06搭建数据库开发环境

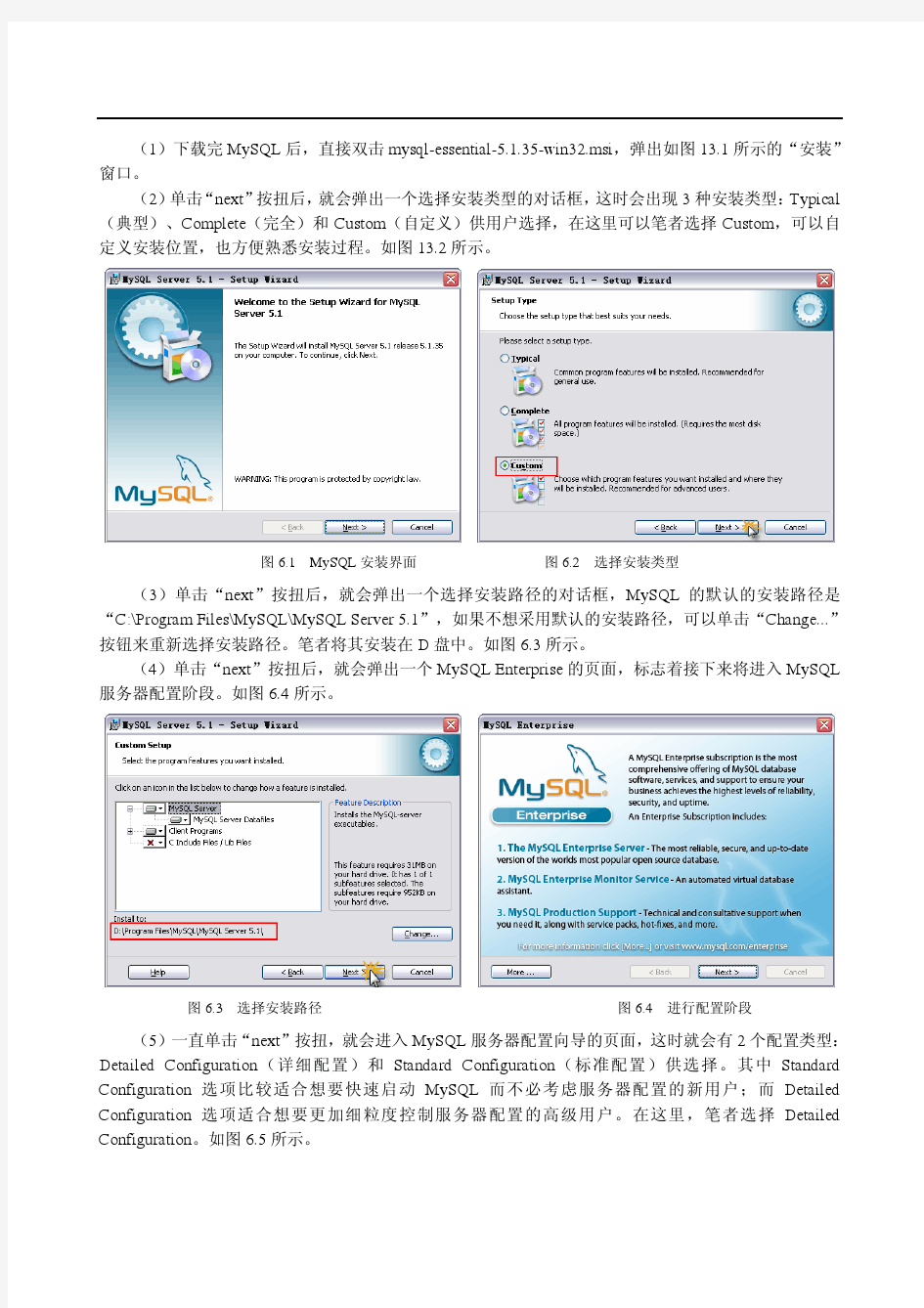
开发环境与测试环境搭建方案
开发环境与测试环境搭建方案 1. 总体原则 1.开发与测试环境单独搭建,开发与测试环境的分离便于利于重现开发环境无法重现的BUG 以及便于开发人员并行地修复BUG ,如果选择开发环境来进行测试,开发人员进行某项误操作后发生系统崩溃或者系统不能正常运行的意外,此时测试工作也不得不停止。 2.测试环境与测试数据库分离,测试环境与测试数据库分离保证测试数据库的稳定性、数据准确性以及今后性能测试指标值的准确性。 3.开发环境与开发数据库共用一台,由于开发环境对及其性能要求不高,因此应用与数据库采用共用。 4.测试环境WEB 应用部署与生产环境相同,测试数据库的配置(用户、表空间、表)也需与生产环境一致。 2. 环境管理 2.1. 系统架构 开发环境构架: 测试环境系统构架: 2.2. 硬件配置 从上述的系统架构图分析需要3台服务器组建开发与测试环境,机型选择普 通的PC Server 机器即可。 2.3. 安装软件 建议方案中给出是环境搭建的主要软件,其他的工具未在罗列中,根据具体 需要自行安装。 服务器 内存 CPU 硬盘 备注 开发服务器 2G 到4G 之间 4C ,主频2G 以上 300G 左右 测试服务器 8G-16G 之间 4C ,主频2G 以上 300G 左右 测试数据服务器 8G-16G 之间 4C ,主频2G 以上 500G 左右
3. 权限管理 3.1. 开发环境 开发人员均可访问开发服务器应用代码与开发数据库,可以修改代码与数据 以及发布部署开发版本以便自测。 3.2. 测试环境 测试环境由版本管理员管理,负责整个测试环境的管理,包括版本部署、服 务启停、数据变更等,测试环境对开发人员只开发查询权限,仅可查询应用日志,服务运行、测试数据。 4. 版本管理 开发与测试环境安装 SVN 版本管理软件,由版本管理员负责对开发与测 试环境的版本管理工作。 5. 备份管理 1.备份主要包括开发与测试环境的代码与配置,备份方式暂为全量备份。 2.每日凌晨3点系统自动对每个项目的代码已经配置文件自动备份,备份文件名:项目名称_code_yyyymmdd.tar ,备份完成后传至备份服务器(服务器待定)。 3.每当长假(元旦、清明、五一、端午、十一、中秋、春节)前期,需手工对开发与测试环境进行全量备份。 4. 服务器 操作系统 中间件 数据库 测试工具 版本管理 工具 开发服务器 RedHat Linux 5.4 64位 Weblogic 9 Oracle 10 无 SVN 测试服务器 RedHat Linux 5.4 64位 Weblogic 9 无 JIRA SVN 测试数据服务器 RedHat Linux 5.4 64位 无 Oracle 10
SQL SERVER 的数据库复制
SQL SERVER 的数据库复制数据库的复制是分布式数据库应用程序中常用的一种数据拷贝技术,它将一个数据库中的数据拷贝到通过局域网(LAN)、广域网(WAN)或Internet网络连接的不同站点或同一个服务器中的不同数据库中,并能够自动保持这些数据的同步,使各个拷贝具有相同的数据。 一、SQL SERVER复制技术 (一)、复制结构 SQL SERVR 数据复制基于“出版—订阅”模型,它由出版者、分发者和订阅者三种服务器构成。出版服务器标识其数据库中的哪些数据用于复制,并检测这些数据的变化和维护该站点中的所有出版信息。 分发服务器中建立一个或多个分发数据库,用来保存出版服务器的出版物,并向订阅者传递它们所订阅的复制数据。 订阅服务器用于存储复制数据和接收对复制数据的更改,SQL SERVE 7.0还允许修改订阅服务器所接收到的出版物。 出版服务器所出版数据的最小单位为条目,出版条目可以是数据库中的表或存储过程。SQL SERVER允许对所出版表添加纵向或横向过滤器,从而使出版条目中只包含表中的某些列或其中的某些数据行,一组出版条目的集合构成一个出版物。 订阅服务器对出版物的订阅方式有推式订阅和拉式订阅两种,SQL SERVER中的每个出版物均支持推式订阅和拉式订阅这两种订阅方式。所谓推式订阅是指当出版物内容被修改时,由出版服务器通知订阅服务器,而不需要订阅服务器进行查询。推式订阅的优点是订阅服务器能够及时了解出版数据的改变情况,但它相应加重了出版服务器的负载。所以,推式订阅适合于需要近乎实时要求的数据复制。 拉式订阅是指由订阅服务器定期轮询出版服务器中出版物的内容是否改变,之后决定是否需要再次进行复制。拉式订阅能够减轻出版服务器的负担,所以常用于拥有大量订阅者的数据复制领域。此外,拉订阅也适合于移动用户,因为移动用户与出版服务器间没有永久固定的通信连接,他们采用订阅方式,只是在需要时才查询出版物内容的变化情况。 (二)复制代理 SQL Server 复制部件采用模块化设计,各种复制操作通过不同的复制代理实现。