多元统计分析实验报告格式

多元统计分析实验报告
姓名及学号:(例:张三20110000000)日期:
1、实验内容
2、实验目的
(。。。指出通过本实验要了解或掌握什么)
3、实验方案分析
(。。。指出实验内容属于什么问题,说明用什么方法来实验,如果是检验问题,那么原假设是什么)
4、操作过程
(。。。。给出有关操作过程)
5、实验结果
(。。。给出实验得到的重要结果)
6、讨论
(。。。对上述得到的结果做出说明与讨论)7、结论
(。。。根据以上的讨论给出恰当的结论)
多元统计分析模拟考题及答案.docx
一、判断题 ( 对 ) 1 X ( X 1 , X 2 ,L , X p ) 的协差阵一定是对称的半正定阵 ( 对 ( ) 2 标准化随机向量的协差阵与原变量的相关系数阵相同。 对) 3 典型相关分析是识别并量化两组变量间的关系,将两组变量的相关关系 的研究转化为一组变量的线性组合与另一组变量的线性组合间的相关关系的研究。 ( 对 )4 多维标度法是以空间分布的形式在低维空间中再现研究对象间关系的数据 分析方法。 ( 错)5 X (X 1 , X 2 , , X p ) ~ N p ( , ) , X , S 分别是样本均值和样本离 差阵,则 X , S 分别是 , 的无偏估计。 n ( 对) 6 X ( X 1 , X 2 , , X p ) ~ N p ( , ) , X 作为样本均值 的估计,是 无偏的、有效的、一致的。 ( 错) 7 因子载荷经正交旋转后,各变量的共性方差和各因子的贡献都发生了变化 ( 对) 8 因子载荷阵 A ( ij ) ij 表示第 i 个变量在第 j 个公因子上 a 中的 a 的相对重要性。 ( 对 )9 判别分析中, 若两个总体的协差阵相等, 则 Fisher 判别与距离判别等价。 (对) 10 距离判别法要求两总体分布的协差阵相等, Fisher 判别法对总体的分布无特 定的要求。 二、填空题 1、多元统计中常用的统计量有:样本均值向量、样本协差阵、样本离差阵、 样本相关系数矩阵. 2、 设 是总体 的协方差阵, 的特征根 ( 1, , ) 与相应的单 X ( X 1,L , X m ) i i L m 位 正 交 化 特 征 向 量 i ( a i1, a i 2 ,L ,a im ) , 则 第 一 主 成 分 的 表 达 式 是 y 1 a 11 X 1 a 12 X 2 L a 1m X m ,方差为 1 。 3 设 是总体 X ( X 1, X 2 , X 3, X 4 ) 的协方差阵, 的特征根和标准正交特征向量分别 为: 1 2.920 U 1' (0.1485, 0.5735, 0.5577, 0.5814) 2 1.024 U 2' (0.9544, 0.0984,0.2695,0.0824) 3 0.049 U 3' (0.2516,0.7733, 0.5589, 0.1624) 4 0.007 U 4' ( 0.0612,0.2519,0.5513, 0.7930) ,则其第二个主成分的表达式是
应用多元统计分析SAS作业审批稿
应用多元统计分析S A S 作业 YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿? 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 2.58 0.9 0.95 1 2.9 1.23 1 1 3.55 1.15 1 1 2.35 1.15 0.79 1 3.54 1.85 0.79 1 2.7 2.23 1.3 1 2.7 1.7 0.48 2 2.25 1.98 1.06 2 2.16 1.8 1.06 2 2.3 3 1.7 4 1.1 2 1.96 1.48 1.04
2 1.94 1.4 1 2 3 1.3 1 2 2.78 1.7 1.48 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=3.19774。还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值2.95、2.15、1.54分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
多元统计分析期末复习
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: )',...,,(),,,(2121P p EX EX EX EX μμμ='=Λ)')((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ
2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变),(~∑μP N X μ∑μ p X X X ,,,21Λ),(~∑μP N X ) ,('A A d A N s ∑+μ)()1(,, n X X ΛX )',,,(21p X X X Λ)')(()()(1X X X X i i n i --∑=n 1 X μ∑μX )1,(~∑n N X P μ),1(∑-n W p X X
多元统计分析实验报告
实验一 一、实验目的及要求 对应分析是你也降维的思想以达到减化数据结构的目的,凤的研究广泛用于定义属性变量构成的列联表利用对应分析方法分析问卷中教育程度与网上购物支付方式之间的相互关系。 二、实验环境 SPSS 19.0 window 7系统 三、实验内容及实验步骤(实践内容、设计思想与实现步骤) 实验题目: 通过分析问卷数据,绘制如下的教育程度与网上购物支付方式的交叉表,运用对应分析方法研究教育程度与网上购物所选择的支付方式之间的相关性,及揭示不同人群网上购物的特征等问题。 设计思想:原假设:H1:χ2>χα2[(n?1)(p?1)] 实现步骤: 1.在变量视窗中录入3个变量,用edu表示【教育程度】,用fangshi表示【在网上购物时采用什么样的支付方式】,用pinshu表示【频数】;如图所示:
2.先对数据进行预处理。执行【数据】→【加权个案】命令,弹出【加权个案】对话框。选中【加权个案】按钮,把【频数】放入【频率变量】框中,点击【确定】按钮完成。 3.打开主窗口,选择菜单栏中的【分析】→【降维】→【对应分析】命令,弹出【对应分析】对话框。 4.将【教育程度】导入【行】,将【在网上购物时采用什么样的支付方式】导入【列】。 5. 单击【定义范围(D)】,打开【对应分析:定义行范围】对话框; 定义行变量分类全距最小值为1,最大值为4,单击【更新】;点击【继续】,返回【对应分析】对话框;同方法打开【对应分析:定义列范围】对话框; 定义列变量全距最小值为1,最大值为5,单击【更新】; 6. 单击【统计量】打开【对应分析:统计量】对话框;选择【行轮廓表】,【列轮廓表】;单击【继续】,返回【对应分析】对话框, 7.选择【绘制】→【对应分析:图】对话框,选择【散点图】中的【行点】、【列点】选择【线图】中的【已转换的行类别】、【已转换的列类别】,单击【继续】,返回【对应分析】对话框。 8.单击【确定】按钮,完成设置并执行列联表分析。 四、调试过程及实验结果(详细记录实验在调试过程中出现的问题及解决方法。记录实验的结果) SPSS实验结果及分析: 上表显示了在32155名被调查者中,大多数消费者在网上购物时选择第三方支付和网上银行支付,在网上购物的消费人群以大学本科生相对最多。
03第三篇 多元统计分析作业题
第三篇 多元统计分析作业题 1 证明题 1)已知ψ==A X E X Z T T T ,这里用到关系1-ψ=E A 。以二变量为例证明: 12*-Λ=ψ=A X A X Z T T T 1)(-=T T A X 。 式中X 为标准化原始变量矩阵,A 为载荷矩阵,Z 为非标准化主成分得分,Z *为标准化的因子得分,E 为单位化特征向量构成的矩阵即正交矩阵,Ψ为特征根的平方根的倒数构成的对角阵,Λ为特征根构成的对角阵,对于二变量有 ?????? ??=ψ21 /10 /1λλ, ?? ? ???=Λ21 00λλ. 2)对于二变量因子模型,我们有 ?? ?++=++=222221122 112211111εεu f a f a x u f a f a x . 试以 x 1为例证明1 2 22==+j x j j u h σ ,这里∑== p k kj j a h 1 2 22 21 211a a +=。 2 计算题 1)现有一组古生物腕足动物贝壳标本的两个变量:长度x 1和宽度x 2。所测数据如下(表2.1)。 要求: ① 利用Excel 对数据进行主成分分析。 ② 借助SPSS 对该数据进行主成分分析,并计算结果与Excel 的计算结果进行对比,理解各个表格所给参数的含义。 ③ 用本例数据验证证明题?的推导结果。 表2.1 古生物腕足动物贝壳标本数据 样品编号 长度x 1 宽度x 2 样品编号 长度x 1 宽度x 2 1 3 2 14 12 10 2 4 10 15 12 11 3 6 5 16 13 6 4 6 8 17 13 14 5 6 10 18 13 15 6 7 2 19 13 17 7 7 13 20 14 7 8 8 9 21 15 13 9 9 5 22 17 13
(完整word版)实用多元统计分析相关习题
