聚类分析作业
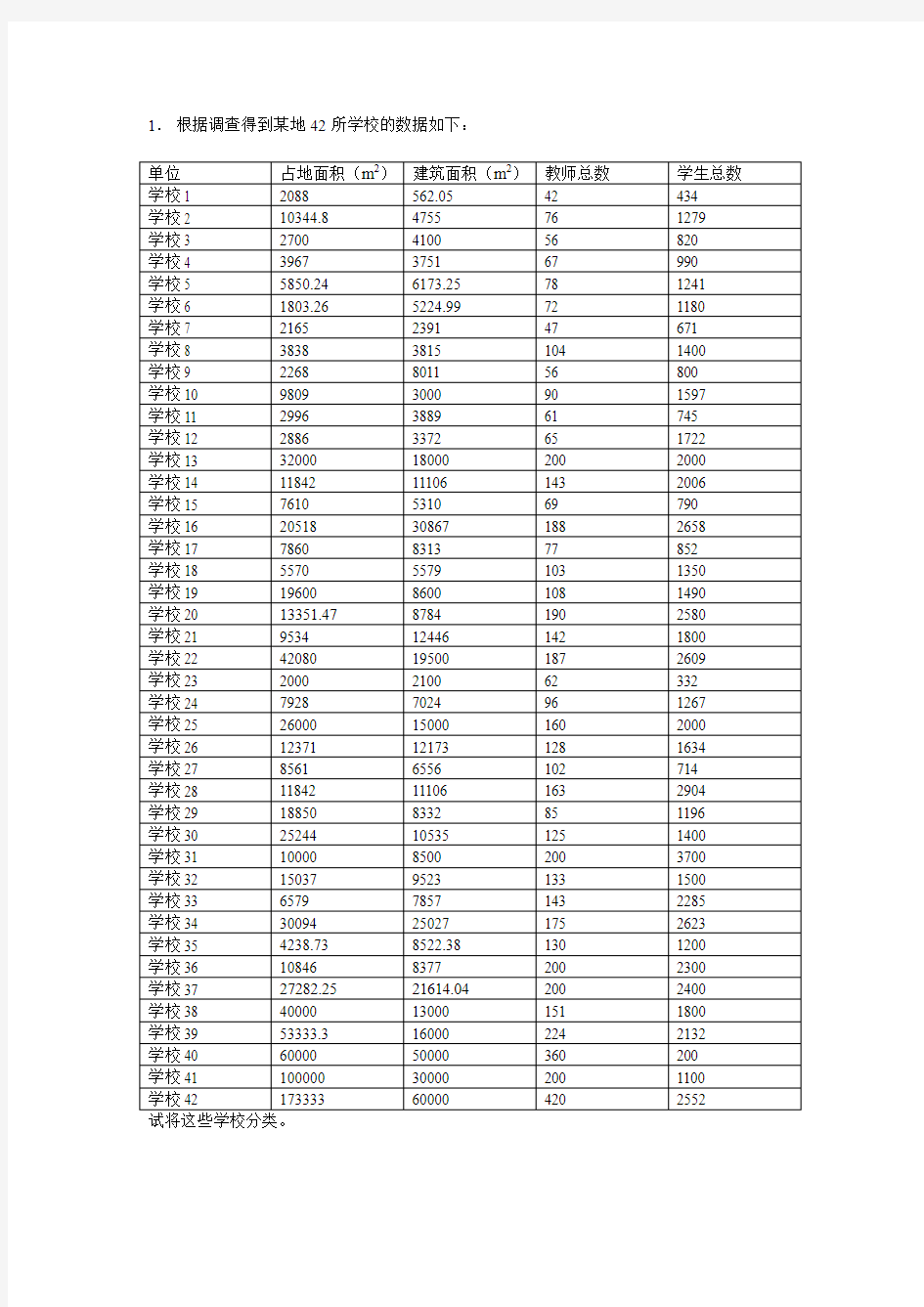

1.根据调查得到某地42所学校的数据如下:
单位占地面积(m2)建筑面积(m2)教师总数学生总数学校1 2088 562.05 42 434
学校2 10344.8 4755 76 1279
学校3 2700 4100 56 820
学校4 3967 3751 67 990
学校5 5850.24 6173.25 78 1241
学校6 1803.26 5224.99 72 1180
学校7 2165 2391 47 671
学校8 3838 3815 104 1400
学校9 2268 8011 56 800
学校10 9809 3000 90 1597
学校11 2996 3889 61 745
学校12 2886 3372 65 1722
学校13 32000 18000 200 2000
学校14 11842 11106 143 2006
学校15 7610 5310 69 790
学校16 20518 30867 188 2658
学校17 7860 8313 77 852
学校18 5570 5579 103 1350
学校19 19600 8600 108 1490
学校20 13351.47 8784 190 2580
学校21 9534 12446 142 1800
学校22 42080 19500 187 2609
学校23 2000 2100 62 332
学校24 7928 7024 96 1267
学校25 26000 15000 160 2000
学校26 12371 12173 128 1634
学校27 8561 6556 102 714
学校28 11842 11106 163 2904
学校29 18850 8332 85 1196
学校30 25244 10535 125 1400
学校31 10000 8500 200 3700
学校32 15037 9523 133 1500
学校33 6579 7857 143 2285
学校34 30094 25027 175 2623
学校35 4238.73 8522.38 130 1200
学校36 10846 8377 200 2300
学校37 27282.25 21614.04 200 2400
学校38 40000 13000 151 1800
学校39 53333.3 16000 224 2132
学校40 60000 50000 360 200
学校41 100000 30000 200 1100
学校42 173333 60000 420 2552
试将这些学校分类。
2.16种饮料的热量、咖啡因、钠及价格四种变量数据如下表:
饮料编号热量咖啡因钠价格
1 207.20 3.30 15.50 2.80
2 36.80 5.90 12.90 3.30
3 72.20 7.30 8.20 2.40
4 36.70 .40 10.50 4.00
5 121.70 4.10 9.20 3.50
6 89.10 4.00 10.20 3.30
7 146.70 4.30 9.70 1.80
8 57.60 2.20 13.60 2.10
9 95.90 .00 8.50 1.30
10 199.0 .00 10.60 3.50
11 49.80 8.00 6.30 3.70
12 16.60 4.70 6.30 1.50
13 38.50 3.70 7.70 2.00
14 .00 4.20 13.10 2.20
15 118.80 4.70 7.20 4.10
16 107.00 .00 8.30 4.20
试将这些饮料分类。
3.20种啤酒的成分和价格数据如下表:
beername calorie sodium alcohol cost Budweiser 144.00 19.00 4.70 .43 Schlitz 181.00 19.00 4.90 .43 Ionenbrau 157.00 15.00 4.90 .48 Kronensourc 170.00 7.00 5.20 .73 Heineken 152.00 11.00 5.00 .77 Old-milnaukee 145.00 23.00 4.60 .26 Aucsberger 175.00 24.00 5.50 .40 Strchs-bohemi 149.00 27.00 4.70 .42 Miller-lite 99.00 10.00 4.30 .43 Sudeiser-lich 113.00 6.00 3.70 .44 Coors 140.00 16.00 4.60 .44 Coorslicht 102.00 15.00 4.10 .46 Michelos-lich 135.00 11.00 4.20 .50 Secrs 150.00 19.00 4.70 .76 Kkirin 149.00 6.00 5.00 .79 Pabst-extra-l 68.00 15.00 2.30 .36 Hamms 136.00 19.00 4.40 .43 Heilemans-old 144.00 24.00 4.90 .43
Olympia-gold- 72.00 6.00 2.90 .46
Schlite-light 97.00 7.00 4.20 .47
试将这些啤酒分类。
4.50名学生参加10个测验项目的测试数据如下表:
学生编号X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
1 8.
