这一章的内容是模型评价与选择断断续续看了两周时间

这一章的内容是模型评估与选择,断断续续看了两周时间,感觉比看模型还费劲。其实这一章的大部分内容我是熟悉的,包括各种模型选择的准则,交叉验证以及bootstrap,这些在实际建模的时候也经常用到,但是关于其原理确实不是很清晰。这一章给出了详尽,但是又不那么理论的阐述。经典确实是经典。闲话不多说了,开始读书笔记。对于同一个问题,比如分类问题或者预测问题,往往会有一系列的模型都可以做。那么这些模型表现的如何,如何从这些模型中选择一个合适的,最好的模型,就成为了一个问题。而这个问题在实际中是非常重要的。我们都知道,模型是建立在训练样本上的,而预测是需要在一个独立的新的样本上进行的。在训练样本上所建立的模型,其在一个新的独立的样本上的表现如何进行评估,是一个非常重要的问题。这一章首先介绍了偏差(bias),方差(variance)以及模型复杂度(model complexity)。我们有一个target variable Y,以及输入向量X,以及通过训练样本得到的对于响应的估计(也就是我们的
模型)f?(X)。此外,我们还应该有一个损失函数L(Y,f?(X))。损失函数可以有多种选择,比如平方损失,绝对值损失,这两个主要是针对定量的响应的,对于定性的响应,也有0-1损失,对数似然之类的。一般而言,损失函数中比较常用的就是这些。有了模型以及损失函数之后,首先定义test error(原谅我在这里中英混杂,因为我发现用这种方法可以更好地区分几个不同的概念)。test error是损失函数在一个新的,
独立的检验样本上的期望。Err=E[L(Y,f?(X))]。这个期望的计算需要涉及到新的检测样本的联合分布。以上是test error的概念。于此对应的是training error的定义,training error是指在训练样本上的损失的平均值。errˉ=1N∑Ni=1L(y i,f?(x i))
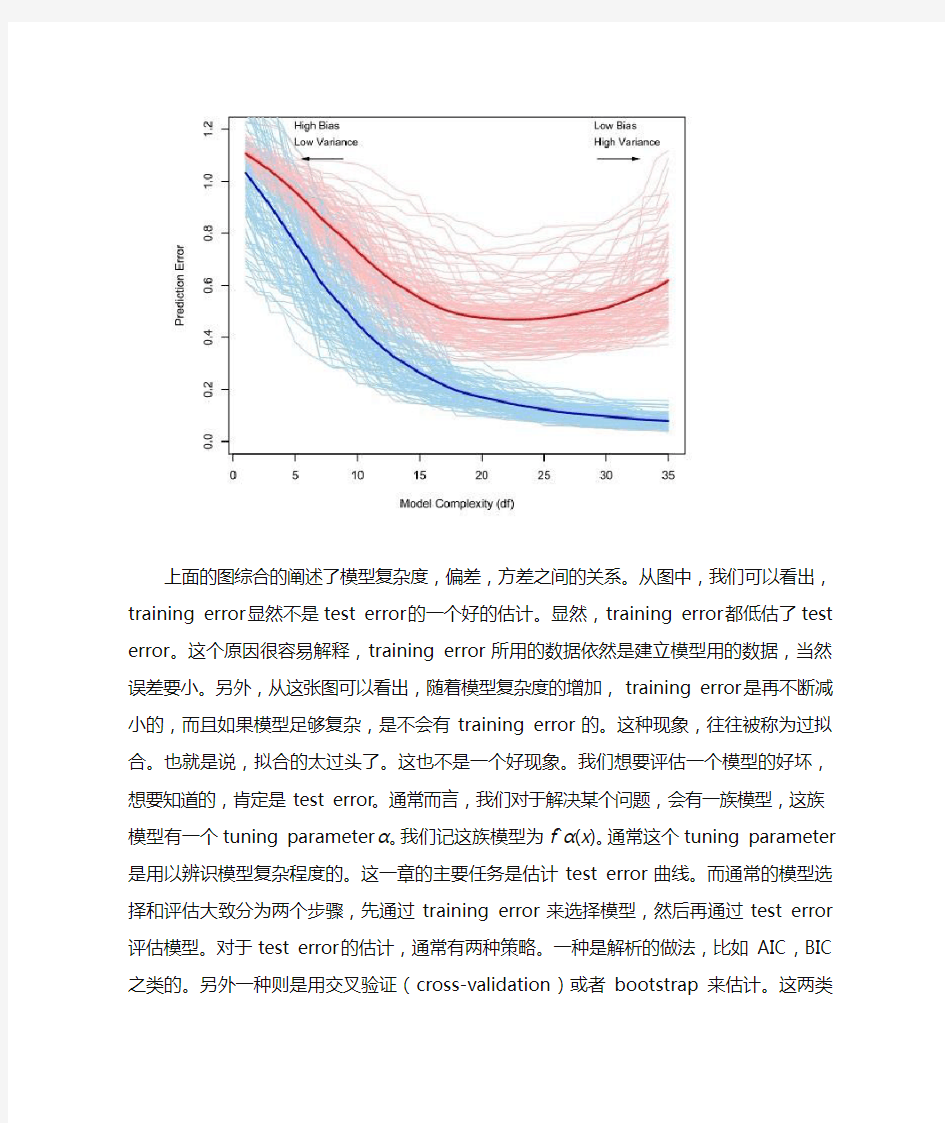
上面的图综合的阐述了模型复杂度,偏差,方差之间的关系。从图中,我们可以看出,training error显然不是test error的一个好的估计。显然,training error都低估了test error。这个原因很容易解释,training error
所用的数据依然是建立模型用的数据,当然误差要小。另外,从这张图可以看出,随着模型复杂度的增加,training error是再不断减小的,而且如果模型足够复杂,是不会有training error的。这种现象,往往被称为过拟合。也就是说,拟合的太过头了。这也不是一个好现象。我们想要评估一个模型的好坏,想要知道的,肯定是test error。通常而言,我们对于解决某个问题,会有一族模型,这族模型有一个tuning parameter
α。我们记这族模型为f?α(x)。通常这个tuning parameter是用以辨识模型复杂程度的。这一章的主要任务是估计test error曲线。而通常的模型选择和评估大致分为两个步骤,先通过training error来选择模型,然后再通过test error评估模型。对于test error的估计,通常有两种策略。一种是解析的做法,比如AIC,BIC之类的。另外一种则是用交叉验证(cross-validation)或者bootstrap来估计。这两类方法也是本书这一章的主要的内容构成。在介绍这些方法之前,有必要先看一看bias-variance分解。Err(x0)=σ2e+Bias2(f(x0))+Variance
通常而言,模型越复杂,bias越低,而方差variance则越高。关于这一部分,在之前的一篇笔记中已经通过一个图提到了,这里也不再详述。通常,training error都是小于test error的。Err在某种意义上是extra-sample error。若我们定义in-sample error,则training error对于test error的乐观估计则更好理解。
in-sample error的定义是Err in=1N∑L(Y newi,f?(x i))。则这个估计的乐观的部分如下定义
op=Err in?E y(errˉ)
而通过推到,我们可以得到(这个推到书上也没有,应该是某一系列论文中的成果,我们这里不具体推,只要知道这个结果就行)
Err in=E y(errˉ)+2N∑cov(y i,y?i)
这个结果揭示了一个很重要的事儿,就是乐观估计的程度与估计值和真实值之间的相关性是密切相关的。写到这我也有点糊涂了,按理说,我们需要的是test error的估计,而现在,我们只需要来估计in-sample error 了。作者在这里说了一句话,
“In-sample error is not usually of direct interest since future values of the features are not likely to coincide with their training set value.But for comparison between models,in-sample error is convenient and often leads to effective model selection”
。那么我们就按照作者的经验,来开始对in-sample error进行估计吧。对于in-sample error的估计,有两个不同的角度可以进行,一种是估计op,然后加到errˉ上即可。这也就是AIC,BIC的思路。另外一种就是利用重抽样,比如cross-validation或者bootstrap的策略,来估计in-sample error。下面的部分,就分别比较详细的介绍一下这些方法。C p统计量:
Err?in=errˉ+op?
是通用的一个式子,不同的准则有对这个式子不同的估计,我们先来看最常用的C p准则。
C p=errˉ+2dNσ2e
这个公式适用于加法模型,而且如果估计值是线性的情况下。AIC准则:
AIC=?2Loglik+2dN.当损失函数对数似然损失函数的时候,这个准则比C p准则更加广义。其所依赖的理论是一个大样本性质,当N趋于无穷大的时候,
?2E[logPrθ?(Y)]~?2N E[loglik]+2dN
其中loglik=∑logPrθ?(y i)
用AIC准则进行模型选择的时候,是选择AIC越小愈好。这一部分书中有一个简单的例子,但是很能说明问题,不在此多说了。BIC准则:
BIC=?2loglik+(logN)d
BIC准则的得来的motivate是非常不同的,选择BIC最小的模型,事实上是在选择后验概率最大的模型。BIC准则的得来,是通过bayes理论推导得到的。这里在书中也有具体的公式推导。MDL:minimum description length。这个部分,我几乎没怎么看明白,其核心是编码理论。以上是一些模型选择的准则。模型选择的准则都涉及到了模型有效参数的个数,因此,这一章也对这个问题做了一些讲解。包括7.6the effective number of parameters以及7.9的Vapnik-Chernovenkis dimension,都是主要讲了模型复杂度的度量。这两部分的内容我看的并不是很清晰,也没什么感觉。希望再读此书能有所收获。这次阅读,这部分我都略过了。以上的一些准则,都是对op的一个比较解析的估计。下面介绍两种通过重抽样的策略,来估计in-sample error的方法。cross-validation:
CV=1N sum Ni=1L(y i,f??k(i)(x i))
交叉验证,就是把训练样本大致平均地分成K分,然后每次剔除一部分,用另外的部分进行模型构建,然后用剔除的那一部分来估计误差,这样做K次,然后平均K次的误差。通常而言,都是用5-cross validation 或者10-cross validation。当然还有每次剔除一个值,leave-one-out。如何选择K是一个问题,当K=N的时候,CV是预测误差的渐进无偏估计。但是方差可能会很大。当K比较小的时候,方差会比较小,但是偏差比较大,也是一个问题。作者说
"over-all five or ten fold cross-validation are recommended as a good compromise"
。拿来用用,比一比即可。bootstrap方法:这一部分我不想多说,在豆瓣里我有分享过关于bootstrap的
相关资料。bootstrap这个方法最早就是stanford的Efron提出的,在模型选择中应用非常广泛,但是我个人还是比较喜好cross-validation的策略一些。差不多今天就到这了,这本书啥时候才能看完啊。
多元时间序列建模分析
应用时间序列分析实验报告
单位根检验输出结果如下:序列x的单位根检验结果:
1967 58.8 53.4 1968 57.6 50.9 1969 59.8 47.2 1970 56.8 56.1 1971 68.5 52.4 1972 82.9 64.0 1973 116.9 103.6 1974 139.4 152.8 1975 143.0 147.4 1976 134.8 129.3 1977 139.7 132.8 1978 167.6 187.4 1979 211.7 242.9 1980 271.2 298.8 1981 367.6 367.7 1982 413.8 357.5 1983 438.3 421.8 1984 580.5 620.5 1985 808.9 1257.8 1986 1082.1 1498.3 1987 1470.0 1614.2 1988 1766.7 2055.1 1989 1956.0 2199.9 1990 2985.8 2574.3 1991 3827.1 3398.7 1992 4676.3 4443.3 1993 5284.8 5986.2 1994 10421.8 9960.1 1995 12451.8 11048.1 1996 12576.4 11557.4 1997 15160.7 11806.5 1998 15223.6 11626.1 1999 16159.8 13736.5 2000 20634.4 18638.8 2001 22024.4 20159.2 2002 26947.9 24430.3 2003 36287.9 34195.6 2004 49103.3 46435.8 2005 62648.1 54273.7 2006 77594.6 63376.9 2007 93455.6 73284.6 2008 100394.9 79526.5 run; proc gplot; plot x*t=1 y*t=2/overlay; symbol1c=black i=join v=none; symbol2c=red i=join v=none w=2l=2; run; proc arima data=example6_4; identify var=x stationarity=(adf=1); identify var=y stationarity=(adf=1); run; proc arima; identify var=y crrosscorr=x; estimate methed=ml input=x plot; forecast lead=0id=t out=out; proc aima data=out; identify varresidual stationarity=(adf=2); run;
数学建模幸福感的评价与量化模型修订稿
数学建模幸福感的评价 与量化模型 WEIHUA system office room 【WEIHUA 16H-WEIHUA WEIHUA8Q8-
幸福感的评价与量化模型 摘要 随着全球经济日益繁荣,在人民物质生活极大程度提高的前提下,幸福指数的评价问题,已成为当今世界广泛讨论和高度重视的问题之一,它属于数学建模中的综合评价问题。而正确的确定影响民众幸福指数的指标体系、确定相应指标的权重和计算民众幸福指数,则能清楚的了解社会运行状况和民众生活状态。 问题一,根据题中附表给出的信息,我们采用模糊综合测评的方法确定了因素集U 和评价等级V。并在附表中选取了大量因素,确定了5个一级指标和18二级指标,设定了5个评价等级。先据附表数据利用matlab 软件对各二级指标进行了单因素评判,再利用变异系数法求解各二级指标的权重,最后利用模糊综合测评法得出评判结果'B。即对网民幸福感的测定结果是,在与附表中调查的幸福程度进行比较,基本符合调查结果,说明我们建立的综合评价体系是合理可行的。 在建立指标模型时,我们采用了分值量化的思想,5个评价等级进行了指标量化,利用模糊综合评价体系中的单因素评判,对各二级指标进行了量化,再利用逐级合成的思想,建立了衡量幸福指数的数学模型。 问题二,通过调查得到的某地区教师和学生的幸福感数据,先利用问题一建立的模糊综合评价体系,分别求解得到该地区教师和学生对幸福程度评价等级的比率'B教, H学。再利用问题一建立的衡量'B学,以及利用该评价等级得到的综合幸福指数' H教,' 幸福指数的数学模型求解得到该地区教师和学生的综合幸福指数H教,H学。对两种方法得到的综合幸福指数进行比较,我们建立的模型计算得到的综合幸福指数和通过调查数据计算得到的综合幸福指数基本吻合,说明我们建立的模型对该地区的教师和学生幸
