决策树分类
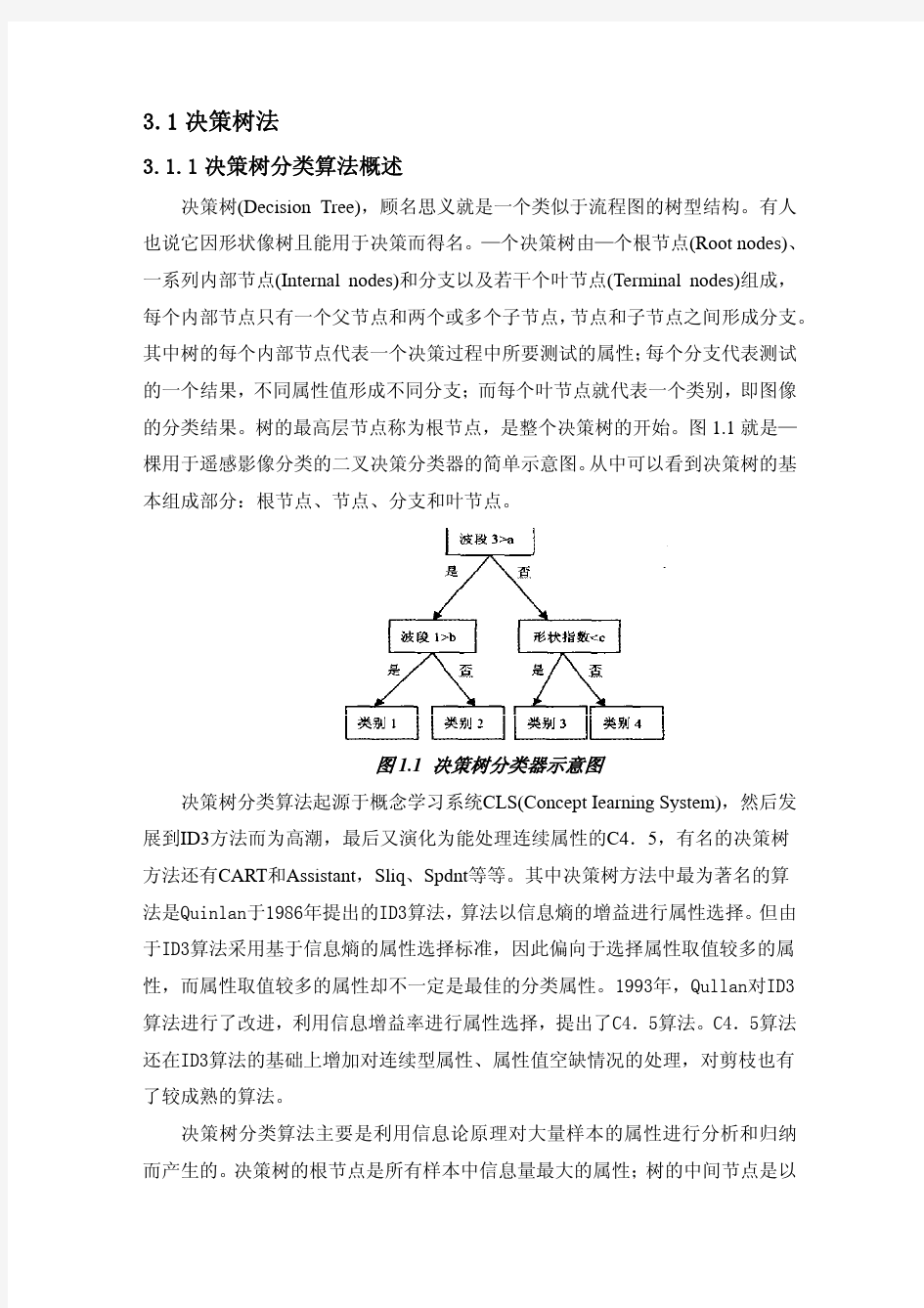

基于决策树的分类方法研究
南京师范大学 硕士学位论文 基于决策树的分类方法研究 姓名:戴南 申请学位级别:硕士 专业:计算数学(计算机应用方向) 指导教师:朱玉龙 2003.5.1
摘要 厂 {数掘挖掘,又称数据库中的知识发现,是指从大型数据库或数据仓库中提取 具有潜在应用价值的知识或模式。模式按其作用可分为两类:描述型模式和预测型模式。分类模式是一种重要的预测型模式。挖掘分娄模式的方法有多种,如决 策树方法、贝叶斯网络、遗传算法、基于关联的分类方法、羊H糙集和k一最临近方、/ 法等等。,/驴 I 本文研究如何用决策树方法进行分类模式挖掘。文中详细阐述了几种极具代表性的决策树算法:包括使用信息熵原理分割样本集的ID3算法;可以处理连续属性和属性值空缺样本的C4.5算法;依据GINI系数寻找最佳分割并生成二叉决策树的CART算法;将树剪枝融入到建树过程中的PUBLIC算法:在决策树生成过程中加入人工智能和人为干预的基于人机交互的决策树生成方法;以及突破主存容量限制,具有良好的伸缩性和并行性的SI,lQ和SPRINT算法。对这些算法的特点作了详细的分析和比较,指出了它们各自的优势和不足。文中对分布式环境下的决策树分类方法进行了描述,提出了分布式ID3算法。该算法在传统的ID3算法的基础上引进了新的数掘结构:属性按类别分稚表,使得算法具有可伸缩性和并行性。最后着重介绍了作者独立完成的一个决策树分类器。它使用的核心算法为可伸缩的ID3算法,分类器使用MicrosoftVisualc++6.0开发。实验结果表明作者开发的分类器可以有效地生成决策树,建树时间随样本集个数呈线性增长,具有可伸缩性。。 ,,荡囊 关键字:数据挖掘1分类规则,决策树,分布式数据挖掘
决策树算法研究及应用概要
决策树算法研究及应用? 王桂芹黄道 华东理工大学实验十五楼206室 摘要:信息论是数据挖掘技术的重要指导理论之一,是决策树算法实现的理论依据。决 策树算法是一种逼近离散值目标函数的方法,其实质是在学习的基础上,得到分类规则。本文简要介绍了信息论的基本原理,重点阐述基于信息论的决策树算法,分析了它们目前 主要的代表理论以及存在的问题,并用具体的事例来验证。 关键词:决策树算法分类应用 Study and Application in Decision Tree Algorithm WANG Guiqin HUANG Dao College of Information Science and Engineering, East China University of Science and Technology Abstract:The information theory is one of the basic theories of Data Mining,and also is the theoretical foundation of the Decision Tree Algorithm.Decision Tree Algorithm is a method to approach the discrete-valued objective function.The essential of the method is to obtain a clas-sification rule on the basis of example-based learning.An example is used to sustain the theory. Keywords:Decision Tree; Algorithm; Classification; Application 1 引言 决策树分类算法起源于概念学习系统CLS(Concept Learning System,然后发展 到ID3
C4.5 分类决策树
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。 C4.5由J.Ross Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。 从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。下图就是一棵典型的C4.5算法对数据集产生的决策树。 数据集如图1所示,它表示的是天气情况与去不去打高尔夫球之间的关系。
图1 数据集 图2 在数据集上通过C4.5生成的决策树 算法描述
C4.5并不一个算法,而是一组算法—C4.5,非剪枝C4.5和C4.5规则。下图中的算法将给出C4.5的基本工作流程: 图3 C4.5算法流程 我们可能有疑问,一个元组本身有很多属性,我们怎么知道首先要对哪个属性进行判断,接下来要对哪个属性进行判断?换句话说,在图2中,我们怎么知道第一个要测试的属性是Outlook,而不是Windy?其实,能回答这些问题的一个概念就是属性选择度量。 属性选择度量 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。
