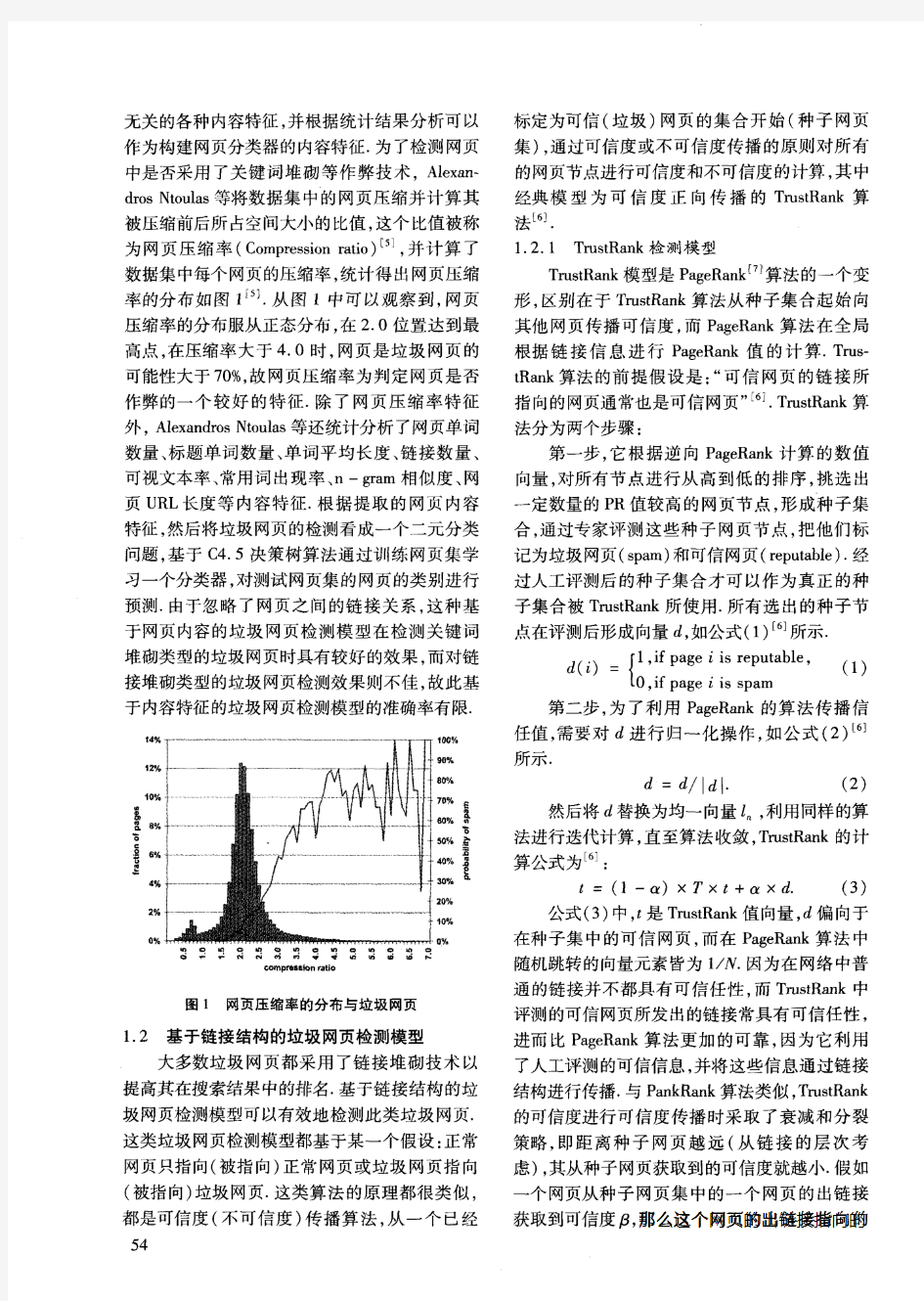
搜索引擎垃圾网页检测模型研究

第四代搜索引擎前沿综述
第四代搜索引擎前沿综述 刁轶夫3061401080 2010年5月 1.介绍 随着因特网的普及,网上信息的发展呈现两个基本的趋势:规模的爆炸性增长,覆盖领域的不断扩大。如何在海量,非结构化信息中,提取对用户有用的信息是信息时代的核心课题。搜索引擎正是通过对信息的自动搜集,索引,在用户发出请求时经过实时排序,为用户呈现其最有价值的信息。 由搜索引擎衍生而来的关键词广告产生了巨大的商业价值,并造就了谷歌、百度等互联网巨头。但同时,谷歌以pagerank为核心的第三代搜索引擎已经不能满足日益增长的需求,数据量的增长和数据覆盖范围的增加迫切呼唤第四代搜索引擎。 我认为,第四代搜索将把个性化信息及人际推荐关系叠加到链接分析上,大大改善搜索结果排序效果;同时,跨媒体搜索将实现诸如用图片搜索图片等功能,打通文字,图片,视频,声音的界限,颠覆现在全部基于关键字的搜索方法,为用户带来更加直观的搜索体验。 2.搜索引擎发展历史及趋势 2.1 搜索引擎发展历史 从Lycos和Yahoo的时代到现在,搜索引擎的发展已经经过了三代。Andrei[1]的文章中对前三代搜索引擎的特征做了描述: Google经过改进Pagerank和一系列技术,演化至第三代,而第四代搜索引擎有大量公司如Cuil,Quora探索,但还未形成成熟的产品。 下图援引自Google创始人论文[2],说明第二代,第三代搜索引擎的主要原理: 首先搜索引擎通过爬虫技术(Crawler),根据网页链接爬取互联网内容;然后建立倒排索引(Inverted Index);同时通过Pagerank技术,基于random walk的思想计算出每个网页的Pagerank。前面几步都是独立于用户查询进行的。当用户提交查询关键词后,搜索
通过搜索引擎推广网站应注意的问题
通过搜索引擎推广网站应注意的问题 在互联网的海洋中,最重要的就是互联互通,不被其他网站引用的网站就是“信息孤岛”。“酒好也怕巷子深”,也许这话说起来有点像垃圾邮件广告,但事实就是这样。所以如果做网站的目的不是孤芳自赏,就需要积极的推广自己的网站。通过搜索引擎推广自己需要注意以下几个方面: 一、 Link Popularity 国内有人译作“链接广泛度”,是Google用来评判一个网站的价值的主要手段。我们都知道Google 工具条上有一个绿色的PageRank标尺,就是用来指示网站的链接广泛度的。一般说来,如果一个网站的PageRank值是4到6的话,说明这个网站已经获得了不错的访问量;如果到了7以上,说明不管是从网站的质量到知名度都非常优秀了。 1. 以量取胜:不一定加入大型网站的分类目录才是网站推广,来自其他网站的任何反相链接都是有用的网站推广比较经典的方式就是加入比较大型门户网站的分类目录,比如:Yahoo!,https://www.360docs.net/doc/e810510040.html,等。其实这里有一个误区:不一定非要加入大型网站的分类目录才是网站推广,因为现在搜索引擎已经不再只是网站目录的索引,而是更全面的网页索引,所以无论来自其他网站任何地方的反相链接都是非常有价值的,哪怕是出现在新闻报道,论坛,邮件列表归档中。 Blogger (Weblog的简称)们也许最深刻地理解了“链接就是一切”这句话的含义,由于Blog的内容之间有大量的相互链接,因此最经常被引用的 Blog页面在搜索引擎中的排名往往比一些大型商业网站的页面还要高。而wiki这样的文档管理系统更加突出了良好引用的特征。 2. 以质取胜:被PageRank高的网站引用能更快地提高PageRank 数量只是关键因素之一,来自PageRank高的页面的链接还能更快的提高被链接目标的PageRank,我只是将一些文章投稿在了ZDNet 中国上,由于页面上有文章出处链接,相应网页和网站整体的PageRank过了一段时间后就有了很大的提升。有时候被什么样的网站引用有时候比引用次数多更重要。这里我要特别感谢的是,当时ZDNet中国是唯一遵循了我的版权声明的要求表明了文章出处,并且有反相链接的网站。 按照这个原则:能够名列Yahoo!和DMOZ这样的大型权威目录的头2层是非常有价值的。 3. 不要吝啬给其他网站的链接:如果一个网页只有大量的进入链接,而缺乏导出链接,也会被搜索引擎认为是没有价值的站点。保证你的网站能够帮助搜索引擎更准确地判断哪些是对用户最有价值的信息,也就是说如果你的网站只有外部反向链接而没有导出链接的话,也会对你的网站在搜索结果中的表现带来负面影响。当然网站中连一个导出链接都没有的情况非常罕见,除非你是刻意这么做。正常情况下大家都会自然地在网页中加上一些其他网站的链接,带领访问者去到我们认为重要或能够提供更多有价值信息的地方,另外在推广自己网站之前也许首先需要了解自己网站目前在一些搜索引擎中的知名度,原理非常简单,可以参考如何评价网站的人气一文。 二、 Page Title 搜索引擎是通过关键词来选择网站的,而网站的标题是搜索引擎寻找关键词的主要目的地-你通过分析Google的搜索结果就可以很清楚地发现这一点。因此,你一定要首先确定你的网站
2020年【搜索引擎】行业调研分析报告
2020年【搜索引擎】行业调研分析报告 2020年2月