时间序列分析资料报告——ARMA模型实验
基于ARMA模型的社会融资规模增长分析 ————ARMA模型实验
第一部分实验分析目的及方法 一般说来,若时间序列满足平稳随机过程的性质,则可用经典的ARMA模型进行建模和预则。但是, 由于金融时间序列随机波动较大,很少满足ARMA模型的适用条件,无法直接采用该模型进行处理。通过对数化及差分处理后,将原本非平稳的序列处理为近似平稳的序列,可以采用ARMA模型进行建模和分析。 第二部分实验数据 2.1数据来源 数据来源于中经网统计数据库。具体数据见附录表5.1 。 2.2所选数据变量 社会融资规模指一定时期(每月、每季或每年)实体经济从金融体系获得的全部资金总额,为一增量概念,即期末余额减去期初余额的差额,或当期发行或发生额扣除当期兑付或偿还额的差额。社会融资规模作为重要的宏观监测指标,由实体经济需求所决定,反映金融体系对实体经济的资金量支持。 本实验拟选取2005年11月到2014年9月我国以月为单位的社会融资规模的数据来构建ARMA模型,并利用该模型进行分析预测。 第三部分 ARMA模型构建 3.1判断序列的平稳性 首先绘制出M的折线图,结果如下图:
图3.1 社会融资规模M曲线图 从图中可以看出,社会融资规模M序列具有一定的趋势性,由此可以初步判断该序列是非平稳的。此外,m在每年同时期出现相同的变动趋势,表明m还存在季节特征。下面对m的平稳性和季节性·进行进一步检验。 为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下: 图3.2 lm曲线图
对数化后的趋势性减弱,但仍存在一定的趋势性,下面观察lm的自相关图 表3.1 lm的自相关图 上表可以看出,该lm序列的PACF只在滞后一期、二期和三期是显著的,ACF随着滞后结束的增加慢慢衰减至0,由此可以看出该序列表现出一定的平稳性。进一步进行单位根检验,由于存在较弱的趋势性且均值不为零,选择存在趋势项的形式,并根据AIC自动选择之后结束,单位根检验结果如下: 表3.2 单位根输出结果 Null Hypothesis: LM has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic - based on SIC, maxlag=12) t-Statistic Prob.*
项目中评价模型和方法研究
关于项目中评价的模型和方法研究 作/转载者:白思俊发布时间:2004-7-6浏览量:120 摘要:本文在对传统项目评价的概念进行扩充之后,提出了项目前评价、项目中评价及项目后评价的概念,并重点对项目中评价的相关评价模型进行了探讨,提出了项目中评价的二维结构模型、聚类评价模型、递进评价模型及项目中评价的DEA评价方法。 关键词:项目评价,项目中评价,项目管理 Research on the Models of Project Interim Evaluation Bai Sijun (Management School of Northwestern Polytechnical University) Abstract: As an important part of project management theory, Project Evaluation (PE) has basically formed a theory and method system. Many project life cycles are similar from the start to the end, including project determination; and then undergoing the project definition, manning, resources allocation, work planning, executing operating and so on. There is a series of evaluation problems in each period. Obviously, these evaluation problems have their related evaluation theory and method system. The set of the theory and method will constitute the perfect system of PE. In this paper, we extend the traditional concept and connotation of PE and present the concept of PE corresponding the whole project life cycle, and divide it into Project Ex Ante Evaluation (PAE), Project Interim Evaluation (PIE) and Project Ex Post Evaluation (PPE), and mainly analyze the models of PIE. This paper presents the model of two-dimensions framework, the model of clustering evaluation, the model of step-advance evaluation and the method of data envelopment analysis. Keywords: Project Evaluation, Project Interim Evaluation, Project Management 1.引言 项目评价作为项目管理的主要理论之一,已得到较为全面的发展,并形成了较为完善的评价理论与评价方法体系,特别是项目前期论证和项目后期评价方面。