练习题 一、填空题 1.人们通过各种实践,发现变量之间的相互关系可以分成(相关)和(不相关)两种类型。多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相关系数。 2.总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。3.回归方程显著性检验时通常采用的统计量是(S R/p)/[S E/(n-p-1)]。 4.偏相关系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的)的相关系数。 5.Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。 6.主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求(降维)的一种方法。 7.主成分分析的基本思想是(设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来替代原来的指标)。 8.主成分表达式的系数向量是(相关系数矩阵)的特征向量。 9.样本主成分的总方差等于(1)。 10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。主成分的协方差矩阵为(对称)矩阵。主成分表达式的系数向量是(相关矩阵特征值)的特征向量。 11.SPSS中主成分分析采用(analyze—data reduction—facyor)命令过程。 12.因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部分为(特殊因子)。 13.变量共同度是指因子载荷矩阵中(第i行元素的平方和)。 14.公共因子方差与特殊因子方差之和为(1)。 15.聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏程度)进行科学的分类。 16.Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。 17.Q型聚类统计量是(距离),而R型聚类统计量通常采用(相关系数)。 18.六种Q型聚类方法分别为(最长距离法)、(最短距离法)、(中间距离法)、(类平均法)、(重心法)、(离差平方和法)。 19.快速聚类在SPSS中由(k-均值聚类(analyze—classify—k means cluster))过程实现。 20.判别分析是要解决在研究对象已(已分成若干类)的情况下,确定新的观测数据属于已知类别中哪一类的多元统计方法。 21.用判别分析方法处理问题时,通常以(判别函数)作为衡量新样本点与各已知组别接近程度的指标。 22.进行判别分析时,通常指定一种判别规则,用来判定新样本的归属,常见的判别准则有(Fisher准则)、(贝叶斯准则)。 23.类内样本点接近,类间样本点疏远的性质,可以通过(类与类之间的距离)与(类内样本的距离)的大小差异表现出来,而两者的比值能把不同的类区别开来。这个比值越大,说明类与类间的差异越(类与类之间的距离越大),分类效果越(好)。24.Fisher判别法就是要找一个由p个变量组成的(线性判别函数),使得各自组内点的
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
实用多元统计分析相关习题学习资料
实用多元统计分析相 尖习题 练习题 一、填空题 1?人们通过各种实践,发现变量之间的相互矢系可以分成(相尖)和(不相尖)两种 类型。多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相尖系数。 2?总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。 3 ?回归方程显著性检验时通常采用的统计量是(S R/P)/[S E/ (n-p-1) ]O 4?偏相尖系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的) 的相尖系数。 5. Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。
