数据压缩技术论文

霍夫曼编码
摘要
在现代社会,通信的发展,使得现代社会更加丰富多彩,我们可以随时随地在任何地方了解到世界各地的信息,而这又必须依赖信息的传递。在信息化高度发达的当今社会,我们必须对信息的传递有着较高的要求,我们希望信息在传递的过程中,能够保持节省性和保密性和无损性,而著名的霍夫曼编码就能够达到这样的要求。因此研究霍夫曼编码对信息的压缩和解压就时相当有必要的,我们用C++对霍夫曼编码给出简单的算法以实现对文件的压缩和解压。
【关键词】霍夫曼编码压缩解压C++
Abstract
In the modern society, communication development makes the modern society more rich and colorful, we can at any time anywhere in any place to all over the world know the information, which must be dependent on the information transfer. In the information highly developed in today's society, we must have the information transfer has a higher request, we hope that in the process of information transmission, can maintain save sex and confidentiality and nondestructive sex, and famous Huffman coding can achieve such requirement. So the Huffman coding information to compression and decompression is quite necessary when, we use c + + to Huffman coding give simple algorithm for document to realize the compression and decompression.
Keywords: Huffman coding compression decompression C + +
【引言】
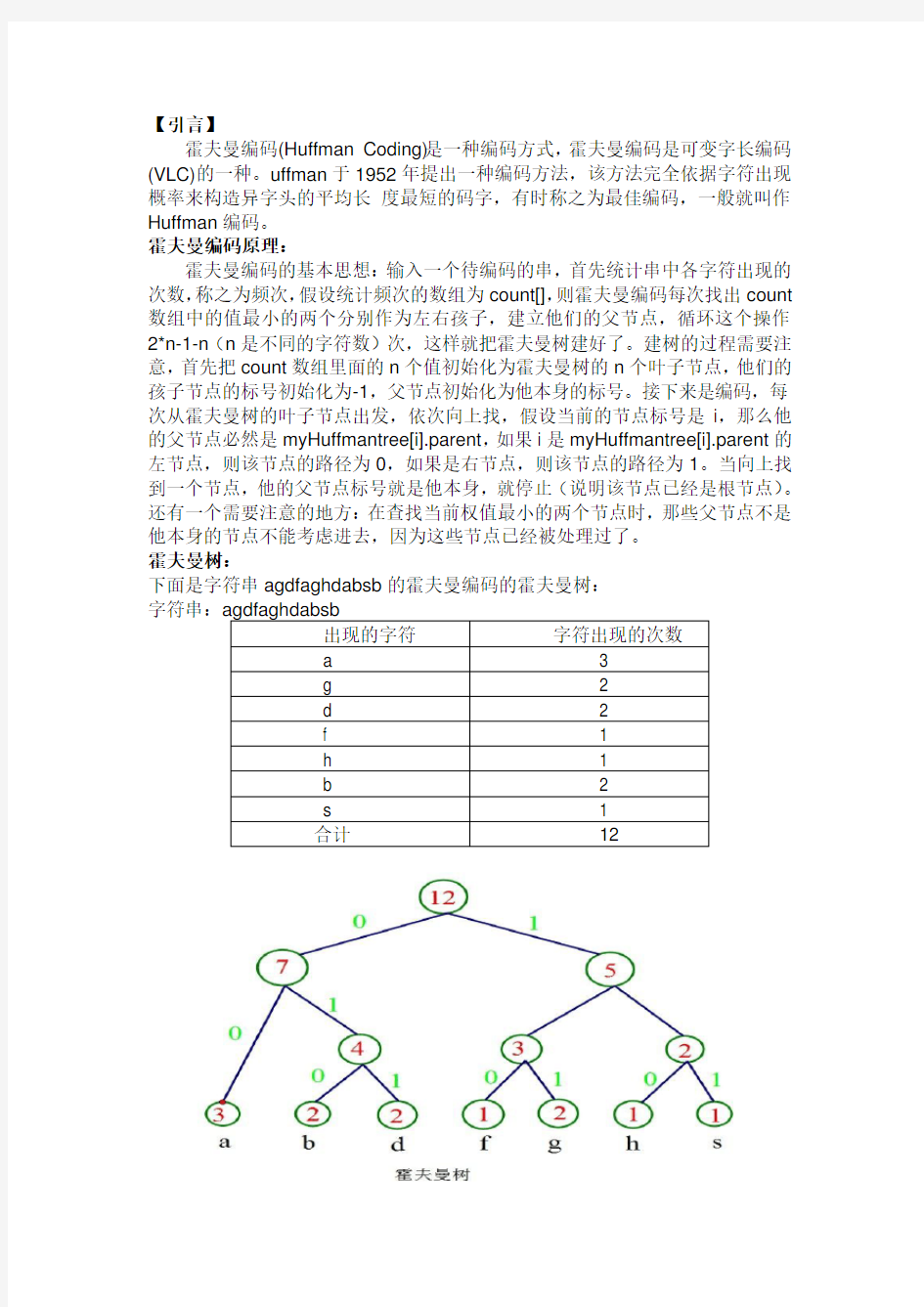
霍夫曼编码(Huffman Coding)是一种编码方式,霍夫曼编码是可变字长编码(VLC)的一种。uffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman编码。
霍夫曼编码原理:
霍夫曼编码的基本思想:输入一个待编码的串,首先统计串中各字符出现的次数,称之为频次,假设统计频次的数组为count[],则霍夫曼编码每次找出count 数组中的值最小的两个分别作为左右孩子,建立他们的父节点,循环这个操作2*n-1-n(n是不同的字符数)次,这样就把霍夫曼树建好了。建树的过程需要注意,首先把count数组里面的n个值初始化为霍夫曼树的n个叶子节点,他们的孩子节点的标号初始化为-1,父节点初始化为他本身的标号。接下来是编码,每次从霍夫曼树的叶子节点出发,依次向上找,假设当前的节点标号是i,那么他的父节点必然是myHuffmantree[i].parent,如果i是myHuffmantree[i].parent的左节点,则该节点的路径为0,如果是右节点,则该节点的路径为1。当向上找到一个节点,他的父节点标号就是他本身,就停止(说明该节点已经是根节点)。还有一个需要注意的地方:在查找当前权值最小的两个节点时,那些父节点不是他本身的节点不能考虑进去,因为这些节点已经被处理过了。
霍夫曼树:
下面是字符串agdfaghdabsb的霍夫曼编码的霍夫曼树:
字符串:
由上面的霍夫曼树可知各个字符的编码如下:
a: 01
b:010
d:011
f:100
g:101
h:110
s:111
所以整个串的编码为:
011010111000110111001101010111010
霍夫曼译码原理:
对于霍夫曼的译码,可以肯定的是其译码结果是唯一的。
证明:因为霍夫曼编码是根据霍夫曼树来确定的,霍夫曼树是一棵二叉树,编码的时候是从树根一直往下走,直到走到叶子节点为止,在其经过的路径上,如果是树的左子树则为0,否则为1。因为每一次都要走到树的叶子节点,多以不可能存在两个编码a和b,使得a是b的前缀或者b是a的前缀。所以编码一定可以唯一确定。
根据上面的结论,我们可以很清楚地直到译码的方法:
定义两个指针p1,p2,P1指向当前编码的开始位置,P2指向当前编码的位置,如果P1-P2这一段编码能在编码库里面找到完全对应的编码结果,则译码成功,该段编码的译码结果就是与编码库里完全对应的编码的字符。循环次操作,直到译码结束!
