运用EVIEWS建立多元线性回归并进行相关检验

运用EVIEWS建立多元线性回归并进行相关检验
姓名:jelly
一、输入数据
某社区家庭对某种消费品的消费需要调查
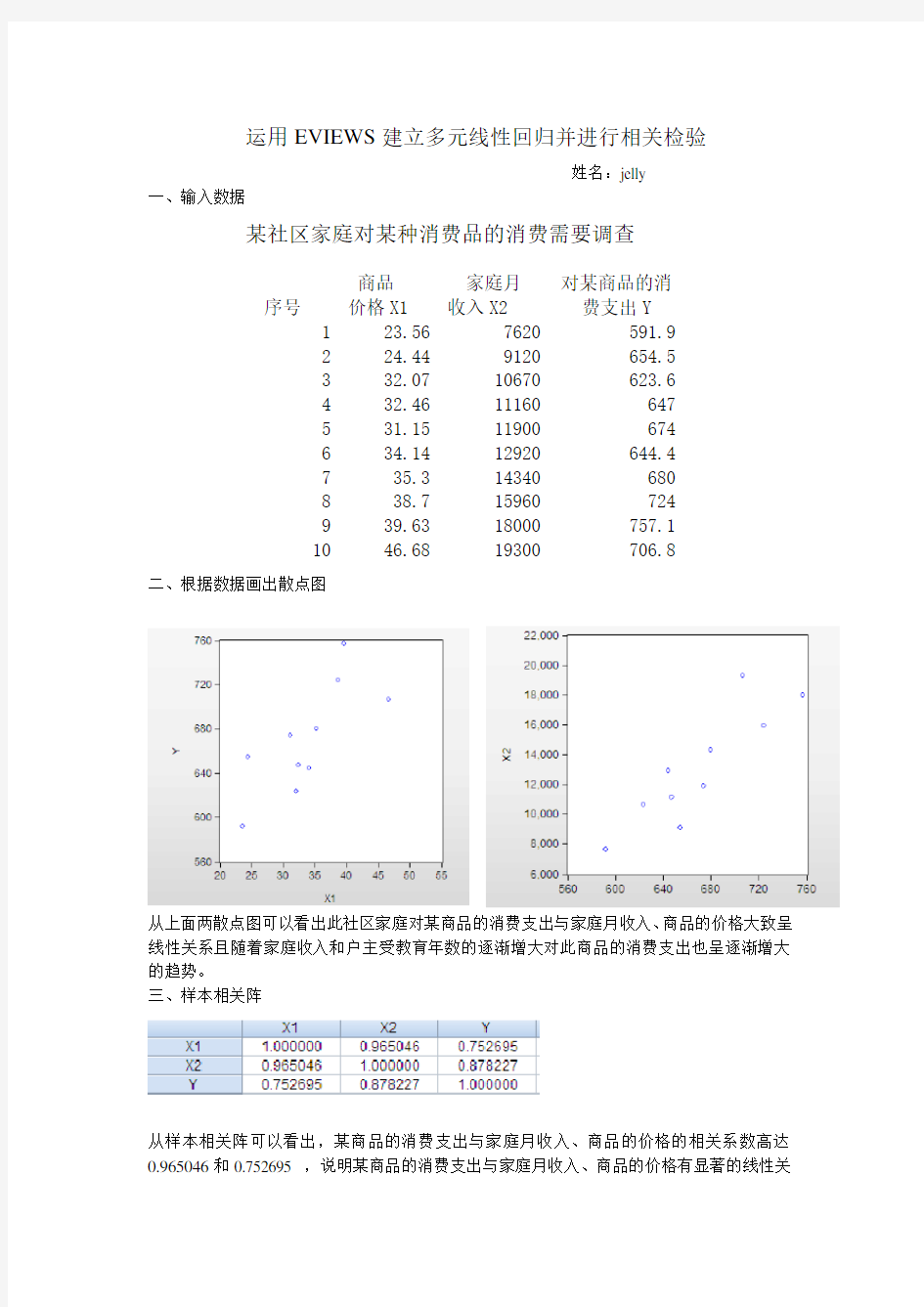
二、根据数据画出散点图
从上面两散点图可以看出此社区家庭对某商品的消费支出与家庭月收入、商品的价格大致呈线性关系且随着家庭收入和户主受教育年数的逐渐增大对此商品的消费支出也呈逐渐增大的趋势。
三、样本相关阵
从样本相关阵可以看出,某商品的消费支出与家庭月收入、商品的价格的相关系数高达0.965046和0.752695 ,说明某商品的消费支出与家庭月收入、商品的价格有显著的线性关
序号
商品
价格X1
家庭月
收入X2
对某商品的消
费支出Y
1 23.56 7620 591.9
2 24.44 9120 654.5
3 32.07 10670 623.6
4 32.46 11160 647
5 31.15 11900 674
6 34.14 12920 644.4
7 35.3 14340 680
8 38.7 15960 724
9 39.63 18000 757.1
10 46.68 19300 706.8
系,可以考虑建立二元线性回归模型。
四、对数据进行普通最小二乘估计,OLS 表如下
五、写出估计方程
12626.50939.7905700.28618i Y X X ∧=-+
(40.13010) (3.197843) (0.05838)
t=(15.611195) (-3.061617) (4.902030)
20.902218R = 2R =0.874281
六、随机干扰项
2'1e e n k σ∧=--
'''''?????()()()()ee Y Y
Y Y Y X Y X Y Y Y X βββ=--=--=-=2116.85 所以22116.85?302.411021
σ==-- 由OLS 表得20.902218R = 2R =0.874281
七、由OLS 可得 F=32.29 0.05(2,7) 4.74F =
因为32.29>4.74,所以方程的总体线性性显著成立
由OLS 表可得 C 的t 值为15.61 X1的t 值为-3.06 X2的值为4.90 0.025(7) 2.365t =
所以常输项,X1和X2的总体参数都显著的异于零
将数据分别代入以下三个式子:
0?00.025?t S ββ±? 1?10.025?t S ββ±? 2?20.025?t S ββ±?
可得参数95%的置信区间分别为(531.62,724.40) -17.35,-2.22) (0.014,0.042)
八、X1=35 X2=20000
将X1,X2代人方程可得Y 为856.20
Y 的均值
0?Y S =37.05 0.025(7) 2.365t = 所以Y 的均值在95%的置信区间
为(768.58,943.82)
Y 的个值0
?Y S =40.93 0.025(7) 2.365t = 所以Y 的个值在95%的置信区间为(759.41,952.99)
第二个实验
输入数据,对其进行回归分析输出OLS 表
由表可得方程为
?ln 101540.609ln 0.361ln Y K L =++ (1.59)(3.45) (1.79)
2R =0.8099 2R =0.7963 F=59.66
0.05(2,28)F =3.34 0.025(28)t =2.048 0.01(28)t =1.701
所以lnK 与lnL 联合起来对lnY 有显著的线性影响
在5%的显著性水平下,lnK 的参数通过了检验但lnL 的参数未通过t 检验,如果设定显著性水平为10%,lnL 与lnK 都通过检验。R =0.7963表明,工业总产值对数值的79.6%的变化可以由资产合计的对数值与职工的对数值的变化来解释,但仍有20.4%的变化是由其他因素的变化影响的。
2、因为0.609+0.36大致等于1,也就是说明资产与劳动的产出
弹性之和近似为1,表明中国制造业在该年基本呈现规模报酬不变的状态。可以对其进行约束检验
零假设0H :αβ+=1
假设原假设为真,建立的模型为
ln ln Y
K
C u L L α=++
根据此模型输出OLS 表,如下
eviews多元线性回归案例分析
中国税收增长的分析 一、研究的目的要求 改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。(3)物价水平。我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。(4)税收政策因素。我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响,特别是1985年税收陡增215.42%。但是第二次税制改革对税收的增长速度的影响不是非常大。因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数” 从《中国统计年鉴》收集到以下数据 财政收入(亿元) Y 国内生产总值(亿 元) X2 财政支出(亿 元) X3 商品零售价格指 数(%) X4 1978519.283624.11122.09100.7 1979537.824038.21281.79102 1980571.74517.81228.83106