6 ?主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求 (降维)的一种方法。 7 ?主成分分析的基本思想是(设法将原来众多具有一定相尖性(比如P个指标),重 新组合成一组新的互相无矢的综合指标来替代原来的指标)。 8 ?主成分表达式的系数向量是(相尖系数矩阵)的特征向量。 9 ?样本主成分的总方差等于(1)。 10 ?在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。主成分的协方差矩阵为(对称)矩阵。主成分表达式的系数向量是(相尖矩阵特征值)的特征向量。 11. SPSS 中主成分分析采用(analyze—data reduction — facyor)命令过程。 12?因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部
分为(特殊因子)。 13 ?变量共同度是指因子载荷矩阵中(第i行元素的平方和)。 14 ?公共因子方差与特殊因子方差之和为(1) o 15 ?聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏 程度)进行科学的分类。 16. Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。 17. Q型聚类统计量是(距离),而R型聚类统计量通常采用(相尖系数)。 18. 六种Q型聚类方法分别为(最长距离法)、(最短距离法)、(中间距离法)、(类平均法)、(重心法)、(离差平方和法)。 19?快速聚类在SPSS中由(k■均值聚类(analyze— classify— k means cluste))过程实 现。 20. 判别分析是要解决在研究对象已(已分成若干类)的情况下,确定新的观测数据属于已知类别中哪一类的多元统计方法。 21. 用判别分析方法处理问题时,通常以(判别函数)作为衡量新样本点与各已知组别接近程度的指标。 22. 进行判别分析时,通常指定一种判别规则,用来判定新样本的归属,常见的判别准则有 (Fisher准则)、(贝叶斯准则)。 23. 类内样本点接近,类间样本点疏
应用多元统计分析习题解答_第五章
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
多元统计分析实验报告,计算协方差矩阵,相关矩阵,SAS
院系:数学与统计学学院 专业:__统计学 年级:2009 级 课程名称:统计分析 ____ 学号:____________ 姓名:_________________ 指导教师:____________ 2012年4月28日 (一)实验名称 1. 编程计算样本协方差矩阵和相关系数矩阵;
2. 多元方差分析MANOVA。 (二)实验目的 1. 学习编制sas程序计算样本协方差矩阵和相关系数矩阵; 2. 对数据进行多元方差分析。 (三)实验数据 第一题: 第二题:
(四)实验内容 1. 打开SAS软件并导入数据; 2. 编制程序计算样本协方差矩阵和相关系数矩阵; 3. 编制sas程序对数据进行多元方差分析; 4. 根据实验结果解决问题,并撰写实验报告; (五)实验体会(结论、评价与建议等) 第一题: 程序如下: proc corr data=sasuser.sha n cov; proc corr data=sasuser.sha n no simple cov; with x3 x4; partial x1 x2; run; 结果如下: (1)协方差矩阵 $AS亲坯 曲;15 Friday, Apr: I SB,沙DO COUR过程 x4 目由度=30 Xi x2x3x4x5X? -10.I9B4944-0.45E2GJ5I.3347097-G.1193E48-£0.e75?GS
-ID. 188494669,36&Q3?9-7.22IO&OS1J5692043I5.49ee^91S.Oa97SM -8.45S2645■7,221050829.S78&S46-6.372E47I-15.3084183-21.7352376-11.5674785 1.3841097 1.G5S2M7t.3726171IJ24?17B 4.e093011 4.4C12473 2.B747CM -G. I1S3S49 1.GS92043-is.soul aa 4.B09B01I68.7978495劣』S670971S.57ai1B3 -IH.05l6l?a15.43S6569-J1.73S2376孔耶124TB27.0387097105.103225&S7.3505S7E: -2D K5752??319-11337204-1L55M7S52r9747?3i19,573118337.3S0&87E33.3SQ6452 (2) 相关系数矩阵 Pearson相关系数” N =引 当HO: Rho=0 时.Prob > |r| Xi Xi xl 1.QQ000 x2 -C.23954 0.2061 x3 -0,30459 0.0957 x4 0.18975 Q.3092 x5 '0.14157 0.4475 x6 -0.83787 0.0630 -0.49292 0.0150 x2-0.23354 1.00000-0.162750.143510.022700.181520.24438 x20.20C10.31:1?0.441?0.90350.32640.1761 x3-0.30459-0.16275 1.00000-0.06219-0.34641-0.