于测试样本,当女生先验概率为1/6
身高体重不相关
最佳决策对于训练样本,当女生先验概率为0.5
心得体会
拿到大作业题目,我们首先对题目进行了分析,并且根据以前所学过的知识和做过的例题找到了解题方法,然后先制定解题步骤,画出解题流程图。再根据流程图编写出MATLAB代码,最后进行调试,
运行,得出结果。整个过程中,我们在编程部分遇到了一些麻烦,但
很快我们就通过查找资料解决了这个问题。再给老师审核时,发现我
们并没有完完全全达到题目要求,后来我们又再次修改。通过这次大
作业,我们从原来拿到题目时的迷茫,到制定出解题方案,再到最后
具体操作,体会到了通过自己的努力解决一个问题的快乐,同时,也
懂得了遇到任何问题,只要通过认真分析,最终都会得到解决的道理,
而且我们也发现审题不清是我们小组的薄弱环节,我们将吸取教训认
真读题审题,且当身高体重不相关时,输出的结果可能有问题,还需
修改。
%éí??ì????à1?,?D±e2aê??ù±?
clc;
clear all;
%ê??ˉ?è?é???ê
P1=input('??éú?è?é???êê?:');
P2=input('?Déú?è?é???êê?:');
%?μá·?ù±?
[FH FW]=textread('C:\Users\xuyd\Desktop\homework\FEMALE.txt','%f %f'); [MH MW]=textread('C:\Users\xuyd\Desktop\homework\MALE.txt','%f %f'); FA=[FH FW];FA=FA';
MA=[MH MW];MA=MA';
a=cov(FA')*(length(FA)-1)/length(FA);
b=cov(MA')*(length(MA)-1)/length(MA);
W1=-1/2*inv(a);
W2=-1/2*inv(b);
Ave1=(sum(FA')/length(FA))';
Ave2=(sum(MA')/length(MA))';
w1=inv(a)*Ave1;
w2=inv(b)*Ave2;
w10=-1/2*Ave1'*inv(a)*Ave1-1/2*log(det(a))+log(P1);
w20=-1/2*Ave2'*inv(b)*Ave2-1/2*log(det(b))+log(P2);
% syms a ;
% syms b ;
% h=[a b]';
% h1=h'*W1*h+w1'*h+w10?D±eoˉêy
% h2=h'*W2*h+w2'*h+w20
%2aê??ù±?
[tH
tW]=textread('C:\Users\xuyd\Desktop\homework\test2.txt','%f %f %*s');
T=[tH tW];
T=T';
%??2aê??ù±?μ??D±e
for j=1:300
g1=T(:,j)'*W1*T(:,j)+w1'*T(:,j)+w10 ;
g2=T(:,j)'*W2*T(:,j)+w2'*T(:,j)+w20 ;
if g1>=g2
XF(:,j)=T(:,j);
else
XM(:,j)=T(:,j);
end
end
n=0;
for i=1:50
if XF(1,i)>0
n=n+1;
end
end
m=0;
for k=51:300
if XM(1,k)>0
m=m+1;
end
end
N=300-m-n;
H=N/300;
N
H
%XF
%XM
%éí??ì???2??à1??D±e2aê??ù±?
clc;
clear all;
%?è?é???ê
P1=input('??éú?è?é???êê?:');
P2=input('?Déú?è?é???êê?:');
%?μá·?ù±?
[FH FW]=textread('C:\Users\xuyd\Desktop\homework\FEMALE.txt','%f %f'); [MH MW]=textread('C:\Users\xuyd\Desktop\homework\MALE.txt','%f %f'); FA=[FH FW];FA=FA';
MA=[MH MW];MA=MA';
a=cov(FA')*(length(FA)-1)/length(FA);
b=cov(MA')*(length(MA)-1)/length(MA);
a(1,2)=0;
a(2,1)=0;
b(1,2)=0;
b(2,1)=0;
W1=-1/2*inv(a);
W2=-1/2*inv(b);
Ave1=(sum(FA')/length(FA))';
Ave2=(sum(MA')/length(MA))';
w1=inv(a)*Ave1;
w2=inv(b)*Ave2;
w10=-1/2*Ave1'*inv(a)*Ave1-1/2*log(det(a))+log(P1);
w20=-1/2*Ave2'*inv(b)*Ave2-1/2*log(det(b))+log(P2);
% syms a ;
% syms b ;
% h=[a b]';
% h1=w1'*h+w10?D±eoˉêy
% h2=w2'*h+w20
%2aê??ù±?
[tH
tW]=textread('C:\Users\xuyd\Desktop\homework\test2.txt','%f %f %*s'); T=[tH tW];
T=T';
%??2aê??ù±?μ??D??
for j=1:300
g1=T(:,j)'*W1*T(:,j)+w1'*T(:,j)+w10 ;
g2=T(:,j)'*W2*T(:,j)+w2'*T(:,j)+w20 ;
if g1>=g2
XF(:,j)=T(:,j);
else
XM(:,j)=T(:,j);
end
end
n=0;
for i=1:50
if XF(1,i)>0
n=n+1;
end
end
m=0;
for k=51:300
if XM(1,k)>0
m=m+1;
end
end
N=300-m-n;
H=N/300;
N
H
%XF
%XM
%×?D?·???Bayes??2?£?éí??ì????à1??D±e2aê??ù±?
clc;
clear all;
%?μá·?ù±?
