怎样快速识别和翻译图片中的文字
怎样快速识别和翻译图片中文字
在生活中我们经常遇到识别图中文字的问题,有时候还需要将图片文字进行翻译,这就很令人头疼了,那有什么快速识别和翻译图中文字的方法吗?小编这就来带大家了解下。
使用工具:迅捷OCR文字识别软件。
1:现在电脑中打开迅捷OCR文字识别软件,因为这是一款PC端的软件,所以整个的操作步骤都是在电脑中完成的,接着将自动弹出来的窗口关闭一下。
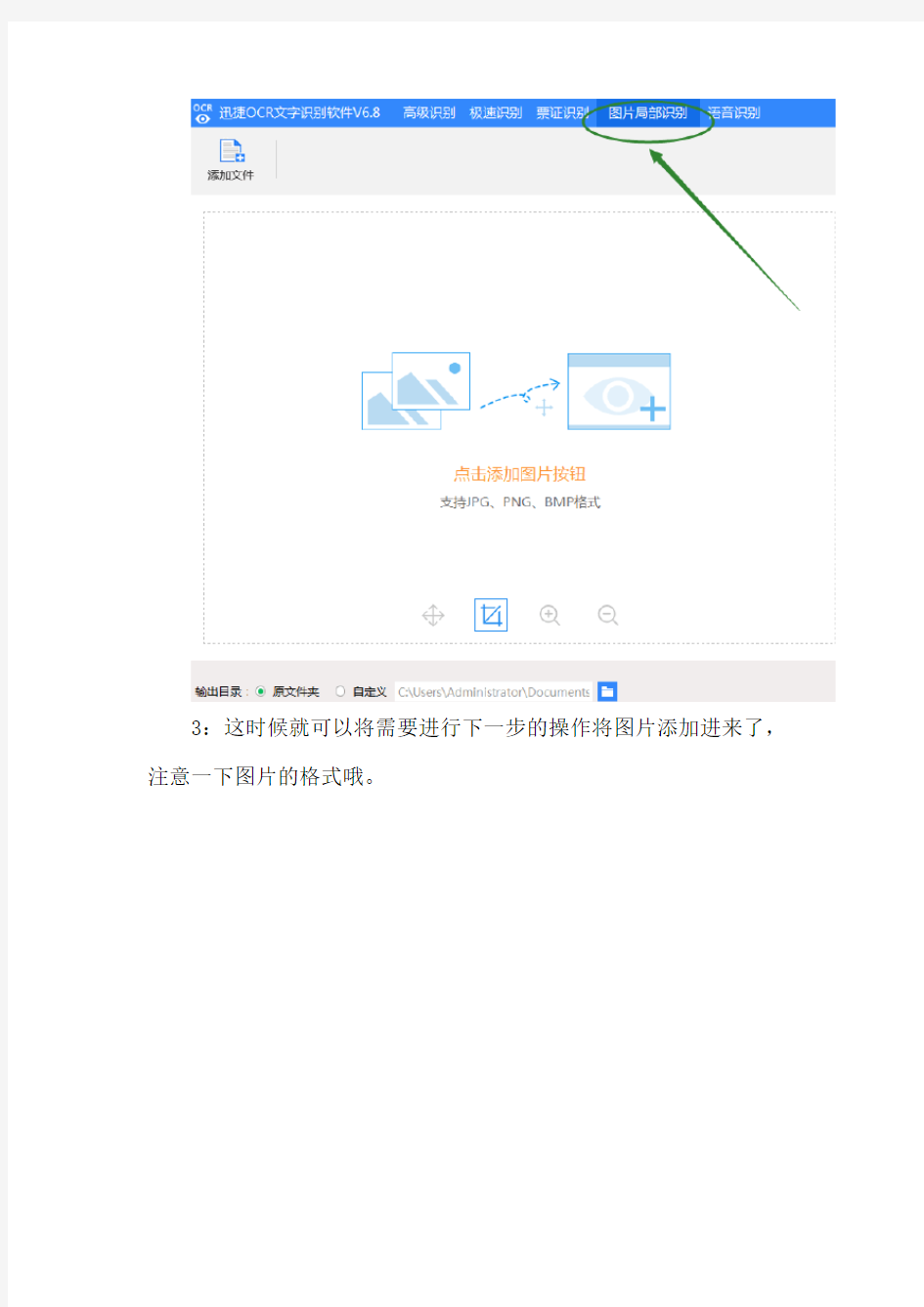
2:关闭弹窗后点击软件上方图片局部识别板块。
3:这时候就可以将需要进行下一步的操作将图片添加进来了,注意一下图片的格式哦。
4:图片添加进来后你会看到下方有一排工具,你可以利用这些小工具来调整一下图片,工具的作用分别是移动图片位置、框选进行识别、放大图片、缩小图片。
5:图片调整好以后,点击框选工具,拖动鼠标在图片上进行文字框选,然后松开鼠标后就可以自动识别了,等待一小会。
6:识别提取出来后的文字会呈现在右边方框里面,翻译文字的话只需在下拉框选择好自己需要翻译成的语言,再点击翻译按钮就好了。
7:翻译出来的文字就会在下面的方框中显示了,这时候点击右下角保存为TXT按钮保存一下就好了,整个的步骤就完成了。
上述的方法是不是很简单呢?希望能对您有所帮助。
图片文字识别有哪些方法
图片文字识别有哪些方法 在生活中经常遇到要将一张图片中的文字识别出来的时候,那你平时会使用到什么工具或者方法去进行图片文字识别呢?如果使用了一种对的方法就会让你快速识别出来图片文字而且识别效果也不错,达到事半功倍的效果,那什么是对的方法呢?跟着小编一起来看看这种方法的操作步骤吧! 使用工具:捷速OCR文字识别软件。 软件介绍:这款软件主要是利用OCR技术通过字符识别的方法将图片转换成可以编辑的文本,它可以帮助你识别多种票据和多种文件格式的图片,支持多种格式文档,包括JPG、PNG、PDF、等快速精准识别,实现文档数字化,如果想要识别图片文字的话,通过使用捷速OCR文字识别软件https://www.360docs.net/doc/837209165.html,就可以帮你解决问题了。具体操作步骤: 1、接下来的步骤使用到的是一款捷速OCR文字识别软件,电脑 中有这款软件的可以直接打开,没有的话也也没有关系,可以 去官网上下载安装一个。
2、打开软件,你会看到这样一个页面,在这上面你可以了解到这 款软件的主要特点优势,看完了之后点击退出按钮退出该页面。
3、接着点击软件上方极速识别功能,这里可以将图片中的文字识 别出来。
4、点击添加文件按钮将你所要识别的图片添加进来,如下图所示: 5、图片添加进来之后它会让你选择识别格式和识别效果,可以根
据你自己的需要来进行选择(这里以DOCX、识别优先为例) 6、接着在软件下方这里设置一下文件保存位置,你可以放在原文 件夹,也可自定义在电脑中的其它地方,根据自己的需要来选 择就好。
7、保存位置设置好就可以开始识别图片了,点击开始识别按钮, 软件就会自动去识别了。
手写文字识别技术的研究