^797-0.23674 x30.095?0.381?<.00010.0563o.oses0 JS97 x40.1S8760.14351-0.86219L000000.400540,313650.22610 x40.30920.4412<.0001 D.02EG Q.085S0.2213 x5-0J 41570.02270-0.946410.40054 1.000000.317370.26750 x50.4J750.90350.0G68Q.025&0.08130 + 1620 x6-0.33?e?0.1S162-0.397970.813650.31787LOOOOO0.82976 x60.0S300.32840.02660.08580.0813C0001辺-0.432920.24938-0.288740.22810 D.267600.92976 1.00000 x70,01500J7610.19970.22130JG20<.0001 第二题: 程序如下: proc anova data=sasuser.hua ng; class kind; model x1-x4=k ind; manova h=k ind; run; 结果如下: (1)分组水平信息 The ANNA Procedure Cla^s Level Informat ion Class Level?Values kind 3 123 Number of observatIons CO (2) x1、x2、x3、x4的方差分析
应用多元统计分析SAS作业第六章资料
6-10 今有6个铅弹头,用“中子活化”方法测得7种微量元素的含量数据(见表1)。 (1) 试用多种系统聚类法对6个弹头进行分类;并比较分类结果; (2) 试用多种方法对7种微量元素进行分类。 问题求解 1对6个弹头进行分类 对数据进行标准化变换,样品间距离定义为欧式距离,系统聚类的方法分别使用类平均法(A VE )、中间距离法(MID )、可变类平均法(FLE )和离差平方合法(WARD )。使用SAS 软件CLUSTER 过程对数据进行聚类分析(程序见附录1)。 1.1类平均法 图1 类平均聚类法相关矩阵特征值图 图2 类平均聚类分析法聚类历史图 由图2可知,NCL=1时半偏R 2最大且伪F 统计量在NCL=2,5时和伪t 方统计量在NCL=1,4时较大。因此,将6个弹头分为两类{}{}(2) (2) 121,2,4,6,3,5G G ==。SAS 绘制的谱系聚类图如图 3所示。
图3 类平均聚类分析法谱系聚类图 1.2中间距离法 图4 中间距离聚类法相关矩阵特征值图 图5 中间距离聚类法聚类历史图 由图5可知,中间距离法与类平均法结果一致。因此,也将6个弹头分为两类 {}{}(2)(2) 121,2,4,6,3,5G G ==。 SAS 绘制的谱系聚类图如图6所示。
图6中间距离聚类法谱系聚类图 1.3可变类平均法 图7可变类平均聚类法分析结果图 图8 可变类平均聚类法聚类历史图 由图8可知,可变类平均法(=0.25 β-)输出结果与前两种方法稍有不同,NCL=1时半偏R2最大且伪F统计量在NCL=2时次大,NCL=5时最大;而伪t方统计量在NCL=1时最大。因此,分
多元统计分析实验报告
多元统计分析实验报告 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
