抽样推断及相关系数计算例题
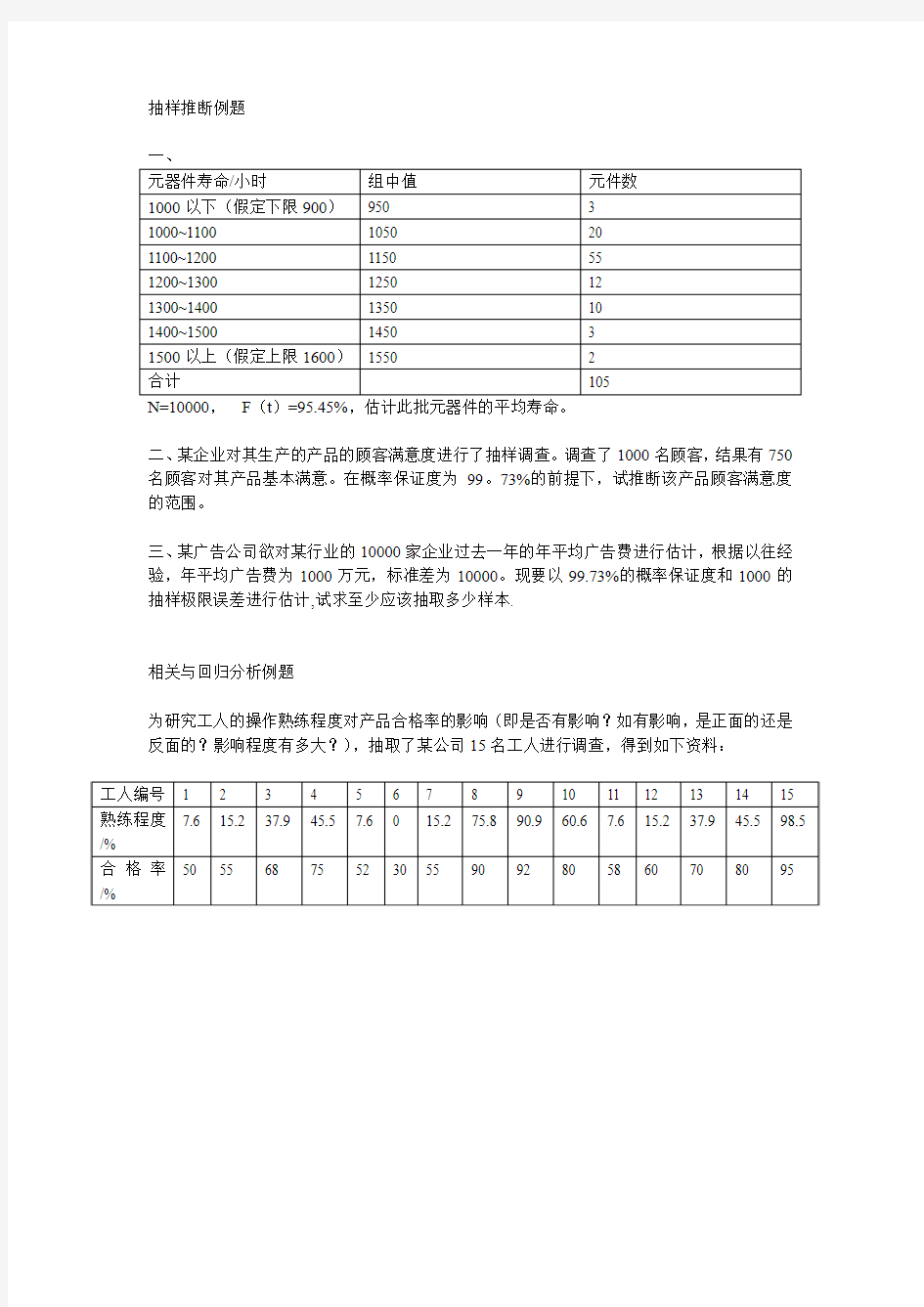
抽样推断例题
N=10000,F(t)=95.45%,估计此批元器件的平均寿命。
二、某企业对其生产的产品的顾客满意度进行了抽样调查。调查了1000名顾客,结果有750名顾客对其产品基本满意。在概率保证度为99。73%的前提下,试推断该产品顾客满意度的范围。
三、某广告公司欲对某行业的10000家企业过去一年的年平均广告费进行估计,根据以往经验,年平均广告费为1000万元,标准差为10000。现要以99.73%的概率保证度和1000的抽样极限误差进行估计,试求至少应该抽取多少样本.
相关与回归分析例题
为研究工人的操作熟练程度对产品合格率的影响(即是否有影响?如有影响,是正面的还是反面的?影响程度有多大?),抽取了某公司15名工人进行调查,得到如下资料:
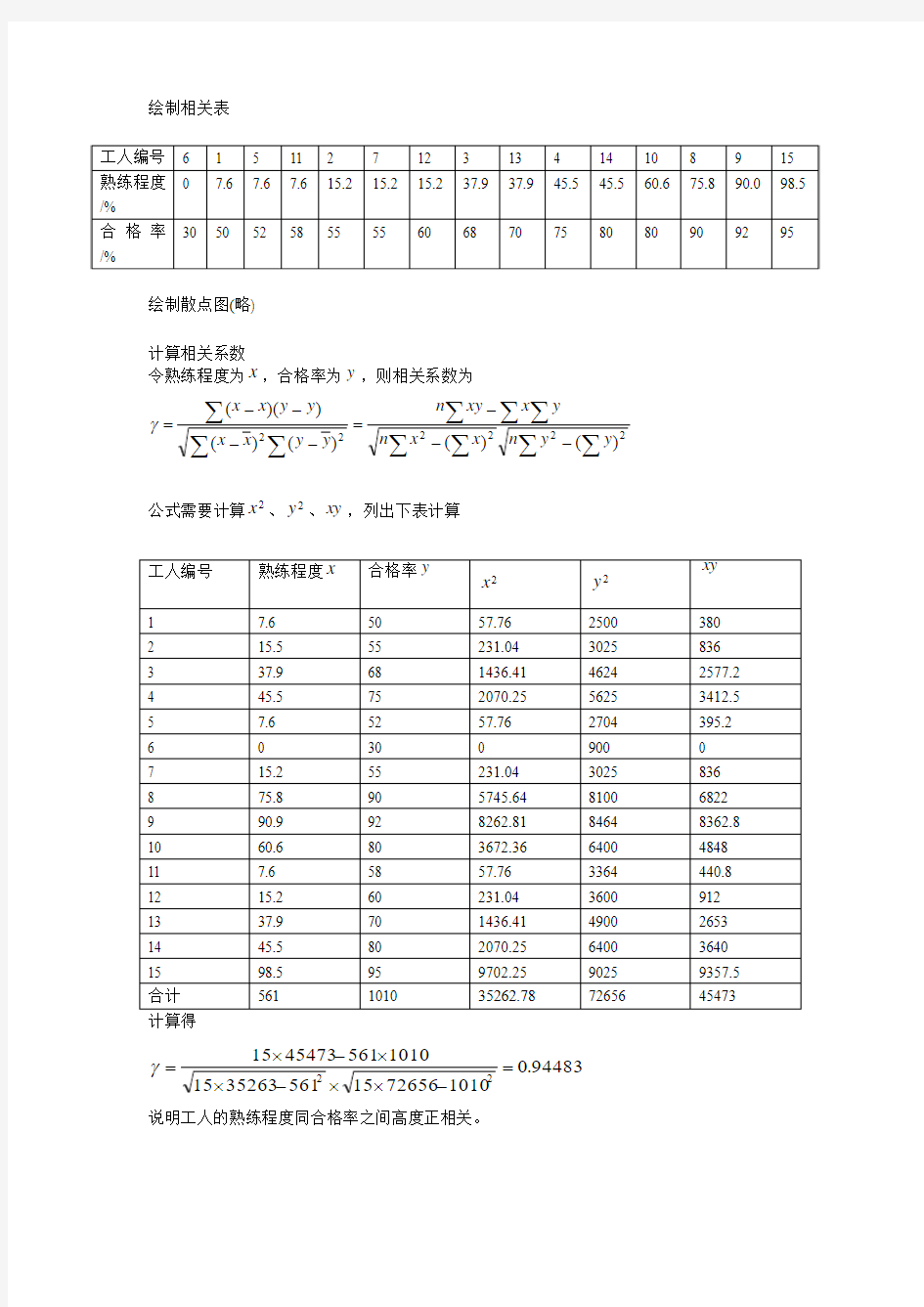
绘制相关表
绘制散点图(略)
计算相关系数
令熟练程度为x ,合格率为y ,则相关系数为
∑∑∑∑∑∑∑∑∑∑---=
----=
2
2
2
2
2
2
)
()
()
()())((y y n x x n y
x xy n y y x x y y x x γ
公式需要计算2
x 、2y 、xy ,列出下表计算
计算得
94483.01010
726561556135263151010
56145473152
2
=-??-??-?=
γ
说明工人的熟练程度同合格率之间高度正相关。
总时差双代号网络图时间计算参数-计算题及答案
总时差(用TFi-j表示),双代号网络图时间计算参数,指一项工作在不影响总工期的前提下所具有的机动时间。用工作的最迟开始时间LSi-j与最早开始时间ESi-j之差表示。 自由时差,指一项工作在不影响后续工作的情况下所拥有的机动时间。用紧后工作的最早开始时间与该工作的最早完成时间之差表示。 网络图时间参数相关概念包括: 各项工作的最早开始时间、最迟开始时间、最早完成时间、最迟完成时间、节点的最早时间及工作的时差(总时差、自由时差)。 1总时差=最迟完成时间—尚需完成时间。计算结果若大于0,则不影响总工期。若小于0则影响总工期。 2拖延时间=总时差+受影响工期,与自由时差无关。 3自由时差=紧后最早开始时间—本工作最早完成时间。 自由时差和总时差-----精选题解(免B) 1、在双代号网络计划中,如果其计划工期等于计算工期,且工作i-j的完成节点j在关键线路上,则工作i-j的自由时差()。 A.等于零 B.小于零 C.小于其相应的总时差 D.等于其相应的总时差 答案:D 解析:
