计量经济学第二次作业-异方差

山东轻工业学院实验报告 成绩
课程名称 指导教师 实验日期
院(系) 专业班级 实验地点
学生姓名 学号 同组人
实验项目名称 异方差的检验与修正方法
一、 实验目的和要求
掌握异方差的基本操作完成对例题的估计与预测并且掌握戈德菲尔德-夸特
检验,怀特检验与斯皮尔曼等级相关系数检验,以及用加权最小二乘法对异方差进行修正。 二、 实验原理
异方差:戈德菲尔德-夸特检验,怀特检验与斯皮尔曼等级相关系数检验,
以及用加权最小二乘法对异方差进行修正。 三、 主要仪器设备、试剂或材料 计算机,eviews 软件 四、 实验方法与步骤
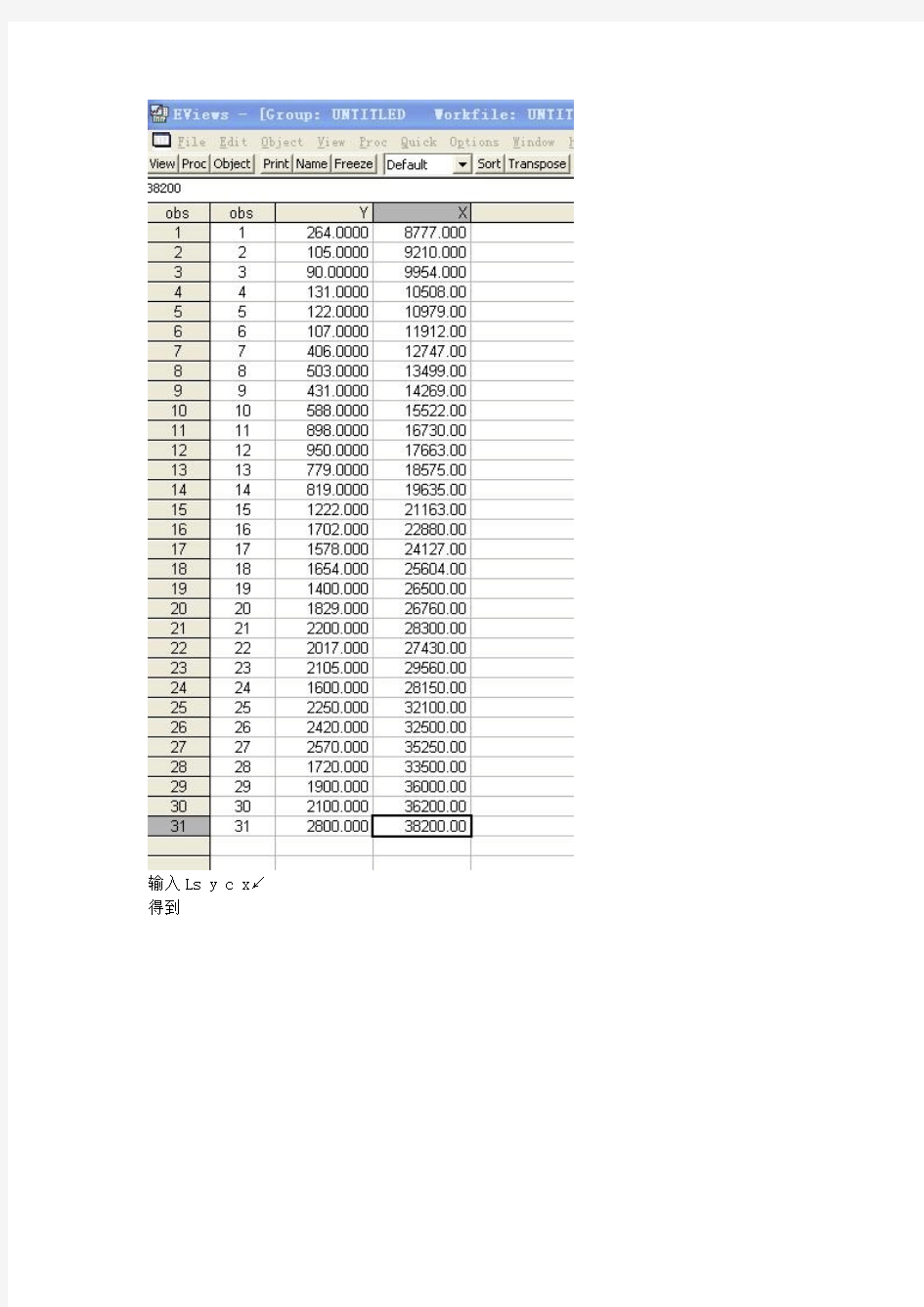
一、建立工作文件 创建工作文件并输入数据
建立计量经济模型
建立工作文件create u 1 31↙
输入数据 data y x ↙ 输入完成的图如下
i
i i u X Y ++=10ββ
输入Ls y c x↙得到
检验异方差
1.图示法输入 scat y x↙得到
Y对X的散点图
2.输入genr e1=resid↙
scat x e1↙得到
残差与X的散点图
两个图形中,横轴是X轴,纵轴是Y轴或Ei轴。从图Y对X的散点图可以看出,随着可支配收入Y的增加,表明随机误差项ui存在异方差性,根据残差与X的散点图,随着可支配收入X的增加,残差项的离散程度加大,表示随机误差项存在异方差。
模拟图与残差图由图可知样本回归方程为
Yi=-700.41+0.09Xi
(-6.0) (18.2)
R2=0.92 ,修正样本可决系数为0.92 ,F=331.09
由于怀疑模型存在异方差性,下面分别用几种不同的方法检验随机误差项的异方差性。
2、解析法 G-Q
Sort x
Smpl 1 11
Ls y c x
Smpl 20 31
Ls y c x
由上图得到的样本回归方程是
^
Yi = -700.41 + 0.09 Xi
(-6.0) (18.2)
2 _2
R = 0.92 R =0.92 F = 335.82
第二个样本的残差平方和为969933.3
构造F统计量为F=969933.3/150867.9=6.43
给出显著性水平a=0.05,查F分布表V1=V2=11-2=9,F0.05(9,9)=3.18,因为F=6.43>3.18,所以接受备择假设,即储蓄计量模型的随机误差项存在异方差性
3、斯皮尔曼等级相关系数检验
sort x
data x d1
genr e1=abs(resid)
sort e1
data e1 d2
genr r=1-6*@sum((d2-d1)^2)/(31^3-31)
genr Z=r*@sqrt(30)
σ
由上图可知r=0.607 , Z=3.33
给定显著性水平a=0.05,查正态分布表得Za/2=1.96,因为Z=3.33 > Za/2=1.96,所以应拒绝H0,接受H1,即等级相关系数是显著的,说明储蓄计量模型的随机误差项存在异方差性。
4、WLS
Smpl 1 31
这里用残差绝对值得倒数为权重
Genr WW=1/abs(resid)
Ls (W=WW) y c x 得下图
5、怀特
View—〉resdual test —〉white heteroskedasicity(no cross terms )
white heteroskedasicity(cross terms ) White Heteroskedasticity Test:
F-statistic 5.819690 Probability 0.007699 Obs*R-squared 9.102584 Probability 0.010554
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 05/08/12 Time: 20:26
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C 19975.98 82774.93 0.241329 0.8111
X -2.198632 8.094419 -0.271623 0.7879
X^2 0.000146 0.000176 0.830046 0.4135
R-squared 0.293632 Mean dependent var 55881.73 Adjusted R-squared 0.243177 S.D. dependent var 77875.67 S.E. of regression 67748.39 Akaike info criterion 25.17675 Sum squared resid 1.29E+11 Schwarz criterion 25.31553 Log likelihood -387.2397 F-statistic 5.819690 Durbin-Watson stat 1.552875 Prob(F-statistic) 0.007699
由图知TR2=9.1025>X0.05(2)=6.0,所以该回归模型存在异方差。
6、修正
