信息熵与图像熵的计算

实验一信息熵与图像熵计算
一、实验目的
1.复习MATLAB 的基本命令,熟悉MATLAB 下的基本函数。
2.复习信息熵基本定义, 能够自学图像熵定义和基本概念。
二、实验仪器、设备
1.计算机-系统最低配置 256M 内存、P4 CPU。
2.Matlab 仿真软件- 7.0 / 7.1 / 2006a 等版本Matlab 软件。
三、实验内容与原理
(1)内容:
1.能够写出MATLAB 源代码,求信源的信息熵。
2.根据图像熵基本知识,综合设计出MATLAB 程序,求出给定图像的图像熵。(2)原理
1. MATLAB 中数据类型、矩阵运算、图像文件输入与输出知识复习。
2.利用信息论中信息熵概念,求出任意一个离散信源的熵(平均自信息量)。自信息是一个随机变量,它是指某一信源发出某一消息所含有的信息量。所发出
的消息不同,它们所含有的信息量也就不同。任何一个消息的自信息量都代表不了信源所包含的平均自信息量。不能作为整个信源的信息测度,因此定义自信息量的
数学期望为信源的平均自信息量:
信息熵的意义:信源的信息熵H是从整个信源的统计特性来考虑的。它是从平均意义上来表征信源的总体特性的。对于某特定的信源,其信息熵只有一个。不同的信源因统计特性不同,其熵也不同。
3.学习图像熵基本概念,能够求出图像一维熵和二维熵。
图像熵是一种特征的统计形式,它反映了图像中平均信息量的多少。图像的一
维熵表示图像中灰度分布的聚集特征所包含的信息量,令P
i 表示图像中灰度值为i的像素所占的比例,则定义灰度图像的一元灰度熵为:
255
log
i i
i
p p =
=∑
H
图像的一维熵可以表示图像灰度分布的聚集特征,却不能反映图像灰度分布的空间
特征,为了表征这种空间特征,可以在一维熵的基础上引入能够反映灰度分布空间
特征的特征量来组成图像的二维熵。选择图像的邻域灰度均值作为灰度分布的空间
特征量,与图像的像素灰度组成特征二元组,记为( i, j ),其中i 表示像素的灰度值
(0 <= i <= 255),j 表示邻域灰度(0 <= j <= 255),
2
(,)/
ij
P f i j N
=
上式能反应某像素位置上的灰度值与其周围像素灰度分布的综合特征,其中f(i, j) 为特征二元组(i, j)出现的频数,N 为图像的尺度,定义离散的图像二维熵为:255
log
ij ij
i
p p =
=∑
H
构造的图像二维熵可以在图像所包含信息量的前提下,突出反映图像中像素位置的灰度信息和像素邻域内灰度分布的综合特征.
四、实验步骤
1.求解信息熵过程:
1) 输入一个离散信源,并检查该信源是否是完备集。
2) 去除信源中符号分布概率为零的元素。
3) 根据平均信息量公式,求出离散信源的熵。
2.图像熵计算过程:
1) 输入一幅图像,并将其转换成灰度图像。
2) 统计出图像中每个灰度阶象素概率。
3) 统计出图像中相邻两象素的灰度阶联合分布矩阵。
4) 根据图像熵和二阶熵公式,计算出一幅图像的熵。五.实验数据及结果分析
程序如下:
Information Theory experiment testing file
jma@https://www.360docs.net/doc/919242452.html,, 22/08/2007
testing Discrete Shannon Entropy
discrete probabilities set
probSet = [ 0.1 0.2 0.3 0.15 0.25];
call CalEntropy function
H = CalEntropy(probSet);
sprintf('Shannon Entropy is: %d',H)
calculate the Image entropy
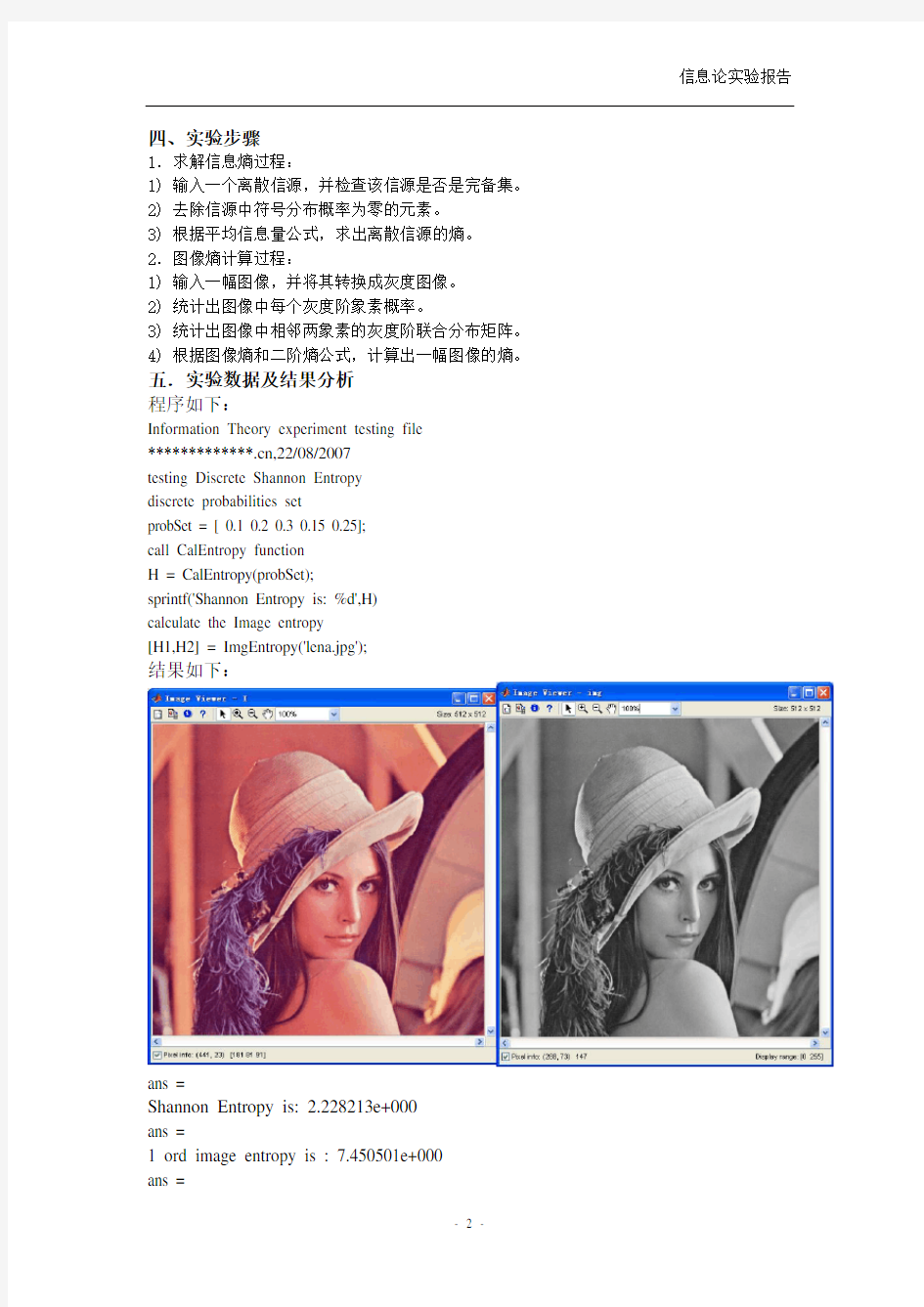
[H1,H2] = ImgEntropy('lena.jpg');
结果如下:
ans =
Shannon Entropy is: 2.228213e+000
ans =
1 ord image entropy is : 7.450501e+000
ans =
2 ord image entropy is : 6.158439e+000
六、思考题
举例说明图像熵、信息熵在现实中有何实践指导意义?
附1:信息熵计算源代码函数源程序CalEntropy.m Information Shannon Entropy calculation jma@https://www.360docs.net/doc/919242452.html,, 22/08/2007
array : Discrete Probabilities Set
H : Output Shannon Entropy
function H = CalEntropy(array)
Vector number
num = length(array);
Check probabilities sum to 1:
if abs(sum(array) - 1) > .00001,
error('Probablities don''t sum to 1.')
end
Remove any zero probabilities %% zeroProbs = find(array < eps);
if ~isempty(zeroProbs),
array(zeroProbs) = [];
disp('Removed zero or negative probabilities.') End
Compute the entropy
H = -sum(array .* log2(array)); % 单位
bit/symbol
附2:图像熵计算源代码
函数源程序 ImgEntropy.m
Image Entropy calculation %%%%%%%% jma@https://www.360docs.net/doc/919242452.html,, 22/08/2007
img : input image data
H1,H2 : Output 1&2 order entropy
function [H1,H2] = ImgEntropy(img)
color image transformation
I = imread(img);
img = rgb2gray(I);
imview(I), imview(img);
[ix,iy] = size(img);
