编码实验报告

实验一香农编码
一、实验目的
1.了解香农编码的基本原理及其特点;
2.熟悉掌握香农编码的方法和步骤;
3.掌握C语言或者Matlab编写香农编码的程序。
二、实验要求
对于给定的信源的概率分布,按照香农编码的方法进行计算机实现.
三、实验原理
给定某个信源符号的概率分布,通过以下的步骤进行香农编码
1.信源符号按概率从大到小排列
2.对信源符号求累加概率,表达式: G i=G i-1+p(x i)
3.求自信息量,确定码字长度。自信息量I(x i)=-log(p(x i));码字长
度取大于等于自信息量的最小整数。
4.将累加概率用二进制表示,并取小数点后码字的长度的码。
四、实验报告
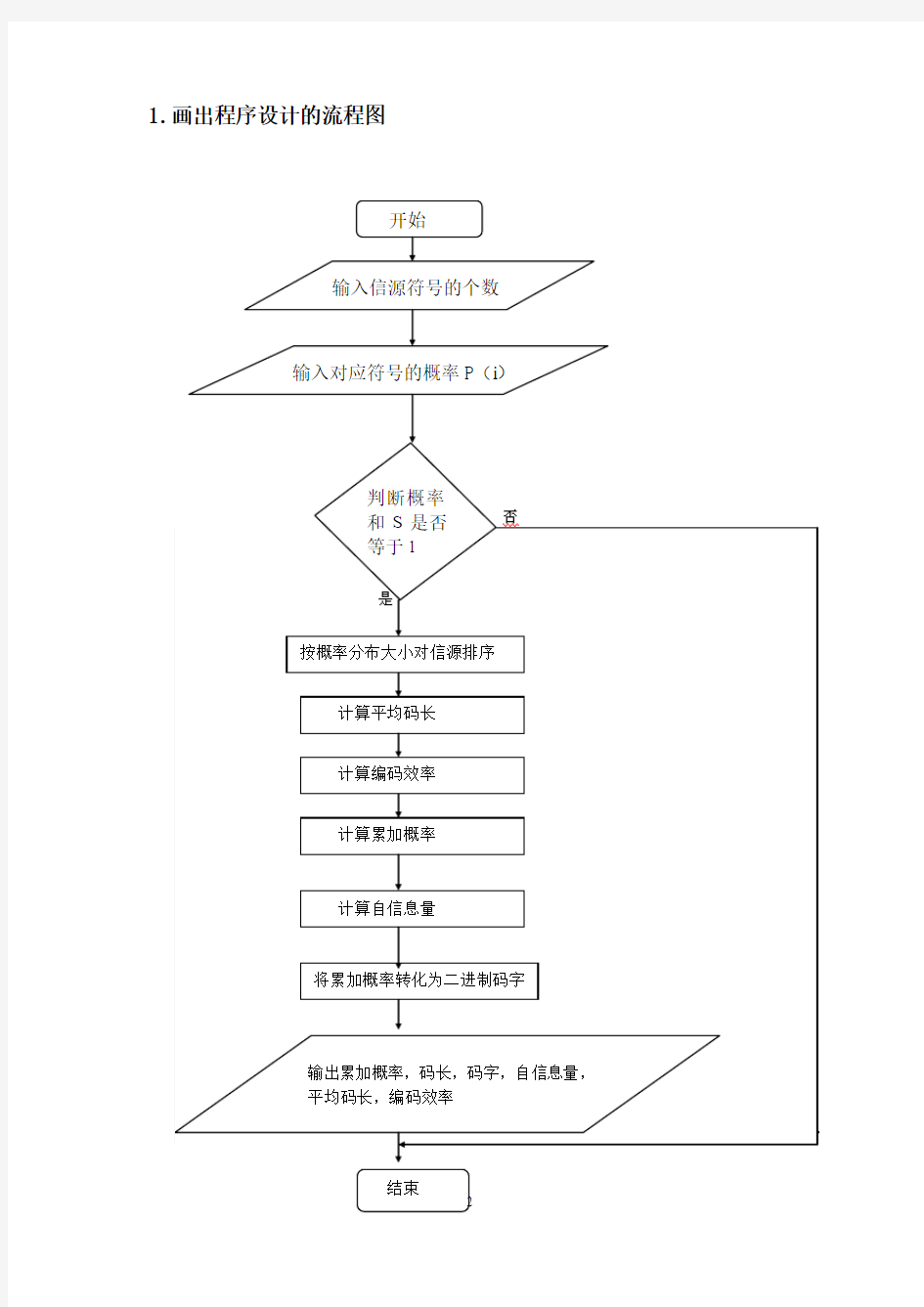
1.画出程序设计的流程图,
2.写出程序代码,
3.写出在调试过程中出现的问题,
4.对实验的结果进行分析
1.画出程序设计的流程图
2.写出程序代码
N=input('N='); %输入信源符号的个数
s=0;
l=0;
H=0;
for i=1:N
p(i)=input('p='); %输入信源符号概率分布矢量,p(i)<1
s=s+p(i)
H=H+(-p(i)*log2(p(i)));I(i)=-log2(p(i)); %计算信源信息熵end
if abs(s-1)>0,
error('不符合概率分布')
end
for i=1:N-1
for j=i+1:N
if p(i) m=p(j); p(j)=p(i); p(i)=m; end end end %按概率分布大小对信源排序 for i=1:N a=-log2(p(i)); if mod(a,1)==0 w=a; else w=fix(a+1); end %计算各信源符号的码长 l=l+p(i)*w; %计算平均码长 end l=l; n=H/l; %计算编码效率 P(1)=0 for i=2:N P(i)=0; for j=1:i-1 P(i)=P(i)+p(j); end end %计算累加概率 for i=1:N for j=1:w W(i,j)=fix(P(i)*2); P(i)=P(i)*2-fix(P(i)*2); end end %将累加概率转化为L(i)位二进制码字disp(W) %显示码字 disp(l) %显示平均码长 disp(n) %显示编码效率 disp(I) %显示自信息 3.写出在调试过程中出现的问题 不知该如何编写程序实现将累加概率转化为L(i)位二进制码字。 4.对实验的结果进行分析 以课本120页的例5.2.1为例,输出结果为: 分析如下: 1)平均码长7 1 () 3.1400i i i L p a l ===∑ 2)编码效率0.8308η= 3)自信息为: 1()2.3219I a = 2()2.3959I a = 3()2.4739 I a = 4()2.5564I a = 5() 2.7370I a = 6() 3.3219I a = 7()6.6439I a = 4)码字为: 1a :0000000,码长为3,即为000; 2a :0011001,码长为3,即为001; 3a :0110001,码长为3,即为011; 4a :1001000,码长为3,即为100; 5a :1011110,码长为3,即为101; 6a :1110001,码长为4,即为1110; 7a :1111110,码长为7,即为1111110; 实验报告 1.实验目的 通过阅读JPEG编码器代码,了解编码原理、编码过程和代码实现。 2.实验要求 (1)详细阅读JPEG编码器代码,结合编码原理,了解整个代码实现的过程(2)输入bmp文件,在VC6.0下跑通代码,查看编码器的压缩倍数 (3)对有些模块进行单步跟踪调试,详细了解其过程 3.实验原理 JPEG编码的基本过程如下 (1)像素阵列分块(分为8*8小块) (2)进行DCT离散余弦变换 (3)进行Z字形扫描,将二维阵列变为一维数列 (4)进行量化 (5)熵编码(Huffman编码) (6)封装为JPG文件 本次试验所用bmp转jpg编码器的编码步骤 (1)读取bmp文件信息,创建并打开jpg文件 (2)8*8分块及色彩空间变换(RGB转YCbCr) (3)快速离散余弦变换FDCT (4)量化 (5)Z字形扫描 (6)使用差分脉冲编码调制对直流系数DC进行编码 (7)使用游程长度编码对交流系数AC编码 (8)霍夫曼熵编码 4.代码分析 整个代码过程可分为三个部分 (1)文件操作 (2)对编码所用信息表进行初始化(int_all) (3)主编码器进行编码(main_encoder) 主函数分析 int main(int argc, char *argv[]) { char BMP_filename[64]; char JPG_filename[64]; WORD width_original,height_original; //the original image dimensions, // before we made them divisible by 8 BYTE len_filename; bitstring fillbits; //filling bitstring for the bit alignment of the