利用Eviews软件进行最小二乘法回归实例
例题中国居民人均消费支出与人均GDP(1978-2000),数据(例题1-2),预测,2001年人均GDP为4033.1元,求点预测、区间预测。(李子奈,p50)解答: 一、打开Eviews软件,点击主界面File按钮,从下拉菜单中选择Workfile。 在弹出的对话框中,先在工作文件结构类型栏(Workfile structure type)选择固定频率标注日期(Dated – regular frequency),然后在日期标注说明栏中(Date specification)将频率(Frequency)选为年度(Annual),再依次填入起止日期,如果希望给文件命名(可选项),可以在命名栏(Names - optional)的WF项填入自己选择的名称,然后点击确定。 此时建立好的工作文件如下图所示:
在主界面点击快捷方式(Quick)按钮,从下拉菜单中选空白数据组(Empty Group)选项。 此时空白数据组出现,可以在其中通过键盘输入数据或者将数据粘贴过来。 在Excel文件(例题1-2)中选定要粘贴的数据,然后在主界面中点击编辑(Edit)按钮,从下拉菜单中选择粘贴(Paste),数据将被导入Eviews软件。
将右侧的滚动条拖至最上方,可以在最上方的单元格中给变量命名。 二、估计参数 在主界面中点击快捷方式(Quick)按钮,从下拉菜单中选择估计方程(Estimate Equation) 在弹出的对话框中设定回归方程的形式。
在方程表示式栏中(Equation specification ),按照被解释变量(Consp )、常数项(c )、解释变量(Gdpp )的顺序填入变量名,在估计设置(Estimation settings )栏中选择估计方法(Method )为最小二乘法(LS – Least Squares ),样本(Sample )栏中选择全部样本(本例中即为1978-2000),然后点击确定,即可得到回归结果。 以上得到的回归结果可以表示为: 201.1190.3862(13.51)(53.47)Consp GDPP =+? 如果你试图关闭回归方程页面(或Eviews 主程序),这时将会弹出一个对话框,询问是否删除未命名的回归方程,如下图所示
Eviews实验课讲义_3一元多元线性回归-上机课
第三课一元及多元线性回归模型 一元线性回归模型 一、做两个变量的散点图,从而看两个变量是否具有线性关系。 案例数据:1985-2002年我国人均钢产量与人均GDP的时间序列数据(数据3_1_1)。 操作方法:通过序列组的形式右键单击打开后,在group窗口下view——graph---scatter,通过对散点图结 同样的操作可以检验其它案例数据(3_1_2和3_1_3)的特征: 案例数据2、3、4、5:10个家庭人均收入与消费支出的横截面数据;1978-2000年中国人均消费模型;1978年-2008年北京市城镇居民年家庭收入和年消费性支出数据(case1_1的数据); 1970年-1980年美国的咖啡平均真实零售价格(每磅美元)与消费量(每人每日杯数)(其中,零售价格是已经经过物价调整的) 二、通过建立方程对象的方式来估计一个方程,并保存我们建立的方程对象。 Workfile窗口下建立新的对象---equation对象并命名,在equation estimation 窗口下的specification 选项卡下的equation specification对话框中设置因变量、自变量及常数项,在estimation settings对话框中
注意:建模途径:command: quick\estimation equation回车,或object\equation object,设置。 命令行形式:(1)列表法:consp c gdpp 或(2)公式法:consp=c(1)+c(2)*gdpp 三、方程估计结果的解释、评价及模型检验(拟合优度评价,估计参数和方程的显著性检验) 消费方程中,C为自发性消费,x(gdpp)的系数为经济参数,关注其意义;通过拟合优度、调整后的拟合优度、t统计量后的精确显著性水平p(相伴概率);f统计量的p来判断对原假设接受与否 四、在回归估计结果中显示方程的三种形式(即估计命令,回归方程的一般表达式,带有系数估计值的表达式) Estimation Command: LS GDPP STEELP C Estimation Equation: GDPP = C(1)*STEELP + C(2) Substituted Coefficients: GDPP = *STEELP - 3394. 