compute probs for each scale level in image
P1 = imhist(img)/(ix*iy);
temp = double(img);
for the index of image piexl
temp = [temp , temp(:,1)];
correlation prob matrix between [ 0 ... 255] gray levels CoefficientMat = zeros(256,256);
for x = 1:ix
for y = 1:iy
i = temp(x,y); j = temp(x,y+1); CoefficientMat(i+1,j+1) = CoefficientMat(i+1,j+1)+1;
end
end
compute the prob of matrix
P2 = CoefficientMat./(ix*iy);
H1 = 0; H2 = 0;
for i = 1:256
calculate 1 ord image entropy
if P1(i) ~= 0
H1 = H1 - P1(i)*log2(P1(i));
end
compute 2 ord image entropy
for j = 1:256
if P2(i,j) ~= 0
H2 = H2 - P2(i,j)*log2(P2(i,j));
end
end
end
H2 = H2/2; % mean entropy /symbol sprintf('1 ord image entropy is : %d',H1) sprintf('2 ord image entropy is : %d',H2) 函数调用实例 test.m
Information Theory experiment testing file jma@https://www.360docs.net/doc/919242452.html,, 22/08/2007
testing Discrete Shannon Entropy discrete probabilities set
probSet = [ 0.1 0.2 0.3 0.15 0.25];
call CalEntropy function
H = CalEntropy(probSet);
sprintf('Shannon Entropy is: %d',H) calculate the Image entropy
[H1,H2] = ImgEntropy('lena.jpg');
(完整版)信息熵在图像处理特别是图像分割和图像配准中的应用——信息与计算科学毕业设计
摘要 信息论是人们在长期通信实践活动中,由通信技术与概率论、随机过程、数理统计等学科相结合而逐步发展起来的一门新兴交叉学科。而熵是信息论中事件出现概率的不确定性的量度,能有效反映事件包含的信息。随着科学技术,特别是信息技术的迅猛发展,信息理论在通信领域中发挥了越来越重要的作用,由于信息理论解决问题的思路和方法独特、新颖和有效,信息论已渗透到其他科学领域。随着计算机技术和数学理论的不断发展,人工智能、神经网络、遗传算法、模糊理论的不断完善,信息理论的应用越来越广泛。在图像处理研究中,信息熵也越来越受到关注。为了寻找快速有效的图像处理方法,信息理论越来越多地渗透到图像处理技术中。本文通过进一步探讨概论率中熵的概念,分析其在图像处理中的应用,通过概念的分析理解,详细讨论其在图像处理的各个方面:如图像分割、图像配准、人脸识别,特征检测等的应用。 本文介绍了信息熵在图像处理中的应用,总结了一些基于熵的基本概念,互信息的定义。并给出了信息熵在图像处理特别是图像分割和图像配准中的应用,最后实现了信息熵在图像配准中的方法。 关键词:信息熵,互信息,图像分割,图像配准
Abstract Information theory is a new interdisciplinary subject developed in people long-term communication practice, combining with communication technology, theory of probability, stochastic processes, and mathematical statistics. Entropy is a measure of the uncertainty the probability of the occurrence of the event in the information theory, it can effectively reflect the information event contains. With the development of science and technology, especially the rapid development of information technology, information theory has played a more and more important role in the communication field, because the ideas and methods to solve the problem of information theory is unique, novel and effective, information theory has penetrated into other areas of science. With the development of computer technology and mathematical theory, continuous improvement of artificial intelligence, neural network, genetic algorithm, fuzzy theory, there are more and more extensive applications of information theory. In the research of image processing, the information entropy has attracted more and more attention. In
实验一 灰度图像信息熵的相关计算与分析
实验一 灰度图像信息熵的相关计算与分析
