计算理论习题答案CHAP1new

第一章
1.1 图给出两台DFA M
1和M
2
的状态图. 回答下述有关问题.
a.M
1的起始状态是q
1
b.M
1的接受状态集是{q
2
}
c.M
2的起始状态是q
1
d.M
2的接受状态集是{q
1
,q
4
}
e.对输入aabb,M
1经过的状态序列是q
1
,q
2
,q
3
,q
1
,q
1
f.M
1
接受字符串aabb吗?否
g.M
2
接受字符串ε吗?是
1.2 给出练习
2.1中画出的机器M
1和M
2
的形式描述.
M 1=(Q
1
,Σ,δ
1
,q
1
,F
1
) 其中
1)Q
1={q
1
,q
2
,q
3
,};
2)Σ={a,b}; 3)δ
1
为:
4)q
1
是起始状态
5)F
1={q
2
}
M
2=(Q
2
,Σ,δ
2
,q
2
,F
2
) 其中
1)Q
2={q
1
,q
2
,q
3
,q
4
};
2)Σ={a,b}; 3)δ
2
为:
3)q
2
是起始状态
4)F 2={q 1,q 4}
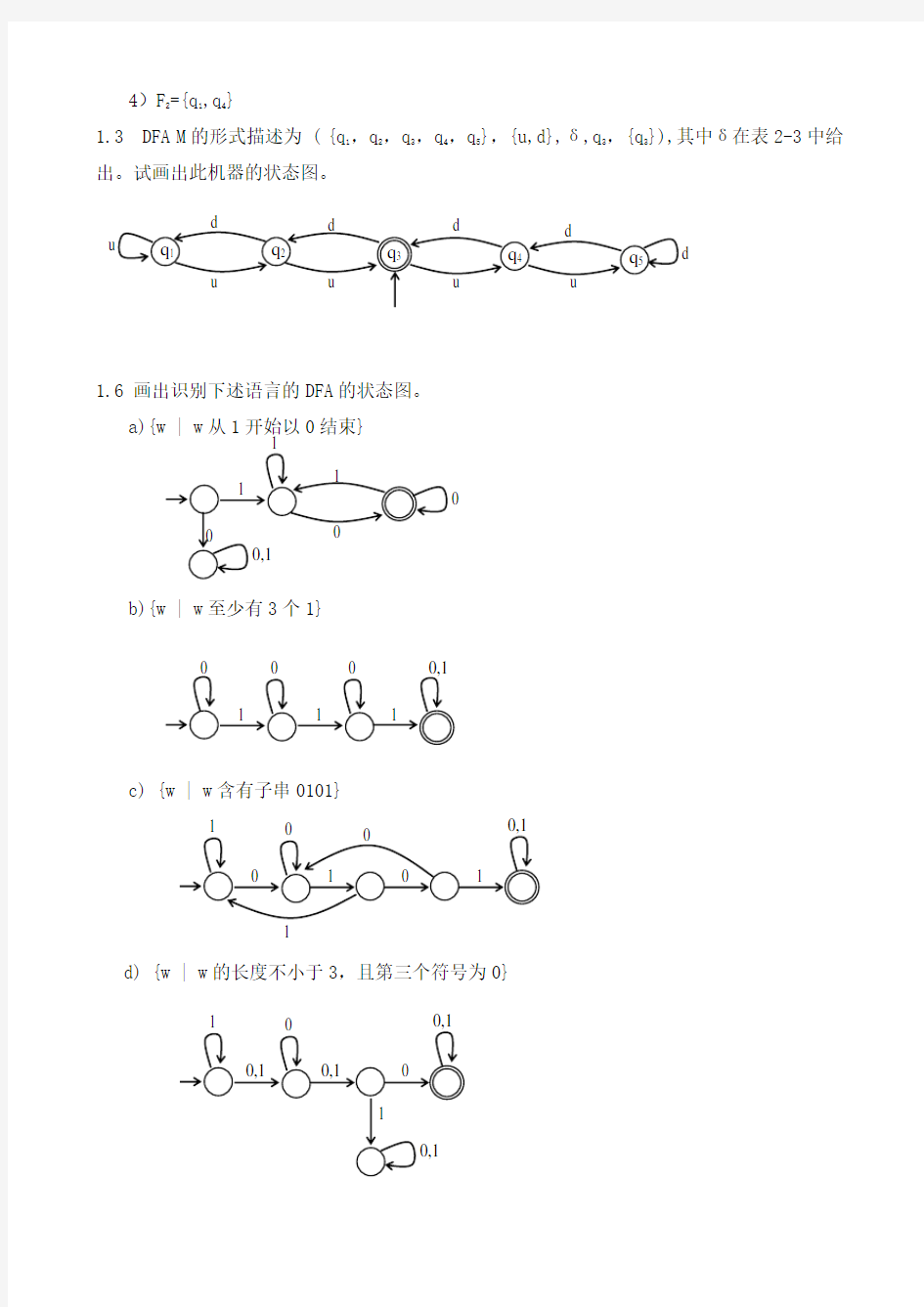
1.3 DFA M 的形式描述为 ( {q 1,q 2,q 3,q 4,q 5},{u,d},δ,q 3,{q 3}),其中δ在表2-3中给出。试画出此机器的状态图。
1.6 画出识别下述语言的DFA 的状态图。
a){w | w 从1开始以0结束}
b){w | w 至少有3个1}
c) {w | w 含有子串0101}
d) {w | w 的长度不小于3,且第三个符号为0}
d
e) {w | w 从0开始且为奇长度,或从1开始且为偶长度}
或
f) {w | w 不含子串110}
g) {w | w 的长度不超过5}
1个1}
k) {ε,0}
0,1
1
l) {w | w 含有偶数个0,或恰好两个1}
1.7 给出识别下述语言的
NFA a. {w | w 以00结束},三个状态
b. 语言{w | w 含有子串0101,即对某个x 和y ,w=x0101y },5个状态.
c. 语言{w | w 含有偶数个0或恰好两个1},6个状态。
d. 语言{0},2个状态。
e.
语言0*1*0*0
,3个状态。
f. 语言{ε},1个状态。
g. 语言0*,1个状态。
1.11证明每一台NFA 都能够转换成等价的只有一个接受状态的NFA 。
证明:设NFA M={Q ,Σ,δ,q 0,F},F={r i1,……,r ik }.添加一个状态p 后,r i1,……,r ik 分别向p 引ε箭头,将r i1,……,r ik 变为非接受状态,p 变为接受状态。又因为添加ε箭头不影响NFA 识别语言,所以命题成立。
1.14 a 证明:设M 是一台语言B 的DFA ,交换M 的接状态与非接受状态得到一台新的DFA ,
则这台新的DFA 是识别B 的补集,因此,正则语言类受在补运算下封闭。 b 举例说明:设M 是一台识别语言B 的NFA ,交换M 的接受状态与非接受状态得到一台新的NFA ,这台新的NFA 不一定识别B 的补集。NFA 识别的语言类在补集下封闭吗?解释你的回答。 解:
a. M 是DFA, M 是{Q,∑,δ,q 0,F},令N={Q,∑,δ,q 0,Q-F},设ω=ω1ω2…ωn 是字母表上任意字符串,因为M 与N 均为DFA,所以必然存在Q 中状态序列r 0,r 1,…,r n ,使得:r 0=q 0, δ(r i , ωi+1)=r i+1, i=0,…,n-1 1)若r n ∈F 则ω∈B;
2)若r n ?F,则r n ∈Q-F,即N 接受ω,若ω?B, 所以N 接受B 的补集,即B 的补集正则。 所以,正则语言类在补运算下封闭。
b. 设B 为{0}。NFA M : 可识别它。
依题对它作变换,得到N :
则N 识别的语言{ε}不是B 的子集。所以交换M 的接受状态与非接受状态得到的新的NFA 不一定识别B 的补集。
但是由于NFA 识别的语言类与DFA 识别的语言类相同,即正则语言类。由a 的证明,正则语言类在补运算封闭,可知,NFA 识别的语言类---正则语言类在补运算下封闭。 若NFA 识别语言A ,必有 等价的DFA 识别A,从而由a 知,可交换DFA 的接受与非接受状态构造识别A 的补集的DFA,则必有等价的NFA 识别A 的补集。只是,该NFA 未必有原NFA 交换接受与非接受状态构造而成。
1.15 给出一个反例,说明下述构造不能证明定理
2.24,即正则语言类在星号运算下封闭。
设N=(Q 1,Σ,δ1,q 1,F 1)识别A 1。如下构造N=(Q 1,Σ,δ1,q 1,F 1)。N 应该识别A 1*。
a. N 的状态集是N 1的状态集。
b. N 的起始状态是N 1的起始状态相同。
c. F={q 1}∪F 1。F 的接受状态是原来的接受状态加上它的起始状态。
d. 定义δ如下:对每一个q 属于Q 和每一个a 属于Σ。
解:设N 1识别语言A={至少含有一个1},其中输入字母表为{0,1},可知A *={空串或至少含有一个1}。
N 1
按上述规定构造N 的状态图如上。可以看出L(N)={0,1}*不等于A *
. 所以如此构造的N 不一定识别A *.
1.16 使用定理
2.19中给出的构造,把下图中的两台非确定型有穷自动机转换成等价的确定型有穷自动机。
a), b)
解:a), b)
1.19对下述每一个语言,给出4个字符串,2个是这个语言的成员,2个不是这个语言的成员。这里假设字母表Σ={a,b}.
a. a *b *
成员:ab ,aab 非成员:aba ,ba b. a(ba)* 成员:ab ,abab 非成员:abb ,aa c. a *?b * 成员:
aaa ,bbb 非成员:ab ,ba
???≠∈?≠?=ε
δεδδa F q q a q a F q a q a q },{),(
),,(),(11111
且若或若a,b
b
d. (aaa)*成员:aaa,aaaaaa 非成员:a,aa
e.Σ*aΣ*bΣ*aΣ* 成员:aba,aaba 非成员:aa,abb
f. aba?bab 成员:aba,bab 非成员:a,b
g. (ε?a)b 成员:b,ab 非成员:a,bb
h. (a?ba?bb) Σ*成员:a,bb 非成员:ε,b
1.21 使用引理
2.32中叙述的过程,把图2-38中的有穷自动机转换成正则表达式。
解: a) a*b(a?ba*b)*
b) ε?(a?b)a
*b[(aa?ab?b)a*b]*(a?ε).