例子:
假设有一段字符含有a,,c,d三个字符,经过编码之后三个字符对应的编码结果分别为:
a:01
c:010
d:011
现在给你一段编码0110101,要求将其译码!
按照上面介绍的方法我们可以知道:
编码的前三个字符是且仅是d的编码,所以011译码为d,依次译码可得整串的译码结果为daa
霍夫曼编码源代码:
#include
#include
#include
#include
using namespace std;
#define INF 0x7fffffff //无穷大
struct Huffmantree //霍夫曼树的节点
{
int weight;
int parent,ld,rd;
};
struct myNode
{
char ch;
int num;
};
struct mycode //字符和其对应的编码
{
char ch; //字符
int s[50]; //ch的编码
int len; //编码长度
};
int nNode; //叶子节点数目
int totalNode; //霍夫曼树的总节点个数
char toCode[100000] ; //待编码的字符串
myNode myToCode[100000]; //待编码的字符串和权值
int weightOfToCode[100000] ; //字符串的权值!
Huffmantree myHuffmantree[1000000]; //霍夫曼树(数组模拟)
char allchar[1000000]; //所哟出现过的字符
mycode coder[1000000]; //字符与对应的编码
int Len; //待编码的字符的总长度
int Coding[100000]; //译码之后的01串
int lenOfCoding ; //01串的长度
void build(int n); //建立霍夫曼树
void select(int &a,int &b); //选择两个权值最小的节点
void Code(); //编码
void printCode(); //打印编码
void deCode(); //译码
int match(int l,int h);
int main()
{
int i;
cout<<"\n=============================霍夫曼编码程序=============================";
cout<<"\n
cout<<"
while(1)
{
printf("请输入待编码的字符串\n");
int flag=0;
gets(toCode);
int len=strlen(toCode);
if(len==1)
{
flag=1;
}
Len=len;
map
for(i=0;i { myMap[toCode[i]]++; } map int h=1; for(iter=myMap.begin();iter!=myMap.end();iter++) { myToCode[h].ch=iter->first; allchar[h]=iter->first; weightOfToCode[h]=iter->second; myToCode[h++].num=iter->second; } nNode=h-1; //叶子节点个数 cout<<"----------------------字符统计如下--------------------------------------"< cout<<" 字符次数"< for(i=1;i { cout<<" "< } cout< totalNode=nNode; //totalNode初始值为nNode cout<<"-----------霍夫曼树节点信息如下(子节点为-1表示是叶子节点)---------------"< build(nNode); cout< Code(); cout<<"\n-------------------------字符串的编码结果如下--------------------------\n"; printCode(); cout<<"\n-------------------------01串的译码结果如下-----------------------------\n"; deCode(); cout<<"\n是否继续?(Y/N)\n"; char con[10]; cin>>con; char fang=toupper(con[0]); if(fang=='N') { break; } getchar(); } return 0; } void build(int n) //建立霍夫曼树 { int i; int m=2*n-1; //n个叶子节点的霍夫曼树总节点数为2*n-1 for(i=1;i<=n;i++) //初始化霍夫曼数组 { myHuffmantree[i].weight=weightOfToCode[i]; //叶子节点权值为字符出现次数 myHuffmantree[i].ld=-1; //叶子节点没有左孩子 myHuffmantree[i].rd=-1; //叶子节点没有右孩子 myHuffmantree[i].parent=i; //叶子节点父节点先初始化为他本身 } for(i=n+1;i<=m;i++) { int a,b; select(a,b); myHuffmantree[a].parent=i; myHuffmantree[b].parent=i; myHuffmantree[i].ld=a; myHuffmantree[i].rd=b; myHuffmantree[i].weight=myHuffmantree[a].weight+myHuffmantree[b].weight; myHuffmantree[i].parent=i; } for(i=1;i<=totalNode;i++) { printf("节点:%3d 权值:%3d 左节点:%3d 右节点:%3d 父节点:%3d \n",i,myHuffmantree[i].weight,myHuffmantree[i].ld,myHuffmantree[i].rd,myHuffmantree[i].paren t); } } void Code() //编码 { int i,j; int numOfCode[100000]; cout<<"--------------------------各字符编码结果如下----------------------------"< if(Len==1) { cout< return ; } for(i=1;i<=nNode;i++) { j=i; int h=0; while(myHuffmantree[j].parent!=j) { int x=j; j=myHuffmantree[j].parent; if(myHuffmantree[j].ld==x) { numOfCode[h++]=0; } else if(myHuffmantree[j].rd==x) { numOfCode[h++]=1; } } cout<<" "< int x=0; coder[i].len=h; coder[i].ch=allchar[i]; for(int k=h-1;k>=0;k--) { coder[i].s[x++]=numOfCode[k]; printf("%d",numOfCode[k]); } cout< } } void select(int &a,int &b) //选择两个权值最小的节点 { int i; int min1=INF; int min2=INF; int sign1=1; //最小值的下标 int sign2=2; //次小值的下标 for(i=1;i<=totalNode;i++) { if(myHuffmantree[i].parent==i) //说明其是已经更新过的节点 { if(myHuffmantree[i].weight { min1=myHuffmantree[i].weight; sign1=i; } } } for(i=1;i<=totalNode;i++) { if(myHuffmantree[i].parent==i) //说明其是已经更新过的节点 { if(myHuffmantree[i].weight { min2=myHuffmantree[i].weight; sign2=i; } } } a=sign1; b=sign2; totalNode++; //总节点数加1 } void printCode() //打印编码结果! { int i; if(Len==1) //长度为1的时候特殊考虑 { cout<<"0\n"; return ; } int h=0; for(i=0;i { for(int j=1;j<=nNode;j++) { if(toCode[i]==coder[j].ch) { for(int k=0;k { printf("%d",coder[j].s[k]); Coding[h++]=coder[j].s[k]; } } } } lenOfCoding=h; cout< } void deCode() //译码 { int i,j; int begin=0; for(i=0;i { if(match(begin,i)!