人口发展模型matlab实现

实验二:人口发展模型
实验目的:
理解马尔萨斯模型和Logistic模型,利用中国人口数据,进行参数估计,并比较模型的优劣。
实验题目:
据统计,建国以来我国人口增长情况如表1:
更适合人口的长期预测?并预测2006年至2015年各年人口总数。
马尔萨斯模型假设单位时间内人口增长量与当前时刻人口数成正比,
即有,其中,代表增长率,为时刻人口总量,易得
,这表明人口按指数变化规律增长。
Logistic模型假设人口增长率是当时人口数量的线性递减函数
。表示按自然资源和环境条件的最大人口容量;表示固有增长率,即人口很少时的增长率;当时,;当时,。由此
建立Logistic模型,求解模型得.
实验程序及注释
%马尔萨斯模型
T=1954:2005;
N=[60.2,61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80. 7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104. 357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85, 121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.98 8,130.756];
y=log(N); %计算对数值
p=polyfit(T,y,1); %线性拟合
Malthus=exp(polyval(p,T)); %求线性函数值
plot(T,N,'o',T,Malthus) %对原始数据和拟合后的值作图
RM=sum((N-Malthus).^2) %求残差平方和
%Logistic模型
b0=[ 241.9598, 0.02985]; %初始参数值
fun=inline('b(1)./(1+(b(1)/60.2-1).*exp(-b(2).*(t-1954)))','b','t');
b1=nlinfit(T,N,fun,b0);
Logistic=b1(1)./(1+( b1(1)/60.2-1).*exp( -b1(2).*(T-1954))); %非线性拟合的方程
plot(T,N,'*',T,Logistic) %对原始数据与曲线拟合后的值作图
RL=sum((N-Logistic).^2) %求残差平方和
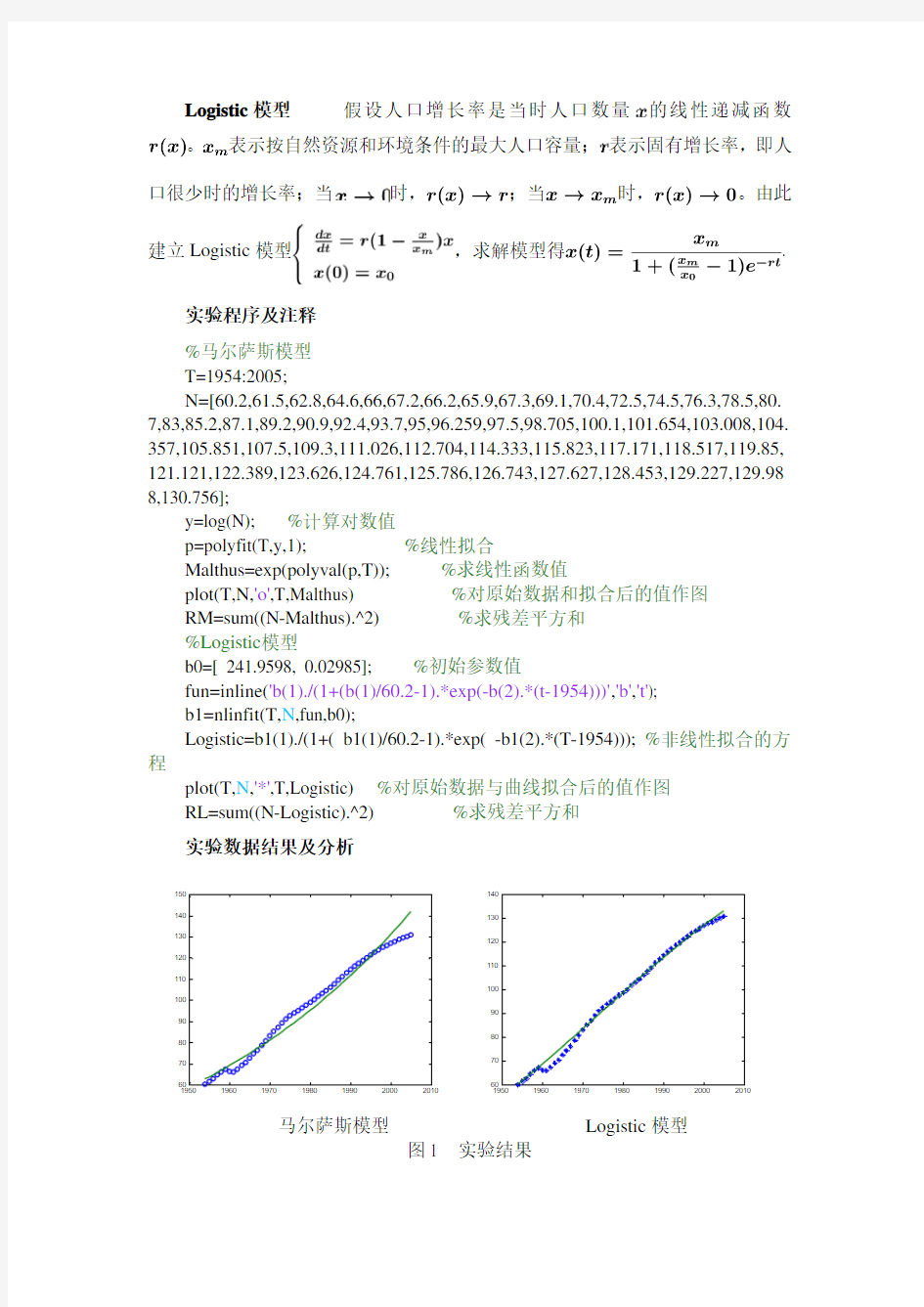
实验数据结果及分析
马尔萨斯模型Logistic模型
图1 实验结果
由上图可以看出,Logistic模型对人口的拟合更加确切,其误差130.8740较马尔萨斯模型的误差757.4464更小。利用Logistic模型预测2006年至2015年各
由马尔萨斯模型可得,随着时间的推移,人口数量将会无限的
增大,这显然是不合理的,导致这一问题的一个明显原因就是,马尔萨斯原型没
有考虑环境的承受能力这一限制。而Logistic模型则
考虑了自然环境对人口数量以及增长率的限制,即随着时间的推移,人口数量会渐渐增大,但人口的增长率会慢慢减小,直至等于0,此时人口将会达到环境所能承受的最大值。
实验结论
相比于马尔萨斯模型,Logistic模型更适合长期的人口预测。
matlab曲线拟合人口增长模型及其数量预测
实验目的 [1] 学习由实际问题去建立数学模型的全过程; [2] 训练综合应用数学模型、微分方程、函数拟合和预测的知识分析和解决实际问题; [3] 应用matlab 软件求解微分方程、作图、函数拟合等功能,设计matlab 程序来求解 其中的数学模型; [4] 提高论文写作、文字处理、排版等方面的能力; 通过完成该实验,学习和实践由简单到复杂,逐步求精的建模思想,学习如何建立反映人口增长规律的数学模型,学习在求解最小二乘拟合问题不收敛时,如何调整初值,变换函数和数据使优化迭代过程收敛。 应用实验(或综合实验) 一、实验内容 从1790—1980年间美国每隔10年的人口记录如表综2.1所示: 表综2.1 用以上数据检验马尔萨斯(Malthus)人口指数增长模型,根据检验结果进一步讨论马尔萨斯人口模型的改进,并利用至少两种模型来预测美国2010年的人口数量。 二、问题分析 1:Malthus 模型的基本假设是:人口的增长率为常数,记为 r 。记时刻t 的人口为x (t ),(即x (t )为模型的状态变量)且初始时刻的人口为x 0,于是得到如下微分方程: ?????==0 )0(d d x x rx t x 2:阻滞增长模型(或Logistic 模型) 由于资源、环境等因素对人口增长的阻滞作用,人 口增长到一定数量后,增长率会下降,假设人口的增长率为x 的减函数,如设r(x)=r(1-x/x m ),其中r 为固有增长率(x 很小时),x m 为人口容量(资源、环境能容纳的最大数量),于是得到如下微分方程: ?? ???=-=0)0()1(d d x x x x rx t x m
交通流中的nasch模型及matlab代码元胞自动机
元胞自动机NaSch模型及其MATLAB代码 作业要求 根据前面的介绍,对NaSch模型编程并进行数值模拟: ●模型参数取值:Lroad=1000,p=0.3,Vmax=5。 ●边界条件:周期性边界。 ●数据统计:扔掉前50000个时间步,对后50000个时间步进行统计,需给出的 结果。 ●基本图(流量-密度关系):需整个密度范围内的。 ●时空图(横坐标为空间,纵坐标为时间,密度和文献中时空图保持一致, 画 500个时间步即可)。 ●指出NaSch模型的创新之处,找出NaSch模型的不足,并给出自己的改进思 路。 ●流量计算方法: 密度=车辆数/路长; 流量flux=density×V_ave。 在道路的某处设置虚拟探测计算统计时间T内通过的车辆数N; 流量flux=N/T。 ●在计算过程中可都使用无量纲的变量。 1、NaSch模型的介绍 作为对184号规则的推广,Nagel和Schreckberg在1992年提出了一个模拟车辆交通的元胞自动机模型,即NaSch模型(也有人称它为NaSch模型)。 ●时间、空间和车辆速度都被整数离散化。
