计量经济学数据范文
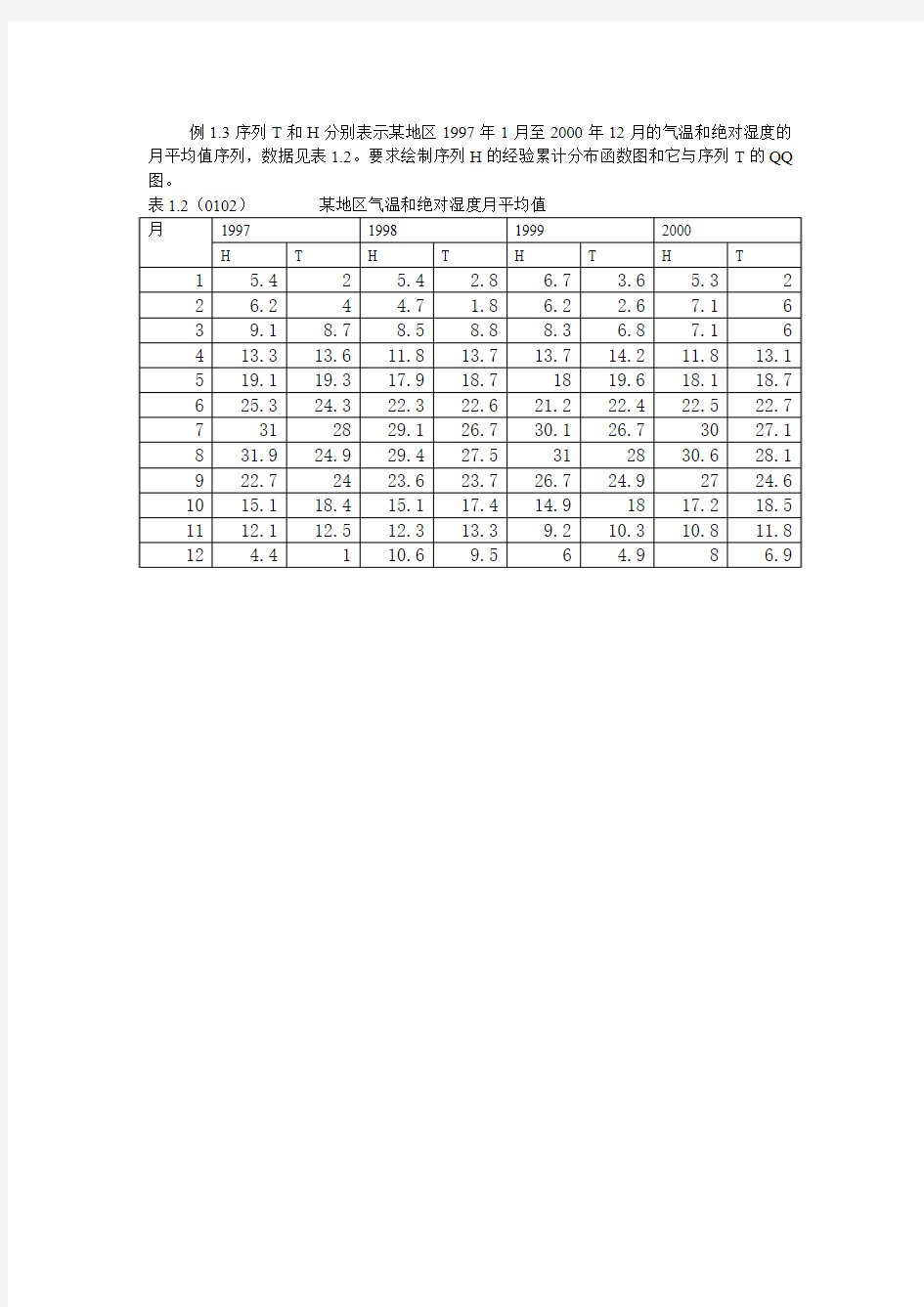

例1.3序列T和H分别表示某地区1997年1月至2000年12月的气温和绝对湿度的月平均值序列,数据见表1.2。要求绘制序列H的经验累计分布函数图和它与序列T的QQ 图。
例2.1表2.1是1950—1987年间美国机动车汽油消费量和影响消费量的变量数值。其中各变量表示:qmg—机动车汽油消费量(单位:千加仑);car—汽车保有量;pmg—机动汽油零售价格;pop—人口数;rgnp—按1982年美圆计算的gnp(单位:十亿美圆);pgnp —gnp指数(以1982年为100)。以汽油量为因变量,其他变量为自变量,建立一个回归模型。
ls qmg c car pmg pop rgnp pgnp
ls car c pmg pop rgnp pgnp
eqcar
scalar vifcar=1/(1-eqcar.@R2) (vifcar是方差扩大因子)
同时工作表中产生vifcar=229.1862
方差扩大因子只要有一个超过10,说明存在多重共建性
检验零假设H0:car对qmg的影响不重要
在主窗口输入eq01.testdrop car
3.多重共建性处理方法:
2.
