应用多元统计分析SAS作业第六章

6-10 今有6个铅弹头,用“中子活化”方法测得7种微量元素的含量数据(见表1)。
(1) 试用多种系统聚类法对6个弹头进行分类;并比较分类结果; (2) 试用多种方法对7种微量元素进行分类。
元素 样品号
Ag(银) (X 1) Al(铝) Cu(铜) Ca(钙) Sb(锑) Bi(铋) Sn(锡)
(X 2) (X 3) (X 4) (X 5) (X 6) (X 7) 1 0.05798
5.5150 347.10 21.910 8586 1742 61.69 2 0.08441 3.9700 347.20 19.710 7947 2000 2440 3 0.07217 1.1530 54.85 3.052 3860 1445 9497 4 0.15010 1.7020 307.50 15.030 12290 1461 6380 5 5.74400 2.8540 229.60 9.657 8099 1266 12520 6
0.21300
0.7058
240.30
13.910
8980
2820
4135
问题求解
1对6个弹头进行分类
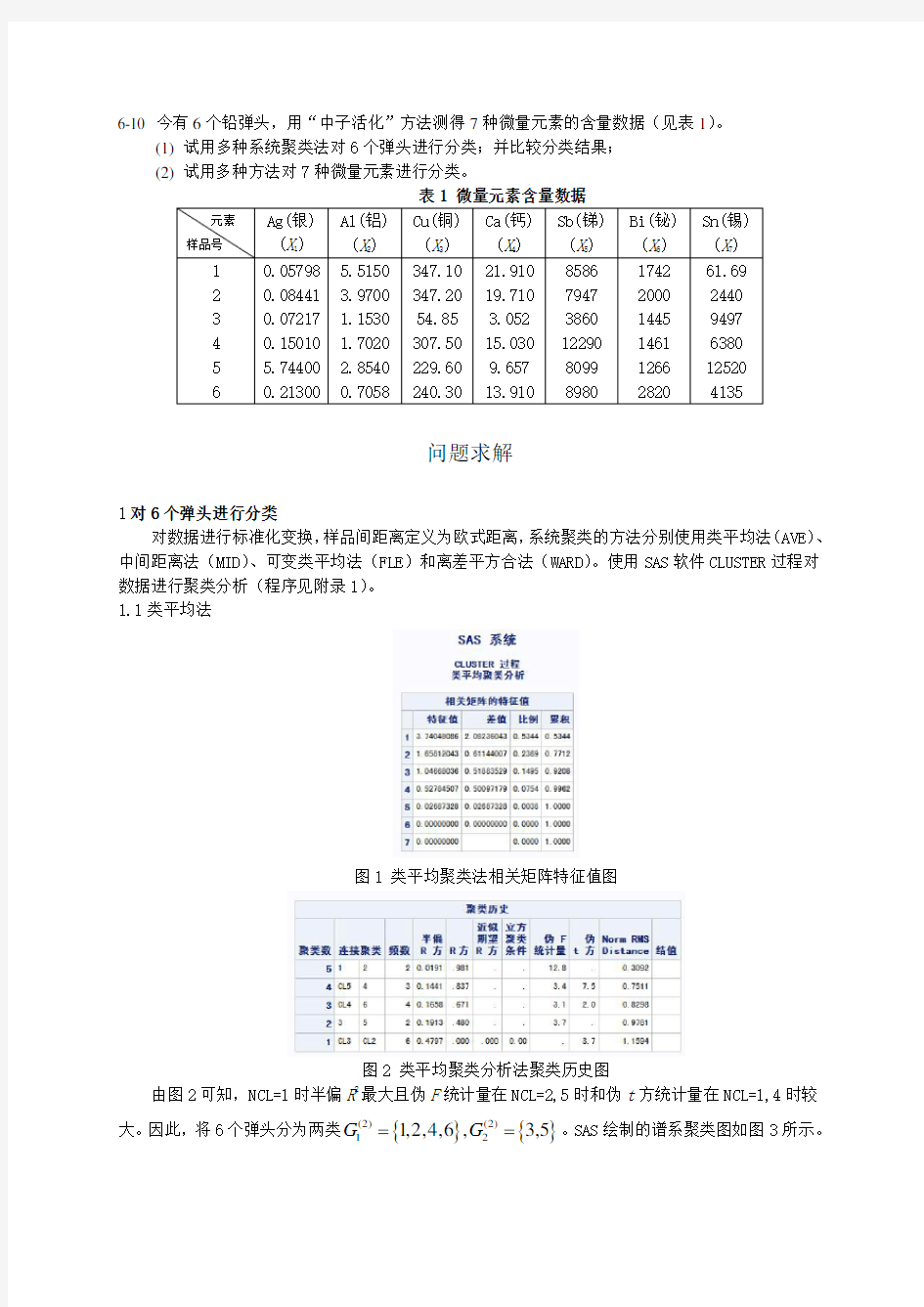
对数据进行标准化变换,样品间距离定义为欧式距离,系统聚类的方法分别使用类平均法(AVE )、中间距离法(MID )、可变类平均法(FLE )和离差平方合法(WARD )。使用SAS 软件CLUSTER 过程对数据进行聚类分析(程序见附录1)。 1.1类平均法
图1 类平均聚类法相关矩阵特征值图
图2 类平均聚类分析法聚类历史图 由图2可知,NCL=1时半偏R 2
最大且伪F 统计量在NCL=2,5时和伪t 方统计量在NCL=1,4时较大。因此,将6个弹头分为两类{}{}(2)
(2)
1
21,2,4,6,3,5G G ==。SAS 绘制的谱系聚类图如图3所示。
图3 类平均聚类分析法谱系聚类图
1.2中间距离法
图4 中间距离聚类法相关矩阵特征值图
图5 中间距离聚类法聚类历史图
由图5可知,中间距离法与类平均法结果一致。因此,也将6个弹头分为两类
{}{}(2)(2)
121,2,4,6,3,5G G ==。
SAS 绘制的谱系聚类图如图6所示。
图6 中间距离聚类法谱系聚类图
1.3可变类平均法
图7可变类平均聚类法分析结果图
图8 可变类平均聚类法聚类历史图
由图8可知,可变类平均法(=0.25
β-)输出结果与前两种方法稍有不同,NCL=1时半偏R2最大且伪F统计量在NCL=2时次大,NCL=5时最大;而伪t方统计量在NCL=1时最大。因此,分类结果
与之前相同,将6个弹头分为两类
{}{}(2)(2)
121,2,4,6,3,5G G ==。
SAS 绘制的谱系聚类图如图9所示。
图9 可变类平均聚类法谱系聚类图
1.4离差平方和法
图10 离差平方和聚类法相关矩阵特征值图
图11 离差平方和聚类法聚类历史
由图11可知,离差平方和法输出结果与可变类平均法结果一致。 SAS 绘制的NCL=2时离差平方和法谱系聚类图和分类结果如下所示。
图12 离差平方和聚类法谱系聚类图
图13 离差平方和聚类法聚类结果图
1.5 综合分析
综上所述,四种分类方法得到的结果一致,都是将6个弹头分为两类
{}{}(2)(2)
121,2,4,6,3,5G G ==。
四种方法中,类平均法和中间距离法结果相近;可变类平均法和离差平方和法得到结果相近且
更加准确(伪t 方统计量在NCL=1时最大)。
2对7种元素进行分类
同问题1,系统聚类的方法分别使用类平均法(AVE )、中间距离法(MID )、可变类平均法(FLE )和离差平方合法(WARD )。使用SAS 软件CLUSTER 过程对数据进行聚类分析(程序见附录2)。 2.1 类平均法
图14 7种元素类平均法聚类历史图
由图14可知,NCL=1,2时半偏R2较大;伪F统计量在NCL=4,5,6时较大;而伪t方统计量在NCL=3,4时较大。因此,较合适的分法是将7种元素分为四类和五类。
SAS绘制的谱系聚类图如下所示。
图15 7种元素类平均法谱系聚类图
2.2 中间距离法
图16 7种元素中间距离法聚类历史图
由图16可知,中间距离法聚类结果中NCL=1,2时半偏R2较大;伪F统计量在NCL=4,5,6时较大;而伪t方统计量在NCL=3,4时较大。因此,与类平均法相同,较合适的分法是将7种元素分为四类和五类。
SAS绘制的谱系聚类图如下所示。
图17 7种元素中间距离法谱系聚类图
2.3 可变类平均法
图18 7种元素可变类平均法聚类历史图
由图18可知,可变类平均法聚类结果与前两种方法结果相同,较合适的分法是将7种元素分为四类和五类。
SAS绘制的谱系聚类图如下所示。
图19 7种元素可变类平均法谱系聚类图
2.4 离差平方和法
图20 7种元素离差平方和法聚类历史图
由图20可知,离差平方和法聚类结果与前三种方法结果也相同,较合适的分法是将7种元素分为四类和五类。
SAS绘制的NCL=4,5时的谱系聚类图和分类结果图如下所示。
图21 7种元素离差平方和法谱系聚类图
图22 分为四类时7种元素聚类结果图
图23 分为五类时7种元素聚类结果图
2.4综合分析
综上所述,四种分类方法结果相同,合适的分法是将7种元素分为四类和五类。 分为四类时,分类结果如下
{}{}{}{}(4)(4)(4)(4)
1234,,,,,,G Ag Al Ca Cu G Bi G Sb G Sn ====;
分为五类时,分类结果如下
