计量经济学第三版课后答案
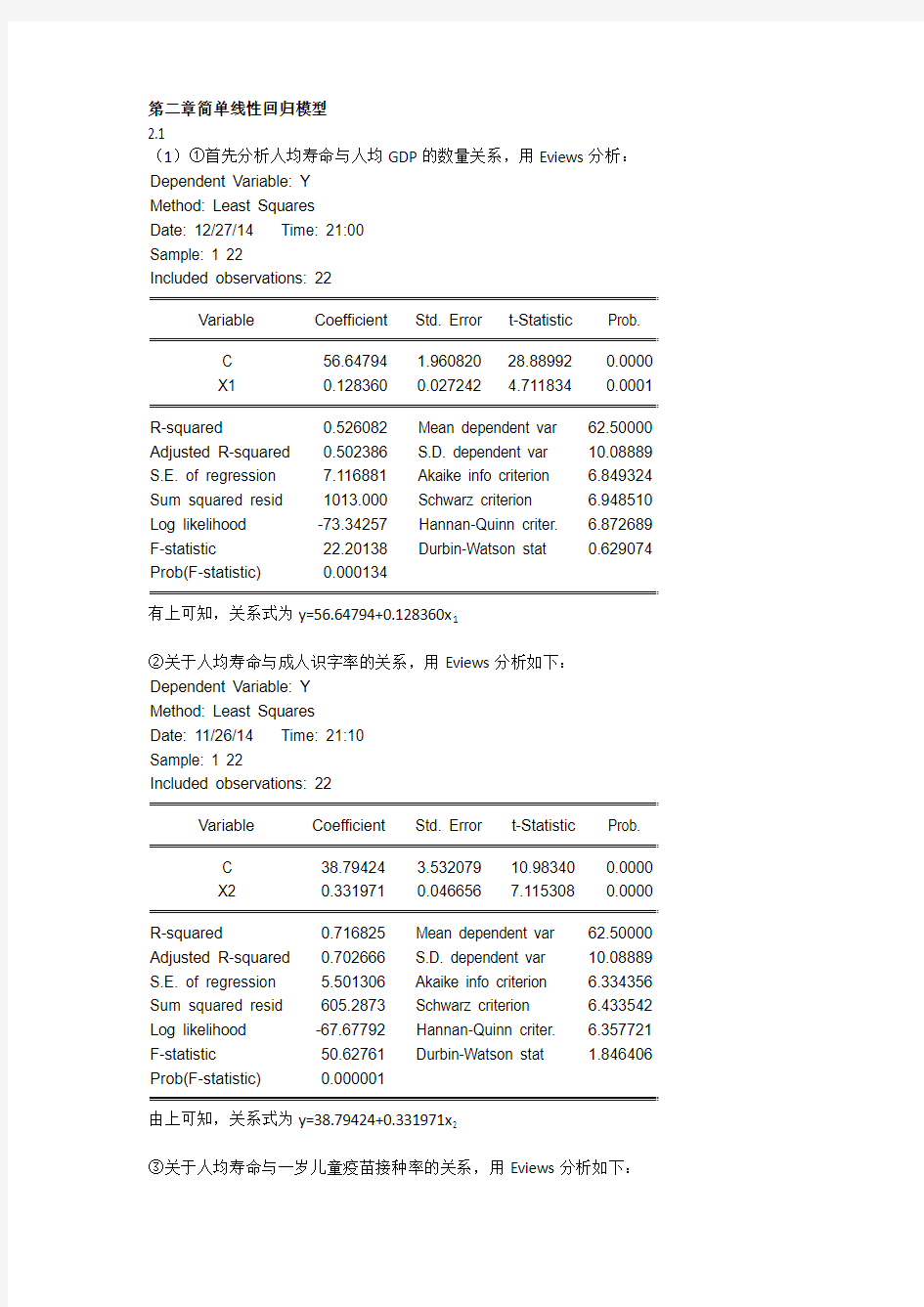

第二章简单线性回归模型
2.1
(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: Y
Method: Least Squares
Date: 12/27/14 Time: 21:00
Sample: 1 22
Included observations: 22
Variable Coefficient Std. Error t-Statistic Prob.
C 56.64794 1.960820 28.88992 0.0000
X1 0.128360 0.027242 4.711834 0.0001
R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134
有上可知,关系式为y=56.64794+0.128360x1
②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: Y
Method: Least Squares
Date: 11/26/14 Time: 21:10
Sample: 1 22
Included observations: 22
Variable Coefficient Std. Error t-Statistic Prob.
C 38.79424 3.532079 10.98340 0.0000
X2 0.331971 0.046656 7.115308 0.0000
R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001
由上可知,关系式为y=38.79424+0.331971x2
③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:
Dependent Variable: Y
Method: Least Squares
Date: 11/26/14 Time: 21:14
Sample: 1 22
Included observations: 22
Variable Coefficient Std. Error t-Statistic Prob.
