正则表达式介绍和例子分析
正则表达式
含义:编写字符串处理的程序或网页时,会有查找符合某复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。它是记录文本规则的代码。
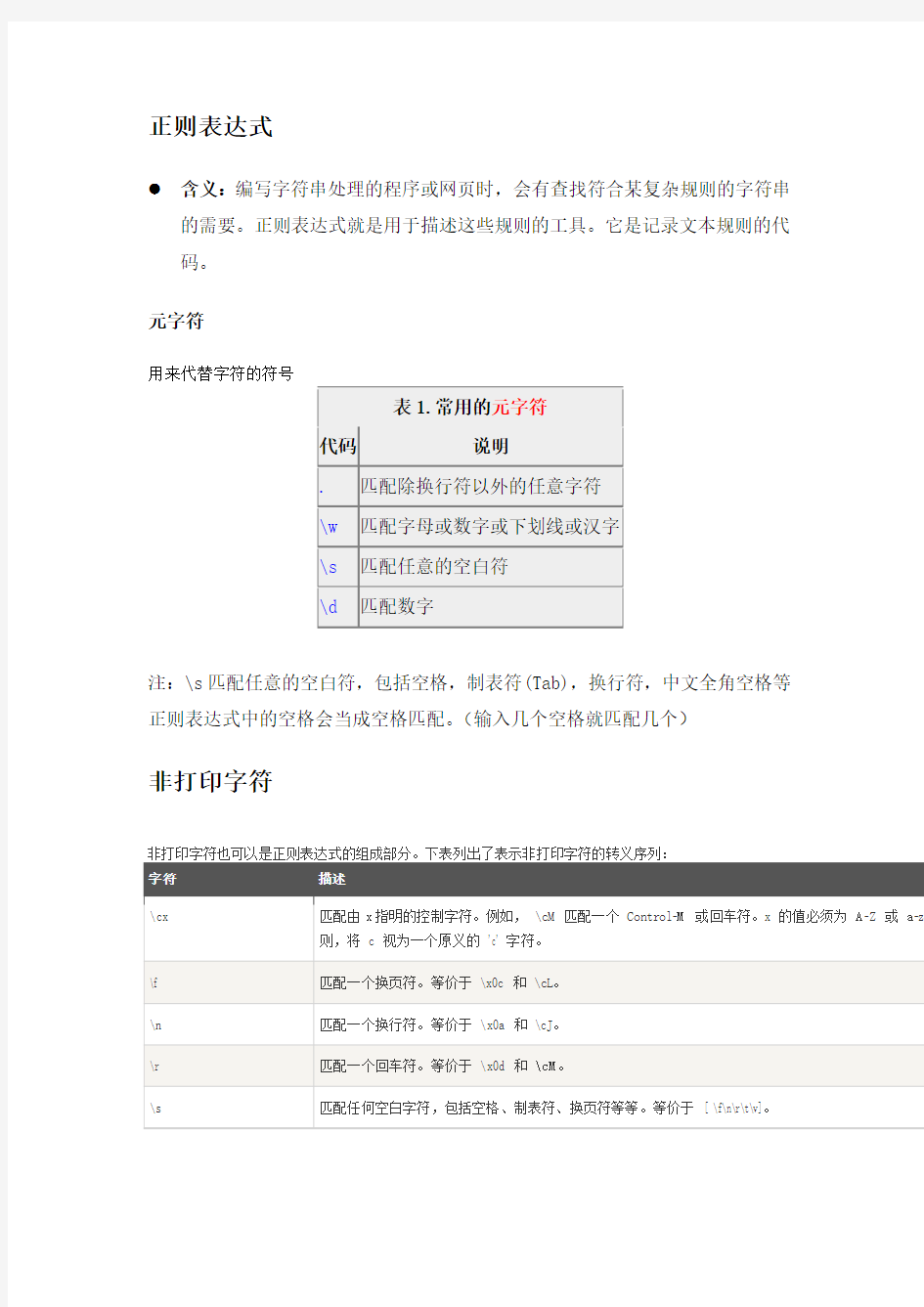
元字符
用来代替字符的符号
注:\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等正则表达式中的空格会当成空格匹配。(输入几个空格就匹配几个)
非打印字符
限定符
重复:表现重复时用的是大括号{}和* + ?,表示范围时用的是中括号[],中括号里面是只选其中一个的组合。表达分组时用圆括号(),一个圆括号表示一个意思。
●字符类[],用来表示取字符的范围区间,用中括号括起来
[0-9]代表\d
[a-z0-9A-Z]表示\w
●分支条件,用|表示或者的关系。
●贪婪与懒惰、最先开始匹配拥有最高优先权
*、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
.*表示尽可能匹配多的字符
.*?表示尽可能少的字符
例如:字符串aabab,用贪婪匹配a.*b得到aabab,用懒惰匹配a.*?b得到
定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达
子表达式分组获取()
●分组,用()把子表达式括起来,给一个组号,后面可以再用
●后向引用,用()定义的分组,可以给它定一个组名,在后面加以利用。
用(?\w+)或者(?’Word’\w+)定义\w+组名为Word,利用方式为
捕获
从下面的例子中可以看到,根据正则表达式,只捕获了括号内的东西到组中,第一个括号前面^\D*匹配到的东西被忽略了。
零宽度断言
(?=exp) 用法:\b\w+(?=ing)\b,匹配以ing结尾的单词的前面部分,如查找I’m singing and dancing,会匹配sing和danc
(?<=exp) 用法:(?<=rea)\w+\b,匹配以rea开头的单词的后面部分,如查找reading a book,会匹配ding
注释:(?#comment)
例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)
反义
反义,找完全相反的内容。注意这里使用的都是大写
平衡组/递归匹配
(?'group')把捕获的内容命名为group,并压入堆栈(Stack)
(?'-group')从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败
(?(group)yes|no)如果堆栈上存在以名为group的捕获内容的话,继续匹配yes 部分的表达式,否则继续匹配no部分
(?!)零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
<[^<>]*(((?'Open'<)[^<>]*)+((?'-Open'>)[^<>]*)+)*(?(Open)(?!))>
可以从xx aa> yy中找到 aa>
]*>[^<>]*(((?'Open']*>)[^<>]*)+((?'-Open'
)[^<>]*) +)*(?(Open)(?!))
可以找到配对的
和
,不管有没有不配对的html出现。
好的例子
将所有地址中的ROAD写成RD.
若地址中的字符不是大写的,先可以都改成大写的。
匹配以罗马数字标示的四位数年份
注:在罗马数字上加一个横线,就会乘以1000倍。所以4000就用??(其中L要带上横线)紧凑正则表达式:
^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
最后对应的松散正则表达式是
匹配电话号码
紧凑正则表达式:(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$松散正则表达式:
编译原理实验报告实验一编写词法分析程序
编译原理实验报告实验名称:实验一编写词法分析程序 实验类型:验证型实验 指导教师:何中胜 专业班级:13软件四 姓名:丁越 学号: 电子邮箱: 实验地点:秋白楼B720 实验成绩: 日期:2016年3 月18 日
一、实验目的 通过设计、调试词法分析程序,实现从源程序中分出各种单词的方法;熟悉词法分析 程序所用的工具自动机,进一步理解自动机理论。掌握文法转换成自动机的技术及有穷自动机实现的方法。确定词法分析器的输出形式及标识符与关键字的区分方法。加深对课堂教学的理解;提高词法分析方法的实践能力。通过本实验,应达到以下目标: 1、掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 2、掌握词法分析的实现方法。 3、上机调试编出的词法分析程序。 二、实验过程 以编写PASCAL子集的词法分析程序为例 1.理论部分 (1)主程序设计考虑 主程序的说明部分为各种表格和变量安排空间。 数组 k为关键字表,每个数组元素存放一个关键字。采用定长的方式,较短的关键字 后面补空格。 P数组存放分界符。为了简单起见,分界符、算术运算符和关系运算符都放在 p表中 (编程时,还应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。 id和ci数组分别存放标识符和常数。 instring数组为输入源程序的单词缓存。 