EOI(end of image) marker if (argc>1) { strcpy(BMP_filename,argv[1]); if (argc>2) strcpy(JPG_filename,argv[2]); else { // replace ".bmp" with ".jpg" strcpy(JPG_filename, BMP_filename); len_filename=strlen(BMP_filename); strcpy(JPG_filename+(len_filename-3),"jpg");//从后三位开始拷贝jpg. } } else exitmessage("Syntax: enc fis.bmp [fis.jpg]"); //BMP_filename=""; load_bitmap(BMP_filename, &width_original, &height_original);//加载bmp文件信息 fp_jpeg_stream = fopen(JPG_filename,"wb");//创建jpg文件流 init_all();//初始化函数,初始化量化、霍夫曼及亮度色差转换表等,为编码做准备 SOF0info.width = width_original; SOF0info.height = height_original;//写入图像的宽和高 writeword(0xFFD8); // SOI,写入图像开始标志 write_A PP0info(); // write_comment("Cris made this JPEG with his own encoder"); write_DQTinfo();//写入量化表 write_SOF0info();//写入帧开始 write_DHTinfo();//写入霍夫曼表 write_SOSinfo();//写入扫描开始信息 // init global variables bytenew = 0; // current byte bytepos = 7; // bit position in this byte main_encoder();//主编码函数 // Do the bit alignment of the EOI marker if (bytepos >= 0) { 实验报告 实验课名称:数据结构实验 实验名称:文件压缩问题 班级:20132012 学号:姓名:时间:2015-6-9 一、问题描述 哈夫曼编码是一种常用的数据压缩技术,对数据文件进行哈夫曼编码可大大缩短文件的传输长度,提高信道利用率及传输效率。要求采用哈夫曼编码原理,统计文本文件中字符出现的词频,以词频作为权值,对文件进行哈夫曼编码以达到压缩文件的目的,再用哈夫曼编码进行译码解压缩。 二、数据结构设计 首先定义一个结构体: struct head { unsigned char b; //记录字符 long count; //权重 int parent,lch,rch; //定义双亲,左孩子,右孩子 char bits[256]; //存放哈夫曼编码的数组 } header[512],tmp; //头部一要定设置至少512个,因为结 点最多可达256,所有结点数最多可 达511 三、算法设计 输入要压缩的文件读文件并计算字符频率根据字符的频率,利用Huffman 编码思想创建Huffman树由创建的Huffman树来决定字符对应的编码,进行文件的压缩解码压缩即根据Huffman树进行译码 设计流程图如图1.1所示。 图1.1 设计流程图 (1)压缩文件 输入一个待压缩的文本文件名称(可带路径)如:D:\lu\lu.txt 统计文本文件中各字符的个数作为权值,生成哈夫曼树;将文本文件利用哈夫曼树进行编码,生成压缩文件。压缩文件名称=文本文件名.COD 如:D:\lu\lu.COD 压缩文件内容=哈夫曼树的核心内容+编码序列 for(int i=0;i<256;i++) { header[i].count=0; //初始化权重 header[i].b=(unsigned char)i; //初始化字符 } ifstream infile(infilename,ios::in|ios::binary); while(infile.peek()!=EOF) { infile.read((char *)&temp,sizeof(unsigned char)); //读入一个字符 header[temp].count++; //统计对应结点字符权重 flength++; //统计文件长度 } infile.close(); //关闭文件 for(i=0;i<256-1;i++) //对结点进行冒泡排序,权重大的放在上面,编码时效率高 for(int j=0;j<256-1-i;j++) if(header[j].count 重庆工程学院 电子信息学院 实验报告 课程名称:_ 数据通信原理开课学期:__ 2015-2016/02_ 院(部): 电子信息学院开课实验室:实训楼512 学生姓名: 舒清清梁小凤专业班级: 1491003 学号: 149100308 149100305 重庆工程学院学生实验报告 课程名 称 数据通信原理实验项目名称汉明码编译实验 开课院系电子信息学院实验日期 2016年5月7 日 学生姓名舒清清 梁小凤 学号 149100308 149100305 专业班级网络工程三班 指导教 师 余方能实验成绩 教师评语: 教师签字:批改时间: 一、实验目的和要求 1、了解信道编码在通信系统中的重要性。 