● 道路被划分为等距离的离散的格子,即元胞。 ● 每个元胞或者是空的,或者被一辆车所占据。 ● 车辆的速度可以在(0~Vmax )之间取值。 2、NaSch 模型运行规则 在时刻t 到时刻t+1的过程中按照下面的规则进行更新: (1)加速:),1min(max v v v n n +→ 规则(1)反映了司机倾向于以尽可能大的速度行驶的特点。 (2)减速:),min(n n n d v v → 规则(2)确保车辆不会与前车发生碰撞。 (3)随机慢化: 以随机概率p 进行慢化,令:)0, 1-min(n n v v → 规则(3)引入随机慢化来体现驾驶员的行为差异,这样既可以反映随机加速行为, 又可以反映减速过程中的过度反应行为。这一规则也是堵塞自发产生的至关重要因素。 (4)位置更新:n n n v x v +→ ,车辆按照更新后的速度向前运动。 其中n v ,n x 分别表示第n 辆车位置和速度;l (l ≥1)为车辆长度; 11--=+n n n x x d 表示n 车和前车n+1之间空的元胞数;p 表示随机慢化概率;max v 为最大速度。 3、NaSch 模型实例 根据题目要求,模型参数取值:L=1000,p=0.3,Vmax=5,用matlab 软件进行编程,扔掉前11000个时间步,统计了之后500个时间步数据,得到如下基本图和时空图。 3.1程序简介 初始化:在路段上,随机分配200个车辆,且随机速度为1-5之间。 图3.1.1是程序的运行图,图3.1.2中,白色表示有车,黑色是元胞。
云模型matlab程序
1.绘制云图 Ex=18 En=2 He=0.2 hold on for i=1:1000 Enn=randn(1)*He+En; x(i)=randn(1)*Enn+Ex; y(i)=exp(-(x(i)-Ex)^2/(2*Enn^2)); plot(x(i),y(i),'*') end Ex=48.7 En=9.1 He=0.39 hold on for i=1:1000 Enn=randn(1)*He+En; x(i)=randn(1)*Enn+Ex; y(i)=exp(-(x(i)-Ex)^2/(2*Enn^2)); plot(x(i),y(i),'*')
end 2.求期望、熵及超熵 X1=[51.93 52.51 54.70 43.14 43.85 44.48 44.61 52.08]; Y1=[0.91169241573 0.921875 0.96032303371 0.75737359551 0.76983848315 0.7808988764 0.78318117978 0.9143258427]; m=8; Ex=mean(X1) En1=zeros(1,m); for i=1:m En1(1,i)=abs(X1(1,i)-Ex)/sqrt(-2*log(Y1(1,i))); end En=mean(En1); He=0; for i=1:m He=He+(En1(1,i)-En)^2; end En=mean(En1) He=sqrt(He/(m-1)) 3.平顶山so2环境: X1=[0.013 0.04 0.054 0.065 0.07 0.067 0.058 0.055 0.045]; Y1=[0.175675676 0.540540541 0.72972973 0.878378378
人口预测 matlab
数学建模第一次实验报告 一.实验目的 学习有关人口预测的模型,了解有关混沌的基本理论,建立人口预报模型,并完成人口总量的预报,能够用软件完成数据计算。 二.实验内容 1.下表为我国自1949年至2000年的人口数据,请根据人口模型,预测出2010、2015 年我国的人口总数,并根据中国统计局的全国人口普查公报的1%调查数据,计
2. 谈谈你所认识的混沌 三. 实验步骤 1. 查阅资料选择模型 通过查阅资料,发现在考虑算法复杂度以及预测效果等综合因素时,阻滞增长 模型(Logistic 模型)要优于其他模型,所以我们选用阻滞增长模型进行本次实验。 2. 建立模型 阻滞增长模型(Logistic 模型)是考虑到自然资源、环境条件等因素对人口增长的阻滞作用,对指数增长模型的基本假设进行修改后得到的。阻滞作用体现在对人口增长率r 的影响上,是的r 随着人口数量x 的增加而下降。若将r 表示为x 的函数 ()r x ,则它应是减函数,于是有: ()()0,0dx r x x x x dt == (1) 对于()r x 的一个最简单的假设是()r x 为x 的线性函数,即:
()(),0,0r x r sx r s =->> (2) 设自然资源和环境所能容纳的最大人口数量为m x ,当m x x =时人口不在增长,即增长率()0m r x =,代入(2)式可得m r s x = ,所以有: ()(1)m r r x r x =- (3) 将(3)式代入(1)式得: ()0(1)0m dx r rx dt x x x ?=-?? ?=? (4) 解(4)可得(5)式: ()0 1(1)e m rt m x x t x x -= +- (5) 3. 根据模型原理进行编程 程序见第五部分。 4. 运行结果 采用1949年到2000年的人口调查结果作为数据,计算得到的模型参数()r x 和 m x 为:()0.0296r x =,()204.5537m x =千万人。 1949年到2000年的预测结果与人口调查结果对比图如图1所示。
DEA的Matlab程序(数据包络分析)
