统计实验与SAS上机简易过程步
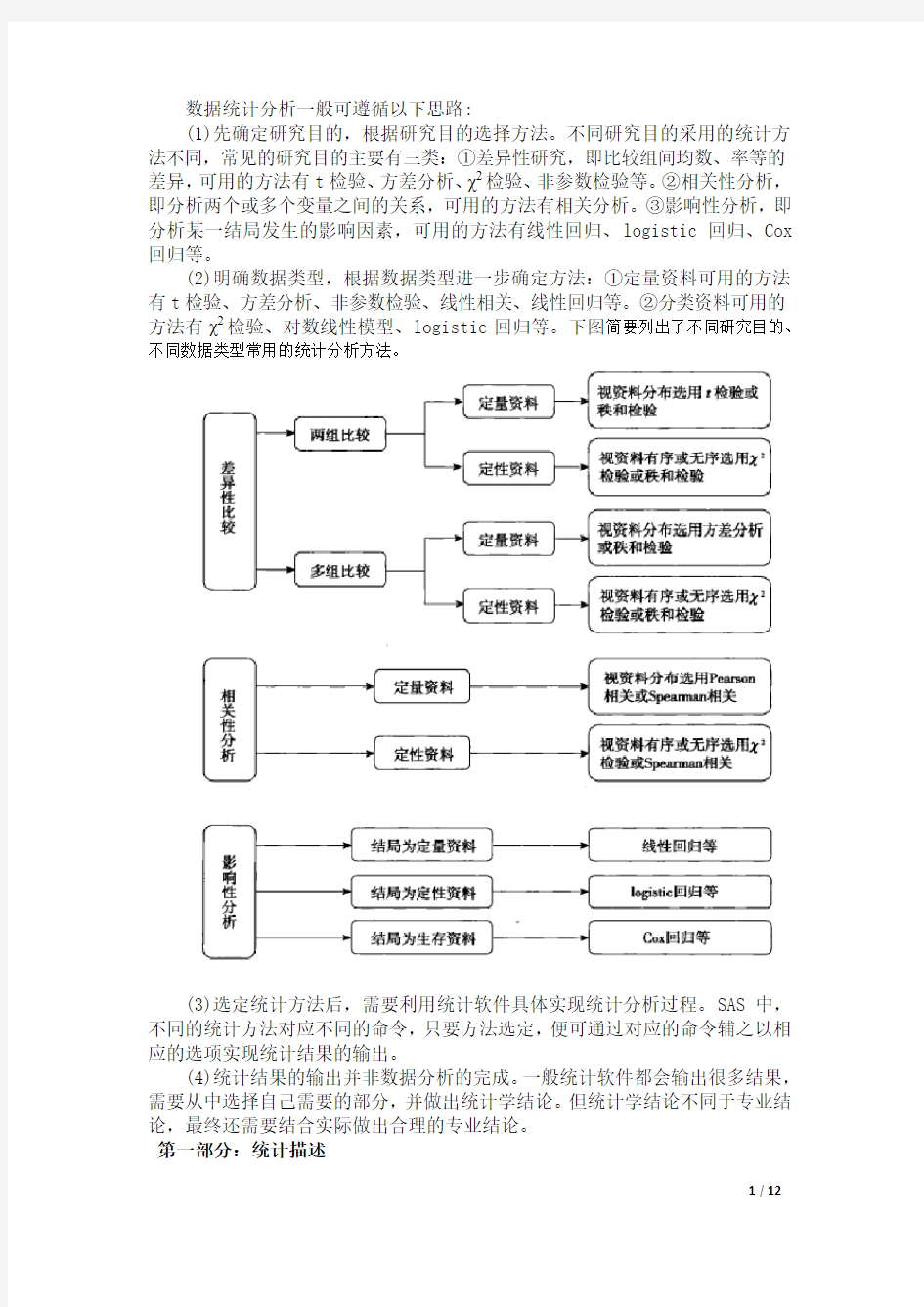

数据统计分析一般可遵循以下思路:
(1)先确定研究目的,根据研究目的选择方法。不同研究目的采用的统计方法不同,常见的研究目的主要有三类:①差异性研究,即比较组间均数、率等的差异,可用的方法有t检验、方差分析、χ2检验、非参数检验等。②相关性分析,即分析两个或多个变量之间的关系,可用的方法有相关分析。③影响性分析,即分析某一结局发生的影响因素,可用的方法有线性回归、logistic回归、Cox 回归等。
(2)明确数据类型,根据数据类型进一步确定方法:①定量资料可用的方法有t检验、方差分析、非参数检验、线性相关、线性回归等。②分类资料可用的方法有χ2检验、对数线性模型、logistic回归等。下图简要列出了不同研究目的、不同数据类型常用的统计分析方法。
(3)选定统计方法后,需要利用统计软件具体实现统计分析过程。SAS中,不同的统计方法对应不同的命令,只要方法选定,便可通过对应的命令辅之以相应的选项实现统计结果的输出。
(4)统计结果的输出并非数据分析的完成。一般统计软件都会输出很多结果,需要从中选择自己需要的部分,并做出统计学结论。但统计学结论不同于专业结论,最终还需要结合实际做出合理的专业结论。
第一部分:统计描述
1.定量资料的统计描述指标及SAS实现;
(1)数据分布检验:PROC UNIVARIATE
①基本格式:
②语句格式示例:
1.PROC UNIVARIATE normal;/*normal选项表示进行正态性检验*/
2.CLASS group;/*指定group为分组变量*/
3.VAR weight;/*指定分析变量为weight*/
4.RUN;
③结果:正态性检验(tests for normality)结果,常用的是Shapiro-Wilk 检验和Kolmogorov-Smirnov检验。当例数小于2000时,采用Shapiro-Wilk检验W值为标准;当例数大于2000时,SAS中不显示Shapiro-Wilk检验结果,采用Kolmogorov-Smirnov检验D值为判断标准。正态性检验的P≤0.05提示不服从正态分布,P>0.05提示服从正态分布。
注:若服从正态分布,进行PROC MEANS过程步;若不服从则计算百分位数,转(3)
(2)数据描述(符合正态分布的数据):PROC MEANS
①基本格式:
关键字(可以无视):不写任何关键字时默认输出n,mean,std,max,min;
n:有效数据记录数(有效样本量) median:中位数
mean:均数 qrange:四分位数间距
std:标准差 var:方差
clm:95%可信区间 max、min:最大、最小值
②语句格式示例:
1.PROC MEANS n mean std median qrange clm;/*关调用proc means过程,
要求输出的指标有例数、均值、标准差、中位数、四分位数间距、95%
可信区间*/
2.CLASS group;/*指定group为分组变量*/
3.VAR weight;/*指定分析变量为weight*/
4.Run;
③结果以“均数±标准差”表示
(3)偏正态分布的统计描述:
①基本思想:计算中位数和百分位数,并且用“中位数(Q1~Q3)”表示
②语句格式示例:
1.proc univariate data=aa;
2.var x;
3.output out=c pctlpre=P pctlpts=0 to 100 by 2.5;/*计算0到100
百分位数,间隔2.5个百分位数,并将结果输出在数据集“aa”中*/
4.run;
5.proc transpose data=c out=d;
6.proc print data=d;
7.run;/*以上是求解百分位数语句*/
1.proc univariate data=aa
2.CIPCTLDF(alpha=0.05);/* 求百分位数的95%可信区间,(alpha=0.05)
此处可缺省;若需求可信区间,只需指定相应的alpha水平*/
3.var x;
4.run;
③结果:a.偏态分布的统计描述以“中位数(Q1~Q3)”表示
b.总体参数的95%可信区间
2.分类(定性)资料的统计描述指标及SAS实现
(1)输出频数表:PROC FREQ
①基本格式:
②语句格式示例:
1.PROC FREQ;
2.TABLE group * weight;/*table后有group和grade两个变量,交叉形
成一个行X列的表格,若group为2类,grade为3类,因此形成2X3=6
个格子,每一格子中给出例数和相应比例*/
3.RUN;
(2)直方图的绘制
①基本语句:histogram 变量x
②语句格式示例:
1.proc univariate;
2.var x;
3.histogram x/midpoints=163 to 183 by 2; /*要求Univariate过程绘
制的直方图中各直条的组中值为163、165、……183(自行改动)*/
4.run;
(3)计算基本统计量和95%可信区间:PROC UNIVARIATE
①基本要求:计算定性资料的95%可信区间
②语句格式示例:
1.proc univariate cibasic; /*基本统计量及其可信区间,对应于
CIBASIC选项*/
2.var x;
3.run;
③结果:此步骤结果只需观察SAS结果中的“基本置信限正态假设”一栏,其他可无视。
第二部分:定量资料的统计分析
1.单一样本均数的检验
(1)直接公式编辑
①适用条件:没有原始数据,而只知道样本均数及已知总体的总体均数时
②方法示例:某医生测量了36名从事某作业的男性工人的血红蛋白含量,其均值为130.83g/L,标准差为25.74g/L。问从事该作业男性工人的血红蛋白含量是否不同于正常成年男性的均值140g/L
③SAS过程步:
1.data aa;
2.n=36;
3.sm=130.83;/*样本均数*/
4.std=2
5.74; /*样本标准差*/
5.pm=140; /*总体均数*/
6.df=n-1; /*自由度*/
7.t=(sm-pm)/(std/sqrt(n)); /*单样本t 检验的计算公式*/
8.p=(1-probt(abs(t),df))*2;/* ①abs(x)函数:返回x的绝对值。②
probt(x,df)函数:是student t分布的概率分布函数,用于计算自
由度为df的t分布在t取x值时的概率。因为是做双侧检验,所以求得