C 31.79956 6.536434 4.864971 0.0001
X3 0.387276 0.080260 4.825285 0.0001
R-squared 0.537929 Mean dependent var 62.50000
Adjusted R-squared 0.514825 S.D. dependent var 10.08889
S.E. of regression 7.027364 Akaike info criterion 6.824009
Sum squared resid 987.6770 Schwarz criterion 6.923194
Log likelihood -73.06409 Hannan-Quinn criter. 6.847374
F-statistic 23.28338 Durbin-Watson stat 0.952555
Prob(F-statistic) 0.000103
由上可知,关系式为y=31.79956+0.387276x3
(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=4.711834>t0.025(20)=2.086,对斜率系数的显著性检验表明,人均GDP对人均寿命有显著影响。
②关于人均寿命与成人识字率模型,由上可知,可决系数为0.716825,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β2)=7.115308>t0.025(20)=2.086,对斜率系数的显著性检验表明,成人识字率对人均寿命有显著影响。
③关于人均寿命与一岁儿童疫苗的模型,由上可知,可决系数为0.537929,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β3)=4.825285>t0.025(20)=2.086,对斜率系数的显著性检验表明,一岁儿童疫苗接种率对人均寿命有显著影响。
2.2
(1)
①对于浙江省预算收入与全省生产总值的模型,用Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/03/14 Time: 17:00
Sample (adjusted): 1 33
Included observations: 33 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
X 0.176124 0.004072 43.25639 0.0000
C -154.3063 39.08196 -3.948274 0.0004
R-squared 0.983702 Mean dependent var 902.5148
Adjusted R-squared 0.983177 S.D. dependent var 1351.009
S.E. of regression 175.2325 Akaike info criterion 13.22880
Sum squared resid 951899.7 Schwarz criterion 13.31949
Log likelihood -216.2751 Hannan-Quinn criter. 13.25931
F-statistic 1871.115 Durbin-Watson stat 0.100021
Prob(F-statistic) 0.000000
②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063
③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显著性:
1)可决系数为0.983702,说明所建模型整体上对样本数据拟合较好。
2)对于回归系数的t检验:t(β2)=43.25639>t0.025(31)=2.0395,对斜率系数的显著性检验表明,全省生产总值对财政预算总收入有显著影响。
④用规范形式写出检验结果如下:
Y=0.176124X—154.3063
(0.004072) (39.08196)
t= (43.25639) (-3.948274)
R2=0.983702 F=1871.115 n=33
⑤经济意义是:全省生产总值每增加1亿元,财政预算总收入增加0.176124亿元。
(2)当x=32000时,
①进行点预测,由上可知Y=0.176124X—154.3063,代入可得:
Y= Y=0.176124*32000—154.3063=5481.6617
②进行区间预测:
先由Eviews分析:
由上表可知,
∑x2=∑(X i—X)2=δ2x(n—1)= 7608.0212 x (33—1)=1852223.473
(X f—X)2=(32000— 6000.441)2=675977068.2
当Xf=32000时,将相关数据代入计算得到:
5481.6617—2.0395x175.2325x√1/33+1852223.473/675977068.2≤
Yf≤5481.6617+2.0395x175.2325x√1/33+1852223.473/675977068.2
即Yf的置信区间为(5481.6617—64.9649, 5481.6617+64.9649)
(3) 对于浙江省预算收入对数与全省生产总值对数的模型,由Eviews分析结果如下:Dependent Variable: LNY
Method: Least Squares
Date: 12/03/14 Time: 18:00
Sample (adjusted): 1 33
Included observations: 33 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LNX 0.980275 0.034296 28.58268 0.0000
C -1.918289 0.268213 -7.152121 0.0000
R-squared 0.963442 Mean dependent var 5.573120
Adjusted R-squared 0.962263 S.D. dependent var 1.684189
S.E. of regression 0.327172 Akaike info criterion 0.662028
Sum squared resid 3.318281 Schwarz criterion 0.752726
Log likelihood -8.923468 Hannan-Quinn criter. 0.692545
F-statistic 816.9699 Durbin-Watson stat 0.096208
Prob(F-statistic) 0.000000
①模型方程为:lnY=0.980275lnX-1.918289
②由上可知,模型的参数:斜率系数为0.980275,截距为-1.918289
③关于浙江省财政预算收入与全省生产总值的模型,检验其显著性:
1)可决系数为0.963442,说明所建模型整体上对样本数据拟合较好。
2)对于回归系数的t检验:t(β2)=28.58268>t0.025(31)=2.0395,对斜率系数的显著性检验表明,全省生产总值对财政预算总收入有显著影响。
④经济意义:全省生产总值每增长1%,财政预算总收入增长0.980275%
2.4
(1)对建筑面积与建造单位成本模型,用Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 12:40
Sample: 1 12
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
X -64.18400 4.809828 -13.34434 0.0000