本题主要考察自由时差和总时差的概念。由于工作i-j的完成节点j在关键线路上,说明节点j为关键节点,即工作i -j的紧后工作中必有关键工作,此时工作i-j的自由时差就等于其总时差。 2、在某工程双代号网络计划中,工作M的最早开始时间为第15天,其持续时间为7天。 该工作有两项紧后工作,它们的最早开始时间分别为第27天和第30天,最迟开始时间分别为第28天和第33天,则工作M的总时差和自由时差()天。 A.均为5 B.分别为6和5 C.均为6 D.分别为11和6 答案:B 解析: 本题主要是考六时法计算方法 1、工作M的最迟完成时间=其紧后工作最迟开始时间的最小值所以工作M 的最迟完成时间等于[28,33]=28 2、工作M的总时差=工作M的最迟完成时间-工作M的最早完成时间等于28-(15+7)=6 3、工作M的自由时差=工作M的紧后工作最早开始时间减工作M的最早完成时间所得之差的最小值: [27-22;30-22]= 5。 3、在工程网络计划中,判别关键工作的条件是该工作()。
抽样推断计算题及答案
5、某工厂有1500个工人,用简单随机重复抽样的方法抽出50个工人作为样本,调查其工资水平,资料如下: 要求: (1)计算样本平均数和抽样平均误差; (2)以95.45%的可靠性估计该工厂的月平均工资和工资总额的区间。 6、采用简单随机重复抽样的方法,在2000件产品中抽查200件,其中合格品190件。 (1)计算合格品率及其抽样平均误差; t=)对合格品的合格品数量进行区间估(2)以95.45%的概率保证程度(2 计; (3)如果极限差为2.31%,则其概率保证程度是多少? 7、某电子产品使用寿命在3000小时以下为不合格品,现在用简单随机抽样方法,从5000个产品中抽取100个对其使用寿命进行调查。其结果如下: 根据以上资料计算: (1)按重复抽样和不重复抽样计算该产品平均寿命的抽样平均误差; (2)按重复抽样和不重复抽样计算该产品合格率的抽样平均误差; t=)(3)根据重复抽样计算的抽样平均误差,以68.27%的概率保证程度(1对该产品的平均使用寿命和合格率进行区间估计。 8、外贸公司出口一种食品,规定每包规格不低于150克,现在用重复抽样的方法抽取其中的100包进行检验,其结果如下:
要求: (1)以99.73%的概率估计这批食品平均每包重量的范围,以便确定平均重量是否达到规格要求; (2)以同样的概率保证估计这批食品合格率范围; 9、某学校有2000名学生参加英语等级考试,为了解学生的考试情况,用不重复抽样方法抽取部分学生进行调查,所得资料如下: 试以95.45%的可靠性估计该学生英语等级考试成绩在70分以上学生所占比重范围。 11、对一批成品按重复抽样方法抽选100件,其中废品4件,当概率为95.45% t=)时,可否认为这批产品的废品不超过6%? (2 14、某乡有5000农户,按随机原则重复抽取100户调查,得平均每户纯收入12000元,标准差2000元。 要求: t=)估计全乡平均每户年纯收入的区间; (1)以95%的概率( 1.96 (2)以同样概率估计全乡农户年纯收入总额的区间范围。 16、某企业生产一种新型产品共5000件,随机抽取100件作质量检验。测试结果,平均寿命为4500小时,标准差300小时。试在90%概率保证下,允许误差缩小一半,试问应抽取多少件产品进行测试? 19、从某年级学生中按简单随机抽样方式抽取100名学生,对某公共课的考试成绩进行检查,及格的有82人,试以95.45%的概率保证程度推断全年级学生的及格率区间范围。如果其他条件不变,将允许误差缩小一半,应抽取多少名学生检查?