SQL Server 中的复制代理包括: 快照代理:快照代理运行在SQL Server 代理服务环境下。其功能是:为复制准备表结构、初始化出版表和存储过程的数据文件、将出版物快照存储到分发服务器的分发数据库中、并记录分发数据库的同步状态信息。每个出版物在分发服务器上均运行着自己的快照代理,并通过快照代理与出版服务器连接。 日志阅读代理:将用于复制的事务从出版服务器的事务日志中拷贝到分发数据库。每一个使用事务复制出版的数据库在分发服务器上均运行着自己的日志阅读代理,并通过该代理与出版服务器连接: 分发代理:将保存在分发数据库中的事务或出版物快照传递到订阅者。分发代理运行在SQL Server 代理服务环境下,可以直接使用SQL 企业管理进行管理。对于快照复制和事务复制,如果在配置推订阅时采用立即同步(所谓同步是指维护出版服务器上
MySQL Cluster单机搭建集群环境
运行环境: centos6.1 Mysql版本: MySQL-cluster-gpl-7.2.6-linux2.6-x86_6 下载地 址:https://www.360docs.net/doc/ed18946256.html,/Downloads/MySQL-Cluster-7.2/mysql-cluster-gpl-7.2.6-linux2. 6-x86_64.tar.gz 对于这第一个MySQL数据库的集群,它由1个单一的MySQL服务引擎(mysqlds)、两个数据节点(ndbd)和一个单一的管理节点(ndb_mgmd)共同组成,所有的节点都运行在同一台主机上。 为配置文件和数据文件创建必要的存储文件夹,分别要建立如下几个文件夹: ① /home/mysql/my_cluster ② /home/mysql/my_cluster/ndb_data ③ /home/mysql/my_cluster/mysqld_data ④ /home/mysql/my_cluster/mysqld_data/mysql ⑤ /home/mysql/my_cluster/mysqld_data/ndbinfo ⑥ /home/mysql/my_cluster/conf 具体安装步骤: 1. 添用加户与组mysql [plain]view plaincopy 1.shell> groupadd mysql 2.shell> useradd -r -d /home/mysql -g mysql mysql [plain]view plain copy 1.shell> groupadd mysql 2.shell> useradd -r -d /home/mysql -g mysql mysql 2. 切换到mysql用户权限下 [plain]view plaincopy 1.shell> su - mysql [plain]view plain copy 1.shell> su - mysql
数据库同步更新
数据库同步更新 一、两类方法实现数据库实时更新 1、简单表更新可通过创建触发器实现时时更新,如果数据量大的话,不建议此类。x 2、数据量大的话,可通过数据库复制技术实现。 二,方法概述: 复制是将数据或数据库对象从一个数据库复制和分发到另外一个数据库,并进行数据同步,从而使源数据库和目标数据库保持一致。使用复制,可以在局域网和广域网、拨号连接、无线连接和 Internet 上将数据分发到不同位置以及分发给远程或移动用户。 一组SQL SERVER2005复制有发布服务器、分发服务器、订阅服务器(图1 复制服务器之间的关系图)组成,他们之间的关系类似于书报行业的报社或出版社、邮局或书店、读者之间的关系。以报纸发行为例说明,发布服务器类似于报社,报社提供报刊的内容并印刷,是数据源;分发服务器相当于邮局,他将各报社的报刊送(分发)到订户手中;订阅服务器相当于订户,从邮局那里收到报刊。在实际的复制中,发布服务器是一种数据库实例,它通过复制向其他位置提供数据,分发服务器也是一种数据库实例,它起着存储区的作用,用于复制与一个或多个发布服务器相关联的特定数据。每个发布服务器都与分发服务器上的单个数据库(称作分发数据库)相关联。分发数据库存储复制状态数据和有关发布的元数据,并且在某些情况下为从发布服务器向订阅服务器移动的数据起着排队的作用。在很多情况下,一个数据库服务器实例充当发布服务器和分发服务器两个角色。这称为“本地分发服务器”。订阅服务器是接收复制数据的数据库实例。一个订阅服务器可以从多个发布服务器和发布接收 数据。 (图1) 复制有三种类:事务复制、快照复制、合并复制。
