数据挖掘概念与技术原书第2版第1章_概述.ppt
数据挖掘概念与技术-课后题答案汇总
数据挖掘概念与技术-课后题答案汇总
数据挖掘——概念概念与技术 Data Mining Concepts and Techniques 习题解答 Jiawei Han Micheline Kamber 著 范明孟晓峰译
目录
第 1 章 引言 1.1 什么是数据挖掘?在你的回答中,针对以下问题: 1.2 1.6 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测 聚 类和演变分析。使用你熟悉的现实生活的数据库,给出每种数据挖掘功 能的例子。 解答: ? 特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征 可 被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特 征包括作为一种高的年级平均成绩(GPA :Grade point aversge) 的信息, 还有所修的课程的最大数量。 ? 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一 般 特性进行比较。例如,具有高 GPA 的学生的一般特性可被用来与具有 低 GPA 的一般特性比较。最终的描述可能是学生的一个一般可比较的 轮廓,就像具有高 GPA 的学生的 75%是四年级计算机科学专业的学生, 而具有低 G PA 的学生的 65%不是。 ? 关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特 征 值的 条 件。 例 如, 一 个数 据 挖掘 系 统可 能 发现 的 关联 规 则为 : major(X, “ c omputing science ”) owns(X, “personal computer ” ) [support=12%, confid ence=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的学生,12% (支持度)主修计算机科学并且拥有一台个人计算机。这个组一个学生 拥有 一 台个人电脑的概率是 98%(置信度? 分类与预测不同,因为前者的作用是构
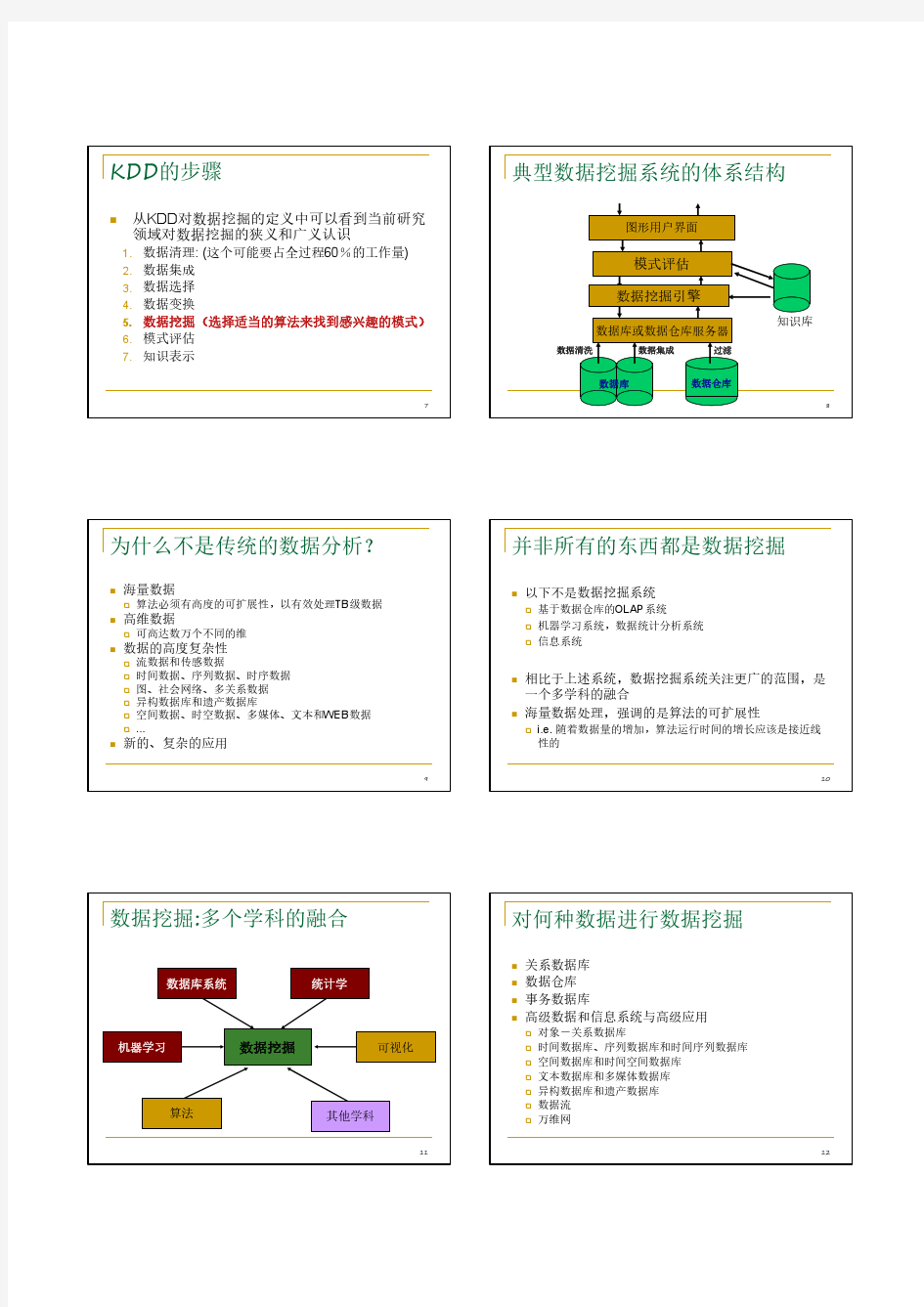
数据挖掘概述
数据挖掘概述 阅读目录 ?何为数据挖掘? ?数据挖掘背后的哲学思想 ?数据挖掘的起源 ?数据挖掘的基本任务 ?数据挖掘的基本流程 ?数据挖掘的工程架构 ?小结 回到顶部何为数据挖掘? 数据挖掘就是指从数据中获取知识。 好吧,这样的定义方式比较抽象,但这也是业界认可度最高的一种解释了。对于如何开发一个大数据环境下完整的数据挖掘项目,业界至今仍没有统一的规范。说白了,大家都听说过大数据、数据挖掘等概念,然而真正能做而且做好的公司并不是很多。
笔者本人曾任职于A公司云计算事业群的数据引擎团队,有幸参与过几个比较大型的数据挖掘项目,因此对于如何实施大数据场景下的数据挖掘工程有一些小小的心得。但由于本系列博文主要是结合传统数据挖掘理论和笔者自身在A云的一些实践经历,因此部分观点会有较强主观性,也欢迎大家来跟我探讨。 回到顶部数据挖掘背后的哲学思想 在过去很多年,首要原则模型(first-principle models)是科学工程领域最为经典的模型。 比如你要想知道某辆车从启动到速度稳定行驶的距离,那么你会先统计从启动到稳定耗费的时间、稳定后的速度、加速度等参数;然后运用牛顿第二定律(或者其他物理学公式)建立模型;最后根据该车多次实验的结果列出方程组从而计算出模型的各个参数。通过该过程,你就相当于学习到了一个知识--- 某辆车从启动到速度稳定行驶的具体模型。此后往该模型输入车的启动参数便可自动计算出该车达到稳定速度前行驶的距离。 然而,在数据挖掘的思想中,知识的学习是不需要通过具体问题的专业知识建模。如果之前已经记录下了100辆型号性能相似的车从启动到速度稳定行驶的距离,那么我就能够对这100个数据求均值,从而得到结果。显然,这一过程是是直接面向数据的,或者说我们是直接从数据开发模型的。 这其实是模拟了人的原始学习过程 --- 比如你要预测一个人跑100米要多久时间,你肯定是根据之前了解的他(研究对象)这样体型的人跑100米用的多少时间做一个估计,而不会使用牛顿定律来算。 回到顶部数据挖掘的起源 由于数据挖掘理论涉及到的面很广,它实际上起源于多个学科。如建模部分主要起源于统计学和机器学习。统计学方法以模型为驱动,常常建立一个能够产生数据的模型;而机器学习则以算法为驱动,让计算机通过执行算法来发现知识。仔细想想,"学习"本身就有算法的意思在里面嘛。
数据挖掘概念与技术(第三版)部分习题答案