3。差分法
其中算子:ls qmg-qmg(-1) car-car(-1) pmg-pmg(-1) pop-pop(-1) rgnp-rgnp(-1) pgnp-pgnp(-1) ls qmg c qmg(-1) car pmg pmg(-1) pop pop(-1) rgnp rgnp(-1) pgnp pgnp(-1)
Qmg t=qmg t-1+cart-0.car t-1
Ls qmg-eq02.@coefs(1)*qmg(-1) c car-eq02.@coefs(1)*car(-1) pmg-eq02.@coefs(1)*pmg(-1)pop-eq02.@coefs(1)*pop(-1) rgnp-eq02.@coefs(1)*rgnp(-1)pgnp-eq02.@coefs(1)*pgnp(-1)
Scalar beta0=eq04.@coefs(1)/(1-eq02.@coefs(1))
得beta0=.38 回归模型为 Qmg=.38+1.4390*car-…… White 检验 打开equation view-
例2.2为研究采取某项保险革新措施的速度y 与保险公司的规模x1和保险公司类型的关系,选取下列数据:y —一个公司提出该项革新直至革新被采纳间隔的月数,x1—公司的资产总额(单位:百万元),x2—定性变量,表示公司类型:其中1表示股份制公司,0表示互助公司。数据资料见表2.5。
表2.5 (0205) 保险公司革新数据
要建立的模型:
i i i i x x y εβββ+++=22110
得到模型为
y=33.87407-0.*x1+8.*x2
差分回归方程:
t t x y ?=?*65.0
即
1165.065.0---=-t t t t x x y y
即
1165.065.0---+=t t t t x x y y
消除自相关的模型:
qmg=.38+1.4390*car-*pmg-503.50*pop-5290.80*rgnp-.4*pgnp
某市楼盘销售价格及相关情况的抽样调查表,其中建筑类别分别用1、2、3、4表示多
层、多层别墅、小高层、高层;交通状况综合分、物业管理综合分、周边配套等级是通过对
1.Y关于X1、X2、X3、X4和X5的回归方程;
2.对回归方程和解释变量做显著性检验;
3.当X1=4,X2=8,X3=7,X4=36%,X5=8时,对楼盘的均价进行预测。
例3.1表3.3是某企业在16个月度的产品产量和单位成本资料,研究二者关系。
表3.3 (0301)某企业某产品产量和单位成本资料
月度序号obs 产量(台)x 单机位成本(元/台)y
1 4300 346.23
2 4004 343.34
3 4300 327.46
4 5016 313.27
5 5511 310.75
6 5648 307.61
7 5876 314.56
8 6651 305.72
9 6024 310.82
10 6194 306.83
11 7558 305.11
12 7381 300.71
13 6950 306.84
14 6471 303.44
15 6354 298.03
16 8000 296.21
为了明确产量和单机成本是何种关系,先绘制散点图。
genr lx=log(x)
genr ly=log(y)
ls ly c lx
ls log(y) c log(x)
log(y)=c(1)+c(2)*log(x)
双曲线模型:y=a+b/x
对数曲线模型:y=a+blnx
双对数曲线模型:lny=a+lnx
在自变量个数K=1,样本量n=16,在显著性水平 =0.01下,d L=0.84,d u=1.00,此时有D.W=1.
D.W=1.
D.W=1.
均有d u=1.0≤D.W=1.≤4- d u=3
说明三种模型来描述x与y的关系都比较好。
例3.2 根据例3.1中数据,用非线性最小二乘法建立成本函数模型
例3.3粮食产量通常由粮食生产劳动力(L)、化肥施用量(K)等因素决定。表3.8是我国粮食生产的有关数据(由于粮食生产劳动力不易统计,假定它在农业劳动力中的比例是一定的,故用农业劳动力的数据代替),研究其间关系,建立Cobb—Douglas生产函数模型。
生产的产出量与投入要素之间并不简单地满足线性关系,通常讨论的生产函数,都是以非线性的形式出现。Cobb—Douglas生产函数模型为
Y=aL b K1-b(3.2.4)
Y=c(1)*l^c(2)*k^(1-c(2))
Y=c(1)*l^c(2)*k^(1-c(2))
Coefficient Std. Error t-Statistic Prob.
C(1) 0. 0. 13.10662 0.0000
C(2) 0. 0. 43.52960 0.0000
R-squared 0. Mean dependent var 40114.73
Adjusted R-squared 0. S.D. dependent var 7222.666
S.E. of regression 1725.278 Akaike info criterion 17.81797
Sum squared resid Schwarz criterion 17.91474
Log likelihood -229.6336 Hannan-Quinn criter. 17.84584
Durbin-Watson stat 1.
表3.8(0308)我国1975—2000年粮食产量、农业劳动力、播种面积和化肥使用量
例4.1我国轿车保有量资料见表4.1
根据表绘制时间序列曲线趋势图。
例4.6我国民航客运量数据的季节调整。有关数据见表4.6
表4.6(0406)我国1993年10月至1998年3月民航客运量数据
例5.4序列Pt是某国1960年至1993年GNP平减指数的季度时间序列。表5.4(0504)某国1960年至1993年GNP平减指数的季度时间序列
例5.6表5.4是我国1990年1月至1997年12月工业总产值的月度资料(1990年不变价格),记作IP t,共有96个观测值,对序列IP t建立ARMA模型。
例5.6 表5.4是我国1990年1月至1997年12月工业总产值2资料(1990年不变价格),记作ipt,共有96个观测值,对序列ipt建立ARMA模型。
例6.1表6.1是某水库1998年至2000年各旬的流量、降水量数据。试对其建立多项式分布滞后模型。
LS VOL C RA RA(-1) RA(-2) RA(-3) RA(-4) RA(-5) RA(-6)
LS VOL c pdl(series name lags order options
LS VOL c pdl(ra,9,6 )
Variable Coefficient Std. Error t-Statistic Prob.