事务复制是将复制启用后的所有发布服务器上发布的内容在修改时传给订阅服务器,数据更改将按照其在发布服务器上发生的顺序和事务边界,应用于订阅服务器,在发布内部可以保证事务的一致性。快照复制将数据以特定时刻的瞬时状态分发,而不监视对数据的更新。发生同步时,将生成完整的快照并将其发送到订阅服务器。合并复制通常是从发布数据库对象和数据的快照开始,并且用触发器跟踪在发布服务器和订阅服务器上所做的后续数据更改和架构修改。订阅服务器在连接到网络时将与发布服务器进行同步,并交换自上次同步以来发布服务器和订阅服务器之间发生更改的所有行。 1、复制实例 这里以配置一个事务复制来说明复制配置过程。 试验在同一台机器的二个实例间进行,实例名分别是SERVER01、SERVER02 。将SERVER01配置发布服务器和分发服务器(也就是前面提到的“本地分发服务器”),SERVER02配置为 订阅服务器。在本例中将SERVER01中一个DBCoper库中person表作为发布的数据,在发布前请确保person表有主键、SQL SERVER 代理自动启动、发布数据库是日志是完整模式。第一步:完全备份SERVER01 DBCopy数据库,在SERVER02上恢复DBCopy数据库(复制前的同步,使用发布的源和目标数据一致) 第二步:在SERVER01上设置发布和分发A 在SERVER01的复制节点—>本地发布右键选择新建订阅(图2) ()(图2) B B 在新建发布向导中首先要求选择分发服务器,本例选择本机作为分发服务器,选择默认值。(图3)
OSM本地数据库搭建(Ubuntu环境)
Build your own OpenStreetMap Server - Ubuntu 08.04 Hardy Heron Submitted by rweait on Sat, 01/19/2013 - 15:07 This article is now archived as https://www.360docs.net/doc/ed18946256.html,/content/build-your-own-openstreetmap-serve r-v1. An updated (2010) article is based on Ubuntu 10.04 Lucid Lynx Build your own OpenStreetMap server. Build your own what? OpenStreetMap is the editable World map of everything. It is the Wikipedia of maps. It is to other on-line maps as Wikipedia is to Britannica. And it is awesome in every possible way. OpenStreetMap is a massive project that started as Steve Coast's, frame-breaking idea in 2004. If I make a map of my neighborhood and give it away, and you make a map of your neighborhood and give it away, then we both have better maps. As of March 2009 there are over 100,000 contributors making maps of their neighborhoods and contributing them to this World wide effort. OpenStreetMap makes the data and the software available to you with Free Software and free data licenses so that you can use, learn from, teach with, improve upon and share with others what you gain from OpenStreetMap. And you can build your own local copy of OpenStreetMap for your business, school, community group or personal interests. The project operates on a massive scale as there is an incredible amount of data, there is more data every day, and there are more people using the data every day. OpenStreetMap has to run on several servers, including a handful of API servers and separate database, development, web and tile servers. This article does not cover the creation of a complete OSM datacentre.