模型((P C2R)的MATLAB程序 clear X=[]; %用户输入多指标输入矩阵X Y=[]; %用户输入多指标输出矩阵Y n=size(X',1); m=size(X,1); s=size(Y,1); A=[-X' Y']; b=zeros(n, 1); LB=zeros(m+s,1); UB=[]; for i=1:n; f= [zeros(1,m) -Y(:,i)']; Aeq=[X(:,i)' zeros(1,s)]; beq=1; w(:,i)=LINPROG(f,A,b,Aeq,beq,LB,UB); %解线性规划,得DMU;的最佳权向量w; E(i, i)=Y(:,i)'*w(m+1:m+s,i); %求出DMU i的相对效率值E ii end w %输出最佳权向量 E %输出相对效率值E ii Omega=w(1:m,:) %输出投入权向量。 mu=w(m+1:m+s,:) %输出产出权向量。 模型(D C2R)的MATLAB程序 clear X=[]; %用户输入多指标输入矩阵X Y=[]; %用户输入多指标输出矩阵Y n=size(X',1); m=size(X,1); s=size(Y,1); epsilon=10^-10; %定义非阿基米德无穷小 =10-10 f=[zeros(1,n) -epsilon*ones(1,m+s) 1]; %目标函数的系数矩阵: 的系数为0,s-,s+的系数为- e, 的系数为1; A=zeros(1,n+m+s+1); b=0; %<=约束; LB=zeros(n+m+s+1,1); UB=[]; %变量约束; LB(n+m+s+1)= -Inf; %-Inf表示下限为负无穷大。 for i=1:n; Aeq=[X eye(m) zeros(m,s) -X(:,i) Y zeros(s,m) -eye(s) zeros(s,1)]; beq=[zeros(m, 1 ) Y(:,i)]; w(:,i)=LINPROG (f,A,b,Aeq,beq,LB,UB); %解线性规划,得DMU的最佳权向量w; end w %输出最佳权向量 lambda=w(1:n,:) %输出 s_minus=w(n+1:n+m,:) %输出s- s_plus=w(n+m+1:n+m+s,:) %输出s+ theta=w(n+m+s+1,:) %输出
中国人口预测模型(精)
中国人口预测模型 天津师范大学数学科学学院 1003班 刘瑶(10505135)周丽(10505110) 2013年6月17日星期一
中 国 人 口 预 测 模 型 摘 要 为了加快中国的经济建设进程,全面落实科学的发展观,按照构建社会主义和谐社会的要求,实现人口与经济社会资源环境的协调和可持续发展。我们确定人口发展战略,必须既着眼于人口本身的问题,又处理好人口与经济社会资源环境之间的相互关系,构建社会主义和谐社会,统筹解决人口数量、素质、结构、分布等问题。 本文是以《中国人口统计年鉴》公布的部分人口数据为基准(其他部分数据通过网站查询得到),通过合理的假设和数学模型得到了对于中国人口增长预测的统计模型。对Leslie 人口模型改进,构建了反映生育率和死亡率变化率负指数函数。基于leslie 的改 进模型: (t)X B B B +(t)X A A A =t)▽n +X(t 22) -(n 3 2112) -(n 3 21 此模型考虑到了生育率的变化,并是针对总人口分布处理的,克服了leslie 模型的不足,很适合做长期预测。得到结论:人口数量先增大后减小,峰值出现在2040年,届时人口数量将达到最大,为15.869亿。 关键词: 人口预测, Leslie 人口模型改进 , 长期预测 一 问题的背景 中国是世界上人口最多的发展中国家,人口多,底子薄,耕地少,人均占有资源相对不足,是我国的基本国情,人口问题一直是制约中国经济发展的首要因素。新中国成立50多年来,我国人口发展经历了前30年高速增长和后20年低速增长两大阶段:从建国初期到上世纪70年代初,中国人口再生产由旧中国的高出生、高死亡率进入高出生、低死亡率的人口高增长时期,1950-1975年人口出生率始终保持在30‰以上, 最高达到37‰(附录1)。70年代以后,人口过快增长的势头得到迅速扭转,人口出生率、自然增长率、妇女总和生育率有了明显下降,人口出生率由70年代初的33‰大幅度下降到80年代的21‰, 妇女总和生育率也由6下降到2.3左右。90年代以来,随着我国经济高速发展,人民文化和健康水平逐步提高,计划生育工作的不断深入,在20-29岁生育旺盛人数年均超过1亿的情况下, 人口出生率依然呈现大幅下降的趋势,到2000年底人口出生率从1990年的21.06‰下降到14.03‰,自然增长率由1990年的14.39‰下降到7.58‰, 妇女总和生育率也下降到2以下。进入90年代末期, 我国人口再生产实现了低出生、低死亡、低增长的历史性转变,我国用20多年时间完成了国外近200年的历程。到2000年底全国总人口为12.6743亿, 成功实现了“九五”计划将人口控制在13亿的奋斗目标。 中国政府自1980年在全国城乡实行计划生育基本国策以来成果卓著,据国家计生委“计划生育投入与效益研究”课题组的研究成果,20年共少生2.5亿个孩子。若从70年代算起,至今至少少生3亿人口,这有效地控制了人口的快速增长,为中国现代化建设、全面实现小康打下坚实的基础, 这同时也是对世界人口的增长和控制做出了杰出贡献。但是由于中国人口基数大,人口增长问题依然十分严峻,1990-1999年每年平均净增人口约1300万,这仍然对我国社会和经济产生巨大的压力。在我国现代化进程中,必须实现人口与经济、社会、
实验一 用MATLAB处理系统数学模型
