高性能海量数据传输技术白皮书_V2.0

Aspera 速铂高性能海量数据传输解决方案
概述
Aspera速铂的核心技术fasp TM是一种全新的软件技术。它彻底克服了传统数据传输软件例如FTP, HTTP以及Windows CIFS中的固有瓶颈,实现了在各种共享和私有网络环境中传输速度的最大化。这种技术可以获得完美的传输效率,不为网络延迟和丢包所限制。并且,用户享有对传输速度以及不同传输流之间带宽共享的无以伦比的控制。不管网络距离和动态性能如何,即便是在最困难的网络条件下(例如卫星,无线和洲际远程链接),文件传输时间仍然可以得到保障。FASP具有内置的,完整的安全性,包括连接节点安全验证,传输中数据加密以及数据完整性验证。
高速文件传输的挑战
和传统的基于磁带的邮件递送相比,通过数字化网络传输来实现海量数据的递送具有经济高效的特点。在理想情况下,数据文件可以通过现有应用程序例如FTP文件传输,HTTP网上递送以及Windows CIFS拷贝实现在全世界范围内IP网络间快速,经济的传输。但是,在实际网络中,传统的手段无一不陷入传输速度的瓶颈中,以至于甚至无法利用已有网络带宽的一小部分。这是由于这些应用都基于同一种传输协议--TCP。
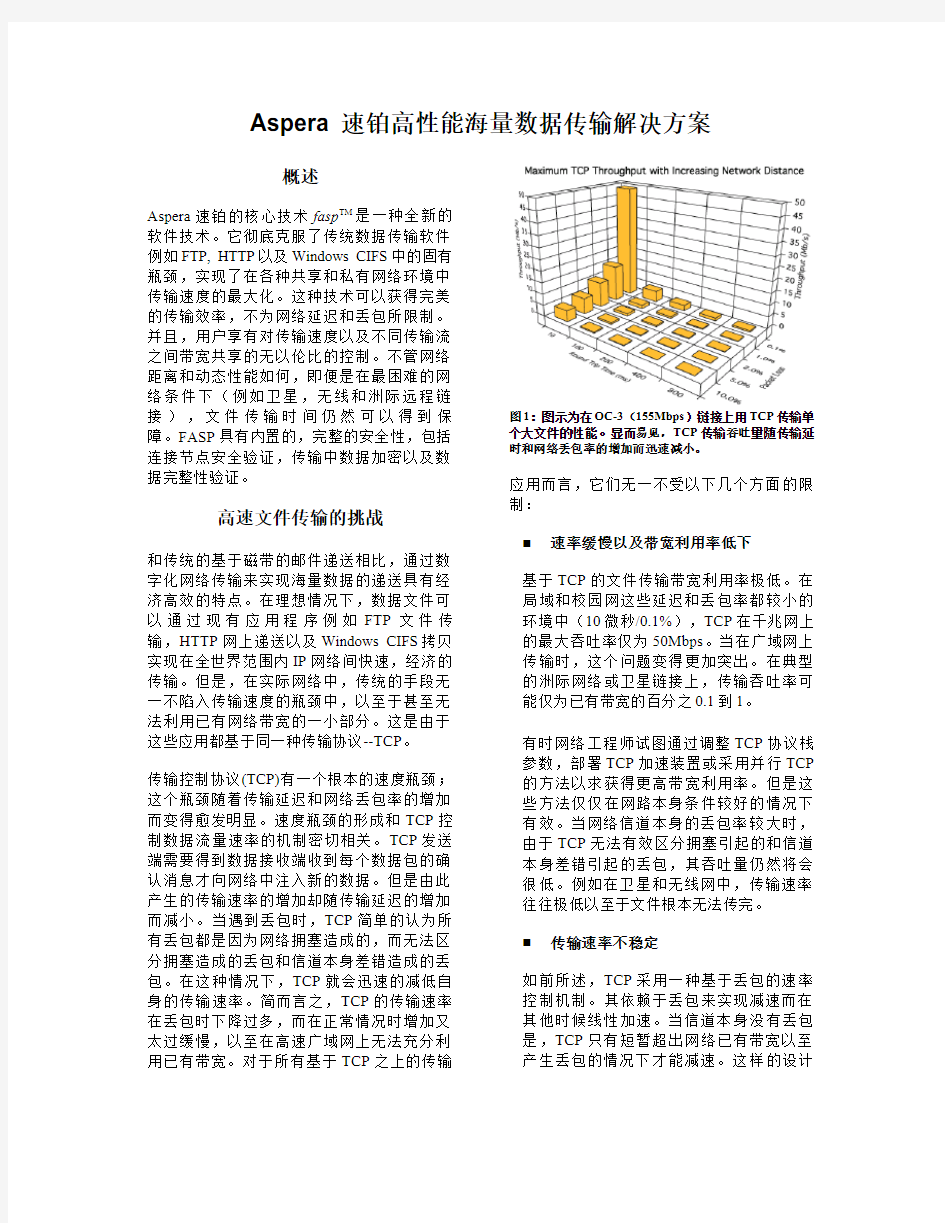
传输控制协议(TCP)有一个根本的速度瓶颈;这个瓶颈随着传输延迟和网络丢包率的增加而变得愈发明显。速度瓶颈的形成和TCP控制数据流量速率的机制密切相关。TCP发送端需要得到数据接收端收到每个数据包的确认消息才向网络中注入新的数据。但是由此产生的传输速率的增加却随传输延迟的增加而减小。当遇到丢包时,TCP简单的认为所有丢包都是因为网络拥塞造成的,而无法区分拥塞造成的丢包和信道本身差错造成的丢包。在这种情况下,TCP就会迅速的减低自身的传输速率。简而言之,TCP的传输速率在丢包时下降过多,而在正常情况时增加又太过缓慢,以至在高速广域网上无法充分利用已有带宽。对于所有基于TCP
之上的传输图1:图示为在OC-3(155Mbps)链接上用TCP传输单个大文件的性能。显而易见,TCP传输吞吐量随传输延时和网络丢包率的增加而迅速减小。
应用而言,它们无一不受以下几个方面的限制:
?速率缓慢以及带宽利用率低下
基于TCP的文件传输带宽利用率极低。在局域和校园网这些延迟和丢包率都较小的环境中(10微秒/0.1%),TCP在千兆网上的最大吞吐率仅为50Mbps。当在广域网上传输时,这个问题变得更加突出。在典型的洲际网络或卫星链接上,传输吞吐率可能仅为已有带宽的百分之0.1到1。
有时网络工程师试图通过调整TCP协议栈参数,部署TCP加速装置或采用并行TCP 的方法以求获得更高带宽利用率。但是这些方法仅仅在网路本身条件较好的情况下有效。当网络信道本身的丢包率较大时,由于TCP无法有效区分拥塞引起的和信道本身差错引起的丢包,其吞吐量仍然将会很低。例如在卫星和无线网中,传输速率往往极低以至于文件根本无法传完。
?传输速率不稳定
如前所述,TCP采用一种基于丢包的速率控制机制。其依赖于丢包来实现减速而在其他时候线性加速。当信道本身没有丢包是,TCP只有短暂超出网络已有带宽以至产生丢包的情况下才能减速。这样的设计
决定了即使在最理想的情况下,TCP也只能在最优速率上下震荡。当网络加载负荷变化时,TCP的传输速率也随之剧烈震荡。某些TCP加速器可以使其速率在无错的环境中更平滑,但是在有丢包的环境中仍然无法避免震荡。
?缺少安全性和可监控性
除了被TCP缓慢和不稳定的传输速率所限制以外,传统的文件传输应用往往不具备现代商业所必需的安全性和可管理性。例如FTP没有内置的安全机制,往往需要额外的机制来确保内容窃取和篡改。而且有关性能和传输的统计数据也常常无法得到。这对管理传输进程极为不利。
速铂FASP解决方案
速铂的文件传输产品线完全基于fasp高速传输协议。fasp是一种全新的应用层协议,特别为企业关键型文件传输所设计,可以满足其所需的高速度,可预测性和百分之百的安全可靠性。fasp出众的性能对所有的网络传输媒体皆适用。
?高速可靠
和TCP吞吐率的特性相比,fasp的传输速率完全不受网络延迟的影响,并且也对网络丢包有很好的鲁棒性。如图2所示,在OC-3(155Mbps)网络链接上,fasp实现了传输速率的最大化,在某些情况下可以比TCP快千倍。其速率具有可预测性。例如在10%的丢包情况下,fasp的吞吐率可以达到网络链接带宽的90%。在极端情况下,fasp的吞吐率仅为终端系统的吞吐能力(通常是磁盘读写吞吐率)所限制。
fasp是在用户数据报协议(UDP)之上开发的应用层协议。和那些基于并行TCP的应用不同,fasp在单个数据流上实现了速度最大化。借助于革新性的文件流线化技术,fasp 的传输速率在分发大批小文件时同样可以得到保障。例如,在从美国到新西兰的OC-3链接上传输一千个2兆字节的小文件,传输速率同样可以接近155Mbps。所以fasp实现了在高速广域网上传输海量数据(和文件大小无关
)的传输速率最大
图2:图示为在OC-3(155Mbps)链接上用fasp TM传输单个大文件的性能。相对于TCP而言,fasp的传输吞吐量不受传输延时的影响,而只随网络丢包率的增加而缓慢减小。
化。相反,并行TCP技术往往在有丢包的高速广域网上无法实现速率最大化,在传输大量小文件时速率也不稳定,而且需要耗费大量系统资源。
作为一种数据传输协议,fasp具有应用层传输的完全可靠性。fasp的可靠性设计是基于一种负反馈的机制:接收端检测到丢包并把需要重传的包信息反馈给发送端。通过理论优化,fasp的重传机制只针对真正的丢包,没有冗余传输和带宽浪费。其重传效率接近百分之一百。
正因为可以提供极高的下载速度,而且其速率稳定不随动态网络条件变化,fasp可以很好的支持渐进式传输,例如在媒体播放器中播放一个远程媒体流。而对于其他基于TCP的应用例如HTTP下载来说,如用于远程播放则通常起始缓慢,并且在播放过程中经常由于网络拥塞而造成图像抖动甚至是播放中断
。
图3:fasp的文件流线化技术使高速传输大批量小文件成为可能。这幅图展示了洲际传输1000个未经归档的2兆字节小文件的性能。传输速率完全平稳,在文件间没有中断。
图4:一个fasp数据流和一个TCP数据流共享带宽。Fasp可以有效利用TCP
所不能利用的带宽。
图5:两个fasp数据流和两个TCP数据流共享带宽。Fasp可以实现和TCP之间的带宽公平共享
?自适应速率控制
在理论上fasp没有速率上限,可以完全利用任意速度网络的带宽。fasp采用和TCP 完全不同的速率控制机制,从而实现带宽利用的最大化以及和已有TCP数据流公平分享带宽。