C 1845.475 19.26446 95.79688 0.0000
R-squared 0.946829 Mean dependent var 1619.333
Adjusted R-squared 0.941512 S.D. dependent var 131.2252
S.E. of regression 31.73600 Akaike info criterion 9.903792
Sum squared resid 10071.74 Schwarz criterion 9.984610
Log likelihood -57.42275 Hannan-Quinn criter. 9.873871
F-statistic 178.0715 Durbin-Watson stat 1.172407
Prob(F-statistic) 0.000000
由上可得:建筑面积与建造成本的回归方程为:
Y=1845.475--64.18400X
(2)经济意义:建筑面积每增加1万平方米,建筑单位成本每平方米减少64.18400元。
(3)
①首先进行点预测,由Y=1845.475--64.18400X得,当x=4.5,y=1556.647
②再进行区间估计:
由上表可知,
∑x2=∑(X i—X)2=δ2x(n—1)= 1.9894192 x (12—1)=43.5357
(X f—X)2=(4.5—3.523333)2=0.95387843
当Xf=4.5时,将相关数据代入计算得到:
1556.647—2.228x31.73600x√1/12+43.5357/0.95387843≤
Yf≤1556.647+2.228x31.73600x√1/12+43.5357/0.95387843
即Yf的置信区间为(1556.647—478.1231, 1556.647+478.1231)
3.1
(1)
①对百户拥有家用汽车量计量经济模型,用Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 11/25/14 Time: 12:38
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
X2 5.996865 1.406058 4.265020 0.0002
X3 -0.524027 0.179280 -2.922950 0.0069
X4 -2.265680 0.518837 -4.366842 0.0002
C 246.8540 51.97500 4.749476 0.0001
R-squared 0.666062 Mean dependent var 16.77355
Adjusted R-squared 0.628957 S.D. dependent var 8.252535
S.E. of regression 5.026889 Akaike info criterion 6.187394
Sum squared resid 682.2795 Schwarz criterion 6.372424
Log likelihood -91.90460 Hannan-Quinn criter. 6.247709
F-statistic 17.95108 Durbin-Watson stat 1.147253
Prob(F-statistic) 0.000001
②得到模型得:
Y=246.8540+5.996865X2-0.524027 X3-2.265680 X4
③对模型进行检验:
1)可决系数是0.666062,修正的可决系数为0.628957,说明模型对样本拟合较好
2)F检验,F=17.95108>F(3,27)=3.65,回归方程显著。
3)t检验,t统计量分别为4.749476,4.265020,-2.922950,-4.366842,均大于
t(27)=2.0518,所以这些系数都是显著的。
④依据:
1)可决系数越大,说明拟合程度越好
2)F的值与临界值比较,若大于临界值,则否定原假设,回归方程是显著的;若小于临界值,则接受原假设,回归方程不显著。
3)t的值与临界值比较,若大于临界值,则否定原假设,系数都是显著的;若小于临界值,则接受原假设,系数不显著。
(2)经济意义:人均GDP增加1万元,百户拥有家用汽车增加5.996865辆,城镇人口比重增加1个百分点,百户拥有家用汽车减少0.524027辆,交通工具消费价格指数每上升1,百户拥有家用汽车减少2.265680辆。
(3)用EViews分析得:
Dependent Variable: Y
Method: Least Squares
Date: 12/08/14 Time: 17:28
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
X2 5.135670 1.010270 5.083465 0.0000
LNX3 -22.81005 6.771820 -3.368378 0.0023
LNX4 -230.8481 49.46791 -4.666624 0.0001
C 1148.758 228.2917 5.031974 0.0000
R-squared 0.691952 Mean dependent var 16.77355
Adjusted R-squared 0.657725 S.D. dependent var 8.252535
S.E. of regression 4.828088 Akaike info criterion 6.106692
Sum squared resid 629.3818 Schwarz criterion 6.291723
Log likelihood -90.65373 Hannan-Quinn criter. 6.167008
F-statistic 20.21624 Durbin-Watson stat 1.150090
Prob(F-statistic) 0.000000
模型方程为:
Y=5.135670 X2-22.81005 LNX3-230.8481 LNX4+1148.758
此分析得出的可决系数为0.691952>0.666062,拟合程度得到了提高,可这样改进。
3.2
(1)对出口货物总额计量经济模型,用Eviews分析结果如下::
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 20:25
Sample: 1994 2011
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
X2 0.135474 0.012799 10.58454 0.0000
X3 18.85348 9.776181 1.928512 0.0729
C -18231.58 8638.216 -2.110573 0.0520
R-squared 0.985838 Mean dependent var 6619.191
Adjusted R-squared 0.983950 S.D. dependent var 5767.152
S.E. of regression 730.6306 Akaike info criterion 16.17670
Sum squared resid 8007316. Schwarz criterion 16.32510
Log likelihood -142.5903 Hannan-Quinn criter. 16.19717
F-statistic 522.0976 Durbin-Watson stat 1.173432
Prob(F-statistic) 0.000000
①由上可知,模型为:
Y = 0.135474X2 + 18.85348X3 - 18231.58
②对模型进行检验:
1)可决系数是0.985838,修正的可决系数为0.983950,说明模型对样本拟合较好
