指导应用时间序列分析资料报告习题问题详解解析汇报

第二章习题答案
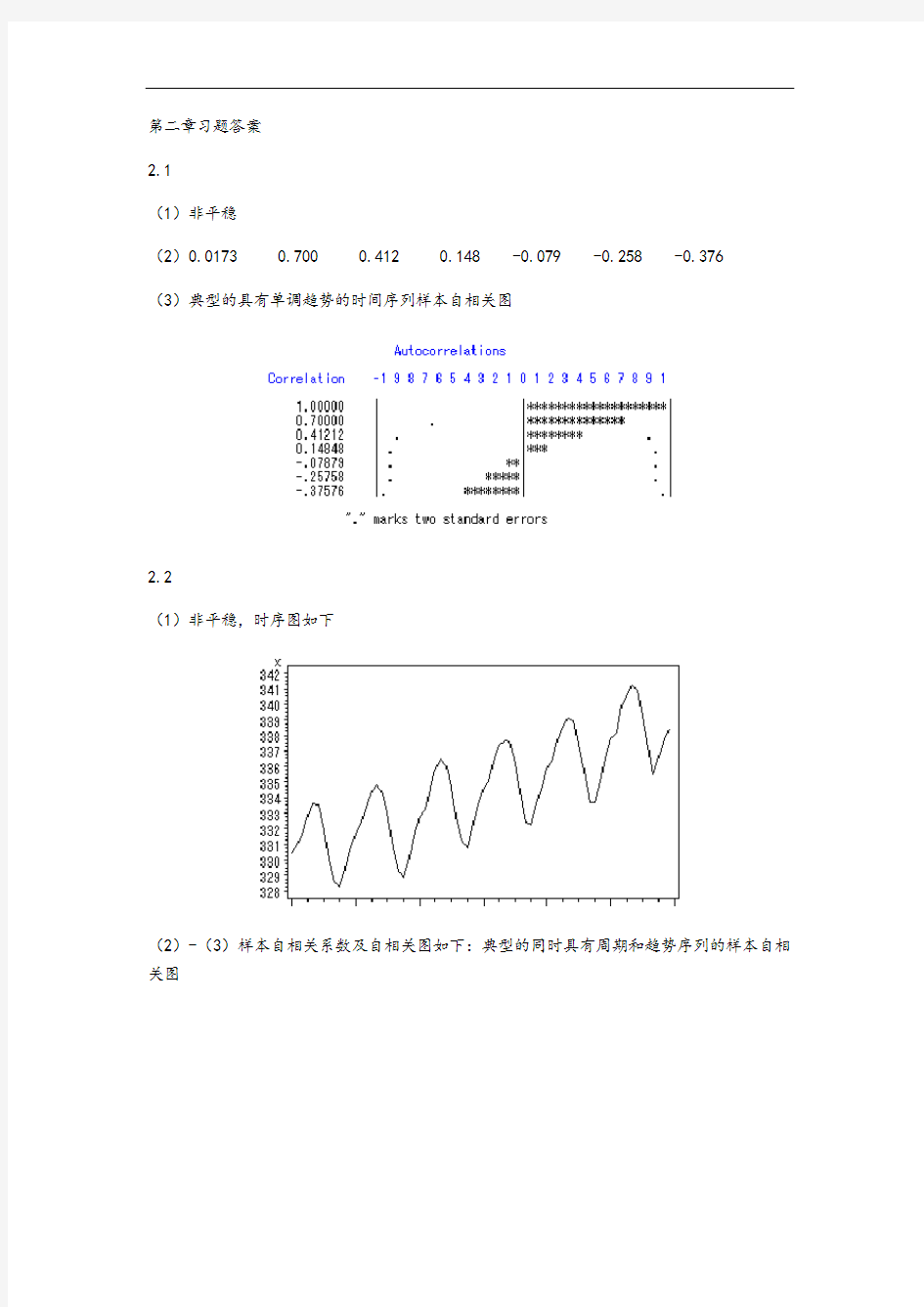
2.1
(1)非平稳
(2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376
(3)典型的具有单调趋势的时间序列样本自相关图
2.2
(1)非平稳,时序图如下
(2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
2.3
(1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118
(2)平稳序列
(3)白噪声序列
2.4
,序列
LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。显著性水平=0.05
不能视为纯随机序列。
2.5
(1)时序图与样本自相关图如下
(2) 非平稳 (3)非纯随机 2.6
(1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机
第三章习题答案
3.1 解:1()0.7()()t t t E x E x E ε-=?+
0)()7.01(=-t x E 0)(=t x E t t x ε=-)B 7.01(
t t t B B B x εε)7.07.01()7.01(221 +++=-=- 229608.149
.011
)(εεσσ=-=
t x Var
49.00212==ρφρ 022=φ
3.2 解:对于AR (2)模型:
??
?=+=+==+=+=-3.05
.021102112
12112011φρφρφρφρρφφρφρφρ 解得:???==15
/115/721φφ
3.3 解:根据该AR(2)模型的形式,易得:0)(=t x E
原模型可变为:t t t t x x x ε+-=--2115.08.0
2212122
)
1)(1)(1(1)(σφφφφφφ-+--+-=
t x Var
2)
15.08.01)(15.08.01)(15.01()
15.01(σ+++--+=
=1.98232σ
?????=+==+==-=2209.04066.06957.0)1/(122130
2112211ρφρφρρφρφρφφρ ??