1.4 数据仓库和数据库有何不同?有哪些相似之处? 答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。它用表组织数据,采用ER 数据模型。 相似:它们都为数据挖掘提供了源数据,都是数据的组合。 1.3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。 答:特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA :Grade point aversge) 的信息, 还有所修的课程的最大数量。 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。例如, 具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75% 是四年级计算机科学专业的学生,而具有低GPA 的学生的65% 不是。 关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。例如,一个数据挖掘系统可能发现的关联规则为:major(X, “ computing science ” ) ? owns(X, “ personal computer ” ) [support=12%, confidence=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的 学生,12% (支持度)主修计算机科学并且拥有一台个人计算机。这个组一个学生拥有一台个人电脑的概率是98% (置信度,或确定度)。 分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。它们的相似性是他们都是预测的工具: 分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值。 聚类分析的数据对象不考虑已知的类标号。对象根据最大花蕾内部的相似性、最小化类之间的相似性的原则进行聚类或分组。形成的每一簇可以被看作一个对象类。聚类也便于分类法组织形式,将观测组织成类分 层结构,把类似的事件组织在一起。 数据演变分析描述和模型化随时间变化的对象的规律或趋势,尽管这可能包括时间相关数据的特征化、区分、关联和相关分析、分类、或预测,这种分析的明确特征包括时间序列数据分析、序列或周期模式匹配、和基于相似性的数据分析 2.3 假设给定的数据集的值已经分组为区间。区间和对应的频率如下。 年龄频率 1~5200 5~15450 15~20300 20~501500 50~80700 80~11044 计算数据的近似中位数值。 解答:先判定中位数区间:N=200+450+300+1500+700+44=3194 ;N/2=1597
数据挖掘工程师工作的职责概述
数据挖掘工程师工作的职责概述 1 职责: 1、针对具体的业务场景需求、定义数据分析及挖掘问题; 2、使用统计学分析方法、挖掘算法、构建有效且通用的数据分析模型,对数据挖掘方案进行验证、开发、改进和优化,实现数据挖掘的功能应用; 3、搭建高扩展高性能的数据分析模型库,作为数据分析团队的基础工具; 4、完成领导安排的其他工作。 任职要求: 1、计算机、统计学、数学相关专业,本科及以上学历; 2、3年及以上相关工作经验,985和211大学的优秀毕业生可放宽至2年以上; 3、熟悉PHM的应用背景、功能定义、系统架构、关键技术; 4、熟练掌握Python进行数据挖掘;会使用Java进行软件开发者优先考虑; 5、熟悉常用数据挖掘算法如分类、聚类、回归、关联规则、神经网络等及其原理,并具备相关项目经验; 6、熟悉数据仓库,熟练使用SQL语言,有良好的数据库编程经验; 7、具备较强的独立解决问题的能力,勤奋敬业、主动性和责任心强。 2 职责: 1、水务行业的数据分析、数据挖掘工作,包括数据模型的需求分析、模型开发和结果分析; 2、按需完成基础数据的清洗、整合与去噪,为分析与建模提供支撑。 3、根据业务需求构建合适的算法及通过数据挖掘、机器学习等手段不断优化策略及算法。 4. 跟踪学习新的建模和数据挖掘技术,与同事共享知识和经验。 任职要求:
1. 计算机、数学、物理等相关专业本科及以上学历, 211、985高校优先 2.具有数据挖掘、机器学习、概率统计基础理论知识,熟悉并应用过常用分类、聚类 等机器学习算法; 3.熟练掌握R编程,熟悉数据库开发技术,并有实际生产使用经验者优先; 4. 学习能力强,拥有优秀的逻辑思维能力,工作认真负责,沟通能力良好,团队合 作意愿强,诚实、勤奋、严谨。 3 职责: 1、负责时间序列分析类算法的维护和设计实现; 2、负责海量内容和业务数据的分析和挖掘、建模,快速迭代算法,提升算法效果; 3、参与搭建和实现大数据平台下的算法处理程序; 4、应用各种机器学习、数据挖掘技术进行数据分析与数据挖掘; 5、根据业务需求进行数学建模,设计并开发高效算法,并对模型及算法进行验证和 实现。 【职位要求】 1、2021届应届毕业生,本科及以上学历,985/211毕业院校优先考虑,计算机软件、通讯相关专业; 2、熟悉linux操作,熟悉oracle数据库及sql语言; 3、掌握数据分析/挖掘方法及相关算法; 4、有R语言开发能力优先; 5、有运营商数据分析,模型构建经验优先。 4 职责: 1、根据公司自主产品需求,研究设计相应数据挖掘方案及算法,分析数据,设计方案,构建原型,快速实现对于数据分析、挖掘的需求;
数据挖掘及其应用
