如何用OPENCV训练自己的分类器

如何用OpenCV训练自己的分类器
最近要做一个性别识别的项目,在人脸检测与五官定位上我采用OPENCV的haartraining进行定位,这里介绍下这两天我学习的如何用opencv训练自己的分类器。在这两天的学习里,我遇到了不少问题,不过我遇到了几个好心的大侠帮我解决了不少问题,特别是无忌,在这里我再次感谢他的帮助。
一、简介
目标检测方法最初由Paul Viola[Viola01]提出,并由Rainer Lienhart[Lienhart02]对这一方法进行了改善。该方法的基本步骤为:首先,利用样本(大约几百幅样本图片)的harr特征进行分类器训练,得到一个级联的boosted分类器。分类器中的"级联"是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。
分类器训练完以后,就可以应用于输入图像中的感兴趣区域的检测。检测到目标区域分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。
目前支持这种分类器的boosting技术有四种:Discrete Adaboost,Real Adaboost,Gentle Adaboost and Logitboost。"boosted"即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。
根据上面的分析,目标检测分为三个步骤:
1、样本的创建
2、训练分类器
3、利用训练好的分类器进行目标检测。
二、样本创建
训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片。
负样本
负样本可以来自于任意的图片,但这些图片不能包含目标特征。负样本由背景描述文件来描述。背景描述文件是一个文本文件,每一行包含了一个负样本图片的文件名(基于描述文件的相对路径)。该文件创建方法如下:
采用Dos命令生成样本描述文件。具体方法是在Dos下的进入你的图片目录,比如我的图片放在D:\face\posdata 下,则:
按Ctrl+R打开Windows运行程序,输入cmd打开DOS命令窗口,输入d:回车,再输入cd D:\face\negdata进入图片路径,再次输入dir/b>negdata.dat,则会图片路径下生成一个negdata.dat文件,打开该文件将最后一行的negdata.dat删除,这样就生成了负样本描述文件。dos命令窗口结果如下图:
正样本
对于正样本,通常的做法是先把所有正样本裁切好,并对尺寸做规整(即缩放至指定大小),如上图所示:
由于HaarTraining训练时输入的正样本是vec文件,所以需要使用OpenCV自带的CreateSamples程序(在你所按照的opencv\bin下,如果没有需要编译opencv\apps\HaarTraining\make下的.dsw文件,注意要编译release版的)将准备好的正样本转换为vec文件。转换的步骤如下:
1)制作一个正样本描述文件,用于描述正样本文件名(包括绝对路径或相对路径),正样本数目以及各正样本在图片
中的位置和大小。典型的正样本描述文件如下:
posdata/1(10).bmp1112323
posdata/1(11).bmp1112323
posdata/1(12).bmp1112323
不过你可以把描述文件放在你的posdata路径(即正样本路径)下,这样你就不需要加前面的相对路径了。同样它的生成方式可以用负样本描述文件的生成方法,最后用txt的替换工具将“bmp”全部替换成“bmp1112323
”就可以了,如果你的样本图片多,用txt替换会导致程序未响应,你可以将内容拷到word下替换,然后再拷回来。bmp 后面那五个数字分别表示图片个数,目标的起始位置及其宽高。这样就生成了正样本描述文件posdata.dat。
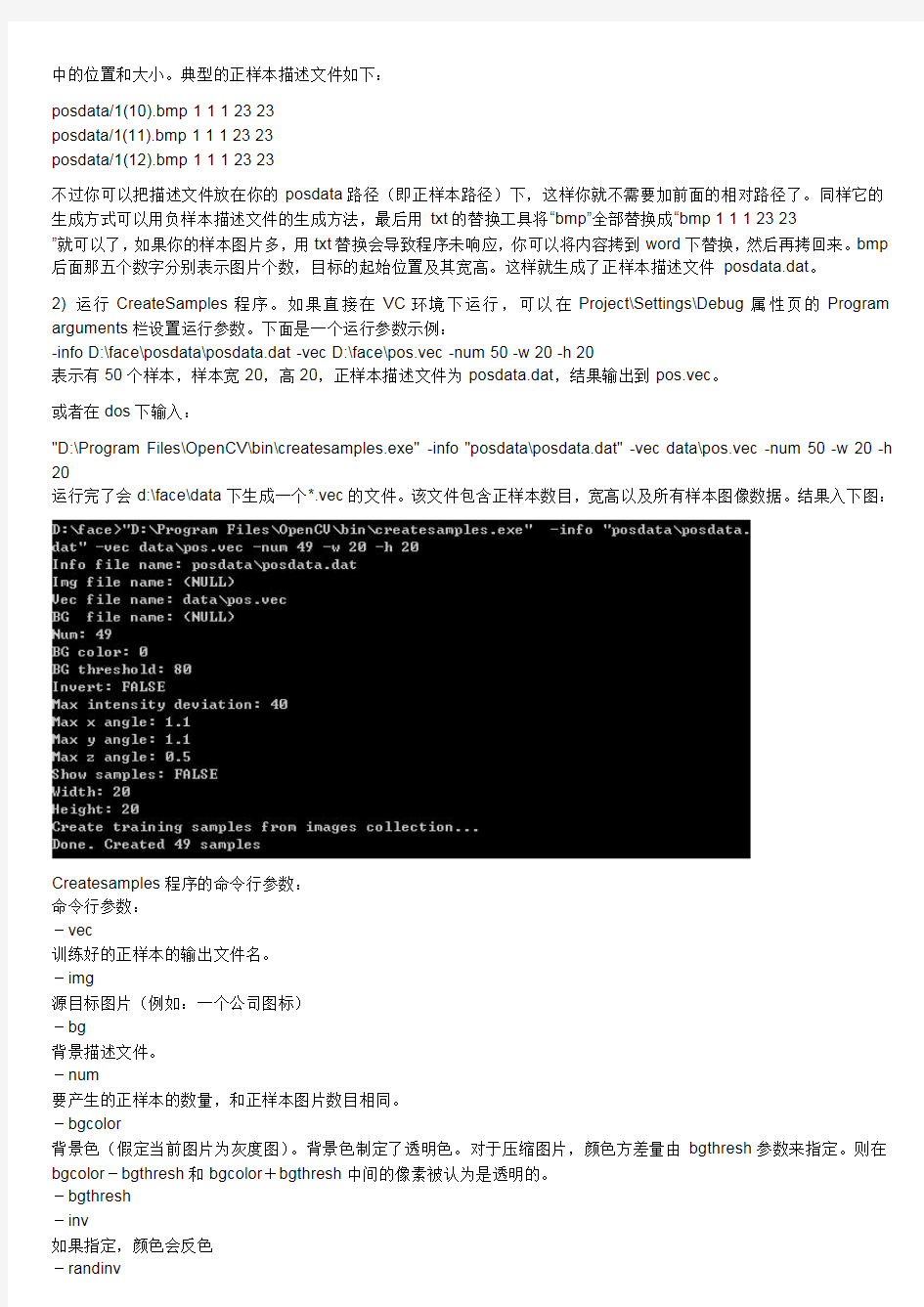
2)运行CreateSamples程序。如果直接在VC环境下运行,可以在Project\Settings\Debug属性页的Program arguments栏设置运行参数。下面是一个运行参数示例:
-info D:\face\posdata\posdata.dat-vec D:\face\pos.vec-num50-w20-h20
表示有50个样本,样本宽20,高20,正样本描述文件为posdata.dat,结果输出到pos.vec。
或者在dos下输入:
"D:\Program Files\OpenCV\bin\createsamples.exe"-info"posdata\posdata.dat"-vec data\pos.vec-num50-w20-h 20
运行完了会d:\face\data下生成一个*.vec的文件。该文件包含正样本数目,宽高以及所有样本图像数据。结果入下图:
Createsamples程序的命令行参数:
命令行参数:
-vec
训练好的正样本的输出文件名。
-img
源目标图片(例如:一个公司图标)
-bg
背景描述文件。
-num
要产生的正样本的数量,和正样本图片数目相同。
-bgcolor
背景色(假定当前图片为灰度图)。背景色制定了透明色。对于压缩图片,颜色方差量由bgthresh参数来指定。则在bgcolor-bgthresh和bgcolor+bgthresh中间的像素被认为是透明的。
-bgthresh
-inv
如果指定,颜色会反色
-randinv
如果指定,颜色会任意反色
-maxidev
背景色最大的偏离度。
-maxangel
-maxangle
-maxzangle
最大旋转角度,以弧度为单位。
-show
如果指定,每个样本会被显示出来,按下"esc"会关闭这一开关,即不显示样本图片,而创建过程继续。这是个有用的debug选项。
-w
输出样本的宽度(以像素为单位)
-h《sample_height》
输出样本的高度,以像素为单位。
到此第一步样本训练就完成了。恭喜你,你已经学会训练分类器的五成功力了,我自己学这个的时候花了我一天的时间,估计你几分钟就学会了吧。
三、训练分类器
样本创建之后,接下来要训练分类器,这个过程是由haartraining程序来实现的。该程序源码由OpenCV自带,且可执行程序在OpenCV安装目录的bin目录下。
Haartraining的命令行参数如下:
-data
存放训练好的分类器的路径名。
-vec
正样本文件名(由trainingssamples程序或者由其他的方法创建的)
-bg
背景描述文件。
-npos
-nneg
