一种优化的舰船噪声连续谱特征提取算法研究

图像中角点(特征点)提取与匹配算法
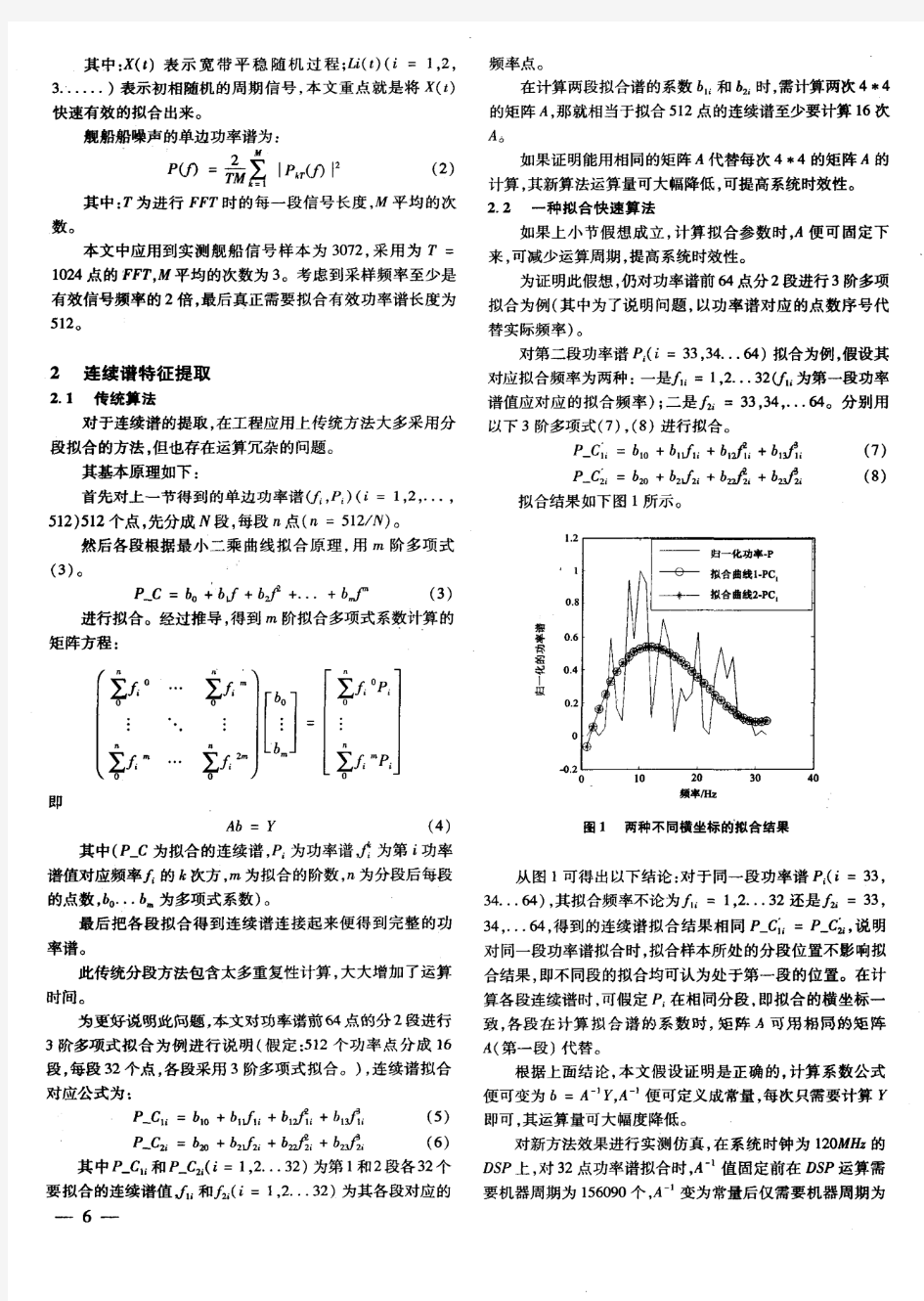
角点提取与匹配算法实验报告 1 说明 本文实验的目标是对于两幅相似的图像,通过角点检测算法,进而找出这两幅图像的共同点,从而可以把这两幅图像合并成一幅图像。 下面描述该实验的基本步骤: 1.本文所采用的角点检测算法是Harris 角点检测算法,该算法的基本原理是取以目标像素点为中心的一个小窗口,计算窗口沿任何方向移动后的灰度变化,并用解析形式表达。设以像素点(x,y)为中心的小窗口在X 方向上移动u ,y 方向上移动v ,Harris 给出了灰度变化度量的解析表达式: 2 ,,|,|,,()(x y x y x u y v x y x y I I E w I I w u v o X Y ??= -=++??∑∑ (1) 其中,,x y E 为窗口内的灰度变化度量;,x y w 为窗口函数,一般定义为2 2 2 ()/,x y x y w e σ +=; I 为图像灰度函数,略去无穷小项有: 222222 ,,[()()2]2x y x y x y x y E w u I v I uvI I Au Cuv Bv = ++=++∑ (2) 将,x y E 化为二次型有: ,[]x y u E u v M v ?? =???? (3) M 为实对称矩阵: 2 ,2 x y x x y x y y I I I M w I I I ???= ???????∑ (4) 通过对角化处理得到: 11 ,200x y E R R λλ-??= ??? (5) 其中,R 为旋转因子,对角化处理后并不改变以u,v 为坐标参数的空间曲面的形状,其特征值反应了两个主轴方向的图像表面曲率。当两个特征值均较小时,表明目标点附近区域为“平坦区域”;特征值一大一小时,表明特征点位于“边缘”上;只有当两个特征值均比较大时,沿任何方向的移动均将导致灰度的剧烈变化。Harris 的角点响应函数(CRF)表达式由此而得到: 2 (,)det()(())C RF x y M k trace M =- (6)
SIFT 特征提取算法详解
SIFT 特征提取算法总结 主要步骤 1)、尺度空间的生成; 2)、检测尺度空间极值点; 3)、精确定位极值点; 4)、为每个关键点指定方向参数; 5)、关键点描述子的生成。 L(x,y,σ), σ= 1.6 a good tradeoff
D(x,y,σ), σ= 1.6 a good tradeoff
关于尺度空间的理解说明:图中的2是必须的,尺度空间是连续的。在 Lowe 的论文中, 将第0层的初始尺度定为1.6,图片的初始尺度定为0.5. 在检测极值点前对原始图像的高斯平滑以致图像丢失高频信息,所以Lowe 建议在建立尺度空间前首先对原始图像长宽扩展一倍,以保留原始图像信息,增加特征点数量。尺度越大图像越模糊。 next octave 是由first octave 降采样得到(如2) , 尺度空间的所有取值,s为每组层数,一般为3~5 在DOG尺度空间下的极值点 同一组中的相邻尺度(由于k的取值关系,肯定是上下层)之间进行寻找
在极值比较的过程中,每一组图像的首末两层是无法进行极值比较的,为了满足尺度 变化的连续性,我们在每一组图像的顶层继续用高斯模糊生成了 3 幅图像, 高斯金字塔有每组S+3层图像。DOG金字塔每组有S+2层图像.
If ratio > (r+1)2/(r), throw it out (SIFT uses r=10) 表示DOG金字塔中某一尺度的图像x方向求导两次 通过拟和三维二次函数以精确确定关键点的位置和尺度(达到亚像素精度)?
直方图中的峰值就是主方向,其他的达到最大值80%的方向可作为辅助方向 Identify peak and assign orientation and sum of magnitude to key point The user may choose a threshold to exclude key points based on their assigned sum of magnitudes. 利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备 旋转不变性。以关键点为中心的邻域窗口内采样,并用直方图统计邻域像素的梯度 方向。梯度直方图的范围是0~360度,其中每10度一个柱,总共36个柱。随着距中心点越远的领域其对直方图的贡献也响应减小.Lowe论文中还提到要使用高斯函 数对直方图进行平滑,减少突变的影响。
文本特征提取方法