决策树算法介绍(DOC)
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
基于决策树的分类算法
1 分类的概念及分类器的评判 分类是数据挖掘中的一个重要课题。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类可用于提取描述重要数据类的模型或预测未来的数据趋势。 分类可描述如下:输入数据,或称训练集(training set)是一条条记录组成的。每一条记录包含若干条属性(attribute),组成一个特征向量。训练集的每条记录还有一个特定的类标签(类标签)与之对应。该类标签是系统的输入,通常是以往的一些经验数据。一个具体样本的形式可为样本向量:(v1,v2,…,…vn:c)。在这里vi表示字段值,c表示类别。 分类的目的是:分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。这种描述常常用谓词表示。由此生成的类描述用来对未来的测试数据进行分类。尽管这些未来的测试数据的类标签是未知的,我们仍可以由此预测这些新数据所属的类。注意是预测,而不能肯定。我们也可以由此对数据中的每一个类有更好的理解。也就是说:我们获得了对这个类的知识。 对分类器的好坏有三种评价或比较尺度: 预测准确度:预测准确度是用得最多的一种比较尺度,特别是对于预测型分类任务,目前公认的方法是10番分层交叉验证法。 计算复杂度:计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据库,因此空间和时间的复杂度问题将是非常重要的一个环节。 模型描述的简洁度:对于描述型的分类任务,模型描述越简洁越受欢迎;例如,采用规则表示的分类器构造法就更有用。 分类技术有很多,如决策树、贝叶斯网络、神经网络、遗传算法、关联规则等。本文重点是详细讨论决策树中相关算法。
如何运用决策树进行分类分析
如何运用决策树进行分类分析 前面我们讲到了聚类分析的基本方法,这次我们来讲讲分类分析的方法。 所谓分类分析,就是基于响应,找出更好区分响应的识别模式。分类分析的方法很多,一般而言,当你的响应为分类变量时,我们就可以使用各种机器学习的方法来进行分类的模式识别工作,而决策树就是一类最为常见的机器学习的分类算法。 决策树,顾名思义,是基于树结构来进行决策的,它采用自顶向下的贪婪算法,在每个结点选择分类的效果最好的属性对样本进行分类,然后继续这一过程,直到这棵树能准确地分类训练样本或所有的属性都已被使用过。 建造好决策树以后,我们就可以使用决策树对新的事例进行分类。我们以一个生活小案例来说什么是决策树。例如,当一位女士来决定是否同男士进行约会的时候,她面临的问题是“什么样的男士是适合我的,是我值得花时间去见面再进行深入了解的?” 这个时候,我们找到了一些女生约会对象的相关属性信息,例如,年龄、长相、收入等等,然后通过构建决策树,层层分析,最终得到女士愿意去近一步约会的男士的标准。 图:利用决策树确定约会对象的条件
接下来,我们来看看这个决策的过程什么样的。 那么,问题来了,怎样才能产生一棵关于确定约会对象的决策树呢?在构造决策树的过程中,我们希望决策树的每一个分支结点所包含的样本尽可能属于同一类别,即结点的”纯度”(Purity )越来越高。 信息熵(Information Entropy )是我们度量样本集合纯度的最常见指标,假定当前样本集合中第K 类样本所占的比例为P k ,则该样本集合的信息熵为: Ent (D )=?∑p k |y| k=1 log 2p k 有了这个结点的信息熵,我们接下来就要在这个结点上对决策树进行裁剪。当我们选择了某一个属性对该结点,使用该属性将这个结点分成了2类,此时裁剪出来的样本集为D 1和D 2, 然后我们根据样本数量的大小,对这两个裁剪点赋予权重|D 1||D|?,|D 2||D|?,最后我们就 可以得出在这个结点裁剪这个属性所获得的信息增益(Information Gain ) Gain(D ,a)=Ent (D )?∑|D V ||D |2 v=1Ent(D V ) 在一个结点的裁剪过程中,出现信息增益最大的属性就是最佳的裁剪点,因为在这个属性上,我们获得了最大的信息增益,即信息纯度提升的最大。 其实,决策树不仅可以帮助我们提高生活的质量,更可以提高产品的质量。 例如,我们下表是一组产品最终是否被质检接受的数据,这组数据共有90个样本量,数据的响应量为接受或拒绝,则|y|=2。在我们还没有对数据进行裁剪时,结点包含全部的样本量,其中接受占比为p 1= 7690,拒绝占比为p 2=1490,此时,该结点的信息熵为: Ent (D )=?∑p k |y|k=1log 2p k =-(7690log 27690+1490log 21490)=0.6235
决策树学习研究综述