数据镜像复制技术
数据镜像复制技术 大型的业务系统中,数据库中的各类数据,如市场数据,客户数据,交易历史数据,财务管理数据、社会综合数据、生产研发数据等,都是公司至关重要的资产,它不仅关系着整个业务系统的稳定和正常运行,还可能关系着巨大的经济利益。数据系统中,存储设备的安全和高可用性与数据库软件系统一样,都至关重要的一旦数据丢失,就有可能面临着百万、千万元的经济损失。 正因为如此,一个大型数据库系统要具有高安全、高可用性,就必须具有以下几个方面的特点: 高可用性HA(High Availability) l有遭受失败的能力 l有单独的服务和资源管理的能力 l通过一种类型的Cluster进行操作 l关键概念是失败转移(takeover) l与容错不同(容错失败是不可见的) 持续可用性CA( Continuous Availability) l一对或Cluster系统,支持100%联机运行 l高度分布式系统 l设计有多层冗余 l设计有客户端自动失败转移 l为非单点失败而设计 l为非计划停机事件而设计 在数据库系统设计中,常用到的系统结构图如: (图2) 如图所示中,数据库软件、主机、HBA卡和网络交换机一般都采用双机方式,通过多台设备间的Active-Active工作方式来保障系统中的高可用性。不过从上图我们也可以看到,整个系统中,只有存储是单台设备。虽然存储设备内部可通过双控制器、双电源和RAID组来实现内部的冗余,但从存储设备整体而言,仍然存在许多单点故障,比如控制器的背板,
磁盘扩展柜等;这与主机和网络层的高可用工作方式是不匹配的。一旦存储设备发生整体故障,将会直接引起整个系统瘫痪,甚至造成数据丢失,给使用者带来具大的损失。 1.1 卷镜像复制和RAID镜像卷 为了提供存储设备的高可用性,保障数据的安全性,常用的一种解决方案是再增加一台备用存储设备,由两台存储设备负责数据库系统的数据存储服务,保障数据库的安全和数据存储服务器稳定。根据两个存储设备之间工作方式的不同,数据同步和复制机制的不同,可分为两种方式,第一种是卷镜像复制方式,第二种是RAID镜像卷方式。 卷镜像复制工作方式的系统结构图如下: (图3) 左侧存储为主存储设备设备,右侧为备用存储设备,再通过卷镜像复制软件、数据备份软件、网络层的存储虚拟化设备、存储设备自带的卷镜像复制功能等多种方式来实现主、备两个存储之间的卷镜像复制,以此来保障数据的安全性,同时备份存储设备也可以作为数据库系统中的数据存储服务功能的一种后备方式,一旦主存储设备发生故障,就需要自动或手动的切换到备份存储设备上,这种切换实际上是主存储设备生产卷到备份存储设备的镜像卷的切换,经常会导致数据库不一致,数据库重起,切换时间过长等问题。。 RAID镜像卷工作方式的系统结构图下:
开发环境与测试环境搭建方案
开发环境与测试环境搭建方案 总体原则 1.开发与测试环境单独搭建,开发与测试环境的分离便于利于重现开发环境无法重现的BUG 以及便于开发人员并行地修复BUG ,如果选择开发环境来进行测试,开发人员进行某项误操作后发生系统崩溃或者系统不能正常运行的意外,此时测试工作也不得不停止。 2.测试环境与测试数据库分离,测试环境与测试数据库分离保证测试数据库的稳定性、数据准确性以及今后性能测试指标值的准确性。 3.开发环境与开发数据库共用一台,由于开发环境对及其性能要求不高,因此应用与数据库采用共用。 4.测试环境WEB 应用部署与生产环境相同,测试数据库的配置(用户、表空间、表)也需与生产环境一致。 环境管理 1.1. 系统架构 开发环境构架: 测试环境系统构架: 1.2. 硬件配置 从上述的系统架构图分析需要3台服务器组建开发与测试环境,机型选择普 通的PC Server 机器即可。 1.3. 安装软件 建议方案中给出是环境搭建的主要软件,其他的工具未在罗列中,根据具体 需要自行安装。 服务器 内存 CPU 硬盘 备注 开发服务器 2G 到4G 之间 4C ,主频2G 以上 300G 左右 测试服务器 8G-16G 之间 4C ,主频2G 以上 300G 左右 测试数据服务器 8G-16G 之间 4C ,主频2G 以上 500G 左右
权限管理 1.4. 开发环境 开发人员均可访问开发服务器应用代码与开发数据库,可以修改代码与数据 以及发布部署开发版本以便自测。 1.5. 测试环境 测试环境由版本管理员管理,负责整个测试环境的管理,包括版本部署、服 务启停、数据变更等,测试环境对开发人员只开发查询权限,仅可查询应用日志,服务运行、测试数据。 2. 版本管理 开发与测试环境安装 SVN 版本管理软件,由版本管理员负责对开发与测 试环境的版本管理工作。 3. 备份管理 1.备份主要包括开发与测试环境的代码与配置,备份方式暂为全量备份。 2.每日凌晨3点系统自动对每个项目的代码已经配置文件自动备份,备份文件名:项目名称_code_yyyymmdd.tar ,备份完成后传至备份服务器(服务器待定)。 3.每当长假(元旦、清明、五一、端午、十一、中秋、春节)前期,需手工对开发与测试环境进行全量备份。 4. 服务器 操作系统 中间件 数据库 测试工具 版本管理 工具 开发服务器 RedHat Linux 5.4 64位 Weblogic 9 Oracle 10 无 SVN 测试服务器 RedHat Linux 5.4 64位 Weblogic 9 无 JIRA SVN 测试数据服务器 RedHat Linux 5.4 64位 无 Oracle 10
搭建Oracle高可用(HA)数据库环境