有效而公平的自动速率控制
和TCP不同,fasp的速率控制是基于网络中的排队延迟。和丢包相比,排队延迟是预测网络拥塞更快更有效的信号。当网络没有负荷(检测不到排队延迟或排队延迟很小)时,fasp可以迅速提速以充分利用带宽。当网络拥塞时,fasp可以迅速减速以获得应有的带宽。fasp的这套速率控制机制还具有带宽共享的公平性。如图4所示,当已有TCP数据流不能充分利用链路带宽时,fasp可以自动提速占据余下的带宽。当链路因为有多个数据流存在而变得拥挤时,fasp数据流可以实现和TCP数据流等量公平共享链路带宽。
响应终端速度瓶颈
如前所述,在超高速网络环境例如千兆网中,速度瓶颈往往不在网络链路本身,而在终端系统,尤其是存储设备的吞吐能力。fasp自适应速率控制不仅可以自动发现现有的网络带宽,而且也能对存储设备动态吞吐率的作出理想的响应。当存储设备设备成为瓶颈是,fasp可以自动减速以避免其超速运转所造成的丢包以及其他负面影响。当检测到存储设备不再繁忙时,fasp自动提速以充分利用其数据吞吐能力。
可灵活设置的带宽策略
用户可以对每个fasp数据流获取带宽的能力进行设置。除了和其他数据流对等共享带宽(如图4所示)外,fasp还支持其他带宽共享机制。比如用户可以选定用固定速率传输,从而使传输速率不受网络负荷的变化而变化。这种策略通常在私有网络环境中适用。此外,用户还可以选定后台传输模式,从而在检测到TCP数据流后减到最低速以便将所有带宽留给TCP数据流。最后,用户还可以将某一些fasp数据流设定成为高优先级的数据流;这些数据流在和其他普通优先级的fasp数据流共享带宽是会获得更高的传输速率。
?完整的安全机制
fasp提供了完整的内置安全机制。fasp的安全模式完全基于开放标准的密码体系,包括了:1)通过标准安全外壳(SSH)对传输终端进行验证;2)对传输中数据加以128位强密码(AES-128)加密;3)对每个数据块进行完整性验证以抵御象中间人以及匿名UDP之类的恶意攻击。另外,在不同系统间进行fasp传输不会改变文件本身的安全属性。引进以上安全机制对传输速率并没有削弱。在加密模式下,fasp可以在个人笔记本上实现40-80Mbps的广域网传输,在P4或单处理器上实现100-150Mbps的传输,在双核或双处理器工作站上实现200-400Mbps的高速传输。
FASP和FTP性能比较
以下几幅图比较了fasp文件传输和FTP文件传输在典型网络条件下的吞吐率和所需时间。所有的fasp和TCP测试都是在Aspera的
实验室完成的。在每一个测试中,一个1GB 的文件在两台预装有fasp和FTP1的测试机之间互传。测试机的芯片为奔腾4,操作系统是Debian Linux。在测试机之间,一台装有NIST NET的工作站被用来模拟不同网络环境,提供应有的传输延迟和丢包率。
?千兆城域网和广域网
传统的基于TCP的文件传输技术譬如FTP 在遇到丢包的时候迅速减速,所以无法在高速网路链接上长期保持平稳的传输速度。例如,在城域网条件下,基于TCP的文件传输的理论最大吞吐量大约是50Mbps,无论链接带宽是多少。如图所示,实际的FTP吞吐量更少只有22 Mbps。相比而言,单个fasp数据流在相同的条件下可以获得100%的带宽利用率。在本图中,fasp数据流的吞吐率为509 Mbps,接近了磁盘读写速度的极限。也许更加重要的是,fasp在延迟和丢包率增加的情况下仍然可以保持几乎相同的速度(在200微秒2%丢包率下达到505 Mbps)。与此同时FTP的吞吐率则减低到了550Kbps。两者的传输速率差距达到了近千倍
。
?跨洲网络传输
一个从洛杉矶至纽约(90微秒延迟)的FTP文件传输在网路丢包较低(0.1%)的时候可以实现5-6 Mbps的速率。但当丢包率增加到1%的时候,FTP的文件传输速率减低到了1.4 Mbps。而Aspera速铂的fasp 的吞吐率在远程跨洲链路上也可以实现最高的文件传输速率。在一个有90微秒延迟,丢包率为1%,带宽为155 Mbps的跨洲网络链接上,fasp的传输速率可以达到154 Mbps,比FTP快100倍。在更典型的45Mbps的跨洲链路上,fasp的传输速率仍然比FTP快30倍左右。
1在实际情况下,FTP的吞吐率在不同操作系统不同版本
的实现,以及不同丢包模式下略微有所不同。但是它们的结果都比较相似
。?洲际网络传输
fasp相对于FTP的速度优势在洲际远程网络链接上也非常明显。在延迟150微秒丢包率2%的环境下,FTP的平均传输速度低于700Kbps。而fasp始终保持着稳定的传输速率。通过fasp,一个1千兆字节的大文件可以在10 Mbps的链接上用少于15分钟的时间传完,实现9.9 Mbps的平均速度,无论网络延迟有多大。如下图所示,在一个45 Mbps的链接上,fasp的传输速率可以达到44.3 Mbps,用3分多钟完成一个1GB文
件的传输。
?高延迟卫星链路
卫星链路特有的高延迟和高丢包率对FTP 的传输性能有极大的影响,甚至使通过卫星传输大量数据变得不切实际。而fasp的传输速率则不为单个或一连串卫星链接所带来的延迟和丢包而受影响。如下图所示,单个fasp数据流可以在45 Mbps的卫星链路上实现接近百分百的带宽利用。即使在超常的丢包率(20%)的条件下,其吞吐率仍可以接近40 Mbps.而FTP的传输吞吐率一直在100 Kbps
以下。
FASP和其余加速技术的比较
如何提高广域网中海量数据传输的速度是一个被广泛关注的问题。工业界和研究机构都试图用不同的方法来提高传输速度。一般来说,已知的不同于fasp TM的解决方法可以被归为以下几类:基于TCP/IP协议的优化;基于UDP的加速;基于纠错编码的机制。
?修改TCP/IP协议栈
对已有TCP/IP协议栈进行参数优化是一种比较常见的加速方式。这些加速方法通常会通过调整协议栈参数从而使TCP可以维持更大的发送窗口,并且有选择性的报告丢包(SACK)以防止TCP在一个往返时间内速率下降过多。一些更高级的机制直接修改TCP的速率控制机制。譬如,这些“高速”TCP协议通常在丢包的时候速率减少更缓慢,而在无网络拥塞的时候速率增加更快。但是,因为这些协议并没有改变TCP根本的基于丢包的速率控制,所以只能在丢包比较小的情况下充分利用带宽,而在丢包比较严重的情况下带宽利用率仍然极其低下。
非标准的TCP/IP协议栈通常以独立的代理服务器的形式部署在数据中心或广域网链接的前端。这通常需要安装新的硬件设备或更换已有的操作系统。相比而言,速铂的产品可以和现有的运行环境无缝集成,无需对已有软硬件设备做出改动。