《数据挖掘论文》 数据挖掘分类方法及其应用 课程名称:数据挖掘概念与技术 姓名 学号: 指导教师: 数据挖掘分类方法及其应用 作者:来煜 摘要:社会的发展进入了网络信息时代,各种形式的数据海量产生,在这些数据的背后隐藏这许多重要的信息,如何从这些数据中找出某种规律,发现有用信息,越来越受到关注。为了适应信息处理新需求和社会发展各方面的迫切需要而发展起来一种新的信息分析技术,这种局势称为数据挖掘。分类技术是数据挖掘中应用领域极其广泛的重要技术之一。各种分类算法有其自身的优劣,适合于不同的领域。目前随着新技术和新领域的不断出现,对分类方法提出了新的要求。 。 关键字:数据挖掘;分类方法;数据分析 引言 数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥有知识的有局限性,所以对于获得知识的可信度就应该打个折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。 数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行科学研究、商业决策或者企业管理,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是
《数据仓库与数据挖掘技术》第1章:数据仓库与数据挖掘概述
数据仓库与数据挖掘技术
第1章数据仓库与数据挖掘概述1.1数据仓库引论1 1.1.1为什么要建立数据仓库1 1.1.2什么是数据仓库2 1.1.3数据仓库的特点7 1.1.4数据进入数据仓库的基本过程与建立数据仓库的步骤11 1.1.5分析数据仓库的内容12 1.2数据挖掘引论13 1.2.1为什么要进行数据挖掘13 1.2.2什么是数据挖掘18 1.2.3数据挖掘的特点21 1.2.4数据挖掘的基本过程与步骤22 1.2.5分析数据挖掘的内容26 1.3数据挖掘与数据仓库的关系28 1.4数据仓库与数据挖掘的应用31 1.4.1数据挖掘在零售业的应用31 1.4.2数据挖掘技术在商业银行中的应用36 1.4.3数据挖掘在电信部门的应用40 1.4.4数据挖掘在贝斯出口公司的应用42 1.4.5数据挖掘如何预测信用卡欺诈42 1.4.6数据挖掘在证券行业的应用43 思考练习题一44
1.1.1为什么要建立数据仓库 数据仓库的作用 建立数据仓库的好处
1.1.2 什么是数据仓库 1.数据仓库的概念 W.H.Inmon在《Building the Data Warehouse》中定义数据仓库为:“数据仓库是面向主题的、集成的、随时间变化的、历史的、稳定的、支持决策制定过程的数据集合。”即数据仓库是在管理人员决策中的面向主题的、集成的、非易失的并且随时间而变化的数据集合。 “DW是作为DSS基础的分析型DB,用来存放大容量的只读数据,为制定决策提供所需的信息。” “DW是与操作型系统相分离的、基于标准企业模型集成的、带有时间属性的。即与企业定义的时间区段相关,面向主题且不可更新的数据集合。” 数据仓库是一种来源于各种渠道的单一的、完整的、稳定的数据存储。这种数据存储提供给可以允许最终用户的可以是一种他们能够在其业务范畴中理解并使用的方式。 数据仓库是大量有关公司数据的数据存储。 仓库提供公司数据以及组织数据的访问功能,其中的数据是一致的(consistent),并且可以按每种可能的商业度量方式分解和组合;数据仓库也是一套查询、分析和呈现信息的工具;数据仓库 是我们发布所用数据的场所,其中数据的质量是业务再工程的驱动器(driver of business reengineering)。 定义的共同特征:首先,数据仓库包含大量数据,其中一些数据来源于组织中的操作数据,也有一些数据可能来自于组织外部;其次,组织数据仓库是为了更加便利地使用数据进行决策;最 后,数据仓库为最终用户提供了可用来存取数据的工具。
数据挖掘概念与技术word版
摘要 随着计算机和网络的发展,对于大数据需要数据分析,在分析数据的时候,数据挖掘的过程也叫知识发现的过程,它是一门涉及面很广的交叉性新兴学科,涉及到数据库、人工智能、数理统计、可视化、并行计算等领域。本文主要综述了数据挖掘中常用的一些关联规则,分类和聚类的算法。 关键字:数据挖掘;分类;聚类;关联规则
1 引言 1.1 数据挖掘介绍 近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括商务管理,生产控制,市场分析,工程设计和科学探索等[1]。 数据挖掘出现于20世纪80年代后期,是数据库研究中一个很有应用价值的新领域,是一门交叉性学科,融合了人工智能、数据库技术、模式识别、机器学习、统计学和数据可视化等多个领域的理论和技术.数据挖掘作为一种技术,它的生命周期正处于沟坎阶段,需要时间和精力去研究、开发和逐步成熟,并最终为人们所接受。20世纪80年代中期,数据仓库之父W.H.In-mon在《建立数据仓库》(Building the Data Warehouse)一书中定义了数据仓库的概念,随后又给出了更为精确的定义:数据仓库是在企业管理和决策中面向主题的、集成的、时变的以及非易失的数据集合。与其他数据库应用不同的是,数据仓库更像一种过程—对分布在企业内部各处的业务数据的整合、加工和分析的过程。传统的数据库管理系统(database management system,DBMS)的主要任务是联机事务处理(on-line transaction processing,OLTP);而数据仓库则是在数据分析和决策方面提供服务,这种系统被称为联机分析处理(on-line analyticalprocessing,OLAP).OLAP的概念最早是由关系数据库之父E.F.Codd于1993年提出的。当时,Codd认为OLTP已不能满足终端用户对数据库查询分析的需要,结构化查询语言(structured query language,SQL)对数据库进行的简单查询也不能满足用户分析的需求.