2)F检验,F=522.0976>F(2,15)=4.77,回归方程显著
3)t检验,t统计量分别为X2的系数对应t值为10.58454,大于t(15)=2.131,系数是显著的,X3的系数对应t值为1.928512,小于t(15)=2.131,说明此系数是不显著的。
(2)对于对数模型,用Eviews分析结果如下:
Dependent Variable: LNY
Method: Least Squares
Date: 12/01/14 Time: 20:25
Sample: 1994 2011
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
LNX2 1.564221 0.088988 17.57789 0.0000
LNX3 1.760695 0.682115 2.581229 0.0209
C -20.52048 5.432487 -3.777363 0.0018
R-squared 0.986295 Mean dependent var 8.400112
Adjusted R-squared 0.984467 S.D. dependent var 0.941530
S.E. of regression 0.117343 Akaike info criterion -1.296424
Sum squared resid 0.206540 Schwarz criterion -1.148029
Log likelihood 14.66782 Hannan-Quinn criter. -1.275962
F-statistic 539.7364 Durbin-Watson stat 0.686656
Prob(F-statistic) 0.000000
①由上可知,模型为:
LNY=-20.52048+1.564221 LNX2+1.760695 LNX3
②对模型进行检验:
1)可决系数是0.986295,修正的可决系数为0.984467,说明模型对样本拟合较好。
2)F检验,F=539.7364> F(2,15)=4.77,回归方程显著。
3)t检验,t统计量分别为-3.777363,17.57789,2.581229,均大于t(15)=2.131,所以这些系数都是显著的。
(3)
①(1)式中的经济意义:工业增加1亿元,出口货物总额增加0.135474亿元,人民币汇率增加1,出口货物总额增加18.85348亿元。
②(2)式中的经济意义:工业增加额每增加1%,出口货物总额增加1.564221%,人民币汇率每增加1%,出口货物总额增加1.760695%
3.3
(1)对家庭书刊消费对家庭月平均收入和户主受教育年数计量模型,由Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 20:30
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
X 0.086450 0.029363 2.944186 0.0101
T 52.37031 5.202167 10.06702 0.0000
C -50.01638 49.46026 -1.011244 0.3279
R-squared 0.951235 Mean dependent var 755.1222
Adjusted R-squared 0.944732 S.D. dependent var 258.7206
S.E. of regression 60.82273 Akaike info criterion 11.20482
Sum squared resid 55491.07 Schwarz criterion 11.35321
Log likelihood -97.84334 Hannan-Quinn criter. 11.22528
F-statistic 146.2974 Durbin-Watson stat 2.605783
Prob(F-statistic) 0.000000
①模型为:Y = 0.086450X + 52.37031T-50.01638
②对模型进行检验:
1)可决系数是0.951235,修正的可决系数为0.944732,说明模型对样本拟合较好。
2)F检验,F=539.7364> F(2,15)=4.77,回归方程显著。
3)t检验,t统计量分别为2.944186,10.06702,均大于t(15)=2.131,所以这些系数都是显著的。
③经济意义:家庭月平均收入增加1元,家庭书刊年消费支出增加0.086450元,户主受教育年数增加1年,家庭书刊年消费支出增加52.37031元。
(2)用Eviews分析:
①
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 22:30
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
T 63.01676 4.548581 13.85416 0.0000
C -11.58171 58.02290 -0.199606 0.8443
R-squared 0.923054 Mean dependent var 755.1222 Adjusted R-squared 0.918245 S.D. dependent var 258.7206 S.E. of regression 73.97565 Akaike info criterion 11.54979 Sum squared resid 87558.36 Schwarz criterion 11.64872 Log likelihood -101.9481 Hannan-Quinn criter. 11.56343 F-statistic 191.9377 Durbin-Watson stat 2.134043 Prob(F-statistic) 0.000000
②
Dependent Variable: X
Method: Least Squares
Date: 12/01/14 Time: 22:34
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
T 123.1516 31.84150 3.867644 0.0014
C 444.5888 406.1786 1.094565 0.2899
R-squared 0.483182 Mean dependent var 1942.933 Adjusted R-squared 0.450881 S.D. dependent var 698.8325 S.E. of regression 517.8529 Akaike info criterion 15.44170 Sum squared resid 4290746. Schwarz criterion 15.54063 Log likelihood -136.9753 Hannan-Quinn criter. 15.45534 F-statistic 14.95867 Durbin-Watson stat 1.052251 Prob(F-statistic) 0.001364
以上分别是y与T,X与T的一元回归
模型分别是:
Y = 63.01676T - 11.58171
X = 123.1516T + 444.5888
(3)对残差进行模型分析,用Eviews分析结果如下:
Dependent Variable: E1
Method: Least Squares
Date: 12/03/14 Time: 20:39
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
E2 0.086450 0.028431 3.040742 0.0078