用来训练每一个分类器阶段的正/负样本。合理的值是:nPos=7000;nNeg=3000
-nstages
训练的阶段数。
-nsplits
决定用于阶段分类器的弱分类器。如果1,则一个简单的stump classifier被使用。如果是2或者更多,则带有number_of_splits个内部节点的CART分类器被使用。
-mem
预先计算的以MB为单位的可用内存。内存越大则训练的速度越快。
-sym(default)
-nonsym
指定训练的目标对象是否垂直对称。垂直对称提高目标的训练速度。例如,正面部是垂直对称的。
-minhitrate《min_hit_rate》
每个阶段分类器需要的最小的命中率。总的命中率为min_hit_rate的number_of_stages次方。
-maxfalsealarm
没有阶段分类器的最大错误报警率。总的错误警告率为max_false_alarm_rate的number_of_stages次方。
-weighttrimming
指定是否使用权修正和使用多大的权修正。一个基本的选择是0.9
-eqw
-mode
选择用来训练的haar特征集的种类。basic仅仅使用垂直特征。all使用垂直和45度角旋转特征。
-w《sample_width》
-h《sample_height》
训练样本的尺寸,(以像素为单位)。必须和训练样本创建的尺寸相同。
一个训练分类器的例子:
"D:\Program Files\OpenCV\bin\haartraining.exe"-data data\cascade-vec data\pos.vec-bg negdata\negdata.dat -npos49-nneg49-mem200-mode ALL-w20-h20
训练结束后,会在目录data下生成一些子目录,即为训练好的分类器。
训练结果如下:
恭喜你,你已经学会训练分类器的九成功力了。
四:利用训练好的分类器进行目标检测。
这一步需要用到performance.exe,该程序源码由OpenCV自带,且可执行程序在OpenCV安装目录的bin目录下。performance.exe-data data/cascade-info posdata/test.dat-w20-h20-rs30
performance的命令行参数如下:
Usage:./performance
-data
-info
[-maxSizeDiff
[-maxPosDiff
[-sf
[-ni]
[-nos
[-rs
[-w
[-h
也可以用opencv的cvHaarDetectObjects函数进行检测:
CvSeq*faces=cvHaarDetectObjects(img,cascade,storage, 1.1,2,CV_HAAR_DO_CANNY_PRUNING, cvSize(40,40));//检测人脸
注:OpenCv的某些版本可以将这些目录中的分类器直接转换成xml文件。但在实际的操作中,haartraining程序却好像永远不会停止,而且没有生成xml文件,后来在OpenCV的yahoo论坛上找到一个haarconv的程序,才将分类器转换为xml文件,其中的原因尚待研究。
基于决策树的分类方法研究
南京师范大学 硕士学位论文 基于决策树的分类方法研究 姓名:戴南 申请学位级别:硕士 专业:计算数学(计算机应用方向) 指导教师:朱玉龙 2003.5.1
摘要 厂 {数掘挖掘,又称数据库中的知识发现,是指从大型数据库或数据仓库中提取 具有潜在应用价值的知识或模式。模式按其作用可分为两类:描述型模式和预测型模式。分类模式是一种重要的预测型模式。挖掘分娄模式的方法有多种,如决 策树方法、贝叶斯网络、遗传算法、基于关联的分类方法、羊H糙集和k一最临近方、/ 法等等。,/驴 I 本文研究如何用决策树方法进行分类模式挖掘。文中详细阐述了几种极具代表性的决策树算法:包括使用信息熵原理分割样本集的ID3算法;可以处理连续属性和属性值空缺样本的C4.5算法;依据GINI系数寻找最佳分割并生成二叉决策树的CART算法;将树剪枝融入到建树过程中的PUBLIC算法:在决策树生成过程中加入人工智能和人为干预的基于人机交互的决策树生成方法;以及突破主存容量限制,具有良好的伸缩性和并行性的SI,lQ和SPRINT算法。对这些算法的特点作了详细的分析和比较,指出了它们各自的优势和不足。文中对分布式环境下的决策树分类方法进行了描述,提出了分布式ID3算法。该算法在传统的ID3算法的基础上引进了新的数掘结构:属性按类别分稚表,使得算法具有可伸缩性和并行性。最后着重介绍了作者独立完成的一个决策树分类器。它使用的核心算法为可伸缩的ID3算法,分类器使用MicrosoftVisualc++6.0开发。实验结果表明作者开发的分类器可以有效地生成决策树,建树时间随样本集个数呈线性增长,具有可伸缩性。。 ,,荡囊 关键字:数据挖掘1分类规则,决策树,分布式数据挖掘
分类器训练
一、简介 目标检测方法最初由Paul Viola [Viola01]提出,并由Rainer Lienhart [Lienhart02]对这一方法进行了改善。该方法的基本步骤为:首先,利用样本(大约几百幅样本图片)的 harr 特征进行分类器训练,得到一个级联的boosted分类器。 分类器中的"级联"是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。 分类器训练完以后,就可以应用于输入图像中的感兴趣区域(与训练样本相同的尺寸)的检测。检测到目标区域(汽车或人脸)分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。 目前支持这种分类器的boosting技术有四种: Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost。 "boosted" 即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。 根据上面的分析,目标检测分为三个步骤: 1、样本的创建 2、训练分类器 3、利用训练好的分类器进行目标检测。 二、样本创建 训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本(例如人脸或汽车等),反例样本指其它任意图片,所有的样本图片都被归一化为同样的尺寸大小(例如,20x20)。 负样本 负样本可以来自于任意的图片,但这些图片不能包含目标特征。负样本由背景描述文件来描述。背景描述文件是一个文本文件,每一行包含了一个负样本图片的文件名(基于描述文件的相对路径)。该文件必须手工创建。 e.g: 负样本描述文件的一个例子: 假定目录结构如下: /img img1.jpg img2.jpg bg.txt 则背景描述文件bg.txt的内容为: img/img1.jpg img/img2.jpg 正样本 正样本由程序createsample程序来创建。该程序的源代码由OpenCV给出,并且在bin目录下包含了这个可执行的程序。 正样本可以由单个的目标图片或者一系列的事先标记好的图片来创建。 Createsamples程序的命令行参数:
液位计的种类、原理及优缺点
液位计的种类、原理及优缺点 磁性浮子液位计 根据浮力原理和磁性耦合作用研制而成。当被测容器中的液位升降时,液位计本体管中的磁性浮子也随之升降,浮子内的永久磁钢通过磁耦合传递到磁翻柱指示器,驱动红、白翻柱翻转,当液位上升时翻柱由白色转变为红色,当液位下降时翻柱由红色转变为白色,指示器的红白交界处为容器内部液位的实际高度,从而实现液位清晰的指示。 可以做到高密封,防泄漏和适用于高温、高压、耐腐蚀的场合。对高温、高压、有毒、有害、强腐蚀介质更显其优越性。 与介质直接接触,浮球密封要求要严格,不能测量粘性介质。磁性材料如退磁易导致液位计不能正常工作 磁性翻板(柱)式液位计 与上同 与上同 翻板容易卡死,造成无法远传指示。磁性材料如退磁易导致液位计不能正常工作。 电磁波雷达液位计(导波雷达液位计) 雷达液位计采用发射—反射—接收的工作模式。雷达液位计的天线发射出电磁波,这些波经被测对象表面反射后,再被天线接收,电磁波从发射到接收的时间与到液面的距离成正比,关系式如下: D=CT/2(D:雷达液位计到液面的距离C:光速T:电磁波运行时间) 雷达液位计记录脉冲波经历的时间,而电磁波的传输速度为常数,则可算出液面到雷达天线的距离,从而知道液面的液位。
不需要传输媒介,不受大气、蒸气、槽内挥发雾影响的特点,能用于挥发介质的液位测量。采用非接触式测量,不受槽内液体的密度、浓度等物理特性的影响。 价格昂贵。仪表需要设置的参数较多,一旦出现问题,通常很难查出是什么原因造成的。如果天线本身不慎沾上介质会报错。如有结晶结冰现象会报错,需加热保温处理,并清理天线。最初安装需要是空仓,即空料位? 超声波液位计 超声波液位计是由微处理器控制的数字物位仪表。在测量中脉冲超声波由传感器(换能器)发出,声波经物体表面反射后被同一传感器接收,转换成电信号。并由声波的发射和接收之间的时间来计算传感器到被测物体的距离。 无机械可动部分,可靠性高,安装简单、方便,属于非接触测量,且不受液体的粘度、密度等影响 精度比较低,测试容易有盲区。不可以测量压力容器,不能测量易挥发性介质。 电容式液位计 采用测量电容的变化来测量液面的高低的。它是一根金属棒插入盛液容器内,金属棒作为电容的一个极,容器壁作为电容的另一极。两电极间的介质即为液体及其上面的气体。由于液体的介电常数ε1和液面上的介电常数ε2不同,比如:ε1》ε2,则当液位升高时,两电极间总的介电常数值随之加大因而电容量增大。反之当液位下降,ε值减小,电容量也减小。所以,可通过两电极间的电容量的变化来测量液位的高低。电容液位计的灵敏度主要取决于两种介电常数的差值,而且,只有ε1和ε2的恒定才能保证液位测量准确,因被测介质具有导电性,所以金属棒电极都有绝缘层覆盖。 传感器无机械可动部分,结构简单、可靠;精确度高;检测端消耗电能小,动态响应快;维护
如何训练分类器
如何用OpenCV训练自己的分类器 另:英文说明http://se.cs.ait.ac.th/cvwiki/opencv:tutorial:haartraining 最近要做一个性别识别的项目,在人脸检测与五官定位上我采用OPENCV的haartraining 进行定位,这里介绍下这两天我学习的如何用opencv训练自己的分类器。在这两天的学习里,我遇到了不少问题,不过我遇到了几个好心的大侠帮我解决了不少问题,特别是无忌,在这里我再次感谢他的帮助。 一、简介 目标检测方法最初由Paul Viola [Viola01]提出,并由Rainer Lienhart [Lienhart02]对这一方法进行了改善。该方法的基本步骤为:首先,利用样本(大约几百幅样本图片)的 harr 特征进行分类器训练,得到一个级联的boosted分类器。 分类器中的"级联"是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。 分类器训练完以后,就可以应用于输入图像中的感兴趣区域的检测。检测到目标区域分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。 目前支持这种分类器的boosting技术有四种:Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost。 "boosted" 即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。 根据上面的分析,目标检测分为三个步骤: 1、样本的创建 2、训练分类器 3、利用训练好的分类器进行目标检测。 二、样本创建 训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片。 负样本 负样本可以来自于任意的图片,但这些图片不能包含目标特征。负样本由背景描述文件来描述。背景描述文件是一个文本文件,每一行包含了一个负样本图片的文件名(基于描述文件的相对路径)。该文件创建方法如下: 采用Dos命令生成样本描述文件。具体方法是在Dos下的进入你的图片目录,比如我的图片放在D:\face\posdata下,则: 按Ctrl+R打开Windows运行程序,输入cmd打开DOS命令窗口,输入d:回车,再输入cd D:\face\negdata进入图片路径,再次输入dir /b > negdata.dat,则会图片路径下生成一个negdata.dat文件,打开该文件将最后一行的negdata.dat删除,这样就生成了负样本描述文件。dos命令窗口结果如下图:
液位传感器的分类方法