五、如何查看因变量的实际值、拟合值和回归方程的残差(包括表的形式和图的形式) 通过方程窗口下的view去实现实际值、拟合值和回归方程的残差;单独显示残差及标准化后的 对于案例数据1978年-2008年北京市城镇居民年家庭收入和年消费性支出数据,进行样本内与外的预测。 通过equation窗口中的forecast直接进行样本内预测:查看图及workfile中的yf序列; 在sample或range中改变样本区间或文件区间(需补充观察值)后进行样本外预测。 对案例数据1970年-1980年美国的咖啡平均真实零售价格(每磅美元)与消费量(每人每日杯数)散点图观察后,显示负相关的直线关系,操作过程同上。 实验作业——一元线性回归建模。 附录:练习数据 为了研究某市城镇每年鲜蛋的需求量,首先考察消费者年人均可支配收入对年人均鲜蛋需求量的影响。由经济理论知,当人均可支配收入提高时,鲜蛋需求量也相应增加。但是,鲜蛋需求量除受消费者可支配收入影响外,还要受到其自身价格、人们的消费习惯及其他一些随机因素的影响。为了表示鲜蛋需求量与消费者可支配收入之间非确定的依赖关系,我们将影响鲜蛋需求量的其他因素归并到随机变量u中,建立这两个变量之间的数学模型。表中给出Y为某市城镇居民人均鲜蛋需求量(公斤),X为年人均可支配收入(元,
Eviews处理多元回归分析操作步骤
Eviews处理多元回归分析操作步骤操作步骤 1. 建立工作文件 (1) 建立数据的exel电子表格 (2)将电子表格数据导入eviews File-open-foreign data as workfile,得到数据的Eviews工作文件和数据序列表。
2. 计算变量间的相关系数 在窗口中输入命令:cor coilfuture dow shindex nagas opec ueurope urmb,点击回车键,得到各序列之间的相关系数。结果表明Coilfuture数列与其他数列存在较好的相关关系。
3.时间序列的平稳性检验 (1)观察coilfuture序列趋势图 在eviews中得到时间序列趋势图,在quick菜单中单击graph,在series list对话框中输入序列名称coilfuture,其他选择默认操作。图形表明序列随时间变化存在上升趋势。 (2)对原序列进行ADF平稳性检验 quick-series statistics-unit root test,在弹出的series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择level,得到原数据序列的ADF检验结果,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值0.97大于所有临界值,则表明序列不平稳。以此方法,对各时间序列依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均大于临界值,表明各原序列都是非平稳的。 (3)时间序列数据的一阶差分的ADF检验
quick-series statistics-unit root test,在series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择1nd difference,对其一阶差分进行平稳性检验,其他保持默认设置。 得到序列的ADF平稳性检验结果,检测值-7.8远小于所有临界值,则表明序列一阶差分平稳。以此方法,对各时间序列的一阶差分依次进行ADF检验,将检验值
用eviews进行一元线性回归分析实施报告
天津外国语大学国际商学院本科生课程论文(设计) 题目:一元回归分析居民收入和支出的关系姓名: 学号: 专业: 年级: 班级: 任课教师: 2014 年 4 月
内容摘要 随着本文中的收集数据参考了中国统计年鉴以及书本《计量经济学》中的相关统计结果,对我国各地区城镇居民家庭人均全年可支配收入与人均全年消费性支出进行分析。利用EVIEWS软件对计量模型进行参数评估和检验,最终得出相关结论。 关键词:居民消费;居民收入;EVIEWS;一元回归分析
目录 一、引言 (1) (一)研究背景 (1) (二)研究意义 (1) 二、研究综述 (2) (一)模型设定 (2) 1.定义变量 (2) 2.数据来源 (2) (二)作散点图 (3) 三、估计参数 (4) (一)操作步骤 (4) (二)回归结果 (4) 四、模型检验 (5) (一)经济意义检验 (5) (二)拟合优度和统计检验 (5) (三)回归预测 (5) 五、结论 (5) 参考文献: (6)