?并行TCP数据流
另一种对已有TCP/IP协议栈提供加速的方法是实施并行TCP数据流。显而易见,当单个TCP数据流带宽利用率很低时,用多个数据流可以使总的带宽利用率增加。但是由于这种简单的方法没有对TCP的速率控制机制做出任何改进,所以在丢包率严重的情况下(大于10%),其性能仍然不能得到保障。打开多个数据流会大量耗费客户端和服务器端的CPU和内存资源。更严重的是,由于TCP的带宽控制是基于丢包的,所以当并行TCP获得更高的带宽利用率的同时,其实际上已经在瓶颈链路上造成了大量的丢包和拥塞,以至于其余应用无法正常工作或导致其速度及其缓慢。?前向差错控制
前向差错控制是(FEC)一种在广域网传输中经常被采用的技术。它的原理是在发送的原始数据之上加传一定比例的冗余码,这样当网络拥塞造成丢包的情况下可以通过校验码恢复部分原始数据。严格来说,前向差错控制并不是一种纯粹的加速机制,而只是一种可靠性手段,因其并未对传输速率有何改善。前向差错控制只能在一般丢包的情况下改善传输的可靠性,而其本身在丢包严重的情况下并不能提供完全的可靠性。前向差错控制相关的编码/解码需要耗费一定量的CPU资源,在高速网络环境中往往通过特殊硬件实现。相比而言,fasp TM所采用的负反馈重传机制可以保证传输100%可靠,并且CPU消耗很小。
?基于UDP的流量喷发
由于传统TCP传输协议的低效,以及修改TCP协议本身的复杂性,近几年人们相应推出了一些基于UDP的传输协议。其中比较常见的开源协议譬如Tsunami和UDT,正被许多商用产品(Signiant, File Catalyst 和Sterling Commerce)使用。不幸的是,这些协议并没有高质量的设计,仅仅是采用了基于UDP的流量喷发。更具体的说,这些协议通常可以保证传输的可靠性,而在此之上采用简单的速率控制来响应网络拥塞。但由于其粗糙的可靠性机制和速率控制设计,这些协议往往传输效率很低,并且会加重网络拥塞造成大量丢包,对网络中其余的TCP数据流有极坏的影响。
以UDT为例,图6汇出了单个UDT数据流在T3广域网络链接上的性能。如图所示,UDT在广域网上(延迟100微秒,丢包1%)上的传输速率极不稳定。由于其过于简单的速率控制机制,传输速率在很多时候大大超过了网络已有带宽,从而造成严重拥塞。尽管从表面上看,T3网络链接的吞吐率接近100%,但这是以大量丢包为代价的。更严重的是,由于UDT可靠性设计上的缺陷,大量的网络带宽被用来反复传递重传数据。而有效的源文件数据只占总数据量的九分之一。简而言之,为了修复1份数据包,UDT重传了8次原始数据!这造成了它的有效带宽利用率很低。
图6:UDT在T3(45Mbps)链路上的性能。其中网络延时为100ms, 丢包率为百分之一。
又如图7所示,正因为UDT本身会造成大量的拥塞和网络丢包,所以在和另一个TCP数据流共享带宽时(45Mbps网络),TCP数据流的性能大大削弱,传输速率几乎降到0。只有当UDT退出时,TCP
才能有效利用带宽。图7:一个UDT数据流和一个TCP数据流在T3(45Mbps)链路上共享带宽。其中网络延时为50ms, 丢包率为0。
而和UDT相反,fasp TM的传输机制可以使其和TCP数据流相对公平的共享带宽。综上所述,我们在表1中总结比较了fasp TM和其他几种加速方式的性能特点。
TM加速TCP/IP并行TCP/IP前向差错控制UDP流量喷发有效传输速率最大
化
高带宽利用率
有效利用CPU资源
高效恢复丢包
协议自身公平性
对TCP协议的公平
性
稳定性
安全性
自带的监控和计费
完全基于软件
表1:fasp TM和其他几种相关加速技术的比较
fasp高速传输协议
在不同网络距离种类和数据量下皆能实现速率的最大化
?实现了在不同种类网络下端对端数据传输的速率最大化。传输速率不受传输距离和网络质量的影响。
?传输大批小文件是的速率和传输单个大文件类似。
?使用非常简便,无需专用设备或高性能硬件去保持很高的传输速率。
无以伦比的带宽控制
?提供了精确的速率控制(预设或在运行中实时调整)以确保传输时间。
?运用自适应带宽控制机制来充分利用空余带宽并且和其他数据流共享也有带宽。
?提供快速的发掘机制可以测量任意发送接收端之间的瓶颈带宽。
?可在运行中动态调整带宽共享的策略。用户可以根据自身所需预设或改变个体的传输速率和完成时间。
?支持完美的渐进式传输,譬如网络媒体播放。传输速度不会因为拥塞和距离锐减,从而确保了对输入数据的迅捷而平滑的处理。
完整的安全性
?包括了完整的,内置的安全机制。开放标准的密码体系进行用户验证,数据加密和数据完整性检验。
100%软件产品
?基于标准的IP网络协议开放的应用层协议和传输软件。不需要对传输端已有操作系统和驱动做任何改动。不需要额外的设备,无需改变现有网络设置。
鲁棒性和可管理性
?自动的断点续传和失败重传机制。
?提供了端对端传输进程的报告和详细的性能统计数据以便于监控和计费。同时提供了可定制的传输前和传输后事件处理。
灵捷开放的架构
?支持在所有主要操作系统之间的跨平台文件目录传输。提供可扩展的软件开放包(SDK),便于用户开发自有程序。
数据库管理系统可行性报告
大型数据库管理系统开发 ¥ 项目可行性报告 >
目录 1项目概述 (5) 2国内外相关技术发展与市场情况说明 (5) 国外数据库产品企业开发情况 (5) 、 甲骨文力推重量级产品10G (5) IBM以新版DB2开拓市场 (5) 国内数据库产品企业开发情况 (6) 金仓数据库管理系统KingbaseES (6) 东软通用数据库系统 (6) 3投标单位概况和已有工作基础 (6) 投标单位名称: (6) 投标单位的性质: (7) ` 基本结构: (7) 财务状况: (9) 运营情况: (9) 技术优势: (9) 产业化优势 (9) 在本投标项目相关领域已有工作基础和取得成果 (9) 项目负责人和项目主要参加人员的情况 (9) 4技术总体方案 (9) $ 项目所依据的技术原理 (9) 主要技术与性能指标 (11) 主要技术 (11) 主要指标参数 (12) 项目拟执行的质量标准类型、质量标准名称 (12)
5项目实施方案 (13) 项目主要内容 (13) 项目的研究对象 (13) { 主要技术与性能指标 (13) 项目技术路线描述 (14) 项目技术实现依据 (15) 设计思想依据 (15) 关键技术实现的依据 (16) 项目技术成熟性 (17) 采用的成熟技术 (17) 已攻克的关键技术 (19) % 待研究的关键技术 (22) 项目产品化 (23) 产品用途 (23) 产品性能 (23) 比较优势 (24) 产品化实施计划 (24) 项目产品化实施计划的具体进度安排 (24) 产品化拟执行的质量标准类型 (25) \ 项目产品应取得的相关许可认证证书 (25) 项目产品市场与竞争 (25) 行业及市场概述 (25) 目标市场 (25) 目标市场容量 (26) 竞争优势分析 (26) 技术优势 (26)