2 5.7 34 14 62 21 39 9 22 5
2 7.8 4.0 36 14 69 22 30 10 19 13
3 10.0 5.0 37 15 57 2
4 23 11 21 14
4 9.0 4.
5 35 14 30 20 2
6 12 19 9
5 8.0 4.0 30 11 43 17 18 9 12 10
6 7.
7 6.3 33 14 35 22 32 10 19 14
7 7.3 4.7 21 14 37 24 19 9 13 12
8 8.7 6.0 33 14 57 24 34 12 20 14
9 8.2 4.7 28 14 29 19 23 10 16 12
10 8.2 4.5 32 15 33 20 30 12 16 13
11 7.2 3.5 26 11 64 19 20 8 15 10
12 7.7 5.7 26 13 29 25 34 8 12 8
13 7.3 6.0 28 12 44 24 19 11 14 10
14 7.7 7.0 31 14 28 24 17 10 20 13
15 7.5 4.2 35 13 45 20 14 9 14 9
16 7.7 4.2 31 13 31 19 30 11 13 15
17 7.7 4.0 36 14 50 25 43 9 18 13
18 10.5 4.5 30 15 51 24 41 12 22 14
19 7.5 6.8 38 15 59 24 34 10 20 16
20 7.7 5.2 29 15 65 26 27 10 14 16
21 7.2 5.5 19 13 20 19 26 6 12 5
22 8.7 4.3 22 11 45 17 36 6 9 9
23 7.2 4.7 27 13 49 18 23 9 14 12
24 8.3 5.3 25 13 52 18 21 8 13 4
25 7.3 5.5 22 13 33 14 20 8 14 12
26 7.8 6.8 32 13 40 26 34 11 18 16
27 8.7 5.7 25 15 40 21 26 10 12 15
28 6.3 5.5 22 15 59 24 10 5 11 7
29 8.5 5.8 15 14 60 21 17 8 13 7
30 7.7 5.2 30 13 57 23 25 11 16 13
31 8.8 5.3 25 14 43 19 20 9 15 12
32 6.3 4.8 27 14 41 18 25 10 19 13
33 7.8 6.7 27 14 37 22 30 8 14 16
34 8.8 5.2 27 14 61 15 21 7 15 9
35 6.3 3.5 23 15 17 18 14 9 11 15
36 8.2 5.7 27 14 45 16 30 9 16 14
37 8.8 6.7 28 15 73 24 41 10 10 14
38 8.0 3.8 24 12 30 17 14 9 13 12
39 7.0 6.3 29 16 41 20 24 13 21 15
40 7.7 7.2 26 16 43 19 21 11 15 16
41 7.0 6.5 23 15 25 15 17 9 12 10
42 8.2 4.5 27 15 26 21 37 12 14 14
43 9.7 7.0 34 15 53 26 31 11 16 16
44 7.5 3.7 22 13 17 19 23 9 12 8
45 9.3 6.2 28 14 40 21 42 12 17 14
46 9.3 7.3 27 15 75 22 26 12 24 13
47 7.5 5.0 29 16 49 21 30 12 19 14
48 7.5 5.5 23 15 28 21 21 7 12 12
49 8.7 4.2 34 14 39 20 34 8 13 7
50 8.7 5.2 27 13 65 20 26 9 19 16 试将学生分类。
5.下表列出了2007年我国31个省、市、自治区和直辖市的城镇居民家庭平均每人全年消
费性支出的8个主要变量数据。利用系统聚类法,对各地区进行聚类分析:
地区食品衣着居住家庭设
备用品
及服务
医疗保
健
交通和
通信
教育文
化娱乐
服务
杂项商
品和服
务
北京4934.05 1512.88 1246.19 981.13 1294.07 2328.51 2383.96 649.66 天津4249.31 1024.15 1417.45 760.56 1163.98 1309.94 1639.83 463.64 河北2789.85 975.94 917.19 546.75 833.51 1010.51 895.06 266.16 山西2600.37 1064.61 991.77 477.74 640.22 1027.99 1054.05 245.07 内蒙古2824.89 1396.86 941.79 561.71 719.13 1123.82 1245.09 468.17 辽宁3560.21 1017.65 1047.04 439.28 879.08 1033.36 1052.94 400.16 吉林2842.68 1127.09 1062.46 407.35 854.8 873.88 997.75 394.29 黑龙江2633.18 1021.45 784.51 355.67 729.55 746.03 938.21 310.67 上海6125.45 1330.05 1412.1 959.49 857.11 3153.72 2653.67 763.8 江苏3928.71 990.03 1020.09 707.31 689.37 1303.02 1699.26 377.37 浙江4892.58 1406.2 1168.08 666.02 859.06 2473.4 2158.32 467.52 安徽3384.38 906.47 850.24 465.68 554.44 891.38 1169.99 309.3 福建4296.22 940.72 1261.18 645.4 502.41 1606.9 1426.34 375.98 江西3192.61 915.09 728.76 587.4 385.91 732.97 973.38 294.6 山东3180.64 1238.34 1027.58 661.03 708.58 1333.63 1191.18 325.64 河南2707.44 1053.13 795.39 549.14 626.55 858.33 936.55 300.19 湖北3455.98 1046.62 856.97 550.16 525.32 903.02 1120.29 242.82 湖南3243.88 1017.59 869.59 603.18 668.53 986.89 1285.24 315.82 广东5056.68 814.57 1444.91 853.18 752.52 2966.08 1994.86 454.09