C -186.6747 134.7779 -1. 0.1711
PDL01 -1. 1. -0. 0.3689
PDL02 -0. 2. -0. 0.7605
PDL03 0. 1. 0. 0.5701
PDL04 0. 0. 0. 0.6400
PDL05 -0. 0. -0. 0.9364
PDL06 -0. 0. -1. 0.3071
PDL07 0. 0. 0. 0.6922
R-squared 0. Mean dependent var 888.0580 Adjusted R-squared 0. S.D. dependent var 1241.393 S.E. of regression 651.1569 Akaike info criterion 15.90403 Sum squared resid Schwarz criterion 16.16306 Log likelihood -540.6890 Hannan-Quinn criter. 16.00679 F-statistic 26.59247 Durbin-Watson stat 1. Prob(F-statistic) 0.
六介多项式的检验T统计量的相关概率太大了,所以相关性不好
LS VOL c pdl(ra,9,5 )
Variable Coefficient Std. Error t-Statistic Prob.
C -189.5507 133.6672 -1. 0.1612
PDL01 -1. 1. -0. 0.4115
PDL02 -0. 1. -0. 0.9449
PDL03 0. 0. 0. 0.6454
PDL04 0. 0. 0. 0.7962
PDL05 0. 0. 1. 0.1799
PDL06 -0. 0. -1. 0.2285
R-squared 0. Mean dependent var 888.0580 Adjusted R-squared 0. S.D. dependent var 1241.393 S.E. of regression 646.7215 Akaike info criterion 15.87764 Sum squared resid Schwarz criterion 16.10428 Log likelihood -540.7784 Hannan-Quinn criter. 15.96755 F-statistic 31.42482 Durbin-Watson stat 1. Prob(F-statistic) 0.
Lag Distribution of
RA i Coefficient Std. Error t-Statistic
. *| 0 30.2731 3.21709 9.41009 . * | 1 8.15629 2.59687 3.14082 * | 2 0.88833 1.72084 0.51622 *. | 3 -0.92771 1.88469 -0.49223 *. | 4 -1.33347 1.61272 -0.82685 *. | 5 -1.01564 1.61361 -0.62942 * | 6 0.69384 1.87788 0.36948 . * | 7 3.81751 1.78166 2.14267 T统计量的相关概率还是太大了0.9449,所以相关性不好
LS VOL c pdl(ra,9,4 )
C -192.7441 134.1490 -1. 0.1557
PDL01 -2. 1. -1. 0.1344
PDL02 1. 0. 1. 0.1061
PDL03 0. 0. 1. 0.0530
PDL04 -0. 0. -4. 0.0001
PDL05 0. 0. 0. 0.5287
R-squared 0. Mean dependent var 888.0580 Adjusted R-squared 0. S.D. dependent var 1241.393 S.E. of regression 649.1779 Akaike info criterion 15.87223 Sum squared resid Schwarz criterion 16.06650 Log likelihood -541.5920 Hannan-Quinn criter. 15.94931 F-statistic 37.13130 Durbin-Watson stat 1. Prob(F-statistic) 0.
Lag Distribution of
RA i Coefficient Std. Error t-Statistic
. *| 0 28.9405 3.03629 9.53153 T统计量的相关概率还是太大了0.9449,所以相关性不好
LS VOL c pdl(ra,9,3 )
Variable Coefficient Std. Error t-Statistic Prob.
C -182.8158 132.6058 -1. 0.1728
PDL01 -2. 1. -2. 0.0376
PDL02 1. 0. 1. 0.1315
PDL03 1. 0. 6. 0.0000
PDL04 -0. 0. -5. 0.0000
R-squared 0. Mean dependent var 888.0580
Adjusted R-squared 0. S.D. dependent var 1241.393
S.E. of regression 646.1344 Akaike info criterion 15.84960
Sum squared resid Schwarz criterion 16.01149
Log likelihood -541.8111 Hannan-Quinn criter. 15.91382
F-statistic 46.75112 Durbin-Watson stat 1.
Prob(F-statistic) 0.
这个就好多了
LS VOL c pdl(ra,9,3 )能不能减小9呢?把9改为6/ 最终发现改为8最好
Variable Coefficient Std. Error t-Statistic Prob.
C -170.8551 128.4471 -1. 0.1881
PDL01 -2. 1. -2. 0.0385
PDL02 1. 0. 1. 0.1800
PDL03 1. 0. 6. 0.0000
PDL04 -0. 0. -3. 0.0006
R-squared 0. Mean dependent var 881.0714
Adjusted R-squared 0. S.D. dependent var 1233.750
S.E. of regression 645.7127 Akaike info criterion 15.84734
Sum squared resid Schwarz criterion 16.00794
Log likelihood -549.6567 Hannan-Quinn criter. 15.91113
F-statistic 46.72448 Durbin-Watson stat 1.
Prob(F-statistic) 0.