搭建Oracle高可用(HA)数据库环境 2008-05-08 10:45 24*7(有些叫法也为24*7*365)的高可用系统越来越多的受到广泛重视与应用,那是因为在实际环境中,不间断的系统代表的就是不间断的义务收入。但是 ◆怎么样搭建与治理24*7的高可用环境? ◆各种各样的高可用环境之间到底有什么差别? ◆我们是否适合于哪种环境? ◆现在高可用环境的主要方式以及以后的发展趋势是什么? 这些话题,都是决策者与实施者都应当考虑的,也是本文所探讨的,我们需要搭建一个怎么样的高可用环境,才能真正做到最适合。 一、什么是高可用(High Availability) 在高可用的解释方面,有人给出了如下的诠释: (1)系统失败或崩溃 (system faults and crashes) (2)应用层或者中间层错误 (application and middleware failures) (3)网络失败 (network failures) (4)介质失败,一般指存放数据的媒体故障 (media failures) (5)人为失误 (Human Error) (6)容灾 (Disasters and extended outages) (7)计划宕机与维护 (Planned downtime, maintenance and management tasks) 可见,高可用不仅仅包含了系统本身故障,应用层的错误,人为错误等等,还应当包括数据冗余、容灾以及计划的维护时间,也就是说,一个真正的高可用环境,不仅仅是能避免系统本身的问题,还应当能防止天灾人祸,以及有一个简单可靠的系统维护方法(如微码升级、软件升级等等计划停机维护)。现在高可用的计算方法一般以年在线率来计算,如规定一年之中的可用环境要达到99.95%,那么24*365*(1-99.95%)=4.38小时(包括维护时间)。那么假定一个系统本身一年之中故障时间是1小时,但是计划维护时间却花了20小时,那么这个系统也不能算是一个满足设计要求的高可用环境。现阶段使用环境中,基本没有真正的100%的在线环境,或者说,假如达到100%的在线能力,将花费非常多的代价,所以一般能达到99.95%以上的可用性的环境,一般都可以认为是
mysql集群部署文档
3台机器搭建集群环境 1. 集群配置如下 (3台机器) 管理节点:192.168.6.134 数据节点1:192.168.6.135 数据节点2:192.168.6.136 sql节点1:192.168.6.135 sql节点2:192.168.6.136 我使用3台机器进行配置,其中两台机器上的数据节点与sql节点在一起 2. 管理节点安装(192.168.6.134) 安装 1.shell> groupadd mysql 2.shell> useradd mysql -g mysql 3.shell> mv mysql-cluster-gpl-7.2.6-linux2.6-x86_6 4.tar.gz /usr/local/ 4.shell> cd /usr/local/ 5.shell> tar zxvf mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz /usr/local/ 6.shell> mv mysql-cluster-gpl- 7.2.6-linux2.6-x86_64 mysql 7.shell> chown -R mysql:mysql mysql 8.shell> cd mysql 9.shell> scripts/mysql_install_db --user=mysql 配置管理节点 1.shell> mkdir /var/lib/mysql-cluster 2.shell> cd /var/lib/mysql-cluster vi config.ini 添加以下内容 1.[ndbd default] 2.NoOfReplicas=2 3.DataMemory=80M 4.IndexMemory=18M 5.[ndb_mgmd]
开发环境搭建文档
开发环境搭建 jdk1.5环境的安装和配置 1.jdk1.5的安装 jdk的安装很简单,双击jdk1.5文件下面的jdk-1_5_0_07-windows-i586-p.exe文件,按照步骤一步一步安装即可。 2.jdk1.5的配置 找到jdk1.5的安装路径D:\Program Files\Java\jdk1.5.0_07\bin目录,将其配置到windows 的环境下。 右击“我的电脑”—>“属性”—>“高级” 选择Path点击编辑 将鼠标移到变量值的最前端,把D:\Program Files\Java\jdk1.5.0_07\bin拷贝进去并以分号结束。
配置CLASSPATH,单击新建按钮 输入变量名CLASSPA TH,变量值为“.”; 3.查看jdk是否安装成功 运行cmd,在命令行中输入java。查看命令行的提示信息。 输入javac,查看提示信息。
提示上述信息,则安装成功。 db2客户端环境的安装和配置 1.db2客户端的安装 db2客户端的安装很简单,双击db2 client目录下的setup.exe按提示一步一步安装即可。 2.db2客户端的配置 选择“开始”—>“所有程序”—>“IBM db2”—>“设置工具”—>“配置助手”,打开配置助手,如下图: 单击“选择”—>“使用向导来添加数据库”
选择“人工配置与数据库的连接”选择,单击“下一步”。 选择“TCP/IP”单击下一步。 主机名框中填写DB2服务器的IP地址,服务名保持默认值,端口号填写DB2端口号(默认为50000),单击“下一步”按钮,出现如下图所示界面。