实验一用MATLAB处理系统数学模型 一、实验原理 表述线性定常系统的数学模型主要有微分方程、传递函数、动态结构图等.求拉氏变换可用函数laplace(ft,t,s),求拉式反变换可用函数illaplace(Fs,s,t);有关多项式计算的函数主要有roots(p),ploy(r),conv(p,q),ployval(n,s);求解微分方程可采用指令 s=dslove(‘a_1’,’a_2’,’···,’a_n’);建立传递函数时,将传递函数的分子、分母多项式的系数写成两个向量,然后用tf()函数来给出,还可以建立零、极点形式的传递函数,采用的函数为zpk(z,p,k);可用函数sys=series(sys1,sys2)来实现串联,用 sys=parallel(sys1,sys2)来实现并联,可用函数sys=feedback(sys1,sys2,sign)来实现系统的反馈连接,其中sign用来定义反馈形式,如果为正反馈,则sign=+1,如果为负反馈,则sign=-1。 二、实验目的 通过MATLAB软件对微分方程、传递函数和动态结构图等进行处理,观察并分析实验结果。 三、实验环境 MATLAB2012b 四、实验步骤 1、拉氏变换 syms s t; ft=t^2+2*t+2; st=laplace(ft,t,s) 2、拉式反变换 syms s t; Fs=(s+6)/(s^2+4*s+3)/(s+2); ft=ilaplace(Fs,s,t) 3、多项式求根 p=[1 3 0 4]; r=roots(p) p=poly(r) 4、多项式相乘 p=[ 3 2 1 ];q=[ 1 4];
云模型简介及个人理解matlab程序
云模型简介及个人理解m a t l a b程序 集团档案编码:[YTTR-YTPT28-YTNTL98-UYTYNN08]
随着不确定性研究的深入,越来越多的科学家相信,不确定性是这个世界的魅力所在,只有不确定性本身才是确定的。在众多的不确定性中,和是最基本的。针对和在处理不确定性方面的不足,1995年我国工程院院士教授在概率论和模糊数学的基础上提出了云的概念,并研究了模糊性和随机性及两者之间的关联性。自李德毅院士等人提出云模型至今,云模型已成功的应用到、、、智能控制、等众多领域. 设是一个普通集合。 , 称为论域。关于论域中的模糊集合,是指对于任意元素都存在一个有稳定倾向的随机数,叫做对的隶属度。如果论域中的元素是简单有序的,则可以看作是基础变量,隶属度在上的分布叫做隶属云;如果论域中的元素不是简单有序的,而根据某个法则,可将映射到另一个有序的论域上,中的一个且只有一个和对应,则为基础变量,隶属度在上的分布叫做隶属云[1] 。 数字特征
云模型表示自然语言中的基元——语言值,用云的数字特征——期望Ex,熵En和超熵He表示语言值的数学性质 [3] 。 期望 Ex:云滴在论域空间分布的期望,是最能够代表定性概念的点,是这个概念量化的最典型样本。 熵 En:“熵”这一概念最初是作为描述热力学的一个状态参量,此后又被引入统计物理学、信息论、复杂系统等,用以度量不确定的程度。在云模型中,熵代表定性概念的可度量粒度,熵越大,通常概念越宏观,也是定性概念不确定性的度量,由概念的随机性和模糊性共同决定。一方面, En是定性概念随机性的度量,反映了能够代表这个定性概念的云滴的离散程度;另一方面,又是定性概念亦此亦彼性的度量,反映了在论域空间可被概念接受的云滴的取值范围。用同一个数字特征来反映随机性和模糊性,也必然反映他们之间的关联性。 超熵 He:熵的不确定性度量,即熵的熵,由熵的随机性和模糊性共同决定。反映了每个数值隶属这个语言值程度的凝聚性,即云滴的凝聚程度。超熵越大,云的离散程度越大,隶属度的随机性也随之增大,云的厚度也越大。
用matlab实现碰撞模型程序代码
用m a t l a b实现碰撞模型程序代码 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
c l c; clear; fill([6,7,7,6],[5,5,0,0],[0,0.5,0]);%右边竖条的填充 holdon;%保持当前图形及轴系的所有特性 fill([2,6,6,2],[3,3,0,0],[0,0.5,0]);%左边竖条的填充 holdon;%保持当前图形及轴系的所有特性 t1=0:pi/60:pi; plot(4-2*sin(t1-pi/2),5-2*cos(t1-pi/2));%绘制中间的凹弧图形gridon;%添加网格线 axis([0,9,0,9]);%定义坐标轴的比例% axis('off');%关闭所有轴标注,标记,背景 fill([1,2,2,1],[5,5,0,0],[0,0.5,0]);%中间长方形的填充 holdon;%保持当前图形及轴系的所有特性 title('碰撞');%定义图题 x0=6; y0=5; head1=line(x0,y0,'color','r','linestyle','.','erasemode','xor','marke rsize',30); head2=line(x0,y0,'color','r','linestyle','.','erasemode','xor','marke rsize',50);%设置小球颜色,大小,线条的擦拭方式 t=0;%设置小球的初始值 dt=0.001;%设置运动周期 t1=0;%设置大球的初始值 dt1=0.001; while1%条件表达式 t=t+dt; x1=9-1*t; y1=5; x3=6; y3=5; ift>0 x2=6; y2=5;%设置小球的运动轨迹 end ift>2.8 t=t+dt; a=sin(t-3); x1=6.1; y1=5.1; x3=4-2*sin(1.5*a); y3=5-2*cos(1.5*a);%设置大球的运动轨迹 end
飞机碰撞模型