按液位计传感器的所属学科分类。可分为物理型、化学型和生物型。把被测量转换成电址参数;化学型是利用化学反应,物理型是利用各种物理效应,把被测量转换成为电量参数;生物型是利用生物 按液位计传感器转换过程中的能量关系分类,可分为能最转换型和能最控制型。能量转换型是磁性翻柱液位计传感器直接将被测量的能最转换为输出量的能量;能量控制型是由外部供给液位计传感器能量。而由被测量来控制输出的能量。 按液位计传感器转换原理分类,可分为电阻式、微波式、激光式、超声式、光电式、热电式、电感式、电容式、电磁式、压电式、髯尔式、光纤式及核辐射式等等。 按液位计传感器转换过程中的物理现象分类,可分为结构型和物性型。结构型是依靠液位计传感器结构变化来实现参数转换的;物性型是利用液位计传感器的敏感元件特性变化实现参数转换的。 按液位计传感器的用途分类。可分为重址、位移、速度、加速度、力、电压、电流、温度、压力、流傲、功率物性参数等等。 效应及机体部分组织、微生物,把被测量转换为电最参数。 按液位计传感器输出量的形式分类,可分为模拟式和数字式。模拟式液位计传感器枪出为模拟量;数字式液位计传感器输出直接为数字量。 按液位计传感器的功能分类。可分为传统型和智能型。传统型磁翻板液位计传感器一般是指只具有显示和输出功能的液位计传感器;真正意义上的智能液位计传感器,推理、感知、应该具备学习、通讯等功能,具有精度高、性能价格比高、使用方便等特点。 智能型液位计传感器发展迅速,目前可实现的功能,概括起来有: 具有自动补偿功能具有自校零、自标定、白校正功能;具有双向通讯、标准化数字输出或者符号输出功能能够自动采集数据,并对数据进行预处理;能够自动进行检验、自选量程、自动诊断故障;具有数据存储、记忆与信息处理功能;具有判断、决策处理功能。 艾驰商城是国内最专业的MRO工业品网购平台,正品现货、优势价格、迅捷配送,是一站式采购的工业品商城!具有10年工业用品电子商务领域研究,以强大的信息通道建设的优势,以及依托线下贸易交易市场在工业用品行业上游供应链的整合能力,为广大的用户提供了传感器、图尔克传感器、变频器、断路器、继电器、PLC、工控机、仪器仪表、气缸、五金工具、伺服电机、劳保用品等一系列自动化的工控产品。 如需进一步了解图尔克、奥托尼克斯、科瑞、山武、倍加福、邦纳、亚德客、施克等各类传感器的选型,报价,采购,参数,图片,批发信息,请关注艾驰商
基于决策树的分类算法
1 分类的概念及分类器的评判 分类是数据挖掘中的一个重要课题。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类可用于提取描述重要数据类的模型或预测未来的数据趋势。 分类可描述如下:输入数据,或称训练集(training set)是一条条记录组成的。每一条记录包含若干条属性(attribute),组成一个特征向量。训练集的每条记录还有一个特定的类标签(类标签)与之对应。该类标签是系统的输入,通常是以往的一些经验数据。一个具体样本的形式可为样本向量:(v1,v2,…,…vn:c)。在这里vi表示字段值,c表示类别。 分类的目的是:分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。这种描述常常用谓词表示。由此生成的类描述用来对未来的测试数据进行分类。尽管这些未来的测试数据的类标签是未知的,我们仍可以由此预测这些新数据所属的类。注意是预测,而不能肯定。我们也可以由此对数据中的每一个类有更好的理解。也就是说:我们获得了对这个类的知识。 对分类器的好坏有三种评价或比较尺度: 预测准确度:预测准确度是用得最多的一种比较尺度,特别是对于预测型分类任务,目前公认的方法是10番分层交叉验证法。 计算复杂度:计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据库,因此空间和时间的复杂度问题将是非常重要的一个环节。 模型描述的简洁度:对于描述型的分类任务,模型描述越简洁越受欢迎;例如,采用规则表示的分类器构造法就更有用。 分类技术有很多,如决策树、贝叶斯网络、神经网络、遗传算法、关联规则等。本文重点是详细讨论决策树中相关算法。
简单分类器的MATLAB实现
简单分类器的MATLAB实现 摘要:本实验运用最小距离法、Fisher线形判别法、朴素贝叶斯法、K近邻法四种模式识别中最简单的方法处理两维两类别的识别问题,最后对实验结果进行了比较。 关键字:MATLAB 最小距离Fisher线形判别朴素贝叶斯K近邻法 一.M atlab语言简介 Matlab 语言(即Matrix 和Laboratory) 的前三位字母组合,意为“矩阵实验室”,Matlab 语言是一种具有面向对象程序设计特征的高级语言,以矩阵和阵列为基本编程单位。Matlab 可以被高度“向量化”,而且用户易写易读。传统的高级语言开发程序不仅仅需要掌握所用语言的语法,还需要对有关算法进行深入的分析。与其他高级程序设计语言相比,Matlab 在编程的效率、可读性以及可移植性等方面都要高于其他高级语言,但是执行效率要低于高级语言,对计算机系统的要求比较高。例如,某数据集是m*n的二维数据组,对一般的高级计算机语言来说,必须采用两层循环才能得到结果,不但循环费时费力,而且程序复杂;而用Matlab 处理这样的问题就快得多,只需要一小段程序就可完成该功能,虽然指令简单,但其计算的快速性、准确性和稳定性是一般高级语言程序所远远不及的。严格地说,Matlab 语言所开发的程序不能脱离其解释性执行环境而运行。 二.样本预处理 实验样本来源于1996年UCI的Abalone data,原始样本格式如下: 1 2 3 4 5 6 7 8 9 其中第一行是属性代码:1.sex 2.length 3.diameter 4.height 5.whole_weight 6.shucked_weight 7 .viscera weight 8. shell weight 9.age 原始样本是一个8维20类的样本集,就是根据Abalone的第一至第八个特征来预测第九个特征,即Abalone的年龄。为简单其见,首先将原始样本处理成两维两类别问题的样本。选取length和weiht作为两个特征向量,来预测第三个特征向量age.(age=6或者age=9),我们将age=6的样本做为第一类,age=12的样本做为第二类。 处理后的样本: length weight age
opencv自己训练分类器进行物体识别
从SVM的那几张图可以看出来,SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。而现实中要解决的问题,往往是多类的问题(少部分例外,例如垃圾邮件过滤,就只需要确定“是”还是“不是”垃圾邮件),比如文本分类,比如数字识别。如何由两类分类器得到多类分类器,就是一个值得研究的问题。 还以文本分类为例,现成的方法有很多,其中一种一劳永逸的方法,就是真的一次性考虑所有样本,并求解一个多目标函数的优化问题,一次性得到多个分类面,就像下图这样: 多个超平面把空间划分为多个区域,每个区域对应一个类别,给一篇文章,看它落在哪个区域就知道了它的分类。 看起来很美对不对?只可惜这种算法还基本停留在纸面上,因为一次性求解的方法计算量实在太大,大到无法实用的地步。 稍稍退一步,我们就会想到所谓“一类对其余”的方法,就是每次仍然解一个两类分类的问题。比如我们有5个类别,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一篇文章是还是不是第1类的;第二次我们把类别2 的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器,如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。到了有文章需要分类的时候,我们就拿着这篇文章挨个分类器的问:是属于你的么?是属于你的