???=-====015.06957.033222111φφφρφ 3.4 解:原模型可变形为:
t t x cB B ε=--)1(2
由其平稳域判别条件知:当1||2<φ,112<+φφ且112<-φφ时,模型平稳。 由此可知c 应满足:1|| 3.5证明:已知原模型可变形为: t t x cB cB B ε=+--)1(3 2 其特征方程为:0))(1(223=-+-=+--c c c λλλλλλ 不论c 取何值,都会有一特征根等于1,因此模型非平稳。 3.6 解:(1)错,)1/()(220 1θσγε-==t x Var 。 (2)错,)1/()])([(2 1210111θσθγργμμε-===---t t x x E 。 (3)错,T l T x l x 1)(?θ=。 (4)错,112211)(+--+-++++++=T l l T l T l T T G G G l e εεεε =11122111+--+-++++++T l l T l T l T εθεθεθε (5)错,2 21221 21111]1[1lim )]([lim )](?[lim εεσθσθθ-=--==-∞→∞→+∞ →l l T l T l T l l e Var l x x Var 。 3.7解:12411112112 11 1-=-+-=?+-=ρρθθθρ MA(1)模型的表达式为:1-+=t t t x εε。 3.8解法1:由1122=+t t t t x μεθεθε----,得111223=+t t t t x μεθεθε------,则 111212230.5=0.5+(0.5)(0.5)+0.5t t t t t t x x μεθεθθεθε------+--, 与123=10+0.5+0.8+t t t t t x x C εεε----对照系数得 12120.510,0.500.50.80.5C μθθθθ=??+=??-=??=?,故1 2 20, 0.5,0.55,0.275C μθθ=??=-??=??=?。 解法2:将123100.50.8t t t t t x x C εεε---=++-+等价表达为 ()23 23223310.82010.510.8(10.50.50.5)t t t B CB x B B CB B B B εε-+-=-=-+++++ 展开等号右边的多项式,整理为 2233 4423243 4 10.50.50.50.50.80.80.50.80.50.5B B B B B B B CB CB +++++ --?-?- ++ + 合并同类项,原模型等价表达为 2 330 20[10.50.550.5(0.50.4)]k k t t k x B B C B ε∞ +=-=+-+-+∑ 当30.50.40C -+=时,该模型为(2)MA 模型,解出0.275C =。 3.9解::0)(=t x E 22222 1 65.1)1()(εεσσθθ=++=t x Var 5939.065.198 .012 2 212111-=-=+++-= θθθθθρ 2424.065 .14.01222122==++-= θθθρ 30≥=k k ,ρ。 3.10解法1:(1))(21 +++=--t t t t C x εεε )(3211 +++=----t t t t C x εεε 11111)1(------++=??? ??+-+=t t t t t t t t C x C x C x εεεεε 即 t t B C x B ε])1(1[)1(--=- 显然模型的AR 部分的特征根是1,模型非平稳。 (2) 11)1(---+=-=t t t t t C x x y εε为MA(1)模型,平稳。 2 21 122111+--=+-= C C C θθρ 解法2:(1)因为22()lim(1)t k Var x kC εσ→∞ =+=∞,所以该序列为非平稳序列。 (2)11(1)t t t t t y x x C εε--=-=+-,该序列均值、方差为常数, ()0t E y =,22 ()1(1)t Var y C εσ??=+-?? 自相关系数只与时间间隔长度有关,与起始时间无关 12 1 ,0,2 1(1)k C k C ρρ-= =≥+- 所以该差分序列为平稳序列。 3.11解:(1)12.1||2>=φ,模型非平稳; =1λ 1.3738 =2λ-0.8736 (2)13.0||2<=φ,18.012<=+φφ,14.112<-=-φφ,模型平稳。 =1λ0.6 =2λ0.5 (3)13.0||2<=θ,16.012<=+θθ,12.112<-=-θθ,模型可逆。 =1λ0.45+0.2693i =2λ0.45-0.2693i (4)14.0||2<=θ,19.012<-=+θθ,17.112>=-θθ,模型不可逆。 =1λ0.2569 =2λ-1.5569 (5)17.0||1<=φ,模型平稳;=1λ0.7 16.0||1<=θ,模型可逆;=1λ0.6 (6)15.0||2<=φ,13.012<-=+φφ,13.112>=-φφ,模型非平稳。 =1λ0.4124 =2λ-1.2124 11.1||1>=θ,模型不可逆;=1λ 1.1。 3.12 解法1: 01G =,11010.60.30.3G G φθ=-=-=, 1111110.30.6,2k k k k G G G k φφ---===?≥ 所以该模型可以等价表示为:10 0.30.6k t t t k k x εε ∞ --==+ ?∑。 解法2:t t B x B ε)3.01()6.01(-=- t t B B B x ε)6.06.01)(3.01(22 +++-= t B B B ε)6.0*3.06.0*3.03.01(322 ++++= j t j j t -∞ =-∑+=εε1 16.0*3.0 10=G ,16.0*3.0-=j j G 3.13解:3)()5.01(])(3[])([2 =-?Θ+=Φt t t x E B E x B E ε 12)(=t x E 。 3.14 证明:已知11 2 φ= ,114θ=,根据(1,1)ARMA 模型Green 函数的递推公式得: 01G =,2110110.50.25G G φθφ=-=-=,1111111,2k k k k G G G k φφφ-+-===≥ 01ρ= 5 2 23211 1 1 1 22450 11111142422(1) 11112 011170.27126111j j j j j j j j j G G G φφφ φφφφφρφφφφφ∞ ∞ ++==∞ ∞ +==++ --+= = ====-+++ -∑∑∑∑ () 1 1 1 1 112220 ,2j j k j j k j j k j j j k k j j j j j j G G G G G G k G G G φρφφρ∞ ∞ ∞ ++-+-===-∞ ∞ ∞==== = ==≥∑∑∑∑∑∑ 3.15 (1)成立 (2)成立 (3)成立 (4)不成立 3.16 解:(1)t t t x x ε+-=--)10(*3.0101, 6.9=T x 88.9])10(*3.010[)()1(?11=+-+==++T T t T x E x E x ε 964.9])10(*3.010[)()2(?212=+-+==+++T T t T x E x E x ε 9892.9])10(*3.010[)()3(?323=+-+==+++T T t T x E x E x ε 已知AR(1)模型的Green 函数为:j j G 1φ=, ,,21=j 121213122130)3(++++++++=++=t t t t t t T G G G e εφεφεεεε 8829.99*)09.03.01()]3([22=++=T e Var 3+t x %的置信区间:的95[9.9892-1.96*8829.9,9.9892+1.96*8829.9] 即[3.8275,16.1509] (2)62.088.95.10)1(?11=-=-=++T T T x x ε 15.10964.962.0*3.0)()1(?21=+==++t T x E x 045.109892.962.0*09.0)()2(?31=+==++t T x E x 81.99*)3.01()]2([22=+=+T e Var 3+t x %的置信区间:的95[10.045-1.96×81.9,10.045+1.96*81.9] 即[3.9061,16.1839]。 