=-1) { int x=match(begin,i); printf("%c",coder[x].ch); begin=i+1; } } printf("\n"); } int match(int l,int h) //译码的辅助函数(寻找匹配){ int i,j,k; int flag=0; for(i=1;i<=nNode;i++) { if(coder[i].len!=h-l+1) { continue; } k=l; for(j=0;j { if(Coding[k]!=coder[i].s[j]) { break; } if(j==coder[i].len-1) { flag=1; goto ok; } k++; } } ok:; if(flag==1) //查找成功返回对应的下表 { return i; } else //查找不成功返回-1; { return -1; } } 霍夫曼编码代码分析: 1.运行环境:win7操作系统,Inter(R) Core(TM) Duo t6600 @ 2.20GHz 2.20GHz 内存:2.00GB,32位操作系统 2.程序运行结果: 3. 程序功能模块分析: 整个程序包含6个函数: A. void build(int n); B. void select(int &a,int &b); C. void Code(); D. void printCode(); E. void deCode(); F. int match(int l,int h); 其中A是用来建立霍夫曼树,B是在A中调用的一个辅助函数,用来查找两个权值最小的节点的下标,C是对字符串编码,D是现实编码结果,E是译码01串,F是E的辅助函数,用来寻找编码的匹配。 包含3个结构体: A.struct Huffmantree //霍夫曼树的节点 { int weight; int parent,ld,rd; }; B.struct myNode //字符和其权值 { char ch; //字符 int num; //权值 }; C.struct mycode //字符和其对应的编码 { char ch; //字符 int s[50]; //ch的编码 int len; //编码长度 }; 各结构功能如注释! 4. 程序效率分析: 该程序要编码的字符比较长,达到10^8长度时运行就会很慢,主要原因在于在建树时每次选择权值最小的两个是用暴力枚举的,还有译码时每次都要在编码库里面去一一匹配,假设编码之后的01串长度为10^7,而其中出现的不同字符数为200,在最坏情况下,译码的时候就需要200*10^7的时间,在这种情况下程序运行就会比较慢,当然,这只是最坏估计,实际上是不可能达到这么高的时间复杂度的,因为不可能每次寻找编码匹配时都要遍历到最后才找到! 5.程序的优化: 既然用该方法效率会很低,那么有没有什么优化方法呢?答案是肯定的!在建树的时候可以用一个优先队列将个节点信息存在队列里面,优先队列按照节点的权值从小到大排序,所以每次只需取出队列的前两个节点就是权值最小的两个节点,而不需遍历所有节点来选择最小的。优先队列里面是右堆来排序的,时间复杂度很低,为lg(n),所以用有限队列能大幅度降低程序建树的时间复杂度! 霍夫曼编码的应用: 随着信息技术的飞速发展,各种各样的信息需要传输,传输信息就要得先经过编码,然后再译码,可见编码技术的提高对整个信息产业有着举足轻重的作用。霍夫曼编码是一种可变的无损压缩方法,其效率也比较高,所以在当今网络传输中意义重大。霍夫曼树是一棵最有二叉树,在各种程序设计中都用到它来降低程序运行的时间复杂度。 参考文献 [1]谭浩强C++面向对象程序设计[M]. 北京:清华大学出版社.2007. [2]谭浩强C程序设计[M].北京:清华大学出版社.2005. [3]田丽华编码理论[M].西安:西安电子科技大学出版社,2007. 数据压缩算法的综述 S1******* 许申益 摘要:数据压缩技术在数据通讯和数据存储应用中都有十分显著的益处。随着数据传输技术和计算机网络通讯技术的普及应用,以及在计算机应用中,应用软件的规模和处理的数据量的急剧增加,尤其是多媒体技术在计算机通讯领域中的出现,使数据压缩技术的研究越来越引起人们的注意。本文综述了在数据压缩算法上一些已经取得的成果,其中包括算术编码、字典式压缩方法以及Huffman码及其改进。 关键字:数据压缩;数据存储;计算机通讯;多媒体技术 1.引言 数据压缩技术在数据通讯和数据存储应用中都有十分显著的益处。在数据的存储和表示中常常存在一定的冗余度,一些研究者提出了不同的理论模型和编码技术降低了数据的冗余度。Huffman 提出了一种基于统计模型的压缩方法,Ziv Jacob 提出了一种基于字典模型的压缩方法。随着数据传输技术和计算机网络通讯技术的普及应用,以及在计算机应用中,应用软件的规模和处理的数据量的急剧增加,尤其是多媒体技术在计算机和通讯两个领域中的出现,使数据压缩技术的研究越来越引起人们的注意。本文综述了在数据压缩算法上的一些已经取得的成果。 本文主要介绍了香农范诺编码以及哈弗曼算法的基本思想,运用其算法的基本思想设计了一个文件压缩器,用Java 语言内置的优先队列、对象序列化等功能实现了文件压缩器的压缩和解压功能。 2数据压缩算法的分类 一般可以将数据压缩算法划分为静态的和动态的两类。动态方法又是又叫做适应性(adaptive)方法,相应的,静态方法又叫做非适应性方法(non-adaptive)。 静态方法是压缩数据之前,对要压缩的数据经过预扫描,确定出信源数据的 当前特种结构的发展现状与趋势 近20年来,我国的建筑取得了突飞猛进的发展。各种新型建筑拔地而起,各种新兴的施工技术在各类建筑工程中得到迅速推广和应用,加上现阶段我国经济发展的需要和环境问题的突出,各类新型的特种结构越来越被需要。下文列举了常见的5类特种结构来简单的阐述一下当前特种结构的发展现状与未来的趋势。 1、现状 1.1支挡结构 支挡结构包括挡土墙、抗滑桩、预应力锚索等支撑和锚固结构。以刚性较大的墙体支承填土和物料并保证及其稳定的称为挡土墙。 早在60年代初,国外的土建工程就已开始应用并逐步发展轻型挡土墙了。我国在这方面的研究虽起步稍晚,但随着新技术的革新和推广,近二三十年来,也取得了长足的发展,尤其是锚锭板挡土墙,自1974年在我国铁路工程上首创和试建以来,到现在已经完成了一套比较完善的理论系统。 1.2深基坑支护结构 深基坑支护结构是建筑工程的一部分,其发展与建筑工程质量与安全密切相关。由于我国住房资源紧张,适当发展多层和高层建筑,向空中和地下发展,是解决我国土地资源紧张地一条重要出路。随着中高层及超高层建筑的大量涌现,深基坑工程越来愈多。同时,密集的建筑物,大深度的基坑周围复杂的地下设施,使得放坡开挖基坑这一传统技术不再能满足现代化建设的需求。因此,深基坑的支护引起 了各方面的广泛重视。 深基坑支护结构类型可分为悬臂式支护结构、拉锚式支护结构、内支撑支护结构、重力式挡土支护结构、土钉支护、复合土钉支护、预应力锚杆柔性支护。