飞机碰撞模型 摘要 第六架在边长为160km的正方形区域内以的飞行角从坐标为(0,0)的点出发,在飞行过程中不与其它五架飞机发生碰撞,即在该区域内与其它任意飞机的距离大于8km,就要不断调整该飞机的飞行角度,使其任意时刻与其他飞机的距离大于8km,利用空间中点的距离定义,计算任意时刻该飞机与其他飞机的距离,找到调整角度的最小值为。 1、问题重述 在约10000km高空的某边长160km的正方形区域内,有5架飞机均以800km/h的速度作水平飞行,不碰撞的标准为在该区域内任意两架飞机的距离大于8km。现有5架飞机在区域内飞行且它们不会碰撞,其初始坐标和飞行方向由下表给出: 现有第6架飞机要进入该区域,坐标为(0,0),飞行角为,如果其与内部的5架飞机发生碰撞,就需要调整其飞行角度,请建立优化模型,确定其与内部5架飞机不碰撞的最小调整角。 2、基本假设 1、五架飞机在规定正方形区域飞行中不随意改变路线; 2、飞机在飞行中不考虑其他未知因素; 3、符号说明 :正方形区域的边长; :第i架飞机飞行的方向角度; :第六架飞机飞行过程中的调整角度; :第架、第架飞机的距离; :第架飞机在区域内飞行的路线长度; :第架飞机的飞行速度; :第架飞机在区域内的飞行时间; :第i架飞机的横坐标; :第i架飞机的纵坐标; 4、模型的建立与求解 1、模型的建立 先根据五架飞机起始点与终点坐标,在规定的网格区域内画出它们的飞行路线,再根据给出的区域长度与各架飞机飞行速度,计算出各架飞机在区域内的飞行时间, 再根据计算得出的时间,得出时刻各架飞机的坐标,求出在该时刻第六架飞机与其他五架飞机的距离 即 当<8时,此时就需要调整第六架飞机的飞行角度,使其与另外五架飞机
云模型简介及个人理解matlab程序文件
随着不确定性研究的深入,越来越多的科学家相信,不确定性是这个世界的魅力所在,只有不确定性本身才是确定的。在众多的不确定性中,随机性和模糊性是最基本的。针对概率论和模糊数学在处理不确定性方面的不足,1995年我国工程院院士李德毅教授在概率论和模糊数学的基础上提出了云的概念,并研究了模糊性和随机性及两者之间的关联性。自李德毅院士等人提出云模型至今,云模型已成功的应用到自然语言处理、数据挖掘、 设是一个普通集合。 , 称为论域。关于论域中的模糊集合,是指对于任意元素都存在一个有稳定倾向的随机数,叫做对的隶属度。如果论域中的元素是简单有序的,则可以看作是基础变量,隶属度在上的分布叫做隶属云;如果论域中的元素不是简单有序的,而根据某个法则,可将映射到另一个有序的论域上,中的一个且只有一个和对应,则为基础变量,隶属度在上的分布叫做隶属云[1] 。 数字特征 云模型表示自然语言中的基元——语言值,用云的数字特征
——期望Ex,熵En和超熵He表示语言值的数学性质[3] 。 期望 Ex:云滴在论域空间分布的期望,是最能够代表定性概念的点,是这个概念量化的最典型样本。 熵 En:“熵”这一概念最初是作为描述热力学的一个状态参量,此后又被引入统计物理学、信息论、复杂系统等,用以度量不确定的程度。在云模型中,熵代表定性概念的可度量粒度,熵越大,通常概念越宏观,也是定性概念不确定性的度量,由概念的随机性和模糊性共同决定。一方面, En是定性概念随机性的度量,反映了能够代表这个定性概念的云滴的离散程度;另一方面,又是定性概念亦此亦彼性的度量,反映了在论域空间可被概念接受的云滴的取值范围。用同一个数字特征来反映随机性和模糊性,也必然反映他们之间的关联性。 超熵 He:熵的不确定性度量,即熵的熵,由熵的随机性和模糊性共同决定。反映了每个数值隶属这个语言值程度的凝聚性,即云滴的凝聚程度。超熵越大,云的离散程度越大,隶属度的随机性也随之增大,云的厚度也越大。 1.绘制云图 Ex=18
用matlab实现碰撞模型程序代码
clc; clear; fill([6,7,7,6],[5,5,0,0],[0,0.5,0]);%右边竖条的填充 hold on; %保持当前图形及轴系的所有特性 fill([2,6,6,2],[3,3,0,0],[0,0.5,0]);%左边竖条的填充 hold on;% 保持当前图形及轴系的所有特性 t1=0:pi/60:pi; plot(4-2*sin(t1-pi/2),5-2*cos(t1-pi/2));%绘制中间的凹弧图形 grid on;%添加网格线 axis([0,9,0,9]);%定义坐标轴的比例% axis('off');%关闭所有轴标注,标记,背景 fill([1,2,2,1],[5,5,0,0],[0,0.5,0]);%中间长方形的填充 hold on;% 保持当前图形及轴系的所有特性 title('碰撞');%定义图题 x0=6; y0=5; head1=line(x0,y0,'color','r','linestyle','.','erasemode','xor','markersize',30); head2=line(x0,y0,'color','r','linestyle','.','erasemode','xor','markersize',50); %设置小球颜色,大小,线条的擦拭方式 t=0;%设置小球的初始值 dt=0.001;%设置运动周期 t1=0;%设置大球的初始值 dt1=0.001; while 1%条件表达式 t=t+dt; x1=9-1*t; y1=5; x3=6; y3=5; if t>0 x2=6; y2=5;%设置小球的运动轨迹 end if t>2.8 t=t+dt; a=sin(t-3); x1=6.1; y1=5.1; x3=4-2*sin(1.5*a); y3=5-2*cos(1.5*a);%设置大球的运动轨迹
基于MATLAB的地震正演模型实现[1]