2、掌握汉明码编译码的原理。 3、掌握汉明码检错纠错原理。 4、理解编码码距的意义。 二、实验内容和原理 汉明码编码过程:数字终端的信号经过串并变换后,进行分组,分组后的数据再经过汉明码编码,数据由4bit变为7bit。 三、主要仪器设备 1、主控&信号源、6号、2号模块各一块 2、双踪示波器一台 3连接线若干 四、实验操作方法和步骤 1、关电,按表格所示进行连线 2、开电,设置主控菜单,选择【主菜单】→【通信原理】→【汉明码】。 (1)将2号模块的拨码开关S12#拨为10100000,拨码开关S22#、S32#、S42#均拨为00000000;(2)将6号模块的拨码开关S16#拨为0001,即编码方式为汉明码。开关S36#拨为0000,即无错模式。按下6号模块S2系统复位键。 3、此时系统初始状态为:2号模块提供32K编码输入数据,6号模块进行汉明编译码,无差错插入模式。 4、实验操作及波形观测。 (1)用示波器观测6号模块TH5处编码输出波形。 (2)设置2号模块拨码开关S1前四位,观测编码输出并填入下表中: 五、实验记录与处理(数据、图表、计算等) 校对输入0000,编码0000000 输入0001,编码0001011 输入0010,编码0010101 输入0011,编码0011110 输入0100,编码0100110 输入0101,编码0101101 输入0110,编码0110011输入0111,编码0111000 实验二游程编码 一、实验目的 1、掌握游程编码原理; 2、理解数据编码压缩和译码输出编码的实现。 二、实验要求 实现游程编码和译码的生成算法。 三、实验内容 输入一幅二值图像,先统计要压缩编码的文件中的字符字母出现的次数,按字符字母和空格出现的概率对其进行哈夫曼编码,然后读入要编码的文件,编码后存入另一个文件;接着再调出编码后的文件,并对其进行译码输出,最后存入另一个文件中。 四、实验原理 1、xx 树的定义: 假设有n 个权值,试构造一颗有n 个叶子节点的二叉树,每个叶子带权值为wi ,其中树带权路径最小的二叉树成为哈夫曼树或者最优二叉树; 2、xx 树的构造: weight为输入的频率数组,把其中的值赋给依次建立的HT Node对象中的data属性,即每一个HT Node对应一个输入的频率。然后根据data属性按从小到大顺序排序,每次从data取出两个最小和此次小的HT Node,将他们的data 相加,构造出新的HTNode作为他们的父节点,指针pare nt,leftchild,rightchild 赋相应值。在把这个新的节点插入最小堆。 按此步骤可以构造出一棵XX树。 通过已经构造出的哈夫曼树,自底向上,由频率节点开始向上寻找parent, 直到parent 为树的顶点为止。这样,根据每次向上搜索后,原节点为父节点的 左孩子还是右孩子,来记录 1 或0,这样,每个频率都会有一个01 编码与之唯一对应,并且任何编码没有前部分是同其他完整编码一样的。 五、实验程序 #include 中南大学 《信息论与编码》实验报告 题目信源编码实验 指导教师 学院 专业班级 姓名 学号 日期 目录 一、香农编码 (3) 实验目的 (3) 实验要求 (3) 编码算法 (3) 调试过程 (3) 参考代码 (4) 调试验证 (7) 实验总结 (7) 二、哈夫曼编码 (8) 实验目的 (8) 实验原理 (8) 数据记录 (9) 实验心得 (10) 一、香农编码 1、实验目的 (1)进一步熟悉Shannon 编码算法; (2)掌握C 语言程序设计和调试过程中数值的进制转换、数值与字符串之间 的转换等技术。 2、实验要求 (1)输入:信源符号个数q 、信源的概率分布p ; (2)输出:每个信源符号对应的Shannon 编码的码字。 3、Shannon 编码算法 1:procedure SHANNON(q,{Pi }) 2: 降序排列{Pi } 3: for i=1 q do 4: F(i s ) 5:i l 2 []log 1/()i p s 6:将累加概率F(i s )(十进制小数)变换成二进制小数。 7:取小数点后i l 个二进制数字作为第i 个消息的码字。 8:end for 9:end procedure ------------------------------------------------------------------------------------------------------------------ 4、调试过程 1、fatal error C1083: Cannot open include file: 'unistd.h': No such file or directory fatal error C1083: Cannot open include file: 'values.h': No such file or directory 原因:unistd.h 和values.h 是Unix 操作系统下所使用的头文件 纠错:删去即可 2、error C2144: syntax error : missing ')' before type 'int' error C2064: term does not evaluate to a function 原因:l_i(int *)calloc(n,sizeof(int)); l_i 后缺少赋值符号使之不能通过编译 纠错:添加上赋值符号 1 1 ()i k k p s -=∑ 压缩技术实验编码 实验一统计编码 实验目的 1.