spss实验课论文
实验课论文
第一章
1、SPSS文件和普通的数据文件有何异同?
不同之处:1:从数据的录入来说,spss要先定义变量名、变量类型、名称、取值范围、数据长度等数据信息,然后在根据问卷录入数据,而普通的数据文件则只能定义变量名,然后再录入数据。所以spss数据文件中可以查看到变量名、变量类型、名称、取值范围、数据长度等数据信息,而普通数据文件不行。2:spss有两个窗口,一个是变量定义窗口,一个是数据窗口,而普通的只有一个窗口。
相同之处:1:都是以表格的形式表现 2:都可以进行简单的数据计算 3:都可以直接看到变量名
2、SPSS对一手数据和二手数据的录入有没有不同?如何处理这两类数据?
一手数据需要人工机械的录入
二手数据可直接通过已获取的资料整体录入或整体打开
第二章
1、变量预处理的作用是什么?
变量预处理的作用:将要处理的变量进行计算、计数、重复值等处理,使其做好变量分析前的准备工作。
使数据更加有规律,便于进行数据的计算与分析。
2、变量预处理中关于数据的操作主要有哪些?关于变量的操作主要有哪些?都是通过哪些SPSS功能来实现的?
处理中关于数据的操作有:1、数据文件的整理、2、数据的排序、3、数据分类汇总、4、数据的拆分、选取和加权5、数据的计数
处理中关于变量的操作有: 1、变量的重复值
第三章
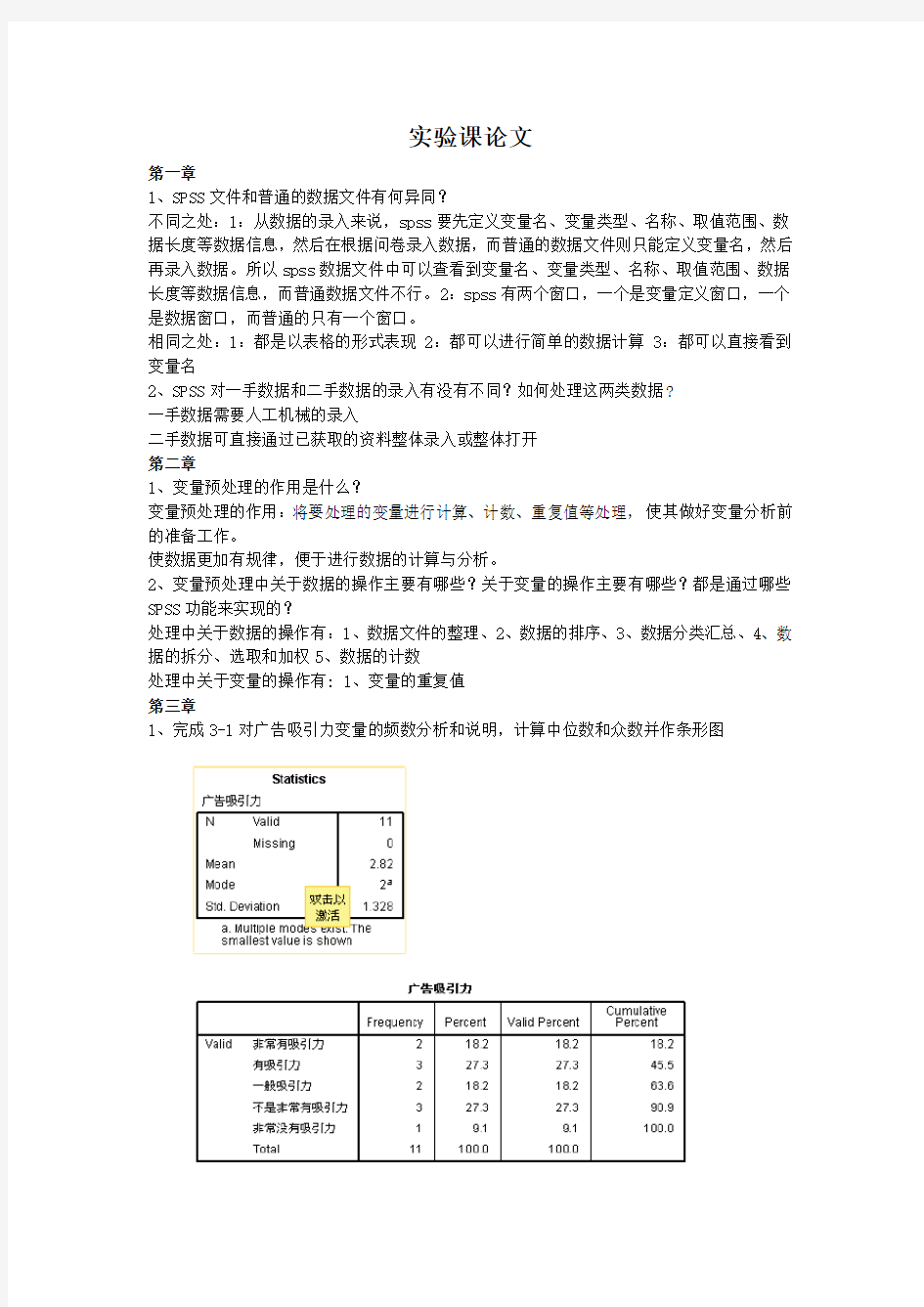
1、完成3-1对广告吸引力变量的频数分析和说明,计算中位数和众数并作条形图
表中给出了总样本量(N),其中变量Gender 的有效个数(Valid)为11 个、缺失值(missing)为0.,Frequency 是频数,Percent 是按总样本量为分母计算的百分比,Valid Percent 是以有效样本量为分母计算的百分比,Cumulative Percent 是累计百分比。
2、完成3-2度量尺度变量“通话时长”按照3分钟进行分组,完成变量重赋值和频数分析,运用P-P图检验数据是否服从正态分布
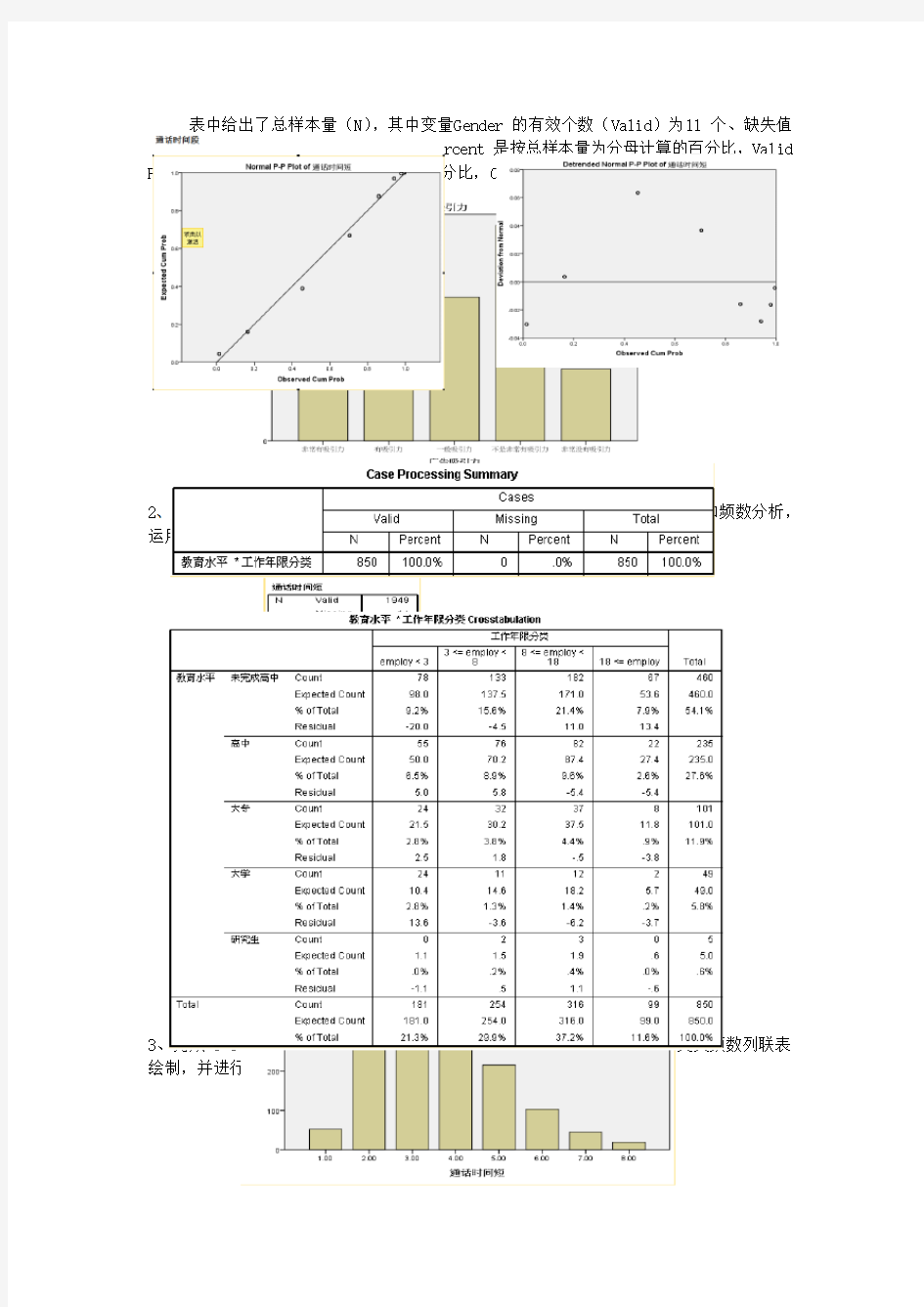
3、完成3-3“教育”与“工作年限”以及“工作年限”与“居住年限”的交叉频数列联表绘制,并进行变量显著性检验。
第四章
1、问卷调查的一般步骤是什么
(1)市场调查
(2)问卷设计
(3)问卷代表性检验
(4)问卷的发放与回收
(5)问卷分析
2、问卷设计中需要注意哪些问题?
(1)考虑目标人群的划分,不同的调查人群对问题的理解会有差异,故明确目标人群对调查问题的设计有显著的影响。
(2)要根据不同的访谈类型设计问卷
(3)避免问卷问题的重复
(4)要避免不愿回答的问题,需要考虑调查对象需要付出的努力、情景、合理的目的、敏感信息等因素,增加调查对象的自愿性。
(5)确认问卷页面的形式和版面设计
(6)预调查
3、利用SPSS完成4-1折半信度系数的计算并进行解释
折半信度系数为0.355,基于标准的折半信度系数为0.579,信度系数偏小,需要修改
第五章
1、检验数据5-1.sav中,人均职工工资是否等于1500元。
a>0.05,接受原假设。人均职工工资等于1500元。
2、5-4.sav,是关于减肥饮茶前后的体重情况,请选择合适的假设检验方法说明减肥茶是否有效果。
前两个表给出了喝茶前后人体重的均值、标准差、均值标准误差以及培训前后成绩的相关系数。从表中看出,喝茶前后体重发生显著的变化。
最后一个表给出了配对样本t检验结果,包括配对变量差值的均值、标准差、均值标准误差以及差值的95%置信度下的区间估计。当然也给出了最为重要的t统计量和p值。结果显示p=0.000<0.05,所以,喝此减肥茶对人的体重具有显著效果。
第六章
1、参数方法和非参数方法有哪些不同?
区别:
第一:从应用范围来看,非参数方法的应用范围要大于参数方法,因为对于随机变量而言,我们了解的永远是少数,许多非常见和非规则的分布是不宜用参数方法来研究的,甚至有些分布都不能写出分布函数或密度函数,只能靠计算机迭代推导其取值概率,而非参数分布不需要假定总体分布,直接从样本出发,因此,任何分布都可以用非参数的方法进行研究,这也决定了非参数方法的应用范围更广。