科技论坛 决策树学习研究综述 叶萌 (黑龙江电力职工大学,黑龙江哈尔滨150030) 1概述 决策树是构建人工智能系统的主要方法之一,随着数据挖掘技术在商业智能等方面的应用,决策树技术将在未来发挥越来越强大的作用[1]。自从Quinlan 在1979年提出构造决策树ID3算法以来,决策树的实现已经有很多算法,常见的有:CLS (concept learning system )学习算法,ID4、ID5R 、C4.5算法,以及CART 、C5.0、FuzzyC4.5、0C1、QUEST 和CAL5等[2]。 现在,许多学者在规则学习与决策树学习的结合方面,做了大量的研究工作。Brako 等的ASSISTANT ,将AQ15中的近似匹配方法引入决策树中。Clark 等的CN2,将ID3算法和AQ 算法编织在一起,用户可选择其中任何一种算法使用。Utgoff 等的ID5R 算法,不要求一次性提供所有的训练实例,训练实例可以逐次提供,生成的决策树逐次精化,以支持增量式学习。洪家荣教授结合实际应用问题对ID3算法作了一些改进,提出了两个ID3和AQ 结合的改进算法,IDAQ 和AQID ,此外,还陆续出现了处理大规模数据集的决策树算法,如SLIQ ,SPRINT 等等[3]。 2决策树算法研究2.1构造决策树算法 决策树学习是从无次序、无规则的样本数据集中推理出决策树表示形式、逼近离散值目标函数的分类规则方法。它采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较并根据不同的属性值判断从该结点向下的分支,在决策树的叶结点得到结论,因此从根结点到叶结点的一条路径就对应着一条规则,整棵决策树就对应着一组表达式规则。我们可将决策树看成是定义布尔函数的一种方法。其输入是一组属性描述的对象,输出为yes/no 决策。决策树代表一个假设,可以写成逻辑公式。决策树的表达能力限于命题逻辑,该对象的任一个属性的任一次测试均是一个命题。在命题逻辑范围内,决策树的表达能力是完全的。一棵决策树可以代表一个决定训练例集分类的决策过程,树的每个结点对应于一个属性名或一个特定的测试,该测试在此结点根据测试的可能结果对训练例集进行划分。划分出的每个部分都对应于相应训练例集子空间的一个分类子问题,该分类子问题可以由一棵决策树来解决。因此,一 棵决策树可以看作是一个对目标分类的划分和获取策略[4] 。 2.2处理大规模数据集的决策树算法 ID3或者C4.5算法都是在建树时将训练集一次性装载入内存的。但当面对大型的有着上百万条纪录的数据库时,就无法实际应用这些算 法。针对这一问题, 前人提出了不少改进方法,如数据采样法、连续属性离散化法或将数据分为若干小块分别建树然后综合成一个最终的树,但这些改进都以降低了树的准确性为代价。直到M etha,Agrawal 和Ris-sane 在1996年提出了SLIQ 方法,以及在此基础上进行改进得到的SPRINT [6]方法。 3决策树学习的常见问题3.1过度拟合 在利用决策树归纳学习时,需要事先给定一个假设空间,且必须在这个假设空间中选择一个,使之与训练实例集相匹配。我们知道任何一个学习算法不可能在没有任何偏置的情况下学习。如果事先知道所要学习的函数属于整个假设空间中的一个很小的子集,那么即使训练实例不完整,也有可能从已有的训练实例集中学习到有用的假设,使它对未来的实例进行正确的分类。当然,我们往往无法事先知道所要学习的函数属于整个假设空间中的哪个很小的子集,即使是知道,我们还是希望有一个大的训练实例集。因为训练实例集越大,关于分类的信息就越多。这时,即使随机地从与训练实例集相匹配的假设集中选择一个,它也能对未知实例的分类进行预测。相反,如果训练实例集与整个假设空间相比 过小,即使在有偏置的情况下,仍有过多的假设与训练实例集相匹配,这 时作出假设的泛化能力将很差。当有过多的假设与训练实例集相匹配,便称为过度拟合(overfit )。 3.2树剪枝 对决策树进行修剪可以控制决策树的复杂程度,避免决策树过于复 杂和庞大。此外, 还可以解决过度拟合的问题。修剪决策树有多种算法,通常分为这样五类。最为常用的是通过预 剪枝(pre-pruning )和后剪枝(post-pruning )完成,或逐步调整树的大小;其次是扩展测试集方法,首先按特征构成是数据驱动还是假设驱动的差别,将建立的特征组合或分割,然后在此基础上引进多变量测试集。第三类方法包括选择不同的测试集评价函数,通过改善连续特征的描述或修改搜索算法本身实现;第四类方法使用数据库约束,即通过削减数据库或实例描述特征集来简化决策树;第五类方法是将决策树转化成另一种数据结构。这些方法通常可以在同另一种算法相互结合中,增强各自的功能。 4决策树在工程中的应用 决策树在工程中的诸多领域获得了非常广泛的应用,主要有以下几个方面: 4.1决策树技术应用于机器人导航 E.Swere 和D .J.M ulvaney 将决策树技术应用于移动机器人导航并取得了一定的成功。 4.2决策树技术应用于地铁中的事故处理 法国的Brezillon 等人成功地将决策树技术应用于地铁交通调度智能系统。他们根据决策树的基本思想开发出上下文图表来帮助驾驶员针对事故做出正确的处理。 4.3决策树技术应用于图像识别 决策树技术应用于包括图像在内的科学数据分析。如利用决策树对上百万个天体进行分类,利用决策树对卫星图像进行分析以估计落叶林和针叶林的基部面积值。 