用户的决策分析需要对关系数据库进行大量计算才能得到结果,因此Codd提出了多维数据库和多维分析的概念[2]。 数据挖掘(Data Mining),就是从存放在数据库,数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘,在人工智能领域,习惯上又称为数据库中知识发现(Knowledge Discovery in Database, KDD),也有人把数据挖掘视为数据库中知识发现过程的一个基本步骤。知识发现过程以下三个阶段组成:(1) 数据准备,(2)数据挖掘,(3) 结果表达和解释。数据挖掘可以与用户或知识库交互。 数据挖掘利用了来自如下一些领域的思想:(1) 来自统计学的抽样、估计和假设检验,(2) 人工智能、模式识别和机器学习的搜索算法、建模技术和学习理论。数据挖掘也迅速地接纳了来自其他领域的思想,这些领域包括最优化、进化
数据挖掘中的文本挖掘的分类算法综述
数据挖掘中的文本挖掘的分类算法综述 摘要 随着Internet上文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术。本文首先对数据挖掘进行了概述包括数据挖掘的常用方法、功能以及存在的主要问题;其次对数据挖掘领域较为活跃的文本挖掘的历史演化、研究现状、主要内容、相关技术以及热点难点问题进行了探讨;在第三章先分析了文本分类的现状和相关问题,随后详细介绍了常用的文本分类算法,包括KNN 文本分类算法、特征选择方法、支持向量机文本分类算法和朴素贝叶斯文本分类算法;;第四章对KNN文本分类算法进行深入的研究,包括基于统计和LSA降维的KNN文本分类算法;第五章对数据挖掘、文本挖掘和文本分类的在信息领域以及商业领域的应用做了详细的预测分析;最后对全文工作进行了总结和展望。 关键词:数据挖掘,文本挖掘,文本分类算法 ABSTRACT With the development of Web 2.0, the number of documents on the Internet increases exponentially. One important research focus on how to deal with these great capacity of online documents. Text classification is one crucial part of information management. In this paper we first introduce the basic information of data mining, including the methods, contents and the main existing problems in data mining fields; then we discussed the text mining, one active field of data mining, to provide a basic foundation for text classification. And several common algorithms are analyzed in Chapter 3. In chapter 4 thorough research of KNN text classification algorithms are illustrated including the statistical and dimension reduction based on LSA and in chapter 5 we make some predictions for data mining, text mining and text classification and finally we conclude our work. KEYWORDS: data mining, text mining, text classification algorithms,KNN 目录 摘要 (1) ABSTRACT (1) 目录 (1)
大数据时代的数据挖掘技术
大数据时代的数据挖掘 技术 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
大数据时代的数据挖掘技术 【摘要】随着大数据时代的到来,在大数据观念不断提出的今天,加强数据大数据挖掘及时的应用已成为大势所趋。那么在这一过程中,我们必须掌握大数据与数据挖掘的内涵,并对数据挖掘技术进行分析,从而明确大数据时代下数据挖掘技术的应用领域,促进各项数据的处理,提高大数据处理能力。 【关键词】大数据时代;数据挖掘技术;应用 大数据时代下的数据处理技术要求更高,所以要想确保数据处理成效得到提升,就必须切实加强数据挖掘技术的应用,才能更好地促进数据处理职能的转变,提高数据处理效率,以下就大数据时代下的数据挖掘技术做出如下分析。 1.大数据与数据挖掘的内涵分析 近年来,随着云计算和物联网概念的提出,信息技术得到了前所未有的发展,而大数据则是在此基础上对现代信息技术革命的又一次颠覆,所以大数据技术主要是从多种巨量的数据中快速的挖掘和获取有价值的信息技术,因而在云时代的今天,大数据技术已经被我们所关注,所以数据挖掘技术成为最为关键的技术。尤其是在当前在日常信息关联和处理中越来越离不开数据挖掘技术和信息技术的支持。大数据,而主要是对全球的数据量较大的一个概括,且每年的数据增长速度较快。而数据挖掘,主要是从多种模糊而又随机、大量而又复杂且不规则的数据中,获得有用的信息知识,从数据库中抽丝剥茧、转换分析,从而掌握其潜在价值与规律[1]。
