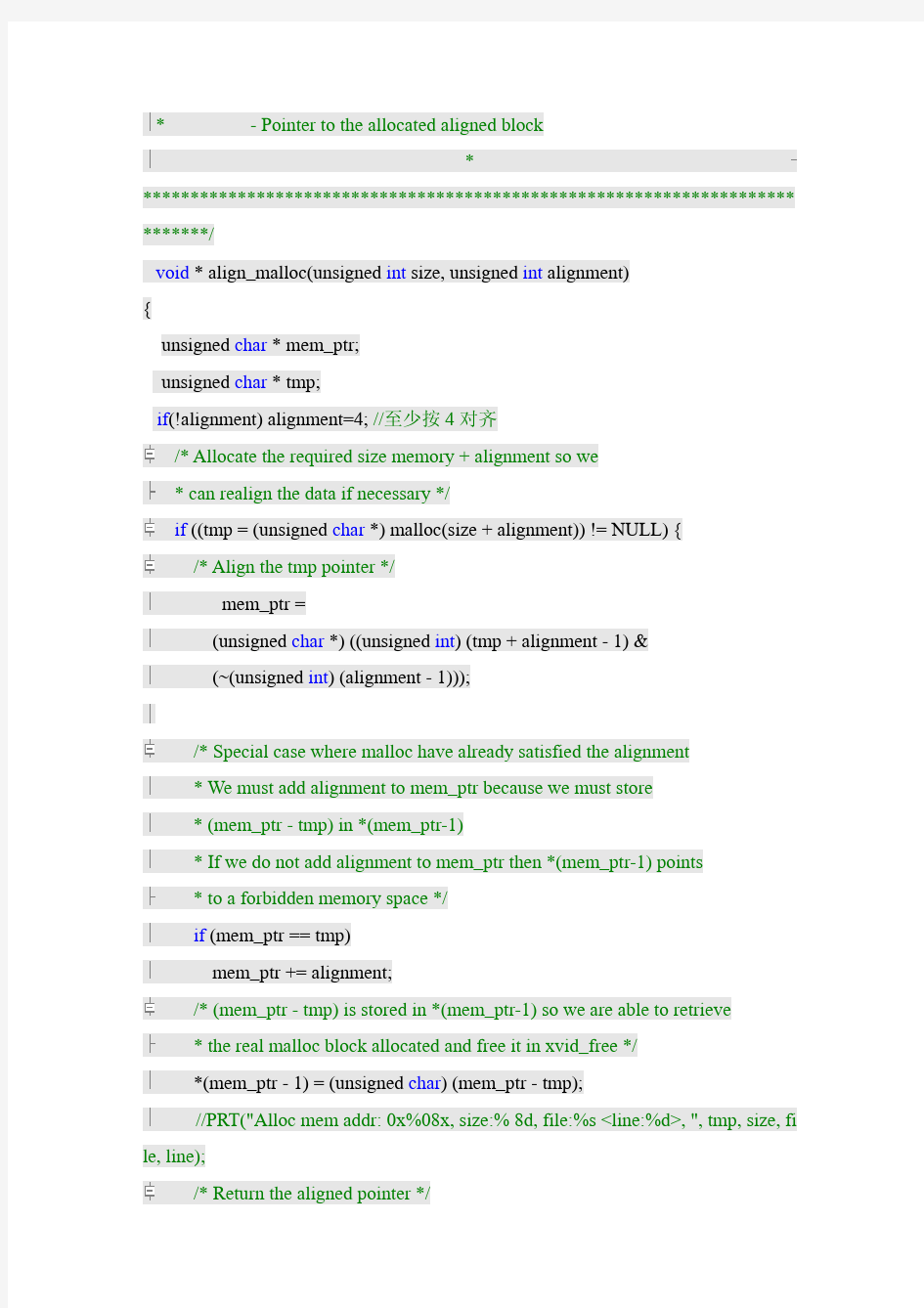
任意字节对齐分配内存

H.264码流结构解析
H.264码流结构解析 1.H.264简介 MPEG(Moving Picture Experts Group)和VCEG(Video Coding Experts Group)已经联合开发了一个比早期研发的MPEG 和H.263性能更好的视频压缩编码标准,这就是被命名为A VC(Advanced Video Coding),也被称为ITU-T H.264建议和MPEG-4的第10 部分的标准,简称为H.264/A VC或H.264。这个国际标准已经与2003年3月正式被ITU-T所通过并在国际上正式颁布。为适应高清视频压缩的需求,2004年又增加了FRExt部分;为适应不同码率及质量的需求,2006年又增加了可伸缩编码SVC。 2.H.264编码格式 H.263定义的码流结构是分级结构,共四层。自上而下分别为:图像层(picturelayer)、块组层(GOB layer)、宏块层(macroblock layer)和块层(block layer)。而与H.263相比,H.264的码流结构和H.263的有很大的区别,它采用的不再是严格的分级结构。 H.264支持4:2:0的连续或隔行视频的编码和解码。H.264压缩与H.263、MPEG-4相比,视频压缩比提高了一倍。 H.264的功能分为两层:视频编码层(VCL, Video Coding Layer)和网络提取层(NAL, Network Abstraction Layer)。VCL数据即编码处理的输出,它表示被压缩编码后的视频数据序列。在VCL数据传输或存储之前,这些编码的VCL数据,先被映射或封装进NAL单元中。每个NAL单元包括一个原始字节序列负荷(RBSP, Raw Byte Sequence Payload)、一组对应于视频编码的NAL头信息。RBSP的基本结构是:在原始编码数据的后面填加了结尾比特。一个bit“1”若干比特“0”,以便字节对齐。 图1 NAL单元序列 3.H.264传输 H.264的编码视频序列包括一系列的NAL单元,每个NAL单元包含一个RBSP,见表1。编码片(包括数据分割片IDR片)和序列RBSP结束符被定义为VCL NAL单元,其余为NAL单元。典型的RBSP单元序列如图2所示。每个单元都按独立的NAL单元传送。单元的信息头(一个字节)定义了RBSP单元的类型,NAL单元的其余部分为RBSP数据。 图2 RBSP序列举例
内存对齐方式
对齐方式 为什么会有内存对齐? 在结构中,编译器为结构的每个成员按其自然对界(alignment)条件分配空间;各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。在缺省情况下,C编译器为每一个变量或数据单元按其自然对界条件分配空间。 字,双字,和四字在自然边界上不需要在内存中对齐。(对字,双字,和四字来说,自然边界分别是偶数地址,可以被4整除的地址,和可以被8整除的地址。)无论如何,为了提高程序的性能,数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;然而,对齐的内存访问仅需要一次访问。 一个字或双字操作数跨越了4字节边界,或者一个四字操作数跨越了8字节边界,被认为是未对齐的,从而需要两次总线周期来访问内存。一个字起始地址是奇数但却没有跨越字边界被认为是对齐的,能够在一个总线周期中被访问。 某些操作双四字的指令需要内存操作数在自然边界上对齐。如果操作数没有对齐,这些指令将会产生一个通用保护异常(#GP)。双四字的自然边界是能够被16整除的地址。其他的操作双四字的指令允许未对齐的访问(不会产生通用保护异常),然而,需要额外的内存总线周期来访问内存中未对齐的数据。 影响结构体的sizeof的因素: 1)不同的系统(如32位或16位系统):不同的系统下int等类型的长度是变化的,如对于16位系统,int的长度(字节)为2,而在32位系统下,int的长度为4;因此如果结构体中有int等类型的成员,在不同的系统中得到的sizeof值是不相同的。 2)编译器设置中的对齐方式:对齐方式的作用常常会让我们对结构体的sizeof 值感到惊讶,编译器默认都是8字节对齐。 对齐: 为了能使CPU对变量进行高效快速的访问,变量的起始地址应该具有某些特性,即所谓的“对齐”。例如对于4字节的int类型变量,其起始地址应位于4字节边界上,即起始地址能够被4整除。变量的对齐规则如下(32位系统)
lwip-mem_init和mem_malloc详解