一侧的概率值后再乘以2*/
9.proc print;
10.var t p;
11.run;
③结果使用t和p值
(2)利用MEANS或UNIVARIATE过程计算
①已知样本资料的原始数据,单样本t 检验可以利用MEANS过程和UNIVARIATE过程实现
②语句格式示例:
1.proc means mean std t ptr;
2.var y;/*y值为每一个观测值与已知总体均数的差值*/
3.run;
或者
1.proc univariate;
2.var y;/*y值为每一个观测值与已知总体均数的差值*/
3.run;
③方法类似于统计描述,结果指标为t和p值
2.完全随机两组正态分布资料的比较
①分析思路:两组比较属于差异性研究,再看是否正太,可考虑方法有独立样本的t检验或Wilcoxon秩和检验,具体还应进一步看资料的分布情况。
②正态性检验:
1.proc univariate normal;
2.class group; var x;
3.run;
若为正态性则可使用t检验,否则使用Wilcoxon秩和检验(见后文)
③t检验语句:
1.proc ttest
2.class group;
3.var x;
4.run;
④结果:观察t值和p值,给出结论
3.完全随机两组非正态分布资料的比较
①思路同上2,首先进行正态性检验;语句略
②非正态分布时两组之间的秩和检验语句:
1.proc npar1way Wilcoxon;/*wilcoxon选项给出wilcoxon和
Kruskal-Wallis检验值*/
2.class group;
3.var x;
4.run;
③秩和检验观察Z值和P值,得出结论
4.完全随机多组正态分布资料的比较
①前提是研究为完全随机设计,需要分析两组数据的变化值,因此可以考虑方差分析或Kruskal-Wallis秩和检验,具体还应进一步看资料是否符合正态分布;
②正态性检验确定具体分析方法,若为正态,使用方差分析,否则为Kruskal-Wallis秩和检验(非参数检验,见后文):正态性检验过程步略···
③方差分析:只有glm过程,anova过程请参考课件
1.proc glm;
2.class group;
3.model x=group;
4.means group/hovtest lsd;/*使用lsd法进行两两比较并给出p值*/
5.run;
④根据两组之间p值是否有意义给出结论
5.完全随机多组非正态分布资料的比较
①同上思路,首先正态检验,不符合时候,使用多组之间的Kruskal-Wallis 秩和检验;
首先进行秩和检验:
1.proc npar1way Wilcoxon;/*wilcoxon选项给出wilcoxon和
Kruskal-Wallis检验值*/
2.class group;
3.var x;
4.run;
②多组非正态分布资料两两之间的比较的过程步:(原理:对研究变量的秩进行排序,用方差分析对秩次进行两两比较);
1.proc rank data=ex12_5 out=rank5;
2.var x;
3.run;
4.proc print data=ranks;
5.run;
6.proc glm data=ranks;
7.class group;
8.model x=group;
9.means group/lsd;
10.run;
完全copyPPT···
③结果观察:先看χ2和p值(总体指标)有无统计学意义,若无意义,无
需进行两两比较,只有总体指标χ2和p值有意义才需进行两两检验。
6.析因设计方差分析
①析因设计有一点重要的是:A和B两个指标之间可能会有交互作用,需考虑二者之间的交互作用a*b
②首先仍然是正态性检验,若符合可直接用析因设计的方差分析,否则可用Kruskal-Wallis秩和检验(类似于完全随机设计);
③析因设计的过程步(符合正态分布):
1.proc glm data=aa;
2.class a b;
3.model x=a b a*b;/*计算a,b以及a*b,之间的相互作用*/
4.output out=glmout P=pred R=resi; /*将三者之间的P值和R值输出到
新的数据集glmout中,并对二者进行赋值*/
5.run;
1.proc gplot data=glmout ;
2.plot pred*a=b/HAIXS=0.5 1 2 2.5 VAIXS=0.1 to 0.2 by 0.02; /*2*2
析因设计交互效应作图*/
3.symbol I=join;
4.run;
③结果参考:同样先看总体之间差异有无统计学意义:若有意义,继续观察
两两之间的p值;若无意义,可无视。
7.配对资料的分析
①配对分析思路:配对设计分析一般以差值作为分析指标,实际上是前后数据分析差值与0相比是否有统计学意义。利用proc univariate程序对差值的正态性及分布进行检验;
②首先正态性检验,过程步略···
③若符合正态分布,可直接用glm过程(若不符合正态分布,其差值具体大小需要结合中位数来看,而不是均数):
1.data aa;
2.input x1 x2@@;
3.y= x1-x2;/*用y来表示配对两者资料的差值*/
4.cards;
5.···············(具体数据)
6.;
7.proc univariate;
8.var y;
9.run;
③结果推断:结合SAS结果中的“Test for Location”结果的S和Pr值判
断是否有意义
8.随机区组资料的分析(配伍组资料分析)
①要点:随机区组设计有分区变量block、分组变量group以及分析变量x;具体分析方法根据正态性选择方差分析或Friedman检验;
②若为正态分布的数据,采用随机区组方差分析:proc glm过程步
1.PROC GLM;
2.CLASS group block; /*将组别和区组均指定为分类变量*/
3.MODEL x=group block;/*model语句指定x为分析变量,group为分组变
量,block为区组变量。如果不加block,其效果等同于完全随机设计的
方差分析*/
4.means a/snk;/*用SNK法分析处理组a间的两两比较*/
5.RUN;
③若非正态分布,采用Friedman检验,即偏态分布时使用的随机区组分析
方法:PROC FREQ语句
1.PROC FREQ;/*调用FREQ命令*/
2.TABLE block*group*den/noprint scores=rank cmh2;/*TABLE语句指明