第二:研究的对象和目标不同,由于参数方法假定了总体的分布,因此其研究目标就是总体的参数,一旦总体的参数全部确定了,总体的分布也就确定了;而非参数的方法直接从样本推导总体的分布,因此非参数方法的目标是总体的分布或者两个总体的分布是否相同。
第三:研究的统计量有所不同,非参数方法中常常采用秩、秩和等来构造统计量,而且通常要求样本数较大,而参数检验很少用到秩来构造统计量,无论样本数大小都能对总体进行推断。
第四:两者的效率有差距,参数方法由于直接假定总体的分布,当总体真实分布就是假定分布或者与假定分布差异不大时,参数方法的准确性很好、效率较高;而非参数方法由于从样本出发,推导出的总体分布可能与真实分布的总体分布有一定的差距,因而效率较低;
但是,当假定的分布不是总体的真实分布时,非参数方法效率要高于参数方法。非参数方法的效能不断提高,有些方法的效能大约在参数方法的95%左右,因此,并非低到不能接受。
2、非参数检验的条件
第一:检验样本是否服从某一分布;
第二:对样本和总体比例的拟合优度进行检验;
第三:当总体分布未知时,通过样本比较两个总体的分布是否相同;
第四:样本数据不确定或样本是分类数据时。
参数检验的应用条件:
检验总体中的某一参数,不涉及总体的分布的检验。参数检验既可以应用于大样本情况,也可以应用于小样本情况。
3、总结分类方法的应用背景和检验灵敏度情况
(1)单样本分布比例的卡方检验:
卡方检验是一个单总体的非参数检验,是检验样本频数和总体的理论比例是否有显著差异。(2)单样本的二项分布检验:
单样本的二项分布检验主要用于检验一个总体中的比率是否等于待检验值p,通过检验样本是否服从一个参数为p的二项分布,即可得到总体的比例是否为p。
(3)单样本K-S检验:单样本K-S检验,该方法能够利用样本数据推断总体是否服从某一理论分布,也是一种拟合优度的检验方法,适合探索连续性总体的分布。
(4)单样本独立性的游程检验
判断一种现象的发生与否是否随机,可以利用非参数检验的游程检验来完成。游程检验通过对样本变量值的分析,实现对总体的变量值出现是否随机进行检验。
(5)两独立样本和两配对样本的非参数检验
两独立样本非参数检验是在总体分布不太了解的情况下,通过对两组独立样本的分析来判断两个总体的分布是否存在显著差异的统计方法。
两配对样本的McNemar检验:是一种变化显著性检验,它将研究对象自身作为对照者检验其“前后”的变化是否显著。
两配对样本的符号检验:符号检验也是用来检验两配对样本所来自的总体的分布是否存在显著差异的非参数方法。
两配对样本的Wilcoxon符号秩检验:Wilcoxon符号秩检验也是通过分析两配对样本,对样本来自的两总体的分布是否存在差异进行判断。
(6)多独立样本和多配对样本非参数检验
多独立样本中位数检验:中位数检验通过对多组独立样本的分析,检验它们来自的总体的中位数是否存在显著差异。
多独立样本Kruskal-Wallis检验:Kruskal-Wallis检验实质是两独立样本的曼-惠特尼U检验在多个样本下的推广,也用于检验多个总体的分布是否存在显著差异。
多独立样本的Jonckheere-Terpstra检验:Jonckheere-Terpstra检验也是用于检验多个独立样本来自的多个总体的分布是否存在显著差异的非参数检验方法。
SPSS中的多配对样本的非参数检验方法主要包括Friedman检验、Cochran Q检验、Kendall 协同系数检验等。
Friedman检验:Friedman检验是利用秩实现对多个总体分布是否存在显著差异的非参数检验方法
Cochran Q检验:通过对多个配对样本的分析,推断样本来自的多个总体的分布是否存在显著差异。
Kendall协同系数检验:它也是一种对多配对样本进行检验的非参数检验方法,与第一种检
验方法向结合,可方便地实现对评判者的评判标准是否一致的分析
4、3.6-8数据,选择合适的检验方法,检验产品的合格率是否在90%以上?