mysql集群架构说明与配置实例-详细过程
Mysql集群架构文档 MySQL Cluster 是MySQL适合于分布式计算环境的高实用、高冗余版本。它采用了NDB Cluster 存储引擎,允许在1个Cluster 中运行多个MySQL服务器。在MyQL 5.0及以上的二进制版本中、以及与最新的Linux版本兼容的RPM中提供了该存储引擎。(注意,要想获得MySQL Cluster 的功能,必须安装mysql-server 和mysql-max RPM)。 目前能够运行MySQL Cluster 的操作系统有Linux、Mac OS X和Solaris(一些用户通报成功地在FreeBSD上运行了MySQL Cluster ,但MySQL AB公司尚未正式支持该特性)。 一、MySQL Cluster概述 MySQL Cluster 是一种技术,该技术允许在无共享的系统中部署“内存中”数据库的Cluster 。通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。此外,由于每个组件有自己的内存和磁盘,不存在单点故障。 MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括MySQL服务器,NDB Cluster 的数据节点,管理服务器,以及(可能)专门的数据访问程序。关于Cluster 中这些组件的关系,请参见下图:
所有的这些节点构成一个完成的MySQL集群体系。数据保存在“NDB存储服务器”的存储引擎中,表(结构)则保存在“MySQL服务器”中。应用程序通过“MySQL服务器”访问这些数据表,集群管理服务器通过管理工具(ndb_mgmd)来管理“N DB存储服务器”。 通过将MySQL Cluster 引入开放源码世界,MySQL为所有需要它的人员提供了具有高可用性、高性能和可缩放性的Cluster 数据管理。 二.安装环境 1.Linux操作系统版本:CentonOS 4.7 2.Mysql数据库版本:mysql-max-5.0.24-linux-i686.tar.gz 共三台机器安装了CentonOS4.7版本,首先保证把系统中没有一个包带有mysql的,有的话
数据库容灾、复制解决方案全分析(绝对精品)要点
数据库容灾、复制解决方案全分析(绝对精品) 目前,针对oracle数据库的远程复制、容灾主要有以下几种技术或解决方案: (1)基于存储层的容灾复制方案 这种技术的复制机制是通过基于SAN的存储局域网进行复制,复制针对每个IO进行,复制的数据量比较大;系统可以实现数据的同步或异步两种方式的复制.对大数据量的系统来说有很大的优势(每天日志量在60G以上),但是对主机、操作系统、数据库版本等要求一致,且对络环境的要求比较高。 目标系统不需要有主机,只要有存储设备就可以,如果需要目标系统可读,需要额外的配置和设备,比较麻烦。 (2)基于逻辑卷的容灾复制方案 这种技术的机制是通过基于TCP/IP的网络环境进行复制,由操作系统进程捕捉逻辑卷的变化进行复制。其特点与基于存储设备的复制方案比较类似,也可以选择同步或异步两种方式,对主机的软、硬件环境的一致性要求也比较高,对大数据量的应用比较有优势。其目标系统如果要实现可读,需要创建第三方镜像。个人认为这种技术和上面提到的基于存储的复制技术比较适合于超大数据量的系统,或者是应用系统的容灾复制。 我一直有一个困惑,存储级的复制,假如是同步的,能保证数据库所有文件一致吗?或者说是保证在异常发生的那一刻有足够的缓冲来保障? 也就是说,复制的时候起文件写入顺序和oracle的顺序一致吗?如果不一致就可能有问题,那么是通过什么机制来实现的呢? 上次一个存储厂商来讲产品,我问技术工程师这个问题,没有能给出答案 我对存储级的复制没有深入的研究过,主要是我自己的一些理解,你们帮我看一下吧…… 我觉得基于存储的复制应该是捕捉原系统存储上的每一个变化,而不是每隔一段时间去复制一下原系统存储上文件内容的改变结果,所以在任意时刻,如果原系统的文件是一致的,那么目标端也应该是一致的,如果原系统没有一致,那目标端也会一样的。形象一点说它的原理可能有点像raid 0,就是说它的写入顺序应该和原系统是一样的。不知道我的理解对不对。另外,在发生故障的那一刻,如果是类似断电的情况,那么肯定会有缓存中数据的损失,也不能100%保证数据文件的一致。一般来说是用这种方式做oracle的容灾备份,在发生灾难以后目标系统的数据库一般是只有2/3的机会是可以正常启动的(这是我接触过的很多这方面的技术人员的一种说法,我没有实际测试过)。我在一个移动运营商那里看到过实际的情况,他们的数据库没有归档,虽然使用了存储级的备份,但是白天却是不做同步的,只有在晚上再将存储同步,到第二天早上,再把存储的同步断掉,然后由另外一台主机来启动目标端存储上的数据库,而且基本上是有1/3的机会目标端数据库是起不来的,需要重新同步。 所以我觉得如果不是数据量大的惊人,其他方式没办法做到同步,或者要同时对数据库和应用进行容灾,存储级的方案是没有什么优势的,尤其是它对网络的环境要求是非常高的,在异地环境中几乎不可能实现。
MySQL_Cluster集群配置方案