1. 正态性检验 Kolmogorov-Smirnov a Shapir o-Wilk 统计量df Sig.统计量df Sig. 净资产收益 .11335.200*.97835.677 率 总资产报酬 .12135.200*.96435.298 率 资产负债率.08635.200*.96235.265 总资产周转 .18035.006.86435.000 率 流动资产周 .16435.018.88535.002 转率 已获利息倍 .28135.000.55135.000 数 销售增长率.10335.200*.94935.104 资本积累率.25135.000.65535.000 *. 这是真实显着水平的下限。 a. Lilliefors 显着水平修正 此表给出了对每一个变量进行正态性检验的结果,因为该例中样本中 n=35<2000,所以此处选用Shapiro-Wilk统计量。由Sig.值可以看到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面的分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成的向量遵从正态分布(尽管事实上并非如此)。这四个指标涉及公司的获利能力、资本结构及成长能力,我们认为这四个指标可以对公司运营能力做出近似的度量。 2. 主体间因子 N
行业电力、煤气及水的 生产和供应业 11 房地行业15 信息技术业9 多变量检验a 效应值F假设 df 误差 df Sig. 截距Pillai 的跟 踪 .967.000 Wilks 的 Lambda .033.000 Hotelling 的跟踪 .000 Roy 的最大 根 .000 行业Pillai 的跟 踪 .481.027 Wilks 的 Lambda .563.025 Hotelling 的跟踪 .698.024 Roy 的最大 根 .559.008 a. 设计 : 截距 + 行业 b. 精确统计量 c. 该统计量是 F 的上限,它产生了一个关于显着性级别的下 限。 上面第一张表是样本数据分别来自三个行业的个数。第二张表是多变量检验表,该表给出了几个统计量,由Sig.值可以看到,无论从哪个统计量来看,三个行业的运营能力(从净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标的整体来看)都是有显着差别的。 3. 主体间效应的检验
多元统计分析实验报告doc
多元统计与程序设计》课程实验报告 项目名称: 学生姓名: 学生学号: 指导教师: 完成日期:
1 实验内容 2 模型建立与求解 2.1聚类分析的形成思路 2.2.1类平均法 2.2.2谱系图的形成 2.3.快速聚类法 (以上内容见课本) 3 实验数据与实验结果 3.1实验数据 设有20个土壤样品分别对5个变量的观测数据如表5.16所示,试利用 聚类法对其进行样品聚类分析 样品号 含沙量1X 淤泥含量2X 粘土含量3X 有机物4X PH 值5X 1 77.3 13.0 9.7 1.5 6.4 2 82.5 10.0 7.5 1.5 6.5 3 66.9 20.0 12.5 2.3 7.0 4 47.2 33.3 19.0 2.8 5.8 5 65.3 20.5 14.2 1.9 6.9 6 83.3 10.0 6.7 2.2 7.0 7 81.6 12.7 5.7 2.9 6.7 8 47.8 36.5 15.7 2.3 7.2 9 48.6 37.1 14.3 2.1 7.2 10 61.6 25.5 12.6 1.9 7.3 11 58.6 26.5 14.9 2.4 6.7 12 69.3 22.3 8.4 4.0 7.0 13 61.8 30.8 7.4 2.7 6.4 14 67.7 25.3 7.0 4.8 7.3 15 57.2 31.2 11.6 2.4 6.3 16 67.2 22.7 10.1 33.3 6.2 17 59.2 31.2 9.6 2.4 6.0 18 80.2 13.2 6.6 2.0 5.8
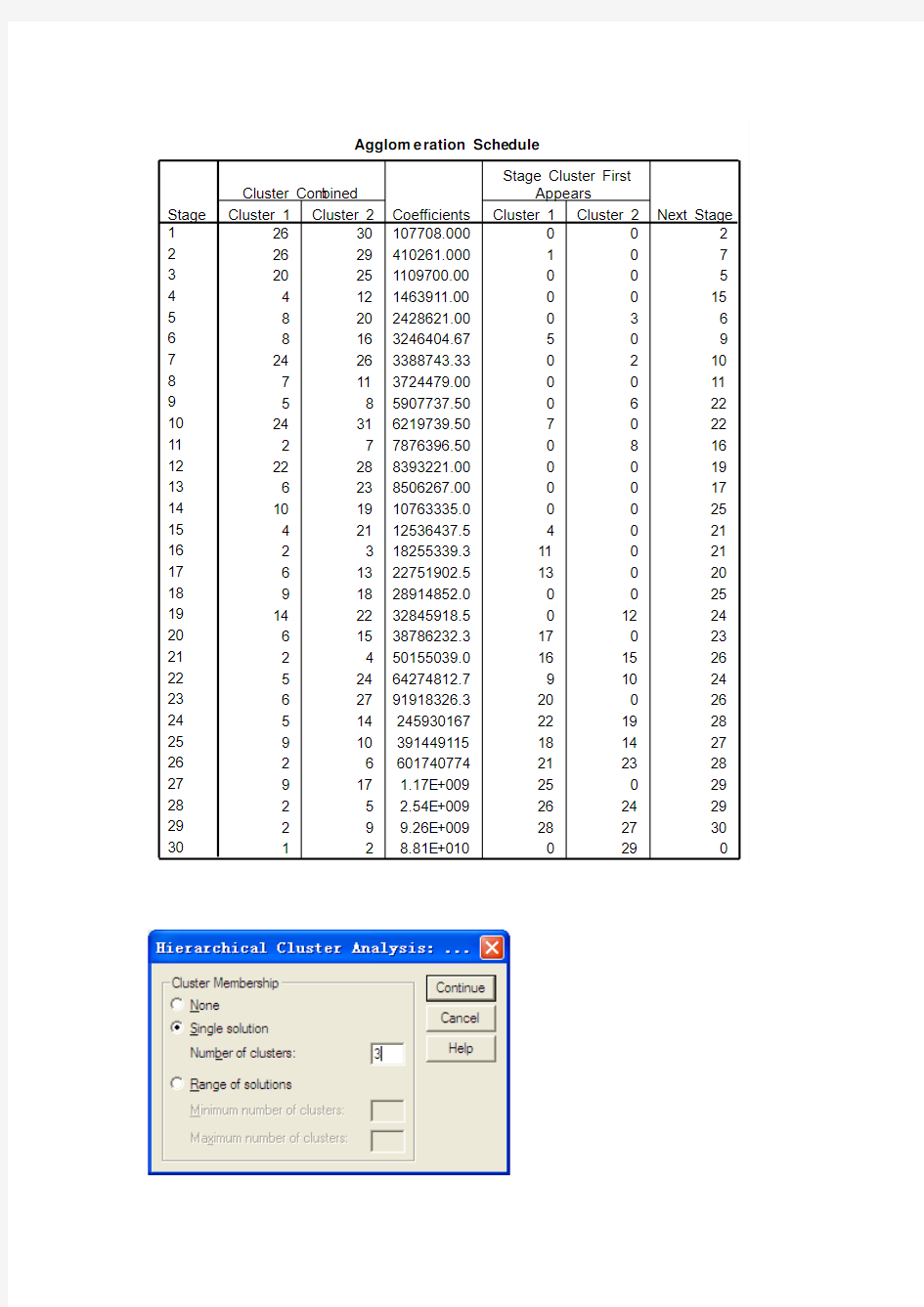
19 82.2 11.1 6.7 2.2 7.2 20 69.7 20.7 9.6 3.1 5.9 3.2实验过程及结果 Case Processing Summary(a) Cases Valid Missing Total N Percent N Percent N Percent 20 100.0% 0 .0% 20 100.0% a Squared Euclidean Distance used 上表是接近度矩阵,计算距离使用的是平方欧氏距离,所以样品间距离越大,样品越相异,由表中矩阵可以看出样品8号和样品9号的距离是最小的,因此它们最先聚为一类。 Average Linkage (Between Groups) Agglomeration Schedule Stage Cluster Combined Coefficient s Stage Cluster First Appears Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2 1 8 9 .153 16
多元统计分析简答题..