【重磅】双代号网络图时间参数计算
双代号网络图时间参数计算 双代号网络图时间参数计算 双代号网络图是应用较为普遍的一种网络计划形式。它是以箭线及其两端节点的编号表示工作的网络图。 双代号网络图中的计算主要有六个时间参数: ES:最早开始时间,指各项工作紧前工作全部完成后,本工作最有可能开始的时刻; EF:最早完成时间,指各项紧前工作全部完成后,本工作有可能完成的最早时刻 LF:最迟完成时间,不影响整个网络计划工期完成的前提下,本工作的最迟完成时间;LS:最迟开始时间,指不影响整个网络计划工期完成的前提下,本工作最迟开始时间;TF:总时差,指不影响计划工期的前提下,本工作可以利用的机动时间; FF:自由时差,不影响紧后工作最早开始的前提下,本工作可以利用的机动时间。 双代号网络图时间参数的计算一般采用图上计算法。下面用例题进行讲解。 例题:试计算下面双代号网络图中,求工作C的总时差? 早时间计算: ES,如果该工作与开始节点相连,最早开始时间为0,即A的最早开始时间ES=0; EF,最早结束时间等于该工作的最早开始+持续时间,即A的最早结束EF为0+5=5; 如果工作有紧前工作的时候,最早开始等于紧前工作的最早结束取大值,即B的最早开始FS=5,同理最早结束EF为5+6=11,而E工作的最早开始ES为B、C工作最早结束(11、8)
取大值为11。 迟时间计算: LF,如果该工作与结束节点相连,最迟结束时间为计算工期23,即F的最迟结束时间LF=23;LS,最迟开始时间等于最迟结束时间减去持续时间,即LS=LF-D; 如果工作有紧后工作,最迟结束时间等于紧后工作最迟开始时间取小值。 时差计算: FF,自由时差=(紧后工作的ES-本工作的EF); TF,总时差=(本工作的最迟开始LS-本工作的最早开始ES)或者=(本工作的最迟结束LF-本工作的最早结束EF)。 该题解析: 则C工作的总时差为3. 总结: 早开就是从左边往右边最大时间 早结=从左往右取最大的+所用的时间 迟开就是从右边往右边最小时间 迟开=从右往左取最小的+所用的时间 总时差=迟开-早开;或者;总时差=迟结-早结 自由差=紧后工作早开-前面工作的早结 希望你看懂啦。呵呵 工作最早时间的计算:顺着箭线,取大值 工作最迟时间的计算:逆着箭线,取小值 总时差:最迟减最早 自由时差:后早始减本早完 1.工作最早时间的计算(包括工作最早开始时间和工作最早完成时间):“顺着箭线计算,依次取大”(最早开始时间--取紧前工作最早完成时间的最大值),起始结点工作最早开始时间为0。用最早开始时间加持续时间就是该工作的最早完成时间。 2.网络计划工期的计算:终点节点的最早完成时间最大值就是该网络计划的计算工期,
统计学(计算题部分)
统计学原理期末复习(计算题) 1.某单位40名职工业务考核成绩分别为: 68 89 88 84 86 87 75 73 72 68 75 82 97 58 81 54 79 76 95 76 71 60 90 65 76 72 76 85 89 92 64 57 83 81 78 77 72 61 70 81 单位规定:60分以下为不及格,60─70分为及格,70─80分为中,80─90 分为良,90─100分为优。 要求: (1) 将参加考试的职工按考核成绩分组并编制一张考核成绩次数分配表; (2)指出分组标志及类型及采用的分组方法; (3)根据整理表计算职工业务考核平均成绩; (4)分析本单位职工业务考核情况。 解:(1) (2)分组标志为"成绩",其类型为"数量标志";分组方法为:变量分组中的开放组距式分组,组限表示方法是重叠组限; (3)平均成绩: 77403080 ==∑∑= f xf x (分) (4)本单位的职工考核成绩的分布呈两头小, 中间大的" 正态分布"的形态,平均成绩为 77分,说明大多数职工对业务知识的掌握达到了该单位的要求。 2.某车间有甲、乙两个生产组,甲组平均每个工人的日产量为36件, 要求:⑴计算乙组平均每个工人的日产量和标准差; ⑵比较甲、乙两生产小组哪个组的日产量更有代表性 解:(1) 50.29100 13 45343538251515=?+?+?+?= = ∑∑f xf X (件)
986.8) (2 =-= ∑∑f f X x σ(件) (2)利用标准差系数进行判断: 267.036 6 .9===X V σ 甲 305.05 .29986 .8== = X V σ 乙 因为 > 故甲组工人的平均日产量更有代表性。 3.采用简单随机重复抽样的方法,在2000件产品中抽查200件,其中合格品190件. 要求:(1)计算合格品率及其抽样平均误差 (2)以%的概率保证程度(t=2)对合格品率和合格品数量进行区间估计。 (3)如果极限误差为%,则其概率保证程度是多少 解:(1)样本合格率 p = n1/n = 190/200 = 95% 抽样平均误差: n p p p )1(-= μ = % (2)抽样极限误差Δp= t ·μp = 2×% = % 下限:-x △p=95%% = % 上限:+x △p=95%+% = % 则:总体合格品率区间:(% %) 总体合格品数量区间(%×2000=1838件 %×2000=1962件) (3)当极限误差为%时,则概率保证程度为% (t=Δ/μ) 4.某单位按简单随机重复抽样方式抽取40名职工,对其业务情况进行考核,考核成绩平均分数77分,标准差为10。54分,以%的概率保证程度推断全体职工业务考试成绩的区间范围。 解: 34 .367.1267 .140 54.10=?=Z =?===x x x n μσμ计算抽样极限误差:计算抽样平均误差: 全体职工考试成绩区间范围是: 下限=分)(66.7334.377=-=?-x x 上限=(分)3.8034.377=+=?+x x
【免费下载】第八章抽样推断【思考练习】题与答案