(注:答案不唯一)
1.29利用泵引理证明下述语言不是正则的。
a. A
1
={0n1n2n| n≥0}。
证明:假设A
1是正则的。设p是泵引理给出的关于A
1
的泵长度。
令S=0p1p2p,
∵S是A
1
的一个成员且S的长度大于p,所以泵引理保证S可被分成3段S=xyz且满足
泵引理的3个条件。根据条件3,y中只含0,xyyz中,0比1、2多,xyyz不是A
1
的成员。违反泵引理的条件1,矛盾。
∴A
1
不是正则的。
b. A
2
={www | w∈{a,b}*}.
证明:假设A
2是正则的。设p是泵引理给出的关于A
2
的泵长度。
令S=a p ba p ba p b,
∵S是A
2
的一个成员且S的长度大于p,所以泵引理保证S可被分成3段S=xyz且满足
泵引理的3个条件。根据条件3,y中只含a,所以xyyz中第一个a的个数将比后两
个a的个数多,故xyyz不是A
2
的成员。违反泵引理的条件1,矛盾。
∴A
2
不是正则的。
c. A
3
={a2n | n≥0}.(在这里,a2n表示一串2n个a .)
证明:假设A
3是正则的。设p是泵引理给出的关于A
3
的泵长度。
令S= a2p,
∵S是A
2
的一个成员且S的长度大于p,所以泵引理保证S可被分成3段S=xyz且满足
泵引理的3个条件。即对任意的i≥0,xy i z都应在A
3
中,且xy i z与xy i+1z的长度都应是2的幂. 而且xy i+1z的长度应是xy i z的长度的2n倍(n≥1)。于是可以选择足够大的i,使得|xy i z|=2n>p. 但是|xy i+1z|-|xy i z|=|y|≤p. 即|xy i+1z|<2n+1, 矛盾。
∴A
3
不是正则的。
1.30下面“证明”0*1*不是正则语言,指出这个“证明”中的错误。(因为0*1*是正则的,所
以一定错误。) 采用反证法证明。假设0*1*是正则的。令P是泵引定理给出的关于0*1*的泵长度。取S为字符串0p1p。S是0*1*的一个成员,但是例2.38已证明S不能被抽取。
于是得到矛盾,所以0*1*不是正则的。
解:在例2.38中的语言是{0n1n | n≥0},取S为字符串0p1p,S确实不能被抽取;但针对语言0*1*,S是能被抽取的。将S分成三段S=xyz,由泵引理的条件3,y仅包含0,而xy i z属于语言0*1*,即S能被抽取,故题设中的“证明”不正确。
1.24有穷状态转换器(FST)是确定性有穷自动机的一种类型。它的输出是一个字符串,而不
仅仅是接受或拒绝。图2—39
2
的状态图。
T 1 T
2
FST的每一个转移用两个符号标记,一个指明该转移的输入符号,另一个指明输出符号。两
个符号之间用斜杠“/”把它们分开。在T
1中,从q
1
到q
2
的转移有输入符号2和输出符号1。
某些转移可能有多对输入-输出,比如T
1中从q
1
到它自身的转移。FST在对输入串w计算时,
从起始状态开始,一个接一个地取输入符号w
1?w
n
,并且比照输入标记和符号序列w
1
?w
n
=w
进行转移。每一次沿一个转移走一步,输出对应的输出符号。例如,对输入2212011,机器
T 1依次进入状态q
1
, q
2
, q
2
, q
2
, q
2
, q
1
, q
1
, q
1
和输出1111000。对输入abbb,T
2
输出1001。
给出在下述每一小题中机器进入的状态序列和产生的输出。
a. T
1对输入串011, 输出:000, 状态序列:q
1
, q
1
, q
1
, q
1
.
0/0 1/1
b. T
1对输入串211, 输出:111, 状态序列:q
1
, q
2
, q
2
, q
2
.
c. T
1对输入串0202, 输出:0101, 状态序列:q
1
, q
1
, q
2
, q
1
, q
2
。
d. T
2对输入串b, 输出:1, 状态序列:q
1
, q
3
.
e. T
2对输入串bbab, 输出:1111, 状态序列:q
1
, q
3
, q
2
, q
3
, q
2
.
f. T
2对输入串bbbbbb, 输出:110110, 状态序列:q
1
, q
3
, q
2
, q
1
, q
3
, q
2
, q
1
。
g. T
2对输入串ε, 输出:ε, 状态序列:q
1
。
1.25 给出有穷状态转换器的形式定义。
解:有穷状态转换器FST是一个五元组(Q,Σ,Г,δ,q0)
1)Q是一个由穷集合,叫做状态集
2)Σ是一个由穷集合,叫做输入字母表
3)Г是一个由穷集合,叫做输出字母表
4)δ:Q×Σ Q×Г是转移函数
5)q
是起始状态
FST计算的形式定义:
M=(Q,Σ,Г,δ,q
0)是一台由穷状态转换器,w=w
1
w
2
?w
n
是输入字母表上的一个字符串。若
存在Q中的状态序列:r
0, r
1
, ?r
n
和输出字母表上的一个字符串s=s
1
…s
n
, 满足下述条
件:
1)r
0=q
;
2)δ(r
i ,w
i+1
)=(r
i+1
, s
i+1
), i=0,1,?,n-1
则M在W的输入下输出s.
1.26利用你给练习
2.20的答案,给出练习2.19中画出的机器T
1和T
2
的形式描述。
解:有穷状态转换器T
1
的形式描述为:
T
1=({q
1
, q
2
}, {0,1,2},δ, q
1
, {0,1})
其中转移函数为:
有穷状态转换器T
2
的形式描述为:
T
2=({{q
1
, q
2
, q
3
}, {a, b},δ, q
1
, {0,1})
其中转移函数为:
1.27 给出一台具有下述行为的FST 的状态图。它的输入、输出字母表都是{0,1}。它输出的字符串与输入的字符串偶数为相同、奇数位相反。例如,对于输入0000111,它应该输出1010010。 解:
1.46 证明:
a) 假设{0n 1m
0n
|m,n ≥0}是正则的,p 是由泵引理给出的泵长度。取s =0p 1q 0p
,q>0。由泵引理
条件3知,|xy|≤p ,故y 一定由0组成,从而字符串xyyz 中1前后0的数目不同,即xyyz 不属于该语言,这与泵引理矛盾。所以该语言不是正则的。
假设{0n 1n |n ≥0}的补集是正则的,则根据正则语言在补运算下封闭可得{0n 1n |n ≥0}是正则的,这与已知矛盾,故假设不成立。所以该语言不是正则的。
记c={0m1n|m ≠n},┐c 为c 的补集,┐c ∩0*1*={0n1n|n ≥0},已知{0n1n|n ≥0}不是正则的。若 ┐c 是正则的,由于0*1*是正则的,那么┐c ∩0*1*也应为正则的。这与已知矛盾,所以 ┐c 不是正则的。由正则语言在补运算下的封闭性可知c 也不是正则的。 b) {w | w ∈{0,1}*不是一个回文}的补集是{w | w ∈{0,1}*是一个回文},设其是正则的,令p
是由泵引理给出的泵长度。取字符串s=0p 1q 0p
,显然s 是一个回文且长度大于p 。由泵引理条件3知|xy|≤p ,故y 只能由0组成。而xyyz 不再是一个回文,这与泵引理矛盾。所以{w | w ∈{0,1}*是一个回文}不是正则的。由正则语言在补运算下的封闭性可知{w |
w ∈{0,1}*不是一个回文}也不是正则的。
1.31 对于任意的字符串w=w 1w 2…w n ,w 的反转是按相反的顺序排列w 得到的字符串,记作w R ,即w R =w n …w 2w 1。对于任意的语言A ,记 A R ={w R | ∈A}证明:如果A 是正则的,则A R 也是正则的。 证明:因为A 是正则语言,所以可以用NFA 来表示该语言,现在来构造A R 的NFA ,将NFA A
中的接受态变为中间态,起始态变为接受态,再添加一新的起始态,并用ε箭头连接至原来的接受态,其它所有的箭头反向。 经过变换后得到NFA 变成描述A R 的NFA.