第七章
光盘数据文件7-2.sav是某大学讲座满意度的市场调查问卷数据集,请对此问卷中的多选项问题Q2、Q18、Q20、Q22等定义多选项集
第八章
8-4.sav,分别以广告方式和销售地区作为控制变量进行单因素方差分析
第九章
1、三个相关系数适用的条件是什么,它们各有什么特点,在应用中如果有极端值,应该采用哪种?
(1)Person简单相关系数:
特点: x与y对称,x、y变量互换位置,r不变;
无量纲数,r是标准化后计算的;
简单相关系数只能刻画线性相关关系,不能很好刻画非线性关系。
(2)Spearman等级相关系数
Spearman等级相关系数的特点:如果两变量正相关性较强,他们秩变化同步,则D值较小,等级相关系数趋于1;如果两变量负相关性较强,他们秩变化相反,则D值较大,等级相关系数趋于-1;如果两变量相关性较弱,他们秩变化互不影响,则D值趋于中间值,等级相关系数趋于0。
(3)kendall τ相关系数:
性质:如果两变量正相关性强,秩同步变化,U应该比较大,V应该比较小,τ趋于1;如果两变量负相关性强,秩变化相反,U比较小,V比较大,τ趋于-1;如果相关关系弱,则U、V大致相等,τ趋于0.
2、偏相关分析和简单相关分析有什么差异,中间变量对相关性的影响如何体现?
进行偏相关分析的变量必须是正态分布,各因素之间应该有关联。只有除去其他变量的影响后再计算相关系数,才能真正反映他们之间的相关关系。
3、计算数据12-1.sav中各变量两两之间的三种相关系数,并说明三者的差异。
4、仍用12-1.sav 数据,在扣除食品消费这个中间变量因素后,计算杂项商品和服务消费与家庭设备用品与服务两变量的偏相关系数,并进行解释。
描述性统计量
均值 标准差 N
杂项商品和服务 243.0442 88.05712 31 家庭设备用品与服务 395.9865 179.92764 31 食品
1980.6603
586.88616
31
结果解释:在扣除食品消费这个中间变量因素后,杂项商品和服务消费与家庭设备用品与服
务的相关性是0.161,相关性非常不明显。显著性是0.392,大于0.05的置信区间。所以,杂
项商品和服务消费与家庭设备用品与服务不存在显著的线性相关关系。
第十章
1、10-5.sav,进行一元回归和多元逐步回归,并解释结果。
一元线性回归分析:
输入/移去的变量a
模型输入的变量移去的变量方法
1 投入高级职称
的人年数b
. 输入
a. 因变量: 投入人年数
b. 已输入所有请求的变量。
模型汇总b
模型R R 方调整 R
方标准估计的
误差
Durbin-Watso
n
1 .988a.976 .975 257.3208 1.703
a. 预测变量: (常量), 投入高级职称的人年数。
b. 因变量: 投入人年数
Anova a
模型平方和df 均方 F Sig.
1 回归78215429.780 1 78215429.780 1181.25
2 .000b 残差1920205.575 29 66213.985
总计80135635.355 30
a. 因变量: 投入人年数
b. 预测变量: (常量), 投入高级职称的人年数。
系数a
模型非标准化系数标准系数t Sig.
B 标准误
差
试用版
1 (常量) 136.326 74.495 1.830 .078 投入高级职称的人年
数
1.940 .056 .988 34.369 .000
a. 因变量: 投入人年数
残差统计量a
极小值极大值均值标准偏差N
预测值182.888 7386.461 2144.387 1614.6767 31
残差-591.4615 617.6022 .0000 252.9958 31
标准预测
值
-1.215 3.247 .000 1.000 31
标准残差-2.299 2.400 .000 .983 31
a. 因变量: 投入人年数
结果解释:在模型汇总中,数据R方为0.976,R接近1,说明Y与X之间的线性相关关系程度很高,也说明模型的拟合优度很好。Durbin-Watson为1.703,接近2。在Anova分析中,显著性水平接近0,说明模型拟合优度很好。在系数中,常量为136.326,投入高级职称的人年数系数为1.940。即,投入高级职称的人年数增加1.940个单位,因变量投入人年数可以增加1个单位。
多元线性回归分析:
模型汇总c
模型R R 方调整 R
方标准估计的
误差
Durbin-Watso
n
1 .988a.976 .975 257.3208
2 1.000b 1.000 1.000 .0000 1.552
a. 预测变量: (常量), 投入高级职称的人年数。
b. 预测变量: (常量), 投入高级职称的人年数, Unstandardized
Residual。
c. 因变量: 投入人年数
Anova a
模型平方和df 均方 F Sig.
1 回归78215429.780 1 78215429.780 1181.25
2 .000b 残差1920205.575 29 66213.985
总计80135635.355 30
2 回归80135635.355 2 40067817.677 . .c 残差.000 28 .000
总计80135635.355 30
a. 因变量: 投入人年数
b. 预测变量: (常量), 投入高级职称的人年数。
c. 预测变量: (常量), 投入高级职称的人年数, Unstandardized Residual。
系数a
模型非标准化系数标准系数t Sig.
B 标准误
差
试用版
1 (常量) 136.326 74.495 1.830 .078 投入高级职称的人年数 1.940 .056 .988 34.369 .000
2 (常量) 136.326 .000 16572223.762 .000 投入高级职称的人年数 1.940 .000 .988
311244009.09
5
.000 Unstandardized
Residual
1.000 .000 .155 4876729
2.627 .000
a. 因变量: 投入人年数
结果分析:在模型汇总中,模型2的调整R方为1,大于模型1的调整R方为0.975。说明模型可解释变异占总变异的比例越来越大,引入方程的变量轴距是显著的。根据模型1建立多元线性回归方程为投入人年数=136.326+1.940*投入高级职称的人年数+轴距。第十二章
Logistic回归的应用条件是什么?