[FH FW]=textread('C:\Users\xuyd\Desktop\homework\FEMALE.txt','%f %f'); [MH MW]=textread('C:\Users\xuyd\Desktop\homework\MALE.txt','%f %f'); FA=[FH FW];FA=FA';
MA=[MH MW];MA=MA';
Ave1=(sum(FA')/length(FA))';
Ave2=(sum(MA')/length(MA))';
a=cov(FA')*(length(FA)-1)/length(FA);
b=cov(MA')*(length(MA)-1)/length(MA);
W1=-1/2*inv(a);
W2=-1/2*inv(b);
w1=inv(a)*Ave1;
w2=inv(b)*Ave2;
w10=-1/2*Ave1'*inv(a)*Ave1;
w20=-1/2*Ave2'*inv(b)*Ave2;
%2aê??ù±?
[tH
tW]=textread('C:\Users\xuyd\Desktop\homework\test2.txt','%f %f %*s'); T=[tH tW];
T=T';
%?è?é???ê?°??2?±í
P1=input('??éú?è?é???êê?:');
P2=input('?Déú?è?é???êê?:');
R=input('??2?±í?a£o');
R11=R(1,1);
R12=R(1,2);
R21=R(2,1);
R22=R(2,2);
%??2aê??ù±?μ??D±e
for j=1:300
g1=T(:,j)'*W1*T(:,j)+w1'*T(:,j)+w10 ;
g2=T(:,j)'*W2*T(:,j)+w2'*T(:,j)+w20 ;
P1F=1/(2*pi)/(det(a))^0.5*exp(g1);
P1M=1/(2*pi)/(det(b))^0.5*exp(g2);
PF1=P1F*P1/(P1F*P1+P1M*P2);
PM1=1-PF1;
R1=R11*PF1+R12*PM1;
R2=R21*PF1+R22*PM1;
if R2>=R1
XF(:,j)=T(:,j);
else
XM(:,j)=T(:,j);
end
end
n=0;
for i=1:50
if XF(1,i)>0
n=n+1;
end
end
m=0;
for k=51:300
if XM(1,k)>0
m=m+1;
end
end
N=300-m-n;
H=N/300;
R
N
H
%×?D?·???Bayes??2?£?éí??ì???2??à1??D±e 2aê??ù±?
clc;
clear all;
%?μá·?ù±?
[FH FW]=textread('C:\Users\xuyd\Desktop\homework\FEMALE.txt','%f %f'); [MH MW]=textread('C:\Users\xuyd\Desktop\homework\MALE.txt','%f %f'); FA=[FH FW];FA=FA';
MA=[MH MW];MA=MA';
Ave1=(sum(FA')/length(FA))';
Ave2=(sum(MA')/length(MA))';
a=cov(FA')*(length(FA)-1)/length(FA);
b=cov(MA')*(length(MA)-1)/length(MA);
a(1,2)=0;
a(2,1)=0;
b(1,2)=0;
b(2,1)=0;
W1=-1/2*inv(a);
W2=-1/2*inv(b);
w1=inv(a)*Ave1;
w2=inv(b)*Ave2;
w10=-1/2*Ave1'*inv(a)*Ave1;
w20=-1/2*Ave2'*inv(b)*Ave2;
%2aê??ù±?