https://www.360docs.net/doc/d88719262.html,/u2/80678/showart_1931389.html 一、课题背景概述 文本挖掘是一门交叉性学科,涉及数据挖掘、机器学习、模式识别、人工智能、统计学、计算机语言学、计算机网络技术、信息学等多个领域。文本挖掘就是从大量的文档中发现隐含知识和模式的一种方法和工具,它从数据挖掘发展而来,但与传统的数据挖掘又有许多不同。文本挖掘的对象是海量、异构、分布的文档(web);文档内容是人类所使用的自然语言,缺乏计算机可理解的语义。传统数据挖掘所处理的数据是结构化的,而文档(web)都是半结构或无结构的。所以,文本挖掘面临的首要问题是如何在计算机中合理地表示文本,使之既要包含足够的信息以反映文本的特征,又不至于过于复杂使学习算法无法处理。在浩如烟海的网络信息中,80%的信息是以文本的形式存放的,WEB文本挖掘是WEB内容挖掘的一种重要形式。 文本的表示及其特征项的选取是文本挖掘、信息检索的一个基本问题,它把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本。使计算机能够通过对这种模型的计算和操作来实现对文本的识别。由于文本是非结构化的数据,要想从大量的文本中挖掘有用的信息就必须首先将文本转化为可处理的结构化形式。目前人们通常采用向量空间模型来描述文本向量,但是如果直接用分词算法和词频统计方法得到的特征项来表示文本向量中的各个维,那么这个向量的维度将是非常的大。这种未经处理的文本矢量不仅给后续工作带来巨大的计算开销,使整个处理过程的效率非常低下,而且会损害分类、聚类算法的精确性,从而使所得到的结果很难令人满意。因此,必须对文本向量做进一步净化处理,在保证原文含义的基础上,找出对文本特征类别最具代表性的文本特征。为了解决这个问题,最有效的办法就是通过特征选择来降维。 目前有关文本表示的研究主要集中于文本表示模型的选择和特征词选择算法的选取上。用于表示文本的基本单位通常称为文本的特征或特征项。特征项必须具备一定的特性:1)特征项要能够确实标识文本内容;2)特征项具有将目标文本与其他文本相区分的能力;3)特征项的个数不能太多;4)特征项分离要比较容易实现。在中文文本中可以采用字、词或短语作为表示文本的特征项。相比较而言,词比字具有更强的表达能力,而词和短语相比,词的切分难度比短语的切分难度小得多。因此,目前大多数中文文本分类系统都采用词作为特征项,称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算。如果把所有的词都作为特征项,那么特征向量的维数将过于巨大,从而导致计算量太大,在这样的情况下,要完成文本分类几乎是不可能的。特征抽取的主要功能是在不损伤文本核心信息的情况下尽量减少要处理的单词数,以此来降低向量空间维数,从而简化计算,提高文本处理的速度和效率。文本特征选择对文本内容的过滤和分类、聚类处理、自动摘要以及用户兴趣模式发现、知识发现等有关方面的研究都有非常重要的影响。通常根据某个特征评估函数计算各个特征的评分值,然后按评分值对这些特征进行排序,选取若干个评分值最高的作为特征词,这就是特征抽取(Feature Selection)。
语音信号特征参数提取方法
语音信号特征参数提取方法 阮雄飞微电子学与固体电子学 摘要:在语音技术的发展过程中使用了大量的语音信号特征参数, 好的语音信号特征参数能对语音识别起至关重要的作用。本文对语音信号特征参数提取方法以及国内外研究现状进行了介绍,最后介绍了Hilbert-Huang 这一新兴理论成果以及在特征提取中的应用。 关键词:语音技术特征提取HHT 1 引言 语音信号是一种短时平稳信号,即时变的,十分复杂,携带很多有用的信息,这些信息包括语义、个人特征等,其特征参数的准确性和唯一性将直接影响语音识别率的高低,并且这也是语音识别的基础[1]。特征参数应该能够比较准确地表达语音信号的特征具有一定的唯一性。 上世纪40年代,potter等人提出了“visiblespeech”的概念,指出语谱图对语音信号有很强的描述能力,并且试着用语谱信息进行语音识别,这就形成了最早的语音特征,直到现在仍有很多的人用语谱特征来进行语音识别[2]。后来,人们发现利用语音信号的时域特征可以从语音波形中提取某些反映语音特性的参数,比如:幅度、短时帧平均能量、短时帧过零率、短时自相关系数、平均幅度差函数等。这些参数不但能减小模板数目运算量及存储量而且还可以滤除语音信号中无用的冗余信息。语音信号特征参数是分帧提取的, 每帧特征参数一般构成一个矢量, 所以语音信号特征是一个矢量序列。我们将语音信号切成一帧一帧, 每帧大小大约是20-30ms。帧太大就不能得到语音信号随时间变化的特性, 帧太小就不能提取出语音信号的特征, 每帧语音信号中包含数个语音信号的基本周期。有时希望相邻帧之间的变化不是太大, 帧之间就要有重叠, 帧叠往往是帧长的1/2或1/3。帧叠大, 相应的计算量也大[3]。随着语音识别技术的不断发展时域特征参数的种种不足逐渐暴露出来,如这些特征参数缺乏较好稳定性且区分能力不好。于是频域参数开始作为语音信号的特征比如频谱共振峰等。经典的特征提取方法主要有LPCC(线性预测倒谱系数)、MFCC(美尔频率倒谱系数)、HMM(隐马尔科夫模型)、DTW(动态时间规整)等。 2 语音信号特征参数提取方法
SIFT特征点提取与匹配算法