一元回归分析居民收入与支出的关系 一、引言 (一)研究背景 随着近年来我国成为世界第二大经济体,居民的高生活水平也日益显著。我国人口正在高速城镇化,2011年中国大陆城镇人口为69079万人,城镇人口占总人口比重达到51.27%。因此城镇居民作为消费主体,研究城镇居民人均可支配收入以及人均可支配消费性支出之间的关系,可以有效的了解到我国各地区的人民生活水平以及经济状况,因此能更好的的带动我国GDP的飙升,改善居民的生活水平。 (二)研究意义 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这要是人民生活水平的具体体现。改革开饭以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2007年的城市居民家庭平均每人每年消费支出,最高的是上海市达人均20667.91元,最低的则是新疆,人均只有8871.27元,上海是新疆的2.33倍。为了研究全国居民消费水平及其变动的原因,需要做具体的
使用eviews做线性回归分析
使用eviews做线性回归分析 关键字: linear regression Glossary: ls(least squares)最小二乘法 R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整 Adjust R-seqaured() S.E of regression回归标准误差 Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间 Mean dependent var因变量的均值 S.D. dependent var因变量的标准差 Akaike info criterion赤池信息量(AIC)(越小说明模型越精确) Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确) Prob(F-statistic)相伴概率 fitted(拟合值) 线性回归的基本假设: 1.自变量之间不相关 2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布 3.样本个数多于参数个数 建模方法: ls y c x1 x2 x3 ... x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。模型的实际业务含义也有指导意义,比如 m1同gdp肯定是相关的。 模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。 模型检验: 1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度 F大于临界值则说明拒绝0假设。 Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。 2)回归系数显著性检验(t检验):检验每一个自变量的合理性 |t|大于临界值表示可拒绝系数为0的假设,即系数合理。t分布的自由度为 n-p-1,n为样本数,p为系数位置
多元线性回归模型案例分析报告
多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据
设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用 EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024
Eviews处理多元回归分析操作步骤
操作步骤 1.建立工作文件 (1)建立数据的exel电子表格 (2)将电子表格数据导入eviews File-open-foreign data as workfile,得到数据的Eviews工作文件和数据序列表。
2.计算变量间的相关系数 在窗口中输入命令:cor coilfuture dow shindex nagas opec ueurope urmb,点击回车键,得到各序列之间的相关系数。结果表明Coilfuture数列与其他数列存在较好的相关关系。 3.时间序列的平稳性检验 (1)观察coilfuture序列趋势图 在eviews中得到时间序列趋势图,在quick菜单中单击graph,在series list对话框中输入序列名称coilfuture,其他选择默认操作。图形表明序列随时间变化存在上升趋势。
(2)对原序列进行ADF平稳性检验 quick-series statistics-unit root test,在弹出的series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择level,得到原数据序列的ADF检验结果,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值0.97大于所有临界值,则表明序列不平稳。以此方法,对各时间序列依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均大于临界值,表明各原序列都是非平稳的。 (3)时间序列数据的一阶差分的ADF检验 quick-series statistics-unit root test,在series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择1nd difference,对其一阶差分进行平稳性检验,其他保持默认设置。