分组变量和分析变量,noprint表示不打印交叉表,scores=rank表示执
行非参数检验,cmh2表示输出行平均得分差值*/
3.RUN;
③结果分析:根据总的差异统计量G和P值得出结论
第三部分:定性资料的统计分析
1.四格表(2×2)资料的分析
①对于两个变量均为二分类变量,首选方法是四个表资料的χ2检验,还可以采用Logistic回归(略);
②四格表资料χ2检验的数据步和过程步:
1.PROC FREQ;/*调用freq程序*/
2.WEIGHT f ;/*表明输人的f是一个权重值*/
3.TABLE a* b/chisq expected relrisk;/*table语句列出列联表,chisq
选项调用χ2检验结果,expected输出理论频数,relrisk输出相对危险
度*/
4.RUN;
③注意点:输入语句中第一个do语句输人行变量,第二个do语句输人列变量,顺序一定要和后面的数据对应起来;input f后一定要有两个@;一定要有output语句,且要在end语句前;end与do语句是相对应的,有几个do语句,output后就要加几个end;weight语句一定要指定频数变量,如果无weight语句,SAS会认为四格表中每个格子的例数均为1。
④结果中会给出χ2检验结果和Fisher检验的结果当研究例数<40或理论频数<1时,用Fisher精确检验更为可靠。危险度请参考课本···
2.R×2表资料的分析
①R×2表含义:R×2表指行变量为多分类的分组指标,列变量为二分类的分析指标,组间差异比较可采用χ2检验。
②分析中只要分析指标为无序变量,则不论分组指标是有序还是无序均可采用χ2检验进行分析。如果组间总的差异有统计学意义,还可进一步做两两比较。
③过程步:
1. PROC FREQ;
2. WEIGHT f;
3. TABLE a*b/nopercent nocolchisq;/*nopercent表示不输出总百分比,nocol表示不输出列百分比,chisq选项调用卡方检验结果*/
4. RUN;
④若需用精确检验法时,可在table语句后加入fisher选项。
3.2×C表无序资料的分析
①2×C表无序资料:2×C表资料指行变量为二分类的分组指标,列变量为多分类的分析指标。如果分析指标为无序分类变量,可用χ2检验分析组间构成比是否有差异,如果例数小于40或有理论频数小于1,可以采用Fisher精确概率检验法。
②过程步同四格表χ2检验程序,无其他特殊语句
4.2×C表有序资料的分析
①2×C表有序资料:如果分析指标为有序分类变量,用χ2检验只能说明组间构成比是否有统计学差异,无法说明等级的差别。如要比较组间等级差异是否有统计学意义,可用Wilcoxon秩和检验
②过程语句
1. PROC NPARIWAY wilcoxon;/*调用秩和检验程序,指定采用Wilcoxon检验*/
2. CLASS group;/*指明分组变量*/
3. VAR effect;/*指明分析变量*/
4. FREQ f ;/*freq语句与proc freq命令中的weight语句类似,因为数据输人都是频数方式,因此通过freq指定f为频数*/
5. RUN;
③例如在检验药品疗效时分析变量有“无效、有效、显效、痊愈”,采用χ2检验,结果显示两组的分布有统计学差异,但是不说明疗效问题,如果将结果指标的顺序打乱,如按“无效、痊愈、显效、有效”的顺序排列,χ2检验的结果仍然不变,而秩和检验的结果会发生变化
5.配对四格表(2×2)资料的分析
①类似于定量资料的配对设计
②语句
1. PROC FREQ;
2. WEIGHT f;
3. TABLE a*b/nopercent nocol norow chisq;
4. RUN;
③检验统计量为结果中第一行的Pearson卡方。
6.Cochran Armitage趋势检验
①属于定性资料χ2检验的一部分,在table语句后面多了一个trend选项
②语句示例
1. PROC FREQ;
2. WEIGHT f;
3. TABLE path*hp/nopercent nocol chisq trend;
4. RUN;
③Cochran-Armitage趋势检验结果中,统计量(Z)≤0时,单侧P值给出的是左侧P值,单侧第一列呈下降趋势。当统计量(Z)>0,单侧P值给出的是右侧P值,表明第一列呈上升趋势。
注:Cochran-Armitage趋势检验只能有两列。
④结果示例:
此结果统计量Z小于0,表示在原始数据中第一列(阴性率)呈下降趋势。
第四部分:相关与回归分析
1.定量资料的相关分析
①首先正态性检验(略),如果符合正态分布,采用Pearson法进行相关分析,否则改用Spearson相关;
②相关分析的过程步:
1. PROC CORR pearson spearman;/*选项pearson和spearman分别输出Pearson和Spearman相关系数*/
2. VAR bmi tc fbg;/*本例有三个分析指标*/
3. RUN;
③结果示例:
如果符合正态分布,则参考Pearson,不符合正态分布采用Spearson相关系数结果。
2.分类资料的相关分析
①分类资料的相关性分析一般可用χ2检验或对数线性模型。对于仅有两个变量的二维列联表χ2是最常用的方法。
②分类资料相关分析的SAS实现
1.PROC FREQ;
2.WEIGHT f;
3.TABLE a*b/chisq;/*两个研究变量a和b*/
4.RUN:
③结果中的输出和χ2检验的结果一样,但是需要的指标不同,单含义不同,相关分析的χ2值反应了相关性是否有统计学意义,同时参考χ2检验中的列联系数,使用列联系数来确定相关性的大小。
3.一般直线回归分析
首先要求对线性回归的应用条件(线性、正态性、等方差性、独立性)进行检验
①线性可以通过做散点图来观察
1.proc plot;
2.plot y*x=‘*’;
3.run;
②正态性检验通过对残差的正态性检验实现,程序:
1.PROC REG;/*调用线性回归分析程序*/
2.MODEL y=x;/*拟合自变量对因变量的关系*/
3.OUTPUT out=res r=r;/*将残差输出到数据集res*/
4.RUN;
5.Proc univariate normal data= res;
6.Var r;
7.Run;
要求残差符合正态分布,否则不能使用reg过程
③等方差性可通过残差图观察,过程步:
1.PROC REG;
2.MODEL y=x;
3.PLOT student.*p./nomodel nostat;/*绘制学生化残差散点图,student.