lwip-mem_init和mem_malloc详解 [cpp] view plain copy <pre name="code" class="cpp">#define MEM_ALIGNMENT 4 //对齐方式为4字节对齐#ifndef LWIP_MEM_ALIGN_SIZE #define LWIP_MEM_ALIGN_SIZE(size) (((size) + MEM_ALIGNMENT - 1) & ~(MEM_ALIGNMENT-1)) //实现待分配数据空间的内存对齐#endif #ifndef LWIP_MEM_ALIGN //地址对齐,对齐方式也为4字节对齐#define LWIP_MEM_ALIGN(addr) ((void *)(((mem_ptr_t)(addr) + MEM_ALIGNMENT - 1) & ~(mem_ptr_t)(MEM_ALIGNMENT-1))) #endif /* MEM_SIZE: the size of the heap memory. If the application will send a lot of data that needs to be copied, this should be set high. */ #define MEM_SIZE (8*1024) //堆的总空间大小,此后在这个基础上划分堆,将在这个空间进行内存分配,内存块结构体和数据都是在这个空间上的 //mem为内存块的结构体,next;,prev都为内存块索引struct mem { /** index (-> ram[next]) of the next struct */ //ram为堆的首地址,相当于数组的首地址,索引基地址mem_size_t next; //next为下一个内存块的索引/** index (-> ram[next]) of the next struct */
Altera的FPGA_常见问题汇总
常见问题汇总 1. alt2gxb模块的每个发送端都需要一个高速的pll_inclk时钟(至少100M以上),请问这个时钟一定要从FPGA外面引进来吗? 通常情况下一定要从FPGA外面引进来,首选是GXB模块的专用时钟引脚,或上下BANK 的专用时钟输入脚。时钟是至少60M以上。 2. 如果我一个FPGA里面有多个alt2gxb模块,是否能共用一个这样的输入时钟? 可以。 3. gxb模块里面的Calibration clk 是干嘛用的,能不能不用它? 校准内部匹配电阻用。此时钟可以内部提供,频率在10M到125M都可以,如果外部时钟不合适的话,甚至可以用逻辑来分频(比如参考钟是156M,内部触发器作个2分频就可以用了。 4. 用到gxb模块的bank的参考电压是否必须接1.5V?因为我看到资料上有3.3V的CML 和LVDS电平(附件里面的截图) gxb用1.5V 或 1.2V, 推荐客户用1.5V. 3.3v是用在别的普通bank的。 5. gxb模块的输入端如果平时不需要传数据,是否置0?还是需要我们在数据线上发送别的数据,是否gxb模块能自动发送同步码? 平时可以置0,但在上电后,你必须首先发送对端接收侧的word aligner码型(通常用k28.5), 这是需要手工控制的。 6. LVDS模块没有同步码,做接收时好像没办法数据对其,比如8比特数据容易错开2、3位,我们现在是另外加逻辑把它调整过来的,请问有别的好的同步的方法吗 通常需要逻辑去进行word aligner操作,如同GXB一样。某些特定情况下可以预先知道边界。这个问题讨论过好多次了,所谓的特定情况你可以看STRATIX II手册(不是Stratix II GX 手册),搜索“Differential I/O Bit Position” 7.请问在alt2gxb模块,有两个时钟:pll_inclk和cali_clk,手册上说cali_clk要求不是很高,可以用计数器产生,那么输入的并行数据txdata_in应该用哪个时钟锁存呢? cali_clk仅用于校准内部匹配电阻用的状态机,跟业务是完全独立的。txdata_in应该用 tx_clkout锁存。 8.pll_inclk可不可以用内部锁相环产生,然后输出经过一个差分时钟驱动,再送到gxb所在bank的REFCLK引脚?或者直接内部锁相环产生,直接送给gxb模块使用? 出于时钟质量考虑,我们不推荐用FPGA内部的锁相环来提供GXB的参考时钟,尤其是2SGX工作在3Gbps以上时。 速率低时如果客户一定要用PLL级联,在quartus.ini文件(注意该文件不是自动产生的,需要用户自己创建,放在当前工程根目录下)中包含下面这句话,如你描述的通过外部走线绕一下提供参考时钟没有必要。 