{}{}{}{}{}(5)(5)(5)(5)(5)
12345,,,,,G Ag Al Ca G Cu G Bi G Sb G Sn =====,。
6-11 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据见表2,试用几种系统聚类方法进行聚类分析,给出综合的分析结果,并与实际情况进行比较。
表2 岩石化学成分的含量数据
类型序号Cu Ag Bi类型序号Cu Ag Bi
含
矿
1 2.580.900.95
不
含
矿
8 2.25 1.98 1.06
2 2.90 1.2
3 1.009 2.16 1.80 1.06
3 3.55 1.15 1.0010 2.33 1.7
4 1.10
4 2.3
5 1.150.7911 1.9
6 1.48 1.04
5 3.54 1.850.7912 1.94 1.40 1.00
6 2.70 2.23 1.3013 3.00 1.30 1.00
7 2.70 1.700.4814 2.78 1.70 1.48
问题求解
1 多种系统聚类方法分析数据
系统聚类的方法分别使用类平均法(AVE)、可变类平均法(FLE)和离差平方合法(WARD)。使用SAS软件CLUSTER过程对数据进行聚类分析(程序见附录3)。
1.1 类平均法
图1 类平均法聚类历史
由图1可知,类平均法聚类结果中NCL=1时半偏R2最大,NCL>1时半偏R2明显减小且缓慢递减;伪F统计量在NCL=2时的值大于NCL=3时的值;而伪t方统计量在NCL=1时的值明显大于NCL=2时的值。因此,将14块岩石标本分为两组较为合适。
SAS绘制的谱系聚类图及聚类结果图如下所示。
图2 类平均法谱系聚类图
图3 类平均法聚类结果图1.2 可变类平均法
图4 可变类平均法聚类历史
由图4可知,可变类平均法聚类结果同类平均法结果基本一致。因此,将14块岩石标本分为两组较为合适。
SAS绘制的谱系聚类图如下所示,聚类结果与类平均法相同(见图3)。
图5 可变类平均法谱系聚类图
1.3 离差平方和法
图6 离差平方和法聚类历史
由图6可知,离差平方和法聚类结果同前两种方法基本一致。因此,同样将14块岩石标本分为两组较为合适。
SAS 绘制的谱系聚类图如下所示,聚类结果见图8。
图7 离差平方和法谱系聚类图
图8 离差平方和法聚类结果
2 综合分析
综上所述,三种系统聚类法得到的聚类结果完全一致。分类结果如下
{}{}(2)(2)
121,2345713,68910111214G G ==,,,,,,,,,,,。
因此,可以发现样品6、13分类有误。样品13应当归为G 1含矿类;而样品6应当归为
G 2不含矿。
6-12 某城市的环保监测站于1982年在全市均匀地布置了16个监测点,每日三次定时抽取大气样品,测量大气中二氧化硫,氮氧化物和飘尘的含量。前后5天,每个取样点(监测点)对每重污染元素实测15次,取15次实测值的平均作为该养点大气污染元素的含量数据见表3。试用几种系统聚类方法进行聚类分析,并给出综合的分析结果。
污染元素样品号二氧化硫
(X1)
氮氧化物
(X2)
飘尘
(X3)
类别
10.0450.0430.2652
20.0660.0390.2642
30.0940.0610.1942
40.0030.0030.1023
50.0480.0150.1063
60.2100.0660.2631
70.0860.0720.2742
80.1960.0720.2111
90.1870.0820.3011
100.0530.0600.2092
110.0200.0080.1123
120.0350.0150.1703
130.2050.0680.2841
140.0880.0580.2152
150.1010.0520.181
160.0450.0050.122
问题求解
1 系统聚类分析
系统聚类的方法分别使用类平均法(AVE)和离差平方合法(WARD)。使用SAS软件CLUSTER 过程对数据进行聚类分析(程序见附录4)。
1.1类平均法
图1 类平均法聚类历史图
由图1可知,类平均法聚类结果中NCL=1,2时半偏R 2分别为最大、次大;伪F统计量在NCL=3,4时分别为最大、次大(NCL<6);而伪t方统计量在NCL=1,2时的值分别为最大、次大。因此,将16个样品划分为三组较为合适。
SAS绘制的谱系聚类图及聚类结果图如下所示。
图2 类平均法谱系聚类图
图3 类平均法聚类结果图
1.2离差平方和法
图4 离差平方和法聚类历史图
由图4可知,离差平方和法聚类结果与类平均法一致。NCL=1,2时半偏R 2
分别为最大、次大;伪F 统计量在NCL=3,4时分别为最大、次大(NCL<6);而伪t 方统计量在NCL=1,2时的值分别为最大、次大。因此,将16个样品划分为三组较为合适。
SAS 绘制的谱系聚类图及聚类结果图如下所示。
图5 离差平方和法谱系聚类图
图6 离差平方和法聚类结果图
2 综合分析
离差平方和法与平均法分类结果相同
{}{}{}(3)(3)(3)
1236,8,9,13,1,2,3,7,10,14,15,4,5,11,12,16G G G ===。
图书馆管理系统用例图、活动图、类图、时序图