为学生化残差,P.为因变量预测值*/
4.RUN;
结果显示所有的学生化残差均在士2的范围内波动,看不出有明显的上升或下降等趋势,可以认为符合等方差性条件。
④若数据符合线性、正态性、等方差性、独立性,进行线性回归,过程步:
1.PROC REG; /*调用线性回归分析程序*/
2.MODEL y=x/stb p; /*拟合自变量x对因变量y的关系.如果加上stb,
可以输出标准化回归系数。如果加上p,可以输出每个观测点的因变量y
的实际值、预测值和残差(实际值与预测值的差值)*/
3.RUN;
reg中其他选项含义:
clm:可以输出因变量预测值均数的双侧95%可信区间
cli:语句为“model y=x/cli”,可以输出因变量预测值个体的95%容许区间
⑤结果与方程:
该方程为:y=426.6253+16.5800×x
注:1. 注意拼写以及中非英文符号
2. 仅供参考
SAS中的SQL语句大全
S A S中的S Q L语句完全教程之一:S Q L简介与基本查询功能本系列全部内容主要以《SQLProcessingwiththeSASSystem(CourseNotes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。 1SQL过程步介绍 过程步可以实现下列功能: 查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL 语句、可以和SAS的数据步进行替换使用。注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。 过程步的特征 SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print 过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL过程步 过程步语句 SELECT:查询数据表中的数据 ALTER:增加、删除或修改数据表的列 CREATE:创建一个数据表 DELETE:删除数据表中的列 DESCRIBE:列出数据表的属性 DROP:删除数据表、视图或索引
RESET:没用过,不知道什么意思 SELECT:选择列进行打印 UPDATE:对已存在的数据集的列的值进行修改 2SQL基本查询功能 语句基本语法介绍 SELECT
统计学简答题参考答案讲解学习
统计学简答题参考答 案
统计学简答题参考答案 第一章绪论 1.什么是统计学?怎样理解统计学与统计数据的关系? 答:统计学是一门收集、整理、显示和分析统计数据的科学。统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。 2.简要说明统计数据的来源。 答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。 3.简要说明抽样误差和非抽样误差。 答:统计调查误差可分为非抽样误差和抽样误差。非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。 4.解释描述统计和推断统计的概念?(P5) 答:描述统计是用图形、表格和概括性的数字对数据进行描述的统计方法。推断统计是根据样本信息对总体进行估计、假设检验、预测或其他推断的统计方法。 第二章统计数据的描述 1描述次数分配表的编制过程。 答:分二个步骤:
(1)按照统计研究的目的,将数据按分组标志进行分组。 按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。 按数量标志进行分组,可分为单项式分组与组距式分组 单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。 统计分组应遵循“不重不漏”原则 (2)将数据分配到各个组,统计各组的次数,编制次数分配表。 2. 一组数据的分布特征可以从哪几个方面进行测度? 答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。常用的指标有均值、中位数、众数、极差、方差、标准差、离散系数、偏态系数和峰度系数。 3.怎样理解均值在统计中的地位? 答:均值是对所有数据平均后计算的一般水平的代表值,数据信息提取得最充分, 具有良好的数学性质,是数据误差相互抵消后的客观事物必然性数量特征的一种反映,在统计推断中显示出优良特性,由此均值在统计中起到非常重要的基础地位。受极端数值的影响是其使用时存在的问题。 4. 简述众数、中位数和均值的特点和应用场合。 答:众数、中位数和均值是分布集中趋势的三个主要测度,众数和中位数是从数据分布形状及位置角度来考虑的,而均值是对所有数据计算后得到的。众数容易计算,但不是总是存在,应用场合较少;中位数直观,不受极端数据的影
SASreport过程介绍
PROC REPORT基础一、PROC REPORT格式: PROC REPORT data= SAS-data-set options ; COLUMNS variable_1 …. variable_n; DEFINE variable_1; DEFINE variable_2; . . . DEFINE variable_n; COMPUTE blocks BREAK … ; RBREAK … ; RUN; COLUMNS:指定输出到报表的列 DEFINE:上述列的格式等 COMPUTE:计算模块 BREAK / RBREAK:生成合计,或报表其它类型的格式。 PROC REPORT的选项Options有很多,下面介绍几个常用的:DATA= 指定做报表的数据集 PROMPT= PROMPT模式 NOWINDOWS= 不输出到结果 REPORT = 指定一个存储的报表来生成新报表 OUTREPT= 指定新路径来存放报表 OUT= 建立新数据集 HEADLINE 在报表变量标题和内容间生成一个水平分隔线HEADSKIP 在报表变量标题和内容间生成一行空格 2 先生成一个基本的报表 先生成数据: data mnthly_sales; length zip $ 5 cty $ 8 var $ 10; input zip $ cty $ var $ sales; label zip="Zip Code" cty="County" var="Variety" sales="Monthly Sales"; datalines; 52423 Scott Merlot 186. 52423 Scott Chardonnay 156.61 52423 Scott Zinfandel 35.5 52423 Scott Merlot 55.3 52388 Scott Merlot 122.89
SAS中的SQL语句大全
SAS中的SQL语句完全教程之一:SQL简介与基本查询功能 本系列全部内容主要以《SQL Processing with the SAS System (Course Notes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。 1 SQL过程步介绍 SQL过程步可以实现下列功能: 查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL语句、可以和SAS的数据步进行替换使用。注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。 SQL过程步的特征 SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL 过程步 SQL过程步语句 SELECT:查询数据表中的数据 ALTER:增加、删除或修改数据表的列 CREATE:创建一个数据表 DELETE:删除数据表中的列 DESCRIBE:列出数据表的属性 DROP:删除数据表、视图或索引 INSERT:对数据表插入数据 RESET:没用过,不知道什么意思 SELECT:选择列进行打印 UPDATE:对已存在的数据集的列的值进行修改 2 SQL基本查询功能 SELECT语句基本语法介绍 SELECT
统计学简答题及答案