1/0
0/0
1.32 令
∑3包括所有高度为3的0和1的列向量。∑3上的字符串给出三行0和1的字符串。把每一行看作一个二进制数,令 B={ w ∈∑3* | w 最下面一行等于上面两行的和} 例如,
证明B 是正则的。
证明:由题设B 的定义可知,w 上面两行之和减去下面一行结果为零,由此可设计NFA M (Q, Σ, δ, q0, F),其中∑=∑3。Q={q 0,q 1}。q 0状态表示上一次运算的进位为0,q 1状态表示上一次运算的进位为1。 δ由下表给出:
F={q 0} 状态图为:
所以可知自动机
M 识别的是语言B R ,因此B R
是正则的。由题2-24的结论可知B 也是正则的。 1.33 令
∑2包含所有高度为2的0和
1的列。∑2上的字符串给出两行0和1的字符串。把每一行看作一个二进制数,令 C={ w ∈∑2*
| w 下面一行等于上面一行的3倍 }。 证明C 是正则的。可以假设已知问题2.24中的结果。
证明:如下的NFA 识别C R :其中q 0状态表示上一次运算的进位为0,
0 0 0 0 0 1 , 0 1 0 , … , ,
1
1 1
∑3=
, ∈B ?B 0 0 1 1 0 0 1
1 0
0 0 1
1
0 1
, , ,
∑2=
0 0 0 1 1
1
1 0 1 0
1 1 0 1 0
0 0
1 1
1 1 0 0 0
1 0
, , , ,
q 1状态表示上一次运算的进位为1, q 2状态表示上一次运算的进位为2。 如下的NFA 识别C :其中状态q 0,q 1,q 2分别表示目前读到的下面的数减上面
的数的3倍余0,1,2的情况。
1.34令 ∑2包含所有高度为2的0和1的列。∑2上的字符串给出两行0和1的字符串。把每一行看作一个二进制数,令
D={ w ∈∑2* | w 上一行大于下一行 }。
证明D 是正则的。
证明:由题设可设计自动机M=(Q, Σ, δ, q, F),其中Q={q 1,q 2},F={q 2}, 转移函数与状态图为:
1.35设∑2与问题
2.26中的相同。把每一行看作0
和1的字符串,令E={w ∈∑2* | w 的下一行是上一行的反转},证明E 不是正则的。
证明:假设E 是正则的,令p
是有泵引理给出的泵长度。
选择字符串
s= 。于是s 能够被划分为xyz 且满足泵引理的条件。
根据条件3,y 仅能取包含 的部分,当添加一个y 时,xyyz 不属于E. 所以E 不是正则
0 0
1 1
0 0
1 1
, , ,
∑2=
0 0 0 1 1
1
1 0 0 0 1
1
0 1 1 1
0 0 1 0 , , , , 1 0 p 0
1 p 1
的.
1.36 令B
n ={a
k
| k是n的整数倍}。证明对于每一个n≥1, B
n
是正则的。
证明:设字母表∑为{a},则a n是一正则表达式。所以,(a n)*也是正则表达式。由题意B
n
=(a n)*,
即B
n 可以用正则表达式表示。所以,B
n
也是正则的。
1.37 令C
n ={x | x是一个二进制数,且是n的整数倍}。证明对于每一个n≥1, C
n
是正则的。
证明:下面的DFA识别C
n
:(正向读)
M=( Q, {0,1} , δ , q
, F ), 其中Q={0,1,2,…,n-1},
δ( i,1)=2i+1 mod n, δ( i,0 )=( 2i mod n), i=0,1,2,…,n-1,
起始状态为0, F={0}.
这里i表示当前数mod n余i.
下面的DFA识别C
n
R:(反向读)
M=( Q, {0,1} , δ , q
, F ), 其中Q={(i,j)|i,j=0,1,2,…,n-1}, δ((i,j),1)=( 2i mod n, (2i+j)mod n ), δ((i,j),0)=( 2i mod n, j ), i,j=0,1,2,…,n-1
起始状态为(1,0), F={ (i,0) | i=0,1,…,n-1}.
这里(i,j)表示当前数mod n余j, 而下一位所表示单位数mod n余i(例如,若读下一位将达到k位,则下一位所表示单位数为10k-1).
1.38 考虑一种叫做全路径NFA的新型有穷自动机。一台全路径NFA M是5元组 ( Q, ∑, δ,
q
, F). 如果M对x∈∑*的每一个可能的计算都结束在F中的状态,则M接受x。注意,相反的,普通的NFA只需有一个计算结束在接受状态,就接受这个字符串。证明:全路径NFA识别正则语言。
证明:一个DFA一定是一个全路径NFA。所以下面只需证明,任意全路径NFA,都有一个与之等价的DFA。
设有一全路径NFA N=( Q, Σ, δ, q
, F),构造一个新与N等价的全路径NFA
N
1=( Q
1
, Σ, δ
1
, q
, F), 其中Q
1
=Q?{s}, s?Q。对于任意q∈Q
1
, a∈Σ
εδ(q,a), q ≠ s, 且δ(q,a) ≠?;
δ1(q,a) = {s}, q ≠ s, 且δ(q,a) =?; {s}, q=s.
现在来构造一个与全路径NFA N
1等价的DFA M=(Q
2
, Σ, δ
2
, q
1
, F
2
). 其中
1) Q
2=Power(Q
1
), 即Q
1
的所有子集组成的集合(也即Q
1
的幂集);
2) 定义函数E: Q 2 Q 2为:对任意R ∈Q 2, ),()(1εδr R E R
r ∈= ;
3) q 1=E(q 0);
4) 对于任意的R 属于Q 2, a 属于Σ, ??? ??=∈),(),(12a r E a R R r δδ .
5) F 2={ R ∈Q 2 | R ?F}。 综上所述,DFA 等价于全路径NFA 。
1.40如果存在字符串z 使得xz=y,则称字符串x 是字符串y 的前缀。如果x 是y 的前缀且x ≠y,则称x 是y 的真前缀。下面每小题定义一个语言A 上的运算。证明:正则语言类在每个运算下封闭。
a) NOPREFIX(A)={ω∈A|ω的任意真前缀都不是A 的元素} b)NOEXTEND(A)={ ω∈A|ω不是A 中任何字符串的真前缀} 证明:假设DFA M=( Q, Σ, δ, q 0, F)识别语言A 。
a) 构造NFA N 1=( Q, Σ, δ1, q 0, F)识别语言NOPREFIX(A)。其中,
对任意q ∈F, a ∈Σε, ;,;;
,,,)},,({),(1εεδδ=∈∈≠-∈??
?
????=a Q q F q a F Q q a q a q
所以,即NOPREFIX(A)为正则语言,亦即正则语言类A 在NOPREFIX(A)运算下封闭。█ b) 构造NFA N 2=( Q, Σ, δ, q 0, F 2)识别语言NOEXTEND(A)。F 2构造如下:
对M 中的任一接受状态q i , 若存在一条从它出发到达某接受状态(含本身)的路径,则将状态q i 改为非接受状态; 最后剩下的接受状态集记为F 2. 所得的NFA N 2即识别NOEXTEND(A)。所以,NOEXTEND(A)为正则语言,亦即正则语言类A 在运算NOEXTEND(A)下封闭。█ 1.48 证明:构造NFA N 如下:
由于该NFA 识别D ,故D 是正则语言。
1.50参见练习1.24中给出的有穷状态转换器的非形式定义。证明不存在FST 对每一个输入w 能够输出w R ,其中输入和输出的字母表为{0,1}。 证明:假设存在一台FST 对每个输入w 能够输出w R
。
则对于输入串w
1 =100, w
2
=101.
该FST可分别输出w
1R=001,w
2
R=101,于是对于它的起始状态和输入字符1,会输出1
和0两个不同字符,这与FST是确定性有穷自动机相矛盾。
所以,不存在一台FST对每个输入w能够输出w R。
1.51证明: 1) 自反性。即对任意字符串x,x≡
L
x。这是因为对于每个字符串z均有xz和xz 同时是或不是L的成员。
2) 对称性。即对任意字符串x和y, 若x≡
L y,则y≡
L
x。这是因为若x≡
L
y,则对
于每个字符串z, xz和yz同时是或不是L的成员,那么yz和xz同时是或不是L的成员, 于是y≡
L
x。
3) 传递性。即对任意字符串x,y和z, 若x≡
L y且y≡
L
z,则x≡
L
z。这是因为对任
意字符串u, 由x≡
L y知xu和yu同时是或不是L的成员, 由y≡
L
z知yu和zu
同时是或不是L的成员, 所以xu和zu同时是或不是L的成员, 此即x≡
L
z。
综上所述,≡
L
是自反的,对称的,传递的,所以是一个等价的关系。
1.53 令Σ={0,1,+,=}和
ADD={ x=y+z | x,y,z是二进制整数,且x是y与z的和}
证明ADD不是正则的。
证明:假设ADD是正则的。设P是泵引理给出的关于ADD的泵长度。令s为1P=10P-1+1P-1。于是s能够被划分成xyz,且满足泵引理的条件。根据条件3,y=1i, i>0. 所以xyyz为1P+i=10P-1+1P-1?ADD。故ADD不是正则的。
1.54证明:语言F={a i b j c k| i,j,k≥0且若i=1,则j=k}满足泵引理的3个条件,虽然它不是正则的。解释这个事实为什么与泵引理不矛盾。
证明:对任意正数p>1,设S是F中的一个成员且S的长度不小于p。
将S分成3段S=xyz。
(1)i=0,j=0. 此时S=c k (k>0)。
取x=ε, y=c, z=c k-1. 则对任意i≥0, xy i z∈F。
(2)i=0,j>0. 此时S=b j c k(j>0, k≥0).
取x=ε, y=b, z=b j-1c k. 则对任意i≥0, xy i z∈F。
(3)i=1. 此时S=ab j c k(j≥0, k≥0).
取x=ε, y=a, z=b j c k. 则对任意i≥0, xy i z∈F。
(4)i=2. 此时S= a2b j c k(j≥0, k≥0).
取x=ε, y=a2, z=b j c k. 则对任意i≥0, xy i z∈F。
(5)i>2. 此时S= a i b j c k(i≥3, j≥0, k≥0).
取x=ε, y=a, z=a i-1b j c k. 则对任意i≥0, xy i z∈F。
综上所述,语言F满足泵引理的3个条件。这一事实不与泵引理矛盾是因为泵引理是正则语言的必要不充分条件。
1.55 求最小泵长度。
a. 0001*的最小泵长度为4.
因为对任何s 若|s|=3则s只含有0,不能被抽取。
若|s|≥4时,把s划分为x=000 y=1 z为其余部分,则xy i z∈0001*。
b. 0*1*最小泵长度为1.
若|s|≥1时,S分两种情况:
1.S以0开头,令x=ε, y=0, z为其余则xy i z∈0*1*.
2.S以1开头,令x=ε, y=1, z为其余则xy i z∈0*1*.
c. (01)*最小泵长度为2.