一种大文件多版本遥感影像数据组织管理方法
一种大文件多版本遥感影像数据组织管理方法 1 引言 近年来,遥感技术[1]的飞速发展为我们提供了丰富的高质量、高清晰影像数据,使“海量”成为遥感影像数据的重要特征,遥感影像在网络上的传输与服务已经成为遥感应用的重要手段,而这也对遥感数据的存储与管理提出了很高的要求。 目前遥感影像数据的管理主要采用数据库管理和文件管理两种方式。使用数据库技术[1] [2]可以保证数据的完整性和较高的共享性,一般多采用Oracle 数据库,但在关系型数据库高并发读写情况下,硬盘I/O无法应付,性能较差。当遥感数据量特别大时,数据的检索速度以及I/O效率就成为了瓶颈,而且受网络带宽的限制,数据量大时传输效率太低。为了提高遥感影像的网络传输效率,许多学者提出了基于文件管理方式的金字塔技术,将一个大数据文件切成许多不同分辨率的瓦片,每个瓦片以一个文件的形式存放在特定的目录下,该目录名包含空间或分辨率信息,以便于检索,NASA World Wind、GeoGlobe 等多采用这种方式[3] [4]。但此方法的缺点在于文件的个数太多,不便于组织管理,文件调用时I/O频繁操作,读写速度慢,而且数据文件的安全性差。 另一方面,随着遥感技术的发展,遥感影像数据的更新越来越快,如何存储以及更新这些多时相遥感影像数据,显得越来越重要。在此背景下,本文提出基于金字塔结构的大文件存储方法,用来存储管理海量影像数据,针对于多时相影像数据提出了基于版本机制的影像数据管理模式。 2 基于大文件的遥感影像数据组织 2.1遥感影像数据的大文件存储管理 2.1.1大文件数据结构 遥感影像数据量非常庞大[5],难以满足实时处理和网络传输的要求。但用户每次在浏览时,也只是浏览一个小的矩形区域,并不需要传送整个影像。所以在对影像数据进行组织存储之前需要对其建立影像金字塔,即对影像分块组织。但传统的文件都是以一块影像一个小文件的形式存在的,造成文件的数据量很大,I/O 操作频繁,读写速度慢,不便于组织管理[6] [7]。 针对传统遥感影像存储管理方式存在的问题,本文提出一种混合模式对海量遥感影像进行组织管理。与传统金字塔分块方法一样,对一个全球或者区域的遥感影像按照一定的
数据库课程设计工厂管理系统大作业
摘要 姓名:颜超丽学号:200915553013027 此文运用了数据字典、数据流图等方法对工厂管理系统进行了需求分析,运用E-R图进行了概念结构设计,在逻辑结构设计中将E-R图转化为关系模型,在物理结构设计中确定该数据库的存储结构,最后通过SQL语言实现数据库的设计。在这过程中,还详细地分析了各个子系统的属性、实体间的联系以及子系统间的关系。在这基础上,通过金仓数据库软件,运用SQL语言将所建工厂管理系统数据库顺利实现。 关键字:数据字典,E-R图,SQL语言 目录 一、系统概述 (1) 二、需求分析 (1) 1信息分析 (1) 2数据流图 (2) 3数据字典 (2) 三、概念结构设计 (4) 1实体列表 (4) 2分E-R图 (4) 3全局E-R图 (5) 四、物理结构设计 (5) 1关系模式存取方式选择 (5) 2确定数据库的存储结构 (5)
3评价物理结构 (5) 五、逻辑结构设计 (6) 六、数据库的实施 (7) 七、设计总结........ (8) 八、文献 (9)
工厂管理系统库 一、系统概述 工厂管理信息化是工厂管理系统应用信息技术及其产品的过程,是信息技术应用于工厂管理的过程。工厂信息化的实施,自下而上而言,必须以管理人员使用信息技术水平的逐步提高为基础;自上而下而言,必须与工厂的制度创新、组织创新和管理创新结合。 工厂管理系统算是比较简单一种信息系统。它主要应用于工厂仓库管理、职工管理、车间管理和零件管理。其中车间对职工和零件来说是很重要的。 工厂管理信息化建设工作具有长期性和内容的多变性;正因为这样,车间管理信息系统也不是一个简单的、静止的、封闭的系统,而是一个开放的,随着时间的推移会逐步变化和发展的系统。 二、需求分析 1、信息分析 根据工厂方面取得的信息资料,得出系统的信息需求和处理要求,得到设计所需的需求信息。这些信息是是选择了对数据库设计直接有用的信息。 A.工厂系统: a.车间:一个工厂有很多个车间,每个车间有车间号、车间主任名、地址、 电话。 b.工人:一个车间有多个工人,每个工人有职工号、姓名、年龄、性别和 工种。 c.产品:一个车间生产多钟产品,产品有产品号,价格。 d.零件:一个车间有多个零件,一个零件也可以由多个车间制造。零件有 零件号、重量和价格。 e.仓库:产品与零件存入仓库中,厂内有多个仓库,仓库有仓库号、仓库 保管员、姓名、电话。 B.系统联系: a.生产:一个车间有多个零件,一个零件也可以由多个车间制造。 b.组成:一个产品由多个零件组成,一种零件也可装配多中产品内。 c.保管:产品与零件存入仓库中,厂内有多个仓库。
大数据处理及分析理论方法技术
大数据处理及分析理论方法技术 (一)大数据处理及分析建设的过程 随着数据的越来越多,如何在这些海量的数据中找出我们需要的信息变得尤其重要,而这也是大数据的产生和发展原因,那么究竟什么是大数据呢?当下我国大数据研发建设又有哪些方面着力呢? 一是建立一套运行机制。大数据建设是一项有序的、动态的、可持续发展的系统工程,必须建立良好的运行机制,以促进建设过程中各个环节的正规有序,实现统合,搞好顶层设计。 二是规范一套建设标准。没有标准就没有系统。应建立面向不同主题、覆盖各个领域、不断动态更新的大数据建设标准,为实现各级各类信息系统的网络互连、信息互通、资源共享奠定基础。
三是搭建一个共享平台。数据只有不断流动和充分共享,才有生命力。应在各专用数据库建设的基础上,通过数据集成,实现各级各类指挥信息系统的数据交换和数据共享。 四是培养一支专业队伍。大数据建设的每个环节都需要依靠专业人员完成,因此,必须培养和造就一支懂指挥、懂技术、懂管理的大数据建设专业队伍。 (二)大数据处理分析的基本理论 对于大数据的概念有许多不同的理解。中国科学院计算技术研究所李国杰院士认为:大数据就是“海量数据”加“复杂数据类型”。而维基百科中的解释为:大数据是由于规模、复杂性、实时性而导致的使之无法在一定时间内用常规软件工具对其进行获取、存储、搜索、分享、分析、可视化的数据集合。 对于“大数据”(Bigdata)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决