么?哪个分类器点头说是了,文章的类别就确定了。这种方法的好处是每个优化问题的规模比较小,而且分类的时候速度很快(只需要调用5个分类器就知道了结果)。但有时也会出现两种很尴尬的情况,例如拿一篇文章问了一圈,每一个分类器都说它是属于它那一类的,或者每一个分类器都说它不是它那一类的,前者叫分类重叠现象,后者叫不可分类现象。分类重叠倒还好办,随便选一个结果都不至于太离谱,或者看看这篇文章到各个超平面的距离,哪个远就判给哪个。不可分类现象就着实难办了,只能把它分给第6个类别了……更要命的是,本来各个类别的样本数目是差不多的,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和嘛),这就人为的造成了上一节所说的“数据集偏斜”问题。 因此我们还得再退一步,还是解两类分类问题,还是每次选一个类的样本作正类样本,而负类样本则变成只选一个类(称为“一对一单挑”的方法,哦,不对,没有单挑,就是“一对一”的方法,呵呵),这就避免了偏斜。因此过程就是算出这样一些分类器,第一个只回答“是第1类还是第2类”,第二个只回答“是第1类还是第3类”,第三个只回答“是第1类还是第4类”,如此下去,你也可以马上得出,这样的分类器应该有5 X 4/2=10个(通式是,如果有k个类别,则总的两类分类器数目为k(k-1)/2)。虽然分类器的数目多了,但是在训练阶段(也就是算出这些分类器的分类平面时)所用的总时间却比“一类对其余”方法少很多,在真正用来分类的时候,把一篇文章扔给所有分类器,第一个分类器会投票说它是“1”或者“2”,第二个会说它是“1”或者“3”,让每一个都投上自己的一票,最后统计票数,如果类别“1”得票最多,就判这篇文章属于第1类。这种方法显然也会有分类重叠的现象,但不会有不可分类现象,因为总不可能所有类别的票数都是0。看起来够好么?其实不然,想想分类一篇文章,我们调用了多少个分类器?10个,这还是类别数为5的时候,类别数如果是1000,要调用的分类器数目会上升至约500,000个(类别数的平方量级)。这如何是好? 看来我们必须再退一步,在分类的时候下功夫,我们还是像一对一方法那样来训练,只是在对一篇文章进行分类之前,我们先按照下面图的样子来组织分类器(如你所见,这是一个有向无环图,因此这种方法也叫做DAG SVM)
几种液位计的原理与选型
几种液位计的原理与选型. 磁翻柱液位计 主要原理 磁翻柱液位计也称为磁翻板液位计,它的结构主要基于浮力和磁力原理设计生产的。带有磁体的浮子(简称磁性浮子)在被测介质中的位置受浮力作用影响。液位的变化导致磁性浮子位置的变化、磁性浮子和磁翻柱(也成为磁翻板)的静磁力耦合作用导致磁翻柱翻转一定角度(磁翻柱表面涂敷不同的颜色),进而反映容器内液位的情况。 配合传感器(磁簧开关)和精密电子元器件等构成的电子模块和变送器模块,可以变送输出电阻值信号、电流值(4~20mA)信号、开关信号以及其他电学信号。从而实现现场观测和远程控制的完美结合。 适用范围及特点 本液位计采用优质磁体和进口电子元件,使产品具有:设计合理、结构简单、使用方便、性能稳定、使用寿命长、便于安装维护等优点。 本液位计输出信号多样,实现远距离的液位指示、检测、控制和记录。 本液位计几乎可以适用于各种工业自动化过程控制中的液位测量与控制。可以广泛运用于石油加工、食品加工、化工、水处理、制药、电力、造纸、冶金、船舶和锅炉等领域中的液位测量、控制与监测。 磁浮球液位计(液位开关) 主要原理 磁浮球液位计(液位开关)结构主要基于浮力和静磁场原理设计生产的。带有磁体的浮球(简称浮球)在被测介质中的位置受浮力作用影响:液位的变化导致磁性浮子位置的变化。浮球中的磁体和传感器(磁簧开关)作用,使串联入电路的元件(如定值电阻)的数量发生变化,进而使仪表电路系统的电学量发生改变。也就是使磁性浮子位置的变化引起电学量的变化。通过检测电学量的变化来反映容器内液位的情况。 该液位计可以直接输出电阻值信号,也可以配合使用变送模块,输出电流值(4~20mA)信号;同时配合其他转换器,输出电压信号或者开关信号(也可以按照客户需求转换器由公司配送)。从而实现电学信号的远程传输、分析与控制。 适用范围及特点 本产品采用优质磁体和进口电子元件,使产品具有:结构简单、使用方便、性能稳定、使用寿命长、便于安装维护等优点。 本产品几乎可以适用与各种工业自动化过程控制中的液位测量与控制,可以广泛运用于石油加工、食品加工、化工、水处理、制药、电力、造纸、冶金、船舶和锅炉等领域中的液位测量、控制与监测。 防爆浮球液位开关 主要原理 防爆浮球液位开关,也称为防爆浮球液位控制器。它是专门为爆炸性环境中使用而设计制造的液位控制仪表,本产品是基于浮力原理和杠杆原理设计的,当容器内液位发生变化时,浮球的位置将随液位的变化而变化,浮球的这种位移将通过杠杆作用于微动开关,进而由微动开关产生开关信号。 适用范围及特点 本产品采用优质材料和进口电子元件,使产品具有:设计合理、结构简单、使用方便、性能
xml分类器训练
分类:数据库/DB2/文章 第一步采集样本 1、将正负样本分别放在两个不同的文件夹下面 分别取名pos和neg,其中pos用来存放正样本图像,neg用来存放负样本 注意事项:1、正样本要统一切成24*24像素(或者其他)的格式,建议保存成灰度图,节省空间 2、正样本的数目越多,训练的时间也将越长,训练出来的效果也就越好 3、负样本的数量想对于正样本一定要足够的多,很多朋友在训练的时候,往往出现了CPU占用率达到了100%,但是训练只是停留在一个分类器长达几小时没有相应,问题出现在取负样本的那个函数icvGetHaarTrainingDataFromBG中; 当剩下所有的negtive样本在临时的cascade Classifier中,evaluate的结果都是0(也就是拒绝了),随机取样本的数目到几百万都是找不到误检测的neg样本了,因而没法跳出循环 2、建立正负样本的说明文件 这里我们假定根目录在D:\boost下面。
在cmd下面进入pos目录,输入dir /b > pos.txt 这个时候会在pos文件加下面生成一个pos.txt文件,打开pos.txt