图书馆管理系统 一.图书馆管理系统需求分析 1、系统目标设计 系统开发的总目标是实现内部图书借阅管理的系统化、规范化和自动化。 能够对图书进行注册登记,也就是将图书的基本信息(如:书的编号、书名、作者、价格等)预先存入数据库中,供以后检索。 能够对借阅人进行注册登记,包括记录借阅人的姓名、编号、班级、年龄、性别、地址、电话等信息。 提供方便的查询方法。如:以书名、作者、出版社、出版时间(确切的时间、时间段、某一时间之前、某一时间之后)等信息进行图书检索,并能反映出图书的借阅情况;以借阅人编号对借阅人信息进行检索;以出版社名称查询出版社联系方式信息。 提供对书籍进行的预先预订的功能。 提供旧书销毁功能,对于淘汰、损坏、丢失的书目可及时对数据库进行修改。 能够对使用该管理系统的用户进行管理,按照不同的工作职能提供不同的功能授权。 提供较为完善的差错控制与友好的用户界面,尽量避免误操作。 2、系统功能需求分析 (1) 读者管理:读者信息的制定、输入、修改、查询,包括种类、性别、 借书数量、借书期限、备注等。 (2) 书籍管理:书籍基本信息制定、输入、修改、查询,包括书籍编号、 类别、关键词、备注。 (3) 借阅管理:包括借书,还书,预订书籍,续借,查询书籍,过期处 理和书籍丢失后的处理。
(4)系统管理:包括用户权限管理,数据管理和自动借还书机的管理 满足以上需求的系统主要包含有一下几个子系统 (1)基本业务功能子系统:该系统中主要包含了借书还书和预订等功能。 (2)基本数据录入功能子系统:该子系统主要包含有书籍信息和读者信息录入功能。 (3)信息查询子系统:包含了多功能的查询书籍信息和读者信息。 (4)数据库管理功能子系统:主要包含了借阅信息管理功能,书籍信息管理功能和预订信息管理功能。 (5)帮助功能子系统。 二、系统动态建模 1、用例图、
应用多元统计分析SAS作业审批稿
应用多元统计分析S A S 作业 YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿? 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 2.58 0.9 0.95 1 2.9 1.23 1 1 3.55 1.15 1 1 2.35 1.15 0.79 1 3.54 1.85 0.79 1 2.7 2.23 1.3 1 2.7 1.7 0.48 2 2.25 1.98 1.06 2 2.16 1.8 1.06 2 2.3 3 1.7 4 1.1 2 1.96 1.48 1.04
2 1.94 1.4 1 2 3 1.3 1 2 2.78 1.7 1.48 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=3.19774。还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值2.95、2.15、1.54分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
软件工程作业用例图,状态图类图
软件工程作业用例图,状态 图类图 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
软件工程设计方案 学院计算机学院 专业软件工程 班级 2012 级 4 班 学号 86 姓名黎伟杰 指导教师崔洪刚 ( 2015 年 1 月)
计算机学院软件工程专业12级4班班学号:86 姓名:黎伟杰协作者:________ 教师评定: 问题定义:为实现一个功能强大的学生宿舍管理信息系统,它主要实现对入住人员的管理及对宿舍的其它管理,如新生、老生的基本信息处理,毕业生退宿,水、电费的超额处理。该系统功能齐全,操作简便,实用性强,主要包括三个模块:资料管理模块、宿舍管理模块、收费管理模块最后还给出实现的设计思想和关键技术。 系统名称:学生宿舍管理系统 作者名称:广东工业大学计算机学院软件工程12(4)班86 黎伟杰 系统功能描述:随着计算机的应用与普及,现在越来越多的学校学生宿舍都是利用计算机来控制和管理的,学校的不断发展,人数的不断增长,生活水平的提高,要求也越来越高。为了改善学校的宿舍管理,为此开发了学生宿舍管理信息系统软件。本系统要学生用户对它进行查询,管理员有效地对它进行管理用户,即随时可以对它进行添加与删除,在没有旁人指导的情况下,用户也可以进入这个系统并且知道该如何使用它,比如,用户点击进入后就会出现一个系统登陆对话框,根据用户的用户名和密码,点击“登陆”按钮,就可进入系统。这个系统可以适用于各大院校,具有管理权限的用户可以对系统进行修改,没有此权限的用户只能对系统进行查询。 用例图:
数据流图:
03第三篇 多元统计分析作业题
第三篇 多元统计分析作业题 1 证明题 1)已知ψ==A X E X Z T T T ,这里用到关系1-ψ=E A 。以二变量为例证明: 12*-Λ=ψ=A X A X Z T T T 1)(-=T T A X 。 式中X 为标准化原始变量矩阵,A 为载荷矩阵,Z 为非标准化主成分得分,Z *为标准化的因子得分,E 为单位化特征向量构成的矩阵即正交矩阵,Ψ为特征根的平方根的倒数构成的对角阵,Λ为特征根构成的对角阵,对于二变量有 ?????? ??=ψ21 /10 /1λλ, ?? ? ???=Λ21 00λλ. 2)对于二变量因子模型,我们有 ?? ?++=++=222221122 112211111εεu f a f a x u f a f a x . 试以 x 1为例证明1 2 22==+j x j j u h σ ,这里∑== p k kj j a h 1 2 22 21 211a a +=。 2 计算题 1)现有一组古生物腕足动物贝壳标本的两个变量:长度x 1和宽度x 2。所测数据如下(表2.1)。 要求: ① 利用Excel 对数据进行主成分分析。 ② 借助SPSS 对该数据进行主成分分析,并计算结果与Excel 的计算结果进行对比,理解各个表格所给参数的含义。 ③ 用本例数据验证证明题?的推导结果。 表2.1 古生物腕足动物贝壳标本数据 样品编号 长度x 1 宽度x 2 样品编号 长度x 1 宽度x 2 1 3 2 14 12 10 2 4 10 15 12 11 3 6 5 16 13 6 4 6 8 17 13 14 5 6 10 18 13 15 6 7 2 19 13 17 7 7 13 20 14 7 8 8 9 21 15 13 9 9 5 22 17 13