4.4决策树应用于制造业 决策树技术已经成功应用于焊接质量的检测以及大规模集成电路 的设计,它不仅可以规划印刷电路板的布线, 波音公司甚至将它用于波音飞机生产过程的故障诊断以及质量控制。 5决策树技术面临的问题和挑战发展至今,决策树技术面临的问题和挑战表现在以下几个方面:5.1决策树方法的效率亟待提高 数据挖掘面临的数据往往是海量的,对实时性要求较高的决策场所,数据挖掘方法的主动性和快速性显得日益重要。应用实时性技术、主动数据库技术和分布并行算法设计技术等现代计算机先进技术,是数据挖掘方法实用化的有效途径。 5.2适应多数据类型、容噪的决策树挖掘方法随着计算机网络和信息的社会化,数据挖掘的对象已不是关系数据库模型,而是分布、异构的多类型数据库,数据的非结构化程度、噪声等现象越来越突出,这也是决策树技术面临的困难问题。 6结论 决策树技术早已被证明是利用计算机模仿人类决策的有效方法,已经得到广泛的应用,并且已经有了许多成熟的系统。但是,解决一个复杂的数据挖掘问题的任何算法都要面临以下问题:从错误的数据中学习、从分布的数据中学习、从有偏的数据中学习、学习有弹性的概念、学习那些抽象程度不同的概念、整合定性与定量的发现等,因此,还有很多未开 发的课题等待研究。若将决策树技术与其他新兴 摘要:决策树分类学习算法是使用广泛、实用性很强的归纳推理方法之一,在机器学习、数据挖掘等人工智能领域有相当重要的理 论意义与实用价值。在详细阐述决策树技术的几种典型算法以及它的一些常见问题后, 介绍了它在工程上的实际应用,最后提出了它的研究方向以及它所面临的问题和挑战。 关键词:决策树;决策树算法;ID3;C4.5;SLIQ ;SPRINT (下转156页)22··
利用决策树方法对数据进行分类挖掘毕业设计论文
目录 摘要 (3) Abstract (iii) 第一章绪论 (1) 1.1 数据挖掘技术 (1) 1.1.1 数据挖掘技术的应用背景 (1) 1.1.2数据挖掘的定义及系统结构 (2) 1.1.3 数据挖掘的方法 (4) 1.1.4 数据挖掘系统的发展 (5) 1.1.5 数据挖掘的应用与面临的挑战 (6) 1.2 决策树分类算法及其研究现状 (8) 1.3数据挖掘分类算法的研究意义 (10) 1.4本文的主要内容 (11) 第二章决策树分类算法相关知识 (12) 2.1决策树方法介绍 (12) 2.1.1决策树的结构 (12) 2.1.2决策树的基本原理 (13) 2.1.3决策树的剪枝 (15) 2.1.4决策树的特性 (16) 2.1.5决策树的适用问题 (18) 2.2 ID3分类算法基本原理 (18) 2.3其它常见决策树算法 (20) 2.4决策树算法总结比较 (24) 2.5实现平台简介 (25) 2.6本章小结 (29) 第三章 ID3算法的具体分析 (30) 3.1 ID3算法分析 (30) 3.1.1 ID3算法流程 (30) 3.1.2 ID3算法评价 (33) 3.2决策树模型的建立 (34) 3.2.1 决策树的生成 (34) 3.2.2 分类规则的提取 (377) 3.2.3模型准确性评估 (388) 3.3 本章小结 (39)
第四章实验结果分析 (40) 4.1 实验结果分析 (40) 4.1.1生成的决策树 (40) 4.1.2 分类规则的提取 (40) 4.2 本章小结 (41) 第五章总结与展望 (42) 参考文献 (44) 致谢 (45) 附录 (46)
决策树分类-8页文档资料
基于专家知识的决策树分类 概述 基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。 如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植被,那些是公园植被。 图1.JPG 图1 专家知识决策树分类器说明图 专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则输入、决策树运行和分类后处理。 1.知识(规则)定义 规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也可以通过经验总结获得。 2.规则输入
将分类规则录入分类器中,不同的平台有着不同规则录入界面。 3.决策树运行 运行分类器或者是算法程序。 4.分类后处理 这步骤与监督/非监督分类的分类后处理类似。 知识(规则)定义 分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。也可以从样本中利用算法来获取,这里要讲述的就是C4.5算法。 利用C4.5算法获取规则可分为以下几个步骤: (1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。 (2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。 (3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当的调整和筛选。这里就是C4.5算法。 4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下: 从树的根节点处的所有训练样本D0开始,离散化连续条件属性。计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。对属性C0的每一个值产生一个分支,分支属性值的相应样本子集被移到新生成的子节点上,如果得到的样本都属于同一个类,那么直接得到叶子结点。相应地将此方法应用于每个子节点上,直到节点的所有样本都分区到某个类中。到达决策树的叶节点的每条路径表示一条分类规则,利用叶列表及指向父结点的指针就可以生成规则表。