图2.1:大数据特征概括为5个V (三)大数据处理及分析的方向 众所周知,大数据已经不简简单单是数据大的事实了,而最重要的现实是对大数据进行分析,只有通过分析才能获取很多智能的,深入的,有价值的信息。那么越来越多的应用涉及到大数据,而这些大数据的属性,包括数量,速度,多样性等等都是呈现了大数据不断增长的复杂性,所以大数据的分析方法在大数据领域就显得尤为重要,可以说是决定
基于大数据的遥感数据质量管理探索
基于大数据的遥感数据质量管理探索 发表时间:2018-07-23T12:20:00.747Z 来源:《基层建设》2018年第18期作者:孙立军李小强仲健民[导读] 摘要:大数据几乎对每个领域都产生了影响,遥感数据作为大数据重要组成部分,其自身也在发生深刻变革。 32023部队辽宁大连 116023 摘要:大数据几乎对每个领域都产生了影响,遥感数据作为大数据重要组成部分,其自身也在发生深刻变革。本文结合大数据时代背景和遥感数据质量管控现势情况,对大数据在遥感数据质量管控方面进行初步探索,浅要分析大数据下的遥感数据质量管理模式。 关键词:大数据;遥感数据;质量管理;探索 1 引言 21世纪,人类进入信息社会,传感器和社会网络产生海量数据,数据积累的量变引发质变,越来越多的企业、行业和国家以数据为资源进行知识和智力开发,挖掘了数据内在的价值,逐步形成了大数据的概念。大数据指的其实就是“海量数据+复杂数据类型”及非结构化数据,其核心在于数据的挖掘和应用产生的多方位价值。具有数据体量(V olumes)巨大、数据类别(Variety)繁多、价值(Value)密度低、处理速度(Velocity)快的特点(简称4V)。 大数据几乎对每个领域都产生了影响,从表象看,大数据就是一个容量特别大,数据类别特别多的数据集,大概能达到PB的级别,其并不是一种新的技术,也不是一种新的产品,而是我们这个时代出现的一种新的现象。从内涵看,大数据的价值还在于大数据内部的关联、挖掘数据与数据的复杂关系以及数据(结构化与非结构化)与业务和决策间的关联等。从资源应用角度看,大数据是一种海量的数据状态以及应对这种状态的处理技术工具,还是未来社会的一项重要基础设施。 2遥感数据质量管理瓶颈 2.1 遥感大数据质量验收 遥感技术正在逐渐建立大数据体系结构,面对海量遥感数据,如何实现数据的质量与数量同步发展是当前一大难题。传统遥感数据质量验收数据量较少,所有项目可以实现一、二级验收100%,部分项目可以实现三级验收100%,数据量在人工验收能力承受范围之内。面对日益增加的遥感数据,验收任务陡增,传统的人工验收已逐渐不能适应当前任务形势。以立体测图为例,现在每年千幅级的任务数量,包含空三、采集、入库等工序,如果每一幅图、每一道工序都通过传统人工验收,需要1个人验收4年,一个验收组(4人)验收1年,才能够基本实现100%验收。传统验收模式效率低,并且对人的主观能动性要求极高,正面临巨大挑战。 2.2 遥感大数据的存储管理 数据生产过程中,产生的一些过程数据,极大地占用了存储空间。以正射影像为例,每一道数据处理工序都需要留存,以备在后期验收过程中出现问题可以及时修改,这就使得实际生产过程中需要原始数据量5倍之多的存储空间来完成任务。大数据对数据传输和数据管理都提出了较高的要求,在海量数据中,如何更快捷的检索、定位、传输数据,都是目前需要解决的难题,而目前的测绘软硬件都不能够完全满足大数据管理要求。 3 基于大数据的质量检验模式的探索 3.1 健全大数据下质量管理体系 建立完善的质量管理体系是加强遥感产品质量管理的重要措施,为及时生产高标准、高质量的遥感产品,从设计、生产建立起一套严密协调的高效能的管理系统。实施全面质量控制,对顶层设计、作业力量、业务机制、业务创新、奖惩措施等各个影响质量建设的因素,进行全面规范、完善和提高。明确规定各部门和每个岗位在测绘生产中的职责,使各项工作正规化、标准化、程序化。制定质量计划,加强质量过程跟踪机制建设,从数据源、数据资料、数据流转、阶段成果等各方面进行全方位的跟踪管控,抓好每一道工序的成果质量。 3.2 完善大数据下遥感数据管理系统 由于数据量大,造成数据在传输、管理上显得有些“笨重”,如何高效快捷的实现数据管理和传输,可以从以下2个方面突破。一是依托集群系统,研究制定协同作业方案,实现数据实时共享和可视化,为数据接边和阶段性成果监视构建交流平台。同时,建立合理有效的数据管控级别,对作业员、指导工程师、验收员、网络管理员分别设置不同级别的访问和使用权限,既节省时间,同时对协同作业有极大的促进作用。二是减少数据流通次数,建立健全合理畅通的数据流通渠道,并且应避免数据的重复存储和版本信息的混乱。 3.3 研发大数据下智能质量分析系统 研发并配备大数据下遥感数据管理系统相应的软件系统,进一步提高质量检查的智能化水平。一方面,针对每一项任务,制定质量评定标准和相应的匹配模板,将所有的数据(成品和半成品)按照模板进行统一规范,利用智能匹配技术和结构分析技术,在少量人工干预的情况下,进行数据的统一质量评定。对作业人员每天提交的数据,可以充分利用夜间空闲时间,利用大数据分析系统和相关质量评定系统,统计数据质量情况、生成相应报告并反馈作业人员,以此实现数据质量跟踪检查。另一方面,依靠自身解决生产过程当中的小问题。充分调动人员积极性,依托科技创新,鼓励作业人员开发小程序、小软件,提高自查能力和效率。同时应考虑集中单位技术力量,研发系统高效的质量检查评价系统。 3.4 根据任务性质和需求把握主次 每一项任务都有其特定需求,如立体采集重点把握数据定位、影像判读、要素取舍、表示方法等,入库数据重点把握属性性质、拓扑关系等,地形图、军事交通图与军事地理图等不同类型的图表示的重点和方法也不同……这就需要根据任务需求、产品性质,明确验收重点,在坚持原则性问题不动摇的基础上合理把握,减少不必要的工作量。 4 结束语 大数据时代的到来,标志人类将进入数字化信息社会,构建世界信息架构。测绘数据作为基础性数据,既可以是大数据的框架数据,也可以依托大数据对自身进行不断的丰富完善。遥感数据成果质量的管理验收工作,必将在大数据的支撑下实现质的飞跃。 参考文献: [1]孔德智,杨晓明,张莹莹.大数据浅析[J].计算机科学与技术,2013,31(11):85-89. [2]胡雄伟,张宝林,李抵飞.大数据研究与应用综述(上)[J].标准科学,2013,9:29-34.