例6.2表6.6中,序列St和Zt分别表示1992年1月至1998年12月经居民消费价格指数调整的中国城镇居民月人均可支配收入和人均生活费支出时间序列,现以人均生活费支出Zt 为因变量,建立自回归分布滞后模型。
表6.6 城镇居民月人均人均生活费支出和可支配收入调整时间序列单位:元
例7.1 表7.1是美国各州和地方政府费用支出数据。其中,GOV为政府开支,AID为联邦政府拨款额,INC为各州收入的自然对数,POP为各州人口总数,PS为小学与中学在校人数。
欲建立如下联立方程模型:
计量经济学课后习题答案
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【B 】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从经济理论和经济模型出发进行计量经济分析的过程,也是对经济理论证实或证伪的过程。这些是以处理数
计量经济学期末考试题库及答案
计量经济学题库 、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是(A )。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量B.控制变量C.政策变量D.滞后变量12.( B )是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是( A )。 A.函数关系与相关关系B.线性相关关系和非线性相关关系
计量经济学要点
第一章 导论 1、什么是计量经济学模型?它有哪些要素?要素的内容是什么? 计量经济模型就是经济变量之间所存在的随机关系的一种数学表达式,其一般形式为: 模型由经济变量(x,y ),随机误差项(u ),参数(β)和方程的形式 f (?)等四个要素构成。 经济变量(x,y )——用于描述经济活动水平的各种量,是经济计量建模的基础 随机误差项(u )——表示模型中尚未包含的影响 因素对因变量的影响,一般假定其满足一定条件。 参数(β)——是模型中表示变量之间 数量关系的系数, 具体说明解释变量对解释变量的影响程度。 方程的形式 f (?) ——是将计量经济模型的三个要素联系 在一起的数学表达式,分为线性模型和非线性模型。 2、经典计量经济学模型的建模步骤及主要内容是什么? 经典计量建模可分为四个连续的阶段:模型设定,参数估计,模型检验,模型应用。模型设定阶段需研究有关经济理论并确定变量以及函数形式,进行样本数据的收集与整理;模型的参数估计阶段要用到统计推断、回归分析方法,经常需要借助于统计软件的帮助得到参数的估计结果,参数一经确定,模型中各变量之间的关系就确定了,模型也就随之确定了。参数估计的主要方法有最小平方法(OLS )及其拓展形式(GLS 、WLS 、2StageLS 等)、最大似然估计法、数值计算法等;模型检验包括经济意义检验、统计检验、计量经济检验;模型可应用于验证与发展经济理论、结构分析、经济预测、政策评价等方面。 3、数据及数据类型 变量的具体取值称为数据(Data)。数据是经济计量分析的原材料,根据形式不同,数据分为时间序列数据、横截面数据和合并数据。 1.时间序列数据(Time series data )是按时间顺序排列而成的数据。 2.截面数据(Cross sectional data )又称横断面数据,是指在同一时间,不同统计单位的相同统计指标组成的数据列。 3.合并数据(Pooled data )是指既有时间序列数据又有横截面数据。 4、试题举例 1、在同一时间不同统计单位的相同统计指标组成的数据列,是( )。 A 、 原始数据 B 、 合并数据 C 、 时间序列数据 D 、 横截面数据 2、既有时间序列数据又有横截面数据的数据是( )。 A 、 原始数据 B 、时间序列数据 C 、合并数据 D 、 截面数据 第二章 一元线性回归 一、主要内容: 1为什么计量经济学模型的理论方程中必须包含随机干扰项?(或:随机误差项包含哪些内容?) 在总体回归函数中引进随机扰动项,主要有以下几方面的原因: (,,) y f x u β=
计量经济学课后习题答案汇总
计量经济学课后习题答 案汇总 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列 分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系 和恒等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从
李子奈《计量经济学》课后习题详解(非经典截面数据计量经济学模型)【圣才出品】
第6章非经典截面数据计量经济学模型 1.在经典截面数据计量经济学模型中,通常选择哪些类型的数据作为样本数据?对被解释变量样本数据有哪些假定? 答:(1)在经典的截面数据计量经济学模型中,通常选择横截面数据作为样本数据。 (2)对被解释变量的样本数据,通常有以下假定: ①假定被解释变量都是连续型的随机抽取的变量; ②假定被解释变量和随机干扰项所服从的分布类型是一致的; ③假定得到的被解释变量的样本观测值可以完全反映被解释变量的实际状态。 2.某一截面数据计量经济学模型Y i=β′X i+μi,被解释变量服从正态分布,其样本观测值为Y1,Y2,…,Y n,其中Y1,Y2,Y3取相同的值α,其他观测值均大于α。分别将该组样本看作未受限制的随机抽取样本、以α为截断点的选择性样本、以α为归并点的选择性样本,分别采用最大似然法估计模型。 (1)写出3种情况下的对数似然函数表达式。 (2)比较3种情况下对数似然函数值的大小,并加以简单证明。 解:(1)①在假设该组样本为未受限制的随机抽样样本时,其似然函数为:
()()() ()()()()2 23222141 2 21 2 /2 12/2 1 ,,, ,21 2i i n i i i i i Y X n n n a X Y X n n L P Y Y Y e e βσ ββσβσ πσπσ ==- -??--+-?????? ∑∑∑== = 对该似然函数方程的左右两边分别取对数,可得其对数似然函数表达式为: ()()()3222 2141ln ln 222n i i i i i n L a X Y X πσββσ==??=---+-?? ?? ∑∑ ②当假设所取的样本为以α为截断点的选择性样本时,其似然函数为: ()() 2 2 2 4 431ln ln 2ln 122n n i i i i i a X n L Y X βπσβσσ ==?-? -??=-----Φ?? ???? ?∑∑ ③当假设所取的样本为以α为归并点的选择性样本时,Y i 的概率密度似然函数分为两部分为两部分,一部分是Y i =α的前三个点,其概率密度函数为: ()()i i i i a X P Y P a X βαμβσ-?? ==≤-=Φ ??? 另一部分是后n -3个点,他们服从正态分布N (X i β,σ2),其概率密度函数为: ()()2 2 21i i Y X i f Y e βσ-- =