然而人们对项目最为重要的执行阶段的相关评价问题却很少进行探讨,本文基于此对传统的项目评价概念(在可行性研究的基础上从宏观和微观的角度,对项目进行全面的技术经济预测、论证和评价)进行了扩充,提出了如下的广泛意义上的项目评价概念: 所谓广义项目评价,即项目在其生命周期全过程中,为了更好地进行项目管理,针对项目生命周期每阶段特点应用科学的评价理论和方法,采用适当的评价尺度所进行的“根据确定的目地来测定对象系统属性,并将这种属性变为客观定量的计值或者主观效用的行为”。 按照上述定义,我们根据项目生命周期各阶段的不同特点将项目评价分为三部分内容:即项目前评价、项目中评价、项目后评价。由于这三个阶段项目管理内容和侧重点不同,其项目评价内容也不同。 项目中评价是指在项目立项上马以后,在项目实施时期,历经项目的发展、实施、竣工三个阶段,对项目状态和项目进展情况进行衡量与监测,对已完成的工作做出评价。其目的在于检测项目实施的实际状态与目标(计划目标)状态的偏差,分析其原因和可能影响因素,及时反馈信息,以便作出决策,采取必要的管理措施来实现或达到既定目标(计划目标),改进项目管理,加强对项目的监督和控制。
时间序列分析及VAR模型
Lecture 6 6. Time series analysis: Multivariate models 6.1Learning outcomes ?Vector autoregression (VAR) ?Cointegration ?Vector error correction model (VECM) ?Application: pairs trading 6.2Vector autoregression (VAR)向量自回归 The classical linear regression model assumes strict exogeneity; hence, there is no serial correlation between error terms and any realisation of any independent variable (lead or lag). As we discovered, serial correlation (or autocorrelation) is very common in financial time series and panel data. Furthermore, we assumed a pre-defined relation of causality: explanatory variable affect the dependent variable? 传统的线性回归模型假设严格的外主性,误差项与可实现的独立变量之间没有序列相关性。金融时间序列及面板数据往往都有很强的自相关性,假定解释变量影响因变量。 We now relax bo什]assumptions using a VAR model. VAR models can be regarded as a generalisation of AR(p) processes by adding additional time series. Hence, we enter the field of multivariate time series analysis. VAR模型可以'"l作是在一般的自回归过程中加入时间序列。 Lefs look at a standard AR(p) process for hvo variables (y( and xj? (1)%= Ql + 琅]仇『一 +仏 (2)x t = a2 + - + £2t The next step is to allow that lagged values of xt can affect y( and vice versa. This means that we obtain a system of equations for two dependent variables(y(and xj?Both dependent variables are influenced by past realisations of y(and x t. By doing that, we violate strict exogeneity (see Lecture 2); however, we can use a more relaxed concept, namely weak exogeneity?As we use lagged values of bodi dependent variables, we can argue that these lagged values are known to us, as we observed them in the previous period? We call these variables predetermined? Predetermined (lagged) variables fulfil weak exogeneity in the sense that they have to be uncorrelated with the contemporaneoiis error term in t? We can still use OLS to estimate the following system of equations, which is called a VAR in reduced form. (3)+y 仇1化_丫+sr=i ^12 +£it (4)X t = a2+2X1021”—, + _i + f2t
优秀项目经理五大模型79条评估实用标准
优秀项目经理五大模型79条评估标准
02 优秀项目经理必备9大能力 一、良好的法律、法规和依法履约的意识 物业项目经理作为项目管理第一负责人,必须全面掌握国家颁布并实施的法律、法规以及地方政府的一些实施细则,如《物业管理条列》、《住宅室装饰、装修管理办法》、《物业收费管理办法》、《贯彻落实全国物业管理条件的实施意见》等一系列指令性文件。只有熟练掌握了这些法律、法规,才能使物业管理工作有法有据、有条不紊地展开;同时,物业项目经理也必须掌握物业管理公司与开发商签订的《前期物业服务合同》、与业主签订的《前期物业管理服务协议》或与业委会签订的《物业服务合同》,明确掌握合同所规定的权利和义务,以及收费标准、期限、时间等一系列条款,这样才便于今后开展各项物业实务操作。做到有法可依。 二、良好的沟通和服务能力 住宅物业管理面对社会方方面面的监督检查,如街道、社区、派出所、房管处、规划局,以及城管、交警、消防、环保、绿化等部门。所有这些公共关系都需要物业项目经理必须具备一定的亲和力,以沟通协调各方面关系的能力。即便是一方面关系的僵化,都会产生各种各样的后果,给物业管理处的正常运作带来麻烦,而物业项目经理与广大业主和员工的及时沟通,则更有利于化解各种矛盾、解决各类问题、树立管理处主任的威信,便于物业管理各项工作的顺利开展。客户服务周全。服务是永恒的主题,物业主任应树立“永远想在业主前面”的思想,认真观察、了解业主(客户)的实际和潜在需求,延伸