基于MATLAB的地震正演模型实现 贾跃玮 (中国地质大学(北京) 北京100083) 摘 要 人工合成地震正演模型是进行三维模型计算的基础。针对地震勘探的原理,本文运用MATLAB强大数学计算和图像可视化功能,对一个三层介质模型制作了人工合成地震记录。文章首先说明了地震记录形成的物理机制,然后介绍了地质模型的构造及参数选择,最后针对该具体地质模型制作了合成地震记录。 关键词 地震;MATLAB;正演 0引 言 地震勘探就是利用地下介质弹性和密度的差异,通过观测和分析大地对人工激发地震波的响应,推断地下岩层的性质和形态的地球物理方法。地震勘探是钻探前勘测石油与天然气资源的重要手段,在煤田和工程地质勘查、区域地质研究和地壳研究等方面,也得到广泛应用。 人工合成二维地震模型记录是各种复杂地震模型正演计算的基础,是对地震勘探经典理论的忠实实现。在实际工作中,针对具体地质构造进行二维地震模拟能够有效帮助地球物理工作者在地震剖面上识别各种地质现象。MATLAB环境集编程、画图于一体,特别适合人工合成地震记录的快速实现。因此,我们在MATLAB环境下设计了一个三层地质模型,并对该模型模拟了地震记录,旨在可视化地观察地震波场记录特征并验证地震褶积模型。 1地震记录形成的物理机制 在地震记录上看到的波形是地震子波叠加的结果,从地下许多反射界面发生反射时形成的地震子波,振幅大小决定于反射界面反射系数的绝对值,极性的正负决定于反射系数的正负,到达时间的先后取决于界面深度和覆盖层的波速。若地震子波波形用S(t)表示,反射系数是双程垂直反射旅行时t的函数,用R(t)表示,地震记录f(t)形成的物理过程在数学上就可表示为:f(t)=S(t)3R(t)=∫0T S(τ)R(t-τ)dτ 地震子波和反射系数资料常常不易取得,因此计算时常做这样一些假设: (1)地质模型的建立是来自大量观察实际地质结构的经验性归纳总结。 (2)为了模型建立和计算过程中突出理论数值,去除了一些干扰因素,对一切衰减、噪声都不进行考虑。 (3)地层在横向上均匀,纵向上是由大量具有不同弹性性质的薄层构成。 (4)地震子波以平面波形式垂直入射到界面,各薄层的反射子波与地震子波形状相同,只是振幅及极性不同。 (5)所有波的转换、吸收及绕射等能量损失都不考虑。 基于以上这些假设条件进行地震记录合就必须已知地震子波以及地层的反射系数,而反射系数又主要由地层的波阻抗反映,所以必须首先获取地层的速度和密度资料。 速度资料可通过连续速度测井获得,密度资料可从密度测井获得,得不到密度资料时,可近似假定密度不变,以速度曲线代替波阻抗曲线来计算反射系数。加德纳根据实际资料提出了一个由速度推算密度的经验公式: ρ=0.23V0.25 (速度单位:英尺/秒) 或 ρ=0.31V0.25 (速度单位:米/秒)
基于云模型的粒计算方法研究
第6章从云模型理解模糊集合的争论与发展
第1章基于云模型的粒计算方法应用 云模型是一个定性定量转换的双向认知模型,正向高斯云和逆向高斯云算法实现了一个基本概念与数据集合之间的转换关系;本文基于云模型和高斯变换提出的高斯云变换方法给出了一个通用的认知工具,不仅将数据集合转换为不同粒度的概念,而且可以实现不同粒度概念之间的柔性切换,构建泛概念树,解决了粒计算中的变粒度问题,有着广阔的应用前景。 视觉是人类最重要的感觉,人类所感知的外界信息至少有80%以上都来自于视觉[130]。图像分割[131]是一种最基本的计算机视觉技术,是图像分析与理解的基础,一直以来都受到人们的广泛关注。目前图像的分割算法有很多,包括大大小小的改进算法在内不下千种,但大致可以归纳为两类[132]。第一类是采用自顶向下的方式,从数学模型的选择入手,依靠先验知识假定图像中的部分属性特征符合某一模型,例如马尔科夫随机场、引力场等,利用模型描述图像的邻域相关关系,将图像低层的原始属性转换到高层的模型特征空间,进而建模优化求解所采用模型的参数,通常是一个复杂度非常高的非线性能量优化问题。在特征空间对图像建模,其描述具有结构性、分割结果也一般具有语义特征,但是由于对数据的未知性、缺乏足够先验知识的指导,导致模型的参数选择存在一定的困难。第二类是采用自底向上的方式,从底层原始数据入手,针对图像灰度、颜色等属性采用数据聚类的方法进行图像分割,聚类所采用的理论方法通常包括高斯变换、模糊集、粗糙集等;或者预先假设图像的统计特性符合一定的分类准则,通过优化准则产生分割结果,例如Otsu方法的最大方差准则[133][134]、Kapur方法的最大熵准则[135][136]等。这类方法虽然缺乏语义信息表达,但是直接在数据空间建模,方法更具普适性和鲁棒性。 随着计算机视觉研究的深入,简单的图像分割已经不能满足个性化的需求,有时候人们恰恰兴趣的是图像中亦此亦彼的那些不确定性区域,基于云模型的粒计算方法是一种不确定性计算方法,发现图像中存在的不确定性区域是它的一个重要能力。如何模拟人类自然视觉中的认知能力进行图像分割一直以来都是一个难点问题,而基于高斯云变换的可变粒计算正是用来模拟人类认知中的可变粒计算过程,因此可以利用高斯云变换对自然视觉认知能力中选择性注意能力进行形式化。武汉大学秦昆教授等曾基于云综合、云分解等云运算实现图像分割,正如第5章中的分析结果,基于内涵的概念计算方法随着层次的提升,概念脱离原始数据会增加误分率,甚至失效,而且无法实现自适应地概念数量和粒度优化。
美国人口增长预测模型
2016年数学建模论文 第一套 论文题目:人口增长模型的确定 组别:第35组 姓名:耿晨闫思娜王强 提交日期:2016年7月4日
题目:美国人口增长预测模型 摘要 本文根据近两个世纪美国每十年一次的人口统计数据,建立了指数增长模型,即Malthus模型,并通过1790-1890年的数据验证了它的准确性。但是,随着时间的推移,拟合函数与统计数据误差逐渐增大,所以,又建立了阻滞增长模型,即Logistic 模型,这个模型的拟合函数与统计数据误差较小,并用该模型对美国未来几年的人口做出了预测。总体来说,阻滞增长模型在预测准确度方面要明显优于原始的马尔萨斯人口指数增长模型。 关键词:指数增长模型,阻滞增长模型,人口预测