误差独立,且同分布于二项分布,因为误差不再服从正态分布,不再使用最小二乘法而
采用极大似然估计回归参数;误差与自变量独立;自变量之间相互独立,即不存在多重共
线性;模型需要较大的样本量,模型能解释的自变量个数与样本量有关,因变量中样本量
较小的分类的样本数除以10,就是大概的模型最多能解释的自变量个数
Logistic回归的结果解释时应该注意什么问题?
块0表示给出的模型是不含任何自变量、自变量取值为0、只有常数项时的输出结果。
块1开始输出模型中引入自变量的结果,采用的是进入方法。
Step:该统计量为每一步与前一步的似然比检验结果;
Block:该统计量为块1和块0的似然比检验结果;
Model:该统计量是上一模型中的变量拟合效果和现在模型中变量拟合效果的似然比检验结
果、
第十三章
1.距离和相关系数在描述相似性方面有哪些不同?
距离:每个样本都有p个变量值,因此每个样本可以看成p维空间中的点,两个样本就是空间中的两个点,根据空间的性质就可以定义距离,距离小时,说明两个点接近,
在聚类时应该分在同一类;相反,距离大时,说明两个点差异明显,不相似,分类
时应该分在不同的类。归纳起来就是距离越小,样本越相似。
相关系数:在对变量进行聚类时,一般不采用距离,而是用相似系数度量变量相似性。变量之间的相似性度量,一般看相似系数的绝对值大小,绝对值越大,相似性越高;
反之,绝对值越小,则相似性越弱。聚类时,要求相似性高的变量分为一类,而相
似性弱的变量分到不同的类。
2.动态聚类的基本思想和流程是什么?
算法思想分析输入:聚类个数k,以及包含n个数据对象的彩色图片。输出:满足方差最小标准的k个聚类。处理流程:
(1)从n个数据对象任意选择k 个对象作为初始聚类中心;
(2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3)重新计算每个(有变化)聚类的均值(中心对象);
(4)循环(2)到(3)直到每个聚类不再发生变化为止。
3.多种层次聚类方法聚类流程是否相同?层次聚类方法的差异体现在何处?
不相同,最短距离:两类样品两两之间的距离最小值作为两类的距离。
最长距离:两类样品两两之间的距离最大值作为两类的距离。
组间平均连接:两类间样品距离的平均距离作为两类间的距离。
组内平均连接法:两类所有样品(包括组内与组间)距离的平均距离作为两类间的距离。
重心法:两类均值点间的距离作为两类间的距离。
离差平方和法(Wald):两类合并所产生的离差平方和的增量作为两类间的距离。
第十五章
用因子分析法分析我国部分省市城市发展情况
第一行为检验变量间偏相关程度的KMO统计量,其值为0.604在0.6以上,所以适合做因子
分析。
下面三行是球形检验结果,原假设是变量不相关,Sig=0.005<0.05,拒绝原假设,所以适合
做因子分析。
由公因子方差可知,每个变量的共同度都比较高说明因子分析的结果比较好。
前两个因子的累计贡献率达到85%,满足因子个数对累计贡献率的要求,因此,可以选择两个因子。同时在表中还注意到,旋转以前和旋转以后虽然因子总方差贡献没变,但是单个因子方差贡献率发生了很大变化。第一个因子的贡献率由58%减少到50%,而第二个因子贡献率由26%增加到35%。
未旋转的因子载荷矩阵
43211347.2500.0347.2753.0347.2884.0347.2865.0X X X X F -++= 43212037.1827.0037.1548.0037.1209.0037.1215.0X X X X F ++-=
旋转以后的因子载荷矩阵,归纳如下:
因子1上载荷较大的变量:经济、教育、健康; 因子2上载荷较大的变量:居住环境。
因此建立因子分析模型:
211256.0854.0F F Z -= 212631.0653.0F F Z -=
213087.0927.0F F Z +=
214966.0008.0F F Z +-=
求得因子得分函数为:
151********.158.112.1......15.151.1z z z z z F ---++= 151********.048.032.0......01.198.0z z z z z F -+----=
由此计算15个城市的主因子得分:
因此 北京、上海等地发展水平较高,贵州、青海等地则发展水平较低。 功能介绍:数据管理功能和完善的结果报告功能 1、数据管理
1)超长变量名:变量名最多可以为64个字符长度,可能还要大大放宽这一限制,以达到对当今各种复杂数据仓库更好的兼容性。 2)改进的Autorecode 过程:该过程将可以使用自动编码模版,从而用户可以按自定义的顺序,而不是默认的ASCII 码顺序进行变量值的重编码。另外,Autorecode 过程将可以同时对多个变量进行重编码,以提高分析效率。
3)改进的日期/时间函数:本次的改进将集中在使得两个日期/时间差值的计算,以及对日期变量值的增减更为容易上。 2.完善的结果报告功能
对数据和结果的图表呈现功能一直是SPSS 改进的重点。SPSS 推出了全新的常规图功能,报表功能也达到了比较完善的地步。将针对使用中出现的一些问题,以及用户的需求对图表功能作进一步的改善。
1)统计图:在经过一年的使用后,新的常规图操作界面已基本完善,本次的改进除使得操作更为便捷外,还突出了两个重点。首先在常规图中引入更多的交互图功能,如图组(Paneled charts ),带误差线的分类图形如误差线条图和线图,三维效果的简单、堆积和分段饼图等。其次是引入几种新的图形,目前已知的有人口金字塔和点密度图两种。
2)统计表:几乎全部过程的输出都将会弃用文本,改为更美观的枢轴表。而且枢轴表的表现和易用性会得到进一步的提高,并加入了一些新的功能,如可以对统计量进行排序、在表格中合并/省略若干小类的输出等。此外,枢轴表将可以被直接导出到PowerPoint 中,这些
无疑都方便了用户的使用。
spss基本描述性统计实验指导
一、实验目的 1.熟悉SPSS软件其它数据预处理; 2.掌握数据的频率分析与基本统计分析; 二、实验容 1、对“职工数据”进行转置; 2、对“居民储蓄数据”中户口和职业作出频数统计,并画出饼图 3、对“居民储蓄数据”中存款金额分成五组分别为小于500元、501~2000元、2001~3500 元、3501~5000元、5000元以上,形成新的变量,并做出频数统计与直方图。 4、“居民储蓄数据”中“存款金额”对城镇户口与农村户口分别做出平均值、标准差、偏 度与峰度统计量。 三、实验步骤 1、对“职工数据”进行转置; 1)通过菜单“数据” “转置”如图一所示,进入图二所示的界面, 2)把“关键变量”职工号选入“名称变量”框中,使职工号成为变量名称,其余变量选入“变量”框中如图三所示 3)点击“确定”按钮,出现如图四所示结果。 图一进入转置界面
图二转置界面 图三转置操作 图四输出结果 2、对“居民储蓄数据”中户口和职业作出频数统计,并画出饼图 1)如图五所示进入频率分析界面 2)在图六所示的界面中,选择频率分析变量“户口”与“职业”,并选中左下角的“显示频率表格”
3)点击图六的“图表”按钮,出现如图七的界面,选择“饼图”4)点击“确定”按钮,出现如图八分析结果。 图五进入频率分析
图六选择频率分析变量 图七选择输出图表 户口 频率百分比有效百分比累积百分比 有效城镇户口223 71.2 71.2 71.2 农村户口90 28.8 28.8 100.0 合计313 100.0 100.0 职业 频率百分比有效百分比累积百分比 有效国家机关27 8.6 8.6 8.6 商业服务业73 23.3 23.3 31.9 文教卫生14 4.5 4.5 36.4 公交建筑业17 5.4 5.4 41.9 经营性公司26 8.3 8.3 50.2 学校22 7.0 7.0 57.2 一般农户43 13.7 13.7 70.9 种粮棉专业户 6 1.9 1.9 72.8 种果菜专业户9 2.9 2.9 75.7 工商运专业户17 5.4 5.4 81.2 退役人员17 5.4 5.4 86.6 金融机构38 12.1 12.1 98.7
SPSS实验报告_线性回归_曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
SPSS实验报告(一)
SPSS实验报告(一)
湖南涉外经济学院 实验报告 课程名称:应用统计软件分析(SPSS) 专业班级: 姓名 学号: 指导教师: 职称:副研究员 实验日期: 2016.4.19 成绩评定指导教 师 签字 签字 日期