广西3398.09 656.69 803.04 491.03 542.07 932.87 1050.04 277.43 海南3546.67 452.85 819.02 519.99 503.78 1401.89 837.83 210.85 重庆3674.28 1171.15 968.45 706.77 749.51 1118.79 1237.35 264.01 四川3580.14 949.74 690.27 562.02 511.78 1074.91 1031.81 291.32 贵州3122.46 910.3 718.65 463.56 354.52 895.04 1035.96 258.21 云南3562.33 859.65 673.07 280.62 631.7 1034.71 705.51 174.23 西藏3836.51 880.1 628.35 271.29 272.81 866.33 441.02 335.66 陕西3063.69 910.29 831.27 513.08 678.38 866.76 1230.74 332.84 甘肃2824.42 939.89 768.28 505.16 564.25 861.47 1058.66 353.65 青海2803.45 898.54 641.93 484.71 613.24 785.27 953.87 331.38 宁夏2760.74 994.47 910.68 480.84 645.98 859.04 863.36 302.17 新疆2760.69 1183.69 736.99 475.23 598.78 890.3 896.79 331.8 试将这些地区分类
6.在全国服装标准制定中,对某地区成年女子的14个部位尺寸(体型尺寸)进行了测量,根据测量数据计算得到14个部位尺寸之间的相关系数矩阵,如下表所示,:试对14个变量进行聚类分析:
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x1上体长 1
x2手臂长0.366 1
x3胸围0.242 0.233 1
x4颈围0.28 0.194 0.59 1
x5总肩宽0.36 0.324 0.476 0.435 1
x6前胸宽0.282 0.263 0.483 0.47 0.452 1
x7后背宽0.245 0.265 0.54 0.478 0.535 0.663 1
x8前腰节高0.448 0.345 0.452 0.404 0.431 0.322 0.266 1
x9后腰节高0.486 0.367 0.365 0.357 0.429 0.283 0.287 0.82 1
x10总体长0.648 0.662 0.216 0.316 0.429 0.283 0.263 0.527 0.547 1
x11身高0.679 0.681 0.243 0.313 0.43 0.302 0.294 0.52 0.558 0.957 1
x12下体长0.486 0.636 0.174 0.243 0.375 0.29 0.255 0.403 0.417 0.857 0.582 1
x13腰围0.133 0.153 0.732 0.477 0.339 0.392 0.446 0.266 0.241 0.054 0.099 0.055 1
x14臀围0.376 0.252 0.676 0.581 0.441 0.447 0.44 0.424 0.372 0.363 0.376 0.321 0.627
7.下表列出了2006年我国31个省、市、自治区和直辖市的12个月的月平均气温数据。数
据来源:中华人民共和国国家统计局网站,现利用聚类法,对各地区进行聚类分析。
主要城市平均气温(2006年)
单位:
摄氏度
城市1月2月3月4月5月6月7月8月9月10月11月12月
北京-1.9 -0.9 8.0 13.5 20.4 25.9 25.9 26.4 21.8 16.1 6.7 -1.0 天津-2.7 -1.4 7.5 13.2 20.3 26.4 25.9 26.4 21.3 16.2 6.5 -1.7 石家庄-0.9 1.6 10.3 15.1 21.3 27.4 27.0 25.9 21.8 17.8 8.0 0.4 太原-3.6 -0.4 6.8 14.5 19.1 23.2 25.7 23.1 17.4 13.4 4.4 -2.5 呼和浩特-9.2 -7.0 2.2 10.3 17.4 21.8 24.5 22.0 16.3 11.5 1.3 -7.7 沈阳-12.7 -8.1 0.5 8.0 18.3 21.6 24.2 24.3 17.5 11.6 0.8 -6.7 长春-14.5 -10.6 -1.3 6.1 17.0 20.2 23.5 23.3 17.1 9.6 -2.3 -9.3 哈尔滨-17.7 -12.6 -2.8 5.9 17.1 19.9 23.4 23.1 16.2 7.4 -4.5 -12.1 上海 5.7 5.6 11.1 16.6 20.8 25.6 29.4 30.2 23.9 22.1 15.7 8.2 南京 3.9 4.3 11.3 17.1 21.2 26.5 28.7 29.5 22.5 20.3 12.8 5.2 杭州 5.8 6.1 12.4 18.3 21.5 25.9 30.1 30.6 23.3 21.9 15.1 7.7 合肥 3.4 4.5 11.7 17.2 21.7 26.7 28.8 29.0 22.2 20.4 12.8 5.0 福州12.5 12.5 14.0 19.4 22.3 26.5 29.4 29.0 25.9 24.4 19.8 14.1 南昌 6.6 6.5 12.7 19.3 22.7 26.0 30.0 30.0 24.3 22.1 15.0 8.1 济南0.0 2.1 10.2 16.5 21.5 26.9 27.4 26.0 21.4 19.5 10.0 1.6 郑州0.3 3.9 11.5 17.1 21.8 27.8 27.1 26.1 21.2 19.0 10.8 3.0 武汉 4.2 5.8 12.8 19.0 23.9 28.4 30.2 29.7 24.0 21.0 14.0 6.8 长沙 5.3 6.2 12.5 19.9 23.6 27.0 30.1 29.5 24.0 21.3 14.7 7.8 广州15.8 17.3 17.9 23.6 25.3 27.8 29.8 29.4 27.0 26.4 21.9 16.0 南宁14.3 14.3 17.5 23.9 25.2 27.6 28.0 27.2 25.7 25.6 20.4 14.0 海口18.5 20.5 21.8 26.7 28.3 29.4 30.0 28.5 27.4 27.1 25.3 20.8 重庆7.8 9.0 13.3 19.2 22.9 25.4 31.0 32.4 24.8 20.6 14.6 9.4 温州 5.8 7.5 12.1 17.9 21.6 24.0 26.9 26.6 20.9 19.0 13.3 6.9 贵阳 4.3 5.4 10.2 17.0 18.9 21.1 23.8 23.2 20.5 16.7 11.2 5.8 昆明10.8 13.2 15.9 18.0 18.0 20.4 21.3 20.6 18.3 16.9 13.2 9.8 拉萨 2.7 5.0 6.2 8.3 12.8 17.8 18.3 17.1 14.7 8.6 3.7 1.2 西安-0.2 4.3 10.8 16.8 21.4 26.5 28.2 26.0 19.5 16.8 9.4 2.3 兰州-6.9 -2.6 3.2 10.3 15.6 20.0 22.2 21.9 13.8 10.2 1.5 -7.4 西宁-6.5 -3.0 1.4 7.1 12.0 15.5 18.7 18.2 11.7 7.6 0.3 -6.4 银川-7.4 -2.2 4.9 13.6 18.8 23.7 24.8 23.8 16.5 13.7 4.4 -4.3 乌鲁木齐-14.2 -6.7 1.2 12.0 16.8 23.2 24.5 24.1 17.6 11.4 1.9 -8.8