siigx_allow_pll_cascade_to_tx_pll=on 9.在仿真时我直接加入激励数据给发送模块,它的串行输出再直接复制给接收模块,可是没有任何结果,请问有没有一种有效的仿真方法来仿真alt2gxb模块? 仿真时你需要激励一下powerdown信号,起始给高电平,过一会儿拉低。同时提供准确频率的参考时钟。 10.如果某个bank用到了LVDS模块,是不是这个bank的参考电压应该接2.5V,而IO电压仍然3.3V? 对lvds, IO电压是3.3V,参考电压不需要提供 11. 我在130 II gx里面放了几个GXB模块,设置的是100M输入时钟,数据率4G,线宽是32位,这样模块就没有rx_outclk这个信号线了,那么receiver的输出数据靠哪个时钟来锁呢? 你把rate matcher那个功能取消掉就可以由rx_outclk的输出了 12. 还有综合的时候报错说:
STM32启动文件详解
STM32启动文件详解 (2012-07-28 11:22:34) 转载▼ 分类:STM32 标签: stm32 启动 在<
字节对齐
字节对齐 Andrew Huang
H264详解
1.引言 H.264的主要目标: 1.高的视频压缩比 2.良好的网络亲和性 解决方案: VCL video coding layer 视频编码层 NAL network abstraction layer 网络提取层 VCL:核心算法引擎,块,宏块及片的语法级别的定义 NAL:片级以上的语法级别(如序列参数集和图像参数集),同时支持以下功能:独立片解码,起始码唯一保证,SEI以及流格式编码数据传送 VCL设计目标:尽可能地独立于网络的情况下进行高效的编解码 NAL设计目标:根据不同的网络把数据打包成相应的格式,将VCL产生的比特字符串适配到各种各样的网络和多元环境中。 NALU头结构:NALU类型(5bit)、重要性指示位(2bit)、禁止位(1bit)。 NALU类型:1~12由H.264使用,24~31由H.264以外的应用使用。 重要性指示:标志该NAL单元用于重建时的重要性,值越大,越重要。 禁止位:网络发现NAL单元有比特错误时可设置该比特为1,以便接收方丢掉该单元。 2.NAL语法语义 NAL层句法: 在编码器输出的码流中,数据的基本单元是句法元素。 句法表征句法元素的组织结构。 语义阐述句法元素的具体含义。 分组都有头部,解码器可以很方便的检测出NAL的分界,依次取出NAL进行解码。 但为了节省码流,H.264没有另外在NAL的头部设立表示起始位置的句法元素。
如果编码数据是存储在介质上的,由于NAL是依次紧密相连的,解码器就无法在数据流中分辨出每个NAL的起始位置和终止位置。 解决方案:在每个NAL前添加起始码:0X000001 在某些类型的介质上,为了寻址的方便,要求数据流在长度上对齐,或某个常数的整数倍。所以在起始码前添加若干字节的0来填充。 检测NAL的开始: 0X000001和0X000000 我们必须考虑当NAL内部出现了0X000001和0X000000 解决方案: H.264提出了“防止竞争”机制: 0X000000——0X00000300 0X000001——0X00000301 0X000002——0X00000302 0X000003——0X00000303 为此,我们可以知道: 在NAL单元中,下面的三字节序列不应在任何字节对齐的位置出现 0X000000 0X000001 0X000002 Forbidden_zero_bit =0; Nal_ref_idc:表示NAL的优先级。0~3,取值越大,表示当前NAL越重要,需要优先受到保护。如果当前NAL是属于参考帧的片,或是序列参数集,或是图像参数集这些重要的单位时,本句法元素必需大于0。 Nal_unit_type:当前NAL 单元的类型 3.H.264的NAL层处理
stm32中使用#pragma pack(非常有用的字节对齐用法说明)
#pragma pack(4) //按4字节对齐,但实际上由于结构体中单个成员的最大占用字节数为2字节,因此实际还是按2字节对齐 typedef struct { char buf[3];//buf[1]按1字节对齐,buf[2]按1字节对齐,由于buf[3]的下一成员word a是按两字节对齐,因此buf[3]按1字节对齐后,后面只需补一空字节 word a; //#pragma pack(4),取小值为2,按2字节对齐。 }kk; #pragma pack() //取消自定义字节对齐方式 对齐的原则是min(sizeof(word ),4)=2,因此是2字节对齐,而不是我们认为的4字节对齐。 这里有三点很重要: 1.