若|s|≥2时,令x=ε, y=01, z为其余, 则xy i z∈(01)*.
d. 01,其最小泵长度为3。
因为语言中只有有限个字符串时,任何一个字符串都不能被抽取。所以有限语言的泵长度为其最长字符串的长度加1。此时没有比泵长度长的字符串,前提假所以命题真。
e. ε,其最小泵长度为1.
理由类似于d中所述。
1.56 证明:设对于每一个k>1,Ak={ w | w包含子串1k-1}?{1}*,下面证明Ak能被一台
k个状态的DFA识别,而不能被只有k-1个状态的DFA识别。
显然,Ak能被k个状态的DFA
M=({q1,q2,…,qk}, {1}, δ, q1, {qk}).
识别, 其中δ(qi,1)=qi+1(i=1,2,…,k-1), δ(qk,1)=qk。
假设AK可以被只有k-1个状态的DFA M1识别。
考虑这样一个输入串s=1k-1,设M识别s的状态序列是r1, r2,…rk,由于M的状态只有k-1个,根据鸽巢原理,r1,r2,…,rk中必有两个重复的状态,假设是ri=rj (0≤i 故Ak不能被只有k-1个状态的DFA M识别。所以,对于每一个k>1,存在AK,使得AK 能被K个状态的DFA识别,而不能被只有k-1个状态的DFA识别.。 每二章 2.2 a. 利用语言A={a m b n c n | m,n ≥0}和A={a n b n c m | m,n ≥0}以及例 3.20,证明上下文无关语 言在交的运算下不封闭。 b. 利用(a)和DeMorgan 律(定理1.10),证明上下文无关语言在补运算下不封闭。 证明:a.先说明A,B 均为上下文无关文法,对A 构造CFG C 1 S →aS|T|ε T →bTc|ε 对B,构造CFG C 2 S →Sc|R|ε R →aRb 由此知 A,B 均为上下文无关语言。 但是由例3.20, A ∩B={a n b n c n |n ≥0}不是上下文无关语言,所以上下文无关语言在交的运算下不封闭。 b.用反证法。假设CFL 在补运算下封闭,则对于(a)中上下文无关语言A,B ,A ,B 也为CFL ,且CFL 对并运算封闭,所以B A ?也为CFL ,进而知道B A ?为CFL ,由DeMorgan 定律B A ?=A ∩B ,由此A ∩B 是CFL,这与(a)的结论矛盾,所以CFL 对补运算不封闭。 2.4和2.5 给出产生下述语言的上下文无关文法和PDA ,其中字母表∑={0,1}。 a. {w | w 至少含有3个1} S →A1A1A1A A →0A|1A|ε b. {w | w 以相同的符号开始和结束} S →0A0|1A1 A →0A|1A|ε 0, ε→ε 0,ε→ε c. {w | w 的长度为奇数} S →0A|1A A →0B|1B|ε B →0A|1A d. {w | w 的长度为奇数且正中间的符号为0} S →0S0|1S1|0S1|1S0|0 e. {w | w 中1比0多} S →A1A A →0A1|1A0|1A|AA|ε f. {w | w=w R } S →0S0|1S1|1|0 g. 空集 S →S 0,ε→ε 1,ε→ε 0,ε→ε 0,ε→0 0,0→ε 0,ε→0 1,0→ε 0,1→ε 0,ε→0 0,0→ε 2.6 给出产生下述语言的上下文无关文法: a .字母表{a,b}上a 的个数是 b 的个数的两倍的所有字符串组成的集合。 S →bSaSaS|aSbSaS|aSaSbS|ε b .语言{a n b n |n ≥0}的补集。见问题3.25中的CFG: S →aSb|bY|Ta T →aT|bT|ε c .{w#x | w, x ∈{0,1}*且w R 是x 的子串}。 S →UV U →0U0|1U1|W W →W1|W0|# V →0V|1V|ε d .{x 1#x 2#?#x k |k ≥1, 每一个x i ∈{a,b}* , 且存在i 和j 使得x i =x j R }。 S →UVW U →A|ε A →aA|bA|#A|# V →aVa|bVb|#B|# B →aB|bB|#B|# W →B|ε 2.8 证明上下文无关语言类在并,连接和星号三种正则运算下封闭。 a. A ?B 方法一:CFG 。设有CFG G 1=(Q 1,∑,R 1,S 1)和G 2=(Q 2,∑,R 2,S 2)且L(G 1)=A, L(G 2)=B 。构造CFG G=(Q,∑,R,S 0),其中 Q= Q 1?Q 2?{S 0}, S 0是起始变元,R= R 1?R 2?{S 0→ S 1|S 2}. 方法二:PDA 。 设P 1=(Q 1,∑,Γ1,δ1,q 1,F 1)识别A ,P 2=(Q 1,∑,Γ2,δ2,q 2,F 2)是识别B 。 则如下构造的P=(Q,∑,Γ,δ,q 0,F)识别A ?B ,其中 1) Q=Q 1?Q 2?{q 0}是状态集, 2) Γ=Γ1?Γ2,是栈字母表, 3) q 0是起始状态, 4) F =F 1?F 2是接受状态集, 5) δ是转移函数,满足对任意q ∈Q, a ∈∑ε,b ∈Γε δ(q,a,b)=.,)(,,)(,,,,),,,(),,,()},,(),,{(221102121else b Q q b Q q b a q q b a q b a q q q εε εδδεεΓ∈∈Γ∈∈===????????若若若 b. 连接AB 方法一:CFG 。设有CFG G 1=(Q 1,∑,R 1,S 1)和G 2=(Q 2,∑,R 2,S 2)且L(G 1)=A, L(G 2)=B 。构造CFG G=(Q,∑,R,S 0),其中 Q= Q 1?Q 2?{S 0}, S 0是起始变元,R= R 1?R 2?{S 0→ S 1S 2}. 方法二:PDA 。 设P 1=(Q 1,∑,Γ1,δ1,q 1,F 1)识别A ,P 2=(Q 1,∑,Γ2,δ2,q 2,F 2)是识别B ,而且P 1满足在接受之前排空栈(即若进入接受状态,则栈中为空)这个要求。 则如下构造的P=(Q,∑,Γ,δ,q 1,F)识别A ?B ,其中 1) Q=Q 1?Q 2是状态集, 2) Γ=Γ1?Γ2,是栈字母表, 3) q 1是起始状态, 4) F =F 1?F 2是接受状态集, 5) δ是转移函数,满足对任意q ∈Q, a ∈∑ε,b ∈Γε δ(q,a,b)=.,,)(,),,,(),,(),(,),,,(,,)},,{(),,(,)(,),,,(222111211111else b Q q b a q b a F q b a q b a F q q b a q b F Q q b a q ?Γ∈∈≠∈==∈?Γ∈-∈????? ???? εεδεεδεεδδ若若若若 c. A * 方法一:CFG 。设有CFG G 1=(Q 1,∑,R 1,S 1),L(G 1)=A 。构造CFG G=(Q,∑,R,S 0),其中Q= Q 1 ?{S 0}, S 0是起始变元,R= R 1?{S 0→S 0S 0|S 1|ε}. 方法二:PDA 。 设P 1=(Q 1,∑,Γ1,δ1,q 1,F 1)识别A ,而且P 1满足在接受之前排空栈(即若进入接受状态,则栈中为空)这个要求。 则如下构造的P=(Q,∑,Γ,δ,q 1,F)识别A *,其中 1) Q=Q 1?{q 0}是状态集, 2) Γ=Γ1,是栈字母表, 3) q 0是起始状态, 第一章 1.比较数字计算机和模拟计算机的特点 解:模拟计算机的特点:数值由连续量来表示,运算过程是连续的;数字计算机的特点:数值由数字量(离散量)来表示,运算按位进行。两者主要区别见 P1 表 1.1 。 2.数字计算机如何分类?分类的依据是什么? 解:分类:数字计算机分为专用计算机和通用计算机。通用计算机又分为巨型机、大型机、 中型机、小型机、微型机和单片机六类。分类依据:专用和通用是根据计算机的效率、速度、价格、运行的经济性和适应性来划分的。 通用机的分类依据主要是体积、简易性、功率损耗、性能指标、数据存储容量、 指令系统规模和机器价格等因素。 3.数字计算机有那些主要应用?(略) 4.冯 . 诺依曼型计算机的主要设计思想是什么?它包括哪些主要组成部分? 解:冯 . 诺依曼型计算机的主要设计思想是:存储程序和程序控制。存储程序:将解题的程序(指令序列)存放到存储器中;程序控制:控制器顺序执行存储的程序,按指令功能控制全机协调地完成运算任务。 主要组成部分有:控制器、运算器、存储器、输入设备、输出设备。 5.什么是存储容量?什么是单元地址?什么是数据字?什么是指令字? 解:存储容量:指存储器可以容纳的二进制信息的数量,通常用单位KB MB GB来度量,存储 容 量越大,表示计算机所能存储的信息量越多,反映了计算机存储空间的大小。单元地址:单元地址简称地址,在存储器中每个存储单元都有唯一的地址编号,称为单元地 址。 数据字:若某计算机字是运算操作的对象即代表要处理的数据,则称数据字。指令字:若某计算机字代表一条指令或指令的一部分,则称指令字。 6.什么是指令?什么是程序? 解:指令:计算机所执行的每一个基本的操作。程序:解算某一问题的一串指令序列称为该问题的计算程序,简称程序。 7.指令和数据均存放在内存中,计算机如何区分它们是指令还是数据? 解:一般来讲,在取指周期中从存储器读出的信息即指令信息;而在执行周期中从存储器中读出的信息即为数据信息。 《数值计算方法》复习试题 一、填空题: 1、????? ?????----=410141014A ,则A 的LU 分解为 A ??? ?????????=? ?????????? ?。 答案: ?? ????????--??????????--=1556141501 4115401411A 2、已知3.1)3(,2.1)2(,0.1)1(===f f f ,则用辛普生(辛卜生)公式计算求得 ?≈3 1 _________ )(dx x f ,用三点式求得≈')1(f 。 