【思考练习】 一、判断题 1.抽样平均误差总是小于抽样极限误差。( ) 2.所有可能的样本平均数的平均数等于总体平均数。( ) 3.类型抽样应尽量缩小组间标志值变异,增大组内标志值变异,从而降低影响抽样误差的总方差。( ) 4.计算抽样平均误差,而缺少总体方差资料时,可以用样本方差代替。( ) 5.整群抽样为了降低抽样平均误差,在总体分群时注意增大群内方差缩小群间方差。( ) 6.抽样估计的置信度就是表明抽样指标和总体指标的误差不超过一定范围的概率保证程度。( ) 7.在抽样推断中,作为推断对象的总体和作为观察对象的样本都是确定的、唯一的。( ) 答案:1.×、2.√、3.×、4.×、5.√、6.√、7.×。 二、单项选择题 1.抽样调查的主要目的是( )。 A.用样本指标来推算总体指标 B.对调查单位作深入研究 C.计算和控制抽样误差 D.广泛运用数学方法 2.抽样调查所必须遵循的基本原则是( )。 A.准确性原则 B.随机性原则 C.可靠性原则 D.灵活性原则 3.反映抽样指标与总体指标之间的抽样误差的可能范围的指标是( )。 A.抽样平均误差 B.抽样误差系数 C.概率度 D.抽样极限误差 4.抽样平均误差反映了样本指标与总体指标之间的( )。 A.实际误差 B.实际误差的绝对值 C.平均误差程度 D.可能误差范围 5.抽样误差是指( )。 A.调查中所产生的登记性误差 B.调查中所产生的系统性误差 C.随机抽样而产生的代表性误差 D.由于违反了随机抽样原则而产生的误差 6.事先将总体各单位按某一标志排列,然后依排列顺序和按相同的间隔来抽选调查单位的抽样称为( )。 A.简单随机抽样 B.类型抽样 C.等距抽样 D.整群抽样7.在其他条件不变的情况下,如果允许误差缩小为原来的 ,则样本容量( )。12A.扩大为原来的4倍 B.扩大为原来的2倍 B. C.缩小为原来的 D.缩小为原来的1214 8.一次抽样调查,同时对总体平均数和总体成数进行推断,计算两个样本容量 ,样本容量应为( )。 220.25,408.02p x n n ==A.220 B.408
概率论与数理统计:协方差和相关系数
协方差和相关系数 对二维随机变量),(Y X ,我们除了讨论X 与Y 的期望和方差之外,还 需讨论X 与Y 之间相互关系的数字特征,本节主要讨论这方面的数字特征。 § 协方差和相关系数 协方差的定义与性质 定义 设(,)X Y 是二维随机变量.若{[()][()]}E X E X Y E Y --存在,则称它为随 机变量 X 与Y 的协方差,记为Cov(,)X Y ,即 Cov(,){[()][()]}X Y E X E X Y E Y =--. 常用下面的式子计算协方差 Cov(,){[()][()]}X Y E X E X Y E Y =--()()()E XY E X E Y =-. 注:(1)X 与Y 的协方差),(Y X Cov 实质上是二维随机变量X 与Y 的函数 )]([()]([(Y E Y X E X -?-的期望,它是一个常数。 (2)当),(Y X 为二维离散型随机变量时,其分布律为 }{),2,1,,2,1(,, =====j i y Y x X P P j i ij ,则 ij i i j i P Y E y X E x Y X Cov )]()][([),(1 1 --= ∑∑∞=∞ =; (3)当),(Y X 为二维连续型随机变量时,),(y x f 为),(Y X 的联合概率密度函数,则dxdy y x f Y E y X E x Y X Cov ),())(())((),(--= ?? +∞∞-+∞ ∞ -。 (4)利用期望的性质可得到协方差有下列计算公式: )()()(),(Y E X E XY E Y X Cov -= 证明: ) ()()( )()()()()()()( )] ()()()([ )] ())(([(),(Y E X E XY E Y E X E Y E X E Y E X E XY E Y E X E Y XE Y X E XY E Y E Y X E X E Y X Cov -=+--=+--=--= 此公式是计算协方差的重要公式,特别地取Y X =时,有
统计抽样计算题(有计算过程)
抽样计算题: 1、某乡水稻总面积20000亩,以不重复抽样方法从中随机抽取400亩实割实 测得样本平均亩产645公斤,标准差72.6公斤。要求极限误差不超过7.2公斤。试对该乡水稻的亩产量和总产量作出估计。 (1))亩产量的上、下限: (公斤)98.63702.7645=-=?-x x (公斤)652.0202.7645=+=?+x x 总产量的上下限: (万公斤)96.12752000098.637=? (万公斤)1304.0420000652.02=? (2)计算该区间下的概率() t F : 抽样平均误差 ()(公斤)3.59 2000040014006.72122=?? ? ? ?- =?? ? ?? -= N n n x σμ 因为抽样极限误差 x x z μ=? 96.159 .302 .7所以≈= ? = μ z 可知概率保证程度()t F =95% 2.某地有8家银行,从它们所有的全体职工中随机性抽取600人进行调查,得知其中的486人在银行里有个人储蓄存款,存款金额平均每人3400元,标准差500元,试以95.45%的可靠性推断: (1)全体职工中有储蓄存款者所占比率的区间范围;(2)平均每人存款金额的区间范围。 (1)全体职工中有储蓄存款者所占比率的区间范围: %81600 486 1=== n n p ()()%23.39%811%811=-?=-= p p p σ
抽样平均误差 %6.1600 3923.0== = n P p σμ 根据给定的概率保证程度()t F ,得到概率度z () %45.95=t F ? 2=z 则抽样极限误差%2.3%6.12=?==?p p t μ 估计区间的上、下限 %8.77%2.3%81=-=?-p p %2.84%2.3%81=+=?+p p (2)平均每人存款金额的区间范围: 抽样平均误差() (元)41.02600 5002 2 ===n x σμ 概率度z=2 则抽样极限误差 (元)82.4041.202=?==?x x z μ 平均每人存款额的上、下限: (元)18.335982.403400=-=?-x x (元)82.440382.403400=+=?+x x 3..某企业生产某种产品的工人有1000人,采用不重复抽样从中随机抽取100人调查当日产量,得到他们的人均日产量为126件,标准差为6.47件,要求在95﹪的概率保证程度下,估计该厂全部工人的日平均产量和日总产量。(F (t )=95%,t=1.96) 抽样平均误差 () (件)61.010********* 47.612 2 =??? ? ??-=??? ? ??-=N n n x σμ 概率度z 或t=1.96 则抽样极限误差 (件)20.161.096.1=?==?x x z μ 全部工人的日平均产量的上、下限: 件) 2.1278.124()2.1126(-=±=?±x x
第4章审计抽样练习题及答案