[tH
tW]=textread('C:\Users\xuyd\Desktop\homework\test2.txt','%f %f %*s'); T=[tH tW];
T=T';
%?è?é???ê?°??2?±í
P1=input('??éú?è?é???êê?:');
P2=input('?Déú?è?é???êê?:');
R=input('??2?±í?a£o');
R11=R(1,1);
R12=R(1,2);
R21=R(2,1);
R22=R(2,2);
%??2aê??ù±?μ??D±e
for j=1:300
g1=T(:,j)'*W1*T(:,j)+w1'*T(:,j)+w10 ;
g2=T(:,j)'*W2*T(:,j)+w2'*T(:,j)+w20 ;
P1F=1/(2*pi)/(det(a))^0.5*exp(g1);
P1M=1/(2*pi)/(det(b))^0.5*exp(g2);
PF1=P1F*P1/(P1F*P1+P1M*P2);
PM1=1-PF1;
R1=R11*PF1+R12*PM1;
R2=R21*PF1+R22*PM1;
if R2>=R1
XF(:,j)=T(:,j);
else
XM(:,j)=T(:,j);
end
end
n=0;
for i=1:50
if XF(1,i)>0
n=n+1;
end
end
m=0;
for k=51:300
if XM(1,k)>0 m=m+1;
end
end
N=300-m-n;
H=N/300;
R
N
H
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/8014421721.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/8014421721.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
模式识别——用身高和或体重数据进行性别分类
用身高和/或体重数据进行性别分类 1、【实验目的】 (1)掌握最小错误率Bayes 分类器的决策规则 (2)掌握Parzen 窗法 (3)掌握Fisher 线性判别方法 (4)熟练运用matlab 的相关知识。 2、【实验原理】 (1)、最小错误率Bayes 分类器的决策规则 如果在特征空间中观察到某一个(随机)向量x = ( x 1 , x 2 ,…, x d )T ,已知类别状态的先验概率为:()i P w 和类别的条件概率密度为(|)1,2,3...i P x w i c =,根据Bayes 公式得到状态的后验概率 有:1 (|)() (|)(|)() i i i c j j j p P P p P ωωωωω== ∑x x x 基本决策规则:如果1,...,(|)max (|)i j j c P P ωω==x x ,则i ω∈x ,将 x 归属后验概率最大的类 别 。 (2)、掌握Parzen 窗法 对于被估计点X : 其估计概率密度的基本公式(x)N k N N N p V =,设区域 R N 是以 h N 为棱长的 d 维超立方体, 则立方体的体积为d N N V h =; 选择一个窗函数(u)?,落入该立方体的样本数为x x 1 ( )i N N N h i k ?-== ∑,点 x 的概率密度: x x 11 1(x)( )N i N N k N N N V h i N p V N ?-== =∑ 其中核函数:x x 1 i K(x,x )( )i N N V h ?-=,满足的条件:i (1) K(x,x )0≥;i (2) K(x,x )dx 1=?。 (3)、Fisher 线性判别方法 Fisher 线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将
身高体重分析
经济运行模拟:身高体重分析 姓名:王萌萌 学号:20094120216 指导老师:乔雅君 院系:经济学院
身高体重分析 王萌萌 (河南财经政法大学经济学院郑州 450000) 一、实验目的 为了研究河南财经政法大学09级经济学院同学身高体重的关系,同时考虑性别因素对体重的影响。建立身高体重模型,首先对经济二班同学的身高体重回归分析。为了进一步说明身高对于体重的影响,同时对经济学院四个班同学的身高体重进行回归分析。 二、数据说明 表 1:09级经济学院四个班学生身高体重数据
以上数据由09级经济学院学生登记提供 三、实证分析 (一)09级经济二班同学的身高体重简单回归分析 1.建立模型 为了分析09级经济二班身高体重的关系。估计模型如下: u H W +?+?=10 其中W 代表体重(kg ),H 代表身高(cm),10??、代表回归系数,u 代表随机误差项。 2.估计结果 通过运行Eviews5.0估计结果如下: 表二:二班同学身高h (cm )体重w (kg )估计结果 Dependent Variable: W Method: Least Squares Date: 05/11/12 Time: 08:41 Sample: 1 43 Included observations: 43