SIFT 特征点匹配算法 基于SIFT 方法的图像特征匹配可分为特征提取和特征匹配两个部分,可细化分为五个部分: ① 尺度空间极值检测(Scale-space extrema detection ); ② 精确关键点定位(Keypoint localization ) ③ 关键点主方向分配(Orientation assignment ) ④ 关键点描述子生成(Keypoint descriptor generation ) ⑤ 比较描述子间欧氏距离进行匹配(Comparing the Euclidean distance of the descriptors for matching ) 1.1 尺度空间极值检测 特征关键点的性质之一就是对于尺度的变化保持不变性。因此我们所要寻找的特征点必须具备的性质之一,就是在不同尺度下都能被检测出来。要达到这个目的,我们可以在尺度空间内寻找某种稳定不变的特性。 Koenderink 和Lindeberg 已经证明,变换到尺度空间唯一的核函数是高斯函数。因此一个图像的尺度空间定义为:(,,)L x y σ,是由可变尺度的高斯函数(,,)G x y σ与输入图像(,)I x y 卷积得到,即: ),(),,(),,(y x I y x G y x L *=σσ (1.1) 其中:2222/)(221 ),,(σπσσy x e y x G +-= 在实际应用中,为了能相对高效地计算出关键点的位置,建议使用的是差分高斯函数(difference of Gaussian )(,,)D x y σ。其定义如下: ) ,,(),,() ,()),,(),,((),,(σσσσσy x L k y x L y x I y x G k y x G y x D -=*-= (1.2) 如上式,D 即是两个相邻的尺度的差(两个相邻的尺度在尺度上相差一个相乘系数k )。
图像特征提取方法
图像特征提取方法 摘要 特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。 至今为止特征没有万能和精确的图像特征定义。特征的精确定义往往由问题或者应用类型决定。特征是一个数字图像中“有趣”的部分,它是许多计算机图像分析算法的起点。因此一个算法是否成功往往由它使用和定义的特征决定。因此特征提取最重要的一个特性是“可重复性”:同一场景的不同图像所提取的特征应该是相同的。 特征提取是图象处理中的一个初级运算,也就是说它是对一个图像进行的第一个运算处理。它检查每个像素来确定该像素是否代表一个特征。假如它是一个更大的算法的一部分,那么这个算法一般只检查图像的特征区域。作为特征提取的一个前提运算,输入图像一般通过高斯模糊核在尺度空间中被平滑。此后通过局部导数运算来计算图像的一个或多个特征。 常用的图像特征有颜色特征、纹理特征、形状特征、空间关系特征。当光差图像时,常 常看到的是连续的纹理与灰度级相似的区域,他们相结合形成物体。但如果物体的尺寸很小 或者对比度不高,通常要采用较高的分辨率观察:如果物体的尺寸很大或对比度很强,只需 要降低分辨率。如果物体尺寸有大有小,或对比有强有弱的情况下同事存在,这时提取图像 的特征对进行图像研究有优势。 常用的特征提取方法有:Fourier变换法、窗口Fourier变换(Gabor)、小波变换法、最 小二乘法、边界方向直方图法、基于Tamura纹理特征的纹理特征提取等。
设计内容 课程设计的内容与要求(包括原始数据、技术参数、条件、设计要求等):一、课程设计的内容 本设计采用边界方向直方图法、基于PCA的图像数据特征提取、基于Tamura纹理特征的纹理特征提取、颜色直方图提取颜色特征等等四种方法设计。 (1)边界方向直方图法 由于单一特征不足以准确地描述图像特征,提出了一种结合颜色特征和边界方向特征的图像检索方法.针对传统颜色直方图中图像对所有像素具有相同重要性的问题进行了改进,提出了像素加权的改进颜色直方图方法;然后采用非分割图像的边界方向直方图方法提取图像的形状特征,该方法相对分割方法具有简单、有效等特点,并对图像的缩放、旋转以及视角具有不变性.为进一步提高图像检索的质量引入相关反馈机制,动态调整两幅图像相似度中颜色特征和方向特征的权值系数,并给出了相应的权值调整算法.实验结果表明,上述方法明显地优于其它方法.小波理论和几个其他课题相关。所有小波变换可以视为时域频域的形式,所以和调和分析相关。所有实际有用的离散小波变换使用包含有限脉冲响应滤波器的滤波器段(filterbank)。构成CWT的小波受海森堡的测不准原理制约,或者说,离散小波基可以在测不准原理的其他形式的上下文中考虑。 通过边缘检测,把图像分为边缘区域和非边缘区域,然后在边缘区域内进行边缘定位.根据局部区域内边缘的直线特性,求得小邻域内直线段的高精度位置;再根据边缘区域内边缘的全局直线特性,用线段的中点来拟合整个直线边缘,得到亚像素精度的图像边缘.在拟合的过程中,根据直线段转角的变化剔除了噪声点,提高了定位精度.并且,根据角度和距离区分出不同直线和它们的交点,给出了图像精确的矢量化结果 图像的边界是指其周围像素灰度有阶跃变化或屋顶变化的那些像素的集合,边界广泛的存在于物体和背 景之间、物体和物体之间,它是图像分割所依赖的重要特征.边界方向直方图具有尺度不变性,能够比较好的 描述图像的大体形状.边界直方图一般是通过边界算子提取边界,得到边界信息后,需要表征这些图像的边 界,对于每一个边界点,根据图像中该点的梯度方向计算出该边界点处法向量的方向角,将空间量化为M级, 计算每个边界点处法向量的方向角落在M级中的频率,这样便得到了边界方向直方图. 图像中像素的梯度向量可以表示为[ ( ,),),( ,),)] ,其中Gx( ,),),G ( ,),)可以用下面的
SIFT特征点提取与匹配算法