2.大数据时代下数据挖掘技术的核心-分析方法 数据挖掘的过程实际就是对数据进行分析和处理,所以其核心就在于数据的分析方法。要想确保分析方法的科学性,就必须确保所采用算法的科学性和可靠性,获取数据潜在规律,并采取多元化的分析方法促进问题的解决和优化。以下就几种常见的数据分析方法做出简要的说明。 一是归类法,主要是将没有指向和不确定且抽象的数据信息予以集中,并对集中后的数据实施分类整理和编辑处理,从而确保所形成的数据源具有特征一致、表现相同的特点,从而为加强对其的研究提供便利。所以这一分析方法能有效的满足各种数据信息处理。 二是关联法,由于不同数据间存在的关联性较为隐蔽,采取人力往往难以找出其信息特征,所以需要预先结合信息关联的表现,对数据关联管理方案进行制定,从而完成基于某种目的的前提下对信息进行处理,所以其主要是在一些信息处理要求高和任务较为复杂的信息处理工作之中。 三是特征法,由于数据资源的应用范围较广,所以需要对其特征进行挖掘。也就是采用某一种技术,将具有相同特征的数据进行集中。例如采用人工神经网络技术时,主要是对大批量复杂的数据分析,对非常复杂的模式进行抽取或者对其趋势进行分析。而采取遗传算法,则主要是对其他评估算法的适合度进行评估,并结合生物进化的原理,对信息数据的成长过程进行虚拟和假设,从而组建出半虚拟、半真实的信息资源。再如可视化技术则是为数据挖掘提供辅助,采取多种方式对数据的
数据挖掘技术
摘要:随着Internet的普及和深入,网络远程教学越来越多地受到了教育工作者的关注和研究,但是目前的网络教学质量体系还显得不够完善、健全。如何建立一个行之有效的网络教学评价模型,已成为远程教育工作者面临的一个重要课题。本文中,通过应用数据挖掘技术实现网上教学评价模型,希望能为教育信息化建设提供有价值的参考。关键词:数据挖掘;网络教学评价;评价模型 0 前言 教学评价是教学活动的一个重要环节,不同的教育价值观就会有不同的网络教学评价体系。随着网上课程改革在全国范围内的不断深入展开,传统教学评价中的弊端也越来越明显地在改革中体现出来。信息技术虽然是一门新兴的学科,受传统教学观念的束缚较少,但它作为一门年轻的学科,在形成具有自身学科特点的教学评价方面还显得比较薄弱。因此,建立一种新的适应远程教学需要的、以学生发展为中心、提高网络教学水平的当代网络教学评价模型,显得非常迫切和必要。 1 数据挖掘技术概述 数据挖掘是一个集统计学、人工智能、模式识别、并行计算、机器学习、数据库等技术于一体的交叉性学科研究领域。数据挖掘技术是指从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程,又被称为数据库中的知识发现(KDD:knowledge discovery in database)。数据挖掘是要发现那些不能靠直觉发现甚至是违背直觉的信息或知识,挖掘后得到的信息可能会出乎意料之外,但是非常有价值,这些信息有利于决策者及时做出有效的决策。 2 数据挖掘的流程 数据挖掘基本过程和主要步骤内容如下: 2.1明确目的 在进行数据挖掘工作前,要清楚地知道数据挖掘的目标。事先明确挖掘的业务目标,确定达到目标的评价方法,这将大大减少挖掘工作的难度和挖掘量,否则就很难获得数据挖掘的效果。 2.2 数据准备 (1)数据的选择 建立了挖掘目标后,为实现这个目标选择数据。这些数据可能是数据仓库或数据市场的子集,也可能是各个联机事务处理系统中的数据。数据可能存在重名、错误、格式不一致等问题,挖掘前要增强数据的质量以保证给数据挖掘工具提供正确的数据。 (2)数据的预处理 在数据采集的过程中,有许多因素影响数据的准确性,所以必须对数据进行再加工,包括检查数据的完整性及数据的一致性、去噪声,填补丢失的域,删除无效数据等。 (3)数据的转换 将数据转换成一个分析模型,这个分析模型是针对挖掘算法建立的。建立一个真正适合挖掘算法的分析模型是数据挖掘成功的关键。 2.3数据挖掘 根据数据功能的类型和数据的特点选择相应的算法,在净化和转换过的数据集上进行数据挖掘。 2.4结果分析 对数据挖掘的结果进行解释和评价,根据用户的决策目的,转换成为能够最终被用户
大数据技术概述
大数据技术 1.什么是数据挖掘,什么是机器学习: 什么是机器学习 关注的问题:计算机程序如何随着经验积存自动提高性能; 研究计算机如何样模拟或实现人类的学习行为,以猎取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能; 通过输入和输出,来训练一个模型。 2.大数据分析系统层次结构:应用层、算法层、系统软件层、基础设施层 3.传统的机器学习流程 预处理-》特征提取-》特征选择-》再到推理-》预测或者识不。手工地选取特征是一件特不费劲、启发式(需要专业知识)的方法,假如数据被专门好的表达成了特征,通常线性模型就能达到中意的精度。 4.大数据分析的要紧思想方法