3.17 (1)平稳非白噪声序列 (2)AR(1) (3) 5年预测结果如下: 3.18 (1)平稳非白噪声序列 (2)AR(1) (3) 5年预测结果如下: 3.19 (1)平稳非白噪声序列 (2)MA(1) (3) 下一年95%的置信区间为(80.41,90.96) 3.20 (1)平稳非白噪声序列 (2)ARMA(1,3)序列 (3)拟合及5年期预测图如下: 第四章习题答案 4.1 解: 1123 1 ?() 4 T T T T T x x x x x +--- =+++ 2112123 15551 ??() 416161616 T T T T T T T T T x x x x x x x x x ++----- =+++=+++ 所以,在2 ? T x +中T x 与1 T x -前面的系数均为 5 16。 4.2 解由 111(1)(1)t t t t t t x x x x x x αααα-++=+-?? =+-? 代入数据得 5.255(1)5.26 5.5(1)t t x x αααα=+-?? =+-? 解得 5.10.4(1)t x αα=? ? =>? 舍去的情况 4.3 解:(1) 21201918171611 ?(+)13+11+10+10+12=11.2 55x x x x x x =+++=() 22212019181711??(+).2+13+11+10+10=11.04 55x x x x x x =+++=(11) (2)利用 1 0.40.6t t t x x x -=+且初始值 01 x x =进行迭代计算即可。另外,22 2120??x x x == 该 题详见Excel 。11.79277 (3)在移动平均法下: 19212016 19 2221201711?55111??555i i i i X X X X X X X ===+=++∑∑ 111655525a =+?= 在指数平滑法中: 22 21202019??0.40.6x x x x x ===+ 0.4b ∴= 6 0.40.1625b a ∴-=-=。 4.4 解:根据指数平滑的定义有(1)式成立,(1)式等号两边同乘(1)α-有(2)式成立 232 3 (1)(1)(2)(1)(2)(1)(1)(1)(1)(1)(1)(2)(1)(2) t t x t t t t x t t t αααααααααααααα=+--+--+--+-= -+--+--+ (1)-(2)得 22(1)(1)(1)(1)1t t x t x t t ααααααααα α =----- =------= - 则1lim lim 1t t t t x t t αα→∞→∞-??- ? == ? ?? ? 。 4.5 该序列为显著的线性递增序列,利用本章的知识点,可以使用线性方程或者holt 两参数指数平滑法进行趋势拟合和预测,答案不唯一,具体结果略。 4.6 该序列为显著的非线性递增序列,可以拟合二次型曲线、指数型曲线或其他曲线,也能使用holt 两参数指数平滑法进行趋势拟合和预测,答案不唯一,具体结果略。 4.7 本例在混合模型结构,季节指数求法,趋势拟合方法等处均有多种可选方案,如下做法仅是可选方法之一,结果仅供参考 (1)该序列有显著趋势和周期效应,时序图如下 (2)该序列周期振幅几乎不随着趋势递增而变化,所以尝试使用加法模型拟合该序列:t t t t x T S I =++。(注:如果用乘法模型也可以) 首先求季节指数(没有消除趋势,并不是最精确的季节指数) 0.960722 0.912575 1.038169 1.064302 1.153627 1.116566 1.04292 0.984162 0.930947 0.938549 0.902281 0.955179 消除季节影响,得序列t t t y x S x =-,使用线性模型拟合该序列趋势影响(方法不唯一): 97.70 1.79268t T t =-+,1,2,3, t = (注:该趋势模型截距无意义,主要是斜率有意义,反映了长期递增速率) 得到残差序列t t t t t I x S x y T =-=-,残差序列基本无显著趋势和周期残留。 预测1971年奶牛的月度产量序列为() mod 12?,109,110,,120t t t x T S x t =+= 得到 771.5021 739.517 829.4208 849.5468 914.0062 889.7989 839.9249 800.4953 764.9547 772.0807 748.4289 787.3327 (3)该序列使用x11方法得到的趋势拟合为 趋势拟合图为 4.8 这是一个有着曲线趋势,但是有没有固定周期效应的序列,所以可以在快速预测程序中用曲线拟合(stepar )或曲线指数平滑(expo )进行预测(trend=3)。具体预测值略。 第五章习题 5.1 拟合差分平稳序列,即随机游走模型 -1=+t t t x x ε,估计下一天的收盘价为289 5.2 拟合模型不唯一,答案仅供参考。 拟合ARIMA(1,1,0)模型,五年预测值为: 5.3 12(1,1,0)(1,1,0)ARIMA ? 5.4 (1)AR(1), (2)有异方差性。最终拟合的模型为 -1 2 -1 =7.472+ =-0.5595+ = =11.9719+0.4127 t t t t t t t t t t x v v h e h v ε εε ? ? ? ? ? ? ? 5.5(1)非平稳 (2)取对数消除方差非齐,对数序列一节差分后,拟合疏系数模型AR(1,3)所以拟合模型为 ln~((1,3),1,0) x ARIMA (3)预测结果如下: 5.6 原序列方差非齐,差分序列方差非齐,对数变换后,差分序列方差齐性。 第六章习题 6.1 单位根检验原理略。 例2.1 原序列不平稳,一阶差分后平稳 例2.2 原序列不平稳,一阶与12步差分后平稳 例2.3 原序列带漂移项平稳 例2.4 原序列不带漂移项平稳 例2.5 原序列带漂移项平稳(=0.06) α,或者显著的趋势平稳。 6.2 (1)两序列均为带漂移项平稳 (2)谷物产量为带常数均值的纯随机序列,降雨量可以拟合AR (2)疏系数模型。 (3)两者之间具有协整关系 (4)23.55210.775549t t =+谷物产量降雨量 6.3 (1)掠食者和被掠食者数量都呈现出显著的周期特征,两个序列均为非平稳序列。但是掠食者和被掠食者延迟2阶序列具有协整关系。即-2{-}t t y x β为平稳序列。 (2)被掠食者拟合乘积模型:5(0,1,0)(1,1,0)ARIMA ?,模型口径为: 551 = 1+0.92874t t x B ε?? 拟合掠食者的序列为: -2-1=2.9619+0.283994+-0.47988t t t t y x εε 未来一周的被掠食者预测序列为: Forecasts for variable x Obs Forecast Std Error 95% Confidence Limits 49 70.7924 49.4194 -26.0678 167.6526 50 123.8358 69.8895 -13.1452 260.8167 51 195.0984 85.5968 27.3317 362.8651 52 291.6376 98.8387 97.9173 485.3579 53 150.0496 110.5050 -66.5363 366.6355 54 63.5621 122.5322 -176.5965 303.7208 55 80.3352 133.4800 -181.2807 341.9511 56 55.5269 143.5955 -225.9151 336.9690 57 73.8673 153.0439 -226.0932 373.8279 58 75.2471 161.9420 -242.1534 392.6475 59 70.0053 189.8525 -302.0987 442.1094 60 120.4639 214.1559 -299.2739 540.2017 61 184.8801 235.9693 -277.6112 647.3714 62 275.8466 255.9302 -225.7674 777.4606 掠食者预测值为: Forecasts for variable y Obs Forecast Std Error 95% Confidence Limits 49 32.7697 14.7279 3.9036 61.6358 50 40.1790 16.3381 8.1570 72.2011 51 42.3346 21.8052 -0.4028 85.0721 52 58.2993 25.9832 7.3732 109.2254 53 78.9707 29.5421 21.0692 136.8722 54 106.5963 32.7090 42.4879 170.7047 55 66.4836 35.5936 -3.2787 136.2458 56 41.9681 38.6392 -33.7634 117.6996 57 46.7548 41.4617 -34.5085 128.0182 58 39.7201 44.1038 -46.7218 126.1619 59 44.9342 46.5964 -46.3930 136.2614 60 45.3286 48.9622 -50.6356 141.2928 61 43.8411 56.4739 -66.8456 154.5279 62 58.1725 63.0975 -65.4964 181.8413 6.4 (1)进出口总额序列均不平稳,但对数变换后的一阶差分后序列平稳。