二 特征点提取算法 1、基于SIFT (Scale Invariant Feature Transform )方法的图像特征匹配 参看David G. Lowe 的“Distinctive Image Features from Scale-Invariant Keypoints ” 基于SIFT 方法的图像特征匹配可分为特征提取和特征匹配两个部分,可细化分为五个部分: ① 尺度空间极值检测(Scale-space extrema detection ); ② 精确关键点定位(Keypoint localization ) ③ 关键点主方向分配(Orientation assignment ) ④ 关键点描述子生成(Keypoint descriptor generation ) ⑤ 比较描述子间欧氏距离进行匹配(Comparing the Euclidean distance of the descriptors for matching ) 1.1 尺度空间极值检测 特征关键点的性质之一就是对于尺度的变化保持不变性。因此我们所要寻找的特征点必须具备的性质之一,就是在不同尺度下都能被检测出来。要达到这个目的,我们可以在尺度空间内寻找某种稳定不变的特性。 Koenderink 和Lindeberg 已经证明,变换到尺度空间唯一的核函数是高斯函数。因此一个图像的尺度空间定义为:(,,)L x y σ,是由可变尺度的高斯函数(,,)G x y σ与输入图像(,)I x y 卷积得到,即: ),(),,(),,(y x I y x G y x L *=σσ (1.1) 其中:2222/)(221 ),,(σπσσy x e y x G +-= 在实际应用中,为了能计算的相对高效,所真正使用的是差分高斯尺度空间(difference of Gaussian )(,,)D x y σ。其定义如下: ) ,,(),,() ,()),,(),,((),,(σσσσσy x L k y x L y x I y x G k y x G y x D -=*-= (1.2) 如上式,D 即是由两个相邻的尺度的差(两个相邻的尺度在尺度上相差一个相乘系数k )。
图像特征提取算法
Histograms of for Human Detection Navneet Dalal and Bill Triggs INRIA Rh?o ne-Alps,655avenue de l’Europe,Montbonnot38334,France {Navneet.Dalal,Bill.Triggs}@inrialpes.fr,http://lear.inrialpes.fr Abstract We study the question of feature sets for ob-ject recognition,adopting linear SVM based human detec-tion as a test case.After reviewing existing edge and gra-dient based descriptors,we show experimentally that grids of Histograms of Oriented Gradient(HOG)descriptors sig-ni?cantly outperform existing feature sets for human detec-tion.We study the in?uence of each stage of the computation on performance,concluding that?ne-scale gradients,?ne orientation binning,relatively coarse spatial binning,and high-quality local contrast normalization in overlapping de-scriptor blocks are all important for good results.The new approach gives near-perfect separation on the original MIT pedestrian database,so we introduce a more challenging dataset containing over1800annotated human images with a large range of pose variations and backgrounds. 1Introduction Detecting humans in images is a challenging task owing to their variable appearance and the wide range of poses that they can adopt.The?rst need is a robust feature set that allows the human form to be discriminated cleanly,even in cluttered backgrounds under dif?cult illumination.We study the issue of feature sets for human detection,showing that lo-cally normalized Histogram of Oriented Gradient(HOG)de-scriptors provide excellent performance relative to other ex-isting feature sets including