第四章审计抽样 一、单项选择题 1、下列各项中,对误差的定义正确的是()。 A、A公司要求订购单必须事先连续编号,注册会计师进行此项控制测试时将订购单未经过被授权人 员签字作为偏差 B、B公司要求验收部门对已收货的商品编制验收单,注册会计师将未编制验收单的情况作为一项误 差 C、注册会计师核对C公司应收账款明细账与总账,将总账和明细账中金额不符的情况作为错报 D注册会计师核对销售商品的发票和账面金额是否相符时,将发票未进行审核的情况作为偏差 2、下列选项中不属于统计抽样的优点的是()。 A、统计抽样能够客观地计量抽样风险 B、统计抽样有助于注册会计师高效地设计样本,计量所获证据的充分性 C、统计抽样通过调整样本规模精确地控制风险 D统计抽样可能发生额外的成本 3、下列各项中,不直接影响控制测试样本规模的因素是()。 A、可容忍偏差率 B、注册会计师在评估风险时对相关控制的依赖程度 C、控制所影响账户的可容忍错报 D拟测试总体的预期偏差率 4、在控制测试中,确定样本规模时一般不需要考虑()。 A、预计总体误差 B、可容忍误差 C、可接受的抽样风险 D总体变异性 5、下列关于影响样本规模的因素的说法中,不恰当的是()。 A、总体变异性在控制测试中无需考虑 B、在既定的可容忍误差下,预计总体误差越大,所需的样本规模越大 C、抽样单元超过5000个的总体视为大规模总体 D无论是统计抽样还是非统计抽样,注册会计师必须对影响样本规模的因素进行量化 6、X注册会计师在对Y公司主营业务收入进行测试的同时,一并对应收账款进行了测试。假定Y 公司2012年12月31日应收账款明细账显示其有 2 000户顾客,账面余额为10 000万元。X注册会 计师拟通过抽样函证应收账款账面余额,抽取130个样本。样本账户账面余额为500万元,审定后
单代号搭接网络计划时间参数计算
单代号搭接网络计划时间参数计算 在一般的网络计划(单代号或双代号)中,工作之间的关系只能表示成依次衔接的关系,即任何一项工作都必须在它的紧前工作全部结束后才能开始,也就是必须按照施工工艺顺序和施工组织的先后顺序进行施工。但是在实际施工过程中,有时为了缩短工期,许多工作需要采取平行搭接的方式进行。对于这种情况,如果用双代号网络图来表示这种搭接关系,使用起来将非常不方便,需要增加很多工作数量和虚箭线。不仅会增加绘图和计算的工作量,而且还会使图面复杂,不易看懂和控制。例如,浇筑钢筋混凝土柱子施工作业之间的关系分别用横道图、双代号网络图和搭接网络图表示,如下图所示。 施工过程 名 称 施工进度(天) 1 2 3 4 5 6 7 8 9 10 11 一.搭接关系的种类及表达方式 单代号网络计划的搭接关系主要是通过两项工作之间的时距来表示的,时距的含义,表示时间的重叠和间歇,时距的产生和大小取决于工艺的要求和施工组织上的需要。用以表示搭接关系的时距有五种,分别是STS (开始到开始)、STF (开始到结束)、FTS (结束到开始)、FTF (结束到结束)和混合搭接关系。 (一)FTS (结束到开始)关系 结束到开始关系是通过前项工作结束到后项工作开始之间的时距(FTS )来表达的。如下图所示。 扎钢筋 浇筑混凝土 支模1 支模2 支模3 1 2 4 3 5 6 8 7 9 10 支模1 2 支模2 2 支模3 2 扎筋2 1 扎筋3 1 扎筋1 1 浇筑混凝土1 2 浇筑混 凝土2 2 浇筑混 凝土3 2 支模 6 扎钢筋 3 浇筑 6 STS=4 FTF=1 STS=1 FTF=4 i j FTS i j FTS D i D j
抽样推断计算题及答案
抽样推断计算题及答案 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
5、某工厂有1500个工人,用简单随机重复抽样的方法抽出50个工人作为样本,调查其工资水平,资料如下: 要求: (1)计算样本平均数和抽样平均误差; (2)以%的可靠性估计该工厂的月平均工资和工资总额的区间。 6、采用简单随机重复抽样的方法,在2000件产品中抽查200件,其中合格品190件。 (1)计算合格品率及其抽样平均误差; (2)以%的概率保证程度(2 t=)对合格品的合格品数量进行区间估计; (3)如果极限差为%,则其概率保证程度是多少 7、某电子产品使用寿命在3000小时以下为不合格品,现在用简单随机抽样方法,从5000个产品中抽取100个对其使用寿命进行调查。其结果如下: 根据以上资料计算: (1)按重复抽样和不重复抽样计算该产品平均寿命的抽样平均误差; (2)按重复抽样和不重复抽样计算该产品合格率的抽样平均误差; (3)根据重复抽样计算的抽样平均误差,以%的概率保证程度 (1 t=)对该产品的平均使用寿命和合格率进行区间估计。
8、外贸公司出口一种食品,规定每包规格不低于150克,现在用重复抽样的方法抽取其中的100包进行检验,其结果如下: 要求: (1)以%的概率估计这批食品平均每包重量的范围,以便确定平均重量是否达到规格要求; (2)以同样的概率保证估计这批食品合格率范围; 9、某学校有2000名学生参加英语等级考试,为了解学生的考试情况,用不重复抽样方法抽取部分学生进行调查,所得资料如下: 试以%的可靠性估计该学生英语等级考试成绩在70分以上学生所占比重范围。 11、对一批成品按重复抽样方法抽选100件,其中废品4件,当概率为%(2 t=)时,可否认为这批产品的废品不超过6% 14、某乡有5000农户,按随机原则重复抽取100户调查,得平均每户纯收入12000元,标准差2000元。 要求: (1)以95%的概率( 1.96 t=)估计全乡平均每户年纯收入的区间; (2)以同样概率估计全乡农户年纯收入总额的区间范围。
第六章抽样调查练习及答案
第 六章 抽样调查 一、填空题 1.抽选样本单位时要遵守 原则,使样本单位被抽中的机会 。 2.常用的总体指标有 、 、 。 3.在抽样估计中,样本指标又称为 量,总体指标又称为 。 4.全及总体标志变异程度越大,抽样误差就 ;全及总体标志变异程度越小, 抽样误差 。 5.抽样估计的方法有 和 两种。 6.整群抽样是对被抽中群内的 进行 的抽样组织方式。 7.误差分为 和代表性误差;代表性误差分为________和偏差;偏差是 ____________________________,也称为________________。 8.简单随机抽样的成数抽样平均误差计算公式是:重复抽样条件下: ; 不重复抽样条件下: 。 9.误差范围△,概率度t 和抽样平均误差μ之间的关系表达式为 。 10.抽样调查的组织形式有: 。 二、单项选择题 1.所谓大样本是指样本单位数在( )及以上 A 30个 B 50个 C 80个 D100个 2.抽样指标与总体指标之间抽样误差的可能范围是( ) A 抽样平均误差 B 抽样极限误差 C 区间估计范围 D 置信区间 3.抽样平均误差说明抽样指标与总体指标之间的( ) A 实际误差 B 平均误差 C 实际误差的平方 D 允许误差 4.是非标志方差的计算公式( ) A P(1-P) B P(1-P)2 C )1(P P - D P 2(1-P) 5.总体平均数和样本平均数之间的关系是( ) A 总体平均数是确定值,样本平均数是随机变量 B 总体平均数是随机变量,样本平均数是确定值 C 两者都是随机变量 D 两者都是确定值 6.对入库的一批产品抽检10件,其中有9件合格,可以( )概率保证合格率不低于80%。 A 95.45% B 99.7396 C 68.27% D 90% 7.在简单随机重复抽样情况下,若要求允许误差为原来的2/3,则样本容量 ( ) A 扩大为原来的3倍 B 扩大为原来的2/3倍 C 扩大为原来的4/9倍 D 扩大为原来的2.25倍 8.根据抽样调查得知:甲企业一等品产品比重为30%,乙企业一等品比重为50%