基于决策树的鸢尾花分类
科技论坛 0 引言 图像识别技术,要运用目前流行的机器学习算法,而目前流行的机器学习算法就有十几种,比如支持向量机、神经网络、决策树。机器学习是人工智能发展的重要一部分,它涉及的学科很多,应用也相当广泛,它通过分析、研究、设计让计算机学习知识,从而提高完善自身的性能。但是神经网络学习的速度较慢,传统的支持向量机则不能解决分类多的问题。 本文针对鸢尾花的特征类别少以及种类少的特点,采用决策树算法对课题进行展开,对比与其他人利用支持向量机、神经元网络模型来进行研究,该系统具有模型简单、便于理解、计算方便、消耗资源少的优点。 1 决策树模型和学习 本文采用决策树算法对鸢尾花进行分类,先建立决策树的模型并进行学习训练,在决策树的训练过程中采用是信息论的知识进行特征选择,对选定的特征采用分支的处理,然后再对分支过后的数据集如此反复的递归生成决策树,在一颗决策树生成完后对决策树进行剪枝,以减小决策树的拟合度,来达到一个对鸢尾花较高的分类准确率。 要对鸢尾花进行分类首先需要大量的鸢尾花数据集作为本文的实验数据,本文采用的数据集是来自加州大学欧文分校UCI数据库中的鸢尾花数据集。该数据集中鸢尾花的属性有四个,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,鸢尾花的类别则有三种,分别是Iris Setosa,Iris Versicolour,Iris Virginica,用简写Se、Ve和Vi表示这三种花,具体数据如图1所示。 ■1.1 信息论 美贝尔电话研究所的数学家香农是信息论的创始人,1948年香农发表了《通讯的数学理论》,成为信息论诞生的标志。信息论的诞生对信息技术革命以及科学技术的发展起到重要作用。信息论中有两个概念信息增益及信息增益率,都是用于衡量原始数据集在按照某一属性特征分裂之后整体信息量的变化值。这样,本文就可以通过这种指标寻找出最优的划分属性,数据集在经过划分之后,节点的“纯度”越来越高,这里的纯度值得是花朵的类别,当某一节点中花朵全为一类时,该节点已经达到最纯状态,无需再进行划分, 反之继续划分。 图1 鸢尾花数据集 1.1.1 信息熵 信息熵用于描述信源的不确定性。即发生每个事件都有不确定性,为了使不确定性降低,我们需要引入一些相关的信息进行学习,引入信息越多,那么得到的准确率越高,信息熵越高,信源越不稳定。例如一束鸢尾花,它可能是Se,可能是Vi,也有可能是Ve,我们利用数据库中的各种鸢尾花的花瓣长度、花瓣宽度、花萼长度和花萼宽度来预测鸢尾花的类别,引入的鸢尾花种类越多,信息熵就越高。 样本集合D的信息熵Ent(D)以下面的公式进行计算,其中集合里第k类样本所占的比例是k p,k的取值范围是从1到y,y值得是总共有y类样本,通过式(1)可以计算得到原始样本集的信息熵。 ()21 Ent D y k k k p log p = =?∑(1) 1.1.2 信息增益 信息增益即在一个条件下,信源不确定性减少的程度。信息增益用于度量节点的纯度。信息增益对可取值数目较多的属性有所偏好。在鸢尾花数据集的D集合中,属性a取到某一取值情况的概率乘该取值情况的信息熵得到的值记为v D,其中V指的是该属性a可以取值的个数,则属性a 的信息增益为: ()()() 1 Gain D,a Ent D V v v v D Ent D D = =?∑(2) 基于决策树的鸢尾花分类 徐彧铧 (浙江省衢州第二中学,浙江衢州,324000) 摘要:针对传统手工分类的不足,满足不了人们对图片分类的需求,本文利用机器学习算法中的决策树算法进行研究。通过模型简单、便于理解、计算方便、消耗资源少的决策树算法模型,并利用现成的数据库,运用图像识别技术对鸢尾花进行分类,以求方便简单快速地识别出不同类别的鸢尾花。在此过程中,学习到图像识别的一些基本分类操作,为我们实现更复杂的模型提供了帮助。 关键词:决策树信息论特征选择;C4.5算法;CART算法 www ele169 com | 99
决策树分类算法
决策树分类算法 决策树是一种用来表示人们为了做出某个决策而进行的一系列判断过程的树形图。决策树方法的基本思想是:利用训练集数据自动地构造决策树,然后根据这个决策树对任意实例进行判定。 1.决策树的组成 决策树的基本组成部分有:决策节点、分支和叶,树中每个内部节点表示一个属性上的测试,每个叶节点代表一个类。图1就是一棵典型的决策树。 图1 决策树 决策树的每个节点的子节点的个数与决策树所使用的算法有关。例如,CART算法得到的决策树每个节点有两个分支,这种树称为二叉树。允许节点含有多于两个子节点的树称为多叉树。 下面介绍一个具体的构造决策树的过程,该方法