目录 1. 搜索引擎行业概况及市场分析 (6) 1.1 搜索引擎行业市场规模分析 (6) 1.2 搜索引擎行业结构分析 (6) 1.3 搜索引擎行业PEST分析 (7) 1.4 搜索引擎行业发展现状分析 (9) 1.5 搜索引擎行业市场运行状况分析 (10) 1.6 搜索引擎行业特征分析 (11) 2. 搜索引擎行业驱动政策环境 (12) 2.1 市场驱动分析 (12) 2.2 政策将会持续利好行业发展 (14) 2.3 行业政策体系趋于完善 (14) 2.4 一级市场火热,国内专利不断攀升 (15) 2.5 宏观环境下搜索引擎行业的定位 (15) 2.6 “十三五”期间搜索引擎建设取得显著业绩 (16) 3. 搜索引擎产业发展前景 (17) 3.1 中国搜索引擎行业市场规模前景预测 (17) 3.2 搜索引擎进入大面积推广应用阶段 (18) 3.3 中国搜索引擎行业市场增长点 (19) 3.4 细分化产品将会最具优势 (19) 3.5 搜索引擎产业与互联网等产业融合发展机遇 (20) 3.6 搜索引擎人才培养市场大、国际合作前景广阔 (21)
3.7 巨头合纵连横,行业集中趋势将更加显著 (22) 3.8 建设上升空间较大,需不断注入活力 (22) 3.9 行业发展需突破创新瓶颈 (23) 4. 搜索引擎行业竞争分析 (24) 4.1 搜索引擎行业国内外对比分析 (24) 4.2 中国搜索引擎行业品牌竞争格局分析 (26) 4.3 中国搜索引擎行业竞争强度分析 (26) 4.4 初创公司大独角兽领衔 (27) 4.5 上市公司双雄深耕多年 (28) 4.6 互联网巨头综合优势明显 (29) 5. 搜索引擎行业存在的问题分析 (30) 5.1 政策体系不健全 (30) 5.2 基础工作薄弱 (30) 5.3 地方认识不足,激励作用有限 (30) 5.4 产业结构调整进展缓慢 (30) 5.5 技术相对落后 (31) 5.6 隐私安全问题 (31) 5.7 与用户的互动需不断增强 (32) 5.8 管理效率低 (33) 5.9 盈利点单一 (33) 5.10 过于依赖政府,缺乏主观能动性 (34) 5.11 法律风险 (34)
全文搜索引擎的设计与实现(文献综述)
全文搜索引擎的设计与实现 前言 面对海量的数字化信息,搜索引擎技术帮助我们在其中发现有价值的信息与资源。我们可以通过google、百度这样的搜索引擎服务提供商帮助我们在Internet上搜索我们需要的信息。但是在一些没有或不便于连入Internet的内部网络或者是拥有海量数据存储的主机,想要通过搜索来发现有价值的信息和资源却不太容易。所以开发一个小型全文搜索引擎,实现以上两种情况下的信息高效检索是十分有必要的。本设计着眼于全文搜索引擎的设计与实现,利用Java ee结合Struts,Spring,Hibernates以及Ajax等框架技术,实现基于apache软件基金会开源搜索引擎框架Lucene下的一个全文搜索引擎。 正文 搜索引擎技术起源1990年,蒙特利尔大学学生Alan Emtage、Peter Deutsch和Bill Wheelan出于个人兴趣,发明了用于检索、查询分布在各个FTP主机中的文件Archie,当时他们的目的仅仅是为了在查询文件时的方便,他们未曾预料到他们的这一创造会成就日后互联网最的广阔市场,他们发明的小程序将进化成网络时代不可或缺的工具——搜索引擎。1991年,在美国CERFnet、PSInet及Alternet网络组成了CIEA (商用Internet 协会)宣布用户可以把它们的Internet子网用于商业用途,开始了Internet商业化的序幕。商业化意味着互联网技术不再为科研和军事领域独享,商业化意味着有更多人可以接触互联网,商业化更意味着潜在的市场和巨大的商机。1994年,Michael Mauldin推出了最早的现代意义上的搜索引擎Lycos,互联网进入了搜索技术的应用和搜索引擎快速发展时期。以上是国际互联网和搜索引擎发展历史上的几个重要日子。互联网从出现至今不过15年左右时间,搜索引擎商业化运作也就10年左右。就在这短短的10年时间里,互联网发生了翻天覆地的变化,呈爆炸性增长。于此同时也成就了google、百度这样的互联网巨头。今天,当我们想要在这片广阔的信息海洋中及时获得想要查找的信息时,已经离不开搜索引擎了。 相关技术
SPIN安装及模型验证实验报告
实验报告 实验题目:基于SPIN的LTL模型检测课程名:形式化方法 姓名:王燕霞 学号:201428013229141
一、SPIN概述 SPIN是由贝尔实验室形式化方法与验证小组用ANSI C开发,可以在所有UNIX操作系统版本使用,也可以在安装了Linux、Windows95以上版本等操作系统中使用,适合于分布式并发系统,尤其是协议一致性的辅助分析检测工具。SPIN模型检验工具的基本思想是求两种自动机所接受语言的交集,若交集为空集,则安全特性得到验证,否则输出不满足安全特性的行为迹。 SPIN可以用于以下三种基础模型中: 1)作为一个模拟器,允许快速对建立的系统模型进行随意的、引导性的或交互的仿真。 2)可以作为一个详尽的分析器,严格的证明用户提出的正确性要求是否满足(使用偏序简约进行最优化检索)。 3)用于大型系统近似性证明,用SPIN可以对大型的协议系统进行有效的正确性分析,即使这个系统覆盖了最大限度的状态空间。 二、SPIN的安装 2.1安装Cygwin Cygwin是一个在windows平台上运行的类UNIX模拟环境,我们可以通过这个软件在windows 系统上模拟简单的unix环境。 (1)首先从官网https://www.360docs.net/doc/e810510040.html,/,下载Cygwin安装包,选择64位windows系统(2)打开软件安装包setup-x86_64.exe,界面如下:
(3)选择install from Internet,下一步 (4)选择安装路径 (5)选择模拟的Unix环境在系统中的路径
(6)选择Use Internet Explorer Proxy Setting,根据自己的网络链接状态选择 (7)选择镜像,最好是选国内的,以.cn结尾或者含有.cn的,国外镜像下载速度只有几K,所以可以不用尝试。在这里我选择的是中科大的一个镜像https://www.360docs.net/doc/e810510040.html, (8)选择要安装的包,Cygwin默认安装的东西很少,像gcc、make、X11、tcl/TK这些都没有,需要自己勾选,可以在Search中直接输入关键字进行查找。如果一次安装没有全都装上也不要紧,可以再次运行setup.exe,然后继续安装其他的包。
[基于,搜索引擎,SIVA]基于搜索引擎的“SIVA”网络营销理论模型的应用研究
基于搜索引擎的“SIVA”网络营销理论模型的应用研究 基于搜索引擎的“SIVA”网络营销理论模型的应用研究 信息技术的到来改变了营销环境,需要建立一种新的由消费者主导的交互市场营销体系。传统的以线性的输出营销系统,都是基于内部驱动的品牌传播方法,而现在,消费者决策体系已由线性变成网状,选择由单一的点变成立体的面,因此,必须建立一种全新的以消费者为核心的交互式的营销模型来适应当今的大数据时代。 一、前言 回顾过去几十年营销理论的发展,从当年的4P理论到逐渐意识要与消费者沟通的4C、4R理论的发展,表明了营销体系的不断推进,消费者的地位不断被提升。要以消费者为中心,要了解消费者真正的需求,要实现与消费者对话,营销者就要不断努力地接近消费者, 改变营销策略,从说服转为倾听,希望能从消费者口中找到营销的最佳时机。 互联网的发展,特别是搜索引擎的出现,让越来越多的企业真正从消费者的心声中发现了商机。LANCOME兰蔻于1935年诞生于法国,兰蔻品牌已发展成为全法国第一和全世界第二 的世界知名化妆品牌。兰蔻以聚集了中国95%以上网民的百度搜索营销平台为基础,将关 键字投放、品牌专区、关联广告、精准广告等不同营销形式有机地整合在一起,各个营销环节层层相扣,全方位开展了网络营销活动。如若有消费者在百度搜索上敲下“兰蔻”两个字搜索关键词栏目即出现包含“兰蔻”的若干主题词。这些主题词与兰蔻产品或品牌的相关性极高,消费者可以从这些主题词的链接中找到自己想要的信息和解决方案。 而在当今的大数据时代,消费者的信息与需求源源不断地涌向互联网这个大口袋里,为企业品牌提供了巨大的机会与便利。消费者与企业双方依托搜索平台进行对接,期待最契合的连接点,相互得到满足。 二、搜索引擎 中国现在有5.64亿网民,4.2亿手机用户,每天在百度上的搜索请求超过50亿次《中国互 联网发展状况统计报告》(2013年1月,第31次)。根据全球最大的网络调查公司CyberAt las的调查表明,网站75%的流量都是来自于搜索引擎。 1.搜索引擎的定义 搜索引擎是指一种基于Internet上的信息查询系统,包括信息存取、信息管理和信息检索。搜索引擎便于网民获取有效信息,成为网民最喜爱的网络信息采集渠道,同时也有利于企业以较低的成本获得较高的信息传播效率,成为企业产品和服务推广的主要手段。 2.搜索引擎的营销功能 (1)对潜在客户的精准定位
搜索引擎的难点包括如下几点
搜索引擎的难点包括如下几点: 1) 是否支持并发的爬取数据,如果要并发,要保证所有采集器能合作采集,不会出现重复采集的情况. 2) 采集的数据还要有一个排重的过程. 只需要采集一个网站更新的数据 3) 对于需要cookie数据的网页如何采集的问题,部分网站需要通过cookie数据登陆网站 4) 自动通过识别码的验证 5) 一些网站对于密集访问的请求会拒绝,技术上也要进行处理 6) 对于一些特殊网页的采集问题, 比如flash网页,一些游戏网页等,很多网站会让采集程序陷入其中,采集数万无效数据,显然是浪费了采集程序的精力 7) 大数据量的存储也是个难点,据说Google的存储是自己开发的架构,没用任何的数据库,因为数据库的查询效率还是有一定损失. 可以采用数据块的模式,然后通过散列表的模式连接. 以上主要列出的是后台采集器的相关技术难点,在前台检索、查询效率等方面仍有许多难点. 21世纪人类社会已进入了信息化时代,作为信息化时代标志之一的因特网在全世界以史无前例的速度和规模不断发展壮大,而因特网上的信息也象原子裂变一样迅速膨胀,面对这些浩瀚无边的信息人们已经显得无所适从了。的确,人们要想在这信息的海洋中准确找到自己所需要的信息是一件很不容易的事情。 为了能够克服这样的困难,人们制作出来了搜索引擎,它通过内部的某些软件程序把