一、问题重述 1790-1980年间美国每隔10年的人口记录如下表所示。 表1:人口记录表 1.试用以上数据建立马尔萨斯(Malthus)人口指数增长模型,并对接下来的每隔十年预测五次人口数量,并查阅实际数据进行比对分析。 2.如果数据不相符,再对以上模型进行改进,寻找更为合适的模型进行预测,并对两次预测结果进行对比分析。 3.查阅资料找出中国人口与表1同时期的人口数量,用以上建立的两个模型进行人口预测与分析。 二、问题分析 影响人口增长的因素很多,其中最主要的两个因素是出生率和死亡率。出生率受到婴儿死亡率、对避孕的态度及措施效果、对堕胎的态度、怀孕期间的健康护理等因素的影响;死亡率则受到卫生设施与公共卫生状况、战争、污染、医疗水平、饮食习惯、心理压力和焦虑等因素的影响。此外,影响人口在一个地区增长的因素还有迁入和迁出、生存空间的限制、水和食物、疾病等。在这些因素中,有些是常态的或者有规律的,这些因素对人口的增长是恒定的;而有些因素是随机的,对人口的增长是没有规律的。因此,当大范围、长时期研究人口增长问题时,对人口增长产生影响的随机因素就不在考虑了。 建立该模型的目的是要能通过模型预测美国后来每十年的人口数具体变化,并与实际的数据进行对比,看误差的大小。在此基础上利用改进的模型对美国人口同时期数量进行预测,并进行总结分析。 三、问题假设 人口指数增长模型中采用以下基本假设: (1)单位时间的人口总量增长与当时的人口呈正比,比例常数为k; (2)假设t时刻的人口为N(t),因为人口数一般是很大的,所以将N(t)近似地视为连续,可微的函数。记初始时刻(t=0)的人口数为N0。新生人口数百分率为a,死亡的百分率为b,那么,经过Δt时间后,人口数量为N(t+Δt)就是原来人口数量加上Δt时间内新生人口数减去死亡人口数。 四、变量说明
人口预测模型
人口问题 摘要 20世纪70年代后期以来,我国开始实行计划生育政策,到21世纪初期,在这30年的时间里计划生育政策对建设中国特色社会主义、实现国家的富强和实现中华民族的伟大复兴产生了巨大的影响,同事也为促进世界人口发展发挥着积极和重大的作用。然而,在经历另外人口生育比率从高到低的变化的转化以后,我国人口的主要矛盾不再是增长过快,而是人口红利的消失、临近超低生率水平、人口老龄化、出生性别比例失调等问题。出现这些问题的根本原因在于上世纪我国对人口增长采取相对宽松的政策,从而造成自然增长率和人口急剧上升,而在在实行计划生育以来我国的出生率和自然增长率急剧下降,上世界的新增人口成为了现在的老龄化人口。本文主要研究计划生育政策的调整对人口数量、结构的影响问题,为了研究方便,我们将该问题分为三个小题来分别讨论。 问题一:我们对中国历年的人口出生率、死亡率、性别比例生育模式的分析,利用Excel软件画出从2000年到2010年人口出生率、死亡率、性别比例和生育模式和Logarithmic模型来预测未来的人口的变化;另外,我们通过对中国历年人口的分析,结合matlab软件加权排序法得到三种模型各自的权重,建立人口预测加权组合模型。用该模型分析计划生育在改革前对我国人口的影响,最终我们预测我国未来10年的人口的变化。 问题二:以问题一的数据作为基础,采用拟合和线性回归的方法预测我国人口老龄化比例的增长的速度和比例,列举三种政策A、双方均为独生子女的允许要练个孩子,B、双方只要有一个是独生子女的允许要两个孩子,C、允许所有的适龄夫妻要两个孩子,并根据现有的数据对三中政策采用插值和分别拟合出人口的变化曲线推测解决现有问题的作用和影响,并作出回归方程,我们对当今的人口状况和未来的人口的发展趋势发表见解。 问题三:针对上海市人口发展问题我们以问题一和问题二为基础讨论对延迟退休年龄对未来人口数量、结构、教育、劳动供给与就业、养老等方面的影响。 关键词 曲线拟合;灰色预测;线性回归;最小二乘法; 1、问题重述 在社会经济发展的过程中人口的数量和结构起着非常重要的影响。人口的数量和结构是影响经济社会发展的重要因素。从20世纪70年代后期以来,我国鼓励晚婚晚育,提倡一对夫妻生育一个孩子。在该政策实施的30多年以来,有效地控制了我国人口的过快增长的现状,对经济发展和人民生活的改善做出了积极的贡献。但另一方面,其负面影响也开始显现。如小学招生人数(1995年以来)、高校报名人数(2009年以来)逐年下降,劳动人口绝对数量开始步入下降通道,人口抚养比的相变时刻即将到来,这些对经济社会健康、可持续发展将产生一系
完全弹性碰撞matlab
Matlab设计实验 课题名称:完全弹性碰撞 一.设计背景: 完全弹性碰撞(Perfect Elastic Collision):在理想情况下,完全弹性碰撞的物理过程满足动量守恒和能量守恒。如果两个碰撞小球的质量相等,联立动量守恒和能量守恒方程时可解得:两个小球碰撞后交换速度。如果被碰撞的小球原来静止,则碰撞后该小球具有了与碰撞小球一样大小的速度,而碰撞小球则停止。多个小球碰撞时可以进行类似的分析。 二.设计意义 真实情况下,由于小球间的碰撞并非理想的弹性碰撞,还会有能量的损失,所以最后小球还是要停下来。 所以该设计主要用于研究能量守恒中的某些问题。还有就是用于实验演示。三.程序设计 该程序主要设置了三个不同颜色的小球,在真空环境下(理想环境下)的碰撞实验演示。 该程序可以通过改变各种参数,研究各种情况下的实验数据。 程序: pole=1.8;%定义摆线的长度 xmax=2;%定义横坐标长度 ymax=2;%定义纵坐标长度 basew=2.3;%定义图中方框的宽度 baseh=2.3;%定义图中方框的高度 instant=0.2;%定义摆线间距 %三视图的初始设置 %第一幅图