学生实验报告实验序号 一、实验目的及要求 实验目的 通过本次实验,使学生熟练掌握转换菜单和数据菜单的具体功能及操作,熟练应用两个菜单中的计算变量、重新编码、选择个案、个案排序、分类汇总等几个主要过程 实验要求 能够根据相关要求选用正确的过程对变量或者文件进行管理和操作,得到结果,并能对得出的结果进行解释。 二、实验描述及实验过程 实验描述一、下载数据(以下情况选一种): (一)分地区(31个省市区)环境污染治理投资数据(2014年) 环境污染治理投资总额(亿元),城市环境基础设施建设投资额(亿元) ,城市燃气建设投资额(亿元) ,城市集中供热建设投资额(亿元),城市排水建设投资额(亿元),城市园林绿化建设投资额(亿元),城市市容环境卫生建设投资额(亿元)
工业污染源治理投资(万元) 建设项目“三同时”环保投资额(亿元) (二)分地区(31个省市区)经济发展总体数据(2014年) 国民总收入,国内生产总值,第一产业增加值,第二产业增加值,第三产业增加值,人均国内生产总值,人口总量,城镇失业率,基尼系数等 (三)各省市房地产开发2014年相关数据 投资额,房地产开发企业个数,从业人员数,收入,税金,利润,资产,负债,平均销售价格,等等。 (四)各省市科技2014年相关数据 包括GDP,研发投入,研发投入强度(研发投入/GDP),R&D研发人员,专利授权数,发明专利授权量。 (五)查找相关行业(钢铁行业、水泥行业、医药制造、工程机械、汽车制造业、旅游酒店行业、航空、电子商务企业等)上市公司2015年度数据。包括销售收入、利润、固定资产净值、总资产利润率、营业利润率、销售净利率、净资产收益率、流动比率、资产负债率、主营业务收入增长率、营收账款周转率、存货周转
多元线性回归SPSS实验报告
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
SPSS实验报告
SPSS实验报告要求 1、为减小文字工作量,提升实验报告要求,每次上课只需要选择一个实验写报告即可,最终上交的实验报告统一命名为实验一、二……六。每个实验下面有超过二个小实验的,只需选择二个定实验报告。 2、实验报告统一使用WORD文档,建议使用宋体五号字,统一装订后,第十八周周五上午交。 3、实验报告参照以下模板
SPSS统计分析与应用 实验报告 班级:社会工作13 学号: 姓名: 学期:2015-2016学年第二学期
实验一建立与编辑数据文件 实验时间:2016-5-26 地点:实验楼2栋4楼 一、实验目的 1、理解数据文件的原理和方法; 2、 3、 二、实验内容 **************************************************************************** ******************************************************************************* ******* 三、实验步骤 1、建立数据文件 简要描述即可 ******************************************************************************* ******************************************************************************* **** 2、选择个案 简要描述即可 ******************************************************************************* ******************************************************************************* **** 四、实验结果 1、建立数据文件 **************************************************************************** ******************************************************************************* ******* 2、选择个案 ****************************************************************************
spss软件分析异常值检验实验报告
实验五:残差分析 【实验目的】 (1)通过残差检验,掌握残差分析的方法 (2)异常值检验 【仪器设备】 计算机、spss软件、何晓群《实用回归分析》表和表的数据 【实验内容、步骤和结果】 对何晓群《实用回归分析》表的数据进行残差分析 原始数据如表1,其中y表示货运总量(亿吨)x1表示工业总产值(亿元)x2表示农业总产值(亿元)x3表示居民非商业支出(亿元) 表1. 对表1数据用spss软件进行分析得以下各表
由上表可知复相关系数R=,决定系数R方=,由决定系数看出回归方程的显著性不高,接下来看方差分析表3 由表3知F值为较小,说明x1、x2、x3整体上对y的影响不太显著。 表4系数 模型非标准化系数标准系数 t Sig. B标准误差试用版 1(常量).096 x1.385.100 x2.535.049 x3.277.284
表4系数 模型 非标准化系数 标准系数 t Sig. B 标准 误差 试用版 1 (常量) .096 x1 .385 .100 x2 .535 .049 x3 .277 .284 回归方程为 123348.280 3.7547.10112.447y x x x =-+++
图1.学生化残差
差 残差: 对数据用spss进行分析得 表6异常值的诊断分析
数据不存在异常值.绝对值最大的删除学生化残差为SDR=,因而根据学生化删除残差诊断认为第6个数据为异常值.其中中心化杠杆值,cook距离为位于第一大.因此第6个数据为异常值. 对何晓群《实用回归分析》表的数据进行残差分析 原始数据为 : 表个啤酒品牌的广告费用和销售量
Spss实验总结
本学期一共学习了七项spss使用方法,分别是数据整理、数据的转换、t检验、方差分析、卡方检验、相关分析与回归方程、图表的制作与编辑。 我觉得spss对我用处非常大,就平时学习来说,我用它计算了几道生物统计题,完成了spss作业和数学建模作业。因为实验指导书有几个实验实验方法与步骤很不详细,我还练习了写实验方法与步骤,但在写实验感受方面还有所欠缺。统计学是一门研究随机事件的学科,这类偶然现象是遵循统计规律的,当随机现象是由大量的成份组成,或者随机现象出现大量的次数时,就能体现统计平均规律。我们只有对数据资料作统计处理,才可能发现它们的内在规律,掌握现象的特征,检验研究的假设,才能得出准确的、可靠的研究结果。 每次实验我开始时都觉得很难,很多时候是因为不知道怎么做表格,比如做卡方检验的时候要交叉值表,一开始我都一直是认为应该把不同因素和不同水平放到不同列里,之后才发现同一因素要写在同一列里,然后在另一列里些他们的水平,这样就会被自动分开。相关分析我到现在还有一点不明白。相关分析和回归方程里的那几道题那些应该用相关分析做,那些应该用回归方程做,当然这是统计学方面的问题了。我以后还要加强对实验结果的解读能力,spss给出的计算结果往往有双侧sig.值等,而我还不太会查表(有个别不清楚查那个表),所以一些题目没有写最终分析。 Spss作为一个工具,本身并无太多原理可言,主要是掌握它的使用方法。 数据输入主要是分为数据列表和变量列表。和excel最不一样的是变量列表。变量列表可以对变量名,变量类型作出规定。而这些尤其是变量类型对后续的统计分析工作有很大影响。 数据整理很重要的一点是排序。Spss可以先按一个变量排,再在此基础上按另一个变量排。这是我以前不了解的一个功能。1.在数据文件中单击菜单项“Data→Sort Cases”,在变量列表中选定按哪(几)个变量的值排序,并用箭头按钮将其移入Sort by矩形框中,单击按纽即会对数据文件中的case进行排序。排列的顺序为:先按第一个变量的值排序,第一个变量的值相同的case按第二个变量排序,依次类推。2.再说变量的转换问题。选择菜单项“Transform→Compute”,在左上方的矩形框中输入要计算的变量(原有的变量和新变量都可以),在右上方的矩形框中输入数学表达式,单击OK按钮即可完成计算。左下方的矩形框中是当前数据文件的变量列表,右下方的矩形框中是SPSS可以使用的函数,选中后都可以用箭头按钮将其移入数学表达式框中,以代替键盘输入。