熟悉统计编码的原理 2.掌握r元Huffman编码的方法; 3.了解Huffman编码效率及冗余度的计算; 二、实验原理 霍夫曼编码,又称最佳编码,根据字符出现概率来构造平均长度最短的变长编码。 Huffman编码步骤: (1)把信源符号x i(i=1,2,…按出现概率的值由大到小的顺序排列; (2)对两个概率最 小的符号分别分配以“ 0和“ 1,'然 后把这两个概率相加作为一个新的辅助符号的概率; (3)将这个新的辅助符号与其他符号一起重新按概率大小顺序排列; ⑷跳到第2步,直到出现概率相加为1为止; (5)用线将符号连接起来,从而得到一个码树,树的N个端点对应N个信源符号; (6)从最后一个概率为1的节点开始,沿着到达信源的每个符号,将一路遇到的二进制码“ 0或“ 1顺序排列起来,就是端点所对应的信源符号的码字。 以上是二元霍夫曼编码。如果是r元霍夫曼编码,则应该如何做呢? 在HUFFMAN 编码方案中,为出现概率较小的信源输出分配较长的码字,而对那些出现可能性较大的信源输出分配较短的码字。为此,首先将r 个最小可能的信源输出合并成为一个新的输出,该输出的概率就是上述的r 个输出的概率之和。重复进行该过程直到只剩下一个输出为止。信源符号的个数q 与r 必须满足如下的关系式: q = (r-1) n + r n 为整数如果不满足上述关系式,可通过添加概率为零的信源符号来满足。这样就生成了一个树,从该树的根节点出发并将0、1 分别分配给任何r 个来自于相同节点的 分支,生成编码。可以证明用这种方法产生的编码在前向树类 苏州科技大学天平学院电子与信息工程学院 信道编码课程设计报告 课设名称卷积码编译及译码仿真 学生姓名圣鑫 学号1430119232 同组人周妍智 专业班级通信1422 指导教师潘欣欲 一、实验名称 基于MAATLAB的卷积码编码及译码仿真 二、实验目的 卷积码就是一种性能优越的信道编码。它的编码器与译码器都比较容易实现,同时它具有较强的纠错能力。随着纠错编码理论研究的不断深入,卷积码的实际应用越来越广泛。本实验简明地介绍了卷积码的编码原理与Viterbi译码原理。并在SIMULINK模块设计中,完成了对卷积码的编码与译码以及误比特统计整个过程的模块仿真。最后,通过在仿真过程中分别改变卷积码的重要参数来加深理解卷积码的这些参数对卷积码的误码性能的影响。经过仿真与实测,并对测试结果作了分析。 三、实验原理 1、卷积码编码原理 卷积码就是一种性能优越的信道编码,它的编码器与解码器都比较易于实现,同时还具有较强的纠错能力,这使得它的使用越来越广泛。卷积码一般表示为(n,k,K)的形式,即将 k个信息比特编码为 n 个比特的码组,K 为编码约束长度,说明编码过程中相互约束的码段个数。卷积码编码后的 n 各码元不经与当前组的 k 个信息比特有关,还与前 K-1 个输入组的信息比特有关。编码过程中相互关联的码元有 K*n 个。R=k/n 就是编码效率。编码效率与约束长度就是衡量卷积码的两个重要参数。典型的卷积码一般选 n,k 较小,K 值可取较大(>10),但以获得简单而高性能的卷积码。 卷积码的编码描述方式有很多种:冲激响应描述法、生成矩阵描述法、多项式乘积描述法、状态图描述,树图描述,网格图描述等。 2、卷积码Viterbi译码原理 卷积码概率译码的基本思路就是:以接收码流为基础,逐个计算它与其她所 有可能出现的、连续的网格图路径的距离,选出其中可能性最大的一条作为译码估值输出。概率最大在大多数场合可解释为距离最小,这种最小距离译码体现的正就是最大似然的准则。卷积码的最大似然译码与分组码的最大似然译码在原理上就是一样的,但实现方法上略有不同。主要区别在于:分组码就是孤立地求解单个码组的相似度,而卷积码就是求码字序列之间的相似度。基于网格图搜索的译码就是实现最大似然判决的重要方法与途径。用格图描述时,由于路径的汇聚消除了树状图中的多余度,译码过程中只需考虑整个路径集合中那些使似然函数最大的路径。如果在某一点上发现某条路径已不可能获得最大对数似然函数,就放弃这条路径,然后在剩下的“幸存”路径中重新选择路径。这样一直进行到最后第 L 级(L 为发送序列的长度)。由于这种方法较早地丢弃了那些不可能的路径,从而减轻了译码的工作量,Viterbi 译码正就是基于这种想法。对于(n, k, K )卷积码,其网格图中共 2kL 种状态。由网格图的前 K-1 条连续支路构成的路径互不相交,即最初 2k_1 条路径各不相同,当接收到第 K 条支路时,每条路径都有 2 条支路延伸到第 K 级上,而第 K 级上的每两条支路又都汇聚在一个节点上。在Viterbi译码算法中,把汇聚在每个节点上的两条路径的对数似然函数累加 数据结构实验报告 ――实验五简单哈夫曼编/译码的设计与实现本实验的目的是通过对简单哈夫曼编/译码系统的设计与实现来熟练掌握树型结 构在实际问题中的应用。