聚类分析练习题20121105
聚类分析和判别分析练习题 一、选择题 1.需要在聚类分析中保序的聚类分析是( )。 A.两步聚类 B.有序聚类 C.系统聚类 D.k-均值聚类 2.在系统聚类中2R 是( )。 A.组内离差平方和除以组间离差平方和 B.组间离差平方和除以组内离差平方和 C.组间离差平方和除以总离差平方和 D.组间均方除以总均方。 3.系统聚类的单调性是指( )。 A.每步并类的距离是单调增的 B.每步并类的距离是单调减的 C.聚类的类数越来越少 D.系统聚类2R 会越来越小 4.以下的系统聚类方法中,哪种系统聚类直接利用了组内的离差平方和。( ) A.最长距离法 B.组间平均连接法 C.组内平均连接法 D.WARD 法 5.以下系统聚类方法中所用的相似性的度量,哪种最不稳健( )。 A.2 1()p ik jk k x x =-∑ B. 1p ik jk k ik jk x x x x =-+∑ C. 21p k =∑ D. 1()()i j i j -'x -x Σx -x 6. 以下系统聚类方法中所用的相似性的度量,哪种考虑了变量间的相关性( )。A.2 1()p ik jk k x x =-∑ B. 1 p ik jk k ik jk x x x x =-+∑ C. 21 p k =∑ D. 1()()i j i j -'x -x Σx -x 7.以下统计量,可以用来刻画分为几类的合理性统计量为( )? A.可决系数或判定系数2R B. G G W P P -
C.()/(1) /() G G W P G P n G -- - D.() G W P W - 8.以下关于聚类分析的陈述,哪些是正确的() A.进行聚类分析的统计数据有关于类的变量 B.进行聚类分析的变量应该进行标准化处理 C.不同的类间距离会产生不同的递推公式 D.递推公式有利于运算速度的提高。D(3)的信息需要D(2)提供。 9.判别分析和聚类分析所要求统计数据的不同是() A.判别分析没有刻画类的变量,聚类分析有该变量 B.聚类分析没有刻画类的变量,判别分析有该变量 C.分析的变量在不同的样品上要有差异 D.要选择与研究目的有关的变量 10.距离判别法所用的距离是() A.马氏距离 B. 欧氏距离 C.绝对值距离 D. 欧氏平方距离 11.在一些条件同时满足的场合,距离判别和贝叶斯判别等价,是以下哪些条件。 () A.正态分布假定 B.等协方差矩阵假定 C.均值相等假定 D.先验概率相等假定 12.常用逐步判别分析选择不了的标准是() A.Λ统计量越小变量的判别贡献更大 B.Λ统计量越大变量的判别贡献更大 C.判定系数越小变量的判别贡献更大 D.判定系数越大变量的判别贡献更大 二、填空题 1、聚类分析是建立一种分类方法,它将一批样本或变量按照它们在性质上的_______________进行科学的分类。 2.Q型聚类法是按_________进行聚类,R型聚类法是按_______进行聚类。 3.Q型聚类相似程度指标常见是、、,而R型聚类相似程度指标通常采用_____________ 、。 4.在聚类分析中需要对原始数据进行无量纲化处理,以消除不同量纲或数量级的影响,达到数据间
第二章作业聚类分析
第二章作业 1.画出给定迭代次数为n的系统聚类法的算法流程框图. 答:算法流程图如下:
2.对如下5个6维模式样本,用最小距离准则进行系统聚类分析: x 1: 0, 1, 3, 1, 3, 4 x 2: 3, 3, 3, 1, 2, 1 x 3: 1, 0, 0, 0, 1, 1 x 4: 2, 1, 0, 2, 2, 1 x 5: 0, 0, 1, 0, 1, 0 解:将每一样本看成单独一类,得 (0) 11{}G x =, (0)22{}G x =,(0)33{}G x = (0)44{}G x =, (0) 55{}G x = 计算各类之间的欧式距离,可得距离矩阵(0)D (表1-1)。 表1-1 ① 矩阵(0) D ,它是(0)3G 和(0) 5G 之间的距离,将它们合并为一类,得 到新的分类为 (1)(0)11{}G G =,(1)(0)22{}G G =,(1)(0)(0) 335{,}G G G = (1)(0) 44{}G G = 计算聚类后的距离矩阵(1)D 。按最小距离准则,分别计算(0)3G 与(1)1G 、(1)2G 、(1)4G ,(0) 5 G 与(1)1G 、(1)2G 、 (1) 4G 之间的两种距离,并选用最小距离。如
(1)(0)(1)(0)(1) 133151min{D G G G G =与的距离,与的距离} }=5 由此可求得距离矩阵(1)D (表1-2) ② 距离矩阵(1) D ,它是(1)3G 和(1)4G 之间的距离,于是合并(1)3G 和(1)4G , 得到新的分类为 (2)(1)11{}G G =,(2)(1)22{}G G =,(2)(1)(1) 334{,}G G G = 按最小距离准则计算距离矩阵(2)D ,得表1-3 表1-3 选择距离阈值(2) D 则算法停止,得到聚类结果G 1(2) ={X1} G 2(2) ={X2} G 3(2)={X3,X5, X4}。 3. 模式样本如下: {X1(0,0),X2(1,0),X3(0,1),X4(1,1),X5(2,1),X6(1,2),X7(2,2),X8(3,2),X9(6,6),X10(7,6),X11(8,6), X12(6,7), X13(7,7), X14(8,7), X15(9,7), X16(7,8), X17(8,8), X18(9,8), X19(8,9), X20(9,9). 选K=2,11210(1)=(00),(1)(7 6)t t z x z x ===,用K —均值算法进行分类。
应用多元统计分析习题解答_第五章
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
SPSS操作方法:聚类分析
实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京 天津 河北 山西 内蒙古 辽宁 吉林 黑龙江 上海 江苏 浙江 安徽 福建 江西 山东 河南 湖北
湖南13.23 广东 广西 海南 四川 贵州 云南 西藏 陕西 甘肃 青海 宁夏 新疆 系统聚类法的SPSS操作: 1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1) 图1 系统聚类法 打开层次聚类法对话如图2。 图2 系统聚类法对话框 选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法: Cases 对样品聚类(Q型;系统默认), Variable 对指标变量聚类(R型),本例选择。 在Display栏中选择默认的输出项。 2. 点击Statistics按钮,打开对话框如图 3. 图3 Statistics对话框 Agglomeration schedule输出凝聚状态表(聚类进度表);本例选择。
SPSS教程-聚类分析-附实例操作