统计学简答题及参考答案 1.简述描述统计学的概念、研究容与目的。 概念:它是研究数据收集、整理和描述的统计学分支。 研究容:搜集数据、整理数据、展示数据和描述性分析的理论与方法。 研究目的:描述数据的特征;找出数据的基本数量规律。 2.简述推断统计学的概念、研究容与目的。 概念:它是研究如何利用样本数据来推断总体特征的统计学分支。 研究容:参数估计和假设检验的理论与方法。 研究目的:对总体特征作出统计推断。 3.什么是总体和样本? 总体是指所研究的全部个体(数据)的集合,其中的每一个元素称为个体(也称为总体单位)。 可分为有限总体和无限总体: ?有限总体的围能够明确确定,且元素的数目是有限的,可数的。 ?无限总体所包括的元素数目是无限的,不可数的。 总体单位数可用N表示。 样本就是从总体中抽取的一部分元素的集合。构成样本的元素的数目称为样本容量,记为n。 4.什么是普查?它有哪些特点? 普查就是为了特定的研究目的,而专门组织的、非经常性的全面调查。它有以下的特点: 1)通常是一次性或周期性的 2)一般需要规定统一的标准调查时间 3)数据的规化程度较高 4)应用围比较狭窄。 5.什么是抽样调查?它有哪些特点? 抽样调查是指从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推断总体特征的数据搜集方法和统计推断方法。 它具有经济性好、时效性强、适应面广、准确性高等特点。 6.简述统计调查方案的概念及应包括的基本容。 答:统计调查方案就是统计调查前所制订的实施计划,它是指导整个调查过程的纲领性文件,是保证调查工作有计划、有组织、有系统地进行的计划书。 它应包括的基本容有: 〈1〉明确调查目的; 〈2〉确定调查对象和调查单位; 〈3〉设计调查项目; 〈4〉设计调查表格和问卷; 〈5〉确定调查时间; 〈6〉组织实施调查计划; 〈7〉调查报告的撰写,等等。 7.简述统计分组的概念、原则和具体方法。 答:(1)概念
SAS软件学习总结
SAS软件知识要点总结 李明 注意:数据集要有名字,变量要有名字,所以 SAS 中对名字(数据集名、变量名、数据库名,等等)有约定:SAS 名字由英文字母、数字、下划线组成,第一个字符必须是字母或下划线,名字最多用8 个字符,大写字母和小写字母不区分。比如,name,abc,aBC,x1,year12,_NULL_等是合法的名字,且abc 和aBC 是同一个名字,而class-1(不能有减号)、a bit(不能有空格)、serial#(不能有特殊字符)、Documents(超长)等不是合法的名字。 二、MODEL 语句 MODEL 语句在一些统计建模过程中用来指定模型的形式。其一般形式为 MODEL 因变量=自变量表 / 选项; 比如 model math=chinese; 即用语文成绩预测数学成绩。 注意:MODEL就是指出谁是因变量,谁是自变量; 三、BY 语句和CLASS 语句 BY语句在过程中一般用来指定一个或几个分组变量,根据这些分组变量值把观测分组,然后对每一组观测分别进行本过程指定的分析。在使用带有BY 语句的过程步之前一般先用 SORT 过程对数据集排序 注意:BY语句就是按某给定指标分类(组) 在一些过程(如方差分析)中,使用CLASS 语句指定一个或几个分类变量,它实际相当于因变量。而在另一些过程(如MEANS)中,CLASS 语句作用与BY 语句类似,可以指 定分类变量,把观测按分类变量分类后分别进行分析。使用CLASS 时不需要先按分类变量 排序。
注意:CLASS语句的作用有两个:1.指定(分类变量),本身就是因变量; 2.与BY类似,指定分类变量并分类; 四、OUTPUT 语句 在过程步中经常用 OUTPUT 语句指定输出结果存放的数据集。不同过程中把输出结果存入数据集的方法各有不同,OUTPUT 语句是用得最多的一种,其一般格式为: OUTPUT OUT=输出数据集名关键字=变量名关键字=变量名?; 其中用OUT=给出了要生成的结果数据集的名字,用“关键字=变量名”的方式指定了输 五、FREQ 语句和WEIGHT 语句 FREQ 语句指定一个重复数变量,每个观测中此变量的值说明这个观测实际代表多少个完全相同的重复观测。FREQ 变量只取整数值。如 freq numcell; WEIGHT 语句指定一个权重变量,在某些允许加权的过程中代表权重,其值与观测对应的方差的倒数成比例。 注意:FREQ是计量频数的;WEIGHT则是计量权重的; 七、WHERE语句(就是条件句) 用WHERE 语句可以选择输入数据集的一个行子集来进行分析,在WHERE 关键字后指定一个条件。比如: where math>=60 and chinese>=60; 指定只分析数学、语文成绩都及格的学生。
统计学简答题答案资料讲解
1、什么是统计学,有哪些特点? 统计学是收集、整理、分析、解释数据并从数据中得到结论的学科。 特点:客观性~~相关性~~实用性~~科学性~~严谨性~~逻辑性~~~ 2、何谓标志,按能否用数量表示可以分为哪两种类型,分别举例说明 标志是指说明总体单位属性或特征的名称。可以分为数量标志和质量标志 品质标志:说明总体单位属性特征的名称,用文字描述。Ex:性别,名族,工种,籍贯数量标志:说明总体单位数量特征的名称,用数量表示。数量标志的具体表现称标志值。 Ex:工人的年龄,工资,工龄 3、什么是离散型变量,连续性变量?举例说明 变量:可变的数量标志和指标; 离散型变量:指变量的数值只能以计数的方法取得,(变量值只能取整数); 连续型变量:指变量的取值连续不断,(变量值能取小数)。 4、简述品质标志和数量标志的区别,并举例说明。 区别:数量标志说明的是总体的数量特征,而品质标志说明的是总体的属性特征。 5、什么是数量指标和质量指标?二者有何关系? 统计指标:反映总体数量特征的科学概念和具体数值。 注意:从理论上讲,一个完整的统计指标由两部分构成:指标名称+指标数值 例如:某地区2009年完成利税总额(指标名称)为1500(指标数值)亿元。 数量指标:用来反映现象的总规模、总水平、或工作总量的指标。其数值大小随总体的研究范围的大小而增减。 质量指标:反映客观现象的劳动效果或工作质量等事物内部数量关系的指标,其数值的大小与总体的研究范围大小无直接联系。 6、统计标志和统计指标有和联系与区别? 区别:1、标志是反映总体单位特征;指标反映总体特征。 2、指标都能用数量表示,标志只有数量标志能用数量表示; 3、标志是一个理论概念,实际应用中只有指标。 联系:1、标志与指标可以相互转化,随研究目的的转化而改变; 2、指标值一般是标志值汇总来的; 3、标志的名称常常就是指标名称。 7、制定一份完整的统计调查方案,应包括哪些内容? 1)明确调查的目的和任务 2)确定调查的对象和调查单位、 3)确定带调查项目、设计调查表或问卷 4)确定调查时间、调查地点和调查方式方法 5)制定调查的组织实施计划 8、举例说明重点调查的概念和特点 重点调查:是在调查对象范围内部选择部分重点调查单位进行的调查。 特点:调查单位少、适用于调查对象的标志值比较集中于某些单位的场合、重点调查的调查方式主要采取专门调查的组织形式(一种是专门组织的一次性调查;另一种是利用定期统计报表经常性地对一些重点单位进行调查。);有点在于花费较少的人力物力和时间就可以获得总体的基本情况资料。 9、简述重点调查、典型调查、抽样调查的联系与区别P31 抽样调查是一种非全面调查,它是按照随机的原则,从总体中抽取一部分单位作为样本来进行观测研究,以抽样样本的指标去推算总体指标的一种调查。
一些常用的SAS命令
常用SAS命令 1. SAS的子窗口主要有浏览器窗口(EXPLORER)、结果窗口(RESULTS)、程序编辑器窗口(program editor)、日志窗口(log)、输出窗口(output); 2.切换至日志窗口的命令是log、热键是F6;切换至输出窗口的命令是output、热键是F7; 3.提交SAS程序的命令是submit; 4. SAS系统是大型集成软件系统,具备完备的数据访问、管理、分析和呈现及应用开发功能; 5. SAS数据集是一类由SAS系统建立、维护和管理的数据文件; 6.为了实现存储和管理面向对象的开发任务,SAS建立目录册(catalog)类型的文件,在这一类文件中可以存储整个应用系统,包括它的界面,源程序和各种对象间的连接; 7. SAS逻辑库是一个逻辑概念,一个逻辑库就是存放在同一文件夹或