我们对它进行如下编辑: (1)、将BMP 替换成为BMP 1 0 0 24 24 注意:1代表此图片出现的目标个数后面的0 0 24 24代表目标矩形框(0,0)到(24,24),用户可以根据自身需要调整数值(2)、删除文本中最后一行的“pos.txt”
2、对负样本进行编辑 在CMD下输入dir /b > neg.txt 同理,打开neg目录下的neg.txt文件,只需要删除最后一行的neg.txt这一句 注意:1、负样本说明文件不能含有目标物体 2、负样本图像尺寸不受到限制,但是尺寸越大,训练所用的时间越长, 3、负样本图像可以是灰度图,也可以不是,笔者建议使用灰度图,这样处理起来可能更有效率 4、负样本图像一定不要重复,增大负样本图像的差异性,可以增加分类器的使用范围,笔者建议可以使用网上的素材库,将1000多张不含目标的图片灰度处理后用来训练,效果更佳 二、使用opencv_createsamples.exe创立样本VEC文件 1、首先我们将要用的的2个程序opencv_createsamples.exe和opencv_haartraining.exe拷到根目录下 在CMD下输入如下命令: opencv_createsamples.exe -vec pos.vec -info pos\pos.txt -bg neg\neg.txt -w 40 -h 40 -num 142 以上参数的含义如下:
水位传感器种类、工作原理介绍
水位传感器种类、工作原理介绍 水位传感器是一种可以检测水位的传感器,主要应用于医疗、食品、化工行业中,进行水位控制、水位的检测。先介绍水位传感器的分类。 水位传感器的种类: 水位传感器种类很多,包括单法兰静压/双法兰差压水位传感器,浮球式水位传感器,磁性水位传感器,投入式水位传感器,电动内浮球水位传感器,电动浮筒水位传感器,电容式水位传感器,磁致伸缩水位传感器,伺服水位传感器等,超声波水位传感器,雷达水位传感器等。 (图片源自网络)
(图片来源于网络)
上图是一个水位传感器种类的大概情况,由此图我们可以看出水位传感器种类较多,主要可以分为接触式和非接触式两种。 浮筒式水位传感器:浮筒式水位变送器是将磁性浮球改为浮筒,水位传感器是根据阿基米德浮力原理设计的。浮筒式水位变送器是利用微小的金属膜应变传感技术来测量液体的水位、界位或密度的,它在工作时可以通过现场按键来进行常规的设定操作。 浮球式水位传感器:浮球式水位变送器由磁性浮球、测量导管、信号单元、电子单元、接线盒及安装件组成,一般磁性浮球的比重小于0.5,可漂于液面之上并沿测量导管上下移动,导管内装有测量元件,它可以在外磁作用下将被测水位信号转换成正比于水位变化的电阻信号,并将电子单元转换成信号输出。浮球开关因为是最简单、最古老的检测方式,有着检测水位不精确的缺点,浮子易卡死。 (图片源自网络)
静压式水位传感器: 该变送器利用液体静压力的测量原理工作,它一般选用硅压力测压传感器将测量到的压力转换成电信号,再经放大电路放大和补偿电路补偿,最后以4~20mA或0~10mA电流方式输出。 超声波式水位传感器: 这是一种振动频率高于声波的机械波,由换能晶片在电压的激励下发生振动产生的超声波,超声波在碰到液体会产生显著反射形成反射成回波。因此以超声波作为检测手段,产生超声波和接收超声波。这就是超声波式的水位传感器工作原理。超声波式水位传感器特点:频率高、波长短、绕射现象小,特别是方向性好、能够成为射线而定向传播。 光电式水位传感器: 光电液位传感器是利用光在两种不同介质界面发生反射折射原理而 开发的新型接触式点液位测控装置。光电水位传感器具有结构简单、定位精度高,没有机械部件,不需调试,灵敏度高及耐腐蚀、耗电少、体积小等诸多优点,还具有耐高温、耐高压、耐强腐蚀,化学性质稳定,对被测介质影响小等特征。
如何运用决策树进行分类分析
如何运用决策树进行分类分析 前面我们讲到了聚类分析的基本方法,这次我们来讲讲分类分析的方法。 所谓分类分析,就是基于响应,找出更好区分响应的识别模式。分类分析的方法很多,一般而言,当你的响应为分类变量时,我们就可以使用各种机器学习的方法来进行分类的模式识别工作,而决策树就是一类最为常见的机器学习的分类算法。 决策树,顾名思义,是基于树结构来进行决策的,它采用自顶向下的贪婪算法,在每个结点选择分类的效果最好的属性对样本进行分类,然后继续这一过程,直到这棵树能准确地分类训练样本或所有的属性都已被使用过。 建造好决策树以后,我们就可以使用决策树对新的事例进行分类。我们以一个生活小案例来说什么是决策树。例如,当一位女士来决定是否同男士进行约会的时候,她面临的问题是“什么样的男士是适合我的,是我值得花时间去见面再进行深入了解的?” 这个时候,我们找到了一些女生约会对象的相关属性信息,例如,年龄、长相、收入等等,然后通过构建决策树,层层分析,最终得到女士愿意去近一步约会的男士的标准。 图:利用决策树确定约会对象的条件
接下来,我们来看看这个决策的过程什么样的。 那么,问题来了,怎样才能产生一棵关于确定约会对象的决策树呢?在构造决策树的过程中,我们希望决策树的每一个分支结点所包含的样本尽可能属于同一类别,即结点的”纯度”(Purity )越来越高。 信息熵(Information Entropy )是我们度量样本集合纯度的最常见指标,假定当前样本集合中第K 类样本所占的比例为P k ,则该样本集合的信息熵为: Ent (D )=?∑p k |y| k=1 log 2p k 有了这个结点的信息熵,我们接下来就要在这个结点上对决策树进行裁剪。当我们选择了某一个属性对该结点,使用该属性将这个结点分成了2类,此时裁剪出来的样本集为D 1和D 2, 然后我们根据样本数量的大小,对这两个裁剪点赋予权重|D 1||D|?,|D 2||D|?,最后我们就 可以得出在这个结点裁剪这个属性所获得的信息增益(Information Gain ) Gain(D ,a)=Ent (D )?∑|D V ||D |2 v=1Ent(D V ) 在一个结点的裁剪过程中,出现信息增益最大的属性就是最佳的裁剪点,因为在这个属性上,我们获得了最大的信息增益,即信息纯度提升的最大。 其实,决策树不仅可以帮助我们提高生活的质量,更可以提高产品的质量。 例如,我们下表是一组产品最终是否被质检接受的数据,这组数据共有90个样本量,数据的响应量为接受或拒绝,则|y|=2。在我们还没有对数据进行裁剪时,结点包含全部的样本量,其中接受占比为p 1= 7690,拒绝占比为p 2=1490,此时,该结点的信息熵为: Ent (D )=?∑p k |y|k=1log 2p k =-(7690log 27690+1490log 21490)=0.6235
如何用OPENCV训练自己的分类器