Genr ww=abs(resid)↙
Ls(w=ww) y c x↙
六、讨论、心得
通过上机操作,我加深了解了EViews软件的基本操作,并且能够运用其软件对问题进行异方差的预测分析,掌握异方差的基本操作完成对例题的估计与预测并且掌握戈德菲尔德-夸特检验,怀特检验与斯皮尔曼等级相关系数检验,以及用加权最小二乘法对异方差进行修正。在上机过程中,要求应以严谨的态度来进行每一个步骤,尤其在输入数据时应检查数据是否输入正确,建立好数学模型,对参数进行有效估计,从而进一步评价模型,最后通过一系列图表和数据进行预测,最终得出结果作出结论。
附件三:实验报告附页
山东轻工业学院实验报告(附页)
计量经济学(伍德里奇第五版中文版)答案
第1章 解决问题的办法 1.1(一)理想的情况下,我们可以随机分配学生到不同尺寸的类。也就是说,每个学生被分配一个不同的类的大小,而不考虑任何学生的特点,能力和家庭背景。对于原因,我们将看到在第2章中,我们想的巨大变化,班级规模(主题,当然,伦理方面的考虑和资源约束)。 (二)呈负相关关系意味着,较大的一类大小是与较低的性能。因为班级规模较大的性能实际上伤害,我们可能会发现呈负相关。然而,随着观测数据,还有其他的原因,我们可能会发现负相关关系。例如,来自较富裕家庭的儿童可能更有可能参加班级规模较小的学校,和富裕的孩子一般在标准化考试中成绩更好。另一种可能性是,在学校,校长可能分配更好的学生,以小班授课。或者,有些家长可能会坚持他们的孩子都在较小的类,这些家长往往是更多地参与子女的教育。 (三)鉴于潜在的混杂因素- 其中一些是第(ii)上市- 寻找负相关关系不会是有力的证据,缩小班级规模,实际上带来更好的性能。在某种方式的混杂因素的控制是必要的,这是多元回归分析的主题。 1.2(一)这里是构成问题的一种方法:如果两家公司,说A和B,相同的在各方面比B公司à用品工作培训之一小时每名工人,坚定除外,多少会坚定的输出从B公司的不同? (二)公司很可能取决于工人的特点选择在职培训。一些观察到的特点是多年的教育,多年的劳动力,在一个特定的工作经验。企业甚至可能歧视根据年龄,性别或种族。也许企业选择提供培训,工人或多或少能力,其中,“能力”可能是难以量化,但其中一个经理的相对能力不同的员工有一些想法。此外,不同种类的工人可能被吸引到企业,提供更多的就业培训,平均,这可能不是很明显,向雇主。 (iii)该金额的资金和技术工人也将影响输出。所以,两家公司具有完全相同的各类员工一般都会有不同的输出,如果他们使用不同数额的资金或技术。管理者的素质也有效果。 (iv)无,除非训练量是随机分配。许多因素上市部分(二)及(iii)可有助于寻找输出和培训的正相关关系,即使不在职培训提高工人的生产力。 1.3没有任何意义,提出这个问题的因果关系。经济学家会认为学生选择的混合学习和工作(和其他活动,如上课,休闲,睡觉)的基础上的理性行为,如效用最大化的约束,在一个星期只有168小时。然后我们可以使用统计方法来衡量之间的关联学习和工作,包括回归分析,我们覆盖第2章开始。但我们不会声称一个变量“使”等。他们都选择学生的变量。 第2章 解决问题的办法
计量经济学第二次作业异方差检验
第三章13题 下表列出了中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业 的工业总产值Y ,资产合计K 及职工人数L 。 序号 工业总产值 Y (亿元) 资产合计 K (亿元) 职工人数L (万人) 序号 工业总产值Y (亿元) 资产合计K (亿元) 职工人数 L (万人) 1 3722.7 3078.22 113 13 4429.19 3785.91 61 2 1442.52 1684.43 67 14 5749.02 8688.03 254 3 1752.37 2742.77 84 15 1781.37 2798.9 83 4 1451.29 1973.82 27 16 1243.07 1808.44 33 5 5149.3 5917.01 327 17 812.7 1118.81 43 6 2291.16 1758.77 120 18 1899.7 2052.16 61 7 1345.17 939.1 58 19 3692.85 6113.11 240 8 656.77 694.94 31 20 4732.9 9228.25 222 9 370.18 363.48 16 21 2180.23 2866.65 80 10 1590.36 2511.99 66 22 2539.76 2545.63 96 11 616.71 973.73 58 23 3046.95 4787.9 222 12 617.94 516.01 28 24 2192.63 3255.29 163 解: ⑴ 先对Y AK L e αβμ=左右两边同时取对数得: ln ln ln ln ln Y C K L C A e αβμ=++=+ 相应的数据变为: 通过Eviews 软件进行回归分析得到如下结果:
计量经济学-李子奈-计算题整理集合