INTERNET上的信息进行分类整理,或者是通过人工组织的方式把某些数据归类,形成一个可供查询的大型数据库。可以说:“搜索是一种组织和查询信息的方式!” 一般来说,在每个搜索引擎中均提供分类目录及关键词检索这两种信息查询的方法。而这些搜索引擎的基本用法是搜索引擎站点中都提供一个可以输入关键词的文本输入框和一个“搜索”的按钮,用户可以在输入框中键入关键词,然后按“搜索”按钮,搜索引擎就会自动地在其内部的数据库中进行检索,最后把与关键词相符合的或者是与关键词相近的网站显示在结果页中,接着用户只需通过搜索引擎提供的链接地址,就可以访问到相关信息。这种查询方法的关键之处在于关键词的选择和表达上。 如果关键词选择不当,搜索的结果会返回大量无用的垃圾信息;或者有用的信息被淹没在大量的冗余的页面之中。所以在选择关键词时,应该熟练掌握关键词语法表达方式,这样就可以少走弯路,能得到更精确的搜索结果,从而迅速找到自己所需要的信息。虽然各个搜索引擎的搜索语法不完全相同,但下面一些搜索语法还是比较通用和常见的,笔者分别举例来说明各个语法符号的使用方法。 (1)直接键入关键字,搜索引擎就把包括关键字的网站和与关键字意义相近的网站地址一起返回给用户。例如:键入“网上教学”,搜索引擎就会把“网上学习”、“远程教学”以及“网上教学”等内容的网址一起反馈给用户,因此这种查询方法往往会返回大量不需要的信息。 图1 直接搜索 (2)利用双引号,来查询完全符合关键字串的网站。例如:键入“电脑硬件”,会找出包含网络资源的网站、但是会忽略过包含“电脑硬件行情”的网站;这种查询方法要求用一对半角的双引号来把关键字包括起来。 (3)加t:在关键字前,搜寻引擎仅会查询网站名称。例如:键入t:电脑,会找出包含电脑的网站名称。 (4)加u:在关键字前,搜寻引擎仅会查询网址(URL)。例如:键入u:yancheng,会找出包含yancheng的网址。 (5)利用+来限定关键字串一定要出现在结果中。例如:键入电脑+网络,会找出包含电脑和网络的网站。 (6)利用-来限定关键字串一定不要出现在结果中。例如:键入电脑-网络,会找出包含电脑但除了网络的网站;键入发如雪-html,会在发如雪的相关网页中过滤掉后缀名为html 网页。
百度搜索点击模型简介
百度搜索点击模型简介 用户的搜索点击模型(Click Model)其实是一个非常大的话题,涉及到用户查询满意度的建模和分析。 百度真实网页权重里有一个satisfyScore(满意度打分),所以搜索点击行为不仅是提升点击权重,连带提高满意度权重。 在今天的搜索引擎技术中,通过Click Model 衍生出了众多的功能,包括搜索满意度的自动监控、搜索结果的自动调权调序等。 这里提到了搜索点击模型会自动改变排名。 而这些技术的出发点都是User Behavior(用户行为)数据。 在Session 信息(a search session 一次搜索周期信息)里,用户的点击行为往往能提供丰富的信息: 百度网页搜索一次完整的搜索周期包含大量信息,有查询词,搜索结果的标签,标题,链接,高度、宽度,模版,排名,数据策略ID,点击校验参数,时间戳,官网认证标识,何种搜索结果,随机样本ID,查询ID,付费名,是否百度首页,是否登录百度账号,搜索形式,搜索框位置,字符编码,输入耗时等几十项信息。 1.在搜索结果从上至下被用户浏览的过程中,当被点击的结果中间出现了跳跃,例如 Query1(第1次搜索)对应的自然排序结果是Result1(第1个结果), Result2(第2个结果), Result3(第3个结果)…,但是如果大量用户的点击是Result1, Result3, 则Result2 的相关性可能存在问题;意思是点击第1、3个结果,不但可以提升第1、3个结果的权重,还可以降低第2个结果的权重。所以对付竞争对手快速点击一个办法是大量点击其他结果。 2.另外一种情况是,如果同一个Query 产生了一次点击后,间隔一段时间后再次出现 了对后面结果的点击,则也许说明了之前结果的满足度不够高。 3.一种在搜索结果页降低竞争对手满意度权重的方式,先点击对方的结果,隔段时间 再点自己网站的结果。 4.在同一个Session 里,用户发生主动Query 变换(或称为Query Re-write)也往往能 说明问题,前面的Query 如果搜索结果质量不高,则很多用户会选择修改查询词,此时前面被点击的Title(搜索结果标题)重要程度往往不如后续的Title,等等各类场景很丰富。 5.另一种一石二鸟的办法是先搜索一个竞争对手排名好的关键词,点了之后,更换另 一个自己网站的相关词点击,亦可降低对方网站的满意度。 以上各类的Click Model 思想虽然在实际线上系统中被广泛运用,但竞赛中没有提供更详细的信息,包括点击结果在搜索中的排序(对于分析点击模型至关重要)、点击发生的时间、点击停留间隔、用户的Cookieid/Userid(暂存用户信息ID/用户ID)等,限制了
由传递函数转换成状态空间模型(1)
由传递函数转换成状态空间模型——方法多!!! SISO 线性定常系统 高阶微分方程化为状态空间表达式 SISO ()()()()()()m n u b u b u b y a y a y a y m m m n n n n ≥+++=++++--- 1102211 )(2 211110n n n n m m m a s a s a s b s b s b s G +++++++=--- 假设1+=m n 外部描述 ←—实现问题:有了部结构—→模拟系统 部描述 SISO ? ??+=+=du cx y bu Ax x 实现问题解决有多种方法,方法不同时结果不同。 一、 直接分解法 因为 1 0111 11()()()()()()()() 1m m m m n n n n Y s Z s Z s Y s U s Z s U s Z s b s b s b s b s a s a s a ----?=? =?++++++++ ???++++=++++=----) ()()() ()()(11 11110s Z a s a s a s s U s Z b s b s b s b s Y n n n n m m m m 对上式取拉氏反变换,则 ? ??++++=++++=----z a z a z a z u z b z b z b z b y n n n n m m m m 1) 1(1)(1)1(1)(0 按下列规律选择状态变量,即设)1(21,,,-===n n z x z x z x ,于是有