此实验可以作为综合实验,阶段性实验时可以选择其中的几 个功能来设计和实现。 一、【问题描述】 利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码,此实验即设计这样的一个简单编/码系统。系统应该具有如下的几个功能: 1、接收原始数据。 从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件nodedata.dat中。 2、编码。 利用已建好的哈夫曼树(如不在存,则从文件nodedata.dat中读入),对文件中的正文进行编码,然后将结果存入文件code.dat中。 3、译码。利用已建好的哈夫曼树将文件code.dat中的代码进行译码,结果存入文件textfile.dat中。 4、打印编码规则。 即字符与编码的一一对应关系。 二、【数据结构设计】 1、构造哈夫曼树时使用静态链表作为哈夫曼树的存储。 在构造哈夫曼树时,设计一个结构体数组HuffNode保存哈夫曼树中各结点的信息,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1个结点,所以数组HuffNode的大小设置为2n-1,描述结点的数据类型为: typedef struct { int weight;//结点权值 int parent; int lchild; int rchild; char inf; }HNodeType; 2、求哈夫曼编码时使用一维结构数组HuffCode作为哈夫曼编码信息的存储。 求哈夫曼编码,实质上就是在已建立的哈夫曼树中,从叶子结点开始,沿结点的双亲链域回退到根结点,没回退一步,就走过了哈夫曼树的一个分支,从而得到一位哈夫曼码值,由于一个字符的哈夫曼编码是从根结点到相应叶子结点所经过的路径上各分支所组成的0、1序列,因此先得到的分支代码为所求编码的低位码,后得到的分支代码位所求编码的高位码,所以设计如下数据类型: #define MAXBIT 10 typedef struct 交通大学信息科学与工程学院综合性设计性实验报告 专业:通信工程专业11级 学号: 2 姓名:徐国健 实验所属课程:移动通信原理与应用 实验室(中心):信息技术软件实验室 指导教师:益才 2014年5月 一、题目 二值图像的游程编码及解码 二、仿真要求 对一幅图像进行编码压缩,然后解码恢复图像。 三、仿真方案详细设计 实验过程分为四步:分别是读入一副图象,将它转换成为二进制灰度图像,然后对其进行游程编码和压缩,最后恢复图象(只能恢复为二值图像)。 1、二值转换 所谓二值图像,就是指图像上的所有像素点的灰度值只用两种可能,不为“0”就为“1”,也就是整个图像呈现出明显的黑白效果。 2、游程编码原理 游程编码是一种无损压缩编码,对于二值图有效。游程编码的基本原理是:用一个符号值或串长代替具有相同值的连续符号,使符号长度少于原始数据的长度。据进行编码时,沿一定方向排列的具有相同灰度值的像素可看成是连续符号,用字串代替这些连续符号,可大幅度减少数据量。游程编码分为定长行程编码和不定长行程编码两种类型。游程编码是连续精确的编码,在传输过程中,如果其中一位符号发生错误,即可影响整个编码序列,使行程编码无法还原回原始数据。 3、游程编码算法 一般游程编码有两种算法,一种是使用1的起始位置和1的游程长度,另一种是只使用游程长度,如果第一个编码值为0,则表示游程长度编码是从0像素的长度开始。这次实验采 用的是前一种算法。两种方法各有优缺点:前一种存储比第二种困难,因此编程也比较复杂。而后一种需要知道第一个像素值,故压缩编码算法中需给出所读出的图的第一个像素值。 压缩流程图: 解压流程图: 实验二十三 时分复用与解复用实验 实验项目一 256K 时分复用帧信号观测 (1)帧同步码观测:用示波器连接复用输出,观测帧头的巴克码。 (2)帧内PN 序列信号观测:用示波器接复用输出,利用储存功能观测3个周期 中的第一时隙的信号。 实验项目二 256K 时分复用及解复用 (1)帧内PCM 编码信号观测:将PCM 信号输入DIN2,观测PCM 数据。以帧同 思考题:PN15序列的数据是如何分配到复用信号中的? 分析分时复用的实质,可知,在模拟传送时,一位用户的数据根据复用划分的时隙以一帧为周期,逐次将8位数据插入每个帧相同的时隙处。对于此次实验中的PN15序列,检测到帧同步信号的帧头时,便插入第一帧数据,在第二次检测到帧头时插入第二帧数据,以此类推,将信号分配到复用信号中,以达到提高信道利用率的目的。 对比观测实验出现的码元,发现为01110010,根据所学知识可知,这串码即为帧头的观测码。 步为触发分别观测PCM编码数据和复用输出的数据。 (2)解复用帧同步信号观测:PCM对正弦波进行编译码。观测复用输出与FSOUT, 观测帧同步上跳沿与帧同步信号的时序关系。 思考题:PCM数据是如何分配到复用信号中去的? 时分多路复用以时间作为信号分割的参量,将各路输入变为变为并行数据,然后按照给端口数据所在的时隙进行帧的拼接,完成一个完整的数据帧。而在本实验中,PCM 的数据输入到DIN2,将其插入到复用信号的第2个时隙,与其它3个时隙拼接为一帧,从而实现了PCM信号分配到复用信号中。 上图分别为PCM编码输入和复用输出的波形。