计算分析题(共3小题,每题15分,共计45分) 1、下表给出了一含有3个实解释变量的模型的回归结果: 方差来源 平方和(SS ) 自由度(d.f.) 来自回归65965 — 来自残差— — 总离差(TSS) 66056 43 (1)求样本容量n 、RSS 、ESS 的自由度、RSS 的自由度 (2)求可决系数)37.0(-和调整的可决系数2 R (3)在5%的显著性水平下检验1X 、2X 和3X 总体上对Y 的影响的显著性 (已知0.05(3,40) 2.84F =) (4)根据以上信息能否确定1X 、2X 和3X 各自对Y 的贡献?为什么? 1、 (1)样本容量n=43+1=44 (1分) RSS=TSS-ESS=66056-65965=91 (1分) ESS 的自由度为: 3 (1分) RSS 的自由度为: d.f.=44-3-1=40 (1分) (2)R 2=ESS/TSS=65965/66056=0.9986 (1分) 2R =1-(1- R 2)(n-1)/(n-k-1)=1-0.0014?43/40=0.9985 (2分) (3)H 0:1230βββ=== (1分) F=/65965/39665.2/(1)91/40 ESS k RSS n k ==-- (2分) F >0.05(3,40) 2.84F = 拒绝原假设 (2分) 所以,1X 、2X 和3X 总体上对Y 的影响显著 (1分) (4)不能。 (1分) 因为仅通过上述信息,可初步判断X 1,X 2,X 3联合起来 对Y 有线性影响,三者的变化解释了Y 变化的约99.9%。但由于 无法知道回归X 1,X 2,X 3前参数的具体估计值,因此还无法 判断它们各自对Y 的影响有多大。 2、以某地区22年的年度数据估计了如下工业就业模型 i i i i i X X X Y μββββ++++=3322110ln ln ln 回归方程如下: i i i i X X X Y 321ln 62.0ln 25.0ln 51.089.3?+-+-= (-0.56)(2.3) (-1.7) (5.8) 2 0.996R = 147.3=DW 式中,Y 为总就业量;X 1为总收入;X 2为平均月工资率;X 3为地方政府的
计量经济学第三次作业
下表列出了某年中国部分省市城镇居民每个家庭平均全年可支配收入X与消费性支出Y 的统计数据。 地区可支配收入 (X)消费性支出 (Y) 地区可支配收入 (X) 消费性支出 (Y) 北京10349.69 8493.49 浙江9279.16 7020.22 天津8140.50 6121.04 山东6489.97 5022.00 河北5661.16 4348.47 河南4766.26 3830.71 山西4724.11 3941.87 湖北5524.54 4644.5 内蒙古5129.05 3927.75 湖南6218.73 5218.79 辽宁5357.79 4356.06 广东9761.57 8016.91 吉林4810.00 4020.87 陕西5124.24 4276.67 黑龙江4912.88 3824.44 甘肃4916.25 4126.47 上海11718.01 8868.19 青海5169.96 4185.73 江苏6800.23 5323.18 新疆5644.86 4422.93 (1)试用普通最小二乘法建立居民人均消费支出与可支配收入的线性模型; (2)检验模型是否存在异方差性; (3)如果存在异方差性,试采用适当的方法估计模型参数。 解: (1)a.建立对象,录入可支配收入X与消费性支出Y,如下图: b. 设定一元线性回归模型为: 点击主界面菜单Quick\Estimate Equation,在弹出的对话框中输入Y、C、X,操作
(2)a.生成残差序列。在工作文件中点击Object\Generate Series…,在弹出的窗口中,在主窗口键入命令如下“e1=resid^2”得到残差平方和序列e1。如下图: (3)a. 设定一元线性回归模型为:
计量经济学各章作业习题(后附答案)
《计量经济学》 习 题 集
第一章绪论 一、单项选择题 1、变量之间的关系可以分为两大类,它们是【】 A 函数关系和相关关系 B 线性相关关系和非线性相关关系 C 正相关关系和负相关关系 D 简单相关关系和复杂相关关系 2、相关关系是指【】 A 变量间的依存关系 B 变量间的因果关系 C 变量间的函数关系 D 变量间表现出来的随机数学关系 3、进行相关分析时,假定相关的两个变量【】 A 都是随机变量 B 都不是随机变量 C 一个是随机变量,一个不是随机变量 D 随机或非随机都可以 4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 5、下面属于截面数据的是【】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 6、同一统计指标按时间顺序记录的数据列称为【】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 7、经济计量分析的基本步骤是【】 A 设定理论模型→收集样本资料→估计模型参数→检验模型 B 设定模型→估计参数→检验模型→应用模型 C 个体设计→总体设计→估计模型→应用模型 D 确定模型导向→确定变量及方程式→估计模型→应用模型 8、计量经济模型的基本应用领域有【】 A 结构分析、经济预测、政策评价 B 弹性分析、乘数分析、政策模拟 C 消费需求分析、生产技术分析、市场均衡分析 D 季度分析、年度分析、中长期分析 9、计量经济模型是指【】