目前,深基坑支护结构的设计计算仍基于极限平衡理论。而极限平衡理论是一种静态设计,而实际上基坑开挖后的土体是一种动态平衡状态,也是一个松弛过程,随着时间的增长,土体强度逐渐下降,并产生一定的变形。工程实践证明,有的支护结构按极限平衡理论计算的安全系数,从理论上讲是局对安全的,但却发生破坏;有的支护结构却恰恰相反,即安全系数虽然比较小,甚至达不到规范的要求,但在实际工程中却能获得成功。 1.3水塔 水塔用于建筑物给水、调剂用水,维持必要水压,并起到沉淀和安全用水的作用。过去欧洲曾建造过一些具有城堡式外形的水塔。法国有一座多功能的水塔,在最高处设置水柜,中部为办公用房,底层是商场。中国也有烟囱和水塔合建在一起的双功能构筑物,是对排出的油烟进行降温,达到油水大量凝结,尽量少排放到大气中,是环保部门要求的一项措施。按水柜形式分为圆柱壳式和倒锥壳式。在中国这两种形式应用最多,此外还有球形、箱形、碗形和水珠形等多种。支筒一般用钢筋混凝土或砖石做成圆筒形。支架多数用钢筋混凝土刚架或钢构架。水塔基础有钢筋混凝土圆板基础、环板基础、单个锥壳与组合锥壳基础和桩基础。当水塔容量较小、高度不大时,也可用砖石材料砌筑的刚性基础。 龙源期刊网 https://www.360docs.net/doc/c614224794.html, 数据压缩技术综述 作者:汪见晗 来源:《科学与财富》2016年第04期 摘要:在现今的电子信息技术领域,正发生着一场有长远影响的数字化革命。由于数字 化的多媒体信息尤其是数字视频、音频信号的数据量特别庞大,如果不对其进行有效的压缩就难以得到实际的应用。因此,数据压缩技术已成为当今数字通信、广播、存储和多媒体娱乐中的一项关键的共性技术。本文从专利文献的视角对数据压缩技术的发展进行了全面的统计分析,总结了与数据压缩相关的专利申请趋势、主要申请人分布,介绍了数据压缩技术的重点技术分支及其发展历程,并分析了全球数据压缩技术演进特点,并绘制了国内重点申请人的技术发展路线图。 关键词:数据压缩;发展路线 1 数据压缩介绍 1.1 数据压缩的分类 目前,通用的主流压缩方法分为无损压缩和有损压缩。无损压缩利用数据的统计冗余进行压缩。数据统计冗余度的理论限制为2:1到5:1,所以无损压缩的压缩比一般比较低。这类方法广泛应用于文本数据、程序和特殊应用场合的图像数据等需要精确存储数据的压缩,通常的无损压缩编码方法有香农-范诺编码,霍夫曼(Huffman)编码,算术编码,字典压缩编码等。 有损压缩方法利用了人类视觉、听觉对图像、声音中的某些频率成分不敏感的特性,允许压缩的过程中损失一定的信息。虽然不能完全恢复原始数据,但是所损失的部分对理解原始图像的影响较小,却换来了比较大的压缩比。有损压缩广泛应用于语音、图像和视频数据的压缩,按照应用领域来分,有损压缩编码分为图像压缩编码,视频压缩编码,音频压缩编码。 2 数据压缩专利申请数据分析 本章主要对全球和国内数据压缩专利申请情况以及国内外专利重要申请人进行分析,从中得到技术发展趋势,以及各阶段专利申请人所属的国家分布和主要申请人。其中以每个同族中最早优先权日期视为该申请的申请日,一系列同族申请视为一件申请。 2.1 全球专利申请状况 2.1.1 全球数据压缩专利申请量 2014级建筑工程技术专业《土木工程概论》课程 论文 土木工程的发展 专业班级:工程造价1402班 学生姓名:刘忱 学号: 143008120234 论文成绩: 评阅教师:刘立 2015年 1月 16日 土木工程的发展 摘要:土木工程师人类历史上年代久远的“技术科学”,作为一种系统的产业活动,土木工程的是指是生产的过程,是一种技术过程。随着社会的产生而产生,当今的土木工程已经得到了一定的发展,土木工程的发展应当与时俱进,去挖掘,去发现,去思考,去想象,去创新土木工程师不可缺少的存在形式。 关键词:土木工程起源发展 1、引言 土木工程在英语中称为“Civil Engineering”,直译是民用工程。它是建造各类工程设施的科学技术的总称。它既指工程建设的对象,既建在地上、地下、水中的各种工程设施,也指应用的材料、设备和进行勘测、设计、施工、保养、维修等技术。 土木工程随着人类社会的发展,至今已经演变为大型综合性学科。它的范围非常广泛,涵盖了关系到人类生存和发展的衣、食、住、行这四大基本要素。称为人们生活中必不可少的基础学科之一。 土木工程为国家经济发展和人民生活水平的提高提供了物质基础。因此,建筑业和房地产业成为许多国家的经济支柱之一。 2、土木工程的定义 土木工程是建造各类工程设施的科学技术的统称。它既指所应用的材料、设备和所进行的勘测、设计、施工、保养维修等技术活动;也指工程建设的对象,即建造在地上或地下、陆上或水中,直接或间接为人类生活、生产、军事、科研服务的各种工程设施,例如房屋、道路、铁路、运输管道、隧道、桥梁、运河、堤坝、港口、电站、飞机场、海洋平台、给水和排水以及防护工程等。土木工程对国家的经济建设和人民生活的影响非常明显和重要。土木工程密切关系到人类赖以生存和繁衍的四大基本要素:衣、食、住、行,为人类提供住宅、宾馆、公寓、衣料生产贮藏基地、食品冷库、公路、机场、铁路、港口、码头、厂房、实验室等现代人类生活和发展的必要场所空间。 3、土木工程历史的三次飞跃 ?哈弗曼编码 A method for the construction of minimum-re-dundancy codes, 耿国华1数据结构1北京:高等教育出版社,2005:182—190 严蔚敏,吴伟民.数据结构(C语言版)[M].北京:清华大学出版社,1997. 冯桂,林其伟,陈东华.信息论与编码技术[M].北京:清华大学出版社,2007. 刘大有,唐海鹰,孙舒杨,等.数据结构[M].北京:高等教育出版社,2001 ?压缩实现 速度要求 为了让它(huffman.cpp)快速运行,同时不使用任何动态库,比如STL或者MFC。它压缩1M数据少于100ms(P3处理器,主频1G)。 压缩过程 压缩代码非常简单,首先用ASCII值初始化511个哈夫曼节点: CHuffmanNode nodes[511]; for(int nCount = 0; nCount < 256; nCount++) nodes[nCount].byAscii = nCount; 其次,计算在输入缓冲区数据中,每个ASCII码出现的频率: for(nCount = 0; nCount < nSrcLen; nCount++) nodes[pSrc[nCount]].nFrequency++; 然后,根据频率进行排序: qsort(nodes, 256, sizeof(CHuffmanNode), frequencyCompare); 哈夫曼树,获取每个ASCII码对应的位序列: int nNodeCount = GetHuffmanTree(nodes); 构造哈夫曼树 构造哈夫曼树非常简单,将所有的节点放到一个队列中,用一个节点替换两个频率最低的节点,新节点的频率就是这两个节点的频率之和。这样,新节点就是两个被替换节点的父 第二章作业 作业总体要求: 1.认真独立的完成 2.让文件名重新命名为自己的学号,然后通过http://10.66.4.241提交。 一.选择题 1.下列说法中不正确的是【B】。 A.有损压缩法会减少信息量 B.有损压缩法可以无失真地恢复原始数据 C.有损压缩法是有损压缩 D.有损压缩法的压缩比一般都比较大 2.下列属于无损压缩的是【B 】。 A.WA VE文件压缩成MP3文件 B.TXT文件压缩成RAR文件 C. BMP文件压缩成JPEG文件 D.A VI文件压缩成RM文件 3.图像序列中的两幅相邻图像,后一幅图像与前一幅图像之间有较大的相关, 这是【 D 】。 A. 空间冗余 B.时间冗余 C.信息熵冗余 D.视觉冗余 4.衡量数据压缩技术性能好坏的主要指标是【C】。 (1)压缩比(2)算法复杂度(3)恢复效果(4)标准化 A. (1)(3) B. (1)(2)(3) C. (1)(3)(4) D.全部 5.MPEG标准不包括下列哪些部分【C 】。 A.MPEG视频 B.MPEG音频 C.MPEG系统 D.MPEG编码 6.下列属于静态图像编码和压缩标准的是【B 】。 