所以对这两个 序列取对数后进行单个序列拟合和协整检验。 (2)出口序列拟合的模型为ln ~(1,1,0)t x ARIMA ,具体口径为: 1 ln =0.14689+ 1-0.38845t t x B ε? 进口序列拟合的模型为ln ~(1,1,0)t y ARIMA ,具体口径为: 1 ln =0.14672+ 1-0.36364t t y B ε? (3)ln t y 和ln t x 具有协整关系 (4)协整模型为:-1ln =0.99179ln +-0.69938t t t t y x εε (5)误差修正模型为:-1ln =0.97861ln -0.22395ECM t t t y x ?? 应用时间序列分析实验报告 单位根检验输出结果如下:序列x的单位根检验结果: 1967 58.8 53.4 1968 57.6 50.9 1969 59.8 47.2 1970 56.8 56.1 1971 68.5 52.4 1972 82.9 64.0 1973 116.9 103.6 1974 139.4 152.8 1975 143.0 147.4 1976 134.8 129.3 1977 139.7 132.8 1978 167.6 187.4 1979 211.7 242.9 1980 271.2 298.8 1981 367.6 367.7 1982 413.8 357.5 1983 438.3 421.8 1984 580.5 620.5 1985 808.9 1257.8 1986 1082.1 1498.3 1987 1470.0 1614.2 1988 1766.7 2055.1 1989 1956.0 2199.9 1990 2985.8 2574.3 1991 3827.1 3398.7 1992 4676.3 4443.3 1993 5284.8 5986.2 1994 10421.8 9960.1 1995 12451.8 11048.1 1996 12576.4 11557.4 1997 15160.7 11806.5 1998 15223.6 11626.1 1999 16159.8 13736.5 2000 20634.4 18638.8 2001 22024.4 20159.2 2002 26947.9 24430.3 2003 36287.9 34195.6 2004 49103.3 46435.8 2005 62648.1 54273.7 2006 77594.6 63376.9 2007 93455.6 73284.6 2008 100394.9 79526.5 run; proc gplot; plot x*t=1 y*t=2/overlay; symbol1c=black i=join v=none; symbol2c=red i=join v=none w=2l=2; run; proc arima data=example6_4; identify var=x stationarity=(adf=1); identify var=y stationarity=(adf=1); run; proc arima; identify var=y crrosscorr=x; estimate methed=ml input=x plot; forecast lead=0id=t out=out; proc aima data=out; identify varresidual stationarity=(adf=2); run; 时间序列分析实验指导 4 2 -2 -4 50100150200250 统计与应用数学学院 前言 随着计算机技术的飞跃发展以及应用软件的普及,对高等院校的实验教学提出了越来越高的要求。为实现教育思想与教学理念的不断更新,在教学中必须注重对大学生动手能力的培训和创新思维的培养,注重学生知识、能力、素质的综合协调发展。为此,我们组织统计与应用数学学院的部分教师编写了系列实验教学指导书。 这套实验教学指导书具有以下特点: ①理论与实践相结合,书中的大量经济案例紧密联系我国的经济发展实际,有利于提高学生分析问题解决问题的能力。 ②理论教学与应用软件相结合,我们根据不同的课程分别介绍了SPSS、SAS、MATLAB、EVIEWS等软件的使用方法,有利于提高学生建立数学模型并能正确求解的能力。 这套实验教学指导书在编写的过程中始终得到财经大学教务处、实验室管理处以及统计与应用数学学院的关心、帮助和大力支持,对此我们表示衷心的感! 限于我们的水平,欢迎各方面对教材存在的错误和不当之处予以批评指正。 统计与数学模型分析实验中心 2007年2月 目录 实验一 EVIEWS中时间序列相关函数操作 【实验目的】熟悉Eviews的操作:菜单方式,命令方式; 练习并掌握与时间序列分析相关的函数操作。 【实验容】 一、EViews软件的常用菜单方式和命令方式; 二、各种常用差分函数表达式; 三、时间序列的自相关和偏自相关图与函数; 【实验步骤】 一、EViews软件的常用菜单方式和命令方式; ㈠创建工作文件 ⒈菜单方式 启动EViews软件之后,进入EViews主窗口 在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框,由用户选择数据的时间频率(frequency)、起始期和终止期。选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日期,然后点击OK按钮,将在EViews 软件的主显示窗口显示相应的工作文件窗口。 工作文件窗口是EViews的子窗口,工作文件一开始其中就包含了两个对象,一个是系数向量C(保存估计系数用),另一个是残差序列RESID(实际值与拟合值之差)。 ⒉命令方式 在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。命令格式为:CREATE 时间频率类型起始期终止期 则菜单方式过程可写为:CREATE A 1985 1998 ㈡输入Y、X的数据 ⒈DATA命令方式 在EViews软件的命令窗口键入DATA命令,命令格式为: DATA <序列名1> <序列名2>…<序列名n> 《时间序列分析》课程实验报告 一、上机练习(P124) 1.拟合线性趋势 12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 程序: data xiti1; input x@@; t=_n_; cards; 12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 ; proc gplot data=xiti1; plot x*t; symbol c=red v=star i=join; run; proc autoreg data=xiti1; model x=t; output predicted=xhat out=out; run; proc gplot data=out; plot x*t=1 xhat*t=2/overlay; symbol2c=green v=star i=join; run; 运行结果: 分析:上图为该序列的时序图,可以看出其具有明显的线性递增趋势,故使用线性模型进行拟合:x t=a+bt+I t,t=1,2,3,…,12 分析:上图为拟合模型的参数估计值,其中a=9.7086,b=1.9829,它们的检验P值均小于0.0001,即小于显著性水平0.05,拒绝原假设,故其参数均显著。从而所拟合模型为:x t=9.7086+1.9829t. 分析:上图中绿色的线段为线性趋势拟合线,可以看出其与原数据基本吻合。 2.