手写文字识别技术的研究 关兵 摘要:随着计算机性能的提高和科技的不断发展,随着信息时代的到来,为适应社会的需要,文字识别技术也将更完善。OCR技术,利用光学技术对文字或字符进行扫描并转换成计算机内码,其工作原理是通过扫描仪或数码相机等输入设备获取文字、表格、图片等信息,利用各种模式算法分析文字形态特征,判断出文字的标准编码存储在文件中。在现实生活中有着广泛的应用价值。 关键词:手写文字识别 OCR技术形态特征模式识别 引言 计算机文字识别,俗称光学文字识别,其英文术语为Optical Character Recognition(缩写为OCR),是指通过计算机技术及光学技术对印刷或书写的文字进行自动的识别,达到认知的目的,是实现文字高速自动录入的一项关键技术。到目前为止,汉字OCR是模式识别技术的一个分支,其主要目的是将汉字(手写体与印刷体)自动读入计算机。而手写文字识别技术,是指通过计算机来识别手写文字的一种识别文字的技术。 随着信息化的到来,OCR文字识别技术发展很快,在日常生活中日益重要。文字识别是中文信息录入的快捷手段,由于汉字是非字母、非拼音化的文字,笔划复杂多样,人工键入速度慢而劳动强度大,计算机自动识别文字或语言方式解决了这一难题,能快速高效地将汉字输入进计算机;文字识别技术是提高办公自动化水平的主要因素。办公自动化就是要借助计算机来进行文档的处理,以代替人们日常的办公活动,在现代社会,图像信息占有较大的比重,存在大量文字信息,因此,文字的自动识别对图像的处理有重要的意义;文字识别技术丰富和完善了文字识别理论。现在人们已可通过手写文件经OCR产品的识别录入计算机,大大推动发展了文字识别理论;文字识别是智能计算机智能接口的重要组成部分,智能计算机能认识文字、图像和景物,能听懂语音、理解文字。视觉是智能计算机接受外界信息的主要手段,而识别文字是智能计算机必备的功能。 一、OCR技术的发展 OCR概念的诞生,要早于计算机的问世。早期的OCR多以文字的识别方法研究为主,识别的文字当时仅为0-9这几个数字。后来随着计算机的出现和发展,OCR研究才在全球范围内广泛研究和发展。OCR发展至今,可分为三个阶段: 1、第一代OCR产品出现于60年代初期,在此期间,IBM公司、NCR等公司分别研制出了自己的OCR软件,最早的OCR产品应该是IBM公司的IBM1418。它们只能识别印刷体的数字, 英文字母及部分符号,而且都是指定的字体。60年代末,日立公司和富士通公司也 研制出了各自的OCR产品。 2、第二代OCR系统是基于手写体字符的识别,前期只限于手写体数字,从时间上来看,是60年代中期到70年代初期。 1965年IBM公司研发出IBM1287,并在纽约世界博览会上展出,开始能识别印刷体数字、英文字母及部分简单的符号。第一个实现信函自动分拣系统的是东芝公司,两年后NEC公司也推出了这样的系统,到1974年,分拣率达到92%-93%。 3、第三代OCR系统要解决的技术问题是对于质量较差的文稿及大字符集的识别,例如汉字的识别。1966年,IBM公司开发的OCR系统利用简单的模板匹配法识别了1000个复杂的印刷体汉字,到了1977年,东芝公司又制出可识别2000多印刷体汉字的单字汉字识别系统。
基于K—means的图像文字识别与提取研究