各地区各行业工资水平的分析(2009年数据) 小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍 1.研究背景及意义 1.1 研究背景 工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。 1.2 研究意义 1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。 2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。 2.数据来源与描述 2.1 数据来源——《中国劳动统计年鉴─2010》 (URL:https://www.360docs.net/doc/a811948614.html,/Navi/YearBook.aspx?id=N2011010069&floor=1###) 主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司 出版社:中国统计出版社 简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。 2.2 数据描述 本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-0 3.分析方法及原理 3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高 描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。 在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。 3.2 通过聚类分析方法,判断哪些地区平均工资水平较高 聚类分析是依据研究对象的个体特征,对其进行分类的方法,分类在经济、管理、社会学、医学等领域,都有广泛的应用。聚类分析能够将一批样本(或变量)数据根据其诸多特征,按照在性质上的亲疏程度在没有先验知识的情况下进行自动分类,产生多个分类结果。类内部个体特征之间具有相似性,不同类间个体特征的差异性较大。 在本案例中,我们将采用两种方法进行聚类分析:一种是系统聚类法,另一种是K-均值法(快速聚类法)。 3.2.1系统聚类法 系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。重复这一过程,直到将所有的样本(或指标)合并为一类。 系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。 在本例中进行的是Q型聚类。 类与类之间距离的计算方法主要有以下几种: (1)最短距离法(Nearest Neighbor),是指两类之间每个个体距离的最小值; (2)最长距离法(Farthest Neighbor),是指两类之间每个个体距离的最大值; (3)组间联接法(Between-groups Linkage),是指两类之间个体之间距离的平均值;
聚类分析实例分析题(推荐文档)
5.2酿酒葡萄的等级划分 5.2.1葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[61.6,81.5]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。 通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7):
考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。 5.2.2建立模型 在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward 最小方差法,又叫做离差平方和法。 聚类分析是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。为了将样品进行分类,就需要研究样品之间关系。这里的最小方差法的基本思想就是将一个样品看作P 维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。面对现在的问题,我们不知道元素的分类,连要分成几类都不知道。现在我们将用SAS 系统里面的stepdisc 和cluster 过程完成判别分析和聚类分析,最终确定元素对象的分类问题。 建立数据阵,具体数学表示为: 1111...............m n nm X X X X X ????=?????? (5.2.1) 式中,行向量1(,...,)i i im X x x =表示第i 个样品; 列向量1(,...,)'j j nj X x x =’,表示第j 项指标。(i=1,2,…,n;j=1,2,…m) 接下来我们将要对数据进行变化,以便于我们比较和消除纲量。在此我们用了使用最广范的方法,ward 最小方差法。其中用到了类间距离来进行比较,定义为: 2||||/(1/1/)kl k l k l D X X n n =-+ (5.2.2) Ward 方法并类时总是使得并类导致的类内离差平方和增量最小。 系统聚类数的确定。在聚类分析中,系统聚类最终得到的一个聚类树,如何确定类的个数,这是一个十分困难但又必须解决的问题;因为分类本身就没有一定标准,人们可以从不同的角度给出不同的分类。在实际应用中常使用下面几种
数理统计第二次大作业——聚类与判别分析
地区生产总值及经济发展状况的统计分析 学号:姓名: 摘要:本文运用统计学方法,基于从2006和2007年度分地区生产总值的各项指标数据对各省市自治区经济发展状况进行了分类研究。研究结果显示了我国各省市的经济优势地区和经济薄弱地区,对更好地进行统筹规划,促进各地区经济健康协调发展有积极意义。 对各地区的经济发展状况进行的聚类和判别分析结果显示,北京﹑上海﹑山东﹑广东等东部沿海省份及直辖市在经济发展中处于领先地位,属于经济较发达地区;辽宁﹑湖南﹑河南等中部省份处于中游,属于中等发达地区;而位于我国西部的西藏﹑青海﹑宁夏等省份,经济发展较为缓慢,属于欠发达地区。分析结果与我国目前地区经济发展情况基本相符。 关键词:地区生产总值,地区经济发展, SPSS,聚类分析,判别分析 1.引言 国内生产总值是某国家领土面积内的经济情况的度量。是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。它不但可反映一个国家的经济表现,更可以反映一国的国力与财富。 地区生产总值是指由地方政府组织、支配的生产总值。是地方经济建设、政府机器运行和各方面事业发展的关键因素和物质基础。分地区生产总值可以较为准确反映地区经济发展状况,通过建立地区生产总值模型,对各地区经济发展状况进行分类,具有一定的准确性和合理性。 本文应用数理统计软件SPSS对各地区生产总值进行聚类和判别分析,分析和评定各地区经济发展情况,同时对各地区进行分类,确定经济优势地区和经济薄弱地区。 2.地区经济发展的聚类和判别分析 分地区生产总值主要包括的内容有: (1)第一产业: 包括农、林、牧、渔业。 (2)第二产业: 包括工业及建筑业。 (3)第三产业: 包括交通运输、仓储和邮政业、批发和零售业、住宿和餐饮业、金融 业、房地产业及其他产业。 (一)相关自变量的选择 本文从分析各地区生产总值的主要内容出发,展开对地区经济发展的聚类分析。鉴于第一产业的各个元素在地区生产总值中所占比重不大,为了便于分析,我们将农林牧渔等第一产业部分合为一类,与工业、建筑业、交通运输、仓储和邮政业、批发和零售业、住宿和餐
Q型聚类分析作业