wavelets[17,22].The proposed descriptors are reminiscent of edge orientation histograms [4,5],SIFT descriptors[12]and shape contexts[1],but they are computed on a dense grid of uniformly spaced cells and they use overlapping local contrast normalizations for im-proved performance.We make a detailed study of the effects of various implementation choices on detector performance, taking“pedestrian detection”(the detection of mostly visible people in more or less upright poses)as a test case.For sim-plicity and speed,we use linear SVM as a baseline classi?er throughout the study.The new detectors give essentially per-fect results on the MIT pedestrian test set[18,17],so we have created a more challenging set containing over1800pedes-trian images with a large range of poses and backgrounds. Ongoing work suggests that our feature set performs equally well for other shape-based object classes. We brie?y discuss previous work on human detection in §2,give an overview of our method§3,describe our data sets in§4and give a detailed description and experimental evaluation of each stage of the process in§5–6.The main conclusions are summarized in§7. 2Previous Work There is an extensive literature on object detection,but here we mention just a few relevant papers on human detec-tion[18,17,22,16,20].See[6]for a survey.Papageorgiou et al[18]describe a pedestrian detector based on a polynomial SVM using recti?ed Haar wavelets as input descriptors,with a parts(subwindow)based variant in[17].Depoortere et al give an optimized version of this[2].Gavrila&Philomen [8]take a more direct approach,extracting edge images and matching them to a set of learned exemplars using chamfer distance.This has been used in a practical real-time pedes-trian detection system[7].Viola et al[22]build an ef?cient moving person detector,using AdaBoost to train a chain of progressively more complex region rejection rules based on Haar-like wavelets and space-time differences.Ronfard et al[19]build an articulated body detector by incorporating SVM based limb classi?ers over1st and2nd order Gaussian ?lters in a dynamic programming framework similar to those of Felzenszwalb&Huttenlocher[3]and Ioffe&Forsyth [9].Mikolajczyk et al[16]use combinations of orientation-position histograms with binary-thresholded gradient magni-tudes to build a parts based method containing detectors for faces,heads,and front and side pro?les of upper and lower body parts.In contrast,our detector uses a simpler archi-tecture with a single detection window,but appears to give signi?cantly higher performance on pedestrian images. 