几个文件夹中的一组SAS文件; 8.在SAS软件系统的信息组织中,总共只有两个层次:SAS逻辑库是高一级的层次,低一级的层次就是SAS文件本身; 9.在SAS系统中,为便于访问一个SAS文件,要为该SAS文件所在的位置指定一个SAS逻辑库,即赋予一个逻辑库名,在指定逻辑库名后,就可使用两级命名的方式引用SAS文件:逻辑库名.文件名; 10.在每个SAS进程一开始,系统就自动地指定了一些逻辑库供用户使用,它们是WORK、SASHELP和SASUSER; 11.在每个SAS进程开始时系统缺省地创建名为work的SAS逻辑库,它是一个临时逻辑库,在引用WORK库中的SAS文件时,可省略逻辑库名; 12.永久逻辑库是指它的内容在当前SAS进程结束时仍被保留的SAS 逻辑库,在SAS系统中除了库名为WORK以外的逻辑库都是永久库; 13. Sashelp包含所安装SAS系统各个产品有关的SAS文件,运行安装的SAS系统所需要的SAS文件缺省地存储在这个逻辑库中;
统计学简答题参考答案
统计学简答题参考答案 第一章绪论 1.什么是统计学?怎样理解统计学与统计数据的关系? 答:统计学是一门收集、整理、显示和分析统计数据的科学。统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。2.简要说明统计数据的来源。 答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。 3.简要说明抽样误差和非抽样误差。 答:统计调查误差可分为非抽样误差和抽样误差。非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。 4.解释描述统计和推断统计的概念?(P5) 答:描述统计是用图形、表格和概括性的数字对数据进行描述的统计方法。推断统计是根据样本信息对总体进行估计、假设检验、预测或其他推断的统计方法。第二章统计数据的描述 1描述次数分配表的编制过程。 答:分二个步骤: (1)按照统计研究的目的,将数据按分组标志进行分组。 按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。 按数量标志进行分组,可分为单项式分组与组距式分组 单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。 统计分组应遵循“不重不漏”原则 (2)将数据分配到各个组,统计各组的次数,编制次数分配表。 2. 一组数据的分布特征可以从哪几个方面进行测度? 答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。常用的指标有均值、中位数、众数、极差、方差、标准差、离散系数、偏态系数和峰度系数。 3.怎样理解均值在统计中的地位? 答:均值是对所有数据平均后计算的一般水平的代表值,数据信息提取得最充分,具有良好的数学性质,是数据误差相互抵消后的客观事物必然性数量特征的一种反映,在统计推断中显示出优良特性,由此均值在统计中起到非常重要的基础地位。受极端数值的影响是其使用时存在的问题。 4. 简述众数、中位数和均值的特点和应用场合。 答:众数、中位数和均值是分布集中趋势的三个主要测度,众数和中位数是从数据分布形状及位置角度来考虑的,而均值是对所有数据计算后得到的。众数容易计算,但不是总是存在,应用场合较少;中位数直观,不受极端数据的影响,但数据信息利用不够充分;均值数据提取的信息最充分,但受极端数据的影响。5.为什么要计算离散系数?
SAS proc mixed 过程步介绍
Introduction to PROC MIXED Table of Contents 1.Short description of methods of estimation used in PROC MIXED 2.Description of the syntax of PROC MIXED 3.References 4. Examples and comparisons of results from MIXED and GLM - balanced data: fixed effect model and mixed effect model, - unbalanced data, mixed effect model 1. Short description of methods of estimation used in PROC MIXED. The SAS procedures GLM and MIXED can be used to fit linear models. Proc GLM was designed to fit fixed effect models and later amended to fit some random effect models by including RANDOM statement with TEST option. The REPEATED statement in PROC GLM allows to estimate and test repeated measures models with an arbitrary correlation structure for repeated observations. The PROC MIXED was specifically designed to fit mixed effect models. It can model random and mixed effect data, repeated measures, spacial data, data with heterogeneous variances and autocorrelated observations.The MIXED procedure is more general than GLM in the sense that it gives a user more flexibility in specifying the correlation structures, particularly useful in repeated measures and random effect models. It has to be emphasized, however, that the PROC MIXED is not an extended, more general version of GLM. They are based on different statistical principles; GLM and MIXED use different estimation methods. GLM uses the ordinary least squares (OLS) estimation, that is, parameter estimates are such values of the parameters of the model that minimize the squared difference between observed and predicted values of the dependent variable. That approach leads to the familiar analysis of variance table in which the variability in the dependent variable (the total sum of squares) is divided into variabilities due to different sources (sum of squares for effects in the model). PROC MIXED does not produce an analysis of variance table, because