是以信息论原理为基础,利用信息论中信息增益寻找数据库中具有最大信息量的字段,建立决策树的一个节点,然后再根据字段的不同取值建立树的分支,在每个分支中重复建立树的下层节点和分支。 ID3算法的特点就是在对当前例子集中对象进行分类时,利用求最大熵的方法,找出例子集中信息量(熵)最大的对象属性,用该属性实现对节点的划分,从而构成一棵判定树。 首先,假设训练集C 中含有P 类对象的数量为p ,N 类对象的数量为n ,则利用判定树分类训练集中的对象后,任何对象属于类P 的概率为p/(p+n),属于类N 的概率为n/(p+n)。 当用判定树进行分类时,作为消息源“P ”或“N ”有关的判定树,产生这些消息所需的期望信息为: n p n log n p n n p p log n p p )n ,p (I 22++-++- = 如果判定树根的属性A 具有m 个值{A 1, A 2, …, A m },它将训练集C 划分成{C 1, C 2, …, C m },其中A i 包括C 中属性A 的值为A i 的那些对象。设C i 包括p i 个类P 对象和n i 个类N 对象,子树C i 所需的期望信息是I(p i , n i )。以属性A 作为树根所要求的期望信息可以通过加权平均得到
决策树分类的定义以及优缺点 (1)
决策树分类 决策树(Decision Tree)又称为判定树,是运用于分类的一种树结构。其中的每个内部结点(internal node)代表对某个属性的一次测试,每条边代表一个测试结果,叶结点(leaf)代表某个类(class)或者类的分布(class distribution),最上面的结点是根结点。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。 构造决策树是采用自上而下的递归构造方法。决策树构造的结果是一棵二叉或多叉树,它的输入是一组带有类别标记的训练数据。二叉树的内部结点(非叶结点)一般表示为一个逻辑判断,如形式为(a = b)的逻辑判断,其中a 是属性,b是该属性的某个属性值;树的边是逻辑判断的分支结果。多叉树(ID3)的内部结点是属性,边是该属性的所有取值,有几个属性值,就有几条边。树的叶结点都是类别标记。 使用决策树进行分类分为两步: 第1步:利用训练集建立并精化一棵决策树,建立决策树模型。这个过程实际上是一个从数据中获取知识,进行机器学习的过程。 第2步:利用生成完毕的决策树对输入数据进行分类。对输入的记录,从根结点依次测试记录的属性值,直到到达某个叶结点,从而找到该记录所在的类。 问题的关键是建立一棵决策树。这个过程通常分为两个阶段: (1) 建树(Tree Building):决策树建树算法见下,可以看得出,这是一个递归的过程,最终将得到一棵树。 (2) 剪枝(Tree Pruning):剪枝是目的是降低由于训练集存在噪声而产生的起伏。 决策树方法的评价。 优点 与其他分类算法相比决策树有如下优点: (1) 速度快:计算量相对较小,且容易转化成分类规则。只要沿着树根向下一直走到叶,沿途的分裂条件就能够唯一确定一条分类的谓词。 (2) 准确性高:挖掘出的分类规则准确性高,便于理解,决策树可以清晰的显示哪些字段比较重要。 缺点 一般决策树的劣势: (1) 缺乏伸缩性:由于进行深度优先搜索,所以算法受内存大小限制,难于处理大训练集。一个例子:在Irvine机器学习知识库中,最大可以允许的数据集仅仅为700KB,2000条记录。而现代的数据仓库动辄存储几个G-Bytes的海量数据。用以前的方法是显然不行的。
论贝叶斯分类、决策树分类、感知器分类挖掘算法的优势与劣势
论贝叶斯分类、决策树分类、感知器分类挖掘算法的优势与劣势 摘要本文介绍了在数据挖掘中数据分类的几个主要分类方法,包括:贝叶斯分类、决策树分类、感知器分类,及其各自的优势与劣势。并对于分类问题中出现的高维效应,介绍了两种通用的解决办法。 关键词数据分类贝叶斯分类决策树分类感知器分类 引言 数据分类是指按照分析对象的属性、特征,建立不同的组类来描述事物。数据分类是数据挖掘的主要内容之一,主要是通过分析训练数据样本,产生关于类别的精确描述。这种类别通常由分类规则组成,可以用来对未来的数据进行分类和预测。分类技术解决问题的关键是构造分类器。 一.数据分类 数据分类一般是两个步骤的过程: 第1步:建立一个模型,描述给定的数据类集或概念集(简称训练集)。通过分析由属性描述的数据库元组来构造模型。每个元组属于一个预定义的类,由类标号属性确定。用于建立模型的元组集称为训练数据集,其中每个元组称为训练样本。由于给出了类标号属性,因此该步骤又称为有指导的学习。如果训练样本的类标号是未知的,则称为无指导的学习(聚类)。学习模型可用分类规则、决策树和数学公式的形式给出。 第2步:使用模型对数据进行分类。包括评估模型的分类准确性以及对类标号未知的元组按模型进行分类。 