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
图书馆管理系统用例图活动图类图时序图
图书馆管理系统 一、图书馆管理系统需求分析 1、系统目标设计 系统开发的总目标就是实现内部图书借阅管理的系统化、规范化与自动化。 能够对图书进行注册登记,也就就是将图书的基本信息(如:书的编号、书名、作者、价格等)预先存入数据库中,供以后检索。 能够对借阅人进行注册登记,包括记录借阅人的姓名、编号、班级、年龄、性别、地址、电话等信息。 提供方便的查询方法。如:以书名、作者、出版社、出版时间(确切的时间、时间段、某一时间之前、某一时间之后)等信息进行图书检索,并能反映出图书的借阅情况;以借阅人编号对借阅人信息进行检索;以出版社名称查询出版社联系方式信息。 提供对书籍进行的预先预订的功能。 提供旧书销毁功能,对于淘汰、损坏、丢失的书目可及时对数据库进行修改。 能够对使用该管理系统的用户进行管理,按照不同的工作职能提供不同的功能授权。 提供较为完善的差错控制与友好的用户界面,尽量避免误操作。 2、系统功能需求分析 (1) 读者管理:读者信息的制定、输入、修改、查询,包括种类、性别、借书数量、借书期限、备注等。 (2) 书籍管理:书籍基本信息制定、输入、修改、查询,包括书籍编号、 类别、关键词、备注。 (3) 借阅管理:包括借书,还书,预订书籍,续借,查询书籍,过期处理与 书籍丢失后的处理。 (4)系统管理:包括用户权限管理,数据管理与自动借还书机的管理
满足以上需求的系统主要包含有一下几个子系统 (1)基本业务功能子系统:该系统中主要包含了借书还书与预订等功能。 (2)基本数据录入功能子系统:该子系统主要包含有书籍信息与读者信息录入功能。 (3)信息查询子系统:包含了多功能的查询书籍信息与读者信息。 (4)数据库管理功能子系统:主要包含了借阅信息管理功能,书籍信息管理功能与预订信息管理功能。 (5)帮助功能子系统。 二、系统动态建模 1、用例图、
应用多元统计分析习题解答_第五章
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
网上购物系统详细精炼版(UML-类图-时序图-数据流图)
附件一 说明书编号:XXXXXX-01 网上商城购物系统需求说明 书 某某软件学院毕业论文精炼版 2011 年7 月20 日
目录 目录 (2) 1引言 (1) 1.1项目背景 (1) 1.2项目意义 (1) 1.3文档目的 (2) 1.4定义 (3) 2任务概述 (4) 2.1系统目标 (4) 2.2用户特点 (4) 2.3应用范围 (4) 2.4假定和约束 (4) 2.5关键性技术 (4) 3需求分析 (4) 3.1业务描述 (6) 3.2用例分析 (9) 3.3系统功能概述 . (15) 5 运行环境规定 (15) 5.1 设备 (23) 5.2支持软件 (23) 5.3控制 (24) 用户确认函 (25)
1引言 1.1项目背景 信息化是当今世界发展的大趋势,是推动经济社会发展和变革的重要力量。随着信息化时代的到来,信息传播发生了深刻的变革,人们的工作方式、生活方式乃至思维方式都发生了前所未有的改变,各行各业都在顺应这一时代变革加强信息化建设。谁能在信息化变革时期先人一步,就能获得先机,抢占鳌头。传统的销售方式是商家把商品放在店铺里供顾客挑选,店铺的规模、位置等客观因素影响着商店的客流量,并且商品的存放与销售需要人力进行管理,雇员的工资、店面的租金等又增加了成本,顾客也不能迅速找到所需要的商品,而开一个网上商店只需要一个可以存放商品的仓库,比租一个店面能节省很多,也不需要太多的人力来管理,不会因为商店的面积影响客流量,客户足不出户就能买东西,并且很容易就能找到所需要的商品。 近年来,随着Internet 的迅速崛起,互联网已日益成为收集提供信息的最 佳渠道并逐步进入传统的流通领域。于是电子商务开始流行起来,越来越多的商家在网上建起在线商店,向消费者展示出一种新颖的购物理念。 网上购物系统作为B2B,B2C(Business to Customer ,即企业对消费者),C2C(Customer to Customer ,即消费者对消费者)电子商务的前端商务平台,在其商务活动全过程中起着举足轻重的作用。本文主要考虑的是如何建设B2C 的网上购物系统。 网上购物是一种具有交互功能的商业信息系统,它向用户提供静态和动态两类信息资源。所谓静态信息是指那些比经常变动或更新的资源,如公司简介、管理规范和公司制度等等;动态信息是指随时变化的信息,如商品报价,会议安排和培训信息等。网上购物系统具有强大的交互功能,可使商家和用户方便的传递信息,完成电子贸易或EDI 交易,这种全新的交易方式实现了公司间文档与资 金的无纸化交换【1】。 可行性研究 建设Web平台系统的必要性取决于需求的迫切性和实现的可能性。可行性并不