计量经济学
名词解释 1、 因果效应:在理想化随机对照实验中得到的,某一给定的行为或处理对结果的影响 2、 实验数据:来源于为评价某种处理(某项政策)抑或某种因果效应而设计的实验 3、 观测数据:通过观察实验之外的实际行为而获得的数据 4、 截面数据:对不同个体如工人、消费者、公司或政府机关等在某一特定时间段内收集到的数据 5、 时间序列数据:对同一个体(个人、公司、国家等)在多个时期内收集到的数据 6、 面板数据:即纵向数据,是多个个体分别在两个或多个时期内观测到的数据 7、 离散型随机变量:一些随机变量是离散的 连续型随机变量:一些随机变量是连续的 8、 期望值:随机变量经过多次重复实验出现的长期平均值,记作E (Y ) 9、 期望:Y 的长期平均值,记作μY 10、方差:是Y 距离其均值的偏差平方的期望值,记作var (Y ) 11、标准差:方差的平方根来表示偏差程度,记作σY 12、独立性:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息 13、标准正态分布:指那些均值102==σμ、方差的正态分布,记作N (0,1) 14、简单随机抽样:n 个对象从总体中抽取,且总体中的每一个个体都有相等的可能性被选入样本 15、独立分布:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息,那么这两个变量X 和Y 独立分布 16、偏差:设Y Y E Y Y μμμμ-??)(为的一个估计量,则偏差是; 一致性:当样本容量增大时,Y μ ?落入真实值Y μ的微小领域区间内的概率接近于1,即Y Y μμ与?是一致的 有效性:如果Y μ ?的方差比Y μ~更小,那么可以说Y Y μμ~?比更有效 17、最小二乘估计量:21)(m i n i -Y ∑ =最小化误差m -i Y 平方和的估计量m 18、P 值:即显著性概率,指原假设为真的情况下,抽取到的统计量与原假设之间的差异程度至少等于样本计算值与 原假设之间差异程度的概率 19、第一类错误:拒绝了实际上为真的原假设 20、一元线性回归模型:i i 10i μββ+X +=Y ;1β代表1X 变化一个单位所导致Y 的变化量 21、普通最小二乘(OLS )估:选择使得估计的回归线与观测数据尽可能接近的回归系数,其中近似程度用给定X 时预 测Y 的误差的平方和来度量 22、回归2R :可以由i X 解释(或预测)的i Y 样本方差的比例,即TSS SSR TSS ESS R -==12 23、最小二乘假设:①给定i X 时误差项i μ的条件均值为零:0)(i i =X μE ; ②从联合总体中抽取的, ,,,),,(n ...21i i i =Y X 满足独立同分布; ③大异常值不存在:即i i Y X 和具有非零有限的四阶距 24、1β置信区间:以95%的概率包含1β真值的区间,即在所有可能随机抽取的样本中有95%包含了1β的真值 25、同方差:若对于任意i=1,2,...,n ,给定) (条件分布的方差时χμμ=X X i i i i var 为常数且不依赖于χ,则 称误差项i μ是同方差
计量经济学作业-第四五章
第四章上机习题 C4.1 如下模型可以用来研究竞选支出如何影响选举结果: ()()u prtystrA endB endA voteA ++++=3210ex p ln ex p ln ββββ 其中,voteA 表示候选人A 得到的选票百分数,endA exp 和endB exp 表示候选人A 和B 的竞选支出,而则是对A 所在党派实力的一种度量(A 所在党派在最近一次总统选举中获得的选票百分比)。 (1)如何解释1β? 解 在回归方程 ()()u prtystrA endB endA voteA ++++=3210ex p ln ex p ln ββββ 中,保持()endB ex p ln 、prtystrA 不变,可得: ().ex p ln 1endA voteA ?=?β 因为()endA endA ex p %ex p ln 100?≈??,所以 () ()()()()() endA endA endA voteA exp %100exp ln 100100exp ln 111??≈???=?=?βββ 所以1001β表示当endA exp 变动%1时vote 变动多少个百分点。 注意:100%1 12?-=?x x x x ,x ?%表示x 的百分数变化。 (2)用参数表示如下虚拟假设:A 的竞选支出提高%1被B 的竞选支出提高%1所抵消。 解 虚拟假设可以表示为 210:ββ-=H 或者0:210=+ββH (3)利用RAW VOTE .1中的数据估计上述模型,并以通常的方式报告