仔细观察可知,对比复用输入信号,复用输出有2帧的延时,且在复用输出的第0时隙为帧头的巴克码,第1时隙没有数据,第2时隙有了数据的存放,即PCM复用编码时被插在了一帧的第2时隙中,在解复用时先寻找巴克码,再按照每一帧的数据存放的相应的时隙进行解复用,之后拼接起来,便实现了PCM的数据恢复。 实验一 m序列产生及特性分析实验 一、实验目得 1.了解m序列得性质与特点; 2。熟悉m序列得产生方法; 3.了解m序列得DSP或CPLD实现方法。 二、实验内容 1。熟悉m序列得产生方法; 2.测试m序列得波形; 三、实验原理 m序列就是最长线性反馈移存器序列得简称,就是伪随机序列得一种。它就是由带线性反馈得移存器产生得周期最长得一种序列。 m序列在一定得周期内具有自相关特性.它得自相关特性与白噪声得自相关特性相似。虽然它就是预先可知得,但性质上与随机序列具有相同得性质.比如:序列中“0”码与“1”码等抵及具有单峰自相关函数特性等。 五、实验步骤 1.观测现有得m序列。 打开移动实验箱电源,等待实验箱初始化完成.先按下“菜单”键,再按下数字键“1”,选择“一、伪随机序列”,出现得界面如下所示: ?再按下数字键“1"选择“1m序列产生”,则产生一个周期为15得m序列。 2。在测试点TP201测试输出得时钟,在测试点TP202测试输出得m序列。 1)在TP201观测时钟输出,在TP202观测产生得m序列波形。 图1-1 数据波形图 实验二 WALSH序列产生及特性分析实验 一.实验目得 1。了解Walsh序列得性质与特点; 2。熟悉Walsh序列得产生方法; 3.了解Walsh序列得DSP实现方法。 二.实验内容 1.熟悉Walsh序列得产生方法; 2.测试Walsh序列得波形; 三。实验原理 Walsh序列得基本概念 Walsh序列就是正交得扩频序列,就是根据Walsh函数集而产生.Walsh函数得取值为+1或者—1。图1-3—1展示了一个典型得8阶Walsh函数得波形W1。n阶Walsh函数表明在Walsh函数得周期T内,由n段Walsh函数组成.n阶得Walsh函数集有n个不同得Walsh函数,根据过零得次数,记为W0、W1、W2等等。 t 图2-1 Walsh函数 Walsh函数集得特点就是正交与归一化,正交就是同阶不同得Walsh函数相乘,在指定得区间积分,其结果为0;归一化就是两个相同得Walsh函数相乘,在指定得区间上积分,其平均值为1。 五、实验步骤 1。观测现有得Walsh序列波形 打开移动实验箱电源,等待实验箱初始化完成. 先按下“菜单"键,再按下数字键“1”,选择“一、伪随机序列”,出现得界面如下所示: 中南大学数据结构课程 姓名:刘阳 班级:信息0703 学号:0903070312 实验时间: 08.11.14 指导老师:赵颖 一、实验内容 根据输入的n 个带权结点,构造出哈夫曼树,并且把构造结果输出到屏幕。 二、实验说明 哈夫曼数,也称最优二叉树,是指对于一组带有确定权值的叶结点,构造的具有最小带权路径长度的二叉树。 设二叉树具有n 个带权值的叶结点,那么从根结点到各个叶结点的路径长度与相应结点权值的乘积之和叫做二叉树的带权路径长度WPL ,记作: WPL=k n k k L W *∑=1。在给定一组具有确定权值的叶结点,可以构造出不同的带权二 叉树。根据哈夫曼树的定义,一棵二叉树要使其WPL 值最小,必须使权值越大的叶结点越靠近根结点,而权值越小的叶结点越远离根结点。 在数据通讯中,经常需要将传送的文字转换成由二进制字符0,1组成的二进制串,我们称之为编码。例如,假设要传送的电文为ABACCDA ,电文中只含有A ,B ,C ,D 四种字符,若这四种字符采用下表所示的编码,则电文的代码为000010000100100111 000,长度为21。 在传送电文时,我们总是希望传送时间尽可能短,这就要求电文代码尽可能短。如果在编码时考虑字符出现的频率,让出现频率高的字符采用尽可能短的编码,出现频率低的字符采用稍长的编码,构造一种不等长编码,则电文的代码就可能更短。并且在建立不等长编码时,必须使任何一个字符的编码都不是另一个字符编码的前缀,以避免反译成原文时,编码出现多义性。 在哈夫曼编码树中,树的带权路径长度的含义是各个字符的码长与其出现次数的乘积之和,也就是电文的代码总长,所以采用哈夫曼树构造的编码是一种能使电文代码总长最短的不等长编码。 采用哈夫曼树进行编码,也不会产生上述二义性问题。因为,在哈夫曼树中,每个字符结点都是叶结点,它们不可能在根结点到其它字符结点的路径上,所以一个字符的哈夫曼编码不可能是另一个字符的哈夫曼编码的前缀,从而保证了译码的非二义性。 数字高程模型 实验讲义 南阳师范学院环旅学院 地理信息系统教研室编 2011年2月 前 言 Miller于1958年提出首次提出了数字高程模型(Digital Elevation Model,DEM)的概念。经过40多年的发展,DEM的诸多基础理论问题都得到了深入的研究,基于DEM的数字地形分析理论与方法体系正在形成,DEM在许多领域的工作中得到了成功应用。DEM已成为各类GIS数据库的核心数据之一。国家测绘部门将DEM作为国家空间数据基础设施(National Spatial data Infrastructure,NSDI)的重要建设项目之一。在理论研究方面,DEM的不确定性、DEM的尺度效应、DEM的地学分析、基于DEM的数据挖掘都取得了很大的突破。