如何用OpenCV训练自己的分类器 最近要做一个性别识别的项目,在人脸检测与五官定位上我采用OPENCV的haartraining进行定位,这里介绍下这两天我学习的如何用opencv训练自己的分类器。在这两天的学习里,我遇到了不少问题,不过我遇到了几个好心的大侠帮我解决了不少问题,特别是无忌,在这里我再次感谢他的帮助。 一、简介 目标检测方法最初由Paul Viola[Viola01]提出,并由Rainer Lienhart[Lienhart02]对这一方法进行了改善。该方法的基本步骤为:首先,利用样本(大约几百幅样本图片)的harr特征进行分类器训练,得到一个级联的boosted分类器。分类器中的"级联"是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。 分类器训练完以后,就可以应用于输入图像中的感兴趣区域的检测。检测到目标区域分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。 目前支持这种分类器的boosting技术有四种:Discrete Adaboost,Real Adaboost,Gentle Adaboost and Logitboost。"boosted"即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。 根据上面的分析,目标检测分为三个步骤: 1、样本的创建 2、训练分类器 3、利用训练好的分类器进行目标检测。 二、样本创建 训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片。 负样本 负样本可以来自于任意的图片,但这些图片不能包含目标特征。负样本由背景描述文件来描述。背景描述文件是一个文本文件,每一行包含了一个负样本图片的文件名(基于描述文件的相对路径)。该文件创建方法如下: 采用Dos命令生成样本描述文件。具体方法是在Dos下的进入你的图片目录,比如我的图片放在D:\face\posdata 下,则: 按Ctrl+R打开Windows运行程序,输入cmd打开DOS命令窗口,输入d:回车,再输入cd D:\face\negdata进入图片路径,再次输入dir/b>negdata.dat,则会图片路径下生成一个negdata.dat文件,打开该文件将最后一行的negdata.dat删除,这样就生成了负样本描述文件。dos命令窗口结果如下图: 正样本 对于正样本,通常的做法是先把所有正样本裁切好,并对尺寸做规整(即缩放至指定大小),如上图所示: 由于HaarTraining训练时输入的正样本是vec文件,所以需要使用OpenCV自带的CreateSamples程序(在你所按照的opencv\bin下,如果没有需要编译opencv\apps\HaarTraining\make下的.dsw文件,注意要编译release版的)将准备好的正样本转换为vec文件。转换的步骤如下: 1)制作一个正样本描述文件,用于描述正样本文件名(包括绝对路径或相对路径),正样本数目以及各正样本在图片
基于决策树的鸢尾花分类
科技论坛 0 引言 图像识别技术,要运用目前流行的机器学习算法,而目前流行的机器学习算法就有十几种,比如支持向量机、神经网络、决策树。机器学习是人工智能发展的重要一部分,它涉及的学科很多,应用也相当广泛,它通过分析、研究、设计让计算机学习知识,从而提高完善自身的性能。但是神经网络学习的速度较慢,传统的支持向量机则不能解决分类多的问题。 本文针对鸢尾花的特征类别少以及种类少的特点,采用决策树算法对课题进行展开,对比与其他人利用支持向量机、神经元网络模型来进行研究,该系统具有模型简单、便于理解、计算方便、消耗资源少的优点。 1 决策树模型和学习 本文采用决策树算法对鸢尾花进行分类,先建立决策树的模型并进行学习训练,在决策树的训练过程中采用是信息论的知识进行特征选择,对选定的特征采用分支的处理,然后再对分支过后的数据集如此反复的递归生成决策树,在一颗决策树生成完后对决策树进行剪枝,以减小决策树的拟合度,来达到一个对鸢尾花较高的分类准确率。 要对鸢尾花进行分类首先需要大量的鸢尾花数据集作为本文的实验数据,本文采用的数据集是来自加州大学欧文分校UCI数据库中的鸢尾花数据集。该数据集中鸢尾花的属性有四个,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,鸢尾花的类别则有三种,分别是Iris Setosa,Iris Versicolour,Iris Virginica,用简写Se、Ve和Vi表示这三种花,具体数据如图1所示。 ■1.1 信息论 美贝尔电话研究所的数学家香农是信息论的创始人,1948年香农发表了《通讯的数学理论》,成为信息论诞生的标志。信息论的诞生对信息技术革命以及科学技术的发展起到重要作用。信息论中有两个概念信息增益及信息增益率,都是用于衡量原始数据集在按照某一属性特征分裂之后整体信息量的变化值。这样,本文就可以通过这种指标寻找出最优的划分属性,数据集在经过划分之后,节点的“纯度”越来越高,这里的纯度值得是花朵的类别,当某一节点中花朵全为一类时,该节点已经达到最纯状态,无需再进行划分, 反之继续划分。 图1 鸢尾花数据集 1.1.1 信息熵 信息熵用于描述信源的不确定性。即发生每个事件都有不确定性,为了使不确定性降低,我们需要引入一些相关的信息进行学习,引入信息越多,那么得到的准确率越高,信息熵越高,信源越不稳定。例如一束鸢尾花,它可能是Se,可能是Vi,也有可能是Ve,我们利用数据库中的各种鸢尾花的花瓣长度、花瓣宽度、花萼长度和花萼宽度来预测鸢尾花的类别,引入的鸢尾花种类越多,信息熵就越高。 样本集合D的信息熵Ent(D)以下面的公式进行计算,其中集合里第k类样本所占的比例是k p,k的取值范围是从1到y,y值得是总共有y类样本,通过式(1)可以计算得到原始样本集的信息熵。 ()21 Ent D y k k k p log p = =?∑(1) 1.1.2 信息增益 信息增益即在一个条件下,信源不确定性减少的程度。信息增益用于度量节点的纯度。信息增益对可取值数目较多的属性有所偏好。在鸢尾花数据集的D集合中,属性a取到某一取值情况的概率乘该取值情况的信息熵得到的值记为v D,其中V指的是该属性a可以取值的个数,则属性a 的信息增益为: ()()() 1 Gain D,a Ent D V v v v D Ent D D = =?∑(2) 基于决策树的鸢尾花分类 徐彧铧 (浙江省衢州第二中学,浙江衢州,324000) 摘要:针对传统手工分类的不足,满足不了人们对图片分类的需求,本文利用机器学习算法中的决策树算法进行研究。通过模型简单、便于理解、计算方便、消耗资源少的决策树算法模型,并利用现成的数据库,运用图像识别技术对鸢尾花进行分类,以求方便简单快速地识别出不同类别的鸢尾花。在此过程中,学习到图像识别的一些基本分类操作,为我们实现更复杂的模型提供了帮助。 关键词:决策树信息论特征选择;C4.5算法;CART算法 www ele169 com | 99