答案:, 3、1)3(,2)2(,1)1(==-=f f f ,则过这三点的二次插值多项式中2 x 的系数为 , 拉格朗日插值多项式为 。 答案:-1, )2)(1(21 )3)(1(2)3)(2(21)(2--------= x x x x x x x L 4、近似值*0.231x =关于真值229.0=x 有( 2 )位有效数字; 5、设)(x f 可微,求方程)(x f x =的牛顿迭代格式是( ); ( 答案 )(1)(1n n n n n x f x f x x x '--- =+ 6、对1)(3 ++=x x x f ,差商=]3,2,1,0[f ( 1 ),=]4,3,2,1,0[f ( 0 ); 7、计算方法主要研究( 截断 )误差和( 舍入 )误差; 8、用二分法求非线性方程 f (x )=0在区间(a ,b )内的根时,二分n 次后的误差限为 ( 1 2+-n a b ); 9、求解一阶常微分方程初值问题y '= f (x ,y ),y (x 0)=y 0的改进的欧拉公式为 ( )] ,(),([2111+++++=n n n n n n y x f y x f h y y ); 10、已知f (1)=2,f (2)=3,f (4)=,则二次Newton 插值多项式中x 2系数为( ); 11、 两点式高斯型求积公式?1 d )(x x f ≈( ?++-≈1 )] 321 3()3213([21d )(f f x x f ),代数精 度为( 5 ); 12、 解线性方程组A x =b 的高斯顺序消元法满足的充要条件为(A 的各阶顺序主子式均 不为零)。 13、 为了使计算 32)1(6 )1(41310-- -+-+ =x x x y 的乘除法次数尽量地少,应将该表 达式改写为 11 ,))64(3(10-= -++=x t t t t y ,为了减少舍入误差,应将表达式 19992001-改写为 199920012 + 。 14、 用二分法求方程01)(3 =-+=x x x f 在区间[0,1]内的根,进行一步后根的所在区间 为 ,1 ,进行两步后根的所在区间为 , 。 15、 、 16、 计算积分?1 5 .0d x x ,取4位有效数字。用梯形公式计算求得的近似值为 ,用辛卜 生公式计算求得的近似值为 ,梯形公式的代数精度为 1 ,辛卜生公式的代数精度为 3 。 17、 求解方程组?? ?=+=+042.01532121x x x x 的高斯—塞德尔迭代格式为 ?????-=-=+++20/3/)51()1(1)1(2)(2)1(1 k k k k x x x x ,该迭 代格式的迭代矩阵的谱半径)(M ρ= 121 。 18、 设46)2(,16)1(,0)0(===f f f ,则=)(1x l )2()(1--=x x x l ,)(x f 的二次牛顿 插值多项式为 )1(716)(2-+=x x x x N 。 19、 求积公式 ?∑=≈b a k n k k x f A x x f )(d )(0 的代数精度以( 高斯型 )求积公式为最高,具 有( 12+n )次代数精度。 第一章 误差 1. 试举例,说明什么是模型误差,什么是方法误差. 解: 例如,把地球近似看为一个标准球体,利用公式2 4A r π=计算其表面积,这个近似看为球体的过程产生 的误差即为模型误差. 在计算过程中,要用到π,我们利用无穷乘积公式计算π的值: 12 222...q q π=? ?? 其中 11 2,3,... n q q n +?=?? ==?? 我们取前9项的乘积作为π的近似值,得 3.141587725...π≈ 这个去掉π的无穷乘积公式中第9项后的部分产生的误差就是方法误差,也成为截断误差. 2. 按照四舍五入的原则,将下列各数舍成五位有效数字: 816.956 7 6.000 015 17.322 50 1.235 651 93.182 13 0.015 236 23 解: 816.96 6.000 0 17.323 1.235 7 93.182 0.015 236 3. 下列各数是按照四舍五入原则得到的近似数,它们各有几位有效数字? 81.897 0.008 13 6.320 05 0.180 0 解: 五位 三位 六位 四位 4. 若1/4用0.25表示,问有多少位有效数字? 解: 两位 5. 若 1.1062,0.947a b ==,是经过舍入后得到的近似值,问:,a b a b +?各有几位有效数字? 解: 已知4311 d 10,d 1022 a b -- 第1章计算机系统概论 1. 什么是计算机系统、计算机硬件和计算机软件?硬件和软件哪个更重要? 解: 计算机系统:由计算机硬件系统和软件系统组成的综合体。 计算机硬件:指计算机中的电子线路和物理装置。 计算机软件:计算机运行所需的程序及相关资料。 硬件和软件在计算机系统中相互依存,缺一不可,因此同样重要。 2. 如何理解计算机的层次结构? 答:计算机硬件、系统软件和应用软件构成了计算机系统的三个层次结构。 (1)硬件系统是最内层的,它是整个计算机系统的基础和核心。 (2)系统软件在硬件之外,为用户提供一个基本操作界面。 (3)应用软件在最外层,为用户提供解决具体问题的应用系统界面。 通常将硬件系统之外的其余层称为虚拟机。各层次之间关系密切,上层是下层的扩展,下层是上层的基础,各层次的划分不是绝对的。 3. 说明高级语言、汇编语言和机器语言的差别及其联系。 答:机器语言是计算机硬件能够直接识别的语言,汇编语言是机器语 言的符号表示,高级语言是面向算法的语言。高级语言编写的程序(源程序)处于最高层,必须翻译成汇编语言,再由汇编程序汇编成机器语言(目标程序)之后才能被执行。 4. 如何理解计算机组成和计算机体系结构? 答:计算机体系结构是指那些能够被程序员所见到的计算机系统的属性,如指令系统、数据类型、寻址技术组成及I/O机理等。计算机组成是指如何实现计算机体系结构所体现的属性,包含对程序员透明的硬件细节,如组成计算机系统的各个功能部件的结构和功能,及相互连接方法等。 5. 冯?诺依曼计算机的特点是什么? 解:冯?诺依曼计算机的特点是:P8 ●计算机由运算器、控制器、存储器、输入设备、输出设备五大 部件组成; ●指令和数据以同同等地位存放于存储器内,并可以按地址访 问; ●指令和数据均用二进制表示; ●指令由操作码、地址码两大部分组成,操作码用来表示操作的 性质,地址码用来表示操作数在存储器中的位置; ●指令在存储器中顺序存放,通常自动顺序取出执行; ●机器以运算器为中心(原始冯?诺依曼机)。 一、证明:设M是一台识别语言B的DFA,交换M的接受状态与非接受状态得到一台新的DFA,则这台新DFA识别B的补集。因而,正则语言类在补运算下封闭。(8分) 参考答案: 设M’是一台将DFA M的接受态与非接受态交换后的DFA,接下来证明M识别B语言,则M’识别B的补集: 假定M’识别x,则对于x 在M’上运行将结束于M’的一个接受态,因为M和M’交换了接受态与非接受态,因此对于x运行于M,将会结束于一个非接受态,所以x∈/B。类似地,如果x不被M’接受,则它一定被M接受。故M’恰好接受所有不被M接受的那些串,因此M’识别B的补集。 既然B是任意的正则语言,且我们已构造出一台自动机识别它的补集,它表明任何正则语言的补也是正则的。因此,正则语言类在补运算下封闭。 二、令∑={0,1,+,=}和ADD={x=y+z | x,y,z是二制整数,且x是y与z的和},证明ADD不是正则的。(8分) 参考答案: 假定ADD是正则的。让P作为泵引理中的泵长度,选择S的串形式为1P=0P+1P作为ADD的一个成员。因为S有长度大于P,由泵引理保证它能分割成形如:S=xyz的三部分,满足泵引理的条件。泵引理的第三个条件有|xy|≤P,《它表明对于K≥1,y就是1K。这是xy2z是串1P+K=OP+1P,而它不是ADD的成员,由泵引理导出矛盾,因此ADD不是正则的。 三、请将下述CFG转换成等价的乔姆斯基范式文法。(8分) A→BAB|B|ε B→00|ε 参考答案: S0→AB|CC|BA|BD|BB|ε A→AB|CC|BA|BD|BB B→CC C→0 D→AB 四、请用泵引理证明语言A={0n#02n#03n | n≥0 }不是上下文无关的。(8分) 参考答案: 由泵引理,让P作为泵长度,s=0p#02p#03p ,接下来证明s=uvxyz不能进行泵抽取。 v和y都不能包含#,否则,xv2wy2z将超过2个#s ,因此,如果我们按#’s将s分成三段如:0p,02p,03p,至少有一段不包含v或y。因此,由于段之间的1:2:3的比例不再维持,xv2wy2z也不语言A中。故语言A={0n#02n#03n | n≥0 }不是上下文无关。的 五、下面的语言都是字母表{0,1}上的语言,请以实现描述水平级给出判定这些语言的图灵机:(8分) 《计算方法》习题答案 第一章 数值计算中的误差 1.什么是计算方法?(狭义解释) 答:计算方法就是将所求的的数学问题简化为一系列的算术运算和逻辑运算,以便在计算机上编程上机,求出问题的数值解,并对算法的收敛性、稳定性和误差进行分析、计算。 2.一个实际问题利用计算机解决所采取的五个步骤是什么? 答:一个实际问题当利用计算机来解决时,应采取以下五个步骤: 实际问题→建立数学模型→构造数值算法→编程上机→获得近似结果 4.利用秦九韶算法计算多项式4)(5 3 -+-=x x x x P 在3-=x 处的值,并编程获得解。 解:400)(2 3 4 5 -+?+-?+=x x x x x x P ,从而 所以,多项式4)(5 3 -+-=x x x x P 在3-=x 处的值223)3(-=-P 。 5.叙述误差的种类及来源。 答:误差的种类及来源有如下四个方面: (1)模型误差:数学模型是对实际问题进行抽象,忽略一些次要因素简化得到的,它是原始问题的近似,即使数学模型能求出准确解,也与实际问题的真解不同,我们把数学模型与实际问题之间存在的误差称为模型误差。 (2)观测误差:在建模和具体运算过程中所用的一些原始数据往往都是通过观测、实验得来的,由于仪器的精密性,实验手段的局限性,周围环境的变化以及人们的工作态度和能力等因素,而使数据必然带有误差,这种误差称为观测误差。 (3)截断误差:理论上的精确值往往要求用无限次的运算才能得到,而实际运算时只能用有限次运算的结果来近似,这样引起的误差称为截断误差(或方法误差)。 (4)舍入误差:在数值计算过程中还会用到一些无穷小数,而计算机受机器字长的限制,它所能表示的数据只能是一定的有限数位,需要把数据按四舍五入成一定位数的近似的有理数来代替。这样引起的误差称为舍入误差。 6.掌握绝对误差(限)和相对误差(限)的定义公式。 答:设* x 是某个量的精确值,x 是其近似值,则称差x x e -=* 为近似值x 的绝对误差(简称误差)。若存在一个正数ε使ε≤-=x x e * ,称这个数ε为近似值x 的绝对误差限(简称误差限或精度)。 把绝对误差e 与精确值* x 之比* **x x x x e e r -==称为近似值x 的相对误差,称 计算方法第3版习题答案 习题1解答 1.1 解:直接根据定义得 *411()102x δ-≤?*411()102r x δ-≤?*3*12211 ()10,()1026 r x x δδ--≤?≤?*2*5331()10,()102r x x δδ--≤?≤ 1.2 解:取4位有效数字 1.3解:433 5124124124 ()()() 101010() 1.810257.563 r a a a a a a a a a δδδδ----++++++≤≤=?++? 123()r a a a δ≤ 123132231123 ()()() a a a a a a a a a a a a δδδ++0.016= 1.4 解:由于'1(),()n n f x x f x nx -==,故***1*(())()()()n n n f x x x n x x x δ-=-≈- 故** * ***(()) (())()0.02()r r n f x x x f x n n x n x x δδδ-= ≈== 1.5 解: 设长、宽和高分别为 ***50,20,10l l h h εεωωεεεε=±=±=±=±=±=± 2()l lh h ωωA =++,*************()2[()()()()()()]l l l h h l h h εδωωδδδωδδωA =+++++ ***4[]320l h εωε=++= 令3201ε<,解得0.0031ε≤, 1.6 解:设边长为x 时,其面积为S ,则有2()S f x x ==,故 '()()()2()S f x x x x δδδ≈= 现100,()1x S δ=≤,从而得() 1 ()0.00522100 S x x δδ≈ ≤ =? 1.7 解:因S ld =,故 S d l ?=?,S l d ?=?,*****()()()()()S S S l d l d δδδ??≈+?? * 2 ()(3.12 4.32)0.010.0744S m δ=+?=, *** ** * () () 0.0744 ()0.55%13.4784 r S S S l d S δδδ= = = ≈ 1.8 解:(1)4.472 (2)4.47 1.9 解:(1) (B )避免相近数相减 (2)(C )避免小除数和相近数相减 (3)(A )避免相近数相减 (3)(C )避免小除数和相近数相减,且节省对数运算 1.10 解 (1)357sin ...3!5!7!x x x x x =-+-+ 故有357 sin ..3!5!7! x x x x x -=-+-, (2) 1 (1)(1)1lnxdx ln ln ln N+N =N N +-N N +N +-? 1 (1)1ln ln N +=N +N +-N 1.11 解:0.00548。 1.12解:21 16 27 3102 ()()() -? 1.13解:0.000021 第三章 上下文无关语言 3.1 略。 3.2 a. 利用语言A={a m b n c n | m,n ≥0}和A={a n b n c m | m,n ≥0}以及例3.20,证明上下文无关语言在交的运算下不封闭。 b. 利用(a)和DeMorgan 律(定理1.10),证明上下文无关语言在补运算下不封闭。 证明:a.先说明A,B 均为上下文无关文法,对A 构造CFG C 1 S →aS|T|ε T →bTc|ε 对B,构造CFG C 2 S →Sc|R|ε R →aRb 由此知 A,B 均为上下文无关语言。 但是由例3.20, A ∩B={a n b n c n |n ≥0}不是上下文无关语言,所以上下文无关语言在交的运算下不封闭。 b.用反证法。假设CFL 在补运算下封闭,则对于(a)中上下文无关语言A,B ,A ,B 也为CFL ,且CFL 对并运算封闭,所以B A ?也为CFL ,进而知道B A ?为CFL ,由DeMorgan 定律B A ?=A ∩B ,由此A ∩B 是CFL,这与(a)的结论矛盾,所以CFL 对补运算不封闭。 3.3 略。 3.4和3.5 给出产生下述语言的上下文无关文法和PDA ,其中字母表∑={0,1}。 a. {w | w 至少含有3个1} S →A1A1A1A A →0A|1A|ε b. {w | w 以相同的符号开始和结束} S →0A0|1A1 A →0A|1A|ε c. {w | w 的长度为奇数} S →0A|1A A →0B|1B|ε B →0A|1A 0, ε→ε 0,ε→ε 0,ε→ε 1,ε→ε 0,ε→ε 东华大学 2010~ 2011学年第二学期研究生期末考试试题参考答案 和评分标准 考试学院:计算机 考试专业:计算机科学与技术 考试课程名称:计算理论导引与算法复杂性 一、单项选择题(每空2分,本题共20分) 1. DFA和NFA的区别在于(B )。 A、NFA能够识别的语言DFA不一定能够识别 B、对同一个输入串两者的计算过程不同 C、DFA能够识别的语言NFA不一定能够识别 D、NFA比DFA多拥有一个栈 2. 若一个语言A是非正则的,对于个给定的一个泵长p,若存在一个串s=xyz,|s|≥p,则 ( A )。 A、|y|可能大于等于0 B、xz∈A C、xyyz∈A D、|xy|不可能小于等于p 3. 下推自动机与图灵机的不同之处是( B )。 A、下推自动机比图灵机识别的语言多 B、下推自动机比图灵机识别的语言少 C、下推自动机识别的语言是不可判定 D、拥有一个无限的存储带 4. 如果一个语言是图灵可判定的,则(A)。 A、对于一个不属于它串s,图灵机计算s时,一定能够到达拒绝状态 B、对于一个不属于它串s,不一定有一个判定器判定s C、对于一个不属于它串s,图灵机计算s时,有可能进入无限循环状态 D、对于一个不属于它串s,图灵机计算s时,一定不会停机 5. 一个集合在条件( C )下是不可数的。 A、该集合为无限集合 B、组成该集合的元素是实数 C、该集合的规模大于自然数集合的规模 D、该集合是一个有限的集合 6. 对于一个语言,( C )的说法是正确的。 A、如果它属于Turing-recognizable,那么,一定属于EXPTIME B、如果它是NP-hard,那么,一定属于NP C、如果它是NP-complete,那么,一定属于NP D、它一定能被图灵机识别 7. 如果A≤m B且B是可判定的,则(A)。 练习 1.1 图给出两台DFA M 1和M 2的状态图. 回答下述有关问题. a. M 1的起始状态是q 1 b. M 1的接受状态集是{q 2} c. M 2的起始状态是q 1 d. M 2的接受状态集是{q 1,q 4} e. 对输入aabb,M 1经过的状态序列是q 1,q 2,q 3,q 1,q 1 f. M 1接受字符串aabb 吗?否 g. M 2接受字符串ε吗?是 1.2 给出练习 2.1中画出的机器M 1和M 2的形式描述. M 1=(Q 1,Σ,δ1,q 1,F 1) 其中 1)Q 1={q 1,q 2,q 3,}; 2)Σ={a,b}; 3 415)F 1={q 2} M 2=(Q 2,Σ,δ2,q 2,F 2) 其中 1)Q 2={q 1,q 2,q 3,q 4}; 2)Σ={a,b}; 3 324)F 2={q 1,q 4} 1.3 DFA M 的形式描述为 ( {q 1,q 2,q 3,q 4,q 5},{u,d},δ,q 3,{q 3}),其中δ在表2-3中给出。试画出此机器的状态图。 d 1.6 画出识别下述语言的DFA 的状态图。 a){w | w 从1开始以0结束} b){w | w 至少有3个1} c) {w | w 含有子串0101} d) {w | w 的长度不小于3,且第三个符号为0} e) {w | w 从0开始且为奇长度,或从1开始且为偶长度} 或 f) {w | w 不含子串110} g) {w | w 的长度不超过5} h){w | w 是除11和111以外的任何字符} i){w | w 的奇位置均为1} j) {w | w 至少含有2个0,且至多含有1个1} k) {ε,0} l) {w | w 含有偶数个0,或恰好两个1} 0,1 1 练习题与答案 练习题一 练习题二 练习题三 练习题四 练习题五 练习题六 练习题七 练习题八 练习题答案 练习题一 一、是非题 1.–作为x的近似值一定具有6位有效数字,且其误差限。() 2.对两个不同数的近似数,误差越小,有效数位越多。() 3.一个近似数的有效数位愈多,其相对误差限愈小。() 4.用近似表示cos x产生舍入误差。 ( ) 5.和作为的近似值有效数字位数相同。 ( ) 二、填空题 1.为了使计算的乘除法次数尽量少,应将该表达式改写 为; 2.–是x舍入得到的近似值,它有位有效数字,误差限 为,相对误差限为; 3.误差的来源是; 4.