常用的分类规则挖掘方法 分类规则挖掘有着广泛的应用前景。对于分类规则的挖掘通常有以下几种方法,不同的方法适用于不同特点的数据:1.贝叶斯方法 2.决策树方法 3.人工神经网络方法 4.约略集方法 5.遗传算法 分类方法的评估标准: 准确率:模型正确预测新数据类标号的能力。 速度:产生和使用模型花费的时间。 健壮性:有噪声数据或空缺值数据时模型正确分类或预测的能力。 伸缩性:对于给定的大量数据,有效地构造模型的能力。 可解释性:学习模型提供的理解和观察的层次。 影响一个分类器错误率的因素 (1) 训练集的记录数量。生成器要利用训练集进行学习,因而训练集越大,分类器也就越可靠。然而,训练集越大,生成器构造分类器的时间也就越长。错误率改善情况随训练集规模的增大而降低。 (2) 属性的数目。更多的属性数目对于生成器而言意味着要计算更多的组合,使得生成器难度增大,需要的时间也更长。有时随机的关系会将生成器引入歧途,结果可能构造出不够准确的分类器(这在技术上被称为过分拟合)。因此,如果我们通过常识可以确认某个属性与目标无关,则将它从训练集中移走。 (3) 属性中的信息。有时生成器不能从属性中获取足够的信息来正确、低错误率地预测标签(如试图根据某人眼睛的颜色来决定他的收入)。加入其他的属性(如职业、每周工作小时数和年龄),可以降低错误率。 (4) 待预测记录的分布。如果待预测记录来自不同于训练集中记录的分布,那么错误率有可能很高。比如如果你从包含家用轿车数据的训练集中构造出分类器,那么试图用它来对包含许多运动用车辆的记录进行分类可能没多大用途,因为数据属性值的分布可能是有很大差别的。 评估方法 有两种方法可以用于对分类器的错误率进行评估,它们都假定待预测记录和训练集取自同样的样本分布。 (1) 保留方法(Holdout):记录集中的一部分(通常是2/3)作为训练集,保留剩余的部分用作测试集。生成器使用2/3 的数据来构造分类器,然后使用这个分类器来对测试集进行分类,得出的错误率就是评估错误率。 虽然这种方法速度快,但由于仅使用2/3 的数据来构造分类器,因此它没有充分利用所有的数据来进行学习。如果使用所有的数据,那么可能构造出更精确的分类器。 (2) 交叉纠错方法(Cross validation):数据集被分成k 个没有交叉数据的子集,所有子集的大小大致相同。生成器训练和测试共k 次;每一次,生成器使用去除一个子集的剩余数据作为训练集,然后在被去除的子集上进行测试。把所有
分类决策树
分类决策树 原理 决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,对未知的数据进行分类。如何预测, 先看看下面的数据表格: 上表根据历史数据,记录已有的用户是否可以偿还债务,以及相关的信息。通过该数据,构建的决策树如下: 如新来一个用户:无房产,单身,年收入55K,那么根据上面的决策树,可以预测他无法偿还债务(蓝色虚线路径)。从上面的决策树,还可以知道是否拥有房产可以很大的决定用户是否可以偿还债务,对借贷业务具有指导意义。 决策树构建的基本步骤如下: 1. 开始所有记录看作一个节点 2. 遍历每个变量的每一种分割方式,找到最好的分割点 3. 分割成两个节点N1和N2
4. 对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止 构建决策树的变量可以有两种: 1)连续型:如前例中的“年收入”。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。 2)分类型:如前例中的“婚姻情况”,使用“=”来分割。 如何评估分割点的好坏?如果一个分割点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分割点。比如上面的例子,“拥有房产”,可以将记录分成了两类,“是”的节点全部都可以偿还债务,非常“纯”;“否”的节点,可以偿还贷款和无法偿还贷款的人都有,不是很“纯”,但是两个节点加起来的纯度之和与原始节点的纯度之差最大,所以按照这种方法分割。构建决策树采用贪心算法,只考虑当前纯度差最大的情况作为分割点。 纯度计算 前面讲到,决策树是根据“纯度”来构建的,如何量化纯度呢?这里介绍三种纯度计算方法。如果记录被分为n类,每一类的比例P(i)=第i类的数目/总数目。还是拿上面的例子,10个数据中可以偿还债务的记录比例为P(1) = 7/10 = 0.7,无法偿还的为 P(2) = 3/10 = 0.3,N = 2。 Gini不纯度: 熵(Entropy): 错误率: 上面的三个公式均是值越大,表示越“不纯”,越小表示越“纯”。三种公式只需要取一种即可,对最终分类准确率的影响并不大,一般使用熵公式。 纯度差,也称为信息增益(Information Gain),公式如下: 其中,I代表不纯度(也就是上面三个公式的任意一种),K代表分割的节点数,一般K = 2。vj表示子节点中的记录数目。上面公式实际上就是当前节点的不纯度减去子节点不纯度的加权平均数,权重由子节点记录数与当前节点记录数的比例决定。 停止条件 决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过度拟合(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