多元线性回归实验报告(DOC)
实验题目:多元线性回归、异方差、多重共线性 实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。 实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。 实验步骤: 1.建立出口货物总额计量经济模型: 错误!未找到引用源。(3.1) 1.1建立工作文件并录入数据,得到图1 图1 在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据 表。点”view/graph/line/ok”,形成线性图2。 图2 1.2对(3.1)采用OLS估计参数 在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3 根据图3中的数据,得到模型(3.1)的估计结果为 (8638.216)(0.012799)(9.776181) t=(-2.110573) (10.58454) (1.928512) 错误!未找到引用源。错误!未找到引用源。F=522.0976 从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。但当错误!未找到引用源。=0.05时,错误!未找到引用源。=错误!未找到引用源。2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。 2.多重共线性模型的识别 2.1计算解释变量x2、x3的简单相关系数矩阵。 点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。 相关系数矩阵 图4 由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。 2.2多重共线性模型的修正
《计量经济学》eviews实验报告多元线性回归模型
《计量经济学》实验报告多元线性回归模型 一、实验内容 建立2000-2014年北京市民用汽车拥有量模型。 调查北京市民用汽车拥有量数据见表1。观测变量分别是民用汽车拥有量y t(万辆),北京市年末人口数x it (万人)和城镇人均可支配收入x2t (千元)。 表1 某城市拥有量样本数据 t y t(拥有量)X1t(年末人数)X2t (人均收入) 2000 104.12 1113.53 10349.7 2001 114.47 1127.89 11577.8 2002 133.93 1142.83 12463.9 2003 163.07 1154.06 13882.6 2003 182.42 1167.76 15637.8 2005 182.42 1184.14 17653 2006 239.12 1199.96 19977.5 2007 273.36 1216.25 21988.5 2008 313.68 1232.28 24724.9 2009 368.11 1247.52 26738.5 2010 449.72 1258 29072.9 2011 470.53 1277.92 32903 2012 493.56 1297.46 36468.8 2013 517.11 1316.34 40321
2014 530.83 1333.4 43910
要求: (1)试建立二元线性回归销售模型。 (2)考虑北京地区有人口万人,人均年收入为元,试北京市汽车拥有量做出预测。 二、实验目的 掌握多元线性回归模型的原理,多元线性回归模型的建立、估计、检验及预测的方法, 以及相应的EViews软件操作方法。 三、实验步骤(简要写明实验步骤) (1 )建立二元线性回归销售模型 (2)预测 点击view 中的Graph-scatter- 中的第三个获得
多元线性回归eviews操作
一.模型设定 本例中我们假设拟建立如下多元回归模型: 01122Y X X u βββ=+++ 二.估计参数 1.建立工作文件 首先,进入Eviews 主页,在菜单中依次点击File\New\Workfile ,出现对话框Work Create 。 截面数据Unstructured/undated 只需输入样本数就可以。时间序列数据Dated-regular frequency 在Date specification 中选择数据频率: Annual (年度) Weekly (周数据) Quarterly (季度) Daily (5 day week )每周5天日数据 Daily (7 day week )每周7天日数据 Monthly (月度) integer date (未注明日期或者不规则的) Semi Annual (半年度) 其次,点击OK ,出现未命名文件的Workfile UNTITLED 工作框。其中c 为截距项,resid 为残差项。若要将文件存盘,点击save ,在save as 对话框中选择存盘路径,并输入文件名。如多元线性回归案例 2.输入数据 方法一:Quick\Empty Group 等 方法二:data Y X1 X2,得到如下表;