多元统计分析期末复习试题
第一章: 多元统计分析研究的容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X均值向量: 随机向量X与Y的协方差矩阵: 当X=Y时Cov(X,Y)=D(X);当Cov(X,Y)=0 ,称X,Y不相关。 随机向量X与Y的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X,Y为随机向量,A,B 为常数矩阵 E(AX)=AE(X); E(AXB)=AE(X)B; D(AX)=AD(X)A’; )' ,..., , ( ) , , , ( 2 1 2 1P p EX EX EX EXμ μ μ = ' = )' )( ( ) , cov(EY Y EX X E Y X- - = q p ij r Y X ? =) ( ) , (ρ
Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变量之间的比较。 4、对数变换:对数变换是将各个原始数据取对数,将原始数据的对数值作为变换后的新值。它将具有指数特征的数据结构变换为线性数据结构。 三、样品间相近性的度量 研究样品或变量的亲疏程度的数量指标有两种:距离,它是将每一个样品看作p 维空),(~∑μP N X μ∑μp X X X ,,,21 ),(~∑μP N X ),('A A d A N s ∑+μ)()1(,,n X X X )',,,(21p X X X )')(()()(1X X X X i i n i --∑=n 1X μ ∑μX )1,(~∑n N X P μ),1(∑-n W p X X
应用多元统计分析SAS作业第六章资料
6-10 今有6个铅弹头,用“中子活化”方法测得7种微量元素的含量数据(见表1)。 (1) 试用多种系统聚类法对6个弹头进行分类;并比较分类结果; (2) 试用多种方法对7种微量元素进行分类。 问题求解 1对6个弹头进行分类 对数据进行标准化变换,样品间距离定义为欧式距离,系统聚类的方法分别使用类平均法(A VE )、中间距离法(MID )、可变类平均法(FLE )和离差平方合法(WARD )。使用SAS 软件CLUSTER 过程对数据进行聚类分析(程序见附录1)。 1.1类平均法 图1 类平均聚类法相关矩阵特征值图 图2 类平均聚类分析法聚类历史图 由图2可知,NCL=1时半偏R 2最大且伪F 统计量在NCL=2,5时和伪t 方统计量在NCL=1,4时较大。因此,将6个弹头分为两类{}{}(2) (2) 121,2,4,6,3,5G G ==。SAS 绘制的谱系聚类图如图 3所示。
图3 类平均聚类分析法谱系聚类图 1.2中间距离法 图4 中间距离聚类法相关矩阵特征值图 图5 中间距离聚类法聚类历史图 由图5可知,中间距离法与类平均法结果一致。因此,也将6个弹头分为两类 {}{}(2)(2) 121,2,4,6,3,5G G ==。 SAS 绘制的谱系聚类图如图6所示。
图6中间距离聚类法谱系聚类图 1.3可变类平均法 图7可变类平均聚类法分析结果图 图8 可变类平均聚类法聚类历史图 由图8可知,可变类平均法(=0.25 β-)输出结果与前两种方法稍有不同,NCL=1时半偏R2最大且伪F统计量在NCL=2时次大,NCL=5时最大;而伪t方统计量在NCL=1时最大。因此,分
多元统计分析期末考试考点整理
二名词解释 1、 多元统计分析:多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理 论和方法,是一元统计学的推广 2、 聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方 法。将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。 使类内对象的同质性最大化和类间对象的异质性最大化 3、 随机变量:是指变量的值无法预先确定仅以一定的可能性 (概率)取值的量。它是由于随 机而获得的非确定值,是概率中的一个基本概念。即每个分量都是随机变量的向量为随机向 量。类 似地,所有元素都是随机变量的矩阵称为随机矩阵。 4、统计量:多元统计研究的是多指标问题 ,为了了解总体的特征,通过对总体抽样得到代表 总体的样本,但因为信息是分散在每个样本上的 ,就需要对样本进行加工,把样本的信息浓缩 到不包含未知量的样本函数中,这个函数称为统计量 二、计算题 ^16 -4 2 k 设H = 其中启= (1Q —纣眉=-4 4-1 [― 试判断叼+ 2吟与 「花一? [是否独立? 解: "10 -6 -15 -6 1 a 2U -16 20 40 故不独立口 -r o 2丿 按用片的联合分帚再I -6 lti 20 -1G 20 ) -1V16 -4 0 -4 A 2 丿"-1