结论。A 的竞选支出或影响结果吗?B 的竞选支出呢?你能用这些结论来检验第(2)部分中的假设吗? 解 估计方程为 ()() ()()793.0,14.10052,173062.0379.0382.0926.3152.0)ln(exp 615.6)ln(exp 083.6079.452===+-+=∧ R SSR n prtystrA endB endA voteA 从回归结果可知,()endA ex p ln 的系数估计值等于6.083,标准误等于0.382,t 统计量为15.919,p 值为0.0000。()endB ex p ln 的系数估计值等于-6.615,标准误等于0.379,t 统计量为-17.463,p 值为0.0000。由此可以看出()endA ex p ln 和()endB ex p ln 的斜率系数在非常小的显著性水平下都是统计上显著异于零,所以A 的竞选支出和B 的竞选支出都会影响竞选结果。在保持其他因素不变的情况下,若A 的竞选支出增加%10,则A 得到的选票百分数将提高约0.608个百分点;若B 的竞选支出增加%10,则A 得到的选票百分数将下降约0.662个百分点. 从以上叙述中我们知道,∧1β和∧2β的符号相反且都符合预期,重要 程度相当,但是我们不能根据这些结论得出∧∧+21ββ的标准误差,也就 不能计算相应的t 统计量,所以不能用这些结论来检验(2)中的假设。 (4)估计一个模型,使之能直接给出检验第(2)部分中假设所需要的t 统计量。你有什么结论?(使用双侧对立假设) 解 令21ββθ+=,则21βθβ-=,把它代入原始的回归方程可得: ()()()()u prtystrA endA endB endA voteA ++-++=320ex p ln ex p ln ex p ln ββθβ 利用RAW VOTE .1的数据重新估计以上方程,得到的估计方程为
计量经济学分析计算题Word版
计量经济学分析计算题(每小题10分) 1.下表为日本的汇率与汽车出口数量数据, X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3= ,Y 554.2=,2 X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义 是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。
问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑ (-)=, 求判定系数和相关系数。 5.有如下表数据 日本物价上涨率与失业率的关系 (1)设横轴是U ,纵轴是P ,画出散点图。根据图形判断,物价上涨率与失业率之间是什么样的关系?拟合什么样的模型比较合适? (2)根据以上数据,分别拟合了以下两个模型: 模型一:1 6.3219.14 P U =-+ 模型二:8.64 2.87P U =- 分别求两个模型的样本决定系数。 7.根据容量n=30的样本观测值数据计算得到下列数据:XY 146.5= ,X 12.6=,Y 11.3=,2X 164.2=,2Y =134.6,试估计Y 对X 的回归直线。 8.下表中的数据是从某个行业5个不同的工厂收集的,请回答以下问题:
计量经济学作业第5章(含答案)
计量经济学作业第5章(含答案)
、单项选择题 1 ?对于一个含有截距项的计量经济模型,若某定性因素有 D. m-k 2 ?在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例 如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出 丫 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 [1 1991# WS D =< 量 r [O f 1毀坪以前,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。贝U 城镇居民线性消费函数的理论方程 可以写作( ) A. h 二几+耳扎+如)拓+斗 3. 对于有限分布滞后模型 在一定条件下,参数儿可近似用一个关于【的阿尔蒙多项式表示 ),其中多项式的阶数 m 必须满足( ) A .障匚上 B . m k C . D .用上上 4. 对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数 据就会( ) A.增加1个 B.减少1个 C.增加2个 D.减 少2个 5. 经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序 列相关性就转化为( ) A. m B. m-1 C. m+1 将其引入模型中,则需要引入虚拟变量个数为( m 个互斥的类型,为 ) B. C. Y 讦 A+ +"0+ 斗 D.