和拓展服务项目,确保服务容的多样性,提升业主(客户)的生活品质和满意度。 三、优秀的品德、良好的敬业精神 “满足广大业主服务需求”应视作一个管理处主任的最高目标。就目前现状来说,物业项目经理应该是一个苦差事,不仅要具备良好的素质,而且还必须要有敬业奉献精神,要有吃苦在前、享受在后、“先天下之忧而忧”的精神。要使物业日常管理能够正常运作,还需要考虑和预见本管理处所辖围的人和事,防患于未燃,这就需要一个物业项目经理全身心投入,例如手机必须保证24小时开机;遇到突发的紧急事件而下属不能处理时,物业项目经理不管风吹雨打,必须赶到现场亲自处理。要有模者的姿态领导。物业经理必须身先士卒,模遵守和执行公司各项规章、标准和程序,忠于企业,勇于承担责任,不推诿、不退缩,充分发挥好“头狼”的作用。 四、良好的组织协调能力和管理能力 一个物业管理处必是由一个团队组成,其人员包括客服管家、保安人员、维修人员、保洁人员。一个物业管理处少则十几个人,多则上百个人,要把这些来自五湖四海的性格、喜好、文化层次均不同的员工,揉合成一个理念一致、步伐一致、全心全意为广大业主服务的团队,需要项目经理付出极大的心血来精心浇铸。如果没有一定的组织协调能力,那么结果是可想而知的。全面管理,不求精通,但求全面。物业管理行业,外部关联部门多,服务对象差异性大,服务容涉及门类杂,专业性和科技含量广,部管理上员工层次多,行业整体职业素质有待提高,对项目经理的专业知识、管理技能和经验要求比较高。 五、利用物业管理平台的经营意识 现在的物业的管理来说,普遍处于微利、保本或亏损状态(在5年以上的住宅物业小区管理中表现得尤为突出)。同时,物业收费标准及收费率普遍不高,广大业主还普遍存在着“房子是我买的,物业不是我选的,交不交费与我无关”的观点,甚至对服务要求无限多,一旦发现某些物业服务瑕疵或者是房地产开发商遗留的质量问题,均认定为物业服务不到位,从而拒付物业费。因此,作为一个物业项目经理,如果没有良好的经营头脑,那么这个管理处的盈
数学建模幸福感的评价及量化模型完整版
数学建模幸福感的评价 及量化模型 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
2011年第八届苏北数学建模联赛 承诺书 我们仔细阅读了第八届苏北数学建模联赛的竞赛规则。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与本队以外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们愿意承担由此引起的一切后果。 我们的参赛报名号为: 参赛组别(研究生或本科或专科): 参赛队员 (签名) : 队员1: 队员2: 队员3: 获奖证书邮寄地址:
2011年第八届苏北数学建模联赛 编号专用页 参赛队伍的参赛号码:(请各个参赛队提前填写好): 2818 竞赛统一编号(由竞赛组委会送至评委团前编号): 竞赛评阅编号(由竞赛评委团评阅前进行编号): 2011年第八届苏北数学建模联赛 题目幸福感的评价与量化模型 摘要 改革开放三十多年,我国经济建设取得了巨大成就,人们物质生活得到了极大改善。但也有越来越多的人开始思考:我们大力发展经济,最终目的是为了什么?温家宝总理近年来多次强调:我们所做的一切,都是为了让人民生活得更加幸福。在今年的全国两会期间,“幸福感”也成为最热门词语之一。 在处理问题(一)时,本文根据题目已给的相关数据,将诸如“非常满意”、“比较满意”、“基本满意”、“不太满意”、“不满意”之类答项并按序排列,分别给予5~1分的分值。建立得分和得票率的函数关系,通过MATLAB进行4次多项式拟合,并算出权重,最后得出幸福指数H具有如下关系, H H=∑H H×H H H=0 在处理问题(二)时,本文利用SPSS软件,对网上搜寻的大量有用信息进行统计分析,通过使用主成份分析法建立模型I,讨论各因素对幸福影响程度的大小,由此确定了影响房幸福指数的主要因素分别是:人际关系、家庭生活、身心健康、个人价值的实现、工作及收入水平。 在处理问题(三)时,本文通过对数据的分析、权值运算以及结果分析角度论述模型I运用于普遍情况的可能性。通过此种方法虽然计算较为繁琐,但其中的方差和统计方法可以有效减少个别指标的变动带来的影响,同时三元链模型中增加了路径可以较好地反应出各个相关量之间的关系,最终通过加权平均法对幸福指数进行总的计算,减少了误差,更能反应出真是情况的幸福指数,具有统计意义。可以推广到更加普遍的人群。 目录 1 问题的背景 (5) 2 问题的提出与重述 (6) 3 基本假设 (6) 4 主要变量符号说明 (6) 5 问题一 (7)
项目周期模型选择
刘小备如何做项目-关于生命周期模型 2009-04-18 03:38:57| 分类:程序文摘| 标签:|字号大中小订阅 关键字: 软件工程生命周期模型 摘自:这里 文章不错,至少是从理论的角度,用通俗的语言讲述了软件工程木常见的“原型法、编码-修改法、传统瀑布、改进瀑布、增量、螺旋、RUP、XP”等软件过程。值得学习! 进行完软件估计后,刘小备开始启动下一阶段的工作选择软件生命周期,可供软件生命周期模型这么多,有原型法、编码-修改法、传统瀑布、改进瀑布、增量、螺旋、RUP、XP,还有什么“V”模型、“W” 模型,到底选择哪一种呢?刘小备想起来头大,索性就不想了,直接去找昔日故交孔小明,如今的孔小明已经是“孔氏项目管理咨询有限公司”的总经理,毕竟有前些年大大小小几十个项目的丰富经历,再加上孔小名扎实的软件开发理论功底,经过孔小明咨询的项目都取得了成功,虽然公司只有十几个人,“孔氏项目管理咨询有限公司”在业界也小有名气了,孔小明早就把他的羽毛扇送到博物馆去了,不离手的是有蓝牙/WLAN/GSM/GPRS/WCDMA的多模智能手机,代步的两轮车也换成了“奔驰2008”。