拟合非线性趋势 1.85 7.48 14.29 23.02 37.42 74.27 140.72 265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 程序: data xiti2; input x@@; t=_n_; cards; 1.85 7.48 14.29 23.02 37.42 74.27 140.72 265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 ; proc gplot data=xiti2; plot x*t; symbol c=red v=star i=none; run; proc nlin method=gauss; model x=a*b**t; parameters a=0.1 b=1.1; der.a=b**t; der.b=a*t*b**(t-1); output predicted=xh out=out; run; proc gplot data=out; plot x*t=1 xh*t=2/overlay; 时间序列分析实验报告 P185#1、某股票连续若干天的收盘价如表5-4 (行数据)所示。 表5-4 304 303 307 299 296 293301 293 301 295 284286 286 287 284 282278 281 278 277279 278 270 268 272 273 279 279280 275 271 277 278279 283 284 282 283279 280 280 279278 283 278 270 275 273 273 272275 273 273 272 273272 273 271 272 271273 277 274 274272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 选择适当模型拟合该序列的发展,并估计下一天的收盘价。 解: (1)通过SA漱件画出上述序列的时序图如下: 程序: data example5_1; in put x@@; time=_ n_; cards ; 304 303 307 299296 293 301 293 301 295 284286286 287 284 282 278 281 278277 279 278 270 268 272 273279279 280 275 271 277 278 279283 284 282 283 279 280 280279278 283 278 270 275 273 273272 275 273 273 272 273 272273271 272 271 273 277 274 274272 280 282 292 295 295 294290291 288 288 290 293 288 289291 293 293 290 288 287 289292288 288 285 282 286 286 287284 283 286 282 287 286 287292292 294 291 288 289 proc gplot data =example5_1; plot x*time= 1; symbol1 c=black v=star i =join; run ; 上述程序所得时序图如下: 上述时序图显示,该序列具有长期趋势又含有一定的周期性,为典型的非平稳序列。又因为该序列呈现曲线形式,所以选择2阶差分。 课程论文时间序列分析 题目时间序列模型在人口增长中的应用学院数学与统计学院 专业统计学 班级统计(二)班 学生殷婷 2010101217 指导教师翠霞 职称 2012 年10 月29 日 引言 人口问题是一个世界各国普遍关注的问题。人作为一种资源,主要体现在人既是生产者,又是消费者。作为生产者,人能够发挥主观能动性,加速科技进步,促进社会经济的发展;作为消费者,面对有限的自然资源,人在发展的同时却又不得不考虑人口数量的问题。我国是一个人口大国,人口数量多,增长快,人口素质低;由于人口众多,不仅造成人均资源的数量很少,而且造成住房、教育、就业等方面的很大压力。所以人口数量是社会最为关注的问题,每年新增加的国民生产总值有相当一部分被新增加的人口所抵消,从而造成社会再生产投入不足,严重影响了国民经济的可持续发展。因此,认真分析研究我国目前的人口发展现状和特点,采取切实可行的措施控制人口的高速增长,已经成为我国目前经济发展中需要解决的首要问题。 本文通过时间序列模型对人口的增长进行预测,国家制定未来人口发展目标和生育政策等有关人口政策的基础,对于国民经济计划的制定和社会战略目标的决策具有重要参考价值。人口的预测,作为经济、社会研究的需要,应用越来越广泛,也越来越受到人们的重视。在描绘未来小康社会的蓝图时,首先应要考虑的是未来中国的人口数量、结构、分布、劳动力、负担系数等等,而这又必须通过人口的预测来一一显示。人口数量在时间上的变化,可以用时间序列模型来预测其继后期的数量。 本文通过时间序列分析的方法对人口增长建立模型,取得了较好 的预测结果。时间序列分析是研究动态数据的动态结构和发展变化规律的统计方法。以1990年至2008年中国人口总数为例,用时间序列分析Eviews软件建立模型,并对人口的增长进行预测,研究时间序列模型在人口增长中的应用。 基本假设 (1) 在预测中国人口的增长趋势时,假设全国人口数量的变化是封闭的即人口的出生率和死亡率是自然变化的,而不考虑与其他国家的迁移状况; (2)在预测的年限,不会出现意外事件使人口发生很大的波动,如战争,疾病; (3) 题目数据能够代表全国的整体人数。。 问题分析 根据抽样的基本原理,预测人口增长趋势最直接的方法就是预测出人口总数的增长量,因此我们运用中华人民国国家统计局得到的1990年到2008年度总人口数据。考虑到迁移率、死亡率、出生率、年龄结构等多个因素对人口数量的影响,求解人口增长趋势的关键是如何在我们的模型中充分的利用这些影响因素从而使我们的预测结果具有较高的精确性。 研究数据: 《统计软件实验报告》SPSS软件的上机实践应用 时间序列分析 数学与统计学学院 一、实验内容: 时间序列是指一个依时间顺序做成的观察资料的集合。时间序列分析过程中最常用的方法是:指数平滑、自回归、综合移动平均及季节分解。 本次实验研究就业理论中的就业人口总量问题。但人口经济的理论和实践表明,就业总量往往受到许多因素的制约,这些因素之间有着错综复杂的联系,因此,运用结构性的因果模型分析和预测就业总量往往是比较困难的。时间序列分析中的自回归求积分移动平均法(ARIMA)则是一个较好的选择。对于时间序列的短期预测来说,随机时序ARIMA是一种精度较高的模型。 我们已辽宁省历年(1969-2005)从业人员人数为数据基础建立一个就业总量的预测时间序列模型,通过spss建立模型并用此模型来预测就业总量的未来发展趋势。 二、实验目的: 1.准确理解时间序列分析的方法原理 2.学会实用SPSS建立时间序列变量 3.学会使用SPSS绘制时间序列图以反应时间序列的直观特征。 4.掌握时间序列模型的平稳化方法。 5.掌握时间序列模型的定阶方法。 6.学会使用SPSS建立时间序列模型与短期预测。 7.培养运用时间序列分析方法解决身边实际问题的能力。 三、实验分析: 总体分析: 先对数据进行必要的预处理和观察,直到它变成稳态后再用SPSS对数据进行分析。 数据的预处理阶段,将它分为三个步骤:首先,对有缺失值的数据进行修补,其次将数据资料定义为相应的时间序列,最后对时间序列数据的平稳性进行计算观察。 数据分析和建模阶段:根据时间序列的特征和分析的要求,选择恰当的模型进行数据建模和分析。 四、实验步骤: SPSS的数据准备包括数据文件的建立、时间定义和数据期间的指定。 SPSS的时间定义功能用来将数据编辑窗口中的一个或多个变量指定为时间序列变量,并给它们赋予相应的时间标志,具体操作步骤是: 1.选择菜单:Date→Define Dates,出现窗口: 中国铁路客运量的时间序列分析辜予薇1303050225统计0502 摘要 首先,本文对中国铁路客运的现状及影响客运量的因素作了简要的分析,并说明了运用时间序列分析方法对中国铁路客运量作预测的现实意义。 接下来,文中收集到了从2002年1月至2008年10月中国铁路客运量的数据,经过一系列分析,对野值进行了相应的替换,并通过平稳化和零均值化将原序列转化为适宜建立时间序列模型的新序列X。 然后,本文用Box-Jekins方法对序列X进行初步识别,拟合出基本模型,并使用F检验定阶法和最佳准则函数定阶法确定模型的阶数,建立了AR(1)模型。 其后,本文还使用Pandit-Wu方法建立起了ARMA(4,3)模型,并将此模型与之前的AR(1)模型作了简单的对比。 