计量经济学题(答案)
《计量经济学》要点 一、单项选择题 知识点: 第一章 若干定义、概念 时间序列数据定义 横截面数据定义 1.同一统计指标按时间顺序记录的数据称为( B )。 A、横截面数据???? B、时间序列数据??? C、修匀数据??? D、原始数据 2.同一时间,不同单位相同指标组成的观测数据称为( B ) A.原始数据B.横截面数据 C.时间序列数据D.修匀数据 变量定义(被解释变量、解释变量、内生变量、外生变量) 单方程中可以作为被解释变量的是(控制变量、内生变量、外生变量); 3.在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C ) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 什么是解释变量、被解释变量? 从变量的因果关系上,模型中变量可分为解释变量(Explanatory variable)和被解释变量(Explained variable)。 在模型中,解释变量是变动的原因,被解释变量是变动的结果。 被解释变量是模型要分析研究的对象,也常称为“应变量”(Dependent variable)、“回归子”(Regressand)等。 解释变量也常称为“自变量”(Independent variable)、“回归元”(Regressor)等,是说明应变量变动主要原因的变量。 因此,被解释变量只能由内生变量担任,不能由非内生变量担任。 4.单方程计量经济模型中可以作为被解释变量的是( C ) A、控制变量 B、前定变量 C、内生变量 D、外生变量 5.单方程计量经济模型的被解释变量是(A ) A、内生变量 B、政策变量 C、控制变量 D、外生变量 6.在回归分析中,下列有关解释变量和被解释变 量的说法正确的有(C) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 双对数模型中参数的含义; 7.双对数模型 01 ln ln ln Y X ββμ =++中,参数1 β的含义是(D ) A .X的相对变化,引起Y的期望值绝对量变化 B.Y关于X的边际变化 C.X的绝对量发生一定变动时,引起因变量Y 的相对变化率 D.Y关于X的弹性 8.双对数模型μ β β+ + =X Y ln ln ln 1 中,参数1 β的含义是(C ) A. Y关于X的增长率 B .Y关于X的发展速度 C. Y关于X的弹性 D. Y关于X 的边际变化 计量经济学研究方法一般步骤 四步12点 9.计量经济学的研究方法一般分为以下四个步骤( B ) A.确定科学的理论依据、模型设定、模型修定、模型应用 B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、检验、结构分析、模型应用 对计量经济模型应当进行哪些方面的检验? 经济意义检验:检验模型估计结果,尤其是参数估计,是否符合经济理论。 统计推断检验:检验参数估计值是否抽样的偶然结果,运用数理统计中的统计推断方法,对模型及参数的统计可靠性做出说明。主要有t,F ,R2等检验; 计量经济学检验:检验模型是否符合计量经济方法的基本假定,例如检验模型是否存在多重共线性,检验模型中的随机扰动项是否存在自相关和
计量经济学数据分析
计量经济学数据分析
计量经济学数据分析 学院:管理与经济学院 专业:技术经济及管理 姓名:葛文 学号:20808172
分析中国经济发展对中国股票市场的影响 本文通过分析2000年到2007年各月股票市场流通市值(value ),成交金额(turnover),GDP 现价和居民储蓄(saving)的相关数据,试图分析我国经济发展对股票市场的影响。数据来源为CCFR 数据库和证监会网站。具体分析如下: 一、绘制四个数据变量的线性图,查看2000年到2007年他们各自的走势。 5000 1000015000 20000250002000200120022003200420052006GDP 4000060000 80000 100000 120000 140000 160000 180000 2000200120022003200420052006SAVING 10000 20000 30000 40000 50000 60000 2000200120022003200420052006turnover 01000020000300004000050000600002000200120022003200420052006value 二、采用最小二乘法(OLS)进行分析
回归表达式:gdp=10433.48+0.191218*turnover 其中:Prob低于0.05,说明对应系数显著不为零;R2=0.195641,说明拟合程度一般;Prob(F-statistic)=0.000013<0.05,说明至少有一个解释变量的回归系数不为零。 回归表达式:gdp=8470.567+0.196853*value 其中:Prob低于0.05,说明对应系数显著不为零;R2=0.154730,说明拟合程度一般;Prob(F-statistic)=0.000125<0.05,说明至少有一个解释变量的回归系数不为零。
计量经济学 习题.
计量经济学 习题(史浩江版) 习题一 一. 单项选择题 1、横截面数据是指(A )。 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 2.对于 12i i i Y b b X e =++,以?σ表示回归标准误差,r 表示相关系数,则有(D )。 A ?0σ =时,r =1 B ?0σ=时,r =-1 C ?0σ =时,r =0 D ?0σ=时,r =1 或r =-1 3.决定系数2 R 是指(C )。 A 剩余平方和占总离差平方和的比重 B 总离差平方和占回归平方和的比重 C 回归平方和占总离差平方和的比重 D 回归平方和占剩余平方和的比重 4.下列样本模型中,哪一个模型通常是无效的B )。 A i C (消费)=500+0.8 i I (收入) B d i Q (商品需求)=10+0.8 i I (收入)+0.9i P (价格) C s i Q (商品供给)=20+0.75 i P (价格) D i Y (产出量)= 0.60.65i L (劳动) 0.4 i K (资本) 5.用一组有30 个观测值的样本估计模型12132i i i i Y B B X B X u =+++后,在0.05的显著性 水平下对2 b 的显著性作t 检验,则 2 b 显著地不等于零的条件是其统计量大于等于(C )。 A 0.05(30) t B 0.025(28) t C 0.025(27) t D 0.025(1,28) F 6.当DW =4时,说明(C ) A 不存在序列相关 B 不能判断是否存在一阶自相关 C 存在完全的正的一阶自相关 D 存在完全的负的一阶自相关