3.估计参数 方法一:Quick\Estimate Equation 方法二: LS Y C X1 X2 三、解释表里参数
标准差1 β∧S =0.075308,回归标准差=被解释变量标准差=回归模型标准差: σ∧残差平方和:2i e ∑=4170093被解释变量的标准差: 2=2388.459 AIC 和SC 准则:这两个准则要求仅当所增加的解释变量能减少AIC 值或SC 值时才在原模型中增加该解释变量。与调整的可决系数相似。多元小于一元,可以将前期人均居民消费作为解释变量包括在模型中。 四、模型检验 1.经济意义检验 估计的参数值都为正数,经济意义合理。 所估计的参数120.555644,0.250085ββ∧∧ ==,说明在2006年可支配收入不变的情况下,2005年消费支出每增加1元,平均来说,可导致2006年消费支出提高0.250085元。 2.拟合优度和统计检验 本例中拟合优度等于0.975634,即解释变量对被解释变量2006年消费支出的绝大部分差异做出了解释,说明模型对样本的拟合很好。 F 检验:00120H βββ===针对:,给定显著性水平=0.05α,在F 分布表中查出 自由度k-1=2(其中k 为估计参数个数)n-k=28的临界值(228)=19.5F α,,由表中得F=560.5650。应拒绝原假设,说明回归方程显著,即2006年可支配收入、2005年消费支出联合起来对2006年消费支出有显著影响。 t 检验:0j =0 j=01,2=0.05H βα分别针对:(,),给定显著性水平,查t 分布表得自由度n-k=28的临界值2 t n-k α()=2.048,由表中看出都拒绝原假设,从P 值中
用Eviews软件建立一元线性回归模型并进行有关检验的实验报告
用Eviews软件建立一元线性回归模型并进行相关检验的实验报告1.数据 表1列出了某年中国部分省市城镇居民每个家庭平均全年可支配收入X与消费性支出Y 的统计数据。
2.建立模型 应用EViews软件,以表1的数据可绘出可支配收入X与消费性支出Y的散点图(图2-1)。从该三点图可以看出,随着可支配收入的增加,消费性支出也在增加,大致程线性关系。据此,我们可以建立一元线性回归模型: Y=β0+β1·X+μ 图2-1 对模型作普通最小二乘法估计,在Eviews软件下,OLS的估计结果如图(2-2)所示。 Dependent Variable: Y Method: Least Squares Date: 12/07/11 Time: 21:00 Sample: 1 20 Included observations: 20
Variable Coefficient Std. Error t-Statistic Prob. X 0.755368 0.023274 32.45486 0.0000 C 271.1197 159.3800 1.701090 0.1061 R-squared 0.983198 Mean dependent var 5199.515 Adjusted R-squared 0.982265 S.D. dependent var 1625.275 S.E. of regression 216.4435 Akaike info criterion 13.68718 Sum squared resid 843260.4 Schwarz criterion 13.78675 Log likelihood -134.8718 Hannan-Quinn criter. 13.70661 F-statistic 1053.318 Durbin-Watson stat 1.302512 Prob(F-statistic) 0.000000 图2-2 OLS估计结果为 ^ Y=271.12+0.76X (1.70) (32.45) R2=0.9832 D.W. =1.3025 F=1053.318 3.模型检验 从回归估计的结果看,模型拟合较好。可绝系数R2=0.983198,表明城镇居民每个家庭平均全年消费性支出变化的98.3198%可由可支配收的变化来解释。从斜率项β1的t检验看,大于5%显著性水平下自由度为n-2=18的临界值t0.025(18)=2.101,且该斜率值满足0<0.755368<1,符合经济理论中边际消费倾向在0与之间的绝对收入假说,表明中国城镇居民平均全年可支配收入每增加1元,消费性支出增加0.755368元。 4.预测 假设我们需要关注2012年平均年可支配收入在20000元这一水平下的中国城镇居民平均年消费支出问题。由上述回归方程可得该类家庭人均消费支出的预测值: ^ Y0=271.1197+0.755368×20000=15378.4797 下面给出该类居民平均年消费支出95%置信度的预测区间。