Variable Coefficient Std. Error t-Statistic Prob. H 1.238985 0.152011 8.150606 0.0000 C -150.4884 25.78017 -5.837373 0.0000 R-squared 0.618365 Mean dependent var 59.41860 Adjusted R-squared 0.609056 S.D. dependent var 12.28284 S.E. of regression 7.679906 Akaike info criterion 6.960487 Sum squared resid 2418.219 Schwarz criterion 7.042403 Log likelihood -147.6505 F-statistic 66.43238 Durbin-Watson stat 1.950340 Prob(F-statistic) 0.000000 估计方程为: H W 238985.14884.150?+-= 25.78017 0.152011 t 值 -5.837373 8.150606 P 值 0.0000 0.0000 2R =0.618365,2R =0.609056,F=66.43238(P=0.0000) 3.模型检验 P 检验:由表一可知,p 值(0.0000),在0.05的显著水平下,p 值小于0.05,拒绝原假设。说明二班同学身高对体重的影响是显著的。 (二)二班数据加虚拟变量回归(加法模型) 1.建立模型 为了研究二班同学身高体重关系,并考虑性别因素建立模型如下 加法模型u S H W +?+?+?=210其中W 代表体重(kg ),H 代表身高(cm ),S 代表性别, ?? ?=女 男10S 为虚拟变量,10??、是回归系数,u 是随机误差项。 表三:二班同学身高体重模型考虑性别因素估计结果(加法模型) Dependent Variable: W Method: Least Squares Date: 05/11/12 Time: 09:12 Sample: 1 43 Included observations: 43 Variable Coefficient Std. Error t-Statistic Prob. S -7.591082 4.365116 -1.739033 0.0897 H 0.820754 0.282592 2.904375 0.0060 C -75.57212 49.89161 -1.514726 0.1377
用身高和体重数据进行性别分类的实验报告
用身高和体重数据进行性别分类的实验报告(二) 一、 基本要求 1、试验非参数估计,体会与参数估计在适用情况、估计结果方面的异同。 2、试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分类器进行比较。 3、体会留一法估计错误率的方法和结果。 二、具体做法 1、在第一次实验中,挑选一次用身高作为特征,并且先验概率分别为男生0.5,女生0.5的情况。改用Parzen 窗法或者k n 近邻法估计概率密度函数,得出贝叶斯分类器,对测试样本进行测试,比较与参数估计基础上得到的分类器和分类性能的差别。 2、同时采用身高和体重数据作为特征,用Fisher 线性判别方法求分类器,将该分类器应用到训练和测试样本,考察训练和测试错误情况。将训练样本和求得的决策边界画到图上,同时把以往用Bayes 方法求得的分类器也画到图上,比较结果的异同。 3、选择上述或以前实验的任意一种方法,用留一法在训练集上估计错误率,与在测试集上得到的错误率进行比较。 三、原理简述及程序框图 1、挑选身高(身高与体重)为特征,选择先验概率为男生0.5女生0.5的一组用Parzen 窗法来求概率密度函数,再用贝叶斯分类器进行分类。 以身高为例 本次实验我们组选用的是正态函数窗,即21()2u u φ?? = -???? ,窗宽为N h h =h 是调节的参量,N 是样本个数) d N N V h =,(d 表示维度)。因为区域是一维的,所以体积为N n V h =。Parzen 公式为()?N P x =111N i i N N x x N V h φ=??- ???∑。 故女生的条件概率密度为11111111N i i n x x p N VN h φ=??-= ??? ∑
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
实验报告
实验三人体身体素质的测定 [实验目的] 掌握测定身体素质的测试方法 [实验对象] 学生xxx [器材] 握力计、背力计、纵跳仪、闭眼单脚站立仪、身高体重仪 [步骤] 1 握力 将握柄调至受试者2—5指的第二关节至大拇指虎口的距离→一手握住握力计,双臂下垂,全力握握力计→读数最大时即为握力值(连测3次,每次中间间隔30S,取最大值)。 2 背力 站于背力计踏板指定位置→上体前倾30度→手心向里紧握把柄,双腿伸直,用最大力量拉背力计(连测3次,每次中间间隔30S,取最大值)。 3纵跳 测试时,受试者站在纵跳仪踏板上,尽力垂直向上跳起。测试两次取最大值记录以厘米为单位,保留小数点后一位。 4、闭眼单脚站立仪 自动测试人闭眼单足站立的时间,反映人体的平衡能力。能准确判断测试者站立脚移动和抬起脚下落的动作。 5、身高体重仪 立正姿势站在测试仪的底板上,上肢自然下垂,脚跟并拢,足尖分开约成60度角。躯干自然挺直,头部正直,两眼平视;赤足。电子进行测试;同时测试出人体体重;并进行BMI的分析。 结果与分析 身高: cm 体重: kg BMI: 为正常还是 握力: kg 背力: kg 纵跳: cm 闭眼单脚站立: s
四、人体ABO血型试验 一、实验目的:掌握测定人体血型的方法 二、原理:血型是红细胞上特异抗原的类型。在 ABO血型系统,根据红细胞上是否含有A、B抗原而分为A、B、AB、O血型。血型鉴定是将受试者的红细胞加入标准A型血清(含足量的抗B抗体)与标准B型血清(含足量的抗A抗体)中,观察有无凝集现象,从而测知受试者红细胞上有无A抗原或B抗原。 三、实验用设备:采血针、玻片、滴管、牙签、标准A、B型血清、酒精棉球、消毒棉签。 四、实验对象:体育学院*班学生 XXX 五、实验内容与方法: 1、酒精棉球消毒左手无名指端,用消毒采血针刺破皮肤。将血液挤压滴在滴在玻片的两侧。 2、将标准 A型与B型血清各一滴,滴在玻片的两侧,分别标用A与B。 3、用两支牙签分别混匀(注意严防两种血清接触)。 4、15min后用肉眼观察有无凝集现象。 六、结果与分析 经检验,本人的血型为
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