一、实验目的 1、复习信息熵,条件熵,联合熵,互信息,相对熵的基本定义, 掌握其计算方法,学习互信息与相对熵的区别之处并比较两者的有效性,加深对所学理论理论知识的理解。 2、掌握图像的的基本处理方法,了解图像的编码原理。 3、学习使用matlab ,掌握matlab 的编程。 4、通过对比分析,。在解决问题的过程中,锻炼自身对问题的研究能力。 二、实验内容与要求 1、计算灰度图像的信息熵,条件熵,联合熵,互信息,相对熵,并比较互信息和相对熵在判别两幅图像的联系与区别。 2、利用matlab 编程计算,并书写完整实验报告。 三、实验原理 1、信息熵 离散随机变量X 的熵H(X)为: ()()log () x H X p x p x χ ∈=-∑ 图像熵是一种特征的统计形式,它反映了图像中平均信息量的多少。图像的一 维熵表示图像中灰度分布的聚集特征所包含的信息量,将图像的灰度值进行数学统计,便可得到每个灰度值出现的次数及概率,则定义灰度图像的一元灰度熵为: 255 log i i i H p p ==-∑ 利用信息熵的计算公式便可计算图像的信息熵,求出任意一个离散信源的熵(平均自信息量)。自信息是一个随机变量,它是指某一信源发出某一消息所含有的信息量。所发出的消息不同,它们所含有的信息量也就不同。任何一个消息的自信息量都代表不了信源所包含的平均自信息量。 信息熵的意义:信源的信息熵H 是从整个信源的统计特性来考虑的。它是从平均意义上来表征信源的总体特性的。对于某特定的信源,其信息熵只有一个。不同的信源因统计特性不同,其熵也不同。 图像的一维熵可以表示图像灰度分布的聚集特征,却不能反映图像灰度分布的空间特征,为了表征这种空间特征,可以在一维熵的基础上引入能够反映灰度分布空间特征的特征量来组成图像的二维熵。选择图像的邻域灰度均值作为灰度分布的空间特征量,与图像的像素灰度组成特征二元组,记为( i, j ),其中i 表示像素的灰度值(0255)i ≤≤,j 表示邻域灰度(0255)j ≤≤, 2 (,)/ij P f i j N =
实验一-信息熵与图像熵计算-正确
实验一信息熵与图像熵计算(2 学时) 一、实验目的 1.复习MATLAB的基本命令,熟悉MATLAB下的基本函数; 2.复习信息熵基本定义,能够自学图像熵定义和基本概念。 二、实验内容 1.能够写出MATLAB源代码,求信源的信息熵; 2.根据图像熵基本知识,综合设计出MATLAB程序,求出给定图像的图像熵。 三、实验仪器、设备 1.计算机-系统最低配置256M内存、P4 CPU; 2.MATLAB编程软件。 四实验流程图 五实验数据及结果分析
四、实验原理 1.MATLAB中数据类型、矩阵运算、图像文件输入与输出知识复习。 2.利用信息论中信息熵概念,求出任意一个离散信源的熵(平均自信息量)。自信息是一个随机变量,它是指某一信源发出某一消息所含有的信息量。所发出的消息不同,它们所含有的信息量也就不同。任何一个消息的自信息量都代表不了信源所包含的平均自信息量。不能作为整个信源的信息测度,因此定义自信息量的数学期望为信源的平均自信息量: 1( ) 1 ( ) [log ] ( ) log ( ) i n i i p a i H E p a p a X 信息熵的意义:信源的信息熵H是从整个信源的统计特性来考虑的。它是从平均意
义上来表征信源的总体特性的。对于某特定的信源,其信息熵只有一个。不同的信源因统计特性不同,其熵也不同。 3.学习图像熵基本概念,能够求出图像一维熵和二维熵。 图像熵是一种特征的统计形式,它反映了图像中平均信息量的多少。图像的一维熵表示图像中灰度分布的聚集特征所包含的信息量,令Pi表示图像中灰度值为i的像素所占的比例,则定义灰度图像的一元灰度熵为: 2550 log i i i p p H 图像的一维熵可以表示图像灰度分布的聚集特征,却不能反映图像灰度分布的空间特征,为了表征这种空间特征,可以在一维熵的基础上引入能够反映灰度分布空间特征的特征量来组成图像的二维熵。选择图像的邻域灰度均值作为灰度2
信息熵
信息熵在遥感影像中的应用 所谓信息熵,是一个数学上颇为抽象的概念,我们不妨把信息熵理解成某种特定信息的出现概率。信源各个离散消息的自信息量得数学期望(即概率加权的统计平均值)为信源的平均信息量,一般称为信息源,也叫信源熵或香农熵,有时称为无条件熵或熵函数,简称熵。 一般而言,当一种信息出现概率更高的时候,表明它被传播得更广泛,或者说,被引用的程度更高。我们可以认为,从信息传播的角度来看,信息熵可以表示信息的价值。这样子我们就有一个衡量信息价值高低的标准,可以做出关于知识流通问题的更多推论。 利用信息论中的熵模型,计算信息量是一种经典的方法,广泛应用于土地管理,城市扩张以及其他领域。熵值可以定量的反应信息的分散程度,将其应用于遥感图像的解译中可以定量的描述影像包含的信息量,从而为基于影像的研究提供科学的依据。利用信息熵方法对遥感影像的光谱特征进行离散化,根据信息熵的准则函数,寻找断点,对属性进行区间分割,以提高数据处理效率。 遥感影像熵值计算大致流程为:遥感影像数据经过图像预处理之后,进行一系列图像配准、校正,图像增强,去除噪声、条带后,进行图像的分类,然后根据研究区域进行数据的提取,结合一些辅助数据对图像进行监督分类后生成新的图像,将新的图像与研究区边界图和方格图生成的熵单元图进行进一步的融合便可得到熵分值图。 1.获得研究区遥感影像 以研究区南京市的2009 年6 月的中巴资源二号卫星分辨率20 米得影像为例,影像是有三幅拼接完成。通过ArGIS9.2 中的选择工具从全国的行政区域图中提取边界矢量图,再通过掩膜工具获得研究区的影像。分辨率的为90 米得DEM 图有两副影像拼接而得,操作的步骤与获取影像一致,为开展目视解译工作提供参考。然后依照相关学者的相关研究以及城市建设中的一些法律法规,参照分类标准,开展影像解译工作,对于中巴资源二号影像开展监督分类,以及开展目视解译工作。 2.二值图像的建立 将两种解译所得的图像按照一定的标准转化为城镇用地和非城镇用地两种,进一步计算二值图像的熵值。 3.熵值单元图 根据一些学者对城市边缘带的研究,其划分的熵值单元为 1 km ×1 km,针对样 区的具体情况,采用500 m ×500 m 的熵值单元。在ERDAS 软件和
图像熵计算