《计量经济学》第5章数据
《计量经济学》各章数据 第5章自相关性 例5.3.1中国城乡居民储蓄存款模型(自相关性检验)。表5.3.1列出了我国城乡居民储蓄存款年底余额(单位:亿元)和GDP指数(1978年=100)的历年统计资料,试建立居民储蓄存款模型,并检验模型的自相关性。 表5.3.1 我国城乡居民储蓄存款与GDP指数统计资料
5.5 案例分析:中国商品进口模型 商品进口是国际贸易交往的一种常用形式,对进口国来说,其经济发展水平决定商品进口情况。这里,研究我国进口商品IM 与国内生产总值GDP 的关系。有关数据见表5.5.1。试建立中国商品进口模型。 表5.5.1 1989-2006年我国商品进口与国内生产总值数据(亿元) 思考与练习 10. 表1给出了美国1958-1969年期间每小时收入指数的年变化率(y )和失业率(x ) 请回答以下问题: (1)估计模型t t t u x b b y ++=1 1 0中的参数10,b b (2)计算上述模型中的DW 值。 (3)上述模型是否存在一阶段自相关?如果存在,是正自相关还是负自相关? (4)如果存在自相关,请用DW 的估计值估计自相关系数ρ。 (5)利用广义差分法重新估计上述模型。自相关问题还存在吗? 表1 美国1958-1969年每小时收入指数变化率和失业率
11.考虑表2中所给数据: 表2 美国股票价格指数和GNP 数据 注:y-NYSE 10亿美元) (1)利用OLS 估计模型:t t t u x b b y ++=10 (2)根据DW 统计量确定在数据中是否存在一阶自相关。 (3)如果存在一阶自相关,用DW 值来估计自相关系数ρ?。 (4)利用估计的ρ ?值,用OLS 法估计广义差分方程: t t t t t v x x b b y y +-+-=---)?()?1(?1101ρρρ (5)利用一阶差分法将模型变换成方程: t t t t t v x x b y y +-=---)(111,或:t t t v x b y +?=?1 的形式,并对变换后的模型进行估计。比较(4)、(5)的回归结果,你能得出什么结论?在变换后的模型中还存在自相关吗?
计量经济学题库(超完整版)及答案.详解
计量经济学题库 计算与分析题(每小题10分) 1.下表为日本的汇率与汽车出口数量数据, X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2 Y Y 68113.6∑ (-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 R 2= F= 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2= 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 ()() n=19 R 2= 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。 问:(1)利用t 值检验参数β的显著性(α=);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=, 求判定系数和相关系数。
计量经济学数据建模分析
计量经济学数据建模分析 一、研究意义 试找出对外承包合同金额和外汇储备量二者与实际利用外资情况之间的关系,特此搜集了1985年至2011年的相关数据,来进一步分析三者的关系,即对外承包合同金额和外汇储备量对于实际利用外资情况有何影响。 二、计量模型分析 (一)变量的选取 影响实际利用外资情况的变量很多,在此只通过对外承包合同金额和外汇储备量这两个变量来进行分析影响实际利用外资情况的因素。 (二)理论模型的建立 建立一个二元的线性回归模型,即Y=β 0+β 1 X 1 +β 2 X 2 +μ Y:实际利用外资情况; X 1 :对外承包工程合同金额; X 2 :外汇储备量。 通过这个建模来分析对外承包合同金额和外汇储备量对于实际利用外资情况的影响。 (三)数据收集 该数据选自于中国国家统计局的统计年鉴,并按照时间序列进行排列,数据完整、精准、可靠。 年份对外承包工程合同金额外汇储备量实际利用外资情况1985 11.16 26.44 47.60 1986 11.89 20.72 76.28 1987 16.48 29.23 84.52 1988 18.13 33.72 102.26 1989 22.12 55.50 100.60 1990 26.04 110.93 102.89 1991 36.09 217.12 115.54 1992 65.85 194.43 192.03 1993 68.00 211.99 389.60 1994 79.88 516.20 432.13 1995 96.72 735.97 481.33 1996 102.73 1050.29 548.05
计量经济学(李子奈)第三版书中表格数据
计量经济学(第3版)例题和习题数据表
P24-25 表2.1.1 某社区家庭每月收入与消费支出统计表
表2.3.1 参数估计的计算表
表2.6.1 中国各地区城镇居民家庭人均全年可支配收入与人均全年消费性支出(元)
表2.6.3 中国居民总量消费支出与收入资料 单位:亿元年份GDP CONS CPI TAX GDPC X Y 19783605.6 1759.1 46.21519.28 7802.5 6678.83806.7 19794092.6 2011.5 47.07537.828694.2 7551.64273.2 19804592.9 2331.2 50.62571.70 9073.7 7944.24605.5 19815008.8 2627.9 51.90629.899651.8 8438.05063.9 19825590.0 2902.9 52.95700.02 10557.3 9235.25482.4 19836216.2 3231.1 54.00775.5911510.8 10074.65983.2 19847362.7 3742.0 55.47947.35 13272.8 11565.06745.7 19859076.7 4687.4 60.652040.79 14966.8 11601.77729.2 198610508.5 5302.1 64.572090.37 16273.7 13036.58210.9 198712277.4 6126.1 69.302140.36 17716.3 14627.78840.0 198815388.6 7868.1 82.302390.47 18698.7 15794.09560.5 198917311.3 