统计学习题第五章_抽样与抽样估计答案
一、填空题 1、在实际工作中,人们通常把 n≥30 的样本称为大样本,而把 n<30 的样本称为小样本。 2、在抽样估计中,常见的样本统计量有样本均值、样本比例、样本标准差或样本方差以及它们的函数。 3、在研究目的一定的条件下,抽样总体是唯一确定的,而样本则有许多个。 4、在抽样调查中,登记性误差和系统性误差都可以尽量避免,而抽样误差则是不可避免的,但可以计算并加以控制。 5、在抽样估计中,抽样估计量是指用于估计总体参数的样本指标(统计量),评价估计量优劣的标准有无偏性、有效性和一致性。 二、选择题 单选题: 1、在其它条件不变的情况下,要使抽样平均误差为原来的1/3,则样本单位数必须 ((2)) (1)增加到原来的3倍(2)增加到原来的9倍 (3)增加到原来的6倍(4)也是原来的1/3 2、在总体内部情况复杂,且各单位之间差异程度大,单位数又多的情况下,宜采用 ((3)) (1)简单随机抽样(2)等距抽样(3)分层抽样(4)整群抽样 3、某厂产品质量检查,确定按5%的比率抽取,按连续生产时间顺序每20小时抽1 小时的全部产进行检验,这种方式是((4)) (1)简单随机抽样(2)等距抽样(3)分层抽样(4)整群抽样 4、其它条件一定,抽样推断的把握程度提高,抽样推断的准确性就会((2)) (1)提高(2)降低(3)不变(4)不一定降低 5、在城市电话网的100次通话中,通话持续平均时间为3分钟,均方差为分钟,则概率为时,通话平均持续时间的抽样极限误差为((2)) (1)(2)(3)(4)
6、假定11亿人口大国和100万人口小国的居民年龄变异程度相同,现在各自用重复抽样方法抽取本国人口的1%计算平均年龄,则平均年龄抽样平均误差((3))(1)两者相等(2)前者比后者大(3)前者比后者小(4)不能确定大小 多选题: 1、降低抽样误差,可以通过下列那些途径((2)(4)(5)) (1)降低总体方差(2)增加样本容量。 (3)减少样本容量(4)改重复抽样为不重复抽样 (5)改简单随机抽样为类型抽样 2、抽样推断中的抽样误差((1)(5)) (1)是不可避免要产生的 (2)是可以通过改进调查方法来消除的 (3)只有调查后才能计算 (4)即不能减少,也不能消除 (5)其大小是可以控制的 3、抽样极限误差((1)(2)(4)) (1)是所有可能的样本指标与总体指标之间的误差范围 (2)也叫允许误差(3)与所做估计的概率保证程度成反比 (4)通常用来表示抽样结果的精确度 4、影响样本容量的因素有((1)(2)(3)(4)(5)) (1)总体方差 (2)所要求的概率保证程度 (3)抽样方法 (4)抽样的组织形式 (5)允许误差法范围的大小 5、不重复抽样的抽样平均误差((2)(4)) (1)总是大于重复抽样的抽样平均误差
抽样调查习题及答案
第四章习题 抽样调查 一、填空题 1. 抽样调查是遵循随机的原则抽选样本,通过对样本单位的调查来对研究对象的总体数量特征作出推断的。 2. 采用不重复抽样方法,从总体为N的单位中,抽取样本容量为n 的可能样本个数为N(N-1)(N-2)……(N-N+1)。 3. 只要使用非全面调查的方法,即使遵守随机原则,抽样误差也不可避免会产生。 4. 参数估计有两种形式:一是点估计,二是区间估计。 5. 判别估计量优良性的三个准则是:无偏性、一致性和有效性。 6. 我们采用“抽样指标的标准差”,即所有抽样估计值的标准差,作为衡量抽样估计的抽样误差大小的尺度。 7. 常用的抽样方法有简单随机抽样、类型(分组)抽样、等距抽样、整群抽样和分阶段抽样。 8. 对于简单随机重复抽样,若其他条件不变,则当极限误差范围Δ缩小一半,抽样单位数必须为原来的4倍。若Δ扩大一倍,则抽样单位数为原来的1/4。 9. 如果总体平均数落在区间960~1040内的概率是95%,则抽样平均数是1000,极限抽样误差是40.82,抽样平均误差是20.41。 10. 在同样的精度要求下,不重复抽样比重复抽样需要的样本容量
少,整群抽样比个体抽样需要的样本容量多。 二、判断题 1. 抽样误差是抽样调查中无法避免的误差。(√) 2. 抽样误差的产生是由于破坏了随机原则所造成的。(×) 3. 重复抽样条件下的抽样平均误差总是大于不重复抽样条件下的抽样平均误差。(√) 4. 在其他条件不变的情况下,抽样平均误差要减少为原来的1/3,则样本容量必须增大到9倍。(√) 5. 抽样调查所遵循的基本原则是可靠性原则。(×) 6. 样本指标是一个客观存在的常数。(×) 7. 全面调查只有登记性误差而没有代表性误差,抽样调查只有代表性误差而没有登记性误差。(×) 8. 抽样平均误差就是抽样平均数的标准差。(×) 三、单项选择题 1. 用简单随机抽样(重复)方法抽取样本单位,如果要使抽样平均误差降低50%,则样本容量需扩大为原来的(C) A. 2倍 B. 3倍 C. 4倍 D. 5倍 2. 事先将全及总体各单位按某一标志排列,然后依固定顺序和间隔来抽选调查单位的抽样组织方式叫做(D) A. 分层抽样 B. 简单随机抽样 C. 整群抽样 D. 等距抽样 3. 计算抽样平均误差时,若有多个样本标准差的资料,应选哪个来
相关系数与协方差的关系