图像熵计算 信息熵: 利用信息论中信息熵概念,求出任意一个离散信源的熵(平均自信息量)。自信息是一个随机变量,它是指某一信源发出某一消息所含有的信息量。一条信息的信息量和它的不确定性有着直接的关系。所发出的消息不同,它们所含有的信息量也就不同。任何一个消息的自信息量都代表不了信源所包含的平均自信息量。不能作为整个信源的信息测度,因此定义自信息量的数学期望为信源的平均自信息量: 信息熵的意义 信源的信息熵H 是从整个信源的统计特性来考虑的。它是从平均意义上来表征信源的总体特性的。对于某特定的信源,其信息熵只有一个。不同的信源因统计特性不同,其熵也不同。信息熵一般用符号H 表示,单位是比特。变量的不确定性越大,熵也就越大。 图像熵: 1.一元灰度熵 图像熵是一种特征的统计形式,它反映了图像中平均信息量的多少。图像的一维熵表示图像中灰度分布的聚集特征所包含的信息量,令P i 表示图像中灰度值为i 的像素所占的比例,则定义灰度图像的一元灰度熵为: 255 log =i i i H p p =∑ 其中P i 是某个灰度在该图像中出现的概率,可由灰度直方图获得。 %% 图像灰度直方图 clear; clc;
close all; ImageData=imread('lena.jpg'); if ndims(ImageData) == 3 figure; imshow(ImageData); title('您选择的是RGB图,将转换为灰度图!'); ImageData = rgb2gray(ImageData); %如果是真彩色图,就将其装换为灰度图 end figure imshow(ImageData) title('您所选择的图像'); figure; h=imhist(ImageData); %一个MATLAB图像处理模块中的函数,用以提取图像中的直方图信息 h1=h(1:2:256); h2=1:2:256; stem(h2,h1,'r--'); %绘出柱状图,红色 title('图像灰度直方图-柱状图'); figure; imhist(ImageData); %一个MATLAB图像处理模块中的函数,用以提取图像中的直方图信息 title('灰度直方图');
信息熵.doc
一些信息熵的含义 (1) 信息熵的定义:假设X是一个离散随即变量,即它的取值范围R={x1,x2...}是有限可数的。设p i=P{X=x i},X的熵定义为: (a) 若(a)式中,对数的底为2,则熵表示为H2(x),此时以2为基底的熵单位是bits,即位。若某一项p i=0,则定义该项的p i logp i-1为0。 (2) 设R={0,1},并定义P{X=0}=p,P{X=1}=1-p。则此时的H(X)=-plogp-(1-p)log(1-p)。该H(x)非常重要,称为熵函数。熵函数的的曲线如下图表示: 再者,定义对于任意的x∈R,I(x)=-logP{X =x}。则H(X)就是I(x)的平均值。此时的I(x)可视为x所提供的信息量。I(x)的曲线如下: (3) H(X)的最大值。若X在定义域R={x1,x2,...x r},则0<=H(X)<=logr。 (4) 条件熵:定义
推导:H(X|Y=y)= ∑p(x|y)log{1/p(x,y)} H(X|Y)=∑p(y)H(X|Y=y)= ∑p(y)*∑p(x|y)log{1/p(x/y)} H(X|Y)表示得到Y后,X的平均信息量,即平均不确定度。 (5) Fano不等式:设X和Y都是离散随机变量,都取值于集合{x1,x2,...x r}。则 H(X|Y)<=H(Pe)+Pe*log(r-1) 其中Pe=P{X≠Y}。Fano表示在已经知道Y后,仍然需要通过检测X才能获得的信息量。检测X的一个方法是先确定X=Y。若X=Y,就知道X;若X≠Y,那么还有r-1个可能。 (6) 互信息量:I(X;Y)=H(X)-H(X|Y)。I(X;Y)可以理解成知道了Y后对于减少X的不确定性的贡献。 I(X;Y)的公式: I(X;Y)=∑(x,y)p(x,y)log{p(y|x)/p(y)} (7)联合熵定义为两个元素同时发生的不确定度。 联合熵H(X,Y)= ∑(x,y)p(x,y)logp(x,y)=H(X)+H(Y|X) (8)信道中互信息的含义 互信息的定义得: I(X,Y)=H(X)-H(X|Y)= I(Y,X)=H(Y)-H(Y|X) 若信道输入为H(X),输出为H(Y),则条件熵H(X|Y)可以看成由于信道上存在干扰和噪声而损失掉的平均信息量。条件熵H(X|Y)又可以看成由于信道上的干扰和噪声的缘故,接收端获得Y后还剩余的对符号X的平均不确定度,故称为疑义度。 条件熵H(Y|X)可以看作唯一地确定信道噪声所需要的平均信息量,故称为噪声熵或者散布度。 (9)I(X,Y)的重要结论
信息熵与图像熵计算
p (a i ) ∑ n 《信息论与编码》课程实验报告 班级:通信162 姓名:李浩坤 学号:163977 实验一 信息熵与图像熵计算 实验日期:2018.5.31 一、实验目的 1. 复习 MATLAB 的基本命令,熟悉 MATLAB 下的基本函数。 2. 复习信息熵基本定义, 能够自学图像熵定义和基本概念。 二、实验原理及内容 1.能够写出 MATLAB 源代码,求信源的信息熵。 2.根据图像熵基本知识,综合设计出 MATLAB 程序,求出给定图像的图像熵。 1.MATLAB 中数据类型、矩阵运算、图像文件输入与输出知识复习。 2.利用信息论中信息熵概念,求出任意一个离散信源的熵(平均自信息量)。自信息是一个随机变量,它是指某一信源发出某一消息所含有的信息量。所发出 的消息不同,它们所含有的信息量也就不同。任何一个消息的自信息量都代表不了信源所包含的平均自信息量。不能作为整个信源的信息测度,因此定义自信息量的数学期望为信源的平均自信息量: H (X ) = E [ log 1 ] = -∑ p (a i ) log p (a i ) i =1 信息熵的意义:信源的信息熵H 是从整个信源的统计特性来考虑的。它是从平均意义上来表征信源的总体特性的。对于某特定的信源,其信息熵只有一个。不同的信源因统计特性不同,其熵也不同。 1. 学习图像熵基本概念,能够求出图像一维熵和二维熵。 图像熵是一种特征的统计形式,它反映了图像中平均信息量的多少。图像的一维熵表示图像中灰度分布的聚集特征所包含的信息量,令 P i 表示图像中灰度值为 i 的像素所占的比例,则定义灰度图像的一元灰度熵为: 255 H = p i log p i i =0
两个matlab实现最大熵法图像分割程序