龙源期刊网 https://www.360docs.net/doc/837209165.html, 基于K—means的图像文字识别与提取研究作者:段银雷 来源:《电子技术与软件工程》2015年第09期 摘要 K-means聚类算法作为最常用的集合元素划分算法,在数字图像文字定位、提取与识别中有着广泛的应用。文中针对当前图像文字识别与提取的最新发展状况,提出一种基于 K-means的图像文字识别与提取算法。经过上机测试,该算法能够有效提高图像文字识别与提取的准确率与执行效率。 【关键词】K-means 图像文字提取文字识别 OCR 1 引言 K-means聚类算法是当前常用的基于划分的分类算法,能够按照既定标准与要求将集合进行划分。在数字图像文字提取与识别中,可以通过对数字图像进行灰度处理,将文字背景与文字前景用不同的灰度像素来表示,并使用K-means聚类算法进行像素划分,从而将文字从数字图像中提取出来,作为OCR识别的图像输入。 2 K-means聚类算法基本原理 K-means聚类算法的基本思想是利用集合元素之间的距离为划分标准,在集合内部按照元素的分布密度的不同将元素划分为不同的子集合。在划分过程中,通过定义元素之间的距离,按照元素到聚类中心之间的距离最小原则将元素进行聚合,从而得到最终的划分结果。主要包括以下几个步骤:(1)根据元素划分的基本要求,从集合元素中随机选择k个元素作为划分结果的中心元素,并针对集合中的每个元素计算其到聚类中心元素的距离大小,并按照最小距离原则把各个元素划分到对应的聚类中心元素集合中;(2)按照划分结果对各个子集合中的元素计算特征均值,并根据计算结果对划分结果进行更新操作;(3)对更新后的子集合元素再次按照第一步中的方法进行聚类操作,从而得到更新后的元素划分结果;(4)按照上述步骤进行循环计算,当两次计算所得到的的聚类中心元素相同时,所得到的划分结果即为聚类结果。 K-means聚类算法的基本流程比较固定,其本质是在给定集合元素距离计算方法后,不断进行聚类迭代与循环运算对元素进行聚类划分,在应用过程中只需要定义合适的距离计算方法即可将K-means算法转化为软件程序进行上机运行。采用K-means聚类算法的缺陷主要是在选择聚类中心元素时,算法受到样本元素的选择随机性和外部噪声的影响比较显著,如果不进行有效的算法优化则比较容易导致算法陷入局部最优,因此在采用K-means的图像文字提取与识别处理中需要根据图像特征对算法进行改进与优化。 3 算法流程设计
开题报告(基于神经网络的车牌字符识别方法研究及仿真实现)(可编辑修改word版)
西安科技大学 毕业设计(论文) 开题报告 题目基于神经网络的车牌字符识别方法研究及仿真实现院、系(部) 通信与电子信息工程学院 专业及班级电子信息工程专业 姓名 学号 指导教师 日期
西安科技大学毕业设计(论文)开题报告
[7]陈振学,汪国有,刘成云. 一种新的车牌图像字符分割与识别算法[J]. 微电子学与计算机, 2007,(02) . [8]朱正礼. 基于三层BP 神经网络的字符识别系统的实现[J]. 现代计算机, 2006,(10) . [9]刘静,周静华,苏俊连,付佳. 基于模板匹配的车牌字符识别算法实现[J]. 科技信息(科学教研), 2007,(24) . [10]苏厚胜. 车牌识别系统的设计与实现[J]. 可编程控制器与工厂自动化, 2006,(03) . [11]胡振稳, 尹朝庆. 基于BP 神经网络的车牌字符识别的研究[J]. 电脑知识与技术(学术交流), 2007,(02) [12]蒋良孝, 李超群. 基于 BP 神经网络的函数逼近方法及其 MATLAB 实现[J]. 