3Overview of the Method This section gives an overview of our feature extraction chain,which is summarized in?g.1.Implementation details are postponed until§6.The method is based on evaluating well-normalized local histograms of image gradient orienta-tions in a dense grid.Similar features have seen increasing use over the past decade[4,5,12,15].The basic idea is that local object appearance and shape can often be characterized rather well by the distribution of local intensity gradients or 1
图像局部特征点检测算法综述
图像局部特征点检测算法综述 研究图像特征检测已经有一段时间了,图像特征检测的方法很多,又加上各种算法的变形,所以难以在短时间内全面的了解,只是对主流的特征检测算法的原理进行了学习。总体来说,图像特征可以包括颜色特征、纹理特等、形状特征以及局部特征点等。其中局部特点具有很好的稳定性,不容易受外界环境的干扰,本篇文章也是对这方面知识的一个总结。 本篇文章现在(2015/1/30)只是以初稿的形式,列出了主体的框架,后面还有许多地方需要增加与修改,例如2013年新出现的基于非线性尺度空间的KAZE特征提取方法以及它的改进AKATE等。在应用方面,后面会增一些具有实际代码的例子,尤其是基于特征点的搜索与运动目标跟踪方面。 1. 局部特征点 图像特征提取是图像分析与图像识别的前提,它是将高维的图像数据进行简化表达最有效的方式,从一幅图像的M×N×3的数据矩阵中,我们看不出任何信息,所以我们必须根据这些数据提取出图像中的关键信息,一些基本元件以及它们的关系。 局部特征点是图像特征的局部表达,它只能反正图像上具有的局部特殊性,所以它只适合于对图像进行匹配,检索等应用。对于图像理解则不太适合。而后者更关心一些全局特征,如颜色分布,纹理特征,主要物体的形状等。全局特征容易受到环境的干扰,光照,旋转,噪声等不利因素都会影响全局特征。相比而言,局部特征点,往往对应着图像中的一些线条交叉,明暗变化的结构中,受到的干扰也少。 而斑点与角点是两类局部特征点。斑点通常是指与周围有着颜色和灰度差别的区域,如草原上的一棵树或一栋房子。它是一个区域,所以它比角点的噪能力要强,稳定性要好。而角点则是图像中一边物体的拐角或者线条之间的交叉部分。 2. 斑点检测原理与举例 2.1 LoG与DoH 斑点检测的方法主要包括利用高斯拉普拉斯算子检测的方法(LOG),以及利用像素点Hessian矩阵(二阶微分)及其行列式值的方法(DOH)。 LoG的方法已经在斑点检测这入篇文章里作了详细的描述。因为二维高斯函数的拉普拉斯核很像一个斑点,所以可以利用卷积来求出图像中的斑点状的结构。 DoH方法就是利用图像点二阶微分Hessian矩阵:
FFT特征提取算法
FFT特征提取算法 来自网络 滚动轴承故障诊断频域特征识别,关键在于转换为频域的实时性是否满足系统实时的工作需要,FFT变换是将时域信号转换为频域的有效方法。FFT具有快速实时,物理关系明确的优点,能以较低的成本得到性能满足要求的系统,所以本课题讨论的故障诊断频域特征识别仍采用FFT变换。 TI公司的DSP有许多适应实时数字信号处理的特点,具有哈佛总线结构、片内缓存技术、流水线结构、特殊的寻址方式、高效的特殊指令以及硬件乘法器、位反转桶形位移器等硬件,因此数据运算速度很快,通常1024点的FFT在毫秒级之内(以所选用的DSP和系统时钟而有别),因此用DSP实现FFT,实时性可以充分满足系统要求。 FFT在DSP处理器实现中采用的是按时间抽取的基2算法。一般情况下,假定FFT程序的输入序列为复数,而在本课题应用背景中待处理序列为实数值,可以采用对称特性有效地计算FFT。在此情况下,可以将原来的N点实数序列压缩为一个N/2点的复数序列。对此压缩复数序列执行N/2点FFT,将得到的N/2点复数输出展开为N点复序列,它与原来N点实数输入信号的FFT相对应。做完FFT变换后,要识别故障特征,还要对变换后的数据序列进行求模,从而判断出故障特征的幅度和频率信息。所以FFT变换的流程如图5.6所示。