探究协方差与相关系数 罗燕 摘要:协方差),(Y X Cov 是描述二维随机变量两个分量间相互关联程度的一个特征数,如果将协方差相应标准化变量就得到相关系数),(Y X Corr 。从而可以引进相关系数),(Y X Corr 去刻画二维随机变量两个分量间相互关联程度。且事实表明,相关系数明显被广泛应用。本文的目的在于从协方差与相关系数的关系的角度去探讨协方差与相关系数的优缺点,并具体介绍协方差和相关系数这两个描述二维随机变量间相关性的特征数。 关键字:协方差),(Y X Cov 相关系数),(Y X Corr 相互关联程度 1 协方差、相关系数的定义及性质 设(X ,Y )是一个二维随机变量,若E{ [ X-E(X) ] [ Y -E(Y) ] }存在,则称此数学期望为X 与Y 的协方差,并记为Cov(X,Y)=E{ [ X-E(X) ] [ Y -E(Y) ] },特别有Cov(X,X)=)(X Var 。 从协方差的定义可以看出,它是X 的偏差“X-E(X) ”与Y 的偏差“Y -E(Y)”的乘积的数学期望。由于偏差可正可负,故协方差也可正可负,也可为零,其具体表现如下: ·当Cov(X,Y)>0时,称X 与Y 正相关,这时两个偏差 [ X-E(X) ] 与[ Y -E(Y) ] 同时增加或同时减少,由于E(X)与E(Y)都是常数,故等价于X 与Y 同时增加或同时减少,这就是正相关的含义。 ·当Cov(X,Y)<0时,称X 与Y 负相关,这时X 增加而Y 减少,或Y 增加而X 减少,这就是负相关的含义。 ·当Cov(X,Y)=0时,称X 与Y 不相关。 也就是说,协方差就是用来描述二维随机变量X 与Y 相互关联程度的一个特征数。协方差Cov(X,Y)是有量纲的量,譬如X 表示人的身高,单位是米(m ),Y 表示人的体重,单位是公斤(k g ),则Cov(X,Y)带有量纲(m ·kg )。为了消除量纲的影响,对协方差除以相同量纲的量,就得到一个新的概念—相关系数,它的定义如下: 设(X ,Y )是一个二维随机变量,且)(X Var >0,)(Y Var >0.则称 ),(Y X C o r r =)()() ,(Y Var X Var Y X Cov =y x Y X Cov σσ),( 为X 与Y 的(线性)相关系数。 利用施瓦茨不等式我们不难得到-1≤),(Y X Corr ≤1.也就是说相关系数是介于-1到1之间的,并且可以对它作以下几点说明: ·若),(Y X Corr =0,则称X 与Y 不相关。不相关是指X 与Y 没有线性关系,但也有可能有其他关系,比如平方关系、立方关系等。 ·若),(Y X Corr =1,则称X 与Y 完全正相关;若),(Y X Corr =-1,则称X 与Y 完全,负相关。
双代号网络图时间参数的计算
双代号网络图时间参数的计算 参数名称符号英文单词 工期 计算工期TCComputer Time 要求工期TR RequireTime 计划工期T P Plan Time 工作的 时间参数 持续时间D i-jDay 最早开始时间ES i-j Earliest Starting Tim e 最早完成时间EF i—j Earliest Finishing Time 最迟完成时间LFi—jLatest Finishing Time 最迟开始时间LSi—jLatest Starting Time 总时差TFi-j Total Float Time 自由时差FF i-j Free Float Time 二、工作计算法 【例题】:根据表中逻辑关系,绘制双代号网络图,并采用工作计算法计算各工作的时间参数。 工作A B C DEFGHI 紧前-A A B B、C C D、E E、 F H、G 时间333854422
(一)工作的最早开始时间ESi—j —-各紧前工作全部完成后,本工作可能开始的最早时刻。 (二)工作的最早完成时间EF i—j EF i-j=ES i-j + D i—j 1。计算工期Tc等于一个网络计划关键线路所花的时间,即网络计划结束工作最早完成时间的最大值,即T c=max{EF i—n} 2.当网络计划未规定要求工期Tr时, Tp=T c 3.当规定了要求工期Tr时,T c≤T p,T p≤T r —-各紧前工作全部完成后,本工作可能完成的最早时刻。
(三)工作最迟完成时间LFi-j 1.结束工作的最迟完成时间LFi-j=T p 2.其他工作的最迟完成时间按“逆箭头相减,箭尾相碰取小值”计算. --在不影响计划工期的前提下,该工作最迟必须完成的时刻。 (四)工作最迟开始时间LS i-j LSi—j=LFi—j—D i-j --在不影响计划工期的前提下,该工作最迟必须开始的时刻。
统计学练习题(计算题)
统计学练习题 (计算题)
第四章----第一部分 总量指标与相对指标 4.1:(1)某企业产值计划完成程度为105%,比上年增长7%,试计算计划规定比上年增长多少?(2)单位产品成本上年为420元,计划规定今年成本降低5%,实际降低6%,试确定今年单位成本的计划数字和实际数字,并计算出降低成本计划完成程度指标。(3)按计划规定,劳动生产率比上年提高10%,实际执行结果提高了12%,劳动生产率计划完成程度是多少? 4.2:某市三个企业某年的下半年产值及计划执行情况如下: 要求: [1]试计算并填写上表空栏,并分别说明(3)、(5)、(6)、(7)是何种相对数; [2]丙企业若能完成计划,从相对数和绝对数两方面说明该市三个企业将超额完成计划多少? 4.3:我国2008年-2013年国内生产总值资料如下: 单位:亿元
根据上述资料,自行设计表格: (1)计算各年的第一产业、第二产业、第三产业的结构相对指标和比例相对指标; (2)计算我国国内生产总值、第一产业、第二产业、第三产业与上年对比的增长率; (3)简要说明我国经济变动情况。 4.4:某公司下属四个企业的有关销售资料如下: 根据上述资料: (1)完成上述表格中空栏数据的计算; (2)若A能完成计划,则公司的实际销售额将达到多少?比计划超额完成多少? (3)若每个企业的计划完成程度都达到B企业的水平,则公司的实际销售额将达到多少?比计划超额完成多少? 第四章-----第二部分 平均指标与变异指标 4.5:已知某地区各工业企业产值计划完成情况以及计划产值资料如下:
要求:(1)根据上述资料计算该地区各企业产值计划的平均完成程度。(2)如果在上表中所给资料不是计划产值而是实际产值,试计算产值计划平均完成程度。、 4.6:已知某厂三个车间生产不同的产品,其废品率、产量和工时资料如下: 计算:(1)三种产品的平均废品率;(2)假定三个车间生产的是同一产品,但独立完成,产品的平均废品率是多少;(3)假定三个车间是连续加工某一产品,产品的平均废品率是多少。 4.7:对某车间甲、乙两工人当日产品中各抽取10件产品进行质量检查,得资料如下: 试比较甲乙两工人谁生产的零件质量较稳定。 4.8:某企业工人基本工资资料如下:
应用统计学:参数估计习题及答案