R语言实验报告—回归分析在女性身高与体重的应用
R语言实验报告 回归分析中 身高预测体重的模型 学院: 班级: 学号: 姓名: 导师: 成绩:
目录 一、实验背景 (1) 二、实验目的 (1) 三、实验环境 (1) 四、实验内容 (1) 1.给出实验女性的身高体重信息; (2) 2.运用简单线性回归分析; (2) 3.运用多项式回归分析 (2) 五、实验过程 (2) (一)简单线性回归 (2) 1.展示拟合模型的详细结果 (2) 2.女性体重的数据 (2) 3.列出拟合模型的预测值 (3) 4.列出拟合模型的残差值 (3) 5.得出身高预测体重的散点图以及回归线 (3) (二)多项式回归 (5) 1.展示拟合模型的详细结果 (5) 2.身高预测体重的二次回归图 (5) 六、实验分析 (7) 七、总结 (7)
一、实验背景 从许多方面来看,回归分析都是统计学的核心。她其实是一个广义的概念,通指那些用一个或多变量(也称自变量或解释变量)来预测响应变量(也称因变量、效标变量或结果变量)的方法。通常,回归分析可以用来挑选与响应变量相关的解释变量,可以描述两者的关系,也可以生成一个等式,通过解释变量来预测响应变量。 二、实验目的 R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具; 本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析; 通过本实验加深对课本知识的理解以及熟练地运用R语言软件来解决一些复杂的问题。 三、实验环境 Windows系统,R或者R Studio 四、实验内容 本实验提供了15个年龄在30—39岁间的女性的身高和体重信息,运用回归分析的方法通过身高来预测体重,获得一个等式可以帮助我们分辨哪些过重或过轻的个体。
人体实验报告
人体实验报告 篇一:人体尺寸实验报告 实验报告 一、实验目的 通过课桌椅设计,切实感受和认识人的因素在产品设计中的重要性,初步领会在产品设计中正确处理人的因素的方法。 同时了解座椅与人体骨骼结构、血液循环、体压、肌肉、神经等生理解剖因素的关系,以及怎么样才能设计符合人体生理解剖要求的课桌椅。 二、实验要求 通过对人体测量部分知识的复习,并对如何进行正确的人体测量,以及各种测量工具使用的介绍,要求学生全面掌握人体测量的正确方法并熟练运用到设计中。利用已掌握的正确人体测量方法,运用相应的测量工具,3-5人一组,完成个人数据的测量,并对如何进行课桌椅的设计展开初步的方案思考。 三、实验步骤: 1、认识测量工具 测量中所需仪器:人体侧高仪、人体测量用直角规、人体测量用弯角规、软卷尺 A、人体侧高仪 技术标准:国标GB5704.1-85
适用范围:适用于读数为1mm,测量范围为0-1996mm人体高度尺寸的测量 B、人体测量用直脚规技术标准:国标GB5704.2-85 适用范围:适用于读数为1mm和0.1mm,测量范围为0-200mm和0-250mm人体尺寸的测量 C、人体测量用弯脚规技术标准:国标GB5704.3-85 适用范围:适用于读数为1mm,测量范围为0-300mm的人体尺寸的测量 2、介绍人体测量方法 1)测量条件 本标准所规定的测量方法,只有在被测者姿势、测量基准面和其他测量条件符合下列要求的前提下始有效。 1.1 基本姿势 1.1.1 直立姿势(简称:立姿)被测者挺胸直立,头部以眼耳平面定位,眼睛平视前方,肩部放松,上肢自然下垂,手伸直,手掌朝向体侧,手指轻贴大腿侧面,膝部自然伸直,左、右足后跟并拢,前端分开,使两足大致呈45°夹角,体重均匀分布于两足。为确保直立姿势正确,被测者应使足后跟、臀部和后背部与同一铅垂面相接触。(内容可略) 1.1.2 坐姿被测者挺胸坐在被调节到腓骨头高度的平面上,头部以眼耳平面定位,眼睛平视前方,左、右大腿大致平行,膝大致弯屈成直角,足平放在地面上,手轻放在大腿上。为确保坐姿正确,被测者的臀部、后背部应同时靠在
数据分析与挖掘实验报告
数据分析与挖掘实验报告
《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30)
1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数
据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组
人体尺寸测量实验报告
人体尺寸测量实验报告 篇一:人体尺寸实验报告 实验报告 一、实验目的 通过课桌椅设计,切实感受和认识人的因素在产品设计中的重要性,初步领会在产品设计中正确处理人的因素的方法。 同时了解座椅与人体骨骼结构、血液循环、体压、肌肉、神经等生理解剖因素的关系,以及怎么样才能设计符合人体生理解剖要求的课桌椅。 二、实验要求 通过对人体测量部分知识的复习,并对如何进行正确的人体测量,以及各种测量工具使用的介绍,要求学生全面掌握人体测量的正确方法并熟练运用到设计中。利用已掌握的正确人体测量方法,运用相应的测量工具,3-5人一组,完成个人数据的测量,并对如何进行课桌椅的设计展开初步的方案思考。 三、实验步骤: 1、认识测量工具 测量中所需仪器:人体侧高仪、人体测量用直角规、人
体测量用弯角规、软卷尺 A、人体侧高仪 技术标准:国标GB5704.1-85 适用范围:适用于读数为1mm,测量范围为0-1996mm人体高度尺寸的测量 B、人体测量用直脚规技术标准:国标GB5704.2-85 适用范围:适用于读数为1mm和0.1mm,测量范围为0-200mm和0-250mm人体尺寸的测量 C、人体测量用弯脚规技术标准:国标GB5704.3-85 适用范围:适用于读数为1mm,测量范围为0-300mm的人体尺寸的测量 2、介绍人体测量方法 1)测量条件 本标准所规定的测量方法,只有在被测者姿势、测量基准面和其他测量条件符合下列要求的前提下始有效。 1.1 基本姿势 1.1.1 直立姿势(简称:立姿)被测者挺胸直立,头部以眼耳平面定位,眼睛平视前方,肩部放松,上肢自然下垂,手伸直,手掌朝向体侧,手指轻贴大腿侧面,膝部自然伸直,左、右足后跟并拢,前端分开,使两足大致呈45°夹角,体