微型机与应用, 2004,(01) [13]崔屹. 数字图象处理技术与应用. 电子工业出版社. [14]董长虹. MATLAB 图象处理. 国防工业出版社. [15]董长虹. MATLAB 神经网络与应用国防工业出版社. [16]MATLAB6.5 辅助图象处理.飞思科技产品研发科技中心. [17]H. S. Kim et al, "Recognition of a car number plate by a neural network", Proc. of Korea Information Science Society(KISS) fill conference,Vol. 18, NO. 2, pp. 259-262,1991. [18]Jang-Hee You,Byung-Tae Chun and Dong-Pil Shin,“A Neural for Recognizing Characters Extracted form Moving Vehicles”,World Congress On Neural Network, pp162-166,1994. [19]M. Momozawa,M.N omua,T.Namai and K. Morisaki,"Accident Vehicle Automatic Detection System by Image Processing Technique”,pp.566-570, 2004..
学会这2种方法轻松提取图片中的文字
当我们在网上搜索一些资料,很多内容是不能复制粘贴的。有的小伙伴的打字速度挺快的,就一点一点将搜索到的内容手动输入下来了。而对于我们这些职场新手来说,打字那是不可能的,这时我们只要学会图片转文字的操作就可以将需要的资料保存下来了。接下来小编给大家分享两种可以轻松提取图片文字的两种方法。 方法一:使用OCR软件 软件介绍: 迅捷OCR文字识别软件是我们在办公中常用的一种办公工具,该软件支持极速识别、OCR文字识别、票证识别、语音识别、文档翻译。 具体图片转换文字的操作一起看看: 打开电脑上的OCR文字识别软件之后,在极速识别和OCR文字识别都是可以完成图片转换文字的操作的,我们选择其中一个即可。如选择OCR文字识别功能。 在OCR文字识别功能的页面中,我们就选择截图识别功能了,页面中有截图的快捷方式,先打开要截图的页面,返回到OCR文字识别的页面中按下快捷键就可以进行截图了。
截取的图片在OCR文字识别的页面中有显示,我们对导出格式和导出目录进行一个简单的调整,点击页面右下角的“开始识别”就搞定啦。 方法二:使用在线网站 网站介绍: 该网站是一个PDF转换器的网站,支持多种PDF文件的转换。具备文档转换,文档处理,文档文本翻译,音视频转换,图片文字识别,语音识别等功能。以下给大家看看详细的操作: 当进入到PDF转换器在线网站后,选择点击“图片文字识别”功能中。
在跳转出的图片文字识别页面,需要添加一下图片文件,这个需要我们提前保存一下图片了。需要转换的图片上传成功后,该网站就会自动进行识别了。识别好的文件点击立即下载即可。 图片转换文字怎么转?这下大家学会了吧!简单的两种操作,可以帮助我们实现图片转换文字的操作,以后提取图片中的文字再也不用手动码字了,有需要的小伙伴们可以学学哈!