在模型建立后,本文分别用两个模型进行了内插和外推预测,比较了它们的预测误差,最后肯定了ARMA(4,3)模型的优越性,并对预测结果进行了简单的分析,提出了自己的建议。 关键词平稳化 Box-Jekins F检验最佳准则函数 Pandit-Wu 预测 1引言 铁路由于具有运距长、全天候、安全性强、运能大、受自然铁条件影响小的优点,在众多的交通工具中具有得天独厚的优势,无论在货运和客运上,都受到社会公众的亲睐。[1]而铁路客运又是我国交通运输体系中与老百姓联系最紧密的运输方式,无论远赴他乡的学子,还是行色匆匆的打工仔,都于长长的列车有着不解之缘。 而我们知道,在高峰时期购票难的问题一直困扰着广大的出行者,现时值春运,国家和有关部门及时获取信息,有效地统筹安排铁道和列车资源就显得尤为重要。 我们认为,在众多的信息中,打算乘火车出行的人数是一个关键,它直接关系着有关部门需要开派多少车的问题。如果车派少了,必然有部分的出行者由于无法买到车票而耽误行程,造成社会公众的不满;但另一方面,如果开派的列车数超过了实际需要,就会有过度“不满员”的情况,不仅加大了列车的运行成本,还造成了资源的浪费。 但由于有关部门也不可能精确地知道未来究竟有多少人打算乘火车出行,所以只有根据历史的规律结合当下的实际情况进行预测。时间序列分析正是这样一种立足于历史,以预测和控制未来现象的方法,在处理这个问题上是有一定的可行性的。 2问题分析 从理论上来讲,影响一个时期铁路客运量的因素有很多,我认为最重要的应该有下面几个: A:节假日分布。一般来讲,节假日分布密集的时期的出行的人数会较一般时段有所增加,如春节前后主要是农民工和学生构成强大的客流,而“五一”和“十一”黄金周外出旅游的人也会大大增加铁路客运压力。 B:外部竞争因素。这主要是指飞机和汽车等交通工具的票价高低。如果某一时段飞机票价居高不下,而一些时间较充裕或购买力不够强的旅客则会选择乘 河南工程学院课程设计 《时间序列分析课程设计》学生姓名学号: 学院:理学院 专业班级: 专业课程:时间序列分析课程设计指导教师: 2017年 6 月 2 日 目录 1. 实验一澳大利亚常住人口变动分析..... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。 2. 实验二我国铁路货运量分析........... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。 3. 实验三美国月度事故死亡数据分析...... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。课程设计体会 ............................ 错误!未定义书签。 第三章平稳时间序列分析 选择合适的模型拟合1950-2008年我国邮路及农村投递线路每年新增里程数序列,见表1: 表1 1950-2008年我国邮路及农村投递线路每年新增里程数序列 一、时间序列预处理 (一)时间序列平稳性检验 1.时序图检验 (1)工作文件的创建。打开EViews6.0软件,在主菜单中选择File/New/Workfile, 在弹出的对话框中,在Workfile structure type中选择Dated-regular frequency(时间序列数据),在Date specification下的Frequency中选择Annual(年度数),在Start date中输入“1950”(表示起始年 份为1950年),在End date中输入“2008”(表示样本数据的结束年份为2008年),然后单击“OK”,完成工作文件的创建。 (2)样本数据的录入。选择菜单中的Quick/Empty group(Edit Series)命令,在弹出的Group对话框中,直接将数据录入,并分别命名为year(表示年份),X(表示新增里程数)。 (3)时序图。选择菜单中的Quick/graph…,在弹出的Series List中输入“year x”,然后单击“确定”,在Graph Options中的Specifi中选择“XYLine”,然后按“确定”,出现时序图,如图1所示: 图1 我国邮路及农村投递线路每年新增里程数序列时序图从图1中可以看出,该序列始终在一个常数值附近随机波动,而且波动的围有界,因而可以初步认定序列是平稳的。为了进一步确认序列的平稳性,还需要分析其自相关图。 2.自相关图检验 选择菜单中的Quick/Series Statistics/Correlogram...,在Series Name 中输入x(表示作x序列的自相关图),点击OK,在Correlogram Specification 中的Correlogram of 中选择Level,在Lags to include中输入24,点击OK,得到图2: 时间序列分析SAS软件实验报告: 以我国2002第一季度到2012年第一季度国内生产总值数据(季节效应模型)分析 班级:统计系统计0姓名: 学号: 指导老师: 20 年月日 时间序列分析报告 一、前言 【摘要】2012年3月5日温家宝代表国务院向大会作政府工作报告。温家宝在报告中提出,2012年国内生产总值增长7.5%。这是我国国内生产总值(GDP)预期增长目标八年来首次低于8%。 温家宝说,今年经济社会发展的主要预期目标是:国内生产总值增长7.5%;城镇新增就业900万人以上,城镇登记失业率控制在4.6%以内;居民消费价格涨幅控制在4%左右;进出口总额增长10%左右,国际收支状况继续改善。同时,要在产业结构调整、自主创新、节能减排等方面取得新进展,城乡居民收入实际增长和经济增长保持同步。 他指出,这里要着重说明,国内生产总值增长目标略微调低,主要是要与“十二五”规划目标逐步衔接,引导各方面把工作着力点放到加快转变经济发展方式、切实提高经济发展质量和效益上来,以利于实现更长时期、更高水平、更好质量发展。提出居民消费价格涨幅控制在4%左右,综合考虑了输入性通胀因素、要素成本上升影响以及居民承受能力,也为价格改革预留一定空间。 对于这一预期目标的调整,温家宝解释说,主要是要与“十二五”规划目标逐步衔接,引导各方面把工作着力点放到加快转变经济发展方式、切实提高经济发展质量和效益上来,以利于实现更长时期、更高水平、更好质量发展。 央行货币政策委员会委员李稻葵表示,未来若干年中国经济增长速度会有所放缓,这个放缓是必要的,是经济发展方式转变的一个必然要求。 【关键词】“十二五”规划目标国内生产总值增长率增速放缓提高发展质量附表:国内生产总值(2012年1季度) 绝对额(亿元)比去年同期增长(%) 国内生产总值107995.0 8.1 第一产业6922.0 3.8 第二产业51450.5 9.1 第三产业49622.5 7.5 注1:绝对额按现价计算,增长速度按不变价计算。注2:该表为初步核算数据。 GDP环比增长速度 环比增长速度(%) 2011年1季度 2.2 2季度 2.3 3季度 2.4 4季度 1.9 2012年1季度 1.8 注:环比增长速度为经季节调整与上一季度对比的增长速度。 此表是我国2012年第一季度国内生产总值及与2011年同期比较来源:前瞻网 河南工程学院课程设计《时间序列分析课程设计》学生姓名学号: 学院:理学院 专业班级: 专业课程:时间序列分析课程设计 指导教师: 2017年6月2日 目录 1. 实验一澳大利亚常住人口变动分析 (1) 1.1 实验目的 (1) 1.2 实验原理 (1) 1.3 实验内容 (2) 1.4 实验过程 (3) 2. 实验二我国铁路货运量分析 (8) 2.1 实验目的 (8) 2.2 实验原理 (8) 2.3 实验内容 (9) 2.4 实验过程 (10) 3. 实验三美国月度事故死亡数据分析 (14) 3.1 实验目的 (14) 3.2 实验原理 (15) 3.3 实验内容 (15) 3.4 实验过程 (16) 课程设计体会 (19) 1.实验一澳大利亚常住人口变动分析 1971年9月—1993年6月澳大利亚常住人口变动(单位:千人)情况如表1-1所示(行数据)。 表1-1 (1)判断该序列的平稳性与纯随机性。 (2)选择适当模型拟合该序列的发展。 (3)绘制该序列拟合及未来5年预测序列图。 1.1 实验目的 掌握用SAS软件对数据进行相关性分析,判断序列的平稳性与纯随机性,选择模型拟合序列发展。 1.2 实验原理 (1)平稳性检验与纯随机性检验 对序列的平稳性检验有两种方法,一种是根据时序图和自相关图显示的特征做出判断的图检验法;另一种是单位根检验法。 (2)模型识别 先对模型进行定阶,选出相对最优的模型,下一步就是要估计模型中未知参数的值,以确定模型的口径,并对拟合好的模型进行显著性诊断。 (3)模型预测 模型拟合好之后,利用该模型对序列进行短期预测。 