2.对某地区农村的百名2周宙男翌的身高、胸圉、上半骨圉进行测虽,得相关数据如下』根据汶往资料,该地区城市2周岁男婴的遠三个指标的均值血二(90Q乩16庆现欲在多元正态性的假定下检验该地区农村男娶是否与城市男婴有相同的均值?伽厂43107-14.62108.946^1 ]丼中乂=60.2x^)-1=(115.6924)-1-14.6210 3.172-37 3760 、8.9464-37 376035.S936」= 0.01, (3,2) = 99.2, 03) =293 隔亠4) =16.7) 答: 2、假设检验问题:比、# =险用‘//H地 r-8.o> 经计算可得:X-^A 22 厂 「3107 -14.6210 ST1=(23J3848)-1 -14.6210 3.172 8 9464 -37 3760 E9464 -37.3760 35.5936 构造检验统计量:尸=旳(丟-間)〃丿(巫-角) = 6x70.0741=420.445 由题目已知热“(3,)= 295由是 ^I =^W3,3)^147.5 所以在显著性水平ff=0.01下,拒绝原设尽即认 为农村和城市的2周岁男婴上述三个指标的均 值有显著性差异 (] 4、设盂=(耳兀.昂工/ ~M((XE),协方差阵龙=P P (1)试从匸出发求X的第一总体主成分; 答: (2)试|可当卩取多大时才链主成分册贡蕭率达阳滋以上.
UML类图和时序图简述
目录 目录 (1) 1类图基本元素符号: (2) 1.1 类(Classes) (2) 1.2 包(Package) (2) 1.3 接口(Interface) (3) 2类图关系: (3) 2.1. 依赖(Dependency) (3) 2.2 关联(Association) (4) 2.3 聚合(Aggregation) (4) 2.4 合成(Composition) (5) 2.5 泛化(Generalization) (5) 2.6 实现(Realization) (5) 3 UML建模之时序图(Sequence Diagram) (6) 3.1. 时序图简介(Brief introduction) (6) 3.2. 时序图元素(Sequence Diagram Elements) (6) 3.2.1 角色(Actor) (6) 3.2.2 对象(Object) (6) 3.2.3 生命线(Lifeline) (7) 3.2.4 控制焦点(Focus of Control) (7) 3.2.5 消息(Message) (8) 3.2.6 自关联消息(Self-Message) (9) 3.2.7 Combined Fragments (10) 3.3. 时序图实例分析(Sequece Diagram Example Analysis) (10) 3.3.1 时序图场景 (10) 3.3.2 时序图实例 (11) 3.3.3 时序图实例分析 (11) 3.4. 总结(Summary) (11)
1类图基本元素符号: 1.1 类(Classes) 类包含3个组成部分。第一个是Java中定义的类名。第二个是属性(attributes)。第三个是该类提供的方法。 属性和操作之前可附加一个可见性修饰符。加号(+)表示具有公共可见性。减号(-)表示私有可见性。#号表示受保护的可见性。省略这些修饰符表示具有package(包)级别的可见性。如果属性或操作具有下划线,表明它是静态的。在操作中,可同时列出它接受的参数,以及返回类型,如下图所示: 1.2 包(Package) 包是一种常规用途的组合机制。UML中的一个包直接对应于Java中的一个包。在Java中,一个包可能含有其他包、类或者同时含有这两者。进行建模时,你通常拥有逻辑性的包,它主要用于对你的模型进行组织。你还会拥有物理性的包,它直接转换成系统中的Java包。每个包的名称对这个包进行了惟一性的标识。
多元统计分析上机作业
多远统计上机作业 指标的原始数据取自《中国统计年鉴, 1995》和《中国教育统计年鉴, 1995》除以各地区相应的人口数得到十项指标值见表 1。其中: X1 X2 X3 X4 X5 X6:为每百万人口高等院校数; :为每十万人口高等院校毕业生数; :为每十万人口高等院校招生数; :为每十万人口高等院校在校生数; :为每十万人口高等院校教职工数; :为每十万人口高等院校专职教师数; X7: 为高级职称占专职教师的比例; X8 :为平均每所高等院校的在校生数; X9 :为国家财政预算内普通高教经费占 国内生产总值的比重; X10: 为生均教育经费。 表 1 我国各地区普通高等教育发展状况数据 地区X1X2X3X4X5X6X7X8X9X10北京 5.96310461155793131944.362615 2.2013631上海 3.39234308103549816135.023052.9012665天津 2.3515722971329510938.403031.869385陕西 1.35811113641505830.452699 1.227881辽宁 1.50881284211445834.302808.547733吉林 1.67861203701535833.532215.767480黑龙江 1.1763932961174435.222528.588570湖北 1.0567922971154332.892835.667262江苏.9564942871023931.543008.397786广东.693971205612434.502988.3711355四川.564057177612332.623149.557693山东.575864181572232.953202.286805甘肃.714262190662628.132657.737282湖南.744261194612433.062618.476477浙江.864271204662629.942363.257704新疆 1.2947732651144625.932060.375719福建 