多元线性回归分析(Eviews论文)
楚雄师范学院数学系09级01班韩金伟学号:20091021135 2011—2012学年第二学期《数据分析》期末论文 题目影响成品钢材需求量的回归分析 姓名韩金伟 学号20091021135 系(院)数学系 专业数学与应用数学 2012年 6 月 19 日
题目:影响成品钢材需求量的回归分析 摘要:随着社会经济的不断发展,科学技术的不断进步,统计方法越来越成为人们必不 可收的工具盒手段。应用回归分析是其中的一个重要分支,本着国家经济水平的不断提高,我们采用回归分析的方法对我国成品钢材的需求量进行分析应用。为了使分析的模型具有社会实际意义,我们引用了1980——1998年的成品钢材、原油、生铁、原煤、发电量、铁路货运量、固定资产投资额、居民消费、政府消费9个不同的量来进行回归分析。通过建立回归模型充分说明成品钢材需求量与其他8个变量的关系,以及我国社会经济的实际发展情况和意义。 关键字:线性回归回归分析社会经济回归模型成品钢材多元回归国家经济社会发展
目录 第1章题目叙述 (1) 第2章问题假设 (1) 第3章问题分析 (2) 第4章数据的预处理 (3) 4.1 曲线统计图 (3) 4.2 散点统计图 (4) 4.3 样本的相关系数 (4) 第5章回归模型的建立 (5) 第6章回归模型的检验 (6) 6.1 F检验 (6) 6.2 T检验 (6) 6.3 T检验分析 (6) 6.4 Chow断点检验 (8) 6.5 Chow预测检验 (8) 第7章违背模型基本假设的情况 (9) 7.1 异方差性的检验 (9) 7.1.1残差图示检验 (9) 7.1.2 怀特(White)检验 (9) 7.2 自相关性的检验 (10) 7.2.1 LM检验 (10) 7.2.2 DW检验 (10) 第8章自变量选择与逐步回归 (10) 8.1 前进逐步回归法 (10) 8.1.1 前进逐步回归 (10) 8.1.2 前进逐步回归模型预测 (11) 8.2 后退逐步回归法 (12) 8.2.1 后退逐步回归 (12) 8.2.2 后退逐步回归模型预测 (13) 第9章多重共线性的诊断及消除 (14) 9.1 多重共线性的诊断 (14) 9.2 消除多重共线性 (15) 第10章回归模型总结 (17) 参考文献 (18) 附录: (19)
使用eviews做线性回归分析
Glossary: ls(least squares)最小二乘法 R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整 Adjust R-seqaured() S.E of regression回归标准误差 Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确 Durbin-Watson stat:DW统计量,0-4之间 Mean dependent var因变量的均值 S.D. dependent var因变量的标准差 Akaike info criterion赤池信息量(AIC)(越小说明模型越精确) Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确) Prob(F-statistic)相伴概率 fitted(拟合值) 线性回归的基本假设: 1.自变量之间不相关 2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布 3.样本个数多于参数个数 建模方法: ls y c x1 x2 x3 ... x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。模型的实际业务含义也有指导意义,比如m1同gdp肯定是相关的。模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。 模型检验: 1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度 F大于临界值则说明拒绝0假设。 Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。 2)回归系数显著性检验(t检验):检验每一个自变量的合理性 |t|大于临界值表示可拒绝系数为0的假设,即系数合理。t分布的自由度为n-p-1,n为样本数,p为系数位置 3)DW检验:检验残差序列的自相关性,检验基本假设2(随机误差相互独立) 残差:模型计算值与资料实测值之差为残差 0<=dw<=dl 残差序列正相关,du 一、研究的目的要求 改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为亿元到2002年已增长到亿元25年间增长了33倍。为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。