8812.6 97.002727.40 17847.4 15035.59085.5 199019347.8 9450.9 100.002821.86 19347.8 16525.99450.9 199122577.4 10730.6 103.422990.17 21830.9 18939.610375.8 199227565.2 13000.1 110.033296.91 25053.0 22056.511815.3 199336938.1 16412.1 126.204255.30 29269.1 25897.313004.7 199450217.4 21844.2 156.655126.88 32056.2 28783.413944.2 199563216.9 28369.7 183.416038.04 34467.5 31175.415467.9 199674163.6 33955.9 198.666909.82 37331.9 33853.717092.5 199781658.5 36921.5 204.218234.04 39988.5 35956.218080.6 199886531.6 39229.3 202.599262.80 42713.1 38140.919364.1 199991125.0 41920.4 199.7210682.58 45625.8 40277.020989.3 200098749.0 45854.6 200.5512581.51 49238.0 42964.622863.9 2001108972.4 49213.2 201.9415301.38 53962.5 46385.424370.1 2002120350.3 52571.3 200.3217636.45 60078.0 51274.026243.2 2003136398.8 56834.4 202.7320017.31 67282.2 57408.128035.0 2004160280.4 63833.5 210.6324165.68 76096.3 64623.130306.2 2005188692.1 71217.5 214.4228778.54 88002.1 74580.433214.4 2006221170.5 80120.5 217.6534809.72 101616.3 85623.136811.2资料来源:根据《中国统计年鉴》(2001,2007)整理。
计量经济学截面数据异方差检验(借鉴资料)
某家庭对某种消费品的消费需要研究 一、经济理论陈述,变量确定 某家庭对某消费品的消费需要可以由该家庭的消费支出来表示,消费支出受商品价格、家庭月收入两个因素影响。用EVIEWS软件对相关数据进行了多元回归分析,得出了相关结论。 其中,被解释变量为:对某商品的消费支出(Y) 解释变量为:商品单价(X1)、家庭月收入(X2)二、模型形式的确定:散点图 通过OLS可得模型的散点图如下:
从散点图可以看出该家庭对某商品的消费支出(Y)和商品单价(X1)、家庭月收入(X2)大体呈现为线性关系, 三、建立模型 利用书P105页第11题数据,建立截面数据的计量经济模型,并进行回归分析。假设建立如下线性二元回归模型: Y=C+β1X1+β2X2+μ 其中,Y表示对某商品的消费支出,X1表示商品单价,X2表示家庭月收入,μ表示随机误差项。 1、参数估计: 假定所建模型及随机扰动项μ满足古典假定,可以用OLS 法估计其参数,运用计算机软件EViews作计量经济分析。通过OLS可得:
参数和估计结果为: =∧Y 626.5093-9.79057X1+0.028618X2 2、经济意义检验 所估计的参数β1=—9.79057,说明商品单价每提高1元,可导致对某商品的消费支出减少9.79057元。β2=0.028618,说明家庭月收入每提高1元,可导致对某商品的消费支出增加0.028618元,这与经济学中边际消费倾向的意义相符。 3、统计学检验 (1)拟合优度检验: 从回归估计的结果看,模型拟合较好:可决系数R 2=0.902218说明所建模型整体上对样本数据拟合较好,即解释变量“商
计量经济学自相关性检验实验报告
计量经济学 自相关性检验实验报告 实验内容:自相关性检验 工业增加值主要由全社会固定资产投资决定。为了考察全社会固 定资产投资对工业增加值的影响,可使用如下模型:Y i = 1 β β+ i X; 其中,X表示全社会固定资产投资,Y表示工业增加值。下表列出了中国1998-2000的全社会固定资产投资X与工业增加值Y的统计数据。 一、估计回归方程
OLS法的估计结果如下: Y=668.0114+1.181861X (2.24039)(61.0963) R2=0.994936,R2=0.994669,SE=951.3388,D.W.=1.282353。 二、进行序列相关性检验 (1)图示检验法
通过残差与残差滞后一期的散点图可以判断,随机干扰项存在正序列相关性。 (2)回归检验法 一阶回归检验 e=0.356978e1-t+εt t 二阶回归检验
e=0.572433e1-t-0.607831e2-t+εt t 可见:该模型存在二阶序列相关。 (3)杜宾-瓦森(D.W)检验法 由OLS法的估计结果知:D.W.=1.282353。本例中,在5%的显 =1.22,著性水平下,解释变量个数为2,样本容量为21,查表得d l d u=1.42,而D.W.=1.282353,位于下限与上限之间,不能确定相关性。(4)拉格朗日乘数(LM)检验法 F-statistic 6.662380 Probability 0.007304 Test Equation: Dependent Variable: RESID Method: Least Squares Date: 12/26/09 Time: 22:55 X 0.005520 0.015408 0.358245 0.7246 RESID(-1) 0.578069 0.195306 2.959807 0.0088 Adjusted R-squared 0.340473 S.D. dependent var 927.2503 S.E. of regression 753.0318 Akaike info criterion 16.25574 Sum squared resid 9639967. Schwarz criterion 16.45469 Log likelihood -166.6852 F-statistic 4.441587 由上表可知:含二阶滞后残差项的辅助回归为: e=-35.61516+0.05520X+0.578069e1-t-0.617998e2-t t (-0.1507) (0.3582) (2.9598) (-3.0757)
建立计量经济学模型的步骤和要点