大数据采集技术概述
智慧IT 大数据采集技术概述 技术创新,变革未来
大数据中数据采集概念 数据采集(DAQ):又称数据获取,是指从传感器和其它待测设备等模拟和数字被测单元中自动及被动采集信息的过程。 数据分类新一代数据体系中,将传统数据体系中没有考虑过的新数据源进行归纳与分类,可将其分为线上行为数据与内容数据两大类。 在大数据领域,数据采集工作尤为重要。目前主流以实时采集、批量采集、ETL相关采集等
大数据的主要来源数据 ?线上行为数据:页面数据、交互数据、表单数据、会话数据等。 ?内容数据:应用日志、电子文档、机器数据、语音数据、社交媒体数据等。 ?大数据的主要来源: 1)商业数据 2)互联网数据 3)传感器数据 4)软件埋点数据等
数据源 分析数据、清洗数据时候。首先弄清除数据的来源。 数据的所有来源是程序。比如:web程序、服务程序等。 数据的形态 两种:日志文件、数据流。 对比: 由于数据流的接口要求比较高。比如有些语言不支持写入kafka。 队列跨语言问题。所以日志文件是主要形态。数据流的用于实时分析较好。 日志文件好处:便于分析、便于跨平台、跨语言。 调试代码注意。 常用的日志文件输出工具log4j。写程序时尽量别写system.out。
互联网日志采集统计常见指标 1、UGC : User Generated Content,也就是用户生成的内容。 2、UV:(unique visitor),指访问某个站点或点击某条新闻的不同IP地址 的人数。现已引申为各个维度的uv泛称。 3、PV:(pageview),即页面浏览量,或点击量。 4、DAU : daily active user,日活跃用户数量、MAU : 月活跃用户量 5、ARPU : Average Revenue Per User 即每用户平均收入,用于衡量 电信运营商和互联网公司业务收入的指标。 6、新增用户数、登录用户数、N日留存(率)、转换率。
(完整版)人大金仓KingbaseES中的用户与模式概念及关联
KingbaseES中的用户与模式概念及关联 一、用户 在实际应用中,作为数据库管理员,必须确保需要访问的数据库的个人具有适当级别的权限,为了使用户能够创建和管理对象,DBA需要为用户授予适当的权限。一旦某个用户创建了一些对象,该用户随之可以被授予操纵这些对象的权限,而DBA不需要涉及对单个用户所创建对象的管理权限。 要想访问数据库,任何人需要成为能够通过数据库身份认证的有效数据库用户,则可以配置应用程序要求每个需要进行访问的个体都具有不同的数据库账户,同时也可以配置应用程序自身作为公共用户连接数据库并在内部处理应用程序级别权限,无论哪一种方式,在数据库中内都需相应地创建一个或多个允许操纵数据的用户。 需要提到的是,在KingbaseES中,用户是实例级的,所以我们平时在KingbaseES中,虽在不同数据库下,查询系统表SYS_USER、SYS_DATABASE中看到关于用户的信息结果都是一致的,记录的是所有的用户、所有的数据库。用户与数据库是一对多的关系。无论当前连接在哪个数据库下,创建的用户都是实例级。 在KingbaseES中创建用户时,该用户默认有当前数据库的connect权限,当需要连接登录到其它用户创建数据库时,需要DBA将其它数据库的CONNECT权限赋予该用户才能正常登录,但该用户需要访问操作数据库下的其他用户所创建的对象时,同样需要被赋予相应的权限才可行。另外,在KingbaseES中,用户拥有connect权限登录数据库后,默认情况下用户拥有PUBLIC模式CREATE 的权限(下文中会详细说明),即默认该用户可以在PUBLIC模式下创建属于自己的数据对象。 数据库管理系统为了方便各用户对数据对象的管理,如同在KingbaseES Help里提到的,在实际应用场景下,为了: ?多个用户使用同一个数据库而不会相互影响。 ?对数据库中的对象进行逻辑分组,更便于管理。 ?各个应用分别使用各自的模式,以避免命名冲突。 而引入模式的概念。 二、模式
大数据支持京东破译“千人千面”
大数据支持京东:破译“千人千面” 用户画像背后需要有复杂的大数据模型的支撑。高水平的大数据平台,不仅仅在于数据量的积累,更重要的是背后的分析模型。 当京东的客服接线员刚刚拿起电话的时候,他就已经能够掌握到打进电话的用户的情绪状态,性格和心理,能够提前做好准备来应对,为用户更好地服务,这不是在假设,京东正在朝着这样的服务迈进,而帮助京东向此迈进的,是背后强大的大数据平台。 “千人千面”的背后是大数据的支持 “千人千面”是互联网时代到来以后,尤其是大数据催使商家提供个性化定制服务之后,各大电商都在追求的目标。过去的这几年,是3C产品(Computer,Communication, Consumer Electronics)的更新迭代是最频繁的几年,这为曾经专注于3C产品的京东赚足了眼球,也赢得了体量庞大的用户数量。 “基于大数据分析的‘用户画像’技术,一直以来都是京东大数据部门的重点研究方向。”京东大数据事业部总经理王晓介绍说。与其他的平台型电子商务平台区别的是,京东拥有电子商务全过程价值链的用户数据。“这样的全过程价值链数据质量是比较高的。”王晓介绍,所谓全过程价值链的用户数据,是指包括浏览、交易、客服、配送和物流等所有有关数据都可以引入用户画像的建模过程,这样一来可以精确描绘用户的全方位特征。“京东目前已经设立了300多个标签,用来定义用户的特征,覆盖用户基本属性、购买能力、行为特征、社交特征、心理特征、兴趣偏好等多个方面。”王晓说。“‘千人千面’在我的理解中就是在大数据的指导下,网站对用户提供个性化的精准营销的重要方法,京东历来都十分重视用户体验,其实这背后的重点还是用户画像技术。”针对为不同行为习惯和兴趣爱好,在标签定向中已经显示出有明确差异的用户,京东采用的是差异化的投放营销方式。王晓介绍,用户画像使得搜索、推荐、广告等营销系统能更加智能地服务用户,同一个搜索词在不同用户不同时刻搜索时,可能有完全不同的购物意图,针对用户的属性特征、性格特点或行为习惯,结合用户行为的上下文分析,陈列或推荐符合该用户偏好的商品,也能很大程度上提高用户购买转化率和重复购买率。 用户画像背后需要有复杂的大数据模型的支撑。高水平的大数据平台,不仅仅在于数据量的积累,更重要的是背后的分析模型。早在2013年下半年,京东的一位大数据研发高层在接受媒体访问时曾这样说:“符合以下两点要求的数据,才能被称之为大数据:第一就是体量要足够大,一般认为BI(Business Intelligence)无法处理的数据才能叫大数据;第二就是数据
大数据关键技术(一)——数据采集知识讲解
大数据开启了一个大规模生产、分享和应用数据的时代,它给技术和商业带来了巨大的变化。 麦肯锡研究表明,在医疗、零售和制造业领域,大数据每年可以提高劳动生产率0.5-1个百 分点。 大数据技术,就是从各种类型的数据中快速获得有价值信息的技术。大数据领域已经涌现出 了大量新的技术,它们成为大数据采集、存储、处理和呈现的有力武器。 大数据关键技术 大数据处理关键技术一般包括:大数据采集、大数据预处理、大数据存储及管理、大数据分 析及挖掘、大数据展现和应用(大数据检索、大数据可视化、大数据应用、大数据安全等)。 然而调查显示,未被使用的信息比例高达99.4%,很大程度都是由于高价值的信息无法获取 采集。 如何从大数据中采集出有用的信息已经是大数据发展的关键因素之一。 因此在大数据时代背景下,如何从大数据中采集出有用的信息已经是大数据发展的关键因素 之一,数据采集才是大数据产业的基石。那么什么是大数据采集技术呢?