?????? ?+----===-u x a x a x a x x x x x n n n n 12113 221 写成矩阵形式 式中,1-n I 为1-n 阶单位矩阵,把这种标准型中的A 系数阵称之为友阵。只要系统状态方程的系数阵A 和输入阵b 具有上式的形式,c 阵的形式可以任意,则称之为能控标准型。 则输出方程 121110x b x b x b x b y m m n n ++++=-- 写成矩阵形式 ??????? ? ????????=--n n m m x x x x b b b b y 12101 1][ 分析c b A ,,阵的构成与传递函数系数的关系。 在需要对实际系统进行数学模型转换时,不必进行计算就可以方便地写出状态空间模型的A 、b 、c 矩阵的所有元素。 例:已知SISO 系统的传递函数如下,试求系统的能控标准型状态空间模型。 4 2383)()(2 3++++=s s s s s U s Y 解:直接得到系统进行能控标准型的转换,即
关于百度搜索引擎的常见问题解答
关于百度搜索引擎的常见问题解答 百度推广和自然搜索结果的关系是什么? 必须要说明一点的是,”竞价排名”这个说法,带有一些误导意味。所以,现在百度对这个业务改称”百度推广”,而不是”竞价排名”了。分享快乐 百度的商业推广和自然搜索,是由完全独立的两个部门分别运营两套独立系统,参加商业推广的网站,在自然结果中一视同仁,没有任何特殊处理。分享快乐 百度的商业推广(包括左侧和右侧)和自然搜索(从前的特征是后面带一个链接,叫百度快照;但现在大部分的开放搜索结果也是不带快照链接的)是两个完全独立的系统。商业推广的原理,不是”给了钱,自然结果中的某些结果就可以排得更靠前”,而是”用户的关键词被分发到两个独立系统中,分别产生了商业结果和自然结果,商业结果在前,自然结果在后,就构成了百度的搜索结果”。分享快乐 关于这一点的认知,误会很深,所以做专门的说明。”不给钱就干掉”的传言,就是在这样的背景下产生的。 更换空间怎么办? 参照以下步骤: ?开通新的空间,并将网站完整的迁移到新空间,并保持流畅访问; ?将域名的服务器指向更新为新空间的ip; ?保证旧空间能持续访问一段时间; ?关注新空间的访问日志,等Baiduspider的抓取完全迁移到新空间后,停止旧空间的服务。 百度是否支持nofollow? 百度支持< a rel=”nofollow” href=”url”>123、两种写法的nofollow,带有nofollow属性的url,不会传递权值。分享快乐 百度支持不支持https协议? 百度目前只能收录少部分https网页,大部分https网页无法收录。网站首页和对所有用户都公开的内容页面,建议不要使用https协议,如果非用不可,尽量将首页和重要页面做个http可访问版,方便百度收录。 Site语法查到的结果数是百度收录的网页数量吗? site语法得到的搜索结果数,只是一个估算的数值,仅供参考。 site语法设定的初衷,其实是期望用户可以设定约束搜索范围,实现更加精准的搜索。这同intitle,inurl,本质上是相同的。而在这些高级语法下的结果数,和常规搜索一样,都是”估值”,而非精确值。因此,很有可能site下的”结果数”减少了,实际被索引数却可能增加了。
模型转换的途径
PIM->PSM 模型转换的途径 mdaSky UML软件工程组织 由MDA 的PIM(平台独立模型)向PSM(平台特定模型)转换的方法目前尚未实现标准化。因此目前市售的工具不得不利用自主方法进行这部分的处理。由PIM 向PSM 的转换方法由于将在2004 年实现标准化,只有这个重要的步骤标准化了,才更加有利于MDA 这项技术的推广。 2004 年将是MDA 大发展的一年,为什么这样说,我们来看看业界一些重要的公司是如何应对MDA 这项技术的。最近,美国Compuware 的OptimalJ 等基于对象技术标准化团体美国OMG (Object Management Group )倡导的模型驱动架构(MDA)的Java 开发工具业已亮相。那么Java 工具阵营的老大哥Borland 公司的JBuilder 是否会支持MDA 那?看看他们是怎么说:“我们也在关注MDA, 但是目前仍在观察其动向。比如说第一点,OptimalJ 等产品与JBuilder,包括价格在内,不属于同一类产品。要是支持MDA 的话,Together 更好一些。JBuilder X 在能够轻松构筑Web 应用的角度上,以比这些工具更低的成本实现了相同的功能。同样,即便1 行代码都不写,也能够自动生成可访问数据库的Web 应用架构,在开发过程中及开发完成后均可轻松变更Web 应用服务器等平台。由PIM 向PSM 的转换方法由于将在2004 年实现标准化,因此到时准备在Together 中配备基于MDA 的模型自动生成功能。”看来Borland 公司也不会轻视MDA 这项技术,准备在Together 产品中支持MDA。 MDA 技术是否会取得较大的成功,让我们拭目以待。 下面简单讲述一下从PIM 到PSM 转化的5 种途径: 1. Marking