截断误差 为; 5.设计算法应遵循的原则 是。 三、选择题 1.–作为x的近似值,它的有效数字位数为( ) 。 (A) 7; (B) 3; (C) 不能确定 (D) 5. 2.舍入误差是( )产生的误差。 (A) 只取有限位数 (B) 模型准确值与用数值方法求得的准确值 (C) 观察与测量 (D) 数学模型准确值与实际值 3.用 1+x近似表示e x所产生的误差是( )误差。 (A). 模型 (B). 观测 (C). 截断 (D). 舍入 4.用s*=g t2表示自由落体运动距离与时间的关系式 (g为重力加速度),s t是在时间t内的实际距离,则s t s*是()误差。 (A). 舍入 (B). 观测 (C). 模型 (D). 截断 5.作为的近似值,有( )位有效数字。 (A) 3; (B) 4; (C) 5; (D) 6。 四、计算题 1.,,分别作为的近似值,各有几位有效数字? 2.设计算球体积允许的相对误差限为1%,问测量球直径的相对误差限最大为多少? 3.利用等价变换使下列表达式的计算结果比较精确: (1), (2) (3) , (4) 4.真空中自由落体运动距离s与时间t的关系式是s=g t2,g为重力加速度。现设g是精确的,而对t有秒的测量误差,证明:当t增加时,距离的绝对误差增加,而相对误差却减少。 5*. 采用迭代法计算,取 k=0,1,…, 若是的具有n位有效数字的近似值,求证是的具有2n位有效数字的近似值。 练习题二 一、是非题 1.单点割线法的收敛阶比双点割线法低。 ( ) 2.牛顿法是二阶收敛的。 ( ) 3.求方程在区间[1, 2]内根的迭代法总是收敛的。( ) 4.迭代法的敛散性与迭代初值的选取无关。 ( ) 5.求非线性方程f (x)=0根的方法均是单步法。 ( ) 二、填空题 作业解答 第一章作业解答 1.1 基本的软件系统包括哪些内容? 答:基本的软件系统包括系统软件与应用软件两大类。 系统软件是一组保证计算机系统高效、正确运行的基础软件,通常作为系统资源提供给用户使用。包括:操作系统、语言处理程序、数据库管理系统、分布式软件系统、网络软件系统、各种服务程序等。 1.2 计算机硬件系统由哪些基本部件组成?它们的主要功能是什么? 答:计算机的硬件系统通常由输入设备、输出设备、运算器、存储器和控制器等五大部件组成。 输入设备的主要功能是将程序和数据以机器所能识别和接受的信息形式输入到计算机内。 输出设备的主要功能是将计算机处理的结果以人们所能接受的信息形式或其它系统所要求的信息形式输出。 存储器的主要功能是存储信息,用于存放程序和数据。 运算器的主要功能是对数据进行加工处理,完成算术运算和逻辑运算。 控制器的主要功能是按事先安排好的解题步骤,控制计算机各个部件有条不紊地自动工作。 1.3 冯·诺依曼计算机的基本思想是什么?什么叫存储程序方式? 答:冯·诺依曼计算机的基本思想包含三个方面: 1) 计算机由输入设备、输出设备、运算器、存储器和控制器五大部件组成。 2) 采用二进制形式表示数据和指令。 3) 采用存储程序方式。 存储程序是指在用计算机解题之前,事先编制好程序,并连同所需的数据预先存入主存储器中。在解题过程(运行程序)中,由控制器按照事先编好并存入存储器中的程序自动地、连续地从存储器中依次取出指令并执行,直到获得所要求的结果为止。 1.4 早期计算机组织结构有什么特点?现代计算机结构为什么以存储器为中心? 答:早期计算机组织结构的特点是:以运算器为中心的,其它部件都通过运算器完成信息的传递。 随着微电子技术的进步,人们将运算器和控制器两个主要功能部件合二为一,集成到一个芯片里构成了微处理器。同时随着半导体存储器代替磁芯存储器,存储容量成倍地扩大,加上需要计算机处理、加工的信息量与日俱增,以运算器为中心的结构已不能满足计算机发展的需求,甚至会影响计算机的性能。为了适应发展的需要,现代计算机组织结构逐步转变为以存储器为中心。 1.5 什么叫总线?总线的主要特点是什么?采用总线有哪些好处? 答:总线是一组可为多个功能部件共享的公共信息传送线路。 总线的主要特点是共享总线的各个部件可同时接收总线上的信息,但必须分时使用总线发送信息,以保证总线上信息每时每刻都是唯一的、不至于冲突。 使用总线实现部件互连的好处: ①可以减少各个部件之间的连线数量,降低成本; ②便于系统构建、扩充系统性能、便于产品更新换代。 1.6 按其任务分,总线有哪几种类型?它们的主要作用是什么? 答:按总线完成的任务,可把总线分为:CPU内部总线、部件内总线、系统总线、外总线。 《计算机原理》练习题 一、填空题 1、为区别不同的进制,在数的末尾用字母表示,二进制为B ,十六进制为H ,十进制为D 。 2、8位二进制数组成一个字节,它是单片机中数的基本单位。 3、硬件技术中三种基本的无源器件是电阻、电容、电感。 4、电感对电流的作用效果可以总结为:阻交流、通直流,交流电流频率越高,电感对电流的阻抗效应越强。 5、电容对电流的作用效果可以总结为:隔直流、通交流,交流电流频率越高,电容对电流的阻抗效应越弱。 6、晶体二极管的一个最重要特征是单向导电。 7、晶体三极管的主要作用是电流放大作用。 8、微机硬件的五大部件是:运算器、控制器、存储器、输入设备和输出设备。 9、单片机又称为微控制器(MCU)。 10、单片机就是在一块芯片上集成了中央处理部件(CPU)、存储器(RAM、ROM)、定时器/计数器和各种输入/输出(I/O)接口等片上外设的微型计算机。 11、单片机构成的四要素是CPU 、ROM 、RAM 和片上外设,它们相互之间通过总线连接。 12、8051单片机是8 位CPU。 13、时钟电路用于产生单片机工作所需要的时钟信号。 14、时钟周期(振荡周期)是指为单片机提供时钟信号的振荡源的周期。 15、机器周期是指单片机完成某种基本操作所需要的时间,它由12 个时钟周期组成。 16、假设单片机时钟频率f=12MHz,则时钟周期为1/12 us,机器周期为1 us。 17、假设单片机时钟频率f=6MHz,则时钟周期为1/6 us,机器周期为2 us。 18、单片机的存储系统包含三大部分:程序存储器(ROM)、数据存储器(RAM) 和特殊功能寄存器(SFR) 。 19、从物理地址空间来看,MCS-51单片机有四个存储器地址空间:即片内ROM 和片外ROM 以 及片内RAM 和片外RAM 。 20、从逻辑上看,单片机存储空间可分为三个部分:64KB程序存储器、256B数据存储器和64KB 数据存储器。 21、在单片机的引脚中,XTAL1和XTAL2用于连接时钟电路。 22、在单片机的引脚中,RESET用于连接复位电路。 23、在单片机的引脚中,EA=1,表示使用内部程序存储器。 24、在单片机的引脚中,EA=0,表示使用外部程序存储器。 25、单片机的时钟电路有:外部时钟电路和内部时钟电路。 26、单片机的并行端口有:P0 、P1 、P2 、P3 。其中P0 端口外接电路时要加上拉电阻,P3 端口主要使用其第二功能。 27、当单片机外接地址总线时,P2 端口作为地址总线高8位,P0 端口作为地址总线低8位。 28、当单片机外扩存储器时,作为数据总线的是P0 端口。 29、单片机复位后,PC= 0000H ,SP= 07H ,P0~P3= 0FFH 。 30、51单片机引脚P3.2的第二功能是:INT0外部中断0输入端,P3.3的第二功能是:INT1外部中断1输入端,P3.4的第二功能是:T0外部计数脉冲输入端0 ,P3.5的第二功能是:T1外部计数脉冲输入端1 。 31、单片机最小系统是能让单片机工作起来的一个最基本的组成电路。 32、C语言程序的基本结构有:顺序结构、选择结构和循环结构。 33、C语言程序中,有且仅有一个main 函数。 34、C程序的基本单位是函数。 35、C语言程序的执行是从main 函数开始,也是在main 函数中结束。 36、在C语言程序的运行过程中,我们称其值不能被改变的量为:常量;其值可以改变的量为:变量。 37、C语言中的变量必须先定义,后使用。 38、C语言规定给变量起名时,只能使用字母、数字、下划线,而且第一个字符不能是数字。 39、C语言中,定义数组a[10],则数组a的第一个元素是:a[0] ,最后一个元素是a[9] 。 40、C语言中,执行语句:x=7/3;则x的值为:2 。 41、C语言中,执行语句:x=7%3;则x的值为:1 。 42、单片机的片内数据存储器低128单元按照功能不同,可分为工作寄存器区、位寻址区、用户RAM 区 计算理论习题解答 练习 1.1 图给出两台DFA M 1和M 2的状态图. 回答下述有关问题. a. M 1的起始状态是q 1 b. M 1的接受状态集是{q 2} c. M 2的起始状态是q 1 d. M 2的接受状态集是{q 1,q 4} e. 对输入aabb,M 1经过的状态序列是q 1,q 2,q 3,q 1,q 1 f. M 1接受字符串aabb 吗?否 g. M 2接受字符串ε吗?是 1.2 给出练习 2.1中画出的机器M 1和M 2的形式描述. M 1=(Q 1,Σ,δ1,q 1,F 1) 其中 1) Q 1={q 1,q 2,q 3,}; 2) Σ={a,b}; 3) δ1为: a b q 1 q 2 q 3 q 2 q 1 q 3 q 3 q 2 q 1 4) q 1是起始状态 5) F 1={q 2} M 2=(Q 2,Σ,δ2,q 2,F 2) 其中 1) Q 2={q 1,q 2,q 3,q 4}; 2) Σ={a,b}; 3)δ2为: a b q 1 q 2 q 3 q 4 q 1 q 2 q 3 q 4 q 2 q 1 q 3 q 4 3) q 2是起始状态 4) F 2={q 1,q 4} 1.3 DFA M 的形式描述为 ( {q 1,q 2,q 3,q 4,q 5},{u,d},δ,q 3,{q 3}),其中δ在表2-3中给出。试画出此机器的状态图。 1.6 画出识别下述语言的DFA 的状态图。 