在为某证券公司设计其OA架构时,初期客户是30万用户在线;然而在项目实施中,客户又提出50万用户同时在线的需求,而且都有写的需求;这样初始的设计master-master-slave,读写分离满足不了客户的要求,所以我们打算采用Mysql Cluster方案;MySQL Cluster 是MySQL适合于分布式计算环境的高实用、高冗余版本。它采用了NDB Cluster 存储引擎,允许在1个Cluster中运行多个MySQL服务器。在MyQL 5.0及以上的二进制版本中、以及与最新的Linux版本兼容的RPM中提供了该存储引擎。 一、MySQL Cluster概述 MySQL Cluster 是一种技术,该技术允许在无共享的系统中部署“内存中”数据库的 Cluster 。通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。此外,由于每个组件有自己的内存和磁盘,不存在单点故障。 MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括MySQL服务器,NDB Cluster 的数据节点,管理服务器,以及(可能)专门的数据访问程序。 所有的这些节点构成一个完成的MySQL集群体系。数据保存在“NDB存储服务器”的存储引擎中,表(结构)则保存在“MySQL服务器”中。应用程序通过“MySQL服务器”访问这些数据表,集群管理服务器通过管理工具(ndb_mgmd)来管理“NDB存储服务器”。 通过将MySQL Cluster 引入开放源码世界,MySQL为所有需要它的人员提供了具有高可用性、高性能和可缩放性的 Cluster 数据管理。 二、MySQL Cluster 基本概念 “NDB” 是一种“内存中”的存储引擎,它具有可用性高和数据一致性好的特点。 MySQL Cluster 能够使用多种故障切换和负载平衡选项配置NDB存储引擎,但在 Cluster 级别上的存储引擎上做这个最简单。MySQL Cluster的NDB存储引擎包含完整的数据集,仅取决于 Cluster本身内的其他数据。 目前,MySQL Cluster的 Cluster部分可独立于MySQL服务器进行配置。在MySQL Cluster中, Cluster的每个部分被视为1个节点。 管理(MGM)节点:这类节点的作用是管理MySQL Cluster内的其他节点,如提供配置数据、启动并停止节点、运行备份等。由于这类节点负责管理其他节点的配置,应在启动其他节点之前首先启动这类节点。MGM节点是用命令 “ndb_mgmd”启动的。 数据节点:这类节点用于保存 Cluster的数据。数据节点的数目与副本的数目相关,是片段的倍数。例如,对于两个副本,每个副本有两个片段,那么就
SQL server 数据库的导入导出与复制
第13章数据库的导入导出与复制 本章内容 13.1 数据库的导入导出 13.2 数据库复制技术 13.1 数据库的导入导出 13.1.1 导入导出概述 13.1.2 导入数据 13.1.3 导出数据 13.1.1 导入导出概述 ?数据导入导出操作(为SQL的数据转换服务)主要解决异构数据源之间相互转换。 ?目的是提高数据库管理系统的适应性,是数据库管理系统的一个核心技术和组件。 数据导入导出实现不同格式的数据在应用程序之间交换 dBase Microsoft Access Microsoft Data Link Microsoft Excel Microsoft Visual FoxPro 其他ODBC数据源 其他OLE DB数据源 Paradox 文本文件 表13-1 数据导入导出方法和工具 13.1.2 导入数据 导入数据的操作步骤: 步骤1: ?在企业管理器中,从“工具”菜单中选择“向导…” ?在“向导”对话框中选择数据转换服务中的DTS导入向导 步骤2 ?打开“数据转换服务导入/导出向导”界面,单击“下一步”按钮 步骤3 ?选择导入数据源。选择文本文件为数据源,在“文件名”编辑框中输入C:\SUPPLIER.TXT 文本文件,将其导入Sales数据库的Supplier表 步骤4 ?单击“下一步”按钮,显示“选择文件格式”对话框 步骤5 ?单击“下一步”按钮,显示“指定列分隔符”对话框。“预览”列表框显示数据文件的数据。 步骤6 ?单击“下一步”按钮,显示“选择目的”对话框。 步骤7 ?单击“下一步”按钮,显示选择源表和视图对话框。选择导入数据的supplier表 步骤8 ?单击“下一步”按钮,显示“保存、调度和复制包”对话框。 步骤9 ?单击“下一步”按钮,在“正在完成DTS导入/导出向导”界面中单击“完成”按钮,运行数据导入工作。最后显示用户操作成功。 13.1.3 导出数据 导出数据的操作步骤:
MYSQL集群搭建指引文档
在PCSERVER上安装MARIADB。 一、先检查主机的环境 如果主机已经安装了MYSQL的早期版本,并且有MYSQL实例正在主机上运行,要先行清理早期的版本,具体步骤如下: 1、优雅地停掉当前正在运行的MYSQL服务。 2、卸载MYSQL早期版本及其组件 rpm -qa|grep -i mysql #查看已经安装的mysql相关包 rpm -ev package_name #package_name包名比如:mysql-server-5.0.51b-1.el5 二、用YUM安装MARIADB 具体步骤如下: 1、cd /etc/yum.repos.d 2、vi MariaDB.repo然后粘上官网上的内容(用CENTOS操作系统举例) Here is your custom MariaDB YUM repository entry for CentOS. Copy and paste it into a file under /etc/yum.repos.d/ (we suggest naming the file MariaDB.repo or something similar). See "Installing MariaDB with yum" for detailed information. 3、执行yum -y install MariaDB-client MariaDB-server MariaDB-devel 4、如果发现用YUM装时,代理服务器的网速下载太慢了导致超时然后报错退出,解决方案如下: A自己用个人电脑到官网下载列表中的RPM文件,