建立计量经济学模型的步骤和要点 | [<<][>>] 一、理论模型的设计 对所要研究的经济现象进行深入的分析,根据研究的目的,选择模型中将包含的因素,根据数据的可得性选择适当的变量来表征这些因素,并根据经济行为理论和样本数据显示出的变量间的关系,设定描述这些变量之间关系的数学表达式,即理论模型。例如上节中的生产函数 就是一个理论模型。理论模型的设计主要包含三部分工作,即选择变量、确定变量之间的数学关系、拟定模型中待估计参数的数值范围。 1. 确定模型所包含的变量 在单方程模型中,变量分为两类。作为研究对象的变量,也就是因果关系中的“果”,例如生产函数中的产出量,是模型中的被解释变量;而作为“原因”的变量,例如生产函数中的资本、劳动、技术,是模型中的解释变量。确定模型所包含的变量,主要是指确定解释变量。可以作为解释变量的有下列几类变量:外生经济变量、外生条件变量、外生政策变量和滞后被解释变量。其中有些变量,如政策变量、条件变量经常以虚变量的形式出现。 严格他说,上述生产函数中的产出量、资本、劳动、技术等,只能称为“因素”,这些因素间存在着因果关系。为了建立起计量经济学模型,必须选择适当的变量来表征这些因素,这些变量必须具有数据可得性。于是,我们可以用总产值来表征产出量,用固走资产原值来表征资本,用职工人数来表征劳动,用时间作为一个变量来表征技术。这样,最后建立的模型是关于总产值、固定资产原值、职工人数和时间变量之间关系的数学表达式。下面,为了叙述方便,我们将“因素”与“变量”间的区别暂时略去,都以“变量”来表示。 关键在于,在确定了被解释变量之后,怎样才能正确地选择解释变量。
计量经济学(李子奈第4版)数据表(全)
计量经济学(第4版)数据表 表2.1.1 某社区家庭每月收入与消费支出统计表 每月家庭可支配收入X (元) 800 1100 1400 1700 2000 2300 2600 2900 3200 3500 每 月 家 庭 消 费 支 出 Y (元) 561 638 869 1023 1254 1408 1650 1969 2090 2299 594 748 913 1100 1309 1452 1738 1991 2134 2321 627 814 924 1144 1364 1551 1749 2046 2178 2530 638 847 979 1155 1397 1595 1804 2068 2266 2629 935 1012 1210 1408 1650 1848 2101 2354 2860 968 1045 1243 1474 1672 1881 2189 2486 2871 1078 1254 1496 1683 1925 2233 2552 1122 1298 1496 1716 1969 2244 2585 1155 1331 1562 1749 2013 2299 2640 1188 1364 1573 1771 2035 2310 1210 1408 1606 1804 2101 1430 1650 1870 2112 1485 1716 1947 2200 2002 共计 2420 4950 11495 16445 19305 23870 25025 21450 21285 15510 表2.3.1 参数估计的计算表 i X i Y i x i y i i y x 2i x 2i y 2i X 2i Y 1 800 638 -1350 -945 892836 640000 407044 2 1100 935 -1050 -648 680295 419774 874225 3 1400 1155 -750 -428 320925 562500 183098 4 1700 1254 -450 -329 14800 5 202500 108175 5 2000 1408 -150 -175 26235 22500 30590 6 2300 1650 150 6 7 10065 22500 4502 7 2600 1925 450 342 153945 202500 117032 8 2900 2068 750 485 363825 562500 235322 9 3200 2266 1050 683 717255 466626 10 3500 2530 1350 947 896998 求和 21500 15829 平均 2150 1583
计量经济学:自相关
自相关 前面几章的讨论中,我们假定随机误差项前后期之间是不相关的。但在经济系统中,经济变量前后期之间很可能有关联,使得随机误差项不能满足无自相关的假定。本章将探讨随机误差项不满足无自相关的古典假定时的参数估计问题。 第一节什么是自相关 一、自相关的概念 自相关(auto correlation)又称序列相关(serial correlation),是指总体回归模型的随机u之间存在相关关系。前面几章中强调,在回归模型的古典假定中是假设随机误差误差项 i
项是无自相关的,即i u 在不同观测点之间是不相关的,即 0),(),(==j i j i u u E u u Cov (j i ≠) (见2.15) 如果该假定不能满足,就称i u 与j u 存在自相关,即不同观测点上的误差项彼此相关。 自相关的程度可用自相关系数去表示,随机误差项t u 与滞后一期的1-t u 的自相关系数为 ∑∑∑=-==-= n t t n t t n t t t u u u u 2 2 122 21 ρ (6.1) (6.1)式定义的自相关系数ρ与普通相关系数的公式形式相同,ρ的取值范围为 11≤≤-ρ。(6.1)式中u t -1是u t 滞后一期的随机误差项,因此,将(6.1)式计算的自相关 系数ρ称为一阶自相关系数。 根据自相关系数ρ的符号可以判断自相关的状态,如果ρ<0,则u t 与u t -1为负相关;如果ρ>0,则u t 与u t -1为正关;如果ρ= 0,则u t 与u t -1不相关。 二、自相关产生的原因 1、经济系统的惯性 自相关现象大多出现在时间序列数据中,而经济系统的经济行为都具有时间上的惯性。例如GDP 、价格、就业等经济数据,都会随经济系统的周期而波动。又如,在经济高涨时期,较高的经济增长率会持续一段时间,而在经济衰退期,较高的失业率也会持续一段时间,这种情况下经济数据很可能表现为自相关。 2、经济活动的滞后效应。 滞后效应是指某一变量对另一变量的影响不仅限于当期,而是延续若干期。由此带来变量的自相关。例如,居民当期可支配收入的增加,不会使居民的消费水平在当期就达到应有水平,而是要经过若干期才能达到。因为人的消费观念的改变存在一定的适应期。 3、数据处理造成的相关。 因为某些原因对数据进行了修正和内插处理,在这样的数据序列中可能产生自相关。例如,将月度数据调整为季度数据,由于采用了加合处理,修匀了月度数据的波动,使季度数据具有平滑性,这种平滑性可能产生自相关。对缺失的历史资料,采用特定统计方法进行内插处理,也可能使得数据前后期相关,而产生自相关。 4、蛛网现象。