1.3 实验内容 (1)判断该序列的平稳性与纯随机性 时序图检验,根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常识值附近波动,而且波动的范围有界。如果序列的时序图显示该序列有明显的趋势性或周期性,那么它通常不是平稳序列。 对自相关图进行检验时,可以用SAS 系统ARIMA 过程中的IDENTIFY 语句来做自相关图。 而单位根检验我们用到的是DF 检验。以1阶自回归序列为例: 11t t t x x φε-=+ 该序列的特征方程为: 0λφ-= 特征根为: λφ= 当特征根在单位圆内时: 11φ< 该序列平稳。 当特征根在单位圆上或单位圆外时: 11φ≥ 该序列非平稳。 对于纯随机性检验,既白噪声检验,可以用SAS 系统中的IDENTIFY 语句来输出白噪声检验的结果。 (2)选择适当模型拟合该序列的发展 摘要 时间序列分析是应用广泛的数量分析方法,主要描述和探索事物随时间发生变化的数量规律,时间序列分析中最典型的ARMA模型和ARIMA模型在近几年的相关研究中有较多的应用并得到广泛关注,而本文基于国家统计局公布的江西省1978—2014年的城镇化水平为分析数据,选择ARIMA模型进行建模处理,一方面是因为ARIMA模型在非平稳时间时间序列分析方面具有独特的优势,另一方面是模型能很好地拟合江西省城镇化发展水平的走势,模型的精度较好反映数据的真实水平。 对于实际问题的分析,结合当前我省城镇化发展水平的形势,本文以有明确记录以来的江西省城镇化率统计数据为依据,并根据SAS软件对这些数据序列的平稳性与纯随机性进行检验,并利用SAS软件处理的结果判断该数据是否为平稳序列且为非白噪声序列,通过对数据进行一阶差分等一系列处理,运用模型拟合数据时间序列,由于时间序列数据之间的相关关系,且历史数据对未来的发展有一定影响,结合对模型有很好预测结果,得出所有预测误差均没有超过1%,而且用来预测未来五年江西省城镇化发展水平达到60%,与省政府预计2020年常住人口城镇化率达到或接近60%的目标基本保持一致,进一步体现了模型拟合的优越性,为对本省未来实现户籍改革一体化、全面提高城市化水平提供了可借鉴的参考且为省政府在制定健全人口信息管理体系政策方面提出建议。 针对分析出的结果以及相关文献资料的查阅,为江西省城镇化发展总结以下几点政策建议:(1)以人为本,科学发展;(2)改革旧体制,消除体制障碍;(3)加大投融资体制改革,多渠道筹措城市建设资金;(4)改善和加强归城镇化的宏观调控。 一、引言 所谓城市化便是伴随经济增长城市增多和城市人口比重上升,首先,城市化是工业化推动的结果,即工业和商业发展形成聚集经济、进而产生对农村劳动力的持续不断的需求;其次,城市预期收入远高于农村,生活条件和个人发展条件比农村优越,因而吸引农村人口大量涌入城市;再次,农村劳动生产率的提高将越来越多的农村劳动力排挤出了农业生产领域,于是农村剩余劳动力就不得不去非农领域特别是城市寻找就业机会。可见,“在一个连续均衡的国民经济中,城市化可能表现为因果链条上的各类事件的最后结果,以导致工业化的贸易和需求的变化开端,以农村劳动力向城市就业的平缓移动为结果。但是,从农村向城市定居迁移的发生早于对劳动力需求的增长,并且越来越由期望的收入决定,而不是现在的工资。因此,除了把城市化看成是生产结构变化的结果以外,还必须把它看成是某种程度上分散的发展过程。此过程受未来收入和对就业的期望,以及政府支出的分配和各种社会因素的影响。”此外,城市化也受到了政府人口流动、迁移和城市就业相关政策的制约,在以时间序列分析中的模型分析中国城市化问题时必须强调的一点。 江西的城镇虽然产生较早,但长期以来商品经济发展缓慢,城市数目少,规模偏小,功能不够健全,因此,拟合模型并预测未来江西省城市化发展水平对于促进我省经济发展,加快城市化进程有重要意义。 二、江西省城市化发展水平的演变过程 在1978—1990年这12年间,江西的城镇化水平较低,平均只有19.31%,年增长率在1%左右,增长速度比较缓慢。从1991—2000年,江西城市化水平将近增长了10%左右,在这一时间段里,城镇化增长率有了一定的提高,但由于这一段时间相关有利影响较多,所以相对而言这段时间的城镇化水平的增长幅度也相对较小。从2001—2010年,江西城市化水平有了较大改观,开始步入城市化的快车道。从江西省城镇化水平的整个发展历程来看,江西的城镇化率在全国的平均水平之下,发展速度也很缓慢,究其原因,与江西省的工业、地理位置、人口等因素有很大关系。江西地处全国中部,多丘陵山区,交通不便,工业欠发达,农村人口基础大。这些因素总体制约了江西城镇化发展水平,所以根据城镇化水 实验6 时间序列分析的spss应用 6.1 实验目的 学会运用SPSS统计软件创建时间数列,熟练掌握长期趋势线性模型拟合和季节变动测定的SPSS方法与技能。 6.2 相关知识(略) 6.3 实验内容 6.3.1 用SPSS统计软件创建时间序列的创建 6.3.2用SPSS统计软件处理长期趋势线性模型的拟合(最小二乘法、指数平滑法)及预测。 6.3.3掌握测定季节变动规律的SPSS测定方法。 6.4实验要求 6.4.1准备实验数据 6.4.2用SPSS统计软件创建彩电出口数量的时间序列 6.4.3用最小二乘法测定长期趋势,拟合线性趋势方程,并进行趋势预测。 6.4.4测定彩电出口数量的季节变动规律。 6.4.5用指数平滑法预测2014和2015年的彩电出口数量。 6.5 实验步骤 6.5.1 实验数据 为了研究某国彩电出口的情况,某研究机构收集了从2003-2013年某国彩电出口的月度数据,如表6-1所示。 表6-1 我国2003-2013年的我国彩电出口的月度数据(单位:万台)1月2月3月4月5月6月7月8月9月10月11月12月2003年12.53 13.73 24.45 28.75 32.45 31.11 25.94 32.98 43.49 42.94 63.29 77.28 2004年30.01 39.63 29.77 42.74 32.25 31.94 32.27 32.59 32.92 30.98 47.44 52.82 2005年24.08 16.42 31.24 29.33 31.88 30.09 28.08 32.99 44.99 47.57 50.36 75.19 2006年39.02 25.81 43.38 37.34 39.22 39.87 51.10 50.99 55.16 62.78 57.75 72.20 2007年28.76 39.38 46.10 39.41 38.74 40.18 45.59 43.31 46.68 54.17 53.65 61.12 2008年28.87 21.23 35.82 26.97 32.33 24.53 29.39 31.96 38.22 39.24 52.95 68.41 安徽建筑大学 时间序列分析课程设计报告书 院系数理学院 专业统计学 班级统计学三班 学号11207040302 姓名朱敏 指导教师俞泽鹏 基于时间序列分析的股票预测模型研究 摘要 在现代金融浪潮的推动下,越来越多的人加入到股市,进行投资行为,以期得到丰厚的回报,这极大促进了股票市场的繁荣。而在这种投资行为的背后,越来越多的投资者逐渐意识到股市预测的重要性。所谓股票预测是指:根据股票现在行情的发展情况地对未来股市发展方向以及涨跌程度的预测行为。这种预测行为只是基于假定的因素为既定的前提条件为基础的。但是在股票市场中,行情的变化与国家的宏观经济发展、法律法规的制定、公司的运营、股民的信心等等都有关联,因此所谓的预测难于准确预计。即使是证券分析师的预测也只能作为股民入市操作的一般参考意见。时间序列数据因为接受到许多偶然因素的影响,会常常表现出随机性,在统计学上称之为序列的依赖关系。时间序列分析是经济预测领域研究的重要工具之一,它描述历史数据随时间变化的规律,并用于预测经济数据。在股票市场上,时间序列预测法常用于对股票价格趋势进行预测,为投资者和股票市场管理管理方提供决策依据。本文主要介绍了时间序列分析方法的概念,性质,特点以及时间序列模型,包括建模时对数据时间序列的预处理、模型识别、参数估计、模型检验、模型优化以及模型预测等。并根据道琼斯指数对收盘价进行短期预测,通过对时间序列分析理论的实证研究分析,建立时间序列模型,说明时间序列分析的方法对于股票价格 的预测趋势有一定的参考价值。 