组建MySQL集群的几种方案,优劣与讨论
组建MySQL集群的几种方案 LVS+Keepalived+MySQL(有脑裂问题?但似乎很多人推荐这个) DRBD+Heartbeat+MySQL(有一台机器空余?Heartbeat切换时间较长?有脑裂问题?) MySQL Proxy(不够成熟与稳定?使用了Lua?是不是用了他做分表则可以不用更改客户端逻辑?) MySQL Cluster (社区版不支持INNODB引擎?商用案例不足?稳定性欠佳?或者还有其他问题?又或者听说现在发展不错?) MySQL + MHA (如果配上异步复制,似乎是不错的选择,又和问题?) MySQL + MMM (似乎反映有很多问题,未实践过,谁能给个说法) 淘宝的Cola(似乎现在停止开发了?)?变形虫Amoeba(事务支持?) 或者,其他方案? 回答1: 不管哪种方案都是有其场景限制或说规模限制,以及优缺点的。 1. 首先反对大家做读写分离,关于这方面的原因解释太多次数(增加技术复杂度、可能导致读到落后的数据等),只说一点:99.8%的业务场景没有必要做读写分离,只要做好数据库设计优化和配置合适正确的主机即可。 2.Keepalived+MySQL --确实有脑裂的问题,还无法做到准确判断mysqld是否HANG 的情况; 3.DRBD+Heartbeat+MySQL --同样有脑裂的问题,还无法做到准确判断mysqld是否HANG的情况,且DRDB是不需要的,增加反而会出问题; 3.MySQL Proxy -- 不错的项目,可惜官方半途夭折了,不建议用,无法高可用,是一个写分离; 4.MySQL Cluster -- 社区版本不支持NDB是错误的言论,商用案例确实不多,主要是跟其业务场景要求有关系、这几年发展有点乱不过现在已经上正规了、对网络要求高; 5.MySQL + MHA -- 可以解决脑裂的问题,需要的IP多,小集群是可以的,但是管理大的就麻烦,其次MySQL + MMM 的话且坑很多,有MHA就没必要采用MMM 建议: 1.若是双主复制的模式,不用做数据拆分,那么就可以选择MHA或Keepalive 或heartbeat
数据库管理系统及其应用开发环境的创建使用
学号:姓名: EMAIL: 学院:专业: 《数据库应用实践》实验一:数据库管理系统及其应用开发环境的创建使用实验目的: 了解数据库应用开发环境的建立与使用;掌握SQL 语言的使用;通过实践理解关系数据模型的相关概念;掌握数据库应用开发环境的使用;掌握创建、删除数据库的方法;掌握创建基本表、查看表属性、修改属性的方法;掌握向表中添加、删除以及修改数据的方法;掌握查询分析器的使用方法;掌握SELECT 语句在单表查询中的应用;掌握复杂查询、多表查询的方法;掌握视图的使用方法;巩固数据库的基础知识。 实验环境: 操作系统: windows 8.1 64 bits 数据库管理系统:Microsoft SQL Server 2008 实验内容: 1.应用背景及设计的数据库名。 a)应用背景:学生选课管理系统,一门课可以由多个老师教授,一个老师可以 教多门课程,一个学生可以选修多门课程,一门可以有多个学生选修 b)数据库名:mrsunday 2. 所设计的各张表结构说明,各表之间关系图说明。 表结构说明: 创建4张表,Student表存储学生信息,Teacher表存储教师信息,Course 表存储课程信息,SC表存储学生选课信息及选课成绩。 数据库各表之间关系图说明:
3. 依据前面实验一实验内容(2),(3)的要求,写出实现相应操作的SQL 语句并给出运行结果的截图。 (2) 以下内容使用SQL 语句完成: 1、设计一个应用场景,创建符合该应用需求的应用数据库。 代码:create database mrsudnay; 截图: 2、在该数据库中创建至少4 个相互关联的基本表,并设置主键、外键、自定 义完整性约束(非空、唯一、默认值、check)。 代码: 1)Student 表 create table Student( Sno char(20)primary key, Sname char(20)not NULL, Ssex char(2)default'男', Sage smallint not NULL check(Sage between 0 and 90), Sdept char(20)not NULL ); 2)Teacher表 create table Teacher ( Tno char(10)primary key, Tname char(20)not NULL, Tsex char(2)default'男', Tage smallint not NULL check(Tage between 20 and 60), Sdept char(20)not NULL); 3)Course表 create table Course ( Cno char(5)primary key, Cname char(20)not NULL, Cpno char(5)NULL,-- Cpno是先修课 Ccredit smallint not NULL, foreign key (Cpno)references Course(Cno) );