%两个程序,亲测可用 clear all a=imread('moon.tif'); figure,imshow(a) count=imhist(a); [m,n]=size(a); N=m*n; L=256; count=count/N;%%每一个像素的分布概率 count for i=1:L if count(i)~=0 st=i-1; break; end end st for i=L:-1:1 if count(i)~=0 nd=i-1; break; end end nd f=count(st+1:nd+1); %f是每个灰度出现的概率 size(f) E=[]; for Th=st:nd-1 %%%设定初始分割阈值为Th av1=0; av2=0; Pth=sum(count(1:Th+1)); %%%第一类的平均相对熵为 for i=0:Th av1=av1-count(i+1)/Pth*log(count(i+1)/Pth+0.00001); end %%%第二类的平均相对熵为 for i=Th+1:L-1 av2=av2-count(i+1)/(1-Pth)*log(count(i+1)/(1-Pth)+0.00001); end E(Th-st+1)=av1+av2; end position=find(E==(max(E))); th=st+position-1
for i=1:m for j=1:n if a(i,j)>th a(i,j)=255; else a(i,j)=0; end end end figure,imshow(a); %%%%%%%%%%%%%%%%%%%%%2-d 最大熵法(递推方法) %%%%%%%%%%% clear all; clc; tic a=imread('trial2_2.tiff'); figure,imshow(a); a0=double(a); [m,n]=size(a); h=1; a1=zeros(m,n); % 计算平均领域灰度的一维灰度直方图 for i=1:m for j=1:n for k=-h:h for w=-h:h; p=i+k; q=j+w; if (p<=0)|( p>m) p=i; end if (q<=0)|(q>n) q=j; end a1(i,j)=a0(p,q)+a1(i,j); end end a2(i,j)=uint8(1/9*a1(i,j)); end
信息熵在图像处理中的应用
信息熵在图像处理中的应用 摘要:为了寻找快速有效的图像处理方法,信息理论越来越多地渗透到图像处理技术中。文章介绍了信息熵在图像处理中的应用,总 结了一些基于熵的图像处理特别是图像分割技术的方法,及其在这一领域内的应用现状和前景 同时介绍了熵在织物疵点检测中的应用。 Application of Information Entropy on Image Analysis Abstract :In order to find fast and efficient methods of image analysis ,information theory is used more and more in image analysis .The paper introduces the application of information entropy on the image analysis ,and summarizes some methods of image analysis based on information entropy ,especially the image segmentation method .At the same time ,the methods and application of fabric defect inspection based on information entropy ale introduced . 信息论是人们在长期通信实践活动中,由通信技术与概率论、随机过程、数理统计等学科相结合而逐步发展起来的一门新兴交叉学科。而熵是信息论中事件出现概率的不确定性的量度,能有效反映事件包含的信息。随着科学技术,特别是信息技术的迅猛发展,信息理论在通信领域中发挥了越来越重要的作用,由于信息理论解决问题的思路和方法独特、新颖和有效,信息论已渗透到其他科学领域。随着计算机技术和数学理论的不断发展,人工智能、神经网络、遗传算法、模糊理论的不断完善,信息理论的应用越来越广泛。在图像处理研究中,信息熵也越来越受到关注。 1 信息熵 1948年,美国科学家香农(C .E .Shannon)发表了一篇著名的论文《通信的数学理论》 。他从研究通信系统传输的实质出发,对信息做了科学的定义,并进行了定性和定量的描述。 他指出,信息是事物运动状态或存在方式的不确定性的描述。其通信系统的模型如下所示: 图1 信息的传播 信息的基本作用就是消除人们对事物的不确定性。信息熵是信息论中用于度量信息量的一个概念。假定X 是随机变量χ的集合,p (x )表示其概率密度,计算此随机变量的信息熵H (x )的公式是 P (x ,y )表示一对随机变量的联合密度函数,他们的联合熵H (x ,y )可以表示为 信息熵描述的是信源的不确定性,是信源中所有目标的平均信息量。信息量是信息论的中心概念,将熵作为一个随机事件的不确定性或信息量的量度,它奠定了现代信息论的科学理论基础,大大地促进了信息论的发展。设信源X 发符号a i ,的概率为Pi ,其中i=1,2,…,r ,P i >O ,要∑=r i Pi 1=1,则信息熵的代数定义形式为:
信息熵在图像分割中的应用毕业论文
信息熵在图像分割中的应用 毕业论文 目录 摘要 ....................................................... .. (1) ABSTRACT (2) 目录 (3) 1 引言 (5) 1.1信息熵的概念 (5) 1.2信息熵的基本性质及证明 (6) 1.2.1 单峰性 (6) 1.2.2 对称性 (7) 1.2.3 渐化性 (7) 1.2.4 展开性 (7) 1.2.5 确定性 (8) 2基于熵的互信息理论 (9) 2.1 互信息的概述 (9) 2.2 互信息的定义 (9) 2.3 熵与互信息的关系 (9) 3 信息熵在图像分割中的应用 (11) 3.1图像分割的基本概念 (11) 3.1.1图像分割的研究现状 (11) 3.1.2 图像分割的方法 (11) 3.2 基于改进粒子群优化的模糊熵煤尘图像分割 (12) 3.2.1 基本粒子群算法 (12) 3.2.2 改进粒子群优化算法 (13) 3.2.3 Morlet变异 (13)