outtoken记录为输出内部表示缓存。 还有一些为造表填表设置的变量。 主程序开始后,先以人工方式输入关键字,造 k表;再输入分界符等造p表。 主程序的工作部分设计成便于调试的循环结构。每个循环处理一个单词;接收键盘上 送来的一个单词;调用词法分析过程;输出每个单词的内部码。 ⑵词法分析过程考虑 将词法分析程序设计成独立一遍扫描源程序的结构。其流程图见图1-1。 图1-1 该过程取名为 lexical,它根据输入单词的第一个字符(有时还需读第二个字符),判断单词类,产生类号:以字符 k表示关键字;i表示标识符;c表示常数;p表示分界符;s表示运算符(编程时类号分别为 1,2,3,4,5)。 对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有 该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id中,将常数 变为二进制形式存入数组中 ci中,并记录其在表中的位置。 lexical过程中嵌有两个小过程:一个名为getchar,其功能为从instring中按顺序取出一个字符,并将其指针pint加1;另一个名为error,当出现错误时,调用这个过程, 输出错误编号。 2.实践部分
编译原理实验--词法分析器
编译原理实验--词法分析器 实验一词法分析器设计 【实验目的】 1(熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。 2(复习高级语言,进一步加强用高级语言来解决实际问题的能力。 3(通过完成词法分析程序,了解词法分析的过程。 【实验内容】 用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符 串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字, 运算符,标识符,常数以及界符)输出。 【实验流程图】
【实验步骤】 1(提取pl/0文件中基本字的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) {
if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {printf("%s\t",wsym[m]);m=14;n=k+1;} } 2(提取pl/0文件中标识符的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]=" "; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) { if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {m=14;n=k+1;} } if(m==13) for(m=0;a[m]!=NULL;m++) printf("%c ",a[m]);
正则表达式 Regular Expression 例子 sample VB版
VS SDK Regular Expression Language Service Example Deep Dive (VB) István Novák (DiveDeeper), Grepton Ltd. May, 2008 Introduction This example implements a small language service for demonstration purposes. This is called Regular Expression Language Service since it can tokenize text by RegEx patterns (lower case letters, capital letters, digits) and can use its own syntax coloring scheme for each token. However, the functionality of this sample is quite far away from a full language service it illustrates the basics. The source files belonging to this code have only about three hundred lines of essential code. When reading through this deep dive you are going to get familiar with the following concepts: How language services should be registered with Visual Studio? What kind of lifecycle management tasks a simple language service has? How to create a very simple language service? How to implement a scanner supporting syntax coloring? To understand concepts treated here it is assumed that you are familiar with the idea of