A.JPEG B.MPEG-1 C.MPEG-2 D.MPEG-4 7.声音信号是声波振幅随时间变化的【A 】信号. A.模拟 B.数字 C.无规律 D.有规律 8.在数字视频信息获取与处理过程中,下述顺序正确的是【A 】。 A.采样、A/D变换、压缩、存储、解压缩、D/A变换 B.采样、D/A变换、压缩、存储、解压缩、A/D变换 C.采样、压缩、A/D变换、存储、解压缩、D/A变换 D.采样、压缩、D/A变换、存储、解压缩、A/D变换 9.一般来说,表示声音的质量越高,则【C 】 A.量化位数越多和采样频率越低 B.量化位数越少和采样频率越低 C.量化位数越多和采样频率越高 D.量化位数越少和采样频率越高 10.5分钟双声道、16位采样位数、44.1kHZ采样频率声音的不压缩数据量是 【 B 】。 A. 48.47MB B. 50.47MB C. 105.84MB D. 25.23MB 11.下列采集的波形声音【 D 】的质量最好。 A、单声道,8位量化,22.05kHz采样频率 B、双声道,8位量化,44.1kHz采样频率 C、单声道,16位量化,22.05kHz采样频率 D、双声道,16位量化,44.1kHz采样频率 12.频率在20HZ-20KHZ的被称为【 A 】 A. 可听声波 B. 次声波 C.超声波 D.超音波 13.MIDI是音乐与【 A 】结合的产物. A.计算机 B.通信 C.高科技 D.通讯 14.Windows中使用录音机录制的声音文本的格式是【B 】 A. MIDI B.WA V C.MP3 D.MOD 螺旋输送装置的研究现状及未来发展的浅析论文 0引言 1887年,美国出现了第一台螺旋输送装置;此后,由于粮食、化工、冶金、码头等多种行业的需求,不断完善,逐渐研制出了多种系列的螺旋输送装置。该装置输送过程中能完成揉搓、压缩、搅拌、混合等处理,在实际生产过程中还能实现变频调速和准确控制输送量,是污泥、栅渣等的专用设备,同时也是喂料或卸料专用装置。 随着螺旋输送装置在多个行业中应用的普及,对其性能要求也越来越高。适用性强、可靠性高、节能环保、效率高、功耗低等特点己成为今后螺旋输送装置发展的主要方向。目前,国际上对螺旋输送装置的研究基本集中在应用先进的方法和计算机技术对传统装置进行理论分析并改进设计、对结构和参数进行优化、进一步修正经验公式、研发新产品及其用新的控制技术等。 1国内外螺旋输送装置的发展状况 1.1国外螺旋输送装置的发展状况 1.1.1理论分析方面 国外螺旋输送装置适用于多种流动性好的物料的中短距离的输送和提升,通常用来输送散装物料和干燥的固体颗粒,并能准确地控制输送量。有很多学者通过对水平和垂直螺旋输送装置的输送过程进行理论分析,对输送性能进行评估,并找出了影响因素及其因素之间的关系。其中,Chris等人研究了机器本身的结构参数对输送性能的影响。CLEARY等人研究了输送对象的特性对输送性能的影响。但是,设计过程中对螺旋输送装置的理论分析不够完善,对一些参数的计算仍根据经验公式来确定,导致机器在输送过程中出现生产率低、功耗大等问题。 1.1.2设计制造方面 国外研制的螺旋输送装置除了常规结构以外也根据不同的应用场合设计出的特种结构型:锥形直径螺旋、锥形轴及变螺距螺旋和锥形轴变螺距螺旋等。这些螺旋输送器由于结构复杂、制造成本高、功耗大,所以不适应生产需求,没有被广泛的应用,需要进一步完善。 除了以上提及的螺旋输送装置以外,把不同规格的水平螺旋输送机和垂直螺旋输送机组合起来形成一个卸船机系统。在国外,很早以前就开始对螺旋卸船机进行了研究,其中技术领先的公司有瑞典的Siwertell和Carlsen公司、意大利的VAM公司以及法国的IBAV 公司,单机卸船能力都能达到1000t/h以上,其中Siwertell公司研发的螺旋卸船机卸船能力达到了2 700t/h。 总第231期2009年第1期 计算机与数字工程 Computer&D ig ital Eng ineer ing V o l.37No.1 32 LZW算法优化及在雷达数据压缩中的应用* 王志刚 常传文 茅文深 (中国电子科技集团公司28研究所 南京 210007) 摘 要 LZ W算法是一种性能优异的字典压缩算法,具有通用性强、字典在编解码过程中动态形成等优点,在无损压缩领域应用广泛。介绍了其算法原理,给出了程序实现的编码步骤,并选取一个实例进行详细分析。设计了一种哈希表对程序进行优化,显著降低检索字典时间,分别选取图片、雷达数据、文本文件进行编码速度对比,获得了较好的效果。最后,使用不同的数据分段选取若干典型的真实雷达数据进行试验,并与游程编码进行了对比,得出若干结论。 关键词 LZ W;哈希表;优化;游程编码 中图分类号 T P301.6 L Z W Algorithm Optimizing and the A pplicatio n in Radar Data Compression Wang Z hig ang Ch ang Chuanwen M a o W enshen (T he28th R esear ch Institute of CET C,N anjing 210007) A bstract L Z W(L em pe l Z iv We lch)algo r ithm is an outstanding dict io nary co mpr ession alg or ithm,which has ma ny excelle nce s such as str ong univer sal ability and can fo rm the dictionar y dy namic ally in coding and e nco ding,and is w idely used in lo ssle ss compr essio n field.T his a rticle intro duces the elem ents of L Z W,sho ws its pr og ra m steps o f co ding,and an a ly ses an exa mple in detail.A Hash T able is desig ned to optimize the pr og ram,which c an decr ease the se arching dictiona r y time o bser vably.I mag es,radar data,and text f iles a re cho sen to be coded r espectively.T he speeds are com pa red and pr ef era ble r esults ar e obtained.At last,w e cho o se seve ra l classica l re al r adar data to do ex periments by using dif fer ent da t a subsect io n,co mpare the re sults w ith R L E(R un L eng th Enco ding),and o bta in sev er al usef ul conclusio ns. Key words L Z W,H ash T able,o ptimize,R L E Class Nu mber T P301.6 1 引言 如果按照压缩前后信息量划分,数据压缩算法可分为有损压缩和无损压缩,常见的无损压缩算法有游程RLE(Run Leng th Encoding)、霍夫曼、LZW(Lempel Ziv Welch)算法、算术编码等,LZW 算法是一种字典压缩算法,字典是在编解码过程中动态形成的,其突出的优点是通用性强,适合各种不同类型的待压缩信源,该算法被广泛应用于如今的数据压缩领域,如流行的压缩软件WINRAR和GIF图像。 本文旨在研究LZW算法,并从数据结构的设计上对程序进行优化,使之满足实时应用的要求,最后利用雷达数据进行分析,讨论不同数据类型下的压缩效果,取得了较好的实验效果。 