图像文字识别中的预处理技术研究综述
2017年第9期 信息通信2017 (总第 177 期)INFORMATION&COMMUNICATIONS(Sum.N o177)图像文字识别中的预处理技术研究综述 弓耀辉 (国防科学技术大学机电工程与自动化学院,湖南长沙410073) 摘要:介绍了图像文字识别中预处理技术的研究现状,依据预处理的实现过程,分析了降噪、数据校正、压缩技术的目的,并对降噪、数据校正、压缩技术的实现原理进行了深入讨论。 关键词:图像文字识别;预处理;降噪;数据校正 中图分类号:TP391文献标识码:A文章编号= 1673-1131(2017)09-0291-02 Survey of Preprocessing Techniques in Optical Character Recognition Gong Yaohui (School of Mechatronics Engineering and Automation, National University of Defense Technology, Changsha410073) Abstract: This paper presented that the current state of research about the preprocessing techniques in optical character recognition. According to the preprocessing process, the technologies of noise reduction, data normalization and com-pression are discussed separately.Further, the theory of noise reduction, data normalization and compression was anal-yzed deeply. Key words: Optical Character recognition;Preprocessing;Noise Reduction;Normalization of the data 〇引言 图像文字识别,又称光学字符识别(Optical Character rec-ognition, OCR) 是图像识别的分支之一,属于模式识别和人工 智能的范畴。OCR技术的目的就是通过光学及计算机智能识 别技术,将手写或打印图像(通常通过扫描仪获取)中的文字 转换成机器可编辑的文本。 OCR技术正在改变人们的工作生活方式,人们可以采用 逐字录入和手写的方式对机器输入信息;能采用OCR技术对 生活中感兴趣的报纸杂志或者工作资料,将其转化为文本资 料留存起来;对于视力障碍的特殊群体,OCR技术更是其克服 阅读障碍、及时获取信息的福音。 部门与部门之间应该建立完善的分工合作的机制,尤其要在 数据资源之间更好地建立一套长效的机制,这样才能够在进 行电网营销管理的过程中,让各部门更加紧密地进行配合,最 终保证数据的一致性。 2.7在电网营销管理系统中更好地植入自动检查的程序 面对在电网营销管理系统中所存在的诸多错误,可以 植入更多类型的自动检查程序对整个系统进行更好地检查。系统的操作人员能够更加巧妙地通过输入相关的查询 工具对整体数据的质量进行检查,之后再将不符合相关逻 辑的错误更好地搜集起来,从而更好地提高系统内数据的 准确率。 2.8重视现场的稽查工作以便更好地提高数据的质量 通过重视现场的稽查工作来更好地提高整改后数据的相 关质量。判断整个整改过程中的效果究竟如何,判断整改的 结果是否和电力系统工作的实际能够更好地相符合,是不是 在整改的过程中出现了更多弄虚作假的现象等等。现场稽查 的工作能够更好地使得整体电网数据的质量得以提升,防止 在调整的过程中使得工作脱离了实际的情况,最终能够提高 整体电网营销内部数据的质量?。 O C R技术按照文字类型可以分为:机打文字识别和手写 文字识别。对于机打文字识别来说,印刷文字有不同的字体、 大小之分,印刷文本有横排和竖排之别,加之各种复杂的表格 列表、图像版面的排列,使得机打文字识别较为困难。而对于 手写文字识别来说,书写的格式因人而异、因时而变,形态变 化万千,增大了识别的复杂度。由于文字图像获取来源广,风 格差异较大,对文字图像的有效预处理对后端文本定位和识 别具有重要的意义。本文将从降噪、数据校正、压缩技术对图 像文字识别中的预处理技术进行阐述。 1图像文字识别中的降噪技术 原始的数据需要根据其获取方式进行一系列的预处理操 3结束语 本文先对电网营销管理系统的概念和外延进行具体的阐 述,再重点介绍提高电网营销管理系统的数据质量意义,之后 再具体从提高电网营销人员的工作素质、在各个部门之间更 好地建立分工合作的机制、在电网营销管理系统中更好地植 入自动检查的程序和在电网中更好地建立相关的监测系统等 手段来更好地提高电网营销管理系统基础数据质量,希望能 够给广大电网营销管理的人员以更多的参考性意见。 