3.2.4改建粒子群优化的图像分割方法 (14) 3.2.5 实验结果及分析 (16) 3.3 一种新信息熵的定义及其在图像分割中的应用 (19) 3.3.1香农熵的概念及性质 (19) 3.3.2一种信息熵的定义及证明 (19) 3.3.3信息熵计算复杂性分析 (21) 3.3.4二维信息熵阈值法 (22) 3.3.5二维信息熵阈值法的复杂性分析 (24) 3.3.6 结论及分析 (25) 4 信息熵在图像配准中的应用 (27) 4.1图像配准的基本概述 (27) 4.2基于互信息的图像配准 (27) 4.3P OWELL算法 (28) 4.4变换 (28) 4.4.1平移变换 (29) 4.4.2旋转变换 (30) 4.5基于互信息的图像配准的设计与实现 (31) 4.5.1总体设计思路和图像配准实现 (31) 4.5.2直方图 (33) 4.5.3联合直方图 (33) 4.5.4灰度级差值技术 (34) 4.4.5优化搜索办法级结论 (35) 5结语 (37) 致谢 (38) 参考文献 (39) 1 引言 1.1.信息熵的概念 1948年,美国科学家发表了一篇著名的论文《通信的数学理论》。他从研究通信系统传输的实质出发,对信息做了科学的定义,并进行了定性和定量的描述。
指标权重确定方法之熵权法计算方法参考
指标权重确定方法之熵权法 一、熵权法介绍 熵最先由申农引入信息论,目前已经在工程技术、社会经济等领域得到了非常广泛的应用。 熵权法的基本思路是根据指标变异性的大小来确定客观权重。 一般来说,若某个指标的信息熵越小,表明指标值得变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。相反,某个指标的信息熵越大,表明指标值得变异程度越小,提供的信息量也越少,在综合评价中所起到的作用也越小,其权重也就越小。 二、熵权法赋权步骤 1.数据标准化 将各个指标的数据进行标准化处理。 假设给定了k个指标,其中。假设对各指标数据标准化后的值为,那么。 2.求各指标的信息熵 根据信息论中信息熵的定义,一组数据的信息熵。其中,如果,则定义。 3.确定各指标权重 根据信息熵的计算公式,计算出各个指标的信息熵为。通过信息熵计算各指标的权重:。
三、熵权法赋权实例 1.背景介绍 某医院为了提高自身的护理水平,对拥有的11个科室进行了考核,考核标准包括9项整体护理,并对护理水平较好的科室进行奖励。下表是对各个科室指标考核后的评分结果。 但是由于各项护理的难易程度不同,因此需要对9项护理进行赋权,以便能够更加合理的对各个科室的护理水平进行评价。 2.熵权法进行赋权 1)数据标准化 根据原始评分表,对数据进行标准化后可以得到下列数据标准化表 表2 11个科室9项整体护理评价指标得分表标准化表 科室X1X2X3X4X5X6X7X8X9 A B C D
E F G H I J K 2)求各指标的信息熵 根据信息熵的计算公式,可以计算出9项护理指标各自的信息熵如下: 表3 9项指标信息熵表 X1X2X3X4X5X6X7X8X9 信息熵 3)计算各指标的权重 根据指标权重的计算公式,可以得到各个指标的权重如下表所示: 表4 9项指标权重表 W1W2W3W4W5W6W7W8W9权重 3.对各个科室进行评分 根据计算出的指标权重,以及对11个科室9项护理水平的评分。设Z l为第l个科室的最终得分,则,各个科室最终得分如下表所示 表5 11个科室最终得分表 科室A B C D E F G H I J K 得分
最新信息熵在图像处理特别是图像分割和图像配准中的应用——信息与计算科学毕业
信息熵在图像处理特别是图像分割和图像配准中的应用——信息与计算科学毕业
摘要 信息论是人们在长期通信实践活动中,由通信技术与概率论、随机过程、数理统计等学科相结合而逐步发展起来的一门新兴交叉学科。而熵是信息论中事件出现概率的不确定性的量度,能有效反映事件包含的信息。随着科学技术,特别是信息技术的迅猛发展,信息理论在通信领域中发挥了越来越重要的作用,由于信息理论解决问题的思路和方法独特、新颖和有效,信息论已渗透到其他科学领域。随着计算机技术和数学理论的不断发展,人工智能、神经网络、遗传算法、模糊理论的不断完善,信息理论的应用越来越广泛。在图像处理研究中,信息熵也越来越受到关注。为了寻找快速有效的图像处理方法,信息理论越来越多地渗透到图像处理技术中。本文通过进一步探讨概论率中熵的概念,分析其在图像处理中的应用,通过概念的分析理解,详细讨论其在图像处理的各个方面:如图像分割、图像配准、人脸识别,特征检测等的应用。 本文介绍了信息熵在图像处理中的应用,总结了一些基于熵的基本概念,互信息的定义。并给出了信息熵在图像处理特别是图像分割和图像配准中的应用,最后实现了信息熵在图像配准中的方法。 关键词:信息熵,互信息,图像分割,图像配准
Abstract Information theory is a new interdisciplinary subject developed in people long-term communication practice, combining with communication technology, theory of probability, stochastic processes, and mathematical statistics. Entropy is a measure of the uncertainty the probability of the occurrence of the event in the information theory, it can effectively reflect the information event contains. With the development of science and technology, especially the rapid development of information technology, information theory has played a more and more important role in the communication field, because the ideas and methods to solve the problem of information theory is unique, novel and effective, information theory has penetrated into other areas of