A.异方差冋 题 B.多重 共线性问题
问题 6. 将一年四个季度对因变量的影响引入到模型中(含截 距项),则需要引入虚 拟变量的个数为( ) A. 4 B. 3 C. 2 D. 1 7. 若 想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(丫代表消费支出;X 代表可支配收入;D 2、D 3表示虚拟变量) () A.Yj"+陆+野 B . 二、多项选择题 1. 以下变量中可以作为解释变量的有 ( ) A.外生变量 B.滞后内生变量 C.虚 拟变量 D.先决变量 E.内生变量 2. 关于衣着消费支出模型为:h 吗+叩左+必史+勺3工』』+ "逅+色,其中 丫为衣着万面的年度支出;X 为收入, 1 女性 "i 大学毕业及以上 D = : D 3i =J o 男性, 3i 其他 则关于模型中的参数下列说法正确的是( ) A. $表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出 (或少 支出)差额 B. 珂表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消 费支 出方面多支出(或少支出)差额 C. 5表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以 下文凭 者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消 费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 、判断题 1 ?通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容 C.序列相关性问题 D.设定误差 £ =坷++以叭JQ+舛 C. 】 D 丄吗皿吗+风+儿
计量经济学第二次作业 异方差检验
第三章13题下表列出了中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L。 解: ⑴ 先对丫二AK〉L:e .左右两边同时取对数得: In 丫二 C : In K 1 In L C = In A": _d n e 相应的数据变为: LOGr LOGL LOGK 8.222204 4 7273B3 8,032107 7274147 4.204593 7.429183 7.468724+.4308177 91S724 7.280208 3295837 7 507726 &.546616579G9600.565587 7.736014 4.737+92 7,472370 7204276 4.060443 6.844922 6J87334 3433987 5.543826 5.S139S9 2 772569 5 895724 7.371716 41SS655 7.828331 6.42439g 4.060443 0,881134 6.426391 3.332205 6.2i612€ 8.395972 41108748.239042 8.6S6785 5537334 9.&69701 7.485138 4 41B841 7 935932 7.125339 3.4965097.500220 6.700362 3761200 7.020021 7 549451 4.110374 7.526^46 8.214154 5480639 8719191 8.462293 54D2677 9130025 7.697196 4 382027 7.9&0899 7.839825 4.664548 7 342133 3.021896 5.402577 8,473847 7692S5T 5.093750 8.083037 通过Eviews软件进行回归分析得到如下结果:
第三版计量经济学第五章习题作业
第五章习题2 根据经济理论建立计量经济模型 i i 10i X Y μββ++= 应用EViews 输出的结果如图1所示。 图1 用普通最小二乘法的估计结果如下: )29,...,2,1(707955.013179.58=+=∧ i X Y i i 利用上述结果计算残差∧ =i i i Y -Y e 。观察i e 的取值,好像随i X 的变化而变化,怀疑模型存在异方差性,下面通过等级相关系数和戈德菲尔特—夸特方法检验随机误差项的异方差性。 1.斯皮尔曼等级相关系数检验 按照斯皮尔曼等级相关检验的步骤,先将X 的样本观测值从小到大排列并划分等级,然后将i e 从小到大划分等级,计算i X 的等级与相应产生的i e 的等级的差i d 及2i d ,详见表1。 表1
计算等级相关系数 2334d 1 i 2i =∑= 0.42512329 -292334 6- 1N -N d 6- 1r 3 3 1i 2i =?==∑= 对等级相关系数进行检验,提出原假设与备择假设 ) ,(),(::28 1 0N 1-N 10N ~r 0 H 0H 10=≠=ρρ 构造Z 统计量 2.2495428*0.4251231 -N 1r Z ===
给定显著水平0.05=α,查正态分布表,得 1.96Z 2 =α因为 1.962.24954Z >=, 所以应拒绝原假设,接收备择假设,即等级相关系数显著,说明其随机误差项存在异方差性。 2. 戈德菲尔特—夸特方法检验 将X 的样本观测值按升序排列,Y 的样本观测值按原来与X 样本观测值的对应关系进行排列,略去中心7个数据,将剩下的22个样本观测值分成容量相等的两个子样本,每个子样本的样本观测值个数均为11。排列结果见表2。 用第一个子样本估计模型,得到的结果如图2所示: 图2
2014计量经济学第二次作业参考答案
2013年计量经济学第二次作业答案 (chap3-4) Part 1:教材课后习题 第三章 3.5 在调查一项大学GPA 与在各项活动中所耗费的时间之关系的研究中,你对几个学生分发 了调查问卷。学生被问到他们每周在学习、睡觉、工作和闲暇这四种活动中各花多少小时。任何活动都被列为这四种活动之一。所以对每个学生来说这四个活动的小时数之和都是168. (i) 在模型 01234GPA study sleep work leisure u βββββ=+++++ 中,保持sleep 、work 和leisure 不变而改变study 是否有意义? 没有意义。通过定义,有study + sleep + work + leisure = 168,因此如果改变study ,我们必须改变sleep 、work 和leisure 中的至少一个变量,以满足它们的和为168。 (ii) 解释为什么这个模型违背了MLR.3? 通过第(i)部分的分析,study 是其余几个解释变量的线性组合,也就是:study = 168 - sleep - work - leisure ,这意味着变量之间存在着完全的线性关系,因此违背MLR.3。 (iii) 你如何才能将这个模型重新表述,使得它的参数具有一个有用的解释,而又不违背假定MLR.3? 只需要删除其中一个解释变量就可以了,比如删除leisure ,建立模型: GP A = 0β + 1βstudy + 2βsleep + 3βwork + u . 此时,参数1β可以解释为保持sleep , work , 和u 不变,当study 增加一个小时,GPA 的改变。 3.6 考虑含有三个自变量的多元回归模型,并满足假定MLR.1~MLR.4, 0112233y x x x u ββββ=++++ 对1x 和2x 的系数之和感兴趣,记12θββ=+。
计量经济学计算题解法汇总
计量经济学:部分计算题解法汇总 1、求判别系数——R^2 已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 2、置信区间 有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y Adjusted R-squared F-statistic Durbin-Watson (1(2)在95%的置信度下检验参数的显著性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在90%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其中29.3x =,2()992.1x x - =∑) 答:(1)回归模型的R 2 =,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。(2分) 家庭收入对消费有显著影响。(2分)对于截距项,
检验。(2分) (3)Y f =+×45=(2分) 90%置信区间为(,+),即(,)。(2分) 注意:a 水平下的t 统计量的的重要性水平,由于是双边检验,应当减半 3、求SSE 、SST 、R^2等 已知相关系数r =,估计标准误差?8σ=,样本容量n=62。 求:(1)剩余变差;(2)决定系数;(3)总变差。 (2)2220.60.36R r ===(2分) 4、联系相关系数与方差(标准差),注意是n-1 在相关和回归分析中,已知下列资料: 222X Y i 1610n=20r=0.9(Y -Y)=2000σσ∑=,=,,,。 (1)计算Y 对X 的回归直线的斜率系数。(2)计算回归变差和剩余变差。(3) (2)R 2=r 2==, 总变差:TSS =RSS/(1-R 2)=2000/=(2分)
计量经济学作业第5章(含答案)
第5章习题 一、单项选择题 1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为() A. m B. m-1 C. m+1 D. m-k 2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。现以1991年为转折时期,设虚拟变 量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可以写作() A. B. C. D. 3.对于有限分布滞后模型 在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足() A. B. C. D. 4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( ) A. 增加1个 B. 减少1个 C. 增加2个 D. 减少2个 5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为() A.异方差问题 B. 多重共线性问题 C.序列相关性问题 D. 设定误差问题 6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚拟变量的个数为() A. 4 B. 3 C. 2 D. 1 7.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(Y代表消费支出;X代表可支配收入;D 2、D 3 表示虚拟变量)() A. B.