C 3.96E-14 13.88083 2.85E-15 1.0000
R-squared 0.366239 Mean dependent var 2.30E-14
Adjusted R-squared 0.326629 S.D. dependent var 71.76693
S.E. of regression 58.89136 Akaike info criterion 11.09370
Sum squared resid 55491.07 Schwarz criterion 11.19264
Log likelihood -97.84334 Hannan-Quinn criter. 11.10735
F-statistic 9.246111 Durbin-Watson stat 2.605783
Prob(F-statistic) 0.007788
模型为:
E1 = 0.086450E2 + 3.96e-14
参数:斜率系数α为0.086450,截距为3.96e-14
(3)由上可知,β2与α2的系数是一样的。回归系数与被解释变量的残差系数是一样的,它们的变化规律是一致的。
3.6
(1)预期的符号是X1,X2,X3,X4,X5的符号为正,X6的符号为负
(2)根据Eviews分析得到数据如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/04/14 Time: 13:24
Sample: 1994 2011
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
X2 0.001382 0.001102 1.254330 0.2336
X3 0.001942 0.003960 0.490501 0.6326
X4 -3.579090 3.559949 -1.005377 0.3346
X5 0.004791 0.005034 0.951671 0.3600
X6 0.045542 0.095552 0.476621 0.6422
C -13.77732 15.73366 -0.875659 0.3984
R-squared 0.994869 Mean dependent var 12.76667
Adjusted R-squared 0.992731 S.D. dependent var 9.746631
S.E. of regression 0.830963 Akaike info criterion 2.728738
Sum squared resid 8.285993 Schwarz criterion 3.025529
Log likelihood -18.55865 Hannan-Quinn criter. 2.769662
F-statistic 465.3617 Durbin-Watson stat 1.553294
Prob(F-statistic) 0.000000
①与预期不相符。
②评价:
1)可决系数为0.994869,数据相当大,可以认为拟合程度很好。
2)F检验,F=465.3617>F(5.12)=3,89,回归方程显著
3)T检验,X1,X2,X3,X4,X5,X6 系数对应的t值分别为:1.254330,0.490501,-1.005377,
0.951671,0.476621,均小于t(12)=2.179,所以所得系数都是不显著的。
(3)根据Eviews分析得到数据如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/03/14 Time: 11:12
Sample: 1994 2011
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
X5 0.001032 2.20E-05 46.79946 0.0000
X6 -0.054965 0.031184 -1.762581 0.0983
C 4.205481 3.335602 1.260786 0.2266
R-squared 0.993601 Mean dependent var 12.76667
Adjusted R-squared 0.992748 S.D. dependent var 9.746631
S.E. of regression 0.830018 Akaike info criterion 2.616274
Sum squared resid 10.33396 Schwarz criterion 2.764669
Log likelihood -20.54646 Hannan-Quinn criter. 2.636736
F-statistic 1164.567 Durbin-Watson stat 1.341880
Prob(F-statistic) 0.000000
①得到模型的方程为:
Y=0.001032 X5-0.054965 X6+4.205481
②评价:
1)可决系数为0.993601,数据相当大,可以认为拟合程度很好。
2)F检验,F=1164.567>F(5.12)=3,89,回归方程显著
3)T检验,X5 系数对应的t值为46.79946,大于t(12)=2.179,所以系数是显著的,即人均GDP对年底存款余额有显著影响。X6 系数对应的t值为-1.762581,小于t (12)=2.179,所以系数是不显著的。
4.3
(1)根据Eviews分析得到数据如下:
Dependent Variable: LNY
Method: Least Squares
Date: 12/05/14 Time: 11:39
Sample: 1985 2011
Included observations: 27
Variable Coefficient Std. Error t-Statistic Prob.
LNGDP 1.338533 0.088610 15.10582 0.0000
LNCPI -0.421791 0.233295 -1.807975 0.0832
C -3.111486 0.463010 -6.720126 0.0000
R-squared 0.988051 Mean dependent var 9.484710
Adjusted R-squared 0.987055 S.D. dependent var 1.425517
S.E. of regression 0.162189 Akaike info criterion -0.695670
Sum squared resid 0.631326 Schwarz criterion -0.551689
Log likelihood 12.39155 Hannan-Quinn criter. -0.652857
F-statistic 992.2582 Durbin-Watson stat 0.522613
Prob(F-statistic) 0.000000
得到的模型方程为:
LNY=1.338533 LNGDP t-0.421791 LNCPI t-3.111486
(2)
①该模型的可决系数为0.988051,可决系数很高,F检验值为992.2582,
明显显著。但当α=0.05时,t(24)=2.064,LNCPI的系数不显著,可能存在多重共线性。
②得到相关系数矩阵如下:
LNGDP,LNCPI之间的相关系数很高,证实确实存在多重共线性。
(3)由Eviews得:
a)
Dependent Variable: LNY
Method: Least Squares
Date: 12/03/14 Time: 14:41
Sample: 1985 2011
Included observations: 27
Variable Coefficient Std. Error t-Statistic Prob.