什么是数据采集? ?数据采集(DAQ):又称数据获取,是指从传感器和其它待测设备等模拟和数字被测单元中自动采集信息的过程。 数据分类新一代数据体系中,将传统数据体系中没有考虑过的新数据源进行归纳与分类,可将其分为线上行为数据与内容数据两大类。 ?线上行为数据:页面数据、交互数据、表单数据、会话数据等。 ?内容数据:应用日志、电子文档、机器数据、语音数据、社交媒体数据等。 ?大数据的主要来源: 1)商业数据 2)互联网数据 3)传感器数据
数据采集与大数据采集区别 传统数据采集 1. 来源单一,数据量相对于大数据较小 2. 结构单一 3. 关系数据库和并行数据仓库 大数据的数据采集 1. 来源广泛,数据量巨大 2. 数据类型丰富,包括结构化,半结构化,非结构化 3. 分布式数据库
国内数据库厂商分析
2018年国内数据库厂商分析 在政府的支持下,经过十余年的发展,国产数据库软件企业在自身实力、产品、技术方面有了质的提升,国产数据库软件在信息安全,提供本土化服务方面有得天独厚的优势。 1.人大金仓 <1)公司介绍 人大金仓是中国电子科技集团公司 金仓酝酿并提出了“人大金仓大数据中心一站式服务”战略,是目前唯一能为用户提供数据存储、管理、分析与展现及相关服务和解决方案的国产数据库厂商。 <2)产品介绍 人大金仓主要产品包括金仓企业级通用数据库、金仓安全数据库、金仓商业智能平台、金仓数据整合工具、金仓复制服务器、金仓高可用软件,覆盖数据库、安全、商业智能、云计算、嵌入式和应用服务等领域,在高性能、分布式处理、并行处理、海量数据管理、数据库安全、数据分析展现等数据库相关技术方面凸显优势,引领国产数据库及相关领域的发展。 人大金仓企业级通用数据库KingbaseES是入选国家自主创新产品目录的唯一数据库软件产品,也是国家级、省部级实际项目中应用最广泛的国产数据库产品。KingbaseES具有大型通用、“三高”<高可靠、高性能、高安全)、“两易”<易管理、易使用)、运行稳定等特点。 图 1 人大金仓数据库软件产品特点 第32卷第10期2011年10月 微计算机应用 MICROCOMPUTER APPLICATIONS Vol.32No.10 Oct.2011海量数据存储管理技术研究 刘阳成周俭谢玉波 (华北计算技术研究所地理信息与数据库研究室北京100083) 摘要:海量数据存储管理在各行业的信息化过程中越来越重要,受到了广泛的关注。综述了海量存储管理技术的研究及应用现状,介绍了一些关键技术,包括数据存储架构,分级存储,数据自动化归档,业务流程控制,并发设计,数据服务等,最后,结合当前海量数据存储管理技术,指出了海量数据存储管理面临的一些新的发展方向。 关键词:海量数据存储管理分级存储业务自动化并发设计数据服务 Mass Data Storage Management Technology Research LIU Yangcheng,ZHOU Jian,XIE Yubo (Department of GIS&DB,North China Institude of Computing Technology,Beijing,100083,China) Abstract:Mass data storage management becomes more and more important in process of many areas.Key techniques about this inclu-ding storage structure,hierarchical storage,auto import,process control,concurrent design and data service were https://www.360docs.net/doc/a03821084.html,st,combi-ning present development of mass data storage and management,it pointed out some new direction of it. Keywords:mass data,storage management,hierarchical storage,business automation,concurrent design,data service 海量存储管理技术得到了越来越多的关注和应用。随着各行各业信息化程度的提高,企业数据急剧膨胀,尤其是近年来卫星遥感技术的发展,海量数据存储管理在国民经济中应用的越来越广泛。结合近年来从事的海量数据存储管理研究及实际项目研发,谈谈海量存储管理的若干技术。 1存储技术发展 海量信息存储早期采用大型服务器存储,基本都是以服务器为中心的处理模式,使用直连存储(Direct Attached Storage),存储设备(包括磁盘阵列,磁带库,光盘库等)作为服务器的外设使用。随着网络技术的发展,服务器之间交换数据或向磁盘库等存储设备备份数据时,开始通过局域网进行,这主要依赖网络附加存储(Network Attached Storage)技术来实现网络存储。NAS实际上使用TCP/IP协议的以太网文件服务器,它安装优化的文件系统和瘦操作系统(弱化计算功能,增强数据的安全管理)。NAS将存储设备从服务器的后端移到通信网络上来,具有成本低、易安装、易管理、有效利用原有存储设备等优点,但这将占用大量的网络开销,严重影响网络的整体性能。为了能够共享大容量,高速度存储设备,并且不占用局域网资源的海量信息传输和备份,就需要专用存储区域网络(Storage Area Network)来实现。 目前海量存储系统大多采用SAN存储架构的文件共享系统,所有服务器(客户端)都以光纤通道(Fibre Channel,简称FC)直接访问盘阵上的共享文件系统(如图1所示)。数据在存储上是共享的,数据在任何一台服务器(客户端)上都可以直接通过FC链路进行访问,无需考虑服务器(客户端)的操作系统平台,存储区 本文于2011-07-26收到。 实验一 实验目的:理解和掌握关系数据库标准sql语言,能够熟使用sql语言完成各种数据库操作和管理任务。 实验工具:安装有金仓数据库的windows7系统。 实验过程: 1,创建模式: 代码:create schema TT AUTHORIZATION system; setsearch_path to "TT"; 2,创建表: 1)表Student 代码:create table Student (Snochar(9) primary key, Sname char(20), Ssex char(2), Sage smallint, Sdept char(20) ); 2)表Course 代码: create table Course (Cno char(4) primary key, Cname char(40) not null, Cpno char(4), Ccreditsmallint, foreign key(Cpno) REFERENCES Course(Cno) ); 3)表SC 代码: create table SC (Sno char(9), Cno char(4), Grade smallint, primary key(Sno,Cno), foreign key(Sno) REFERENCES Student(Sno), foreign key(Cno) references Course(Cno) ); 结果截图: 3.插入数据: 如插入表Student的一条信息代码: insert into Student values('1','李思','m',123,'123333'); 4.修改基本表 1)显示当前搜索路径。 show search_path; 截图: 2)向Student表加入“入学时间”列,类型为日期型 alter table Student ADD S_entrance DATE; 效果截图 3)将年龄的数据类型由字符型改为整型(原来假设为字符型)alter table Student alter column Sage int; 4)增加课程名称必须取惟一值的约束条件。 alter table Course add unique(Cname); 金仓安全数据库中的用户权限管理技术 1. 概述 安全是信息安全的基础环节和重要支撑。为应对纷繁复杂的多样化数据安全保护需求,金仓重力打造完全遵照安全数据库国家标准GB/T 20273-2006的结构化保护级(第四级)技术的企业级安全数据库产品“金仓安全数据库”,为用户提供核心级数据保护能力。 金仓安全数据库具备完整系统的安全功能,通过全新结构化系统设计和强化的多样化强制访问控制模型框架,在身份鉴别、用户权限,以及数据访问、存储和传输等方面的安全增强提高了数据库系统的整体安全性,提供了包括强化身份鉴别、自主访问控制、安全标记、强制访问控制、特权分立、安全审计、资源限制、客体重用,以及程序运行和数据存储完整性、数据存储透明加密、数据传输加密等在内的主要安全功能和控制手段,可以从容应对复杂多样的安全业务场景,保障敏感数据的安全。 下面详细介绍一下特权分立和受限DBA的安全性能: 1.1.特权分立 金仓安全数据库采用了三权分立的安全管理体制,数据库三权分立是为了解决数据库超级用户权力过度集中的问题,参照行政、立法、司法三权分立的原则来设计的安全管理机制。金仓安全数据库把数据库管理员分为数据库管理员、安全管理员、审计管理员三类。 ?数据库管理员,主要负责执行数据库日常管理各种操作和自主存取控制。 ?安全管理员,主要负责强制存取控制规则的制定和管理。 ?审计管理员,主要负责数据库的审计,监督前两类用户的操作。 特权分立的优点: 这三类用户是相互制约又相互协作共同完成数据库的管理工作。安全管理员可以授 权用户查看某些敏感数据(强制存取控制授权),但是并不意味着这个用户就可以 看到这些敏感数据,它还需要得到数据库管理员的授权(自主存取控制授权)。