每个成员分别按自己的方式对齐,并能最小化长度 2.复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度 3.对齐后的结构体整体长度必须是成员中最大的对齐参数的整数倍,这样在处理数组时可以保证每一项都边界对齐 补充一下,对于数组,比如: char a[3];这种,它的对齐方式和分别写3个char是一样的.也就是说它还是按1个字节对齐. 如果写: typedef char Array3[3]; Array3这种类型的对齐方式还是按1个字节对齐,而不是按它的长度. 不论类型是什么,对齐的边界一定是1,2,4,8,16,32,64....中的一个. 声明: 整理自网络达人们的帖子,部分参照MSDN。 作用: 指定结构体、联合以及类成员的packing alignment; 语法: #pragma pack( [show] | [push | pop] [, identifier], n ) 说明: 1,pack提供数据声明级别的控制,对定义不起作用; 2,调用pack时不指定参数,n将被设成默认值; 3,一旦改变数据类型的alignment,直接效果就是占用memory的减少,但是performance会下降; 语法具体分析: 1,show:可选参数;显示当前packing aligment的字节数,以warning message的形式被显示; 2,push:可选参数;将当前指定的packing alignment数值进行压栈操作,这里的栈是the internal compiler stack,同时设置当前的packing alignment为n;如果n没有指定,则将当前的packing alignment数值压栈; 3,pop:可选参数;从internal compiler stack中删除最顶端的record;如果没有指定n,则当前栈顶record即为新的packing alignment 数值;如果指定了n,则n将成为新的packing aligment数值;如果指定了identifier,则internal compiler stack中的record都将被pop 直到identifier被找到,然后pop出identitier,同时设置packing alignment数值为当前栈顶的record;如果指定的identifier并不存在于internal compiler stack,则pop操作被忽略; 4,identifier:可选参数;当同push一起使用时,赋予当前被压入栈中的record一个名称;当同pop一起使用时,从internal compiler stack 中pop出所有的record直到identifier被pop出,如果identifier没有被找到,则忽略pop操作; 5,n:可选参数;指定packing的数值,以字节为单位;缺省数值是8,合法的数值分别是1、2、4、8、16。 重要规则: 1,复杂类型中各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个类型的地址相同; 2,每个成员分别对齐,即每个成员按自己的方式对齐,并最小化长度;规则就是每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数中较小的一个对齐; 3,结构体、联合体或者类的数据成员,第一个放在偏移为0的地方;以后每个数据成员的对齐,按照#pragma pack指定的数值和这个数据成员自身长度两个中比较小的那个进行;也就是说,当#pragma pack指定的值等于或者超过所有数据成员长度的时候,这个指定值的大小将不产生任何效果; 4,复杂类型(如结构体)整体的对齐是按照结构体中长度最大的数据成员和#pragma pack指定值之间较小的那个值进行;这样当数据成员为复杂类型(如结构体)时,可以最小化长度; 5,复杂类型(如结构体)整体长度的计算必须取所用过的所有对齐参数的整数倍,不够补空字节;也就是取所用过的所有对齐参数中最大的那个值的整数倍,因为对齐参数都是2的n次方;这样在处理数组时可以保证每一项都边界对齐; 对齐的算法:由于各个平台和编译器的不同,现以本人使用的gcc version 3.2.2编译器(32位x86平台)为例子,来讨论编译器对struct 数据结构中的各成员如何进行对齐的。 在相同的对齐方式下,结构体内部数据定义的顺序不同,结构体整体占据内存空间也不同,如下: 设结构体如下定义: struct A { int a; //a的自身对齐值为4,偏移地址为0x00~0x03,a的起始地址0x00满足0x00%4=0;
dm9000中文芯片手册