在左上方的矩形框中输入要计算的变量后,可以单击“Type&Label”按钮,对变量进一步进行定义。3.如果要对数据重新编码,则选择菜单项“Transform→Record→Into Same Variables”,在左边的变量列表中,选中要重新编码的变量并将其移入右边的矩形框中(若选入多个,将一次性对其作相同的处理,而不是逐个处理),单击“if”按钮选择要进行重新编码的case(方法同前),然后单击“Old and New Values”按钮,将弹出如下定义新旧变量值关系的对话框,然后在“New Value”框中设定对应的新值。 均数比较(t检验):1.单样本t检验用于一个样本的均数检验,即检验某样本的总体均数是否等于某一特定值。选择菜单项“Analyze→Compare Means→One-sample T test”,把想要检验的变量移入“Test V ariables”框中,在“Test Value”后面的输入框中输入要检验的值即可。2.配对样本t检验中的配对样本可以是个案在前后两种状态下某种属性的两种状态,也可以是对某事物两个不同侧面或方面的描述。其差别在于抽样不是相互独立的,而是互相关联的。选择菜单项“Analyze→Compare Means→Paired-samples T test”,左边矩形框中是变量列表,同时选中两个配对的变量(按住Ctrl键单击),用箭头按钮将变量对移入右边的Paired Variable框。3.独立样本t检验操作方法与配对样本t检验类似,只是成组样本之间是
实验指导一:spss简介(数据与画图)
实验一 一、实验目的: 1.掌握SPSS的数据编辑功能 利用SPSS的数据编辑器窗口,可以对打开的数据文件进行增加、删除、复制、剪切和粘贴等一般性操作,还可以对数据文件中的数据进行顺序、转置、拆分、聚合、加权等操作,对多个数据文件可以根据变量或个案进行合并。可以根据需要把将要分析的变量集中到一个集合中,打开时指定打开该集合,而不必打开整个数据文件。 2.掌握表格的生成和编辑 利用SPSS可以生成数十种风格的表格,利用编辑窗口或监视器可以编辑所要生成的表格。在SPSS的高级版本中,统计成果多被归纳为表格或图形的形式。 3.掌握图形的生成和编辑 利用SPSS可以生成数十种基本图形和交互式图形。其中基本图形包括条形图、线形图、面积图、圆饼图、高低图、帕雷托图、控制图、箱形图、误差条形图、散点图、直方图、ROC曲线图、P-P概率图、Q—Q图、序列图和时间序列图等。交互式图形比基本图形更漂亮,可有不同风格的2D、3D图形。交互式图形包括条形交互作用图、点形交互作用图、线形交互作用图、带形交互作用图、圆形交互作用图、箱形交互作用图、误差条形交互作用图、直方交互作用图和散点交互作用图等。 4.会用SPSS的简单统计功能 (1)摘要性分析摘要性分析是对原始数据进行描述性分析,是统计工作的出发点。统计学的一系列基本描述指标,不仅让人了解资料的特征,而且可启发人们对之作进一步的深入分析。SPSS统计软件通过调用摘要性分析,可完成均数、标准差、标准误差等指标的 计算,对于计数和一些等级资料,可完成构成比率等指标的计算和 2 检验。SPSS的摘要性 分析包括以下几个过程: 1) Frequencies(频数)过程调用此过程可进行频数分布表的分析。频数分布表是描述性统计中最常用的方法之一,此外还可对数据的分布趋势进行初步分析。 2) Descriptives(描述)过程调用此过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,且可将原始数据转换成标准Z分值并存人数据库。 3) Explore(探索)过程调用此过程可对变量进行更为深入详尽的描述性统计分析,即探索性统计。它是在一般描述性统计指标的基础上,增加有关数据其他特征文字与图形描述,有助于思考对数据进行分析的方案。 二、实验指导 (一)SPSS的启动与主窗口 1.SPSS的启动 SPSS安装完毕后,系统会自动在Windows(窗口)菜单中创建快捷方式。单击Windows 的“开始”按钮,在“程序”菜单的SPSS for Windows中找到SPSS l3.0 for Windows并单击,即可启动SPSS。 2.SPSS数据编辑窗口 SPSS主界面有两个,一个是SPSS数据编辑窗口,另一个是SPSS结果输出窗口。 SPSS的数据编辑窗口由标题栏、菜单栏、工具栏、编辑栏、变量名称栏、内容区、窗
回归分析实验报告
实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日
一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1)
图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏
5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。
spss实验课
1、启动及关闭SPSS 1.1启动SPSS 1.2关闭SPSS 或者是点击界面右上角的中的
2、界面初识 2.1进入的初始界面 单击Cancel或是选择Type in data进入数据编辑窗口 2.2各大窗口的介绍 每个窗口都有各自得菜单、功能按钮实现自己的各项功能,具体的说明在今后应用时再具体涉及,在此首先只介绍数据窗口。
3、数据的录入和编辑 单击Cancel或是选择Type in data进入数据编辑窗口: 3.1在Variable View选项卡中定义和编辑变量的属性 输入数据之前首先要定义变量,定义变量的步骤如下: (1)单击Variable View选项卡,使数据编辑窗口置于定义变量的状态,每行定义一个变量 (2)定义变量名,光标置于Name列的空单元格中,输入变量名,如下表中的no,gender… (3)定义变量的默认属性值 ·Type:变量类型,默认类型就是数值型 ·Width:变量长度,默认长度为8 ·Decimals:小数位数,默认小数位数为2 ·Lable:变量标签,用户自定 ·Values∶值标签,用户自定 ·Missing:缺失值,用户自定 ·Columns:列宽,变量一般所占列宽默认为是8 ·Align:对齐方式,默认为右对齐 ·Measure:测度方式 注:在定义所有属性值时,都是单击单元格,相应跳出对话框或是删节号或是上下
箭头按钮等,自动调节自己需要的状态。(下表为一个实例) 补充:在Value Labels对话框,Value空格里输入变量值如“0”,在Value Label空格中输入对该值含义的解释如“女生”,单击Add,则一个值标签就被加入到第三个框中。 3.2 数据的录入 在定义完变量之后,单击Data View选项卡,录入数据,基本操作与EXCEL等相似,每一列代表一个变量,每一行代表一个观察值。在此不具体介绍。根据3.1的变量定义得到如下图的数据表: 3.3数据的编辑 3.3.1·:Go to case图标按钮,开打对话框,
实验二--SPSS数据录入与编辑
实验二--SPSS数据录入与编辑
实验二 SPSS数据录入与编辑 一、实验目的 通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.录入数据 2.保存数据文件 3.编辑数据文件 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗 4.按要求录入数据 5.联系基本的数据修改编辑方法 6.保存数据文件 7.关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 一、定义变量 1.试录入以下数据文件,并按要求进行变量定义。 