2 LZW算法介绍 LZW算法是在1984年由TA Welch对LZ编码中的LZ78算法修改而成的一种实用的算法。其不同于费诺编码、霍夫曼编码和算术编码,在使用时不需要对信源进行概率统计;也不同于游程编码,它既可以对重复字符编码,也可以对不同但重复出现的字符 *收稿日期:2008年10月6日,修回日期:2008年11月15日作者简介:王志刚,男,高级工程师,研究方向:信号与信息处理研究。 ****** 研究生姓名*** 学科(专业)结构工程 研究方向********* 指导教师********** 2014年10月26日填 选题报告须知 一、选题原则 (一)博士生: 1、应选择学科前沿,对科学技术进步有重要的理论意义或较大理论意义的课题,也可选择对国民经济发展有重要或较大理论意义或实用价值的课题。 2、课题具有很大的难度,便于作者做出创新性成果。 3、要有先进的科学实验或运算手段验证理论作保证。 4、要尽量结合导师的科研任务进行选题。 5、要广泛阅读文献资料,要对本学科及相关学科研究状况和最新进展有全面的了解,写出文献综述。 (二)硕士生: 1、应选择有较大的科学研究意义或有一定理论意义的课题,也可以选择对国民经济建设有较大实用价值或一定价值的课题。 2、课题要具有先进性,便于作者提出新见解。 3、课题要有一定的份量和难度,同时要考虑在一年内完成。 4、要对实验条件,计算手段有恰当的估计。 5、要尽量结合导师的科研任务进行选题。 6、要广泛阅读文献资料,了解本领域国内外学术研究动态,写出文献综述。 二、基本要求 1、查阅文献资料一般要:博士生中外文献限于近5年内50篇以上;硕士生30篇以上。 2、博士生通过选题报告后与论文答辩申请相隔期为1.5年,硕士生为1年。博士生要在省级以上科技情报所进行查新。 3、书写格式: (1)论文题目(或选题范围) (2)综述(国内外在这一领域已进行的工作及自己要进行的研究) (3)课题的实用价值或理论意义 (4)课题研究方案 (5)实验、试验设想 (6)所阅读的文献、资料 (7)论文工作安排 选题报告 价值工程 置,是一项十分有意义的工作。另外恶意代码的检测和分析是一个长期的过程,应对其新的特征和发展趋势作进一步研究,建立完善的分析库。 参考文献: [1]CNCERT/CC.https://www.360docs.net/doc/c614224794.html,/publish/main/46/index.html. [2]LO R,LEVITTK,OL SSONN R.MFC:a malicious code filter [J].Computer and Security,1995,14(6):541-566. [3]KA SP ER SKY L.The evolution of technologies used to detect malicious code [M].Moscow:Kaspersky Lap,2007. [4]LC Briand,J Feng,Y Labiche.Experimenting with Genetic Algorithms and Coupling Measures to devise optimal integration test orders.Software Engineering with Computational Intelligence,Kluwer,2003. [5]Steven A.Hofmeyr,Stephanie Forrest,Anil Somayaji.Intrusion Detection using Sequences of System calls.Journal of Computer Security Vol,Jun.1998. [6]李华,刘智,覃征,张小松.基于行为分析和特征码的恶意代码检测技术[J].计算机应用研究,2011,28(3):1127-1129. [7]刘威,刘鑫,杜振华.2010年我国恶意代码新特点的研究.第26次全国计算机安全学术交流会论文集,2011,(09). [8]IDIKA N,MATHUR A P.A Survey of Malware Detection Techniques [R].Tehnical Report,Department of Computer Science,Purdue University,2007. 0引言 现有的压缩算法有很多种,但是都存在一定的局限性,比如:LZw [1]。主要是针对数据量较大的图像之类的进行压缩,不适合对简单报文的压缩。比如说,传输中有长度限制的数据,而实际传输的数据大于限制传输的数据长度,总体数据长度在100字节左右,此时使用一些流行算法反而达不到压缩的目的,甚至增大数据的长度。本文假设该批数据为纯数字数据,实现压缩并解压缩算法。 1数据压缩概念 数据压缩是指在不丢失信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率的一种技术方法。或按照一定的算法对数据进行重新组织,减少数据的冗余和存储的空间。常用的压缩方式[2,3]有统计编码、预测编码、变换编码和混合编码等。统计编码包含哈夫曼编码、算术编码、游程编码、字典编码等。 2常见几种压缩算法的比较2.1霍夫曼编码压缩[4]:也是一种常用的压缩方法。其基本原理是频繁使用的数据用较短的代码代替,很少使用 的数据用较长的代码代替,每个数据的代码各不相同。这些代码都是二进制码,且码的长度是可变的。 2.2LZW 压缩方法[5,6]:LZW 压缩技术比其它大多数压缩技术都复杂,压缩效率也较高。其基本原理是把每一个第一次出现的字符串用一个数值来编码,在还原程序中再将这个数值还成原来的字符串,如用数值0x100代替字符串ccddeee"这样每当出现该字符串时,都用0x100代替,起到了压缩的作用。 3简单报文数据压缩算法及实现 3.1算法的基本思想数字0-9在内存中占用的位最 大为4bit , 而一个字节有8个bit ,显然一个字节至少可以保存两个数字,而一个字符型的数字在内存中是占用一个字节的,那么就可以实现2:1的压缩,压缩算法有几种,比如,一个自己的高四位保存一个数字,低四位保存另外一个数字,或者,一组数字字符可以转换为一个n 字节的数值。N 为C 语言某种数值类型的所占的字节长度,本文讨论后一种算法的实现。 3.2算法步骤 ①确定一种C 语言的数值类型。 —————————————————————— —作者简介:安建梅(1981-),女,山西忻州人,助理实验室,研究方 向为软件开发与软交换技术;季松华(1978-),男,江苏 南通人,高级软件工程师,研究方向为软件开发。 数据快速压缩算法的研究以及C 语言实现 The Study of Data Compression and Encryption Algorithm and Realization with C Language 安建梅①AN Jian-mei ;季松华②JI Song-hua (①重庆文理学院软件工程学院,永川402160;②中信网络科技股份有限公司,重庆400000)(①The Software Engineering Institute of Chongqing University of Arts and Sciences ,Chongqing 402160,China ; ②CITIC Application Service Provider Co.,Ltd.,Chongqing 400000,China ) 摘要:压缩算法有很多种,但是对需要压缩到一定长度的简单的报文进行处理时,现有的算法不仅达不到目的,并且变得复杂, 本文针对目前一些企业的需要,实现了对简单报文的压缩加密,此算法不仅可以快速对几十上百位的数据进行压缩,而且通过不断 的优化,解决了由于各种情况引发的解密错误,在解密的过程中不会出现任何差错。 