VSPackages and you know how to build and register very simple (even non-functional) packages. To get more information about packages, please have a look at the Package Reference Sample (VisualBasic Reference.Package sample). Very basic knowledge about regular expressions is also expected. Regular Expression Language Service Open the Microsoft Visual Studio 2008 SDK Browser and select the Samples tab. In the top middle list you can search for the “VisualBasic Example.RegExLangServ” sample. Please, use the “Open this sample in Visual Studio” link at the top right panel of the browser app to prepare the sample. The application opens in Visual Studio 2008. Running the sample Rebuild the package and start it with the Experimental Hive! Without creating a new solution, add a new text file with the File|New|File... menu function. Use the File|Save As menu function to store the text file with the RegexFile.rgx name. To avoid attaching the .txt extension to the end of the file name, set the “Save as type” to “All files (*.*)” as illustrated in Figure 1:
实验1-3-《编译原理》词法分析程序设计方案
实验1-3 《编译原理》S语言词法分析程序设计方案 一、实验目的 了解词法分析程序的两种设计方法之一:根据状态转换图直接编程的方式; 二、实验内容 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 三、实验要求 1.能对任何S语言源程序进行分析 在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。 2.能检查并处理某些词法分析错误 词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。 本实验要求处理以下两种错误(编号分别为1,2): 1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。 2:源程序文件结束而注释未结束。注释格式为:/* …… */ 四、保留字和特殊符号表
编译原理实验词法分析实验报告
编译技术实验报告 实验题目:词法分析 学院:信息学院 专业:计算机科学与技术学号: 姓名:
一、实验目的 (1)理解词法分析的功能; (2)理解词法分析的实现方法; 二、实验内容 PL0的文法如下 …< >?为非终结符。 …::=? 该符号的左部由右部定义,可读作“定义为”。 …|? 表示…或?,为左部可由多个右部定义。 …{ }? 表示花括号内的语法成分可以重复。在不加上下界时可重复0到任意次 数,有上下界时可重复次数的限制。 …[ ]? 表示方括号内的成分为任选项。 …( )? 表示圆括号内的成分优先。 上述符号为“元符号”,文法用上述符号作为文法符号时需要用引号…?括起。 〈程序〉∷=〈分程序〉. 〈分程序〉∷= [〈变量说明部分〉][〈过程说明部分〉]〈语句〉 〈变量说明部分〉∷=V AR〈标识符〉{,〈标识符〉}:INTEGER; 〈无符号整数〉∷=〈数字〉{〈数字〉} 〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉} 〈过程说明部分〉∷=〈过程首部〉〈分程序〉{;〈过程说明部分〉}; 〈过程首部〉∷=PROCEDURE〈标识符〉; 〈语句〉∷=〈赋值语句〉|〈条件语句〉|〈过程调用语句〉|〈读语句〉|〈写语句〉|〈复合语句〉|〈空〉 〈赋值语句〉∷=〈标识符〉∶=〈表达式〉 〈复合语句〉∷=BEGIN〈语句〉{;〈语句〉}END 〈条件〉∷=〈表达式〉〈关系运算符〉〈表达式〉 〈表达式〉∷=〈项〉{〈加法运算符〉〈项〉} 〈项〉∷=〈因子〉{〈乘法运算符〉〈因子〉} 〈因子〉∷=〈标识符〉|〈无符号整数〉|'('〈表达式〉')' 〈加法运算符〉∷=+|- 〈乘法运算符〉∷=* 〈关系运算符〉∷=<>|=|<|<=|>|>= 〈条件语句〉∷=IF〈条件〉THEN〈语句〉 〈字母〉∷=a|b|…|X|Y|Z 〈数字〉∷=0|1|2|…|8|9 实现PL0的词法分析
编译原理词法分析和语法分析报告+代码(C语言版)