LNGDP 1.185739 0.027822 42.61933 0.0000
C -3.750670 0.312255 -12.01156 0.0000
R-squared 0.986423 Mean dependent var 9.484710 Adjusted R-squared 0.985880 S.D. dependent var 1.425517 S.E. of regression 0.169389 Akaike info criterion -0.642056 Sum squared resid 0.717312 Schwarz criterion -0.546068 Log likelihood 10.66776 Hannan-Quinn criter. -0.613514 F-statistic 1816.407 Durbin-Watson stat 0.471111 Prob(F-statistic) 0.000000
b)
Dependent Variable: LNY
Method: Least Squares
Date: 12/03/14 Time: 14:41
Sample: 1985 2011
Included observations: 27
Variable Coefficient Std. Error t-Statistic Prob.
LNCPI 2.939295 0.222756 13.19511 0.0000
C -6.854535 1.242243 -5.517871 0.0000
R-squared 0.874442 Mean dependent var 9.484710 Adjusted R-squared 0.869419 S.D. dependent var 1.425517 S.E. of regression 0.515124 Akaike info criterion 1.582368 Sum squared resid 6.633810 Schwarz criterion 1.678356 Log likelihood -19.36196 Hannan-Quinn criter. 1.610910 F-statistic 174.1108 Durbin-Watson stat 0.137042 Prob(F-statistic) 0.000000
c)
Dependent Variable: LNGDP
Method: Least Squares
Date: 12/05/14 Time: 11:11
Sample: 1985 2011
Included observations: 27
Variable Coefficient Std. Error t-Statistic Prob.
LNCPI 2.511022 0.158302 15.86227 0.0000
C -2.796381 0.882798 -3.167634 0.0040
R-squared 0.909621 Mean dependent var 11.16214 Adjusted R-squared 0.906005 S.D. dependent var 1.194029
S.E. of regression 0.366072 Akaike info criterion 0.899213
Sum squared resid 3.350216 Schwarz criterion 0.995201
Log likelihood -10.13938 Hannan-Quinn criter. 0.927755
F-statistic 251.6117 Durbin-Watson stat 0.099623
Prob(F-statistic) 0.000000
①得到的回归方程分别为
1)LNY=1.185739 LNGDP t-3.750670
2)LNY=2.939295 LNCPI t-6.854535
3)LNGDP t=2.511022 LNCPI t-2.796381
②对多重共线性的认识:
单方程拟合效果都很好,回归系数显著,判定系数较高,GDP和CPI对进口的显著的单一影响,在这两个变量同时引入模型时影响方向发生了改变,这只有通过相关系数的分析才能发现。
(4)建议:如果仅仅是作预测,可以不在意这种多重共线性,但如果是进行结构分析,还是应该引起注意的。
4.4
(1)按照设计的理论模型,由Eviews分析得:
Dependent Variable: CZSR
Method: Least Squares
Date: 12/03/14 Time: 11:40
Sample: 1985 2011
Included observations: 27
Variable Coefficient Std. Error t-Statistic Prob.
CZZC 0.090114 0.044367 2.031129 0.0540
GDP -0.025334 0.005069 -4.998036 0.0000
SSZE 1.176894 0.062162 18.93271 0.0000
C -221.8540 130.6532 -1.698038 0.1030
R-squared 0.999857 Mean dependent var 22572.56
Adjusted R-squared 0.999838 S.D. dependent var 27739.49
S.E. of regression 353.0540 Akaike info criterion 14.70707
Sum squared resid 2866884. Schwarz criterion 14.89905
Log likelihood -194.5455 Hannan-Quinn criter. 14.76416
F-statistic 53493.93 Durbin-Watson stat 1.458128
Prob(F-statistic) 0.000000
从回归结果可见,可决系数为0.999857,校正的可决系数为0.999838,模型拟合的很好。F的统计量为53493.93,说明在α=0.05,水平下,回归方程回归方程整体上是显著的。但是t检验结果表明,国内生产总值对财政收入的影响显著,但回归系数的符号为负,与实际不符合。由此可得知,该方程可能存在多重共线性。
(2)得到相关系数矩阵如下:
由上表可知,CZZC与GDP,CZZC与SSZE,GDP与SSZE之间的相关系数都非常高,说明确实存在多重共线性。
计量经济学题库及答案
计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用
计量经济学第三版课后习题答案
第二章简单线性回归模型 2.1 (1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析: Dependent Variable: Y Method: Least Squares Date: 12/23/15 Time: 14:37 Sam pie: 1 22 In eluded observatio ns: 22 Variable Coeffieie nt Std. Error t-Statistie P rob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D.dependent var 10.08889 S.E. of regressi on 7.116881 Akaike info eriteri on 6.849324 Sum squared resid 1013.000 Sehwarz eriteri on 6.948510 Log likelihood -73.34257 Hannan-Quinn eriter. 6.872689 F-statistie 22.20138 Durbin-Wats on stat 0.629074 P rob(F-statistie) 0.000134 有上可知,关系式为y=56.64794+0.128360x i ②关于人均寿命与成人识字率的关系,用 Eviews分析如下: Dependent Variable: Y Method: Least Squares Date: 12/23/15 Time: 15:01 Sam pie: 1 22 In eluded observatio ns: 22 Variable Coeffieie nt Std. Error t-Statistie P rob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D.dependentvar 10.08889 S.E. of regressi on 5.501306 Akaike info eriterio n 6.334356 Sum squared resid 605.2873 Sehwarz eriterio n 6.433542 Log likelihood -67.67792 Hannan-Quinn eriter. 6.357721 F-statistie 50.62761 Durbin-Wats on stat 1.846406 P rob(F-statistie) 0.000001 由上可知,关系式为y=38.79424+0.331971X2 ③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:
计量经济学习题及答案汇总
《 期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使 ∑=-n t t t Y Y 1)?(达到最小值 B.使∑=-n t t t Y Y 1达到最小值 C. 使 ∑=-n t t t Y Y 1 2 )(达到最小值 D.使∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. B. % C. 2 D. % 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) ~ A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(2 2R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机误 差项μ的方差估计量2 ?σ 为( ) D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2 i )V ar(u i σ= C. 0)u E(u j i ≠ ) D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2 i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( )
计量经济学题库(超完整版)及答案.详解
计量经济学题库 计算与分析题(每小题10分) 1 X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2Y Y 68113.6∑ (-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。 问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 求判定系数和相关系数。 5.有如下表数据
计量经济学(庞皓)课后思考题答案
思考题答案 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u βX αY ++= 其中,Y 为居民消费支出,X 为居民家庭收入,二者是经济变量;α和β为参数;u 是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议,
计量经济学试卷及答案
《计量经济学》期末考试试卷(A )(课程代码:070403014) 1.计量经济模型的计量经济检验通常包括随机误差项的序列相关检验、异方差性检验、解释变量的多重共线性检验。 2. 普通最小二乘法得到的参数估计量具有线性,无偏性,有效性统计性质。 3.对计量经济学模型作统计检验包括_拟合优度检验、方程的显著性检验、变量的显著性检验。 4.在计量经济建模时,对非线性模型的处理方法之一是线性化,模型β α+= X X Y 线性 化的变量变换形式为Y *=1/Y X *=1/X ,变换后的模型形式为Y *=α+βX *。 5.联立方程计量模型在完成估计后,还需要进行检验,包括单方程检验和方程系统检验。 1.计量经济模型分为单方程模型和(C )。 A.随机方程模型 B.行为方程模型 C.联立方程模型 D.非随机方程模型 2.经济计量分析的工作程序(B ) A.设定模型,检验模型,估计模型,改进模型 B.设定模型,估计参数,检验模型,应用模型 C.估计模型,应用模型,检验模型,改进模型 D.搜集资料,设定模型,估计参数,应用模型 3.对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的(B )。
A.i C (消费)i I 8.0500+=(收入) B.di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格) C.si Q (商品供给)i P 75.020+=(价格) D.i Y (产出量)6.065.0i K =(资本)4 .0i L (劳动) 4.回归分析中定义的(B ) A.解释变量和被解释变量都是随机变量 B.解释变量为非随机变量,被解释变量为随机变量 C.解释变量和被解释变量都为非随机变量 D.解释变量为随机变量,被解释变量为非随机变量 5.最常用的统计检验准则包括拟合优度检验、变量的显著性检验和(A )。 A.方程的显著性检验 B.多重共线性检验 C.异方差性检验 D.预测检验 6.总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是(B )。 A.RSS=TSS+ESS B.TSS=RSS+ESS C.ESS=RSS-TSS D.ESS=TSS+RSS 7.下面哪一个必定是错误的(C )。 A. i i X Y 2.030?+= 8.0=XY r B. i i X Y 5.175? +-= 91.0=XY r
计量经济学题库超完整版及答案
四、简答题(每小题5分) 令狐采学 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。 2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步调。4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的?6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么?8.总体回归模型与样本回归模型的区别与联系。 9.试述回归阐发与相关阐发的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质?11.简述BLUE 的含义。 12.对多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验? 13.给定二元回归模型:01122t t t t y b b x b x u =+++,请叙述模型的古典假定。 14.在多元线性回归阐发中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数2R 及其作用。16.罕见的非线性回归模型有几种情况? 17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或
都是或都不是。 ①t t t u x b b y ++=310②t t t u x b b y ++=log 10 ③t t t u x b b y ++=log log 10④t t t u x b b y +=)/(10 18. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=log 10②t t t u x b b b y ++=)(210 ③t t t u x b b y +=)/(10④t b t t u x b y +-+=)1(11 0 19.什么是异方差性?试举例说明经济现象中的异方差性。 20.产生异方差性的原因及异方差性对模型的OLS 估计有何影响。21.检验异方差性的办法有哪些? 22.异方差性的解决办法有哪些?23.什么是加权最小二乘法?它的基本思想是什么? 24.样天职段法(即戈德菲尔特——匡特检验)检验异方差性的基来源根基理及其使用条件。 25.简述DW 检验的局限性。26.序列相关性的后果。27.简述序列相关性的几种检验办法。 28.广义最小二乘法(GLS )的基本思想是什么?29.解决序列相关性的问题主要有哪几种办法? 30.差分法的基本思想是什么?31.差分法和广义差分法主要区别是什么? 32.请简述什么是虚假序列相关。33.序列相关和自相关的概念和规模是否是一个意思? 34.DW 值与一阶自相关系数的关系是什么?35.什么是多重共线
计量经济学习题及参考答案解析详细版
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间 N S S x = = 4 5= 用 =,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174± 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/2510/25 X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?480/16 X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
计量经济学课后习题答案
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【B 】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从经济理论和经济模型出发进行计量经济分析的过程,也是对经济理论证实或证伪的过程。这些是以处理数
计量经济学题库及答案
2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入