it uses estimation methods based on different principles. PROC MIXED has three options for the method of estimation. They are: ML (Maximum Likelihood), REML (Restricted or Residual maximum likelihood, which is the default method) and MIVQUE0 (Minimum Variance Quadratic Unbiased Estimation). ML and REML are based on a maximum likelihood estimation approach. They require the assumption that the distribution of the dependent variable (error term and the random effects) is normal. ML is just the regular maximum likelihood method,that is, the parameter estimates that it produces are such values of the model parameters that maximize the likelihood function. REML method is a variant of maximum likelihood estimation; REML estimators are obtained not from maximizing the whole likelihood function, but only that part that is invariant to the fixed effects part of the linear model. In other words, if y = X b + Zu + e, where X b is the
统计学简答题答案
1.“统计”一词有哪些含义?什么就是统计学? (1)统计工作或统计实践活动:对现象的数量进行搜集、整理与分析的活动过程 (2)统计资料:通过统计实践活动取得的说明对象某种数量特征的数据 (3)统计学:就是关于数据的一门科学 统计学就是一门收集、整理、显示与分析统计数据的科学,其目的就是探索数据内在的数量规律性。 2.一组数据的分布特征可以从哪几个方面进行测度? 一组数据的分布特征可以从以下三个方面进行测度: 集中趋势的测度(众数、中位数、分位数、均值、几何平均数、切尾均值) 离散程度测度(极差、内距、方差与标准差、离散系数) 偏态与峰度测度(偏态及其测度、峰度及其测度) 3.分布集中趋势的测度指标有哪些? 众数、中位数、分位数、均值、几何平均数、切尾均值 4.简述众数、中位数与均值的特点与应用场合。 众数最容易计算,但不就是永远存在,它不受极端值影响、具有不惟一性、作为集中趋势代表值应用的场合较少,数据分布偏斜程度较大时应用,在编制物价指数时,农贸市场上某种商品的价格常以很多摊位报价的中数值为代表。 中位数很容易理解、很直观,它不受极端值的影响,这既就是它有价值的方面,也就是它数据信息利用不够充分的地方; 均值就是对所有数据平均后计算的一般水平代表值,数据信息提取的最充分,数据对称分布或接近对称分布时应用,它在整个统计方法中应用最广,对经济管理与工程等实际工作也就是最重要的代表值与统计量。 5.分布离散程度的测度指标有哪些? 极差、内距、方差与标准差、离散系数 6、常用的概率抽样方法有哪些?各自的含义如何? (1)简单随机抽样:从总体N个单位中随机地抽取n个单位作为样本,使得每一个总体单位都有相同的机会(概率)被抽中,这样的抽样方式称为简单随机抽样。 (2)分层抽样:在抽样之前先将总体的单位按某种特征或某种规则划分为不同的层,然后从不同的层中抽取一定数量的单位组成一个样本,这样的抽样方式称为分层抽样。 (3)系统抽样:在抽样中先将总体各单位按某种顺序排列,并按某种规则确定一个随机起点,每隔一定的间隔抽取一个单位,直至抽取n个单位形成一个样本。 (4)整群抽样:调查时先将总体划分成若干群,然后再以群作为调查单位从中抽取部分群,进而对抽中的各个群中所包含的所有个体单位进行调查或观察。 (5)多阶段抽样:先抽取群,但并不就是调查群内的所有单位,而就是再进行一步抽样,从选中的群中抽取出若干个单位进行调查。 群就是初级抽样单位,第二阶段抽取的就是最终抽样单位。将该方法推广,使抽样的段数增多,就称为多阶段抽样。 7、什么就是抽样分布? 就就是由样本n个观察值计算的统计量的概率分布。 8、什么就是匹配样本? 一个样本中的数据与另一个样本中的数据相对应,这样的样本称为匹配样本。 9、假设检验的思想以及假设检验中的两类错误就是什么? 假设检验的基本思想就是小概率反证法思想。小概率思想就是指小概率事件(P<0、01或P<0、
SAS中的描述性统计过程
SAS中的描述性统计过程 (2012-08-01 18:07:01) 转载▼ 分类:数据分析挖掘 标签: 杂谈 SAS中的描述性统计过程 描述性统计指标的计算可以用四个不同的过程来实现,它们分别是means过程、summary 过程、univariate过程以及tabulate过程。它们在功能范围和具体的操作方法上存在一定的差别,下面我们大概了解一下它们的异同点。 相同点:他们均可计算出均数、标准差、方差、标准误、总和、加权值的总和、最大值、最小值、全距、校正的和未校正的离差平方和、变异系数、样本分布位置的t检验统计量、遗漏数据和有效数据个数等,均可应用by语句将样本分割为若干个更小的样本,以便分别进行分析。 不同点: (1)means过程、summary过程、univariate过程可以计算样本的偏度(skewness)和峰度(kurtosis),而tabulate过程不计算这些统计量; (2)univariate过程可以计算出样本的众数(mode),其它三个过程不计算众数; (3)summary过程执行后不会自动给出分析的结果,须引用output语句和print过程来显示分析结果,而其它三个过程则会自动显示分析的结果; (4)univariate过程具有统计制图的功能,其它三个过程则没有; (5)tabulate过程不产生输出资料文件(存储各种输出数据的文件),其它三个均产生输出资料文件。 统计制图的过程均可以实现对样本分布特征的图形表示,一般情况下可以使用的有chart过程、plot过程、gchart过程和gplot过程。大家有没有发现前两个和后两个只有一个字母‘g’(代表graph)的差别,其实它们之间(只差一个字母g的过程之间)的统计描述功能是相同的,区别仅在于绘制出的图形的复杂和美观程度。 chart过程和plot过程绘制的图形类似于我们用文本字符堆积起来的图形,只能概括地反映出资料分布的大体形状,实际上这两个过程绘制的图形并不能称之为图形,因为他根本就没有涉及一般意义上图形的任何一种元素(如颜色、分辨率等)。而gchart过程和gplot过程给出的是真正意义上的图形,可以用很多的语句和选项来控制图形的各方面的性质和特征。 chart和gchart与plot和gplot的区别则体现在不同的作图功能,前两个过程可以绘制出的图形主要有条形图(包括横条和竖条)、圆图、环形图和星形图等,后两个过程通常用一个记录中的两个变量值表示点的坐标来绘制图形,如散点图和线图等。 描述性统计过程的一般格式 1. means过程的一般格式
常用sas语句总结
Engine(引擎)是一种访问架构,SAS系统通过它迅速地对其它数据库管理系统中文件进行读入和写出。 1.LIBNAME语句 1.1解读 定义SAS 逻辑库。具体地说,它可以 (1)向SAS 标识SAS 逻辑库 (2)将引擎与逻辑库关联 (3)让您指定逻辑库的选项 (4)为逻辑库指定逻辑库引用名 通俗得讲,LIBNAME语句把一个libref(库标记名)和一个目录联系起来,使用户可以在SAS语句中使用库标记来指示这个目录。提交该程序时自动引用该SAS 逻辑库 1.2 语句格式 1、LIBNAME libref