1、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设H0和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2/21exp 2np n e tr n λ????=-?? ?????S S 00p H =≠ΣΣI : /2/2**1exp 2np n e tr n λ????=-?? ????? S S 检验12k ===ΣΣΣ012k H ===ΣΣΣ: 统计量/2/2/2/211i i k k n n pn np k i i i i n n λ===∏∏S S 2. 针对一个总体均值向量的检验而言,在协差阵已知和未知的两种情形下,如何分别构造的统计量? 3. 作多元线性回归分析时,自变量与因变量之间的影响关系一定是线性形式的吗?多元线性回归分析中的线性关系是指什么变量之间存在线性关系? 答:作多元线性回归分析时,自变量与因变量之间的影响关系不一定是线性形式。当自变量与因变量是非线性关系时可以通过某种变量代换,将其变为线性关系,然后再做回归分析。 多元线性回归分析的线性关系指的是随机变量间的关系,因变量y 与回归系数βi 间存在线性关系。 多元线性回归的条件是: (1)各自变量间不存在多重共线性; (2)各自变量与残差独立; (3)各残差间相互独立并服从正态分布; (4)Y 与每一自变量X 有线性关系。 4.回归分析的基本思想与步骤 基本思想:
应用多元统计分析课后答案
应用多元统计分析课后答案 第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1()()p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-= +∑
多元统计分析实验报告
多元统计分析实验报告 1、实验内容 根据课本习题3-12做相关分析。 2、实验目的 (1)检验H0:;H1:协方差阵不全相等。 (2)检验H0: U1=U2 ; H1:U1≠U2; (3)检验H0: U1=U2 =U3 ; H1:U1,U2,U3不全等; (4)检验三种化学成分相互独立。 3、实验方案分析 (1)这是关于判断三个3元正态总体的协方差阵是否相等的问题; (2)均值是否相等,在两个协方差阵相等的情况下均值是否相等的问题; (3)比较三组的3项指标是否有差异的问题,就是多总体均值向量是否相等的检验问题; (4)检验 是否独立相当于检验任意2个子向量的协方差阵是否为零矩阵; 4、实验原理及操作过程,结果如下: (1)SAS 代码实现过程如下: data d3121; input y1-y3 group @@; cards; 47.22 5.06 0.10 1 1 23 ==∑∑∑
47.45 4.35 0.15 1 47.52 6.85 0.12 1 47.86 4.19 0.17 1 47.31 7.57 0.18 1 54.33 6.22 0.12 2 56.17 3.31 0.15 2 54.40 2.43 0.22 2 52.62 5.92 0.12 2 43.12 10.33 0.05 3 42.05 9.67 0.08 3 42.50 9.62 0.02 3 40.77 9.68 0.04 3 ; proc iml; n1=5;n2=4;n3=4; n=n1+n2+n3;k=3; p=3; use d3121(obs=5); xa={y1 y2 y3 }; read all var xa into x1; print x1; use d3121(firstobs=6 obs=9); read all var xa into x2; print x2; use d3121(firstobs=10 obs=13); read all var xa into x3; print x3; xx=x1//x2//x3; ln={[5] 1} ; x10=(ln*x1)/n1; print x10; mm1=i(n1)-j(n1,n1,1)/n1; mm=i(n)-j(n,n,1)/n; a1=x1`*mm1*x1; print a1; ln={[4] 1} ; x10=(ln*x2)/n2; print x20;