1.045371218632629.012099.297106山西.855365218763025.632555.435580河北.814366188612329.822313.315704安徽.593547146462032.832488.335628云南.663640130441928.551974.489106江西.774363194672328.812515.344085海南.703351165471827.342344.287928内蒙古.844348171652927.652032.325581西藏 1.692645137753312.10810 1.0014199河南.553246130441728.412341.305714广西.602843129391731.932146.245139宁夏 1.394862208773422.701500.425377贵州.64233293371628.121469.345415青海 1.483846151633017.871024.387368
应用多元统计分析课后答案
应用多元统计分析课后答案 第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1()()p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-= +∑
图书管理系统(用例图、类图、时序图)
软件系统分析与设计 实验报告 学院:计算机科学与技术学院专业:软件工程 学号:********* 姓名:*** 实验名称:图书管理系统用例建模时间:
一、实验内容与要求 本实验要求学生对学校的图书馆管理系统进行需求分析,对系统功能进行用例建模,画出用例图,类图以及相应的时序图。在使用UML对系统建模时,学会使用UML建模工具,熟悉工具中的功能。 二、用例分析 1、读者“借书还书系统”用例图 (f 还书 (from Use Cases) 1.1、行为者: 主要行为者:读者。 1.2、前置条件: 读者进入图书管理系统。 1.3、事件流: 1.3.1、主要事件流: 1.3.1.1:读者检索所需图书信息,并查看; 1.3.1.2:读者检索到所需图书,登录系统,开始借书; 1.3.1.3:系统查询图书信息,图书数目是否可借; 1.3.1.3.1:图书显示可借,借书成功;
1.3.1.3.2:图书显示不可借,借书失败; 1.3.1.4:进入续借图书界面,续借图书; 1.3.1.5:系统查看预约记录, 1.3.1.5.1:没有冲突,续借成功; 1.3.1.5.2:有冲突,续借失败;1.3.3.1: 1.3.1.6:读者归还图书; 1.3.1.6.1:归还时间没有逾期,归还成功; 1.3.1.5.2:归还时间逾期,逾期处罚,归还成功; 1.3.2、备选事件流: 1.3. 2.1:图书检索信息失败,未检索到图书,重新输入信息检索; 1.3. 2.2:未曾检索到用户检索的图书,系统显示相关联的信息的图书; 1.3. 2.3:用户名或密码输入错误,登录系统失败,重新输入用户名或密码登录; 1.3. 2.4:系统显示图书不可借后,进入图书预约界面,输入信息预约图书; 1.3.3、异常事件流: 1.3.3.1:读者登录系统失败,未曾注册用户; 1.3.3.1.1:返回系统注册用户后,重新登录。 1.4、后置条件:退出系统。 1.5、 1.6、扩展点:无。 2、“图书信息管理系统”用例图 新书信息录入 (f 逾期通知 (from Use Cases) (from Use Cases)
多元统计分析期末试题汇编
一、填空题(20分) 1、若),2,1(),,(~)(n N X p =∑αμα 且相互独立,则样本均值向量X 2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。 3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。 4、Q 型聚类是指对_样品_进行聚类,R 型聚类是指对_指标(变量)_进行聚类。 5、设样品),2,1(,),,('21n i X X X X ip i i i ==,总体),(~∑μp N X ,对样品进行分类常用的距离有:明氏距 离,马氏距离2 ()ij d M =)()(1j i j i x x x x -∑'--,兰氏距离()ij d L = 6、因子分析中因子载荷系数ij a 的统计意义是_第i 个变量与第j 个公因子的相关系数。 7、一元回归的数学模型是:εββ++=x y 10,多元回归的数学模型是: εββββ++++=p p x x x y 22110。 8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。 9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。 二、计算题(60分) 1、设三维随机向量),(~3∑μN X ,其中??? ? ? ??=∑200031014,问1X 与2X 是否独立?),(21'X X 和3X 是否 独立?为什么? 解: 因为1),cov(21=X X ,所以1X 与2X 不独立。 把协差矩阵写成分块矩阵??? ? ??∑∑∑∑=∑22211211,),(21'X X 的协差矩阵为11∑因为12321),),cov((∑='X X X ,而012=∑,所以),(21'X X 和3X 是不相关的,而正态分布不相关与相互独 立是等价的,所以),(21'X X 和3X 是独立的。