C5402的DSPLIB库提供了一套全面优化的用于实数和复数FFT的函数和一个位反转例程(cbrev)。实数FFT函数rfft是一个宏,其如下调用Cfft和cbrev: #definerfft(x,nx,type) { Cfft_##type(x,nx/2); Cbrev(x,x,nx/2); unpack(x,nx); } FFT变换程序不仅要调用DSPL工B中的cfft--SCALE函数,而且还要对变换完后的数据进行位翻转和数据打包,所以分别调用了库中的cbrev和unPack函数,最后还要对输出数据进行求模来判断幅度和频率等参数。
基于全局视角的点云特征提取方法与设计方案
本技术公开了一种基于全局视角的点云特征提取方法,该方法先获取点云模型中原始三维点云坐标点,并结合主成分分析法,获得三个特征向量;将每个原始三维点云坐标点投影到三个特征向量,获得三个投影值,并结合刚体变换方法,获得每个原始三维点云坐标点对应的投影坐标;将全部投影坐标划分成三个二维平面,并将每个二维平面划分成N个网格区域;根据每个网格区域内的深度因子、面积因子、坐标面积因子,获得每个网格区域的特征数值,并结合N个网格区域,获得每个二维平面的特征数值;根据每个二维平面的特征数值,提取点云模型的总特征。采用本技术技术方案不用时刻受到不同扫描视角的影响而导致点云特征提取的精确度低,同时降低了时间复杂度。 权利要求书
1.一种基于全局视角的点云特征提取方法,其特征在于,包括: 获取点云模型中原始三维点云数据,其中,所述原始三维点云数据包括D个原始三维点云坐标点,D为大于1的整数; 根据所述D个原始三维点云坐标点,结合主成分分析法,获得三个特征向量,其中,所述三个特征向量相互正交; 将每个所述原始三维点云坐标点分别一一投影到所述三个特征向量,获得三个投影值,并结合预设的刚体变换方法对所述三个投影值进行处理,依次获得每个所述原始三维点云坐标点对应的投影坐标; 将全部所述投影坐标划分成三个二维平面,并分别将每个所述二维平面划分成N*N个网格区域,其中,N为大于1的整数; 根据每个网格区域内的深度因子、面积因子、坐标面积因子,获得每个网格区域的特征数值,并结合所述N*N个网格区域,获得每个二维平面的特征数值; 根据所述每个二维平面的特征数值,提取所述点云模型的总特征。 2.如权利要求1所述的基于全局视角的点云特征提取方法,其特征在于,所述根据所述D个原始三维点云坐标点,结合主成分分析法,获得三个特征向量,具体为: 将所述D个原始三维点云坐标点的每个维度取均值,获得D*3矩阵数据; 计算所述矩阵数据的的协方差矩阵,获得D*D协方差矩阵; 根据主成分分析方法,将所述协方差矩阵的特征值按大小排序,并同时计算出与所述协方差矩阵的特征值对应的特征向量,获得第一主成分特征向量、第二主成分特征向量和第三主成分特征向量。
SIFT算法分析
SIFT算法分析 1 SIFT 主要思想 SIFT算法是一种提取局部特征的算法,在尺度空间寻找极值点,提取位置,尺度,旋转不变量。 2 SIFT 算法的主要特点: a)SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。 b)独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进 行快速、准确的匹配。 c)多量性,即使少数的几个物体也可以产生大量SIFT特征向量。 d)高速性,经优化的SIFT匹配算法甚至可以达到实时的要求。 e)可扩展性,可以很方便的与其他形式的特征向量进行联合。 3 SIFT 算法流程图:
4 SIFT 算法详细 1)尺度空间的生成 尺度空间理论目的是模拟图像数据的多尺度特征。 高斯卷积核是实现尺度变换的唯一线性核,于是一副二维图像的尺度空间定义为: L( x, y, ) G( x, y, ) I (x, y) 其中G(x, y, ) 是尺度可变高斯函数,G( x, y, ) 2 1 2 y2 (x ) 2 e / 2 2 (x,y)是空间坐标,是尺度坐标。大小决定图像的平滑程度,大尺度对应图像的概貌特征,小尺度对应图像的细节特征。大的值对应粗糙尺度(低分辨率),反之,对应精细尺度(高分辨率)。 为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。 D( x, y, ) (G( x, y,k ) G( x, y, )) I ( x, y) L( x, y,k ) L( x, y, ) DOG算子计算简单,是尺度归一化的LoG算子的近似。图像金字塔的构建:图像金字塔共O组,每组有S层,下一组的图像由上一 组图像降采样得到。 图1由两组高斯尺度空间图像示例金字塔的构建,第二组的第一副图像由第一组的第一副到最后一副图像由一个因子2降采样得到。图2 DoG算子的构建: 图1 Two octaves of a Gaussian scale-space image pyramid with s =2 intervals. The first image in the second octave is created by down sampling to last image in the previous
文本特征提取方法研究