数学建模多元统计分析
实验报告 一、实验名称 多元统计分析作业题。 二、实验目的 (一)了解并掌握主成分分析与因子分析的基本原理和简单解法。 (二)学会使用matlab编写程序进行因子分析,求得特征值、特征向量、载荷矩阵等值。(三)学会使用排序、元胞数组、图像表示最后的结果,使结果更加直观。 三、实验内容与要求
四、实验原理与步骤 (一)第一题: 1、实验原理: 因子分析简介: (1) 1.1 基本因子分析模型 设p维总体x=(x1,x2,....,xp)'的均值为u=(u1,u2,....,u3)',因子分析的一般模型为 x1=u1+a11f1+a12f2+........+a1mfm+ε 1 x2=u2+a21f1+a22f2+........+a2mfm+ε 2 ......... xp=up+ap1f1+fp2f2+..........+apmfm+εp 其中,f1,f2,.....,fm为m个公共因子;εi是变量xi(i=1,2,.....,p)所独有的特殊因子,他们都是不可观测的隐变量。称aij(i=1,2,.....,p;j=1,2,.....,m)为变量xi的公共因子fi上的载荷,它反映了公共因子对变量的重要程度,对解释公共因子具有重要的作用。上式可以写为矩阵形式 x=u+Af+ε
其中A=(aij)pxm 称为因子载荷矩阵;f=(f1,f2,....,fm)'为公共因子向量;ε=(ε1,ε2,.....εp)称为特殊因子向量 (2) 1.2 共性方差与特殊方差 xi的方差var(xi)由两部分组成,一个是公共因子对xi方差的贡献,称为共性方差;一个是特殊因子对xi方差的贡献,称为特殊方差。每个原始变量的方差都被分成了共性方差和特殊方差两部分。 (3) 1.3 因子旋转 因子分析的主要目的是对公共因子给出符合实际意义的合理解释,解释的依据就是因子载荷阵的个列元素的取值。当因子载荷阵某一列上各元素的绝对值差距较大时,并且绝对值大的元素较少时,则该公共因子就易于解释,反之,公共因子的解释就比较困难。此时可以考虑对因子和因子载荷进行旋转(例如正交旋转),使得旋转后的因子载荷阵的各列元素的绝对值尽可能量两极分化,这样就使得因子的解释变得容易。 因子旋转方法有正交旋转和斜交旋转两种,这里只介绍一种普遍使用的正交旋转法:最大方差旋转。这种旋转方法的目的是使因子载荷阵每列上的各元素的绝对值(或平方值)尽可能地向两极分化,即少数元素的绝对值(或平方值)取尽可能大的值,而其他元素尽量接近于0. (4) 1.4 因子得分 在对公共因子做出合理解释后,有时还需要求出各观测所对应的各个公共因子的得分,就比如我们知道某个女孩是一个美女,可能很多人更关心该给她的脸蛋、身材等各打多少分,常用的求因子得分的方法有加权最小二乘法和回归法。 注意:因子载荷矩阵和得分矩阵的区别: 因子载荷矩阵是各个原始变量的因子表达式的系数,表达提取的公因子对原始变量的影响程度。因子得分矩阵表示各项指标变量与提取的公因子之间的关系,在某一公因子上得分高,表明该指标与该公因子之间关系越密切。简单说,通过因子载荷矩阵可以得到原始指标变量的线性组合,如X1=a11*F1+a12*F2+a13*F3,其中X1为指标变量1,a11、a12、a13分别为与变量X1在同一行的因子载荷,F1、F2、F3分别为提取的公因子;通过因子得分矩阵可以得到公因子的线性组合,如F1=a11*X1+a21*X2+a31*X3,字母代表的意义同上。 (5) 1.5 因子分析中的Heywood(海伍德)现象 如果x的各个分量都已经标准化了,则其方差=1。即共性方差与特殊方差的和为1。也就是说共性方差与特殊方差均大于0,并且小于1。但在实际进行参数估计的时候,共性方差