参考文献: [1]罗国忠.关于建立电力营销数据分析系统[J].供电企业管 理,2013(3):25-28. [2]王锐,马德涛,陈晨.数据挖掘技术及其应用现状探析[J].电 脑应用技术.2013⑵:36-39. [3]简桂林.电力系统营销模式与自动化建设[J].中国高新技 术企业,2015(6): 68-72. [4]张建.电力营销MIS系统数据分离[J].农村电气化,2015(9): 72-75. [5]余南华,陈云端.通信技术[M].中国电力出版社,2014⑶: 98-102. 291
有什么可以从图片中识别文字并翻译的软件
迅捷文字识别。不仅支持识别图片、文档上的文字,还支持二十多种语言全文互译,文字排版也能保留原文档的排版,最关键还支持导出文档。 图片中文字识别并翻译有两种操作方式,可以看看自己更需要那种。 方法一:先识别再翻译 打开软件,然后点击下面的相机图标,就可以对着你需要识别翻译的文字拍照了,或者是你直接上传相册中的图片也可以。 选择印书体或者手写体可以帮助你更好的识别,精准度更高。如果你有很多需要翻译,使用旁边的连续拍摄就比较省事一些。 拍照或者上传图片之后,可以全篇识别,也可以调整选框区域识别。
识别完成之后,点击下面的翻译,就可以看到翻译结果了,自动检测识别结果的语言,然后可以选择需要翻译的语言。 支持二十多种语言全文互译,包括简体中文、繁体中文、英文、日文、韩文、法文、德文、西班牙文、阿拉伯文、俄文、葡萄牙文、意大利语等等。
这个方法有一点的好处,就是识别出来的文档可以进行编辑、复制和导出,翻译之后的结果也支持编辑、复制和导出。 导出文档支持TXT、Word、PDF和图片。
方法二:直接翻译 这个方法可以跳过中间识别的那个步骤,操作起来更快一些。 同样是首页点击下面的相机图标,然后找到拍照翻译,就可以对你需要翻译的内容进行拍照了,或者点击快门旁边的相册图标,直接上传图片也可以。
可以整页识别,或者自己选择需要识别的区域,然后点击下一步,基本上几秒钟就能快速识别翻译出来。 直接就能看到翻译结果,省去了中间点击翻译的那一步,其他的操作基本上都差不多了,翻译的语言可以自己调整。
这个方法跟上面一个方法相比就是,识别出来的原文档只支持编辑、复制,不过翻译后的文档是一样的,都支持编辑、复制和导出。 除了拍照识别文字和拍照翻译之外,还有表格识别、证件照扫描和云端上传的功能,感兴趣的可以自己去看看。
图片文字识别如何实现
图片文字识别如何实现 工作中难免会遇到各种各样,奇葩的问题,就像图片文字识别的问题,乍一听,大家肯定都不知道如何操作吧,其实方法很简单的,但前提是我们要借助图片文字识别软件来进行操作,那么今天我们就一起来看一下借助图片文字识别软件,是如何实现图片文字识别的吧。需要用到的工具:捷速OCR文字识别软件 软件介绍:该软件具备改进图片处理算法功能:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本。所以要想实现图片转换为其它格式、PDF文件和caj文件转换,或者是票证识别,捷速OCR文字识别https://www.360docs.net/doc/837209165.html,都是不错的选择。 方法讲解: 步骤一:我们要先将需要用到的工具安装到电脑上,打开电脑浏览器搜索并下载捷速OCR文字识别软件。 步骤二:软件安装好后,打开该软件,同时会跳出一个插入图片的选
项,点击“退出”按钮,退出该选项。 步骤三:然后在软件的左上方,选择“图片局部识别”的选项。 步骤四:进入图片局部识别的页面后,点击软件左上角“添加图片”的选项,将需要识别的图片添加进来。
步骤五:图片添加进来后,先不用急着开始识别,我们可在软件的左下角,修改图片识别后的文件的储存位置。 步骤六:储存位置修改好后,按住鼠标左键,将需要识别的文字用文字框框出来,然后软件就会对被框选出来的文字进行自动识别了。
步骤七:等待图片识别好后,点击右下角“保存为TXT的按钮”,将其识别内容进行保存,这样图片文字识别的操作就完成了。 图片文字识别如何实现的操作已经为大家分享结束了,操作简单。工作中再遇到图片文字识别的问题,只需要按照上面的操作步骤进行即可。
将图片中的英文字符提取并翻译为中文方法
将图片中的英文字符提取并翻译为中文方法(修改版) 有时我们会需要将图片中的英文句子翻译成中文,以弄明白其中的含义。譬如,电脑使用中突然出现蓝屏并且满屏英文字符。又或者买到的工具,其外包装上全是英文,没有一个中文字。如要弄懂其含义,传统的方法是得花时间,一个一个单词、句子抄下来,再通过电脑上的翻译软件,一个一个输入进输字框内后,再通过翻译软件给翻译出来。如果是要翻译的英文句子不长的话,还不算麻烦,但要翻译的英文句子较长,就很费时费力了,有时不注意还会抄错。譬如,最近本人用了七年的台式电脑,最近就多次在正常使用中突然发生蓝屏并满屏英文字符。原想用笔抄下来的,但看着满屏的英文字符,真是头大。如图1所示(注:该电脑蓝屏英文图片是用照相机拍摄下来的)。