4.1三个思维上的转变 关注全集(不是随机样本而是全体数据):面临大规模数据时,依靠于采样分析;统计学习的目的——用尽可能少的数据来证实尽可能重大的发觉;大数据是指不用随机分析如此的捷径,而是采纳大部分或全体数据。 关注概率(不是精确性而是概率):大数据的简单算法比小数据的复杂算法更有效 关注关系(不是因果关系而是相关关系):建立在相关关系分析法基础上的预测是大数据的核心,相关关系的核心是量化两个数据值之间的数理关系,关联物是预测的关键。 4.2数据创新的思维方式 可量化是数据的核心特征(将所有可能与不可能的信息数据化);挖掘数据潜在的价值是数据创新的核心;三类最有价值的信息:位置信息、信令信息以及网管和日志。 数据混搭为制造新应用提供了重要支持。 数据坟墓:提供数据服务,其他人都比我聪慧! 数据废气:是用户在线交互的副产品,包括了扫瞄的页面,停留了多久,鼠标光标停留的位置、输入的信息。
4.3大数据分析的要素 大数据“价值链”构成:数据、技术与需求(思维);数据的价值在于正确的解读。 5.数据化与数字化的区不 数据化:将现象转变为可制表分析的量化形式的过程; 数字化:将模拟数据转换成使用0、1表示的二进制码的过程 6.基于协同过滤的推举机制 基于协同过滤的推举(这种机制是现今应用最为广泛的推举机制)——基于模型的推举(SVM、聚类、潜在语义分析、贝叶斯网络、线性回归、逻辑回归) 余弦距离(又称余弦相似度):表示是否有相同的倾向 欧几里得距离(又称欧几里得相似度):表示绝对的距离 这种推举方法的优缺点: 它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的;推举是开放的,能够共用他人的经验,专门好的支持用户发觉潜在的兴趣偏好。 数据稀疏性问题,大量的用户只是评价了一小部分的项目,而大多数的项目是没有进行评分;冷启动问题,新物品和新用户依靠
数据挖掘概念与技术 课后题答案汇总
数据挖掘——概念概念与技术 Data Mining Concepts and Techniques 习题解答 Jiawei Han Micheline Kamber 著 范明孟晓峰译
目录
第1章引言 1.1 什么是数据挖掘?在你的回答中,针对以下问题: 1.2 1.6 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚 类和演变分析。使用你熟悉的现实生活的数据库,给出每种数据挖掘功 能的例子。 解答: ?特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特 征包括作为一种高的年级平均成绩(GPA:Grade point aversge) 的信息, 还有所修的课程的最大数量。 ?区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。例如,具有高GPA 的学生的一般特性可被用来与具有 低GPA 的一般特性比较。最终的描述可能是学生的一个一般可比较的 轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生, 而具有低GPA 的学生的65%不是。 ?关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。例如,一个数据挖掘系统可能发现的关联规则为: major(X, “c omputing science”) owns(X, “personal computer”) [support=12%, confid e nce=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的学生,12% (支持度)主修计算机科学并且拥有一台个人计算机。这个组一个学生 拥有一台个人电脑的概率是98%(置信度,或确定度)。 ?分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效 的、并且通常是数字的数据值。它们的相似性是他们都是预测的工具: 分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的 数字型数据的值。
数据挖掘技术及应用综述
作者简介:韩少锋,男,1980年生,中北大学在读硕士研究生。研究方向:人工智能技术。 引言 “人类正被信息淹没,却饥渴于知识.”这是1982年 趋势大师JohnNaisbitt的首部著作《大趋势》(Mega-trends)中提到的。 随着数据库技术的迅速发展,如何从含有海量信息的数据库中提取更有价值、更直观的信息和知识?人们结合统计学﹑数据库﹑机器学习﹑神经网络﹑模式识别﹑模糊数学﹑粗糙集理论等技术,提出‘数据挖掘’这一新的数据处理技术来解决这一难题。数据挖掘(DataMining)就是从大量的﹑不完全的﹑有噪声的﹑模糊的﹑随机的数据中,提取隐含在其中的﹑人们事先不知道的﹑但又是潜在的有用的信息和知识的过程。这些数据可以是:结构化的,半结构化的,分布在网络上的异构性数据。数据挖掘在许多领域得到了成功的应用,使数据库技术进入了一个更高级的发展阶段,很多专题会议也把数据挖掘和知识发现列为议题之一。 1数据挖掘技术概述 1.1数据挖掘的概念 数据挖掘的概念有多种描述,最常见的有两种:(1)G.PiatetskyShapior,W.J.Frawley数据挖掘定义为:从数据库的大量数据中揭示出隐含的、先进而未知的、潜在有用信息的频繁过程。(2)数据挖掘的广义观点:数据挖掘是从存放在数据库、数据仓库或其他信息库中的大量数据中挖掘有趣知识的过程。