保理系统自动化验证模型
保理系统自动化验证模型 一、借款企业自动拒绝条件 1.企业成立低于2年; 2.企业年营业额低于1000万元; 3.企业负债率大于90%; 4.企业当前有贷款逾期; 5.企业最近两年累计逾期大于5次; 6.企业最近两年有逾期1+; 7.企业与买家合作低于1年; 8.关联企业; 9.涉及两高一剩行业:两高行业指高污染、高能耗的资源性的行业;一剩行业即产能过剩行业。主要包括钢铁、造纸、电解铝、平板玻璃、风电和光伏等产业;10.企业经营地位于东北、新疆、西藏、云南、贵州; 11.企业实际控制人有吸毒、赌博等不良嗜好; 12.企业有当前未判决被诉讼记录且涉案金额超过100万元; 13.企业有过往被诉讼记录且被判决涉及诈骗、拒不履合同或协议; 14.企业或者其实际控制人被列入失信人名单的; 15.内部黑名单名录; 16.外部黑名单名录(第三方外部黑名单提供商)。 二、内部黑名单数据库 1.提供的核心贸易资料或证明其自身实力的财务数据为虚假资料被发现的;2.逾期30天仍未回购应收账款(对供应商); 3.有三笔或多于三笔应付账款逾期超30天(对核心企业); 4.企业最近两年累计逾期大于5次; 5.企业最近两年有逾期M1+; 三、反欺诈监控模型 1.贸易真实性审查,贷前审查买卖双方贸易背景是否真实、合法、有效;所提供的商务合同、商业发票、货运及质检单据等所显示的信息能够相互印证,对产品信息、买卖双方名称、结算方式等重要信息的规定应保持一致;
2.贷中对保理业务期限、还款资金来源是否合理合规;对买方资金的监控,保证买方资金按期回流; 3.贷后需规范卖方企业的频繁回购行为,对于频繁回购的企业,对回购资金来源的审查,回购资金不得为平台信贷资金(如新发放的保理预付款或贴现资金等),以避免企业出现假交易真融资或重复融资的行为; 4.系统收集买卖双方过往交易数据并动态监测,系统自动交叉验证并进行简单趋势预测。 5.第三方数据的借用,如:全国工商企业信用网、中国裁判文书网、中国人民银行征信中心、风险信息网、被执行人信息查询网、中国执行信息公开网、风控搜、巨潮资讯网等等; 6.交易双方的物流、信息流、资金流闭环的动态监控。
我国搜索引擎评价研究的现状_问题及对策_马志杰
我国搜索引擎评价研究的现状、问题及对策* 马志杰 【摘要】从评价指标、评价方法、评价对象、评价主体四个方面对我国搜索引擎评价研究进行总结和分析,指出其存在研究团队薄弱;理论基础薄弱,缺乏创新性;实践活动薄弱,缺乏实证研究;绩效评价研究较少;综合评价方法不太成熟等问题。为促进该研究,应坚持定性与定量相结合的发展方向;坚持用户导向开展搜索引擎评价工作;坚持理论与实践相结合,加强实证研究与创新研究;建立权威的搜索引擎评价组织;加强绩效评价。 【关键词】搜索引擎评价指标评价方法 Abstract:This paper summarizes and analyzes the research to the field of search engine evaluation from the aspects of evaluation index,evaluation methods,evaluation objects and evaluation subjects.And then it points out the main problems in the current search engine evaluation study,including weak research team;weak theoretical foundation,lack of innovation;weak practical activities,the lack of empirical research;less study of performance evaluation;less mature comprehensive evaluation method.To promote the research,it should be taken to adhere to the combination of qualitative and quantitative development direction,persist in the user-oriented search engine evaluation,uphold the theory and practice combine to strengthen empirical research and innovation research,establish the authoritative evaluation organization,and strengthen performance evaluation. Key words:search engine evaluation index evaluation method 随着互联网的迅速发展,搜索引擎已经成为互联网上访问全球信息资源的最重要的检索工具。搜索引擎的出现及其日益显著的重要性促进了关于搜索引擎的评价研究的发展。国内搜索引擎评价研究已经成为搜索引擎研究领域的一个热点问题,取得了一定的成果,然而也存在着一些不足。