在应用方面,也从一般的地形因子提取、支持三维漫游等简单应用向更多样的形式、更广泛的领域发展。可以说,DEM所代表的已经不仅仅是一种记录海拔的空间数据,更代表着一种地学处理的方法。 适应于学科发展和实践需要,各高等院校的有关专业,特别是地理信息系统、空间信息与数字工程、测绘工程等专业都纷纷将数字高程模型作为本科和研究生课程。我学院办有地理信息系统和测绘工程等专业,数字高程模型一直是此二专业的重要课程。在多年教学经验的基础上,我们编写了本实验讲义,供地理信息系统专业、测绘工程专业的本科教学使用。本实验讲义中,以验证、探索理论知识和传授技能作为基础目标,另外还注重意识和能力的培养。当代教育理论认为,如果说知识和技能是人才素质的基础,意识则决定了运用知识和技能的动机,能力则是运用知识和技能的方法。当代地学人才不仅需要具有充足的专业知识和技能,而且应该具备一系列意识和能力。虽然,高校通常设置培养意识和能力的公共课程;但是,专业课教学也应该将其作为教学目标之一。这样以来,可以根据专业课程的特点有目的地培养特定的意识和能力。本课程所涉及的意识和能力主要包括科学精神、团队意识、创新能力和统合能力等。 本讲义共7个实验,需要16个实验课时。实验类型包括基础型、综合型和设计型。每个实验都有明确的实验目的,有实验原理的详细介绍,实验过程中的必要之处作了解释和提示。实验后安排了思考题,要求学生们通过在实验中的探索来回答这些问题,有助于学生更好地理解和掌握DEM的理论和方法。 本科生实验报告 实验课程信息论与编码 学院名称信息科学与技术学院 专业名称通信工程 学生姓名 学生学号 指导教师谢振东 实验地点6C601 实验成绩 二〇一五年十一月二〇一五年十一月 实验一:香农(Shannon )编码 一、实验目的 掌握通过计算机实现香农编码的方法。 二、实验要求 对于给定的信源的概率分布,按照香农编码的方法进行计算机实现。 三、实验基本原理 给定某个信源符号的概率分布,通过以下的步骤进行香农编码 1、将信源消息符号按其出现的概率大小排列 )()()(21n x p x p x p ≥≥≥ 2、确定满足下列不等式的整数码长K i ; 1)(l o g )(l o g 22+-<≤-i i i x p K x p 3、为了编成唯一可译码,计算第i 个消息的累加概率 ∑ -== 1 1 )(i k k i x p p 4、将累加概率P i 变换成二进制数。 5、取P i 二进制数的小数点后K i 位即为该消息符号的二进制码。 四、源程序: #include int i,j; for(i=0;i 哈夫曼编码译码器实验报告(免费) ————————————————————————————————作者:————————————————————————————————日期: 问题解析与解题方法 问题分析: 设计一个哈夫曼编码、译码系统。对一个ASCII编码的文本文件中的字符进行哈夫曼编码,生成编码文件;反过来,可将编码文件译码还原为一个文本文件。 (1)从文件中读入任意一篇英文短文(文件为ASCII编码,扩展名为txt); (2)统计并输出不同字符在文章中出现的频率(空格、换行、标点等也按字符处理);(3)根据字符频率构造哈夫曼树,并给出每个字符的哈夫曼编码; (4)将文本文件利用哈夫曼树进行编码,存储成压缩文件(编码文件后缀名.huf)(5)用哈夫曼编码来存储文件,并和输入文本文件大小进行比较,计算文件压缩率;(6)进行译码,将huf文件译码为ASCII编码的txt文件,与原txt文件进行比较。 根据上述过程可以知道该编码译码器的关键在于字符统计和哈夫曼树的创建以及解码。 哈夫曼树的理论创建过程如下: 一、构成初始集合 对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合 F={T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结 点,它的左右子树均为空。 二、选取左右子树 在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二 叉树的根结点的权值为其左右子树的根结点的权值之和。 三、删除左右子树 从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。 四、重复二和三两步, 重复二和三两步,直到集合F中只有一棵二叉树为止。 因此,有如下分析: 1.我们需要一个功能函数对ASCII码的初始化并需要一个数组来保存它们; 2.定义代表森林的数组,在创建哈夫曼树的过程当中保存被选中的字符,即给定报文 中出现的字符,模拟哈夫曼树选取和删除左右子树的过程; 3.自底而上地创建哈夫曼树,保存根的地址和每个叶节点的地址,即字符的地址,然 后自底而上检索,首尾对换调整为哈夫曼树实现哈弗曼编码; 4.从哈弗曼编码文件当中读入字符,根据当前字符为0或者1的状况访问左子树或者 右孩子,实现解码; 5.使用文件读写操作哈夫曼编码和解码结果的写入; 解题方法: 结构体、数组、类的定义: 1.定义结构体类型的signode 作为哈夫曼树的节点,定义结构体类型的hufnode 作为 重庆交通大学信息科学与工程学院综合性设计性实验报告 专业:通信工程专业11级 学号:631106040222 姓名:徐国健 实验所属课程:移动通信原理与应用 实验室(中心):信息技术软件实验室 指导教师:李益才 2014年5月 一、题目 二值图像的游程编码及解码 二、仿真要求 对一幅图像进行编码压缩,然后解码恢复图像。 