C. D. 二、多项选择题 1.以下变量中可以作为解释变量的有() A. 外生变量 B. 滞后内生变量 C. 虚拟变量 D. 先决变量 E. 内生变量 2.关于衣着消费支出模型为:,其中 Y i 为衣着方面的年度支出;X i 为收入, ? ? ? =女性 男性 1 2i D; ? ? ? =大学毕业及以上 其他 1 3i D 则关于模型中的参数下列说法正确的是() A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额 B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额 C.表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 三、判断题 1.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容量大小有关。 2.虚拟变量的取值只能取0或1。 3.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与模型有无截距项无关。 四、问答题 1.Sen和Srivastava(1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型(括号内的数值为对应参数估计值t值): 其中:X是以美元计的人均收入;Y是以年计的期望寿命。
计量经济学计算题
1、某农产品试验产量Y (公斤/亩)和施肥量X (公斤/亩)7块地的数据资料汇总如下: ∑=255i X ∑=3050i Y ∑=71.12172i x ∑=429.83712i y ∑=857.3122i i y x 后来发现遗漏的第八块地的数据:208=X ,4008=Y 。 要求汇总全部8块地数据后进行以下各项计算,并对计算结果的经济意义和统计意义做简要的解释。 (1)该农产品试验产量对施肥量X (公斤/亩)回归模型Y a bX u =++进行估计; (2)对回归系数(斜率)进行统计假设检验,信度为; (3)估计可决系数并进行统计假设检验,信度为。 解:首先汇总全部8块地数据: 871 81 X X X i i i i +=∑∑== =255+20 =275 n X X i i ∑==8 1 )8(375.348 275 == 2) 7(7 127 127X x X i i i i +=∑∑== =+7?2 7255?? ? ??=10507 287 1 28 1 2X X X i i i i +=∑∑== =10507+202 = 10907 2) 8(8 1 28 1 28X X x i i i i +=∑∑== = 10907-8?2 8275?? ? ??= 87 1 81 Y Y Y i i i i +=∑∑===3050+400=3450 25.4318 3450 8 1 )8(== =∑=n Y Y i i 2) 7(7 1 2 712 7Y y Y i i i i +=∑∑== =+7?2 73050??? ??=1337300 287 1 2 81 2Y Y Y i i i i +=∑∑== =1337300+4002 = 1497300 2)8(8 1 28128Y Y y i i i i +=∑∑== =1497300 -8?( 8 3450)2 == ) 7()7(7 1 7 17Y X y x Y X i i i i i i +=∑∑== ==+7??? ??7255??? ? ??73050 =114230 887 1 81 Y X Y X Y X i i i i i i +=∑∑== =114230+20?400 =122230
计量经济学第五章答案
第五章 思考题 5.2 各种异方差检验的基本思想是,基于不同的假定,分析随机误差项的方差与解释变量之间的相关性,以判断随机误差项的方差是否随解释变量变化而变化。其中,戈德菲尔德-夸特检验、怀特检验、ARCH检验和Glejser检验都要求大样本,其中戈德菲尔德-夸特检验、怀特检验和Glejser检验对时间序列和截面数据模型都可以检验,ARCH检验只适用于时间序列数据模型中。戈德菲尔德-夸特检验和ARCH检验只能判断是否存在异方差,怀特检验在判断基础上还可以判断出是哪一个变量引起的异方差。Glejser检验不仅能对异方差的存在进行判断,而且还能对异方差随某个解释变量变化的函数形式进行诊断。 5.4 产生异方差的原因:①模型设定误差②测量误差的变化③截面数据中总体各单位的差异。 经济现象中的异方差性:研究低收入组的家庭消费情况与高收入组的家庭消费情况时,由于高收入组家庭有更多的可支配收入,因而消费的分散程度较大,造成不同组别收入的家庭消费偏离均值程度的差异,反映在随机误差项偏离均值的程度时出现异方差。 5.5 异方差对模型的影响:①当模型中的误差项存在异方差时,参数估计仍然是无偏的但方差不再是最小的;②在异方差存在的情况下,参数估计量的方差会比真实估计量的方差大,会严重破坏t检验和F检验的有效性;③Y预测值的精确度降低。异方差的存在会对回归模型的正确建立和统计推断带来严重后果,不能进行应用分析。 练习题 5.1 (1)设f(X i)=,则Var(u i)=σ,得: =β1+β2+β3+ 则Var()=Var(u i)=σ
5.2 (1) Y=-50.01991+0.X+52.37082T t = (-1.011) (2.944) (10.067)
计量经济学作业第二章练习12