数据挖掘的特点有:1)用户需要借助数据挖掘技术从大量的信息中找到感兴趣的信息;2)处理的数据量巨大;3)要求对数据的变化做出及时的响应;4)数据挖掘既要发现潜在的规则,也要管理和维护规则,规则的改变随着新数据的不断更新而更新;5)数据挖掘规则的发现基于统计规律,发现的规则不必适用于全部的数据。 数据挖掘要面对的是巨大的信息来源;通过数据挖 掘,有价值的知识、规则或高层次的信息就能从数据库的相关数据集合中抽取出来,并从不同角度显示,从而使大型数据库作为一个丰富可靠的资源为知识归纳服务。 1.2数据挖掘的简史 从数据库中知识发现(KDD)一词首先出现在1989 年举行的第十一届国际联合人工智能学术会议上。目前为止,由美国人工智能协会主办的KDD国际研讨会已经召开了8次,规模由原来的专题讨论会发展到国际学术大会,研究重点也从发现方法转向系统应用。1999年,亚太地区在北京召开的第三届PAKDD会议收到158篇论文,研讨空前热烈。 目前,数据挖掘技术在零售业的购物篮分析﹑金融风险预测﹑产品质量分析﹑通讯及医疗服务﹑基因工程研究等许多领域得到了成功的应用。 1.3数据挖掘的对象 数据挖掘的对象包含大量数据信息的各种类型数 据库。如关系数据库,面向对象数据库等,文本数据数据源,多媒体数据库,空间数据库,时态数据库,以及 Internet等类型数据或信息集均可作为数据挖掘的对 象。 1.4数据挖掘的工具 许多软件公司和研究机构,根据商业的实际需要 开发出许多数据挖掘工具。例如:有多种数据操控和转换特点的SASEnterpriseMiner;采用决策树、神经网络和聚类技术综合的数据挖掘工具集-IBMInterlligentMiner;可以提供多种统计分析、 决策树和回归方法,在Teradata数据库管理系统上原地挖掘的Teradata WarehouseMiner;以及同时具有数据管理和数据概括能力,能够用于多种商业平台的SPSSClementine。以上 主流数据挖掘工具都能提供常用的挖掘过程和挖掘模 数据挖掘技术及应用综述 韩少锋 陈立潮 (中北大学计算机科学与技术系 山西 太原 030051) 【摘要】介绍了数据挖掘技术的背景、概念、流程、数据挖掘算法,并阐述了数据挖掘技术的应用现状。 【关键词】数据挖掘 知识发现 人工智能 数据仓库 【中图分类号】TP311.138 【文献标识码】B 【文章编号】1003-773X(2006)02-0023-02 第2期(总第89期)机械管理开发 2006年4月No.2(SUMNo.89)MECHANICALMANAGEMENTANDDEVELOPMENT Apr.2006 23??
数据挖掘技术的重要作用
数据挖掘技术的重要作用 姓名:沙岚雨学号:160711119 数据挖掘就是从海量的数据中挖掘隐含在其中的、事先不为人知的、潜在的、有用信息和知识的技术。这些信息是可能有潜在价值的,是用户感兴趣的、可理解的、可运用的,支持决策,可以为企业带来利益,或者为科学研究寻找突破口。 数据挖掘的应用非常广泛,只要该产业有分析价值与需求的数据库,皆可利用数据挖掘工具进行有目的的发掘分析,在当今数据和内容作为互联网的核心,不论是传统行业还是新型行业,谁率先与互联网融合成功,能够从大数据的金矿中发现暗藏的规律,就能够抢占先机,成为技术改革的标志,获得利益。常见的应用案例多发生在零售业、制造业、财务金融保险、通讯及医疗服务。大数据挖掘商业价值的方法主要分为四种:第一:客户群体细分,然后为每个群体量定制特别的服务。第二:模拟现实环境,发掘新的需求同时提高投资的回报率。第三:加强部门联系,提高整条管理链条和产业链条的效率。第四:降低服务成本,发现隐藏线索进行产品和服务的创新。在理论上来看:所有产业都会在数据挖掘的发展中受益。 例如在电子商务中数据挖掘的作用越来越大,可以用其对网站进行分析,识别用户的行为模式,保留客户,提供个性化服务,优化网站设计,帮助电子商务网站把真正有价值的知识从海量的信息提取出来,从而更好地为电子商务网站的用户提供更方便的服务以及指导企业决策,数据挖掘在电子商务中的具体应用:在电子商务中应用数据挖掘技术可以直接跟踪数据,分析顾客的购买行为并辅助商家快速做出商业决策。在电子商务营销方面的应用它是以市场营销学的市场细分原理为基础,其基本假定是消费者过去的行为是其今后消费倾向的最好说明。通过收集、加工和处理涉及消费者消费行为的大量信息,确定特定消费群体或个体的兴趣、消费习惯、消费倾向和消费需求,进而推断出相应消费群体或个体下一步的消费行为。需要做到产品生命周期策略分析,市场细分,制定合理的产品策略和定价策略,制定合理的产品营销策略,优化促销活动。 数据挖掘在未来的发展趋势上,在我看来,Web网路中数据挖掘的应用,特别是在互联网上建立数据挖掘服务器,与数据库服务器配合,实现数据挖掘,从而建立强大的数据挖掘引擎与数据挖掘服务市场。融合各种异构数据的挖掘技术,加强对各种非结构化数据的开采,如对文本数据,图形数据,视频图像数据,声音数据乃至综合多媒体数据的开采。
数据挖掘概念与技术原书第版范明、孟小峰绎第一章课后习题