图1 还有,买到的一个皮带打孔机,外包装上全是英文,不知道其上面的含义,如图2所示。 图2 下面,通过在线文字识别网站(https://www.360docs.net/doc/837209165.html,),用图文方式详细说明如何将图片中的英文字符提取出来,这里以上面两张图片为例,并且再通过翻译软件翻译成能看懂的中文方法。 先将要翻译的内含英文字符的内容用相机拍摄下来(也可以是从网上“复制”、“截屏”的内容),并将拍成的图片保存在电脑桌面新建的临时文件夹中。在“百度”搜索框中输入“在线文字识别网址”:https://www.360docs.net/doc/837209165.html,,打开后如下图3所示:
点击在线翻译左侧(选择文件)按钮,打开要插入图片页面,如下所示,从中选择要提取文字的图片,这里选择编号“1766”就是电脑蓝屏的英文字符图片,如下图片4所示。 点击图片后,再点击按钮。
把图片变成文字—图文转换工具+方法
把图片变成文字—图文转换工具方法 第一种方法:用SnagIt工具进行文字提取。 首先使用SnagIt的文字捕捉功能将文字提取出来。SnagIt当前版本为7.02,大小为8903KB,下载地址可以在https://www.360docs.net/doc/837209165.html,/soft/2290.html,汉化补丁可以在https://www.360docs.net/doc/837209165.html,/soft/2291.html。启动SnagIt,选择菜单“输入/区域”,选择菜单“工具/文字捕获”,然后我们打开要捕捉的文件窗口,按下捕捉快捷键,选定捕捉区域即可捕捉到文字。 接着用相应工具重排文字。此时我们发现提取的文字可能会有很多空格或段落错乱等现象,而且字号、字体等不合自己的心意。这时我们可以用熟悉的WPS或Word软件进行重新编排。我们以WPSOffice2003为例看看如何对付提取后文章的编排。 用WPSOffice2003打开提取文章;然后选择“工具”菜单下的“文字”/“段落重排”,这时你会看到提取文章重新进行排版;接下来选择“工具”菜单下的“文字”/“删除段首空格”命令,使得文章的每段参差不齐的行首空格被删除;再选择“工具”菜单下的“文字”/“增加段首空格”,文章变为正常的书写格式;提取文章一般都留有空段,为删除这些空段,继续选择“工具”菜单下的“文字”/“删除空段”命令,这时文
章完全变为我们所要的形式;用你熟悉的界面任意编辑文章吧。 第二种方法:用屏幕截图然后让OCR软件识别。 打开带有文字的图片或电子书籍,翻到你希望提取的页面,点击键盘上的打印屏幕键(PrintScreen)进行屏幕捕获;打开Windows自带的画图工具,将刚才捕获的屏幕截图,粘贴进去,保存为一个.bmp文件;接着打开刚才保存的文件,在编辑器中进行修正,根据你所要提取的文字进行裁剪,尽量去除不要的部分;最后启动OCR软件,在OCR中打开刚才保存的修改文件,进行文字识别,然后可随心所欲进行编辑 https://www.360docs.net/doc/837209165.html,/soft/27951.htm 一个mini OCR软件
华为手机如何扫描图片转文字
华为手机如何扫描图片转文字 手机怎么扫描图片转文字呢?因为小编用的是华为手机,所以就以华为为例和大家分享一下方法吧,不是和小编用的一个牌子的手机也不要担心,第二种方法适合很多的智能机。 1.快捷翻译 输入需要翻译的文字或者是语句,然后选择需要翻译的语言,可提供实时翻译。 操作方法: 打开华为键盘后选择快捷翻译——输入需要翻译的内容选择单翻译的语言——前往。
2.文字扫描 作用:将纸纸质文档胡图片文字进行翻译,然后可以进行复制、分享等操作,可以快速的将纸质文档转换为电子档和图片文字转Word,适合现在的高效办公。 操作方法: 同时在键盘里选择文字扫描,然后将手机对准文字;还可以对扫描的结果进行其他简单的操作。
另:不是华为手机的朋友们也不不用担心,在应用市场里找到一点翻译,此工具可以对文件、图片、短句进行实时翻译。 操作方法: 在此以图片翻译为列:
点击图片识别后会出现一个选择图片的页面,在此页面找到需要翻译的文字图片后点击确定。新的页面选择好需要翻译的语言然后点击页面下的立即翻译。
这时会出现一个图片翻译页面,页面提示正在翻译,在此等待一下翻译的过程。翻译完成后会出现一个新的页面在此可以对翻译的结果进行分享等操作。