关键词:股票,预测,时间序列分析,AR(1 )模型 ABSTRACT In the modern financial wave, more and more people join the stock market to invest, expecting to get rich return, which has greatly promoted the stock market’s prosperity. While under this behavior, an increasing large number of people become to realize the importance of stock forecast. The so-called stock forecast is defined: with the help of the stock’s recent condition, we’ll predict the future stock’s development, including its later development directions and fluctuations. This prediction based on the assumption of behavior is the prerequisite for established factor basis. But the stock’s index is always changing with the country’s macroeconomic development, the formulation of laws and regulations, the company’s operations, the confidence of investors and so on, which results in that it is very difficult to accurately predict. Even securities analysts’forecast results can only be operated as a general reference. Time-series data often show some kinds of randomness and dependence between each other because of the influence of various accidental factors. Time series analysis is one of the most important tools for economy research, and it describe the variation of data with time, and used to forecast economic data.Time series analysis is often used to predict the stock price, which provides decision-making basis for investors and the stock market managers. This thesis mainly introduces time series analysis theory, including its notion, character as well as the expression and description of some models derived from it ,including method of data simulation, method of parameter estimation and method of testing degree of fitting and arrange them by the numbers. And according to the Dow Jones 时间序列分解算法和d ecompose函数实现 李思亮 55531469@https://www.360docs.net/doc/bf3924245.html, 目录 时间序列分解算法和decompose函数实现 (1) 1 数据读入并生成时间序列 (2) 2 数据可视化 (4) 3 时间序列分解 (7) 在时间序列分析的过程中,往往需要对时间序列作出初步分析,本文主要采用R语言作为分析平台,从数据的读入,可视化图,分解(decompose)为趋势项,季节项,随机波动等角度对数据开展分析的几个案例。最后对分解算法作出初步描述并探讨其预测预报中的潜在应用。本文的数据和部分内容主要采用https://www.360docs.net/doc/bf3924245.html,/en/latest/中的内容,感兴趣的读者可以参考。 1 数据读入并生成时间序列 对于数据分析来讲,数据读入是一个比较关键的步骤。常用的数据读入函数有scan,read.table 等。下面列举了几种常见的数据。 首先是https://www.360docs.net/doc/bf3924245.html,/tsdldata/misc/kings.dat,中包含了英国国王的寿命从William开始,数据来源(Hipel and Mcleod, 1994)。 > kings <- scan("https://www.360docs.net/doc/bf3924245.html,/tsdldata/misc/kings.dat",skip=3) Read 42 items > kings [1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56 上述例子中,读入了连续42个公国国王的寿命并将其赋给变量‘kings’ 如果我们希望对读入数据开展分析,下一步就是将其转化为时间序列对象(时间序列类),R提供了很多函数用于分析时间序列类数据。可以使用ts函数将变量转化为时间序列类。 > kingsts <- ts(kings) > kingsts Time Series: Start = 1 End = 42 Frequency = 1 [1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56 对于上述数据操作的好处是将数据转化为特定的“时间序列类”便于我们使用R中的函数分析数据。 有时候我们会按照一定的时间周期来收集数据,这个周期可能是季度,月,日,小时,分。在大数据时代,有些情况下的数据是按照秒来采集收集。这种情况下,我们需要对数据的周期或频率进行设置。这里采用ts函数中的frequency参数可以实现这种功能。比方说,若按1年为一个周期,我们的月度时间 应用时间序列分析课程论文 班级:13应用统计1班学号:20133695 姓名:彭鹏 学习了本学期的应用时间序列分析课程内容,学习了使用EVIEWS软件对平稳时间序列的平稳性进行分析,学习平稳时间序列模型的建立、学会根据自相关系数和偏自相关系数判断ARMA模型的阶数p 和q,学会利用信息准则对估计的ARMA模型进行诊断,以及掌握利用ARMA模型进行预测。 在统计研究中,有大量的数据是按照时间顺序排列的,用数学方法来表述就是使用一组随机序列表示随机事件的时间序列即为{Xt} 通常的ARMR建模过程,B-J方法具体步骤如下: 一、对时间序列进行特性分析。从随机性、平稳性、季节性考虑。 对于一个非平稳时间序列,若要建模首先将其平稳化,其方法 有三种: 1差分,一些序列可以通过差分使其平稳化。 2季节差分,如果序列具有周期波动特点,为了消除周期波动 的影响,通常引用季节差分。 3函数变换与差分结合运用,某些序列如果具有某类函数趋势,我们可以先引入某种函数变换将序列转化为线性趋势,然后再 进行差分以消除线性趋势。 二、模型识别与建立。模型识别和模型定阶。 三、模型的评价,并利用模型进行评价。 下面从网上搜寻数据,1949-2014年城镇人口数(单位万人,其中有些年份缺失数据,数据来源于中国统计年鉴)。进行处理分析 绘制序列时序图有看来有明显增长趋势为非平稳序列,进行一阶差分y=d(r): 由图得出序列y仍然非平稳 1.对原序列进行二阶差分z=d(r,2) 相关图检 验:序列z为平稳序列,进行单位根检验: 稳序列。有相关图看出为非白噪声序列。 可见均值非零;在原序列上生成0均值序列在输入x=z-28.59184 得到序列x为0均值的平稳非白噪声序列 由相关图看出自相关系数一阶截尾,考虑MA(1)模型多元时间序列建模分析
统计学之时间序列分析报告
时间序列分析实验报告(3)
时间序列分析实验报告
时间序列分析期末论文 (1)
spss时间序列模型
时间序列分析课程设计报告 (1)
应用时间序列实验报告
时间序列实验报告
时间序列分析实验报告
应用时间序列实验报告
时间序列分析课程论文
实验·6时间序列分析报告地spss应用
时间序列分析课程设计报告
时间序列分解Decompose
应用时间序列分析课程论文