选项说明 2.length语句 SAS变量的基本类型有两种:数值型和字符型。数值型变量在数据集中的存贮一般使用8个字节。SAS的字符型变量缺省的长度是8个英文字符,可以使用LENGTH语句指定变量长度,LENGTH语句一般应出现在定义变量的Input语句之前,格式为:LENGTH 字符型变量名$长度 例如:length name $20 ; 3. input 语句 3.1解读 INPUT语句用于向系统表明如何读入每一条记录。它的主要功能有:读入由语句指定的数据列;为相应
的数据域定义变量名;确定变量的读入模式(共有四种模式:column模式,formatted模式,list模式及named模式)。 input语句执行后,SAS将读取的数据暂时先保存在内存缓冲区,然后执行后面的语句,后面的语句可以对暂存在内存缓冲区中的变量值进行修改,到最后才将整条数据写入数据集,写入数据集的数据就不能在当前data步中再修改。 注意:INFILE语句用于确定一个包含原始数据的外部文件,必须在执行INPUT语句前执行,如果要在程序中直接嵌入数据,就用CARDS语句代替INFILE 语句。 3.2 语句格式(Column模式) INPUT variable <$> start-column<-end-column><.decimals><@|@@>; 说明: variable 变量名 $ 跟在变量后面,表明这个变量是字符型变量 start-column 起始列号 end-column 结束列号,如果变量值只包含一列,则可省略 .decimals 如果输入值中没有包含一个隔开整数部分
统计学简单题答案整理doc资料
统计学简答题 2.统计学研究对象有哪些特点? 参考答案:(1)数量性:从数量上认识事物的性质和规律,是统计研究的基本特点;统计研究的不是抽象的数量,而是有特定内容的具体数量。统计是在质的规定性下研究与所研究现象内容性质密切联系的具体数量。 (2)总体性:统计是以现象总体的数量特征作为自己的研究对象。统计要对总体中各单位普遍存在的事实进行大量观察和综合分析,得出反映现象总体的数量特征。 (3)变异性:总体各单位的标志特征由于复杂的随机因素而有不同的表现,它是统计研究的前提。 ⒊什么是标志和指标?两者有何区别与联系? 参考答案: 指标与标志的区别: (1)指标是说明总体特征的,而标志则是说明总体单位特征的。 (2)标志有不能用数值表示的品质标志与能用数值表示的数量标志,而指标都是用数值表示的,没有不能用数值表示的统计指标。 指标与标志的联系: (1)有许多统计指标的数值是从总体单位的数量标志值汇总而来的,如一个煤炭工业局(公司)的煤炭总产量,是从所属各煤炭工业企业的产量汇总出来的。 (2)指标与标志(数量标志)之间存在着变换关系。由于研究的目的不同,原来的统计总体如果变成总体单位,则相对应的统计指标也就变成数量标志,反之亦然。 (比如:如果调查研究各分支煤炭工业企业的产量情况,那么分支企业是总体指标,如果转为研究煤炭工业局的总产量情况,那么各分支公司就成了个体标志) (一)指标与标志之间联系:(1)、标志和指标的关系是个别和整体的关系。标志反映总体单位的属性和特征,而指标则反映总体的数量特征。许多统计指标是由各单位的数量标志值汇总而来的。(2)、由于总体和单位的概念会随着研究目的不同而变化,在一定条件下,指标和标志之间存在一定的变换关系。因此指标与标志的概念也是相对而言的。 (二)指标和标志的区别:①指标是说明总体数量特征的概念,而标志是说明总体单位特征的概念。前者范围大些, 后者的范围小些;②指标都是用数值表示的, 而标志有的是用数字表示, 有的是用文字表示。③指标是由数量标志汇总得出来的,而标志仅是某一个体现象,未经过任何汇总
SAS复习总结
蔡泽蕲 Freq 过程: Proc Freq data=dataset; table x*y/option; By var1; Class var2; Weight f; Run; 输出x*y的频数表,by语句的使用要求var1已经排过序. option可为chisp,分析x、y(两独立样本)的不同水平的差异是否显著,卡方检验。当x、y为两配对样本时,option为agree,进行配对样本差异是否显著的检验。 Sort 过程: Proc sort data=dataset out=dataset; By (descending) var1 (descending) var2; Run; 对数据集中的var1、var2变量依次排序,默认从小到大,descending为从大到小。缺失out 时新数据集覆盖原数据集。 Means 过程 Proc means data=dataset option; Var x; By var1; Class var2; Freq var3; /*不能用weight*/ Output out=输出数据集统计量名=自定义名; Run; 输出option统计量,当包含t和prt 时输出x的期望为0的t检验,用于配对样本的t检验。无option时,默认输出N、std、mean、min、max五个统计量。还可输出其它很多统计计量。特别的两个选项:maxdec=n ,alpha=value分别指定结果保留位数和置信度 Univariate 过程 Proc univariate data=dataset option; Var x; By var1; Freq var2; Output out=输出数据集统计量=自定义变量名; Run; Option 可为freq(生成频数表)、normal(检验变量是否服从正态分布)、plot(生成茎叶图、箱线图、正太概率图)、cibasic(计算均值置信区间)、cipctldf(计算中位数置信区间)。 统计量可为:各检验统计量及分位数。 当option为“mu0=scalar”时,计算x的期望(中位数)为scalar的t检验和符号秩和检验。符号秩和检验适用于非正太样本,而t检验则用于正太样本。配对样本计算配对差,独立样本使用class。Cibasic基于正太分布,cipctldf基于非正态分布。
统计学简答题及答案
统计学简答题及参考答案 1、简述描述统计学的概念、研究内容与目的。 概念:它就是研究数据收集、整理与描述的统计学分支。 研究内容:搜集数据、整理数据、展示数据与描述性分析的理论与方法。 研究目的:描述数据的特征;找出数据的基本数量规律。 2、简述推断统计学的概念、研究内容与目的。 概念:它就是研究如何利用样本数据来推断总体特征的统计学分支。 研究内容:参数估计与假设检验的理论与方法。 研究目的:对总体特征作出统计推断。 3、什么就是总体与样本? 总体就是指所研究的全部个体(数据)的集合,其中的每一个元素称为个体(也称为总体单位)。 可分为有限总体与无限总体: ?有限总体的范围能够明确确定,且元素的数目就是有限的,可数的。 ?无限总体所包括的元素数目就是无限的,不可数的。 总体单位数可用N表示。 样本就就是从总体中抽取的一部分元素的集合。构成样本的元素的数目称为样本容量,记为n。 4、什么就是普查?它有哪些特点? 普查就就是为了特定的研究目的,而专门组织的、非经常性的全面调查。它有以下的特点: 1)通常就是一次性或周期性的 2)一般需要规定统一的标准调查时间 3)数据的规范化程度较高 4)应用范围比较狭窄。5、什么就是抽样调查?它有哪些特点? 抽样调查就是指从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推断总体特征的数据搜集方法与统计推断方法。 它具有经济性好、时效性强、适应面广、准确性高等特点。 6、简述统计调查方案的概念及应包括的基本内容。 答:统计调查方案就就是统计调查前所制订的实施计划,它就是指导整个调查过程的纲领性文件,就是保证调查工作有计划、有组织、有系统地进行的计划书。 它应包括的基本内容有: 〈1〉明确调查目的; 〈2〉确定调查对象与调查单位; 〈3〉设计调查项目; 〈4〉设计调查表格与问卷; 〈5〉确定调查时间; 〈6〉组织实施调查计划; 〈7〉调查报告的撰写,等等。 7、简述统计分组的概念、原则与具体方法。 答:(1)概念 根据统计研究的目的与客观现象的内在特点,按照某个标志(或几个标志)