数据挖掘实验报告 超市商品销售分析及数据挖掘
通信与信息工程学院 课程设计说明书 课程名称: 数据仓库与数据挖掘课程设计题目: 超市商品销售分析及数据挖掘专业/班级: 电子商务(理) 组长: 学号: 组员/学号: 开始时间: 2011 年12 月29 日完成时间: 2012 年01 月 3 日
目录 1.绪论 (1) 1.1项目背景 (1) 1.2提出问题 (1) 2.数据仓库与数据集市的概念介绍 (1) 2.1数据仓库介绍 (1) 2.2数据集市介绍 (2) 3.数据仓库 (3) 3.1数据仓库的设计 (3) 3.1.1数据仓库的概念模型设计 (4) 3.1.2数据仓库的逻辑模型设计 (5) 3.2 数据仓库的建立 (5) 3.2.1数据仓库数据集成 (5) 3.2.2建立维表 (8) 4.OLAP操作 (10) 5.数据预处理 (12) 5.1描述性数据汇总 (12) 5.2数据清理与变换 (13) 6.数据挖掘操作 (13) 6.1关联规则挖掘 (13) 6.2 分类和预测 (17) 6.3决策树的建立 (18) 6.4聚类分析 (22) 7.总结 (25) 8.任务分配 (26)
数据挖掘实验报告 1.绪论 1.1项目背景 在商业领域中使用计算机科学与技术是当今商业的发展方向,而数据挖掘是商业领域与计算机领域的乔梁。在超市的经营中,应用数据挖掘技术分析顾客的购买习惯和不同商品之间的关联,并借由陈列的手法,和合适的促销手段将商品有魅力的展现在顾客的眼前, 可以起到方便购买、节约空间、美化购物环境、激发顾客的购买欲等各种重要作用。 1.2提出问题 那么超市应该对哪些销售信息进行挖掘?怎样挖掘?具体说,超市如何运用OLAP操作和关联规则了解顾客购买习惯和商品之间的关联,正确的摆放商品位置以及如何运用促销手段对商品进行销售呢?如何判断一个顾客的销售水平并进行推荐呢?本次实验为解决这一问题提出了解决方案。 2.数据仓库与数据集市的概念介绍 2.1数据仓库介绍 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它并不是所谓的“大型数据库”。........ 2.2数据集市介绍 数据集市,也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库。....... 3.数据仓库 3.1数据仓库的设计 3.1.1数据库的概念模型 3.1.2数据仓库的模型 数据仓库的模型主要包括数据仓库的星型模型图,我们创建了四个
身高体重实验报告
身 高 体 重 关 系 实 验 报 告 姓名:李智辉 班级:经济二班 学号:20094120213
实验报告:身高体重模型 李智辉 (河南财经政法大学经济2班河南郑州) 一、实验目的 首先以09级经济二班的身高体重数据得出身高与体重的关系是不显著的,这是因为数据偏少造成的。于是,扩大数据容量,以经济学院09级四个班的身高体重数据进行模型估计,得出身高与体重的关系是显著的。然后引入了性别虚拟变量,分别对男、女的身高体重的关系进行了估计,最后得出了“无论男女,身高与体重的关系都是显著的”的结论。 最终的实验目的是通过对身高体重模型的估计,得出身高与体重的关系是显著的。 二、数据说明 通过对河南财经政法大学经济学院四个班的学生进行实际调查统计,我们得到四个班同学的身高(cm)、体重(kg)、数据,如下列表: 表1:经济二班的数据 身高H体重W性别S身高H体重W性别S 18080男16147女 17259男16051女 17066男16045女 16952女16052女 16452女16054女 17055男16046女 16050女16257女 17254女17671男 16247女18770男 18290男18770男 16453女17256男 17055男17875男 17680男17560男 17668男16342女 16854女17861男 16757女17560男 16553女17575男 16350女17964男 16251女17695男 16046女16255女 16752女17575男 16550女
表2:经济学院四个班身高体重数据 经济一班经济二班经济三班经济四班 身高体 重 性 别 身 高 体 重 性 别 身 高体重 性 别 身 高体重 性 别 165 58 女180 80 男165 70 男160 46 女170 60 男172 59 男160 63 女165 55 女176 56 男170 66 男171 62 女165 50 女168 58 女169 52 女174 62 男161 53 女164 50 女164 52 女158 46 女168 58 女173 75 男170 55 男158 47 女166 60 女169 54 女160 50 女179 65 男177 63 男162 55 女172 54 女175 64 男159 54 女173 59 男162 47 女160 60 女161 53 女170 63 男182 90 男163 55 女157 52 女165 55 男164 53 女161 60 女165 55 男176 68 男170 55 男163 55 女159 54 女173 60 男176 80 男158 40 女162 53 女173 58 男176 68 男167 52 女160 58 女172 55 男168 54 女180 62 男160 48 女155 45 女167 57 女172 65 男163 48 女186 88 男165 53 女175 65.5 男162 47 女175 56 男163 50 女160 50 女163 55 女165 55 男162 51 女180 78 男162 47 女168 54 女160 46 女158 53 女160 51 女170 65 男167 52 女181 