a){w | w 从1开始以0结束} b){w | w 至少有3个1} q 1 q 5 q 4 q 2 q 3 u d u u u u d d d d 0 0 1 1 1 0,1 0 0 1 0 0 1 1 0,1 《数值计算方法》复习试题 一、填空题: 1、????? ?????----=410141014A ,则A 的LU 分解为 A ??? ?????????=? ?????????? ?。 答案: ?? ????????--??????????--=1556141501 4115401411A 3、1)3(,2)2(,1)1(==-=f f f ,则过这三点的二次插值多项式中2 x 的系数 为 ,拉格朗日插值多项式为 。 答案:-1, )2)(1(21 )3)(1(2)3)(2(21)(2--------= x x x x x x x L 4、近似值*0.231x =关于真值229.0=x 有( 2 )位有效数字; 5、设)(x f 可微,求方程)(x f x =的牛顿迭代格式是( ); 答案 )(1)(1n n n n n x f x f x x x '--- =+ 6、对1)(3 ++=x x x f ,差商=]3,2,1,0[f ( 1 ),=]4,3,2,1,0[f ( 0 ); 7、计算方法主要研究( 截断 )误差和( 舍入 )误差; 8、用二分法求非线性方程 f (x )=0在区间(a ,b )内的根时,二分n 次后的误差限为 ( 1 2+-n a b ); 10、已知f (1)=2,f (2)=3,f(4)=5.9,则二次Ne wton 插值多项式中x 2系数为 ( 0.15 ); 11、 解线性方程组A x =b 的高斯顺序消元法满足的充要条件为(A 的各阶顺序主子式均 不为零)。 12、 为了使计算 32)1(6 )1(41310-- -+-+ =x x x y 的乘除法次数尽量地少,应将该 第五章 7.试比较缺页中断机构与一般的中断,他们之间有何明显的区别? 答:缺页中断作为中断,同样需要经历保护CPU现场、分析中断原因、转缺页中断处理程序进行处理、恢复CPU现场等步骤。但缺页中断又是一种特殊的中断,它与一般中断的主要区别是: ( 1)在指令执行期间产生和处理中断信号。通常,CPU都是在一条指令执行完后去检查是否有中断请求到达。若有便去响应中断;否则继续执行下一条指令。而缺页中断是在指令执行期间,发现所要访问的指令或数据不在内存时产生和处理的。 (2)一条指令在执行期间可能产生多次缺页中断。例如,对于一条读取数据的多字节指令,指令本身跨越两个页面,假定指令后一部分所在页面和数据所在页面均不在内存,则该指令的执行至少产生两次缺页中断。 8.试说明请求分页系统中的页面调入过程。 答:请求分页系统中的缺页从何处调入内存分三种情况: (1)系统拥有足够对换区空间时,可以全部从对换区调入所需页面,提高调页速度。在进程运行前将与该进程有关的文件从文件区拷贝到对换区。 (2)系统缺少足够对换区空间时,不被修改的文件直接从文件区调入;当换出这些页面时,未被修改的不必换出,再调入时,仍从文件区直接调入。对于可能修改的,在换出时便调到对换区,以后需要时再从对换区调入。 (3)UNIX 方式。未运行页面从文件区调入。曾经运行过但被换出页面,下次从对换区调入。UNIX 系统允许页面共享,某进程请求的页面有可能已调入内存,直接使用不再调入。 19.何谓工作集?它是基于什么原理确定的? 答:工作集:在某段时间间隔里,进程实际所要访问页面的集合。 原理:用程序的过去某段时间内的行为作为程序在将来某段时间内行为的近似。 24.说明请求分段式系统中的缺页中断处理过程。 答:在请求分段系统中,每当发现运行进程所要访问的段尚未调入内存时,便由缺段中断机构产生一缺段中断信号,进入操作系统后由缺段中断处理程序将所需的段调入内存。缺段中断机构与缺页中断机构类似,它同样需要在一条指令的执行期间,产生和处理中断,以及在一条指令执行期间,可能产生多次缺段中断。 二章-信息量和熵习题解 2.1 莫尔斯电报系统中,若采用点长为0.2s ,1划长为0.4s ,且点和划出现的概率分别为2/3和1/3,试求它的信息速率(bits/s)。 解: 平均每个符号长为: 15 44.0312.032=?+?秒 每个符号的熵为9183.03log 3 123log 32=?+?比特/符号 所以,信息速率为444.34159183.0=?比特/秒 2.2 一个8元编码系统,其码长为3,每个码字的第一个符号都相同(用于同步),若每秒产生1000个码字,试求其信息速率(bits /s)。 解: 同步信号均相同不含信息,其余认为等概,每个码字的信息量为 3*2=6 比特; 所以,信息速率为600010006=?比特/秒 2.3 掷一对无偏的骰子,若告诉你得到的总的点数为:(a ) 7;(b ) 12。 试问各得到了多少信息量? 解: (a)一对骰子总点数为7的概率是 36 6 所以,得到的信息量为 585.2)36 6(log 2= 比特 (b) 一对骰子总点数为12的概率是36 1 所以,得到的信息量为 17.5361log 2= 比特 2.4 经过充分洗牌后的一付扑克(含52张牌),试问: (a) 任何一种特定排列所给出的信息量是多少? (b) 若从中抽取13张牌,所给出的点数都不相同时得到多少信息量? 解: (a)任一特定排列的概率为! 521, 所以,给出的信息量为 58.225!521log 2 =- 比特 (b) 从中任取13张牌,所给出的点数都不相同的概率为 1313 1313525213!44A C ?= 所以,得到的信息量为 21.134 log 1313522=C 比特. 2.5 设有一个非均匀骰子,若其任一面出现的概率与该面上的点数成正比,试求各点 出现时所给出的信息量,并求掷一次平均得到的信息量。 解:易证每次出现i 点的概率为 21i ,所以 比特比特 比特 比特 比特 比特 比特 398.221 log 21)(807.1)6(070.2)5(392.2)4(807.2)3(392.3)2(392.4)1(6,5,4,3,2,1,21 log )(2612=-==============-==∑=i i X H x I x I x I x I x I x I i i i x I i 2.6 园丁植树一行,若有3棵白杨、4棵白桦和5棵梧桐。设这12棵树可随机地排列, 且每一种排列都是等可能的。若告诉你没有两棵梧桐树相邻时,你得到了多少关 于树的排列的信息? 解: 可能有的排列总数为 27720! 5!4!3!12= 没有两棵梧桐树相邻的排列数可如下图求得, Y X Y X Y X Y X Y X Y X Y X Y 图中X 表示白杨或白桦,它有???? ??37种排法,Y 表示梧桐树可以栽种的位置,它有? ??? ??58种排法, 所以共有???? ??58*??? ? ??37=1960种排法保证没有两棵梧桐树相邻, 因此若告诉你没有两棵梧桐树相邻时,得到关于树排列的信息为1960log 27720log 22-=3.822 比特 2.7 某校入学考试中有1/4考生被录取,3/4考生未被录取。被录取的考生中有50%来 自本市,而落榜考生中有10%来自本市,所有本市的考生都学过英语,而外地落榜考生中以及被录取的外地考生中都有40%学过英语。 (a) 当己知考生来自本市时,给出多少关于考生是否被录取的信息? 计算理论习题答案CHAP2new 2.2 a. 利用语言A={a m b n c n | m,n ≥0}和A={a n b n c m | m,n ≥0}以及例 3.20,证 明上下文无关语言在交的运算下不封闭。 b. 利用(a)和DeMorgan 律(定理1.10),证明上下文无关语言在补运算下不封闭。 证明:a.先说明A,B 均为上下文无关文法,对A 构造CFG C 1 S →aS|T|ε T →bTc|ε 对B,构造CFG C 2 S →Sc|R|ε R →aRb 由此知 A,B 均为上下文无关语言。 但是由例3.20, A ∩B={a n b n c n |n ≥0}不是上下文无关语言,所以上下文无关语言在交的运算下不封闭。 b.用反证法。假设CFL 在补运算下封闭,则对于(a)中上下文无关语言A,B , A , B 也为CFL ,且CFL 对并运算封闭,所以B A ?也为CFL ,进而知道B A ?为CFL ,由DeMorgan 定律 B A ?=A ∩B ,由此A ∩B 是CFL,这与(a)的结论矛盾,所以CFL 对补运算不封闭。 2.4和2.5 给出产生下述语言的上下文无关文法和PDA ,其中字母表∑={0,1}。 a. {w | w 至少含有3个1} S →A1A1A1A A →0A|1A|ε ε,1→ 1, 0, ε,1→ ε,1→ b. {w | w 以相同的符号开始和结束} S →0A0|1A1 A →0A|1A|ε c. {w | w 的长度为奇数} S →0A|1A A →0B|1B|ε B →0A|1A d. {w | w 的长度为奇数且正中间的符号为0} S →0S0|1S1|0S1|1S0|0 e. {w | w 中1比0多} S →A1A 1,ε→ 0,ε→0,ε→1,1→ 0,0→0,ε→1,ε→0,ε→0,ε→ 0,ε→0,0→ε,ε→ ε,$→计算机组成原理_第四版课后习题答案(完整版)[]
《数值计算方法》试题集及答案
计算方法引论课后答案.
计算机组成原理第二版课后习题答案
计算理论试题及答案
计算方法的课后答案
计算方法习题答案
计算理论课后题及答案2
计算理论导引--研究生考试试卷格式
计算理论习题答案CHAP1newedit
计算方法练习题与答案
计算机组成原理课后习题答案(一到九章)
计算机原理练习题答案
计算理论习题解答
《数值计算方法》试题集及答案
计算机操作系统(第四版)课后习题答案第五章
信息与编码理论课后习题答案
计算理论习题答案CHAP2new