学习成绩的聚类分析 现有一个班的10名同学的政治、英语、数学、物理、语文成绩。对这些成绩进行聚类,分析哪些课程是属于一个类的。 为描述性统计量,个案的有效值个数和缺失值个数信息
* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * * * * * * * * * * * Dendrogram using Average Linkage (Between Groups) Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ 10912603 3 -+ 10912605 5 -+---+ 10912608 8 -+ +---------+ 10912602 2 ---+-+ +-------+ 10912604 4 ---+ | | 10912606 6 -+-------------+ +-------------------------+ 10912609 9 -+ | | 10912601 1 -+---------------------+ | 10912610 10 -+ | 10912607 7 -------------------------------------------------+ 为树形图,以水平放置的树形结构呈现了聚类分析中的每一次类合并的情况。
SPSS操作方法:聚类分析
. 实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61 天津10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57 河北9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65 山西8.35 23.53 7.51 8.62 17.42 10.00 1.04 11.21 内蒙古9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51 辽宁7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29 吉林8.19 30.50 4.72 9.78 16.28 7.60 2.52 10.32 黑龙江7.73 29.20 5.42 9.43 19.29 8.49 2.52 10.00 上海8.28 64.34 8.00 22.22 20.06 15.52 0.72 22.89 江苏7.21 45.79 7.66 10.36 16.56 12.86 2.25 11.69 浙江7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87 安徽8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28 福建10.60 52.41 7.70 9.98 12.53 11.70 2.31 14.69 江西 6.25 35.02 4.72 6.28 10.03 7.15 1.93 10.39 山东8.82 33.70 7.59 10.98 18.82 14.73 1.78 10.10 河南9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76 湖北8.67 36.05 7.31 7.75 16.67 11.68 2.38 12.88
spss软件聚类分析怎么用
spss软件聚类分析怎么用,从输入数据到结果,树状图结果。整个操作怎么进行。需要基本思路。 excel表:整理一份excel数据表,第一列为材料或数据的名称,后几列为各项数值 导入数据:打开SPSS,点击File——Open——DATA, 选择已经编辑好的excel表 点击analyze——Classify——Hierarchical cluster analysis——数据导入variables,表头项导入label case by; 选择Method 项,根据需要选择方法,点击Plots选择dendrogram(打对勾),其余各项根据自己需要选择要计算的统计量,点击ok即可。 于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法) 层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解. (一)层次聚类 Analyze--> C1assify-->Hierachical Cluster 在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“Vanables”;要进行观测量聚类指定“Cases”。 指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的“Variable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。 如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。 1.确定聚类方法 在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即“Hierachical Cluster Analysis:Method”。
聚类分析案例
SPSS软件操作实例——某移动公司客户细分模型 数据准备:数据来源于,如图1所示,Customer_ID表示客户编号,Peak_mins 表示工作日上班时期电话时长,OffPeak_mins表示工作日下班时期电话时长等。 图1 数据 分析目的:对移动手机用户进行细分,了解不同用户群体的消费习惯,以更好的对其进行定制性的业务推销,所以需要运用聚类分析。 操作步骤: 1,从菜单中选择【文件】——【打开】——【数据】,在打开数据窗口中选择数据位置以及文件类型,将数据导入SPSS软件中,如图2所示。 图2 打开数据菜单选项
2,从菜单中选择【分析】——【描述统计】——【描述】,然后在描述性窗口中,将需要标准化的变量选到右边的“变量列表”,勾选“将标准化得分另存为变量”,点确定,如图3所示。 ¥ 图3 数据标准化 3,从菜单中选择【分析】——【分类】——【K-均值聚类】,在K-均值聚类分析窗口中将标准化之后的结果选入右边“变量列表”,客户编号选入“个案标记依据”,聚类数改为5。点击迭代按钮,在迭代窗口将最大迭代次数改为100,点击继续。点击保存按钮,在保存窗口勾选“聚类成员”、“与聚类中心的距离”,点击继续。点击选项按钮,在选项窗口勾选“ANOVA表”、“每个个案的聚类信息”,点击继续。点击确定按钮,运行聚类分析,如图4所示。
图 4 聚类分析操作 结果分析 表1 最终聚类中心 聚类 1 2 3 \ 4 5 Zscore: 工作日上班时期电话时长 .61342 .37303 Zscore: 工作日下班时期电话时长 .46081 : Zscore: 周末电话时长 .35845
聚类分析例题及解答