80 男160 57 女170 55 男165 50 女172 60 男160 44 女165 53 女161 47 女172 76 男165 51.5 女165 53 女160 51 女176 73 男162 50 女163 48 女160 45 女163 52 女170 60 男159 55 女160 52 女173 65 男175 65 男181 78 男160 54 女161 60 女170 58 男170 66 男160 46 女164 50 女171 80 男158 46 女162 57 女166 53 女166 59 男162 50 女176 71 男187 80 男167 54 女168 62 女187 70 男163 53 女167 55 女163 50 女187 70 男161 55 女170 60 男165 54 女172 56 男173 65 男172 76 男159 52 女178 75 男176 70 男170 55 男168 52 女175 60 男178 69 男176 70 男155 50 女163 42 女170 60 男169 61 男163 60 女178 61 男172 56 女169 72 男160 58 女175 60 男163 53 女170 72 男160 45 女175 75 男174 60 男172 55 男168 58 女179 64 男158 43 女178 75 男163 50 女176 95 男167 55 男175 65 男175 65 男162 55 女 175 75 男
数据挖掘实验报告一
数据预处理 一、实验原理 预处理方法基本方法 1、数据清洗 去掉噪声和无关数据 2、数据集成 将多个数据源中的数据结合起来存放在一个一致的数据存储中 3、数据变换 把原始数据转换成为适合数据挖掘的形式 4、数据归约 主要方法包括:数据立方体聚集,维归约,数据压缩,数值归约,离散化和概念分层等二、实验目的 掌握数据预处理的基本方法。 三、实验内容 1、R语言初步认识(掌握R程序运行环境) 2、实验数据预处理。(掌握R语言中数据预处理的使用) 对给定的测试用例数据集,进行以下操作。 1)、加载程序,熟悉各按钮的功能。 2)、熟悉各函数的功能,运行程序,并对程序进行分析。 对餐饮销量数据进统计量分析,求销量数据均值、中位数、极差、标准差,变异系数和四分位数间距。 对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 3)数据预处理 缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理 对连续属性离散化:用等频、等宽等方法对数据进行离散化处理 四、实验步骤 1、R语言运行环境的安装配置和简单使用 (1)安装R语言 R语言下载安装包,然后进行默认安装,然后安装RStudio 工具(2)R语言控制台的使用 1.2.1查看帮助文档
1.2.2 安装软件包 1.2.3 进行简单的数据操作 (3)RStudio 简单使用 1.3.1 RStudio 中进行简单的数据处理 1.3.2 RStudio 中进行简单的数据处理
2、R语言中数据预处理 (1)加载程序,熟悉各按钮的功能。 (2)熟悉各函数的功能,运行程序,并对程序进行分析 2.2.1 销量中位数、极差、标准差,变异系数和四分位数间距。 , 2.2.2对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。
用身高和体重数据进行分类实验
用身高和体重数据进行性别分类的实验报告 一、基本要求: 1.用FAMALE.TXT和MALE.TXT的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。二、具体做法: (1)应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。在分类器设计时可以考察采用不同先验概率(如0.5对0.5, 0.75对0.25, 0.9对0.1等)进行实验,考察对决策规则和错误率的影响。 (2)应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关,在正态分布假设下估计概率密度,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。比较相关假设和不相关假设下结果的差异。在分类器设计时可以考察采用不同先验概率(如0.5 vs. 0.5, 0.75 vs. 0.25, 0.9 vs. 0.1等)进行实验,考察对决策和错误率的影响。 (3)自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。 三、原理简述及程序框图 最小错误率Bayes分类器 (1)基于身高 第一步求出训练样本的方差和期望 第二步利用单变量正态分布公式算出条件概率 第三步将前两步的值带入贝叶斯公式
第四步 若pF>=pM ,则判断其为第一类,反之,第二类 (2-1) 假设身高与体重不相关 令协方差矩阵次对角元素为零 判别函数可简化为()0T T i i i i g x x W x w x w =++ 其中 11 2 i i W -=-∑,1i i w μ-=∑ ()1 01122 i T i i i i w u u In InP ω-=-∑-∑+ 具体算法步骤如下: 第一步将训练样本集数据转为矩阵FA ,MA 。 第二步分别对FA ,MA 求取协方差12,∑∑,令协方差矩阵次对角 元素为零,平均值12,μμ并输入先验概率()()12,P P ωω 第三步将第二步所得数值代入判别函数表达式得()()12,g x g x 。 第四步将待测样本集数据转为矩阵T ,将T 中数值依次代()()12g x g x - ,若()()120g x g x ->,则判断其为第一类,反之,第二类。
数据挖掘实验报告(参考)