1.9习题 1.1 什么是数据挖掘?在你的回答中,强调以下问题: (a)它是又一种广告宣传吗? (b)它是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用吗? (c)我们提出了一种观点,说数据挖掘是数据库技术进化的结果。你认为数据挖掘也是机器学习研究进化的结果吗?你能基于该学科的发展历史提出这一观点吗?针对统计学和模式识别领域,做相同的事。 (d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。 答:简单地说,数据挖掘其实就是从大量的数据中发现有用的信息,它是从大量数据中挖掘有趣模式和知识的过程。数据挖掘不是一种广告宣传,而是身处在信息时代数据如此庞大的今天,我们对由海量的数据转化为有用信息的迫切需要,所以它是信息技术自然进化的结果,而不是一种广告宣传。 数据挖掘也不是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用,它涉及到了很多领域的技术,比如统计学、机器学习、模式识别、数据库和数据仓库、信息检索、可视化、神经网络、高性能计算、算法以及许多应用领域的大量技术。 数据挖掘起始于20世纪下半叶,是在当时多个学科发展的基础上发展起来的。随着数据库技术的发展应用,数据的积累不断膨胀,导致简单的查询和统计已经无法满足企业的商业需求,所以急需一种新型的技术去获取有用的信息,当时计算机领域的人工智能也取得了巨大进展,进入了机器学习的阶段,人们就将两者结合起来,用数据库管理系统存储数据,用计算机分析数据,这两者的结合就促就以这一门新兴的学科,所以数据挖掘不是机器学习研究进化的结果,而是结合了机器学。 数据挖掘的步骤包括:(1)数据收集;(2)数据清洗、脱敏;(3)数据存储;(4)数据分析;(5)数据可视化。 1.2数据仓库与数据库有何不同?他们有哪相似之处? 答:数据库是按照数据结构来组织、存储和管理数据的仓库,它是以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度的特点、是与应用程序彼此独立的数据集合。
大数据技术概述(内涵与意义)
大数据技术概述 一、大数据的时代价值 1.大数据内涵 大数据(big data,mega data)或称巨量资料,指的是需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值密度)、Veracity (真实性)。 大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。 例如,日本企业通过对电力大数据进行分析,创造出一系列新型服务项目。换句话说,大数据分析促进了新的商业服务模式诞生。东京市内三井不动产公司管理的新建商品住宅小区住户,最近通过手机不断接收到各种各样的服务信息,如餐馆的打折优惠券,旅行社的半价机票等等。不过,即便是居住在同一栋大楼的住户,收到的服务内容却不尽相同,这是怎么回事?原来,这是该公司利用家庭用能源管理系统,经过对客户电力数据分析研究,按照各个家庭的不同生活方式为其发送有针对性的电子服务信息。比如餐馆的优惠券是发送给晚餐时间段用电较少的家庭,因为通过用电数据分析可知对方总在外面用餐;反之,傍晚时分电力消费较多的家庭,肯定是经常在家做饭,因此要向其发送厨房用品打折卡;如果用户在周末的电力消费少,说明他们家经常外出,可以推定为喜欢旅行的家庭;如果家里洗衣机的使用频率很高,可能家庭成员较多,就要为其提供相应的商品服务信息。目前该公司在其管理的东京市内两个小区开始提供基于电力大数据分析的信息服务。本来是为购买该公司房产的用户提供增值服务,却受到电力公司的极大关注,因为它能够创造电力服务之外的高附加值。 2.大数据的意义
数据挖掘技术教学大纲
《数据挖掘技术》课程教学大纲 一、课程基本信息 二、课程教育目标 (一)总体目标 数据挖掘是高级数据处理和分析技术。通过本课程学习,使学生了解数据挖掘这种现代数据分析和知识挖掘方法的思想与技术,了解数据挖掘的基本理论,掌握重要的数据挖掘方法,掌握如何利用Clementine实现数据分析和挖掘,并使学生具有进一步学习的基本与能力。 (二)具体目标 1. 能够导入、输出各种类型的数据,并对数据进行简单描述统计 2. 能够编写建立线性回归模型、非纯性回归模型、编写回归模型的程序,
并能够通过程序检验模型 3. 能够对数据进行聚类分析、分类分析、关联分析、能够对文本数据进行数据挖掘 三、课程学时分配 四、课程内容 第一章数据挖掘和Clementine使用概述 【教学内容】 1.1 数据挖掘的产生背景 1.数据挖掘产生的背景 2.数据挖掘的发展 3. 数据挖掘概述 1.2 什么是数据挖掘 1. 数据挖掘概念 2. 数据挖掘分类 3. 数据挖掘体系结构 1.3 Clementine软件概述 1. Clementine的配置
2. Clementine操作基础 【学习目标】 本章作为绪论,其目的是让学生对数据挖掘技术有一个总体的认识。因此,主要内容是对数据挖掘技术的概念、产生背景、发展趋势以及应用等进行提炼和概括,并熟悉Clementine软件的使用环境。要求学生掌握以下内容:1.数据挖掘的发展 2.数据挖掘基本知识 3.数据挖掘功能 4. 数据挖掘应用 5. 数据挖掘的热点问题 6. 熟悉Clementine软件 【重点、难点】 1.重点: (1)数据挖掘概念 (2)数据挖掘分类 2.难点:Clementine操作基础 【教学方法】 1.通过多媒体课件和传统教学相结合,阐明课程与教学基本原理,丰富学生课程与教学的基本知识结构,培养学生的职业规范; 2.通过案例分析,强调理论与实践相结合,促进学生知识整合,培养学生的反思能力。 第二章 Clementine数据管理 【教学内容】 2.1 数据源节点(Sources)