刘小备到“孔氏项目管理咨询有限公司”时,正赶上孔小明给一家叫什么“新盛”的系统集成公司新接的一个千万级的项目做咨询结束,对方的公司老总握着孔小明的手不放,技术总监和项目经理也一脸崇拜的看着孔小明,孔小明很客气的把他们送走,然后转身把刘小备请进办公室。还没坐下刘小备就直奔主题(以下是两个人的对话,刘小备用刘代替,孔小明用孔代替) 刘:孔总,虽然我也做过几个项目,但对于生命周期模型一直也没有搞清楚孰优孰劣,所以在选择时往往是跟着感觉走,今天来就是想把这个问题彻底弄清楚,一劳永逸。 孔:在讲各种生命周期模型前,我想强调一下,任何项目,不管采用什么模型有四项活动都是必不可少的。不管是有意识还是无意识,这些活动都会出现在项目过程中。 刘:哪四项活动? 孔:就是需求、设计、编码和测试。这也是最重要的四项活动,其他的活动其实都是为这些活动服务的,不管是配置管理、还是风险管理、还是评审等等。 刘:哦!这个问题没有考虑过,不过你说出来再一想确实是这么回事。 孔:生命周期的定义咱们就不讨论了,我直接就常用的模型的优缺点和使用条件进行说明。 刘:太好了! 孔:我先说第一种:编码-修改模型。也称Code And Fix方法,是历史最悠久一种模型,从人类开始写程序的第一天这种模型就出现了,我们每个人开始学写程序时也不自觉的采用了这种模型。 刘:这个我知道了。这种模型没有规划、没有控制、开发过程混乱,软件质量完全依靠程序员个人的能力,后期基本不能维护,尤其是有人员变动,这应该是造成上世纪70年代软件危机的主要根源。 孔:即便在现在,这种模型也很有市场的,很多的中小型公司采用的仍然是这种开发模型。 刘:那是不是说,这个模型应该彻底的抛弃? 孔:那到不尽然。毕竟个人在开始学习编程时,这种方法是一个很好的选择,即使对于企业也不是完全不可取,比如有些项目对质量要求不高,但需要把东西攒起来,否则就丢单,这时如果在四平八稳的好好的规划和设计,那么到时候“黄瓜菜都凉了”。
数学建模幸福感的评价与量化模型
2011年第八届苏北数学建模联赛 承诺书 我们仔细阅读了第八届苏北数学建模联赛的竞赛规则。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与本队以外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们愿意承担由此引起的一切后果。 我们的参赛报名号为: 参赛组别(研究生或本科或专科): 参赛队员 (签名) : 队员1: 队员2: 队员3: 获奖证书邮寄地址:
2011年第八届苏北数学建模联赛 编号专用页 参赛队伍的参赛号码:(请各个参赛队提前填写好): 2818 竞赛统一编号(由竞赛组委会送至评委团前编号): 竞赛评阅编号(由竞赛评委团评阅前进行编号): 2011年第八届苏北数学建模联赛 题目幸福感的评价与量化模型 摘要 改革开放三十多年,我国经济建设取得了巨大成就,人们物质生活得到了极大改善。但也有越来越多的人开始思考:我们大力发展经济,最终目的是为了什么?温家宝总理近年来多次强调:我们所做的一切,都是为了让人民生活得更加幸福。在今年的全国两会期间,“幸福感”也成为最热门词语之一。 在处理问题(一)时,本文根据题目已给的相关数据,将诸如“非常满意”、“比较满意”、“基本满意”、“不太满意”、“不满意”之类答项并按序排列,分别给予5~1分的分值。建立得分和得票率的函数关系,通过MATLAB进行4次多项式拟合,并算出权重,最后得出幸福指数H 具有如下关系, 在处理问题(二)时,本文利用SPSS软件,对网上搜寻的大量有用信息进行统计分析,通过使用主成份分析法建立模型I,讨论各因素对幸福影响程度的大小,由此确定了影响房幸福指数的主要因素分别是:人际关系、家庭生活、身心健康、个人价值的实现、工作及收入水平。 在处理问题(三)时,本文通过对数据的分析、权值运算以及结果分析角度论述模型I运用于普遍情况的可能性。通过此种方法虽然计算较为繁琐,但其中的方差和统计方法可以有效减少个别指标的变动带来的影响,同时三元链模型中增加了路径可以较好地反应出各个相关量之间的关系,最终通过加权平均法对幸福指数进行总的计算,减少了误差,更能反应出真是情况的幸福指数,具有统计意义。可以推广到更加普遍的人群。 目录 1 问题的背景 (5) 2 问题的提出与重述 (6) 3 基本假设 (6) 4 主要变量符号说明 (6) 5 问题一 (7) 5.1 建模思路 (7) 5.2 最小二乘法模型建立 (7)
时间序列分析法原理及步骤
时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征, 以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动, 即方差和数学期望稳定为常数 识别序列特征可利用函数 ACF :其中是的 k 阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于 0, 前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上, 预测模型大都难以满足这些条件, 现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归 AR(p模型
模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用 PACF 函数判别 (从 p 阶开始的所有偏自相关系数均为 0 2》移动平均 MA(q模型 识别条件
平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到 0, 则该时间序列可能是 ARMA(p,q模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解 p,q 和φ、θ的值,检验和的值。 模型阶数 实际应用中 p,q 一般不超过 2. 3》自回归综合移动平均 ARIMA(p,d,q模型 模型含义 模型形式类似 ARMA(p,q模型, 但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用 ARMA(p,q模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中 d (差分次数一般不超过 2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是 ARIMA(p,d,q模型。若时间序列存在周期性波动, 则可按时间周期进
Eviews时间序列分析实例.