science. With the development of computer technology and mathematical theory, continuous improvement of artificial intelligence, neural network, genetic algorithm, fuzzy theory, there are more and more extensive applications of information theory. In the research of image processing, the information entropy has attracted more and more attention. In order to find the fast and effective image processing method, information theory is used more and more frequently in the image processing technology. In this paper, through the further discussion on concept of entropy, analyzes its application in image processing, such as image segmentation, image registration, face recognition, feature detection etc. This paper introduces the application of information entropy in image processing, summarizes some basic concepts based on the definition of entropy, mutual information. And the information entropy of image processing especially for image segmentation and image registration. Finally realize the information entropy in image registration. Keywords: Information entropy, Mutual information, Image segmentation, Image registration
图像处理--采用最大熵方法进行图像分割
数字图象处理课程设计 题目:采用最大熵方法进行图像分割 班级:电信121 学号:3120412014 姓名:吴向荣 指导老师:王栋 起止时间:2016.1.4~2016.1.8 西安理工大学
源代码: clear,clc image=imread('C:\Users\Administrator\Desktop\图像课设\3.jpg'); subplot(2,2,1);imshow(image);title('原始彩图') %% %灰度图 imagegray=rgb2gray(image); %彩色图转换为灰度图 subplot(2,2,2);imshow(imagegray);title('灰度图') %计算灰度直方图分布counts和x分别为返回直方图数据向量和相应的彩色向量count=imhist(imagegray); subplot(2,2,3);imhist(imagegray);title('灰度直方图') [m,n]=size(imagegray); imagegray=fun_maxgray(count,imagegray,m,n); subplot(2,2,4);imshow(imagegray);title('最大熵处理后的图') %% 彩色图 % r=image(:,:,1);countr=imhist(r);r=fun_maxgray(countr,r,m,n); % subplot(2,2,1);imshow(r); % g=image(:,:,2);countg=imhist(g);g=fun_maxgray(countg,g,m,n); % subplot(2,2,2);imshow(g); % b=image(:,:,3);countb=imhist(b);b=fun_maxgray(countb,b,m,n); % subplot(2,2,3);imshow(b); b=0; for z=1:3 figure titleName = strcat('第',num2str(z),'通道灰度直方图'); titleName1 = strcat('第',num2str(z),'通道最大熵处理后图'); a=image(:,:,z);subplot(1,2,1);imhist(a);title(titleName) countr=imhist(a);a=fun_maxgray(countr,a,m,n); subplot(1,2,2);imshow(a);title(titleName1) b=b+a; end figure,imshow(b);title('彩色各通道处理后叠加图') 最大熵方法进行图像分割的子函数: function sample=fun_maxgray(count,sample,m,n) countp=count/(m*n); %每一个像素的分布概率 E=[]; E1=0; E2=0;
最新信息熵的matlab程序实例资料