笔者现从评价的指标、方法、对象、主体4个方面就搜索引擎评价研究发展状况做出全面、系统的总结和分析,并在此基础上,深入探讨当前搜索引擎评价研究中存在的主要问题和发展策略。 1搜索引擎评价研究发展状况 1.1搜索引擎评价指标 1995年开始,国内开始了对搜索引擎进行比较和评价,但是由于搜索引擎自身的功能和规模问题,以及缺少搜索引擎评价技术的支持,对搜索引擎的评价、比较绝大多数仍然以定性描述为主[1][2][3][4]。这种评价方法局限于对单个搜索引擎各因素的描述和某几个搜索引擎之间的比较,却不能从整体上评价各搜索引擎的优劣。 随着搜索引擎评价研究的发展,国内出现了成套的整体性的搜索引擎体系评价研究。1997年,曾民族在综合国内外搜索引擎评价研究成果的基础上首次提出了一个综合性的搜索引擎评价指标体系,其中包括数据库规模和内容(覆盖范围、索引组成、更新周期)、索引方法(自动、人工索引,用户登录)、检索功能(布尔检索(含嵌套)、截词检索、字段检索、大小写有别、概念检索、词语加权、词语限定、特定字段限定、缺省值、中断退出、重复辨别、上下文关键词、查询集操作)、检索结果(相关性排序、显示内容、输出数量选择、显示格式选择)、用户界面(帮助文件、数据库和检索功能说明、查询举例)、查准率和响应时间7个方面的指标。这是国内最早的有关搜索 11 RESEARCH ON LIBRARY SCIENCE *本文系国家社科基金青年项目“网络信息资源的绩效评估体系研究”(项目编号:09CTQ029)的研究成果之一。DOI:10.15941/https://www.360docs.net/doc/e810510040.html,ki.issn1001-0424.2013.04.007
移动搜索市场研究报告完整版
编号:TQC/K811 移动搜索市场研究报告完 整版 Daily description of the work content, achievements, and shortcomings, and finally put forward reasonable suggestions or new direction of efforts, so that the overall process does not deviate from the direction, continue to move towards the established goal. 【适用信息传递/研究经验/相互监督/自我提升等场景】 编写:________________________ 审核:________________________ 时间:________________________ 部门:________________________
移动搜索市场研究报告完整版 下载说明:本报告资料适合用于日常描述工作内容,取得的成绩,以及不足,最后提出合理化的建议或者新的努力方向,使整体流程的进度信息实现快速共享,并使整体过程不偏离方向,继续朝既定的目标前行。可直接应用日常文档制作,也可以根据实际需要对其进行修改。 Ⅰ. 数据来源 该报告数据主要来自于比达咨询 (BigData-Research)数据中心相关监测 数据的整理分析、《微参与》移动用户调 查。此外,研究过程中还充分参考了专家 访谈、企业公开数据及桌面资料等信息内 容。 Ⅱ. 概念定义 移动搜索:移动搜索是指依托移动互 联网,借助手机、iPad等移动设备在综合 搜索网站、垂直搜索网站等多类搜索网站
搜索引擎技术与发展综述
工程技术 Computer CD Software and Applications 2012年第14期 — 24 — 搜索引擎技术与发展综述 孙宏,李戴维,董旭阳,季泽旭 (中国电子科技集团第十五研究所信息技术应用系统部,北京 100083) 摘 要:随着信息技术的飞速发展和互联网的广泛普及,信息检索技术越来越受到重视。阐述了搜索引擎的产生与发展,并对搜索引擎的核心技术、评价指标和工作原理进行了深入研究。介绍了一些著名的搜索引擎。在此基础上,对搜索引擎的发展方向进行了预测。 关键词:信息技术;信息检索;搜索引擎 中图分类号:TP311.52 文献标识码:A 文章编号:1007-9599 (2012) 14-0024-03 一、引言 信息技术如今迅速发展,Internet 也得到了广泛的普及,网络上的信息量正在以指数趋势上升。其信息来源分布广泛,种类繁多。如果不能对信息进行有序化管理,用户将很难从如此海量的信息中提取出他们需要的信息。目前,搜索引擎已经成为人们获取信息的主要手段之一。搜索引擎就是在繁琐复杂的互联网信息中通过特定的检索策略,对信息进行搜索与分类,通过分析用户提交的请求,按照用户的要求和习惯进行组织,从而达到用户快速检索特定信息的目的。目前搜索引擎提供的搜索方式主要有整句、主题词、自由词等等,用以适应不同用户的需求。 二、搜索引擎的产生与发展 蒙特利尔大学的Alan Emtage 实现了最初的搜索引擎,称为Archie 引擎,Archie 引擎可以在特定的网络中进行相关的信息检索。由于其工作原理与现代搜索引擎非常接近,我们通常认为他 开创了现代搜索引擎领域。搜索引擎的发展大致经历过了三代: (1)第一代搜索引擎是1994年Michael Mauldin 将John Leavitt 的“网络爬虫”程序接入到其索引程序中的Lycos 。由于 结构和技术相对不成熟,它的搜索速度比较慢,更新速度也不能满足用户的检索要求。 (2)美国斯坦福大学的David Filo 和美籍华人杨致远合作开发成功了第二代搜索引擎,它创立了一些用户关心的目录,用户可以通过目录进行检索。 (3)Google 的正式推出标志着第三代搜索引擎的诞生。其集成了搜索、分类、多语言支持等功能,同时提供了摘要、排序、快照等功能,另外与强大的硬件系统配合,大大改变了互联网用户检索网络信息的方式。第三代搜索引擎主要结构如图-1所示。 查询接口的作用是用户进行交互,即提取用户的输入,并将检索结果返回。 检索器依据用户的需求,可以方便地索引库中查找相应的文档,按照相关度规则进行重排后返回。 索引器负责对文档建立索引,使文档以便于检索的方式重新组织。 分析器负责对收集器收集的信息进行分析和整理。 信息收集器的主要任务是对互联网上的各种信息进行收集,同时记录信息URL 地址(网络 爬虫完成这项工作)。 图1 搜索引擎结构图 三、搜索引擎的工作原理 搜索引擎不是搜索互联网,它搜索的是预先整理好的索引数据库;同样,搜索引擎也不能理解网页上的内容,它只能匹配网页上的文字。搜索引擎的工作流 程如图-2所示。 图2 搜索引擎的工作流程 搜索引擎的工作流程可主要分为四个步骤:通过网络爬虫(Spider )从互联网上根据相关算法(深度优先、广度优先)抓取网页,抓取网页后对网页中的信息进行加工,加工后将处理后的信息保存到索引数据库中。当用户在索引数据库中搜索查询相 关的信息资源时,搜索结果通过搜索引擎的处理后,对返回结果进行排序,展现给用户。即: (1)利用网络爬虫从互联网上抓取网页:利网络爬虫,按照某种搜索策略,沿着URL 链接爬到其他网页,重复这些过程,并把所有爬过的网页抓取回来。 (2)建立索引数据库:对爬取到的网页进行分析,提取相关关键信息,得到每一个网页针对页面中文字及链接中每一个关键词的重要性,屏蔽掉不重要的词语后,用信息建立网页索引数据库。 (3)处理用户的查询请求:系统接收到用户要查询的关键字后,调用检索器进行搜索,并将返回的结果进行相关度排序,最后按照优先度降序的方式存储在返回结果集合中。 (4)将查询结果返回给用户:搜索结果以网页的形式将结果集中的返回给用户。方便用户查看。 按照上面的步骤就可以简单的架构一个搜索引擎系统供用户使用。目前有很多开源的搜索引擎产品已经完成了上述相关内容,使用者只需要进行相应的配置就可以使用,大大的简化了搜索引擎的开发。目前,比较流行的开源搜索引擎有Nutch 、Solr 等等。 四、搜索引擎的核心技术 搜索引擎的核心技术包括索引技术和检索技术。 (一)索引技术 顺序查找,即通过线性匹配文本进行查找是一种不使用索引进行检索的例子。它无需对文档中的信息进行预处理。这种检索方式在文本较大时检索速度会变得非常慢,通常情况下不使用这种检索方式。
搜索引擎的特点与评价标准
搜索引擎的特点与评价标准 一、搜索引擎的分类 搜索引擎按其工作方式主要分为三种,分别是全文搜索引擎、目录索引类搜索引擎和元搜索引擎。 全文搜索引擎是名副其实的搜索引擎,国外具有代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,百度(Baidu)目前所做的应该属于全文搜索引擎。由于它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。虽然百度拥有自己的检索程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,但它们所能提供的信息绝大程度上由它所搜索的网站决定的。 评价标准及其局限性 在搜索引擎的发展初期,人们对它的要求较低,只要它能把互连网上相关的网站搜出来,搜到的网站尽量多一点,无关的网站能少一点就能满足。所以那时候,人们评测搜索引擎的方法是用几个关键词,测试对比它们的搜索速度、搜索数量和无关网站的多少。简单说就是全、快、准。而那时的搜索引擎技术大家差别不大,所以这样的评测方法是可行的。此后,独特的搜索引擎技术此起彼伏,层出不穷,到现在明显处于战国时代。但是,人们的评测方法却没多大变化,现在常见的评测还是简单的用几个关键词比较搜索速度、搜索结果数量
和各自介绍的搜索准确性。搜索引擎的评价标准与目前搜索引擎的发展状况并非完全吻合。下面,我们就目前常用的评价指标进行分别介绍。 第一,搜索引擎的查全率。既然是搜索引擎,当然比较搜索的范围就应该首当其冲。但是,由于收录网页的数量都是各搜索引擎自己宣布的,未可全信,而同一个关键词的搜索结果却是显而易见的,所以一般的评测都以这个为准。但以这个为准仍有很多不足之处,因为多数象样一点的搜索引擎都可以找出一批关键词来证明它的搜索结果是最全的。因为网页索引数量虽然有大小,但robot和spider程序不同,索引范围和索引标准也不尽相同,在最大的搜索引擎上搜不到的有可能在小得多的搜索引擎上搜到。还有一点,搜索引擎是可以针对特定的关键词进行结果优化的,评测的公正性谁来保证?如果其中某个被评测搜索引擎事先知道所用的关键词,那么只要轻松优化一下,冠军就非它莫属了。 第二,搜索的速度。如果搜索引擎索引的网页虽多,但是搜索一次要五、六秒或更长,那么仍然没有优势可言。当然了速度的问题首先还是在关键词,单关键词搜索快的不一定多关键词搜索快。然后是访问量的问题,对一个日访问量一亿以上的搜索引擎和一个日访问量几万的搜索引擎做同样的测试本身已是不公平。还有网页索引数量的问题,一个搜索引擎索引了10亿的网页,另一个搜索引擎索引了一千万的网页,让它们对同一个关键词在各自的数据库里搜索比搜索速度,这样的结果如何让人信服?而且,除了事先优化的问题外,