DM9000介绍 1、总体介绍 该DM9000是一款完全集成的和符合成本效益单芯片快速以太网MAC控制器与一般处理接口,一个10/100M自适应的PHY和4K DWORD值的SRAM 。它的目的是在低功耗和高性能进程的3.3V与5V的支持宽容。 DM9000还提供了介质无关的接口,来连接所有提供支持介质无关接口功能的家用电话线网络设备或其他收发器。该DM9000支持8位,16位和32 -位接口访问内部存储器,以支持不同的处理器。DM9000物理协议层接口完全支持使用10MBps下3类、4类、5类非屏蔽双绞线和100MBps下5类非屏蔽双绞线。这是完全符合IEEE 8 02.3u规格。它的自动协调功能将自动完成配置以最大限度地适合其线路带宽。还支持IEEE 802.3x全双工流量控制。这个工作里面DM9000是非常简单的,所以用户可以容易的移植任何系统下的端口驱动程序。 2、特点 支持处理器读写内部存储器的数据操作命令以字节/ 字/ 双字的长度进行 集成10/100M自适应收发器 支持介质无关接口 支持背压模式半双工流量控制模式 IEEE802.3x流量控制的全双工模式 支持唤醒帧,链路状态改变和远程的唤醒 4K双字SRAM 支持自动加载EEPROM里面生产商ID和产品ID 支持4个通用输入输出口 超低功耗模式 功率降低模式 电源故障模式 可选择1:1或5:4变压比例的变压器降低格外功率 兼容3.3v和5.0v输入输出电压 100脚CMOS LQFP封装工艺 3、引脚描述 I=输入O=输出I/O=输入/输出O/D=漏极开路P=电源LI=复位锁存输入#=普遍低电位 介质无关接口引脚 引脚号引脚名I/O 功能描述 37 LINK_I I 外部介质无关接口器件连接
c++中关于结构体长度的计算问题
[C++]字节对齐与结构体大小 [C++] 2010-09-24 21:40:26 阅读172 评论0 字号:大中小订阅 说明: 结构体的sizeof值,并不是简单的将其中各元素所占字节相加,而是要考虑到存储空间的字节对齐问题。这些问题在平时编程的时候也确实不怎么用到,但在一些笔试面试题目中出是常常出现,对sizeof我们将在另一篇文章中总结,这篇文章我们只总结结构体的sizeof,报着不到黄河心不死的决心,终于完成了总结,也算是小有收获,拿出来于大家分享,如果有什么错误或者没有理解透的地方还望能得到提点,也不至于误导他人。 一、解释 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。 各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如
有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int 型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。 二、准则 其实字节对齐的细节和具体编译器实现相关,但一般而言,满足三个准则: 1. 结构体变量的首地址能够被其最宽基本类型成员的大小所整除; 2. 结构体每个成员相对于结构体首地址的偏移量都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节; 3. 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。 三、基本概念
C语言内存字节对齐规则20180718
C语言内存字节对齐规则 在C语言面试和考试中经常会遇到内存字节对齐的问题。今天就来对字节对齐的知识进行小结一下。 首先说说为什么要对齐。为了提高效率,计算机从内存中取数据是按照一个固定长度的。以32位机为例,它每次取32个位,也就是4个字节(每字节8个位,计算机基础知识,别说不知道)。字节对齐有什么好处?以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如图a-1。如果不对齐,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,这样效率也就降低了。 图:a-1 图:a-2 内存对齐是会浪费一些空间的。但是这种空间上得浪费却可以减少取数的时间。这是典型的一种以空间换时间的做法。空间与时间孰优孰略这个每个人都有自己的看法,但是C 语言既然采取了这种以空间换时间的策略,就必然有它的道理。况且,在存储器越来越便宜的今天,这一点点的空间上的浪费就不算什么了。 需要说明的是,字节对齐不同的编译器可能会采用不同的优化策略,以下以GCC为例讲解结构体的对齐. 一、原则: 1.结构体内成员按自身按自身长度自对齐。