文本特征提取方法研究 ______________________________________________________ 一、课题背景概述 文本挖掘是一门交叉性学科,涉及数据挖掘、机器学习、模式识别、人工智能、统计学、计算机语言学、计算机网络技术、信息学等多个领域。文本挖掘就是从大量的文档中发现隐含知识和模式的一种方法和工具,它从数据挖掘发展而来,但与传统的数据挖掘又有许多不同。文本挖掘的对象是海量、异构、分布的文档(web);文档内容是人类所使用的自然语言,缺乏计算机可理解的语义。传统数据挖掘所处理的数据是结构化的,而文档(web)都是半结构或无结构的。所以,文本挖掘面临的首要问题是如何在计算机中合理地表示文本,使之既要包含足够的信息以反映文本的特征,又不至于过于复杂使学习算法无法处理。在浩如烟海的网络信息中,80%的信息是以文本的形式存放的,WEB文本挖掘是WEB内容挖掘的一种重要形式。 文本的表示及其特征项的选取是文本挖掘、信息检索的一个基本问题,它把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本。使计算机能够通过对这种模型的计算和操作来实现对文本的识别。由于文本是非结构化的数据,要想从大量的文本中挖掘有用的信息就必须首先将文本转化为可处理的结构化形式。目前人们通常采用向量空间模型来描述文本向量,但是如果直接用分词算法和词频统计方法得到的特征项来表示文本向量中的各个维,那么这个向量的维度将是非常的大。这种未经处理的文本矢量不仅给后续工作带来巨大的计算开销,使整个处理过程的效率非常低下,而且会损害分类、聚类算法的精确性,从而使所得到的结果很难令人满意。因此,必须对文本向量做进一步净化处理,在保证原文含义的基础上,找出对文本特征类别最具代表性的文本特征。为了解决这个问题,最有效的办法就是通过特征选择来降维。 目前有关文本表示的研究主要集中于文本表示模型的选择和特征词选择算法的选取上。用于表示文本的基本单位通常称为文本的特征或特征项。特征项必须具备一定的特性:1)特征项要能够确实标识文本内容;2)特征项具有将目标文本与其他文本相区分的能力;3)特征项的个数不能太多;4)特征项分离要比较容易实现。 在中文文本中可以采用字、词或短语作为表示文本的特征项。相比较而言,词比字具有更强的表达能力,而词和短语相比,词的切分难度比短语的切分难度小得多。因此,目前大多数中文文本分类系统都采用词作为特征项,称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算。如果把所有的词都作为特征项,那么特征向量的维数将过于巨大,从而导致计算量太大,在这样的情况下,要完成文本分类几乎是不可能的。特征抽取的主要功能是在不损伤文本核心信息的情况下尽量减少要处理的单词数,以此来降低向量空间维数,从而简化计算,提高文本处理的速度和效率。文本特征选择对文本内容的过滤和分类、聚类处理、自动摘要以及用户兴趣模式发现、知识发现等有关方面的研究都有非常重要的影响。通常根据某个特征评估函数计算各个特征的评分值,然后按评分值对这些特征进行排序,选取若干个评分
脑电信号特征提取及分类
脑电信号特征提取及分类
第 1 章绪论 1.1引言 大脑又称端脑,是脊椎动物脑的高级的主要部分,由左右两半球组成及连接两个半球的中间部分,即第三脑室前端的终板组成。它是控制运动、产生感觉及实现高级脑功能的高级神经中枢[1]。大脑是人的身体中高级神经活动中枢,控制着人体这个复杂而精密的系统,对人脑神经机制及高级功能进行多层次、多学科的综合研究已经成为当代脑科学发展的热点方向之一。 人的思维、语言、感知和运动能力都是通过大脑对人体器官和相应肌肉群的有效控制来实现的[2]。人的大脑由大约1011个互相连接的单元体组成,其中每个单元体有大约104个连接,这些单元体称做神经元。在生物学中,神经元是由三个部分组成:树突、轴突和细胞体。神经元的树突和其他神经元的轴突相连,连接部分称为突触。神经元之间的信号传递就是通过这些突触进行的。生物电信号的本质是离子跨膜流动而不是电子的流动。每有一个足够大的刺激去极化神经元细胞时,可以记录到一个持续1-2ERP的沿轴突波形传导的峰形电位-动作电位。动作电位上升到顶端后开始下降,产生一些小的超极化波动后恢复到静息电位(静息电位(Resting Potential,RP)是指细胞未受刺激时,存在于细胞膜内外两侧的外正内负的电位差)。人的神经细胞的静息电位为-70mV(就是膜内比膜外电位低70mV)。这个变化过程的电位是局部电位。局部电位是神经系统分析整合信息的基础。细胞膜的电特性决定着神经元的电活动[3]。当神经元受到外界刺激时,神经细胞膜内外两侧的电位差被降低从而提高了膜的兴奋性,当兴奋性超过特定阈值时就会产生神经冲动或兴奋,神经冲动或兴奋通过突触传递给下一个神经元。由上述可知,膜电位是神经组织实现正常功能的基本条件,是兴奋产生的本质。膜电位使神经元能够接收刺激信号并将这一刺激信号沿神经束传递下去。在神经元内部,树突的外形就像树根一样发散,由很多细小的神经纤维丝组成,可以接收电信号,然后传递给细胞体。如果说树突是树根的话,那么细胞体就是树桩,对树突传递进来的信号进行处理,如果信号超过特定的阈值,细胞体就把信号继续传递给轴突。轴突的形状像树干,是一根细长的纤维体,它把细胞体传递过来的信号通过突触发送给相邻神经元的树突。突触的连接强度和神经元的排列方式都影响着神经组织的输出结果。而正是这种错综复杂的神经组织结构和复杂的信息处理机制,才使得人脑拥有高度的智慧。我们的大脑无时无刻不在产生着脑电波,对脑来说,脑细胞就像是脑内一个个“微小的发电站”。早在1857年,英国的青年生理科学工作者卡通(R.Caton)就在猴脑和兔脑上记录