(完整版)ENVI决策树分类
遥感专题讲座——影像信息提取(三、基于专家知识的决策树分类) 基于专家知识的决策树分类 可以将多源数据用于影像分类当中,这就是专家知识的决策树分类器,本专题以ENVI中Decision Tree为例来叙述这一分类器。 本专题包括以下内容: ? ?●专家知识分类器概述 ? ?●知识(规则)定义 ? ?●ENVI中Decision Tree的使用 概述 基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。 如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植 被,那些是公园植被。
图1 专家知识决策树分类器说明图 专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则 输入、决策树运行和分类后处理。 1.知识(规则)定义 规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也 可以通过经验总结获得。 2.规则输入 将分类规则录入分类器中,不同的平台有着不同规则录入界面。 3.决策树运行 运行分类器或者是算法程序。 4.分类后处理 这步骤与监督/非监督分类的分类后处理类似。 知识(规则)定义 分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。也可以从样本中利用算法来获取,这里要讲述的就是C4.5 算法。 利用C4.5算法获取规则可分为以下几个步骤:(1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。 (2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。 (3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当 的调整和筛选。这里就是C4.5算法。 4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下: 从树的根节点处的所有训练样本D0开始,离散化连续条件属性。计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。对属性C0的每一个值产生一个分支,分支属性值的相应样本子集被移
遥感专题讲座——影像信息提取(三、基于专家知识的决策树分类)
基于专家知识的决策树分类 可以将多源数据用于影像分类当中,这就是专家知识的决策树分类器,本专题以ENVI中Decision Tree为例来叙述这一分类器。 本专题包括以下内容: ? ?●专家知识分类器概述 ? ?●知识(规则)定义 ? ?●ENVI中Decision Tree的使用 概述 基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。 如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植被, 那些是公园植被。
图1 专家知识决策树分类器说明图 专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则 输入、决策树运行和分类后处理。 1.知识(规则)定义 规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也 可以通过经验总结获得。 2.规则输入 将分类规则录入分类器中,不同的平台有着不同规则录入界面。 3.决策树运行 运行分类器或者是算法程序。 4.分类后处理 这步骤与监督/非监督分类的分类后处理类似。 知识(规则)定义 分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。也可以从样本中利用算法来获取,这里要讲述的就是C4.5 算法。 利用C4.5算法获取规则可分为以下几个步骤:(1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。 (2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。 (3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当的 调整和筛选。这里就是C4.5算法。 4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下: 从树的根节点处的所有训练样本D0开始,离散化连续条件属性。计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。对属性C0的每一个值产生一个分支,分支属性值的相应样本子集被移到