三、仿真方案详细设计 实验过程分为四步:分别是读入一副图象,将它转换成为二进制灰度图像,然后对其进行游程编码和压缩,最后恢复图象(只能恢复为二值图像)。 1、二值转换 所谓二值图像,就是指图像上的所有像素点的灰度值只用两种可能,不为“0”就为“1”,也就是整个图像呈现出明显的黑白效果。 2、游程编码原理 游程编码是一种无损压缩编码,对于二值图有效。游程编码的基本原理是:用一个符号值或串长代替具有相同值的连续符号,使符号长度少于原始数据的长度。据进行编码时,沿一定方向排列的具有相同灰度值的像素可看成是连续符号,用字串代替这些连续符号,可大幅度减少数据量。游程编码分为定长行程编码和不定长行程编码两种类型。游程编码是连续精确的编码,在传输过程中,如果其中一位符号发生错误,即可影响整个编码序列,使行程编码无法还原回原始数据。 3、游程编码算法 一般游程编码有两种算法,一种是使用1的起始位置和1的游程长度,另一种是只使用游程长度,如果第一个编码值为0,则表示游程长度编码是从0像素的长度开始。这次实验采 用的是前一种算法。两种方法各有优缺点:前一种存储比第二种困难,因此编程也比较复杂。而后一种需要知道第一个像素值,故压缩编码算法中需给出所读出的图的第一个像素值。 压缩流程图: 解压流程图: 《信道编码》实验报告 姓名李聪罗贵阳 学号11211060 11211015 指导教师姚冬萍 时间2014年5月14日 目录 一、线性分组码原理简介 (2) 1、编码 (2) 2、译码 (2) 二、(7,4)码Labview实现 (3) 一、读取图片产生数据流 (3) 二、汉明码编码 (4) 主要模块: (4) 三、BPSK调制 (4) 四、加性高斯白噪声信道传输 (5) 五、PSK解调 (5) 六、解码 (6) 七、重构图像 (7) 三、实验中遇到的问题 (8) 四、实验心得 (9) 五、参考文献: (10) 基于Labview 的(7,4)线性分组码仿真 一、线性分组码原理简介 1、编码 令(7,4)分组码的生成矩阵为矩阵G 如下: 根据生成矩阵,输出码字可按下式计算: 所以有: 信息位 冗余位 由以上关系可以得到(7,4)汉明码的全部码字如表1所示。 表1 (7,4)汉明码的全部码字 2、译码 (7,4)汉明码的译码将输入的7位汉明码翻译成4位的信息码,并且纠正其中可能出现 1000110010001100101110001101G ???? ? ?=?????? 3210321010001100100011(,,,)(,,,)00101110001101b a a a a G a a a a ?? ?? ? ?=?=???????231013210210 b a a a b a a a b a a a =⊕⊕=⊕⊕=⊕⊕63524130 b a b a b a b a ==== 的一个错误。 由于生成矩阵G 已知且G = [I k Q ] ,可以得到矩阵Q 的值 110011111101T Q P ???? ? ?==?????? 又因为T P Q =则: 101111100111P ?? ??=?? ???? 而校验矩阵H 满足 H =[P I r ] ,则: 101110011100100111001H ?? ??=?? ???? 由校正子S = BH T =(A + E )H T = EH T 可以看出校正子S 与错误图样E 是一一对 应的。通过计算校正子得到对应的错误图样,根据式子A =B + E 便可得到纠正了一位可能错误的信息位,完成解码。 二、(7,4)码Labview 实现 一、读取图片产生数据流 LabVIEW 提供了一个能够读取JPEG 格式的图像并输出图像数据的模块。提供的还原像素图.vi 完成图像数据到一维二进制数据的转换(图像数据→十进制二维数组→二进制一维数组),输出信源比特流。 二、实验内容 1.根据给出的字符以及这些字符的使用频率构建哈夫曼树。 2.根据哈夫曼树对字符进行哈夫曼编码,并保存这些编码。 三、实验原理、方法和手段 试构造出问题模型,并编程实现这一问题的求解。根据实验内容编程,上机调试、得出正确的运行程序;编译运行程序,观察运行情况和输出结果。 六、实验步骤 1. 建立哈夫曼树的存储结构和哈夫曼编码的存储结构。 2. 建立哈夫曼树的函数; 3. 哈夫曼编码的函数; 4.哈夫曼编码的解码函数 5. 设计测试用例进行测试。 七、实验报告 记录数据结构与算法设计的过程及实验步骤、上机过程中遇到的困难及解决办法、遗留的问题、托福考位意见和建议等。格式见实验报告模板。测试数据及测试结果请在上交的资料中写明。 #include JPEG编码器实验报告代码分析
数据结构 哈夫曼编码实验报告
汉明码编码实验报告
游程编码实验报告
香农编码实验报告
压缩技术实验编码
卷积码实验报告
数据结构哈夫曼编码实验报告
游程编码实验报告材料
PCM编码 实验报告
移动通信实验报告
哈夫曼编码实验报告
《数字高程模型》实验讲义[1]
信息论与编码实验报告.
哈夫曼编码译码器实验报告免费
游程编码实验报告
labview-信道编码-李聪-11211060
哈夫曼编码实验报告