求一维序列的信息熵(香浓熵)的matlab程序实例 对于一个二维信号,比如灰度图像,灰度值的范围是0-255,因此只要根据像素灰度值(0-255)出现的概率,就可以计算出信息熵。 但是,对于一个一维信号,比如说心电信号,数据值的范围并不是确定的,不会是(0-255)这么确定,如果进行域值变换,使其转换到一个整数范围的话,就会丢失数据,请高手指点,怎么计算。 比如数字信号是x(n),n=1~N (1)先用Hist函数对x(n)的赋值范围进行分块,比如赋值范围在0~10的对应第 一块,10~20的第二块,以此类推。这之前需要对x(n)做一些归一化处理 (2)统计每一块的数据个数,并求出相应的概率 (3)用信息熵公式求解 以上求解方法获得的虽然是近似的信息熵,但是一般认为,这么做是没有问题的 求一维序列的信息熵的matlab程序代码如下:(已写成调用的函数形式) 测试程序: fs=12000; N=12000; T=1/fs; t=(0:N-1)*T; ff=104; sig=0.5*(1+sin(2*pi*ff*t)).*sin(2*pi*3000*t)+rand(1,length(t)); Hx=yyshang(sig,10) %———————求一维离散序列信息熵matlab代码 function Hx=yyshang(y,duan) %不以原信号为参考的时间域的信号熵 %输入:maxf:原信号的能量谱中能量最大的点 %y:待求信息熵的序列 %duan:待求信息熵的序列要被分块的块数 %Hx:y的信息熵 %duan=10;%将序列按duan数等分,如果duan=10,就将序列分为10等份 x_min=min(y); x_max=max(y); maxf(1)=abs(x_max-x_min); maxf(2)=x_min; duan_t=1.0/duan; jiange=maxf(1)*duan_t; % for i=1:10 % pnum(i)=length(find((y_p>=(i-1)*jiange)&(y_p 1 第5讲 随机变量的信息熵 在概率论和统计学中,随机变量表示随机试验结果的观测值。随机变量的取值是不确定的,但是服从一定的概率分布。因此,每个取值都有自己的信息量。平均每个取值的信息量称为该随机变量的信息熵。 信息熵这个名称是冯诺依曼向香农推荐的。在物理学中,熵是物理系统的状态函数,用于度量一个物理系统内部状态和运动的无序性。物理学中的熵也称为热熵。信息熵的表达式与热熵的表达式类似,可以视为热熵的推广。香农用信息熵度量一个物理系统内部状态和运动的不确定性。 信息熵是信息论的核心和基础概念,具有多种物理意义。香农所创立的信息论是从定义和研究信息熵开始的。这一讲我们学习信息熵的定义和性质。 1. 信息熵 我们这里考虑离散型随机变量的信息熵,连续型随机变量的信息熵以后有时间再讨论,读者也可以看课本上的定义,先简单地了解一下。 定义1.1 设离散型随机变量X 的概率空间为 1 21 2 ......n n x x x X p p p P ?? ??=???????? 我们把X 的所有取值的自信息的期望称为X 的平均自信息量,通常称为信息熵,简称熵(entropy ),记为H(X),即 1 1 ()[()]log n i i i H X E I X p p === ∑ (比特) 信息熵也称为香农熵。 注意,熵H (X )是X 的概率分布P 的函数,因此也记为H (P )。 定义1.2 信息熵表达式中的对数底可取任何大于等于2的整数r ,所得结果称为r-进制熵,记为H r (X ),其单位为“r-进制单位”。 我们有 2 ()() log r X H H r X = 注意,在关于熵的表达式中,我们仍然约定 0log 00 0log 00 x ==, 信息熵的物理意义: 信息熵可从多种不同角度来理解。 (1) H(X)是随机变量X 的取值所能提供的平均信息量。 (2) 统计学中用H(X)表征随机变量X 的不确定性,也就是随机性的大小。 例如,假设有甲乙两只箱子,每个箱子里都存放着100个球。甲里面有红蓝色球各50个,乙里面红、蓝色的球分别为99个和1个。显然,甲里面球的颜色更具有不确定性。从两个箱子各摸出一个球,甲里面摸出的球更不好猜。 (3) 若离散无记忆信源的符号概率分布为P ,则H(P)是该信源的所有无损编码的“平均 码长”的极限。 令X 是离散无记忆信源的符号集,所有长度为n 的消息集合为 {1,2, ,}n M X = 每个消息i 在某个无损编码下的码字为w i ,码字长为l i 比特。假设各消息i 出现的概率为p i ,则该每条消息的平均码长为 1 M n i i i L p l ==∑ 因此,平均每个信源符号的码长为 1 1M n i i i L p l n n ==∑ 这个平均每个信源符号的码长称为该编码的平均码长,其量纲为(码元/信源)。 我们有 () lim () n n n L L H X H X n n →∞≥=且 这是信源编码定理的推论。 中文信息处理报告 课题名称搜索引擎中的关键技术及解决学院(系)电子信息与工程学院 专业计算机科学与技术 学号072337 学生姓名张志佳 完成时间2009年1月 3 日 目前,国内的每个行业,领域都在飞速发展,这中间产生了大量的中文信息资源,为了能够及时准确的获取最新的信息,中文搜索引擎应运而生。中文搜索引擎与西文搜索引擎在实现的机制和原理上大致相同,但由于汉语本身的特点,必须引入对于中文语言的处理技术,而汉语自动分词技术就是其中很关键的部分,也是进行后续语义或者是语法分析的基础。汉语自动分词到底对搜索引擎有多大影响?对于搜索引擎来说,最重要的并不是找到所有结果,最重要的是把最相关的结果排在最前面,这也称为相关度排序。中文分词的准确与否,常常直接影响到对搜索结果的相关度排序。分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,在Internet上有上百亿可用的公共Web页面,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,都需要达到很高的要求。 更具体的说,现在的搜索引擎要达到下面的三要求,才能适应当今这样一个信息爆炸的时代,分别是:数据量达到亿,单次查询毫秒级,每日查询总数能支持千万级。撇开搜索引擎要用到的数量庞大的服务器硬件和速度巨快的网络环境不提,就单单说说搜索引擎中软件部分的三大核心技术。我个人以为:一个优秀的搜索引擎,它必需在下面三个方面的技术必须是优秀的:中文分词,网络机器人(Spider)和后台索引结构。而这三方面又是紧密相关的,想要解决中文分词问题,就要解决搜索时间和搜索准确率两方面的难题。而搜索时间上便是通过网络机器人(Spider)和后台索引结构的改进实现的,搜索准确率则是通过分词本身算法的求精来实现的。下面的文章将从这两个大的方面来解决这两方面的问题。 为了能够更清楚的来说明现在的搜索引擎是如何解决这几个难题的,首先对搜索引擎的组成及工作原理在这里简要的说明一下。 搜索引擎的工作,可以看做三步:从互联网上抓取网页,建立索引数据库,在索引数据库中搜索排序。从互联网上抓取网页利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。下面是搜索引擎的工作原理图:Array 搜索引擎工作原理图1第5讲信息熵课件
中文公众事件信息熵计算方法