时间序列的模型法和数据挖掘两种方法比较分析研究 实验目的:通过实验能对时间序列的模型法和数据挖掘两种方法的原理和优缺点有更清楚的认识和比较. 实验内容:选用1952-2006年的中国GDP,分别对之用自回归移动平均模型(ARIMA) 和时序模型的数据挖掘方法进行分析和预测,并对两种方法的趋势和预测结果进行比较并 给出解释. 实验数据:本文研究选用1952-2006年的中国GDP,其资料如下 日期国内生产总值(亿元)日期国内生产总值(亿元) 2006-12-312094071997-12-3174772 2005-12-311830851996-12-31 2004-12-311365151995-12-31 2003-12-311994-12-31 2002-12-311993-12-31 2001-12-311992-12-31 2000-12-31894041991-12-31 1999-12-31820541990-12-31 1998-12-31795531989-12-31 1988-12-311969-12-31 1987-12-311968-12-31 1986-12-311967-12-31 1985-12-311966-12-311868 1984-12-3171711965-12-31 1983-12-311964-12-311454 1982-12-311963-12-31 1981-12-311962-12-31 1980-12-311961-12-311220 1979-12-311960-12-311457 1978-12-311959-12-311439 1977-12-311958-12-311307 1976-12-311957-12-311068 1975-12-311956-12-311028 1974-12-311955-12-31910 1973-12-311954-12-31859 1972-12-311953-12-31824 1971-12-311952-12-31679 1970-12-31 表一 国内生产总值(GDP)是指一个国家或地区所有常住单位在一定时期内生产活动的最终成果。这个指标把国民经济全部活动的产出成果概括在一个极为简明的统计数字之中为评价和衡量国家经济状况、经济增长趋势及社会财富的经济表现提供了一个最为综合的尺度,可以说,
用身高和或体重数据进行性别分类的实验
未来若干次作业需要用到的数据文件: ●FAMALE.TXT 50个女生的身高、体重数据 ●MALE.TXT 50个男生的身高、体重数据 ----- 训练样本集 ●test1.txt 35个同学的身高、体重、性别数据(15个女生、20个男生) ●test2.txt 300个同学的身高、体重、性别数据(50个女生、250个男生) ----- 测试样本集 作业. 用身高和/或体重数据进行性别分类的实验(一) 基本要求: 用FAMALE.TXT和MALE.TXT的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。 具体做法: 1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。在分类器设计时可以考察采用不同先验概率(如0.5对 0.5, 0.75对0.25, 0.9对0.1等)进行实验,考察对决策规则和错误率的影响。2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关,在正态分布假设下估计概率密度,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。比较相关假设和不相关假设下结果的差异。在分类器设计时可以考察采用不同先验概率(如0.5 vs. 0.5, 0.75 vs. 0.25, 0.9 vs. 0.1等)进行
数据挖掘文本分类实验报告
北京邮电大学 ****学年第1学期实验报告 课程名称:数据仓库与数据挖掘 实验名称:文本的分类 实验完成人: 姓名:*** 学号:*&*** 姓名:** 学号:**
日期:
实验一:文本的分类 1.实验目的 ◆掌握数据预处理的方法,对训练集数据进行预处理; ◆掌握文本分类建模的方法,对语料库的文档进行建模; ◆掌握分类算法的原理,基于有监督的机器学习方法,训 练文本分类器; ◆了解SVM机器学习方法,可以运用开源工具完成文本分 类过程。 2.实验分工 ***: (1)对经过分词的文本进行特征提取并用lisvm进行训练 (2)用训练的模型对测试数据进行预测 ***: (1)数据采集和预处理 (2)分词 3.实验环境 Ubuntu 13.04+jdk1.7
4.主要设计思想 4.1 实验工具介绍 1.NLPIR_ICTCLAS2013 NLPIR (又名ICTCLAS2013),是由中科院张华平博士倾力打造的汉语分词系统。其主要功能包括中文分词、词性标注、命名实体识别、用户词典功能、支持GBK编码、UTF8编码、BIG5编码等。 从NLPIR官网可以下载其最新版的Java发布包,然后导入Eclipse,配置运行环境,实现对于语料库的分词。 最新的NLPIR可以通过更改源代码实现新增新词识别、关键词提取、微博分词等功能,极大地方便了使用。 2. Eclipse for Java Eclipse 是一个开放源代码的、基于Java的可扩展开发平台。就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境。幸运的是,Eclipse 附带了一个标准的插件集,包括Java开发工具(Java Development Kit,JDK)。 3. LibSVM 本次实验中我们采用的是台湾大学林智仁博士等开发设计的LIBSVM方法。这是一个操作简单、易于使用、快速有效的通用SVM 软件包,可以解决分类问题(包括C?SVC 、ν?SVC ),回归问题(包括ε ? SVR 、v? SVR ) 以及分布估计(one ?