计量经济学题库超完整版)及答案-计量经济学题库
计量经济学题库一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是()。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有()。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指()。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性
伍德里奇计量经济学第六版答案Appendix-E
271 APPENDIX E SOLUTIONS TO PROBLEMS E.1 This follows directly from partitioned matrix multiplication in Appendix D. Write X = 12n ?? ? ? ? ? ???x x x , X ' = (1'x 2'x n 'x ), and y = 12n ?? ? ? ? ? ??? y y y Therefore, X 'X = 1 n t t t ='∑x x and X 'y = 1 n t t t ='∑x y . An equivalent expression for ?β is ?β = 1 11n t t t n --=??' ???∑x x 11n t t t n y -=??' ??? ∑x which, when we plug in y t = x t β + u t for each t and do some algebra, can be written as ?β= β + 1 11n t t t n --=??' ???∑x x 11n t t t n u -=??' ??? ∑x . As shown in Section E.4, this expression is the basis for the asymptotic analysis of OLS using matrices. E.2 (i) Following the hint, we have SSR(b ) = (y – Xb )'(y – Xb ) = [?u + X (?β – b )]'[ ?u + X (?β – b )] = ?u '?u + ?u 'X (?β – b ) + (?β – b )'X '?u + (?β – b )'X 'X (?β – b ). But by the first order conditions for OLS, X '?u = 0, and so (X '?u )' = ?u 'X = 0. But then SSR(b ) = ?u '?u + (?β – b )'X 'X (?β – b ), which is what we wanted to show. (ii) If X has a rank k then X 'X is positive definite, which implies that (?β – b ) 'X 'X (?β – b ) > 0 for all b ≠ ?β . The term ?u '?u does not depend on b , and so SSR(b ) – SSR(?β) = (?β– b ) 'X 'X (?β – b ) > 0 for b ≠?β. E.3 (i) We use the placeholder feature of the OLS formulas. By definition, β = (Z 'Z )-1Z 'y = [(XA )' (XA )]-1(XA )'y = [A '(X 'X )A ]-1A 'X 'y = A -1(X 'X )-1(A ')-1A 'X 'y = A -1(X 'X )-1X 'y = A -1?β . (ii) By definition of the fitted values, ?t y = ?t x β and t y = t z β. Plugging z t and β into the second equation gives t y = (x t A )(A -1?β ) = ?t x β = ?t y . (iii) The estimated variance matrix from the regression of y and Z is 2σ(Z 'Z )-1 where 2σ is the error variance estimate from this regression. From part (ii), the fitted values from the two
(完整word版)计量经济学习题与答案
期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使∑=-n t t t Y Y 1 )?(达到最小值 B.使∑=-n t t t Y Y 1 达到最小值 C. 使 ∑=-n t t t Y Y 1 2 )(达到最小值 D.使∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. 0.75 B. 0.75% C. 2 D. 7.5% 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k ) R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(22R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) A.1 B.n-2 C.2 D.n-3 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机 误差项μ的方差估计量2 ?σ 为( ) A.33.33 B.40 C.38.09 D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2 i )V ar(u i σ= C. 0)u E(u j i ≠ D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2 i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( ) A.简单相关系数矩阵法 B. t 检验与F 检验综合判断法 C. DW 检验法 D.ARCH 检验法 E.辅助回归法
伍德里奇---计量经济学第8章部分计算机习题详解(STATA)
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r
20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016
计量经济学课后习题答案汇总
计量经济学课后习题答 案汇总 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列 分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系 和恒等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从
计量经济学题库(超完整版)及答案
四、简答题(每小题5分) 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步骤。 4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的? 6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么? 8.总体回归模型与样本回归模型的区别与联系。 9.试述回归分析与相关分析的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质? 11.简述BLUE 的含义。 12.对于多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验? 13.给定二元回归模型: 01122t t t t y b b x b x u =+++,请叙述模型的古典假定。 14.在多元线性回归分析中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数2R 及其作用。 16.常见的非线性回归模型有几种情况? 17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=310 ②t t t u x b b y ++=log 10 ③ t t t u x b b y ++=log log 10 ④t t t u x b b y +=)/(10 18. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=log 10 ②t t t u x b b b y ++=)(210 ③ t t t u x b b y +=)/(10 ④t b t t u x b y +-+=)1(110 19.什么是异方差性?试举例说明经济现象中的异方差性。