学号姓名性 别生日身高 (cm) 体重 (kg) 英语(总 分100 分) 数学(总 分100 分) 生活费 ($代表 人民币) 200201 刘一迪男1982.01.12 156.42 47.54 75 79 345.00 200202 许兆辉男1982.06.05 155.73 37.83 78 76 435.00 200203 王鸿屿男1982.05.17 144.6 38.66 65 88 643.50 200204 江飞男1982.08.31 161.5 41.68 79 82 235.50 200205 袁翼鹏男1982.09.17 161.3 43.36 82 77 867.00 200206 段燕女1982.12.21 158 47.35 81 74 200207 安剑萍女1982.10.18 161.5 47.44 77 69 1233.00 200208 赵冬莉女1982.07.06 162.76 47.87 67 73 767.80 200209 叶敏女1982.06.01 164.3 33.85 64 77 553.90 200210 毛云华女1982.09.12 144 33.84 70 80 343.00 200211 孙世伟男1981.10.13 157.9 49.23 84 85 453.80 200212 杨维清男1981.12.6 176.1 54.54 85 80 843.00 200213 欧阳已 祥 男1981.11.21 168.55 50.67 79 79 657.40 200214 贺以礼男1981.09.28 164.5 44.56 75 80 1863.90 200215 张放男1981.12.08 153 58.87 76 69 462.20 200216 陆晓蓝女1981.10.07 164.7 44.14 80 83 476.80 200217 吴挽君女1981.09.09 160.5 53.34 79 82 200218 李利女1981.09.14 147 36.46 75 97 452.80 200219 韩琴女1981.10.15 153.2 30.17 90 75 244.70 200220 黄捷蕾女1981.12.02 157.9 40.45 71 80 253.00 1)对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。 3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
利用SPSS进行统计检验
第四节利用SPSS进行统计检验 在教育技术研究中,经常需要利用不同的教学媒体或教学资源对不同的对象进行教学改革 试验,但教学试验的总体往往都有较大数量,限于人力、物力与时间,通常都采用抽取一定的 样本作为研究对象,这样,就存在样本的特征数量能否反映总体特征的问题,也存在着两种不 同的样本的数量标志的参数是否存在差异的问题,这就必需对样本量数进行定量分析与推断, 在教育统计学中称为“统计检验”。 一、统计检验的基本原理 统计检验是先对总体的分布规律作出某种假说,然后根据样本提供的数据,通过统计运算,根据运算结果,对假说作出肯定或否定的决策。如果现要检验实验组和对照组的平均数(μ1和μ2)有没有差异,其步骤为: 1.建立虚无假设,即先认为两者没有差异,用表示; 2.通过统计运算,确定假设成立的概率P。 ⒊根据P 的大小,判断假设是否成立。如表6-12所示。 二、大样本平均数差异的显著性检验——Z检验 Z检验法适用于大样本(样本容量小于30)的两平均数之间差异显著性检验的方法。它是 通过计算两个平均数之间差的Z分数来与规定的理论Z值相比较,看是否大于规定的理论Z值,从而判定两平均数的差异是否显著的一种差异显著性检验方法。其一般步骤: 第一步,建立虚无假设,即先假定两个平均数之间没有显著差异。 第二步,计算统计量Z值,对于不同类型的问题选用不同的统计量计算方法。 (1)如果检验一个样本平均数()与一个已知的总体平均数()的差异是否显著。其 Z值计算公式为:
其中是检验样本的平均数; 是已知总体的平均数; S是样本的方差; n是样本容量。 (2)如果检验来自两个的两组样本平均数的差异性,从而判断它们各自代表的总体的差异 是否显著。其Z值计算公式为: 其中,1、2是样本1,样本2的平均数; 是样本1,样本2的标准差; 是样本1,样本2的容量。 第三步,比较计算所得Z值与理论Z值,推断发生的概率,依据Z值与差异显著性关系表 作出判断。如表6-13所示。 第四步,根据是以上分析,结合具体情况,作出结论。 【例6-5】某项教育技术实验,对实验组和控制组的前测和后测的数据分别如表6-14所示,比较两组前测和后测是否存在差异。
SPSS实验指导书
SPSS统计分析软件概述 SPSS(Statistical Package for the Social Science)社会科学统计软件包; SPSS(Statistical Product and Service Solutions)统计产品与服务解决方案。 20世纪60年代末,美国斯坦福大学的三位研究生研制开发了最早的统计分析软件SPSS,并于1975年在芝加哥成立了研发和经营SPSS软件的SPSS公司。随着微型计算机和操作系统的发展,SPSS公司相继推出了17个版本。 SPSS使用基础(安装和启动略) SPSS有两个基本窗口,分别是数据编辑窗口(Data Editor)和结果输出窗口(Viewer)。 数据编辑窗口(Data Editor) 是SPSS的主程序窗口,在软件启动时自动打开,直到退出。运行时只能打开一个数据编辑窗口,关闭该窗口意味着退出。该窗口的主要功能:定义SPSS 数据的结构、录入编辑和管理待分析的数据。SPSS的所有统计分析功能都是针对该窗口中的数据的。这些数据通常以SPSS数据文件的形式保存在计算机磁盘上,其文件扩展名为.sav。数据编辑窗口由窗口主菜单、工具栏、数据编辑区、系统状态显示区组成。 1、窗口主菜单 窗口主菜单将SPSS常用的数据编辑、加工和分析的功能列了出来。
2、工具栏 将一些常用的功能以图形按钮的形式组织在工具栏,使操作更加快捷和方便。 3、数据编辑区 显示和管理SPSS数据结构和数据内容的区域。(数据视图和变量视图) 4、系统状态显示区 显示系统的当前运行状态。 SPSS结果输出窗口(Viewer) 该窗口的主要功能是显示管理SPSS统计分析结果、报表及图形,允许同时创建或打开多个输出窗口。SPSS统计分析的所有输出结果都显示在该窗口中。
spss实验心得体会.doc
spss实验心得体会 篇一:SPSS学习报告总结心得 应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSspss实验心得体会)S也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。最后总结出这篇报告,以巩固所学。 SPSS,全称是StatisticalProductandServiceSolutions,即“统计产品与服务解决方案”软件,是Ibm公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。这门课中也会用到AmoS软件。关于SPSS的书,很多都是首先介绍软件的。这个软件易于安装,我装的是19.0的,虽然20.0有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、
结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是T检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。结果出来后依然分不清楚是接受原假设还是拒绝原假设。不过现在弄懂了。这部分很有用的是T检验。T检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。T检验分为单样本T检验、独立样本T检验、配对样本T检验。其中,单样本T检验是样本均数与总体均数的比较的T检验,用于推断样本所代表的未知总体 均数μ与已知的总体均数uo有无差别;独立样本T检验主要用于检验两个样本是否来自具有相同均值的总体,即比较两个样本的均值是否相同,要求两个样本是相互独立的;配对样本T检验中,要正确理解“配对”的含义,主要用于检验两个有联系的正态总体的均值是否有显著差异,跟独立检验的区别就是样本是否是配对样本。这几个方法用软件操作起来都是相对简单的,关键是分清楚什么时候用这个什么时候用那个。 然后是方差分析。方差分析就是将索要处理的观测值作为一个整体,按照变异的不同来源把观测值总变异的平方和以及自由度分解为两个或多个部分,获得不同变异来源的均值与误差均方,通过比较不同变异来源的均方与误差均方,判断各样本所属总体方差是否相等。方差
spss实验报告心得体会
spss实验报告心得体会 篇一:SPSS学习报告总结心得 应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。最后总结出这篇报告,以巩固所学。 SPSS,全称是Statistical Product and Service Solutions,即“统计产品与服务解决方案”软件,是IBM公司推出的一系