自身长度,如char=1,short=2,int=4,double=8,。所谓自对齐,指的是该成员的起始位置的内存地址必须是它自身长度的整数倍。如int只能以0,4,8这类的地址开始 2.结构体的总大小为结构体的有效对齐值的整数倍 结构体的有效对齐值的确定: 1)当未明确指定时,以结构体中最长的成员的长度为其有效值 2)当用#pragma pack(n)指定时,以n和结构体中最长的成员的长度中较小者为其值。 3)当用__attribute__ ((__packed__))指定长度时,强制按照此值为结构体的有效对齐值 二、例子 1) struct AA{ //结构体的有效对齐值为其中最大的成员即int的长度4 char a; int b; char c; }aa 结果,sizeof(aa)=12 何解?首先假设结构体内存起始地址为0,那么地址的分布如下 0 a 1 2 3 4 b 5 b 6 b 7 b 8 c 9 10 11 char的字对齐长度为1,所以可以在任何地址开始,但是,int自对齐长度为4,必须以4的倍数地址开始。所以,尽管1-3空着,但b也只能从4开始。再加上c后,整个结构体的总长度为9,结构体的有效对齐值为其中最大的成员即int的长度4,所以,结构体的大小向上扩展到12,即9-11的地址空着。 2) //结构体的有效对齐值为其中最大的成员即int的长度4 struct AA{ char a; char c; int b; }aa sizeof(aa)=8,为什么呢 0 a 1 c
C语言字节对齐
定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐 对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同一些平台对某些特定类型的数据只能从某些特定地址开始存取其他平台可能没有这种情况, 台的要求对数据存放进行对齐,会在存取效率上带来损失比如有些平台每次读都是从偶地址开始,如果数据显然在读取效率上下降很多这也是空间和时间的博弈 不需要考虑对齐问题编译器会替我们选择适合目标平台的对齐策略当然,我们也可以通知给编译器传递预编译指令而改变对指定数据的对齐方法 话,常常会对一些问题感到迷惑最常见的就是结果,出乎意料为此,我们需要对对齐算法所了解 数据结构中的各成员如何进行对齐的 型数据一个 字节但是因为编译器要对数据成员在空间上进行对齐现在把该结构体调整成员变量的顺序
8 7 ,单位字节 )数据类型自身的对齐值:就是上面交代的基本数据类型的自身对齐值 )结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值 )数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小的那个值 有了这些值,我们就可以很方便的来讨论具体数据结构的成员和其自身的对齐方式有效对齐值 最终用来决定数据存放地址方式的值,最重要有效对齐 而数据结构中的数据变量都是按定义的先后顺序来排放的第一个数据变量的数据结构的起始地址结构体的成员变量要对齐排放,结构体本身也要根据自身的有效对 结合下面例子理解)这样就不难理解上面的几个例子的值了
开始排放该例子中没有定义指定对齐值,在笔者环境下,该值默认为 第三个变量 内容再看数据结构 所占用故 的变量又 的八个字节所以
#pragma指令用法汇总和解析
#pragma指令用法汇总和解析 一. message 参数。 message 它能够在编译信息输出窗 口中输出相应的信息,这对于源代码信息的控制是非常重要的。其使用方法为: #pragma message(“消息文本”) 当编译器遇到这条指令时就在编译输出窗口中将消息文本打印出来。 当我们在程序中定义了许多宏来控制源代码版本的时候,我们自己有可能都会忘记有没有正确的设置这些宏,此时我们可以用这条 指令在编译的时候就进行检查。假设我们希望判断自己有没有在源代码的什么地方定义了_X86这个宏可以用下面的方法 #ifdef _X86 #pragma message(“_X86 macro activated!”) #endif 当我们定义了_X86这个宏以后,应用程序在编译时就会在编译输出窗口里显示“_ X86 macro activated!”。我们就不会因为不记得自己定义的一些特定的宏而抓耳挠腮了 二. 另一个使用得比较多的#pragma参数是code_seg。