词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 3.2 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。
编译原理词法分析实验报告
词法分析器实验报告 一、实验目的 选择一种编程语言实现简单的词法分析程序,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 各种单词符号对应的种别码: 表各种单词符号对应的种别码 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根
据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn 用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。
编译原理实验报告(词法分析器语法分析器)
编译原理实验报告
实验一 一、实验名称:词法分析器的设计 二、实验目的:1,词法分析器能够识别简单语言的单词符号 2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。 三、实验要求:给出一个简单语言单词符号的种别编码词法分析器 四、实验原理: 1、词法分析程序的算法思想 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 2、程序流程图 (1 (2)扫描子程序
3
五、实验内容: 1、实验分析 编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。 2 实验词法分析器源程序: #include #include #include int i,j,k; char c,s,a[20],token[20]={'0'}; int letter(char s){ if((s>=97)&&(s<=122)) return(1); else return(0); } int digit(char s){ if((s>=48)&&(s<=57)) return(1); else return(0); } void get(){ s=a[i]; i=i+1; } void retract(){ i=i-1; } int lookup(char token[20]){ if(strcmp(token,"while")==0) return(1); else if(strcmp(token,"if")==0) return(2); else if(strcmp(token,"else")==0) return(3); else if(strcmp(token,"switch")==0) return(4); else if(strcmp(token,"case")==0) return(5); else return(0); } void main() { printf("please input string :\n"); i=0; do{i=i+1; scanf("%c",&a[i]);
编译原理实验词法分析语法分析
本代码只供学习参考: 词法分析源代码: #include #include #include using namespace std; string key[8]={"do","end","for","if","printf","scanf","then","while"}; string optr[4]={"+","-","*","/"}; string separator[6]={",",";","{","}","(",")"}; char ch; //判断是否为保留字 bool IsKey(string ss) { int i; for(i=0;i<8;i++) if(!strcmp(key[i].c_str(),ss.c_str())) return true; return false; } //字母判断函数 bool IsLetter(char c) { if(((c>='a')&&(c<='z'))||((c>='A')&&(c<='Z'))) return true; return false; } //数字判断函数 bool IsDigit(char c) { if(c>='0'&&c<='9') return true; return false; } //运算符判断函数 bool IsOptr(string ss) { int i; for(i=0;i<4;i++) if(!strcmp(optr[i].c_str(),ss.c_str())) return true ; return false; } //分界符判断函数 bool IsSeparator(string ss) { int i; for(i=0;i<6;i++) if(!strcmp(separator[i].c_str(),ss.c_str()))
编译原理词法分析和语法分析报告+代码(C语言版)
信息工程学院实验报告(2010 ~2011 学年度第一学期) 姓名:柳冠天 学号:2081908318 班级:083
词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 := + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 表2.1 各种单词符号对应的种别码 2.3 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图:
编译原理实验报告2词法分析程序的设计
实验2 词法分析程序的设计 一、实验目的 掌握计算机语言的词法分析程序的开发方法。 二、实验内容 编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。 三、实验要求 1、根据以下的正规式,编制正规文法,画出状态图; 标识符<字母>(<字母>|<数字字符>)* 十进制整数0 | ((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*) 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和界符+ - * / > < = ( ) ; 关键字if then else while do 2、根据状态图,设计词法分析函数int scan( ),完成以下功能: 1)从文本文件中读入测试源代码,根据状态转换图,分析出一个单词, 2)以二元式形式输出单词<单词种类,单词属性> 其中单词种类用整数表示: 0:标识符 1:十进制整数 2:八进制整数 3:十六进制整数 运算符和界符,关键字采用一字一符,不编码 其中单词属性表示如下: 标识符,整数由于采用一类一符,属性用单词表示 运算符和界符,关键字采用一字一符,属性为空 3、编写测试程序,反复调用函数scan( ),输出单词种别和属性。 四、实验环境 PC微机 DOS操作系统或Windows 操作系统 Turbo C 程序集成环境或Visual C++ 程序集成环境 五、实验步骤 1、根据正规式,画出状态转换图;
编译原理实验(词法分析)
编译原理实验报告 实验一 实验题目:词法分析 指导老师:任姚鹏 专业班级:计算机科学与技术系网络工程方向1002班姓名:xxxx
2013年 4月13日 实验类型__验证性__ 实验室_软件实验室三__ 一、实验项目的目的和任务: 了解和掌握词法分析的方法,编程实现给定源语言程序的词法分析器,并利用该分析器扫描源语言程序的字符串,按照给定的词法规则,识别出单词符号作为输出,发现其中的词法错误。 二、实验内容: 1.设计一个简单的程序设计语言(语言中有若干运算符和分界符;有若干关健字;若干标识符及若干常数) 2.确定编译中使用的表格、词法分析器的输出形式、标识符与关键字的区分方法。 3.把词法分析器设计成一个独立的过程。 三、实验要求: 1.从键盘上输入源程序; 2.处理各单词,计算个单词的值和类型; 3.输出个单词名、单词的值和类型。 四、实验代码 #include #include char file[1024]; int length=0; int index; char keywords[][10]={"auto","short","int","long","float", "double","char","struct","union","enum", "typedef","const","unsigned","signed","extern", "register","static","volatile","void","default", "if","else","switch","case","for", "do","while","goto","continue","break", "sizeof","return"}; char limits[]={'(',')','[',']','{','}',',',';'}; char operators[]={'+', '-', '*', '/', '%', '>','<','&','|','^', '~','!','='}; //13 int IsChar(char ch) //是否是字符 { if ( (ch>='a'&&ch<='z') || (ch>='A'&&ch<='Z')) return 1; return 0;}
编译原理词法分析器
一、实验目的 了解词法分析程序的两种设计方法:1.根据状态转换图直接编程的方式;2.利用DFA 编写通用的词法分析程序。 二、实验内容及要求 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 2.编写DFA模拟程序 算法如下: DFA(S=S0,MOVE[][],F[],ALPHABET[]) /*S为状态,初值为DFA的初态,MOVE[][]为状态转换矩阵,F[] 为终态集,ALPHABET[] 为字母表,其中的字母顺序与MOVE[][] 中列标题的字母顺序一致。*/ { Char Wordbuffer[10]=“”//单词缓冲区置空 Nextchar=getchar();//读 i=0; while(nextchar!=NULL)//NULL代表此类单词 { if (nextcha r!∈ALPHABET[]){ERROR(“非法字符”),return(“非法字符”);} S=MOVE[S][nextchar] //下一状态 if(S=NULL)return(“不接受”);//下一状态为空,不能识别,单词错误 wordbuffer[i]=nextchar ;//保存单词符号 i++; nextchar=getchar(); } Wordbuffer[i]=‘\0’;
编译原理词法分析程序实现实验报告