聚类分析作业 例题: country populatn density urban religion lifeexpf lifeexpm literacy pop_incr Afghanistan 20,500 25、0 18 Muslim 44 45 29 2、8 Bangladesh 125,000 800、0 16 Muslim 53 53 35 2、4 Cambodia 10,000 55、0 12 Buddhist 52 50 35 2、9 China 1,205,200 124、0 26 Taoist 69 67 78 1、1 HongKong 5,800 5,494、0 94 Buddhist 80 75 77 -0、1 India 911,600 283、0 26 Hindu 59 58 52 1、9 Indonesia 199,700 102、0 29 Muslim 65 61 77 1、6 Japan 125,500 330、0 77 Buddhist 82 76 99 0、3 Malaysia 19,500 58、0 43 Muslim 72 66 78 2、3 N、Korea 23,100 189、0 60 Buddhist 73 67 99 1、8 Pakistan 128,100 143、0 32 Muslim 58 57 35 2、8 Philippines 69,800 221、0 43 Catholic 68 63 90 1、9 S、Korea 45,000 447、0 72 Protstnt 74 68 96 1、0 Singapore 2,900 4,456、0 100 Taoist 79 73 88 1、2 Taiwan 20,944 582、0 71 Buddhist 78 72 91 0、9 Thailand 59,400 115、0 22 Buddhist 72 65 93 1、4 Vietnam 73,100 218、0 20 Buddhist 68 63 88 1、8 进行聚类分析,步骤如下: 1、标准化的欧式距离聚类 各类所属 得出以上结果,以欧氏距离为计算距离方法,把以上17个亚洲国家地区按6个变量欧氏距离划分为三类。 第一类为:Bangladesh 第二类为:China 第三类为:Malaysia 2、尝试其她类间距离方法
多元统计分析聚类分析的各种方法spss
多元统计分析 (第一次作业) 学院:信息与计算科学学院 专业: ____________ 指导老师: ____________ 小组成员:罗健水(20080560) 许志欢(20080574) 庄娜(20080595) 卓玛(20080561)
2011年4月10日
题目:某行政系统所属独立核算工业企业16个行业经济实力强弱的聚类分析 独立核算:独立核算是指对本单位的业务经营活动过程及其成果进行全面、系统的会计核算。独立核算单位的特点是:在管理上有独立的组织形式,具有一定数量的资金,在当地银行开户;独立进行经营活动,能同其他单位订立经济合同;独立计算盈亏,单独设置会计机构并配备会计人员,并有完整的会计工作组织体系。 非独立核算又称报帐制,是把本单位的业务经营活动有关的日常业务资料,逐日或定期报送上级单位,由上级单位进行核算。非独立核算单位的特点是:一般由上级拔给一定数额的周转金,从事业务活动,一切收入全面上缴,所有支出向上级报销,本身不单独计算盈亏,只记录和计算几个主要指标,进行简易核算 数据来源:上海市青浦区统计局数据链接:数据5?11.sav 固定资产原价:指企业在建造、改置、安装、改建、扩建、技固定资产计量术改造固定资产时实际支出的全部货币总额。该指标根据企业会计"资产负债表"中"固定资产原价"项的期末数填列。 固定资产净值平均余额:每月逐步减少。有部分企业单位,是按季度计提折旧,那么在没有提折旧的月 份,比如10月份,和9月份比较,固定资产净值平均余额就没有变化,也就是说,还是等于9月份的 固定资产净值平均余额 例:如09年底的固定资产净值余额为5000万元,2010年元月份完成固定资产投资1000万元,那么元月份的固定资产净值平均余额是多少?2月份又完成投资500万元,那2月份的固定资产净值平均余额是多少?(计算公式是怎样) 解:平均余额等于期初的加期末的除以2 所以一月份=(5000+6000-当月折旧)/2 二月份的=(6000+6500-两个月的折旧)/2 所有者权益(Owne' s Equities:资产扣除负债后由所有者应享的剩余利益。即一个会计主体在一定时期所拥有或可控制的具有未来经济利益资源的净额。 营业税金及附加:主营业务税金及附加”科目改名为“营业税金及附加”, “营业税金及附加”科目用法如下: 一、本科目核算企业经营活动发生的营业税、消费税、城市维护建设税、资源税和教育费附加等相关税费。 房产税、车船使用税、土地使用税、印花税在“管理费用”等科目核算,不在本科目核算。 二、企业按规定计算确定的与经营活动相关的税费,借记本科目,贷记“应交税费”等科目。企业收到的返还的消费税、营业税等原记入本科目的各种税金,应按实际收到的金额,借记“银行存款”科目,贷记本科目。
06聚类分析方法与操作
技术资料6: 聚类分析方法与操作 聚类是一种应用非常广泛的数据分析方法,它是统计学的一个分支,目前在诸多领域,包括数据挖掘、图像处理、市场研究等,都能凸显出其重要性。聚类是将一个对象的集合分成不同的类,从而描述数据。通过这种方式,人们能够将密集的和稀疏的区域区分开来,从而发现全局的分布模式,以及数据属性之间有趣的相互关系。 很久以前人们就对聚类方法有所研究。传统的聚类方法主要是基于距离的聚类,例如欧氏距离、切比雪夫距离、马氏距离[1]等。 在今天,聚类分析也是数据挖掘和知识发现领域中的重要课题。迄今为止,人们已经提出了许多数据聚类的算法,试图解决各种领域的聚类问题。 从目前来看,对数据挖掘中聚类方法的研究大都集中于计算机科学领域,更多注重聚类算法的研究,或者对现有聚类方法进行算法上的改进,而很少真正从统计学角度出发对数据挖掘中的聚类问题进行深入分析。若尝试从统计学视角出发,以统计理论为基础,以统计方法与算法相结合为基本思路,将一些现有的优秀统计方法,如因子分析、对应分析等引入数据挖掘领域,则能够使其应用于海量数据的聚类分析。 (一)聚类分析的基本概念 聚类是指将一群物理的或抽象的对象,根据它们之间的相似程度,分为若干组,并使得同一个组内的数据对象具有较高的相似度,而不同组中的数据对象则是不相似的。一个聚类就是由彼此相似的一组对象所构成的集合。在很多应用中,我们可以把同一个类的数据对象当做一个整体来处理。 聚类的严格数学描述如下:假设被研究的样本集为E ,类C 定义为E 的一个非空子集,即: E C ?,且C ≠? 聚类就是满足以下两个条件的类1C ,2C ,…,k C 的集合: (1) 1C 2C … E C k =
:聚类分析SPSS操作方法09
:聚类分析SPSS操作方法09 实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61 天津10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57 河北9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65
系统聚类法的SPSS操作:
1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1) 图1 系统聚类法 打开层次聚类法对话如图2。 图2 系统聚类法对话框 选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法: Cases 对样品聚类(Q型;系统默认), Variable 对指标变量聚类(R型),本例选择。 在Display栏中选择默认的输出项。 2. 点击Statistics按钮,打开对话框如图 3.