格式如: #pragma code_seg( [ [ { push | pop}, ] [ identifier, ] ] [ "segment-name" [, "segment-class" ] ) 该指令用来指定函数在.obj文件中存放的节,观察OBJ文件可以使用VC自带的dumpbin命令行程序,函数在.obj文件中默认的存放节 为.text节 如果code_seg没有带参数的话,则函数存放在.text节中 push (可选参数) 将一个记录放到内部编译器的堆栈中,可选参数可以为一个标识符或者节名 pop(可选参数) 将一个记录从堆栈顶端弹出,该记录可以为一个标识符或者节名 identifier (可选参数) 当使用push指令时,为压入堆栈的记录指派的一个标识符,当该标识符被删除的时候和其相关的堆栈中的记录将被弹出堆栈 "segment-name" (可选参数) 表示函数存放的节名 例如: //默认情况下,函数被存放在.text节中 void func1() { // stored in .text } //将函数存放在.my_data1节中 #pragma code_seg(".my_data1") void func2() { // stored in my_data1 } //r1为标识符,将函数放入.my_data2节中 #pragma code_seg(push, r1, ".my_data2") void func3() { // stored in my_data2 } int main() { } 三. #pragma once (比较常用) 这是一个比较常用的指令,只要在头文件的最开始加入这条指令就能够保证头文件被编译一次 四. #pragma hdrstop表示预编译头文件到此为止,后面的头文件不进行预编译。
C语言内存对齐
解析C语言结构体对齐(内存对齐问题) C语言结构体对齐也是老生常谈的话题了。基本上是面试题的必考题。内容虽然很基础,但一不小心就会弄错。写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的变量总长度要大,这是怎么回事呢? 开始学的时候,也被此类问题困扰很久。其实相关的文章很多,感觉说清楚的不多。结构体到底怎样对齐? 有人给对齐原则做过总结,具体在哪里看到现在已记不起来,这里引用一下前人的经验(在没有#pragma pack宏的情况下): 原则1、数据成员对齐规则:结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储)。 原则2、结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储。) 原则3、收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。 这三个原则具体怎样理解呢?我们看下面几个例子,通过实例来加深理解。 例1:struct { short a1; short a2; short a3; }A; struct{ long a1; short a2; }B; sizeof(A) = 6; 这个很好理解,三个short都为2。 sizeof(B) = 8; 这个比是不是比预想的大2个字节?long为4,short为2,整个为8,因为原则3。 例2:struct A{ int a; char b; short c; }; struct B{ char b; int a; short c; }; sizeof(A) = 8; int为4,char为1,short为2,这里用到了原则1和原则3。 sizeof(B) = 12; 是否超出预想范围?char为1,int为4,short为2,怎么会是12?还是原则1和原则3。
华为笔试题done
试题 选择题 1、以下程序的输出结果是: 2 0 \r\n 正确值2 0 \r转义符:回车,\n转义符:换行 #include
enum ENUM_A { x1, y1, z1 = 5, a1, b1 }; enum ENUM_A enumA = y1; enum ENUM_A enumB = b1; 请问enumA和enumB的值是多少?1 7 x1=0,y1=1,a1=6,b1=7 4、若有函数max(a,b),并且函数指针变量p已经指向函数,当调用该函数时正确的调用方法是:(*p)(,) 5、对栈S进行下列操作:push(1), push(5), pop(), push(2), pop(), pop(), 则此时栈顶元素是: NULL 6、在一个32位的操作系统中,设void *p = malloc(100),请问sizeof(p)的结果是:4