数学建模多元统计分析
实验报告 一、实验名称 多元统计分析作业题。 二、实验目的 (一)了解并掌握主成分分析与因子分析的基本原理和简单解法。 (二)学会使用matlab编写程序进行因子分析,求得特征值、特征向量、载荷矩阵等值。(三)学会使用排序、元胞数组、图像表示最后的结果,使结果更加直观。 三、实验内容与要求
四、实验原理与步骤 (一)第一题: 1、实验原理: 因子分析简介: (1) 1.1 基本因子分析模型 设p维总体x=(x1,x2,....,xp)'的均值为u=(u1,u2,....,u3)',因子分析的一般模型为 x1=u1+a11f1+a12f2+........+a1mfm+ε 1 x2=u2+a21f1+a22f2+........+a2mfm+ε 2 ......... xp=up+ap1f1+fp2f2+..........+apmfm+εp 其中,f1,f2,.....,fm为m个公共因子;εi是变量xi(i=1,2,.....,p)所独有的特殊因子,他们都是不可观测的隐变量。称aij(i=1,2,.....,p;j=1,2,.....,m)为变量xi的公共因子fi上的载荷,它反映了公共因子对变量的重要程度,对解释公共因子具有重要的作用。上式可以写为矩阵形式 x=u+Af+ε
其中A=(aij)pxm 称为因子载荷矩阵;f=(f1,f2,....,fm)'为公共因子向量;ε=(ε1,ε2,.....εp)称为特殊因子向量 (2) 1.2 共性方差与特殊方差 xi的方差var(xi)由两部分组成,一个是公共因子对xi方差的贡献,称为共性方差;一个是特殊因子对xi方差的贡献,称为特殊方差。每个原始变量的方差都被分成了共性方差和特殊方差两部分。 (3) 1.3 因子旋转 因子分析的主要目的是对公共因子给出符合实际意义的合理解释,解释的依据就是因子载荷阵的个列元素的取值。当因子载荷阵某一列上各元素的绝对值差距较大时,并且绝对值大的元素较少时,则该公共因子就易于解释,反之,公共因子的解释就比较困难。此时可以考虑对因子和因子载荷进行旋转(例如正交旋转),使得旋转后的因子载荷阵的各列元素的绝对值尽可能量两极分化,这样就使得因子的解释变得容易。 因子旋转方法有正交旋转和斜交旋转两种,这里只介绍一种普遍使用的正交旋转法:最大方差旋转。这种旋转方法的目的是使因子载荷阵每列上的各元素的绝对值(或平方值)尽可能地向两极分化,即少数元素的绝对值(或平方值)取尽可能大的值,而其他元素尽量接近于0. (4) 1.4 因子得分 在对公共因子做出合理解释后,有时还需要求出各观测所对应的各个公共因子的得分,就比如我们知道某个女孩是一个美女,可能很多人更关心该给她的脸蛋、身材等各打多少分,常用的求因子得分的方法有加权最小二乘法和回归法。 注意:因子载荷矩阵和得分矩阵的区别: 因子载荷矩阵是各个原始变量的因子表达式的系数,表达提取的公因子对原始变量的影响程度。因子得分矩阵表示各项指标变量与提取的公因子之间的关系,在某一公因子上得分高,表明该指标与该公因子之间关系越密切。简单说,通过因子载荷矩阵可以得到原始指标变量的线性组合,如X1=a11*F1+a12*F2+a13*F3,其中X1为指标变量1,a11、a12、a13分别为与变量X1在同一行的因子载荷,F1、F2、F3分别为提取的公因子;通过因子得分矩阵可以得到公因子的线性组合,如F1=a11*X1+a21*X2+a31*X3,字母代表的意义同上。 (5) 1.5 因子分析中的Heywood(海伍德)现象 如果x的各个分量都已经标准化了,则其方差=1。即共性方差与特殊方差的和为1。也就是说共性方差与特殊方差均大于0,并且小于1。但在实际进行参数估计的时候,共性方差
应用多元统计分析习题解答-主成分分析
主成分分析 6.1 试述主成分分析的基本思想。 答:我们处理的问题多是多指标变量问题,由于多个变量之间往往存在着一定程度的相关性,人们希望能通过线性组合的方式从这些指标中尽可能快的提取信息。当第一个组合不能提取止。这就是主成分分析的基本思想。 6.2 主成分分析的作用体现在何处? 答:一般说来,在主成分分析适用的场合,用较少的主成分就可以得到较多的信息量。以各个主成分为分量,就得到一个更低维的随机向量;主成分分析的作用就是在降低数据“维数” 6.3 简述主成分分析中累积贡献率的具体含义。 答:主成分分析把p 个原始变量12,, ,p X X X 的总方差()tr Σ分解成了p 个相互独立的变量p 个主成分的,忽略 一些带有较小方差的主成分将不会给总方差带来太大的影响。这里我们()m p <个主成分,则称1 1 p m m k k k k ψλλ ===∑∑ 为主成分1, ,m Y Y 的累计贡献率,累计贡献率表明1,,m Y Y 综合12,, ,p X X X 的能力。通常取m ,使得累计贡 献率达到一个较高的百分数(如85%以上)。 答:这个说法是正确的。 即原变量方差之和等于新的变量的方差之和 6.5 试述根据协差阵进行主成分分析和根据相关阵进行主成分分析的区别。 答:从相关阵求得的主成分与协差阵求得的主成分一般情况是不相同的。从协方差矩阵出发的,其结果受变量单位的影响。主成分倾向于多归纳方差大的变量的信息,对于方差小的变量就可能体现得不够,也存在“大数吃小数”的问题。实际表明,这种差异有时很大。我 6.6 已知X =()’的协差阵为 试进行主成分分析。 解:=0 计算得 当 时 ,