Abstract:Although,there are many kinds of compression algorithm,the need for encryption and compression of a length of a simple message processing,the existing algorithm is not only counterproductive,but also complicated.To some enterprises need,this paper realizes the simple message of compression and encryption.This algorithm can not only fast for tens of hundreds of data compression,but also,solve the various conditions triggered by decryption errors through continuous optimization;therefore,the decryption process does not appear in any error. 关键词:压缩;解压缩;数字字符;简单报文Key words:compression ;decompression ;encryption ;message 中图分类号:TP39文献标识码:A 文章编号:1006-4311(2012)35-0192-02 ·192· 第三章多媒体数据压缩 3.1 数据压缩的 基本原理和方法 3.1 数据压缩的基本原理和方法 ?压缩的必要性 音频、视频的数据量很大,如果不进行处理,计算机系统几乎无法对它进行存取和交换。 例如,一幅具有中等分辨率(640×480)的真彩色图像(24b/像素),它的数据量约为7.37Mb/帧,一个 100MB(Byte)的硬盘只能存放约100帧图像。若要达到每秒25帧的全动态显示要求,每秒所需的数据量为 184Mb,而且要求系统的数据传输率必须达到184Mb/s。 对于声音也是如此,若采用16b样值的PCM编码,采样速 率选为44.1kH Z ,则双声道立体声声音每秒将有176KB的 数据量。 3.1 数据压缩的基本原理和方法 ?视频、图像、声音有很大的压缩潜力 信息论认为:若信源编码的熵大于信源的实际熵,该信源中一定存在冗余度。 原始信源的数据存在着很多冗余度:空间冗余、时间冗余、视觉冗余、听觉冗余等。 3.1.1 数据冗余的类型 ?空间冗余:在同一幅图像中,规则物体和规则背景的表面物理特性具有相关性,这些相关性的光成像结果在数字化图像中就表现为数据冗余。 –一幅图象中同一种颜色不止一个象素点,若相邻的象素点的值相同,象素点间(水平、垂直)有冗余。 –当图象的一部分包含占主要地位的垂直的源对象时,相邻 线间存在冗余。 3.1.1 数据冗余的类型 ?时间冗余:时间冗余反映在图像序列中就是相邻帧图像之间有较大的相关性,一帧图像中的某物体或场景可以由其它帧图像中的物体或场景重构出来。 –音频的前后样值之间也同样有时间冗余。 –若图象稳定或只有轻微的改变,运动序列帧间存在冗余。 申明:本文中思想及图片都是参照EVSystems(网址如下)说明文档,版权归其所有,鄙人只管翻译和归纳。要转载本文也请说明出处,谢谢! https://www.360docs.net/doc/c614224794.html, sfriedenthal@https://www.360docs.net/doc/c614224794.html, 实时数据压缩算法(GE Historian Compression Methods) 一、GE Historian Compression Methods 1. CC:Collector Compression ‘X’表示丢弃的数,圆表示保留的数。 方法:选一个点为起始点,以此点为中心,在y轴方向规定一个‘Dead band’区域,在区域内的点丢弃,直到遇到一个不再区域内的点,该点作为新的起始点,从而设定新的‘Dead band’区域。 此方法的缺点是:不能丢弃‘保持斜率不变’的点,如图中‘Constant slope line’。 2. AC:Archive Compression(存档压缩) 此方法通过判断斜率区域来丢弃多余的点,可识别并丢弃‘保持斜率不变’的点,AC一般在CC之后使用。具体实现方法在下文中说明。 CC和AC组合实现实时数据压缩,统称为:GE Historian Compression Methods 二、OSI PI Swinging Door Comrpession(美国OSI公司:游泳门压缩) 方法:选一个点为起始点(存储点)如图中‘Archived Point’,图中‘New Point ’称为当前点。然后依次选取后面的点(做当前点)做平行四边形,如下图所示: 当产生的平行四边形不能容纳上个存储点到当前点之间的所有数据点时,即 有数据点落在当前平行四边形覆盖面积之外时,则将‘当前点’的前一个数据点保存,作为新的存储点,其他点舍弃。以此往复。如下图所示: 判断一个点是否在当前平行四边形覆盖面积之内的方法如下图(能看懂就不翻译了): 该方法的缺点是:计算量大,CPU占时太多,程序实现复杂。 GE Historian Compression Methods和Swinging Door Comrpession不同之处在于:其丢弃点动作的触发条件不一样,它不计算一个点是否在平行四边形中,通过斜率范围来判断,即判断“存储点和但前点之间连线是否与他们中间各个点的dead band 线相交”,其判断方法及整体示意图如下两图所示: 浅述基坑支护结构的类型及设计原则 摘要:本文主要对基坑支护结构的类型及设计原则进行了深入浅出的说明, 同时得出了基坑支护是一种特殊的结构方式,具有很多的功能。不同的支护结构适应于不同的水文地质条件,因此,要根据具体问题,具体分析,从而选择经济适用的支护结构。 关键字:基坑支护,特点,设计原则 一、前言 无论是高层建筑还是地铁的深基坑工程,由于都是在城市中进行开挖,基坑周围通常存在交通要道、已建建筑或管线等各种构筑物,这就涉及到基坑开挖的一个很重要内容,要保护其周边构筑物的安全使用。而一般的基坑支护大多又是临时结构、投资太大也易造成浪费,但支护结构不安全又势必会造成工程事故。因此,如何安全、合理地选择合适的支护结构并根据基坑工程的特点进行科学的设计是基坑工程要解决的主要内容。以下简单介绍当前基坑工程中常见的支护结构类型及不同地基土条件下的基坑工程支护结构选型原则。 二、正文 我国大量的深基坑工程始于20世纪80年代,由于城市高层建筑的迅速发展,地下停车场、高层建筑埋深、人防等各种需要,高层建筑需要建设一定的地下室。近几年,由于城市地铁工程的迅速发展地铁车站、局部区间明挖等也涉及大量的基坑工程,在双线交叉的地铁车站,基坑深达20-30m。水利、电力也存在着地下厂房、地下泵房的基坑开挖问题。 无论是高层建筑还是地铁的深基坑工程,由于都是在城市中进行开挖,基坑周围通常存在交通要道、已建建筑或管线等各种构筑物,这就涉及到基坑开挖的一个很重要内容,要保护其周边构筑物的安全使用。而一般的基坑支护大多又是临时结构、投资太大也易造成浪费,但支护结构不安全又势必会造成工程事故。因此,如何安全、合理地选择合适的支护结构并根据基坑工程的特点进行科学的设计是基坑工程要解决的主要内容。以下简单介绍当前基坑工程中常见的支护结构类型及不同地基土条件下的基坑工程支护结构选型原则。 1 基坑支护的类型及其特点和适用范围 1.1 放坡开挖 南昌大学研究生(工程硕士)2006~2007学年第二学期 期末考试试卷 课程名称:《多媒体技术》专业:软件工程 学生姓名:学号:C2007271 学院:信息工程学院得分: 任课教师签:洪春勇时间:2007.8 多媒体数据压缩技术综述 摘要:本文侧重介绍多媒体各种数据类型和数据描述,讨论数据 压缩技术在各种媒体数据上的应用及发展趋势。 关键词:多媒体数据、数据压缩、JPEG、MPEG-4、发展趋势、一、引言 多媒体在我国的定义是:能对多种载体(媒介)上的信息和多种存储体(媒介)上的信息进行处理的技术。多媒体传统关键技术主要集中在以下四类中:数据压缩技术、大规模集成电路(VLSI)制造技术、大容量的光盘存储器(CD-ROM)、实时多任务操作系统。因为这些技术取得了突破性的进展,多媒体技术才得以迅速的发展。网络技术的发展使多媒体技术的应用空间得到了快速拓展。