Eviews时间序列分析实例 时间序列是市场预测中经常涉及的一类数据形式,本书第七章对它进行了比较详细的介绍。通过第七章的学习,读者了解了什么是时间序列,并接触到有关时间序列分析方法的原理和一些分析实例。本节的主要内容是说明如何使用Eviews软件进行分析。 一、指数平滑法实例 所谓指数平滑实际就是对历史数据的加权平均。它可以用于任何一种没有明显函数规律,但确实存在某种前后关联的时间序列的短期预测。由于其他很多分析方法都不具有这种特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。 (-)一次指数平滑 一次指数平滑又称单指数平滑。它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到预测结果。 一次指数平滑的特点是:能够跟踪数据变化。这一特点所有指数都具有。预测过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。这样,预测值总是反映最新的数据结构。 一次指数平滑有局限性。第一,预测值不能反映趋势变动、季节波动等有规律的变动;第二,这种方法多适用于短期预测,而不适合作中长期的预测;第三,由于预测值是历史数据的均值,因此与实际序列的变化相比有滞后现象。 指数平滑预测是否理想,很大程度上取决于平滑系数。Eviews提供两种确定指数平滑系数的方法:自动给定和人工确定。选择自动给定,系统将按照预测误差平方和最小原则自动确定系数。如果系数接近1,说明该序列近似纯随机序列,这时最新的观测值就是最理想的预测值。 出于预测的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。平滑系数取什么值比较合适呢?一般来说,如果序列变化比较平缓,平滑系数值应该比较小,比如小于0.l;如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。若平滑系数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预测。 [例1]某企业食盐销售量预测。现在拥有最近连续30个月份的历史资料(见表l),试预测下一月份销售量。 表1 某企业食盐销售量单位:吨 解:使用Eviews对数据进行分析,第一步是建立工作文件和录入数据。有关操作在本
企业战略定位选择与评价与衡量模型设计
企业战略定位选择与评价模型设计 【摘要】战略管理是指对企业全局性、长远的发展方向、目标、任务和政策,以及资源配置做出的决策和管理的过程。企业应用战略管理工具,一般按照战略分析、战略定位、战略评价和控制、战略调整等程序进行。本文主要研究了企业战略定位的选择和评价问题,在战略定位选择的研究中,主要介绍了总体战略定位分析和基本竞争战略定位分析中的问题;在评价模型设计中,主要介绍了通过SWOT定性分析发现问题,进而进行定量分析,在定量分析中主要介绍了IFE矩阵模型、EFE矩阵模型和QSPM矩阵模型,以期帮助企业科学进行战略定位选择以及正确评价方案优劣,减少决策失误。 【关键词】战略分析战略定位战略评价 一、企业战略定位的选择 企业战略定位是通过对企业所处的外部环境、产业环境和自身发展条件进行分析,根据分析结果制定企业战略目标的过程,战略定位为战略管理指明方向。战略定位分析可以反映出企业竞争力,为战略管理者提供战略透视,可以使战略管理者有的放矢。 企业战略定位分析可以分为总体战略定位分析和基本
竞争战略定位分析。 (一)总体战略定位分析 总体战略定位分析是指通过对企业外部环境、产业环境和部环境进行SWOT分析,找出企业战略定位的四种备选模式,分别为SO、WO、ST、WT战略选择,构成了四种备选模式,分别为发展战略、分散战略、退出战略和维持战略。如图表1所示。 发展威胁 1.发展战略。是企业处于外部优势和部优势的组合方式,在这种条件下企业具有较强的竞争实力,同时面临的外部环境是发展机会多,发展威胁少,这是最为理想的战略环境,在这种环境下企业可以选择进攻性的发展战略,能够发挥现有优势,利用现有条件,加快企业发展。 定位于发展战略,企业一方面可以利用自身丰富的资源优势、技术水平优势、资金优势、管理能力和品牌效应,对现有企业进行技术改造,提高经济效益,同时进行横向扩,加快兼并收购、实现跨区域或跨国经营,加大市场占有率,进一步巩固竞争优势。另一方面,企业也可以分析自身在行业价值链中的位置,在价值链分析的基础上,利用现有资金、管理优势采取纵向整合,发展一体化,增加产品附加值,发掘新的利润增长点,集聚实力把企业做大做强。 2.分散战略。是企业的外部发展机会和部劣势的组合方
项目投资拓展评估模型
1.评估模型概况 2.项目投资拓展类型要求 在土地拓展过程中,针对不同类型的项目,需要满足以下基本要求: 相关定义及解释: 一级土地获取:指开发商通过国有土地出让获取土地。项目用地完成规划选址、土地预审,完成土地使用性质、容积率、建筑密度、绿地率、建筑限高、公共设施等规划调整,完成建设用地指标调拨。 二手转让项目:指原企业因资金短缺或经营问题,转让项目土地。此项目要求土地产权清晰无抵押、质押;手续齐全:国有土地使用证在手(建设规划许可证、施工规划许可证,
建筑施工许可证齐全最好);项目范围内无拆迁物、权属不清、历史遗留问题等现象;项目公司无负债或负债在成本可接受范围内。 合作开发项目;满足一级土地开发或二手转让项目的基本要求;我司要求占51%以上股权,利于项目后期开发建设(注:满足一级土地开发或二手转让项目的基本要求指:项目用地完成规划选址、土地预审,完成土地使用性质、容积率、建筑密度、绿地率、建筑限高、公共设施等规划调整,完成建设用地指标调拨。项目范围内无拆迁物、权属不清、历史遗留问题等现象。土地使用权归属完整,无抵押,土地权属无争议,取得土地使用权或公司股权的程序及交易方式合法,具有可操作性。)。 城市更新项目:城市更新意愿达双80%以上,我司在拆迁补偿完成前不实质性投入;拆迁补偿完成后我司以收购项目公司、合作开发等方式成为项目实施主体(注:双80%指项目范围内建筑面积和占地面积达到80%以上同意城市更新;拆迁补偿完成前不实质性投入指前期拆迁我司不负责但可缴纳一定项目保证金,待项目公司完成拆迁补偿后再投入;收购项目公司或合作开发的我司必须控股操盘,实施主体资格确保确认在我司名下) 3.项目投资拓展指标要求: 为保证集团可持续发展,避免出现销售额“大小年”及发展断层,项目拓展过程中既需关注近期经济利益明显的短平快项目,也应该关注销售利润率高,投资回报率高的中长期项目,更需包括早期投入低,项目周期长,后期收益高的土地储备项目。一般短平快项目土地储备应该占土地储备总数的20%-30%。