简答题 1、矩估计的推断思路如何?有何优劣? 2、极大似然估计的推断思路如何?有何优劣? 3、什么是抽样误差?抽样误差的大小受哪些因素影响? 4、简述点估计和区间估计的区别和特点。 5、确定重复抽样必要样本单位数应考虑哪些因素? 计算题 1、对于未知参数的泊松分布和正态分布分别使用矩法和极大似然法进行点估计,并考量估计结果符合什么标准 2、某学校用不重复随机抽样方法选取100名高中学生,占学生总数的10%,学生平均体重为50公斤,标准差为48.36公斤。要求在可靠程度为95%(t=1.96)的条件下,推断该校全部高中学生平均体重的范围是多少? 3、某县拟对该县20000小麦进行简单随机抽样调查,推断平均亩产量。根据过去抽样调查经验,平均亩产量的标准差为100公斤,抽样平均误差为40公斤。现在要求可靠程度为95.45%(t=2)的条件下,这次抽样的亩数应至少为多少? 4、某地区对小麦的单位面积产量进行抽样调查,随机抽选25公
顷,计算得平均每公顷产量9000公斤,每公顷产量的标准差为1200公斤。试估计每公顷产量在8520-9480公斤的概率是多少?(P(t=1)=0.6827, P(t=2)=0.9545, P(t=3)=0.9973) 5、某厂有甲、乙两车间都生产同种电器产品,为调查该厂电器产品的电流强度情况,按产量等比例类型抽样方法抽取样本,资料如下: 试推断: (1)在95.45%(t=2)的概率保证下推断该厂生产的全部该种电器产品的平均电流强度的可能范围 (2)以同样条件推断其合格率的可能范围 (3)比较两车间产品质量 6、采用简单随机重复和不重复抽样的方法在2000件产品中抽查200件,其中合格品190件,要求: (1)计算样本合格品率及其抽样平均误差
协方差和相关系数
二维随机变量的期望与方差 对于二维随机变量,如果存在,则 称为二维随机变量的数学期望。 1 、当( X ,Y ) 为二维离散型随机变量时 2 、当( X ,Y ) 为二维连续型随机变量时 例题 2.39 设,求。与一维随机变量函数的期望一样,可求出二维随机变量函数的期望。 对二维离散型随机变量( X ,Y ) ,其函数的期望为 对二维连续型随机变量( X ,Y ) ,其函数的期望为
例题 2.40 设,求 2.41 设( X ,Y ) 服从区域A 上的均匀分布,其中A 为x 轴、y 轴及直线 围成的三角形区域,如图2-10 所示。求函数的数学期望。 随机变量的数学期望和方差的三个重要性质: 1 、 推广: 2 、设X 与Y 相互独立,则 推广:设相互独立,则 3 、设X 与Y 相互独立,则 推广:设相互独立,则 仅对性质 3 就连续型随机变量加以证明 证明3
由于X 与Y 相互独立,所以与相互独立,利用性质 2 、知道 从而有, 可以证明:相互独立的随机变量其各自的函数间,仍然相互独立。 例题 2.42 某学校流行某种传染病,患者约占,为此学校决定对全校1000 名师生进 行抽血化验。现有两个方案:①逐个化验;②按四个人一组分组,并把四个人抽到的血混合在一起化验,若发现有问题再对四个人逐个化验。问那种方案好? 2.10.2 协方差与相关系数 分析协方差与相关系数反映随机变量各分量间的关系;结合上面性质 3 的证明,可以得到以下结论: 若X 与Y 相互独立,则 可以用来刻划X 与Y 之间的某种关系。 定义设( X ,Y ) 为二维随机变量,若 存在,则称它为随机变量X 与Y 的协方差,记作或,即 特别地 故方差,是协方差的特例。计算协方差通常采用如下公式:
医学统计学分析计算题答案
第二单元计量资料的统计推断 分析计算题 2.1某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表 4: 表4某年某地健康成年人的红细胞数和血红蛋白含量 指标性另U例数均数标准差标准值* 红细胞数/1012L-1男360 4.660.58 4.84 女255 4.180.29 4.33 血红蛋白/g L-1男360134.57.1140.2 女255117.610.2124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值 (若测定方法相同)? 2.1 解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV)比较二者的变异程度。 S 0 29 女性红细胞数的变异系数CV = 100% —9 100% 6.94% X 4.18 女性血红蛋白含量的变异系数CV 2 100%竺2100% 8.67% X 117.6 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误S X来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误S X -5-。竺0.031 (1012/L) J n 7360 5 7 1 男性血红蛋白含量的标准误S X丁丁一0.374 (g/L) J n V360
可视为大样本。 未知,但n 足够大,故总体均数的区间估计按 该地男性红细胞数总体均数的 95%可信区间为: (4.66— 1.96 0.031 , 4.66+ 1.96 E .031),即(4.60,4.72)1012/L 。 该地女性红细胞数总体均数的 95%可信区间为: (4.18— 1.96 0.018,4.18+ 1.96 0.018), 即(4.14,4.22)1012/L 。 (4)两成组大样本均数的比较,用 u 检验。 1) 建立检验假设,确定检验水准 H 0: 1 2 ,即该地健康成年男、女血红蛋白含量均数无差别 H 1: 1 2 ,即该地健康成年男、女血红蛋白含量均数有差别 0.05 2) 计算检验统计量 3) 确定P 值,作出统计推断 查t 界值表(尸呦寸)得PV0.001,按 0.05水准,拒绝H 。,接受H 1,差别 有统 计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同, 男性高 于女性。 (5)样本均数与已知总体均数的比较,因样本含量较大,均作近似 u 检验。 1)男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准 女性红细胞数的标准误S X S 0.29 ?、n .255 0.018(10 /L ) 女性血红蛋白含量的标准误 S X S 10.2 、、n . 255 0.639 (g/L ) (3)本题采用区间估计法估计男、 女红细胞数的均数。样本含量均超过100, (X u /2S X , X u /2S X )计算。 134.5 117.6 22.829 u X 1 X 2 2 2 7.1 10.2 360 255