但是网络现状的局限性也使得各种多媒体技术应用受到制约,因此对于多媒体数据的压缩技术显得非常重要和关键。 二、多媒体数据类型及其数据描述 (一)多媒体数据类型 1.文字 文字是人与计算机之间进行信息交换的主要媒体。在计算机发展的早期,比较实用的终端为一般文字终端,在屏幕上显示的都是文字信息。由于人们在现实生活中用语言进行交流,所以开始时文字终端比较流行,但是后来出现了图形、图像、声音等媒体,这样也就相应地出现了多种终端设备。在现实世界中,文字是人们进行通信的主要形式,文字包括西文与中文。在计算机中,文字用二进制编码表示,即使用不同的二进制编码来代表不同的文字。 2.音频 音频(Audio)指的是20HZ~20kHz的频率范围,但实际上“音频”常常被作为“音频信号”或“声音”的同义语,是属于听觉类媒体,主要分为波形声音、语音和音乐。 3.视觉媒体 能够利用视觉传递信息的媒体都是视觉媒体。位图图像、矢量图像、动态图像、符号等都是视觉媒体。 4.动画 动画是指运动的画面,动画在多媒体中是一种非常有用的信息交换工具。计算机动画的研究始于20世纪60年代初期。1963年Bell实验室制作了第一部计算机动画片。最初主要集中在二维动画的研制,作为示教和辅助制作传统动画片之用。三维计算机动画的研究始于20世纪70年代初,但真正进入实用化还是80年代中后期。随着具有实时处理能力的超级图形工作站的出现,以及三维造型技术、真实感图形生成技术的迅速发展,推出了一些可生成具有高逼真度视觉效果的实用化、商品化的三维动画系统。20世纪90年代初,计算机动画技术成功地应用于电影特技,取得了出色的成就,由此可见计算机动画技术的重要意义。(二)多媒体数据的描述 1.音频文件 在多媒体声音处理技术中,最常见的几种声音存储格式是:WAVE波形文件,MIDI音乐数字文件和目前非常流行的MP3 数据压缩技术 一、课程标准中的相关内容 1.认识多媒体技术对人类生活、社会发展的影响 2.初步了解多媒体信息采集、加工原理 3.掌握应用多媒体技术促进交流并解决实际问题的思想与方法 二、教学目标 1.知识与技能 ①理解压缩的含义 ②理解实现数据压缩的条件 ③分别了解无损压缩和有损压缩 ④了解无损压缩的简单原理 ⑤初步掌握二叉树编码 2.过程与方法 ①通过阅读、观察、探索等方式理解数据压缩技术 ②设计一系列渐进式问题引导学生自主探究。 3.情感态度与价值观 ①理解和领悟交流的乐趣 ②培养分析能力和信息归纳能力 ③加深对本学科的技术分支认识 三、学生分析 本课的教学对象是高中一年级的学生。学生通过在初中阶段的系统学习,已经地掌握了一定信息处理能力,如文本处理,图像处理,压缩处理等,但大部分学生对此多局限于操作层面,与原理上的理解认知并不同步。特别是对于技术层面较高的知识,学生之间的差异就更大了。本课时对操作和理解原理能力同步性要求较高,为了让学生能够顺利的完成任务,获得成就感,任务的设计必须有一定的层次关系,且有充足的学习资源配套使用。 四、教材分析 本内容选自选修2《多媒体技术应用》第3.2.6节《数据压缩技术》(P46)。高中阶段的课程,尤其是选修模块,较初中阶段更强调理论与实践的结合——已不是单纯的熟练操作,还应从原理上去把握技术的实质,这也体现了课标中“原理性”的要求。 对于数据压缩技术,其实很多学生使用计算机的时候都在不知不觉中享受着它带来的便利,只是他们对此并没有足够的认识而已。课本对数据压缩技术的介绍概括性较强。如果仅仅照本宣科的话,学生的理解是有一定困难的,也容易让他们对原理性的知识产生抗拒感。经过对教材的多次梳理,我确定了教学的重点为数据压缩技术的概念、类型和实现条件;难点为二叉树编码的原理。 五、教学重点难点 1.教学重点: ①压缩的概念与实现条件 ②压缩的两种基本类型——无损压缩和有损压缩 2.教学难点: ①理解压缩实现的原理 ②初步掌握二叉树编码 六、教学策略 新课程标准中特别强调从问题解决出发,让学生亲历处理信息、开展交流、相互合作的过程。特别强调结合学生的生活和学习实际设计问题,让学生在活动过程中掌握应用信息技术解决问题的思想和方法,同时鼓励学生将所学的信息技术积极应用到生产、生活乃至技术革新等实践活动中。本节主要采用“问题解决”的教学模式。“问题解决”教学模式是指依据教学内容和要求,由教师创设问题情境,以问题的发现、探究和解决来激发学生求知欲和主体意识,培养学生的实践和创新能力的一种教学模式。其中,教师创设问题情境是教学设计的中心环节,即围绕某一“问题”进行渐进式的、全方位的设问。流程如下图所示 论钢筋混凝土结构 【摘要】预应力构件的原理,以及预应力构件的优点、缺点、在工程中的应用,展望其广阔的应用前景。 【关键词】预应力混凝土;工程应用;发展概况 钢筋混凝土结构是指用配有钢筋增强的混凝土制成的结构,承重的主要构件是用钢筋混凝土建造的。用钢筋和混凝土制成的一种结构,钢筋承受拉力,混凝土承受压力,具有坚固、耐久、防火性能好、比钢结构节省钢材和成本低等优点。用在工厂或施工现场预先制成的钢筋混凝土构件,在现场拼装而成。 1、钢筋混凝土结构的构成及受力: 混凝土是由水泥、砂子、石子和水按一定的比例拌和而成,凝固后坚硬如石,受压能力好,但受拉能力差,容易因受拉而断裂(图a),为了解决这个矛盾,充分发挥混凝土的受压能力,常在混凝土受拉区域内或相应部位加入一定数量的钢筋,使两种材料粘结成一个整体,共同承受外力。这种配有钢筋的混凝土,称为钢筋混凝土(图b)。钢筋混凝土粘结锚固能力可以由四种途径得到:①钢筋与混凝土接触面上吸附作用力,也称胶结力。②混凝土收缩,将钢筋紧紧握固而产生摩擦力。③钢筋表面凹凸不平与混凝土之间产生的咬合作用,也称咬合力。④钢筋端部加弯钩、弯折或在锚固区焊短钢筋、焊角钢来提供锚固能力。 (图a) (图b) 由于混凝土的抗拉强度远低于抗压强度,因而素混凝土结构不能用于受有拉应力的梁和板。如果在混凝土梁、板的受拉区内配置钢筋,则混凝土开裂后的拉力即可由钢筋承担,这样就可充分发挥混凝土抗压强度较高和钢筋抗拉强度较高的优势,共同抵抗外力的作用,提高混凝土梁、板的承载能力。 (1)混凝土干缩结硬(或硬化)后能产生较大的黏结力(或称握裹力),使钢筋与混凝土能可靠的结合成一整体,从而在荷载的作用下能够很好的共同变形和传递应力。 (2)二者具有相近的线胀系数,不会由于温度变化产生较大的温度应力和相对变形而破坏粘结力。 (3)呈碱性的混凝土可以保护钢筋,使钢筋混凝土结构具有较好的耐久性,这是因为水泥水化作用后,产生碱性反应在钢筋表面产生一种水泥石质薄膜,可防止有害介质的直接侵蚀。 2、钢筋混凝土结构的主要优缺点: 优点: (1)在混凝土结构中,砼强度是随时间而增长的,又钢筋被砼包裹而不致锈蚀。故其耐久性好,耐火性好;此外,还可据需配置不同性能的混凝土,以满足不同的耐久性要求。 (2)结构整体性好,刚度较大,变形小,抗震及振动冲击工作性能好;同时,可有效的用于对变形有要求的建筑物中。 (3)可模性好,根据设计需要,便于实现浇筑成各种构件和结构型式。 (4)结构中混凝土包裹着钢筋,由于混凝土传热性能差,在火灾中对钢筋有保护作用,结构不致因钢筋迅速软化而破坏 (5)砂石料等可就地取材,降低成本。 缺点: (1)自重大g=25kN/m3 。 (2)抗裂性差。 (3)施工受气候影响较大 (4)现浇钢筋混凝土结构须耗用模板 (5)修补和拆除较困难 3、混凝土结构的工程应用 (1)房屋建筑工程 (2)桥梁工程 (3)特种结构与高耸结构 (4)水利及其他工程 预应力混凝土结构的应用,是利用混凝土的受拉区施加预应力,以提高混凝土结构的抗裂度,减轻构件的自重结构体系的丰富不同用途、不同数据压缩,算法的综述
当前特种结构的发展现状与趋势(论文)
数据压缩技术综述
《土木工程概论》课程论文土木工程的发展
五种大数据压缩算法
多媒体技术基础(数据压缩、标准、音频、图像)作业及答案
螺旋输送装置的研究现状及未来发展的浅析论文
LZW算法优化及在雷达数据压缩中的应用
结构工程硕士选题报告(DOC)
数据快速压缩算法的C语言实现
数据压缩的基本原理和方法(pdf 87页)
实时数据压缩算法(GE Historian Compression Methods)
特种结构结课论文
多媒体数据压缩技术综述
《数据压缩技术》教学设计
钢筋混凝土 论文