安全感指数的量化评价模型
安全感指数的量化评价模型 北京邮电大学世纪学院耿雪、王汝珍、卢云婷 摘要 安全感指数是一个模糊、感性的概念,它是由很多指标组成的,仅由主观衡量是很难的,所以将人们的感受加以量化,并对其进行评价。 对问题一,通过发放调查问卷形式,将调查结果进行整理并分类,将安全感划分为三个方面:社会治安、自身情况、人际交往,然后进行分层确定权重,建立模糊评价模型,利用此模型求出安全感指数,得到所调查人员的安全感指数为% 60,相对误差为% . 18 .0。 30 对问题二,计算出某社区安全感指数为% 67,并得知,影响社区 . 00 安全感的主要因素是社区管理、收入及消费、邻里信任。 最后,对模型进行分析总结可得到:所确定的安全感调查指标体系,能够比较准确、客观地反映人们安全感程度。 关键字:安全感指数层次分析法模糊评价模型
一、问题重述 1.1 问题背景 安全感是公众对社会状况的主观感受和评价,是人们对社会安全与否的认识的整体反映,它是由社会中个体的安全感来体现的,人类社会快速发展的今天,人们在追求更高层次的需求时,潜意识里要求的还是基本的安全感,安全感是反映社会治安是否完善的重要指标,是心理需要的第一要素,是人格中最为重要,最为基础的部分,也是人类最重要的需要。 1.2 需要解决的问题 (1)通过调查问卷,得到数据,建立安全感的评价指标体系,通过利用这些数据建立数学模型,来评价安全感,得到所调查人员的安全感指数。 (2)通过查找相关资料,建立某一社区安全感的数学模型,并找出影响他们安全感的主要因素。 二、问题分析 2.1 问题1的分析 通过网上问卷调查的形式,对问题进行分类并整理将其安全感划分为三个方面:社会治安、自身情况、人际交往。这三个方面能够较全面的评价安全感,但是安全感是一个模糊、抽象的概念,相对主观来说是很难去衡量的,所以我们又将其细化,细分为十四个小的方面,包括当前社会刑事犯罪、食品安全、住房条件等。 通过对调查的问题进行分类、整理并进行分层,运用模糊层次法得到安全感评价体系。利用层次分析法确定权重,建立安全感模型,利用此模型可求出安全感指数。
现代时间序列分析模型
现代时间序列分析模型§1 时间序列平稳性和单位根检验§2 协整与误差修正模型经典时间序列分析模型: MA、AR、ARMA 平稳时间序列模型分析时间序列自身的变化规律现代时间序列分析模型:分析时间序列之间的关系单位根检验、协整检验现代宏观计量经济学§1 时间序列平稳性和单位根检验一、时间序列的平稳性二、单整序列三、单位根检验一、时间序列的平稳性 Stationary Time Series ⒈问题的提出经典计量经济模型常用到的数据有:时间序列数据(time-series data ;截面数据cross-sectional data 平行/面板数据(panel data/time-series cross-section data 时间序列数据是最常见,也是最常用到的数据。经典回归分析暗含着一个重要假设:数据是平稳的。数据非平稳,大样本下的统计推断基础――“一致性”要求――被破怀。数据非平稳,往往导致出现“虚假回归”(Spurious Regression)问题。表现为两个本来没有任何因果关系的变量,却有很高的相关性。例如:如果有两列时间序列数据表现出一致的变化趋势(非平稳的),即使它们没有任何有意义的关系,但进行回归也可表现出较高的可决系数。 2、平稳性的定义假定某个时间序列是由某一随机过程(stochastic process)生成的,即假定时间序列 Xt (t 1, 2, …)的每一个数值都是从一个概率分布中随机得到,如果满足下列条件:均值E Xt ?是与时间t 无关的常数;方差Var Xt ?2是与时间t 无关的常数;协方差Cov Xt,Xt+k ?k 是只与时期间隔k有关,与时间t 无关的常数;则称该随机时间序列是平稳的(stationary ,
基于层次分析法的供应商选择与评价
大学毕业论文 基于层次分析法的供应商 评价与选择研究 A Research on Supplier Evaluation and Selection Based on Analytic Hierarchy Process 2011届经济管理学院 专业物流管理 学号 20071262 学生姓名 指导教师 完成日期 2011年 6 月 1 日
毕业论文成绩单 学生姓名学号20071262 班级经0708 专业物流管理毕业论文题目基于层次分析法的供应商评价与选择研究 指导教师姓名郭跃显 指导教师职称副教授 评定成绩 指导教 得分 师 评阅人得分 答辩小 组组长得分 成绩: 院长(主任) 签字: 年月日
毕业论文任务书 题目基于层次分析法的供应商评价与选择研究 学生姓名学号20071262 班级经0708 专业物流管理 承担指导任务单位工商管理系导师 姓名 导师 职称 副教授 一、主要内容 供应链管理已成为国内外备受关注的一种新型管理理念与企业运作模式,供应商选择是供应链管理研究的热点问题之一,也是集成化供应链管理的核心。要求学生完成以下内容的资料收集与写作: 1、概括供应链管理的相关理论及供应链环境下供应商选择和管理相关理论。 2、分析供应链环境下的供应商合作关系,讨论供应链环境下供应商分类特点。 3、基于供应商评价指标体系的原则,设计供应链环境下供应商评价指标体系。 4、应用层次分析法构建供应商选择的模型与方法,并提供实际例证和对策建议。 二、基本要求 毕业论文应具有科学性、先进性和创新性,要努力揭示供应链环境下的供应商的选择和管理规律,论文要有新意;论文结构要以提出问题——分析问题——解决问题三段式的逻辑结构为原则;论文的三要素力争做到:论点正确、深刻、有创新,论据真实、典型、充分,论文严密、有力;语言表达严谨、准确、流畅。 三、主要技术指标 论文正文不少于1.3万字,查阅文献资料不少于15篇,其中外文文献2篇以上,翻译与课题有关的外文资料不少于3000汉字。 四、应收集的资料及参考文献 [1] 姜建华,汪波.基于企业中对供应商评价方法的研究[J].西安电子科技大 学学报,2006(04) [2] 秦建玲,贾旭光.供应商评价指标体系中定性指标的筛选[J].消费导 刊.2008(06) [3] 赵红梅,韩丽萍.基于供应链绩效的供应商选择与评价指标体系的构建 [J].内蒙古工业大学学报(自然科学版),2007(03) 五、进度计划 时间内容完成情况教师签字第1周—第2周开题报告 第3周—第7周论文大纲及初稿 第8周—第9周修改论文 第10周—第11周论文定稿、装订及答辩 教研室主任签字时间2011年4月5日