手机扫描图片转文字的方法到此就结束了,有需要的可以自己去试试。When you are old and grey and full of sleep, And nodding by the fire, take down this book, And slowly read, and dream of the soft look Your eyes had once, and of their shadows deep; How many loved your moments of glad grace,
图片文字提取方法大全
光学字符识别技术OCR(Optical Character Recognition的简称),是自动识别技术研究和应用中的一个重要领域,我们识别图片中的文字,用的就是OCR 技术。 目前有很多OCR识别软件,例如Office Document Imaging、汉王OCR,清华紫光OCR、尚书6号等等。但需要注意,通常OCR软件只能够识别比较规范的印刷体,手写文本目前在识别上仍有困难。 下面简单介绍一下几款OCR识别软件及使用方法。 方法一、利用Office Document Imaging 提取文字 Office在2003版中增加了Document Imaging工具,用它可以把文字给“抠”出来。注意:Microsoft Office Document Imaging不是Office 2003默认的安装选项,初次启用时,如果该组件未安装,则需要插入Office的安装光盘进行安装。 使用方法 1、在“文件”中打开图片,若是提取扫描仪中的印刷品文字,选择“扫描新文档”,即可将印刷品的文字扫描到电脑上。 2、工具-->使用OCR识别文本,OCR识别程序就会对图片进行识别,完成后选择:工具-->将文本发送到Word ,程序会自动打开Word文档,展现在你面前的就是从图片中“抠”出来的文字。 注意事项 1、若图片中是英文,可在工具-->选项-->OCR-->OCR 语言,选择english,再进行识别。 2、Office Document Imaging只支持MDI、TIF等图片格式。如需识别其他格式的图片,需要利用图片处理软件转换一下,或者利用Office Document Imaging 组件中的“Microsoft Office Document Imaging Writer”的虚拟打印机,将图片打印成一个MDI文件,然后再进行识别。 方法二、使用文字识别工具提取文字 1、清华紫光OCR用法简介 1)打开带有文字的图片,根据所要提取的文字进行裁剪(如果是电子书籍,可按下“Print Screerl”屏幕捕获键将其保存为图片)。 2)启动紫光OCR,打开已裁减的图片,用鼠标在图片中绘制出待识别的文字区域,按下工具栏“识别”按钮即可。文字识别结束后,会自动在一个文本编辑器中打开已提取文字,将结果复制粘贴至其他文档中即可。 2、尚书六号用法简介 1)进入"尚书六号"的界面,界面如下: 1
图片文字翻译
ArtA 是BIG在新西兰的第一件作品,一贯性的遵循了BIG在博物馆建筑中的风格。BIG在最近完成的丹麦国家海洋博物馆中将海洋历史的元素与走廊文化这一创新理念完美的融合在了一起。其他的现代建筑包括在乐高家乡的乐高屋,在丹麦西部的地堡博物馆,以及最近开放的蒙彼利埃人体博物馆和法国波尔多的MECA文化中心。 荣誉 主管的合伙人:~~~~~ 项目负责人:~~~~~ 项目建设者:~~~~ 团队人员:~~~~
黑盒子、白立方体 我们提出一个建筑理念伴有两个极端:面向现代城市的影剧院和面向古老河道的艺术博物馆 斜向的组织架构 整个建筑对角线方向被斜分为影剧院结构和艺术博物馆结构 艺术广场 中间是一个从地表艺术广场到屋顶冬季花园的循环开阶梯式渗透空间。并且有餐厅面向河道。 主结构架次 一种简单的旋转理念使建筑形成了一个倾斜的艺术广场,联系了地表与屋顶。并且使这两个单元相互融合。 公众元素 整个建筑形成了一个带有屋顶的公共空间,入口位于新尼德兰大街的中心位置,面向整个街道,并且为户外的艺术活动提供了良好的空间。
视野 站在屋顶,从两个角度看去有着令人激动的视野。咖啡馆面向莱茵河,并且整个建筑面向城市。 落址 这个方位的落址使得周围的艺术工作者在这典型的四合院似的建筑中集群 水、城市 此处的落址的中心轴线象征性的链接了这个历史名城和古老的莱茵河 建筑高度 整幢建筑最高设计高度30米 开放、闭合
建筑体的一面是光滑的,从开放的海滨一角环绕着艺术广场直至俯视整个城市的屋顶冬季花园。整个扭曲的窗户折射着日光,使博物馆的参观者和过路人难以忘怀。 3D艺术广场 这两组结构合并成了3维立体空间-艺术广场。使得业主与艺术、公众、教育、娱乐相互融合。 定稿 黑盒子与白立方被认为是两种建筑风格的完美融合,使得它成为了独一无二的产物。是一次有机、理性、透明、独特、新颖、复杂多元素的完美整合。