列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。这门课中也会用到AMOS软件。 关于SPSS的书,很多都是首先介绍软件的。这个软件易于安装,我装的是的,虽然有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是T检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东
实验一 spss入门
SPSS是什么? 1968年,美国斯坦福大学三名研究生为解决社会学研究中的统计分析问题,研发了SPSS软件软件包,原意为Statistical Package for the Social Sciences,即“社会科学统计软件包”。 2000年,随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司正式将英文全称更改为Statistical Product and Service Solutions,意为“统计产品与服务解决方案”. 2009年,随着SPSS公司成为预测分析领域的领导者,SPSS公司旗下主要产品的名称前面统一冠以PASW字样,全称为“Predictive Analysis Software”, 即“预测分析软件”。这样主要产品家族,称为PASW Statistics, PASW modeler,PASW PES,PASW Data Collection等. 2010年,随着SPSS公司被IBM公司并购,各子产品前面不再以PASW为名,修改为统一加IBM SPSS字样. 相关网站https://www.360docs.net/doc/9b17871227.html, https://www.360docs.net/doc/9b17871227.html,。 SPSS Statistics的运行模式 SPSS Statistics(以下简称SPSS)主要有两种运行模式: 1.完全窗口菜单运行模式 这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单易用。 2. 程序运行模式这种模式是在语句( Syntax)窗口中直接运行编写好的 程序或者在脚本( script)窗口中运行脚本程序的一种运行方式。这种模式 要求掌握 SPSS的语句或脚本语言。 SPSS Statistics的启动 运行windows[开始]→[程序]→[IBM SPSS Statistics]->[IBM SPSS Statistics 19],进入IBM SPSS Statistics 系统。 SPSS Statistics主要窗口介绍
SPSS实验报告
《统计分析与SPSS的应用》 实验报告 班级:090911 学号:09091141 姓名:律江山 评分: 南昌航空大学经济管理学院 南昌航空大学经济管理学院学生实验报告 实验课程名称:统计分析与SPSS的应用 专业经济学班级学号09091141 姓名律江山成绩 实验地点G804 实验性质:演示性 验证性综合性设计性 实验项目名称基本统计分析(交叉分组下的频数分析)指导教师周小刚一、实验目的 掌握利用SPSS 软件进行基本统计量均值与均值标准误、中位数、众数、全距、方差和标准差、四分位数、十分位数和百分位数、频数、峰度、偏度的计算,进行标准化Z分数及其线形转换,统计表、统计图的显示。 二、实验内容及步骤(包括实验案例及基本操作步骤) (1)实验案例:居民储蓄存款。 (2)基本步骤:1、单击菜单选项analyze→descriptive statistics→crosstabs 2、选择行变量到row(s)框中,选择列变量到column(s)框中 3、选择dispiay clustered bar charts选项,指定绘制各变量交叉分组下的频数分布棒图。 三、实验结论(包括SPSS输出结果及分析解释) 实验结论: 较大部分储户认为在未来收入会基本不变,收入会增加的比例高于会减少的比例;城镇储户中认为 收入会增加的比例高于会减少的比例,但农村储户恰恰相反;可见城镇和农村储户在对该问题的看法上存在分歧。 城镇户口较内存户口收入有明显的增加,但未来收入减少的比例差距不大。其中二者未来收入大部分基本保持不变。
南昌航空大学经济管理学院学生实验报告 实验课程名称:统计分析与SPSS的应用 专业经济学班级学号09091141 姓名律江山成绩实验地点G804 实验性质:演示性 验证性综合性设计性 实验项目名称参数检验(两独立样本T检验) 指导 教师 周小刚 一、实验目的 掌握利用 SPSS 进行单样本 T 检验、两独立样本 T 检验和两配对样本 T 检验的基本方法,并能够解释软件运行结果。利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。 二、实验内容及步骤(包括实验案例及基本操作步骤) (1)实验案例;居民储蓄存款 (2)实验步骤;1、单击菜单analyze→compare means→independent→sample t test; 2、选择实验变量到testariable(s)框; 3、选择总体标志变量到grouping variable框中; 4、单击define groups 定义两总体的标志值。 5、两独立样本t检验的option选项含义与单体样本t检验的相同。 三、实验结论(包括SPSS输出结果及分析解释) 实验结论: t统计量的观测值为0.879,对应的双尾概率P值为0.380.如果显著性水平a为0.05,由于概率P的值大于0.05,不能拒绝零假设,即城镇储户和农村储户一次存款金额的平均值无显著差异。
SPSS19.0学生实验指导书20150001
S P S S 实验指导书统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。现代的数据分析工作如果离开统计软件几乎是无法正常开展。在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。 常见的统计软件有SAS,SPSS,MINITAB ,EXCEL 等。这些统计软件的功能和作用大同小异,各自有所侧重。其中的SAS和SPSS是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。特别是SPSS其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操作管理和开放的数据接口以及灵活而美观的统计图表制作。SPSS在各类院校以及科研机构中更为流行。 SPSS(Statistical Product and Service Solutio ns意为统计产品与服务解决方案)。自20世纪60年代SPSS诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的SPSS for Windows大同小异,在本实验课程中我们选择SPSS 19.0 作为统计分析应用实验活动的工具。 1. SPSS的运行模式 SPSS主要有三种运行模式: (1 )批处理模式 这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上[SPSS for Win dows]—[Production Mode Facility]程序运行。 (2)完全窗口菜单运行模式这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单易用。 (3)程序运行模式 这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。这种模式要求掌握SPSS的语句或脚本语言。 本实验指导手册为初学者提供入门实验教程,采用“完全窗口菜单运行模式” 。 2. SPSS的启动 (1)在windows[开始]—[程序]—[IBM SPSS Statistics],在它的次级菜单中单击IBM SPSS 19”即可启动SPSS软件,进入SPSS for Windows对话框,如图1.1 ,图1.2 所示。 图1.1 SPSS启动 图1.1 SPSS启动对话框 3. SPSS软件的退出 SPSS软件的退出方法与其他Windows应用程序相同,有两种常用的退出方法:按