编译原理词法分析程序实现实验报告实验一词法分析程序实现 一、实验内容 选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。输入:由无符号数和+,,,*,/, ( , ) 构成的算术表达式,如 1.5E+2,100。输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。二、设计部分 因为需要选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来,而其中的关键则为无符号数的识别,它不仅包括了一般情况下的整数和小数,还有以E为底数的指数运算,其中关于词法分析的无符号数的识别过程流程图如下: 输入字符p指向第一个字符 符号识别*p=+||-||*||/ YYNN*p=0~9*p=E*p=0~9||"." N无效符号Y *p=“.”GOTO 2 GOTO 1 GOTO 1: NY无符号数GOTO 1*p=0~9*p='/0' YN P++NNP++*p=E*p='+'||'-' YY P++P++continue
YY *p=0~9*p=0~9 NN 无符号数无符号数 P++P++ continuecontinue GOTO 2: GOTO 2 *p=Econtinue Y 无符号数 P++ continue 三、源程序代码部分 #include #include #include #define MAX 100 #define UNSIGNEDNUMBER 1 #define PLUS 2 #define SUBTRACT 3 #define MULTIPLY 4 #define DIVIDE 5 #define LEFTBRACKET 6 #define RIGHTBRACKET 7 #define INEFFICACIOUSLABEL 8 #define FINISH 111
编译原理实验 词法分析&语法分析程序
编译原理实验 词 法 分 析 程 序
实验一:词法分析程序 1、实验目的 从左至右逐个字符的对源程序进行扫描,产生一个个单词符号,把字符串形式的源程序改造成单词符号形式的中间程序。 2、实验内容 表C语言子集的单词符号及内码值 单词符号种别编码助记符内码值 while 1 while -- if 2 if -- else 3 else -- switch 4 switch -- case 5 case -- 标识符 6 id id在符号表中的位置 常数7 num num在常数表中的位置 + 8 + -- - 9 - -- * 10 * -- <= 11 relop LE < 11 relop LT == 11 relop LQ = 12 = -- ; 13 ; -- 输入源程序如下 if a==1 a=a+1; else a=a+2; 输出对应的单词符号形式的中间程序 3、实验过程 实验上机程序如下: #include "stdio.h" #include "string.h" int i,j,k; char s ,a[20],token[20]; int letter() { if((s>=97)&&(s<=122))return 1; else return 0; } int Digit() {if((s>=48)&&(s<=57))return 1;
else return 0; } void get() { s=a[i]; i=i+1; } void retract() {i=i-1;} int lookup() { if(strcmp(token, "while")==0) return 1; else if(strcmp(token, "if")==0) return 2; else if(strcmp(token,"else")==0) return 3; else if(strcmp(token,"switch")==0) return 4; else if(strcmp(token,"case")==0) return 5; else return 0; } void main() { printf("please input you source program,end('#'):\n"); i=0; do { i=i+1; scanf("%c",&a[i]); }while(a[i]!='#'); i=1; memset(token,0,sizeof(char)*10); j=0; get(); while(s!='#') { if(s==' '||s==10||s==13) get(); else { switch(s)
词法分析小结
词法分析小结 -总结 []词法是编译器的第一阶段,它的工作就是从输入(源代码)中取得token,以作为parser (语法分析)的输入,一般在词法分析阶段都会把一些无用的空白字符(white space,即空格、tab和换行)以及注释剔除,以降低下一步分析的复杂度,词法分析器一般会提供一个gettoken()这样的,parser可以在做语法分析时调用词法分析器的这个方法来得到下一个token,所以词法分析器并不是一次性遍历所有源代码,而是采取这种on-demand的方式:只在parser需要时才工作,并且每次只取一个token,。token和lexeme 首先,token不等于lexeme。token和lexeme的关系就类似于面向对象语言中“类”和“实例”(或“对象”)之间的关系,这个用中文不知该如何解释才好,比如语言中的变量a和b,它们都属于同一种token:identifier,而a的lexeme是”a”,b则是”b”,而每个关键字都是一种token。