使用SPSS软件进行因子分析和聚类分析的方法
使用SPSS软件进行因子分析和聚类分析的方法 一、方法原理 1.因子分析(FactorAnalysis) 因子分析是从多个变量指标中选择出少数几个综合变量指标的一种降维的多元统计方法。 我们在多元分析中处理的是多指标的问题,观察指标的增加是为了使研究过程趋于完整,但由于指标太多,使得分析的复杂性增加;同时在实际工作中,指标间经常具备一定的相关性,使得观测数据所放映的信息有重叠,故人们希望用较少的指标代替原来较多的指标,但依然能放映原有的全部信息,于是就产生了因子分析方法。 2.聚类分析(ClusterAnlysis) 聚类分析是根据事物本身特性来研究个体分类的统计方法,是按照物以类聚的原则来研究的事物分类。 3.市场细分方法的流程图
二、实证分析
已调查35个城市的总人口、生产总值、消费总额、人均年工资、年度储蓄总额、年度财政总收入等数据,试对上述城市进行分类研究。 1.因子分析: ·选用Analyze→DataReduction→Factor…… ·引入因子分析的6个变量(总人口、生产总值、消费总额、人均年工资、年度总储蓄额、年度财政总收入) ·提取公因子的方法(Method):主成分分析法 ·提取(Extract)可选:提取特征值大于1的因子 ·旋转(Rotation)的方法:方差最大正交旋转 ·因子得分(FactorScores):作为新变量存入 表 1 方差解释表(Total Variance Explained) 表 2 旋转后的因子负荷矩阵(Rotated Component Matrix)
2.聚类分析: ·选用Analyze→Classify→K-MeansCluster…… ·引入聚类分析的2个变量(即上面的2个公因子) ·聚类的数目(NumberofClusters):3类 ·聚类方法(Method):仅分类 ·储存新变量(SaveNewVariables):聚类成员 表 3 各类数量分布表(Number of Cases in each Cluster)
聚类分析作业
聚类分析:p230.6.9 1. (1)用快速聚类法分为3类:(年份) 初始聚类中心 聚类 1 2 3 第一产业所占百分比50.5 37.6 18.6 第二产业所占百分比20.9 38.0 49.3 第三产业所占百分比28.6 24.4 32.1 上表展示了3个类的初始中心情况,3个初始类中心点的数据分别为 (50.5,20.9,28.6),(37.6,38.0,24.4),(18.6,49.3,32.1)对应的年份分别是1952年,1966年,1998年。(每次分类得到的初始聚类中心和最终聚类中心不一样,是因为快速聚类法采用的选取初始聚点的方法不同。) 分三类的聚类结果为: 第一类:1952,1953,1954,1955,1956,1957,1961,1962,196,1964,1965,1967,1968,1969 第二类:1959,1960,1985,1986,1987,1988,1989,1990,1991,1992,1993,1994,1995,1996,1997,1998 第三类:1958,1966,1970,1971,1972,1973,1974,1975,1976,1977,1978,1979,1980,1981,1982,1983,1984 从聚类的情况分析,第一类是第一产业(农业)所占百分比大的年份,第二类是第一产业和第二产业(工业建筑)所占百分比较大年份,第三类是第二产业所占百分比较大年份,从1952年到1998年,时间大致分类的顺序为第一类、第三类、第二类,表明我国第一产业农业所占比例的逐步降低,第二类产业工业建筑等行业和第三产业所占比例的升高,也表明了我国从一个农业大国向工业性大国的转变,工业性等产业的的快速发展。 上表是2个类的最终类中心,类中心数据分别是(41.8,29.8,28.4,), (32.7,44.0,23.3),(23.5,45.4,31.2)与初始据点的数据有差异,但总的不是很大,仍然是表明农业所占比例的减少和工业建筑类的高速发展。 画出(X1,date)图
应用多元统计分析习题解答聚类分析
应用多元统计分析习题 解答聚类分析 TPMK standardization office【 TPMK5AB- TPMK08- TPMK2C- TPMK18】
第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()( )p q q ij ik jk k d q X X ==-∑ q 取不同值,分为
(1)绝对距离(1q =) (2)欧氏距离(2q =) (3)切比雪夫距离(q =∞) (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 (一)夹角余弦 (二)相关系数 5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则? 答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。 (1). 最短距离法 (2)最长距离法 (3)中间距离法 2 2222 121pq kq kp kr D D D D β++=
应用多元统计分析习题解答聚类分析
第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()( )p q q ij ik jk k d q X X ==-∑ q 取不同值,分为
(1)绝对距离(1 q=) (2)欧氏距离(2 q=) (3)切比雪夫距离(q=∞) (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。将变量看作p维空间的向量,一般用 (一)夹角余弦 (二)相关系数 5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则? 答:设d ij 表示样品X i与X j之间距离,用D ij表示类G i与G j之间的距离。 (1). 最短距离法 (2)最长距离法 (3)中间距离法 其中 2 2 2 2 2 1 2 1 pq kq kp kr D D D Dβ + + =