figure('name','理想情况下能量守恒定律 1','position',[500,340,440,320]);%定义第一幅图的标题和位置 fill([xmax,xmax,-xmax,-xmax,xmax,xmax-0.05,xmax-0.05,- xmax+0.05,-xmax+0.05,xmax-0.05],[ymax,-ymax,- ymax,ymax,ymax,ymax-0.05,-ymax+0.05,-ymax+0.05,ymax- 0.05,ymax-0.05],[0,1,1]); %填充底座背景 hold on;%保持当前图形及坐标所有特性 fill([xmax-0.05,xmax-0.05,-xmax+0.05,-xmax+0.05],[ymax- 0.5 ,ymax-0.55,ymax-0.55,ymax-0.5],'g');%填充方框内横杆背景 hold on;%保持当前图形及坐标所有特性 text(-0.25,1.7,'1');text(0,1.7,'2');text(0.25,1.7,'3');%在坐标处标识 说明文字 text( -1.0,1.7,'a');text( -1.0,-1.7,'b');%在坐标处标识说明文字 text(1.0,1.7,'真空容器');text(-1.8,1.7,'主视图');%在坐标处标识说明文 字 axis([-basew,basew,-baseh,baseh]);%定义背景坐标范围在x(-2.3~2.3) Y(-2.3~2.3)之间 %axis('off');%覆盖坐标刻度并填充背景 theta0=7 *pi/6;%摆线1的初始角度 x0=pole*cos(theta0);%摆线1末端x坐标 y0=pole*sin(theta0)+1.5;%摆线1末端y坐标 body1=line([-instant,x0-instant],[1.5,y0],'color','r','linestyle','- ','erasemode','xor');%设置摆线1 head1=line(x0- instant,y0,'color','r','linestyle','.','erasemode','xor','markersize',40);%设置第一个小球颜色,大小 theta1=3*pi/2;%摆线2,3的角度 x1=pole*cos(theta1);%摆线2,3末端x坐标 y1=pole*sin(theta1)+1.5;%摆线2,3末端y坐标 body=line([-0.001,x1],[1.5,y1],'color','k','linestyle','- ','erasemode','xor');%设置摆线2
实验四 用MATLAB求解状态空间模型
实验四 用MATLAB 求解状态空间模型 1、实验设备 MATLAB 软件 2、实验目的 ① 学习线性定常连续系统的状态空间模型求解、掌握MATLAB 中关于求解该模型的主要函数; ② 通过编程、上机调试,进行求解。 3、实验原理说明 Matlab 提供了非常丰富的线性定常连续系统的状态空间模型求解(即系统运动轨迹的计算)的功能,主要的函数有: 初始状态响应函数initial()、阶跃响应函数step()以及可计算任意输入的系统响应数值计算函数lsim()和符号计算函数sym_lsim()。 数值计算问题可由基本的Matlab 函数完成,符号计算问题则需要用到Matlab 的符号工具箱。 4、实验步骤 ① 根据所给状态空间模型,依据线性定常连续系统状态方程的解理论,采用MATLAB 编程。 ② 在MATLAB 界面下调试程序,并检查是否运行正确。 习题1:试在Matlab 中计算如下系统在[0,5s]的初始状态响应,并求解初始状态响应表达式。 Matlab 程序如下: A=[0 1; -2 -3]; B=[]; C=[]; D=[]; x0=[1; 2]; sys=ss(A,B,C,D); [y,t,x]=initial(sys,x0,0:5); plot(t,x) 0011232????==????--????x x x
习题2:试在Matlab 中计算如下系统在[0,10s]内周期为3s 的单位方波输入下的状态响应。并计算该系统的单位阶跃状态响应表达式。 Matlab 程序如下: A=[0 1; -2 -3]; B=[0; 1]; C=[]; D=[]; x0=[1; 2]; sys=ss(A,B,C,D); [u t]=gensig('square',3,10,0.1) 0011232????==????--???? x x x
正向云发生器代码(matlab)
正向云发生器matlab代码 %正向云算法:由数字特征到定量数据表示 %直接在程序中固定EX/EN/HE的值 Ex=0; En=1; He=0.2; n=2000; X = zeros(1,n); %产生一个1*n型矩阵,其元素都为0 Y = zeros(1,n); X= normrnd ( En, He, 1, n); %产生一个1*n型正态随机数矩阵,EX为期望,ENN为方差for i=1:n Enn=X(1,i); X(1, i) = normrnd ( Ex, Enn, 1) ; %产生一个正态随机数,EX为期望,ENN为方差(1*1型) Y(1, i) = exp ( - (X(1, i) - Ex) ^2 / (2* Enn^2) ) ; end plot(X(1,:),Y(1,:),'r.'); %画图语句 %倘若X(1,i)是确定的随机数时,本代码是自己输入确定值 %保存为.m文件时,文件名要是字母名,不要中文名 disp('- - - - -云发生器程序开始- - - - -'); Ex = input('输入期望值Ex:'); En = input('输入熵值En:'); He = input('输入超熵值He:'); n = input('输入需重复计算次数:'); X = zeros(1,n); %产生一个1*n型矩阵,其元素都为0 Y = zeros(1,n); X= normrnd ( En, He, 1, n); %产生一个1*n型正态随机数矩阵,EX为期望,He为方差Xi = input('输入随机数X(1,i):'); %手动输入固定随机数X for i=1:n