如何用OpenCV训练自己的分类器
如何用OpenCV训练自己的分类器 2009-09-04 22:15 最近要做一个性别识别的项目,在人脸检测与五官定位上我采用OPENCV的haartraining进行定位,这里介绍下这两天我学习的如何用opencv训练自己的分类器。在这两天的学习里,我遇到了不少问题,不过我遇到了几个好心的大侠帮我解决了不少问题,特别是无忌,在这里我再次感谢他的帮助。 一、简介 目标检测方法最初由Paul Viola [Viola01]提出,并由Rainer Lienhart [Lienhart02]对这一方法进行了改善。该方法的基本步骤为:首先,利用样本(大约几百幅样本图片)的 harr 特征进行分类器训练,得到一个级联的boosted分类器。 分类器中的"级联"是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。 分类器训练完以后,就可以应用于输入图像中的感兴趣区域的检测。检测到目标区域分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。 目前支持这种分类器的boosting技术有四种: Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost。 "boosted" 即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。 根据上面的分析,目标检测分为三个步骤: 1、样本的创建 2、训练分类器 3、利用训练好的分类器进行目标检测。 二、样本创建 训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片。 负样本 负样本可以来自于任意的图片,但这些图片不能包含目标特征。负样本由背景描述文件来描述。背景描述文件是一个文本文件,每一行包含了一个负样本图片的文件名(基于描述文件的相对路径)。该文件创建方法如下: 采用Dos命令生成样本描述文件。具体方法是在Dos下的进入你的图片目录,比如我的图片放在D:\face\posdata下,则: 按Ctrl+R打开Windows运行程序,输入cmd打开DOS命令窗口,输入 d:回车,再输入cd D:\face\negdata进入图片路径,再次输入dir /b > negdata.dat,则会图片路径下生成一个negdata.dat文件,打开该文件将最后一行的
常用的液位计有哪几种
西安祥天和电子科技有限公司详情咨询官网https://www.360docs.net/doc/95700678.html, 液位传感器水泵控制箱报警器液位自动控制仪表,液位控制器,无线传输收发器等 常用的液位计有哪几种 传统液位计种类很多,有玻璃管液位计、玻璃板液位计、磁翻板液位计等等。玻璃板/管液位计的原理很简单,就是在水箱外通过拷克阀门将水引到一个玻璃管内。因为玻璃管是透明的,所以可以通过玻璃管看见液位高低。再好一点的就是在外面加一衬托、标尺等,让人们能容易看到液位状态。但这种液位计只能现场显示,无法将液位信号转换为电信号,实现远距离监控。而磁翻板液位计是在钢管内装有磁性浮球,管外加装干簧管和标尺,可以将液位开关信号传到远方。所以磁翻板是目前在热水水位控制中采用的主要方式之一。但从实际使用效果来看,现在的所有热水液位控制,水温在80℃以下时,使用寿命还可以。一旦超过80℃甚至到90℃以上时,使用寿命就大打折扣了。因为磁性材料的磁性会随着温度的升高而衰减,到100℃时会下降到常温的70%。所以水位控制中有2个难点,一个就是污水,一个就是高温的热水。现在,污水中可以采用GKY液位传感器,而热水则可以采用传统玻璃管外加监控装置来实现,具体原理如下: 如果是普通的水,在玻璃管内放一个普通的浮子就可以了。玻璃管外放置一收一发2个光电管。当浮子经过时,遮住光路,转换器就将水位信号发送出去。 如果是热水,玻璃管最好采用石英管,它的硬度、透明度、耐酸性、耐高温性和耐磨性都要远高于玻璃管。液位计两端的阀门也可以采用针型阀,不只起截止阀的作用,其内部的钢球
具有逆止阀的功能,当液位计发生意外破损泄漏时,钢球可在介质压力作用下自动关闭液体通道,防止液体大量外流起到平安维护作用。在石英管内放一个耐高温的浮子,热水浮子采用新兴的有机高分子材料制作,可以耐受150℃以上的高温。浮子随水位上下浮动。玻璃管外放置一发光电管,另一端接一根光纤,将光信号引出来。因为光接收管易受温度影响,所以必须用光纤引出光信号。当浮子经过时,遮住光路,转换器就将水位信号发送出去。这种方式可以解决高温热水的液位控制问题。 热水的液位控制一直是一个难点。一方面是因为热水浮子里面要放置磁铁,中间是空的。一直在高温中煮泡,热胀冷缩很容易损坏。另一方面是因为浮子的磁性随着温度的升高而衰减,100℃时会衰减到常温的70%。所以磁性浮子用在温度较高的热水中使用寿命较短。而在传统液位计上加装光电监控装置,其使用的热水浮子采用新型耐高温材料制成,比重很轻,可以在水中浮起来。这种实芯浮子耐150℃的高温,可以在热水中长期使用。另外,这种方式的检测方法和磁性无关,所以使用寿命长而且精度高。因为浮子一挡住发射的光线,转换器可以立刻将信号传递出来。所以传统液位计加监控可以解决热水水位控制难的问题。 液位计加监控通过转换器可以接入GKY类液位控制仪表,设计时只需在原仪表型号后加标BL就可以了。如需要选用GKY2-4T仪表,则型号为GKY2-4T-BL就可以了。GKY液位控制仪表,具有各种功能,可以满足多种液位控制的需求。仪表一般可以装在控制箱的面板上,功能较多,液位显示比较直观。控制器通常是仪表的简化,只具备简单的控制和报警功能。下表列出了一些液位控制仪表和控制器的功能和型号,方便大家选择。 常用液位控制仪表和控制器简表 产品名称产品型号配备的传感器数量和型号功能简介 GKY 系列仪表GKY2个GKY液位传感器液位显示/供水排水选择/手动自动转 换/水泵故障报警 GKY-4T4个GKY液位传感器双保险/超高超低水位报警/液位显示 /供水排水选择/手动自动转换/水泵 故障报警 双台泵专用仪表GKY2-4T4个GKY液位传感器双台泵交替使用/紧急情况双台泵同 时启动/超高或超低水位报警/液位显 示/供水排水选择/水泵故障报警/报 警端口输出