7、若已定义: int a[9], *p = a;并在以后的语句中未改变p的值,不能表示a[1]地址的表达式是: C a的值不能改变 A)p+1 B)a+1 C) a++ D) ++p 8、设有如下定义: unsigned long plArray[] = {6,7,8,9,10}; unsigned long *pulPtr; 则下列程序段的输出结果是什么?D pulPtr = plArray; *(pulPtr + 2) += 2; printf("%d, %d\r\n", *pulPtr, *(pulPtr + 2)); A) 8, 10 B) 6, 8 C) 7, 9 D) 6, 10 9、以下程序运行后,输出结果是什么? C void main() { char *szStr = "abcde"; szStr += 2; printf("%1u\r\n", szStr); return; } A) cde B) 字符c的ASCII码值C) 字符c的地址D) 出错
C语言结构体的字节对齐及指定对齐方式
内存中结构体的内存对齐 一、字节对齐作用和原因: 对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐,其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit 数据,显然在读取效率上下降很多。 二、字节对齐规则: 四个重要的概念: 1.数据类型自身的对齐值:对于char型的数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4个字节。 2.结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。 3.指定对齐值:#pragma pack (value)时指定的对齐value。 4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。补充: 1).每个成员分别按自己的方式对齐,并能最小化长度。 2).复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度。 3).对齐后的长度必须是成员中最大的对齐参数的整数倍,这样在处理数组时可以保证每一项都边界对齐。 #pragma pack(1) struct test { static int a; //static var double m4; char m1; int m3; } #pragma pack() //sizeof(test)=13;
H.264 NAL层解析(0x00000001,编码,打包,NALU)
H.264 NAL层解析(0x00000001,编码,打包,NALU) 1.引言 H.264的主要目标: 1.高的视频压缩比 2.良好的网络亲和性 解决方案: VCL video coding layer 视频编码层 NAL network abstraction layer 网络提取层 VCL:核心算法引擎,块,宏块及片的语法级别的定义 NAL:片级以上的语法级别(如序列参数集和图像参数集),同时支持以下功能:独立片解码,起始码唯一保证,SEI以及流格式编码数据传送 VCL设计目标:尽可能地独立于网络的情况下进行高效的编解码 NAL设计目标:根据不同的网络把数据打包成相应的格式,将VCL产生的比特字符串适配到各种各样的网络和多元环境中。 NALU头结构:NALU类型(5bit)、重要性指示位(2bit)、禁止位(1bit)。 NALU类型:1~12由H.264使用,24~31由H.264以外的应用使用。 重要性指示:标志该NAL单元用于重建时的重要性,值越大,越重要。 禁止位:网络发现NAL单元有比特错误时可设置该比特为1,以便接收方丢掉该单元。 2.NAL语法语义 NAL层句法: 在编码器输出的码流中,数据的基本单元是句法元素。 句法表征句法元素的组织结构。 语义阐述句法元素的具体含义。 分组都有头部,解码器可以很方便的检测出NAL的分界,依次取出NAL进行解码。但为了节省码流,H.264没有另外在NAL的头部设立表示起始位置的句法元素。如果编码数据是存储在介质上的,由于NAL是依次紧密相连的,解码器就无法在数据流中分辨出每个NAL的起始位置和终止位置。 解决方案:在每个NAL前添加起始码:0X000001 在某些类型的介质上,为了寻址的方便,要求数据流在长度上对齐,或某个常数的整数倍。所以在起始码前添加若干字节的0来填充。 检测NAL的开始: 0X000001和0X00000001 我们必须考虑当NAL内部出现了0X000001和0X000000 如果NALU对应的Slice为一帧的开始,则用4字节表示,即0x00000001;否则用3字节表示,0x000001。