第2章练习12 下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。 单位:亿元地区Y GDP 地区Y GDP 北京1435.7 9353.3 湖北434.0 9230.7 天津438.4 5050.4 湖南410.7 9200.0 河北618.3 13709.5 广东2415.5 31084.4 山西430.5 5733.4 广西282.7 5955.7 内蒙古347.9 6091.1 海南88.0 1223.3 辽宁815.7 11023.5 重庆294.5 4122.5 吉林237.4 5284.7 四川629.0 10505.3 黑龙江335.0 7065.0 贵州211.9 2741.9 上海1975.5 12188.9 云南378.6 4741.3 江苏1894.8 25741.2 西藏11.7 342.2 浙江1535.4 18780.4 陕西355.5 5465.8 安徽401.9 7364.2 甘肃142.1 2702.4 福建594.0 9249.1 青海43.3 783.6 江西281.9 5500.3 宁夏58.8 889.2 山东1308.4 25965.9 新疆220.6 3523.2 河南625.0 15012.5 要求,以手工和运用Eviews软件: (1)作出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义; (2)对所建立的回归方程进行检验; (3)若2008年某地区国内生产总值为8500亿元,求该地区税收收入的预测值及预测区间。
解: (1)作出散点图,如下图所示 2500 2000 1500 Y 1000 500 010000200003000040000 GDP Dependent Variable: Y Method: Least Squares Date: 10/18/14 Time: 13:18 Sample: 1 31 Included observations: 31 Variable Coefficient Std. Error t-Statistic Prob. GDP 0.071047 0.007407 9.591245 0.0000 C -10.62963 86.06992 -0.123500 0.9026 R-squared 0.760315 Mean dependent var 621.0548 Adjusted R-squared 0.752050 S.D. dependent var 619.5803 S.E. of regression 308.5176 Akaike info criterion 14.36378 Sum squared resid 2760310. Schwarz criterion 14.45629 Log likelihood -220.6385 F-statistic 91.99198 Durbin-Watson stat 1.570523 Prob(F-statistic) 0.000000
计量经济学大作业建立模型
计量经济学大作业建立 模型 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
学院:__________金融学院_____________ 上课学期: ___ 2011-2012第一学期_________课程名称: _______ 金融计量学_____________指导教师:_______ _ ______________ 实验主题:_ GDP增长与三大产业关系模型____小组成员: 二零一一年十一月二十四日 目录 摘要 (3) 1.引言 (3) 2.提出问题 (4) 3.建立模型 (4) 4.制作散点图 (4) 5.模型参数估计 (8) 6.模型的检验 (9) .计量经济学检验 (9) 多重共线性检验 (9) 简单回归系数检验 (10) 找出最简单的回归形式 (10) 逐步回归法检验 (14) 异方差性检验 (15) 图示检验法 (15) 检验 (16) 异方差的修正 (17) 随即扰动项序列相关检验 (18) 检验 (18) 6.拉格朗日乘数(LM)检验 (19) 序列相关性修正 (19) .经济意义检验 (20) .统计检验 (21) 拟合优度检验 (21) 方程显着性检验——F检验 (21) 参数显着性检验——t检验 (21) 7.结论 (22) 8.对策与建议 (23) 9.参考文献: (23)
摘要 经济发展是以GDP增长为前提的,而GDP增长与产业结构变动又有着密不可分的关系。本文采用1981年至2010年的统计数据,通过建立多元线性回归模型,运用最小二乘法,研究三大产业增长对我国GDP增长的贡献,从而得出调整产业结构对转变经济发展方式,促进我国经济可持续发展的重要性。 关键字:GDP增长;三大产业;产业结构 1.引言 GDP增长通常是指在一个较长的时间跨度上,一个国家人均产出(或人均收入)水平的持续增加。GDP增长率的高低体现了一个国家或地区在一定时期内经济总量的增长速度,也是衡量一个国家或地区总体经济实力增长速度的标志。它构成了经济发展的物质基础,而产业结构的调整与优化升级对于GDP增长乃至经济发展至关重要。 一个国家产业结构的状态及优化升级能力,是GDP发展的重要动力。十六大报告提出,推进产业结构优化升级,形成以高新技术产业为先导、基础产业和制造业为支撑、服务业全面发展的产业格局。十七大报告明确指出,推动产业结构优化升级,这是关系国民经济全局紧迫而重大的战略任务。《十二五规划纲要》又将经济结构战略性调整作为主攻方向和核心任务。产业结构优化升级对于促进我国经济全面协调可持续发展具有重要作用。 2.提出问题 我国把各种产业划分为第一产业,第二产业和第三产业。他们在整个国民经济中各自发挥着不同程度的作用。近几十年来来我国的经济已经发生了天翻地覆的变化。各大产业在整个国民经济中所占的地位和作用也在发生着相应的变化和调整。对于这种变化是否符合我国的经济发展趋势,对我国的经济影响作用是否明显,他们与国内生产总值又有着怎样的关系,对整个国内生产总值又有多大的影响,对于三大产业,在新的条件下哪一产业对国内生产总值的影响更明显,随着我国经济的不断发展以及改革开放的不断深入,研究经济的发展状况及经济发展的各个因素,成为决策部门的一个重要课题。伴随着这些想法我们小组做了下面的模型进行分析。