token 可以附带有一个值属性,例如变量a,当调用词法分析器的gettoken()时,会返回一个identifier类型的token,这个token带有一个属性“a”,属性可以是多样的,例如表示数字的token可以带有一个表示数字值的属性,它是整型的。如下代码:int age = 23;int count = 50;可以依次提取出8个token:int(值为”int”),id(值为”age”),assign(值为”=”),number(值为整型数值23),int(值为”int”),id(值为”count”),assign(值为”=”),number(值为50)正则表达式 正则表达式可以用来描述字符串模式,例如我们可以用digit+来表示number的token,其中digit表示单个数字(这里说正则表达式并不完全和实现的正则引擎所识别的正则表达式等价,这里只是为了描述问题而已)。然而像c语言的的多行注释,用正则表达式来描述就比较麻烦,此时更倾向于直接用有穷自动机(finite automaton)来描述,因为用它来描述非常直观且很容易。有穷自动机(finite automata) 有穷自动机也称为有限状态机,状态在输入字符的作用下发生迁移,因此,它可以用来识别token,也因此,我们只要画得出fa,之后再用代码实现这个fa,那词法分析器也就差不多弄好了。有穷自动机分确定性(dfa)和非确定性(nfa)两种,如果对于同一个输入,只会有一个确定的状态迁移线,也就是只有一个确定的“下一状态”,那就是dfa,否则就是nfa。因为dfa对于同一个输入只有一个确定的下一状态,所以词法分析器当然优先采用它,那nfa拿来干嘛用呢?nfa用来做描述用时更方便,我们可以非常迅速地画出一个识别token的nfa图,但要想直接画出个dfa那要动不少脑筋。根据正则表达式构建nfa 如上所述,nfa更容易画出,那我们就先研究nfa,在定义token时,我们可以用正则表达式来描述它,因为正则表达式干这行很合适,例如一个digit+就可以描述数字,多方便。因此,我们需要根据正则表达式画出与之等价的nfa。而这个算法非常简单,就是tompson’s construction,这个书上写得很清楚了。将nfa转化成dfa(nfa的确定化)对于计算机来说,面对同一个输入,如果有多个下一状态,那计算机就不清楚要转到哪个状态,所以我们期望能从正则表达式得到dfa,而不是nfa,因为这样将来编程实现时比较(同一输入有确定的一个下一状态),而幸运的是,每个nfa都可以转化成dfa。为什么nfa 可以转化成dfa?因为fa(finite automata)中的状态都是我们自己画的,只要fa能正确的识别token,那就ok了,也就是,如果nfa和dfa都可以达到一样的效果:识别token,那其它的我们就不管了。而nfa确定化的本质,就是将原来多个状态改用一个状态来表示,新状态其实是一个状态集,比如nfa中状态s1在输入a下可以到达s2和s3,那么,在dfa中,就把s2和s3合起来认为是一个状态。还有一个问题是nfa中的空转换(?输入),如果s1在?输入下可以到达s2,就表示s1可以无条件地转移到s2,那s1和s2自然可以合并起来作为dfa中的一个状态,于是nfa转dfa的算法也就好理解了。但首先得先定义下空闭包
编译原理词法分析及语法分析
编译原理 实验报告 实验名称:词法分析及语法分析专业班级: 姓名: 学号: 完成日期:
实验一、sample语言的词法分析 一、实验目的 给出SAMPLE文法规范,要求编写SAMPLE语言的词法分析程序。 二、实验准备 了解sample语言单词的定义,选择任一种编程语言实现词法分析。 三、实验内容 给出SAMPLE语言文法,输出单词(关键字、专用符号以及其它标记)。 1、格式 输入:源程序文件。输出:关键字、专用符号以及其它标记。 2、实现原理 程序中先判断这个句语句中每个单元为关键字、常数、运算符、界符,对与不同的单词符号给出不同编码形式的编码,用以区分之。 3、实验方法 读懂Sample源代码,自己重点独立实现对常量的判别。 四、实验设计 1、设计SAMPLE语言的词法分析器 A、字符集定义 1. <字符集> → <字母>│<数字>│<单界符> 2. <字母> → A│B│…│Z│a│b│…│z 3. <数字> → 0│1│2│…│9 4. <单界符> → +│-│*│/│=│<│>│(│)│[│]│:│. │; │, │' B、单词集定义 5.<单词集> → <保留字>│<双界符>│<标识符>│<常数>│<单界符> 6.<保留字> → and│array│begin│bool│call│case│char│constant│dim│do│else │end│false│for│if│input│integer│not│of│or│output│procedure│program │read│real│repeat│set│stop│then│to│true│until│var│while│write 7.<双界符> → <>│<=│>=│:= │/*│*/│.. 8.<标识符> → <字母>│<标识符> <数字>│<标识符> <字母> 9.<常数> → <整数>│<布尔常数>│<字符常数> 10.<整数> → <数字>│<整数> <数字> 11.<布尔常数> → true│false 12.<字符常数> → ' 除 {'} 外的任意字符串 ' 2、词法分析系统流程设计