同理,如果只有数据库管理员的自主存取控制授权而没有安全管理员的强制存取控制授权,用户还是无法看到它不应当看到的敏感数据。审计管理员拥有一套机制,可以保护审计记录数据不会被数据库管理员或者安全管理员删除或者篡改。 这三类用户彼此隔离,互不包容,各自维护自己权限许可范围内的对象,不能跨范 围操作,也不能相互授权。数据库管理员不能对安全、审计相关的用户及数据库对象进行操作,不能将任何用户修改为安全员或审计员,不能授予、回收安全员、审计员的权限,不能切换到安全员、审计员的许可认证;安全员只能管理安全员和安全相关的系统对象,同理,审计员只能管理审计员和审计相关的系统对象。 三权分立堵住了以前滥用数据库超级用户特权的安全漏洞,进一步提高了数据库的 整体安全性。 1.2.受限DBA 受限DBA指对数据库管理权限进行相应限制的DBA。金仓安全数据库提供了受限DBA 功能,可有效限制DBA对其他用户的默认数据访问权限。金仓安全数据库通过提供系统配置参数 restricted_DBA 来配置受限DBA功能。只有系统安全员(SSO)对受限DBA功能有打开或关闭权限。所有用户可以查询受限DBA功能的当前工作状态。 金仓安全数据库中的权限可以分为以下三类,系统权限、对象权限、列级权限。针对系统中权限结构,可以理解为权限所有者主要有三种:DBA、属主(owner)、被属主直接授权或间接授权的用户(通过grant进行的ACL授权,下文简称ACL授权用户)。 ?系统权限,是执行特定操作的权限。这些权限包括:CREATE DATABASE、CREATE USER、CREATE ROLE 的权限,具体分为 SUPERUSER、SSO、SAO、CREATEDB 和 CREATEROLE 五个系统权限。 ?对象权限,是对给定的用户授予在给定对象(例如表)上执行的操作集。这些操作可以指明为 INSERT 、SELECT 等,具体各类对象具有的权限类型可参见 GRANT 和REVOKE 语句的说明。 ?列级权限,是对给定的用户授予在给定表或视图上某些列执行操作集。此动作只能为INSERT、UPDATE和REFERENCES。 现如今,很多人都听说过大数据,这是一个新兴的技术,渐渐地改变了我们的生活,正是由 于这个原因,越来越多的人都开始关注大数据。在这篇文章中我们将会为大家介绍两种大数 据技术,分别是大数据采集技术和大数据预处理技术,有兴趣的小伙伴快快学起来吧。 首先我们给大家介绍一下大数据的采集技术,一般来说,数据是指通过RFID射频数据、传 感器数据、社交网络交互数据及移动互联网数据等方式获得的各种类型的结构化、半结构化 及非结构化的海量数据,是大数据知识服务模型的根本。重点突破高速数据解析、转换与装 载等大数据整合技术设计质量评估模型,开发数据质量技术。当然,还需要突破分布式高速 高可靠数据爬取或采集、高速数据全映像等大数据收集技术。这就是大数据采集的来源。 通常来说,大数据的采集一般分为两种,第一就是大数据智能感知层,在这一层中,主要包 括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实 现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信 号转换、监控、初步处理和管理等。必须着重攻克针对大数据源的智能识别、感知、适配、 传输、接入等技术。第二就是基础支撑层。在这一层中提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。重点攻克 分布式虚拟存储技术,大数据获取、存储、组织、分析和决策操作的可视化接口技术,大数 据的网络传输与压缩技术,大数据隐私保护技术等。 下面我们给大家介绍一下大数据预处理技术。大数据预处理技术就是完成对已接收数据的辨析、抽取、清洗等操作。其中抽取就是因获取的数据可能具有多种结构和类型,数据抽取过 程可以帮助我们将这些复杂的数据转化为单一的或者便于处理的构型,以达到快速分析处理 的目的。而清洗则是由于对于大数并不全是有价值的,有些数据并不是我们所关心的内容, 而另一些数据则是完全错误的干扰项,因此要对数据通过过滤去除噪声从而提取出有效数据。在这篇文章中我们给大家介绍了关于大数据的采集技术和预处理技术,相信大家看了这篇文 章以后已经知道了大数据的相关知识,希望这篇文章能够更好地帮助大家。 龙源期刊网 https://www.360docs.net/doc/a03821084.html, 京东大数据的思考和探索 作者:刘彦伟 来源:《软件和集成电路》2018年第08期 京东大数据平台是京东大数据业务的基础服务平台,为京东大数据业务的实现提供一站式、自助式的大数据处理全流程解决方案。涵盖数据接入、存储、处理、分析、挖掘、可视化、机器学习等产品和服务,致力于大幅降低大数据消费门槛,帮助京东大数据业务快速落地,助力京东实践以数据为驱动的业务变革与发展。京东在大数据方向上的思考和探索非常多,今天主要和大家分享实时数仓、存储计算分离与容器化。 我针对京东大数据的业务场景和特点,对实时数仓这个领域大概做了三个分类,即实时应用、实时分析、实时数仓。关于实时应用,比如,实时大屏、京东聊吧等,京东内部用的实时报表,为京东的高层或京东业务人员提供决策支持类系统,就是非常典型的实时应用。这些实时应用类业务的技术,在业内发展得比较成熟,比如Storm、Flink、SparkStreaming等的技术框架已经非常成熟,京东基于技术框架再去落地这些应用。这些应用的特点是:门槛高。正因为用了这些比较流行的实时计算框架,京东在数据时效性上可以达到秒级的延迟。 关于实时分析,实时分析是实时应用里一个非常典型的产品。大家在访问京东App、京东网站时,当你浏览一些商品之后,京东能够根据你的实时浏览行为,为你推荐需要的产品,因为每个人在京东看到的商品或广告不一样。实时主要是体现在数据时效性上,通过实时OLAP 分析平台,可以让我们的业务人员或分析师看到分钟级或秒级延迟数据。通过技术手段提升OLAP引擎的数据时效性,从而解决实时分析对数据分析场景的支持。实时分析的场景具有不确定性,分析人员需要获取什么样的数据相对不确定。分析人员需要的订单类型数据可能基于地域分析,也可能基于渠道分析,也可能基于不同时间窗口分析。总之,需求相对不确定。数据相对确定,要么基于订单数据分析,要么基于流量数据分析。实时分析需要研发人员和研发资源的参与,研发人员需要构建OLAP产品底层的模型,研发资源的投入永远不够。京东的业务非常广泛,除了物流、配送、供应链等核心业务之外,还有大量长尾需求。对于长尾需求在实时性上的需求没办法满足,因为没有这么多研发资源投入进来去帮他们构建实时应用或实时OLAP的基础产品。随着实时分析的广泛应用,各个部门对实时计算的需求非常迫切,为了更好地满足客户的需求,我们提出了实时数仓概念。 实时数仓概念是相对于传统数据仓库而言,通过技术手段把传统数据仓库升级为实时数仓,可以达到分钟级时延,实时数仓可以满足有长尾需求的所有用户。实时数仓平台是通用型解决方案,京东的任意一个业务部门可以基于体系内的引擎,通过流式计算引擎的方式,实时写入实时数仓平台中。通过实时数仓的构建,京东所有业务人员的采销、运营都具备了获取实时数据的能力,有了实时数仓的体系之后,业务人员上线业务的第一天,就能看到他实时的数据。所以,我们认为,实时数仓可以改变整个大数据体系的未来。实时数仓通过实时数据总线,将存在数据库里的数据、放在服务器上的日志型数据、结构化数据、非结构化数据等,全部接入流式计算引擎中,流式计算引擎将数据分发到不同存储中。第一类是在线存储,第二类 资源数据采集技术方案 公司名称 2011年7月 二O一一年七月 目录 第 1 部分概述 (3) 1.1 项目概况 (3) 1.2 系统建设目标 (3) 1.3 建设的原则 (3) 1.3.1 建设原则 (3) 1.4 参考资料和标准 (5) 第 2 部分系统总体框架与技术路线 (5) 2.1 系统应用架构 (5) 2.2 系统层次架构 (6) 2.3 关键技术与路线 (6) 第 3 部分系统设计规范 (9) 第 4 部分系统详细设计 (9) 第 1 部分概述 1.1 项目概况 Internet已经发展成为当今世界上最大的信息库和全球范围内传播知识的主要渠道,站点遍布全球的巨大信息服务网,为用户提供了一个极具价值的信息源。无论是个人的发展还是企业竞争力的提升都越来越多地依赖对网上信息资源的利用。 现在是信息时代,信息是一种重要的资源,它在人们的生活和工作中起着重要的作用。计算机和现代信息技术的迅速发展,使Internet成为人们传递信息的一个重要的桥梁。网络的不断发展,伴随着大量信息的产生,如何在海量的信息源中查找搜集所需的信息资源成为了我们今后建设在线预订类旅游网重要的组成部分。 因此,在当今高度信息化的社会里,信息的获取和信息的及时性。而Web数据采集可以通过一系列方法,依据用户兴趣,自动搜取网上特定种类的信息,去除无关数据和垃圾数据,筛选虚假数据和迟滞数据,过滤重复数据。直接将信息按照用户的要求呈现给用户。可以大大减轻用户的信息过载和信息迷失。 1.2 系统建设目标 在线预订类旅游网是在线提供机票、酒店、旅游线路等旅游商品为主,涉及食、住、行、游、购、娱等多方面的综合资讯信息、全方位的旅行信息和预订服务的网站。 如果用户要搜集这一类网站的相关数据,通常的做法是人工浏览网站,查看最近更新的信息。然后再将之复制粘贴到Excel文档或已有资源系统中。这种做法不仅费时费力,而且在查找的过程中可能还会遗漏,数据转移的过程中会出错。针对这种情况,在线预订类旅游网信息自动采集的系统可以实现数据采集的高效化和自动化。 1.3 建设的原则 1.3.1 建设原则 由于在线预订类旅游网的数据采集涉及的方面多、数据量大、采集源数据结构多样化的海量数据存储管理技术研究
金仓数据库mysql的一般实例
人大金仓安全数据库中的用户权限管理
大数据采集技术和预处理技术
京东大数据的思考和探索
资源大数据采集技术方案设计要点