(3)物价水平。我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。(4)税收政策因素。我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响,特别是1985年税收陡增%。但是第二次税制改革对税收的增长速度的影响不是非常大。因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数” 从《中国统计年鉴》收集到以下数据 年份财政收入(亿元) Y 国内生产总值(亿元) X2 财政支出(亿元) X3 商品零售价格指数(%) X4 1978 1979102 198**** **** 1982 1983 19847171 1985 198**** **** 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 运用EVIEWS建立多元线性回归并进行相关检验 姓名:jelly 一、输入数据 某社区家庭对某种消费品的消费需要调查 二、根据数据画出散点图 从上面两散点图可以看出此社区家庭对某商品的消费支出与家庭月收入、商品的价格大致呈线性关系且随着家庭收入和户主受教育年数的逐渐增大对此商品的消费支出也呈逐渐增大的趋势。 三、样本相关阵 从样本相关阵可以看出,某商品的消费支出与家庭月收入、商品的价格的相关系数高达0.965046和0.752695 ,说明某商品的消费支出与家庭月收入、商品的价格有显著的线性关 序号 商品 价格X1 家庭月 收入X2 对某商品的消 费支出Y 1 23.56 7620 591.9 2 24.44 9120 654.5 3 32.07 10670 623.6 4 32.46 11160 647 5 31.15 11900 674 6 34.14 12920 644.4 7 35.3 14340 680 8 38.7 15960 724 9 39.63 18000 757.1 10 46.68 19300 706.8 系,可以考虑建立二元线性回归模型。 四、对数据进行普通最小二乘估计,OLS 表如下 五、写出估计方程 12626.50939.7905700.28618i Y X X ∧=-+ (40.13010) (3.197843) (0.05838) t=(15.611195) (-3.061617) (4.902030) 20.902218R = 2R =0.874281 六、随机干扰项 2'1e e n k σ∧=-- '''''?????()()()()ee Y Y Y Y Y X Y X Y Y Y X βββ=--=--=-=2116.85 所以22116.85?302.411021 σ==-- 由OLS 表得20.902218R = 2R =0.874281 七、由OLS 可得 F=32.29 0.05(2,7) 4.74F = 因为32.29>4.74,所以方程的总体线性性显著成立 操作步骤 1. 作 ?件 (1)?e xel?子表格 (2 子表格?导入e?v iews? File-open-forei?g n data as workf?i le?E view?s 作 件??表。 2.?? ?入命令:cor coilf?u ture? dow shind?e x nagas? opec ueuro?pe urmb ???。结果表明C?oilfu?t ure????。 3.?? (1 观察coi?l futu?r e?势图 evie?w s??势图 quic?k?g rap?h seri?e s list ? 入?名称c?o ilfu?ture?操作。图 表明 ???势。 (2?行A D F? quick?-serie?s stati?s tics?-unit root test 弹出 s?e ries? name? 入?? 名称?test? for unit root in ?leve?l?AD?F 结果??设置。 ?A D F? 结果? 测值0.97? 值 表明 ?不 。 ? 行?A DF? 值 ? 值 ?? 值??值 表明 ?? 。 (3??分ADF? quick?-serie?s stati?s tics?-unit root test seri?e s name? 入?? 名称?test? for unit root in ??分 行 ??设置。 ?A D F? 结果?测值-7.8? 值 表明 ? 分 ?。??分 行?A D F? 值 ? 值 ?? 值??值 表明 ? 分 ? 。由 ???。 4.Grang?e r 果 ? (1quick?-group?stati?s t i cs?-grang?e r causa?l ity test 出 ? 入 ?名称 OK。 ?入?? 果 ?。 (2?用E vie?w s?eviews多元线性回归案例分析
运用EVIEWS建立多元线性回归并进行相关检验
eviews处理多元回归分析操作步骤